
Mapping Classes to Tables
The easiest way to translate classes into tables is to make a one-to-one mapping (see Figure 9-2). I strongly recommend against this approach, yet it is done more often than you might realize. One-to-one mapping can lead to the following problems:
Figure 9-2. Remulak class diagram

Too many tables: Most object-to-relational translations done with one-to-one mapping produce more tables than are actually necessary.
Too many joins: If there are too many tables, then logically there will be too many SQL join operations.
Missed tables: Any many-to-many association (e.g., Customer and Address) will require a third relational table to physically associate particular objects (e.g., a given Customer with a given Address). At a minimum, the columns found in that table will be the primary identifier (primary key) from both classes.
In the Remulak Productions class diagram, outlined again in Figure 9-2, an association class, Role, is defined between Customer and Address. This class was defined because we want to capture important information about the association—namely, the role that Address serves (mailing, shipping, and billing) for a given Customer/Address pair. This class also conveniently handles the relational issue of navigating in either direction.
In the association between OrderLine and Shipment, however, no association class is defined. This is completely normal and common from the object viewpoint (this association has no interesting information that we care to capture), but from the relational perspective an intersection table is necessary to implement the relationship.
Inappropriate handling of generalization/specialization (inheritance) associations: Most often the knee-jerk reaction is to have a table for each class in the generalization/specialization association. The result can be nonoptimal solutions that impair performance. Later in this chapter we review specific implementation alternatives and rules of thumb for when to take which approach.
Denormalization of data: Many applications are report intensive, and the table design might be directed to address their unique needs. For such applications, more denormalization of data might occur (i.e., the same data may be duplicated in multiple tables).
Rather than one-to-one mapping of classes to tables, a better approach is to revisit the pathways through the use-cases, especially how they manifest themselves as sequence diagrams. The class diagram, too, should be addressed. Other useful artifacts are the usage matrices created in Chapter 7.
James Rumbaugh once used the term object horizon when referring to the available messaging pathways that objects have in a given domain. For example, if the sequence diagrams suggest multiple occurrences of Customer messaging to Order objects and then to OrderLine objects, the physical database must be structured to support this navigation very efficiently.
The event/frequency matrix we created in Chapter 7 also is invaluable during this phase. Any action (event) will trigger a given sequence diagram into action. The frequency of these actions forces us to focus more closely on their performance. The biggest bottleneck in most applications is usually disk input/output (I/O). Too many tables will lead to excessive joins, which will lead to additional I/O. This is not to say that poor key selection (addressed later in the chapter) cannot also affect performance. But too many tables in the first place will lead to additional I/O. And whereas CPU speeds are doubling every 18 months (Moore's Law), raw disk I/O speeds have less than doubled in the past five years.
Mapping Simple Associations
Before we can begin transforming classes into relational entities, we must ask a question of each class: Does it even need to be persisted? Some classes—for example, most boundary and control classes—will never be persisted to a physical repository. Classes that are not persisted are called transient because they are instantiated, typically used for the lifecycle of either a transaction or the actor's session (in which many transactions might be executed), and then destroyed. A good example of a transient class in the EJB environment would be a stateless session bean.
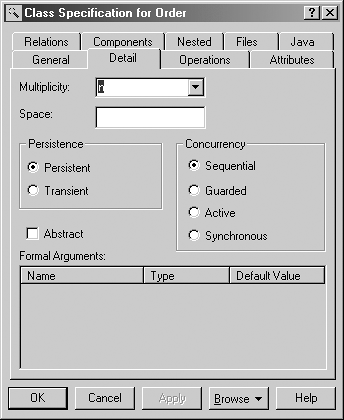
Visual modeling tools use this property of classes during generation of the SQL DDL for the database table structures to determine whether particular classes should be considered. Figure 9-3 shows the Class Specification for Order dialog box for Rational Rose. The Detail tab shows the specification of the persistence property of the class Order.
Figure 9-3. Class Specification for Order dialog box for Rational Rose
We have not yet addressed navigation. When creating the initial class diagram, we usually consider every association to be bidirectional, which means that it can be traversed in either direction of the association (however, in my experience most associations are unidirectional). Treating every association as bidirectional is good policy because we momentarily cease to consider whether we actually need to be able to navigate from, say, Customer to Order, as well as from Order to Customer. This decision will affect the language implementation as well as the translation to the relational design.
Semantically, navigation in UML pertains to objects of a given class being able to send messages to other objects with which they might have an association. Nothing is said about the implications that navigation might impose on the supporting database table design. However, this is a very important consideration. On the surface we are referencing an object instance, but below that the ability to traverse an association will ultimately depend on the database technology (at least for classes that are persisted).
UML represents navigability as a stick arrowhead pointing in the direction of the navigation. Figure 9-4 illustrates a scenario involving the Customer and Order classes and the fact that Customer will navigate only in the direction of Order (each Customer object has a list of Order objects because the multiplicity can be infinite).
Figure 9-4. Customer and Order classes with explicit navigation
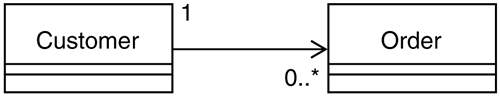
From this figure we can infer that an Order object does not know its associated Customer object. However, this scenario isn't very practical for our use and as such won't meet our navigational requirements (Remulak Productions' system requirements state that we must be able to navigate in both directions). Figure 9-5 shows Customer and Order taken from the class diagram for Remulak given in Figure 9-2.
Figure 9-5. Customer and Order classes with implied navigation

At this point you might be thinking that on the basis of our definition of navigation, we can't navigate in either direction. In UML, the navigational adornments may be omitted as a convenience and to manage clutter. A problem could result, however, if we did have an association that didn't have navigational requirements in either direction. Because this situation is highly unusual in practice, the navigational indicators are typically omitted. In the case of the class diagram for Remulak Productions, every relationship will be bidirectional and implied in the model (arrowheads omitted).
Suppose we want to translate the two classes, with their multiplicity and dual navigability, into relational tables. This process would require the following DDL (in ANSI SQL-92 format):
CREATE TABLE T_Customer (
customerId INTEGER NOT NULL,
customerNumber CHAR(14) NOT NULL,
firstName CHAR(20),
lastName CHAR(20),
middleInitial CHAR(4),
prefix CHAR(4),
suffix CHAR(4),
phone1 CHAR(15),
phone2 CHAR(15),
eMail CHAR(30),
CONSTRAINT PK_T_Customer12 PRIMARY KEY (customerId),
CONSTRAINT TC_T_Customer32 UNIQUE (customerNumber),
CONSTRAINT TC_T_Customer31 UNIQUE (customerId));
CREATE TABLE T_Order (
orderId INTEGER NOT NULL,
customerId INTEGER NOT NULL,
orderNumber CHAR(10) NOT NULL,
orderDateTime DATE NOT NULL,
terms VARCHAR(30) NOT NULL,
salesPerson VARCHAR(20) VARCHAR NOT NULL,
discount DECIMAL(17,2) NOT NULL,
courtesyMessage VARCHAR(50) NOT NULL,
CONSTRAINT PK_T_Order16 PRIMARY KEY (orderId),
CONSTRAINT TC_T_Order37 UNIQUE (orderNumber),
CONSTRAINT TC_T_Order36 UNIQUE (orderId));
Note
Class names in tables are prefaced by T_ in accordance with the default-naming convention used by Rational Rose when generating a DDL from the class diagram, which can of course be changed if desired. Note that you don't need a visual modeling tool to do any of this. However, I am a firm believer that a visual modeling tool vastly improves the traceability and success of a project.
Notice in the preceding code fragment the other artifacts that are strictly relational in nature and that are not part of the class diagramming specifications (although they can all be handled as tagged val ues in UML). These artifacts include such items as data types for the relational database (e.g., CHAR and DECIMAL) and precision (e.g., DECIMAL(17,2)).
Notice also the absence of a reference in the T_Customer table to the T_Order table. The reason this reference is missing is that a Customer can have many Order objects but the database cannot handle multiple Order objects in the T_Customer table.
Note
Many relational databases today, including Oracle, support the concept of nested relationships. Database vendors are slowly crafting themselves as object relational in their ability to model more-complex relationship types.
A Customer object can find all of its Order objects simply by requesting them all from the T_Order table, in which the value of customerId is equal to a supplied number.
Table 9-1 explains the translation from multiplicity to the resulting database action. Keep in mind that this translation is done after the decision of whether or not to persist a table has been made.
Next we review the classes that have simple associations (including association classes such as Role) for Remulak Productions and apply the rules for translation. The result is shown in Table 9-2.
Other class-related tables are addressed in the next several sections.
Mapping Inheritance to the Relational Database
Creating generalization/specialization associations (inheritance) is one of the more interesting translation exercises during implementation of an object design in an RDBMS. Similar constructs that might have appeared in relational modeling are the subtype/supertype relationships. Figure 9-6 shows the generalization/specialization association portion of the Remulak Productions class diagram.
Figure 9-6. Generalization/specialization and relational design

| Class | Table |
|---|---|
| Address | T_Address |
| Locale | T_Locale |
| Customer | T_Customer |
| Invoice | T_Invoice |
| Payment | T_Payment |
| Shipment | T_Shipment |
| T_OrderLineShipment (intersection table for OrderLine and Shipment) |
We can follow any of three alternatives when translating a generalization/specialization association to a relational design, as outlined in Table 9-3.
These choices might seem a bit overwhelming, but which one to choose is usually clear. Following are some sample scenarios to help you make the decision:
If the number of rows is somewhat limited (in Remulak Productions' case, if the product database is small), the preference might be to insulate the application from future change and provide a more robust database design. Thus option 1 might be the most flexible. However, this option yields the worst performance (it involves lots of joins).
If the number of attributes in the superclass is small compared to the number of its subclasses, option 3 might be the most prudent choice. The result would be better performance than that provided by option 1, and extending the model by adding more classes later would be easier.
If the amount of data in the subclasses is sparse, option 2 might be best. This option enables the best performance, although it has the worst potential for future flexibility.
In the case of Remulak Productions, we use option 1 because the company later might want to expand its product line and would want the least amount of disruption when that happened. As an implementation alternative, we will also present option 3 in the code you can download for this book.
| Option | Benefits and Drawbacks |
|---|---|
| 1. Create a table for each class and a SQL view for each superclass/subclass pair. | Results in a more flexible design, allowing future subclasses to be added with no impact on other classes and views.
Results in the most RDBMS objects (in the case of Remulak Productions, seven separate objects: four tables and three views). Might hinder performance because each access will always require a SQL join through the view. |
| 2. Create one table (of the superclass), and denormalize all column information from the subclasses into the one superclass table. Sometimes called the roll-up method. | Results in the least number of SQL objects (and in the case of Remulak Productions, only one table: T_Product).
Typically results in the best overall performance because there is only one table. Requires table modifications and, if future subclassing is needed, possibly data conversion routines. Requires “dead space” in the superclass table, T_Product, for those columns not applicable to the subclass in question. This ultimately increases row length and could affect per formance because fewer rows are returned in each physical database page access. |
| 3. Create a table for each subclass and denormalize all superclass column information into each subclass table. Sometimes called the roll-down method. | When a change is required, results in somewhat less impact than option 2. If further subclassing is required, the other subclasses and the superclass will require no modifications.
If the superclass later must be changed, each subclass table also must be changed and potentially undergo conversion. Results in adequate performance because in many cases fewer tables are needed (in the case of Remulak Productions, only three tables would be needed: T_Guitar, T_SheetMusic, and T_Supplies). |
Remember that this decision in no way changes the programmatic view of the business (except for the SQL statements). To the Java developer, the view of the business is still based on the class diagram.
Table 9-4 outlines classes and their associated tables.
| Class | Table |
|---|---|
| Product | T_Product |
| Guitar | T_Guitar V_Product_Guitar (view of joined Product and Guitar) |
| SheetMusic | T_SheetMusic V_Product_SheetMusic (view of joined Product and SheetMusic) |
| Supplies | T_Supplies V_Product_Supplies (view of joined Product and Supplies) |
Mapping Aggregation and Composition to the Relational Database
In a relational database, aggregation and composition are modeled in an identical fashion to simple associations. The same rules that apply to the entries in Table 9-4 also apply to aggregation and composition. Often aggregation and composition relationships involve many one-to-one relationships. Composition relationships almost always are implemented as just one relational table (the aggregation or composition class, such as T_Order for Remulak Productions). If the composition is implemented as separate tables, then the cascading of deletes must be addressed and implemented in the physical DBMS. Aggregation relationships, however, might end up as separate tables because the leaf classes (those being aggregated) can stand on their own.
For Remulak Productions, we create three composition associations as shown in Figure 9-7. We also create two relational tables: T_Order and T_OrderLine. Table 9-5 recaps the class-to-table translations for the Remulak Productions composition association.
Figure 9-7. Composition and relational design
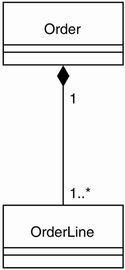
| Class | Table |
|---|---|
| Order | T_Order |
| OrderLine | T_OrderLine |
Mapping Reflexive Associations to the Relational Database
Remulak Productions' order entry application has one reflexive association—the Product class—as shown in Figure 9-8.
Figure 9-8. Remulak reflexive association
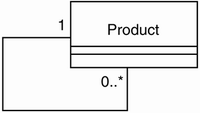
Recall that this association is necessary to support the requirement that products be related for cross-selling opportunities. A reflexive association, called a recursive relationship in relational modeling, re sults in the addition of columns that are themselves primary keys to an other product. So each row in the T_Product table will have not only a productId column as its primary key, but also another productId column as a foreign key. This setup allows, for example, a specific set of strings (Supplies) to be related to a particular guitar (Guitar).
If the multiplicity for a reflexive association is one to many, no additional relational tables—but just an additional column in the T_Product table—are required for implementing the solution. However, let's as sume a many-to-many multiplicity for the reflexive association. In this case the additional productId instance added to the T_Product table is moved to another table. This new table, perhaps called T_Product_R, would contain, at a minimum, two productId keys: one a parent product, the other a child product. The two keys are necessary because any given product could be both a parent and a child.