
The most important purpose of an IDE is to browse and edit code. Therefore, perhaps even more than any other IDE platform, the Eclipse editor framework has grown into a highly evolved, flexible, easy-to-use, and easy-to-extend environment for editing program source files. In this chapter, we look at what support exists for writing editors and how easy it is to plug them into the Eclipse IDE platform.
Eclipse provides rich support for creating editors that operate on text, such as programming language editors or document editors. The framework has been designed in several layers of increasing coupling to the Eclipse Platform. Some of the lower-level components can easily be used outside Eclipse in stand-alone applications, and other parts can be used only within a running Eclipse Platform. Using this framework, you can quickly create a powerful editor with surprisingly little work.
The text infrastructure is so vast that it can be very difficult to figure out where to begin. Here is a little roadmap to the various plug-ins that provide facilities for text processing:
org.eclipse.text. This plug-in is one of very few that have no connection to any other plug-ins. Because it has no dependence on the Eclipse Platform or even on SWT, this plug-in can easily be used in a stand-alone application. This plug-in provides a model for manipulating text and has no visual components, so it can be used by headless programs that process or manipulate text. Think of this plug-in as a rich version ofjava.lang.StringBufferbut with support for event change notification, partitions, search and replace, and other text-processing facilities.org.eclipse.swt. SWT is covered elsewhere in this book, but in the context of text editing, the classStyledTextneeds to be mentioned here.StyledTextis the SWT user-interface object for displaying and editing text. Everything the user sees is rooted here: colors, fonts, selections, the caret (I-beam cursor), and more. You can add all kinds of listeners to this widget to follow what the user is doing. Some of the fancier features include word wrapping; bi-directional text, used by many non-Latin languages; and printing support.org.eclipse.jface.text. This plug-in is the marriage of the model provided byorg.eclipse.textand the view provided byStyledText. True to the philosophy of JFace, the intent here is not to hide the SWT layer but to augment the visual presentation with a rich model and controllers. This plug-in is the heart of the text framework, and the list of features it provides is far too long to enumerate. To name just a few, it supports Content Assist, rule-based text scanners and partitioners, a vertical ruler, incremental reconciling, formatters, and hover displays. Many of these features are explored in more detail by other FAQs in this chapter.org.eclipse.ui.workbench.texteditor. This plug-in couples the text framework to the Eclipse Platform. You can’t use the features provided here without being part of a running Eclipse workbench. In particular, this plug-in supports text editors that appear in the workbench editor area and features a large collection ofActionsubclasses for manipulating the contents of an editor, as well as support for annotations, incremental search, and more. If you’re designing a text editor for use within the Eclipse Platform, you’ll be subclassing theAbstractTextEditorclass found in this plug-in. This abstract editor contains most of the functionality of the default text editor in Eclipse but without making any assumptions about where the content being edited is stored; it does not have to be in the workspace. This plug-in is appropriate for use in an RCP application that requires text editing support.org.eclipse.ui.editors. This plug-in provides the main concrete editor in the base Eclipse Platform: the default text editor. You generally don’t need to use this plug-in when writing your own editor, as all the useful functionality has been abstracted out into the plug-ins we’ve already mentioned. This concrete editor is typically used on anIFileEditorInputon anIFilein the local workspace.
Start browsing through the editor plug-ins, and a lot of names come out at you: IDocument, StyledText, ISourceViewer, ITextViewer, Text, ITextEditor, and many more. Furthermore, many of these pieces seem to overlap; they often provide similar functionality, and it’s not easy to figure out which piece you should be looking at when implementing a feature.
It’s not easy for the newcomer to grasp, but these overlapping pieces represent carefully designed layers of abstraction that allow for maximum reuse. Eclipse is designed to be extended by a large number of third parties with all kinds of different requirements. Instead of presenting a monolithic API that attempts to cater to all these needs, the editor framework gives you a loosely coupled toolkit that you can draw from, based on the needs of your particular application. A high-level overview helps when you’re starting out.
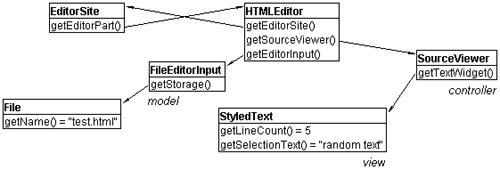
The text-editing framework follows the same architectural principles as the rest of the Eclipse Platform. The four layers are the model (core), the view (SWT), the controller (JFace), and the presentation context (usually the workbench). The model and the view are self-contained pieces that know nothing about each other or the rest of the world. If you have a simple GUI application, you can get away with creating the view and manipulating it directly. Some tools operate directly on the model and don’t care about the presentation. Often, the model, view, and controller are all used, but the same triad might appear in different contexts: in a workbench part, in a dialog, and so on. If your application demands it, you can replace any of these layers with a completely different implementation but reuse the rest.
Figure 15.1 show how these layers map onto the text-editing framework. The core is org.eclipse.jface.text.IDocument, with no dependency on any UI pieces. The view is org.eclipse.swt.custom.StyledText. Don’t be fooled by org.eclipse.swt.widgets.Text; this is a (usually) native widget with very basic functionality. It’s suitable for simple entry fields in dialogs but does not provide rich editing features. StyledText is the real widget for presenting text editors. The basic controller layer is provided by org.eclipse.jface.text.ITextViewer. This is extended by org.eclipse.jface.text.ISourceViewer to provide features particular to programming language editors. The context for presenting text editors in a workbench part is provided by org.eclipse.ui. texteditor.ITextEditor. This is the text framework extension to the generic editor interface, org.eclipse.ui.IEditorPart.
Follow the steps in FAQ 211 to create a platform editor extension, but instead of the basic EditorPart, subclass AbstractTextEditor. You don’t need to override createPartControl this time, because the abstract editor builds the visual representation for you. In fact, you need to do nothing more; simply subclassing AbstractTextEditor will give you a generic text editor implementation right out of the box.
To customize your editor, you need to create your own subclass of SourceViewerConfiguration defined in package org.eclipse.jface.text.source when the editor is created. This class is the locus of all editor customization. Just about every time you want to add a feature to a text editor, you start by subclassing a method in the configuration. Browse through the methods of this class to get an idea of the kinds of customization you can add.
Another entry point for editor customization is the document provider. The editor’s document provider is a factory method for supplying the model object (an IDocument) that represents the editor’s contents. The document provider’s main function is to transform an IEditorInput into an appropriate IDocument.
By subclassing the generic document provider, you can create a customized document, such as a document that is divided into multiple partitions or a document that uses a different character encoding. This is also a good place for adding listeners to the document so you can be notified when it changes.
You’ll also want to customize the actions available to your editor. The abstract text editor provides some actions, but if you want to add extra tools, you’ll need actions for them. This is done by overriding the method createActions in your editor. Be sure to call super.createActions to allow the abstract editor to install the default set of text-editing actions, such as Cut, Copy, Paste, and Undo. The editor framework supplies more actions that are not automatically added to the abstract editor, but you can add them from your implementation of createActions. Look in the package org.eclipse.ui.texteditor for more available actions.
The FAQs in this chapter will use a running example of a simple HTML editor. We have used a simple text editor for writing HTML because it’s the only editor that gives you complete control over the contents and won’t insert all those funny tags that most editors insert to ensure that your pages won’t be compatible with everyone’s browser. Still, it’s nice to have some syntax highlighting, Content Assist, and other time-saving features, so we wrote a simple HTML editor for Eclipse. The fact that this book is written in HTML gave us added incentive: another opportunity to eat our own dog food. As with all other examples in this book, complete source is available on the accompanying CD-ROM, and on this book’s Web site (http://eclipsefaq.org).
Here is the skeleton of the HTMLEditor class, showing the customization entry points:
public class HTMLEditor extends AbstractTextEditor {
public HTMLEditor() {
//install the source configuration
setSourceViewerConfiguration(new HTMLConfiguration());
//install the document provider
setDocumentProvider(new HTMLDocumentProvider());
}
protected void createActions() {
super.createActions();
//... add other editor actions here
}
}
Note
FAQ 262 What support is there for creating custom text editors?
Go to Platform Plug-in Developer Guide > Programmer’s Guide > Editors > Configuring a source viewer.
The underlying model behind text editors is represented by the interface IDocument and its default implementation, Document, both of which are declared in the org.eclipse.jface.text package. You can use documents to manipulate text inside and outside a text editor. Documents are created with a simple constructor that optionally takes a string representing the initial input. The document contents can be obtained and replaced by using get() and set(String). The document model has a powerful search method and several methods for querying or replacing portions of the document. The following example uses a document to implement search and replace:
String searchAndReplace(String input, String search,
String replace) throws BadLocationException {
Document doc = new Document(input);
int offset = 0;
while (offset < doc.getLength()) {
offset = doc.search(offset, search, true, true, true);
if (offset < 0)
break;
doc.replace(offset, search.length(), replace);
offset += replace.length();
}
return doc.get();
}
This example only scratches the surface of the capabilities of the IDocument model. Documents also provide change notification, mapping between line numbers and character offsets, partitions, and much more. Other FAQs in this chapter dig into some of these concepts in more detail.
Each document is divided into one or more nonoverlapping partitions. Many of the text-framework features can be configured to operate differently for each partition. Thus, an editor can have different syntax highlighting, formatting, or Content Assist for each partition. For example, the Java editor in Eclipse has different partitions for strings, characters, and comments.
If no partitions are explicitly defined, the single default partition is of type IDocument.DEFAULT_CONTENT_TYPE. If the explicitly defined partitions do not span the entire document, all remaining portions of the document implicitly belong to this default partition. In other words, every character in the document belongs to exactly one partition. Most editors define explicit partitions for small portions of the document that need custom behavior, and the bulk of the document remains in the default partition.
Documents are partitioned by connecting them to an instance of org.eclipse.jface.text.IDocumentPartitioner. In the case of editors, this is usually added by the document provider as soon as the document is created. You can implement the partitioner interface directly if you want complete control, but in most cases you can simply use the default implementation, DefaultPartitioner. This example from the HTML editor defines a partitioner and connects it to a document:
IDocumentPartitioner partitioner =
new DefaultPartitioner(
createScanner(),
new String[] {
HTMLConfiguration.HTML_TAG,
HTMLConfiguration.HTML_COMMENT });
partitioner.connect(document);
document.setDocumentPartitioner(partitioner);
The default partitioner’s constructor takes as arguments a scanner and an array of partition types for the document. The partition scanner is responsible for computing the partitions. It is given a region of the document and must produce a set of tokens describing each of the partitions in that region. When a document is created, the scanner is asked to create tokens for the entire document. When a document is changed, the scanner is asked to repartition only the region of the document that changed. Figure 15.2 shows the relationships among editor, document, partitioner, and scanner.
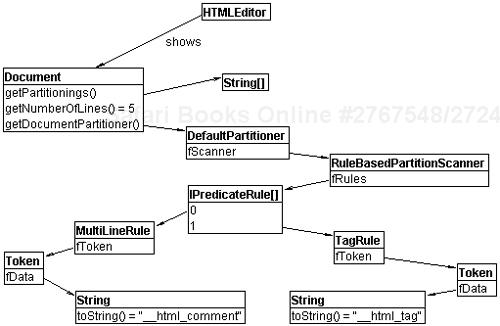
The text framework provides a powerful rule-based scanner infrastructure for creating a scanner based on a set of predicate rules. You simply create an instance of the scanner and plug in the rules that define the regions in your document. Each rule is given a stream of characters and must return a token representing the characters if they match the rule. Browse through the type hierarchy of IPredicateRule to see what default rules are available. The following snippet shows the creation of the scanner for the HTML editor example:
IPartitionTokenScanner createScanner() {
IToken cmt = new Token(HTMLConfiguration.HTML_COMMENT);
IToken tag = new Token(HTMLConfiguration.HTML_TAG);
IPredicateRule[] rules = new IPredicateRule[2];
rules[0] = new MultiLineRule("", cmt);
rules[1] = new TagRule(tag);
RuleBasedPartitionScanner scanner =
new RuleBasedPartitionScanner();
scanner.setPredicateRules(rules);
return sc;
}
Note
FAQ 264 How do I get started with creating a custom text editor?
Go to Platform Plug-in Developer Guide > Programmer’s Guide > Editors > Documents and partitions.
As with most editor features, Content Assist is added to a text editor from your editor’s SourceViewerConfiguration. In this case, you need to override the getContentAssistant method. Here is the implementation of this method in our HTML editor example:
public IContentAssistant
getContentAssistant(ISourceViewer sv) {
ContentAssistant ca = new ContentAssistant();
IContentAssistProcessor pr =
new TagCompletionProcessor();
ca.setContentAssistProcessor(pr, HTML_TAG);
ca.setContentAssistProcessor(pr,
IDocument.DEFAULT_CONTENT_TYPE);
ca.setInformationControlCreator(
getInformationControlCreator(sv));
return ca;
}
Although IContentAssistant is the top-level type that provides Content Assist, most of the work is done by an IContentAssistProcessor. Documents are divided into partitions to represent different logical segments of the text, such as comments, keywords, and identifiers. The IContentAssistant’s main role is to provide the appropriate processor for each partition of your document. In our HTML editor example, the document is divided into three partitions: comments, tags, and everything else, represented by the default content type.
In the preceding snippet, we have installed a single processor for tags and the default content type and no processor for comments. The final line before the return statement sets the information control creator for the content assistant. The information control creator is a factory for creating those information pop-ups that frequently appear in text editors, such as the Java editor. In the context of Content Assist, the information control creator is used to create the information pop-up that provides more details about a recommended completion.
After configuring the content assistant, the next step is to create one or more IContentAssistProcessors. When the user invokes Content Assist at a given position in the editor, the computeCompletionProposals method is called. This method’s job is to figure out what completions, if any, are appropriate for that position. The method returns one or more ICompletionProposal instances, which is typically an instance of the generic class CompletionProposal.
A completion proposal encapsulates all the information that the text framework needs for presenting the completions to the user and for inserting a completion if the user selects one. Most of this information is self-explanatory, but a couple of items in the proposal need a bit more information: the context information and the additional proposal information.
Additional proposal info is displayed in a pop-up window when the user highlights a proposal but has not yet inserted it. As the name implies, the purpose of this information is to help the user decide whether the selected proposal is the desired completion. For our HTML tag processor, the additional information is a string describing the function of that tag. This information will be displayed only if your Content Assistant has installed an information control creator. See the earlier snippet of the getContentAssistant method to see how this is done.
Context information, if applicable, is displayed in a pop-up after the user has inserted a completion. The purpose here is to give the user extra information about what text needs to be entered after the completion has been inserted. This is best explained with an example from the Java editor. After the user has inserted a method using Content Assist in the Java editor, context information is used to provide information about the method parameters. As the user types in the method parameters, the context information shows the data type and parameter name for each parameter.
The final step in implementing Content Assist in your editor is to add an action that will allow the user to invoke Content Assist. The text framework provides an action for this purpose, but it is not installed in the abstract text editor because it isn’t applicable to all flavors of text editors. The action is installed by overriding your editor’s createActions method. The action class is ContentAssistAction. Here is a snippet from the createActions method in our example HTML editor:
Action action = new ContentAssistAction(resourceBundle,
"ContentAssistProposal.", this);
String id =
ITextEditorActionDefinitionIds.CONTENT_ASSIST_PROPOSALS
action.setActionDefinitionId(id);
setAction("ContentAssistProposal", action);
markAsStateDependentAction("ContentAssistProposal", true);
Line 1 creates the Action instance, supplying a resource bundle where the display strings should be taken from, along with a prefix for that action. The message bundle on disk would look something like this:
ContentAssistProposal.label=Content assist ContentAssistProposal.tooltip=Content assist ContentAssistProposal.description=Provides Content Assistance
Line 3 associates a well-known ID with the action that will tell the UI’s command framework that this is the action for Content Assist. This allows the user to change the key binding for Content Assist generically and have it apply automatically to all editors that provide Content Assist.
Line 4 registers the action with the editor framework, using a unique ID. This ID can be used to identify the action when constructing menus and is used by the editor action bar contributor to reference actions defined by the editor. The final line in the snippet indicates that the action needs to be updated whenever the editor’s state changes.
That’s it! The Content Assist framework has a lot of hooks to allow you to customize the behavior and presentation of proposals and context information, but it would take far too much space to describe them here. See the sample HTML editor’s implementation of Content Assist for a simple example to get you started. For a real-world example, we recommend browsing through the Java editor’s Content Assist implementation. It can be found in the package org.eclipse.jdt.internal.ui.text.java in the org.eclipse.jdt.ui plug-in.
Syntax coloring in a JFace text editor is performed by a presentation reconciler, which divides the document into a set of tokens, each describing a section of the document that has a different foreground, background, or font style. Note that this sounds very similar to a partition token scanner, which divides the document into a series of partitions.
The tokens produced by the presentation reconciler are much more fine-grained than the ones produced by the partition scanner. For example, a Java file may be divided into partitions representing either javadoc or code. Within each partition, the presentation reconciler will produce separate tokens for each set of characters that have the same color and font. So, a Java keyword would be one token, and a string literal would be another. Each partition can have a different presentation reconciler installed, allowing for different rules to be used, depending on the type of content in the partition.
Once the initial presentation of a document is calculated, it needs to be incrementally maintained as the document is modified. The presentation reconciler uses two helper classes to accomplish this: a damager and a repairer. The damager takes as input a description of how the document changed and produces as output a description of the regions of the document whose presentation needs to be updated. For example, if a user deletes the “>” character representing the end of a tag in an HTML file, the region up to the next “>” character now needs to be colored as an HTML tag. The repairer’s job is to update the presentation for all the damaged regions.
This all sounds very complicated, but the text framework will usually do most of this work for you. Typically you simply need to create a set of rules that describe the various tokens in your document. The framework has a default presentation reconciler that allows you to plug these rules into it, and the rest of the reconciling work is done for you. As an example, this is a scanner created by the sample HTML editor for scanning HTML tags:
ITokenScanner scanner = new RuleBasedScanner();
IToken string = createToken(colorString);
IRule[] rules = new IRule[3];
// Add rule for double quotes
rules[0] = new SingleLineRule(""", """, string, ''),
// Add a rule for single quotes
rules[1] = new SingleLineRule("'", "'", string, ''),
// Add generic whitespace rule.
rules[2] = new WhitespaceRule(whitespaceDetector);
scanner.setRules(rules);
scanner.setDefaultReturnToken(createToken(colorTag));
This scanner creates unique tokens for string literals within a tag so it can color them differently. Outside of strings, the rest of the tag is divided into white-space-separated tokens, using a white-space rule.
The createToken method instantiates a Token object for a particular color:
private IToken createToken(Color color) {
return new Token(new TextAttribute(color));
}
This scanner is finally fed to a standard presentation reconciler in the SourceConfiguration subclass. You need to specify a different damager/repairer for each partition of your document:
public IPresentationReconciler getPresentationReconciler(
ISourceViewer sv) {
PresentationReconciler rec = new PresentationReconciler();
DefaultDamagerRepairer dr =
new DefaultDamagerRepairer(getTagScanner());
rec.setDamager(dr, HTML_TAG);
rec.setRepairer(dr, HTML_TAG);
... same for other partitions ...
return rec;
}
For more complex documents or for optimized reconciling, you can build your own custom damager and repairer instances by directly implementing IPresentationDamager and IPresentationRepairer, respectively. However, for most kinds of documents, a simple rule-based approach is sufficient.
Note
FAQ 266 What is a document partition?
Go to Platform Plug-in Developer Guide > Programmer’s Guide > Editors > Syntax coloring.
The JFace source viewer has infrastructure for supporting content formatters. A content formatter’s job is primarily to adjust the whitespace between words in a document to match a configured style. A JFace formatter can be configured to operate on an entire document or on a region within a document. Typically, if a document contains several content types, a different formatting strategy will be used for each type. As usual, a formatter is installed from your subclass of SourceViewerConfiguration. To provide a configured formatter instance, override the method getContentFormatter. Most of the time, you can create an instance of the standard formatting class, MultiPassContentFormatter. This class requires that you specify a single master formatting strategy and optionally a slave formatting strategy for each partition in your document.
The following snippet from the Java source configuration installs a master strategy (JavaFormattingStrategy) that is used to format Java code and a slave formatting strategy for formatting comments:
MultiPassContentFormatter formatter= new MultiPassContentFormatter( getConfiguredDocumentPartitioning(viewer), IDocument.DEFAULT_CONTENT_TYPE); formatter.setMasterStrategy( new JavaFormattingStrategy()); formatter.setSlaveStrategy( new CommentFormattingStrategy(...), IJavaPartitions.JAVA_DOC);
The work of formatting the characters in the document is performed by the formatting-strategy classes that are installed on the formatter. JFace doesn’t provide much common infrastructure for doing this formatting as it is based largely on the syntax of the language you are formatting.
Finally, you will need to create an action that invokes the formatter. No generic formatting action is defined by the text infrastructure, but it is quite easy to create one of your own. The action’s run method can simply call the following on the source viewer to invoke the formatter:
sourceViewer.doOperation(ISourceViewer.FORMAT);
Text editors have no public API to insert text. Furthermore, they do not expose their StyledText widget used to edit the underlying document. Therefore, inserting text in the currently active editor is not trivial. One could start with the SWT shell, search the widget containment hierarchy, and eventually locate the widget to enter text into. Fortunately, an easier way is available.
Text editors obtain a document model by using a document provider. This provider functions as synchronizer for multiple editors, notifying each when the other changes the document. By acting as one of the editors on a document, one can easily insert text into the editor of choice. The next code snippet locates the active editor, gets its document provider, requests the underlying document, and inserts some text into it:
IWorkbenchPage page = ...; IEditorPart part = page.getActiveEditor(); if (!(part instanceof AbstractTextEditor) return; ITextEditor editor = (ITextEditor)part; IDocumentProvider dp = editor.getDocumentProvider(); IDocument doc = dp.getDocument(editor.getEditorInput()); int offset = doc.getLineOffset(doc.getNumberOfLines() -4); doc.replace(offset, 0, pasteText+" ");
The provider will notify all other editors to update their presentation as a result.
ITextEditor has two similar concepts for singling out a portion of the editor contents: selection and highlight range. The selection is the highlighted segment of text typically set by the user when dragging the mouse or moving the caret around while holding the shift key. The selection can be obtained programmatically via the editor’s selection provider:
ITextEditor editor = ...;//the text editor instance ISelectionProvider sp = editor.getSelectionProvider(); ISelection selection = sp.getSelection(); ITextSelection text = (ITextSelection)selection;
The selection can also be changed using the selection provider, but ITextEditor provides a convenience method, selectAndReveal, that will change the selection and also scroll the editor so that the new selection is visible.
Highlight range also defines a subset of the editor contents, but it cannot be directly manipulated by the user. Its most useful feature is that the editor can be toggled to show only the current highlight range. This is used in the Java editor to support the “Show source of selected element only” mode. The default implementation of ITextEditor also links the highlight range to the ISourceViewer concept of range indication. The source viewer in turn creates an annotation in the vertical ruler bar that shades the portion of the editor corresponding to the highlight range. To use the Java editor as an example again, you’ll notice this shading indicates the range of the method currently being edited. The following snippet sets the highlight range of a text editor and then instructs the editor to display only the highlighted portion:
ITextEditor editor = ...; editor.setHighlightRange(offset, length, true); editor.showHighlightRangeOnly(true);
By default, double-clicking in a text editor will cause the complete word under the mouse to be selected. When creating your own text-based editor, you can change this behavior from your SourceConfiguration by overriding the method getDoubleClickStrategy. The method must return an instance of ITextDoubleClickStrategy, a simple interface that gets called whenever the user double-clicks within the editor area.
When double-clicking in a text-based editor, the selection will typically change to incorporate the nearest enclosing syntactic unit. For example, clicking next to a brace in the Java editor will expand the selection to include everything in the matched set of braces. Double-clicking in the sample HTML editor will cause the word under the mouse to be selected or, if no word is under the mouse, the entire HTML element. This involves scanning the document forwards and backwards from the current cursor position and then setting the selection accordingly. The following example is a bit contrived and is English-specific, but it illustrates the usual steps by selecting the text range up to the next vowel. If no vowel is found, nothing is selected:
public void doubleClicked(ITextViewer part) {
final int offset = part.getSelectedRange().x;
int length = 0;
IDocument doc = part.getDocument();
while (true) {
char c = doc.getChar(offset + length);
if (c=='a'||c=='e'||c=='i'||c=='o'||c=='u')
break;
if (offset + ++length >= doc.getLength())
return;
}
part.setSelectedRange(offset, length);
}
Of course, double-clicking doesn’t have to change the selection. You can perform any manipulation you want on the editor or its document from within a double-click strategy implementation. For example, double-clicking could trigger Content Assist or present possible refactorings. The only real restriction is that you can’t use double-click to perform a manipulation on an existing text selection as the first click of the double-click will have eliminated any previous selection.
Advanced text editors, such as those for programming languages or Web development, often have an underlying object model that represents the elements being shown in the editor. Such models are often used for semantic manipulation, such as refactoring, or for querying by other tools. As the user types in such an editor, the text can become out of sync with this underlying model. For example, an HTML editor may have a model that contains information about hyperlinks in and out of the document. As the user edits the document, adding or removing links and anchors, this model will invariably become out of date. If another tool makes a query on this model while it is out of date, invalid results may occur.
When the editor is operating on a file in the workspace, one approach to solving this problem is to use an incremental project builder to update the model. With autobuild enabled, the model would be updated every time the user saved the document. However, if autobuild is turned off, this strategy can result in long periods of time in which the model is out of date. If the model update is a costly computation, this might be the only practical trade-off. By turning autobuild off, the user can control the build frequency.
For a lighter-weight model that can be updated with little overhead, it is preferable to update the model more frequently. This is where a text editor reconciler comes into play. When a reconciler is installed on an editor, a queue is created to record all the changes that occur. Each change is represented as a DirtyRegion object, and the regions are added to a DirtyRegionQueue. The reconciler removes items from the queue and updates the model accordingly. If several edits occur in the document before the reconciler processes them, the DirtyRegion objects in the queue will merge where appropriate. For example, continuously typing in an editor will create one large dirty region rather than individual dirty regions for each character pressed. The reconciler can analyze the DirtyRegion objects to see what portions of the text have been invalidated, allowing it to perform more optimized updates.
A reconciler can be installed by overriding the getReconciler method declared in your subclass of SourceViewerConfiguration. You can choose from a couple of built-in reconcilers, or you can implement the IReconciler interface directly. Most of the time, you can use MonoReconciler, an implementation that does not distinguish between reconciling in different document partitions. This reconciler runs in a low-priority background thread, allowing multiple changes to be added to the queue before processing them. Performing the reconciliation asynchronously allows the user to continue editing the document while it is being reconciled, although this results in a short period in which the document will be out of date.
Note that reconcilers are generally not an adequate replacement for builders but can play a complementary role. For example, in the JDT plug-ins, the reconciler performs a parse of the class as the user makes changes. This parser gathers enough information to update the Java model, allowing accurate content assist, refactoring, and other common operations. When the user saves and builds the file, an incremental builder performs a full compilation, generating class files and recompiling any other files affected by the change. This way, the expensive processing is deferred, but the domain model always stays up to date.