
Chapter 13. XML
In a few short years, XML has grown from an obscure specification into the world’s de facto data language. XML stands for Extensible Markup Language. Whereas HTML is designed to express appearance, XML is designed to express raw information absent any implied notion about how the data should be rendered. It’s a simple language that is entirely text based, making it particularly well suited to travel over text-based protocols such as HTTP, and that has no predefined tags as HTML does. XML provides the rules. You provide the rest.
XML finds several applications in business and, increasingly, in everyday life. It provides a common data format for companies that want to exchange documents. It’s used by Web services to encode messages and data in a platform-independent manner. It’s even used to build Web sites, where it serves as a tool for cleanly separating content from appearance.
There’s little remarkable about XML in and of itself. What makes XML important is the fact that the computer industry has accepted it as a standard, and as such numerous tools are available for reading and writing XML. If someone hands you a large free-formatted text file containing thousands of records and your job is to get the records into a database, you’ll probably end up writing a parser to extract the records from the file and write them to the database. If the text file is an XML file, your job is much simpler. You can use one of the many XML parsers already available to read the records. XML doesn’t make your life easier because it’s a great language. It makes your life easier because tools for reading, writing, and manipulating XML data are almost as common as word processors.
When it comes to handling XML, nothing rivals the .NET Framework class library (FCL) for ease of use. A few simple statements will read an entire XML file and write its contents to a database, or query a database and write out the results as XML. It’s equally easy to perform XPath queries on XML documents or convert XML into HTML on the fly using XSL transformations.
This chapter is about the XML support in the FCL. A comprehensive treatment of the subject could easily fill 200 pages or more, so I’ll attempt to strike a reasonable balance between detail and succinctness. In the pages that follow, you’ll learn about the classes and namespaces that form the cornerstone for the FCL’s XML support. Before we start slinging code, however, let’s take a brief look at XML itself.
XML Primer
XML is a language for describing data and the structure of data. XML data is contained in a document, which can be a file, a stream, or any other storage medium, real or virtual, that’s capable of holding text. A proper XML document begins with the following XML declaration, which identifies the document as an XML document and specifies the version of XML that the document’s contents conform to:
<?xml version="1.0"?>
The XML declaration can also include an encoding attribute that identifies the type of characters contained in the document. For example, the following declaration specifies that the document contains characters from the Latin-1 character set used by Windows 95, 98, and ME:
<?xml version="1.0" encoding="ISO-8859-1"?>
The next example identifies the character set as UTF-16, which consists of 16-bit Unicode characters:
<?xml version="1.0" encoding="UTF-16"?>
The encoding attribute is optional if the document consists of UTF-8 or UTF-16 characters because an XML parser can infer the encoding from the document’s first five characters: “<?xml”. Documents that use other encodings should identify the encodings that they use to ensure that an XML parser can read them.
XML declarations are actually specialized forms of XML processing instructions, which contain commands for XML processors. Processing instructions are always enclosed in <? and ?> symbols. Some browsers interpret the following processing instruction to mean that the XML document should be formatted using a style sheet named Guitars.xsl before it’s displayed:
<?xml-stylesheet type="text/xsl" href="Guitars.xsl"?>
You’ll see this processing instruction used in an XML Web page near the end of this chapter.
The XML declaration is followed by the document’s root element, which is usually referred to as the document element. In the following example, the document element is named Guitars:
<?xml version="1.0"?> <Guitars> ... </Guitars>
The document element is not optional; every document must have one. The following XML is legal because Guitar elements are nested within the document element Guitars:
<?xml version="1.0"?> <Guitars> <Guitar> ... </Guitar> <Guitar> ... </Guitar> </Guitars>
The document in the next example, however, is not legal because it lacks a document element:
<?xml version="1.0"?> <Guitar> ... </Guitar> <Guitar> ... </Guitar>
Element names conform to a set of rules prescribed in the XML 1.0 specification, which you can read at http://www.w3.org/TR/REC-xml. The spec essentially says that element names can consist of letters or underscores followed by letters, digits, periods, hyphens, and underscores. Spaces are not permitted in element names.
Elements
Elements are the building blocks of XML documents. Elements can contain data, other elements, or both, and are always delimited by start and end tags. XML has no predefined elements; you define elements as needed to adequately describe the data contained in an XML document. The following document describes a collection of guitars:
<?xml version="1.0"?> <Guitars> <Guitar> <Make>Gibson</Make> <Model>SG</Model> <Year>1977</Year> <Color>Tobacco Sunburst</Color> <Neck>Rosewood</Neck> </Guitar> <Guitar> <Make>Fender</Make> <Model>Stratocaster</Model> <Year></Year> <Color>Black</Color> <Neck>Maple</Neck> </Guitar> </Guitars>
In this example, Guitars is the document element, Guitar elements are children of Guitars, and Make, Model, Year, Color, and Neck are children of Guitar. The Guitar elements contain no data (just other elements), but Make, Model, Year, Color, and Neck contain data. The line
<Year></Year>
signifies an empty element—one that contains neither data nor other elements. Empty elements are perfectly legal in XML. An empty Year element can optionally be written this way for conciseness:
<Year/>
Unlike HTML, XML requires that start tags be accompanied by end tags. Therefore, the following XML is never legal:
<Year>1977
Also unlike HTML, XML is case-sensitive. A <Year> tag closed by a </year> tag is not legal because the cases of the Y’s do not match.
Because XML permits elements to be nested within elements, the content of an XML document can be viewed as a tree. Example 13-12 shows the tree that corresponds to the XML document above. The tree clearly diagrams the parent-child relationships among the document’s elements and is helpful in visualizing the document’s structure.
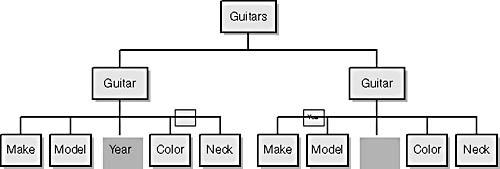
Attributes
XML allows you to attach additional information to elements by including attributes in the elements’ start tags. Attributes are name/value pairs. The following Guitar element expresses Year as an attribute rather than as a child element:
<Guitar Year="1977"> <Make>Gibson</Make> <Model>SG</Model> <Color>Tobacco Sunburst</Color> <Neck>Rosewood</Neck> </Guitar>
Attribute values must be enclosed in single or double quotation marks and may include spaces and embedded quotation marks. (An attribute value delimited by single quotation marks can contain double quotation marks and vice versa.) Attribute names are subject to the same restrictions as element names and therefore can’t include spaces. The number of attributes an element can be decorated with is not limited.
When defining a document’s structure, it’s sometimes unclear—especially to XML newcomers—whether a given item should be defined as an attribute or an element. In general, attributes should be used to define out-of-band data and elements to define data that is integral to the document. In the example above, it probably makes sense to define Year as an element rather than an attribute because Year provides important information about the instrument in question. But consider the following element definition:
<Guitar Image="MySG.jpeg"> <Make>Gibson</Make> <Model>SG</Model> <Year>1977</Year> <Color>Tobacco Sunburst</Color> <Neck>Rosewood</Neck> </Guitar>
The Image attribute contains additional information that an application might use to decorate a table containing information about the guitar with a picture. Because no one other than the software processing this document is likely to care about the image, and since the image is an adjunct to (rather than a part of) the guitar’s definition, Image is properly cast as an attribute instead of an element.
CDATA, PCDATA, and Entity References
Textual data contained in an XML element can be expressed as character data (CDATA), parsed character data (PCDATA), or a combination of the two. Data that appears between <![CDATA[ and ]]> tags is CDATA; any other data is PCDATA. The following element contains PCDATA:
<Color>Tobacco Sunburst</Color>
The next element contains CDATA:
<Color><![CDATA[Tobacco Sunburst]]></Color>
And this one contains both:
<Color>Tobacco <![CDATA[Sunburst]]></Color>
XML parsers ignore CDATA but parse PCDATA—that is, interpret it as markup language. The practical implication is that you can put anything between <![CDATA[ and ]]> tags and an XML parser won’t care. Data not enclosed in <![CDATA[ and ]]> tags, however, must conform to the rules of XML.
Why does XML distinguish between CDATA and PCDATA? Certain characters—notably <, >, and &—have special meaning in XML and must be enclosed in CDATA sections if they’re to be used verbatim. For example, suppose you wanted to define an element named Range whose value is “0 < x < 100”. Because < is a reserved character, you can’t define the element this way:
<Range>0 < x < 100</Range>
You can, however, define it this way:
<Range><[CDATA[0 < x < 100]]></Range>
CDATA sections are useful for including mathematical equations, code listings, and even other XML documents in XML documents.
Another way to include <, >, and & characters in an XML document is to replace them with entity references. An entity reference is a string enclosed in & and ; symbols. XML predefines the following entities:
|
Symbol |
Corresponding Entity |
|
< |
lt |
|
> |
gt |
|
& |
amp |
|
’ |
apos |
|
" |
quot |
Here’s an alternative method for defining a Range element with the value “0 < x < 100”:
<Range>0 < x < 100</Range>
You can also represent characters in PCDATA with character references, which are nothing more than numeric character codes enclosed in &# and ; symbols, as in
<Range>0 < x < 100</Range>
Character references are useful for representing characters that can’t be typed from the keyboard. Entity references are useful for escaping the occasional special character, but for large amounts of text containing arbitrary content, CDATA sections are far more convenient.
Namespaces
Namespaces, which are documented in the XML namespaces specification at http://www.w3.org/TR/REC-xml-names, are a crucial component of XML. Namespaces are a mechanism for qualifying element and attribute names to avoid naming collisions. The following example defines three namespaces and three namespace prefixes. It uses the namespace prefixes to qualify its elements so that the elements won’t clash if used in the same document with other elements having the same names but different definitions:
<?xml version="1.0"?> <win:Guitars xmlns:win="http://www.wintellect.com/classic-guitars" xmlns:gibson="http://www.gibson.com/finishes" xmlns:fender="http://www.fender.com/finishes"> <win:Guitar> <win:Make>Gibson</win:Make> <win:Model>SG</win:Model> <win:Year>1977</win:Year> <gibson:Color>Tobacco Sunburst</gibson:Color> <win:Neck>Rosewood</win:Neck> </win:Guitar> <win:Guitar> <win:Make>Fender</win:Make> <win:Model>Stratocaster</win:Model> <win:Year>1990</win:Year> <fender:Color>Black</fender:Color> <win:Neck>Maple</win:Neck> </win:Guitar> </win:Guitars>
In this example, the namespace names are URLs. You can name a namespace anything you want, but in accordance with the namespaces specification, developers typically use Uniform Resource Identifiers (URIs). The URI doesn’t have to point to anything; it just has to be unique. It’s not far-fetched to think that two different people somewhere in the world might define an XML element named “Guitar,” but it’s unlikely that both will assign it to a namespace named http://www.wintellect.com/classic-guitars.
A namespace prefix is valid for the element in which the prefix is declared and for the element’s children. In the preceding example, the win prefix is both declared and used in the same element:
<win:Guitars xmlns:win="http://www.wintellect.com/classic-guitars" ...>
It’s also used to qualify child elements:
<win:Guitar> ... </win:Guitar>
Interestingly enough, an element’s attributes are not automatically scoped to a namespace, even if the element is. In the following example, the Image attribute doesn’t belong to a namespace:
<win:Guitar Image="MySG.jpeg"> ... </win:Guitar>
However, you can use namespace prefixes to join attributes to namespaces:
<win:Guitar win:Image="MySG.jpeg"> ... </win:Guitar>
Because attributes are scoped by the elements they’re associated with, they’re typically used without namespace prefixes unless needs dictate otherwise.
XML also supports the concept of default namespaces. A default namespace is declared with an xmlns attribute but without a prefix. The element in which a default namespace is declared and all of its children automatically belong to that namespace unless otherwise specified. The following example is equivalent to the first example in this section, but it uses a default namespace—http://www.wintellect.com/classic-guitars—to eliminate the repeated win prefixes:
<?xml version="1.0"?> <Guitars xmlns="http://www.wintellect.com/classic-guitars" xmlns:gibson="http://www.gibson.com/finishes" xmlns:fender="http://www.fender.com/finishes"> <Guitar> <Make>Gibson</Make> <Model>SG</Model> <Year>1977</Year> <gibson:Color>Tobacco Sunburst</gibson:Color> <Neck>Rosewood</Neck> </Guitar> <Guitar> <Make>Fender</Make> <Model>Stratocaster</Model> <Year></Year> <fender:Color>Black</fender:Color> <Neck>Maple</Neck> </Guitar> <Guitars>
The Color elements in this example belong to the http://www.gibson.com/finishes and http://www.fender.com/finishes namespaces, but all other elements belong to http://www.wintellect.com/classic-guitars.
Why do document authors use XML namespaces, and when is it appropriate to omit them? XML elements intended for use by one person or application typically have no need for namespaces because their owner can prevent naming collisions. XML elements intended for public consumption, however, should be qualified with namespaces because their owner can’t control how they’re used or what other elements they’re used with.
Document Validity and Schemas
An XML document that conforms to the rules of XML is said to be a well-formed document. The following document is well-formed:
<?xml version="1.0"?> <Guitars> <Guitar> <Make>Gibson</Make> <Model>SG</Model> <Year>1977</Year> <Color>Tobacco Sunburst</Color> <Neck>Rosewood</Neck> </Guitar> <Guitar> <Make>Fender</Make> <Model>Stratocaster</Model> <Year>1990</Year> <Color>Black</Color> <Neck>Maple</Neck> </Guitar> </Guitars>
The document below is not well-formed. In fact, it contains three flaws. Can you spot them?
<?xml version="1.0"?> <Guitar> <Make>Gibson</Make> <Model>SG</Model> <Year>1977</Year> <Color>Tobacco Sunburst</Color> <Neck>Rosewood</Neck> </guitar> <Guitar> <Make>Fender</Make> <Model>Stratocaster</Model> <Year>1990 <Color>Black</Color> <Neck>Maple</Neck> </Guitar>
The first flaw is the lack of a document element. The second is the mismatched case in the first Guitar element’s start and end tags. The third is the complete lack of an end tag for the second Year element. Any of these flaws is sufficient to make an XML parser quit and report an error. An easy way to determine whether a document is well-formed is to load it into Internet Explorer. IE will apprise you of any well-formedness errors.
A more stringent test of a document’s veracity is whether or not the document is valid. A valid document is one that is well-formed and that conforms to a schema. Schemas define acceptable document structure and content. If you allow other companies to invoice your company by transmitting XML invoices, you can provide them with a schema specifying what format you expect their XML documents to be in. When an invoice arrives, you can validate it against the schema to verify that the sender acceded to your wishes.
In the early days of XML, developers used document type definitions (DTDs) to validate XML document content. Today they use XML Schema Definitions (XSDs), which are described at http://www.w3.org/TR/xmlschema-1 and http://www.w3.org/TR/xmlschema-2. XSD is an XML-based language for describing XML documents and the types that they contain. A full treatment of the language could easily fill a book, but just to give you a feel for what XML schemas are all about, here’s one that defines the valid format of an XML document describing guitars:
<?xml version="1.0"?> <xsd:schema id="Guitars" xmlns="" xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:element name="Guitars"> <xsd:complexType> <xsd:choice maxOccurs="unbounded"> <xsd:element name="Guitar"> <xsd:complexType> <xsd:sequence> <xsd:element name="Make" type="xsd:string" /> <xsd:element name="Model" type="xsd:string" /> <xsd:element name="Year" type="xsd:gYear" minOccurs="0" /> <xsd:element name="Color" type="xsd:string" minOccurs="0" /> <xsd:element name="Neck" type="xsd:string" minOccurs="0" /> </xsd:sequence> </xsd:complexType> </xsd:element> </xsd:choice> </xsd:complexType> </xsd:element> </xsd:schema>
This schema, which might be stored in an XSD file, can be used to validate the XML document that leads off this section. It says that a valid document must contain a Guitars element, that the Guitars element must contain one or more Guitar elements, and that a Guitar element must contain exactly one Make element and one Model element and may contain one Year element, one Color element, and one Neck element, in that order. It also says that Make, Model, Color, and Neck elements contain string data, while Year contains a Gregorian calendar year. The following XML document is not valid with respect to this schema because its one and only Guitar element lacks a Make element and contains two Color elements:
<?xml version="1.0"?> <Guitars> <Guitar> <Model>SG</Model> <Year>1977</Year> <Color>Tobacco Sunburst</Color> <Color>Gun-Metal Gray</Color> <Neck>Rosewood</Neck> </Guitar> </Guitars>
Schemas are meant to be consumed by computers, not humans. Numerous software tools are available for validating XML documents against schemas and for generating schemas from XML documents. One such tool is the Xsd.exe utility that comes with the .NET Framework SDK. Among other things, Xsd.exe is capable of inferring a schema from an XML document and writing the schema to an XSD file. You may have to tweak the XSD file to make sure the schema reflects your true intent, but changing a few statements here and there in an existing schema is far easier than generating a schema from scratch.
XML Parsers
There’s nothing inherently magic about XML itself. What’s magic is that software tools called XML parsers are readily available to help you read XML documents and extract data from them while shielding you from the syntax of the language.
Most XML parsers implement one of two popular APIs: DOM or SAX. DOM stands for Document Object Model and is described at http://www.w3.org/TR/DOM-Level-2-Core. SAX stands for Simple API for XML and is an unofficial (that is, non-W3C) standard that grew out of a grass roots effort in the Java community. It’s currently documented at http://www.saxproject.org. Both APIs define a programmatic interface that abstracts the physical nature of XML documents, but they differ in how they go about it.
SAX is an event-based API. You provide a SAX parser with one or more interfaces containing known sets of callback methods, and as the parser parses the document, it calls you back to let you know what it found. Consider the following XML document:
<Greeting>Hello, world</Greeting>
An application that wants to read this document using a SAX parser implements a well-known interface containing methods named startDocument, endDocument, startElement, endElement, and characters, among others. As the parser moves through the document, it invokes these methods on the client in the following order:
startDocument // Signals start of document startElement // Signals start of Greeting element characters // Transmits "Hello, world" ... endElement // Signals end of Greeting element endDocument // Signals end of document
Calls to startElement and endElement are accompanied by the element names. The ellipsis following characters indicates that characters is called an indeterminate number of times. Some SAX parsers might call it once and pass “Hello, world” in one chunk, but others might call it several times and transmit “Hello, world” in bite-sized pieces. SAX is extremely useful for parsing large documents because it doesn’t require entire documents to be read into memory at once. SAX’s chief downside is that it’s a forward-only, stream-based API; you can’t arbitrarily move backward and forward within a document. Nor can you easily identify relationships between items in the document, since a callback from a SAX parser provides precious little information about the context in which the callback occurred.
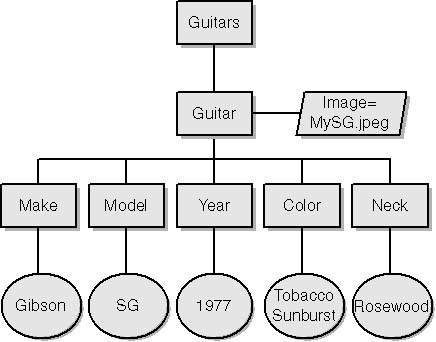
DOM is an alternative API that reads a document into memory and supports random access to the document’s content items. Microsoft provides a free DOM-style parser in a DLL named MSXML.dll, better known as the “MSXML parser” or simply “MSXML.” (Newer versions of MSXML support SAX too.) MSXML layers a DOM Level 2–compliant object model onto XML documents. Individual items within a document—elements, attributes, comments, text, and so on—are represented as nodes. Figure 13-2 shows the in-memory node tree that MSXML builds from the following XML document:
<?xml version="1.0"?> <Guitars> <Guitar Image="MySG.jpeg"> <Make>Gibson</Make> <Model>SG</Model> <Year>1977</Year> <Color>Tobacco Sunburst</Color> <Neck>Rosewood</Neck> </Guitar> </Guitars>
Each block in the diagram represents a node. Rectangles represent element nodes (elements in the XML document), ellipses represent text nodes (textual content within those elements), and the parallelogram represents an attribute. Had the document included processing instructions and other XML items, they too would have been represented as nodes in the tree. Each node is an object that provides methods and properties for navigating the tree and extracting content. For example, each node has a hasChildNodes property that reveals whether the node has child nodes, and firstChild and lastChild properties that return references to child nodes.
What’s it like to use the DOM API to parse an XML document? Check out the example in Example 13-4. It’s an unmanaged console application written in C++ that uses MSXML to load an XML document and parse it for Guitar elements. For each Guitar element that it finds, the application reads the values of the Make and Model subelements and writes them to the console window. If you run it against the XML file in Example 13-3, the application responds with the following output:
Gibson SG Fender Stratocaster
Guitars.xml
<?xml version="1.0"?> <Guitars> <Guitar Image="MySG.jpeg"> <Make>Gibson</Make> <Model>SG</Model> <Year>1977</Year> <Color>Tobacco Sunburst</Color> <Neck>Rosewood</Neck> </Guitar> <Guitar Image="MyStrat.jpeg" PreviousOwner="Eric Clapton"> <Make>Fender</Make> <Model>Stratocaster</Model> <Year>1990</Year> <Color>Black</Color> <Neck>Maple</Neck> </Guitar> </Guitars>
How does the ReadXml application work? Briefly, the statement
hr = CoCreateInstance (CLSID_DOMDocument, NULL, CLSCTX_INPROC_SERVER, IID_IXMLDOMDocument, (void**) &pDoc);
instantiates a DOMDocument object from a COM class implemented in MSXML.dll and returns an IXMLDOMDocument interface pointer. The statement
hr = pDoc->load (var, &success);
loads an XML document from disk, and the statement
hr = pDoc->getElementsByTagName (tag, &pNodeList);
asks the DOMDocument object for a list of Guitar nodes. The list is returned as an IXMLDOMNodeList interface. The application enumerates the Guitar nodes by calling get_item repeatedly on the node list. Each call to get_item returns an IXMLDOMNode interface pointer representing a node that is in reality a Guitar element. The sample program passes the interface pointer to a local function named ShowGuitarType, which performs various acrobatics involving a node list of its own to find the Make and Model subelements and extract their text. Implemented this way, the application can find Guitar elements anywhere in any XML file and extract their Make and Model elements, no matter what order those elements appear in.
ReadXml.cpp
#include <stdio.h>
#include <windows.h>
void ShowGuitarType (IXMLDOMNode* pNode);
BOOL GetChildElementByTagName (LPOLESTR pName, IXMLDOMNode* pParent,
IXMLDOMNode** ppNode);
BOOL IsElementNamed (LPOLESTR pName, IXMLDOMNode* pNode);
int main (int argc, char* argv[])
{
HRESULT hr = CoInitialize (NULL);
// Instantiate the MS XML parser
IXMLDOMDocument* pDoc;
hr = CoCreateInstance (CLSID_DOMDocument, NULL,
CLSCTX_INPROC_SERVER, IID_IXMLDOMDocument, (void**) &pDoc);
if (SUCCEEDED (hr)) {
// Load Guitars.xml
VARIANT_BOOL success;
BSTR file = SysAllocString (OLESTR ("Guitars.xml"));
VARIANT var;
var.vt = VT_BSTR;
var.bstrVal = file;
pDoc->put_async (VARIANT_FALSE);
hr = pDoc->load (var, &success);
SysFreeString (file);
if (SUCCEEDED (hr) && hr != S_FALSE) {
// Get a list of elements named "Guitar"
IXMLDOMNodeList* pNodeList;
BSTR tag = SysAllocString (OLESTR ("Guitar"));
hr = pDoc->getElementsByTagName (tag, &pNodeList);
SysFreeString (tag);
if (SUCCEEDED (hr)) {
// Get a count of the elements returned
long count;
hr = pNodeList->get_length (&count);
if (SUCCEEDED (hr)) {
pNodeList->reset ();
// Walk the list element by element
for (int i=0; i<count; i++) {
IXMLDOMNode* pNode;
hr = pNodeList->get_item (i, &pNode);
if (SUCCEEDED (hr)) {
// Show the Make and Model subelements
ShowGuitarType (pNode);
pNode->Release ();
}
}
}
pNodeList->Release ();
}
}
pDoc->Release ();
}
CoUninitialize ();
return 0;
}
void ShowGuitarType (IXMLDOMNode* pNode)
{
IXMLDOMNode* pMakeNode;
IXMLDOMNode* pModelNode;
// Get an IXMLDOMNode pointer to the Make subelement
if (GetChildElementByTagName (OLESTR ("Make"), pNode,
&pMakeNode)) {
// Get the Make subelement’s text
BSTR make;
HRESULT hr = pMakeNode->get_text (&make);
if (SUCCEEDED (hr) && hr != S_FALSE) {
// Get an IXMLDOMNode pointer to the Model subelement
if (GetChildElementByTagName (OLESTR ("Model"), pNode,
&pModelNode)) {
// Get the Model subelement’s text
BSTR model;
hr = pModelNode->get_text (&model);
if (SUCCEEDED (hr) && hr != S_FALSE) {
// Output the guitar’s make and model
wprintf (OLESTR ("%s %s
"), make, model);
SysFreeString (model);
}
pModelNode->Release ();
}
SysFreeString (make);
}
pMakeNode->Release ();
}
}
BOOL GetChildElementByTagName (LPOLESTR pName, IXMLDOMNode* pParent,
IXMLDOMNode** ppNode)
{
// Get a list of nodes that are children of pParent
IXMLDOMNodeList* pNodeList;
HRESULT hr = pParent->get_childNodes (&pNodeList);
if (SUCCEEDED (hr)) {
// Get a count of the nodes returned
long count;
hr = pNodeList->get_length (&count);
if (SUCCEEDED (hr)) {
pNodeList->reset ();
// Walk the list node by node
for (int i=0; i<count; i++) {
IXMLDOMNode* pNode;
hr = pNodeList->get_item (i, &pNode);
if (SUCCEEDED (hr)) {
// If the node is an element whose name matches
// the input name, return an IXMLDOMNode pointer
if (IsElementNamed (pName, pNode)) {
*ppNode = pNode;
pNodeList->Release ();
return TRUE;
}
pNode->Release ();
}
}
}
pNodeList->Release ();
}
return FALSE;
}
BOOL IsElementNamed (LPOLESTR pName, IXMLDOMNode* pNode)
{
BOOL retval;
// Get the node type
DOMNodeType type;
HRESULT hr = pNode->get_nodeType (&type);
if (SUCCEEDED (hr) && type == NODE_ELEMENT) {
// If the node is an element, get its name
BSTR name;
hr = pNode->get_nodeName (&name);
if (SUCCEEDED (hr)) {
// If the element name matches the input name, return
// TRUE to indicate a match
retval = (wcscmp (name, pName) == 0) ? TRUE : FALSE;
SysFreeString (name);
}
}
return retval;
}Dear reader: the code in Example 13-4 is hard to write and even harder to maintain. It involves so many COM interface pointers and BSTRs (COM’s language-neutral string data type) that the tiniest slip could result in memory leaks. There’s too much code like this in the real world, which is one reason why so many applications leak memory and have to be restarted periodically. Admittedly, the code would have been much simpler had it been written in Visual Basic rather than C++, but the fact remains that this is no way to write production code.
Enter the .NET Framework class library. The FCL features a handy little class named XmlDocument that provides a managed DOM implementation and makes parsing truly simple. To demonstrate, Example 13-5 contains the C# equivalent of the application in Example 13-4. Which of the two would you rather write and maintain?
ReadXml.cs
using System;
using System.Xml;
class MyApp
{
static void Main ()
{
XmlDocument doc = new XmlDocument ();
doc.Load ("Guitars.xml");
XmlNodeList nodes = doc.GetElementsByTagName ("Guitar");
foreach (XmlNode node in nodes) {
Console.WriteLine ("{0} {1}", node["Make"].InnerText,
node["Model"].InnerText);
}
}
}Reading and Writing XML
The FCL’s System.Xml namespace offers a variety of classes for reading and writing XML documents. For DOM lovers, there’s the XmlDocument class, which looks and feels like MSXML but is simpler to use. If you prefer a stream-based approach to reading XML documents, you can use XmlTextReader or the schema-aware XmlValidatingReader instead. A complementary class named XmlTextWriter simplifies the process of creating XML documents. These classes are the first line of defense when battle plans call for manipulating XML.
The XmlDocument Class
XmlDocument provides a programmatic interface to XML documents that complies with the DOM Level 2 Core specification. It represents a document as an upside-down tree of nodes, with the root element, or document element, at the top. Each node is an instance of XmlNode, which exposes methods and properties for navigating DOM trees, reading and writing node content, adding and removing nodes, and more. XmlDocument derives from XmlNode and adds methods and properties of its own supporting the loading and saving of documents, the creation of new nodes, and other operations.
The following statements create an XmlDocument object and initialize it with the contents of Guitars.xml:
XmlDocument doc = new XmlDocument ();
doc.Load ("Guitars.xml");Load parses the specified XML document and builds an in-memory representation of it. It throws an XmlException if the document isn’t well-formed.
A successful call to Load is often followed by reading the XmlDocument’s DocumentElement property. DocumentElement returns an XmlNode reference to the document element, which is the starting point for a top-to-bottom navigation of the DOM tree. You can find out whether a given node (including the document node) has children by reading the node’s HasChildNodes property. You can enumerate a node’s children by reading its ChildNodes property, which returns an XmlNodeList representing a collection of nodes. The combination of HasChildNodes and ChildNodes makes possible a recursive approach to iterating over all the nodes in the tree. The following code loads an XML document and writes a list of its nodes to a console window:
XmlDocument doc = new XmlDocument ();
doc.Load ("Guitars.xml");
OutputNode (doc.DocumentElement);
.
.
.
void OutputNode (XmlNode node)
{
Console.WriteLine ("Type={0} Name={1} Value={2}",
node.NodeType, node.Name, node.Value);
if (node.HasChildNodes) {
XmlNodeList children = node.ChildNodes;
foreach (XmlNode child in children)
OutputNode (child);
}
}Run against Guitars.xml in Example 13-3, it produces the following output:
Type=Element Name=Guitars Value= Type=Element Name=Guitar Value= Type=Element Name=Make Value= Type=Text Name=#text Value=Gibson Type=Element Name=Model Value= Type=Text Name=#text Value=SG Type=Element Name=Year Value= Type=Text Name=#text Value=1977 Type=Element Name=Color Value= Type=Text Name=#text Value=Tobacco Sunburst Type=Element Name=Neck Value= Type=Text Name=#text Value=Rosewood Type=Element Name=Guitar Value= Type=Element Name=Make Value= Type=Text Name=#text Value=Fender Type=Element Name=Model Value= Type=Text Name=#text Value=Stratocaster Type=Element Name=Year Value= Type=Text Name=#text Value=1990 Type=Element Name=Color Value= Type=Text Name=#text Value=Black Type=Element Name=Neck Value= Type=Text Name=#text Value=Maple
Notice the varying node types in the listing’s first column. Element nodes represent elements in an XML document, and text nodes represent the text associated with those elements. The following table lists the full range of possible node types, which are represented by members of the XmlNodeType enumeration. Whitespace nodes represent “insignificant” white space—that is, white space that appears between markup elements and therefore contributes nothing to a document’s content—and aren’t counted among a document’s nodes unless you set XmlDocument’s PreserveWhitespace property, which defaults to false, equal to true before calling Load.
|
XmlNodeType |
Example |
|
Attribute |
<Guitar Image="MySG.jpeg”> |
|
CDATA |
<![CDATA["This is character data"]]> |
|
Comment |
<!-- This is a comment --> |
|
Document |
<Guitars> |
|
DocumentType |
<!DOCTYPE Guitars SYSTEM “Guitars.dtd"> |
|
Element |
<Guitar> |
|
Entity |
<!ENTITY filename “Strats.xml"> |
|
EntityReference |
< |
|
Notation |
<!NOTATION GIF89a SYSTEM “gif"> |
|
ProcessingInstruction |
<?xml-stylesheet type="text/xsl” href="Guitars.xsl”?> |
|
Text |
<Model>Stratocaster</Model> |
|
Whitespace |
<Make/> <Model/> |
|
XmlDeclaration |
<?xml version="1.0”?> |
Observe that the preceding output contains no attribute nodes even though the input document contained two elements having attributes. That’s because attributes get special treatment. A node’s ChildNodes property doesn’t include attributes, but its Attributes property does. Here’s how you’d modify the OutputNode method to list attributes as well as other node types:
void OutputNode (XmlNode node)
{
Console.WriteLine ("Type={0} Name={1} Value={2}",
node.NodeType, node.Name, node.Value);
if (node.Attributes != null) {
foreach (XmlAttribute attr in node.Attributes)
Console.WriteLine ("Type={0} Name={1} Value={2}",
attr.NodeType, attr.Name, attr.Value);
}
if (node.HasChildNodes) {
foreach (XmlNode child in node.ChildNodes)
OutputNode (child);
}
}An XmlNode object’s NodeType, Name, and Value properties expose the type, name, and value of the corresponding node. For some node types (for example, elements), Name is meaningful and Value is not. For others (text nodes, for instance), Value is meaningful but Name is not. And for still others—attributes being a great example—both Name and Value are meaningful. Name returns a node’s qualified name, which includes a namespace prefix if a prefix is present (for example, win:Guitar). Use the LocalName property to retrieve names without prefixes.
You don’t have to iterate through every node in a document to find a specific node or set of nodes. You can use XmlDocument’s GetElementsByTagName, SelectNodes, and SelectSingleNode methods to target particular nodes. The sample application in Example 13-5 uses GetElementsByTagName to quickly create an XmlNodeList targeting all of the document’s Guitar nodes. SelectNodes and SelectSingleNode execute XPath expressions. XPath is introduced later in this chapter.
XmlDocument can be used to write XML documents as well as read them. The following code sample opens Guitars.xml, deletes the first Guitar element, adds a new Guitar element, and saves the results back to Guitars.xml:
XmlDocument doc = new XmlDocument ();
doc.Load ("Guitars.xml");
// Delete the first Guitar element
XmlNode root = doc.DocumentElement;
root.RemoveChild (root.FirstChild);
// Create element nodes
XmlNode guitar = doc.CreateElement ("Guitar");
XmlNode elem1 = doc.CreateElement ("Make");
XmlNode elem2 = doc.CreateElement ("Model");
XmlNode elem3 = doc.CreateElement ("Year");
XmlNode elem4 = doc.CreateElement ("Color");
XmlNode elem5 = doc.CreateElement ("Neck");
// Create text nodes
XmlNode text1 = doc.CreateTextNode ("Gibson");
XmlNode text2 = doc.CreateTextNode ("Les Paul");
XmlNode text3 = doc.CreateTextNode ("1959");
XmlNode text4 = doc.CreateTextNode ("Gold");
XmlNode text5 = doc.CreateTextNode ("Rosewood");
// Attach the text nodes to the element nodes
elem1.AppendChild (text1);
elem2.AppendChild (text2);
elem3.AppendChild (text3);
elem4.AppendChild (text4);
elem5.AppendChild (text5);
// Attach the element nodes to the Guitar node
guitar.AppendChild (elem1);
guitar.AppendChild (elem2);
guitar.AppendChild (elem3);
guitar.AppendChild (elem4);
guitar.AppendChild (elem5);
// Attach the Guitar node to the document node
root.AppendChild (guitar);
// Save the modified document
doc.Save ("Guitars.xml");Other XmlDocument methods that are useful for modifying document content include PrependChild, InsertBefore, InsertAfter, RemoveAll, and ReplaceChild. As an alternative to manually creating text nodes and making them children of element nodes, you can assign text by writing to elements’ InnerText properties. By the same token, reading an element node’s InnerText property is a quick way to retrieve the text associated with an XML element.
XmlDocument is typically used by applications that read XML documents and care about the relationships between nodes. Figure 13-6 shows one such application. Called XmlView, it’s a Windows Forms application that reads an XML document and displays it in a tree view control. Each item in the control represents one node in the document. Items are color-coded to reflect node types. Items without colored blocks represent attributes.
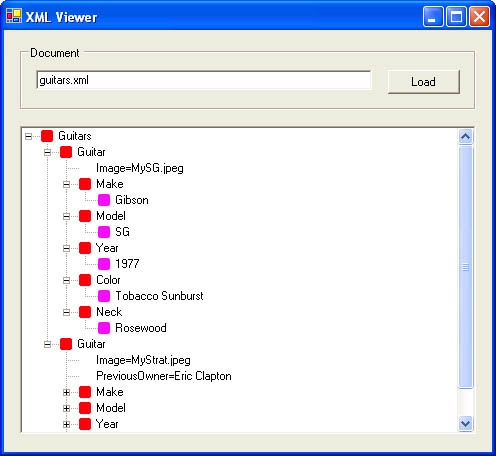
XmlView’s source code appears in Example 13-7. Clicking the Load button activates XmlViewForm.OnLoadDocument, which loads an XmlDocument from the specified data source and calls a local method named AddNodeAndChildren to recursively navigate the document tree and populate the tree view control. The end result is a graphic depiction of the document’s structure and a handy tool for digging around in XML files to see what they’re made of. XmlView is compiled slightly differently than the Windows Forms applications in Chapter 4. Here’s the command to compile it:
csc /t:winexe /res:buttons.bmp,Buttons xmlview.cs
The /res switch embeds the contents of Buttons.bmp in XmlView.exe and assigns the resulting resource the name “Buttons”. Buttons.bmp contains an image depicting the colored blocks used in the tree view control. The statement
NodeImages.Images.AddStrip (new Bitmap (GetType (), "Buttons"));
loads the image and uses it to initialize the ImageList named NodeImages. Packaging the image as an embedded resource makes the resulting executable self-contained.
XmlView.cs
using System;
using System.Drawing;
using System.Windows.Forms;
using System.Xml;
class XmlViewForm : Form
{
GroupBox DocumentGB;
TextBox Source;
Button LoadButton;
ImageList NodeImages;
TreeView XmlView;
public XmlViewForm ()
{
// Initialize the form’s properties
Text = "XML Viewer";
ClientSize = new System.Drawing.Size (488, 422);
// Instantiate the form’s controls
DocumentGB = new GroupBox ();
Source = new TextBox ();
LoadButton = new Button ();
XmlView = new TreeView ();
// Initialize the controls
Source.Anchor =
AnchorStyles.Top | AnchorStyles.Left | AnchorStyles.Right;
Source.Location = new System.Drawing.Point (16, 24);
Source.Size = new System.Drawing.Size (336, 24);
Source.TabIndex = 0;
Source.Name = "Source";
LoadButton.Anchor = AnchorStyles.Top | AnchorStyles.Right;
LoadButton.Location = new System.Drawing.Point (368, 24);
LoadButton.Size = new System.Drawing.Size (72, 24);
LoadButton.TabIndex = 1;
LoadButton.Text = "Load";
LoadButton.Click += new System.EventHandler (OnLoadDocument);
DocumentGB.Anchor =
AnchorStyles.Top | AnchorStyles.Left | AnchorStyles.Right;
DocumentGB.Location = new Point (16, 16);
DocumentGB.Size = new Size (456, 64);
DocumentGB.Text = "Document";
DocumentGB.Controls.Add (Source);
DocumentGB.Controls.Add (LoadButton);
NodeImages = new ImageList ();
NodeImages.ImageSize = new Size (12, 12);
NodeImages.Images.AddStrip (new Bitmap (GetType(), "Buttons"));
NodeImages.TransparentColor = Color.White;
XmlView.Anchor = AnchorStyles.Top | AnchorStyles.Bottom |
AnchorStyles.Left | AnchorStyles.Right;
XmlView.Location = new System.Drawing.Point (16, 96);
XmlView.Size = new System.Drawing.Size (456, 308);
XmlView.ImageList = NodeImages;
XmlView.TabIndex = 2;
XmlView.Name = "XmlView";
// Add the controls to the form
Controls.Add (DocumentGB);
Controls.Add (XmlView);
}
void OnLoadDocument (object sender, EventArgs e)
{
try {
XmlDocument doc = new XmlDocument ();
doc.Load (Source.Text);
XmlView.Nodes.Clear ();
AddNodeAndChildren (doc.DocumentElement, null);
}
catch (Exception ex) {
MessageBox.Show (ex.Message);
}
}
void AddNodeAndChildren (XmlNode xnode, TreeNode tnode)
{
TreeNode child = AddNode (xnode, tnode);
if (xnode.Attributes != null) {
foreach (XmlAttribute attribute in xnode.Attributes)
AddAttribute (attribute, child);
}
if (xnode.HasChildNodes) {
foreach (XmlNode node in xnode.ChildNodes)
AddNodeAndChildren (node, child);
}
}
TreeNode AddNode (XmlNode xnode, TreeNode tnode)
{
string text = null;
TreeNode child = null;
TreeNodeCollection tnodes = (tnode == null) ?
XmlView.Nodes : tnode.Nodes;
switch (xnode.NodeType) {
case XmlNodeType.Element:
case XmlNodeType.Document:
tnodes.Add (child = new TreeNode (xnode.Name, 0, 0));
break;
case XmlNodeType.Text:
text = xnode.Value;
if (text.Length > 128)
text = text.Substring (0, 128) + "...";
tnodes.Add (child = new TreeNode (text, 2, 2));
break;
case XmlNodeType.CDATA:
text = xnode.Value;
if (text.Length > 128)
text = text.Substring (0, 128) + "...";
text = String.Format ("<![CDATA]{0}]]>", text);
tnodes.Add (child = new TreeNode (text, 3, 3));
break;
case XmlNodeType.Comment:
text = String.Format ("<!--{0}-->", xnode.Value);
tnodes.Add (child = new TreeNode (text, 4, 4));
break;
case XmlNodeType.XmlDeclaration:
case XmlNodeType.ProcessingInstruction:
text = String.Format ("<?{0} {1}?>", xnode.Name,
xnode.Value);
tnodes.Add (child = new TreeNode (text, 5, 5));
break;
case XmlNodeType.Entity:
text = String.Format ("<!ENTITY {0}>", xnode.Value);
tnodes.Add (child = new TreeNode (text, 6, 6));
break;
case XmlNodeType.EntityReference:
text = String.Format ("&{0};", xnode.Value);
tnodes.Add (child = new TreeNode (text, 7, 7));
break;
case XmlNodeType.DocumentType:
text = String.Format ("<!DOCTYPE {0}>", xnode.Value);
tnodes.Add (child = new TreeNode (text, 8, 8));
break;
case XmlNodeType.Notation:
text = String.Format ("<!NOTATION {0}>", xnode.Value);
tnodes.Add (child = new TreeNode (text, 9, 9));
break;
default:
tnodes.Add (child =
new TreeNode (xnode.NodeType.ToString (), 1, 1));
break;
}
return child;
}
void AddAttribute (XmlAttribute attribute, TreeNode tnode)
{
string text = String.Format ("{0}={1}", attribute.Name,
attribute.Value);
tnode.Nodes.Add (new TreeNode (text, 1, 1));
}
static void Main ()
{
Application.Run (new XmlViewForm ());
}
}Incidentally, the FCL includes a class named XmlDataDocument that’s closely related to and, in fact, derives from XmlDocument. XmlDataDocument is a mechanism for treating relational data as XML data. You can wrap an XmlDataDocument around a DataSet, as shown here:
DataSet ds = new DataSet (); // TODO: Initialize the DataSet with a database query XmlDataDocument doc = new XmlDataDocument (ds);
This action layers an XML DOM over a DataSet and allows the DataSet’s contents to be read and written using XmlDocument semantics.
The XmlTextReader Class
XmlDocument is an efficient and easy-to-use mechanism for reading XML documents. It allows you to move backward, forward, and sideways within a document and even make changes to the document as you go. But if your intent is simply to read XML and you’re less interested in the structure of the document than its contents, there’s another way to go about it: the FCL’s XmlTextReader class. XmlTextReader, which, like XmlDocument, belongs to the System.Xml namespace, provides a fast, forward-only, read-only interface to XML documents. It’s stream-based like SAX. It’s more memory-efficient than XmlDocument, especially for large documents, because it doesn’t read an entire document into memory at once. And it makes it even easier than XmlDocument to read through a document searching for particular elements, attributes, or other content items.
Using XmlTextReader is simplicity itself. The basic idea is to create an XmlTextReader object from a file, URL, or other data source, and to call XmlTextReader.Read repeatedly until you find the content you’re looking for or reach the end of the document. Each call to Read advances an imaginary cursor to the next node in the document. XmlTextReader properties such as NodeType, Name, Value, and AttributeCount expose information about the current node. Methods such as GetAttribute, MoveToFirstAttribute, and MoveToNextAttribute let you access the attributes, if any, attached to the current node.
The following code fragment wraps an XmlTextReader around Guitars.xml and reads through the entire file node by node:
XmlTextReader reader = null;
try {
reader = new XmlTextReader ("Guitars.xml");
reader.WhitespaceHandling = WhitespaceHandling.None;
while (reader.Read ()) {
Console.WriteLine ("Type={0} Name={1} Value={2}",
reader.NodeType, reader.Name, reader.Value);
}
}
finally {
if (reader != null)
reader.Close ();
}Running it against the XML document in Example 13-3 produces the following output:
Type=XmlDeclaration Name=xml Value=version="1.0" Type=Element Name=Guitars Value= Type=Element Name=Guitar Value= Type=Element Name=Make Value= Type=Text Name= Value=Gibson Type=EndElement Name=Make Value= Type=Element Name=Model Value= Type=Text Name= Value=SG Type=EndElement Name=Model Value= Type=Element Name=Year Value= Type=Text Name= Value=1977 Type=EndElement Name=Year Value= Type=Element Name=Color Value= Type=Text Name= Value=Tobacco Sunburst Type=EndElement Name=Color Value= Type=Element Name=Neck Value= Type=Text Name= Value=Rosewood Type=EndElement Name=Neck Value= Type=EndElement Name=Guitar Value= Type=Element Name=Guitar Value= Type=Element Name=Make Value= Type=Text Name= Value=Fender Type=EndElement Name=Make Value= Type=Element Name=Model Value= Type=Text Name= Value=Stratocaster Type=EndElement Name=Model Value= Type=Element Name=Year Value= Type=Text Name= Value=1990 Type=EndElement Name=Year Value= Type=Element Name=Color Value= Type=Text Name= Value=Black Type=EndElement Name=Color Value= Type=Element Name=Neck Value= Type=Text Name= Value=Maple Type=EndElement Name=Neck Value= Type=EndElement Name=Guitar Value= Type=EndElement Name=Guitars Value=
Note the EndElement nodes in the output. Unlike XmlDocument, XmlText-Reader counts an element’s start and end tags as separate nodes. XmlTextReader also includes whitespace nodes in its output unless told to do otherwise. Setting its WhitespaceHandling property to WhitespaceHandling.None prevents a reader from returning whitespace nodes.
Like XmlDocument, XmlTextReader treats attributes differently than other nodes and doesn’t return them as part of the normal iterative process. If you want to enumerate attribute nodes, you have to read them separately. Here’s a revised code sample that outputs attribute nodes as well as other nodes:
XmlTextReader reader = null;
try {
reader = new XmlTextReader ("Guitars.xml");
reader.WhitespaceHandling = WhitespaceHandling.None;
while (reader.Read ()) {
Console.WriteLine ("Type={0} Name={1} Value={2}",
reader.NodeType, reader.Name, reader.Value);
if (reader.AttributeCount > 0) {
while (reader.MoveToNextAttribute ()) {
Console.WriteLine ("Type={0} Name={1} Value={2}",
reader.NodeType, reader.Name, reader.Value);
}
}
}
}
finally {
if (reader != null)
reader.Close ();
}A common use for XmlTextReader is parsing an XML document and extracting selected node values. The following code sample finds all the Guitar elements that are accompanied by Image attributes and echoes the attribute values to a console window:
XmlTextReader reader = null;
try {
reader = new XmlTextReader ("Guitars.xml");
reader.WhitespaceHandling = WhitespaceHandling.None;
while (reader.Read ()) {
if (reader.NodeType == XmlNodeType.Element &&
reader.Name == "Guitar" &&
reader.AttributeCount > 0) {
while (reader.MoveToNextAttribute ()) {
if (reader.Name == "Image") {
Console.WriteLine (reader.Value);
break;
}
}
}
}
}
finally {
if (reader != null)
reader.Close ();
}Run against Guitars.xml (Example 13-3), this sample produces the following output:
MySG.jpeg MyStrat.jpeg
It’s important to close an XmlTextReader when you’re finished with it so that the reader, in turn, can close the underlying data source. That’s why all the samples in this section call Close on their XmlTextReaders and do so in finally blocks.
The XmlValidatingReader Class
XmlValidatingReader is a derivative of XmlTextReader. It adds one important feature that XmlTextReader lacks: the ability to validate XML documents as it reads them. It supports three schema types: DTD, XSD, and XML-Data Reduced (XDR). Its Schemas property holds the schema (or schemas) that a document is validated against, and its ValidationType property specifies the schema type. ValidationType defaults to ValidationType.Auto, which allows XmlValidatingReader to determine the schema type from the schema document provided to it. Setting ValidationType to ValidationType.None creates a nonvalidating reader—the equivalent of XmlTextReader.
XmlValidatingReader doesn’t accept a file name or URL as input, but you can initialize an XmlTextReader with a file name or URL and wrap an XmlValidatingReader around it. The following statements create an XmlValidatingReader and initialize it with an XML document and a schema document:
XmlTextReader nvr = new XmlTextReader ("Guitars.xml");
XmlValidatingReader reader = new XmlValidatingReader (nvr);
reader.Schemas.Add ("", "Guitars.xsd");The first parameter passed to Add identifies the target namespace, if any, specified in the schema document. An empty string means the schema defines no target namespace.
Validating a document is as simple as iterating through all its nodes with repeated calls to XmlValidatingReader.Read:
while (reader.Read ());
If the reader encounters well-formedness errors as it reads, it throws an XmlException. If it encounter validation errors, it fires ValidationEventHandler events. An application that uses an XmlValidatingReader can trap these events by registering an event handler:
reader.ValidationEventHandler += new ValidationEventHandler (OnValidationError);
The event handler receives a ValidationEventArgs containing information about the validation error, including a textual description of it (in ValidationEventArgs.Message) and an XmlSchemaException (in ValidationEventArgs.Exception). The latter contains additional information about the error such as the position in the source document where the error occurred.
Example 13-8 lists the source code for a console app named Validate that validates XML documents against XSD schemas. To use it, type the command name followed by the name or URL of an XML document and the name or URL of a schema document, as in
validate guitars.xml guitars.xsd
As a convenience for users, Validate uses an XmlTextReader to parse the schema document for the target namespace that’s needed to add the schema to the Schemas collection. (See the GetTargetNamespace method for details.) It takes advantage of the fact that XSDs, unlike DTDs, are XML documents themselves and can therefore be read using XML parsers.
Validate.cs
using System;
using System.Xml;
using System.Xml.Schema;
class MyApp
{
static void Main (string[] args)
{
if (args.Length < 2) {
Console.WriteLine ("Syntax: VALIDATE xmldoc schemadoc");
return;
}
XmlValidatingReader reader = null;
try {
XmlTextReader nvr = new XmlTextReader (args[0]);
nvr.WhitespaceHandling = WhitespaceHandling.None;
reader = new XmlValidatingReader (nvr);
reader.Schemas.Add (GetTargetNamespace (args[1]), args[1]);
reader.ValidationEventHandler +=
new ValidationEventHandler (OnValidationError);
while (reader.Read ());
}
catch (Exception ex) {
Console.WriteLine (ex.Message);
}
finally {
if (reader != null)
reader.Close ();
}
}
static void OnValidationError (object sender, ValidationEventArgs e)
{
Console.WriteLine (e.Message);
}
public static string GetTargetNamespace (string src)
{
XmlTextReader reader = null;
try {
reader = new XmlTextReader (src);
reader.WhitespaceHandling = WhitespaceHandling.None;
while (reader.Read ()) {
if (reader.NodeType == XmlNodeType.Element &&
reader.LocalName == "schema") {
while (reader.MoveToNextAttribute ()) {
if (reader.Name == "targetNamespace")
return reader.Value;
}
}
}
return "";
}
finally {
if (reader != null)
reader.Close ();
}
}
}The XmlTextWriter Class
The FCL’s XmlDocument class can be used to modify existing XML documents, but it can’t be used to generate XML documents from scratch. XmlTextWriter can. It features an assortment of Write methods that emit various types of XML, including elements, attributes, comments, and more. The following example uses some of these methods to create an XML file named Guitars.xml containing a document element named Guitars and a subelement named Guitar:
XmlTextWriter writer = null;
try {
writer = new XmlTextWriter ("Guitars.xml", System.Text.Encoding.Unicode);
writer.Formatting = Formatting.Indented;
writer.WriteStartDocument ();
writer.WriteStartElement ("Guitars");
writer.WriteStartElement ("Guitar");
writer.WriteAttributeString ("Image", "MySG.jpeg");
writer.WriteElementString ("Make", "Gibson");
writer.WriteElementString ("Model", "SG");
writer.WriteElementString ("Year", "1977");
writer.WriteElementString ("Color", "Tobacco Sunburst");
writer.WriteElementString ("Neck", "Rosewood");
writer.WriteEndElement ();
writer.WriteEndElement ();
}
finally {
if (writer != null)
writer.Close ();
}Here’s what the generated document looks like:
<?xml version="1.0" encoding="utf-16"?> <Guitars> <Guitar Image="MySG.jpeg"> <Make>Gibson</Make> <Model>SG</Model> <Year>1977</Year> <Color>Tobacco Sunburst</Color> <Neck>Rosewood</Neck> </Guitar> </Guitars>
Setting an XmlTextWriter’s Formatting property to Formatting.Indented before writing begins produces the indentation seen in the sample. Skipping this step omits the indents and the line breaks too. The default indentation depth is 2, and the default indentation character is the space character. You can change the indentation depth and indentation character using XmlTextWriter’s Indentation and IndentChar properties.
XPath
XPath, which is short for XML Path Language, is a language for addressing parts of an XML document. Its name includes the word “path” because of the similarities between XML paths and file system paths. In a file system, for example, BookChap13 identifies the Chap13 subdirectory of the root directory’s Book subdirectory. In an XML document, /Guitars/Guitar identifies all elements named Guitar that are children of the root element Guitars. “/Guitars/Guitar” is an XPath expression. XPath expressions are fully described in the XPath specification found at http://www.w3.org/TR/xpath.
XPath can be put to work in a variety of ways. Later in this chapter, you’ll learn about XSL Transformations (XSLT), which is a language for converting XML documents from one format to another. XSLT uses XPath expressions to identify nodes and node sets. Another common use for XPath is extracting data from XML documents. Used this way, XPath becomes a query language of sorts—the XML equivalent of SQL, if you will. The W3C is working on an official XML query language called XQuery (http://www.w3.org/TR/xquery), but for the moment, an XPath processor is the best way to extract information from XML documents without having to manually traverse DOM trees. The FCL comes with an XPath engine named System.Xml.XPath.XPathNavigator. Before we discuss it, let’s briefly review XPath.
XPath Basics
Expressions are the building blocks of XPath. The most common type of expression is the location path. The following location path evaluates to all Guitar elements that are children of a root element named Guitars:
/Guitars/Guitar
This one evaluates to all attributes (not elements) named Image that belong to Guitar elements that in turn are children of the root element Guitars:
/Guitars/Guitar/@Image
The next expression evaluates to all Guitar elements anywhere in the document:
//Guitar
The // prefix is extremely useful for locating elements in a document regardless of where they’re positioned.
XPath also supports wildcards. This expression selects all elements that are children of a root element named Guitars:
/Guitars/*
The next example selects all attributes belonging to Guitar elements anywhere in the document:
//Guitar/@*
Location paths can be absolute or relative. Paths that begin with / or // are absolute because they specify a location relative to the root. Paths that don’t begin with / or // are relative paths. They specify a location relative to the current node, or context node, in an XPath document.
The components of a location path are called location steps. The following location path has two location steps:
/Guitars/Guitar
A location step consists of three parts: an axis, a node test, and zero or more predicates. The general format for a location step is as follows:
axis::node-test[predicate1][predicate2][...]
The axis describes a relationship between nodes. Supported values include child, descendant, descendant-or-self, parent, ancestor, and ancestor-or-self, among others. If you don’t specify an axis, the default is child. Therefore, the expression
/Guitars/Guitar
could also be written
/child::Guitars/child::Guitar
Other axes can be used to qualify location paths in different ways. For example, this expression evaluates to all elements named Guitar that are descendants of the root element:
/descendant::Guitar
The next expression evaluates to all Guitar elements that are descendants of the root element or are themselves root elements:
/descendant-or-self::Guitar
In fact, // is shorthand for /descendant-or-self. Thus, the expression
//Guitar
is equivalent to the one above. Similarly, @ is shorthand for attribute. The statement
//Guitar/@*
can also be written
//Guitar/attribute::*
Most developers prefer the abbreviated syntax, but both syntaxes are supported by XPath 1.0–compliant expression engines.
The predicate is the portion of the location path, if any, that appears in square brackets. Predicates are nothing more than filters. For example, the following expression evaluates to all Guitar elements in the document:
//Guitar
But this one uses a predicate to narrow down the selection to Guitar elements having attributes named Image:
//Guitar[@Image]
The next one evaluates to all Guitar elements that have attributes named Image whose value is “MyStrat.jpeg”:
//Guitar[@Image = "MyStrat.jpeg"]
Predicates can include the following comparison operators: <, >, =, !=, <=, and >=. The following expression targets Guitar elements whose Year elements designate a year after 1980:
//Guitar[Year > 1980]
Predicates can also include and and or operators. This expression selects guitars manufactured after 1980 by Fender:
//Guitar[Year > 1980][Make = "Fender"]
The next expression does the same, but combines two predicates into one using the and operator:
//Guitar[Year > 1980 and Make = "Fender"]
Changing and to or identifies guitars that were manufactured by Fender or built after 1980:
//Guitar[Year > 1980 or Make = "Fender"]
XPath also supports a set of intrinsic functions that are often (but not always) used in predicates. The following expression evaluates to all Guitar elements having Make elements whose text begins with the letter G. The key is the starts-with function invoked in the predicate:
//Guitar[starts-with (Make, "G")]
The next expression uses the text function to return all text nodes associated with Make elements that are subelements of Guitar elements. Like DOM, XPath treats the text associated with an element as a separate node:
//Guitar/Make/text ()
The starts-with and text functions are but two of many that XPath supports. For a complete list, refer to the XPath specification.
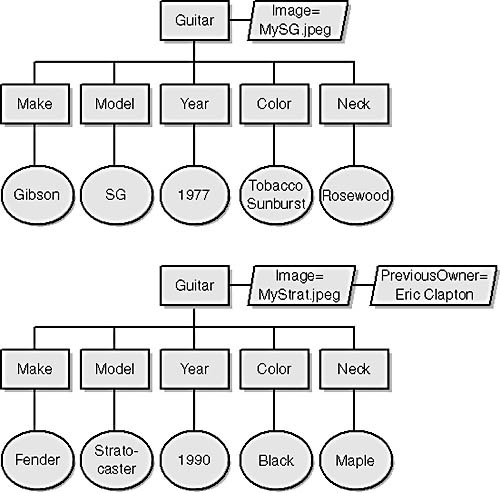
When executed by an XPath processor, a location path returns a node set. XPath, like DOM, uses tree-structured node sets to represent XML content. Suppose you’re given the XML document in Example 13-3 and you execute the following location path against it:
//Guitar
The resulting node set contains two nodes, each representing a Guitar element. Each Guitar element is the root of a node tree containing Make, Model, Year, Color, and Neck subelement nodes (Figure 13-9). Each subelement node is the parent of a text node that holds the element’s text. XPath node types are defined separately from DOM node types, although the two share many similarities. XPath defines fewer node types than DOM, which make XPath node types a functional subset of DOM node types.
XPathNavigator and Friends
The .NET Framework class library’s System.Xml.XPath namespace contains classes for putting XPath to work in managed applications. Chief among those classes are XPathDocument, which represents XML documents that you want to query with XPath; XPathNavigator, which provides a mechanism for performing XPath queries; and XPathNodeIterator, which represents node sets generated by XPath queries and lets you iterate over them.
The first step in performing XPath queries on XML documents is to create an XPathDocument wrapping the XML document itself. XPathDocument features a variety of constructors capable of initializing an XPathDocument from a stream, a URL, a file, a TextReader, or an XmlReader. The following statement creates an XPathDocument object and initializes it with the content found in Guitars.xml:
XPathDocument doc = new XPathDocument ("Guitars.xml");Step two is to create an XPathNavigator from the XPathDocument. XPathDocument features a method named CreateNavigator for just that purpose. The following statement creates an XPathNavigator object from the XPathDocument created in the previous step:
XPathNavigator nav = doc.CreateNavigator ();
The final step is actually executing the query. XPathNavigator features five methods for executing XPath queries. The two most important are Evaluate and Select. Evaluate executes any XPath expression. It returns a generic Object that can be a string, a float, a bool, or an XPathNodeIterator, depending on the expression and the type of data that it returns. Select works exclusively with expressions that return node sets and is therefore an ideal vehicle for evaluating location paths. It always returns an XPathNodeIterator representing an XPath node set. The following statement uses Select to create a node set representing all nodes that match the expression “//Guitar”:
XPathNodeIterator iterator = nav.Select ("//Guitar");XPathNodeIterator is a simple class that lets you iterate over the nodes returned in a node set. Its Count property tells you how many nodes were returned:
Console.WriteLine ("Select returned {0} nodes", iterator.Count);XPathNodeIterator’s MoveNext method lets you iterate over the node set a node at a time. As you iterate, XPathNodeIterator’s Current property exposes an XPathNavigator object that represents the current node. The following code iterates over the node set, displaying the type, name, and value of each node:
while (iterator.MoveNext ()) {
Console.WriteLine ("Type={0}, Name={1}, Value={2}",
iterator.Current.NodeType,
iterator.Current.Name,
iterator.Current.Value);
}The string returned by the XPathNavigator’s Value property depends on the node’s type and content. For example, if Current represents an attribute node or an element node that contains simple text (as opposed to other elements), then Value returns the attribute’s value or the text value of the element. If, however, Current represents an element node that contains other elements, Value returns the text of the subelements concatenated together into one long string.
Each node in the node set that Select returns can be a single node or the root of a tree of nodes. Traversing a tree of nodes encapsulated in an XPathNavigator is slightly different from traversing a tree of nodes in an XmlDocument. Here’s how to perform a depth-first traversal of the node trees returned by XPathNavigator.Select:
while (iterator.MoveNext ())
OutputNode (iterator.Current);
.
.
.
void OutputNode (XPathNavigator nav)
{
Console.WriteLine ("Type={0}, Name={1}, Value={2}",
nav.NodeType, nav.Name, nav.Value);
if (nav.HasAttributes) {
nav.MoveToFirstAttribute ();
do {
OutputNode (nav);
} while (nav.MoveToNextAttribute ());
nav.MoveToParent ();
}
if (nav.HasChildren) {
nav.MoveToFirstChild ();
do {
OutputNode (nav);
} while (nav.MoveToNext ());
nav.MoveToParent ();
}
}XPathNavigator features a family of Move methods that you can call to move any direction—up, down, or sideways—in a tree of nodes. This sample uses five of them: MoveToFirstAttribute, MoveToNextAttribute, MoveToParent, MoveToFirstChild, and MoveToNext. Observe also that the XPathNavigator itself exposes the properties of the nodes that you iterate over, in much the same manner as XmlTextReader.
So how might you put this knowledge to work in a real application? Look again at Example 13-5. The application listed there uses XmlDocument to extract content from an XML document. Content can also be extracted—often with less code—with XPath. To demonstrate, the application in Example 13-10 is the functional equivalent of the one in Example 13-5. Besides demonstrating the basic semantics of XPathNavigator usage, it shows that you can perform subqueries on node sets returned by XPath queries by calling Select on the XPathNavigator exposed through an iterator’s Current property. XPathDemo first calls Select to create a node set representing all Guitar elements that are children of Guitars. Then it iterates through the node set, calling Select on each Guitar node to select the node’s Make and Model child elements.
XPathDemo.cs
using System;
using System.Xml.XPath;
class MyApp
{
static void Main ()
{
XPathDocument doc = new XPathDocument ("Guitars.xml");
XPathNavigator nav = doc.CreateNavigator ();
XPathNodeIterator iterator = nav.Select ("/Guitars/Guitar");
while (iterator.MoveNext ()) {
XPathNodeIterator it = iterator.Current.Select ("Make");
it.MoveNext ();
string make = it.Current.Value;
it = iterator.Current.Select ("Model");
it.MoveNext ();
string model = it.Current.Value;
Console.WriteLine ("{0} {1}", make, model);
}
}
}A Do-It-Yourself XPath Expression Evaluator
To help you get acquainted with XPath, the application pictured in Figure 13-11 is a working XPath expression analyzer that evaluates XPath expressions against XML documents and displays the results. Like Microsoft SQL Server’s query analyzer, which lets you test SQL commands, the XPath expression analyzer—Expressalyzer for short—lets you experiment with XPath queries. To try it out, type a file name or URL into the Document box and click Load to point Expressalyzer to an XML document. Then type a location path into the Expression box and click the Execute button. The results appear in the tree view control in the lower half of the window.
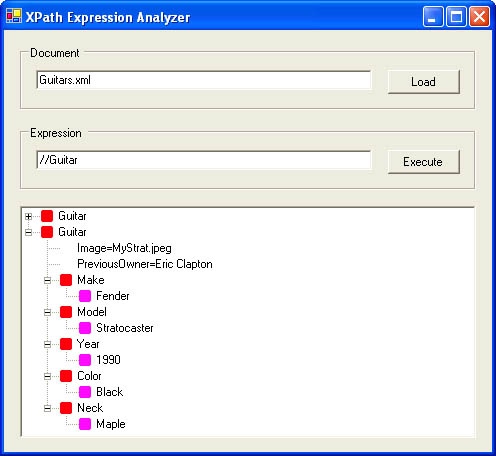
Expressalyzer’s source code appears in Example 13-12. Expressalyzer is a Windows Forms application whose main form is an instance of AnalyzerForm. Clicking the Load button activates the form’s OnLoadDocument method, which wraps an XPathDocument around the data source. Clicking the Execute button activates the OnExecuteExpression method, which executes the expression by calling Select on the XPathDocument. If you need more real estate, resize the Expressalyzer window and the controls inside it will resize too. That little piece of magic results from the AnchorStyles assigned to the controls’ Anchor properties. For a review of Windows Forms anchoring, refer to Chapter 4.
Expressalyzer.cs
using System;
using System.Drawing;
using System.Windows.Forms;
using System.Xml.XPath;
class AnalyzerForm : Form
{
GroupBox DocumentGB;
TextBox Source;
Button LoadButton;
GroupBox ExpressionGB;
TextBox Expression;
Button ExecuteButton;
ImageList NodeImages;
TreeView XmlView;
XPathNavigator Navigator;
public AnalyzerForm ()
{
// Initialize the form’s properties
Text = "XPath Expression Analyzer";
ClientSize = new System.Drawing.Size (488, 422);
// Instantiate the form’s controls
DocumentGB = new GroupBox ();
Source = new TextBox ();
LoadButton = new Button ();
ExpressionGB = new GroupBox ();
Expression = new TextBox ();
ExecuteButton = new Button ();
XmlView = new TreeView ();
// Initialize the controls
Source.Anchor =
AnchorStyles.Top | AnchorStyles.Left | AnchorStyles.Right;
Source.Location = new System.Drawing.Point (16, 24);
Source.Size = new System.Drawing.Size (336, 24);
Source.TabIndex = 0;
Source.Name = "Source";
LoadButton.Anchor = AnchorStyles.Top | AnchorStyles.Right;
LoadButton.Location = new System.Drawing.Point (368, 24);
LoadButton.Size = new System.Drawing.Size (72, 24);
LoadButton.TabIndex = 1;
LoadButton.Text = "Load";
LoadButton.Click += new System.EventHandler (OnLoadDocument);
DocumentGB.Anchor =
AnchorStyles.Top | AnchorStyles.Left | AnchorStyles.Right;
DocumentGB.Location = new Point (16, 16);
DocumentGB.Size = new Size (456, 64);
DocumentGB.Text = "Document";
DocumentGB.Controls.Add (Source);
DocumentGB.Controls.Add (LoadButton);
Expression.Anchor =
AnchorStyles.Top | AnchorStyles.Left | AnchorStyles.Right;
Expression.Location = new System.Drawing.Point (16, 24);
Expression.Size = new System.Drawing.Size (336, 24);
Expression.TabIndex = 2;
Expression.Name = "Expression";
ExecuteButton.Anchor = AnchorStyles.Top | AnchorStyles.Right;
ExecuteButton.Location = new System.Drawing.Point (368, 24);
ExecuteButton.Size = new System.Drawing.Size (72, 24);
ExecuteButton.TabIndex = 3;
ExecuteButton.Text = "Execute";
ExecuteButton.Enabled = false;
ExecuteButton.Click +=
new System.EventHandler (OnExecuteExpression);
ExpressionGB.Anchor =
AnchorStyles.Top | AnchorStyles.Left | AnchorStyles.Right;
ExpressionGB.Location = new System.Drawing.Point (16, 96);
ExpressionGB.Name = "ExpressionGB";
ExpressionGB.Size = new System.Drawing.Size (456, 64);
ExpressionGB.Text = "Expression";
ExpressionGB.Controls.Add (Expression);
ExpressionGB.Controls.Add (ExecuteButton);
NodeImages = new ImageList ();
NodeImages.ImageSize = new Size (12, 12);
NodeImages.Images.AddStrip (new Bitmap (GetType (), "Buttons"));
NodeImages.TransparentColor = Color.White;
XmlView.Anchor = AnchorStyles.Top | AnchorStyles.Bottom |
AnchorStyles.Left | AnchorStyles.Right;
XmlView.Location = new System.Drawing.Point (16, 176);
XmlView.Size = new System.Drawing.Size (456, 232);
XmlView.ImageList = NodeImages;
XmlView.TabIndex = 4;
XmlView.Name = "XmlView";
// Add the controls to the form
Controls.Add (DocumentGB);
Controls.Add (ExpressionGB);
Controls.Add (XmlView);
}
void OnLoadDocument (object sender, EventArgs e)
{
try {
XPathDocument doc = new XPathDocument (Source.Text);
Navigator = doc.CreateNavigator ();
ExecuteButton.Enabled = true;
}
catch (Exception ex) {
MessageBox.Show (ex.Message);
}
}
void OnExecuteExpression (object sender, EventArgs e)
{
try {
XPathNodeIterator iterator =
Navigator.Select (Expression.Text);
XmlView.Nodes.Clear ();
while (iterator.MoveNext ())
AddNodeAndChildren (iterator.Current, null);
}
catch (Exception ex) {
MessageBox.Show (ex.Message);
}
}
void AddNodeAndChildren (XPathNavigator nav, TreeNode tnode)
{
TreeNode child = AddNode (nav, tnode);
if (nav.HasAttributes) {
nav.MoveToFirstAttribute ();
do {
AddAttribute (nav, child);
} while (nav.MoveToNextAttribute ());
nav.MoveToParent ();
}
if (nav.HasChildren) {
nav.MoveToFirstChild ();
do {
AddNodeAndChildren (nav, child);
} while (nav.MoveToNext ());
nav.MoveToParent ();
}
}
TreeNode AddNode (XPathNavigator nav, TreeNode tnode)
{
string text = null;
TreeNode child = null;
TreeNodeCollection tnodes = (tnode == null) ?
XmlView.Nodes : tnode.Nodes;
switch (nav.NodeType) {
case XPathNodeType.Root:
case XPathNodeType.Element:
tnodes.Add (child = new TreeNode (nav.Name, 0, 0));
break;
case XPathNodeType.Attribute:
text = String.Format ("{0}={1}", nav.Name, nav.Value);
tnodes.Add (child = new TreeNode (text, 1, 1));
break;
case XPathNodeType.Text:
text = nav.Value;
if (text.Length > 128)
text = text.Substring (0, 128) + "...";
tnodes.Add (child = new TreeNode (text, 2, 2));
break;
case XPathNodeType.Comment:
text = String.Format ("<!--{0}-->", nav.Value);
tnodes.Add (child = new TreeNode (text, 4, 4));
break;
case XPathNodeType.ProcessingInstruction:
text = String.Format ("<?{0} {1}?>", nav.Name, nav.Value);
tnodes.Add (child = new TreeNode (text, 5, 5));
break;
}
return child;
}
void AddAttribute (XPathNavigator nav, TreeNode tnode)
{
string text = String.Format ("{0}={1}", nav.Name, nav.Value);
tnode.Nodes.Add (new TreeNode (text, 1, 1));
}
static void Main ()
{
Application.Run (new AnalyzerForm ());
}
}XSL Transformations (XSLT)
For programmers laboring in the trenches with XML, XSLT is one of the brightest stars in the XML universe. XSLT stands for Extensible Stylesheet Language Transformations. It is a language for converting XML documents from one format to another. Although it can be applied in a variety of ways, XSLT enjoys two primary uses:
Converting XML documents into HTML documents
Converting XML documents into other XML documents
The first application—turning XML into HTML—is useful for building Web pages and other browser-based documents in XML. XML defines the content and structure of data, but it doesn’t define the data’s appearance. Using XSLT to generate HTML from XML is a fine way to separate content from appearance and to build generic documents that can be displayed however you want them displayed. You can also use cascading style sheets (CSS) to layer appearance over XML content, but XSLT is more versatile than CSS and provides substantially more control over the output.
XSLT is also used to convert XML document formats. Suppose company A expects XML invoices submitted by company B to conform to a particular format (that is, fit a particular schema), but company B already has an XML invoice format and doesn’t want to change it to satisfy the whims of company A. Rather than lose company B’s business, company A can use XSLT to convert invoices submitted by company B to company A’s format. That way both companies are happy, and neither has to go to extraordinary lengths to work with the other. XML-to-XML XSLT conversions are the nucleus of middleware applications such as Microsoft BizTalk Server that automate business processes by orchestrating the flow of information.
Figure 13-13 illustrates the mechanics of XSLT. You feed a source document (the XML document to be transformed) and an XSL style sheet that describes how the document is to be transformed to an XSLT processor. The XSLT processor, in turn, generates the output document using the rules in the style sheet.
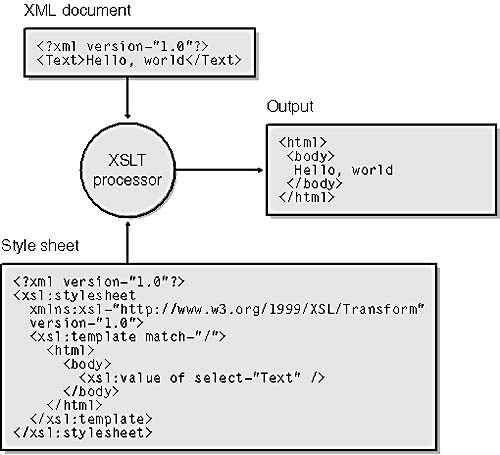
MSXML is an XSLT processor. So is the XslTransform class located in the FCL’s System.Xml.Xsl namespace. XslTransform is one of the coolest classes in the FCL. It’s exceedingly simple to use, and it’s an essential tool to have at your disposal when the need arises to programmatically convert XML documents from one format to another. The following sections describe how to put XslTransform to work.
Converting XML to HTML on the Client
If you’ve never worked with XSLT before, a great way to get acquainted with it is to build a simple XML document and transform it to HTML using Internet Explorer (which, under the hood, relies on MSXML to perform XSL transformations). Here’s how:
Copy Example 13-16’s Guitars.xml and Guitars.xsl to the directory of your choice.
Temporarily delete (or comment out) the following statement in Guitars.xml:
<?xml-stylesheet type="text/xsl" href="Guitars.xsl"?>
Open Guitars.xml in Internet Explorer. The file is displayed as XML (Figure 13-14).
Restore (or uncomment) the statement you deleted (or commented out) in step 2.
Open Guitars.xml again in Internet Explorer. This time, the file is displayed as HTML (Figure 13-15).
Example 13-16. XML file and an XSL style sheet for transforming it into HTML.Guitars.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="Guitars.xsl"?> <Guitars> <Guitar> <Make>Gibson</Make> <Model>SG</Model> <Year>1977</Year> <Color>Tobacco Sunburst</Color> <Neck>Rosewood</Neck> </Guitar> <Guitar> <Make>Fender</Make> <Model>Stratocaster</Model> <Year>1990</Year> <Color>Black</Color> <Neck>Maple</Neck> </Guitar> </Guitars>
Guitars.xsl
<?xml version="1.0"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:template match="/"> <html> <body> <h1>My Guitars</h1> <hr /> <table width="100%" border="1"> <tr bgcolor="gainsboro"> <td><b>Make</b></td> <td><b>Model</b></td> <td><b>Year</b></td> <td><b>Color</b></td> <td><b>Neck</b></td> </tr> <xsl:for-each select="Guitars/Guitar"> <tr> <td><xsl:value-of select="Make" /></td> <td><xsl:value-of select="Model" /></td> <td><xsl:value-of select="Year" /></td> <td><xsl:value-of select="Color" /></td> <td><xsl:value-of select="Neck" /></td> </tr> </xsl:for-each> </table> </body> </html> </xsl:template> </xsl:stylesheet>
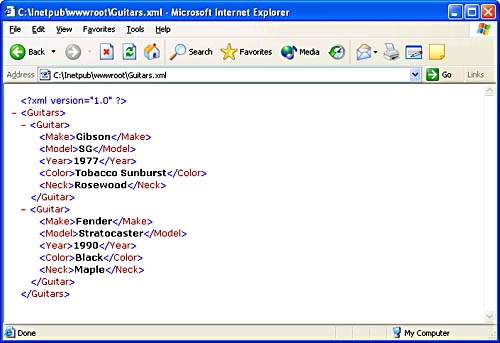
What happened? The statement
<?xml-stylesheet type="text/xsl" href="Guitars.xsl"?>
is a processing instruction informing Internet Explorer that Guitars.xsl is a style sheet containing instructions for converting the content found in Guitars.xml to another format. IE downloaded the style sheet and ran it against Guitars.xml, producing HTML.
Most XSL transformations are template-driven. In Guitars.xsl, the statement
<xsl:template match="/">
marks the beginning of a template that applies to the entire document. “/” is an XPath expression that signifies the root of the document. The first several statements inside the template output the beginnings of an HTML document that includes an HTML table. The for-each element iterates over all the Guitar elements that are subelements of Guitars (note the XPath expression “Guitar/Guitars” defining the selection). Each iteration adds another row to the table, and the value-of elements initialize the table’s cells with the values of the corresponding XML elements.
Converting XML to HTML on the Server
That’s one way to convert XML to HTML. One drawback to this approach is that the XML document must contain a processing directive pointing to the style sheet. Another drawback is that the transformation is performed on the client. It doesn’t work in IE 4 and probably won’t work in most third-party browsers because XSLT wasn’t standardized until recently. Unless you can control the browsers that your clients use, it behooves you to perform the transformation on the server where you can be sure an up-to-date XSLT processor is available.
How do you perform XSL transformations on the server? With XslTransform, of course. The Web page in Example 13-18—Quotes.aspx—demonstrates the mechanics. It contains no HTML; just a server-side script that generates HTML from an XML input document named Quotes.xml and a style sheet named Quotes.xsl. XslTransform.Transform performs the transformation. Its first parameter is an XPathDocument object wrapping the source document. The third parameter specifies the destination for the output, which in this example is the HTTP response. The second parameter, which is not used here, is an XsltArgumentList containing input arguments. Before calling XslTransform.Transform, Quotes.aspx calls another XslTransform method named Load to load the style sheet that governs the conversion. The resulting Web page is shown in Figure 13-17.
Quotes.aspx
<%@ Page Language="C#" %>
<%@ Import Namespace="System.Xml.XPath" %>
<%@ Import Namespace="System.Xml.Xsl" %>
<%
XPathDocument doc =
new XPathDocument (Server.MapPath ("Quotes.xml"));
XslTransform xsl = new XslTransform ();
xsl.Load (Server.MapPath ("Quotes.xsl"));
xsl.Transform (doc, null, Response.OutputStream);
%>Quotes.xml
<?xml version="1.0"?> <Quotes> <Quote> <Text>Give me chastity and continence, but not yet.</Text> <Author>Saint Augustine</Author> </Quote> <Quote> <Text>The use of COBOL cripples the mind; its teaching should therefore be regarded as a criminal offense.</Text> <Author>Edsger Dijkstra</Author> </Quote> <Quote> <Text>C makes it easy to shoot yourself in the foot; C++ makes it harder, but when you do, it blows away your whole leg.</Text> <Author>Bjarne Stroustrup</Author> </Quote> <Quote> <Text>A programmer is a device for turning coffee into code.</Text> <Author>Jeff Prosise (with an assist from Paul Erdos)</Author> </Quote> <Quote> <Text>I have not failed. I've just found 10,000 ways that won't work.</Text> <Author>Thomas Edison</Author> </Quote> <Quote> <Text>Blessed is the man who, having nothing to say, abstains from giving wordy evidence of the fact.</Text> <Author>George Eliot</Author> </Quote> <Quote> <Text>I think there is a world market for maybe five computers.</Text> <Author>Thomas Watson</Author> </Quote> <Quote> <Text>Computers in the future may weigh no more than 1.5 tons.</Text> <Author>Popular Mechanics</Author> </Quote> <Quote> <Text>I have traveled the length and breadth of this country and talked with the best people, and I can assure you that data processing is a fad that won't last out the year.</Text> <Author>Prentice-Hall business books editor</Author> </Quote> <Quote> <Text>640K ought to be enough for anybody.</Text> <Author>Bill Gates</Author> </Quote> </Quotes>
Quotes.xsl
<?xml version="1.0"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:template match="/"> <html> <body> <h1 style="background-color: teal; color: white; font-size: 24pt; text-align: center; letter-spacing: 1.0em"> Famous Quotes </h1> <table border="1"> <tr style="font-size: 12pt; font-family: verdana; font-weight: bold"> <td style="text-align: center">Quote</td> <td style="text-align: center">Author</td> </tr> <xsl:for-each select="Quotes/Quote"> <xsl:sort select="Author" /> <tr style="font-size: 10pt; font-family: verdana"> <td><xsl:value-of select="Text"/></td> <td><i><xsl:value-of select="Author"/></i></td> </tr> </xsl:for-each> </table> </body> </html> </xsl:template> </xsl:stylesheet>
As you might guess, there’s much more to XSLT than these examples demonstrate. In addition to supporting for-each and value-of elements, for example, XSLT supports if and choose elements for conditional branching, variable elements for declaring variables, sort elements for sorting (look closely and you’ll see sort used in Quotes.xsl), and a whole lot more. For a complete list of elements and a summary of XSLT’s syntax, refer to the XSLT specification at http://www.w3.org/TR/xslt.
Converting XML Document Formats
To put an exclamation point at the end of this chapter, Example 13-19 contains the source code for a simple application that transforms an XML document using the specified XSL style sheet and writes the results to the host console window. It’s a handy tool for debugging style sheets by previewing their output. The following command lists the HTML that’s generated when Quotes.xml is transformed with Quotes.xsl:
transform quotes.xml quotes.xsl
As you can see, the XslTransform class makes such a utility exceedingly easy to write—just one more piece of evidence of how valuable and capable a tool the .NET Framework class library is for reading, writing, and manipulating XML documents.
Transform.cs
using System;
using System.Xml.XPath;
using System.Xml.Xsl;
class MyApp
{
static void Main (string[] args)
{
if (args.Length < 2) {
Console.WriteLine ("Syntax: TRANSFORM xmldoc xsldoc");
return;
}
try {
XPathDocument doc = new XPathDocument (args[0]);
XslTransform xsl = new XslTransform ();
xsl.Load (args[1]);
xsl.Transform (doc, null, Console.Out);
}
catch (Exception ex) {
Console.WriteLine (ex.Message);
}
}
}Summary
Classes in the .NET Framework class library’s System.Xml namespace and its children vastly simplify the reading, writing, and manipulating of XML documents. Key members of those namespaces include XmlDocument, which provides a DOM interface to XML documents; XmlTextReader and XmlValidatingReader, which combine SAX’s efficiency with an easy-to-use pull model for reading XML and optionally validating it too; XmlTextWriter, which writes XML documents; XPathDocument, XPathNavigator, and XPathNodeIterator, which enable you to perform XPath queries on XML documents and iterate over the results; and XslTransform, which performs XSL transformations on XML data. Working with XML is an inescapable fact of life in software development today. The FCL’s XML classes make life with XML a great deal easier.