
9.1 Swap Space, Paging, and Virtual Memory Management
9.2 How Much Swap Space Do I Need?
9.3 Configuring Additional Swap Devices
9.4 When Dump Space Is Used
9.5 Including Page Classes in the Crashdump Configuration
9.6 Configuring Additional Dump Space
9.7 The savecrash Process
9.8 Dump and Swap Space in the Same Volume
In Chapter 8, we looked at a major use of volumes, i.e., filesystems. In this chapter, we look at the two other main uses of disk and volumes: swap and dump space. Arguably, there is a fourth use—raw volumes—but in those scenarios the volumes are under the control of some third-party application and are, therefore, outside this discussion.
An age-old problem is how much swap space to configure. On large-memory systems these days, we will invariably configure less swap space than main memory. This flies in the face of the old rule-of-thumb of “at least twice as much swap space as main memory.” We discuss pseudo-swap, how it is configured, and why the virtual memory system is considered a paging system as opposed to a swapping system.
Most conversations regarding swap space somehow lead to discussions of dump space. I think this is a legacy from the time when our dump space had to be configured as part of the root volume group (vg00), and by default, the dump space was configured as being our primary swap device. Yes, I agree that we need to configure a certain proportion of disk space just in case our system crashes and we want to preserve the crashdump. But like swap space, there was an old rule-of-thumb something along the lines of “at least 1.5 times the amount of main memory.” This rule-of-thumb needs revising! And when we find a crashdump, what do we do then? In reality, we need the services of our local HP Response Center in order to diagnose why the system crashed. In my experience, what we as administrators can do is to provide as much relevant information as possible to the Response Center to assist them in gaining access to the crashdump files so that they can start a root-cause-analysis investigation. In this chapter, we simply look at the sequence of events that occur as a result of a system crash. In the next chapter, we look at how to distinguish between a PANIC, a TOC, and a HPMC. This will influence whether we place a software support call or hardware support call, which can help our local Response Center make some basic decisions on how to initially deal with the problem. In the end, all we want is the speediest resolution to the problem.
First, let's get the names sorted out. HP-UX, like many other versions of UNIX, no longer swaps an entire process from memory to disk. The virtual memory system is said to be a paging system, where parts of a process are paged to and from disk. When a process starts up, at least three pages of information are brought into memory: a page of text (code), a page of data, and an empty/zero page. Once the instructions or data the process is using are no longer contained in those pages, the virtual memory system will page-in more data and code as is necessary. This is known as a demand-paged virtual memory system. Page-ins are a normal feature of this system. Page-outs happen as a consequence of not having enough memory. For historical reasons, we still refer to the process of swapping and the disk devices as swap devices, although this is now technically naïve. There's nothing wrong with being a little sentimental. The age-old question of “how much swap space do I need?” is still not an easy question. To answer it, we need to be able to respond to these four simple questions:
Being able to answer all four questions is not as easy as we would first think. To understand how we could begin to answer them, we need to have a brief discussion on the virtual memory system itself.
Processes think they exist in a world where they have an entire 32-bit or 64-bit address space all their own. An address space is a list of memory addresses accessible by the process. A 64-bit address space gives a process (theoretically) 16EB of memory to operate in. The address space a process uses is known as a Virtual Address Space (VAS). The addresses the process thinks are valid aren't really a true representation of what's happening in real memory. We can't have every process in the system referencing address 0x2030498282, can we? The addresses used by a process to access memory are actually composed of two parts: a Space ID and an Offset. The Space ID is unique for each process allowing HP-UX to manage a multitude of Virtual Address Spaces. In 64-bit HP-UX (wide mode), both the Space ID and the Offset are 64 bits in size:
Space ID | Offset |
(64 bit) | (64 bit) |
This theoretically allows HP-UX to manage 264 worth of processes, each with 264 (16EB) worth of data. Currently, HP doesn't think we need that amount of flexibility yet, so the Space ID is actually only 32 bits in size, and the offset is limited to 44 bits (=16TB). The way to think of an Offset is like a real memory address. Remember, the process thinks it has 64 bits worth of memory all to its own. The Offset is going to help get us to a particular memory location, whereas the Space ID gets us to an individual process. The only other thing to mention is that HP-UX uses the idea of partitioning memory into quadrants. This is a simple way that operating systems use to know how a particular memory address equates to a particular type of information. If the address (Offset) equates to a particular quadrant, the operating system knows you must be referencing private data, as an example. Certain types of memory access are allowed for different quadrants; i.e., you can't change code/text when it's in memory (try to overwrite a program while it's running and you get this message: text file busy). So memory partitioning makes life a little easier for operating systems when it comes to managing memory. If this is all getting a bit confusing, then it must be time for a diagram. Figure 9-1 shows how a Space ID and Offset together reference individual processes and addresses within individual processes.
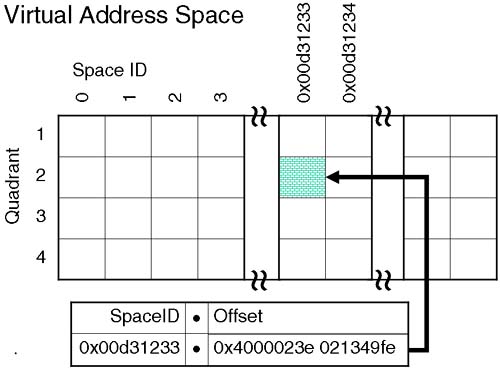
Each quadrant has a particular use, i.e., private data, private text, and shared object (shared libraries, shared memory). Whether we are talking about 32-bit or 64-bit HP-UX determines what each quadrant is used for. At the moment, that's not too important to us. Because we are not using the entire 64 bits of the Space ID, not the full 64 bits of the offset, HP-UX does some clever footwork with both numbers to produce something called a Global Virtual Address (GVA) of 64 bits in size. Being a 64-bit object makes life easier for the kernel. This is all operating system type stuff. We don't need to worry much about the technicalities of how it works, just that the Virtual Address is what the process sees. The process thinks it has 264 worth of code/data to work with. In reality, memory is a limited resource so the kernel (with the aid of some hardware) will manage to fit into memory only the code/data each process needs to continue running.
So, a process is using a Virtual Address to reference its code and data. Something must be converting a Virtual Address into a real Physical Address. That's where the kernel and some special hardware come in. The hardware components include some special Space Registers and the Translation Lookaside Buffer (TLB). The TLB will, we hope, contain a match between a Virtual Page Number (VPN = top 52 bits of the GVA) and a Physical Page Number (PPN). If so, we check whether the page is actually in the processor cache (usually a separate data and instruction cache). If so, the processor can start working on the data. If the VPN ↔ PPN mapping isn't in the TLB, the kernel receives an interrupt, instructing it to find the VPN ↔ PPN mapping in a kernel structure called the Page Directory (PDIR), although now it uses a Hashed Page Table (HTBL), which is easier and quicker to search. If the VPN ↔ PPN is in the Page Directory, then the data has been paged-in to memory at some time. If the VPN ↔ PPN isn't in the Page Directory, then the kernel needs to organize for the data to be brought in from disk. When the data is brought into memory, a Page Directory Entry (pde) is established in order to store, among other things, the VPN ↔ PPN. If that isn't complicated enough, to help it keep track of how processes relate to pages and how pages relate back to process, the kernel maintains a number of other structures. A fundamental structure used by the kernel is known as the Page Frame Data Table (pfdat). Every pageable page is referenced in the pfdat structure. Not every page of memory is pageable (we can't page-out parts of the kernel; otherwise, the OS would stop) and the pfdat structure references a subset of all possible pages available in the system. Entries in the pfdat structure reference chunks of memory. A chunk is a good thing because we can reference multiple pages with a single chunk. Within the chunk structure, we reference individual pages. Individual pages either are in memory or they aren't. Entries in the chunk structure will tell the kernel whether the page is in memory or out on disk. Part of the chunk structure is a pair of entities collectively known as a vfd/bdb. A vfd (virtual frame descriptor) will tell the kernel the Virtual Page Number of a page of data in memory. If the page is not in memory, it must be on disk. This is where the other half of this pair comes in; the dbd (disk block descriptor) will reference where to find the page-out on disk. If the vfd is valid, the kernel knows where to find it in memory. If the vfd is invalid, the kernel uses the dbd to find it on disk. This is also useful when a page is kicked out of memory because the kernel can simply invalidate the vfd, update the dbd if necessary (data pages are paged-out to a swap device, whereas text pages can be brought back from the filesystem), and free up a page of memory. How does this relate to a process, you ask?
As the process grows, it will be made up of chunks of private and shared objects known as pregions (per process region). A pregion (via a bigger structure called a region which associates a group of virtual pages together for a common purpose, e.g., private or shared) references a chunk of memory. It's at this point that the kernel has a link between a process and a page of memory. Remember, the chunk of memory has the vfd to tell the kernel where the page is in memory (via the Virtual Page Number and an appropriate entry in the pfdat structure), or where the kernel can find the page-out on disk via the dbd (the kernel can navigate through the vnodes the process has open in order to find the file descriptors the process has open, and hence to the inodes and then to data blocks on disk).
In summary, the operating system translates a Virtual Address to a Physical Address via a hardware TLB. The TLB is the best place for this translation to exist. Otherwise, the kernel must search a Page Directory (the Hashed Page Table) to find an appropriate translation. While the OS has its view of pages of memory, we have processes that think they are operating in a 264 world of memory all their own. Unbeknown to the process, the Virtual Memory system brings code and data into memory only when we need it. As a process runs, it will grow and grow, gaining more structures to represent more and more areas of memory it is using. The kernel maintains a number of structures in order to keep track of all this and to instruct it which pages are in memory (and where they are) and which pages are still out on disk.
Lots of detail has been left out of this description of how processes grow and how they are described via various structures maintained by the kernel. The point of the discussion is to remind us that as a process grows, it will consume more and more memory. Here is a stylized diagram (Figure 9-2) of how all these structures relate. NOTE: This is not an HP-UX internals class, so I know there are many structures missing.
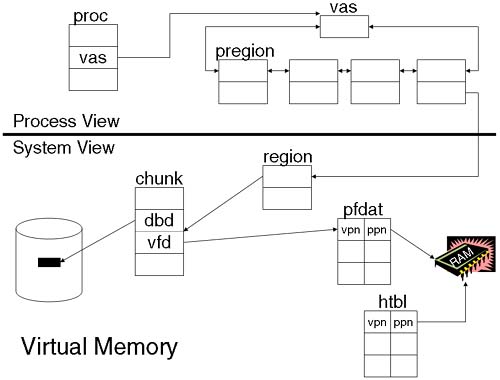
As more and more memory is consumed by a process, at some point the virtual memory system may decide that it is just about to run out of memory and start reclaiming pages that haven't been used recently. This is where swap space comes in.
Swap space is disk space that we hope we will never need. If we actually use swap space, it means that at some time our system was running out of memory to such as extent that the virtual memory system decided to get rid of some data from memory and store it out on disk, on a swap device. This basic idea of when the virtual memory system works helps us when we are trying to decide how much swap space to configure.
An old rule-of-thumb went something like this: “twice as much swap space as main memory.” I can't categorically say that this is either a good or bad rule-of-thumb. Remember the four questions we asked at the beginning? We need to answer these questions before we can calculate how much swap space to configure:
How much main memory do you have?
How much data will your applications want in memory at any one time?
How much application data will be locked in memory?
How does the virtual memory system decide when it's time to start paging-out?
Some of these questions are harder to answer than others. Let's start at the beginning:
How much main memory do you have?
This one isn't too difficult because we can gather this information either from the
dmesgcommand or fromsyslog.log.root@hpeos003[] dmesg | grep Physical Physical: 1048576 Kbytes, lockable: 742136 Kbytes, available: 861432 Kbytes root@hpeos003[]Physical memory is how much is installed and configured in the system.
Available memory is the amount of memory left after the operating system has taken what it initially needs.
Lockable memory is the amount of memory that is able to be locked by process using
plock()andshmctl()system calls. By default, only root process can be locked in memory (see the discussion on Privilege Groups in Chapter 29, Dealing with Immediate Security Threats). Lockable memory should always be less than available memory. The amount of Lockable memory is controlled by the kernel parameterunlockable_mem. Available memory = Lockable memory +unlockable_mem. Ifunlockable_memis less than or equal to zero, the kernel will calculate a suitable value.How much data will your applications want in memory at any one time?
This is possibly the hardest question to answer. The only way to attempt to calculate it is to analyze a running system at its busiest. Using tools like
glance,top,ipcs, andps, we can monitor how much memory the processes are using. We can only assume that at their busiest processes will be as big as they will ever be. Some applications will define a large working area in which they store application data. The application will manage how big this area is and make a call to the operating system to populate this area with data. If this global area is part of an application, it can be an excellent measure as to a vast proportion of an application's needs. Just looking at the size of the application database is not sufficient because it is unlikely that we will ever suck the entire database into memory.How much application data will be locked in memory?
We mentioned lockable memory in question 1. Some applications are coded with system calls to lock parts of the application into memory, usually only the most recently used parts of the application. A user process needs special privileges in order to do this (see Chapter 29, Dealing with Immediate Security Threats for a discussion on
setprivgrp). If a process is allowed to lock parts of the application in memory; the virtual memory system will not be able to page those parts of the application to a swap device. It should be noted that application developers need to be aware of the existence of process locking in order to use it effectively in their applications. The application installation instructions should detail the need for the application to have access to this feature.How does the virtual memory system decide when it's time to start paging-out?
This last question leads us to a discussion on virtual memory, reserving swap space, the page daemon, and a two-handed clock.
While a process is running, it may ask the operating system for access to more memory, i.e., the process is growing in size. The virtual memory system would love to keep giving a process more memory, but it's a bit worried because it knows that we have a finite amount of memory. If we keep giving memory to processes, there will come a point when we need to page-out processes and we will want to know we can fit them all out on the swap device. This is where reserving swap comes in. Every time a process requests more memory, the virtual memory system will want to reserve some swap space in case it needs to page-out that process in the future. Reserving swap is one of the safety nets used to ensure that the memory system doesn't get overloaded. Let's get one thing clear here: Reserving swap space does not mean going to disk and setting aside some disk space for a process. That is called allocating swap space, and it only happens when we start running out of memory. Reserving swap space only puts on hold enough space for every process in the system. This gives us an idea of how much swap space is an absolute minimum. If we need a pool of swap space from which to reserve, surely that pool needs to be at least as big as the main memory. In the old days, that was the case. Now systems can have anything up to 512GB of RAM. We hope that we will never need to swap! Taking the old analogy regarding reserving swap, we would need to configure at least 512GB of swap space in order to achieve our pool of swap space from which we can start reserving space for processes. That would be an awful lot of swap space doing nothing. Consequently, HP-UX utilizes something called pseudo-swap. Pseudo-swap allows us to continue allocating memory once our pool of device and filesystem swap is exhausted. It's almost like having an additional but fictitious (pseudo) swap device that makes the total swap space on the system seem like more than we have actually configured. The size of pseudo-swap is set at 7/8 of the Available memory at system startup time. The use of pseudo-swap is controlled by the kernel parameter swapmem_on,which defaults to 1 (on). This means that our total swap space on the system can be calculated as such:
Total swap space = (device swap + filesystem swap) + pseudo-swap
If there is no device or filesystem swap; the system uses pseudo-swap as a last resort. Pseudo-swap is never reserved; it is either free or pseudo-allocated. In reality, we never swap to a pseudo-swap device, because it's in memory. If we utilize pseudo-swap, we need to appreciate that it is simply a mechanism for fooling the virtual memory system into thinking we have more swap space than we actually have. It was designed with large memory systems in mind, where it is unlikely we will ever need to actually use swap space, but we do need to configure some swap space.
If we think about it, the use of pseudo-swap means that the absolute minimum amount of device/filesystem swap we could configure is 1/8 of all memory. Every time we add more memory to our system, we would have to review the amount of total configured swap space. We could get to a situation where the Virtual Memory system could not reserve any swap space for a process. This would mean that a process would not be able to grow even though there was lots of (our recently installed) memory available.
I would never suggest using the “1/8 of real memory” minimum in real life, but this is the theoretical minimum. It's not a good idea because if we get to the point where processes are actually being paged-out to disk, we could get into a situation where we haven't enough space to accommodate the processes that are in memory. At that time, the system would go through a time where it is thrashing, i.e., spending more time paging than doing useful work. This is a bad idea because processes get little opportunity to execute and the system effectively hangs.
The virtual memory system has a number of kernel variables that it monitors on a constant basis. If these variables reach certain thresholds, it's time to start freeing up memory because we are just about to run out. The main process that takes care of freeing pages is known as vhand, the page daemon. The main kernel parameters that control when vhand wakes up are lotsfree, desfree, and minfree. Each of these parameters is associated with a trigger value that activates vhand. These trigger values are based on the amount of non-kernel (Available) memory available in your system (see Table 9-1):
Table 9-1. Virtual Memory Triggers
Parameter | Amount of Non-kernel Memory (NkM) available | Description and default value |
|---|---|---|
lotsfree | NkM 32MB | 1/8 of NkM not to exceed 256 pages (1MB) |
32MB NkM 2GB | 1/16 of NkM not to exceed 8192 pages (32MB) | |
2GB < NkM | 16382 pages (64MB) | |
desfree | NkM 32MB | 1/16 of NkM not to exceed 60 pages (240KB). |
32MB NkM 2GB | 1/64 of NkM not to exceed 1024 pages (4MB) | |
2GB < NkM | 3072 pages (12MB) | |
minfree | NkM 32MB | 1/2 of desfree not to exceed 25 pages (100KB) |
32MB NkM 2GB | 1/4 desfree not to exceed 256 pages (1MB) | |
2GB < NkM | 1280 pages (5MB) |
We can view the relationship between these parameters as follows in Figure 9-3:
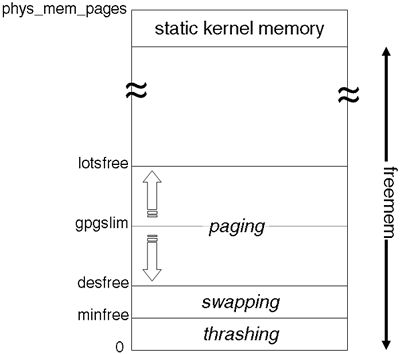
When the number of free pages falls below lotsfree, vhand wakes up and tunes its internal parameters in preparation for starting to page process to disk. The variable we haven't mentioned here is gpgslim. This variable is initially set 1/4 of the distance between lotsfree and desfree and activates vhand into stealing pages if freemem falls below gpgslim. gpgslim will float between lotsfree and desfree depending on current memory pressure.
vhand decides when to steal pages by performing a simple test; has this page been referenced recently? When awakened, vhand runs eight times per second by default and will only consume 10 percent of the CPU cycles for that interval. This is an attempt to be aggressive but not too aggressive at stealing pages. Initially, vhand will scan 1/16 of a pregion of an active process before moving to the next process. In doing so, it sets the reference bit for that page to equal 0 in the Page Directory (it also purges the TLB entry to ensure that the next reference must go through the Page Directory). This is known as aging a page. If the owning process comes along and uses the page, the reference bit is reset and vhand now knows that the page has been referenced recently. If the process doesn't access the page, vhand has to decide when it's time to steal the page. The time between aging a page and stealing a page is the result of continual assessment by the virtual memory system as to how aggressively it needs to steal pages. The whole process can be visualized by imagining a two-handed clock with the age-hand clearing the reference bit and the steal-hand running sometime behind the age-hand. When the steal-hand comes to recheck the reference bit, if it hasn't been reset, vhand knows this page hasn't been referenced recently and can schedule for that page to be written out to disk. vhand can steal that page. If the process suddenly wakes back up, it can reclaim the page before it is actually written out to disk. If not, the page is paged-out and memory is freed up for other processes/threads to use. If vhand manages to free up enough pages in order to get freemem above gpgslim, it can relax a little, stop stealing pages, and just age them. If, however, it can't free up enough pages, gpgslim will rise and vhand will become more aggressive in trying to steal pages (the two hands move round the clock quicker and scan more pages faster). Eventually, if vhand is unsuccessful at keeping freemem above gpgslim, we could get to a point where freemem is less that desfree. At this time, the kernel will start to deactivate processes that haven't run in the last 20 seconds. This is the job of the swapper process. Process deactivation is where the process is taken off the run queue and all its pages are put in front of the steal-hand (the age-hand is on its way, so the pages will soon be destined for the swap device). If this fails and freemem falls below minfree, swapper realizes that things are getting desperate and chooses any active process to be deactivated in an attempt to steal enough pages as quickly as possible. At this stage, the system is thrashing, i.e., paging-in/out more than it is doing useful work.
The parameters lotsfree, desfree, and minfree are kernel tunable parameters, but unless you really know what you're doing, it's suggested that you leave them at the values listed above.
There still isn't an easy answer to this. We now know about pseudo-swap and how it allows us to continue to use main memory even when we have run out of device/filesystem swap. We also know when the virtual memory system will start to steal pages in order to avoid a shortfall in available memory. Has this allowed us to get any nearer to an answer to our question? We need to return to those four questions we asked initially and remind ourselves that we need to establish how much data our application will require at peak time. This is not easy. We could come up with a formula of the form:
Start with the absolute minimum of 12.5 percent (1/8) of main memory. Realistically, we need to be starting at about 25 percent of main memory.
Add up all the shared memory segments used by all your applications. This might be available as a global area figure used by the application. If the global area is going to be locked in memory, we can't count it because it will never be paged-out.
Add up all private VM requirements of every process on the system at their busiest period. This is known as the virtual set-size and includes local/private data structure for each process. The only tool readily available that shows the
vssfor a process is HP'sglanceutility.Add an additional 10-15 percent for process structures that could be paged-out (this also factors in a what-if amount, just in case).
We have added up the shared and private areas to give us a figure that will be added to the minimum 12.5 percent of main memory. This gives us a figure of the amount of device/filesystem swap to configure. This will constitute the pool of swap space we use to reserve space for running processes. The addition of pseudo-swap should accommodate any unforeseen spikes in demand. This formula makes some kind of sense because we have tried to establish every data element that could possibly be in memory at any one time. We haven't factored in text pages, as they are not paged to a swap area. If needed, text pages will simply be discarded, because we can always page-in the text from the program in the filesystem. This figure is not easy to come to. If you can get some idea of what the figure is likely to be, you are well on your way to working out how much memory your system needs. With a few minor modifications, we could re-jig the swap space formula to look something like:
20-30MB for the kernel.
Five percent of memory for the initial allocation of the dynamic buffer cache (kernel parameter
dbc_min_pct). Thedbc_max_pctneeds to be monitored carefully (50 percent by default). This is the maximum amount of memory that the dynamic buffer cache can consume. Like other memory users, we will only steal buffer pages when we get to thelotsfreethreshold.Ten percent of memory for network packet reassembly (kernel parameter
netmemmax).Additional memory for any additional networking products such as NFS, IPv6, IPSec, SSH, HIDS, CDE, and so on. Reaching a precise number for this is difficult without careful analysis of all related processes.
Add up all resident (in memory) shared memory requirements. This includes shared memory segments, shared libraries (difficult to calculate unless you know all the shared libraries loaded by an application), text, and all applications using locked memory. The only sensible way to calculate this is to talk to your application supplier and ask about the size of programs, the size of the global area, and how much of that global area is normally required in memory at any one time.
Add up all the resident private data elements for every program running on the system (=resident set size;
RSS). This is similar to theVSSexcept that it is the actual data that made it into memory as opposed to theVSSthat is local data that might make it into memory. Again, work with your application supplier to work this out (or useglance).
In brief, there is no easy answer. More often than not, we have to work with our application suppliers to establish a reasonable working set of text/data that is probably going to be required in memory at any one time. From there, we can establish how much text/data is likely to be used at any one time. These figures can help us work out how much physical memory and swap space we will need to configure.
Being cheaper, swap space will probably always be bigger than main memory, although we now know that is not a necessity; it's just that most administrators feel safer that way. For most people, the prospect of having a system thrashing because the actual amount of swap space can't accommodate the amount of data in memory is not a pleasant prospect. That is where a sizing exercise is crucial.
Once we have decided how much swap space we need, we need to decide how to configure it. In the event that we do start paging, like other IO to disk, it would be best if we can spread the load over multiple physical disks. HP-UX uses swap device priorities to select the next device to swap to. Disks and volumes that are configured as swap device have a default priority of 1. A higher number means a lower priority. The virtual memory system will use devices with the highest priority first and then move on to devices with a lower priority. With a default priority = 1, this means that the virtual memory system will interleave evenly across all configured swap devices with the same priority. As such, it's a good idea if we can try to make all swap devices the same size, configured on different physical disks, and all with the same (default) priority. Being the same size means they will fill up at the same rate, maintaining our interleaving behavior. Device swap areas (except primary swap which must be strictly contiguous) do not need to be of any special volume configuration, although it does make sense to mirror swap volumes if possible.
Filesystem swap comes next but should be avoided at all costs; the virtual memory system will be competing with the filesystem for IO as well as disk space. In fact, even if a filesystem swap area has a lower priority, it will not be used until all device swap areas are full. Use filesystem swap as a last resort.
Before we go headlong into the swapon command, there are some kernel parameters that affect how much swap space we can configure:
maxswapchunks: To total the number of swap chunks allowed on the system. This parameter will size a kernel table known as the swap table (swaptab) that lists all of the chunks of swap space available on all device/filesystem swap areas. The maximum for the parameter is 16,384. NOTE: At the time of this writing, this parameter was still a configurable parameter in HP-UX on the PA-RISC platform. This situation may have changed by the time you read this.swchunk: The size of a chunk of allocated swap space (default = 2048, 1K blocks = 2MB). Together withmaxswapchunks, we can work out how the maximum amount of swap space that can be configured on a system:16384 (
maxswapchunks) x 2048 (swchunk= 2MB) = 32GB
If we need to increase that maximum amount of swap space available on a system, we can consider retuning
maxswapchunksand/orswchunk. If we exceed the maximum allowed value, we will receive an error message whenever we use theswaponcommand.nswapdev: The total number of disk/volume device swap areas allowed (10 by default).nswapfs: The total of filesystem swap areas allowed (10 by default).remote_nfs_swap: Enable this only if you have an NFS diskless server. Swapping across the network doesn't even bear thinking about.swapmem_on: Whether or not to use pseudo-swap. The default is 1 (ON) for good reason.
All these kernel parameters will require a reboot if you need to change them.
Below, a VxVM volume is added to the list of swap devices.
root@hpeos003[] vxprint -g ora1 dump3 TY NAME ASSOC KSTATE LENGTH PLOFFS STATE TUTIL0 PUTIL0 v dump3 fsgen ENABLED 204800 - ACTIVE - - pl dump3-01 dump3 ENABLED 204800 - ACTIVE - - sd ora_disk2-02 dump3-01 ENABLED 204800 0 - - - root@hpeos003[] swapon /dev/vx/dsk/ora1/dump3 root@hpeos003[] swapinfo Kb Kb Kb PCT START/ Kb TYPE AVAIL USED FREE USED LIMIT RESERVE PRI NAME dev 2097152 0 2097152 0% 0 - 1 /dev/vg00/lvol2 dev 204800 0 204800 0% 0 - 1 /dev/vx/dsk/ora1/dump3 reserve - 120396 -120396 memory 743024 25132 717892 3% root@hpeos003[]
We should all be aware of the format of the swapinfo command. The lines to note are the reserve line and the memory line. The reserve line details the data currently in memory that has had swap space put on hold (reserved) in case the data needs to be paged-out. The memory line lists the amount of pseudo-swap configured. Also note that the usage on the memory line includes usage by other kernel subsystems and not just pseudo-swap.
Finally, remember to add an appropriate entry to the /etc/fstab file to ensure that your additional swap areas are activated after reboot.
The elusive question “How much swap space do I need to configure?” remains. As always the answer is “It depends.” We have looked at why and how swap space is used and configured. I hope we have shed some light on the elusive dark art of virtual memory. If your system is using swap space, the problem is simple; it has breached, at least the lotsfree threshold and vhand as paged-out part of, at least one process. This is a classic symptom of a memory bottleneck. If the situation persists, you may see a significant increase in system-level processing (vhand executing) as well as a significant increase in system-level IO (vhand posting data pages to the swap area). I was once asked how to tune a system for best swap space utilization. My answer was simple: Buy more memory.
Dump space is disk space reserved to store the resulting data in the event of a system crash after an unexpected event. As such, some people regard dump space as disk space that is wasted. We hope that our systems will never crash, but when or if they do, it is a good idea to be able to capture enough information for our local Response Center engineers to analyze the resulting crashdump and diagnose what the problem was. The problem could be hardware or software related. We need to ensure that there is sufficient space to accommodate a crashdump and that the appropriate information is included in the crashdump.
With our crashdump configuration, we need to ensure all of the useful data that was in memory at the time of the system crash is saved. The important phrase in the previous sentence is useful data. Prior to HP-UX 11.0, a crashdump would have constituted a complete image of main memory at the time of the crash. This meant that the dump space we configured had to be at least as big as main memory. In fact, due to the organization of the dump, it was suggested to make the dump space at least 10 percent bigger than main memory. Imagine the amount of dump space we would have had to reserve on a 64-way, 512GB Integrity Superdome partition. Now the default behavior of HP-UX at the time of a crash is to dump only the data elements stored in memory. This includes kernel data pages as well as data pages relating to user processes. To see our current crashdump configuration, we use the crashconf command:
root@hpeos003[] crashconf CLASS PAGES INCLUDED IN DUMP DESCRIPTION -------- ---------- ---------------- ------------------------------------- UNUSED 157446 no, by default unused pages USERPG 25089 no, by default user process pages BCACHE 35796 no, by default buffer cache pages KCODE 2581 no, by default kernel code pages USTACK 839 yes, by default user process stacks FSDATA 193 yes, by default file system metadata KDDATA 26932 yes, by default kernel dynamic data KSDATA 13268 yes, by default kernel static data Total pages on system: 262144 Total pages included in dump: 41232 DEVICE OFFSET(kB) SIZE (kB) LOGICAL VOL. NAME ------------ ---------- ---------- ------------ --------------------- 31:0x01f000 117600 2097152 64:0x000002 /dev/vg00/lvol2 ---------- 2097152 root@hpeos003[]
The difficult task is knowing how big these data elements are going to be and which ones to include. As far as the page classes to include, the default list that you can see above should be sufficient; we can always get a copy of the kernel code from /stand/vmunix, and user program code is available via the programs stored in the filesystem if we need it. In some instances, we may be requested (by our local HP Response Center) to include more page classes into our dump configuration in order for the Response Center engineers to diagnose a particular problem. Adding page classes can be done online and takes immediate effect. As an example, we may have been experiencing system crashes on a 64-bit machine running 32-bit code. Sometimes, we need to include kernel code pages (KCODE) in a crashdump for these types of situations because the /stand/vmunix file may be slightly different than the kernel image in memory. Only when prompted by a Response Center engineer would I include KCODE pages in with our crashdump. We simply use the crashconf command to add pages classes in the dump configuration:
root@hpeos003[] crashconf -i KCODE root@hpeos003[] crashconf Crash dump configuration has been changed since boot. CLASS PAGES INCLUDED IN DUMP DESCRIPTION -------- ---------- ---------------- ------------------------------------- UNUSED 157691 no, by default unused pages USERPG 25023 no, by default user process pages BCACHE 35641 no, by default buffer cache pages KCODE 2581 yes, forced kernel code pages USTACK 815 yes, by default user process stacks FSDATA 209 yes, by default file system metadata KDDATA 26916 yes, by default kernel dynamic data KSDATA 13268 yes, by default kernel static data Total pages on system: 262144 Total pages included in dump: 43789 DEVICE OFFSET(kB) SIZE (kB) LOGICAL VOL. NAME ------------ ---------- ---------- ------------ ------------------------- 31:0x01f000 117600 2097152 64:0x000002 /dev/vg00/lvol2 ---------- 2097152 root@hpeos003[]
This change was immediate, and the “Total pages included in dump” has gone up accordingly. If this change is to survive a reboot, we must edit the file /etc/rc.config.d/crashconf:
root@hpeos003[] vi /etc/rc.config.d/crashconf #!/sbin/sh # @(#)B.11.11_LR # Crash dump configuration # # # CRASHCONF_ENABLED: Configure crash dumps at boot time. CRASHCONF_ENABLED=1 # CRASH_INCLUDED_PAGES: A blank-separated list of page classes that must be # included in any dump. crashconf -v will give you a list of # valid page classes. Specify "all" to force full dumps. CRASH_INCLUDED_PAGES="KCODE" ... root@hpeos003[]
Additionally, we should monitor our system over a period of time, especially during the time when the system has most processes running in order to monitor how big the crashdump will be by monitoring the “Total pages included in dump” from the crashconf output. From the output above, we can see the size of a crashdump on this system would be 41,232 pages in size. A page being 4KB means the dump is approximately 160MB currently. Typically, an HP-UX system running only HP-UX will have an initial dump requirement of 10-20 percent the size of main memory. The only dump device configured is /dev/vg00/lvol2, which is 2GB in size; that's more than enough to store our current crashdump. Should it get to a point were the crashdump wouldn't fit in the dump device(s), we need to configure more dump space.
Dump space is one or a series of disk devices used to store a system crashdump. By default, HP-UX will configure a single dump device. The initial dump device is also configured as the primary swap device. Primary swap is a contiguous volume, and as such it is not easy to extend its size. Consequently, in order to configure additional dump space, we will need to configure additional dump devices that can be either individual disks or volumes (LVM or VxVM). If we are using volumes, the volumes do not need to be created in the root volume/disk group. Together with our initial dump device, they form our total dump space. If we are going to create a volume to act as a dump device, there is a criterion to which dump devices must adhere:
Dump devices must be strictly contiguous.
For LVM volumes, this means using the options
–C y(contiguous allocation) and–r n(no bad block relocation).For VxVM volumes, this means using the
contiglayout policy.
If we don't follow this strict criterion, the volume will not be added to the list of dump devices. If the size of our crashdump exceeds the size of our configured dump space, it is time to configure additional dump devices. To add a device to the list of current dump devices, we use the crashconf command again. Here's an example using an LVM volume that doesn't match the strict criterion for the organization of a dump area:
root@hpeos003[] lvcreate -L 1000 -n dump2 /dev/vgora1 Logical volume "/dev/vgora1/dump2" has been successfully created with character device "/dev/vgora1/rdump2". Logical volume "/dev/vgora1/dump2" has been successfully extended. Volume Group configuration for /dev/vgora1 has been saved in /etc/lvmconf/vgora1.conf root@hpeos003[] crashconf /dev/vgora1/dump2 /dev/vgora1/dump2: error: unsupported disk layout root@hpeos003[]
We will have to remove the volume and recreate it using the appropriate options:
root@hpeos003[] lvremove /dev/vgora1/dump2 The logical volume "/dev/vgora1/dump2" is not empty; do you really want to delete the logical volume (y/n) : y Logical volume "/dev/vgora1/dump2" has been successfully removed. Volume Group configuration for /dev/vgora1 has been saved in /etc/lvmconf/vgora1.conf root@hpeos003[] lvcreate -L 1000 -n dump2 -C y -r n /dev/vgora1 Logical volume "/dev/vgora1/dump2" has been successfully created with character device "/dev/vgora1/rdump2". Logical volume "/dev/vgora1/dump2" has been successfully extended. Volume Group configuration for /dev/vgora1 has been saved in /etc/lvmconf/vgora1.conf root@hpeos003[] crashconf /dev/vgora1/dump2 root@hpeos003[] crashconf Crash dump configuration has been changed since boot. CLASS PAGES INCLUDED IN DUMP DESCRIPTION -------- ---------- ---------------- ------------------------------------- UNUSED 157473 no, by default unused pages USERPG 25075 no, by default user process pages BCACHE 35771 no, by default buffer cache pages KCODE 2581 yes, forced kernel code pages USTACK 839 yes, by default user process stacks FSDATA 205 yes, by default file system metadata KDDATA 26932 yes, by default kernel dynamic data KSDATA 13268 yes, by default kernel static data Total pages on system: 262144 Total pages included in dump: 43789 DEVICE OFFSET(kB) SIZE (kB) LOGICAL VOL. NAME ------------ ---------- ---------- ------------ ------------------------- 31:0x01f000 117600 2097152 64:0x000002 /dev/vg00/lvol2 31:0x001000 2255296 1024000 64:0x010005 /dev/vgora1/dump2 ---------- 3121152 root@hpeos003[]
Here's another example using a VxVM volume this time:
root@hpeos003[] vxassist -g ora1 make dump3 200M layout=contig root@hpeos003[] crashconf /dev/vx/dsk/ora1/dump3 root@hpeos003[] crashconf Crash dump configuration has been changed since boot. CLASS PAGES INCLUDED IN DUMP DESCRIPTION -------- ---------- ---------------- ------------------------------------- UNUSED 157383 no, by default unused pages USERPG 25174 no, by default user process pages BCACHE 35771 no, by default buffer cache pages KCODE 2581 yes, forced kernel code pages USTACK 843 yes, by default user process stacks FSDATA 209 yes, by default file system metadata KDDATA 26940 yes, by default kernel dynamic data KSDATA 13268 yes, by default kernel static data Total pages on system: 262144 Total pages included in dump: 43789 DEVICE OFFSET(kB) SIZE (kB) LOGICAL VOL. NAME ------------ ---------- ---------- ------------ ------------------------- 31:0x01f000 117600 2097152 64:0x000002 /dev/vg00/lvol2 31:0x001000 2255296 1024000 64:0x010005 /dev/vgora1/dump2 31:0x048000 7793120 204800 1:0x768f97 /dev/vx/dsk/ora1/dump3 ---------- 3325952 root@hpeos003[]
If we want these dump devices to be activated after a reboot, we need to add an appropriate entry to the /etc/fstab file:
root@hpeos003[] vi /etc/fstab ... /dev/vgora1/dump2 ... dump defaults 0 0 /dev/vx/dsk/ora1/dump3 ... dump defaults 0 0 root@hpeos003[]
There's one other issue regarding the size of our dump space. During the process of crashing, we are given the opportunity on the system console to perform a full dump of everything in memory. This is effectively an image of main memory written to the dump device(s). In order to perform a full dump, we would need to have enough dump space to accommodate an image that will be slightly (approximately 10 percent) bigger than the size of the RAM configured in our system. A full dump is seldom needed these days, but if requested by our local Response Center engineers, we may have to configure even more dump space/devices. Now we need to consider what happens after the system crashes.
When the system crashes, the kernel uses entry points into the IODC code to help it write the crashdump to disk. Before invoking the dumpsys() routines, we will be given a 10-second window of opportunity on the system console to interrupt the crashdump process and decide what kind of crashdump to create. We can choose a Full dump (an image of memory), a Selective dump (only the page classes defined earlier), or No dump. Once the dump has been written to disk, the system will reboot. The problem we have is that a dump device is an empty volume with no filesystem in it. As such, we need a utility to read the binary information from the dump device(s) and create a series of files in the filesystem; this is the job of the savecrash command. After the system has rebooted, a process known as savecrash is run in order to get the crashdump out of the dump devices and into a usable format in the filesystem. The default location for the files created by savecrash is under the directory /var/adm/crash. The files created will be in subdirectories named crash.0, crash.1 for each crash that has occurred. The savecrash command may decide to compress the files, depending on the size of the crashdump and the amount of available space under /var/adm/crash. There will be a number of files in this directory. There are basically two types of file; an INDEX file and image files. The INDEX file is a text file giving a brief description of when the crash happened, the files making up the crashdump, as well as a panic string. Don't get confused about my use of the term panic string. The panic string in the INDEX files is simply a term used to describe the one-liner issued by the kernel to describe the instruction or event that caused the system to crash. The image files are a series of files (referenced in the INDEX file) that contain the crashdump itself. The number of image files created depends on how big the crashdump is and will be determined by the savecrash command. If our system is crashing often, we may have decide to create /var/adm/crash as a separate volume or use a different directory altogether to store our crashdumps. To configure the behavior of savecrash, e.g., which directory to store crashdumps, we configure the file /etc/rc.config.d/savecrash:
root@hpeos003[] vi /etc/rc.config.d/savecrash #!/sbin/sh # @(#)B.11.11_LR # Savecrash configuration # # # SAVECRASH: Set to 0 to disable saving system crash dumps. # SAVECRASH=1 # SAVECRASH_DIR:Directory name for system crash dumps. Note: the filesystem # in which this directory is located should have as much free # space as your system has RAM. # SAVECRASH_DIR=/var/adm/crash root@hpeos003[]
As you can see, most of the options are commented out and, hence, take default values. The comments you can see above regarding the amount of space in the filesystem is a little out of date because crashdumps are no longer a Full dump by default.
After a system crash, we should also see a message added by the savecrash command in the file /var/adm/shutdownlog (if it exists). Ultimately, the files under the /var/adm/crash directory need to be analyzed by an experienced Response Center engineer trained in kernel internals. It is their job to find the root cause as to why our system crashed. In the next chapter, we discuss how we can assist in that process by distinguishing between an HPMC, a TOC, and a PANIC.
I mentioned at the beginning of this chapter that some people consider reserving dump space as a waste of space. I hope that we can see the value of ensuring that we capture a crashdump. The problem with dump space is that it is empty disk space that is waiting for an event that might never happen. Lots of administrators I know who have numerous dump devices will also use them as swap devices. This is a good idea because the more swap devices we have, the more swap space interleaving can take place, should we ever need to use swap space. If we were being especially careful, we could think about swap space first to establish how much swap space we want to achieve. We could then create multiple dump devices (remember, a dump device must be contiguous, but swap space doesn't need to be) that happened to match the requirements of our swap system. We can then configure our dump devices to be swap devices as well, simply by having a swap and a dump entry in the /etc/fstab file.
root@hpeos003[] cat /etc/fstab
...
/dev/vgora1/dump2 ... dump defaults 0 0
/dev/vx/dsk/ora1/dump3 ... dump defaults 0 0
/dev/vgora1/dump2 ... swap defaults 0 0
/dev/vx/dsk/ora1/dump3 ... swap defaults 0 0
root@hpeos003[]
This makes good use of a device that will, we hope, never be used; while the system is up, we can swap to it, and when the system crashes, we can use it as a dump device.
If we have a device that is both a swap and dump device, we need to think about what happens if there is a crashdump to save and the swapping system wants to use the space. The default behavior for the savecrash utility is to allow swapping as soon as the crashdump has been saved (check the /etc/rc.config.d/savecrash file to configure alternative behavior). This means that using multiple swap/dump areas is a good idea because if there is an alternative swap device, it will be used while the crashdump is written to the /var/adm/crash/crash.X directory.
We hope that we never actually have to make use of dump space. When our system crashes, we need to be able to preserve the relevant information to disk in order to have the resulting crashdump analyzed by our local HP Response Center engineers. At the time of this writing, there is a new feature available to help speed up the process of performing a crashdump. It's known as a Compressed Dump. It is available for HP-UX 11i version 1, but will be enabled only where there are more than five processors. It's a free download from http://software.hp.com. I can't comment further than being interested in any product that speeds up a crashdump, allowing me to return my system to my users.
A crash can be caused by hardware or software problems. Ultimately, it will be up to our local Response Center to perform root cause analysis and help us make sure it never happens again.