
Load balancing is intended to mean evenly balancing the workload across the machines in a cluster. Specifically, in a web-based environment, work is short—very short. Typical requests can take as little as a few milliseconds to complete, and a server can handle thousands of static page requests per second and almost as many dynamic pages per second. The nature of these transactions makes the concept of system load inappropriate.
Imagine a cluster of servers equally utilized. A new server is brought online and initially has a system load of 0. Balancing on system load alone would cause all subsequent requests to be directed to this new machine. Thousands will arrive in the first second, and the load will be zero. Thousands more will arrive in the next second, and the load will be...that’s right...zero. The system load won’t update for another 5 seconds, and, even when it does, it will be the 1-minute average. This in no way reflects the current workload of the machine because web requests are too short and too fast to measure in this way. By the time the load changes to reflect the current workload, the machine will have been thrashed, and it will be far too late to correct. This problem is called staleness. The metrics are so stale, decisions on them are nonsensical.
So what is the right approach to load balancing? The answer to that is academically difficult, but it is based on a simple concept: effective resource utilization.
Some practical approaches taken by available load-balancing products (both hardware and software) are
-
Round robin—One request per server in a uniform rotation. This suffers from a classic queueing-theory problem where servers that become overworked don’t have the reprieve they require to settle down again.
-
Least connections—Assuming that the implementation is good, this is a relatively sound algorithm. Although no guarantees are given that resources are used optimally, the faster a machine can service connections (accept, satisfy, and disconnect), the more work they will receive. Conversely, if a machine is slow, the connections will backlog, and the server will not be dealt more requests. This technique has serious problems if several load balancers are used, and each is making decisions in parallel.
-
Predictive—Usually based on either round robin or least connections with some added ad-hoc expressions to compensate in the information staleness issues induced in rapid transaction environments. However, vendors rarely publish the actual details of the algorithms they use, so your mileage may vary.
-
Available resources—Although this is an ideal concept, the staleness issue is severe, and good results can rarely be extracted from this model.
-
Random—Randomized algorithms have taken computer science by storm over the last 10 years, posing elegant solutions to complicated problems that yield good probabilistic outcomes. Although a purely random assignment of requests across machines in a cluster sounds silly (because it completely disregards available resources), combining this methodology with resource-based algorithms as a probabilistically decent solution to the staleness problem is an excellent approach.
-
Weighted random—Weighting anything administratively is a kooky concept. Is a dual processor system twice as fast as a single processor system? The answer is “it depends.” Assigning some arbitrary constant (such as 2) to the faster machines in a clustered environment is making an assumption that should make any self-respecting engineer cry. Although this technique can work well, it requires a lot of manual tweaking, and when servers are added or upgraded, the tweaking process begins all over again. Load balancing is about effectively allocating available resources, not total resources.
In addition to the problem of choosing a method to decide which server is the best, multiple parallel load balancers also must work in unison. If two (or more) load balancers are deployed side-by-side (as peers), and both are active and balancing traffic, the game plan has changed substantially. As has been mentioned, the only way to make perfect decisions is to know the future. This is not possible, so algorithms that estimate current conditions and/or attempt to predict the effects of decisions are employed in an attempt to make “good” decisions.
The situation is greatly complicated when another system attempts to make decisions based on the same information without cooperation. If two machines make the same decisions in concert, the effects of naive decisions will be twice that which was intended by the algorithm designer. Cooperative algorithms limit the solution space considerably. You might find a random distribution beating out the smartest uncooperative algorithms.
A tremendous amount of academic and industry research has taken place on the topic of load balancing in the past five or more years. This specific research topic had the burning coals of the dot-com barbeque under it, and the endless stream of investment money making it hotter. Although that has been all but extinguished, the product is pretty impressive!
The Association of Computing Machinery’s Special Interest Group SIGMETRIC has published countless academic papers detailing concepts and approaches to modeling and evaluating load-balancing schemes. Having read many of these while doing research at the Center for Networking and Distributed Systems (CNDS) on the Backhand Project, I can say that the single biggest problem is that no one model applies equally well to all practical situations.
Far from the purely academic approach to the problem, countless autonomous groups were concurrently developing completely ad-hoc balancing solutions to be used in practice. Many were building tools to prove it was easy and that you didn’t need to spend a fortune on hardware solutions; others were building them out of the desperate need for growth without venture funding.
As always, the most prominent solutions were those that were mindful of the progress on both fronts: maintaining the goal of building a valuable and usable product. Many excellent products are on the market today, software and hardware, open and proprietary, that make large web services tick.
Specifically with regard to the topic of web serving, it is impossible for two machines to share a single IP address on the same Ethernet segment because the address resolution protocol (ARP) poses a fundamental obstacle. As such, without a load-balancing device that provides virtual IP services, the rule is at least one distinct IP address per machine.
What does this mean? Well, a lot actually. DNS allows the exposure of multiple IP addresses for a single hostname. Multiple IP addresses are being used to provide the same service. It should be noted that nothing in the DNS specification guarantees an even distribution of traffic over the exposed IP addresses (or a distribution at all). However, in practice, a distribution is realized. Although the distribution is uniform over a large time quantum, the methodology is naive and has no underlying intelligence. Given its shortcomings, you will see its usefulness in specific environments in Chapter 6, “Static Content Serving for Speed and Glory.”
For example, dig www.yahoo.com yields something like the following:
;; ANSWER SECTION:
www.yahoo.com. 1738 IN CNAME www.yahoo.akadns.net.
www.yahoo.akadns.net. 30 IN A 216.109.118.70
www.yahoo.akadns.net. 30 IN A 216.109.118.67
www.yahoo.akadns.net. 30 IN A 216.109.118.64
www.yahoo.akadns.net. 30 IN A 216.109.118.77
www.yahoo.akadns.net. 30 IN A 216.109.118.69
www.yahoo.akadns.net. 30 IN A 216.109.118.74
www.yahoo.akadns.net. 30 IN A 216.109.118.73
www.yahoo.akadns.net. 30 IN A 216.109.118.68
This means that you could visit any of the preceding IP addresses to access the Yahoo! World Wide Web service. However, consider secure hypertext transport protocol (HTTPS), commonly referred to as SSL (even though SSL applies to much more than just the Web).
The HTTP protocol allows for arbitrary headers to be added to any request. One common header is the Host: header used to specify which web real estate you want to query. This technique, called name-based virtual hosting, allows several web real estates to be serviced from the same IP address.
However, when using SSL, the client and server participate in a strong cryptographic handshake that allows the client to verify and trust that the server is who it claims to be. Unfortunately, this handshake is required to occur before HTTP requests are made, and as such no Host: header has been transmitted. This shortcoming of HTTP over SSL inhibits the use of name-based virtual hosting on secure sites. Although the question whether this is good or bad can be argued from both sides, the fact remains that servicing multiple secure websites from the same IP address is not feasible.
If you expose a single IP address for each web service, you need one IP address for each secure web real estate in service. But if multiple (N) IP addresses are used for each web service, you need N IP addresses for each secure web real estate. This can be wasteful if you manage thousands of secure websites.
There are two workarounds for this. The first is to run SSL on a different port than the default 443. This is a bad approach because many corporate firewalls only allow SSL connections over port 443, which can lead to widespread accessibility issues that are not easily rectified.
The second approach is to use a delegate namespace for all secure transactions. Suppose that we host www.example1.com through www.example1000.com, but do not want to allocate 1,000 (or N times 1,000) IP addresses for SSL services. This can be accomplished by using secure.example.com as the base site name for all secure transactions that happen over the hosted domains. This approach may or may not be applicable in your environment. Typically, if this is not a valid approach, it is due to the business issue of trust.
If you visit a site www.example1000.com and are transferred to secure.example.com for secure transactions, users will be aware that they were just tossed from one domain to another. Although it may not be so obvious with those domain names, consider a hosting company named acmehosting.com and a client named waldoswidgets.com. To preserve IP space, ACME hosting chooses to put all client SSL transactions through a single host named secure.acmehosting.com. However, the end customer who is expecting to purchase something from Waldo’s Widgets is oblivious to the fact that Waldo chose ACME as a hosting company.
The end-user placed enough trust in waldoswidgets.com to conduct a secure transaction, but suddenly that user is placed on secure.acmehosting.com to conduct this transaction. Although the user can be put at ease by having seamless creative continuity between the two sites (both sites look the same), the URL in the browser has still changed, and that hand-off has diminished trust.
Although there is no real way to fix IP consumption issues with running a tremendous number of SSL sites, it can certainly be alleviated by running each secure site on at most one IP address. This approach brings up a scalability issue—which is why this discussion belongs in this chapter.
If you expose only a single IP address for a service, that IP must be capable of servicing all requests directed there. If it is a large site and the workload exceeds the capacity of a single web server, we have a problem that can only be solved by load balancing.
Web switches, or black-box load balancers, are by far the most popular technology deployed in the Internet for scaling highly trafficked websites. There are good and bad reasons for choosing web switches as the technology behind an end solution.
Throughout this book, we present the advantages of solutions followed by the disadvantages, usually leading to a better approach or a better technology that doesn’t suffer the same shortcomings. With web switches, we’ll take the opposite approach because web switches are sometimes the only viable solution given their features.
Web switches come in all shapes and sizes, from small 1U units to carrier-class units capable of aggregating the largest of environments. During the dot-com era, the marketplace had several key high availability and load balancing players, and competition was fierce. This led to stable, efficient products. The major players in the space are Nortel Networks, Foundry, Cisco, and Extreme Networks, just to name a few.
In layman’s terms, web switches act like network address translation (NAT) capable routers—just backward. Your corporate firewall or your $50 wireless hub and cable modem can use NAT to allow multiples of your private machines (a few laptops and PCs) to share a single routable IP address to access the Internet. A web switch does the opposite by exposing the resources of several private machines through a single routable IP address to hosts on the Internet (that is, end-users) as shown in Figure 5.1.
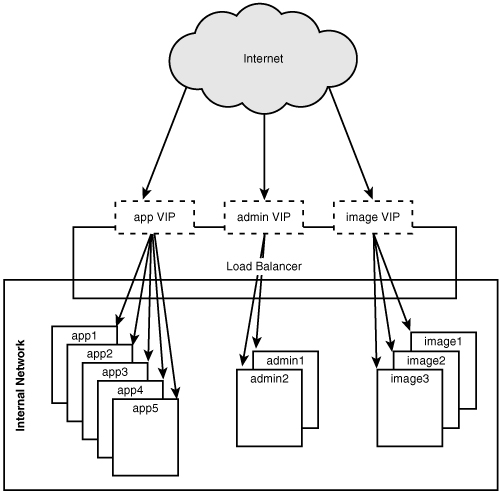
The one thing that truly sets web switches (at least the good ones) apart from other load-balancing solutions is their raw performance. Several switches on the market are capable of sustaining upwards of 15 million concurrent sessions and switching more than 50 gigabits/second of data. Those astounding performance metrics combined with simplistic balancing mechanics make for a solution that can drive the largest of Internet sites.
Arguing about the stability of these products seems to be a no-win endeavor. Everyone has his own unique experience. I have managed installations with chronic (weekly or daily) problems with high availability/load balancing device malfunctions, and I have deployed solutions that ran for three years without a single login.
However, one issue must be addressed: Do you really need a web switch? Chapter 4 discussed the irony of needing a high availability solution for your high availability/load balancing device. The irony may be amusing, but the accompanying price tag is not. These devices are useful when needed and cumbersome in many ways when they are not. The next few sections present several alternatives to web switches that may make more sense in architectures that don’t need to sustain 15 million concurrent sessions or are capable of exposing their services over several IP addresses. Chapter 6 details a viable and proven solution that tackles a problem of considerable scale without employing the use of any web switches.
IP virtual servers (IPVS) are almost identical in purpose and use to web switches, the difference being only that they aren’t specifically a piece of networking hardware. Instead, they are components that run on traditional (often commodity) servers and employ either a user space application, modified IP stack, or a combination of the two to provide a distribution point for IP traffic. By exposing a single virtual IP address for a service and distributing the traffic across a configured set of private machines, IPVS accomplishes the task of load balancing inbound traffic.
From a network topology perspective, a configuration using IPVS looks identical to a configuration based on web switches. Aside from the fact that web switches typically have several Ethernet ports to which servers can be connected and generally higher performance metrics, there is little difference between the placement and operation of IP virtual servers and web switches.
In stark comparison to web switches and IPVS systems, application layer load balancers operate entirely in user space. As such, they have a few feature advantages over their low-level counterparts. Along with these extra features come rather apparent limitations—specifically in the area of performance. These applications must play in the sandbox that is user space and as such are forced to deal with application programming interfaces (APIs) and limitations exposed therein.
A few examples of application-layer load balancers are
-
Zeus Load Balancer
-
Eddie
-
Apache and mod_backhand
These products are fast and flexible, but the concurrency and performance they boast are pale when compared to the enterprise and carrier-class layer 4 and layer 7 switches available on the market. Layers 1 through 7 are defined by the OSI network model and are depicted in Figure 5.2.
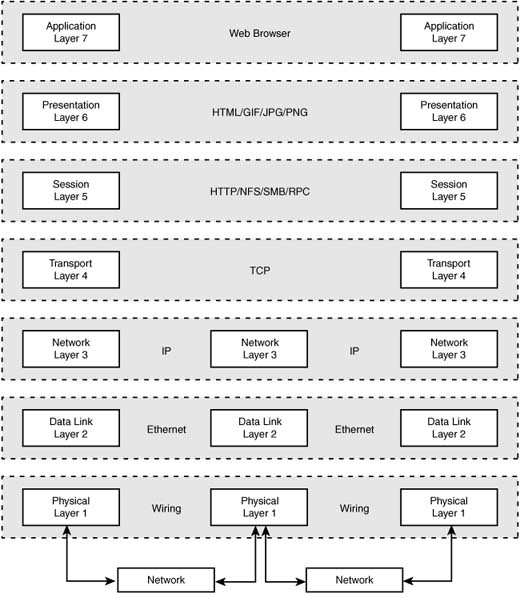
The advantage of operating on layer 3 is that the solution does not need intimate knowledge of the application-specific protocols (in this case, SSL and HTTP). This advantage yields two benefits. First, layers 3 and under are fairly simple, and hardware accelerated solutions are much easier to come by. This results in performance that is orders of magnitude better than application-level solutions can provide. Second, because layer 3 is the foundation for almost everything that happens on the Internet, the solution is more versatile and can support a wide array of services such as SMTP, POP3, IMAP, DNS, FTP, and NTTP without understanding the intricacies of those high-level IP-based protocols.
Many layer 3 web switches claim to operate above layer 7. The truth is that some appear to work on layer 7 but actually act on layer 3. For the most part, this has advantages, but it also introduces some limitations. A web switch passes all traffic from connecting clients to real servers behind the switch. The same is true with IPVS systems. Although these devices can certainly inspect the traffic as it passes, they typically operate on the IP level with the capability to translate TCP/IP sessions to back-end servers. It is important to understand the difference between translation and proxying. When translating, the packets are simply manipulated (which can be done on an immense scale). Proxying requires processing all the data from the client and the real servers to which traffic is being sent, which includes reforming and originating all needed packets—that is substantially more expensive. Because these devices transit the web users’ sessions, they can inspect the payload of packets to make decisions based on layer 7 information while affecting traffic on layer 3.
If a device can perform its duties without modifying packets above layer 5, why would you ever employ a technology like an application-level load balancer? Certain mechanisms cannot be employed without handling and fully processing information through the entire OSI network stack. These mechanisms are often safely ignored in large-scale architectures, but often is not always, so we stand to benefit discussing it here.
The following are some things that can be done by application-level load balancers that are difficult to do on web switches and IPVS devices:
-
Requests can be allocated based on information in an encrypted SSL session.
-
Requests of subsequent transactions in a pipelined HTTP session can be allocated to different real servers.
-
Business rules can be used as the basis for customized allocation algorithms instead of predetermined vendor rules.
Certain high traffic environments have session concurrency requirements that make web switches and IPVS solutions more reasonable to deploy than an application-level solution. However, as should be apparent, requirements dictate the final solution more so than does convenience. If a web switch or IPVS simply can’t fit the bill due to functional limitations, the solution is not bumped down the preference list; it is eliminated entirely.
A variety of uses of application-level load balancers can operate fully to layer 7. The most obvious are those that need to base allocation decisions on information in the request while employing SSL. SSL provides a mechanism for a client to validate the identity and authenticity of a server and optionally vice versa via a public key infrastructure (PKI). Additionally, using asymmetric cryptography, a symmetric key is negotiated and used to encrypt the session. Due to this safely negotiated keying, a man in the middle cannot compromise the information as it passes by.
Web switches and IPVS solutions typically do not terminate SSL connections. If they do, they are often application layer load balancing systems in disguise. Because they do not terminate the SSL session, they cannot see the payload and thus cannot use the information therein for decisions. Application-level load balancers, on the other hand, can.
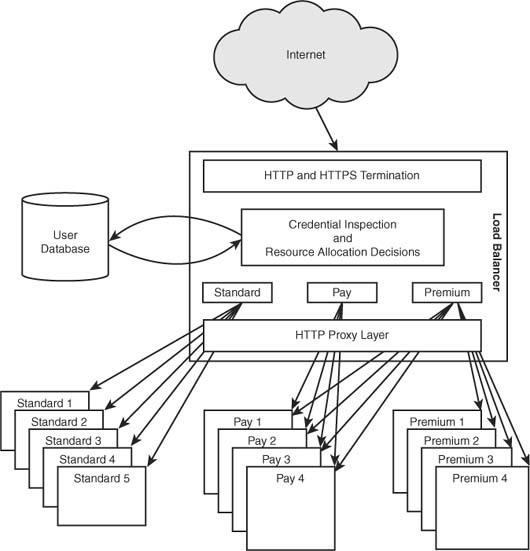
Suppose that you have a news site serviced over SSL where three levels of users access the site. Premium customers are issued client SSL certificates and offered real-time news with stringent quality of service guarantees. Paying customers are given access to real-time data but less stringent quality of service guarantees. Nonpaying users access the site with no guarantees and no access to real-time data. The one kink in the plan is that all sites need to be serviced by the same URL schema. In other words, the complete URLs must be identical across all users because they tend to migrate from one service level to another on a regular basis, and it is essential that their bookmarks all continue to function and that naive users are not confused by different URLs or hostnames.
As such, you need something more than a load balancer. You need a resource allocation framework. Load balancers are, in effect, resource allocation frameworks; however, their allocation techniques are primarily focused on equalizing utilization across the machines for which they front. The beauty of application load balancers is that they implement all the plumbing necessary to proxy user-originating connections back to a set of real servers, and, because they are implemented as user-space applications, different decision-making algorithms are often easy to implement.
Both Eddie and mod_backhand can be used as general purpose resource allocation frameworks. This allows you to make simple modifications to the algorithms to accomplish the presented goal of your news site. The service requires the use of SSL, so the solution used must terminate the SSL connection to inspect the payload. As such, these frameworks are privy to the details of the connection, session, and payload. If an SSL certificate is presented by the client, this tier can validate the certificate, ensure that the user is still in good standing, and choose the appropriate real server based on more than just utilization. Figure 5.3 depicts a basic flow of this setup.
Load balancing is a consistently abused term. In the industry, it is used without thought to mean high availability and a linear scaling of services. Chapter 4 should have reinforced why load balancing and high availability, although partners in crime, are completely different concepts.
Linear scaling is simply a falsehood. By increasing a cluster from one server to two, we can only double the capacity if our algorithm for allocating requests across the machines was optimal. Optimal algorithms require future knowledge. The smallest inkling of reasoning tells us that because we lack knowledge of the future, we cannot be optimal, nor can we double our capacity by doubling our machinery, and thus the increase in performance due to horizontal scaling is sublinear. With one machine, we can realize 100% resource utilization. However, as more machines are added, the utilization is less impressive.
Although clustered systems that tackle long-term jobs (such as those tackled in supercomputing environments) tend to have relatively good clusterwide utilization, web systems do not. High performance computing (HPC) systems boast up to 95% utilization with a steady stream of jobs. Due to the nature of web requests (their short life and rapid queueing), the error margins of algorithms are typically much higher. A good rule of thumb is to expect to achieve as low as 70% per-server utilization on clusters larger than three servers.
Capacity Planning Rule of Thumb
Expect to achieve an average of 70% utilization on each server in clusters with three or more nodes. Although better utilization is possible, be safe and bet on 70%.
Although the term load balancing is often used in situations where it means something else, there are some things to be gained by “abusing” the term. The first thing we talked about in this chapter was that balancing load isn’t a good goal to have, so the name itself is off base. Twisting the definition slightly to suit the purpose of web requests, we arrive at the concept of equal resource utilization across the cluster.
Resources on the real servers should be allocated evenly to power a particular service...or should they? The bottom line is that load balancers should provide a framework or infrastructure for allocating real server resources to power a service. With a framework, the architect can decide how to approach resource allocation. This approach allows for architectural flexibility such as new and improved balancing algorithms or even intelligent artificial segmentation such as the one presented earlier in Figure 5.3.
The Internet is much larger than the World Wide Web. Although more and more services are being built on top of HTTP due to its prevalence, a plethora of commonly used protocols are available for external and internal services. The distinct advantage of load balancing devices that do not operate above layer 4 is that they are multidisciplinary. Load balancing devices that operate on layer 3 or layer 4 (like most web switches and IPVS solutions) are capable of distributing service load across real servers for almost any IP-based protocol. A few of the most commonly load balanced IP-based protocols are
-
Web Services (HTTP/HTTPS)
-
Domain Name Service (DNS)
-
Network News Transfer Protocol (NNTP)
-
Local Directory Access Protocol (LDAP/LDAPS)
-
Internet Mail Access Protocol (IMAP/IMAPS)
-
Post Office Protocol (POP/POPS)
-
Simple Mail Transfer Protocol (SMTP)
-
Local Mail Transfer Protocol (LMTP)
-
File Transfer Protocol (FTP)
Regardless of the need, almost every large architecture has at least one load balancer deployed to distribute some IP traffic. For architectures that are centralized (single geographic installation), the choice to use an expensive, high-performance load balancer is usually sound. As illustrated in Chapter 4, load balancing does not provide high availability. Because there is still a single point of failure when deploying load balancers, two must be deployed, and a high availability solution must be instantiated between them. The “expensive” load balancer just doubled in price.
For centralized architectures, two devices often suffice, which makes the costs understood and usually reasonable. However, when an architecture decentralizes for political, business, or technical reasons, scalability is no longer efficient. The expensive price for dual load balancers now must be replicated across each cluster. Given four installations throughout the world, eight load balancers must be purchased for high availability, load balancing, and consistency. At that point, alternative approaches may be more appropriate.
The biggest misconception I’d like to lay to rest is that of mixing the concept of balancing load and session stickiness. Session stickiness is an approach to ensure that a specific visitor to the site is serviced by a machine in the cluster and that that visitor will continue to return to that machine throughout the life of his visit. If a request arrives at a load balancer and it assigns it to a machine based on information other than load metrics, it is not really balancing load.
One can argue that the attempt is to balance the load of a complete session rather than the load of an individual request. The Web exists on the terms of one short request after another. The act of bundling them into large composite transactions for the purpose of application design makes sense. However, doing this on the level of the load balancer leads to poor resource utilization and complicated resource allocation needs.
Many application programmers will tell you that all complicated web applications require application or web servers to store the state of the session locally (because sticking it in a centralized place is too expensive) and that this need mandates the use of session-sticky load balancing. Session information can be stored locally on the application or web server—this technique necessitates sticky sessions. Sticking a user to a specific web server because her session information is stored there and only there should have some pretty obvious implications on the fault-tolerance of the solution. If that server were to become unavailable, that user and every other user unfortunate enough to have been “stuck” to that server would certainly be aware of a single point of failure in your system architecture.
Sessions information can also be stored on some shared storage medium such as a database; this approach is common but can require tremendous horsepower. However, one other party is involved that web application designers always seem to forget about—the client.
Far too little attention is given to the art of cookies. At times, session information is so large that it could never conceivably fit in a user’s cookie. However, I have yet to be presented with an architecture where a user’s session data could not be split into rarely accessed or rarely updated components stored in a centralized backing store and frequently accessed or frequently updated components stored securely in a client’s cookie. If this can be done, the load balancing techniques used in the architecture can be radically changed for the better.
Load balancing is a theoretically complicated problem. In and of itself, it is an academically difficult problem to solve completely. But, Given the constrained nature of most web environments and a good engineer, many adequate solutions are available today.
Because load balancing is a tricky academic problem, most of the solutions available are ad-hoc systems for solving real-world, web-based, load-balancing problems. Some are naive, others are extremely insightful, but most importantly, all of them seem to have their place.
Throughout the rest of this book, we will look at various architectural challenges, and when load balancing is part of the solution, we will discuss why the technology presented is a good fit.