
Defining columns and rows in a table
After logical and physical database design is complete, you implement the definitions that were created during physical design. This section describes how to implement:
Columns. See “Determining column attributes”
Data types. See “Choosing a data type for the column” on page 224
Null and default values. See “Using null and default values” on page 233
Check constraints. See “Enforcing validity of column values with check constraints” on page 237
Throughout the implementation phase of database design, refer to the complete descriptions of SQL statement syntax and usage for each SQL statement that you work with.
Determining column attributes
A column contains values that have the same data type. If you are familiar with the concepts of records and fields, you can think of a value as a field in a record. A value is the smallest unit of data that you can manipulate with SQL. For example, in the EMP table, the EMPNO column identifies all employees by a unique employee number. The HIREDATE column contains the hire dates for all employees. You cannot overlap columns.
In Version 8, online schema enhancements provide flexibility that lets you change a column definition. Carefully consider the decisions that you make about column definitions. After you implement the design of your tables, you can change a column definition with minimal disruption of applications.
The two basic components of the column definition are the name and the data type.
Generally, the database administrator (DBA) is involved in determining the names of attributes (or columns) during the physical database design phase. To make the right choices for column names, DBAs follow the guidelines that the organization's data administrators have developed.
Sometimes columns need to be added to the database after the design is complete. In this case, DB2 rules for making column names unique must be followed. Column names must be unique within a table, but you can use the same column name in different tables. Try to choose a meaningful name to describe the data in a column to make your naming scheme intuitive. The maximum length of a column name is 30 bytes.
Choosing a data type for the column
“Choosing data types for attributes” on page 91 explains the need to determine what data type to use for each attribute. Every column in every DB2 table has a data type. The data type influences the range of values that the column can have and the set of operators and functions that apply to it. You specify the data type of each column at the time you create the table. ![]()
In Version 8, you can also change the data type of a table column. The new data type definition is applied to all data in the associated table when the table is reorganized.
Some data types have parameters that further define the operators and functions that apply to the column. DB2 supports both IBM-supplied data types and user-defined data types. The data types that IBM supplies are sometimes called built-in data types. This section describes implementation of the following built-in data types:
“String data types” on page 225
“Numeric data types” on page 227
“Date, time, and timestamp data types” on page 229
“Large object data types” on page 230
“ROWID data type” on page 231
In DB2 UDB for z/OS, user-defined data types are called distinct types. You can read more about distinct types in “Defining and using distinct types” on page 232.
String data types
DB2 supports several types of string data. Character strings contain text and can be either a fixed length or a varying length. Graphic strings contain graphic data, which can also be either a fixed length or a varying length. The third type of string data is binary large object (BLOB) strings, which you use for varying-length columns that contain strings of binary bytes. You will read more about BLOB data types in “Defining large objects” on page 268.
Table 7.1 describes the different string data types and indicates the range for the length of each string data type.
| Data type | Denotes a column of... |
|---|---|
| CHARACTER(n) | Fixed-length character strings with a length of n bytes. n must be greater than 0 and not greater than 255. The default length is 1. |
| VARCHAR(n) | Varying-length character strings with a maximum length of n bytes. n must be greater than 0 and less than a number that depends on the page size of the table space. |
| CLOB(n) | Varying-length character strings with a maximum of n characters. n cannot exceed 2,147,483,647. The default length is 1. |
| GRAPHIC(n) | Fixed-length graphic strings containing n double-byte characters. n must be greater than 0 and less than 128. The default length is 1. |
| VARGRAPHIC(n) | Varying-length graphic strings. The maximum length, n, must be greater than 0 and less than a number that depends on the page size of the table space. |
| DBCLOB(n) | Varying-length string of double-byte characters with a maximum of n double-byte characters. n cannot exceed 1,073,741,824. The default length is 1. |
| BLOB(n) | Varying-length binary string with a length of n bytes. n cannot exceed 2,147,483,647. The default length is 1. |
In most cases, the content of the data that a column will store dictates the data type that you choose.
Example: The DEPT table has a column, DEPTNAME. The data type of the DEPTNAME column is VARCHAR(36). Because department names normally vary considerably in length, the choice of a varying-length data type seems appropriate. If you choose a data type of CHAR(36), for example, the result is a lot of wasted, unused space. DB2 would assign all department names, regardless of length, the same amount of space (36 bytes). A data type of CHAR(6) for the employee number (EMPNO) is a reasonable choice because all values are fixed-length values (6 bytes).
Choosing the encoding scheme
Within a string, all the characters are represented by a common encoding representation. You can encode strings in Unicode, ASCII, or EBCDIC.
Multinational companies that engage in international trade often store data from more than one country in the same table. Some countries use different coded character set identifiers. DB2 UDB for z/OS supports the Unicode encoding scheme, which represents many different geographies and languages. (Unicode UTF-8 is for mixed-character data, and UCS2 or UTF-16 is for graphic data.) If you need to perform character conversion on Unicode data, the conversion is more likely to preserve all of your information. ![]()
In some cases, you might need to convert characters to a different encoding representation. The process of conversion is known as character conversion. Most users do not need a knowledge of character conversion. When character conversion does occur, it does so automatically and a successful conversion is invisible to the application and users.
Choosing CHAR or VARCHAR
Using VARCHAR saves disk space, but it incurs a 2-byte overhead cost for each value. Using VARCHAR also requires additional processing for varying-length rows. Therefore, using CHAR is preferable to using VARCHAR unless the space that you save with VARCHAR is significant. The savings are not significant if the maximum column length is small or if the lengths of the values do not have a significant variation.
 | Recommendations: |
Generally, do not define a column as VARCHAR(n) or CLOB(n) unless n is at least 18 characters.
Place VARCHAR and CLOB columns after the fixed-length columns of the table for better performance.
Using string subtypes
If an application that accesses your table uses a different encoding scheme than your DBMS uses, the following string subtypes can be important:
BIT
Does not represent characters.
Represents single-byte characters.
MIXED
Represents single-byte characters and multibyte characters.
String subtypes apply only to CHAR, VARCHAR, and CLOB data types.
Choosing graphic or mixed data
When columns contain double-byte character set (DBCS) characters, you can define them as either graphic data or mixed data.
Graphic data can be either GRAPHIC, VARGRAPHIC, or DBCLOB. Using VARGRAPHIC saves disk space, but it incurs a 2-byte overhead cost for each value. Using VARGRAPHIC also requires additional processing for varying-length rows. Therefore, using GRAPHIC data is preferable to using VARGRAPHIC unless the space that you save by using VARGRAPHIC is significant. The savings are not significant if the maximum column length is small or if the lengths of the values do not vary significantly.
Recommendation:
 Generally, do not define a column as VARGRAPHIC(n) unless n is at least 18 double-byte characters (which is a length of 36 bytes).
Generally, do not define a column as VARGRAPHIC(n) unless n is at least 18 double-byte characters (which is a length of 36 bytes).
Mixed-data character string columns can contain both single-byte character set (SBCS) and DBCS characters. You can specify the mixed-data character string columns as CHAR, VARCHAR, or CLOB with MIXED DATA.
Recommendation:
 If all of the characters are DBCS characters, use the graphic data types. (Kanji is an example of a language that requires DBCS characters.) For SBCS characters, use mixed data to save 1 byte for every single-byte character in the column.
If all of the characters are DBCS characters, use the graphic data types. (Kanji is an example of a language that requires DBCS characters.) For SBCS characters, use mixed data to save 1 byte for every single-byte character in the column.
Numeric data types
For numeric data, use numeric columns rather than string columns. Numeric columns require less space than string columns, and DB2 verifies that the data has the assigned type.
Example: Assume that DB2 is calculating a range between two numbers. If the values have a string data type, DB2 assumes that the values can include all combinations of alphanumeric characters. In contrast, if the values have a numeric data type, DB2 can calculate a range between the two values more efficiently.
Table 7.2 describes the numeric data types.
| Data type | Denotes a column of... |
|---|---|
| SMALLINT | Small integers. A small integer is an IBM System/390 2-byte binary integer of 16 bits; the range is –32,768 to +32,767. |
| INTEGER or INT | Large integers. A large integer is an IBM System/390 fullword binary integer of 32 bits; the range is –2,147,483,648 to +2,147,483,647. |
| DECIMAL or NUMERIC | IBM System/390 packed-decimal numbers with an implicit decimal point. The position of the decimal point is determined by the precision and the scale of the number. The scale, which is the number of digits in the fractional part of the number, cannot be negative or greater than the precision. The maximum precision is 31 digits. |
| All values of a decimal column have the same precision and scale. The range of a decimal variable or the numbers in a decimal column is –n to +n, where n is the largest positive number that can be represented with the applicable precision and scale. The maximum range is 1 – 10**31 to 10**31 – 1. | |
| REAL | A single-precision floating-point number is an IBM System/390 short floating-point number of 32 bits. The range of single precision floating-point numbers is approximately –7.2E+75 to 7.2E+75. |
| DOUBLE | A double-precision floating-point number is an IBM System/390 long floating-point number of 64 bits. The range of double precision floating-point numbers is approximately –7.2E+75 to 7.2E+75. |
| Note: zSeries and z/Architecture use the S/390® format and support IEEE floating point. | |
For integer values, SMALLINT or INTEGER (depending on the range of the values) is generally preferable to DECIMAL.
You can define an exact numeric column as an identity column. An identity column has an attribute that enables DB2 to automatically generate a unique numeric value for each row that is inserted into the table. Identity columns are ideally suited to the task of generating unique primary-key values. Applications that use identity columns might be able to avoid concurrency and performance problems that sometimes occur when applications implement their own unique counters. You can read more about concurrency and performance in “Improving performance for multiple users: Locking and concurrency” on page 301.
Date, time, and timestamp data types
Although you might consider storing dates and times as numeric values, instead you can take advantage of the datetime data types: DATE, TIME, and TIMESTAMP.
Table 7.3 describes the data types for dates, times, and timestamps.
| Data type | Denotes a column of... |
|---|---|
| DATE | Dates. A date is a three-part value representing a year, month, and day in the range of 0001-01-01 to 9999-12-31. |
| TIME | Times. A time is a three-part value representing a time of day in hours, minutes, and seconds, in the range of 00.00.00 to 24.00.00. |
| TIMESTAMP | Timestamps. A timestamp is a seven-part value representing a date and time by year, month, day, hour, minute, second, and microsecond, in the range of 0001-01-01-00.00.00.000000 to 9999-12-31-24.00.00.000000. |
DB2 stores values of datetime data types in a special internal format. When you load or retrieve data, DB2 can convert it to or from any of the formats in Table 7.4.
| Format name | Abbreviation | Typical date | Typical time |
|---|---|---|---|
| International Standards Organization | ISO | 2003-12-25 | 13.30.05 |
| IBM USA standard | USA | 12/25/2003 | 1:30 PM |
| IBM European standard | EUR | 25.12.2003 | 13.30.05 |
| Japanese Industrial Standard Christian Era | JIS | 2003-12-25 | 13:30:05 |
Example: The following query displays the dates on which all employees were hired, in IBM USA standard form, regardless of the local default:
SELECT EMPNO, CHAR(HIREDATE, USA) FROM EMP;
When you use datetime data types, you can take advantage of DB2 built-in functions that operate specifically on datetime values and you can specify calculations for datetime values.
Example: Assume that a manufacturing company has an objective to ship all customer orders within five days. You define the SHIPDATE and ORDERDATE columns as DATE data types. The company can use datetime data types and the DAYS built-in function to compare the shipment date to the order date. Here is how the company might code the function to generate a list of orders that have exceeded the five-day shipment objective:
DAYS(SHIPDATE) — DAYS(ORDERDATE) > 5
As a result, programmers don't need to develop, test, and maintain application code to perform complex datetime arithmetic that needs to allow for the number of days in each month.
You can use the following sample user-defined functions (which come with DB2) to modify the way dates and times are displayed. ![]()
ALTDATE returns the current date in a user-specified format or converts a user-specified date from one format to another.
ALTTIME returns the current time in a user-specified format or converts a user-specified time from one format to another.
At installation time, you also have the option of supplying an exit routine to make conversions to and from any local standard.
When loading date or time values from an outside source, DB2 accepts any format that Table 7.4 lists. DB2 converts valid input values to the internal format. For retrieval, a default format is determined when installing DB2. You can override that default by using a precompiler option for all statements in a program or by using the scalar function CHAR for a particular SQL statement and specifying the desired format.
“Preparing an application program to run” on page 182 has information about the precompiler.
Large object data types
The VARCHAR and VARGRAPHIC data types have a storage limit of 32 KB. Although this limit might be sufficient for small- to medium-size text data, applications often need to store large text documents. They might also need to store a wide variety of additional data types such as audio, video, drawings, mixed text and graphics, and images.
If the size of the data is greater than 32 KB, use the corresponding LOB data type. Storing such data as LOB data rather than as VARCHAR FOR BIT DATA provides advantages, even if the entire row fits on a page.
DB2 provides three LOB data types to store these data objects as strings of up to 2 GB in size:
Character large objects (CLOBs)
Use CLOB to store SBCS or mixed data, such as documents that are written with a single character set. Use this data type if your data is larger (or may grow larger) than VARCHAR permits.
Double-byte character large objects (DBCLOBs)
Use DBCLOB to store large amounts of DBCS data, such as documents that are written with a DBCS character set.
Binary large objects (BLOBs)
Use BLOB to store large amounts of noncharacter data, such as pictures, or voice and mixed media.
If your data does not fit entirely within a data page, you can define one or more columns as LOB columns. An advantage to using LOBs is that you can create user-defined functions that are allowed only on LOB data types. “Large object table spaces” on page 248 has more information about the advantages of using LOBs.
ROWID data type
You use the ROWID data type to uniquely and permanently identify rows in a DB2 subsystem. DB2 can generate a value for the column when a row is added, depending on the option that you choose (GENERATED ALWAYS or GENERATED BY DEFAULT) when you define the column. You can use a ROWID column in a table for several reasons.
You can define a ROWID column to include LOB data in a table; you can read about large objects in “Defining large objects” on page 268.
You can use the ROWID column as a partitioning key for partitioned table spaces; you can read about partitioned table spaces in “Defining partitioned table spaces” on page 246.
You can use direct-row access so that DB2 accesses a row directly through the ROWID column. If an application selects a row from a table that contains a ROWID column, the row ID value implicitly contains the location of the row. If you use that row ID value in the search condition of subsequent SELECT statements, DB2 might be able to navigate directly to the row.
Comparing data types
DB2 compares values of different types and lengths. A comparison occurs when both values are numeric, both values are character strings, or both values are graphic strings. Comparisons can also occur between character and graphic data or between character and datetime data if the character data is a valid character representation of a datetime value. Different types of string or numeric comparisons might have an impact on performance.
Defining and using distinct types
A distinct type is a user-defined data type that is based on existing built-in DB2 data types. That is, they are internally the same as built-in data types, but DB2 treats them as a separate and incompatible type for semantic purposes. Defining your own distinct types ensures that only functions that are explicitly defined on a distinct type can be applied to its instances. ![]()
Example: You might define a US_DOLLAR distinct type that is based on the DB2 DECIMAL data type to identify decimal values that represent United States dollars. The US_DOLLAR distinct type does not automatically acquire the functions and operators of its source type, DECIMAL.
Although you can have different distinct types based on the same built-in data types, distinct types have the property of strong typing. With this property, you cannot directly compare instances of a distinct type with anything other than another instance of that same type. Strong typing prevents semantically incorrect operations (such as explicit addition of two different currencies) without first undergoing a conversion process. You define which types of operations can occur for instances of a distinct type.
If your company wants to track sales in many countries, you must convert the currency for each country in which you have sales.
Example: You can define a distinct type for each country. For example, to create US_DOLLAR types and CANADIAN_DOLLAR types, you can use the following CREATE DISTINCT TYPE statements:
CREATE DISTINCT TYPE US_DOLLAR AS DECIMAL (9,2); CREATE DISTINCT TYPE CANADIAN_DOLLAR AS DECIMAL (9,2);
Example: After you define distinct types, you can use them in your CREATE TABLE statements:
CREATE TABLE US_SALES (PRODUCT_ITEM_NO INTEGER, MONTH INTEGER, YEAR INTEGER, TOTAL_AMOUNT US_DOLLAR); CREATE TABLE CANADIAN_SALES (PRODUCT_ITEM_NO INTEGER, MONTH INTEGER, YEAR INTEGER, TOTAL_AMOUNT CANADIAN_DOLLAR);
User-defined functions support the manipulation of distinct types. You can read about defining user-defined functions in “Defining user-defined functions” on page 278.
Using null and default values
As you create table columns, you will discover that the content of some columns cannot always be specified; users and applications must be allowed to not supply a value. This section explains the use of null values and default values and provides some tips on when to choose each type of value.
Null values
Some columns cannot have a meaningful value in every row. DB2 uses a special value indicator, the null value, to stand for an unknown or missing value. “Null values” on page 93 introduces the concept of a null value, which is an actual value and not a zero value, a blank, or an empty string. It is a special value that DB2 interprets to mean that no data is present.
If you do not specify otherwise, the default is that any column can contain null values. Users can create rows in the table without providing a value for the column.
The NOT NULL clause disallows null values in the column. Primary keys must be defined as NOT NULL.
Example: The table definition for the DEPT table specifies when you can use a null value. Notice that you can use nulls for the MGRNO column only:
CREATE TABLE DEPT (DEPTNO CHAR(3) NOT NULL, DEPTNAME VARCHAR(36) NOT NULL, MGRNO CHAR(6) , ADMRDEPT CHAR(3) NOT NULL, PRIMARY KEY (DEPTNO) ) IN MYDB.MYTS;
Before you decide whether to allow nulls for unknown values in a particular column, you should be aware of how nulls affect results of a query:
Nulls in application programs
Nulls do not satisfy any condition in an SQL statement other than the special IS NULL predicate. DB2 sorts null values differently than nonnull values. Null values do not behave like other values. For example, if you ask DB2 whether a null value is larger than a given known value, the answer is UNKNOWN. If you then ask DB2 whether a null value is smaller than the same known value, the answer is still UNKNOWN.
If getting UNKNOWN is unacceptable for a particular column, you could define a default value instead. Programmers are familiar with the way default values behave.
Nulls in a join operation
Nulls need special handling in join operations. If you perform a join operation on a column that can contain null values, consider using an outer join. (You read about joins in “Joining data from more than one table” on page 152.)
Default values
DB2 defines some default values, and you define others (by using the DEFAULT clause in the CREATE TABLE or ALTER TABLE statement).
If the column is defined as NOT NULL WITH DEFAULT or if you do not specify NOT NULL, DB2 stores a default value for a column whenever an insert or load does not provide a value for that column.
If the column is defined as NOT NULL, DB2 does not supply a default value.
DB2-defined defaults
DB2 generates a default value for ROWID columns. DB2 also determines default values for columns that users define with NOT NULL WITH DEFAULT, but for which no specific value is specified. See Table 7.5.
| For columns of... | Data types | Default |
|---|---|---|
| Numbers | SMALLINT, INTEGER, DECIMAL, NUMERIC, REAL, DOUBLE, or FLOAT | 0 |
| Fixed-length strings | CHAR or GRAPHIC | Blanks |
| Varying-length strings | VARCHAR, CLOB, VARGRAPHIC, DBCLOB, or BLOB | Empty string |
| Dates | DATE | CURRENT DATE |
| Times | TIME | CURRENT TIME |
| Timestamps | TIMESTAMP | CURRENT TIMESTAMP |
| ROWIDs | ROWID | DB2-generated |
User-defined defaults
You can specify a particular default, such as:
DEFAULT 'N/A'
When you choose a default value, you must be able to assign it to the data type of the column. For example, all string constants are VARCHAR. You can use a VARCHAR string constant as the default for a CHAR column even though the type isn't an exact match. However, you could not specify a default value of 'N/A' for a column with a numeric data type.
In the next example, the columns are defined as CHAR (fixed length). The special registers (USER and CURRENT SQLID) that are referenced are varying length starting in Version 8. This example is valid.
Example: If you want a record of each user who inserts any row of a table, define the table with two additional columns:
You can then create a view that omits those columns and allows users to update the view instead of the base table. DB2 then adds, by default, the primary authorization ID and the SQLID of the process. You can read about authorization in “Authorizing users to access data” on page 328.
When you add columns to an existing table, you must define them as nullable or as not null with default. Assume that you add a column to an existing table and specify not null with default. If DB2 reads from the table before you add data to the column, the column values that you retrieve are the default values. With few exceptions, the default values for retrieval are the same as the default values for insert. ![]()
Default for ROWID
DB2 always generates the default values for ROWID columns.
Comparing null values and default values
In some situations, using a null value is easier and better than using a default value.
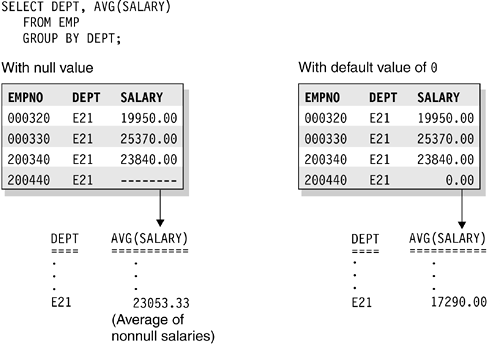
Example: Suppose that you want to find out the average salary for all employees in a department. The salary column does not always need to contain a meaningful value, so you can choose between the following options:
Allowing null values for the SALARY column
Using a nonnull default value (such as, 0)
By allowing null values, you can formulate the query easily, and DB2 provides the average of all known or recorded salaries. The calculation does not include the rows that contain null values. In the second case, you probably get a misleading answer unless you know the nonnull default value for unknown salaries and formulate your query accordingly.
Figure 7.1 shows two scenarios. The table in the figure excludes salary data for employee number 200440 because the company just hired this employee and has not yet determined the salary. The calculation of the average salary for department E21 varies, depending on whether you use null values or nonnull default values.
The left side of the figure assumes that you use null values. In this case, the calculation of average salary for department E21 includes only the three employees (000320, 000330, and 200340) for whom salary data is available.
The right side of the figure assumes that you use a nonnull default value of zero (0). In this case, the calculation of average salary for department E21 includes all four employees, although valid salary information is available for only three employees. As you can see, only the use of a null value results in an accurate average salary for department E21.
Figure 7.1. When nulls are preferable to default values
Enforcing validity of column values with check constraints
“Check constraints” on page 57 explains that a check constraint is a rule that specifies the values that are allowed in one or more columns of every row of a table. You can use check constraints to ensure that only values from the domain for the column or attribute are allowed. As a result of using check constraints, programmers don't need to develop, test, and maintain application code that performs these checks.
You can choose to define check constraints by using the SQL CREATE TABLE statement or ALTER TABLE statement. For example, you might want to ensure that each value in the SALARY column of the EMP table contains more than a certain minimum amount.
DB2 enforces a check constraint by applying the relevant search condition to each row that is inserted, updated, or loaded. An error occurs if the result of the search condition is false for any row. ![]()
Inserting rows into tables with check constraints
When you use the INSERT statement to add a row to a table, DB2 automatically enforces all check constraints for that table. If the data violates any check constraint that is defined on that table, DB2 does not insert the row.
Example: Assume that the NEWEMP table has the following two check constraints:
Employees cannot receive a commission that is greater than their salary.
Department numbers must be between '001' and '100,' inclusive.
Consider this INSERT statement, which adds an employee who has a salary of $65,000 and a commission of $6,000:
INSERT INTO NEWEMP
(EMPNO, FIRSTNME, LASTNAME, DEPT, JOB, SALARY, COMM)
VALUES ('100125', 'MARY', 'SMITH','055', 'SLS', 65000.00, 6000.00);
The INSERT statement in this example succeeds because it satisfies both constraints.
Example: Consider this INSERT statement:
INSERT INTO NEWEMP
(EMPNO, FIRSTNME, LASTNAME, DEPT, JOB, SALARY, COMM)
VALUES ('120026', 'JOHN', 'SMITH','055', 'DES', 5000.00, 55000.00 );
The INSERT statement in this example fails because the $55,000 commission is higher than the $5,000 salary. This INSERT statement violates a check constraint on NEWEMP.
“Loading the tables” on page 277 provides more information about loading data into tables on which you have defined check constraints.
Updating tables with check constraints
DB2 automatically enforces all check constraints for a table when you use the UPDATE statement to change a row in the table. If the intended update violates any check constraint that is defined on that table, DB2 does not update the row.
Example: Consider this UPDATE statement:
This update succeeds because it satisfies the constraints that are defined on the NEWEMP table.
Example: Consider this UPDATE statement:
UPDATE NEWEMP SET DEPT = '166' WHERE FIRSTNME = 'MARY' AND LASTNAME= 'SMITH';
This update fails because the value of DEPT is '166,' which violates the check constraint on NEWEMP that DEPT values must be between '001' and '100.'
Designing rows
An important consideration in the design of a table is the record size. In DB2, a record is the storage representation of a row. DB2 stores records within pages that are 4 KB, 8 KB, 16 KB, or 32 KB in size. Generally, you cannot create a table with a maximum record size that is greater than the page size. No other absolute limit exists, but you risk wasting storage space if you ignore record size in favor of implementinga good theoretical design.
If the record length is larger than the page size, consider using a large object (LOB) data type (described in “Large object data types” on page 230).
Record length—fixed or varying
Ina table whose columns all have fixed-length data types, all rows (and therefore all records) are the same size. Otherwise, the size of records can vary.
Fixed-length records are generally preferable to varying-length records because DB2 processing is most efficient for fixed-length records. A fixed-length record never needs to move from the page on which it is first stored. Updates to varying-length records, however, can cause the record length to grow so that it no longer fits on the original page. In that case, the record moves to another page. Each time that a record is accessed, an additional page reference occurs. Therefore, use varying-length columns only when necessary.
Record lengths and pages
The sum of the lengths of all the columns is the record length. The length of data that is physically stored in the table is the record length plus DB2 overhead for each row and each page.
If row sizes are very small, use the 4-KB page size. Use the default of 4-KB page sizes when access to your data is random and typically requires only a few rows from each page.
Some situations require larger page sizes. DB2 provides three larger page sizes of 8 KB, 16 KB, and 32 KB to allow for longer records. For example, when the size of individual rows is greater than 4 KB, you must use a larger page size. In general, you can improve performance by using pages for record lengths that best suit your needs.
Designs that waste space
Space is wasted in a table space that contains only records that are slightly longer than half a page because a page can hold only one record. If you can reduce the record length to just under half a page, you need only half as many pages. Similar considerations apply to records that are just over a third of a page, a quarter of a page, and so on.