
Chapter 4. Principle of Domain ownership
Data mesh, at its core, is founded in decentralization and distribution of responsibility to people who are closest to the data in order to support continuous change and scalability. The question is, how do we decentralize and decompose the components of the data ecosystem and their ownership. The components include the analytical data, its associated information that makes the data usable and understandable (aka metadata), the code that maintains the data and its integrity, and the computation and infrastructure necessary to create and serve it.
Contrary to the existing data architectures, Data Mesh follows the seams of organizational units as the axis of decomposing data. It does not follow the borders set by the underlying technology solutions, such as lake or warehouse implementations, nor the functional lines such as the centralized data or analytics team.
Our organizations today are decomposed based on their business domains. Such decomposition localizes the impact of continuous change and evolution - for the most part - to the domain. As you saw in <Chapter 3, Before the Inflection Point>, traditional data architectures are partitioned around technology, e.g. data warehouse, and give data ownership to teams performing activities related to the technology, e.g. data warehouse team. The traditional architectures mirror an organizational structure that centralizes the responsibility of sharing analytical data to a data team, which has originally been setup to localize complexity of dealing with the new field of analytical data management. Data Mesh partitions data around business domains, e.g. podcasts, and gives data ownership to the domains, e.g. podcasts team. Data Mesh gives the data sharing responsibility to those who are most intimately familiar with the data, are first-class users of the data and are already in control of its point of origin.
This rather intuitive division of responsibility solves one problem but introduces others: it leads to a distributed logical data architecture, creates challenges around data interoperability and connectivity between domains. I will address these challenges with the introduction of the other principles in the upcoming chapters.
In this section, I unpack how to apply Domain-Driven-Design (DDD) strategies to decompose data and its ownership and introduce the transformational changes organizations need to put in place.
Apply DDD’s Strategic Design to Data
Eric Evans’s book Domain-Driven Design (2003) has deeply influenced modern architectural thinking and, consequently organizational modeling. It has influenced the microservices architecture by decomposing the systems into distributed services built around business domain capabilities. It has fundamentally changed how the teams form, so that a team can independently and autonomously own a domain capability.
Though we have adopted domain-oriented decomposition and ownership when implementing operational systems, curiously, ideas of decomposition based on business domains have yet to penetrate the analytical data space. The closest application of DDD in data platform architecture, I have seen, is for source operational systems to emit their business domain events and for the monolithic data platform to ingest them. However beyond the point of ingestion the domain teams’ responsibility ends, and data responsibilities are transferred to the data team. The further transformations are performed by the data team the more removed the data becomes from its original form and intention. For example, in Daff Inc.’s podcasts’ domain emits logs of podcasts being played on a short-retention log. Then downstream, a centralized data team will pick these events up and attempt to transform, aggregate, and store them as long-lived files or tables.
In his original book Eric Evans introduces a set of complementary strategies to scale modeling at the enterprise level called DDD’s Strategic Design. These strategies are designed for organizations with complex domains and many teams. DDD’s Strategic Design techniques move away from the two widely used modes of modeling and ownership: (1) organizational-level central modeling or (2) siloes of internal models with limited integration, causing cumbersome inter-team communications. Eric Evan observed that total unification of the domain models of the organization into one, is neither feasible nor cost-effective. This is similar to data warehouse modeling. Instead, DDD’s Strategic Design embraces modeling the organization based on multiple models each contextualized to a particular domain, called Bounded Context, with clear boundaries and, most importantly, with the articulation of the relationship between Bounded Contexts with Context Mapping.
Data Mesh, similarly to modern distributed operational systems and teams, adopts the boundary of Bounded Contexts to distribute the modeling of analytical data, the data itself and its ownership. For example, suppose an organization has already adopted a microservices or domain-oriented architecture and has organized its teams around domains’ bounded contexts. In this case, Data Mesh simply extends this by including the analytical data responsibilities in the existing domains. This is the foundation of scale in a complex system like enterprises today.
Consider Daff Inc. for example, there is a ‘media player’ team who is responsible for the mobile and web digital media players. The ‘media player’ application emits ‘play events’ that show how listeners interact with the player. The data can be used for many downstream use cases, from improving the player applications performance to reconstructing the ‘listener’s session’ and the longitudinal journey of discovering and listening to music. In the absence of a Data Mesh implementation, the ‘media player’ team basically dumps the play events - with whatever quality and cadence - on some sort of a short-retention streaming infrastructure or worse in its transactional database, which is then get picked up by the centralized data team to put into a lake or warehouse or likely both. This changes with Data Mesh. Data Mesh extends the responsibility of the ‘media player’ team to provide high-quality long-retention analytical view of the ‘play events’ — real-time and aggregated. The ‘media player’ team now has the end-to-end responsibility of sharing the ‘play event’ analytical data directly to the data analysts, data scientists or other persons who are interested in the data. The ‘play events’ analytical data is then transformed by the ‘listener session’ domain to get aggregated into a journey-based view of the listener interactions. The ‘recommendations’ domain uses the ‘listener sessions’ to create new datasets —graphs to recommend music based on listeners’ social network’s play behavior.
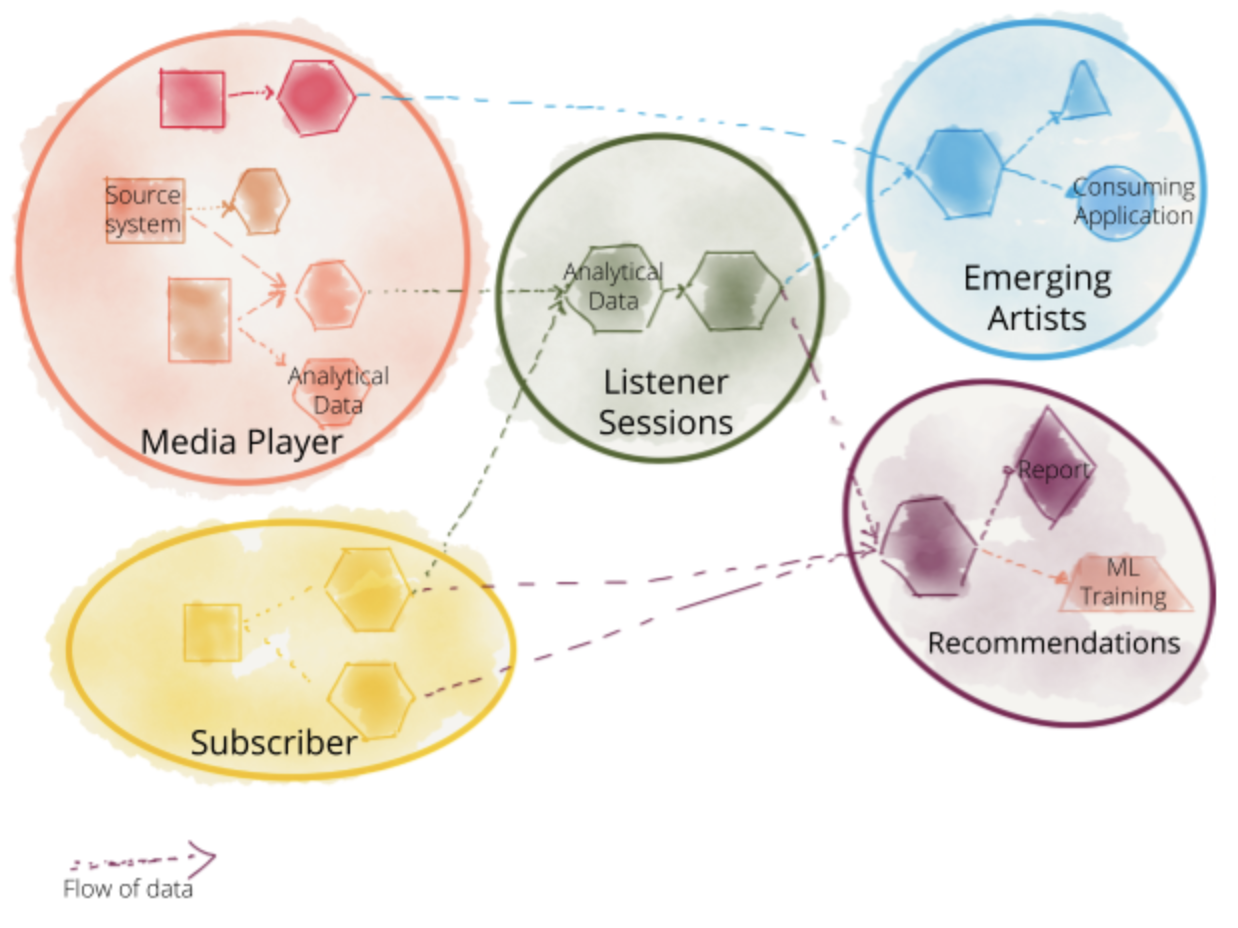
Figure 4-1. Decomposing the ownership and architecture of analytical data, aligned with the existing or new business domains.
Domain Data Archetypes
When we map the Data Mesh to an organization and its domains, we discover a few different archetypes of domain-oriented analytical data. While Data Mesh principles don’t differentiate between the archetypes of domains, at a practical level, recognizing their characteristics help with optimizing the implementation and planning of the execution.
There are three archetypes of domain-oriented data:
Source-aligned domain data: analytical data reflecting the business facts generated by the operational systems. This is also called native data product.
Aggregate domain data: analytical data that is an aggregate of multiple upstream domains.
Consumer-aligned domain data: analytical data transformed to fit the needs of one or multiple specific use cases and consuming applications. This is also called fit-for-purpose domain data.
Figure 4-2 expands on our previous example and demonstrates the archetypes of the domain-oriented data. For example, the ‘media player’ domain serves source-aligned analytical data directly correlated with the ‘media player’ application events. The ‘listener sessions’ serve aggregate data products that transform and aggregate individual listener player events into constructed sessions of interaction. And, ‘recommendations’ domain data is a fit-for-purpose data that serves the specific needs of the recommender service.

Figure 4-2. Example of domain data archetypes
Source-aligned Domain Data
Some domains naturally align with the source, where the data originates. The source-aligned domain datasets represent the facts and reality of the business. They capture the data that is mapped very closely to what the operational systems of their origin, systems of reality, generate. In our example, facts of the business such as ‘how the users are interacting with the media players', or ‘the process of onboarding labels’ lead to the creation of source-aligned domain data such as ‘user play events', ‘audio play quality stream’ and ‘onboarded labels’. These facts are best known and generated by their corresponding operational systems. For example the ‘media player’ system knows best about the ‘user play events’.
In summary, Data Mesh assumes that organizational units are responsible for providing business capabilities and responsible for providing the truths of their business domain as source-aligned domain datasets.
The business facts are best presented as business Domain Events, and can be stored and served as distributed logs of time-stamped events for any authorized consumer to access. In addition to timed events, source-aligned domain data should also be provided in easily consumable historical slices, aggregated over a time interval that closely reflects the interval of change in the business domain. For example in an ‘onboarded labels’ source-aligned domain, the monthly aggregation is a reasonable view to provide, ‘onboarded labels in month <m>’, processed and shared on a monthly basis.
Note that, source-aligned business events are not modeled or structured like the source application’s transactional database; an anti-pattern is often observed, particularly when events are sourced through Change Data Capture tooling or Data Virtualization on top of the application’s database. The application database model serves a very different purpose, and is often modeled for speed of performing transactions as needed by the application. The analytical data is structured for ease of understanding and access for reporting, machine learning training and other non-transactional use cases.
The nature of the domain data—data on the outside—is very different from the internal data that the operational systems use to do their job - data on the inside. Analytical data often has much larger volume and represents immutable timestamped information over an infinite1 time. Its modeling likely changes less frequently than the source system, and its underlying storage and access technology should satisfy data access and querying for reporting and machine learning training, efficiently over a large body of data.
Source-aligned domain data is the most foundational. It is expected to be permanently captured and made available. As the organization evolves, its data-driven and intelligence services can always go back to the business facts, and create new aggregations or projections.
Note that source-aligned domain datasets closely represent the raw data at the point of creation, and are not fitted or modeled for a particular consumer. The archetypes introduced next cover the aggregations or the further transformations that might be needed for specific consumptions.
Aggregate Domain Data
There is never a one to one mapping between a domain concept and a source system at an enterprise scale. There are often many systems that can serve parts of the data that belong to a shared concept—some legacy systems, some half modernized and some fresh greenfield ones. Hence there might be many source-aligned data aka reality data that ultimately need to be aggregated into a more aggregate view of a concept. For example, attributes that define ‘subscribers’, ‘songs’, or ‘artists’ can be mapped from many different points of origin. For example, the ‘subscriber management’ domain can have profile-related information about the subscribers, while the ‘player’ domain knows about their music preferences. There are use cases, such as marketing or sales, that demand a holistic view of the subscriber. This demands a new long-standing aggregate domain to be created with the responsibility of consuming and composing data from multiple source-aligned domains and sharing the aggregate data.
Note
I strongly caution you against creating ambitious aggregate domain data; aggregate domain data that attempts to capture all facets of a particular concept like ‘customer 360’. Such aggregate can become too complex and unwieldy to manage and difficult to understand and use for any particular use case. In the past, the discipline of Master Data Management (MDM) has attempted to aggregate all facets of shared data assets in one place and in one model. MDM suffers from the complexity and out-of-date challenges of a single unified cross-organizational canonical modeling.
Consumer-aligned Domain Data
Some domains align closely with the consuming use cases. The consumer-aligned domain data, and the teams who own them, aim to satisfy a closely related group of use cases. For example the ’social recommendation domain’ that focuses on providing recommendations based on users’ social connections, creates domain data that fit this specific need; perhaps through a ‘graph representation of the social network of users’. While this graph data is useful for recommendation use cases, it might also be useful for other use cases such as a ‘listeners notifications’ domain. The ‘listeners notification’ domain provides data regarding different information sent to the listener, including what people in their social network are listening to.
Engineered features to train machine learning models often fall into this category. For example, Daff Inc. introduces a machine learning model that analyses the sentiment of a song, e.g. is positive or negative. Then uses this information for recommendation and ranking of their music. However, to perform sentiment analysis on a piece of music, data scientists need to extract a few features and additional information from the song such as ‘liveliness’, ‘danceability’, ‘acousticness’, ‘valence’, etc. Once these attributes (features) are extracted, they can be maintained and shared as a consumer-aligned domain data to train the ‘sentiment analysis’ domain or other adjacent models such as ‘playlist’ creation.
The consumer-aligned domain data have a different nature in comparison to source-aligned domains data. They structurally go through more changes, and they transform the source domain events to structures and content that fit a particular use case.
I sometimes call these fit-for-purpose domain data.
Transition to Domain Ownership
Domain-oriented data ownership feels organic, and a natural progression of modern organizations’ domain-driven digital journey. Despite that, it disputes some of the archaic rules of analytical data management. Below is a list of a few and I’m sure you can think of others.
Push Data Ownership Upstream
Data architecture nomenclature has flourished from the source of life itself: water. Data lake, Lakeshore marts, Dataflow, Lakehouse, data pipelines, lake hydration, etc. I do admit, it’s a reassuring symbol, it’s soothing and simply beautiful. However there is a dangerous notion lurking underneath it. The notion that data must flow from source to some other place - e.g. the centralized lake - to become useful, to become meaningful, to have value and to be worthy of consumption. There is an assumption that data upstream is less valuable or useful than data downstream.
Data Mesh challenges this assumption. Data can be consumable and useful right at the source domain, I called this source-aligned domain data. It doesn’t need to flow from source to consumer through purifying pipelines, before it can be used. Data must be cleansed and made ready for consumption for analytical purposes upstream, by the source domain. The accountability for sharing quality analytical data is pushed upstream.
Of course at a later point downstream, source-aligned domain data can be aggregated and transformed to create a new higher order insight. I called these, aggregate domain data or fit-for-purpose domain data. This transformation happens within the context of downstream domains, under the domain’s long-term ownership. There is no intelligent transformation that happens in the no man’s land of in-between domains, in what is called a data pipeline, today.
Define Multiple Connected Models
Data warehousing techniques and central data governance teams have been in the search of the one canonical model holy grail. It’s a wonderful idea, one model that describes the data domains and can be used to provide meaning and data to all use cases. But in reality systems are complex, continuously changing and no one model can tame this messy life. Data Mesh in contrast follows DDD’s Bounded Context and Context Mapping modeling of the data. Each domain can model their data according to their context, share these models and the corresponding data thoughtfully with others, and identify how one model can link and map to others.
This means there could be multiple models of the same concept in different domains and that is OK. For example, the ‘artist’ representation in the ‘payment’ includes payment attributes, which is very different from the ‘artist’ model in the ‘recommendation’ domain, that includes artist profile and genre. But the mesh should allow to map ‘artist’ from one domain to another, and be able to link artist data from one domain to the other. There are multiple ways to achieve this, including a unified identification scheme, a single ID used by all domains that include an ‘artist’.
Polysemes, shared concepts across different domains, create linked data and models across domains.
Embrace the Most Relevant Domain, and Don’t Expect the Single Source of Truth
Another myth is that we shall have a single source of truth for each concept or entity. For example, one source of truth to know everything about ‘subscribers’ or ‘playlists’, etc. This is a wonderful idea, and is placed to prevent multiple copies of out-of-date and untrustworthy data. But in reality it’s proved costly, an impediment to scale and speed, or simply unachievable. Data Mesh does not enforce the idea of one source of truth. However, it places multiple practices in place that reduces the likelihood of multiple copies of out-of-date data.
The long-term domain-oriented ownership and accountability for providing discoverable, easily usable and of high quality, suitable for a wide range of users — analysts and scientists — reduces the need for copying.
Data Mesh endorses multiple models of the data, and hence data can be read from one domain, transformed and stored by another domain. For example, ‘emerging artists’ domain reads ‘play events’ domain data and transforms and then stores it as ‘emerging artists’. This mimics the real world, data moves around, gets copied and gets reshaped. It’s very difficult to maintain the ideology of a single source of truth under such a dynamic topology. Data Mesh embraces such dynamism for scale and speed. However, it continuously observes the mesh and prevents errors that often arise when data gets copied. Data Mesh prevents these errors through a set of complementary non-negotiable capabilities of the mesh and data shared on the mesh: immutability, time-variance, read-only access, discoverability and recognition of polysemes’ unified identities cross-domain multiple domains. See <Chapter 9, Data Product Logical Architecture> for more on these.
Hide the Data Pipelines as Domains’ Internal Implementation
The need for cleansing, preparing, aggregating and sharing data remains, so does the usage of data pipeline, regardless of using a centralized data architecture or Data Mesh. The difference is that in traditional data architectures, data pipelines are first-class architectural concerns that integrate to compose more complex data transformation and movement. In Data Mesh, a data pipeline is simply an internal implementation of the data domain and is handled internally within the domain. It’s an implementation detail that must be abstracted from outside of the domain. As a result, when transitioning to Data Mesh, you will be redistributing different pipelines and their jobs to different domains.
For example the source-aligned domains need to include the cleansing, deduplicating, enriching of their domain events so that they can be consumed by other domains, without replication of cleansing downstream. Each domain data must establish a Service Level Objective for the quality of the data it provides: timeliness, accuracy, etc.
Consider Daff: our ‘media player’ domain providing audio ‘play events’ can include cleansing and standardization data pipeline in their domain that provides a stream of de-duped near-real-time ‘play events’ that conform to the organization’s standards of encoding events.
Equally, we will see that aggregation stages of a centralized pipeline move into implementation details of aggregate or fit-for-purpose domain data.
One might argue that this model leads to duplicated effort in each domain to create their own data processing pipeline implementation, technology stack and tooling. Data Mesh addresses this concern with the self-serve data platform, described in <Chapter 6>. Having said that, domains are taking on additional responsibilities, the responsibilities and efforts shift from a centralized data team to domains, to gain agility and authenticity.
Recap
Arranging data and its ownership around technology has been an impediment to scale, it simply has been orthogonal to how change happens and features develop. Centrally-organized data teams have been the source of friction. There is an alternative, the alternative is a tried and tested method to scale modelling at enterprise level: Domain-oriented Bounded Context modeling. Data Mesh adapts this concept to the world of analytical data. It demands domain teams who are closest to the data to own the analytical data and serve the domain’s analytical data to the rest of the organization. Data Mesh supports creation of new domain’s data by composing, aggregating and projecting existing domains.
1 Infinite time captures data from a particular epoch to an unbounded future. Epoch may vary from system to system, depending on the retention policies of the domain. However it is expected to be long term.