
Chapter 14. A World of Uses: Noncommercial Applications Based on RDF
My first introduction to RDF didn’t come about because I developed a sudden and overwhelming interest in the Semantic Web. My interest had more prosaic beginnings than that—through exposure to RDF/XML in Mozilla, an open source browser/application framework.
Then and now, RDF/XML formed the format for the table of contents (TOC)-based structures that formed favorites lists, the sidebar, and pretty much anything expressible in a table of contents infrastructure. One of the frustrating things about the effort, though, is that it seemed that the RDF/XML used by Mozilla kept changing. And it also seemed that I couldn’t get the knack of using it correctly. So, I decided the only thing to do was access the RDF specifications directly and learn about RDF and RDF/XML from the source. The rest, as they say, is history, culminating in my writing this book.
One mark of a mature specification is its use within commercial products, and we’ll look at commercial applications of RDF and RDF/XML in the next chapter. However, these commercial products are based, in principle and in spirit, on earlier open source and noncommercial applications built by a specification’s earliest adopters. Without these uses of RDF, the path wouldn’t be laid for the business use of RDF.
This chapter takes a look at some of what I classify as noncommercial uses of RDF and RDF/XML, open source or not. The applications included are just a sampling of those available and include applications that haven’t been covered elsewhere in the book. The best place to start is Mozilla.
Mozilla
Mozilla started out as a redesign of Netscape’s browser but ended up being more than anyone expected. It became an effort to develop a component-based architecture and framework for a development environment, on which Mozilla, the browser, was then implemented. Because of this underlying framework, other applications could use bits and pieces of Mozilla, or the underlying technology, for their own efforts.
Right from the start, Mozilla incorporated the use of RDF/XML to manage all TOC- and other tree-structured data, such as the favorites list, sidebar, and so on. As stated earlier, it was through Mozilla’s work with RDF/XML that I was originally introduced to the specification—an introduction that colors my view of RDF as more of a “practical” specification then one necessary for Semantic Web efforts.
Tip
You can download the most recent release of Mozilla at http://mozilla.org. Developer documentation is located at http://mozilla.org/catalog/, and a development forum and repository is at http://www.mozdev.org/.
Mozilla contains many components, but the one we’ll focus on because of its association with RDF/XML is XUL (eXtensible User interface Language)—the component that controls the user interface, including all windowing and window components.
XUL Briefly
Rather than hardcode a user interface for each of the visual components of Mozilla, the Mozilla Working Group decided to use XML to define user interface components and then provide behind-the-scenes functionality to make these components active. By using this approach, rather than having to use some form of code to change or create a new application interface, you’d just create a new XML file, hooking in the appropriate functionality as needed.
For instance, the XML to create a window with two buttons would be as follows:
<?xml version="1.0"?>
<?xml-stylesheet href="chrome://global/skin/" type="text/css"?>
<window id="example-window" title="Example 2.2.1"
xmlns:html="http://www.w3.org/1999/xhtml"
xmlns="http://www.mozilla.org/keymaster/gatekeeper/there.is.only.xul">
<button label="Practical"/>
<button label="RDF"/>
</window>Opening the window in Mozilla, or some other browser that supports XUL, would show a window similar to that in Figure 14-1. Of course, clicking on any of the buttons doesn’t do anything at this point; you’ll need to use a little scripting to add functionality.
Clicking on a button or a list item or opening or closing windows all trigger events that you can trap and use to perform some action, such as the following, added to a button to call a JavaScript function that’s defined in an external file:
<button label="Open New Window" oncommand="openBrowser( );" />
The script is then included in the XUL document with the script tag:
<script src="open.js" />
Mozilla has ways of connecting to the core functionality of the underlying engine through XPConnect, in addition to XBL (Extensible Binding Language), which offers a way of binding behaviors to an XUL widget. However, both of these are considerably beyond the scope of this book. What is within scope is RDF/XML’s place in the Mozilla effort, through its use with templates, discussed next.
XUL Templates
When building a new application interface, for the most part
you’ll add static components—adding the XML for one button, one
browser window, one menu or toolbar, etc. However, you may also want
to display a list or treeview based
on larger amounts of data likely to change over time. In this case,
you’ll want to use an XUL template in your XML and then connect the
template with an external RDF/XML datafile. Using this approach, the
data in the RDF/XML file can change without your having to alter the
XML for the user interface directly.
At its simplest, a template is nothing more than a set of rules
that maps XUL components to RDF/XML elements, repeating the XUL
components for each RDF/XML element found that matches the specific
rule. Templates can be used with most XUL widgets, including listboxes
and buttons, but one of the more common uses is binding RDF/XML data
into a treeview.
A treeview control is
actually a container for several other XUL widgets, each of which
controls a different part of the treeview. The structure of the widgets
is:
treeOuter
treeviewcontainertreecolsContainer for
treecolwidgetstreecolA column within the
treeviewtreechildrenContainer for the data rows
treeitemControls the top row within the
treeviewand also the behavior of each other row within thetreeviewtreerowOne individual row in the
treeviewtreecellOne individual cell (cross-section between a unique column and a unique row)
Before showing you the XML for treeview as well as the RDF/XML data source,
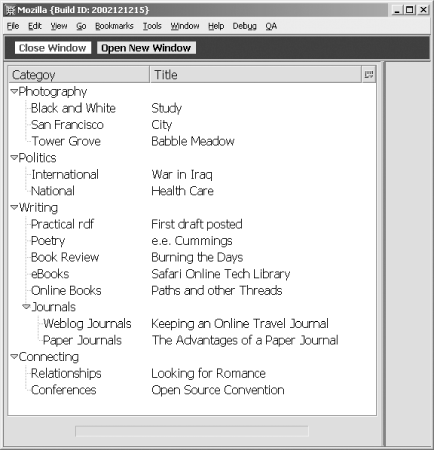
Figure 14-2 shows an XUL
application in development that’s using a treeview to manage data in the left-most box
in the page. This particular view is two columns, with a category in
the left column, and a title in the right. Clicking on any category
opens up the display and shows all the titles underneath. One of the
rows can be selected and the column widths altered by moving the
sizing bar between the columns.
The first part of the XUL created is the tree definition. Among
the attributes you can define is one called datasources, and it’s to this attribute that
you assign an RDF/XML document:
<tree flex="1" width="200" height="200"
datasources="postings.rdf" ref="urn:weblog:data">In addition to the datasources attribute, there’s also a
ref attribute that points to the
start of data access within the document. This is matched to an
rdf:about value, which you’ll see
later when we get to the datafile.
The next XML added to the document defines the columns and provides a titlebar for each:
<treecols> <treecol id="category" label="Category" primary="true" flex="1"/> <treecol id="title" label="Title" flex="2"/> </treecols>
Following the columns, the template element and the rule element
are added, because at this point, all of the treeview structure is connected to the data
in some way. This simple case needs only one rule because there is no
processing splitting the data across different columns or some other
specialized processing.
Following the template and rule is the treeitem element, containing an attribute,
uri, which tells the processor to
repeat this element for every resource within the file:
<treeitem uri="rdf:*">
The “resource” referenced is the resource identified with a URI.
It is defined using a standard rdf:Description element within the
RDF/XML.
Finally, the rest of the treeview elements are added; for every
left-side treecell, the data
defined as category is displayed.
For every right treecell, the data
defined as title is displayed, as
shown next.
<treerow> <treecell label="rdf:http://weblog.burningbird.net/postings#category"/> <treecell label="rdf:http://weblog.burningbird.net/postings#title"/> </treerow>
Since the application isn’t using any advanced template
processing, the entire treeview
isn’t very large (see Example
14-1, which contains a complete XUL application containing the
treeview just described).
<?xml version="1.0"?>
<?xml-stylesheet href="chrome://global/skin" type="text/css"?>
<window xmlns:html="http://www.w3.org/1999/xhtml"
xmlns="http://www.mozilla.org/keymaster/gatekeeper/there.is.only.xul"
align="vertical">
<tree flex="1" width="500"
datasources="postings.rdf" ref="urn:weblog:data">
<treecols>
<treecol id="category" label="Category" primary="true" flex="1"/>
<treecol id="title" label="Title" flex="2"/>
</treecols>
<template>
<rule>
<treechildren>
<treeitem uri="rdf:*">
<treerow>
<treecell label="rdf:http://weblog.burningbird.net/postings#category"/>
<treecell label="rdf:http://weblog.burningbird.net/postings#title"/>
</treerow>
</treeitem>
</treechildren>
</rule>
</template>
</tree>
</window>If you were to open this page in a browser that supports XUL,
such as Mozilla, you’d see only an empty treeview control because you also need the
RDF/XML document, postings.rdf.
The RDF/XML used for XUL templates isn’t anything odd or unusual, and no special namespaces are needed other than those you create for your own data. The structure of the data is to some extent determined by the outcome of the display, but the RDF/XML is, itself, nothing more than valid RDF/XML (with a caveat, as you’ll see later).
For this use, the categories and their associated titles become
list items within a container, a Seq to be exact. Each category is given a
different container, and each title a different list item. This
provides the structure of the TOC. To add the data, each resource is
defined in a separate block, with properties matching the cell values
contained within the resource. Though it’s a bit large for the book,
the entire RDF/XML document for the example is duplicated in Example 14-2 as it’s important to
see the mapping between the RDF/XML document, the template, and the
treeview.
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:bbd="http://weblog.burningbird.net/postings#">
<rdf:Description rdf:about="urn:weblog:photos">
<bbd:category>Photography</bbd:category>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:photos:bwstudy">
<bbd:category>Black and White</bbd:category>
<bbd:title>Study</bbd:title>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:photos:sanfran" >
<bbd:category>San Francisco</bbd:category>
<bbd:title>City</bbd:title>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:photos:tower">
<bbd:category>Tower Grove</bbd:category>
<bbd:title>Babble Meadow</bbd:title>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:politics">
<bbd:category>Politics</bbd:category>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:politics:international">
<bbd:category>International</bbd:category>
<bbd:title>War in Iraq</bbd:title>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:politics:national">
<bbd:category>National</bbd:category>
<bbd:title>Health Care</bbd:title>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:writing">
<bbd:category>Writing</bbd:category>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:writing:rdfbook">
<bbd:category>Practical rdf</bbd:category>
<bbd:title>First draft posted</bbd:title>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:writing:poetry">
<bbd:category>Poetry</bbd:category>
<bbd:title>e.e. Cummings</bbd:title>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:writing:review">
<bbd:category>Book Review</bbd:category>
<bbd:title>Burning the Days</bbd:title>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:writing:ebook">
<bbd:category>eBooks</bbd:category>
<bbd:title>Safari Online Tech Library</bbd:title>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:writing:online">
<bbd:category>Online Books</bbd:category>
<bbd:title>Paths and other Threads</bbd:title>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:writing:journal">
<bbd:category>Journals</bbd:category>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:writing:journal:weblog">
<bbd:category>Weblog Journals</bbd:category>
<bbd:title>Keeping an Online Travel Journal</bbd:title>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:writing:journal:paper">
<bbd:category>Paper Journals</bbd:category>
<bbd:title>The Advantages of a Paper Journal</bbd:title>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:connecting">
<bbd:category>Connecting</bbd:category>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:connecting:relationships">
<bbd:category>Relationships</bbd:category>
<bbd:title>Looking for Romance</bbd:title>
</rdf:Description>
<rdf:Description rdf:about="urn:weblog:connecting:conferences">
<bbd:category>Conferences</bbd:category>
<bbd:title>Open Source Convention</bbd:title>
</rdf:Description>
<rdf:Seq rdf:about="urn:weblog:data">
<rdf:li>
<rdf:Seq rdf:about="urn:weblog:photos">
<rdf:li rdf:resource="urn:weblog:photos:bwstudy"/>
<rdf:li rdf:resource="urn:weblog:photos:sanfran"/>
<rdf:li rdf:resource="urn:weblog:photos:tower"/>
</rdf:Seq>
</rdf:li>
<rdf:li>
<rdf:Seq rdf:about="urn:weblog:politics">
<rdf:li rdf:resource="urn:weblog:politics:international"/>
<rdf:li rdf:resource="urn:weblog:politics:national"/>
</rdf:Seq>
</rdf:li>
<rdf:li>
<rdf:Seq rdf:about="urn:weblog:writing">
<rdf:li rdf:resource="urn:weblog:writing:rdfbook"/>
<rdf:li rdf:resource="urn:weblog:writing:poetry"/>
<rdf:li rdf:resource="urn:weblog:writing:review"/>
<rdf:li rdf:resource="urn:weblog:writing:ebook"/>
<rdf:li rdf:resource="urn:weblog:writing:online"/>
<rdf:li>
<rdf:Seq rdf:about="urn:weblog:writing:journal">
<rdf:li rdf:resource="urn:weblog:writing:journal:weblog"/>
<rdf:li rdf:resource="urn:weblog:writing:journal:paper"/>
</rdf:Seq>
</rdf:li>
</rdf:Seq>
</rdf:li>
<rdf:li>
<rdf:Seq rdf:about="urn:weblog:connecting">
<rdf:li rdf:resource="urn:weblog:connecting:relationships"/>
<rdf:li rdf:resource="urn:weblog:connecting:conferences"/>
</rdf:Seq>
</rdf:li>
</rdf:Seq>
</rdf:RDF>Note that the top-level rdf:Seq is given a URI of urn:weblog:data, matching the starting
position given in the template. Each major category is given its own
sequence and its own resource. Each title item is listed as an
rdf:li and defined as a separate
resource with both category and title.
When the data is processed, the rule attached in the template
basically states that all category values are placed in the left
column, and all titles in the right. Since the major categories don’t
have titles, the treecells for
these values are blank. However, clicking on the drop-down indicator
next to the categories displays both the minor category (subcategory)
and titles for each row.
Earlier I mentioned there was a caveat about the validity of the
RDF/XML used in the example. The RDF/XML document shown in Example 14-2 validates with the
RDF Validator, but not all RDF/XML documents used in providing data
for templates in Mozilla do. For instance, I separated out each
rdf:Seq element, something that’s
not necessary with XUL but is necessary to maintain the RDF/XML
striping (arc-node-arc-node). In addition, many of the XUL RDF/XML
documents also don’t qualify the about or resource attributes, which is discouraged in
the RDF specifications. This doesn’t generate an error, but does
generate warnings. However, when you create your own RDF/XML
documents, you can use the qualified versions without impacting on the
XUL processing.
Tip
The Mozilla group wasn’t the only organization to use RDF/XML to facilitate building a user interface. The Haystack project at MIT, http://haystack.lcs.mit.edu/, uses RDF as the primary data modeling framework.
Creative Commons License
The Creative Commons (CC) is an organization formed in 2002 to facilitate the movement of artists’ work to the public domain. One of the outputs from the organization is the Creative Commons licenses: licenses that can be attached to a work of art such as a writing, a graphic, or a song, that provides information about how that material can be used and reused by others.
Tip
The Creative Commons web site is at http://creativecommons.org.
The CC licenses don’t replace copyright and fair use laws; they primarily signal an artist’s interest in licensing certain aspects of his copyright to the public, such as the right to copy a work, to derive new works from an original creation, and so on. The license is associated with the art in whatever manner is most expeditious, but if the art is digitized on the Web, the license is usually included with the art as RDF/XML.
The RDF/XML for use can be generated at the CC web site when you pick what particular license you want to apply. For instance, the following RDF/XML is generated when you pick a license that requires attribution and doesn’t allow derivative works and/or commercial use:
<rdf:RDF xmlns="http://web.resource.org/cc/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<Work rdf:about="">
<license rdf:resource="http://creativecommons.org/licenses/by-nd-nc/1.0" />
</Work>
<License rdf:about="http://creativecommons.org/licenses/by-nd-nc/1.0">
<requires rdf:resource="http://web.resource.org/cc/Attribution" />
<permits rdf:resource="http://web.resource.org/cc/Reproduction" />
<permits rdf:resource="http://web.resource.org/cc/Distribution" />
<prohibits rdf:resource="http://web.resource.org/cc/CommercialUse" />
<requires rdf:resource="http://web.resource.org/cc/Notice" />
</License>
</rdf:RDF>Normally this RDF/XML is included as part of a larger HTML block, and the RDF is enclosed in HTML comments to allow the page to validate as XHTML. Unfortunately, since HTML comments are also XML comments, this precludes accessing the RDF/XML directly from the page for most parsers, which will ignore the data much as the HTML browsers do.
The CC RDF Schema makes use of several Dublin Core elements, such as dc:title, dc:description, dc:subject and so on. You can see the model
breakdown at http://creativecommons.org/learn/technology/metadata/implement#learn
and the schema itself at http://creativecommons.org/learn/technology/metadata/schema.rdf.
The schema includes definitions for the CC elements, though it uses the
dc:description and dc:title elements for this rather than the
RDFS equivalents of rdfs:comment and
rdfs:label. The namespace for the
Creative Commons schema is http://web.resource.org/cc/, and the prefix
usually used is cc.
Though CC makes use of Dublin Core elements, the data contained
within these elements does differ from other popular uses of Dublin
Core. A case in point is dc:creator.
For the most part, dc:creator usually
contains a string literal representing the name of the person who
created the work. However, the CC folks, following from an earlier
overly involved discussion in the RDF Interest Group surrounding the
concept that “strings don’t create anything,” provided a bit more detail
— in this case, that a dc:creator is
an “agent,” with a dc:title
equivalent to the agent’s name. In the following RDF/XML, the dc:creator field is boldfaced to demonstrate
the structure of the data used by CC:
<rdf:RDF xmlns="http://web.resource.org/cc/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<Work rdf:about="http://rdf.burningbird.net">
<dc:title>Practical RDF</dc:title>
<dc:date>2003-2-1</dc:date>
<dc:description>Sample CC license for book</dc:description>
<dc:creator><Agent>
<dc:title>Shelley Powers</dc:title>
</Agent></dc:creator>
<dc:rights><Agent>
<dc:title>O'Reilly</dc:title>
</Agent></dc:rights>
<dc:type rdf:resource="http://purl.org/dc/dcmitype/Text" />
<license rdf:resource="http://creativecommons.org/licenses/by-nd-nc/1.0" />
</Work>
<License rdf:about="http://creativecommons.org/licenses/by-nd-nc/1.0">
<requires rdf:resource="http://web.resource.org/cc/Attribution" />
<permits rdf:resource="http://web.resource.org/cc/Reproduction" />
<permits rdf:resource="http://web.resource.org/cc/Distribution" />
<prohibits rdf:resource="http://web.resource.org/cc/CommercialUse" />
<requires rdf:resource="http://web.resource.org/cc/Notice" />
</License>
</rdf:RDF>The data type for dc:creator is
PCDATA, which means that the CC innovation wouldn’t validate using the
DC DTD. However, there’s no requirement that RDF/XML validate, only that
it be well formed. Still, if you’re processing this field for a string
representing a name, and you get this structure instead, you’re going to
have some interesting processing challenges. All of this demonstrates
that, though RDF helps in the process of defining a metamodel for data,
it doesn’t necessarily close all the doors leading to
confusion.
MIT’s DSpace System Documentation
DSpace is a repository and multitier application being developed by MIT and HP Labs to track the intellectual output at MIT. It’s based in Java and implemented as a J2EE application residing on Unix and using PostgreSQL as a database. The application has been carefully documented, including detailed installation instructions, as well as excellent overall architecture and usage documentation.
Tip
DSpace is a Source Forge project, with a home page at http://www.dspace.org/. Download the source at http://sourceforge.net/projects/dspace/ or at the HP Labs download page (at http://www.hpl.hp.com/research/downloads/). View systems documentation at http://dspace.org/technology/system-docs/index.html. DSpace is open source, available under a BSD license.
DSpace works by allowing to the establishment of major organization divisions, which the project calls communities. Within the communities, intellectual output is further categorized into collections. Each unique output item gets a Dublin Core record attached to it and is then combined with any external material such as images into a bundle. This bundle is then formatted as a bitstream, and the format for the bitstream is attached to it. With this infrastructure in place, each output is a complete package including the metadata information associated with it, through the addition of the Dublin Core record.
DSpace users can submit a document or other material for inclusion with the system, and its inclusion can be reviewed and accepted or rejected. If accepted, the material can be uploaded; information about the material is then available for search and browsing. In addition, when the material is loaded, it’s assigned a handle based on the CNRI Handle System for direct access to the material.
Tip
More information on CNRI can be found at http://www.handle.net/.
The type of material that can be accommodated within DSpace includes documents in all forms, books, multimedia, computer applications, data sets, and so on. In addition to getting access to the material through search, browsing, or directly through the handle, users can also subscribe to a specific collection within a DSpace community and be notified by email when a new item has been added.
FOAF: Friend-of-a-Friend
For use of RDF to become widespread, its growth must occur in two directions: through use in sophisticated commercial applications such as those detailed in the next chapter, and through small, friendly, easy-to-use, and open source applications such as FOAF — Friend-of-a-Friend.
Tip
You can find out more about FOAF at the its main web site at http://rdfweb.org/foaf/. In addition, an FOAF Wiki is at http://rdfweb.org/rweb/wiki/wiki.pl?FoafVocab. The RDF Schema for FOAF is at http://xmlns.com/foaf/0.1/. A mailing list for interested persons can be found at http://rdfweb.org/pipermail/rdfweb-dev/.
FOAF is a way of providing affiliation and other social
information about yourself; it’s also a way of describing a network of
friends and others we know for one reason or another, in such a way that
automated processes such as web bots can find this information and
incorporate it with other FOAF files. The data is combined in a social
network literally based on one predicate: knows.
Consider the scenario: I know Dorothea and she knows Mark and he
knows Ben and Ben knows Sam and Sam knows... and so on. If the old adage
about there being only six degrees of separation between any two people
in the world is true, it should take only six levels of knows to connect Dorothea to Mark to Ben and
so on. Then, once the network is established, it’s very easy to verify
who a person knows and in what context, and you have what could become a
web of knowledge, if not exactly a web of trust.
The FOAF namespace is http://xmlns.com/foaf/0.1/, and the classes
are Organization, Project, Person, and Document. There is no special meaning attached
to each of these classes, they’re meant to be taken at face value. In
other words, a document is a document, not a special type of document.
Though the other classes are available, most FOAF files are based on
Person, and that’s what’s most
used.
There are several FOAF properties, many of which are rarely used,
a few of which are even a joke (dnaChecksum comes instantly to mind). However,
almost every FOAF files uses the following properties:
mboxAn Internet email address in a valid URI format
surnamePerson’s surname
nickPerson’s nickname
firstnameFirst name of person
givennameGiven name of person
homepagePerson’s home page URL
projectHomepageURL of a project home page
titlePerson’s title or honorific
phonePerson’s phone
publicationsLink to person’s publications
knowsA person the person knows
There are other properties, but if you examine several FOAF files for people you’ll find that the ones just listed are the most commonly used. In fact, the best way to understand how to create an FOAF file for yourself is to look at the FOAF files for people you know. Another way is to create the beginnings of a FOAF file using the FOAF-A-Matic.
The FOAF-A-Matic
I derived the name for my Query-O-Matic tools described in Chapter 10 in some part from the FOAF-A-Matic name. However, unlike my tools, which query existing RDF/XML, the FOAF-A-Matic is used to generate the RDF/XML for a specific FOAF file.
Tip
Access the original FOAF-A-Matic at http://www.ldodds.com/foaf/foaf-a-matic.html. Work is underway for a new version of the FOAF-A-Matic at the following web site: http://www.ldodds.com/wordtin/Wiki.jsp?page=FOAFaMaticMark2.
The FOAF-A-Matic is a web form with several fields used to record information such as name, home page, email, workplace information, and so on. In addition, the form also allows you to specify people that you know, including their name and a page to see more about them. In the example, I added two people: Simon St.Laurent, the editor of this book, and Dorothea Salo, one of the tech editors. When the fields are filled in, clicking the FOAF Me! button generates the RDF/XML, as shown in Example 14-3. You can then copy this, save it to a file, and modify the values—changing or adding new properties and more friends, whatever.
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:foaf="http://xmlns.com/foaf/0.1/">
<foaf:Person>
<foaf:name>Shelley Powers</foaf:name>
<foaf:title>Ms</foaf:title>
<foaf:firstName>Shelley</foaf:firstName>
<foaf:surname>Powers</foaf:surname>
<foaf:nick>Burningbird</foaf:nick>
<foaf:mbox_sha1sum>cd2b130288f7c417b7321fb51d240d570c520720</foaf:mbox_sha1sum>
<foaf:homepage rdf:resource="http://weblog.burningbird.net"/>
<foaf:workplaceHomepage rdf:resource="http://burningbird.net"/>
<foaf:workInfoHomepage rdf:resource="http://burningbird.net/about.htm"/>
<foaf:schoolHomepage rdf:resource="http://www.cwu.edu/"/>
<foaf:knows>
<foaf:Person>
<foaf:name>Simon St.Laurent</foaf:name>
<foaf:mbox_sha1sum>65d7213063e1836b1581de81793bfcb9ad596974</foaf:mbox_sha1sum>
<rdfs:seeAlso rdf:resource="http://www.simonstl.com/"/>
</foaf:Person>
</foaf:knows>
<foaf:knows>
<foaf:Person>
<foaf:name>Dorothea Salo</foaf:name>
<foaf:mbox_sha1sum>69d0c538f12014872164be6a3c16930f577388a8</foaf:mbox_sha1sum>
<rdfs:seeAlso rdf:resource="http://www.yarinareth.net/caveatlector/"/>
</foaf:Person></foaf:knows>
</foaf:Person>
</rdf:RDF>Notice in the example that the property mbox_shalsum is used instead of mbox. That’s because one of the options used
to generate the file was the ability to encode the email address so
that it can’t easily be scraped on the Web by email spambots—annoying little critters.
Notice also in the example that rdfs:seeAlso is used to map to a person’s
URL of interest. FOAF is first and foremost RDF/XML, which means the
data it describes can be combined with other related, valid
RDF/XML.
Once the FOAF file is to your liking, you can link to it from
your home page using the link tag,
as so:
<link rel="meta" type="application/rdf+xml" href="my-foaf-file.xrdf" />
This enables FOAF autodiscovery, or automatic discovery of your FOAF file by web bots and other friendly critters. Speaking of friendly critters, what else can you do with your FOAF file?
FOAF Technologies
Any technology that can work with RDF/XML can work with FOAF data. You can query FOAF files to find out who knows whom, to build a page containing links to your friends’ pages, and so on. However, in addition to using traditional RDF/XML technologies with the FOAF data, there are also some FOAF-specialized technologies.
Edd Dumbill, the editor of XML.com, created what is known as the FOAFBot. This automated process sits quietly in the background monitoring an IRC (Internet Relay Chat) channel until such time as a member of the channel poses a question to it. For instance, at the FOAFBot web site a recorded question and answer exchange between an IRC member and the FOAFBot is:
<edd> foafbot, edd's name
<foafbot> edd's name is 'Edd Dumbill', according to Dan Brickley,
Anon35, Niel Bornstein, Jo Walsh, Dave Beckett, Edd Dumbill,
Matt Biddulph, Paul FordFOAFBot has access to a knowledge base consisting of data that’s been gleaned from FOAF files on the Internet. You can read more about FOAFBot and download the Python source code at http://usefulinc.com/foaf/foafbot. (Note the source code is built on Dave Beckett’s Redland framework, described in Chapter 11.)
In the FOAFBot page that opens, there’s also a link to an article about how to digitally sign your FOAF file.
Another use of FOAF data is the codepiction project, which uses the foaf:depiction property to search for images
in which two or more people are depicted together in the same photo.
You can read more about the codepiction project at http://rdfweb.org/2002/01/photo/index.html and
see a working prototype at http://swordfish.rdfweb.org/discovery/2001/08/codepict/.
Finally, there’s been effort to extend the concept of FOAF to a corporate environment, including defining a new vocabulary more in line with corporate connectivity than personal connectivity. You can check out the work on this project, called FOAFCorp, at http://rdfweb.org/foaf/corp/intro.html.