
8.1 Basic Filesystem Characteristics
8.2 HFS Internal Structure
8.3 Tuning an HFS Filesystem
8.4 HFS Access Control Lists
8.5 VxFS Internal Structures Including VxFS Access Control Lists
8.6 Online JFS Features
8.7 Tuning a VxFS Filesystem
8.8 VxFS Snapshots
8.9 Navigating through Filesystems via the VFS Layer
In this chapter, we look at one of the main uses of disk and volumes: filesystems. The HP-UX kernel can support many filesystem types including Network FS, CDFS, Distributed FS, Auto FS, Cache FS, CIFS, and Loopback FS. We look at the two main filesystem types: HFS and VxFS. Understanding the structure of a filesystem can help you reap rewards when it comes to fixing filesystems, i.e., running fsck. When we run fsck and are prompted with questions regarding fixing the filesystem, we normally reply YES. This is good practice for the vast majority of situations. Understanding what fsck is asking you can lead you to make some other decisions in certain circumstances. We look at the structure of a filesystem as well as managing its many aspects. When I am talking about and creating filesystems, I use both LVM logical volumes and VxVM volumes. There are only a few instances when the commands know or care which type of filesystem is in the underlying logical disk.
The basic premise of most filesystems is to store our data in such a way that it:
Is relatively easy to retrieve.
Stores data in a secure manner to allow access only to authorized users.
Offers performance features that mean retrieval minimizes any impacts on overall system performance.
This last point, relating to performance, has always been the Holy Grail of filesystem designers. Disks are invariably the slowest components in our system. To minimize this, filesystem designers employ miraculous sleight of hand with the underlying filesystem structures in an attempt to minimize the amount of time that read/write heads spend traversing the disk, as well as minimizing the time spent waiting for the platters to spin in order to position the correct sectors under the read/write heads. As disk administrators, we are trying to aid this process by employing clever technologies such as striping, mirroring, and RAID in the underlying design of logical devices.
We start our discussions by looking at HFS: the High performance Files system. As we all (probably) know, HFS is not the most high performance filesystem anymore. It serves as a basis to talk about the most prevalent filesystem in HP-UX: VxFS. With its many online capabilities, its use of ACLs, and its performance-related tuning and mount options, VxFS has become the filesystem of choice for today's administrators.
I want to get the problem of largefiles out of the way immediately because it applies to all filesystem types. When we create a filesystem, the default behavior, regardless of whether it is HFS or VxFS, is to not support largefiles in a particular filesystem. To establish whether your filesystem supports largefiles, we use the fsadm –F <hfs|vxfs> <character device file> command. This feature can be turned ON for individual filesystems that require it with the fsadm –F <hfs|vxfs> -o largefiles <filesystem> command or with a similar option to the newfs command when the filesystem is first created. A largefile is a file greater than 2GB in size. This might seem like a ridiculously small value these days. I agree with you. The problem is that the computing industry in general can't really decide on how to treat largefiles. The issue harkens back to the days of 32-bit operating systems. In a 32-bit operating system, we have an address range of 232 = 4GB. When we seek around in a file, we can supply an address offset from our current position. With an offset, we can go forward as well as back, i.e., the offset is a signed integer. Consequently, we don't have the entire 32 bits, but only 31 bits to specify our offset. A 31-bit address range is 2GB in size. Traditional UNIX commands like tar, cpio, dump, and restore cannot safely handle largefiles (or user IDs greater than 60,000); they are limited to files up to 2GB in size. If we are to use largefiles in our filesystems, we must understand this limitation, because some third-party backup/check-pointing routines will actually be simple interfaces to a traditional UNIX command such as cpio. All HP-UX filesystems support largefiles with the largest file (and filesystem) currently being 2TB in size (a 41-bit address range; at the moment, this seems adequate in most situations). Having to manage files of this size will require special, non-standard backup/check-pointing routines. We should check with our application suppliers to find out how they want us to deal with these issues.
The High performance filesystem is known by many names: the McKusick filesystem (after Marshall Kirk McKusick of Berkeley University, one of its authors), the Berkeley filesystem (see Marshall Kirk McKusick), UFS, and the UNIX filesystem (although this accolade should really go to the original 512-byte block filesystem created by the guys at AT&T Bell research labs, guys like Ken Thompson and Dennis Ritchie, who wrote the earliest versions of what we call UNIX). HFS has been around since the mid- to late 1980s. It has stood the test of time because it does simple things really well. In its day, it was seen as a massive leap forward, especially in the way the files were organized on disk, which led to massive improvements in IO performance. However, it has been something of a letdown when it has to check the underlying filesystem structure after a system crash. In these situations, it has to check the entire filesystem for any corruption, even the filesystem structures written two days ago. It has no log of when updates to the structure took place and whether those updates actually completed. On large filesystems, this can be a serious problem after a system crash. An individual filesystem can take more than an hour to check itself before marking itself as clean and allowing the system to continue booting. This is one of the main reasons that HFS has lost favor over the years.
The basic design ideas employed in the HFS filesystem can still be seen in today's advanced filesystems. The key was to try to localize the control information (inodes) and the data (data blocks) for individual files as close together as possible. By doing so, we are attempting to minimize read/write head movement as well as any rotational delays in waiting for platters to spin by switching access to adjacent platter. This led to splitting the filesystem into logical chunks known as cylinder groups (see Figure 8-1).
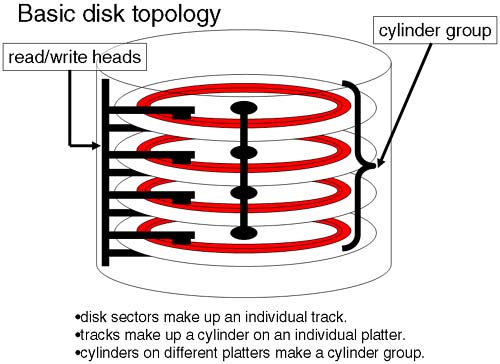
If we attempted to store the data blocks for an individual file in a single cylinder group, the disk's read/write heads didn't need to move very far to retrieve the data, because we could switch between individual read/write heads far quicker than the server to position the read/write heads to a new location. The number of cylinder groups created was determined by the overall size of the filesystem (usually 16 cylinders per group). The drawback with this design is in the code to understand and be able to interface with all these structures. This was overcome with the superblock. The superblock is an 8KB block of data that details the size and configuration of the filesystem as well as the location of all the cylinder groups, the location of the inode table within each cylinder group, and the free space maps for inodes and disk blocks. The superblock is read into memory at mount time for easy access. If we lost the primary superblock, we could always recover it from a backup superblock stored in each cylinder group. The backup superblocks contained the static information relating to the filesystem, e.g., size, number of inodes, location, and number of cylinder groups. The dynamic information could be reconstructed by simply traversing the entire filesystem calculating how many actual block and inodes were in use. If we think of the cylinder group as simply a chunk of disk space, we can view the overall filesystem structure as we see in Figure 8-2.
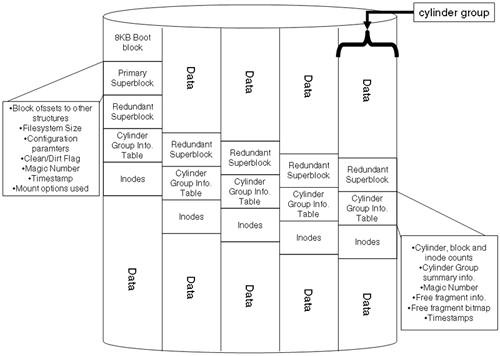
The idea of having the structural elements of the filesystem offset on disk was to try to alleviate the problem of a head crash scrubbing a particular section of this disk.
The number of inodes in an HFS filesystem is fixed at newfs time. The default of having one inode for every 6KB of space makes it unlikely that we will run out of inodes. However, it means that we could be wasting a significant amount of disk space on inodes that we don't need (an HFS inode being 128 bytes in size). The inode density is one configuration parameter that we may choose to modify at filesystem creation time.
McKusick and his buddies were clever with how inodes were allocated. If we think about files in the same directory, they probably mean something to each other, i.e., they belong to the same user or application. The notion of locality of data extended to allocating inodes. A new file (hence, a new inode) would ideally be created in the same cylinder group as its parent. If this is not available, then either an inode recently purged or, if we have a preference, an inode from a cylinder group with the fewest inode and directory entries is in use. Similarly, the data blocks for the file would be in the same cylinder group. To avoid a single file swamping a cylinder group, there is a configuration parameter, which allows only 25 percent (by default) of the space in a cylinder group to be used by a single file (maxpbg = max block per group). Where we have only one or two files in a single directory, e.g., a large database file, it would be worthwhile changing maxbpg = bpg (blocks per group). This makes sense only at filesystem creation time before individual blocks are allocated.
Inodes are at the heart of the filesystem because an inode stores the characteristics of a file and points us to the data blocks where our data resides. An HFS inode is 128 bytes in size. This fixed size makes locating an individual inode a trivial exercise. The superblock can calculate which cylinder group holds a specific inode and where the inode table beings within that cylinder group; also, using the inode number x 128 bytes as an offset, it can quickly locate an inode in order to determine whether we are allowed to read the data held within. File type, permissions, ownerships, timestamps, and ACL references are all listed in an inode as well as a series of pointers that direct us to where our data is located within the filesystem. Figure 8-3 gives you an idea of the structure of an inode utilizing an 8KB block.
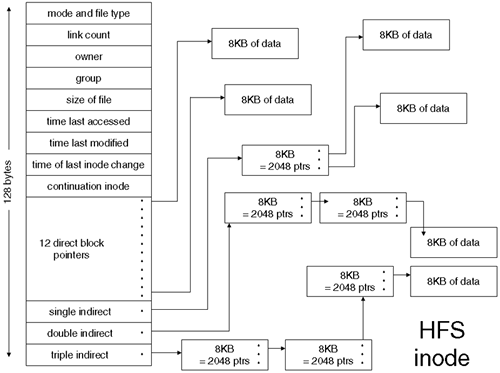
To avoid wasting space in an entire block, the smallest addressable object is a fragment. A fragment is 1/8 of a block (1KB by default). The size of a block and fragment are fixed at filesystem creation time. The default sizes have been shown to be adequate in most situations. Where you have only a few large files in an HFS filesystem, it makes sense to create a filesystem with larger block and fragment sizes (up to 64KB and 8KB, respectively). This will cut down the number of individual inode and disk reads in order to address any given quantity of data. The use of double and triple (seldom used) indirect pointers can cause a significant increase in the number of IO to a filesystem.
The root inode of a filesystem is always inode 2. Subsequent allocation is based on the allocation policy we mentioned previously. Directories have data blocks like any other file; the difference is that the data for a directory is a list of filenames and inode numbers. When we locate a file, we implicitly read the inode number from the directory. This will point us toward another inode, possibly another directory, until we finally locate the file of interest. Let's look at an example where we want to examine the content of a file called /hfs/system. Ignore the fact that we need to traverse the root filesystem first (which is VxFS). We need to locate the root inode in the /hfs filesystem. We know that it is always at inode 2. I will use the fsdb command to traverse through the inodes in the filesystem until I find the file I am looking for. NOTE: The use of fsdb is dangerous. In this instance, we are looking only at filesystem structures. Should you happen to change a filesystem using fsdb, you could render the entire filesystem unusable. This is for demonstration purposes only:
root@hpeos003[] bdf /hfs Filesystem kbytes used avail %used Mounted on /dev/vg00/hfs.data 103637 15 93258 0% /hfs root@hpeos003[] fsdb -F hfs /dev/vg00/hfs.data file system size = 106496(frags) isize/cyl group=48(Kbyte blocks) primary block size=8192(bytes) fragment size=1024 no. of cyl groups = 44 2i i#:2 md: d---rwxr-xr-x ln: 3 uid: 0 gid: 0 sz: 1024 ci:0 a0 : 120 a1 : 0 a2 : 0 a3 : 0 a4 : 0 a5 : 0 a6 : 0 a7 : 0 a8 : 0 a9 : 0 a10: 0 a11: 0 a12: 0 a13: 0 a14: 0 at: Wed Nov 12 20:48:27 2003 mt: Wed Nov 12 20:48:23 2003 ct: Wed Nov 12 20:48:23 2003
We can see the file type and mode (d---rwxr-xr-x). Because we are dealing with a directory, we can use the formatting instruction to instruct fsdb to print block 0 as a list of directories.
a0.fd
d0: 2 .
d1: 2 . .
d2: 3 l o s t + f o u n d
d3: 4 s y s t e m
d4: 5 p a s s w d
d5: 6 h o s t s
From this, we can see that the system file is located at inode 4 (directory slot d3). To make inode 4 our working inode, we simply use the command 4i:
4i
i#:4 md: f---r--r--r-- ln: 1 uid: 0 gid: 3 sz: 1146 ci:0
a0 : 107 a1 : 0 a2 : 0 a3 : 0 a4 : 0 a5 : 0
a6 : 0 a7 : 0 a8 : 0 a9 : 0 a10: 0 a11: 0
a12: 0 a13: 0 a14: 0
at: Wed Nov 12 20:48:23 2003
mt: Wed Nov 12 20:48:23 2003
ct: Wed Nov 12 20:48:23 2003
From here, we can examine the content of the file if we like:
107b.fc
326000 : * * * * * * * * * * * * * * * * * * * * * *
326040 : * * * * * * *
* S o u r c e : / u x /
326100 : f i l e s e t s . i n f o / C O R E - K R N
326140 : @ ( # ) B . 1 1 . 1 1 _ L R
*
* * *
326200 : * * * * * * * * * * * * * * * * * * * * * *
326240 : i t i o n a l d r i v e r s r e q u i r
326300 : y m a c h i n e - t y p e t o c r e a
326340 : e t e
* s y s t e m f i l e d u r i
326400 : s t a l l . T h i s l i s t i s e
326440 : r t h a t t h e
* m a s t e r . d /
326500 : n o t f o r c e o n t h e s y s t e
326540 : t i d e n t i f i a b l e b y
* i o
326600 : h e r C P U - t y p e s p e c i f i c
326640 : e x i s t f o r t h e i r s p e c i a
326700 : s e e c r e a t e _ s y s f i l e ( 1
326740 : * * * * * * * * * * * * * * * * * * * * * *
327000 : *
*
* D r i v e r s / S u b s y s t e
327040 :
b t l a n
c 7 2 0
s c t l
s d i s k
327100 : t o P C I
t d
c d f s
f c p
f c T 1
327140 : r f
o l a r _ p s m
o l a r _ p s m _ i
327200 :
d i a g 0
d i a g 1
d i a g 2
d m e
327240 : i g
i o m e m
n f s _ c o r e
n f s _
327300 : _ s e r v e r
n f s m
r p c m o d
a u
327340 : e f s c
m a c l a n
d l p i
t o k e n
327400 : u i p c
t u n
t e l m
t e l s
n e t
327440 : h p s t r e a m s
c l o n e
s t r l o g
327500 : s c
t i m o d
t i r d w r
p i p e d e
327540 : f f s
l d t e r m
p t e m
p t s
p t
327600 : i 4
g e l a n
G S C t o P C I
v x v m
327640 :
v o l s
i o p _ d r v
b s _ o s m
i
327700 :
v x p o r t a l
b t l a n 1
l v m
l
327740 : a p e
t a p e 2
C e n t I f
l p r 2
This demonstration of traversing the filesystem using primitive objects (i.e., inodes) is to try to demonstrate the amount of work the filesystem has to undertake when accessing files within an HFS filesystem.
There are few changes we can make to HFS filesystems. Any changes that are made should be made when the filesystem is created or shortly thereafter. The changes involve the size of blocks, fragments, inode density, as well as proportion of space that an individual file can take from a cylinder group. The following sections provides some examples.
In this instance, we know up front that this filesystem will be used solely by a few large files. We want to allocate space to the files as efficiently as possible. In this instance, we will:
Use the largest block and fragment size possible.
newfs –b 65536 –f 8192
Lower the inode density to increase user data space.
newfs –i 65536 ...
Ensure that the minimum amount of free space in the filesystem does not fall below 10 percent.
tunefs –m 10 ...
When the designers of HFS were performing tests on the performance of the filesystem, they discovered that, on average, if the free space in the filesystem fell below 10 percent, the ability of the filesystem to find free resources dropped dramatically. For large filesystems these days, it may be appropriate to drop this percentage by a few percentage points. The difference being that in the 1980s, the designers of HFS were dealing with filesystems of a few hundred megabytes. Today, we are dealing with filesystems of a few hundred gigabytes. Ten percent of 500GB is somewhat different from 10 percent of 500MB.
Allow largefiles.
newfs –o largefiles ...
Allow a single file to utilize an entire cylinder group.
tunefs –b <bpg> ...
Ensure that the rotational delay in the filesystem is set to zero.
tunefs –r 0 ...
The first two changes will need to be made at filesystem creation time. At that time, we can include options 3 and 4, although both can be implemented later. The last two tasks should be undertaken as soon as the filesystem is created. If not, the allocation policies used initially will be less than optimal, and files will be created in such a way that fixing them will require us to delete the file and restore it from a backup tape. Options 1, 4, and 5 will, we hope, see a performance benefit when our filesystem consists of only a few large files, while options 2, 3, and 4 are capacity related. Let's start with a simple baseline test where we create a single large file. This is not necessarily a complete test, because we should test for both sequential and random IO (large and small IO requests). It will simply indicate whether we are seeing in difference in the performance of the filesystem by changing the way the filesystem is created. To start with, we will simply create the filesystem with default options.
root@hpeos003[] newfs -F hfs /dev/vx/rdsk/ora1/archive mkfs (hfs): Warning - 224 sector(s) in the last cylinder are not allocated. mkfs (hfs): /dev/vx/rdsk/ora1/archive - 4194304 sectors in 6722 cylinders of 16 tracks, 39 sectors 4295.0Mb in 421 cyl groups (16 c/g, 10.22Mb/g, 1600 i/g) Super block backups (for fsck -b) at: 16, 10040, 20064, 30088, 40112, 50136, 60160, 70184, 80208, 90232, 100256, 110280, 120304, 130328, 140352, 150376, 159760, 169784, 179808, 189832, ... 4193456 root@hpeos003[]
We will now mount the filesystem and time how long it takes to create a 1GB file in the filesystem.
root@hpeos003[] mkdir /test root@hpeos003[] mount /dev/vx/dsk/ora1/archive /test root@hpeos003[] cd /test root@hpeos003[test] time prealloc 1GB.file 1073741824 real 11:38.8 user 0.1 sys 29.1 root@hpeos003[test]
I took some samples of IO performance (using sar) during this test:
root@hpeos003[] sar -d 5 5
HP-UX hpeos003 B.11.11 U 9000/800 11/13/03
00:02:53 device %busy avque r+w/s blks/s avwait avserv
00:02:58 c1t15d0 0.59 0.50 0 2 6.96 18.60
c0t4d0 100.00 31949.50 82 1302 150717.84 97.60
c4t12d0 100.00 22443.50 164 2620 144854.70 49.21
00:03:03 c1t15d0 3.45 0.50 3 13 5.71 15.57
c0t4d0 100.00 31470.00 110 1756 147746.78 72.94
c4t12d0 100.00 21586.50 178 2852 151833.02 44.99
00:03:08 c1t15d0 1.20 0.50 1 4 5.19 15.61
c0t4d0 100.00 30945.00 101 1612 158546.36 78.75
c4t12d0 100.00 20772.00 149 2385 157004.81 51.24
00:03:13 c1t15d0 4.01 0.50 3 9 6.57 22.09
c0t4d0 100.00 30477.00 86 1374 164202.09 93.72
c4t12d0 100.00 20001.50 159 2535 158627.81 52.65
00:03:18 c1t15d0 2.21 0.50 2 6 6.20 19.53
c0t4d0 100.00 29947.50 127 2022 163093.66 63.05
c4t12d0 100.00 19147.50 184 2937 165405.70 43.43
Average c1t15d0 2.28 0.50 2 7 6.07 18.47
Average c0t4d0 100.00 30895.00 101 1611 157029.62 79.25
Average c4t12d0 100.00 20775.00 167 2665 155637.33 48.07
root@hpeos003[]
I can't believe the average wait time for IO requests. I suppose that if you look at the average service time and the average queue size, it starts to make sense. From the fsdb output below, we can see that we are now using the double indirect pointer (a13). This will increase the amount of IO to the filesystem:
root@hpeos003[test] ll -i total 2098208 4 -rw-rw-rw- 1 root sys 1073741824 Nov 12 23:59 1GB.file 3 drwxr-xr-x 2 root root 8192 Nov 12 23:52 lost+found root@hpeos003[test] echo "4i" | fsdb -F hfs /dev/vx/rdsk/ora1/archive file system size = 4194304(frags) isize/cyl group=200(Kbyte blocks) primary block size=8192(bytes) fragment size=1024 no. of cyl groups = 421 i#:4 md: f---rw-rw-rw- ln: 1 uid: 0 gid: 3 sz: 1073741824 ci:0 a0 : 280 a1 : 288 a2 : 296 a3 : 304 a4 : 312 a5 : 320 a6 : 328 a7 : 336 a8 : 344 a9 : 352 a10: 360 a11: 368 a12: 9992 a13: 79880 a14: 0 at: Wed Nov 12 23:53:30 2003 mt: Wed Nov 12 23:59:55 2003 ct: Thu Nov 13 00:05:07 2003 root@hpeos003[test]
Let's try the same test, but on a filesystem created with the features listed above.
root@hpeos003[] umount /test root@hpeos003[] newfs -F hfs -b 65536 -f 8192 -i 65536 -o largefiles /dev/vx/rdsk/ora1/archive mkfs (hfs): Warning - 224 sector(s) in the last cylinder are not allocated. mkfs (hfs): /dev/vx/rdsk/ora1/archive - 4194304 sectors in 6722 cylinders of 16 tracks, 39 sectors 4295.0Mb in 421 cyl groups (16 c/g, 10.22Mb/g, 512 i/g) Super block backups (for fsck -b) at: 64, 10112, 20160, 30208, 40256, 50304, 60352, 70400, 80448, 90496, 100544, 110592, 120640, 130688, 140736, 150784, 159808, 169856, 179904, ... 4193600 root@hpeos003[]
We will now tune the filesystem to ensure that a single file can utilize an entire cylinder group (maxbpg = bpg):
root@hpeos003[] tunefs -v /dev/vx/rdsk/ora1/archive super block last mounted on: magic 5231994 clean FS_CLEAN time Thu Nov 13 00:19:27 2003 sblkno 8 cblkno 16 iblkno 24 dblkno 32 sbsize 8192 cgsize 8192 cgoffset 8 cgmask 0xfffffff0 ncg 421 size 524288 blocks 514175 bsize 65536 bshift 16 bmask 0xffff0000 fsize 8192 fshift 13 fmask 0xffffe000 frag 8 fragshift 3 fsbtodb 3 minfree 10% maxbpg 39 maxcontig 1 rotdelay 0ms rps 60 csaddr 32 cssize 8192 csshift 12 csmask 0xfffff000 ntrak 16 nsect 39 spc 624 ncyl 6722 cpg 16 bpg 156 fpg 1248 ipg 512 nindir 16384 inopb 512 nspf 8 nbfree 64269 ndir 2 nifree 215548 nffree 14 cgrotor 0 fmod 0 ronly 0 fname fpack featurebits 0x3 id 0x0,0x0 optimize FS_OPTTIME cylinders in last group 2 blocks in last group 19 root@hpeos003[] tunefs -e 156 /dev/vx/rdsk/ora1/archive maximum blocks per file in a cylinder group changes from 39 to 156 root@hpeos003[]
The rotational delay is zero, as we wanted it to be. We can now try our test:
root@hpeos003[] mount /dev/vx/dsk/ora1/archive /test root@hpeos003[] cd /test root@hpeos003[test] time prealloc 1GB.file 1073741824 real 54.8 user 0.0 sys 4.4 root@hpeos003[test]
This is an astonishing difference in times. I managed to capture similar sar output during this test.
root@hpeos003[] sar -d 5 5
HP-UX hpeos003 B.11.11 U 9000/800 11/13/03
00:22:05 device %busy avque r+w/s blks/s avwait avserv
00:22:10 c1t15d0 2.79 0.50 14 123 4.86 2.70
c0t4d0 100.00 2254.00 520 66561 10704.99 15.34
c4t12d0 100.00 1793.00 530 67788 10670.21 15.10
00:22:15 c1t15d0 6.40 21.34 23 102 52.45 17.21
c0t4d0 71.60 2658.75 298 36509 8667.97 18.07
c4t12d0 55.60 2718.96 218 26109 6239.87 18.49
00:22:20 c1t15d0 0.20 0.50 0 1 0.11 10.28
c0t4d0 100.00 4338.00 336 41197 4008.19 23.88
c4t12d0 100.00 4222.50 352 43235 3945.94 23.03
00:22:25 c0t4d0 100.00 2569.00 371 47226 8976.19 21.73
c4t12d0 100.00 2483.12 344 43610 9085.68 23.28
00:22:30 c0t4d0 100.00 940.60 280 35142 13835.80 28.58
c4t12d0 100.00 883.60 296 37280 13772.03 27.08
Average c1t15d0 1.88 13.29 8 45 34.02 11.69
Average c0t4d0 94.32 2604.22 361 45335 9252.38 20.74
Average c4t12d0 91.12 2515.36 348 43614 8971.14 20.78
root@hpeos003[]
While the disks are still maxed out most of the time, the average wait time has been significantly reduced. The average service time has been cut drastically, hinting that the disk is finding it easier to perform the IO. The read/writes and the number of blocks transferred have also increased. All this has led to a dramatic reduction in the average queue size. At first, I thought these figures were too different, so I ran the same tests a number of times, all with the same results. I checked my diagnostic logs for any hardware errors; there were none. If we look at the structure of the inode, we have avoided the double-indirect pointer (a13).
root@hpeos003[test] ll -i total 2097408 4 -rw-rw-rw- 1 root sys 1073741824 Nov 13 00:22 1GB.file 3 drwxr-xr-x 2 root root 65536 Nov 13 00:19 lost+found root@hpeos003[test] echo "4i" | fsdb -F hfs /dev/vx/rdsk/ora1/archive file system size = 524288(frags) isize/cyl group=64(Kbyte blocks) primary block size=65536(bytes) fragment size=8192 no. of cyl groups = 421 i#:4 md: f---rw-rw-rw- ln: 1 uid: 0 gid: 3 sz: 1073741824 ci:0 a0 : 72 a1 : 80 a2 : 88 a3 : 96 a4 : 104 a5 : 112 a6 : 120 a7 : 128 a8 : 136 a9 : 144 a10: 152 a11: 160 a12: 1256 a13: 0 a14: 0 at: Thu Nov 13 00:21:54 2003 mt: Thu Nov 13 00:22:32 2003 ct: Thu Nov 13 00:22:49 2003 root@hpeos003[test]
I then had a flash of inspiration. The VxVM volume I am using is a relayout of a RAID 5 volume to a concat-mirror. I was wondering if this could be the issue. I removed the volume entirely and created it as a simple concatenated volume. Let's get back to the test, first with the baseline configuration.
root@hpeos003[] newfs -F hfs /dev/vx/rdsk/ora1/archive ... root@hpeos003[] mount /dev/vx/dsk/ora1/archive /test root@hpeos003[] cd /test root@hpeos003[test] time prealloc 1GB.file 1073741824 real 2:31.6 user 0.1 sys 8.1 root@hpeos003[test]
This is a dramatic difference! Here are the sar statistics collected during this test:
root@hpeos003[] sar -d 5 5
HP-UX hpeos003 B.11.11 U 9000/800 11/13/03
01:19:12 device %busy avque r+w/s blks/s avwait avserv
01:19:17 c1t15d0 0.80 0.50 2 9 0.20 10.56
c4t13d0 100.00 50608.50 1081 17297 7996.79 6.30
01:19:22 c1t15d0 4.20 10.96 16 73 30.94 15.32
c4t13d0 100.00 45837.00 935 14839 13218.79 9.83
01:19:27 c4t13d0 100.00 40412.00 1223 19524 17993.24 6.51
01:19:32 c4t13d0 100.00 34814.50 1016 16222 23178.15 7.93
01:19:37 c4t13d0 100.00 29783.00 996 15899 27687.47 8.04
Average c1t15d0 1.00 9.58 4 16 26.88 14.69
Average c4t13d0 100.00 40430.61 1050 16756 17924.13 7.62
root@hpeos003[]
And now with the enhanced options:
root@hpeos003[test] umount /test umount: cannot unmount /test : Device busy root@hpeos003[test] cd / root@hpeos003[] newfs -F hfs -b 65536 -f 8192 -i 65536 -o largefiles /dev/vx/rdsk/ora1/archive mkfs (hfs): Warning - 224 sector(s) in the last cylinder are not allocated. mkfs (hfs): /dev/vx/rdsk/ora1/archive - 4194304 sectors in 6722 cylinders of 16 tracks, 39 sectors ... root@hpeos003[] mount /dev/vx/dsk/ora1/archive /test root@hpeos003[] cd /test root@hpeos003[test] time prealloc 1GB.file 1073741824 real 47.9 user 0.0 sys 4.1 root@hpeos003[test]
With sar statistics of:
root@hpeos003[] sar -d 5 5
HP-UX hpeos003 B.11.11 U 9000/800 11/13/03
01:24:39 device %busy avque r+w/s blks/s avwait avserv
01:24:44 c1t15d0 0.80 0.50 2 8 1.82 8.79
c4t13d0 100.00 2146.50 482 61726 11380.62 16.58
01:24:49 c4t13d0 70.00 3447.08 288 32566 9157.99 14.85
01:24:54 c1t15d0 2.80 8.41 11 54 20.88 14.90
c4t13d0 100.00 6522.11 457 52835 3078.64 17.41
01:24:59 c1t15d0 0.20 0.50 0 0 0.12 12.11
c4t13d0 100.00 4171.00 461 57635 8195.14 17.39
01:25:04 c4t13d0 100.00 1913.00 443 55488 13146.13 18.20
Average c1t15d0 0.76 6.92 3 12 17.27 13.79
Average c4t13d0 94.00 3628.46 426 52054 8977.38 17.04
root@hpeos003[]
This demonstrates two things: We need to be careful that the detail of our tests is clearly understood, and while the use of advanced features in volume management products may be useful, they can have a dramatic effect on how our applications perform.
NOTE: This test is a simplistic test designed to show that differences in filesystem construction can have an impact on IO throughput in certain circumstances. In real life, I would be more rigorous about the tests I perform, as well as the sampling techniques used. If I were to perform small, random IO to this filesystem, there is no guarantee that I would see any performance improvement at all. As always with performance tuning, “It depends.” It depends on your own specific circumstance. The moral of the story is this: Always do a baseline measure, modify, and then measure again. Ensure that you use the same test data and same test conditions throughout.
Unlike VxFS, to resize an HFS filesystem, you have to unmount the filesystem to effect the change. This is a major problem when working in a High Availability environment when you will have to tell users to stop using the filesystem, probably by shutting down an associated application. This is unfortunate but entirely necessary. In this first step, I am simply resizing the volume:
root@hpeos003[] bdf /test Filesystem kbytes used avail %used Mounted on /dev/vx/dsk/ora1/archive 4113400 1048736 2653320 28% /test root@hpeos003[] vxassist -g ora1 growby archive 1G root@hpeos003[] vxprint -g ora1 archive TY NAME ASSOC KSTATE LENGTH PLOFFS STATE TUTIL0 PUTIL0 v archive fsgen ENABLED 5242880 - ACTIVE - - pl archive-01 archive ENABLED 5242880 - ACTIVE - - sd ora_disk4-04 archive-01 ENABLED 5242880 0 - - - root@hpeos003[] root@hpeos003[] bdf /test Filesystem kbytes used avail %used Mounted on /dev/vx/dsk/ora1/archive 4113400 1048736 2653320 28% /test root@hpeos003[]
As you can see, the filesystem hasn't grown even though the volume has been increased in size. Next, we need to unmount the filesystem in order to run the extendfs command:
root@hpeos003[] umount /test root@hpeos003[] extendfs -F hfs /dev/vx/rdsk/ora1/archive max number of sectors extendible is 1048576. extend file system /dev/vx/rdsk/ora1/archive to have 1048576 sectors more. Warning: 592 sector(s) in last cylinder unallocated extended super-block backups (for fsck -b#) at: 4203648, 4213696, 4223744, 4233792, 4243840, 4253888, 4263936, 4273984, 428403, 4304128, 4313152, 4323200, 4333248, 4343296, 4353344, 4363392, 4373440, 438348, 4403584, 4413632, 4423680, 4433728, 4443776, 4453824, 4463872, 4472896, 448294, 4503040, 4513088, 4523136, 4533184, 4543232, 4553280, 4563328, 4573376, 458342, 4603520, 4613568, 4623616, 4632640, 4642688, 4652736, 4662784, 4672832, 468288, 4702976, 4713024, 4723072, 4733120, 4743168, 4753216, 4763264, 4773312, 478336, 4802432, 4812480, 4822528, 4832576, 4842624, 4852672, 4862720, 4872768, 488281, 4902912, 4912960, 4923008, 4933056, 4943104, 4952128, 4962176, 4972224, 498227, 5002368, 5012416, 5022464, 5032512, 5042560, 5052608, 5062656, 5072704, 508275, 5102848, 5111872, 5121920, 5131968, 5142016, 5152064, 5162112, 5172160, 518220, 5202304, 5212352, 5222400, 5232448, 5242496, root@hpeos003[] mount /dev/vx/dsk/ora1/archive /test root@hpeos003[] bdf /test Filesystem kbytes used avail %used Mounted on /dev/vx/dsk/ora1/archive 5141816 1048744 3578888 23% /test root@hpeos003[]
This is one of the most limiting factors of using an HFS filesystem. There is no way we can reduce the size of the filesystem without destroying it entirely. The situation is similar for defragmenting a filesystem; you would store all the data elsewhere, e.g., tape, recreate the filesystem from scratch, tune the filesystem, and then restore the data. In doing so, the data will be laid out in the filesystem in an optimal fashion.
We all know the difference between symbolic and hard links. This is just a simple demonstration on how they work from an inode perspective. First, we will set up a symbolic and a hard link to our 1GB file.
root@hpeos003[test] ll total 2097408 -rw-rw-r-- 1 root sys 1073741824 Nov 13 01:25 1GB.file drwxr-xr-x 2 root root 65536 Nov 13 01:23 lost+found root@hpeos003[test] ln -s 1GB.file 1GB.soft root@hpeos003[test] ln 1GB.file 1GB.hard root@hpeos003[test] ll total 4194704 -rw-rw-r-- 2 root sys 1073741824 Nov 13 01:25 1GB.file -rw-rw-r-- 2 root sys 1073741824 Nov 13 01:25 1GB.hard lrwxrwxr-x 1 root sys 8 Nov 13 01:39 1GB.soft -> 1GB.file drwxr-xr-x 2 root root 65536 Nov 13 01:23 lost+found root@hpeos003[test]
It's interesting to note the way in which soft and hard links are implemented. A hard link is simply a directory entry referencing the same inode:
root@hpeos003[test] echo "2i.fd" | fsdb -F hfs /dev/vx/rdsk/ora1/archive file system size = 524288(frags) isize/cyl group=64(Kbyte blocks) primary block size=65536(bytes) fragment size=8192 no. of cyl groups = 421 d0: 2 . d1: 2 . . d2: 3 l o s t + f o u n d d3: 4 1 G B . f i l e d4: 5 1 G B . s o f t d5: 4 1 G B . h a r d root@hpeos003[test]
While a symbolic link is a unique file in its own right (inode 5), the interesting thing is the way the symbolic link is implemented.
root@hpeos003[test] echo "5i" | fsdb -F hfs /dev/vx/rdsk/ora1/archive file system size = 524288(frags) isize/cyl group=64(Kbyte blocks) primary block size=65536(bytes) fragment size=8192 no. of cyl groups = 421 i#:5 md: l---rwxrwxr-x ln: 1 uid: 0 gid: 3 sz: 8 ci:0 a0 : 400 a1 : 0 a2 : 0 a3 : 0 a4 : 0 a5 : 0 a6 : 0 a7 : 0 a8 : 0 a9 : 0 a10: 0 a11: 0 a12: 0 a13: 0 a14: 0 at: Thu Nov 13 01:39:56 2003 mt: Thu Nov 13 01:39:47 2003 ct: Thu Nov 13 01:39:47 2003 root@hpeos003[test] root@hpeos003[test] echo "5i.f0c" | fsdb -F hfs /dev/vx/rdsk/ora1/archive file system size = 524288(frags) isize/cyl group=64(Kbyte blocks) primary block size=65536(bytes) fragment size=8192 no. of cyl groups = 421 14400000 : 1 G B . f i l e � � � � � � � � � � � � � � � � � � � � � � � � 14400040 ... root@hpeos003[test]
It is evident that the pathname used in the ln command is stored in the data fragment of the symbolic link. There is a kernel parameter called create_fastlinks, which would allow HFS to store the pathname (if it was 13 characters or smaller) directly in the inode, without using a data fragment.
root@hpeos003[test] kmtune -q create_fastlinks
Parameter Current Dyn Planned Module Version
=============================================================================
create_fastlinks 0 - 0
root@hpeos003[test]
This feature is turned off by default. While this isn't going to suddenly make your system run much faster, it might make a slight difference. The only proviso is that once you change the kernel parameter, you need to delete and recreate the symbolic links again.
When we delete a symbolic link, it simply disappears because it is treated like any other file. When we delete a hard link, the link count of the inode is consulted:
root@hpeos003[test] echo "4i" | fsdb -F hfs /dev/vx/rdsk/ora1/archive file system size = 524288(frags) isize/cyl group=64(Kbyte blocks) primary block size=65536(bytes) fragment size=8192 no. of cyl groups = 421 i#:4 md: f---rw-rw-r-- ln: 2 uid: 0 gid: 3 sz: 1073741824 ci:0 a0 : 72 a1 : 80 a2 : 88 a3 : 96 a4 : 104 a5 : 112 a6 : 120 a7 : 128 a8 : 136 a9 : 144 a10: 152 a11: 160 a12: 1256 a13: 0 a14: 0 at: Thu Nov 13 01:24:27 2003 mt: Thu Nov 13 01:25:06 2003 ct: Thu Nov 13 01:39:54 2003 root@hpeos003[test]
When we delete a hard link, the directory entry is zeroed and the link count of the inode is decreased by one.
root@hpeos003[test] rm 1GB.file root@hpeos003[test] root@hpeos003[test] echo "4i" | fsdb -F hfs /dev/vx/rdsk/ora1/archive___ file system size = 524288(frags) isize/cyl group=64(Kbyte blocks) primary block size=65536(bytes) fragment size=8192 no. of cyl groups = 421 i#:4 md: f---rw-rw-r-- ln: 1 uid: 0 gid: 3 sz: 1073741824 ci:0 a0 : 72 a1 : 80 a2 : 88 a3 : 96 a4 : 104 a5 : 112 a6 : 120 a7 : 128 a8 : 136 a9 : 144 a10: 152 a11: 160 a12: 1256 a13: 0 a14: 0 at: Thu Nov 13 01:24:27 2003 mt: Thu Nov 13 01:25:06 2003 ct: Thu Nov 13 02:04:54 2003 root@hpeos003[test] root@hpeos003[test] echo "2i.fd" | fsdb -F hfs /dev/vx/rdsk/ora1/archive file system size = 524288(frags) isize/cyl group=64(Kbyte blocks) primary block size=65536(bytes) fragment size=8192 no. of cyl groups = 421 d0: 2 . d1: 2 . . d2: 3 l o s t + f o u n d d3: 5 1 G B . s o f t d4: 4 1 G B . h a r d root@hpeos003[test]
Only when the link count drops to zero does an inode get deleted.
Finally, on symbolic links, I love the idea of being able to (symbolic) link to something that doesn't exist (see 1GB.soft):
root@hpeos003[test] ll total 2097424 -rw-rw-r-- 2 root sys 1073741824 Nov 13 01:25 1GB.hard lrwxrwxr-x 1 root sys 8 Nov 13 01:39 1GB.soft -> 1GB.file drwxr-xr-x 2 root root 65536 Nov 13 01:23 lost+found root@hpeos003[test] ln -s cat mouse root@hpeos003[test] ln -s mouse cat root@hpeos003[test] ll total 2097456 -rw-rw-r-- 2 root sys 1073741824 Nov 13 01:25 1GB.hard lrwxrwxr-x 1 root sys 8 Nov 13 01:39 1GB.soft -> 1GB.file lrwxrwxr-x 1 root sys 5 Nov 13 01:56 cat -> mouse drwxr-xr-x 2 root root 65536 Nov 13 01:23 lost+found lrwxrwxr-x 1 root sys 3 Nov 13 01:56 mouse -> cat root@hpeos003[test]
It doesn't make much sense to be able to point to black hole, but that's life! What would happen if I ran the command cat mouse?
Access Control Lists (ACLs) allow us to give individual users their own read, write, and execute permissions on individual files and directories. HFS has supported ACLs since its inception, and they are managed by the commands lsacl and chacl. We will take our 1G.file created earlier and apply ACLs to it for a couple of users: fred and barney:
root@hpeos003[test] pwget -n barney barney:acGNA0B.QxKYI:110:20::/home/barney:/sbin/sh root@hpeos003[test] pwget -n fred fred:rK23oXbRNKgAo:109:20::/home/fred:/sbin/sh root@hpeos003[test] lsacl -l 1GB.file 1GB.file: rw- root.% rw- %.sys rw- %.% root@hpeos003[test] chacl '(fred.%, rwx)' 1GB.file root@hpeos003[test] lsacl -l 1GB.file 1GB.file: rw- root.% rwx fred.% rw- %.sys rw- %.% root@hpeos003[test] root@hpeos003[test] chacl '(barney.%, ---)' 1GB.file root@hpeos003[test] lsacl -l 1GB.file 1GB.file: rw- root.% rwx fred.% --- barney.% rw- %.sys rw- %.% root@hpeos003[test]
We can see that fred has read, write, and execute, while barney has no access.
Interestingly, HFS stores ACLs in a structure known as a continuation inode (see the ci field in the inode). Simply put, this is an additional inode used by file 1G.file to store the additional ACL entries. We can see this with fsdb:
root@hpeos003[test] echo "4i" | fsdb -F hfs /dev/vx/rdsk/ora1/archive file system size = 524288(frags) isize/cyl group=64(Kbyte blocks) primary block size=65536(bytes) fragment size=8192 no. of cyl groups = 421 i#:4 md: f---rw-rw-rw- ln: 1 uid: 0 gid: 3 sz: 1073741824 ci:6 a0 : 72 a1 : 80 a2 : 88 a3 : 96 a4 : 104 a5 : 112 a6 : 120 a7 : 128 a8 : 136 a9 : 144 a10: 152 a11: 160 a12: 1256 a13: 0 a14: 0 at: Thu Nov 13 00:21:54 2003 mt: Thu Nov 13 00:22:32 2003 ct: Thu Nov 13 00:53:21 2003 root@hpeos003[test] echo "6i" | fsdb -F hfs /dev/vx/rdsk/ora1/archive file system size = 524288(frags) isize/cyl group=64(Kbyte blocks) primary block size=65536(bytes) fragment size=8192 no. of cyl groups = 421 i#:6 md: C------------ ln: 1 uid: 109 gid: -36 md:7 uid: 110 gid: -36 md:0 uid: -35 gid: -35 md:0 uid: -35 gid: -35 md:0 uid: -35 gid: -35 md:0 uid: -35 gid: -35 md:0 uid: -35 gid: -35 md:0 uid: -35 gid: -35 md:0 uid: -35 gid: -35 md:0 uid: -35 gid: -35 md:0 uid: -35 gid: -35 md:0 uid: -35 gid: -35 md:0 uid: -35 gid: -35 md:0 root@hpeos003[test]
In addition to the base ACL entries stored in the primary inode, HFS allows 13 additional ACLs per file and/or directory. If we are considering widely using HFS ACLs, it may have an impact on the density of inodes that we create at newfs time.
VxFS first made its appearance in HP-UX version 10.01. Since then, it has grown in use and has become the default filesystem type in HP-UX version 11.X. With its current incarnation, it supports all the features of HFS including ACLs which were missing until layout version 4 (JFS version 3.3). Version 3.3 is available for HP-UX version 11.X as well as HP-UX version 10.20. As such, VxFS is the way forward as far as filesystems are concerned for HP-UX. The product is known by two main names: JFS (Journaled File System), which is the name associated with the software product itself, and VxFS (Veritas extended File System), which is the filesystem type. The easy way to remember this is that JFS is the product used to access VxFS filesystems.
The key benefits to using VxFS can be summarized as follows:
Fast File System Recovery: Using journaling techniques, the filesystem can track pending changes to the filesystem by using an intent log. After a system crash, only the pending changes need to be checked and replayed in the filesystem. All other changes are said to be complete and need no further checking. In some instances, the filesystem in its entirety is marked as dirty. Such a filesystem will require the
fsck –o full,nologcommand to be run against it in order to perform a full integrity check.Online Administration: Most tasks associated with managing a filesystem can be performed while the filesystem is mounted. These include resizing, defragmenting, setting allocation policies for individual files, as well as online backups via filesystem snapshots.
Extent based allocation: This allows for contiguous filesystem blocks (called an extent) to be referenced by a single inode entry. A filesystem block is sized by the
newfscommand to be:1KB for filesystems less than 8GB in size
2KB for filesystems less than 16GB in size
4KB for filesystems less than 32GB in size
8KB for filesystems greater than 32GB in size
Allowing inodes to reference an entire extent does away with the notion of a fixed block size and the problems of having to use multiple inode pointers to reference large chunks of data. This can be used to dramatically improve IO performance for large files.
When we look at the basic building blocks of VxFS, they appear to be similar to the building blocks of HFS (Figure 8-4).
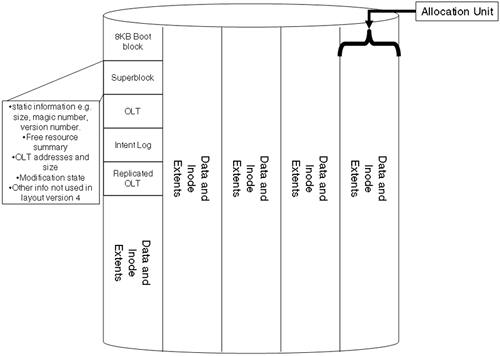
In comparison to HFS, there are a number of conceptual similarities; we have a Superblock, which is a road map to the rest of the filesystem. An Allocation Unit is similar to the concept of a Cylinder Group in HFS in that it is a localized collection of tracks and cylinders. In VxFS, an Allocation Unit is 32MB in size (possibly with the exception of the last AU). There are some fundamental differences that are not immediately apparent.
The OLT is the Object Location Table. This structure references a number of structural elements that I haven't shown in Figure 8-4. Information stored in the OLT includes information relating to where to find the initial inodes describing the filesystem, the device configuration (HP-UX currently allows only one device per filesystem, even if it is a logical device), where to find redundant superblocks, as well as space for information not maintained in version 4 layout such as the Current Usage Table. One of the main elements in the OLT is a reference to a list of fileset headers. A fileset is essentially a collection of files/inodes stored within the data blocks of the filesystem. When I was first told this, I immediately equated a fileset to an inode list. This is a fair comparison, if a little naive. In VxFS, we (currently) have two filesets. Fileset 1 (known as the Structural Fileset) and Fileset 999 (known as the Unnamed or Primary Fileset). You and I, as users, will interface with the Primary Fileset because it references inodes that are user visible, i.e., regular files, directories, links, device files, etc., and it is the fileset that is mounted by default (in the future, it may be possible to support and mount more filesets; cloning a fileset may be possible). The Structural Fileset contains structural information relating to the filesystem, and there are no standard user-accessible commands to view files/inodes within Fileset 1. Fileset 1 is there to be used by the filesystem as it sees fit; for example, an inode in the Primary Fileset may reference and inode in the Structural Fileset for BSD-style quota information.
In VxFS, we have inodes that work in a similar way to inodes in an HFS filesystem; i.e., they reference the file type and mode, ownership, size, timestamps, and references to data blocks. This is where things start to change. VxFS are 256 bytes in size. One of the reasons an inode is bigger is that VxFS inodes can have attributes associated with them (more on attributes later). Another reason an inode is bigger is that we need to store information relating to allocation flags set by the setext command, e.g., contiguous allocation of extents for this file. One other fundamental difference is the way an inode will reference the data blocks (=extents) associated with the user file. This is known as the Inode Organization Type (i_orgtype). There are four organization types:
i_orgtype = 0: Used for character and block device file where there is no data area. The inode will contain anrdevreference to the device file. Also known asIORG_NONE.root@hpeos003[] ll -i /dev/kmem 68 crw-r----- 1 bin sys 3 0x000001 Aug 12 07:52 /dev/kmem root@hpeos003[] echo "68i" | fsdb -F vxfs /dev/vg00/lvol3 inode structure at 0x00001089.0000 type IFCHR mode 20640 nlink 1 uid 2 gid 3 size 0 atime 1068715134 460056 (Thu Nov 13 09:18:54 2003 BST) mtime 1060671154 0 (Tue Aug 12 07:52:34 2003 BST) ctime 1068715134 460017 (Thu Nov 13 09:18:54 2003 BST) aflags 0 orgtype 0 eopflags 0 eopdata 0 fixextsize/fsindex 0 rdev/reserve/dotdot/matchino 50331649 blocks 0 gen 0 version 0 318 iattrino 0 root@hpeos003[]
i_orgtype = 1: The most common organization type where the inode contains 10 direct block pointers similar to the direct block pointers in an HFS inode. The difference here is that the inode will store the starting block number (de= direct extent) and the number of subsequent, adjacent blocks to reference (des= direct extent size); in other words, we can reference multiple 1KB blocks known as an extent. Indirect pointers are available but not used (seei_orgtype = 3). Also known asIORG_EXT4.root@hpeos003[] ll -i /etc/hosts 5 -r--r--r-- 1 bin bin 2089 Oct 23 15:31 /etc/hosts root@hpeos003[] echo "5i" | fsdb -F vxfs /dev/vg00/lvol3 inode structure at 0x00000579.0100 type IFREG mode 100444 nlink 1 uid 2 gid 2 size 2089 atime 1068727100 180003 (Thu Nov 13 12:38:20 2003 BST) mtime 1066919463 900011 (Thu Oct 23 15:31:03 2003 BST) ctime 1066919463 900011 (Thu Oct 23 15:31:03 2003 BST) aflags 0 orgtype 1 eopflags 0 eopdata 0 fixextsize/fsindex 0 rdev/reserve/dotdot/matchino 0 blocks 3 gen 1 version 0 4576 iattrino 0 de: 2965 0 0 0 0 0 0 0 0 0 des: 3 0 0 0 0 0 0 0 0 0 ie: 0 0 ies: 0 root@hpeos003[]
i_orgtype = 2: Referred to as Immediate Inode Data. Where a directory or symbolic link is less than 96 characters in length, the filesystem will not allocate a data block but it will store the directory/symbolic link information directly in the inode itself. Similar to thecreate_fastlinksconcept in HFS. Also known asIORG_IMMED.root@hpeos003[] mkdir -p /stuff/more root@hpeos003[] ll -id /stuff 7470 drwxrwxr-x 3 root sys 96 Nov 13 12:44 /stuff root@hpeos003[] echo "7470i" | fsdb -F vxfs /dev/vg00/lvol3 inode structure at 0x00103dc3.0200 type IFDIR mode 40775 nlink 3 uid 0 gid 3 size 96 atime 1068727492 180001 (Thu Nov 13 12:44:52 2003 BST) mtime 1068727492 180002 (Thu Nov 13 12:44:52 2003 BST) ctime 1068727492 180002 (Thu Nov 13 12:44:52 2003 BST) aflags 0 orgtype 2 eopflags 0 eopdata 0 fixextsize/fsindex 0 rdev/reserve/dotdot/matchino 2 blocks 0 gen 45 version 0 374 iattrino 0 root@hpeos003[] ll -i /stuff total 0 7546 drwxrwxr-x 2 root sys 96 Nov 13 12:44 more root@hpeos003[] root@hpeos003[] echo "7470i.im.p db" | fsdb -F vxfs /dev/vg00/lvol3 immediate directory block at 00103dc3.0250 - total free (d_tfree) 76 00103dc3.0254: d 0 d_ino 7546 d_reclen 92 d_namlen 4 m o r e root@hpeos003[]
i_orgtype = 3: Used for files beyond the capabilities ofIORG_EXT4. The inode contains six entries that can reference a block and size entry in the same way as anIORG_EXT4entry or can reference an Indirect block. The Indirect block can reference data blocks or further indirection. The levels of Indirection are only limited by the size of the filesystem. This is similar in concept to the single, double, and triple indirect pointers that we see in HFS, except that the Indirection is unlimited. Also known asIORG_TYPED.root@hpeos003[] ll –i /logdata/db.log 4 -rw-rw-r-- 1 root sys 212726016 Nov 13 13:04 /logdata/db.log root@hpeos003[] echo "4i" | fsdb -F vxfs /dev/vx/dsk/ora1/logvol inode structure at 0x000003f8.0400 type IFREG mode 100664 nlink 1 uid 0 gid 3 size 212726016 atime 1068728572 410003 (Thu Nov 13 13:02:52 2003 BST) mtime 1068728665 710006 (Thu Nov 13 13:04:25 2003 BST) ctime 1068728665 710006 (Thu Nov 13 13:04:25 2003 BST) aflags 0 orgtype 3 eopflags 0 eopdata 0 fixextsize/fsindex 0 rdev/reserve/dotdot/matchino 0 blocks 51938 gen 2 version 0 92 iattrino 0 ext0: INDIR boff: 0x00000000 bno: 67584 len: 2 ext1: NULL boff: 0x00000000 bno: 0 len: 0 ext2: NULL boff: 0x00000000 bno: 0 len: 0 ext3: NULL boff: 0x00000000 bno: 0 len: 0 ext4: NULL boff: 0x00000000 bno: 0 len: 0 ext5: NULL boff: 0x00000000 bno: 0 len: 0 root@hpeos003[] root@hpeos003[] echo "67584b; p 128 T | more" | fsdb -F vxfs /dev/vx/dsk/ora1/logvol 0x00010800.0000: DATA boff: 0x00000000 bno: 1290 len: 6492 0x00010800.0010: DATA boff: 0x0000195c bno: 14336 len: 6528 0x00010800.0020: DATA boff: 0x000032dc bno: 28672 len: 4096 0x00010800.0030: DATA boff: 0x000042dc bno: 7831552 len: 4096 0x00010800.0040: DATA boff: 0x000052dc bno: 7841792 len: 6144 0x00010800.0050: DATA boff: 0x00006adc bno: 7854080 len: 5104 0x00010800.0060: DATA boff: 0x00007ecc bno: 7800832 len: 8192 0x00010800.0070: DATA boff: 0x00009ecc bno: 7815168 len: 5120 0x00010800.0080: DATA boff: 0x0000b2cc bno: 7827456 len: 4096 0x00010800.0090: DATA boff: 0x0000c2cc bno: 65536 len: 2048 0x00010800.00a0: DATA boff: 0x0000cacc bno: 69632 len: 20 0x00010800.00b0: NULL boff: 0x00000000 bno: 0 len: 0 0x00010800.00c0: NULL boff: 0x00000000 bno: 0 len: 0 ... root@hpeos003[]
Inodes are referenced via entries in the Inode List Table. This table can reference clumps of inodes known as Inode Extents, much in the same way that normal inodes reference clumps (extents) of data. The Inode List Table is a Structural File and has its own Structural inode, which follows the same organization type definitions as normal inodes. In VxFS, we do not create inodes until we need them (dynamic inode allocation). Consequently, Inode Extents may not necessarily contiguous. Inside the Inode Extent will be an Inode Allocation Unit Table, which stores information used to allocate inodes for that Inode List Table. All this proves that files/inodes in the Structural Fileset are used much in the same way as files/inodes in the Primary Fileset; it's just that we don't normally deal with them directly.
The last piece of VxFS theory we discuss is inode attributes. There are 72 bytes reserved at the end of the inode dedicated to attributes. In addition, an inode can have an attribute inode (similar in concept to a continuation inode in HFS). If used, an attribute inode is referenced via the iattrino structure in the general inode (there's a list of corresponding attribute inodes for every general inode). Who uses these attributes? Applications that are VxFS-aware can use them if they so desire. Take a backup application such as the Hierarchical Storage Management products like DataProtector. If coded properly, there's nothing to say that these applications could store a “tape archived” attribute with the inode every time it's backed up. This has nothing to do with standard filesystem commands (that don't know anything about this attribute), but might mean lots to the backup application. The only standard filesystem commands that currently use attributes are VxFS ACLs. We have discussed ACLs previously, but just let me do a quick recap. With ACLs, we can give users their own access permissions for files and directories. This allows a filesystem to meet a specific part of the C2 (U.S. Department of Defense: Orange Book) level of security. VxFS ACLs are managed by the getacl and setacl commands. Here, fred and barney are given their own permissions to the /logdata/db.log file:
root@hpeos003[] pwget -n fred fred:rK23oXbRNKgAo:109:20::/home/fred:/sbin/sh root@hpeos003[] pwget -n barney barney:acGNA0B.QxKYI:110:20::/home/barney:/sbin/sh root@hpeos003[] root@hpeos003[] getacl /logdata/db.log # file: /logdata/db.log # owner: root # group: sys user::rw- group::rw- class:rw- other:r-- root@hpeos003[] setacl -m "user:fred:rwx" /logdata/db.log root@hpeos003[] setacl -m "user:barney:---" /logdata/db.log root@hpeos003[] getacl /logdata/db.log # file: /logdata/db.log # owner: root # group: sys user::rw- user:fred:rwx user:barney:--- group::rw- class:rwx other:r-- root@hpeos003[]
Let's see if we can find the attributes just applied:
root@hpeos003[] ll -i /logdata/db.log 4 -rw-rwxr-- 1 root sys 212726016 Nov 13 13:04 /logdata/db.log root@hpeos003[] root@hpeos003[] echo "4i" | fsdb -F vxfs /dev/vx/dsk/ora1/logvol inode structure at 0x000003f8.0400 type IFREG mode 100674 nlink 1 uid 0 gid 3 size 212726016 atime 1068728572 410003 (Thu Nov 13 13:02:52 2003 BST) mtime 1068728665 710006 (Thu Nov 13 13:04:25 2003 BST) ctime 1068736084 820007 (Thu Nov 13 15:08:04 2003 BST) aflags 0 orgtype 3 eopflags 0 eopdata 0 fixextsize/fsindex 0 rdev/reserve/dotdot/matchino 0 blocks 51938 gen 2 version 0 96 iattrino 0 ext0: INDIR boff: 0x00000000 bno: 67584 len: 2 ext1: NULL boff: 0x00000000 bno: 0 len: 0 ext2: NULL boff: 0x00000000 bno: 0 len: 0 ext3: NULL boff: 0x00000000 bno: 0 len: 0 ext4: NULL boff: 0x00000000 bno: 0 len: 0 ext5: NULL boff: 0x00000000 bno: 0 len: 0 root@hpeos003[]
As we can see, iattrino has not been set. This means that if we do not look for the attribute inode, the attribute will be stored in the last 72 bytes of this inode. We can dump the attributes with the fsdb attr command:
root@hpeos003[] echo "4i.attr.p 18 x" | fsdb -F vxfs /dev/vx/dsk/ora1/logvol 000003f8.04b8: 00000001 0000003c 00000001 00000001 000003f8.04c8: 00000003 00000000 00000002 0000006d 000003f8.04d8: 00070000 00000002 0000006e 00000000 000003f8.04e8: 00000004 00000000 00060000 00000000 000003f8.04f8: 00000000 00000000 00008180 00000001 root@hpeos003[]
This takes a little deciphering, but look at each highlighted element in turn:
Format = 0x00000001 = Attribute Immediate
Length = 0x0000003c = 60 bytes
Class = 0x00000001 = ACL class
Subclass = 0x00000001 = SVr4 ACL (see
/usr/include/sys/aclv.h)ACL type = 0x00000002 = User record
User ID = 0x0000006d = 109 = fred
Permissions = 0x00070000 = rwx
ACL type = 0x00000002 = User record
User ID = 0x0000006e = 110 = barney
Permissions = 0x0000000 = ---
This introduction into the background behind VxFS will allow us to understand how VxFS works and may help us to answer some questions when we run fsck. What we need to discuss now are the additional administrative features related that the Online JFS brings to our system.
The additional administrative features that we need to look at regarding VxFS include the following:
Upgrading an older VxFS filesystem.
Converting an exiting HFS filesystem to VxFS.
Resizing a filesystem online.
Defragmenting a filesystem online.
Logging levels used by the intent log.
Setting extent attributes for individual files.
Tuning a VxFS filesystem.
Additional mount options to affect IO performance.
VxFS snapshots.
The additional features will require us to purchase a license for the Online JFS product. If we purchase a Mission Critical HP-UX 11i Operating Environment, the license to use Online JFS is included.
Some of the features we have looked at (ACL being a case in point) are supported only with the most recent version of the VxFS filesystem layout. If we have upgraded an older operating system, we may have filesystems using an older version. To upgrade to the most recent layout version of VxFS, we simply use the vxupgrade command. This is performed on a mounted filesystem and hence requires a license for the OnlineJFS product.
root@hpeos003[] vxupgrade /applicX /applicX: vxfs file system version 3 layout root@hpeos003[] root@hpeos003[] vxupgrade -n 4 /applicX root@hpeos003[] root@hpeos003[] vxupgrade /applicX /applicX: vxfs file system version 4 layout root@hpeos003[]
This process allows us to take an existing HFS filesystem and convert it to VxFS. The reasons for doing this are numerous. We have seen in the previous section some of the performance benefits we can use to improve the IO performance of the HFS filesystem. To some people, this is nothing compared to the benefits that VxFS can offer in terms of High Availability and Performance.
In order to convert an HFS filesystem to VxFS, approximately 10-15 percent of free space must be available in the filesystem:
root@hpeos003[] fstyp /dev/vg00/library hfs root@hpeos003[] bdf /library Filesystem kbytes used avail %used Mounted on /dev/vg00/library 103637 26001 67272 28% /library root@hpeos003[]
If we think about it, this is not unreasonable, because the vxfsconvert command needs space in the filesystem in order to rewrite all the underlying HFS filesystem structures in VxFS format. This includes structures such as ACLs.
root@hpeos003[] lsacl -l /library/data.finance
/library/data.finance:
rwx root.%
rwx fred.%
--x barney.%
r-x %.sys
r-x %.%
root@hpeos003[]
Before we use the vxfsconvert command, we should make a full backup of the filesystem. If the system should crash midway through the conversion, the mid-conversion filesystem is neither HFS nor VxFS and is completely unusable. When we are ready to start the conversion, we must make sure that the filesystem is umounted:
root@hpeos003[] umount /library root@hpeos003[] /sbin/fs/vxfs/vxfsconvert /dev/vg00/library vxfs vxfsconvert: Do you wish to commit to conversion? (ynq) y vxfs vxfsconvert: CONVERSION WAS SUCCESSFUL root@hpeos003[]
Before we mount the filesystem, we must run a full fsck. This will update all data structures in the new VxFS filesystem superblock.
root@hpeos003[] fsck -F vxfs -y -o full,nolog /dev/vg00/rlibrary pass0 - checking structural files pass1 - checking inode sanity and blocks pass2 - checking directory linkage pass3 - checking reference counts pass4 - checking resource maps fileset 1 au 0 imap incorrect - fix (ynq)y fileset 999 au 0 imap incorrect - fix (ynq)y no CUT entry for fileset 1, fix? (ynq)y no CUT entry for fileset 999, fix? (ynq)y au 0 emap incorrect - fix? (ynq)y au 0 summary incorrect - fix? (ynq)y au 1 emap incorrect - fix? (ynq)y au 1 summary incorrect - fix? (ynq)y au 2 emap incorrect - fix? (ynq)y au 2 summary incorrect - fix? (ynq)y au 3 emap incorrect - fix? (ynq)y au 3 summary incorrect - fix? (ynq)y fileset 1 iau 0 summary incorrect - fix? (ynq)y fileset 999 iau 0 summary incorrect - fix? (ynq)y free block count incorrect 0 expected 79381 fix? (ynq)y free extent vector incorrect fix? (ynq)y OK to clear log? (ynq)y set state to CLEAN? (ynq)y root@hpeos003[] root@hpeos003[] fstyp -v /dev/vg00/library vxfs version: 4 f_bsize: 8192 f_frsize: 1024 f_blocks: 106496 f_bfree: 79381 f_bavail: 74420 f_files: 19876 f_ffree: 19844 f_favail: 19844 f_fsid: 1073741836 f_basetype: vxfs f_namemax: 254 f_magic: a501fcf5 f_featurebits: 0 f_flag: 0 f_fsindex: 7 f_size: 106496 root@hpeos003[]
We can now attempt to mount and use the filesystem.
root@hpeos003[] mount /dev/vg00/library /library root@hpeos003[] ll /library/ total 51976 -rwxrwxr-x+ 1 root sys 26590752 Nov 14 01:03 data.finance drwxr-xr-x 2 root root 12288 Nov 14 01:02 lost+found root@hpeos003[] getacl /library/data.finance # file: /library/data.finance # owner: root # group: sys user::rwx user:fred:rwx user:barney:--x group::r-x class:rwx other:r-x root@hpeos003[]
The last job is to ensure that we update the /etc/fstab to reflect the new filesystem type.
Online resizing includes increasing as well as decreasing filesystem sizes. With layout version 4, the possibility of reducing the size has increased dramatically with the way the filesystem uses Allocation Units. When trying to reduce the filesystem size, an attempt to move data blocks will be made if it realized that current data blocks would stop the resizing process from completing. Increasing the size of the filesystem is ultimately easier because we do not need to move data blocks; we are adding space instead of reducing it. The thing to remember is the order of performing tasks.
Increasing the size of a filesystem.
Increase the size of the underlying volume.
Here, we simply need to ensure that the VxVM/LVM volume is bigger than its current size.
root@hpeos003[] bdf /library Filesystem kbytes used avail %used Mounted on /dev/vg00/library 106496 27115 74427 27% /library root@hpeos003[] lvextend -L 200 /dev/vg00/library Logical volume "/dev/vg00/library" has been successfully extended. Volume Group configuration for /dev/vg00 has been saved in /etc/lvmconf/vg00.conf root@hpeos003[] bdf /library Filesystem kbytes used avail %used Mounted on /dev/vg00/library 106496 27115 74427 27% /library root@hpeos003[]
It should be noted that this increases only the size of the volume, not the filesystem. That is the next step.
Increase the size of the filesystem.
If the filesystem is HFS, or if we haven't purchased a license for the OnlineJFS product, we must use the
extendfscommand on an unmounted filesystem.root@hpeos003[] vxlicense -p vrts:vxlicense: INFO: Feature name: HP_OnlineJFS [50] vrts:vxlicense: INFO: Number of licenses: 1 (non-floating) vrts:vxlicense: INFO: Expiration date: Sun Feb 15 08:00:00 2004 (93.2 days from now) vrts:vxlicense: INFO: Release Level: 35 vrts:vxlicense: INFO: Machine Class: All vrts:vxlicense: ERROR: Cannot read lic key from /etc/vx/elm/50.t00720 root@hpeos003[]With the license installed, we can use the
fsadmcommand:root@hpeos003[] fsadm -F vxfs -b 200M /library vxfs fsadm: /dev/vg00/rlibrary is currently 106496 sectors - size will be increased root@hpeos003[] bdf /library Filesystem kbytes used avail %used Mounted on /dev/vg00/library 204800 27139 166564 14% /library root@hpeos003[]
Reducing the size of the filesystem.
Reduce the size of the filesystem.
If any filesystem blocks are in use, this will be reported during the
fsadmcommand. If an attempt to move them fails, we can try to defragment the filesystem and then try to reduce the filesystem size again:root@hpeos003[] bdf /library Filesystem kbytes used avail %used Mounted on /dev/vg00/library 204800 157075 44748 78% /library root@hpeos003[] root@hpeos003[] fsadm -F vxfs -b 160M /library vxfs fsadm: /dev/vg00/rlibrary is currently 204800 sectors - size will be reduced vxfs fsadm: allocations found in shrink range, moving data root@hpeos003[] bdf /library Filesystem kbytes used avail %used Mounted on /dev/vg00/library 163840 156995 6423 96% /library root@hpeos003[]
NOTE: This is not possible with an HFS filesystem without running
newfs.Reduce the size of the underlying volume.
Although, technically this step is not necessary, it makes sense to make the underlying volume the same size as the filesystem. At this point, we may realize that, if using LVM, we need to ensure that the filesystem is a multiple of our LVM volume extent size.
root@hpeos003[] lvreduce -L 160 /dev/vg00/library When a logical volume is reduced useful data might get lost; do you really want the command to proceed (y/n) : y Logical volume "/dev/vg00/library" has been successfully reduced. Volume Group configuration for /dev/vg00 has been saved in /etc/lvmconf/vg00.conf root@hpeos003[]
If the filesystem in question was contained within a VxVM volume, we could have performed these tasks in one step using the vxresize command. This command increases/decreases the size of the volume and the filesystem if both are using Veritas products. If we have a license for the OnlineJFS product, this can be accomplished while the filesystem is mounted:
root@hpeos003[] bdf /logdata Filesystem kbytes used avail %used Mounted on /dev/vx/dsk/ora1/logvol 31457280 393648 30578268 1% /logdata root@hpeos003[] /etc/vx/bin/vxresize -g ora1 logvol 2G root@hpeos003[] bdf /logdata Filesystem kbytes used avail %used Mounted on /dev/vx/dsk/ora1/logvol 2097152 391852 1678660 19% /logdata root@hpeos003[] vxprint -g ora1 logvol TY NAME ASSOC KSTATE LENGTH PLOFFS STATE TUTIL0 PUTIL0 v logvol fsgen ENABLED 2097152 - ACTIVE - - pl logvol-01 logvol ENABLED 2097216 - ACTIVE - - sd oralog01 logvol-01 ENABLED 699072 0 - - - sd oralog02 logvol-01 ENABLED 699072 0 - - - sd oralog03 logvol-01 ENABLED 699072 0 - - - root@hpeos003[]
In the lifetime of a filesystem, many files can be created, deleted, increased in size, and decreased in size. While the filesystem will try to maintain the best allocation policy for blocks and extents, it is not unbelievable that over time blocks for files will become misaligned. When trying to access files (especially sequentially), it is best if we can align consecutive filesystem blocks. This also applies to directories; it's best if directory entries are ordered such that searches are most efficient.
Both of these situations can be rectified with the fsadm command. The –e option defragments extents, while the –d option reorders directory entries. Here's a summary of the tasks each can perform:
Extent defragmentation:
Reduces the number of extents in large files
Makes small files contiguous
Moves recently used files close to inodes
Optimizes free space into larger extents
Directory de-fragmentation:
Removes empty entries from directories
Moves recently accessed files to the beginning of directory lists
Utilizes the immediate area of an inode for small directories
The respective uppercase options (-E and –D) can be used to provide a report of the number of extents and directories that need to be defragmented.
This process can produce a significant amount of IO in the filesystem. As a result, we should consider running this command during a quiescent time. A good time to run the command is before a system backup because it will produce a defragmented filesystem, improving IO for online use, as well as improving the IO performance for the impending backup.
root@hpeos003[] fsadm -F vxfs -de -DE /logdata
Directory Fragmentation Report
Dirs Total Immed Immeds Dirs to Blocks to
Searched Blocks Dirs to Add Reduce Reduce
total 2 1 1 0 0 0
Directory Fragmentation Report
Dirs Total Immed Immeds Dirs to Blocks to
Searched Blocks Dirs to Add Reduce Reduce
total 2 1 1 0 0 0
Extent Fragmentation Report
Total Average Average Total
Files File Blks # Extents Free Blks
10 9738 3 426325
blocks used for indirects: 2
% Free blocks in extents smaller than 64 blks: 0.02
% Free blocks in extents smaller than 8 blks: 0.00
% blks allocated to extents 64 blks or larger: 99.97
Free Extents By Size
1: 5 2: 2 4: 1
8: 1 16: 2 32: 1
64: 2 128: 3 256: 1
512: 1 1024: 1 2048: 1
4096: 1 8192: 1 16384: 1
32768: 2 65536: 1 131072: 2
262144: 0 524288: 0 1048576: 0
2097152: 0 4194304: 0 8388608: 0
16777216: 0 33554432: 0 67108864: 0
134217728: 0 268435456: 0 536870912: 0
1073741824: 0 2147483648: 0
Extent Fragmentation Report
Total Average Average Total
Files File Blks # Extents Free Blks
10 9738 3 426325
blocks used for indirects: 2
% Free blocks in extents smaller than 64 blks: 0.02
% Free blocks in extents smaller than 8 blks: 0.00
% blks allocated to extents 64 blks or larger: 99.97
Free Extents By Size
1: 5 2: 2 4: 1
8: 1 16: 2 32: 1
64: 2 128: 3 256: 1
512: 1 1024: 1 2048: 1
4096: 1 8192: 1 16384: 1
32768: 2 65536: 1 131072: 2
262144: 0 524288: 0 1048576: 0
2097152: 0 4194304: 0 8388608: 0
16777216: 0 33554432: 0 67108864: 0
134217728: 0 268435456: 0 536870912: 0
1073741824: 0 2147483648: 0
root@hpeos003[]
The Intent Log will record transactions that are in flight during updates to filesystem structures such as inodes and the superblock. Transactions are recorded in the Intent Log before the update occurs. Updates that are marked as COMPLETE have actually been written to disk. Should a transaction be incomplete at the time of a system crash, the fsck command will perform a log replay to ensure that the filesystem is up to date and complete.
An issue we should deal with here is the size of the Intent Log. By default, the Intent Log is 1MB (1024 blocks) when the block size is 1KB. The filesystem block size will determine the size of the Intent Log. The default sizes have been seen to be sufficient in most situations. If the application using the filesystem makes updates to filesystem structures such as inodes, it may be worth considering increasing the size of the Intent Log. A filesystem that is NFS-exported will make significant use of filesystem structures. An NFS-exported filesystem will perform better if it has a bigger Intent Log than the default. If we have outstanding updates to make (in the Intent Log), subsequent updates may be blocked until a free-slot is available in the Intent Log. The maximum size of the Intent Log is 16MB. Changing the size of the Intent Log will require you to rebuild the filesystem, i.e., run mkfs/newfs. This is obviously destructive and should be undertaken only after you have performed a full backup of the filesystem.
After we have decided on the size of our Intent Log, we should decide when the filesystem will record transactions in the Intent Log. In total, we have six options that affect the operation of the Intent Log via the mount command. The first four affect how much logging will occur via the Intent Log, while the last two options affect how/if data blocks are managed via the mount command.
nolog: With this option, no attempt is made to maintain consistency in the filesystem. After a reboot, the filesystem will have to be recreated with thenewfscommand. As such, this option should be used only for filesystems used for completely transient information.tmplog: This option maintains a minimal level of consistency in the filesystem only to the extent that transactions are recorded but not necessarily written to disk until the filesystem is unmounted. At that time, the files with current transactions still in the filesystem will be updated. These updates may not reflect the true state of the filesystem. Likenolog, this option should be used only for filesystems that contain purely temporary information. In layout version 4,nologis equivalent totmplog.delaylog: This option behaves in a very similar fashion to how an HFS filesystem works in that updates to open files will be recorded in the buffer cache but flushed to disk only every few seconds when the sync daemon (syncer) runs. When a file is removed, renamed or closed, outstanding operations are guaranteed to be written to disk.log: This is the default option. Every update to the filesystem is written to the Intent Log before control is returned to the calling function. This maintains complete integrity in the filesystem while sacrificing performance.blkclear: This mode is used where data security is of paramount importance. Increased security is provided by clearing filesystem extents before they are allocated to a file. In this way, there is no way that old data can ever appear in a file inadvertently. This requires a synchronous write in order to zero the necessary filesystem blocks. The increased security is at the cost of performance.datainlog|nodatainlog: A VxFS filesystem has the ability to store synchronous inode and data transactions in the intent log (datainlog). This would require one less write to the filesystem. This can be bad for the integrity of the data. The premise ofdatainlogis that most disks perform bad block re-vectoring; in other words, if we get a bad spot on the disk, the disk will re-vector a sector to somewhere else on the disk. Withdatainlog(and bad block re-vectoring), a synchronous write will store both the data and the inode update in the Intent Log. This requires one less IO. However, if the disk does fail, the application has been told that the data synchronous write was completed, when in fact it wasn't. This is dangerous and should be avoided in my opinion. Thenodatainlogis the default for good reason!
It would seem that most installations are happy to use the delaylog mount option. This is an acceptable compromise between integrity and performance. The appropriate option should be included in field 4 (the mount options field) of the /etc/fstab file.
As we have seen, the dynamic nature of files can lead to a less-than-optimal allocation of extents for large data files. To alleviate this we can reserve space for individual files before applications actually use them. By using a particular allocation policy we can construct a file using particular attributes. The allocation policy flags we use will determine how the file is constructed on disk during the initial reservation and the use of disk space in the future. To set allocation policies we use the setext command.
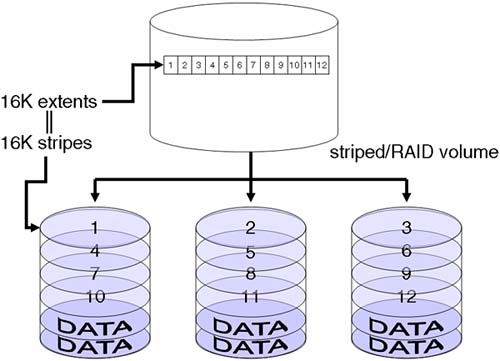
A common task is to reserve aligned space using a fixed extent size for application files, e.g., a database files and large video capture files, before the application has actually stored any data. In this way, we can ensure that an optimal allocation policy is applied to allocating current extents now and in the future. The size of the reserve will be the initial amount of disk space allocated to the file. The alignment will ensure that we align extents on a fixed extent size boundary relative to the beginning of a device (prior to layout version 3, the alignment was based on allocation unit). With this, we can marry the fixed extent size to the size of the underlying disk configuration, e.g., stripe size in a stripe/RAID set (see Figure 8-5), ensuring that subsequent extents are aligned in the filesystem and sector-aligned within our stripe set. This, along with the size of our stripe size, has been geared toward performing IO in units that are compatible with our user application.
Some extent attributes are persistent and stored in the inode (fields such as alignment, fixed extent size, and initial reservation). Other allocation attributes apply only to the current attempt to reserve space for the file. A common misconception is the use of the contiguous flag. This applies only to the current attempt to reserve space for the file in the filesystem. Any future extents need not be contiguous or even aligned with any disk/stripe boundaries. These flags I mention are applied using the –f <flag> option to the setext command. In fact, the only flags that are persistent and influence future extent allocation are the align and the noextend (no more space can be allocated for the file; it's stuck with what it currently has). If further extent allocation contravenes the allocation policy, changes to the files allocation will fail. For preexisting files or for pre-used filesystems, there is no guarantee that setext will work. In this example, we will try to reserve 1GB of aligned space for a database file /db/db.finance, and we will sector-align fixed extents over the 16KB stripes in our stripe set. First, we need to establish the filesystem block size:
root@hpeos003[] bdf /db Filesystem kbytes used avail %used Mounted on /dev/vx/dsk/ora1/dbvol 10485760 3430 10154766 0% /db root@hpeos003[] echo "8192B; p S" | fsdb -F vxfs /dev/vx/dsk/ora1/dbvol super-block at 00000004.0000 magic a501fcf5 version 4 ctime 1068808191 186592 (Fri Nov 14 11:09:51 2003 BST) log_version 9 logstart 0 logend 0 bsize 2048 size 5242880 dsize 5242880 ninode 0 nau 0 defiextsize 0 oilbsize 0 immedlen 96 ndaddr 10 aufirst 0 emap 0 imap 0 iextop 0 istart 0 bstart 0 femap 0 fimap 0 fiextop 0 fistart 0 fbstart 0 nindir 2048 aulen 32768 auimlen 0 auemlen 4 auilen 0 aupad 0 aublocks 32768 maxtier 15 inopb 8 inopau 0 ndiripau 0 iaddrlen 4 bshift 11 inoshift 3 bmask fffff800 boffmask 7ff checksum e55a9e6e free 5241165 ifree 0 efree 3 1 0 1 2 1 2 1 0 0 0 1 1 1 1 3 2 2 2 2 1 1 0 0 0 0 0 0 0 0 0 0 flags 0 mod 0 clean 3c time 1068808193 530000 (Fri Nov 14 11:09:53 2003 BST) oltext[0] 21 oltext[1] 1802 oltsize 1 iauimlen 1 iausize 4 dinosize 256 checksum2 827 checksum3 0 root@hpeos003[]
The block size is 2KB. We can now use the setext command. setext uses a multiple of filesystem blocks as arguments to options. Here, we will attempt the extent allocation policy mentioned above. In order to achieve this, we will need to:
Reserve 524288 filesystem blocks
Make the extents 8 blocks in size = 16KB
Ensure that the extents are aligned
root@hpeos003[] touch /db/db.finance root@hpeos003[] root@hpeos003[] setext -r 524288 -e 8 -f align /db/db.finance root@hpeos003[] getext /db/db.finance /db/db.finance: Bsize 2048 Reserve 524288 Extent Size 8 align root@hpeos003[] root@hpeos003[] ll /db/db.finance -rw-rw-r-- 1 root sys 0 Nov 14 11:14 /db/db.finance root@hpeos003[]
As you can see, we have set the extent allocation policy for this file, even though there appears to be no disk space allocated to the file. In fact, VxFS has allocated all the extents necessary to accommodate the current allocation policy. We can confirm this by using fsdb on the inode.
root@hpeos003[] ll -i /db/db.finance 4 -rw-rw-r-- 1 root sys 0 Nov 14 11:23 /db/db.finance root@hpeos003[] root@hpeos003[] echo "4i" | fsdb -F vxfs /dev/vx/dsk/ora1/dbvol inode structure at 0x0000069f.0400 type IFREG mode 100664 nlink 1 uid 0 gid 3 size 0 atime 1068820230 0 (Fri Nov 14 14:30:30 2003 BST) mtime 1068820230 0 (Fri Nov 14 14:30:30 2003 BST) ctime 1068820257 730015 (Fri Nov 14 14:30:57 2003 BST) aflags 4 orgtype 1 eopflags 0 eopdata 0 fixextsize/fsindex 8 rdev/reserve/dotdot/matchino 524288 blocks 524288 gen 11 version 0 917 iattrino 0 de: 524288 0 0 0 0 0 0 0 0 0 des: 524288 0 0 0 0 0 0 0 0 0 ie: 0 0 ies: 0 root@hpeos003[]
It should come as no surprise that the filesystem has allocated us one huge extent. Some people would say that this is contiguous allocation. It is, but only because the underlying allocation policy of the filesystem wants to make life as easy as possible. It is a consequence of having an empty filesystem that we have coincidentally been allocated a contiguous extent. The fact that the filesystem has given us one huge extent means that addressing this amount of data requires reading only one direct extent address from the inode. Even though we specified a fixed extent size, this only means that we will be allocated a multiple of 16KB when we need additional space in the file. When this one huge extent is transposed into disk allocation, we have ensured, with a fixed extent size, that multiples of our stripe size are always allocated from the filesystem.
With our db.finance file, we now have space allocated from the filesystem. The actual size of the data within the file will be determined when the database is populated with data. Some administrators find it weird to have space allocated for a file that isn't displayed by an ls –l command. If we wanted to make life easy for ourselves, we could have used the –f chgsize option to the initial setext command to change the size of the file to match the current reservation. If we want to apply this idea to our existing file, we would have to delete it and reallocate the extents.
root@hpeos003[] rm /db/db.finance root@hpeos003[] touch /db/db.finance root@hpeos003[] setext -r 524288 -e 8 -f align -f chgsize /db/db.finance root@hpeos003[] ll -i /db total 4558980 4 -rw-rw-r-- 1 root sys 1073741824 Nov 14 14:42 db.finance 3 drwxr-xr-x 2 root root 96 Nov 14 11:09 lost+found root@hpeos003[] echo "4i" | fsdb -F vxfs /dev/vx/dsk/ora1/dbvol inode structure at 0x0000069f.0400 type IFREG mode 100664 nlink 1 uid 0 gid 3 size 1073741824 atime 1068820961 0 (Fri Nov 14 14:42:41 2003 BST) mtime 1068820961 0 (Fri Nov 14 14:42:41 2003 BST) ctime 1068820975 60022 (Fri Nov 14 14:42:55 2003 BST) aflags 4 orgtype 1 eopflags 0 eopdata 0 fixextsize/fsindex 8 rdev/reserve/dotdot/matchino 524288 blocks 524288 gen 12 version 0 923 iattrino 0 de: 524288 0 0 0 0 0 0 0 0 0 des: 524288 0 0 0 0 0 0 0 0 0 ie: 0 0 ies: 0 root@hpeos003[]
Remember to always use setext on newly created files in an empty filesystem, in order to obtain the optimal allocation policy.
With JFS 3.3 (layout version 4), we get a new command: vxtunefs. In order for the vxtunefs command to have a significant impact on performance, it should be used in concert with all the other configuration settings we have established up until now: settings for volumes, filesystems, and even extent attributes for individual files. The result, we hope, will be significantly improved performance of the slowest device in our system, the humble disk drive.
With vxtunefs, we can tune the underlying IO characteristics of the filesystem to work in harmony with the other configuration settings we have so far established. Let's continue the discussion from where we left it with setting extent attributes for individual files. There, we set the extent size to match our stripe size, which in turn matches the IO size of our user application. It makes sense (to me) to try to match the IO size of the filesystem to match these parameters, i.e., get the filesystem to perform IO in chunks of 16KB. The other question to ask is how many IOs should the filesystem perform at any one time? This leads to a question regarding our underlying disk technology. If our stripe set is configured on a JBOD connected via multiple interfaces, it would make sense (to me) to send an IO request that was a multiple of the number of disks in the stripe set. In our example in Figure 8-5, this would equate to three IOs. The IO subsystem is quite happy with this, because the disks are connected via multiple interfaces and hence IOs will be spread across all interfaces. The disks are happy because individually they are performing one IO each. The filesystem is happy because it is performing multiple IOs and hence reading/writing bigger chunks of data to/from the disks (the filesystem may also be performing read-aheads, which can even further improve the quantity of data being shipped each interval).
When we are talking about a RAID 5 layout, the only other consideration is when we perform a write. In those instances, we will want to issue a single write that constitutes the size of one entire stripe of data. In this way, the RAID5 subsystem receives an entire stripe of data whereby it calculates the parity information and then issues writes to all the disks in the stripe set.
This discussion becomes a little more complex when we talk about disk arrays. Commonly, disk arrays, e.g., HPs XP, VA, and EVA disk arrays, will stripe data over a large number of disks at a hardware level. To the operating system, the disk is one device. The operating system does not perform any software striping and views the disk as contiguous. In this instance, we need to understand how the disk array has striped the data over its physical disks. If we know how many disks are used in a stripe set, we can view the disk arrays in a similar way to a JBOD with software RAID. The similarity ends by virtue of the fact that we very seldom talk directly to a disk drive on a disk array. We normally talk to an area of high-speed cache memory on the array. Data destined for an entire stripe will normally be contained in at least one page of cache memory. Ideally, we will want to perform IO in a multiple of the size of a single page of array cache, i.e., send the array an IO that will fill at least one page of cache memory. This is when we need to know how many disks the array is using in a stripe set, the stripe size, and the cache page size. On some arrays, data is striped over every available disk. In this instance, our calculation is based on the cache page size, the IO capacity of the array interface, and other IO users of the array.
On top of all these considerations is the fact that the IO/array interfaces we are using commonly have a high IO bandwidth and can therefore sustain multiple IOs to multiple filesystem extents simultaneously.
With this information at hand, we can proceed to consider some of the filesystem parameters we can tune with vxtunefs. When run against a disk/volume, vxtunefs will display the current value for these parameters:
root@hpeos003[] vxtunefs /dev/vg00/lvol3
Filesystem i/o parameters for /
read_pref_io = 65536
read_nstream = 1
read_unit_io = 65536
write_pref_io = 65536
write_nstream = 1
write_unit_io = 65536
pref_strength = 10
buf_breakup_size = 131072
discovered_direct_iosz = 262144
max_direct_iosz = 524288
default_indir_size = 8192
qio_cache_enable = 0
max_diskq = 1048576
initial_extent_size = 8
max_seqio_extent_size = 2048
max_buf_data_size = 8192
root@hpeos003[]
I have chosen to display the parameters for the root filesystem because I know these parameters will assume default values. VxFS can understand disk layout parameters if we use VxVM volumes. When we look at the parameters for the filesystem we have been using recently (the VxVM volume = dbvol), we will see that VxFS has been suggesting some values for us:
root@hpeos003[] vxtunefs /dev/vx/dsk/ora1/dbvol
Filesystem i/o parameters for /db
read_pref_io = 16384
read_nstream = 12
read_unit_io = 16384
write_pref_io = 16384
write_nstream = 12
write_unit_io = 16384
pref_strength = 20
buf_breakup_size = 262144
discovered_direct_iosz = 262144
max_direct_iosz = 524288
default_indir_size = 8192
qio_cache_enable = 0
max_diskq = 3145728
initial_extent_size = 4
max_seqio_extent_size = 2048
max_buf_data_size = 8192
root@hpeos003[]
The parameters that I am particularly interested in initially are read/write_pref_io and read/write_nstream.
read_pref_io: The preferred read request size. The filesystem uses this in conjunction with theread_nstreamvalue to determine how much data to read ahead. The default value is 64K.read_nstream: The number of parallel read requests of sizeread_pref_ioto have outstanding at one time. The filesystem uses the product ofread_nstreamandread_pref_ioto determine its read ahead size. The default value forread_nstreamis 1.write_pref_io: The preferred write request size. The filesystem uses this in conjunction with thewrite_nstreamvalue to determine how to do flush behind on writes. The default value is 64K.write_nstream: The number of parallel write requests of sizewrite_pref_ioto have outstanding at one time. The filesystem uses the product ofwrite_nstreamandwrite_pref_ioto determine when to do flush behind on writes. The default value forwrite_nstreamis 1.
For these parameters to take effect, VxFS must detect access to contiguous filesystem blocks in order to “read ahead” or “write behind”. With “read ahead”, more blocks will be read into the buffer cache that are actually needed by the application. The idea is to perform larger but fewer IOs. With “write behind”, the idea is to reduce the number of writes to disk by holding more blocks in the buffer cache because we are expecting subsequent updates to be to the next blocks in the filesystem. If IO is completely random in nature or multiple processes/threads are randomizing the IO stream, these parameters will have no effect. In such a situation, we will rely on the randomness of IO being distributed, on average over multiple disks in our stripe set. These parameters work only for the “standard” IO routines, i.e., read() and write(). Memory-mapped files don't use read-ahead or write-behind. The key here is knowing the typical workload that your applications put on the IO subsystem.
Thinking about the configuration of the underlying volume, I think we can understand why the preferred IO size has been set to 16KB; the underlying disk (a VXVM volume) has been configured with a 16KB stripe size:
root@hpeos003[] vxprint -g ora1 -rtvs dbvol RV NAME RLINK_CNT KSTATE STATE PRIMARY DATAVOLS SRL RL NAME RVG KSTATE STATE REM_HOST REM_DG REM_RLNK V NAME RVG KSTATE STATE LENGTH READPOL PREFPLEX UTYPE PL NAME VOLUME KSTATE STATE LENGTH LAYOUT NCOL/WID MODE SD NAME PLEX DISK DISKOFFS LENGTH [COL/]OFF DEVICE MODE SV NAME PLEX VOLNAME NVOLLAYR LENGTH [COL/]OFF AM/NM MODE DC NAME PARENTVOL LOGVOL SP NAME SNAPVOL DCO dm ora_disk1 c0t4d0 simple 1024 71682048 FAILING dm ora_disk2 c4t8d0 simple 1024 71682048 - dm ora_disk3 c4t12d0 simple 1024 71682048 - v dbvol - ENABLED ACTIVE 10485760 SELECT dbvol-01 fsgen pl dbvol-01 dbvol ENABLED ACTIVE 10485792 STRIPE 3/16 RW sd ora_disk1-01 dbvol-01 ora_disk1 0 3495264 0/0 c0t4d0 ENA sd ora_disk2-01 dbvol-01 ora_disk2 0 3495264 1/0 c4t8d0 ENA sd ora_disk3-01 dbvol-01 ora_disk3 0 3495264 2/0 c4t12d0 ENA root@hpeos003[]
The reason it has chosen to read and write 12 read and write streams is due to the Veritas software trying to understand the underlying disk technology. We are using Ultra Wide LVD SCSI disks, so Veritas has calculated that we can quite happily perform 12x 16KB = 192KB of IO with no perceptible problems for the IO subsystem. We would need to consider all other volumes configured on these disks as well as other disks on these interfaces before commenting whether or not these figures are appropriate. The best measure of this is to run our applications with a normal workload and measure the IO performance against an earlier benchmark. We can increase or decrease these values without unmounting the filesystem, although if performing performance tests, it would be advisable to remount the filesystem with the new parameter settings before running another benchmark.
Thinking about the discussion we had earlier regarding sending multiple IOs to the filesystem, we can now equate that discussion to these tunable parameters. For a striped volume, we would set read_pref_io and write_pref_io size to be stripe unit size. We would set read_nstream and write_nstream to be a multiple of the number of columns in our stripe set. For a RAID 5 volume, we would set write_pref_io to be the size of an entire data stripe and set write_nstream to equal 1.
For filesystems that are accessed sequentially, e.g., containing redo logs or video capture files, here are some other parameters we may consider:
discovered_direct_iosz: When an application is performing large IOs to data files, e.g., a video image, if the IO request is larger thandiscovered_direct_iosz, the IO is handled as a discovered direct IO. A discovered direct IO is unbuffered, i.e., it bypasses the buffer cache, in a similar way to synchronous IO. The difference with discovered direct IO is that when the file is extended or blocks allocated, the inode does not need to be synchronously updated as well. This may seem a little crazy because the buffer cache is intended to improve IO performance. The buffer cache is intended to even out the randomness of small and irregular IO and improve IO performance for everyone. In this case, the CPU time involved to set up buffers and to buffer the IO into the buffer cache becomes more expensive than performing the IO itself. In this case, it makes sense for the filesystem to perform an unbuffered IO. The trick is to know what size IO requests your applications are making. If you set this parameter too high, IOs smaller than this will still be buffered and cost expensive buffer-related CPU cycles. The default value is 256KB.max_seqio_extent_size: Increases or decreases the maximum size of an extent. When the filesystem is following its default allocation policy for sequential writes to a file, it allocates an initial extent that is large enough for the first write to the file. When additional extents are allocated, they are progressively larger (the algorithm tries to double the size of the file with each new extent), so each extent can hold several writes worth of data. This reduces the total number of extents in anticipation of continued sequential writes. When there are no more writes to the file, unused space is freed for other files to use. In general, this allocation stops increasing the size of extents at 2048 filesystem blocks, which prevents one file from holding too much unused space. Remember, in an ideal world, we would establish an extent allocation policy for individual files. This parameter will affect the allocation policy for files without their own predefined (setext) allocation policy.max_direct_iosz: If we look at the value that VxFS has set for ourdbvolfilesystem, it happens to correspond to the amount of memory in our system: 1GB. If we were to perform large IO requests (invoking direct IO if it was larger thandiscovered_direct_iosz) to this filesystem, VxFS would allow us to issue an IO request the same size as memory. The idea is that this parameter will set a maximum size of a direct I/O request issued by the filesystem. If there is a larger I/O request, it is broken up into max_direct_ioszchunks. This parameter defines how much memory an IO request can lock at once. In our case, the filesystem would allow us to issue a 1GB direct IO to this filesystem. It is suggested that we not set this parameter beyond 20 percent of memory in order to avoid a single process from swamping memory with large direct IO requests. The parameter is set as a multiple of filesystem blocks. In my case, if I have 1GB of RAM, taking the 20 percent guideline (20% of 1GB = 104857.6, 2KB filesystem blocks), I would set this parameter to be at least 104448.The parameters
buf_breakup_sz,qio_cache_enable,pref_strength,read_unit_io, andwrite_unit_ioare currently not supported on HP-UX.
When we have established which parameters we are interested in, we need to set the parameters to the desired values now and ensure that the parameters retain their values after a reboot. To set the values now, we use the vxtunefs command. If we wanted to set the read_nstream to be 6 instead of 12 because we realized there were significant other IO users on those disks, the command would look something like this:
root@hpeos003[] vxtunefs –s -o read_nstream=6 /dev/vx/dsk/ora1/dbvol vxfs vxtunefs: Parameters successfully set for /db root@hpeos003[] vxtunefs –p /dev/vx/dsk/ora1/dbvol Filesystem i/o parameters for /db read_pref_io = 16384 read_nstream = 6 read_unit_io = 16384 write_pref_io = 16384 write_nstream = 12 write_unit_io = 16384 pref_strength = 20 buf_breakup_size = 262144 discovered_direct_iosz = 262144 max_direct_iosz = 524288 default_indir_size = 8192 qio_cache_enable = 0 max_diskq = 3145728 initial_extent_size = 4 max_seqio_extent_size = 2048 max_buf_data_size = 8192 root@hpeos003[]
We would continue in this vein until all parameters were set to appropriate values. To ensure these values sustain a reboot we need to setup the file /etc/vx/tunefstab. This file does not exist by default. Here is how I setup the file for the parameters I want to set:
root@hpeos003[] cat /etc/vx/tunefstab
/dev/vx/dsk/ora1/dbvol read_nstream=6
/dev/vx/dsk/ora1/dbvol write_nstream=6
/dev/vx/dsk/ora1/dbvol max_direct_iosz=104448
root@hpeos003[]
I have only set three parameters for this one filesystem. I would list all parameters for all filesystems in this file. You can specify all options for a single filesystem on a single line. Personally I think it easier to read, manage and understand having individual parameters on a single line. Once we have setup our file we can test it by using the vxtunefs –f command.
root@hpeos003[] vxtunefs –s -f /etc/vx/tunefstab vxfs vxtunefs: Parameters successfully set for /db root@hpeos003[] vxtunefs /dev/vx/dsk/ora1/dbvol Filesystem i/o parameters for /db read_pref_io = 16384 read_nstream = 6 read_unit_io = 16384 write_pref_io = 16384 write_nstream = 6 write_unit_io = 16384 pref_strength = 20 buf_breakup_size = 262144 discovered_direct_iosz = 262144 max_direct_iosz = 104448 default_indir_size = 8192 qio_cache_enable = 0 max_diskq = 3145728 initial_extent_size = 4 max_seqio_extent_size = 2048 max_buf_data_size = 8192 root@hpeos003[]
The other parameters are explained in the man page for vxtunefs. Some of them may apply in particular situations. As always, you should test the performance of your configuration before, during, and after making any changes. If you are unsure of what to set these parameters to, you should leave them at their default values.
Now that we have looked at how we can attempt to improve IO performance through customizing intent logging, using extent attributes, and tuning the filesystem, we will look at additional mount options that can have an effect on performance, for good or bad. We discussed the use of mount options to affect the way the intent log is written to. The intent log is used to monitor and manage structural information (metadata) relating to the filesystem. The mount options we are about to look at affect how the filesystem deals with user data. The normal behavior for applications is to issue read()s and write()s to data files. These IOs are asynchronous IO and are buffered in the buffer cache to improve overall system performance. Applications can use synchronous IO to ensure that data is written to disk before continuing. An example of synchronous IO is committing changes to a database file; the application wants to ensure that the data resides on disk before continuing. It should be noted that there are two forms of synchronous IO: full and data. Full synchronous IO (O_SYNC) is where data and inode changes are written to disk synchronously. Data synchronous IO (O_DSYNC) is where changes to data are written to disk synchronously but inode changes are written asynchronously. The mount options we are going to look at affect the use of the buffer cache (asynchronous IO) and the use of synchronous IO. We are not going to look at every option; that's what the man pages are for. We look at some common uses.
The biggest use of the mincache directive is in the use of mincache=direct. This causes all IO to be performed direct to disk, bypassing the buffer cache entirely. This may seem like a crazy idea because, for normal files, every IO would bypass the buffer cache and be performed synchronously (O_SYNC). Where this is very useful is for large RDBMS applications that buffer their data in large shared memory segments, e.g., Oracle's System Global Area. In this case, the RDBMS buffers the data and then issues a write(), which may or may not be buffered again by the filesystem. Where all the files in a filesystem are going to be managed by the RDBMS, that specific filesystem could be mounted with the mincache=direct directive. Be careful that no normal files exist in this filesystem because IO to those files will be performed synchronously.
Most other situations will use the default buffering used by the filesystem. Where you want to improve the integrity of files for systems that are turned off by users, i.e., desktop HP-UX workstations, you may want to consider the mincache=closesync where a file is guaranteed to be written to disk when it is closed. This would mean that there was only a possibility of data lost for files that were open when the user hits the power button.
To make a filesystem go faster, there is the caching directive mincache=tmpcache. It should be used with extreme caution, because a file could contain junk after a system crash. Normally, when a user extends the size of a file, the user data is written to disk and then the inode is updated, ensuring that the inode points only to valid user data. If a system crashed before the inode was updated, the data would be lost and the inode would not be affected. With mincache=tmpcache, the inode is updated first, returning control to the calling function (the application can proceed), and then sometime later the data is written to disk. This could lead to an inode pointing to junk if the system crashes before the user data is written to disk. This is dangerous. Be careful.
Straight away, I must state that changing the behavior of synchronous IO is exceptionally dangerous. If we think about applications that perform synchronous IO, they are doing it to ensure that data is written to disk, e.g., checkpoint and commit entries in a database. This information is important and needs to be on disk; that's why the application is using synchronous IO. Changing the use of synchronous (convosync = convert O_SYNC) IO means that you are effectively saying, “No, Mr. Application, your data isn't important; I'm going to decide when it gets written to disk.” Two options that might be considered to speed up an application could be convosync=delay where all synchronous IO is converted to asynchronous, negating any data integrity guarantees offered by synchronous IO. I think this is the maddest thing to do in a live production environment. Where you want to make a filesystem perform at its peak, this might be a good idea, but at the cost of data integrity. For some people, convosync=closesync is a compromise where synchronous and data synchronous IO is delayed until the file is closed. I won't go any further because all these options give me a serious bad feeling. In my opinion, synchronous IO is sacrosanct; application developers use it only when they have to, and when they use it, they mean it. In live production environments, don't even think about messing with this!
When we have decided which mount options to use, we need to ensure that we update the /etc/fstab file with these new mount options. I don't need to tell you the format of the /etc/fstab file, but I thought I would just remind you to make sure that you remount your filesystem should you change the current list of mount options:
root@hpeos003[] mount -p /dev/vg00/lvol3 / vxfs log 0 1 /dev/vg00/lvol1 /stand hfs defaults 0 0 /dev/vg00/lvol8 /var vxfs delaylog,nodatainlog 0 0 /dev/vg00/lvol9 /var/mail vxfs delaylog,nodatainlog 0 0 /dev/vg00/lvol7 /usr vxfs delaylog,nodatainlog 0 0 /dev/vg00/lvol4 /tmp vxfs delaylog,nodatainlog 0 0 /dev/vg00/lvol6 /opt vxfs delaylog,nodatainlog 0 0 /dev/vx/dsk/ora1/logvol /logdata vxfs log,nodatainlog 0 0 /dev/vg00/library /library vxfs log,nodatainlog 0 0 /dev/vg00/lvol5 /home vxfs delaylog,nodatainlog 0 0 /dev/vx/dsk/ora1/dbvol /db vxfs log,nodatainlog 0 0 root@hpeos003[] root@hpeos003[] vi /etc/fstab # System /etc/fstab file. Static information about the file systems # See fstab(4) and sam(1M) for further details on configuring devices. /dev/vg00/lvol3 / vxfs delaylog 0 1 /dev/vg00/lvol1 /stand hfs defaults 0 1 /dev/vg00/lvol4 /tmp vxfs delaylog 0 2 /dev/vg00/lvol5 /home vxfs delaylog 0 2 /dev/vg00/lvol6 /opt vxfs delaylog 0 2 /dev/vg00/lvol7 /usr vxfs delaylog 0 2 /dev/vg00/lvol8 /var vxfs delaylog 0 2 /dev/vg00/lvol9 /var/mail vxfs delaylog 0 2 /dev/vx/dsk/ora1/dbvol /db vxfs delaylog,nodatainlog,mincache=direct 0 2 /dev/vg00/library /library vxfs defaults 0 2 /dev/vx/dsk/ora1/logvol /logdata vxfs defaults 0 2 root@hpeos003[] root@hpeos003[] mount -o remount /db root@hpeos003[]
Logically, a VxFS snapshot is the same idea as a VxVM snapshot in that they give us a freeze-frame view of our data so that we can perform online actions, such as backups, while users are accessing the data. Whereas with a VxVM snapshot, we could resynchronize the original volume from the snapshot (reverse resync), a VxFS filesystem is a read-only freeze frame of the current filesystem. There is no additional copy of the data made for a VxFS snapshot like in a VxVM snapshot; the snapshot occurs immediately, and access is immediate as well. Fundamentally, the concepts are the same, but the way they are implemented is quite different. Figure 8-6 gives us an idea of how a VxFS snapshot works.
The snapshot is taken using the
mountcommand. Both the user and the backup utility have the same view of all data blocks in the filesystem. The snapshot uses a (smaller) volume for storing original blocks should an update occur in the filesystem.The user makes a change to the online snapped filesystem. The update is blocked. The original blocks are copied to the temporary volume used by the snapshot. The user update is now written to the online snapped filesystem.
The view of the filesystem seen by the backup utility will always be the view as seen at the time of the snapshot. When accessing a block that has been snapped, the block in the snapshot is accessed instead of the blocks in the original filesystem. This is completely transparent to the backup utility.
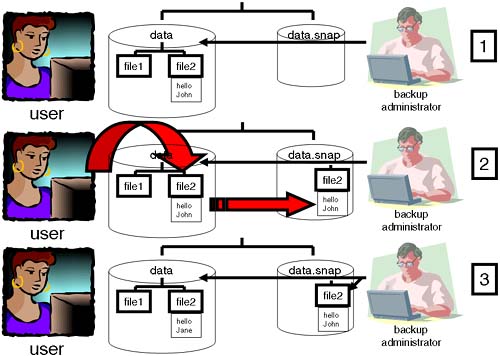
One drawback of this scenario is that the snapshot is a read-only filesystem. Some backup utilities (fbackup for one) will attempt to update inode timestamps as part of the backup process. If this will cause a backup utility to fail, then a VxFS snapshot is not the best solution for online backups.
Other things to consider before using VxFS snapshots:
You should try to inactivate the application before taking the snapshot. It is important that the snapshot is a stable view of the data.
Read performance of the snapped filesystem should not be affected. Write performance of the snapped filesystem will be affected the first time a change occurs to a block in the snapped filesystem. An initial update to the snapped filesystem will require the original blocks to be written to the snapshot. Subsequent writes to the same blocks are not affected. Some studies have shown that heavily used OLTP applications can see an overall downturn in performance of as much as 10-20 percent while a snapshot is active.
Make sure that the snapshot is housed on physical disk other than the original filesystem to ensure that writes to the snapshot don't cause massive movements of read-write heads on the online disks.
Performance of the snapshot will be affected if the snapped filesystem is busy because reads from the snapshot are coming from the online snapped filesystem.
Try to take snapshots at quiet times of the day, when online activity is at it quietest.
The size of the snapshot volume needs to accommodate as many changes as can occur in the filesystem during the time the snapshot is active. If every block in the online snapped filesystem changed the snapshot volume would have to be as big (plus approximately 1 percent of additional space for snapshot structural data) as the original volume. On average, a snapshot volume should be at least 15-20 percent the size of the original volume.
The process of taking a snapshot is relatively simple:
Create a new volume to house the snapshot. You should create the snapshot volume on a different disk(s) than the online filesystem. The configuration of the snapshot volume is not restricted to a concatenated volume.
root@hpeos003[] lvcreate -L 500 -n snapdb /dev/vg00 Warning: rounding up logical volume size to extent boundary at size "504" MB. Logical volume "/dev/vg00/snapdb" has been successfully created with character device "/dev/vg00/rsnapdb". Logical volume "/dev/vg00/snapdb" has been successfully extended. Volume Group configuration for /dev/vg00 has been saved in /etc/lvmconf/vg00.conf root@hpeos003[] root@hpeos003[] newfs -F vxfs /dev/vg00/rsnapdb version 4 layout 516096 sectors, 516096 blocks of size 1024, log size 1024 blocks unlimited inodes, largefiles not supported 516096 data blocks, 514880 free data blocks 16 allocation units of 32768 blocks, 32768 data blocks last allocation unit has 24576 data blocks root@hpeos003[]
Use the
mountcommand to take the snapshot.root@hpeos003[] mount -o snapof=/db /dev/vg00/snapdb /snapdb root@hpeos003[] bdf | grep db /dev/vx/dsk/ora1/dbvol 10485760 2282920 7946508 22% /db /dev/vg00/snapdb 10485760 2282920 7946502 22% /snapdb root@hpeos003[]
As you can see, even though our snapshot volume is only 500MB, all reads through the snapshot are as if they were coming from the original snapped filesystem.
Perform online backups.
I will simply demonstrate that updates to the original snapped filesystem will not affect the view of the data in the snapshot:
root@hpeos003[] ll /db total 4558980 -rw-rw-r-- 1 root sys 1073741824 Nov 14 14:42 db.finance -rw-rw-r-- 1 root sys 1260447712 Nov 14 12:43 db.finance2 drwxr-xr-x 2 root root 96 Nov 14 11:09 lost+found root@hpeos003[] ll /snapdb total 4558980 -rw-rw-r-- 1 root sys 1073741824 Nov 14 14:42 db.finance -rw-rw-r-- 1 root sys 1260447712 Nov 14 12:43 db.finance2 drwxr-xr-x 2 root root 96 Nov 14 11:09 lost+found root@hpeos003[] cp /stand/vmunix /db root@hpeos003[] rm /db/db.finance2 /db/db.finance2: ? (y/n) y root@hpeos003[] ll /db total 2131504 -rw-rw-r-- 1 root sys 1073741824 Nov 14 14:42 db.finance drwxr-xr-x 2 root root 96 Nov 14 11:09 lost+found -rwxr-xr-x 1 root sys 17586896 Nov 15 12:09 vmunix root@hpeos003[] ll /snapdb total 4558980 -rw-rw-r-- 1 root sys 1073741824 Nov 14 14:42 db.finance -rw-rw-r-- 1 root sys 1260447712 Nov 14 12:43 db.finance2 drwxr-xr-x 2 root root 96 Nov 14 11:09 lost+found root@hpeos003[]
Remember that updates to the snapshot are not allowed because it is a read-only filesystem:
root@hpeos003[] grep snap /etc/mnttab /dev/vg00/snapdb /snapdb vxfs ro,snapof=/dev/vx/dsk/ora1/dbvol,snapsize=516096 0 0 1068897785 root@hpeos003[] > /snapdb/testfile sh[2]: /snapdb/testfile: Cannot create the specified file. root@hpeos003[]
Unmount the snapshot when backups have finished.
root@hpeos003[] umount /snapdb root@hpeos003[] bdf | grep db /dev/vx/dsk/ora1/dbvol 10485760 1069182 9122318 10% /db root@hpeos003[]
It is up to you what you do with the snapshot volume. If you decide to keep the volume for the next time you are going to perform a snapshot, remember to recreate the filesystem in the snapshot volume. The process of taking a snapshot has effectively corrupted the filesystem in the snapshot beyond all recognition:
root@hpeos003[] fstyp /dev/vg00/snapdb unknown_fstyp (no matches) root@hpeos003[] mount /dev/vg00/snapdb /snapdb /dev/vg00/snapdb: unrecognized file system root@hpeos003[] mount -o snapof=/db /dev/vg00/snapdb /snapdb /dev/vg00/snapdb: unrecognized file system root@hpeos003[]
The HP-UX kernel supports a multitude of filesystems. HP-UX, like most other versions of UNIX, provides a standard interface to users to manage files and directories. The example we used of hard and soft links in the HFS section would work as well in the VxFS section. To users, we have one monolithic filesystem. In reality, the underlying filesystems can be UFS, VxFS, NFS, CDFS, DFS, AutoFS, CacheFS, CIFS, and Loopback FS. The technology that allows us to present this single interface to users is known as the Virtual Filesystem Layer that uses virtual nodes (vnode) to reference each individually mounted filesystem (Figure 8-7).
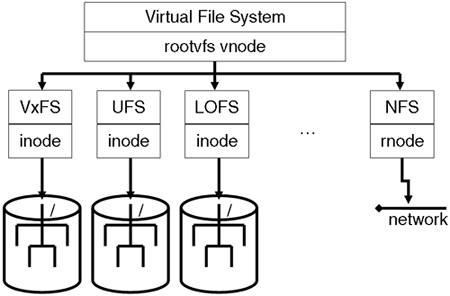
The VFS structures hide the technicalities of mount points and filesystems away from users. When navigating through a multitude of filesystems, the code can locate an individual file in an individual filesystem while being guided by the VFS layer to a superblock structure on a particular disk (the mount command tells the kernel on which device to find a filesystem), which subsequently guides us to where the inodes for files are held on disk. Once read into memory (into the inode cache), we can index through the inode cache to locate a particular inode from a particular device. Here's a simple example of navigating through a filesystem tree. When we read the /stand/system file, we have to traverse through two different filesystem types: VxFS for the root filesystem and HFS for the /stand filesystem. There are some assumptions to make before we start:
The kernel has established where the root filesystem is at boot time and set up a special kernel structure called
rootdirreferencing thevnodethat points to the root inode.Inode 2 is the root inode of a filesystem.
The kernel has established at boot time a special kernel variable called
rootvfsthat references the top of thevnodestructure.Inode structures in memory are a superset of the inode structures stored on disk. Inodes in memory have indexing and other information that makes searching for them and finding them quicker.
If an inode is not in memory, the kernel will have to interface via the superblock (referenced through the vnode structure) to locate the inode on disk and read it into the inode cache in memory.
Figure 8-8 shows a summarized view of how walking through the filesystem would work.
Locate the vnode for the root filesystem.
We can then locate the inode for the root filesystem. This will be a directory. We hope that permissions will allow us to read further. The inode will reference the disk (dev=0x40000003 − major=0x40(=64) minor=0x000003 − vg00/lvol3) containing the data blocks for the directory. Reading the data blocks, we realize that the
standentry is inode 7.We can index through the inode cache looking for an inode from the same device but with inode 7.
Eventually locating the inode, we discover that this is also a directory. Whenever we discover a directory, we need to make sure that it is not a mountpoint for a filesystem.
Referencing back to the vnode, we realize that this is a mountpoint (vfsmountedhere references back to a valid vfs structure).
We now know which device is the mountpoint for our new filesystem. We now have a new device ID (dev=0x40000001 = vg00/lvol1) to index through the inode cache.
We eventually find an HFS inode = 2 for our new device ID. It is a directory, and we have permission to read.
Reading the directory blocks, we realize the inode for the
systementry is inode 16.We can index through the inode cache looking for inode = 16 dev =0x40000001. Locating the inode, we have permission to read.
The inode tells us that this is a regular file. We analyze the block pointers in the inode to get to the data blocks. We eventually get to our data.
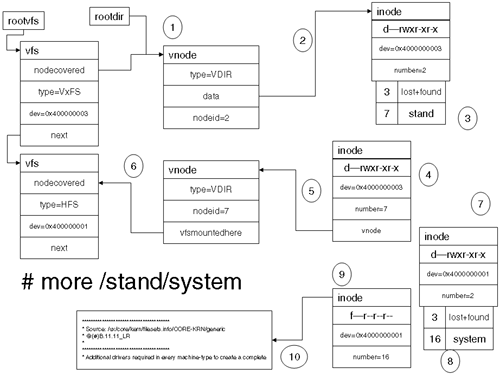
All in the blink of an eye.
Do we need to know or understand the vagaries of this process? No, we don't. What we need to appreciate is that every time we perform long directory searches and set up a multitude of symbolic links all over the place, we are asking the kernel to do a considerable amount of work. Making life easier for the kernel with simple measures like shorter directory paths can recoup benefits for overall system health and performance.
Filesystems allow us to organize and manage our data in files and directories. This is not difficult to understand. What may be a little more taxing mentally are the various tricks that HFS and VxFS use to try to make managing our data as efficient an exercise as possible. There is little doubt that HFS was a major advancement in filesystem technology when it was first published. Nowadays, some would say that HFS is “showing its age;” VxFS offers all the features of HFS and more, including fine-tuning of intent logging and mount options, as well as fine-tuning IO characteristics. In our discussions, we have looked at the internal structure of both HFS and VxFS. Some people comment that all the internal “stuff” is too much information and not necessary. Personally, I think if you have an understanding of how a filesystem works, then you can make informed decisions when something goes wrong. At the beginning of the chapter, we mentioned times when saying “no” to fsck might be perfectly okay. Here's a simple example of why having a basic understanding of structures such as inodes can help you make informed decisions regarding how to fix a filesystem:
The example uses an HFS filesystem, just for simplicity. This could apply to VxFS as well (although less likely).
The corruption occurred due to an unexpected system crash.
We want to retain one of the affected files; the other file will need to be deleted. The only safe and supported way to delete the corrupted file is via
fsck.Figure 8-9 summarizes the problem:
Here is a listing of the actual files:
root@hpeos003[] ll -i /data total 40 5 -r--r--r-- 1 root sys 566 Feb 11 14:04 hosts 3 drwxr-xr-x 2 root root 8192 Feb 11 14:03 lost+found 4 -r--r--r-- 1 root sys 10651 Feb 11 14:04 passwd root@hpeos003[]Both files are referencing block number 144:
root@hpeos003[] umount /data root@hpeos003[] fsdb -F hfs /dev/vg00/lvol10 file system size = 102400(frags) isize/cyl group=48(Kbyte blocks) primary block size=8192(bytes) fragment size=1024 no. of cyl groups = 42 2i.fd d0: 2 . d1: 2 . . d2: 3 l o s t + f o u n d d3: 4 p a s s w d d4: 5 h o s t s 4i i#:4 md: f---r--r--r-- ln: 1 uid: 0 gid: 3 sz: 10651 ci:0 a0 : 144 a1 : 107 a2 : 0 a3 : 0 a4 : 0 a5 : 0 a6 : 0 a7 : 0 a8 : 0 a9 : 0 a10: 0 a11: 0 a12: 0 a13: 0 a14: 0 at: Wed Feb 11 14:04:16 2004 mt: Wed Feb 11 14:04:16 2004 ct: Wed Feb 11 14:04:16 2004 5i i#:5 md: f---r--r--r-- ln: 1 uid: 0 gid: 3 sz: 566 ci:0 a0 : 144 a1 : 0 a2 : 0 a3 : 0 a4 : 0 a5 : 0 a6 : 0 a7 : 0 a8 : 0 a9 : 0 a10: 0 a11: 0 a12: 0 a13: 0 a14: 0 at: Wed Feb 11 14:04:16 2004 mt: Wed Feb 11 14:04:16 2004 ct: Wed Feb 11 14:04:16 2004
Problems are evident only when we try to access the files. Due to the file size (the
szfield in the inode), commands such ascatwill display only the specified number of bytes.root@hpeos003[] cat /data/hosts root:*:0:3::/:/sbin/sh daemon:*:1:5::/:/sbin/sh bin:*:2:2::/usr/bin:/sbin/sh sys:*:3:3::/: adm:*:4:4::/var/adm:/sbin/sh uucp:*:5:3::/var/spool/uucppublic:/usr/lbin/uucp/uucico lp:*:9:7::/var/spool/lp:/sbin/sh nuucp:*:11:11::/var/spool/uucppublic:/usr/lbin/uucp/uucico hpdb:*:27:1:ALLBASE:/:/sbin/sh oracle:*:102:102:Oracle:/home/oracle:/usr/bin/sh nobody:*:-2:-2::/: www:*:30:1::/: smbnull:*:101:101:DO NOT USE OR DELETE - needed by Samba:/home/smbnull:/sbin/sh webadmin:*:40:1::/usr/obam/server/nologindir:/usr/bin/false oracle2:*:104:102:orroot@hpeos003[]In this instance, we see only 566 bytes from the data block. This looks like data from a
passwdfile and demonstrates to me that this file is corrupt. The file/data/passwdlooks like it is intact:root@hpeos003[] cat /data/passwd root:*:0:3::/:/sbin/sh daemon:*:1:5::/:/sbin/sh bin:*:2:2::/usr/bin:/sbin/sh sys:*:3:3::/: adm:*:4:4::/var/adm:/sbin/sh uucp:*:5:3::/var/spool/uucppublic:/usr/lbin/uucp/uucico lp:*:9:7::/var/spool/lp:/sbin/sh nuucp:*:11:11::/var/spool/uucppublic:/usr/lbin/uucp/uucico hpdb:*:27:1:ALLBASE:/:/sbin/sh oracle:*:102:102:Oracle:/home/oracle:/usr/bin/sh nobody:*:-2:-2::/: www:*:30:1::/: smbnull:*:101:101:DO NOT USE OR DELETE - needed by Samba:/home/smbnull:/sbin/sh webadmin:*:40:1::/usr/obam/server/nologindir:/usr/bin/false oracle2:*:104:102:oracle2:/home/oracle2:/usr/sbin/sh ... fred:*:2000:30:Fred Flinstone:/home/fred:/usr/sbin/sh barney:*:2001:40:Barney Rubble:/home/barney:/usr/sbin/sh root@hpeos003[]If we were to manage these files using standard commands such as
rm, we would eventually cause a system PANIC (with a PANIC string of “freeing free frag”), i.e., we delete the file called/data/passwd; the filesystem will release bock 144. We then delete the file/data/hostsusing thermcommand. This secondrmcommand will confuse the filesystem because it already has block 144 on its free list, hence, the system PANIC.We will now run
fsck. I will say “no” to questions relating to the deletion of the file/data/passwd. I will say “yes” to questions relating to the deletion of the file/data/hosts. Here goes:root@hpeos003[] umount /data root@hpeos003[] fsck -F hfs /dev/vg00/rlvol10 ** /dev/vg00/rlvol10 ** Last Mounted on /data ** Phase 1 - Check Blocks and Sizes 144 DUP I=5 ** Phase 1b - Rescan For More DUPS 144 DUP I=4 ** Phase 2 - Check Pathnames DUP/BAD I=4 OWNER=root MODE=100444 SIZE=10651 MTIME=Feb 11 14:04 2004 FILE=/passwd REMOVE? n DUP/BAD I=5 OWNER=root MODE=100444 SIZE=566 MTIME=Feb 11 14:04 2004 FILE=/hosts REMOVE? y ** Phase 3 - Check Connectivity ** Phase 4 - Check Reference Counts BAD/DUP FILE I=5 OWNER=root MODE=100444 SIZE=566 MTIME=Feb 11 14:04 2004 CLEAR? y FREE INODE COUNT WRONG IN SUPERBLK FIX? y ** Phase 5 - Check Cyl groups 1 BLK(S) MISSING BAD CYLINDER GROUPS FIX? y ** Phase 6 - Salvage Cylinder Groups 3 files, 0 icont, 20 used, 99649 free (9 frags, 12455 blocks) ***** FILE SYSTEM WAS MODIFIED ***** root@hpeos003[] fsck -F hfs /dev/vg00/rlvol10 ** /dev/vg00/rlvol10 ** Last Mounted on /data ** Phase 1 - Check Blocks and Sizes ** Phase 2 - Check Pathnames ** Phase 3 - Check Connectivity ** Phase 4 - Check Reference Counts ** Phase 5 - Check Cyl groups 3 files, 0 icont, 20 used, 99649 free (9 frags, 12455 blocks) root@hpeos003[] root@hpeos003[] mount /dev/vg00/lvol10 /data root@hpeos003[] ll -i /data total 38 3 drwxr-xr-x 2 root root 8192 Feb 11 14:03 lost+found 4 -r--r--r-- 1 root sys 10651 Feb 11 14:04 passwd root@hpeos003[] ll -i /data/lost+found total 0 root@hpeos003[]
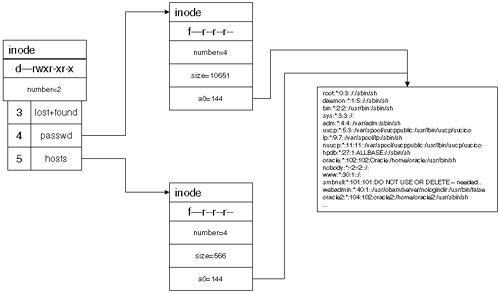
We have now fixed the filesystem safely using fsck. The passwd file has been retained, and the corrupted hosts file has been safely deleted and can be restored from a recent backup (it does not appear in the lost+found directory because this is used for orphaned files, i.e., inodes with no corresponding directory entry). Without an understanding of the basic operation of the filesystem, we would not be in a position to make an informed decision regarding the questions posed by fsck.