
In the last chapter, you learned about the three pillars that sustained your security posture, and two of them (detection and response) are directly correlated with the incident response (IR) process. To enhance the foundation of your security posture, you need to have a solid incident response process. This process will dictate how to handle security incidents and rapidly respond to them. Many companies do have an incident response process in place, but they fail to constantly review it to incorporate lessons learned from previous incidents, and on top of that, many are not prepared to handle security incidents in a cloud environment.
In this chapter, we're going to be covering the following topics:
- The incident response process
- Handling an incident
- Post-incident activity
- Considerations regarding IR in the cloud
First, we will cover the incident response process.
The incident response process
There are many industry standards, recommendations, and best practices that can help you to create your own incident response. You can still use those as a reference to make sure you cover all the relevant phases for your type of business. The one that we are going to use as a reference in this book is the computer security incident response (CSIR)—publication 800-61R2 from NIST [1]. Regardless of the one you select to use as a reference, make sure to adapt it to your own business requirements. Most of the time in security the concept of "one size fits all" doesn't apply; the intent is always to leverage well-known standards and best practices and apply them to your own context. It is important to retain the flexibility to accommodate your business needs in order to provide a better experience when operationalizing it.
Reasons to have an IR process in place
Before we dive into more details about the process itself, it is important to be aware of the terminology that is used, and what the final goal is when using IR as part of enhancing your security posture. Let's use a fictitious company to illustrate why this is important.
The following diagram has a timeline of events [2] that leads the help desk to escalate the issue and start the incident response process:

Figure 1: Events timeline leading to escalation and the beginning of the incident response process
The following table has some considerations about each step in this scenario:
| Step | Description | Security considerations |
|
1 |
While the diagram says that the system is working properly, it is important to learn from this event. |
What is considered normal? Do you have a baseline that can give you evidence that the system was running properly? Are you sure there is no evidence of compromise before the email? |
|
2 |
Phishing emails are still one of the most common methods used by cybercriminals to entice users to click on a link that leads to a malicious/compromised site. |
While technical security controls must be in place to detect and filter these types of attack, the users must be taught how to identify a phishing email. |
|
Many of the traditional sensors (IDS/IPS) used nowadays are not able to identify infiltration and lateral movement. |
To enhance your security posture, you will need to improve your technical security controls and reduce the gap between infection and detection. |
|
|
4 |
This is already part of the collateral damage done by this attack. Credentials were compromised, and the user was having trouble authenticating. This sometimes happens because the attackers already changed the user's password. |
There should be technical security controls in place that enable IT to reset the user's password and at the same time enforce multifactor authentication. |
|
5 |
Not every single incident is security related; it is important for the help desk to perform their initial troubleshoot to isolate the issue. |
If the technical security controls in place (step 3) were able to identify the attack, or at least provide some evidence of suspicious activity, the help desk wouldn't have to troubleshoot the issue—it could just directly follow the incident response process. |
|
6 |
At this point in time, the help desk is doing what it is supposed to do, collecting evidence that the system was compromised and escalating the issue. |
The help desk should obtain as much information as possible about the suspicious activity to justify the reason why they believe that this is a security- related incident. |
|
7 |
At this point the IR process takes over and follows its own path, which may vary according to the company, industry segment, and standard. |
It is important to document every single step of the process and, after the incident is resolved, incorporate the lessons learned with the aim of enhancing the overall security posture. |
While there is much room for improvement in the previous scenario, there is something that exists in this fictitious company that many other companies around the world are missing: the incident response itself. If it were not for the incident response process in place, support professionals would exhaust their troubleshooting efforts by focusing on infrastructure-related issues. Companies that have a good security posture would have an incident response process in place.
They would also ensure that the following guidelines are adhered to:
- All IT personnel should be trained to know how to handle a security incident.
- All users should be trained to know the core fundamentals about security in order to perform their job more safely, which will help avoid getting infected.
- There should be integration between their help desk system and the incident response team for data sharing.
This scenario could have some variations that could introduce different challenges to overcome. One variation would be if no indicator of compromise (IoC) was found in step 6. In this case, the help desk could easily continue troubleshooting the issue. What if at some point "things" started to work normally again? Is this even possible? Yes, it is! When an IoC is not found it doesn't mean the environment is clean; now you need to switch gears and start looking for an indicator of attack (IoA), which involves looking for evidence that can show the intent of an attacker. When investigating a case, you may find many IoAs, that may or may not lead to an IoC. The point is, understanding the IoA will lead you to better understand how an attack was executed, and how you can protect against it.
When an attacker infiltrates the network they usually want to stay invisible, moving laterally from one host to another, compromising multiple systems, and trying to escalate privileges by compromising an account with administrative-level privileges. That's the reason it is so important to have good sensors not only in the network, but also in the host itself. With good sensors in place, you would be able to not only detect the attack quickly, but also identify potential scenarios that could lead to an imminent threat of violation [3].
In addition to all the factors that were just mentioned, some companies will soon realize that they must have an incident response process in place to be compliant with regulations that are applicable to the industry in which they belong. For example, the Federal Information Security Management Act of 2002 (FISMA) requires federal agencies to have procedures in place to detect, report, and respond to a security incident.
Creating an incident response process
Although the incident response process will vary according to the company and its needs, there are some fundamental aspects of it that will be the same across different industries.
The following diagram shows the foundational areas of the incident response process:

Figure 2: The incident response process and its foundational areas of Objective, Scope, Definition/Terminology, Roles and responsibilities, and Priorities/Severity Level
The first step to create your incident response process is to establish the objective—in other words, to answer the question: what's the purpose of this process? While this might look redundant as the name seems to be self-explanatory, it is important that you are very clear as to the purpose of the process so that everyone is aware of what this process is trying to accomplish.
Once you have the objective defined, you need to work on the scope. Again, you start this by answering a question, which in this case is: To whom does this process apply?
Although the incident response process usually has a company-wide scope, it can also have a departmental scope in some scenarios. For this reason, it is important that you define whether this is a company-wide process or not.
Each company may have a different perception of a security incident; therefore, it is imperative that you have a definition of what constitutes a security incident, with examples for reference.
Along with the definition, companies must create their own glossary with definitions of the terminology used. Different industries will have different sets of terminologies, and if these terminologies are relevant to a security incident, they must be documented.
In an incident response process, the roles and responsibilities are critical. Without the proper level of authority, the entire process is at risk.
The importance of the level of authority in an incident response is evident when you consider the question: Who has the authority to confiscate a computer in order to perform further investigation? By defining the users or groups that have this level of authority, you are ensuring that the entire company is aware of this, and if an incident occurs, they will not question the group that is enforcing the policy.
Another important question to answer is regarding the severity of an incident. What defines a critical incident? The criticality will lead to resource distribution, which brings another question: How are you going to distribute your manpower when an incident occurs? Should you allocate more resources to incident "A" or to incident "B"?
Why? These are only some examples of questions that should be answered in order to define the priorities and severity level. To determine the priority and severity level, you will need to also take into consideration the following aspects of the business:
- Functional impact of the incident on the business: The importance of the affected system for the business will have a direct effect on the incident's priority. All stakeholders for the affected system should be aware of the issue, and will have their input in the determination of priorities.
- Type of information affected by the incident: Every time you deal with personal identifiable information (PII), your incident will have high priority; therefore, this is one of the first elements to verify during an incident.
- Recoverability: After the initial assessment, it is possible to give an estimate of how long it will take to recover from an incident. Depending on the amount of time to recover, combined with the criticality of the system, this could drive the priority of the incident to high severity.
In addition to these fundamental areas, an incident response process also needs to define how it will interact with third parties, partners, and customers.
For example, if an incident occurs and during the investigation process it is identified that a customer's PII was leaked, how will the company communicate this to the media? In the incident response process, communication with the media should be aligned with the company's security policy for data disclosure. The legal department should also be involved prior to the press release to ensure that there is no legal issue with the statement. Procedures to engage law enforcement must also be documented in the incident response process. When documenting this, take into consideration the physical location—where the incident took place, where the server is located (if appropriate), and the state. By collecting this information, it will be easier to identify the jurisdiction and avoid conflicts.
Incident response team
Now that you have the fundamental areas covered, you need to put the incident response team together. The format of the team will vary according to the company size, budget, and purpose. A large company may want to use a distributed model, where there are multiple incident response teams with each one having specific attributes and responsibilities. This model can be very useful for organizations that are geo-dispersed, with computing resources located in multiple areas. Other companies may want to centralize the entire incident response team in a single entity. This team will handle incidents regardless of the location. After choosing the model that will be used, the company will start recruiting employees to be part of the team.
The incident response process requires personnel with technically broad knowledge while also requiring deep knowledge in some other areas. The challenge is to find people with depth and breadth in this area, which sometimes leads to the conclusion that you need to hire external people to fill some positions, or even outsource part of the incident response team to a different company.
The budget for the incident response team must also cover continuous improvement via education, and the acquisition of proper tools, software, and hardware. As new threats arise, security professionals working with incident response must be ready and trained to respond well. Many companies fail to keep their workforce up to date, which may expose the company to risk. When outsourcing the incident response process, make sure the company that you are hiring is accountable for constantly training their employees in this field.
If you plan to outsource your incident response operations, make sure you have a well-defined service-level agreement (SLA) that meets the severity levels that were established previously. During this phase, you should also define the team coverage, assuming the need for 24-hour operations.
In this phase you will define:
- Shifts: How many shifts will be necessary for 24-hour coverage?
- Team allocation: Based on these shifts, who is going to work on each shift, including full-time employees and contractors?
- On-call process: It is recommended that you have on-call rotation for technical and management roles in case the issue needs to be escalated.
Incident life cycle
Every incident that starts must have an end, and what happens in between the beginning and the end are different phases that will determine the outcome of the response process. This is an ongoing process that we call the incident life cycle. What we have described until now can be considered the preparation phase. However, this phase is broader than that—it also has the partial implementation of security controls that were created based on the initial risk assessment (this was supposedly done even before creating the incident response process).
Also included in the preparation phase is the implementation of other security controls, such as:
- Endpoint protection
- Malware protection
- Network security
The preparation phase is not static, and you can see in the following diagram that this phase will receive input from post-incident activity. The other phases of the life cycle and how they interact are also shown in this diagram:

Figure 3: Phases of the Incident life cycle
The DETECTION and CONTAINMENT phases could have multiple interactions within the same incident. Once the loop is over, you will move on to the post-incident activity phase. The sections that follow will cover these last three phases in more detail.
Handling an incident
Handling an incident in the context of the IR life cycle includes the detection and containment phases.
In order to detect a threat, your detection system must be aware of the attack vectors, and since the threat landscape changes so rapidly, the detection system must be able to dynamically learn more about new threats and new behaviors, and trigger an alert if a suspicious activity is encountered.
While many attacks will be automatically detected by the detection system, the end user has an important role in identifying and reporting the issue in case they find a suspicious activity.
For this reason, the end user should also be aware of the different types of attack and learn how to manually create an incident ticket to address such behavior. This is something that should be part of the security awareness training.
Even with users being diligent by closely watching for suspicious activities, and with sensors configured to send alerts when an attempt to compromise is detected, the most challenging part of an IR process is still the accuracy of detecting what is truly a security incident.
Oftentimes, you will need to manually gather information from different sources to see if the alert that you received really reflects an attempt to exploit a vulnerability in the system. Keep in mind that data gathering must be done in compliance with the company's policy. In scenarios where you need to bring the data to a court of law, you need to guarantee the data's integrity.
The following diagram shows an example where the combination and correlation of multiple logs is necessary in order to identify the attacker's ultimate intent:

Figure 4: The necessity of multiple logs in identifying an attacker's ultimate intent
In this example, we have many IoCs, and when we put all the pieces together we can validate the attack. Keep in mind that depending on the level of information that you are collecting in each one of those phases, and how conclusive it is, you may not have evidence of compromise, but you will have evidence of an attack, which is the IoA for this case.
The following table explains the diagram in more detail, assuming that there is enough evidence to determine that the system was compromised:
| Step | Log | Attack/Operation |
|
1 |
Endpoint protection and operating system logs can help determine the IoC |
Phishing email |
|
2 |
Endpoint protection and operating system logs can help determine the IoC |
Lateral movement followed by privilege escalation |
|
3 |
Server logs and network captures can help determine the IoC |
Unauthorized or malicious processes could read or modify the data |
|
4 |
Assuming there is a firewall in between the cloud and on-premises resources, the firewall log and the network capture can help determine the IoC |
Data extraction and submission to command and control |
As you can see, there are many security controls in place that can help to determine the indication of compromise. However, putting them all together in an attack timeline and cross-referencing the data can be even more powerful.
This brings back a topic that we discussed in the previous chapter: that detection is becoming one of the most important security controls for a company. Sensors that are located across the network (on-premises and cloud) will play a big role in identifying suspicious activity and raising alerts. A growing trend in cybersecurity is the leveraging of security intelligence and advanced analytics to detect threats more quickly and reduce false positives. This can save time and enhance the overall accuracy.
Ideally, the monitoring system will be integrated with the sensors to allow you to visualize all events on a single dashboard. This might not be the case if you are using different platforms that don't allow interaction between one another.
In a scenario similar to the one we looked at previously, the integration between the detection and monitoring system can help to connect the dots of multiple malicious actions that were performed in order to achieve the final mission—data extraction and submission to command and control.
Once the incident is detected and confirmed as a true positive, you need to either collect more data or analyze what you already have. If this is an ongoing issue, where the attack is taking place at that exact moment, you need to obtain live data from the attack and rapidly provide a remediation to stop the attack. For this reason, detection and analysis are sometimes done almost in parallel to save time, and this time is then used to rapidly respond.
The biggest problem arises when you don't have enough evidence that there is a security incident taking place, and you need to keep capturing data in order to validate the veracity. Sometimes the incident is not detected by the detection system. Perhaps it is reported by an end user, but they can't reproduce the issue at that exact moment. There is no tangible data to analyze, and the issue is not happening at the time you arrive. In scenarios like this, you will need to set up the environment to capture data and instruct the user to contact support when the issue is actually happening.
Best practices to optimize incident handling
You can't determine what's abnormal if you don't know what's normal. In other words, if a user opens a new incident saying that the server's performance is slow, you must know all the variables before you jump to a conclusion. To know if the server is slow, you must first know what's considered to be a normal speed. This also applies to networks, appliances, and other devices. In order to establish this understanding, make sure you have the following in place:
- System profile
- Network profile/baseline
- Log-retention policy
- Clock synchronization across all systems
Based on this, you will be able to establish what's normal across all systems and networks. This will be very useful when an incident occurs and you need to determine what's normal before starting to troubleshoot the issue from a security perspective.
Post-incident activity
The incident priority may dictate the containment strategy—for example, if you are dealing with a DDoS attack that was opened as a high-priority incident, the containment strategy must be treated with the same level of criticality. It is rare that the situations where the incident is opened as high severity are prescribed medium-priority containment measures, unless the issue was somehow resolved in between phases.
Real-world scenario
Let's use the WannaCry outbreak as a real-world example, using the fictitious company Diogenes & Ozkaya Inc. to demonstrate the end-to-end incident response process.
On May 12, 2017, some users called the help desk saying that they were receiving the following screen:
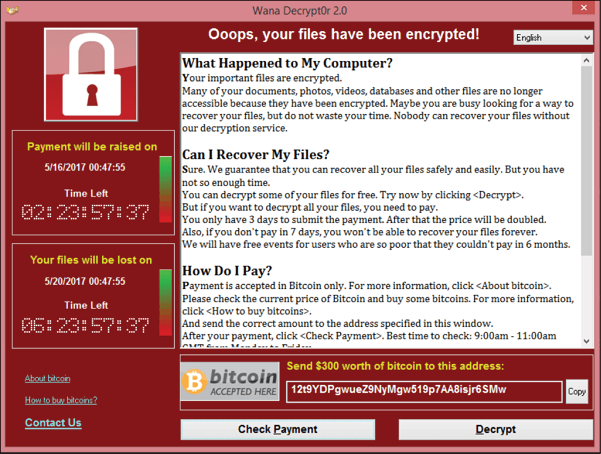
Figure 5: A screen from the WannaCry outbreak
After an initial assessment and confirmation of the issue (detection phase), the security team was engaged and an incident was created. Since many systems were experiencing the same issue, they raised the severity of this incident to high. They used their threat intelligence to rapidly identify that this was a ransomware outbreak, and to prevent other systems from getting infected, they had to apply the MS17-00(3) patch.
At this point, the incident response team was working on three different fronts: one to try to break the ransomware encryption, another to try to identify other systems that were vulnerable to this type of attack, and another one working to communicate the issue to the press.
They consulted their vulnerability management system and identified many other systems that were missing this update. They started the change management process and raised the priority of this change to critical. The management system team deployed this patch to the remaining systems.
The incident response team worked with their anti-malware vendor to break the encryption and gain access to the data again. At this point, all other systems were patched and running without any problems. This concluded the containment eradication and recovery phase.
Lessons learned
After reading this scenario, you can see examples of many areas that were covered throughout this chapter and that will come together during an incident. But an incident is not finished when the issue is resolved. In fact, this is just the beginning of a whole different level of work that needs to be done for every single incident—document the lessons learned.
One of the most valuable pieces of information that you have in the post-incident activity phase is the lessons learned. This will help you to keep refining the process through the identification of gaps in the process and areas of improvement. When an incident is fully closed, it will be documented. This documentation must be very detailed, with the full timeline of the incident, the steps that were taken to resolve the problem, what happened during each step, and how the issue was finally resolved outlined in depth.
This documentation will be used as a base to answer the following questions:
- Who identified the security issue?
- A user or the detection system?
- Was the incident opened with the right priority?
- Did the security operations team perform the initial assessment correctly?
- Is there anything that could be improved at this point?
- Was the data analysis done correctly?
- Was the containment done correctly?
- Is there anything that could be improved at this point?
- How long did it take to resolve this incident?
The answers to these questions will help refine the incident response process and also enrich the incident database. The incident management system should have all incidents fully documented and searchable. The goal is to create a knowledge base that can be used for future incidents. Oftentimes, an incident can be resolved using the same steps that were used in a similar previous incident.
Another important point to cover is evidence retention. All the artifacts that were captured during the incident should be stored according to the company's retention policy, unless there are specific guidelines for evidence retention. Keep in mind that if the attacker needs to be prosecuted, the evidence must be kept intact until legal actions are completely settled.
When organizations start to migrate to the cloud and have a hybrid environment (on-premise and connectivity to the cloud), their IR process may need to pass through some revisions to include some deltas that are related to cloud computing. In the next section, you will learn more about IR in the cloud.
Incident response in the cloud
When we speak about cloud computing, we are talking about a shared responsibility [4] between the cloud provider and the company that is contracting the service. The level of responsibility will vary according to the service model, as shown in the following diagram:

Figure 6: Shared responsibility in the cloud
For Software as a service (SaaS), most of the responsibility is on the cloud provider; in fact, the customer's responsibility is basically to keep their infrastructure on premises protected (including the endpoint that is accessing the cloud resource). For Infrastructure as a service (IaaS), most of the responsibility lies on the customer's side, including vulnerability and patch management.
Understanding the responsibilities is important in order to understand the data gathering boundaries for incident response purposes. In an IaaS environment, you have full control of the virtual machine and have complete access to all logs provided by the operating system. The only missing information in this model is the underlying network infrastructure and hypervisor logs. Each cloud provider [5] will have its own policy regarding data gathering for incident response purposes, so make sure that you review the cloud provider policy before requesting any data.
For the SaaS model, the vast majority of the information relevant to an incident response is in the possession of the cloud provider. If suspicious activities are identified in a SaaS service, you should contact the cloud provider directly, or open an incident via a portal [6]. Make sure that you review your SLA to better understand the rules of engagement in an incident response scenario.
Updating your IR process to include cloud
Ideally, you should have one single incident response process that covers both major scenarios—on-premises and cloud. This means you will need to update your current process to include all relevant information related to the cloud.
Make sure that you review the entire IR life cycle to include cloud-computing-related aspects. For example, during the preparation, you need to update the contact list to include the cloud provider contact information, on-call process, and so on. The same applies to other phases:
- Detection: Depending on the cloud model that you are using, you want to include the cloud provider solution for detection in order to assist you during the investigation [7].
- Containment: Revisit the cloud provider capabilities to isolate an incident in case it occurs, which will also vary according to the cloud model that you are using. For example, if you have a compromised VM in the cloud, you may want to isolate this VM from others in a different virtual network and temporarily block access from outside.
For more information about incident response in the cloud, we recommend that you read Domain 9 of the Cloud Security Alliance Guidance [8].
Appropriate toolset
Another important aspect of IR in the cloud is to have the appropriate toolset in place. Using on-premises related tools may not be feasible in the cloud environment, and worse, may give you the false impression that you are doing the right thing.
The reality is that with cloud computing, many security-related tools that were used in the past are not efficient for collecting data and detecting threats. When planning your IR, you must revise your current toolset and identify the potential gaps for your cloud workloads.
In Chapter 12, Active Sensors, we will cover some cloud-based tools that can be used in the IR process, such as Azure Security Center and Azure Sentinel.
IR Process from the Cloud Solution Provider (CSP) perspective
When planning your migration to the cloud and comparing the different CSPs solutions, make sure to understand their own incident response process. What if another tenant in their cloud starts sending attacks against your workloads that reside on the same cloud? How will they respond to that? These are just examples of a couple of questions that you need to think about when planning which CSP will host your workloads.
The following diagram has an example of how a CSP could detect a suspicious event, leverage their IR process to perform the initial response, and notify their customer about the event:

Figure 7: How a CSP might detect a potential threat, form an initial response, and notify the customer
The handover between CSP and customer must be very well synchronized, and this should be settled during the planning phase for the cloud adoption.
Summary
In this chapter, you learned about the incident response process, and how this fits into the overall purpose of enhancing your security posture.
You also learned about the importance of having an incident response process in place to rapidly identify and respond to security incidents. By planning each phase of the incident response life cycle, you create a cohesive process that can be applied to the entire organization. The foundation, of the incident response plan is the same for different industries, and on top of this foundation, you can include the customized areas that are relevant to your own business. You also came across the key aspects of handling an incident, and the importance of post-incident activity—which includes full documentation of the lessons learned—and using this information as input to improve the overall process. Lastly, you learned the basics of incident response in the cloud and how this can affect your current process.
In the next chapter, you will gain an understanding about the mindset of an attacker, the different stages of an attack, and what usually takes place in each one of these phases. This is an important concept for the rest of the book, considering that the attack and defense exercises will be using the cybersecurity kill chain as a foundation.
References
- You can download this publication at http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-61r2.pdf.
- According to Computer Security Incident Response (CSIR)—Publication 800-61R2 from NIST, an event is "any observable occurrence in a system or network". More information at http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-61r2.pdf.
- More information about this patch at https://technet.microsoft.com/en-us/library/security/ms17-010.aspx.
- More information about this subject at https://blog.cloudsecurityalliance.org/2014/11/24/shared-responsibilities-for-security-in-the-cloud-part-1/.
- For Microsoft Azure, read this paper for more information about incident response in the cloud https://gallery.technet.microsoft.com/Azure-Security-Response-in-dd18c678.
- For Microsoft Online Services, you can use this from https://cert.microsoft.com/report.aspx.
- Watch the author Yuri Diogenes demonstrating how to use Azure Security Center to investigate a cloud incident https://channel9.msdn.com/Blogs/Azure-Security-Videos/Azure-Security-Center-in-Incident-Response.
- You can download this document from https://cloudsecurityalliance.org/document/incident-response/.