
Chapter 13. Distributed Transactions
To maintain order in a distributed system, we have to guarantee at least some consistency. In “Consistency Models”, we talked about single-object, single-operation consistency models that help us to reason about the individual operations. However, in databases we often need to execute multiple operations atomically.
Atomic operations are explained in terms of state transitions: the database was in state A before a particular transaction was started; by the time it finished, the state went from A to B. In operation terms, this is simple to understand, since transactions have no predetermined attached state. Instead, they apply operations to data records starting at some point in time. This gives us some flexibility in terms of scheduling and execution: transactions can be reordered and even retried.
The main focus of transaction processing is to determine permissible histories, to model and represent possible interleaving execution scenarios. History, in this case, represents a dependency graph: which transactions have been executed prior to execution of the current transaction. History is said to be serializable if it is equivalent (i.e., has the same dependency graph) to some history that executes these transactions sequentially. You can review concepts of histories, their equivalence, serializability, and other concepts in “Serializability”. Generally, this chapter is a distributed systems counterpart of Chapter 5, where we discussed node-local transaction processing.
Single-partition transactions involve the pessimistic (lock-based or tracking) or optimistic (try and validate) concurrency control schemes that we discussed in Chapter 5, but neither one of these approaches solves the problem of multipartition transactions, which require coordination between different servers, distributed commit, and rollback protocols.
Generally speaking, when transferring money from one account to another, you’d like to both credit the first account and debit the second one simultaneously. However, if we break down the transaction into individual steps, even debiting or crediting doesn’t look atomic at first sight: we need to read the old balance, add or subtract the required amount, and save this result. Each one of these substeps involves several operations: the node receives a request, parses it, locates the data on disk, makes a write and, finally, acknowledges it. Even this is a rather high-level view: to execute a simple write, we have to perform hundreds of small steps.
This means that we have to first execute the transaction and only then make its results visible. But let’s first define what transactions are. A transaction is a set of operations, an atomic unit of execution. Transaction atomicity implies that all its results become visible or none of them do. For example, if we modify several rows, or even tables in a single transaction, either all or none of the modifications will be applied.
To ensure atomicity, transactions should be recoverable. In other words, if the transaction cannot complete, is aborted, or times out, its results have to be rolled back completely. A nonrecoverable, partially executed transaction can leave the database in an inconsistent state. In summary, in case of unsuccessful transaction execution, the database state has to be reverted to its previous state, as if this transaction was never tried in the first place.
Another important aspect is network partitions and node failures: nodes in the system fail and recover independently, but their states have to remain consistent. This means that the atomicity requirement holds not only for the local operations, but also for operations executed on other nodes: changes have to be durably propagated to all of the nodes involved in the transaction or none of them [LAMPSON79].
Making Operations Appear Atomic
To make multiple operations appear atomic, especially if some of them are remote, we need to use a class of algorithms called atomic commitment. Atomic commitment doesn’t allow disagreements between the participants: a transaction will not commit if even one of the participants votes against it. At the same time, this means that failed processes have to reach the same conclusion as the rest of the cohort. Another important implication of this fact is that atomic commitment algorithms do not work in the presence of Byzantine failures: when the process lies about its state or decides on an arbitrary value, since it contradicts unanimity [HADZILACOS05].
The problem that atomic commitment is trying to solve is reaching an agreement on whether or not to execute the proposed transaction. Cohorts cannot choose, influence, or change the proposed transaction or propose any alternative: they can only give their vote on whether or not they are willing to execute it [ROBINSON08].
Atomic commitment algorithms do not set strict requirements for the semantics of transaction prepare, commit, or rollback operations. Database implementers have to decide on:
-
When the data is considered ready to commit, and they’re just a pointer swap away from making the changes public.
-
How to perform the commit itself to make transaction results visible in the shortest timeframe possible.
-
How to roll back the changes made by the transaction if the algorithm decides not to commit.
We discussed node-local implementations of these processes in Chapter 5.
Many distributed systems use atomic commitment algorithms—for example, MySQL (for distributed transactions) and Kafka (for producer and consumer interaction [MEHTA17]).
In databases, distributed transactions are executed by the component commonly known as a transaction manager. The transaction manager is a subsystem responsible for scheduling, coordinating, executing, and tracking transactions. In a distributed environment, the transaction manager is responsible for ensuring that node-local visibility guarantees are consistent with the visibility prescribed by distributed atomic operations. In other words, transactions commit in all partitions, and for all replicas.
We will discuss two atomic commitment algorithms: two-phase commit, which solves a commitment problem, but doesn’t allow for failures of the coordinator process; and three-phase commit [SKEEN83], which solves a nonblocking atomic commitment problem,1 and allows participants proceed even in case of coordinator failures [BABAOGLU93].
Two-Phase Commit
Let’s start with the most straightforward protocol for a distributed commit that allows multipartition atomic updates. (For more information on partitioning, you can refer to “Database Partitioning”.) Two-phase commit (2PC) is usually discussed in the context of database transactions. 2PC executes in two phases. During the first phase, the decided value is distributed, and votes are collected. During the second phase, nodes just flip the switch, making the results of the first phase visible.
2PC assumes the presence of a leader (or coordinator) that holds the state, collects votes, and is a primary point of reference for the agreement round. The rest of the nodes are called cohorts. Cohorts, in this case, are usually partitions that operate over disjoint datasets, against which transactions are performed. The coordinator and every cohort keep local operation logs for each executed step. Participants vote to accept or reject some value, proposed by the coordinator. Most often, this value is an identifier of the distributed transaction that has to be executed, but 2PC can be used in other contexts as well.
The coordinator can be a node that received a request to execute the transaction, or it can be picked at random, using a leader-election algorithm, assigned manually, or even fixed throughout the lifetime of the system. The protocol does not place restrictions on the coordinator role, and the role can be transferred to another participant for reliability or performance.
As the name suggests, a two-phase commit is executed in two steps:
- Prepare
-
The coordinator notifies cohorts about the new transaction by sending a
Proposemessage. Cohorts make a decision on whether or not they can commit the part of the transaction that applies to them. If a cohort decides that it can commit, it notifies the coordinator about the positive vote. Otherwise, it responds to the coordinator, asking it to abort the transaction. All decisions taken by cohorts are persisted in the coordinator log, and each cohort keeps a copy of its decision locally. - Commit/abort
-
Operations within a transaction can change state across different partitions (each represented by a cohort). If even one of the cohorts votes to abort the transaction, the coordinator sends the
Abortmessage to all of them. Only if all cohorts have voted positively does the coordinator send them a finalCommitmessage.
This process is shown in Figure 13-1.
During the prepare phase, the coordinator distributes the proposed value and collects votes from the participants on whether or not this proposed value should be committed. Cohorts may choose to reject the coordinator’s proposal if, for example, another conflicting transaction has already committed a different value.

Figure 13-1. Two-phase commit protocol. During the first phase, cohorts are notified about the new transaction. During the second phase, the transaction is committed or aborted.
After the coordinator has collected the votes, it can make a decision on whether to commit the transaction or abort it. If all cohorts have voted positively, it decides to commit and notifies them by sending a Commit message. Otherwise, the coordinator sends an Abort message to all cohorts and the transaction gets rolled back. In other words, if one node rejects the proposal, the whole round is aborted.
During each step the coordinator and cohorts have to write the results of each operation to durable storage to be able to reconstruct the state and recover in case of local failures, and be able to forward and replay results for other participants.
In the context of database systems, each 2PC round is usually responsible for a single transaction. During the prepare phase, transaction contents (operations, identifiers, and other metadata) are transferred from the coordinator to the cohorts. The transaction is executed by the cohorts locally and is left in a partially committed state (sometimes called precommitted), making it ready for the coordinator to finalize execution during the next phase by either committing or aborting it. By the time the transaction commits, its contents are already stored durably on all other nodes [BERNSTEIN09].
Cohort Failures in 2PC
Let’s consider several failure scenarios. For example, as Figure 13-2 shows, if one of the cohorts fails during the propose phase, the coordinator cannot proceed with a commit, since it requires all votes to be positive. If one of the cohorts is unavailable, the coordinator will abort the transaction. This requirement has a negative impact on availability: failure of a single node can prevent transactions from happening. Some systems, for example, Spanner (see “Distributed Transactions with Spanner”), perform 2PC over Paxos groups rather than individual nodes to improve protocol availability.

Figure 13-2. Cohort failure during the propose phase
The main idea behind 2PC is a promise by a cohort that, once it has positively responded to the proposal, it will not go back on its decision, so only the coordinator can abort the transaction.
If one of the cohorts has failed after accepting the proposal, it has to learn about the actual outcome of the vote before it can serve values correctly, since the coordinator might have aborted the commit due to the other cohorts’ decisions. When a cohort node recovers, it has to get up to speed with a final coordinator decision. Usually, this is done by persisting the decision log on the coordinator side and replicating decision values to the failed participants. Until then, the cohort cannot serve requests because it is in an inconsistent state.
Since the protocol has multiple spots where processes are waiting for the other participants (when the coordinator collects votes, or when the cohort is waiting for the commit/abort phase), link failures might lead to message loss, and this wait will continue indefinitely. If the coordinator does not receive a response from the replica during the propose phase, it can trigger a timeout and abort the transaction.
Coordinator Failures in 2PC
If one of the cohorts does not receive a commit or abort command from the coordinator during the second phase, as shown in Figure 13-3, it should attempt to find out which decision was made by the coordinator. The coordinator might have decided upon the value but wasn’t able to communicate it to the particular replica. In such cases, information about the decision can be replicated from the peers’ transaction logs or from the backup coordinator. Replicating commit decisions is safe since it’s always unanimous: the whole point of 2PC is to either commit or abort on all sites, and commit on one cohort implies that all other cohorts have to commit.

Figure 13-3. Coordinator failure after the propose phase
During the first phase, the coordinator collects votes and, subsequently, promises from cohorts, that they will wait for its explicit commit or abort command. If the coordinator fails after collecting the votes, but before broadcasting vote results, the cohorts end up in a state of uncertainty. This is shown in Figure 13-4. Cohorts do not know what precisely the coordinator has decided, and whether or not any of the participants (potentially also unreachable) might have been notified about the transaction results [BERNSTEIN87].

Figure 13-4. Coordinator failure before it could contact any cohorts
Inability of the coordinator to proceed with a commit or abort leaves the cluster in an undecided state. This means that cohorts will not be able to learn about the final decision in case of a permanent coordinator failure. Because of this property, we say that 2PC is a blocking atomic commitment algorithm. If the coordinator never recovers, its replacement has to collect votes for a given transaction again, and proceed with a final decision.
Many databases use 2PC: MySQL, PostgreSQL, MongoDB,2 and others. Two-phase commit is often used to implement distributed transactions because of its simplicity (it is easy to reason about, implement, and debug) and low overhead (message complexity and the number of round-trips of the protocol are low). It is important to implement proper recovery mechanisms and have backup coordinator nodes to reduce the chance of the failures just described.
Three-Phase Commit
To make an atomic commitment protocol robust against coordinator failures and avoid undecided states, the three-phase commit (3PC) protocol adds an extra step, and timeouts on both sides that can allow cohorts to proceed with either commit or abort in the event of coordinator failure, depending on the system state. 3PC assumes a synchronous model and that communication failures are not possible [BABAOGLU93].
3PC adds a prepare phase before the commit/abort step, which communicates cohort states collected by the coordinator during the propose phase, allowing the protocol to carry on even if the coordinator fails. All other properties of 3PC and a requirement to have a coordinator for the round are similar to its two-phase sibling. Another useful addition to 3PC is timeouts on the cohort side. Depending on which step the process is currently executing, either a commit or abort decision is forced on timeout.
As Figure 13-5 shows, the three-phase commit round consists of three steps:
- Propose
-
The coordinator sends out a proposed value and collects the votes.
- Prepare
-
The coordinator notifies cohorts about the vote results. If the vote has passed and all cohorts have decided to commit, the coordinator sends a
Preparemessage, instructing them to prepare to commit. Otherwise, anAbortmessage is sent and the round completes. - Commit
-
Cohorts are notified by the coordinator to commit the transaction.

Figure 13-5. Three-phase commit
During the propose step, similar to 2PC, the coordinator distributes the proposed value and collects votes from cohorts, as shown in Figure 13-5. If the coordinator crashes during this phase and the operation times out, or if one of the cohorts votes negatively, the transaction will be aborted.
After collecting the votes, the coordinator makes a decision. If the coordinator decides to proceed with a transaction, it issues a Prepare command. It may happen that the coordinator cannot distribute prepare messages to all cohorts or it fails to receive their acknowledgments. In this case, cohorts may abort the transaction after timeout, since the algorithm hasn’t moved all the way to the prepared state.
As soon as all the cohorts successfully move into the prepared state and the coordinator has received their prepare acknowledgments, the transaction will be committed if either side fails. This can be done since all participants at this stage have the same view of the state.
During commit, the coordinator communicates the results of the prepare phase to all the participants, resetting their timeout counters and effectively finishing the transaction.
Coordinator Failures in 3PC
All state transitions are coordinated, and cohorts can’t move on to the next phase until everyone is done with the previous one: the coordinator has to wait for the replicas to continue. Cohorts can eventually abort the transaction if they do not hear from the coordinator before the timeout, if they didn’t move past the prepare phase.
As we discussed previously, 2PC cannot recover from coordinator failures, and cohorts may get stuck in a nondeterministic state until the coordinator comes back. 3PC avoids blocking the processes in this case and allows cohorts to proceed with a deterministic decision.
The worst-case scenario for the 3PC is a network partition, shown in Figure 13-6. Some nodes successfully move to the prepared state, and now can proceed with commit after the timeout. Some can’t communicate with the coordinator, and will abort after the timeout. This results in a split brain: some nodes proceed with a commit and some abort, all according to the protocol, leaving participants in an inconsistent and contradictory state.
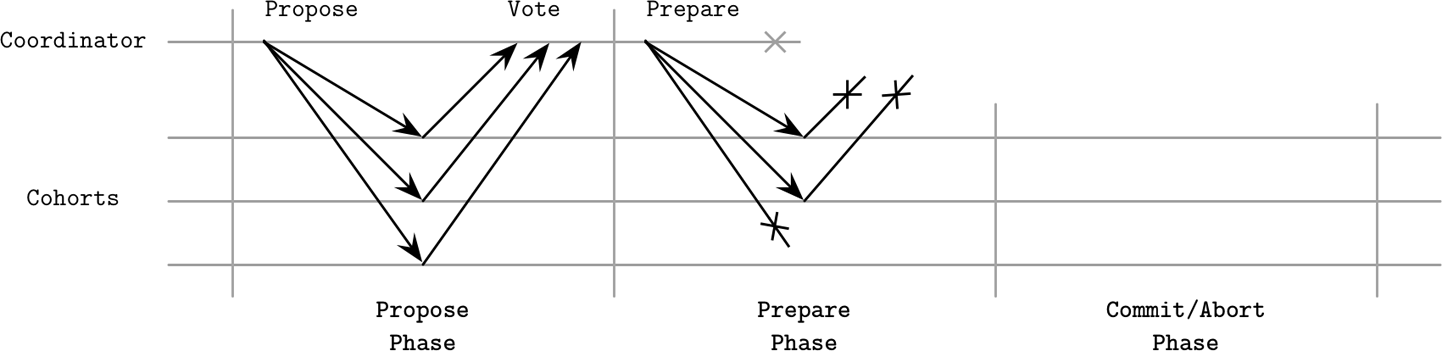
Figure 13-6. Coordinator failure during the second phase
While in theory 3PC does, to a degree, solve the problem with 2PC blocking, it has a larger message overhead, introduces potential contradictions, and does not work well in the presence of network partitions. This might be the primary reason 3PC is not widely used in practice.
Distributed Transactions with Calvin
We’ve already touched on the subject of synchronization costs and several ways around it. But there are other ways to reduce contention and the total amount of time during which transactions hold locks. One of the ways to do this is to let replicas agree on the execution order and transaction boundaries before acquiring locks and proceeding with execution. If we can achieve this, node failures do not cause transaction aborts, since nodes can recover state from other participants that execute the same transaction in parallel.
Traditional database systems execute transactions using two-phase locking or optimistic concurrency control and have no deterministic transaction order. This means that nodes have to be coordinated to preserve order. Deterministic transaction order removes coordination overhead during the execution phase and, since all replicas get the same inputs, they also produce equivalent outputs. This approach is commonly known as Calvin, a fast distributed transaction protocol [THOMSON12]. One of the prominent examples implementing distributed transactions using Calvin is FaunaDB.
To achieve deterministic order, Calvin uses a sequencer: an entry point for all transactions. The sequencer determines the order in which transactions are executed, and establishes a global transaction input sequence. To minimize contention and batch decisions, the timeline is split into epochs. The sequencer collects transactions and groups them into short time windows (the original paper mentions 10-millisecond batches), which also become replication units, so transactions do not have to be communicated separately.
As soon as a transaction batch is successfully replicated, sequencer forwards it to the scheduler, which orchestrates transaction execution. The scheduler uses a deterministic scheduling protocol that executes parts of transaction in parallel, while preserving the serial execution order specified by the sequencer. Since applying transaction to a specific state is guaranteed to produce only changes specified by the transaction and transaction order is predetermined, replicas do not have to further communicate with the sequencer.
Each transaction in Calvin has a read set (its dependencies, which is a collection of data records from the current database state required to execute it) and a write set (results of the transaction execution; in other words, its side effects). Calvin does not natively support transactions that rely on additional reads that would determine read and write sets.
A worker thread, managed by the scheduler, proceeds with execution in four steps:
-
It analyzes the transaction’s read and write sets, determines node-local data records from the read set, and creates the list of active participants (i.e., ones that hold the elements of the write set, and will perform modifications on the data).
-
It collects the local data required to execute the transaction, in other words, the read set records that happen to reside on that node. The collected data records are forwarded to the corresponding active participants.
-
If this worker thread is executing on an active participant node, it receives data records forwarded from the other participants, as a counterpart of the operations executed during step 2.
-
Finally, it executes a batch of transactions, persisting results into local storage. It does not have to forward execution results to the other nodes, as they receive the same inputs for transactions and execute and persist results locally themselves.
A typical Calvin implementation colocates sequencer, scheduler, worker, and storage subsystems, as Figure 13-7 shows. To make sure that sequencers reach consensus on exactly which transactions make it into the current epoch/batch, Calvin uses the Paxos consensus algorithm (see “Paxos”) or asynchronous replication, in which a dedicated replica serves as a leader. While using a leader can improve latency, it comes with a higher cost of recovery as nodes have to reproduce the state of the failed leader in order to proceed.

Figure 13-7. Calvin architecture
Distributed Transactions with Spanner
Calvin is often contrasted with another approach for distributed transaction management called Spanner [CORBETT12]. Its implementations (or derivatives) include several open source databases, most prominently CockroachDB and YugaByte DB. While Calvin establishes the global transaction execution order by reaching consensus on sequencers, Spanner uses two-phase commit over consensus groups per partition (in other words, per shard). Spanner has a rather complex setup, and we only cover high-level details in the scope of this book.
To achieve consistency and impose transaction order, Spanner uses TrueTime: a high-precision wall-clock API that also exposes an uncertainty bound, allowing local operations to introduce artificial slowdowns to wait for the uncertainty bound to pass.
Spanner offers three main operation types: read-write transactions, read-only transactions, and snapshot reads. Read-write transactions require locks, pessimistic concurrency control, and presence of the leader replica. Read-only transactions are lock-free and can be executed at any replica. A leader is required only for reads at the latest timestamp, which takes the latest committed value from the Paxos group. Reads at the specific timestamp are consistent, since values are versioned and snapshot contents can’t be changed once written. Each data record has a timestamp assigned, which holds a value of the transaction commit time. This also implies that multiple timestamped versions of the record can be stored.
Figure 13-8 shows the Spanner architecture. Each spanserver (replica, a server instance that serves data to clients) holds several tablets, with Paxos (see “Paxos”) state machines attached to them. Replicas are grouped into replica sets called Paxos groups, a unit of data placement and replication. Each Paxos group has a long-lived leader (see “Multi-Paxos”). Leaders communicate with each other during multishard transactions.

Figure 13-8. Spanner architecture
Every write has to go through the Paxos group leader, while reads can be served directly from the tablet on up-to-date replicas. The leader holds a lock table that is used to implement concurrency control using the two-phase locking (see “Lock-Based Concurrency Control”) mechanism and a transaction manager that is responsible for multishard distributed transactions. Operations that require synchronization (such as writes and reads within a transaction) have to acquire the locks from the lock table, while other operations (snapshot reads) can access the data directly.
For multishard transactions, group leaders have to coordinate and perform a two-phase commit to ensure consistency, and use two-phase locking to ensure isolation. Since the 2PC algorithm requires the presence of all participants for a successful commit, it hurts availability. Spanner solves this by using Paxos groups rather than individual nodes as cohorts. This means that 2PC can continue operating even if some of the members of the group are down. Within the Paxos group, 2PC contacts only the node that serves as a leader.
Paxos groups are used to consistently replicate transaction manager states across multiple nodes. The Paxos leader first acquires write locks, and chooses a write timestamp that is guaranteed to be larger than any previous transactions’ timestamp, and records a 2PC prepare entry through Paxos. The transaction coordinator collects timestamps and generates a commit timestamp that is greater than any of the prepare timestamps, and logs a commit entry through Paxos. It then waits until after the timestamp it has chosen for commit, since it has to guarantee that clients will only see transaction results whose timestamps are in the past. After that, it sends this timestamp to the client and leaders, which log the commit record with the new timestamp in their local Paxos group and are now free to release the locks.
Single-shard transactions do not have to consult the transaction manager (and, subsequently, do not have to perform a cross-partition two-phase commit), since consulting a Paxos group and a lock table is enough to guarantee transaction order and consistency within the shard.
Spanner read-write transactions offer a serialization order called external consistency: transaction timestamps reflect serialization order, even in cases of distributed transactions. External consistency has real-time properties equivalent to linearizability: if transaction T1 commits before T2 starts, T1’s timestamp is smaller than the timestamp of T2.
To summarize, Spanner uses Paxos for consistent transaction log replication, two-phase commit for cross-shard transactions, and TrueTime for deterministic transaction ordering. This means that multipartition transactions have a higher cost due to an additional two-phase commit round, compared to Calvin [ABADI17]. Both approaches are important to understand since they allow us to perform transactions in partitioned distributes data stores.
Database Partitioning
While discussing Spanner and Calvin, we’ve been using the term partitioning quite heavily. Let’s now discuss it in more detail. Since storing all database records on a single node is rather unrealistic for the majority of modern applications, many databases use partitioning: a logical division of data into smaller manageable segments.
The most straightforward way to partition data is by splitting it into ranges and allowing replica sets to manage only specific ranges (partitions). When executing queries, clients (or query coordinators) have to route requests based on the routing key to the correct replica set for both reads and writes. This partitioning scheme is typically called sharding: every replica set acts as a single source for a subset of data.
To use partitions most effectively, they have to be sized, taking the load and value distribution into consideration. This means that frequently accessed, read/write heavy ranges can be split into smaller partitions to spread the load between them. At the same time, if some value ranges are more dense than other ones, it might be a good idea to split them into smaller partitions as well. For example, if we pick zip code as a routing key, since the country population is unevenly spread, some zip code ranges can have more data (e.g., people and orders) assigned to them.
When nodes are added to or removed from the cluster, the database has to re-partition the data to maintain the balance. To ensure consistent movements, we should relocate the data before we update the cluster metadata and start routing requests to the new targets. Some databases perform auto-sharding and relocate the data using placement algorithms that determine optimal partitioning. These algorithms use information about read, write loads, and amounts of data in each shard.
To find a target node from the routing key, some database systems compute a hash of the key, and use some form of mapping from the hash value to the node ID. One of the advantages of using the hash functions for determining replica placement is that it can help to reduce range hot-spotting, since hash values do not sort the same way as the original values. While two lexicographically close routing keys would be placed at the same replica set, using hashed values would place them on different ones.
The most straightforward way to map hash values to node IDs is by taking a remainder of the division of the hash value by the size of the cluster (modulo). If we have N nodes in the system, the target node ID is picked by computing hash(v) modulo N. The main problem with this approach is that whenever nodes are added or removed and the cluster size changes from N to N’, many values returned by hash(v) modulo N’ will differ from the original ones. This means that most of the data will have to be moved.
Consistent Hashing
In order to mitigate this problem, some databases, such as Apache Cassandra and Riak (among others), use a different partitioning scheme called consistent hashing. As previously mentioned, routing key values are hashed. Values returned by the hash function are mapped to a ring, so that after the largest possible value, it wraps around to its smallest value. Each node gets its own position on the ring and becomes responsible for the range of values, between its predecessor’s and its own positions.
Using consistent hashing helps to reduce the number of relocations required for maintaining balance: a change in the ring affects only the immediate neighbors of the leaving or joining node, and not an entire cluster. The word consistent in the definition implies that, when the hash table is resized, if we have K possible hash keys and n nodes, on average we have to relocate only K/n keys. In other words, a consistent hash function output changes minimally as the function range changes [KARGER97].
Distributed Transactions with Percolator
Coming back to the subject of distributed transactions, isolation levels might be difficult to reason about because of the allowed read and write anomalies. If serializability is not required by the application, one of the ways to avoid the write anomalies described in SQL-92 is to use a transactional model called snapshot isolation (SI).
Snapshot isolation guarantees that all reads made within the transaction are consistent with a snapshot of the database. The snapshot contains all values that were committed before the transaction’s start timestamp. If there’s a write-write conflict (i.e., when two concurrently running transactions attempt to make a write to the same cell), only one of them will commit. This characteristic is usually referred to as first committer wins.
Snapshot isolation prevents read skew, an anomaly permitted under the read-committed isolation level. For example, a sum of x and y is supposed to be 100. Transaction T1 performs an operation read(x), and reads the value 70. T2 updates two values write(x, 50) and write(y, 50), and commits. If T1 attempts to run read(y), and proceeds with transaction execution based on the value of y (50), newly committed by T2, it will lead to an inconsistency. The value of x that T1 has read before T2 committed and the new value of y aren’t consistent with each other. Since snapshot isolation only makes values up to a specific timestamp visible for transactions, the new value of y, 50, won’t be visible to T1 [BERENSON95].
Snapshot isolation has several convenient properties:
-
It allows only repeatable reads of committed data.
-
Values are consistent, as they’re read from the snapshot at a specific timestamp.
-
Conflicting writes are aborted and retried to prevent inconsistencies.
Despite that, histories under snapshot isolation are not serializable. Since only conflicting writes to the same cells are aborted, we can still end up with a write skew (see “Read and Write Anomalies”). Write skew occurs when two transactions modify disjoint sets of values, each preserving invariants for the data it writes. Both transactions are allowed to commit, but a combination of writes performed by these transactions may violate these invariants.
Snapshot isolation provides semantics that can be useful for many applications and has the major advantage of efficient reads, because no locks have to be acquired since snapshot data cannot be changed.
Percolator is a library that implements a transactional API on top of the distributed database Bigtable (see “Wide Column Stores”). This is a great example of building a transaction API on top of the existing system. Percolator stores data records, committed data point locations (write metadata), and locks in different columns. To avoid race conditions and reliably lock tables in a single RPC call, it uses a conditional mutation Bigtable API that allows it to perform read-modify-write operations with a single remote call.
Each transaction has to consult the timestamp oracle (a source of clusterwide-consistent monotonically increasing timestamps) twice: for a transaction start timestamp, and during commit. Writes are buffered and committed using a client-driven two-phase commit (see “Two-Phase Commit”).
Figure 13-9 shows how the contents of the table change during execution of the transaction steps:
-
a) Initial state. After the execution of the previous transaction,
TS1is the latest timestamp for both accounts. No locks are held. -
b) The first phase, called prewrite. The transaction attempts to acquire locks for all cells written during the transaction. One of the locks is marked as primary and is used for client recovery. The transaction checks for the possible conflicts: if any other transaction has already written any data with a later timestamp or there are unreleased locks at any timestamp. If any conflict is detected, the transaction aborts.
-
c) If all locks were successfully acquired and the possibility of conflict is ruled out, the transaction can continue. During the second phase, the client releases its locks, starting with the primary one. It publishes its write by replacing the lock with a write record, updating write metadata with the timestamp of the latest data point.
Since the client may fail while trying to commit the transaction, we need to make sure that partial transactions are finalized or rolled back. If a later transaction encounters an incomplete state, it should attempt to release the primary lock and commit the transaction. If the primary lock is already released, transaction contents have to be committed. Only one transaction can hold a lock at a time and all state transitions are atomic, so situations in which two transactions attempt to perform operations on the contents are not possible.

Figure 13-9. Percolator transaction execution steps. Transaction credits $150 from Account2 and debits it to Account1.
Snapshot isolation is an important and useful abstraction, commonly used in transaction processing. Since it simplifies semantics, precludes some of the anomalies, and opens up an opportunity to improve concurrency and performance, many MVCC systems offer this isolation level.
One of the examples of databases based on the Percolator model is TiDB (“Ti” stands for Titatium). TiDB is a strongly consistent, highly available, and horizontally scalable open source database, compatible with MySQL.
Coordination Avoidance
One more example, discussing costs of serializability and attempting to reduce the amount of coordination while still providing strong consistency guarantees, is coordination avoidance [BAILIS14b]. Coordination can be avoided, while preserving data integrity constraints, if operations are invariant confluent. Invariant Confluence (I-Confluence) is defined as a property that ensures that two invariant-valid but diverged database states can be merged into a single valid, final state. Invariants in this case preserve consistency in ACID terms.
Because any two valid states can be merged into a valid state, I-Confluent operations can be executed without additional coordination, which significantly improves performance characteristics and scalability potential.
To preserve this invariant, in addition to defining an operation that brings our database to the new state, we have to define a merge function that accepts two states. This function is used in case states were updated independently and bring diverged states back to convergence.
Transactions are executed against the local database versions (snapshots). If a transaction requires any state from other partitions for execution, this state is made available for it locally. If a transaction commits, resulting changes made to the local snapshot are migrated and merged with the snapshots on the other nodes. A system model that allows coordination avoidance has to guarantee the following properties:
- Global validity
-
Required invariants are always satisfied, for both merged and divergent committed database states, and transactions cannot observe invalid states.
- Availability
-
If all nodes holding states are reachable by the client, the transaction has to reach a commit decision, or abort, if committing it would violate one of the transaction invariants.
- Convergence
-
Nodes can maintain their local states independently, but in the absence of further transactions and indefinite network partitions, they have to be able to reach the same state.
- Coordination freedom
-
Local transaction execution is independent from the operations against the local states performed on behalf of the other nodes.
One of the examples of implementing coordination avoidance is Read-Atomic Multi Partition (RAMP) transactions [BAILIS14c]. RAMP uses multiversion concurrency control and metadata of current in-flight operations to fetch any missing state updates from other nodes, allowing read and write operations to be executed concurrently. For example, readers that overlap with some writer modifying the same entry can be detected and, if necessary, repaired by retrieving required information from the in-flight write metadata in an additional round of communication.
Using lock-based approaches in a distributed environment might be not the best idea, and instead of doing that, RAMP provides two properties:
- Synchronization independence
-
One client’s transactions won’t stall, abort, or force the other client’s transactions to wait.
- Partition independence
-
Clients do not have to contact partitions whose values aren’t involved in their transactions.
RAMP introduces the read atomic isolation level: transactions cannot observe any in-process state changes from in-flight, uncommitted, and aborted transactions. In other words, all (or none) transaction updates are visible to concurrent transactions. By that definition, the read atomic isolation level also precludes fractured reads: when a transaction observes only a subset of writes executed by some other transaction.
RAMP offers atomic write visibility without requiring mutual exclusion, which other solutions, such as distributed locks, often couple together. This means that transactions can proceed without stalling each other.
RAMP distributes transaction metadata that allows reads to detect concurrent in-flight writes. By using this metadata, transactions can detect the presence of newer record versions, find and fetch the latest ones, and operate on them. To avoid coordination, all local commit decisions must also be valid globally. In RAMP, this is solved by requiring that, by the time a write becomes visible in one partition, writes from the same transaction in all other involved partitions are also visible for readers in those partitions.
To allow readers and writers to proceed without blocking other concurrent readers and writers, while maintaining the read atomic isolation level both locally and system-wide (in all other partitions modified by the committing transaction), writes in RAMP are installed and made visible using two-phase commit:
- Prepare
-
The first phase prepares and places writes to their respective target partitions without making them visible.
- Commit/abort
-
The second phase publishes the state changes made by the write operation of the committing transaction, making them available atomically across all partitions, or rolls back the changes.
RAMP allows multiple versions of the same record to be present at any given moment: latest value, in-flight uncommitted changes, and stale versions, overwritten by later transactions. Stale versions have to be kept around only for in-progress read requests. As soon as all concurrent readers complete, stale values can be discarded.
Making distributed transactions performant and scalable is difficult because of the coordination overhead associated with preventing, detecting, and avoiding conflicts for the concurrent operations. The larger the system, or the more transactions it attempts to serve, the more overhead it incurs. The approaches described in this section attempt to reduce the amount of coordination by using invariants to determine where coordination can be avoided, and only paying the full price if it’s absolutely necessary.
Summary
In this chapter, we discussed several ways of implementing distributed transactions. First, we discussed two atomic commitment algorithms: two- and three-phase commits. The big advantage of these algorithms is that they’re easy to understand and implement, but have several shortcomings. In 2PC, a coordinator (or at least its substitute) has to be alive for the length of the commitment process, which significantly reduces availability. 3PC lifts this requirement for some cases, but is prone to split brain in case of network partition.
Distributed transactions in modern database systems are often implemented using consensus algorithms, which we’re going to discuss in the next chapter. For example, both Calvin and Spanner, discussed in this chapter, use Paxos.
Consensus algorithms are more involved than atomic commit ones, but have much better fault-tolerance properties, and decouple decisions from their initiators and allow participants to decide on a value rather than on whether or not to accept the value [GRAY04].
1 The fine print says “assuming a highly reliable network.” In other words, a network that precludes partitions [ALHOUMAILY10]. Implications of this assumption are discussed in the paper’s section about algorithm description.
2 However, the documentation says that as of v3.6, 2PC provides only transaction-like semantics: https://databass.dev/links/7.