
Chapter 14
Advanced DAX concepts
So far in the book, we have provided a complete description of the pillars of DAX: row context, filter context and context transition. In previous chapters, we made several references to this chapter as the chapter where we would uncover all the secrets of DAX. You might want to read this chapter multiple times, for a complete understanding of certain concepts. In our experience, the first read can make a developer wonder, “Why should it be so complicated?” However, after learning the concepts outlined here for the first time, readers start to realize that many of the concepts they struggled in learning have a common denominator; once they grasp it, everything becomes clear.
We introduced several chapters saying that the goal of the chapter was to move the reader to the next level. If each chapter is a level, this is the boss level! Indeed, the concepts of expanded tables and of shadow filter contexts are hard to learn. Once learned, they shed a completely different light upon everything described so far. It is fair to say that—after finishing this chapter—a second read of the whole book is strongly suggested. A second read will likely uncover many details that did not seem helpful at first read. We realize that a full second read of the book takes a lot of effort. But then we did promise that reading The Definitive Guide to DAX would transform the reader into a DAX guru. We never said it would be an easy task.
Introducing expanded tables
The first—and most important—concept to learn is that of expanded tables. In DAX, every table has a matching expanded version. The expanded version of a table contains all the columns of the original table, plus all the columns of the tables that are on the one-side of a chain of many-to-one relationships starting from the source table.
Consider the model in Figure 14-1.
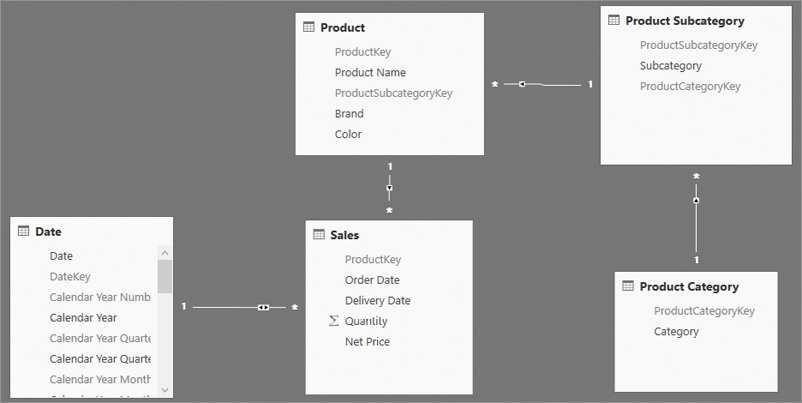
Table expansion goes towards the one-side. Therefore, to expand a table, one starts from the base table and adds to the base table all the columns of the related tables that are on the one-side of any relationships. For example, Sales has a many-to-one relationship with Product, so the expanded version of Sales contains also all the columns of Product. On the other hand, the expanded version of Product Category only contains the base table. Indeed, the only table with a relationship with Product Category is Product Subcategory, but it is on the many-side of the relationship. Thus, table expansion goes from Product Subcategory to Product Category, but not the other way around.
Table expansion does not stop at the first level. For example, from Sales one can reach Product Category following only many-to-one relationships. Thus, the expanded version of Sales contains Product, Product Subcategory, and Product Category columns. Moreover, because Sales is on the many side of a many-to-one relationship with Date, the expanded version of Sales contains Date too. In other words, the expanded version of Sales contains the entire data model.
The Date table requires a bit more attention. In fact, it can be filtered by Sales because the relationship that links Sales and Date has a bidirectional filter direction. Though this relationship is bidirectional, it is not a many-to-one: It is a one-to-many. The expanded version of Date only contains Date itself, even though Date can be filtered by Sales, Product, Product Subcategory, and Product Category. When filtering occurs because a relationship is bidirectional, the mechanism that applies the filtering is not that of expanded tables. Instead, filters are injected by the DAX code using a different mechanism, which is out of the scope of this chapter. Bidirectional filter propagation is discussed in Chapter 15, “Advanced relationships.”
When repeating the same exercise for the other tables in the data model, we create the expanded tables described in Table 14-1.
Table 14-1 Expanded versions of the tables
Table |
Expanded Version |
|---|---|
Date |
Date |
Sales |
All the tables in the entire model |
Product |
Product, Product Subcategory, Product Category |
Product Subcategory |
Product Subcategory, Product Category |
Product Category |
Product Category |
There might be different kinds of relationships in a data model: one-to-one relationships, one-to-many relationships, and many-to-many relationships. The rule is always the same: Expansion goes towards the one-side of a relationship. Nevertheless, some examples might help in understanding the concept better. For example, consider the data model in Figure 14-2, which does not follow best practices in data modeling but is useful for educational purposes.

We purposely used complex kinds of relationships in this model, where the Product Category table has one row for each value in Subcategory, so there are multiple rows for each category in such a table, and the ProductCategoryKey column does not contain unique values. Both relationships have a bidirectional filter. The relationship between Product and Product Details is a one-to-one relationship, whereas the one between Product and Product Category is a weak relationship where both sides are the many-side. The rule is always the same: Expansion goes towards the one-side of a relationship, regardless of the side it starts from.
Consequently, Product Details expands to Product, and Product expands to Product Details at the same time. The expanded version of the two tables, Product and Product Details, is indeed the same. Moreover, Product Category does not expand to Product, nor does Product expand to Product Category. The reason is that both tables are on the many-side of a weak relationship. When both sides of a relationship are the many-side, expansion does not happen. When both sides of a relationship are set as the many-side, the relationship becomes automatically a weak relationship. Not that they have any kind of weakness—weak relationships, like bidirectional filtering, work with a different goal than that of table expansion.
Expanded tables are a useful concept because they provide a clear explanation of how filter context propagation works within a DAX formula. Once a filter is being applied to a column, all the expanded tables containing that column are filtered. This statement deserves further explanation.
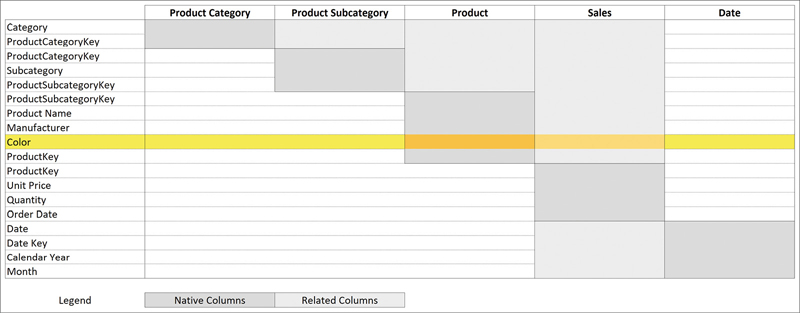
We present the expanded tables of the model used in Figure 14-1 on a diagram, which is shown in Figure 14-3.

The chart in Figure 14-3 lists all the columns of the model on the horizontal lines and each table name on the vertical lines. Please note that some column names appear multiple times. Duplicate column names come from the fact that different tables may have column names in common. We colored the cells to distinguish between the columns of the base table and the columns belonging to the expanded table. There are two types of columns:
Native columns are the columns that originally belong to the base table, colored in a slightly darker grey.
Related columns are the columns added to the expanded table by following the existing relationships. These columns are light grey in the diagram.
The diagram helps in finding which tables are filtered by a column. For example, the following measure uses CALCULATE to apply a filter on the Product[Color] column:
RedSales :=
CALCULATE (
SUM ( Sales[Quantity] ),
'Product'[Color] = "Red"
)We can use the diagram to highlight the tables containing the Product[Color] column. Looking at Figure 14-4, we can immediately conclude that both Product and Sales are the affected tables.
We can use the same diagram to check how the filter context propagates through relationships. Once DAX filters any column on the one-side of a relationship, it filters all the tables that contain that column in their expanded version. This includes all the tables that are on the many-side of the relationships.
Thinking in terms of expanded tables makes the whole filter context propagation much easier. Indeed, a filter context operates on all the expanded tables containing the filtered columns. When speaking in terms of expanded tables, one no longer needs to consider relationships as part of the discussion. Table expansion uses relationships. Once a table has been expanded, the relationships have been included in the expanded tables. They no longer need to be taken into account.
![]() Note
Note
Please note that the filter on Color propagates to Date too, though technically, Color does not belong to the expanded version of Date. This is the effect of bidirectional filtering at work. It is important to note that the filter on Color reaches Date through a completely different process, not through expanded tables. Internally, DAX injects a specific filtering code to make bidirectional relationships work, whereas filtering on expanded tables occurs automatically. The difference is only internal, yet it is important to point it out. The same applies for weak relationships: They do not use expanded tables. Weak relationships use filter injection instead.
Understanding RELATED
Whenever one references a table in DAX, it is always the expanded table. From a semantic point of view, the RELATED keyword does not execute any operation. Instead, it gives a developer access to the related columns of an expanded table. Thus, in the following code the Unit Price column belongs to the expanded table of Sales, and RELATED permits access to it through the row context pointing to the Sales table:
SUMX (
Sales,
Sales[Quantity] * RELATED ( 'Product'[Unit Price] )
)One important aspect of table expansion is that it takes place when a table is defined, not when it is being used. For example, consider the following query:
EVALUATE
VAR SalesA =
CALCULATETABLE (
Sales,
USERELATIONSHIP ( Sales[Order Date], 'Date'[Date] )
)
VAR SalesB =
CALCULATETABLE (
Sales,
USERELATIONSHIP ( Sales[Delivery Date], 'Date'[Date] )
)
RETURN
GENERATE (
VALUES ( 'Date'[Calendar Year] ),
VAR CurrentYear = 'Date'[Calendar Year]
RETURN
ROW (
"Sales From A", COUNTROWS (
FILTER (
SalesA,
RELATED ( 'Date'[Calendar Year] ) = CurrentYear
)
),
"Sales From B", COUNTROWS (
FILTER (
SalesB,
RELATED ( 'Date'[Calendar Year] ) = CurrentYear
)
)
)
)SalesA and SalesB are two copies of the Sales table, evaluated in a filter context where two different relationships are active: SalesA uses the relationship between Order Date and Date, whereas SalesB activates the relationship between Delivery Date and Date.
Once the two variables are evaluated, GENERATE iterates over the years; it then creates two additional columns. The two additional columns contain the count of SalesA and SalesB, applying a further filter for the rows where RELATED ( 'Date'[Calendar Year] ) equals the current year. Please note that we had to write rather convoluted code in order to avoid any context transition. Indeed, no context transitions are taking place in the whole GENERATE function call.
The question here is understanding what happens when the two highlighted RELATED functions are called. Unless one thinks in terms of expanded tables, the answer is problematic. When RELATED is executed, the active relationship is the one between Sales[Order Date] and Date[Date] because the two variables have already been computed earlier and both USERELATIONSHIP modifiers have finished their job. Nevertheless, both SalesA and SalesB are expanded tables, and the expansion occurred when there were two different relationships active. Because RELATED only gives access to an expanded column, the consequence is that when iterating over SalesA, RELATED returns the order year, whereas while iterating over SalesB, RELATED returns the delivery year.
We can appreciate the difference by looking at the result in Figure 14-5. Without the expanded table, we would have expected the same number of rows for each order year in both columns.

Using RELATED in calculated columns
The RELATED function accesses the expanded columns of a table. The table expansion occurs when the table is defined, not when it is used. Because of these facts, changing the relationships in a calculated column turns out to be problematic.
As an example, look at the model in Figure 14-6, with two relationships between Sales and Date.

A developer might be interested in adding a calculated column in Sales that checks whether the delivery happened in the same quarter as the order. The Date table contains a column—Date[Calendar Year Quarter]—that can be used for the comparison. Unfortunately, it is easy to obtain the quarter of the order date, whereas retrieving the quarter of the delivery proves to be more challenging.
Indeed, RELATED ( 'Date'[Calendar Year Quarter] ) returns the quarter of the order date by using the default active relationship. Nevertheless, writing an expression like the following will not change the relationship used for RELATED:
Sales[DeliveryQuarter] =
CALCULATE (
RELATED ( 'Date'[Calendar Year Quarter] ),
USERELATIONSHIP (
Sales[Delivery Date],
'Date'[Date]
)
)There are several problems here. The first is that CALCULATE removes the row context, but CALCULATE is needed to change the active relationship for RELATED. Thus, RELATED cannot be used inside the formula argument of CALCULATE because RELATED requires a row context. There is a second sneaky problem: Even if it were possible to do that, RELATED would not work because the row context of a calculated column is created when the table is defined. The row context of a calculated column is generated automatically, so the table is always expanded using the default relationship.
There is no perfect solution to this problem. The best option is to rely on LOOKUPVALUE. LOOKUPVALUE is a search function that retrieves a value from a table, searching for columns that are equal to certain values provided. The delivery quarter can be computed using the following code:
Sales[DeliveryQuarter] =
LOOKUPVALUE (
'Date'[Calendar Year Quarter], -- Returns the Calendar Year quarter
'Date'[Date], -- where the Date[Date] column is equal
Sales[Delivery Date] -- to the value of Sales[Delivery Date]
)LOOKUPVALUE searches for values that are equal. One cannot add more complex conditions. If needed, then a more complex expression using CALCULATE would be required. Moreover, in this case we used LOOKUPVALUE in a calculated column, so the filter context is empty. But even in cases where the filter context is actively filtering the model, LOOKUPVALUE would ignore it. LOOKUPVALUE always searches for a row in a table ignoring any filter context. Finally, LOOKUPVALUE accepts a last argument, if provided alone, that is the default value in case there is no match.
Understanding the difference between table filters and column filters
In DAX there is a huge difference between filtering a table and filtering a column. Table filters are powerful tools in the hands of an experienced DAX developer, but they can get quite confusing if used improperly. We will start by looking at a scenario where table filters produce an incorrect result. Later in this section, we will demonstrate how to leverage table filters properly in complex scenarios.
Often a novice DAX developer makes the mistake of thinking that the two following expressions compute the same value:
CALCULATE (
[Sales Amount],
Sales[Quantity] > 1
)
CALCULATE (
[Sales Amount],
FILTER (
Sales,
Sales[Quantity] > 1
)
)The two definitions are actually very different. One is filtering a column; the other is filtering a table. Even though the two versions of the code provide the same result in several scenarios, they are, in fact, computing a completely different expression. To demonstrate their behavior, we included the two definitions in a query:
EVALUATE
ADDCOLUMNS (
VALUES ( 'Product'[Brand] ),
"FilterCol", CALCULATE (
[Sales Amount],
Sales[Quantity] > 1
),
"FilterTab", CALCULATE (
[Sales Amount],
FILTER (
Sales,
Sales[Quantity] > 1
)
)
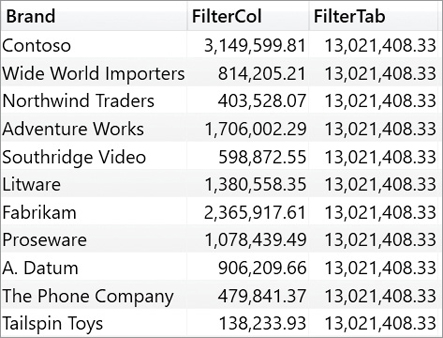
)The result is surprising to say the least, as we can see in Figure 14-7.
FilterCol returns the expected values, whereas FilterTab always returns the same number that corresponds to the grand total of all the brands. Expanded tables play an important role in understanding the reason for this result.
We can examine the behavior of the FilterTab calculation in detail. The filter argument of CALCULATE iterates over Sales and returns all the rows of Sales with a quantity greater than 1. The result of FILTER is a subset of rows of the Sales table. Remember: In DAX a table reference always references the expanded table. Because Sales has a relationship with Product, the expanded table of Sales contains the whole Product table too. Among the many columns, it also contains Product[Brand].
The filter arguments of CALCULATE are evaluated in the original filter context, ignoring the context transition. The filter on Brand comes into effect after CALCULATE has performed the context transition. Consequently, the result of FILTER contains the values of all the brands related to rows with a quantity greater than 1. Indeed, there are no filters on Product[Brand] during the iteration made by FILTER.
When generating the new filter context, CALCULATE performs two consecutive steps:
It operates the context transition.
It applies the filter arguments.
Therefore, filter arguments might override the effects of context transition. Because ADDCOLUMNS is iterating over the product brand, the effects of context transition on each row should be that of filtering an individual brand. Nevertheless, because the result of FILTER also contains the product brand, it overrides the effects of the context transition. The net result is that the value shown is always the total of Sales Amount for all the transactions whose quantity is greater than 1, regardless of the product brand.
Using table filters is always challenging because of table expansion. Whenever one applies a filter to a table, the filter is really applied to the expanded table, and this can cause several side effects. The golden rule is simple: Try to avoid using table filters whenever possible. Working with columns leads to simpler calculations, whereas working with tables is much more problematic.
![]() Note
Note
The example shown in this section might not be easily applied to a measure defined in a data model. This is because the measure is always executed in an implicit CALCULATE to produce the context transition. For example, consider the following measure:
Multiple Sales :=
CALCULATE (
[Sales Amount],
FILTER (
Sales,
Sales[Quantity] > 1
)
)When executed in a report, a possible DAX query could be:
EVALUATE
ADDCOLUMNS (
VALUES ( 'Product'[Brand] ),
"FilterTabMeasure", [Multiple Sales]
)The expansion of the table drives the execution of this corresponding query:
EVALUATE
ADDCOLUMNS (
VALUES ( 'Product'[Brand] ),
"FilterTabMeasure", CALCULATE (
CALCULATE (
[Sales Amount],
FILTER (
Sales,
Sales[Quantity] > 1
)
)
)
)The first CALCULATE performs the context transition that affects both arguments of the second CALCULATE, including the FILTER argument. Even though this produces the same result as FilterCol, the use of a table filter has a negative impact on performance. Therefore, it is always better to use column filters whenever possible.
Using table filters in measures
In the previous section, we showed a first example where being familiar with expanded tables helped make sense of a result. However, there are several other scenarios where expanded tables prove to be useful. Besides, in previous chapters we used the concept of expanded tables multiple times, although we could not describe what was happening in detail just yet.
For example in Chapter 5, “Understanding CALCULATE and CALCULATETABLE,” while explaining how to remove all the filters applied to the model, we used the following code in a report that was slicing measures by category:
Pct All Sales :=
VAR CurrentCategorySales =
[Sales Amount]
VAR AllSales =
CALCULATE (
[Sales Amount],
ALL ( Sales )
)
VAR Result =
DIVIDE (
CurrentCategorySales,
AllSales
)
RETURN
ResultWhy does ALL ( Sales ) remove any filter? If one does not think in terms of expanded tables, ALL should only remove filters from the Sales table, keeping any other filter untouched. In fact, using ALL on the Sales table means removing any filter from the expanded Sales table. Because Sales expands to all the related tables, including Product, Customer, Date, Store, and any other related tables, using ALL ( Sales ) removes any filter from the entire data model used by that example.
Most of the time this behavior is the one desired and it works intuitively. Still, understanding the internal behavior of expanded tables is of paramount importance; failing to gain that understanding might be a root cause for inaccurate calculations. In the next example, we demonstrate how a simple calculation can fail simply due to a subtlety of expanded tables. We will see why it is better to avoid using table filters in CALCULATE statements, unless the developer is purposely looking to take advantage of the side effects of expanded tables. The latter are described in the following sections.
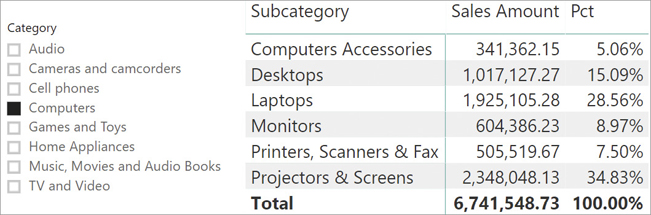
Consider the requirements of a report like the one in Figure 14-8. The report contains a slicer that filters the Category, and a matrix showing the sales of subcategories and their respective percentage against the total.
Because the percentage needs to divide the current Sales Amount by the corresponding Sales Amount for all the subcategories of the selected category, a first (inaccurate) solution might be the following:
Pct :=
DIVIDE (
[Sales Amount],
CALCULATE (
[Sales Amount],
ALL ( 'Product Subcategory' )
)
)The idea is that by removing the filter on Product Subcategory, DAX retains the filter on Category and produces the correct result. However, the result is wrong, as we can see in Figure 14-9.
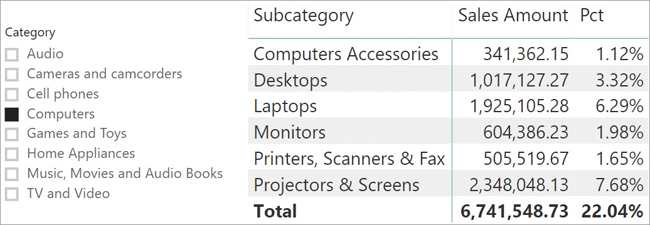
The problem with this formula is that ALL ( 'Product Subcategory' ) refers to the expanded Product Subcategory table. Product Subcategory expands to Product Category. Consequently, ALL removes the filter not only from the Product Subcategory table, but also from the Product Category table. Therefore, the denominator returns the grand total of all the categories, in turn calculating the wrong percentage.
There are multiple solutions available. In the current report, they all compute the same value, even though they use slightly different approaches. For example, the following Pct Of Categories measure computes the percentage of the selected subcategories compared to the total of the related categories. After removing the filter from the expanded table of Product Subcategory, VALUES restores the filter of the Product Category table:
Pct Of Categories :=
DIVIDE (
[Sales Amount],
CALCULATE (
[Sales Amount],
ALL ( 'Product Subcategory' ),
VALUES ( 'Product Category' )
)
)Another possible solution is the Pct Of Visual Total measure, which uses ALLSELECTED without an argument. ALLSELECTED restores the filter context of the slicers outside the visual, without the developer having to worry about expanded tables:
Pct Of Visual Total :=
DIVIDE (
[Sales Amount],
CALCULATE (
[Sales Amount],
ALLSELECTED ()
)
)ALLSELECTED is attractive because of its simplicity. However, in a later section of this chapter we introduce shadow filter contexts. These will provide the reader with a fuller understanding of ALLSELECTED. ALLSELECTED can be powerful, but it is also a complex function that must be used carefully in convoluted expressions.
Finally, another solution is available using ALLEXCEPT, thus comparing the selected subcategories with the categories selected in the slicer:
Pct :=
DIVIDE (
[Sales Amount],
CALCULATE (
[Sales Amount],
ALLEXCEPT ( 'Product Subcategory', 'Product Category' )
)
)This last formula leverages a particular ALLEXCEPT syntax that we have never used so far in the book: ALLEXCEPT with two tables, instead of a table and a list of columns.
ALLEXCEPT removes filters from the source table, with the exception of any columns provided as further arguments. That list of columns can include any column (or table) belonging to the expanded table of the first argument. Because the expanded table of Product Subcategory contains the whole Product Category table, the code provided is a valid syntax. It removes any filter from the whole expanded table of Product Subcategory, except for the columns of the expanded table of Product Category.
It is worth noting that expanded tables tend to cause more issues when the data model is not correctly denormalized. As a matter of fact, in most of this book we use a version of Contoso where Category and Subcategory are stored as columns in the Product table, instead of being tables by themselves. In other words, we denormalized the category and subcategory tables as attributes of the Product table. In a correctly denormalized model, table expansion takes place between Sales and Product in a more natural way. So as it often happens, putting some thought into the model makes the DAX code easier to author.
Understanding active relationships
When working with expanded tables, another important aspect to consider is the concept of active relationships. It is easy to get confused in a model with multiple relationships. In this section, we want to share an example where the presence of multiple relationships proves to be a real challenge.
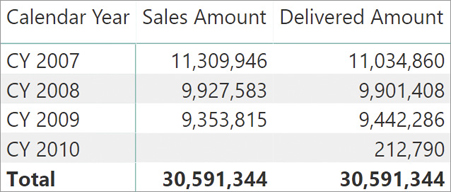
Imagine needing to compute Sales Amount and Delivered Amount. These two measures can be computed by activating the correct relationship with USERELATIONSHIP. The following two measures work:
Sales Amount :=
SUMX (
Sales,
Sales[Quantity] * Sales[Net Price]
)
Delivered Amount :=
CALCULATE (
[Sales Amount],
USERELATIONSHIP ( Sales[Delivery Date], 'Date'[Date] )
)The result is visible in Figure 14-10.
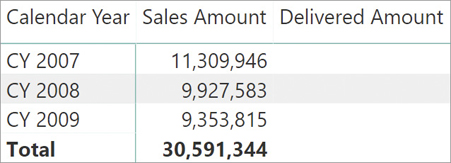
It is interesting to see a variation of the Delivered Amount measure that does not work because it uses a table filter:
Delivered Amount =
CALCULATE (
[Sales Amount],
CALCULATETABLE (
Sales,
USERELATIONSHIP ( Sales[Delivery Date], 'Date'[Date] )
)
)This new—and unfortunate—formulation of the measure produces a blank result, as we can see in Figure 14-11.
We now investigate why the result is a blank. This requires paying a lot of attention to expanded tables. The result of CALCULATETABLE is the expanded version of Sales, and among other tables it contains the Date table. When Sales is evaluated by CALCULATETABLE, the active relationship is the one with Sales[Delivery Date]. CALCULATETABLE therefore returns all the sales delivered in a given year, as an expanded table.
When CALCULATETABLE is used as a filter argument by the outer CALCULATE, the result of CALCULATETABLE filters Sales and Date through the Sales expanded table, which uses the relationship between Sales[Delivery Date] and Date[Date]. Nevertheless, once CALCULATETABLE ends its execution, the default relationship between Sales[Order Date] and Date[Date] becomes the active relationship again. Therefore, the dates being filtered are now the order dates, not the delivery dates any more. In other words, a table containing delivery dates is used to filter order dates. At this point, the only rows that remain visible are the ones where Sales[Order Date] equals Sales[Delivery Date]. There are no rows in the model that satisfy this condition; consequently, the result is blank.
To further clarify the concept, imagine that the Sales table contains just a few rows, like the ones in Table 14-2.
Table 14-2 Example of Sales table with only two rows
Order Date |
Delivery Date |
Quantity |
|---|---|---|
12/31/2007 |
01/07/2008 |
100 |
01/05/2008 |
01/10/2008 |
200 |
If the year 2008 is selected, the inner CALCULATETABLE returns the expanded version of Sales, containing, among many others, the columns shown in Table 14-3.
Table 14-3 The result of CALCULATETABLE is the expanded Sales table, including Date[Date] using the Sales[Delivery Date] relationship
Order Date |
Delivery Date |
Quantity |
Date |
|---|---|---|---|
12/31/2007 |
01/07/2008 |
100 |
01/07/2008 |
01/05/2008 |
01/10/2008 |
200 |
01/10/2008 |
When this table is used as a filter, the Date[Date] column uses the active relationship, which is the one between Date[Date] and Sales[Order Date]. At this point, the expanded table of Sales appears as in Table 14-4.
Table 14-4 The expanded Sales table using the default active relationship using the Sales[Order Date] column
Order Date |
Delivery Date |
Quantity |
Date |
|---|---|---|---|
12/31/2007 |
01/07/2008 |
100 |
12/31/2007 |
01/05/2008 |
01/10/2008 |
200 |
01/05/2008 |
The rows visible in Table 14-3 try to filter the rows visible in Table 14-4. However, the Date column is always different in the two tables, for each corresponding row. Because they do not have the same value, the first row will be removed from the active set of rows. Following the same reasoning, the second row is excluded too.
At the end, only the rows where Sales[Order Date] equals Sales[Delivery Date] survive the filter; they produce the same value in the Date[Date] column of the two expanded tables generated for the different relationships. This time, the complex filtering effect comes from the active relationship. Changing the active relationship inside a CALCULATE statement only affects the computation inside CALCULATE, but when the result is used outside of CALCULATE, the relationship goes back to the default.
As usual, it is worth pointing out that this behavior is the correct one. It is complex, but it is correct. There are good reasons to avoid table filters as much as possible. Using table filters might result in the correct behavior, or it might turn into an extremely complex and unpredictable scenario. Moreover, the measure with a column filter instead of a table filter works fine and it is easier to read.
The golden rule with table filters is to avoid them. The price to pay for developers who do not follow this simple suggestion is twofold: A significant amount of time will be spent understanding the filtering behavior, and performance becomes the worst it could possibly be.
Difference between table expansion and filtering
As explained earlier, table expansion solely takes place from the many-side to the one-side of a relationship. Consider the model in Figure 14-12, where we enabled bidirectional filtering in all the relationships of the data model.

Though the relationship between Product and Product Subcategory is set with bidirectional filtering, the expanded Product table contains subcategories, whereas the expanded Product Subcategory table does not contain Product.
The DAX engine injects filtering code in the expressions to make bidirectional filtering work as if the expansion went both ways. A similar behavior happens when using the CROSSFILTER function. Therefore, in most cases a measure works just as if table expansion took place in both directions. However, be mindful that table expansion actually does not go in the many-side direction.
The difference becomes important with the use of SUMMARIZE or RELATED. If a developer uses SUMMARIZE to perform a grouping of a table based on another table, they have to use one of the columns of the expanded table. For example, the following SUMMARIZE statement works well:
EVALUATE
SUMMARIZE (
'Product',
'Product Subcategory'[Subcategory]
)Whereas the next one—which tries to summarize subcategories based on product color—does not work:
EVALUATE
SUMMARIZE (
'Product Subcategory',
'Product'[Color]
)The error is “The column ‘Color’ specified in the ‘SUMMARIZE’ function was not found in the input table,” meaning that the expanded version of Product Subcategory does not contain Product[Color]. Like SUMMARIZE, RELATED also works with columns that belong to the expanded table exclusively.
Similarly, one cannot group the Date table by using columns from other tables, even when these tables are linked by a chain of bidirectional relationships:
EVALUATE SUMMARIZE ( 'Date', 'Product'[Color] )
There is only one special case where table expansion goes in both directions, which is the case of a relationship defined as one-to-one. If a relationship is a one-to-one relationship, then both tables are expanded one into the other. This is because a one-to-one relationship makes the two tables semantically identical: Each row in one table has a direct relationship with a single row in the other table. Therefore, it is fair to think of the two tables as being one, split into two sets of columns.
Context transition in expanded tables
The expanded table also influences context transition. The row context converts into an equivalent filter context for all the columns that are part of the expanded table. For example, consider the following query returning the category of a product using two techniques: the RELATED function in a row context and the SELECTEDVALUE function with a context transition:
EVALUATE
SELECTCOLUMNS (
'Product',
"Product Key", 'Product'[ProductKey],
"Product Name", 'Product'[Product Name],
"Category RELATED", RELATED ( 'Product Category'[Category] ),
"Category Context Transition", CALCULATE (
SELECTEDVALUE ( 'Product Category'[Category] )
)
)
ORDER BY [Product Key]The result of the query includes two identical columns, Category RELATED and Category Context Transition, as shown in Figure 14-13.

The Category RELATED column shows the category corresponding to the product displayed on the same line of the report. This value is retrieved by using RELATED when the row context on Product is available. The Category Context Transition column uses a different approach, generating a context transition by invoking CALCULATE. The context transition filters just one row in the Product table; this filter is also applied to Product Subcategory and Product Category, filtering the corresponding rows for the product. Because at this point the filter context only filters one row in Product Category, SELECTEDVALUE returns the value of the Product Category column in the only row filtered in the Product Category table.
While this side effect is well known, it is not efficient to rely on this behavior when wanting to retrieve a value from a related table. Even though the result is identical, performance could be very different. The solution using a context transition is particularly expensive if used for many rows in Product. Context transition comes at a significant computational cost. Thus, as we will see later in the book, reducing the number of context transitions is important in order to improve performance. Therefore, RELATED is a better solution to this specific problem; it avoids the context transition required for SELECTEDVALUE to work.
Understanding ALLSELECTED and shadow filter contexts
ALLSELECTED is a handy function that hides a giant trap. In our opinion, ALLSELECTED is the most complex function in the whole DAX language, even though it looks harmless. In this section we provide an exhaustive technical description of the ALLSELECTED internals, along with a few suggestions on when to use and when not to use ALLSELECTED.
ALLSELECTED, as any other ALL* function, can be used in two different ways: as a table function or as a CALCULATE modifier. Its behavior differs in these two scenarios. Moreover, ALLSELECTED is the only DAX function that leverages shadow filter contexts. In this section, we first examine the behavior of ALLSELECTED, then we introduce shadow filter contexts, and finally we provide a few tips on using ALLSELECTED optimally.
ALLSELECTED can be used quite intuitively. For example, consider the requirements for the report in Figure 14-14.

The report uses a slicer to filter certain brands. It shows the sales amount of each brand, along with the percentage of each given brand over the total of all selected brands. The percentage formula is simple:
Pct :=
DIVIDE (
[Sales Amount],
CALCULATE (
[Sales Amount],
ALLSELECTED ( 'Product'[Brand] )
)
)Intuitively, our reader likely knows that ALLSELECTED returns the values of the brands selected outside of the current visual—that is, the brands selected between Adventure Works and Proseware. But what Power BI sends to the DAX engine is a single DAX query that does not have any concept of “current visual.”
How does DAX know about what is selected in the slicer and what is selected in the matrix? The answer is that it does not know these. ALLSELECTED does not return the values of a column (or table) filtered outside a visual. What it does is a totally different task, which as a side effect returns the same result most of the time. The correct definition of ALLSELECTED consists of the two following statements:
When used as a table function, ALLSELECTED returns the set of values as visible in the last shadow filter context.
When used as a CALCULATE modifier, ALLSELECTED restores the last shadow filter context on its parameter.
These last two sentences deserve a much longer explanation.
Introducing shadow filter contexts
In order to introduce shadow filter contexts, it is useful to look at the query that is executed by Power BI to produce the result shown in Figure 14-14:
DEFINE
VAR __DS0FilterTable =
TREATAS (
{
"Adventure Works",
"Contoso",
"Fabrikam",
"Litware",
"Northwind Traders",
"Proseware"
},
'Product'[Brand]
)
EVALUATE
TOPN (
502,
SUMMARIZECOLUMNS (
ROLLUPADDISSUBTOTAL (
'Product'[Brand],
"IsGrandTotalRowTotal"
),
__DS0FilterTable,
"Sales_Amount", 'Sales'[Sales Amount],
"Pct", 'Sales'[Pct]
),
[IsGrandTotalRowTotal], 0,
'Product'[Brand], 1
)
ORDER BY
[IsGrandTotalRowTotal] DESC,
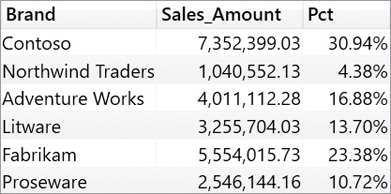
'Product'[Brand]The query is a bit too complex to analyze—not because of its inherent complexity but because it is generated by an engine and is thus not designed to be human-readable. The following is a version of the formula that is close enough to the original, but easier to understand and describe:
EVALUATE
VAR Brands =
FILTER (
ALL ( 'Product'[Brand] ),
'Product'[Brand]
IN {
"Adventure Works",
"Contoso",
"Fabrikam",
"Litware",
"Northwind Traders",
"Proseware"
}
)
RETURN
CALCULATETABLE (
ADDCOLUMNS (
VALUES ( 'Product'[Brand] ),
"Sales_Amount", [Sales Amount],
"Pct", [Pct]
),
Brands
)The result of this latter query is nearly the same as the report we examined earlier, with the noticeable difference that it is missing the total. We see this in Figure 14-15.
Here are some useful notes about the query:
The outer CALCULATETABLE creates a filter context containing six brands.
ADDCOLUMNS iterates over the six brands visible inside the CALCULATETABLE.
Both Sales Amount and Pct are measures executed inside an iteration. Therefore, a context transition is taking place before the execution of both measures, and the filter context of each of the two measures only contains the currently iterated brand.
Sales Amount does not change the filter context, whereas Pct uses ALLSELECTED to modify the filter context.
After ALLSELECTED modifies the filter context inside Pct, the updated filter context shows all six brands instead of the currently iterated brand.
The last point is the most helpful point in order to understand what a shadow filter context is and how DAX uses it in ALLSELECTED. Indeed, the key is that ADDCOLUMNS iterates over six brands, the context transition makes only one of them visible, and ALLSELECTED needs a way to restore a filter context containing the six iterated brands.
Here is a more detailed description of the query execution, where we introduce shadow filter contexts in step 3:
The outer CALCULATETABLE creates a filter context with six brands.
VALUES returns the six visible brands and returns the result to ADDCOLUMNS.
Being an iterator, ADDCOLUMNS creates a shadow filter context containing the result of VALUES, right before starting the iteration.
The shadow filter context is like a filter context, but it remains dormant, not affecting the evaluation in any way.
A shadow filter context can only be activated by ALLSELECTED, as we are about to explain. For now, just remember that the shadow filter context contains the six iterated brands.
We distinguish between a shadow filter context and a regular filter context by calling the latter an explicit filter context.
During the iteration, the context transition occurs on one given row. Therefore, the context transition creates a new explicit filter context containing solely the iterated brand.
When ALLSELECTED is invoked during the evaluation of the Pct measure, ALLSELECTED does the following: ALLSELECTED restores the last shadow filter context on the column or table passed as parameter, or on all the columns if ALLSELECTED has no arguments. (The behavior of ALLSELECTED without parameters is explained in the following section.)
Because the last shadow filter context contained six brands, the selected brands become visible again.
This simple example allowed us to introduce the concept of shadow filter context. The previous query shows how ALLSELECTED takes advantage of shadow filter contexts to retrieve the filter context outside of the current visual. Please note that the description of the execution does not use the Power BI visuals anywhere. Indeed, the DAX engine is not cognizant of which visual it is helping to produce. All it receives is a DAX query.
Most of the time ALLSELECTED retrieves the correct filter context; indeed, all the visuals in Power BI and, in general, most of the visuals generated by any client tool all generate the same kind of query. Those auto-generated queries always include a top-level iterator that generates a shadow filter context on the items it is displaying. This is the reason why ALLSELECTED seems to restore the filter context outside of the visual.
Having taken our readers one step further in their understanding of ALLSELECTED, we now need to examine more closely the conditions required for ALLSELECTED to work properly:
The query needs to contain an iterator. If there is no iterator, then no shadow filter context is present, and ALLSELECTED does not perform any operation.
If there are multiple iterators before ALLSELECTED is executed, then ALLSELECTED restores the last shadow filter context. In other words, nesting ALLSELECTED inside an iteration in a measure will most likely produce unwanted results because the measure is almost always executed in another iteration of the DAX query produced by a client tool.
If the columns passed to ALLSELECTED are not filtered by a shadow filter context, then ALLSELECTED does not do anything.
At this point, our readers can see more clearly that the behavior of ALLSELECTED is quite complex. Developers predominantly use ALLSELECTED to retrieve the outer filter context of a visualization. We also used ALLSELECTED previously in the book for the very same purpose. In doing so, we always double-checked that ALLSELECTED was used in the correct environment, even though we did not explain in detail what was happening.
The fuller semantics of ALLSELECTED are related to shadow filter contexts, and merely by chance (or, to be honest, by careful and masterful design) does its effect entail the retrieving of the filter context outside of the current visual.
A good developer knows exactly what ALLSELECTED does and only uses it in the scenarios where ALLSELECTED works the right way. Overusing ALLSELECTED by relying on it in conditions where it is not expected to work can only produce unwanted results, at which point the developer is to blame, not ALLSELECTED....
The golden rule for ALLSELECTED is quite simple: ALLSELECTED can be used to retrieve the outer filter context if and only if it is being used in a measure that is directly projected in a matrix or in a visual. By no means should the developer expect to obtain correct results by using a measure containing ALLSELECTED inside an iteration, as we are going to demonstrate in the following sections. Because of this, we, as DAX developers, use a simple rule: If a measure contains ALLSELECTED anywhere in the code, then that measure cannot be called by any other measure. This is to avoid the risk that in the chain of measure calls, a developer could start an iteration that includes a call to a measure containing ALLSELECTED.
ALLSELECTED returns the iterated rows
To further demonstrate the behavior of ALLSELECTED, we make a small change to the previous query. Instead of iterating over VALUES ( Product[Brand] ), we make ADDCOLUMNS iterate over ALL ( Product[Brand] ):
EVALUATE
VAR Brands =
FILTER (
ALL ( 'Product'[Brand] ),
'Product'[Brand]
IN {
"Adventure Works",
"Contoso",
"Fabrikam",
"Litware",
"Northwind Traders",
"Proseware"
}
)
RETURN
CALCULATETABLE (
ADDCOLUMNS (
ALL ( 'Product'[Brand] ),
"Sales_Amount", [Sales Amount],
"Pct", [Pct]
),
Brands
)In this new scenario, the shadow filter context created by ADDCOLUMNS before the iteration contains all the brands—not simply the selected brands. Therefore, when called in the Pct measure, ALLSELECTED restores the shadow filter context, thus making all brands visible. The result shown in Figure 14-16 is different from that of the previous query shown in Figure 14-15.

As you can see, all the brands are visible—and this is expected—but the numbers are different than before, even though the code computing them is the same. The behavior of ALLSELECTED in this scenario is correct. Developers might think that it behaves unexpectedly because the filter context defined by the Brands variable is ignored by the Pct measure; however, ALLSELECTED is indeed behaving as it was designed to. ALLSELECTED returns the last shadow filter context; In this latter version of the query, the last shadow filter context contains all brands, not only the filtered ones. Indeed, ADDCOLUMNS introduced a shadow filter context on the rows it is iterating, which includes all brands.
If one needs to retain the previous filter context, they cannot rely solely on ALLSELECTED. The CALCULATE modifier that retains the previous filter context is KEEPFILTERS. It is interesting to see the result when KEEPFILTERS comes into play:
EVALUATE
VAR Brands =
FILTER (
ALL ( 'Product'[Brand] ),
'Product'[Brand]
IN {
"Adventure Works",
"Contoso",
"Fabrikam",
"Litware",
"Northwind Traders",
"Proseware"
}
)
RETURN
CALCULATETABLE (
ADDCOLUMNS (
KEEPFILTERS ( ALL ( 'Product'[Brand] ) ),
"Sales_Amount", [Sales Amount],
"Pct", [Pct]
),
Brands
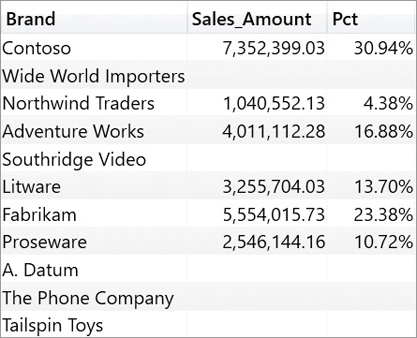
)When used as a modifier of an iterator, KEEPFILTERS does not change the result of the iterated table. Instead, it instructs the iterator to apply KEEPFILTERS as an implicit CALCULATE modifier whenever context transition occurs while iterating on the table. As a result, ALL returns all the brands and the shadow filter context also contains all the brands. When the context transition takes place, the previous filter applied by the outer CALCULATETABLE with the Brands variable is kept. Thus, the query returns all the brands, but values are computed considering only the selected brands, as we can see in Figure 14-17.
ALLSELECTED without parameters
As the name suggests, ALLSELECTED belongs to the ALL* family. As such, when used as a CALCULATE modifier, it acts as a filter remover. If the column used as a parameter is included in any shadow filter context, then it restores the last shadow filter context on that column only. Otherwise, if there is no shadow filter context then it does not do anything.
When used as a CALCULATE modifier, ALLSELECTED, like ALL, can also be used without any parameter. In that case, ALLSELECTED restores the last shadow filter context on any column. Remember that this happens if and only if the column is included in any shadow filter context. If a column is filtered through explicit filters only, then its filter remains untouched.
The ALL* family of functions
Because of the complexity of the ALL* family of functions, in this section we provide a summary of their behavior. Every ALL* function behaves slightly differently, so mastering them takes time and experience. In this chapter about advanced DAX concepts, it is time to sum up the main concepts.
The ALL* family includes the following functions: ALL, ALLEXCEPT, ALLNOBLANKROW, ALLCROSSFILTERED, and ALLSELECTED. All these functions can be used either as table functions or as CALCULATE modifiers. When used as table functions, they are much easier to understand than when used as CALCULATE modifiers. Indeed, when used as CALCULATE modifiers, they might produce unexpected results because they act as filter removers.
Table 14-5 provides a summary of the ALL* functions. In the remaining part of this section we provide a more complete description of each function.
Table 14-5 Summary of the ALL* family of functions
Function |
Table function |
CALCULATE modifier |
|---|---|---|
ALL |
Returns all the distinct values of a column or of a table. |
Removes any filter from columns or expanded tables. It never adds a filter; it only removes them if present. |
ALLEXCEPT |
Returns all the distinct values of a table, ignoring filters on some of the columns of the expanded table. |
Removes filters from an expanded table, except from the columns (or tables) passed as further arguments. |
ALLNOBLANKROW |
Returns all the distinct values of a column or table, ignoring the blank row added for invalid relationships. |
Removes any filter from columns or expanded tables; also adds a filter that only removes the blank row. Thus, even if there are no filters, it actively adds one filter to the context. |
ALLSELECTED |
Returns the distinct values of a column or a table, as they are visible in the last shadow filter context. |
Restores the last shadow filter context on tables or columns, if a shadow filter context is present. Otherwise, it does not do anything. It always adds filters, even in the case where the filter shows all the values. |
ALLCROSSFILTERED |
Not available as a table function. |
Removes any filter from an expanded table, including also the tables that can be reached directly or indirectly through bidirectional cross-filters. ALLCROSSFILTERED never adds a filter; it only removes filters if present. |
The “Table function” column in Table 14-5 corresponds to the scenario where the ALL* function is being used in a DAX expression, whereas the “CALCULATE modifier” column is the specific case when the ALL* function is the top-level function of a filter argument in CALCULATE.
Another significant difference between the two usages is that when one retrieves the result of these ALL* functions through an EVALUATE statement, the result contains only the base table columns and not the expanded table. Nevertheless, internal calculations like the context transition always use the corresponding expanded table. The following examples of DAX code show the different uses of the ALL function. The same concepts can be applied to any function of the ALL* family.
In the following example, ALL is used as a simple table function.
SUMX (
ALL ( Sales ), -- ALL is a table function
Sales[Quantity] * Sales[Net Price]
)In the next example there are two formulas, involving iterations. In both cases the Sales Amount measure reference generates the context transition, and the context transition happens on the expanded table. When used as a table function, ALL returns the whole expanded table.
FILTER (
Sales,
[Sales Amount] > 100 -- The context transition takes place
-- over the expanded table
)
FILTER (
ALL ( Sales ), -- ALL is a table function
[Sales Amount] > 100 -- The context transition takes place
-- over the expanded table anyway
)In the next example we use ALL as a CALCULATE modifier to remove any filter from the expanded version of Sales:
CALCULATE (
[Sales Amount],
ALL ( Sales ) -- ALL is a CALCULATE modifier
)This latter example, although similar to the previous one, is indeed very different. ALL is not used as a CALCULATE modifier; instead, it is used as an argument of FILTER. In such a case, ALL behaves as a regular table function returning the entire expanded Sales table.
CALCULATE (
[Sales Amount],
FILTER ( ALL ( Sales ), Sales[Quantity] > 0 ) -- ALL is a table function
-- The filter context receives the
-- expanded table as a filter anyway
)The following are more detailed descriptions of the functions included in the ALL* family. These functions look simple, but they are rather complex. Most of the time, their behavior is exactly what is needed, but they might produce undesired effects in boundary cases. It is not easy to remember all these rules and all the specific behaviors. We hope our reader finds Table 14-5 useful when unsure about an ALL* function.
ALL
When used as a table function, ALL is a simple function. It returns all the distinct values of one or more columns, or all the values of a table. When used as a CALCULATE modifier, it acts as a hypothetical REMOVEFILTER function. If a column is filtered, it removes the filter. It is important to note that if a column is cross-filtered, then the filter is not removed. Only direct filters are removed by ALL. Thus, using ALL ( Product[Color] ) as a CALCULATE modifier might still leave Product[Color] cross-filtered in case there is a filter on another column of the Product table. ALL operates on the expanded table. This is why ALL ( Sales ) removes any filter from the tables in the sample model: the expanded Sales table includes all the tables of the entire model. ALL with no arguments removes any filter from the entire model.
ALLEXCEPT
When used as a table function, ALLEXCEPT returns all the distinct values of the columns in a table, except the columns listed. If used as a filter, the result includes the full expanded table. When used as a filter argument in CALCULATE, ALLEXCEPT acts exactly as an ALL, but it does not remove the filter from the columns provided as arguments. It is important to remember that using ALL/VALUES is not the same as ALLEXCEPT. ALLEXCEPT only removes filters, whereas ALL removes filters while VALUES retains cross-filtering by imposing a new filter. Though subtle, this difference is important.
ALLNOBLANKROW
When used as a table function, ALLNOBLANKROW behaves like ALL, but it does not return the blank row potentially added because of invalid relationships. ALLNOBLANKROW can still return a blank row, if blanks are present in the table. The only row that is never returned is the one added automatically by the engine to fix invalid relationships. When used as a CALCULATE modifier, ALLNOBLANKROW replaces all the filters with a new filter that only removes the blank row. Therefore, all the columns will only filter out the blank value.
ALLSELECTED
When used as a table function, ALLSELECTED returns the values of a table (or column) as filtered in the last shadow filter context. When used as a CALCULATE modifier, it restores the last shadow filter context on each column. If multiple columns are present in different shadow filter contexts, it uses the last shadow filter context for each column.
ALLCROSSFILTERED
ALLCROSSFILTERED can be used only as a CALCULATE modifier and cannot be used as a table function. ALLCROSSFILTERED has only one argument that must be a table. ALLCROSSFILTERED removes all the filters on an expanded table (like ALL) and on columns and tables that are cross-filtered because of bidirectional cross-filters set on relationships directly or indirectly connected to the expanded table.
Understanding data lineage
We introduced data lineage in Chapter 10, “Working with the filter context,” and we have shown our readers how to control data lineage using TREATAS. In Chapter 12, “Working with tables,” and Chapter 13, “Authoring queries,” we described how certain table functions can manipulate the data lineage of the result. This section is a summary of the rules to remember about data lineage, with additional information we could not cover in previous chapters.
Here are the basic rules of data lineage:
Each column of a table in a data model has a unique data lineage.
When a filter context filters the model, it filters the model column with the same data lineage of the columns included in the filter context.
Because a filter is the result of a table, it is important to know how a table function may affect the data lineage of the result:
In general, columns used to group data keep their data lineage in the result.
Columns containing the result of an aggregation always have a new data lineage.
Columns created by ROW and ADDCOLUMNS always have a new data lineage.
Columns created by SELECTEDCOLUMNS keep the data lineage of the original column whenever the expression is just a copy of a column in the data model; otherwise, they have a new data lineage.
For example, the following code seems to produce a table where each product color has a corresponding Sales Amount value summing all the sales for that color. Instead, because C2 is a column created by ADDCOLUMNS, it does not have the same lineage as Product[Color], even though it has the same content. Please note that we had to use several steps: first, we create the C2 column; then we select that column only. If other columns remain in the same table, then the result would be very different.
DEFINE
MEASURE Sales[Sales Amount] =
SUMX ( Sales, Sales[Quantity] * Sales[Net Price] )
EVALUATE
VAR NonBlueColors =
FILTER (
ALL ( 'Product'[Color] ),
'Product'[Color] <> "Blue"
)
VAR AddC2 =
ADDCOLUMNS (
NonBlueColors,
"[C2]", 'Product'[Color]
)
VAR SelectOnlyC2 =
SELECTCOLUMNS ( AddC2, "C2", [C2] )
VAR Result =
ADDCOLUMNS ( SelectOnlyC2, "Sales Amount", [Sales Amount] )
RETURN Result
ORDER BY [C2]The previous query produces a result where the Sales Amount column always has the same value, corresponding to the sum of all the rows in the Sales table. This is shown in Figure 14-18.

TREATAS can be used to transform the data lineage of a table. For example, the following code restores the data lineage to Product[Color] so that the last ADDCOLUMNS computes Sales Amount leveraging the context transition over the Color column:
DEFINE
MEASURE Sales[Sales Amount] =
SUMX ( Sales, Sales[Quantity] * Sales[Net Price] )
EVALUATE
VAR NonBlueColors =
FILTER (
ALL ( 'Product'[Color] ),
'Product'[Color] <> "Blue"
)
VAR AddC2 =
ADDCOLUMNS (
NonBlueColors,
"[C2]", 'Product'[Color]
)
VAR SelectOnlyC2 =
SELECTCOLUMNS ( AddC2, "C2", [C2] )
VAR TreatAsColor =
TREATAS ( SelectOnlyC2, 'Product'[Color] )
VAR Result =
ADDCOLUMNS ( TreatAsColor, "Sales Amount", [Sales Amount] )
RETURN Result
ORDER BY 'Product'[Color]As a side effect, TREATAS also changes the column name, which must be correctly referenced in the ORDER BY condition. The result is visible in Figure 14-19.

Conclusions
In this chapter we introduced two complex concepts: expanded tables and shadow filter contexts.
Expanded tables are at the core of DAX. It takes some time before one gets used to thinking in terms of expanded tables. However, once the concept of expanded tables has become familiar, they are much simpler to work with than relationships. Only rarely does a developer have to deal with expanded tables, but knowing about them proves to be invaluable when they are the only way to make sense of a result.
In this regard, shadow filter contexts are like expanded tables: They are hard to see and understand, but when they come into play in the evaluation of a formula, they explain exactly how the numbers were computed. Making sense of a complex formula that uses ALLSELECTED without first mastering shadow filter contexts is nearly impossible.
However, both concepts are so complex that the best thing to do is to try to avoid them. We do show a few examples of expanded tables being useful in Chapter 15. Shadow filter contexts are useless in code; they are merely a technical means for DAX to let developers compute totals at the visual level.
Try to avoid using expanded tables by only using column filters and not table filters in CALCULATE filter arguments. Doing this, the code will be much easier to understand. Usually, it is possible to ignore expanded tables, as long as they are not required for some complex measure.
Try to avoid shadow filter context by never letting ALLSELECTED be called inside an iteration. The only iteration before ALLSELECTED needs to be the outermost iteration created by the query engine—mostly Power BI. Calling a measure containing ALLSELECTED from inside an iteration makes the calculation more complex.
When you follow these two pieces of advice, your DAX code will be correct and easy to understand. Remember that experts can appreciate complexity, but they also understand when it is better to stay away from complexity. Avoiding table filters and ALLSELECTED inside iterations does not make a developer look uneducated. Rather, it puts the developer in the category of experts that want their code to always work smoothly.