
2.1. Grid infrastructure components
This section describes the grid infrastructure components and how they map with the Globus Toolkit. It will also address how each of the components can affect the application architecture, design, and deployment.
The main components of a grid infrastructure are security, resource management, information services, and data management.
Security is an important consideration in grid computing. Each grid resource may have different security policies that need to be complied with. A single sign-on authentication method is a necessity. A commonly agreed upon method of negotiating authorization is also needed.
When a job is submitted, the grid resource manager is concerned with assigning a resource to the job, monitoring its status, and returning its results.
For the grid resource manager to make informed decisions on resource assignments, the grid resource manager needs to know what grid resources are available, and their capacities and current utilization. This knowledge about the grid resources is maintained and provided by Grid Information Service (GIS), also known as the Monitoring and Discovery Service (MDS).
Data management is concerned with how jobs transfer data or access shared storage.
Let us look at each of these components in more detail.
2.1.1. Security
Security is an important component in the grid computing environment. If you are a user running jobs on a remote system, you care that the remote system is secure to ensure that others do not gain access to your data.
If you are a resource provider that allows jobs to be executed on your systems, you must be confident that those jobs cannot corrupt, interfere with, or access other private data on your system.
Aside from these two perspectives, the grid environment is subject to any and all other security concerns that exist in distributed computing environments.
The Globus Toolkit, at its base, has the Grid Security Infrastructure (GSI), which provides many facilities to help manage the security requirements of the grid environment.
As you are developing applications targeted for a grid environment, you will want to keep security in mind and utilize the facilities provided by GSI.
The security functions within the grid architecture are responsible for the authentication, authorization, and secure communication between grid resources.
Grid security infrastructure (GSI)
Let us see how GSI provides authentication, authorization, and secure communications.
Authentication
GSI contains the infrastructure and facilities to provide a single sign-on environment. Through the grid-proxy-init command or its related APIs, a temporary proxy is created based on the user’s private key. This proxy provides authentication and can be used to generate trusted sessions and allow a server to decide on the user’s authorization.
A proxy must be created before a user can submit a job to be run or transfer data through the Globus Toolkit facilities. Depending on the configuration of the environment, a proxy may or may not be required to query the information services database.
Other facilities are available outside of the Globus Toolkit, such as GSI-Enabled OpenSSH, that utilize the same authentication mechanism to create secure communications channels.
For more information on the GSI-Enabled OpenSSH, visit:
http://grid.ncsa.uiuc.edu/ssh/
Authorization
Authentication is just one piece of the security puzzle. The next step is authorization. That is, once a user has been authenticated to the grid, what they are authorized to do.
In GSI this is handled by mapping the authenticated user to a local user on the system where a request has been received.
The proxy passed by the operation request (such as a request to run a job) contains a distinguished name of the authenticated user. A file on the receiving system is used to map that distinguished name to a local user.
Through this mechanism, either every user of the grid could have a user ID on each system within the grid (which would be difficult to administer if the number of systems in the grid becomes large and changes often), or users could be assigned to virtual groups. For example, all authenticated users from a particular domain may be mapped to run under a common user ID on a particular resource. This helps separate the individual user ID administration for clients from the user administration that must be performed on the various resources that make up the grid.
Grid secure communication
It is important to understand the communication functions within the Globus Toolkit. By default, the underlying communication is based on the mutual authentication of digital certificates and SSL/TLS.
To allow secure communication within the grid, the OpenSSL package is installed as part of the Globus Toolkit. It is used to create an encrypted tunnel using SSL/TSL between grid clients and servers.
The digital certificates that have been installed on the grid computers provide the mutual authentication between the two parties. The SSL/TLS functions that OpenSSL provides will encrypt all data transferred between grid systems. These two functions together provide the basic security services of authentication and confidentiality.
Other grid communication
If you cannot physically access your grid client or server, it may be necessary to gain remote access to the grid. While your operating system’s default telnet program works fine for remote access, the transmission of the data is in clear text. That means that the data transmission would be vulnerable to someone listening or sniffing the data on the network. While this vulnerability is low, it does exist and needs to be dealt with.
To secure the remote communication between a client and grid server, the use of Secure Shell (SSH) can be used. SSH will establish an encrypted session between your client and the grid server. Using a tool such as the GSI-Enabled OpenSSH, you get the benefits of the secure shell while also using the authentication mechanism already in place with GSI.
Application enablement considerations - Security
When designing grid-enabled applications, security concerns must be taken into consideration. The following list provides a summary of some of these considerations.
Single sign-on: ID mapping across systems
GSI provides the authentication, authorization, and secure communications as described above. However, the application designer needs to fully understand the security administration and implications. For instance:
- Is it acceptable to have multiple users mapped to the same user ID on a target system?
- Must special auditing be in place to understand who actually launched the application?
- The application should be independent of the fact that different user ID mappings may be used across the different resources in the grid.
Multi-platform
Though the GSI is based on open and standardized software that will run on multiple platforms, the underlying security mechanisms of various platforms will not always be consistent. For instance, the security mechanisms for reading, writing, and execution on traditional Unix or Linux-based systems is different than for a Microsoft Windows environment. The application developer should take into account the possible platforms on which the application may execute.
Utilize GSI
For any application-specific function that might also require authentication or special authorization, the application should be designed to utilize GSI in order to simplify development and the user’s experience by maintaining the single sign-on paradigm.
Data encryption
Though GSI, in conjunction with the data-management facilities covered later, provides secure communication and encryption of data across the network, the application designer should also take into account what happens to the data after it has arrived at its destination. For instance, if sensitive data is passed to a resource to be processed by a job and is written to the local disk in a non-encrypted format, other users or applications may have access to that data.
2.1.2. Resource management
The grid resource manager is concerned with resource assignments as jobs are submitted. It acts as an abstract interface to the heterogeneous resources of the grid. The resource management component provides the facilities to allocate a job to a particular resource, provides a means to track the status of the job while it is running and its completion information, and provides the capability to cancel a job or otherwise manage it.
In Globus, the remote job submission is handled by the Globus Resource Allocation Manager (GRAM).
Globus Resource Allocation Manager (GRAM)
When a job is submitted by a client, the request is sent to the remote host and handled by a gatekeeper daemon. The gatekeeper creates a job manager to start and monitor the job. When the job is finished, the job manager sends the status information back to the client and terminates.
The GRAM subsystem consists of the following elements:
The globusrun command and associated APIs
Resource Specification Language (RSL)
The gatekeeper daemon
The job manager
Dynamically-Updated Request Online Coallocator (DUROC)
Each of these elements are described briefly below.
The globusrun command
The globusrun command (or its equivalent API) submits a job to a resource within the grid. This command is typically passed an RSL string (see below) that specifies parameters and other properties required to successfully launch and run the job.
Resource Specification Language (RSL)
RSL is a language used by clients to specify the job to be run. All job submission requests are described in an RSL string that includes information such as the executable file; its parameters; information about redirection of stdin, stdout, and stderr; and so on. Basically it provides a standard way of specifying all of the information required to execute a job, independent of the target environment. It is then the responsibility of the job manager on the target system to parse the information and launch the job in the appropriate way.
The syntax of RSL is very straightforward. Each statement is enclosed within parenthesis. Comments are designated with parenthesis and asterisks, for example, (* this is a comment *). Supported attributes include the following:
arguments: Information or flags to be passed to the executable
stdin: Specifies the remote URL and local file used for the executable
stdout: Specifies the remote file to place standard output from the job
stderr: Specifies the remote file to place standard error from the job
queue: Specifies the queue to submit the job (requires a scheduler)
project: Specifies a project account for the job (requires a scheduler)
maxMemory: Specifies the maximum amount of memory in MBs required for the job
minMemory: Specifies the minimum amount of memory in MBs required for the job
hostCount: Specifies the number of nodes in a cluster required for the job
environment: Specifies environment variables that are required for the job
jobType: Specifies the type of job single process, multi-process, mpi, or condor
maxTime: Specifies the maximum execution wall or cpu time for one execution
maxWallTime: Specifies the maximum walltime for one execution
maxCpuTime: Specifies the maximum cpu time for one execution
gramMyjob: Specifies the whether the gram myjob interface starts one process/thread (independent) or more (collective)
The following examples show how RSL scripts are used with the globusrun command. The following is a list of files included in this example:
MyScript.sh: Shell script that executes the ls -al and ps -ef commands.
#!/bin/sh -x ls -al ps -ef
MyTest.rsl: RSL script that calls the shell script /tmp/MySrcipt.sh. It runs the script in the /tmp directory and stores the standard output of the script in /tmp/temp. The contents are below.
& (rsl_substitution = (TOPDIR "/tmp"))(executable = $(TOPDIR)/MyScript.sh ) (directory=/tmp)(stdout=/tmp/temp)(count = 1)
MyTest2.rsl: RSL script that executes the /bin/ps -ef command and stores the standard output of the script in /tmp/temp2.
& (rsl_substitution = (EXECDIR "/bin"))(executable = $(EXECDIR)/ps ) (arguments=ef)(directory=/tmp)(stdout=/tmp/temp)(count =1)
In Example 2-1, the globusrun command is used with MyTest.rsl to execute MyTest.sh on the resource (system) t3. The output of the script stored in /tmp/temp is then displayed using the Linux more command.
Example 2-1. Executing MyTest.sh with MyTest.rsl
[t3user@t3 guser]$ globusrun -r t3 -f MyTest.rsl globus_gram_client_callback_allow successful GRAM Job submission successful GLOBUS_GRAM_PROTOCOL_JOB_STATE_ACTIVE GLOBUS_GRAM_PROTOCOL_JOB_STATE_DONE [t3user@t3 guser]$ more /tmp/temp total 116 drwxrwxrwt 9 root root 4096 Mar 12 15:45 . drwxr-xr-x 22 root root 4096 Feb 26 20:44 .. drwxrwxrwt 2 root root 4096 Feb 26 20:45 .ICE-unix -r--r--r-- 1 root root 11 Feb 26 20:45 .X0-lock drwxrwxrwt 2 root root 4096 Feb 26 20:45 .X11-unix drwxrwxrwt 2 xfs xfs 4096 Feb 26 20:45 .font-unix -rw-r--r-- 1 t3user globus 0 Mar 10 11:57 17487_output [t3user@t3 guser]$ |
In Example 2-2, MyTest2.rsl is used to display the currently executing processes using the ps command.
Example 2-2. Executing ps -ef with MyTest.2.rsl
[t3user@t3 guser]$ globusrun -r t3 -f MyTest2.rsl globus_gram_client_callback_allow successful GRAM Job submission successful GLOBUS_GRAM_PROTOCOL_JOB_STATE_ACTIVE GLOBUS_GRAM_PROTOCOL_JOB_STATE_DONE [t3user@t3 guser]$ more /tmp/temp2 UID PID PPID C STIME TTY TIME CMD root 1 0 0 Feb26 ? 00:00:04 init root 2 1 0 Feb26 ? 00:00:00 [keventd] root 2 1 0 Feb26 ? 00:00:00 [keventd] root 3 1 0 Feb26 ? 00:00:00 [kapmd] root 4 1 0 Feb26 ? 00:00:00 [ksoftirqd_CPUO] root 5 1 0 Feb26 ? 00:00:09 [kswapd] root 6 1 0 Feb26 ? 00:00:00 [bdflush] root 7 1 0 Feb26 ? 00:00:01 [kupdated] root 8 1 0 Feb26 ? 00:00:00 [mdrecoveryd] root 12 1 0 Feb26 ? 00:00:20 [kjournald] root 91 1 0 Feb26 ? 00:00:00 [khubd] root 196 1 0 Feb26 ? 00:00:00 [kjournald] [t3user@t3 guser]$ |
Although there is no way to directly run RSL scripts with the globus-job-run command, the command utilizes RSL to execute jobs. By using the dumprsl parameter, globus-job-run is a useful tool to build and understand RSL scripts.
Example 2-3. Using globus-job-run -dumprsl to generate RSL
[t3user@t3 guser]$ globus-job-run -dumprsl t3 /tmp/MyScript &(executable="/tmp/MyTest") [t3user@t3 guesr]$ |
Gatekeeper
The gatekeeper daemon provides a secure communication mechanism between clients and servers. The gatekeeper daemon is similar to the inetd daemon in terms of functionality. However, the gatekeeper utilizes the security infrastructure (GSI) to authenticate the user before launching the job. After authentication, the gatekeeper initiates a job manager to launch the actual job and delegates the authority to communicate with the client.
Job manager
The job manager is created by the gatekeeper daemon as part of the job requesting process. It provides the interfaces that control the allocation of each local resource. It may in turn utilize other services such as job schedulers. The default implementation performs the following functions and forks a new process to launch the job:
Parses the RSL string passed by the client
Allocates job requests to local resource managers
Sends callbacks to clients, if necessary
Receives status requests and cancel requests from clients
Sends output results to clients using GASS, if requested
Dynamically-Updated Request Online Coallocator (DUROC)
The Dynamically-Updated Request Online Coallocator (DUROC) API allows users to submit multiple jobs to multiple GRAMs with one command. DUROC uses a coallocator to execute and manage these jobs over several resource managers. To utilize the DUROC API you can use RSL (described above), the API within a C program, or the globus-duroc command.
The RSL script that contains the DUROC syntax is parsed at the GRAM client and allocated to different job managers.
Application enablement considerations - Resource Mgmt
There are several considerations for application architecture, design, and deployment related to resource management.
In its simplest form GRAM is used by issuing a globusrun command to launch a job on a specific system. However, in conjunction with MDS (usually through a broker function), the application must ensure that the appropriate target resource(s) are used. Some of the items to consider include:
Choosing the appropriate resource
By working in conjunction with the broker, ensure that an appropriate target resource is selected. This requires that the application accurately specifies the required environment (operating system, processor, speed, memory, and so on). The more the application developer can do to eliminate specific dependencies, the better the chance that an available resource can be found and that the job will complete.
Multiple sub-jobs
If an application includes multiple jobs, the designer must understand (and maybe reduce) their interdependencies. Otherwise, they will have to build logic to handle items such as:
- Inter-process communication
- Sharing of data
- Concurrent job submissions
Accessing job results
If a job returns a simple status or a small amount of output, the application may be able to simply retrieve the data from stdout and stderr. However, the capturing of that output will need to be correctly specified in the RSL string that is passed to the globusrun command. If more complex results must be retrieved, the GASS facility may need to be used by the application to transfer data files.
Job management
GRAM provides mechanisms to query the status of the job as well as perform operations such as cancelling the job. The application may need to utilize these capabilities to provide feedback to the user or to clean up or free up resources when required. For instance, if one job within an application fails, other jobs that may be dependent on it may need to be cancelled before needlessly consuming resources that could be used by other jobs.
2.1.3. Information services
Information services is a vital component of the grid infrastructure. It maintains knowledge about resource availability, capacity, and current utilization. Within any grid, both CPU and data resources will fluctuate, depending on their availability to process and share data. As resources become free within the grid, they can update their status within the grid information services. The client, broker, and/or grid resource manager uses this information to make informed decisions on resource assignments.
The information service is designed to provide:
Efficient delivery of state information from a single source
Common discovery and enquiry mechanisms across all grid entities
Information service providers are programs that provide information to the directory about the state of resources. Examples of information that is gathered includes:
Static host information
Operating system name and version, processor vendor/model/version/ speed/cache size, number of processors, total physical memory, total virtual memory, devices, service type/protocol/port
Dynamic host information
Load average, queue entries, and so on
Storage system information
Total disk space, free disk space, and so on
Network information
Network bandwidth, latency, measured and predicted
Highly dynamic information
Free physical memory, free virtual memory, free number of processors, and so on
The Grid Information Service (GIS), also known as the Monitoring and Discovery Service (MDS), provides the information services in Globus. The MDS uses the Lightweight Directory Access Protocol (LDAP) as an interface to the resource information.
Monitoring and Discovery Service (MDS)
MDS provides access to static and dynamic information of resources. Basically, it contains the following components:
Grid Resource Information Service (GRIS)
Grid Index Information Service (GIIS)
Information providers
MDS client
Figure 2-1 represents a conceptual view of the MDS components. As illustrated, the resource information is obtained by the information provider and it is passed to GRIS. GRIS registers its local information with the GIIS, which can optionally also register with another GIIS, and so on. MDS clients can query the resource information directly from GRIS (for local resources) and/or a GIIS (for grid-wide resources).
Figure 2-1. MDS overview
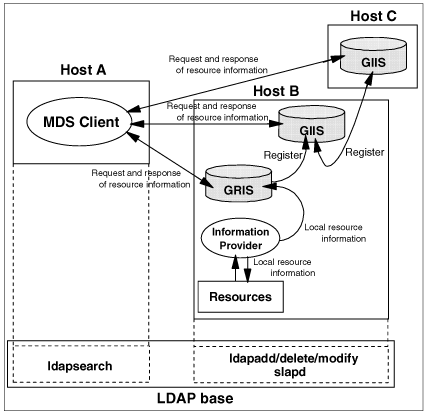
Grid Resource Information Service (GRIS)
GRIS is the repository of local resource information derived from information providers. GRIS is able to register its information with a GIIS, but GRIS itself does not receive registration requests. The local information maintained by GRIS is updated when requested, and cached for a period of time known as the time-to-live (TTL). If no request for the information is received by GRIS, the information will time out and be deleted. If a later request for the information is received, GRIS will call the relevant information provider(s) to retrieve the latest information.
Grid Index Information Service (GIIS)
GIIS is the repository that contains indexes of resource information registered by the GRIS and other GIISs. It can be seen as a grid-wide information server. GIIS has a hierarchical mechanism, like DNS, and each GIIS has its own name. This means client users can specify the name of a GIIS node to search for information.
Information providers
The information providers translate the properties and status of local resources to the format defined in the schema and configuration files. In order to add your own resource to be used by MDS, you must create specific information providers to transfer the properties and status to GRIS.
MDS client
The MDS client is based on the LDAP client command, ldapsearch, or an equivalent API. A search for information about resources in the grid environment is initially performed by the MDS client.
Application enablement considerations - Information Services
Considerations related to information services include:
It is important to fully understand the requirements for a specific job so that the MDS query can be correctly formatted to return resources that are appropriate.
Ensure that the proper information is in MDS. There is a large amount of data about the resources within the grid that is available by default within the MDS. However, if your application requires special resources or information that is not there by default, you may need to write your own information providers and add the appropriate fields to the schema. This may allow your application or broker to query for the existence of the particular resource/requirement.
MDS can be accessed anonymously or through a GSI authenticated proxy. Application developers will need to ensure that they pass an authenticated proxy if required.
Your grid environment may have multiple levels of GIIS. Depending on the complexity of the environment and its topology, you want to ensure that you are accessing an appropriate GIIS to search for the resources you require.
2.1.4. Data management
When building a grid, the most important asset within your grid is your data. Within your design, you will have to determine your data requirements and how you will move data around your infrastructure or otherwise access the required data in a secure and efficient manner. Standardizing on a set of grid protocols will allow you to communicate between any data source that is available within your design.
You also have choices for building a federated database to create a virtual data store or other options including Storage Area Networks, network file systems, and dedicated storage servers.
Globus provides the GridFTP and Global Access to Secondary Storage (GASS) data transfer utilities in the grid environment. In addition, a replica management capability is provided to help manage and access replicas of a data set. These facilities are briefly described below.
GridFTP
The GridFTP facility provides secure and reliable data transfer between grid hosts. Its protocol extends the File Transfer Protocol (FTP) to provide additional features including:
Grid Security Infrastructure (GSI) and Kerberos support allows for both types of authentication. The user can set various levels of data integrity and/or confidentiality.
Third-party data transfer allows a third party to transfer files between two servers.
Parallel data transfer using multiple TCP streams to improve the aggregate bandwidth. It supports the normal file transfer between a client and a server. It also supports the third-party data transfers between two servers.
Striped data transfer that partitions data across multiple servers to further improve aggregate bandwidth.
Partial file transfer that allows the transfer of a portion of a file.
Reliable data transfer that includes fault recovery methods for handling transient network failures, server outages, and so on. The FTP standard includes basic features for restarting failed transfer. The GridFTP protocol exploits these features, and substantially extends them.
Manual control of TCP buffer size allows achieving maximum bandwidth with TCP/IP. The protocol also has support for automatic buffer size tuning.
Integrated instrumentation. The protocol calls for restart and performance markers to be sent back.
GridFTP server and client
Globus Toolkit provides the GridFTP server and GridFTP client, which are implemented by the in.ftpd daemon and by the globus-url-copy command (and related APIs), respectively. They support most of the features defined for the GridFTP protocol.
The GridFTP server and client support two types of file transfer: Standard and third party. The standard file transfer is where a client sends or retrieves a file to/from the remote machine, which runs the FTP server. An overview is shown in Figure 2-3.
Figure 2-2. Standard file transfer

Third-party data transfer allows a third party to transfer files between two servers.
Figure 2-3. Third-party file transfer

Global Access to Secondary Storage (GASS)
GASS is used to transfer files between the GRAM client and the GRAM server. GASS also provides libraries and utilities for the opening, closing, and pre-fetching of data from datasets in the Globus environment. A cache management API is also provided. It eliminates the need to manually log into sites, transfer files, and install a distributed file system.
For further information, refer to the Globus GASS Web site:
http://www-fp.globus.org/gass/
Replica management
Another Globus facility for helping with data management is replica management. In certain cases, especially with very large data sets, it makes sense to maintain multiple replicas of all or portions of a data set that must be accessed by multiple grid jobs. With replica management, you can store copies of the most relevant portions of a data set on local storage for faster access. Replica management is the process of keeping track of where portions of the data set can be found.
Globus Replica Management integrates the Globus Replica Catalog (for keeping track of replicated files) and GridFTP (for moving data), and provides replica management capabilities for grids.
Application enablement considerations - Data management
Data management is concerned with collectively maximizing the use of the limited storage space, networking bandwidth, and computing resources. The following are some of the data management issues that need to be considered in application design and implementation:
Dataset size
For large datasets, it is not practical and may be impossible to move the data to the system where the job will actually run. Using data replication or otherwise copying a subset of the entire dataset to the target system may provide a solution.
Geographically distributed users, data, computing and storage resources
If your target grid is geographically distributed with limited network connection speeds, you must take into account design considerations around slow or limited data access.
Data transfer over wide-area networks
Take into account the security, reliability, and performance issues when moving data across the Internet or another WAN. Build the required logic to handle situations when the data access may be slow or prevented.
Scheduling of data transfers
There are at least two issues to consider here. One is the scheduling of data transfers so that the data is at the appropriate location at the time that it is needed. For instance, if a data transfer is going to take one hour and the data is required by a job that must run at 2:00AM, then schedule the data transfer in advance so that it is available by the time the job requires it.
You should also be aware of the number and size of any concurrent file transfers to or from any one resource at the same time.
If you are using the Globus Data Replication service, you will want to add the logic to your application to handle selecting the appropriate replica, that is, one that will contain the data that you need, while also providing the performance requirements that you have.
2.1.5. Scheduler
The Globus Toolkit does not provide a job scheduler or meta-scheduler. However, there are a number of job schedulers available that already are or can be integrated with Globus. For instance, the Condor-G product utilizes the Globus Toolkit and provides a scheduler designed for a grid environment.
Scheduling jobs and load balancing are important functions in the Grid.
Most grid systems include some sort of job-scheduling software. This software locates a machine on which to run a grid job that has been submitted by a user. In the simplest cases, it may just blindly assign jobs in a round-robin fashion to the next machine matching the resource requirements. However, there are advantages to using a more advanced scheduler.
Some schedulers implement a job-priority system. This is sometimes done by using several job queues, each with a different priority. As grid machines become available to execute jobs, the jobs are taken from the highest priority queues first. Policies of various kinds are also implemented using schedulers. Policies can include various kinds of constraints on jobs, users, and resources. For example, there may be a policy that restricts grid jobs from executing at certain times of the day.
Schedulers usually react to the immediate grid load. They use measurement information about the current utilization of machines to determine which ones are not busy before submitting a job. Schedulers can be organized in a hierarchy. For example, a meta-scheduler may submit a job to a cluster scheduler or other lower-level scheduler rather than to an individual machine.
More advanced schedulers will monitor the progress of scheduled jobs managing the overall work-flow. If the jobs are lost due to system or network outages, a good scheduler will automatically resubmit the job elsewhere. However, if a job appears to be in an infinite loop and reaches a maximum timeout, then such jobs should not be rescheduled. Typically, jobs have different kinds of completion codes, some of which are suitable for resubmission and some of which are not.
Reserving resources on the grid in advance is accomplished with a reservation system. It is more than a scheduler. It is first a calendar-based system for reserving resources for specific time periods and preventing any others from reserving the same resource at the same time. It also must be able to remove or suspend jobs that may be running on any machine or resource when the reservation period is reached.
Condor-G
The Condor software consists of two parts, a resource-management part and a job-management part. The resource-management part keeps track of machine availability for running the jobs and tries to best utilize them. The job-management part submits new jobs to the system or put jobs on hold, keeps track of the jobs, and provides information about the job queue and completed jobs.
The machine with the resource-management part is referred to as the execution machine. The machine with the job-submission part installed is referred to as the submit machine. Each machine may have one or both parts. Condor-G provides the job management part of Condor. It uses the Globus Toolkit to start the jobs on the remote machine instead of the Condor protocols.
The benefits of using Condor-G include the ability to submit many jobs at the same time into a queue and to monitor the life-cycle of the submitted jobs with a built-in user interface. Condor-G provides notification of job completions and failures, and maintains the Globus credentials that may expire during the job execution. In addition, Condor-G is fault tolerant. The jobs submitted to Condor-G and the information about them are kept in persistent storage to allow the submission machine to be rebooted without losing the job or the job information. Condor-G provides exactly-once-execution semantics. Condor-G detects and intelligently handles cases such as the remote grid resource crashing.
Condor makes use of Globus infrastructure components such as authentication, remote program execution, and data transfer to utilize the grid resources. By using the Globus protocols, the Condor system can access resources at multiple remote sites. Condor-G uses the GRAM protocol for job submission and local GASS servers for file transfer.
Application enablement considerations - Scheduler
When considering enabling an application for a grid environment, there are several considerations related to scheduling. Some of these considerations include:
Data management: Ensuring data is available when the job is scheduled to run. If data needs to be moved to the execution node, then data movement may also need to be scheduled.
Communication: Any inter-process communication between related jobs will require that the jobs are scheduled to run concurrently.
Scheduler’s domain: In an environment with multiple schedulers, such as those with meta schedulers, the complexities of coordinating concurrent jobs, or ensuring certain jobs execute at a specific time, can become complex, especially if there are different schedulers for different domains.
Scheduling policy: Scheduling can be implemented with different orientations:
Grid information service: The interaction between the scheduler and the information service can be complex. For instance, if the resource is found through MDS before the job is actually scheduled, then there may be an assumption that the current resource status will not change before execution of the job. Or a more proactive mechanism could be used to predict possible changes in the resource status so proactive scheduling decisions may be made.
Resource broker: Typically a resource broker must interface with the scheduler.
2.1.6. Load balancing
Load balancing is concerned with the distribution of workload among the grid resources in the system. Though the Globus Toolkit does not provide a load-balancing function, under certain environments it is a desired service.
As the work is submitted to a grid job manager, the workload may be distributed in a push model, pull model, or combined model. A simple implementation of a push model could be built where the work is sent to grid resources in a round-robin fashion. However, this model does not consider the job queue lengths. If each grid resource is sent the same number of jobs, a long job queue could build up in some slower machines or a long-running job could block others from starting if not carefully monitored. One solution may be to use a weighted round-robin scheme.
In the pull model, the grid resources take the jobs from a job queue. In this model, synchronization and serialization of the job queue will be necessary to coordinate the taking of jobs by multiple grid resources. Local and global job queue strategies are also possible. In the local pull model strategy, each group of grid resources is assigned to take jobs from a local job queue. In the global pull model strategy, all the grid resources are assigned the same job queue. The advantage of the local pull model is the ability to partition the grid resources. For example, proximity to data, related jobs, or jobs of certain types requiring similar resources may be controlled in this way.
A combination of the push and the pull models may remove some previous concerns. The individual grid resources may decide when more work can be taken, and send a request for work to a grid job server. New work is then sent by the job server.
Failover conditions need to be considered in both of the load-balancing models. The non-operational grid resources need to be detected, and no new work should be sent to failed resources in the push model. In addition, all the submitted jobs that did not complete need to be taken care of in both push and pull models. All the uncompleted jobs in the failed host need to be either redistributed or taken over by other operational hosts in the group. This may be accomplished in one of two ways. In the simplest, the uncompleted jobs can be resent to another operational grid resource in the push model, or simply added back to the job queue in the pull model. In a more sophisticated approach, multiple grid resources may share job information such as the jobs in the queue and checkpoint information related to running jobs, as shown in Figure 2-4. In both models, the operational grid resources can take over the uncompleted jobs of a failed grid resource.
Figure 2-4. Share job information for fault-tolerance

Application-enablement considerations - Load balancing
When enabling applications for a grid environment, design issues related to load balancing may need to be considered. Based on the load-balancing mechanism that is in place (manual, push, pull, or some hybrid combination), the application designer/developer needs to understand how this will affect the application, and specifically its performance and turn-around time. Applications with many individual jobs that each may be affected or controlled by a load-balancing system can benefit from the improved overall performance and throughput of the grid, but may also require more complicated mechanisms to handle the complexity of having its jobs delayed or moved to accommodate the overall grid.
2.1.7. Broker
As already described, the role of a broker in a grid environment can be very important. It is a component that will likely need to be implemented in most grid environments, though the implementation can vary from relatively simple to very complex.
The basic role of a broker is to provide match-making services between a service requester and a service provider. In the grid environment, the service requesters will be the applications or the jobs submitted for execution, and the service providers will be the grid resources.
With the advent of OGSA, the future service requester may be able to make requests of a grid service or a Web service via a generic service broker. A candidate for such a generic service broker may be IBM WebSphere Business Connection, which is currently a Web services broker.
The Globus toolkit does not provide the broker function. It does, however, provide the grid information services function through the Monitoring and Discovery Service (MDS). The MDS may be queried to discover the properties of the machines, computers, and networks such as the number of processors available at this moment, what bandwidth is provided, and the type of storage available.
Application enablement considerations - Broker
When designing an application for execution in a grid environment, it is important to understand how resources will be discovered and allocated. It may be up to the application to identify its resource requirements to the broker so that the broker can ensure that the proper and appropriate resources are allocated to the application.
2.1.8. Inter-process communications (IPC)
A grid system may include software to help jobs communicate with each other. For example, an application may split itself into a large number of sub-jobs. Each of these sub-jobs is a separate job in the grid. However, the application may implement an algorithm that requires that the sub-jobs communicate some information among them. The sub-jobs need to be able to locate other specific sub-jobs, establish a communications connection with them, and send the appropriate data. The open standard Message Passing Interface (MPI) and any of several variations are often included as part of the grid system for just this kind of communication.
MPICH-G2
MPICH-G2 is an implementation of MPI optimized for running on grids. It combines easy secure job startup, excellent performance, data conversion, and multi-protocol communication. However, when communicating over wide-area networks, applications may encounter network congestion that severely impacts the performance of the application.
Application-enablement considerations - IPC
There are many possible solutions for inter-process communication, of which MPICH-G2 described above is just one. However, requiring inter-process communication between jobs always increases the complexity of an application, and when possible should be kept to a minimum. However, in large complex applications, it often cannot be avoided. In these cases, understanding the IPC mechanisms that are available and minimizing the effect of failed or slowed communications can help ensure the overall success of the applications.
2.1.9. Portal
A grid portal may be constructed as a Web page interface to provide easy access to grid applications. The Web user interface provides user authentication, job submission, job monitoring, and results of the job.
The Web user interface and interaction of a grid portal may be provided using an application server such as the WebSphere Application Server. See Figure 2-5 on page 35.
Figure 2-5. Grid portal on an application server

Application-enablement considerations - Portal
Whatever the user interface might be to your grid application, ease-of-use and the requirements of the user must be taken into account. As with any user interface, there are trade-offs between ease-of-use and the ability for advanced users to provide additional input to the application or to specify run-time parameters unique for a specific invocation of the job. By utilizing the GRAM facilities in the Globus Toolkit, it is also possible to obtain job status and to allow for job management such as cancelling a job in progress. When designing the portal, the users requirements in these areas must be understood and addressed.
Developing a portal for grid applications is described in more detail in Chapter 8, “Developing a portal” on page 215.