
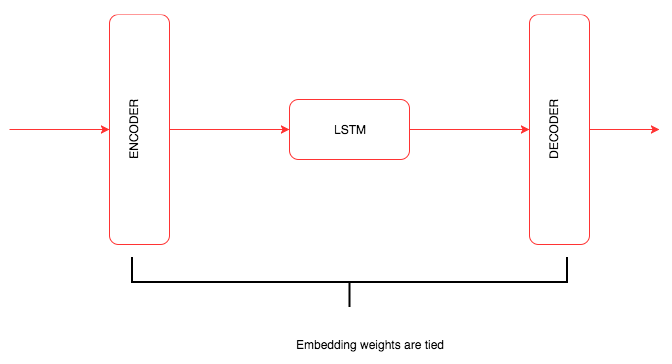
We defined a model that is a bit similar to the networks that we saw in Chapter 6, Deep Learning with Sequence Data and Text, but it has some key differences. The high-level architecture of the network looks like the following image:
As usual, let's take a look at the code and then walk through the key parts of it:
class RNNModel(nn.Module):
def __init__(self,ntoken,ninp,nhid,nlayers,dropout=0.5,tie_weights=False):
#ntoken represents the number of words in vocabulary.
#ninp Embedding dimension for each word ,which is the input for the LSTM.
#nlayer Number of layers required to be used in the LSTM .
#Dropout to avoid overfitting.
#tie_weights - use the same weights for both encoder and decoder.
super().__init__()
self.drop = nn.Dropout()
self.encoder = nn.Embedding(ntoken,ninp)
self.rnn = nn.LSTM(ninp,nhid,nlayers,dropout=dropout)
self.decoder = nn.Linear(nhid,ntoken)
if tie_weights:
self.decoder.weight = self.encoder.weight
self.init_weights()
self.nhid = nhid
self.nlayers = nlayers
def init_weights(self):
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange,initrange)
self.decoder.bias.data.fill_(0)
self.decoder.weight.data.uniform_(-initrange,initrange)
def forward(self,input,hidden):
emb = self.drop(self.encoder(input))
output,hidden = self.rnn(emb,hidden)
output = self.drop(output)
s = output.size()
decoded = self.decoder(output.view(s[0]*s[1],s[2]))
return decoded.view(s[0],s[1],decoded.size(1)),hidden
def init_hidden(self,bsz):
weight = next(self.parameters()).data
return (Variable(weight.new(self.nlayers,bsz,self.nhid).zero_()),Variable(weight.new(self.nlayers,bsz,self.nhid).zero_()))
In the __init__ method, we create all the layers such as embedding, dropout, RNN, and decoder. In earlier language models, embeddings were not generally used in the last layer. The use of embeddings, and tying the initial embedding along with the embeddings of the final output layer, improves the accuracy of the language model. This concept was introduced in the papers Using the Output Embedding to Improve Language Models (https://arxiv.org/abs/1608.05859) by Press and Wolf in 2016, and Tying Word Vectors and Word Classifiers: A Loss Framework for Language Modeling (https://arxiv.org/abs/1611.01462) by Inan and his co-authors in 2016. Once we have made the weights of encoder and decoder tied, we call the init_weights method to initialize the weights of the layer.
The forward function stitches all the layers together. The last linear layers map all the output activations from the LSTM layer to the embeddings that are of the size of the vocabulary. The flow of the forward function input is passed through the embedding layer and then passed on to an RNN (in this case, an LSTM), and then to the decoder, another linear layer.