Key Structures and Normalization
You might have seen some column names such as customerId and productId in previous tables. These columns relate to keys and normalization. Every persistent object in the system must be uniquely identified; the nature of object design and implementation frees us, somewhat, from having to worry about object uniqueness. When an object of a given class is created, it is assigned a unique ID for its lifetime; this is done internally in the language subsystem. However, unique IDs are not assigned when the object is persisted to, for example, Microsoft SQL Server or Oracle. When making the transition from the object view to the relational view, we need to consider the primary identifiers, or keys, that will make every row in a table unique.
We can take either of two approaches to identifying keys in a relational database. The first is to select natural keys. A natural key is a meaningful column, or columns, that has a context and semantic relationship to the application. A good example is found in the DDL presented earlier in the chapter. The T_Customer table has a 14-character column called customerNumber (although this column contains both numbers and characters, it is still called a number). This column is an ideal, natural primary key for the T_Customer table because it is unique and has meaning to the application domain.
The second approach to identifying keys in a relational database is to pick keys that have no meaning to the application domain. This type of key is called a surrogate, or programming, key. Most often this type of key is a random integer or a composite creation of a modified time stamp. At first glance this approach might seem absurd. However, it can have some very positive ramifications for the design and performance of the system, as follows:
The primary key of every table in the system is of the same data type. This promotes consistency, as well as speed in joins. Most database optimizers are much more efficient when joining on Integer-type columns. The reason is that the cardinality, or the distribution of possible values, is much smaller (a 14-byte character field versus a 4-byte Integer).
Joins will be limited to single columns across tables. Often if the primary-key selection results in a compound composite key (i.e., more than one column is needed to uniquely identify the rows in the table), the ability to join on that key results in poorer performance and much more difficult SQL code.
Storage needs are reduced. If the natural key of customerNumber is chosen as the primary key of T_Customer, the T_Order table will contain a customerNumber column as a foreign key to facilitate the join. This key will require 14 bytes in T_Order. However, if the primary key of T_Customer is a 4-byte Integer, the foreign key in T_Order will be only 4 bytes. This might not seem like much saved space, but for thousands or tens of thousands of orders the amount quickly adds up.
More rows are returned in a physical page I/O. All databases fetch rows at the page level (at a minimum). They access pages ranging from 2K to 8K. Actually, in some cases, if a database vendor “senses” that you're reading sequentially, it might access pages in 32K and 64K increments. So the smaller the row size, the more rows will be on a page, resulting in more data being in memory when the next row is requested. Memory access is always faster than disk access, so if smaller primary keys exist, those same efficient keys will also be defined as foreign keys elsewhere. Overall, a physical page typically has more rows, thereby resulting in a few more rows being made available to the application at a much higher potential access rate.
Quite often I see implementations that use the surrogate key approach but use an automatically generated sequential number. Be careful with sequential integers as primary keys. The reason for caution here has to do with index management. If your index is not utilizing a hashing algorithm and being maintained in a typically B-tree structure, then a sequential integer will generate hot spots in your index data set. A hot spot means that you continually have to split the tree because your keys are continually increasing in sequence. Without going into the subtleties of B-tree performance, let me say that this scenario can kill applications that are insert intensive.
The Remulak Productions' relational design will use a surrogate key as the primary key of every relational table. The column names will be similar across tables, each using the mask of tablenameId, where tablename is the respective table in the system. This surrogate key will be stored as an Integer in the database and programmed as an Integer in Java. The next chapter introduces code that generates this surrogate key before the row is inserted into the table.
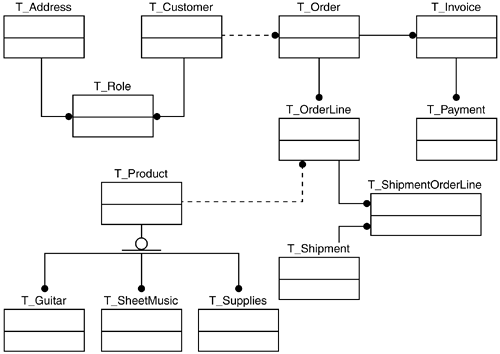
Figure 9-9 is an entity relationship diagram that shows the tables necessary to implement the Remulak Productions class diagram. The no tation is in the industry-standard entity definition schema, the IDEF1X format.
Figure 9-9. Entity relationship diagram for Remulak Productions