
To better understand this question and its answer, it is necessary first to clearly define the problem space. There are several business and technical problems that distributed database technologies attempt to solve.
Data resiliency is perhaps the most common reason for deploying such a technology. The goal is not to change the way the architecture works or performs but to ensure that if primary architecture is lost (due to a natural disaster or a terrorist attack), a complete, consistent, and current copy of the data is located elsewhere in the world. The technique can also be applied on a local level to maintain a copy of production data on a second server local to the production architecture to protect against hardware failures. This often entails shipping modifications to the production dataset in near real-time off to a second location.
Operational failover is above and beyond data resiliency. The goal is to have both data resiliency and the capability to assume normal operations in case of a catastrophe. This technique is often referred to as warm-standby or hot-standby.
The difference between warm- and hot-standby is not related so much to the type of replication but rather to the effort involved in having the production architecture start using the second database in the event of a failure. Hot-standby means that it is automatic, and engineers are informed that a failure has occurred, as well as a failover. Warm-standby, on the other hand, means that when a failure occurs, an engineer must perform actions to place the standby into the production architecture.
Operational failover is the most common implementation of distributed database technology. The only difference between this technique and plain data resiliency is the need for a usable, production-grade architecture supporting the replica.
Databases are the core technologies at the heart of most IT infrastructures, be it back office or the largest dot com. As a site scales up, the demands placed on the database are increased, and the database must keep up. Most architectures (but notably not all) have a high read-to-write ratio. This means that most of the time the database is being used to find stored information, not store new information.
There is a delineation between high read/write ratio architectures and others because when databases are distributed, compromises must be made. Database usage like this can allow for compromises that are infeasible in more write-intensive scenarios.
The approach here is to set up one or more databases and maintain on them an up-to-date copy of the production dataset (just as in an operation failover situation). However, we can guarantee that these databases will never become a master and that no data modification will occur on any system. This allows clients to perform read-only queries against these “slave” systems, thereby increasing performance. We will discuss the ramifications and limits placed on clients in the “Master-Slave Replication” section later in this chapter.
The operational failover (as a hot-standby) sounds like it will provide seamless failover and perfect reliability. This, however, is not necessarily true because the technique used ships changes to the production dataset in near real-time. As anyone in the banking industry will tell you, there is a big difference between nearly accurate and accurate.
For nonstop reliability, transactions that occur on one server must not be allowed to complete (commit) until the second server has agreed to commit them; otherwise, transactions that occur on one machine immediately prior to a complete failure may never make it to the second machine. It’s a rare edge condition, right? Tell me that again when one of the mysteriously missing transactions is a million-dollar wire transfer.
This master-master (parallel server) technology is common at financial institutions and in other systems that require nonstop operation. The compromise here is speed. What was once a decision for a single database to make (whether to commit or not) now must be a collaborative effort between that database and its peer. This adds latency and therefore has a negative impact on performance.
This is the true distributed database. Here we have the same needs as master-master, but the environment is not controlled. In a geographically distributed operation the large, long-distance networking circuits (or even the Internet) connect various databases all desperately attempting to maintain atomicity, consistency, isolation, and durability (ACID).
Even in the best-case scenario, latencies are several orders of magnitude higher than traditional parallel server configurations. In the worst-case scenario, one of the database peers can disappear for seconds, minutes, or even hours due to catastrophic network events.
From a business perspective, it does not seem unreasonable to ask that a working master-master distributed database be geographically separated for more protection from real-world threats. However, “simply” splitting a master-master solution geographically or “simply” adding a third master to the configuration is anything but simple.
Why is replication such a challenging problem? The short answer is ACID. Although this isn’t intended to be a databases primer, you do need a bit of background on how databases work and what promises they make to their users. Here is what ACID buys us:
-
Atomicity—All the data modifications that occur within a transaction must happen completely or not at all. No partial transaction can be recorded even in the event of a hardware or software failure.
-
Consistency—All changes to an instance of data must be reflected in all instances of that data. If $300 is subtracted from my savings account, my total aggregated account value should be $300 less.
-
Isolation—The elements of a transaction should be isolated to the user performing that transaction until it is completed (committed).
-
Durability—When a hardware or software failure occurs, the information in the database must be accurate up to the last committed transaction before the failure.
Databases have been providing these semantics for decades. However, enforcing these semantics on a single machine is different from enforcing them between two or more machines on a network. Although it isn’t a difficult technical challenge to implement, the techniques used internally to a single system do not apply well to distributed databases from a performance perspective.
Single database instances use single system specific facilities such as shared memory, interthread and interprocess synchronization, and a shared and consistent file system buffer cache to increase speed and reduce complexity. These facilities are fast and reliable on a single host but difficult to generalize and abstract across a networked cluster of machines, especially wide-area networked.
Instead of attempting to build these facilities to be distributed (as do single-system-image clustering solutions), distributed databases uses specific protocols to help ensure ACID between more than one instance. These protocols are not complicated, but because they speak over the network they suffer from performance and availability fluctuations that are atypical within a single host.
People have come to expect and rely on the performance of traditionally RDBMS solutions and thus have a difficult time swallowing the fact that they must make a compromise either on the performance front or the functionality front.
Multimaster replication is the “holy grail” of distributed databases. In this model, all data is located at more than one node, and all nodes are completely capable of processing transactions. Most systems do not require what multimaster replication offers. However, traditionally most nontechnical people (and even many technical people) assume this model when speaking of database replication. As time goes on and replicated databases become common in both small and large architectures, this interpretation will change. It is my hope that people will lean toward more descriptive names for their replication setups. For now, when we say replication, we’ll refer to the whole kit and caboodle—multimaster replication.
Why is this problem so hard? Let’s step back and look what ACID requires:
-
Atomicity seems to be a simple thing to ensure. It simply means we do all or nothing, right? Yes; however, when at the end of a transaction, we must commit. Now, it is not as simple as closing out the transaction. With a single instance, we commit, and if anything goes horribly wrong we return an error that the transaction could not be committed. In a distributed system, we must commit on more than one node, and all must succeed or all must fail, or an inconsistency is introduced.
-
Consistency requires that all instances of perspectives on a datum are updated when a transaction is complete. In and of itself this isn’t a problem. However, we have introduced a complication in the “scheduling” of database operations. When operating in a single instance, the database engine will arbitrarily order concurrent transactions so that one commit takes place before another. Concurrent transactions take on a whole new meaning when transactions operating on the same data can initiate and run their course at different nodes. It means that there must be a consistent global ordering of transaction commits—not so easy.
-
Isolation is not really affected by the fact that transactions are happening at the same time in different places.
-
Durability requires that in the event of a crash, the copy must correctly reflect all information through the last committed transaction and not any information that was part of an uncommitted transaction. When multiple copies of the same data exist on separate machines, this task proves more difficult because agreeing on clusterwide commits is now necessary.
Although there are several technical approaches to the problem of multimaster database replication and several real-world implementations, they often require sacrifices—such as decreased performance, network topology limitations, and/or application restrictions—that are impossible to make.
Suppose that you have a database that performs 2,000 transactions per second. The obvious goal is to have that replicated in three locations around the world and be able to increase the transactional throughput to 6,000 transactions per second. This is a pipe dream—a pure impossibility for general database uses. Increasing a cluster’s size by a factor of three resulting in a threefold increase in performance would be an optimal solution. We know that optimal solutions don’t exist for general problems. However, what the true performance “speedup” is may be alarming. Although read-only query performance can often be increased almost linearly, the total transactional throughput decreases if the transactions affect the same data.
There is a special case where an almost linear performance gain can be achieved. That case is when replication takes the pure form of data aggregation. If the operations on the datasets at each location are disjointed, and this is an assumption in the architecture of the replication technology itself, atomicity and consistency can be enforced without collaboration. Because this is an edge case, we’ll ignore it for now.
Two-phase commit (and to a lesser degree three-phase commit) has been used for decades to safely and reliably coordinate transactions between two separate database engines. The basic idea is that the node attempting the transaction will notify its peers that it is about to commit, and they will react by preparing the transaction and notifying the originating node that they are ready to commit. The second phase is noticing any aborts in the process and then possibly following through on the commit (hopefully everywhere).
The two-phase commit is not perfect, but it is considered sufficient for applications such as stock trading and banking—which are considered to be the most stringent industries when it comes to data consistency, aside from perhaps aerospace operations.
The glaring problem with 2PC is that it requires the lock-step progress on each node for a transaction to finish. With a single node down, progress can be halted. If a node is marked offline to allow progress, resynchronization must occur. This approach simply isn’t ideal for wide-area replication against hostile networks (the Internet is considered a hostile network in this case).
Despite its shortcomings, the only common “correct” multimaster replication technique used today is the 2PC, and, due to its overhead costs, it is not widely used for geographic replication.
Extended virtual synchrony (EVS) is a concept from the world of group communications. The EVS Engine itself is a product of the group communication world and has been commercialized by Spread Concepts, LLC. The theoretical approach to this replication technique is well documented and proven correct in the PhD thesis of Yair Amir (one of the Spread Concepts guys).
If you just sit back and consider for a moment who would have the best ideas on how to get multiple computers to communicate, organize, and collaborate on an effort to accomplish some goal (say ACID), it would be the group communications people. On the other hand, the only people you trust your data to are the database people. The requirement that these two groups must collaborate poses a roadblock for the evolution of more advanced data replication approaches.
Techniques from the group communication world can help overcome the challenges posed by disconnected networks and network partitions. In typical multimaster replication configurations all nodes must concur that an operation will happen and then execute on it using 2PC. This might work well in two-node scenarios; however, when more nodes are involved and they are not local with respect to each other, serious complications are introduced that can seriously affect progress in these systems.
To take a conceptually simple architecture for multimaster replication, we can look at a company in the United States that has offices in six states. Each office wants a local copy of the enterprise’s database. To modify the content in that database, that database must know that it will not produce a conflict with any of its peers. This sounds simple until one of the long-haul networking circuits used to transit information goes down. This will cause some partition in the working set of databases, and it is likely that there will be two or more views of the participating databases.
Assume that we have two West Coast, two East Coast, and two Midwest databases. After a networking disaster, a VPN failure, or some other unexpected but probable event, a partition in the working set of databases will occur. Those on the West Coast and in the Midwest can all see each other and believe that the eastern nodes have crashed, while the two eastern nodes can see each other and believe that the four nodes to their west have gone down. This is called a network partition. When network partitions occur, you have two options: manual magic and quorums.
The first step is to stop all operations; after any data modification on any database node you will not be able to effectively perform a commit because you cannot form a unanimous vote to do so. In this model, an operator must intervene and instruct the participating machines that they only need a consensus across a newly defined set of the nodes. For example, the eastern operators do nothing, and the western operators reconfigure their replication scheme to exclude the two nodes that are unavailable to them. This is often the case in local area replication schemes because the expectation is that network partitions will not occur and that if a node becomes unavailable it is because something disastrous happened to that node. Aside from the manual intervention required to allow progress in the event of a network partition, techniques and procedures must be developed to handle resynchronizing those machines excluded from the replication configuration during the time of the partition—this is hard—it’s magic...black magic.
The second option is to establish a quorum. Our friends in the group communication field have had to deal with this problem from the beginning of the exploration of their field. It isn’t a concept at all related to databases but rather one related to group decision making. A quorum is defined as an improper subset of the total possible group that can make a decision. A correct quorum algorithm ensures that regardless of the number of machines, as long as every machine follows that algorithm there will exist at most one quorum at any time. The most simple quorum algorithm to imagine is one when a majority of the total configuration is represented in the working set. With the six machine configuration just described, this would be any time a group of four or more machines can communicate. That grouping is the quorum. More complicated quorum algorithms exist that are more robust than the simple majority algorithm, but they are outside the scope of this book.
By establishing and executing a quorum algorithm, the overall replication configuration can guarantee progress in the event of arbitrary network configuration changes that could induce partitions and subsequent merges. Some believe the downside of this is that an administrator could make better business decisions on which partition should be allowed to make progress because they have access to outside influence and information. However, it should be recognized that quorum algorithms can be efficient in preserving business continuity if the proper considerations are incorporated into the adoption or development of the quorum algorithm used in the system.
If we introduce the fact that our New York database (one of the two eastern databases) is at the corporate headquarters and that, if at all possible, it should be able to make progress, we can change our quorum algorithm to reflect that. For example, if the group of connected nodes contains the New York database, it is a quorum. Probably safer than that is a quorum defined by either five of the six machines or any two machines if one is in New York.
On top of this quorum system, EVS Engine allows reliable, ordered messaging among members without the cost of 2PC. A message is sent to the current group; an EVS system guarantees that when it is delivered, you will know the exact membership of the group at the time of delivery and that everyone else who received the message also saw the same membership at the time of delivery. Using this, it proves that you can replicate ACID databases.
Although EVS Engine is available in some fashion or another from Spread Concepts, LLC., it has a long way to go before it is accepted as a standard approach to multimaster replication. It has considerable opposition from the database community for unsubstantiated reasons, but when that intergroup dynamic resolves, you can expect replication over extended virtual synchrony to be the de facto replication paradigm.
In the end, multimaster replication isn’t ready for prime time in most environments for the sole reason that people tend to want multimaster replication for increased availability and performance, and it isn’t possible to have both.
As an interesting aside, the PostgreSQL Slony-II project is implementing an algorithm similar in nature to EVS Engine. Its algorithm replaces some of the more challenging problems tackled by EVS Engine with more simple (and practical) solutions. The Slony-II project is positioned to lead the industry with respect to achieving scalable and efficient geographically separated multimaster database configurations.
A special case of the multimaster replicated database approach is when we limit the system to exactly two nodes with a low latency interconnect (like local Ethernet). This is master-master replication, and the common distributed consistency protocols such as 2PC and 3PC don’t pose an unreasonable overhead.
Even over a wide area network, there is no advantage to using newer, less tried, and more complicated replication techniques that are emerging in the multinode multimaster replication environments. So, in two-node systems, 2PC is “how replication is done.”
Many commercial databases support database replication via the two-phase commit method. Although this is really useful and fundamental in highly available systems design, it certainly doesn’t add any scalability to a solution. Given this, we won’t dig much deeper.
Master-slave replication is indeed replication, yet it satisfies an entirely different need than that of multimaster schemes. It does not provide the same availability and fault tolerance guarantees as do multimaster techniques. If there is one thing I hope you walk away from this book with, it would be “the right tool for the job” mentality. Despite the fact that master-slave replication is different from multimaster replication, it is vital that this difference not be interpreted as a weakness. It is a different tool with different applications, and there are many places where it is simply an excellent tool for the job at hand.
Master-slave replication is a solution for a different problem. In this configuration, data modification may occur only at the master because there is no attempt to coordinate atomic transactions or view consistency between the slaves and their master. If you can’t modify data at the slaves, what good are they? Clearly you can perform both simple and complicated read-only operations against the slaves.
By replicating authoritative data from a master to many slave nodes, you can increase the performance of read-intensive database applications almost linearly and sometimes super-linearly. How does this help with write-intensive applications? That is a complicated answer and depends heavily on the underlying replication technology used to push database modification from the master to its slaves. Understanding this will debunk some myths about the performance gains of master-slave replication systems.
When a database processes a request for data modification (commonly referred to as DML, which stands for data modification language), it does a bit of work behind the scenes.
The first step is to understand the question and what datasets are required to answer the question. This is the parsing and planning phase of processing DML. Because SQL is a complicated language that can consist of arbitrarily complicated queries that feed into the modification being performed, after the database arrives at a satisfactory plan to answer the question, it attempts to process it and apply the required changes. The changes are applied, or the operation is rolled back and the transaction is complete.
There are two common methods to replicate a master database to a set of slaves based on the preceding transaction flow. The first is to replicate the operation—that is, distribute the statement that resulted in the change to all the slave nodes and allow them to plan and then execute the operation to (hopefully) arrive at the same result. The second technique consists of tracking the actual data changes (called a changeset) and distributing the data that has changed to each slave. We will call the first DML replication, and the second DML log replication because the first replicates the actual data modification language, whereas the second replicates the log of what happened due to the data modification language.
One of these methods may seem much better than the other, and that is typically the case. However, half the population thinks DML replication is better, whereas the other half thinks DML log replication is better. Who is right?
Each of these techniques has trade-offs. After you have a clear understanding of your own problems, you can better match your issues to the trade-offs to arrive at the best solution.
To understand better where these techniques both excel and fall short, let’s define four types of DML:
-
Cheap DML with small data change—This would be a query such as
UPDATE USERS SET LAST_LOGON=SYSDATE WHERE USERID=: userid, where the columnuseridhas a unique index. It is computationally cheap and guaranteed to affect at most a single row. -
Expensive DML with small data change—This would be a query such as
INSERT INTO REGISTRATION_SUMMARY SELECT TRUNC(SYSATE), a.CNT, b.CNT FROM (SELECT COUNT(*) AS CNT FROM USERS WHERE TRUNC(REG_DATE)=TRUNC(SYSDATE-1)) a, (SELECT COUNT(*) AS CNT FROM HITS WHERE TRUNC(HIT_DATE)=TRUNC(SYSDATE-1)) b. Although we could have an index onreg_dateandhit_date, it still requires an index scan and could process millions of rows of data, all to insert just a single row. This is computationally expensive, and yet will never affect more than a single row. -
Expensive DML with large data change—This would be a query such as
UPDATE USERS SET ACCESS=’ineligible’ WHERE USERID IN (SELECT USERID FORM HITS WHERE HIT_CODE=’opt-out’ MINUS SELECT USERID FROM PAYMENT_HISTORY WHERE STATUS=’approved’), which may induce a massive data change and is relatively expensive to perform because we are revoking access to users who opted out but have never successfully purchased anything, and theHITStable could have a billion rows andPAYMENT_HISTORYtables could have several hundred thousand rows. -
Cheap DML with large data change—Perhaps the easiest to demonstrate are queries that are simple to calculate, but dramatic data-level changes ensue. Queries such as
DELETE FROM HITS WHERE HIT_DATE < SYSDATE-30, which would delete all rows in a table older than 30 days, could induce multimillion row data changes with little or no computation effort by the database.
So, ask yourself which of the preceding examples characterizes the queries run against the database that you want to replicate. Expensive DML with large changesets and cheap DML with small changesets have similar costs under both replication models—they don’t compel a choice one way or the other. It is difficult to ascertain whether you will spend more time planning and executing on the slave node than you would shipping over the changes and applying them directly.
On the other hand, the difference between the other two usage patterns is astounding. Cheap DML operations that result in massive data updates mean that you ship over the query and have the slave node delete or update a slew of rows (using DML replication), or you can ship over every single row that has changed as a result of the query and reapply each individually to each slave (using DML log replication). That sounds awful. However, you really should not be performing massive data changes on an online transaction processing (OLTP) data system. So, if you classify many of your queries in this category, perhaps you should revisit your queries and data model and determine a way to avoid them in the first place.
Expensive DML operations that result in small data updates mean that you spend hours on the master performing a query that ultimately changes a few rows of data and then ships that query to each slave so that they can perform several hours of computational mimicking to update the same few rows of data (using DML replay). However, using the DML log replay technique, the master spends several hours calculating the resultset (which is unavoidable) and then ships a few snippets of data change to the clients. If you classify many of your queries in this category, DML log replay is a huge win. However, just as with cheap DML with massive changes, this type of operation should be rare in a production OLTP environment.
So, where does that leave us? Both solutions are good. In my personal experience, changeset is more reliable and adapts more easily to cross-platform database replication (such as Oracle to PostgreSQL or Oracle to MySQL), which can be useful to get the best of all worlds.
Oracle’s primary method of master-slave replication is via changeset replication. As data is changed, the changes are shipped to slave instances and applied. This is commonly called applying archive redo logs. This means that if you have a write-intensive database usage pattern on the master node, the slave node will be able to keep up so long as there is sufficient network bandwidth to transmit the changes and sufficient I/O bandwidth on the slave to apply the changes. This makes Oracle’s replication lackluster in the cases where cheap DML is applied, resulting in massive data updates. However, it is perfect for expensive DML that results in small data updates, meaning that if you run a lot of reporting and statistical aggregation on the master, the slaves can be much weaker machines and still have no issues “keeping up” with the master’s replication needs.
MySQL, on the other hand, has the concept of a binlog that stores every query that induced a data modification. This binlog is transferred to slave MySQL databases, and the operations are re-performed. This makes a million-row delete very quick to replicate to slaves, but it also means that if the updates were expensive to plan and execute, you will pay that cost on every single slave.
Some costs cannot be avoided, but some can. Simple updates with complicated where clauses that induce a nontrivial amount of load to execute are difficult to engineer around. However, the example for expensive DML with small data change that was used previously was an INSERT INTO SELECT . . . statement that would insert a single row. This type of load can be avoided on the slave nodes by splitting the queries into two. Because the binlog contains only queries that induce data modification, if the expensive SELECT is run in the application and then the result is inserted back into the database via a subsequent INSERT statement, the cost will be negligible on the slave nodes.
Given that most online transaction processing systems have many queries that are inexpensive and induce small data change, choosing between operation and changeset replication is really a “six to one, half-dozen to another” argument. As such, sticking to your existing database vendor is most likely a good approach unless your typical usage patterns unequivocally fall into one of the other two DML patterns.
In general on local area networks, network bandwidth and I/O bandwidth are cheaper than CPU cycles and memory. This makes changeset replication ideal for local clusters. For wide area replication where network bandwidth can easily be more expensive than CPU cycles and memory, operation replication makes more sense.
After the preceding discussion of replication technologies, you might be thoroughly confused about what a good replication strategy is. This confusion isn’t a bad thing—it is the decision in disguise. The goal here is scalability, and as such we need to ensure that we can scale horizontally. This means that if we need more power we want to be able to simply add more nodes for a linear performance benefit. Although a linear speed-up is a theoretical best, it’s still our goal, and we should design the system to target that goal.
Master-master replication is two nodes. As such, adding nodes is not possible. Multimaster replication using two-phase commit is too expensive to scale horizontally. If you attempt a 100-node configuration, the cost of each node performing 2PC with 99 other systems will cause everything to come crashing down. Master-slave replication is the only approach left standing.
For the increased interest of this discussion, assume that our news site is running against Oracle. Why Oracle? The demands on the OLTP system that drives the site are intense (remember, we are trying to solve that here), and a tremendous amount of maintenance and auditing goes on in stored procedures. Additionally, there is a need for extensive data mining against an operational data store that pulls information from the OLTP system and exposes it to analysts. That operational data store runs Oracle because the analysts requested to use some of the data mining and reporting tools that Oracle provides. The real answer, of course, is that the architect, VP of Engineering, and CTO sat down with a group of vendors and liked what they heard from Oracle. All that matters is that the system is running Oracle, it is way too busy, and we want to scale to many more users.
The site’s dynamic content is serviced centrally via a small cluster of web application servers directly referencing the master OLTP Oracle database that services the end-user and an even smaller set of web application servers that serve administrative users (columnists, editors, and so on). The operational data store hangs off the OLTP database and services some administrative users to perform business tasks and in-depth analysis. Figure 8.1 illustrates this architecture.
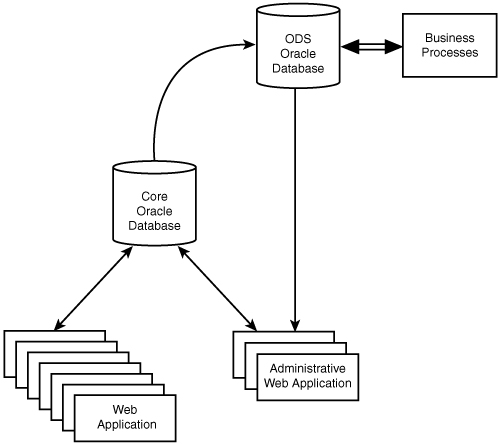
We could simple deploy slave Oracle instances (two) onsite with each web cluster location and perform master-slave replication. Technically this would work, but financially—not a chance. Let’s assume that we have content web servers in each of our four worldwide locations as shown in Figure 6.8 in Chapter 6, “Static Content Serving for Speed and Glory.” Assuming 10 dual processor machines in each location, that would be Oracle licenses for 4 clusters x 2 nodes/cluster x 2 processors/node = 16 processors! The price for that would make more than a casual dent in the year’s operating budget. If you aren’t familiar with Oracle’s licensing policies, it is typically on a per-feature, per-processor basis. This policy is friendly for those who want to vertically scale their solutions, but as discussed, the goal is horizontal scalability.
It is important to remember that Oracle does not “enable” our architecture. It is a relational database solution that can be queried via SQL, and, most importantly, there are many others just like it. We could switch our infrastructure to use something less costly knowing now that we want to scale out to many more nodes; however, one rule of thumb is don’t change what works if you can help it.
We really want to make as few changes as possible to our existing core architecture but enable the web application deployed at each data center to have a locally accessible database with an accurate copy of data managed at the core. We want to be able to scale up and down without incurring a large operating expense or a large capital expense. It so happens that our developers’ expertise is against Oracle, and we want to leverage as much of that as possible. Between PostgreSQL and MySQL, PostgreSQL is more similar in feature set and usage to Oracle than is MySQL.
An Oracle core infrastructure with 16 PostgreSQL replicas (shown in Figure 8.2) is an architecture that does not pose a substantial financial risk or an enormous technical risk with respect to leveraging existing application developer expertise.

What we hope to leverage here is the replication of heavily queried data to our various clusters. The data, as with most heavily used website data, changes infrequently with respect to the frequency it is referenced in read-only operations. In other words, the read-to-write ratio is high. In our case, we need to replicate the news articles, administrative users (authors, editors, approvers), and customers (the end-user). Of course, this book isn’t only on this topic, so the example here will aim to be complete and accurate with respect to the limited problem we are going to tackle. An actual implementation would likely encompass much more data. Here we will talk about three tables, but I’ve used this technique before to handle a multiterabyte schema with more than 1,200 tables.
Implementing cross-vendor database replication in a generic manner can revolutionize the way problems are tackled in an architecture. If done correctly, it can allow you to truly choose the right tool for the job when it comes to databases. If we have some tasks that can be solved using features only found in MySQL or Postgres or Oracle or SQL Server, we simply replicate the necessary information to and from them and our problem is solved.
As discussed, there are a variety of database replication techniques, and what each offers is different. Our goals are met by master-slave database replication, which fortunately is easy to implement in an application external to the source and destination databases.
Specifically, we have three tables in Oracle that we want to replicate to 16 PostgreSQL nodes: AdminUsers is rather small with only about 5,000 rows; SiteUsers is large, and we see about 0.1% change on that table (by row count) on a daily basis (that is, of the 100 million rows, about 100,000 rows change during the course of a normal day). NewsArticles contains the articles that are published, and this can be between 50 and 2,000 new articles per day, and many more updates as articles are written, edited, and approved. The code listing for source database CREATE TABLE DDL follows:
CREATE TABLE AdminUsers (
UserID INTEGER PRIMARY KEY,
UserName VARCHAR2(32) NOT NULL UNIQUE,
Password VARCHAR2(80) NOT NULL,
EmailAddress VARCHAR2(255) NOT NULL
);
CREATE TABLE SiteUsers (
SiteUserID INTEGER PRIMARY KEY,
CreatedDate DATE NOT NULL,
UserName VARCHAR2(32) NOT NULL UNIQUE,
Password VARCHAR2(80) NOT NULL,
EmailAddress VARCHAR2(255) NOT NULL,
Country VARCHAR2(3) NOT NULL,
PostalCode VARCHAR2(10) NOT NULL
);
CREATE TABLE NewsArticles (
ArticleID INTEGER PRIMARY KEY,
Author INTEGER NOT NULL REFERENCES AdminUsers(UserID),
Editor INTEGER REFERENCES AdminUsers(UserID),
Approver INTEGER REFERENCES AdminUsers(UserID),
CreatedDate DATE NOT NULL,
LastModifiedDate DATE NOT NULL,
PublishedDate DATE, Title VARCHAR2(200),
AbstractText VARCHAR2(1024),
BodyText CLOB,
isAvailable INTEGER DEFAULT 0 NOT NULL
);
The SiteUsers table in particular has far fewer rows than we would expect our real site to have. But all tables are kept a bit thin on columns only to help the brevity of the example.
The basic concept here is to replicate the changes that happen against these tables to another database. So, the obvious first step is to attempt to keep track of the changes. Changes in databases all come in one of three forms: addition, removal, and change (that is, INSERT, DELETE, and UPDATE).
Keeping track of INSERT, DELETE, and UPDATE is actually easy because SQL provides a trigger on each of these. Before we jump the gun and write ourselves a trigger to track the changes, we’ll need some place to stick the data itself. This is where the techniques can vary from one approach to another.
In our model, we care only about representing the most recent view available, and it isn’t vitally important for us to play each transaction on the source forward and commit them individually on the destination. Although it isn’t any more difficult to do this sort of thing, we simply want to know all the missed transactions and replay them to achieve a “current” resultset. As such, we don’t care how the record changed, just that it is likely different. It is wholly sufficient to track just the primary key of the records that have been modified in some way.
The first step is to create the tables that will store the primary keys that get modified. We will tackle the NewsArticles and SiteUsers tables this way and leave the AdminUsers for the next section. We need to know what row changed (by primary key), and it would make our lives easier if we knew what transaction the changes happened in (so that we can more easily track what we have done already) and for database maintenance (such as cleaning out the DML log because when it gets old we should track the time at which the modification took place). The code listing for DDL to create DML logs follows:
CREATE TABLE SiteUsersDML (
TXNID VARCHAR2(20) NOT NULL,
SiteUserID INTEGER NOT NULL,
InsertionDate DATE NOT NULL
);
CREATE INDEX SiteUsersDML_TXNID_IDX ON SiteUsersDML(TXNID);
CREATE INDEX SiteUsersDML_InsertionDate_IDX ON SiteUsersDML(InsertionDate);
CREATE TABLE NewsArticlesDML (
TXNID VARCHAR2(20) NOT NULL,
ArticleID INTEGER NOT NULL,
InsertionDate DATE NOT NULL
);
CREATE INDEX NewsArticlesDML_TXNID_IDX ON NewsArticlesDML(TXNID);
CREATE INDEX NewsArticlesDML_InsertionDate_IDX ON NewsArticlesDML(InsertionDate);
Now that we have some place to track our changes, let’s do it. Each time we insert or update data, we want to place the new primary key (SiteUserID for SiteUsers and ArticleID for NewsArticles) into the DML table along with the current time and the transaction ID. Any time we delete data, we want to take the same action except on the old primary key (in SQL talk, there is no “new” row for a delete because it is gone). The code listing for DML tracking triggers follows:
CREATE OR REPLACE TRIGGER SiteUsersDMLTracker
AFTER INSERT OR UPDATE OR DELETE
ON SiteUsers
REFERENCING NEW as NEW OLD as OLD
FOR EACH ROW
BEGIN
IF (deleting)
THEN
INSERT INTO SiteUsersDML
(TXNID, SiteUserID, InsertionDate)
VALUES (DBMS_TRANSACTION.local_transaction_id,
:OLD.SiteUserID, SYSDATE);
ELSE
INSERT INTO SiteUsersDML
(TXNID, SiteUserID, InsertionDate)
VALUES (DBMS_TRANSACTION.local_transaction_id,
:NEW.SiteUserID, SYSDATE);
END IF;
END;
CREATE OR REPLACE TRIGGER NewsArticlesDMLTracker
AFTER INSERT OR UPDATE OR DELETE
ON NewsArticles
REFERENCING NEW as NEW OLD as OLD
FOR EACH ROW
BEGIN
IF (deleting)
THEN
INSERT INTO NewsArticlesDML
(TXNID, ArticleID, InsertionDate)
VALUES (DBMS_TRANSACTION.local_transaction_id,
:OLD.ArticleID, SYSDATE);
ELSE
INSERT INTO NewsArticlesDML
(TXNID, ArticleID, InsertionDate)
VALUES (DBMS_TRANSACTION.local_transaction_id,
:NEW.ArticleID, SYSDATE);
END IF;
END;
After these triggers are in place, every modification to a row in both the SiteUsers and NewsArticles tables will be tracked in this table as well. The InsertionDate in these tables is only for removing rows from these DML tables after they have been applied to all the slave nodes; however, it cannot be used for tracking replication progress.
The next step is for a slave to connect to the master server and request all the transactions that have occurred since the last time it ran. You might think that it would be correct to have the slave store the last (latest) InsertionDate time stamp it witnessed as a high water mark and request all DML that has occurred since that point in time. This is terribly wrong.
The concept of “since” applies intuitively to time. However, in databases, what has happened “since” the last time you looked has nothing to do with when it happened but rather when it was committed. Oracle, unfortunately, does not expose the ability to place a trigger before commit, so there is no way to tell when all the rows inserted into our DML log left the isolation of their transaction and were actually committed for others to see. Our replication process is one of those “others,” so this is a big issue. If we relied on time, we could have a race condition (shown in Figure 8.3), which would lead to a wholly inconsistent copy on the slaves.
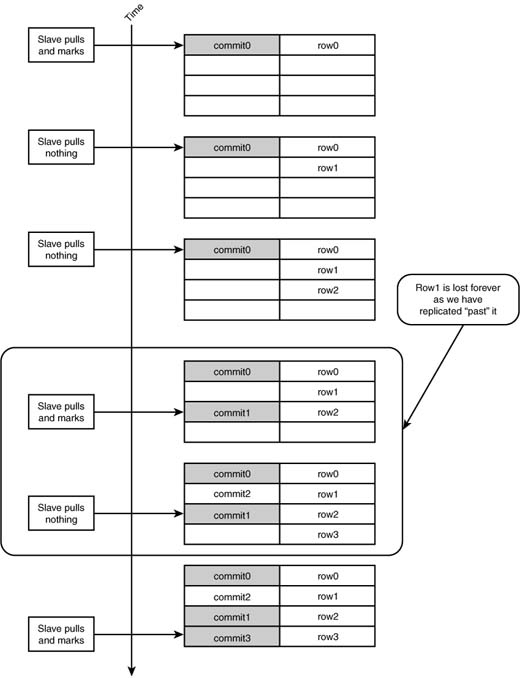
Instead of playing back by time, we should play back by transaction ID. This, unfortunately, requires us to maintain a list of transactions that each node has processed so that it can determine which transactions are “new” on each subsequent run. The code listing for the DDL to create tables for replication progress follows:
CREATE TABLE SiteUsersDMLProcessed (
NodeName VARCHAR2(80) NOT NULL,
TXNID VARCHAR2(20) NOT NULL,
PRIMARY KEY(NodeName, TXNID)
);
CREATE INDEX SiteUsersDMLP_NN_IDX ON SiteUsersDMLProcessed(NodeName);
CREATE TABLE NewsArticlesDMLProcessed (
NodeName VARCHAR2(80) NOT NULL,
TXNID VARCHAR2(20) NOT NULL,
PRIMARY KEY(NodeName, TXNID)
);
CREATE INDEX NewsArticlesDMLP_NN_IDX ON NewsArticlesDMLProcessed(NodeName);
Now that we have all our building blocks in place on the master, we can tackle the actual replication from the slave’s perspective.
Clearly we can’t put any data into our PostgreSQL replica until we have the necessary tables in place. We need tables to hold the SiteUsers and NewsArticles as well as stored procedures (or functions in PostgreSQL) to apply changes as they come in. The code listing for DDL to create target tables in PostgreSQL follows:
CREATE TABLE SiteUsers (
SiteUserID INTEGER PRIMARY KEY,
CreatedDate TIMESTAMP NOT NULL,
UserName VARCHAR(32) NOT NULL UNIQUE,
Password VARCHAR(80) NOT NULL,
EmailAddress VARCHAR(255) NOT NULL,
Country VARCHAR(3) NOT NULL,
PostalCode VARCHAR(10) NOT NULL
);
CREATE TABLE NewsArticles (
ArticleID INTEGER PRIMARY KEY,
Author INTEGER NOT NULL,
Editor INTEGER,
Approver INTEGER,
CreatedDate TIMESTAMP NOT NULL,
LastModifiedDate TIMESTAMP NOT NULL,
PublishedDate TIMESTAMP,
Title VARCHAR(200),
AbstractText VARCHAR(1024),
BodyText TEXT,
isAvailable INTEGER NOT NULL DEFAULT 0
);
Now that we have our tables in place, we need to write the stored procedures (or functions) in PostgreSQL for each table to apply the changes that we pull from our master Oracle instance. These stored procedures are fairly generic, and you could write an automated procedure for generating them from DDL information. The code listing for SiteUsers_Apply and NewsArticles_Apply follows:
01: CREATE FUNCTION
02: SiteUsers_Apply(integer, integer, timestamp, varchar,
03: varchar, varchar, varchar, varchar)
04: RETURNS void
05: AS $$
06: DECLARE
07: v_refid ALIAS FOR $1;
08: v_SiteUserID ALIAS FOR $2;
09: v_CreatedDate ALIAS FOR $3;
10: v_UserName ALIAS FOR $4;
11: v_Password ALIAS FOR $5;
12: v_EmailAddress ALIAS FOR $6;
13: v_Country ALIAS FOR $7;
14: v_PostalCode ALIAS FOR $8;
15: BEGIN
16: IF v_SiteUserID IS NULL THEN
17: DELETE FROM SiteUsers WHERE SiteUserID = v_refid;
18: RETURN;
19: END IF;
20: UPDATE SiteUsers
21: SET SiteUserID = v_SiteUserID, CreatedDate = v_CreatedDate,
22: UserName = v_UserName, Password = v_Password,
23: EmailAddress = v_EmailAddress, Country = v_Country,
24: PostalCode = v_PostalCode
25: WHERE SiteUserID = v_refid;
26: IF NOT FOUND THEN
27: INSERT INTO SiteUsers
28: (SiteUserID, CreatedDate, UserName, Password,
29: EmailAddress, Country, PostalCode)
30: VALUES (v_SiteUserID, v_CreatedDate, v_UserName, v_Password,
31: v_EmailAddress, v_Country, v_PostalCode);
32: END IF;
33: END;
34: $$ LANGUAGE 'plpgsql';
35:
36: CREATE FUNCTION
37: NewsArticles_Apply(integer, integer, integer, integer, integer,
38: timestamp, timestamp, timestamp, varchar,
39: varchar, text, integer)
40: RETURNS void
41: AS $$
42: DECLARE
43: v_refid ALIAS FOR $1;
44: v_ArticleID ALIAS FOR $2;
45: v_Author ALIAS FOR $3;
46: v_Editor ALIAS FOR $4;
47: v_Approver ALIAS FOR $5;
48: v_CreatedDate ALIAS FOR $6;
49: v_LastModifiedDate ALIAS FOR $7;
50: v_PublishedDate ALIAS FOR $8;
51: v_Title ALIAS FOR $9;
52: v_AbstractText ALIAS FOR $10;
53: v_BodyText ALIAS FOR $11;
54: v_isAvailable ALIAS FOR $12;
55: BEGIN
56: IF v_ArticleID IS NULL THEN
57: DELETE FROM NewsArticles WHERE ArticleID = v_refid;
58: RETURN;
59: END IF;
60: UPDATE NewsArticles
61: SET ArticleID = v_ArticleID, Author = v_Author,
62: Editor = v_Editor, Approver = v_Approver,
63: CreatedDate = v_CreatedDate,
64: LastModifiedDate = v_LastModifiedDate,
65: PublishedDate = v_PublishedDate,
66: Title = v_Title, AbstractText = v_AbstractText,
67: BodyText = v_BodyText, isAvailable = v_isAvailable
68: WHERE ArticleID = v_refid;
69: IF NOT FOUND THEN
70: INSERT INTO NewsArticles
71: (ArticleID, Author, Editor, Approver, CreatedDate,
72: LastModifiedDate, PublishedDate, Title,
73: AbstractText, BodyText, isAvailable)
74: VALUES (v_ArticleID, v_Author, v_Editor, v_Approver,
75: v_CreatedDate, v_LastModifiedDate, v_PublishedDate,
76: v_Title, v_AbstractText, v_BodyText, v_isAvailable);
77: END IF;
78: END;
79: $$ LANGUAGE 'plpgsql';
The basic concept behind these two routines is the same. The program that will pull changes from Oracle and apply them to PostgreSQL will know the original primary key of the row that was changed and the new full row (primary key and other columns) as it is in Oracle. The original primary keys are the reference primary keys, and the new full row represents how that referenced row should now appear. We have three cases to deal with:
-
If the new full row has a NULL value in the nonreference primary key, it means that the row was not in the master. This means that we should delete the row from the slave (based on the reference primary key). Lines: 16–19 and 56–59.
-
If the new full row has a valid (not NULL) primary key and the reference primary key exists in the slave table already, we must update that row to reflect the new information provided. Lines: 20–25 and 60–68.
-
If the new full row has a valid (not NULL) primary key and the reference primary key does not exist in the slave table, we must insert this new row. Lines: 26–32 and 69–77.
We now have the necessary back-end infrastructure in place in Oracle and PostgreSQL and must write the actual workhorse. We’ll use Perl for this example because the DBI (Database independent interface for Perl) is simple, sweet, and entirely consistent across all the DBDs (database drivers), including the one for Oracle and the one for PostgreSQL
Although the concept of tracking your changes using triggers is straightforward, there are several moving parts. The slave side is much simpler in both concept and implementation. Basically, a slave does the following:
-
Connects to the master
-
Requests all modifications it has not yet processed
-
Applies those modifications
-
Informs the master it has applied them
-
Commits at the slave and the master
-
Repeats
A majority of the legwork here is authoring the queries that will serve to interact with the master and slave. We will make an effort to generalize the query generation so that adding new tables is easy. You should note that writing this as a single procedural Perl script is likely not the best way to go about putting a piece of critical infrastructure into your system. Making this into a clean, well-separated Perl replication framework is left as an exercise for the reader (and a rather simple one at that). Here it is as one procedural script so that we can walk through it section by section to match it against our six-item checklist without chasing down different classes and methods. The code listing for dml_replay.pl follows:
001: #!/usr/bin/perl
002:
003: use strict;
004: use DBI;
005: use POSIX qw/uname/;
006: use Getopt::Long;
007: use vars qw/%db %sql_ops %ops %tableinfo
008: $nodename $interval $print_usage $verbose/;
009:
010: ($nodename = [POSIX::uname]->[1]) =~ s/..*//; # short hostname
011: $interval = 5; # 5 sec default
012:
013: sub vlog { printf STDERR @_ if($verbose); }
014:
015: GetOptions( 'n|nodename=s' => $nodename,
016: 'i|interval=i' => $interval,
017: 'v|verbose' => $verbose,
018: 'h|help' => $print_usage);
019:
020: if($print_usage) {
021: print "$0 [-n node] [-i seconds] [-v] [-h]
";
022: exit;
023: }
024:
025: $db{master} = DBI->connect("dbi:Oracle:MASTER", "user", "pw",
026: { AutoCommit => 0, RaiseError => 1 } ) ||
027: die "Could not connect to master";
028: $db{slave} = DBI->connect("dbi: Pg:database=slave", "user", "pw",
029: { AutoCommit => 0, RaiseError => 1 } ) ||
030: die "Could not connect to slave";
031:
032: # define our tables (names, keys, and other columns)
033: %tableinfo = (
034: 'SiteUsers' =>
035: { 'keys' => [ 'SiteUserID' ],
036: 'columns' => [ 'CreatedDate', 'UserName', 'Password',
037: 'EmailAddress', 'Country', 'PostalCode'],
038: },
039: 'NewsArticles' =>
040: { 'keys' => [ 'ArticleID' ],
041: 'columns' => [ 'Author', 'Editor', 'Approver', 'CreatedDate',
042: 'LastModifiedDate', 'PublishedDate', 'Title',
043: 'AbstractText', 'BodyText', 'isAvailable' ],
044: },
045: );
046:
047: %sql_ops = (
048: master => {
049: fetchlogs => sub {
050: my ($table, $pks, $cols) = @_;
051: return qq{
052: SELECT l.txnid, }.join(',', map { "l.$_" } (@$pks)).", ".
053: join(',', map { "t.$_" } (@$pks, @$cols)).qq{
054: FROM $table t, ${table}DML l, ${table}DMLProcessed p
055: WHERE l.txnid = p.txnid(+) /* left join l to p and from */
056: AND p.nodename(+) = ?/* our node's view to remove */
057: AND p.txnid is NULL/* all seen txnids in p */
058: /* then left join against t on the primary key to*/
059: /* pull the changed row even if it has been deleted. */
060: AND }.join(' AND ', map { "l.$_ = t.$_(+)" } @$pks).qq{
061: ORDER BY l.txnid};
062: },
063: record => sub {
064: my ($table, $pks, $cols) = @_;
065: return qq{
066: INSERT INTO ${table}DMLProcessed (txnid, nodename)
067: VALUES (?, ?)
068: };
069: },
070: },
071: slave => {
072: apply = > sub {
073: my ($table, $pks, $cols) = @_;
074: # reference primary keys, new primary keys, new columns
075: return qq{ SELECT ${table}_Apply(}.
076: join(',', map { "?" } (@$pks, @$pks, @$cols)).
077: ')';
078: }
079: }
080: );
081:
082: # transform %sql_ops into %ops where the operations are now
083: # DBI statement handles instead of SQL text.
084: while (my($table,$props) = each %tableinfo) {
085: for my $connection ('master', 'slave') {
086: while(my($op,$tsql) = each %{$sql_ops{$connection}}) {
087: # use our template to build sql for this table
088: # ($tsql is coderef that generates our SQL statements)
089: my $sql = $tsql->($table,$props->{keys},$props->{columns});
090: $ops{$connection}->{$table}->{$op} =
091: $db{$connection}->prepare($sql) ||
092: die "Could not prepare $sql on $connection";
093: }
094: }
095: }
096:
097: sub dml_replay($) {
098: my $table = shift;
099: my $rows = 0;
100: my %seen_txns;
101: eval {
102: my $master = $ops{master}->{$table};
103: my $slave = $ops{slave}->{$table};
104: vlog("Fetch the $table logs from the master
");
105: $master->{fetchlogs}->execute($nodename);
106: while(my @row = $master->{fetchlogs}->fetchrow()) {
107: # txnid is the first column, pass the remaining to apply
108: my $txnid = shift @row;
109: vlog("[$txnid] Apply the changed row to the slave
");
110: $slave->{apply}->execute(@row);
111: $seen_txns{$txnid}++;
112: $rows++;
113: }
114: foreach my $txnid (keys %seen_txns) {
115: vlog("[$txnid] Record the application to the master
");
116: $master->{record}->execute($txnid, $nodename);
117: }
118: $master->{fetchlogs}->finish();
119: if($rows) {
120: my $txns = scalar(keys %seen_txns); # get a count
121: vlog("[$table] commit $txns txns / $rows rows
");
122: for ('slave', 'master') { $db{$_}->commit(); }
123: }
124: };
125: if($@) {
126: vlog("rollback DML replication on $table: $@
");
127: for ('slave', 'master') { eval { $db{$_}->rollback(); }; }
128: }
129: }
130:
131: my $stop;
132: $SIG{'INT'} = sub { $stop = 1; };
133: while(!$stop) {
134: foreach my $table (keys %tableinfo) {
135: dml_replay($table);
136: }
137: sleep($interval);
138: }
139:
140: vlog("Disconnecting...
");
141: for my $connection ('slave', 'master') {
142: $db{$connection}->disconnect();
143: }
Let’s walk over the checklist again and cross-reference it with our script:
-
Connect to the master. This is handled in lines 25–30.
-
Request all modifications it has not yet processed. The method for generating the SQL is defined in lines 49–62. That method is used and the result prepared on the database handle in lines 82–95. The request and the loop over the response set are in lines 105–106.
-
Apply those modifications. The SQL for applying the changes to the slave table is defined in lines 63–69 and prepared as a statement handle in lines 82–95. The resultset of the previous step is then applied to the slave table, and the transaction IDs that are applied are tracked in lines 107–112.
-
Inform the master that it has applied them. The SQL for recording applied transactions with the master is defined in lines 72–78 and prepared as a statement handle in lines 82–95. Lines 114–117 execute this statement handle to inform the master of the transactions we applied in the previous step.
-
Commit at the slave and the master. The changes are committed in lines 119–123. If there was an error during any of the previous steps, the eval block would be exited and the rollback induced in lines 125–128.
-
Repeat. Lines 131–138 loop over the preceding steps.
Perhaps a more straightforward recap of the script itself would be
-
Lines 25–30 connect.
-
Lines 32–45 define the tables we will be replicating.
-
Lines 47–80 define methods to generate all the SQL we will need to do our job.
-
Lines 82–95 prepare all the SQL for all the tables on the appropriate database handle (master or slave).
-
Lines 97–129 apply the process of fetching changes from the master, applying them to the slave, recording the application with the master, and committing (or rolling back on failure).
-
Lines 131–138 continually do this work on a defined interval.
All in all, it is simple. To start, we run the script (and leave it running); then we export the master table and import it manually. From that point on, the script will keep the replica up-to-date (within $interval seconds).
One nuance that was not addressed in this example is that the DMLProcessed tables will grow unbounded. There should be periodic, automated administrative action taken to remove old records from the DML logs on the master.
Now is a perfect time to take a detour. We have one table that is rather small. AdminUsers is only roughly 5,000 rows. The act of pulling that data from the database is tiny, and the act of creating a new table of that size is hardly worthy of mention.
Tables like these often do not merit the complexity of tracking changes, shipping them over, and reapplying them to slave nodes. Instead, each slave node can simply truncate its copy, pull a new one, insert it, and commit. On some databases this has unappealing, locking behavior and can affect read-only queries referencing the target table. We see this in PostgreSQL sometimes, so we will implement something called flipping snapshots.
The concept is simple. We have two copies of the table, and we alternate between them, applying the snapshot procedure. At the end of each procedure, we replace a publicly used view to reference the table that we just finished populating.
The first thing we need, as in the DML replay examples, is a table to hold our AdminUsers information. Unlike the DML replay example, we will not use the name of the table directly because we want to alternate between two snapshots. We do this by creating two identical snapshot tables and a view against one of them:
CREATE TABLE AdminUsers_snap1 (
UserID INTEGER PRIMARY KEY,
UserName VARCHAR(32) NOT NULL UNIQUE,
Password VARCHAR(80) NOT NULL,
EmailAddress VARCHAR(255) NOT NULL
);
CREATE TABLE AdminUsers_snap2 (
UserID INTEGER PRIMARY KEY,
UserName VARCHAR(32) NOT NULL UNIQUE,
Password VARCHAR(80) NOT NULL,
EmailAddress VARCHAR(255) NOT NULL
);
CREATE VIEW AdminUsers AS SELECT * FROM AdminUsers_snap1;
Now our tables and view are there, but they are empty. Populating a snapshot table is much more straightforward than the previous examples because it is not fine-grained. Although the process is clearly less efficient, for small tables that change infrequently it is a simple and easy solution because it requires no instrumentation on the master node.
The process of populating tables is simple:
-
Truncate the local, unused snapshot table (the one to which the view is not pointing to).
-
Pull all rows from the master table and insert them into the now empty snapshot table.
-
Alter the view to point to the snapshot table we just populated.
-
Commit.
As you can imagine, there are several ways to do this. In most databases, performing bulk data loads efficiently requires using a separate API: Oracle has sqlldr, PostgreSQL has COPY, and MySQL has LOAD DATA INFILE. Additionally, many databases support the concept of dblinks, which are direct connections to other databases usually over some connection such as ODBC. Using a direct dblink or a native bulk loading method is the correct implementation of this, but we will use a generic (yet less efficient) approach here so that the code is less baroque and more generally applicable. The code for snapshot.pl follows:
01: #!/usr/bin/perl
02:
03: use strict;
04: use DBI;
05:
06: my $master = DBI->connect("dbi:Oracle:MASTER", "user", "pw",
07: { AutoCommit = > 0, RaiseError = > 1 } ) ||
08: die "Could not connect to master";
09: my $slave = DBI->connect("dbi:Pg:database=slave", "user", "pw",
10: { AutoCommit = > 0, RaiseError = > 1 } ) ||
11: die "Could not connect to slave";
12:
13: # This is how we will find out the view's current source table
14: my $whichsnap = $slave->prepare(q{
15: SELECT substring(definition from '%_snap#"_#"%' for '#')
16: FROM pg_views
17: WHERE viewname = lower(?)
18: }) || die "Cannot prepare snapshot detector
";
19:
20: while(my $table = shift) {
21: eval {
22: # Which snapshot is the view pointint to? (1 or 2)
23: $whichsnap->execute($table);
24: my($snap) = $whichsnap->fetchrow();
25: $whichsnap->finish();
26:
27: # Choose the non-active snapshot for population
28: my $newsnap;
29: $newsnap = "${table}_snap2" if($snap eq '1'),
30: $newsnap = "${table}_snap1" if($snap eq '2'),
31: $newsnap || die "[$table] which snapshot to use?
";
32:
33: # Empty the snapshot table
34: $slave->do(qq{TRUNCATE TABLE $newsnap}) ||
35: die "[$table] could not truncate $newsnap
";
36:
37: # Pull all the rows from the master and put them
38: # in the slave table
39: my $src = $master->prepare(qq{SELECT * FROM $table});
40: $src->execute();
41: # Our column names are @{$src->{NAME}}
42: my $dst = $slave->prepare(qq{
43: INSERT INTO $newsnap (}. join(',', @{$src->{NAME}}).q{)
44: VALUES (}.join(',', map { "?" } @{$src->{NAME}}).')'),
45: while(my $row = $src->fetchrow_hashref()) {
46: $dst->execute(map { $row->{$_} } @{$src->{NAME}});
47: }
48: $src->finish();
49:
50: # Replace the view with a view onto the new snapshot
51: $slave->do(qq{CREATE OR REPLACE VIEW $table AS
52: SELECT * FROM $newsnap}) ||
53: die "[$table] cannot replace view
";
54:
55: $slave->commit();
56: };
57: # Rollback on any sort of error
58: if($@) { eval { $slave->rollback(); }; }
59: }
60: $master->disconnect();
61: $slave->disconnect();
The preceding code sample is much simpler than the DML replay script. In this script we simply connect to the database (lines 6–11), determine which snapshot the current view references (lines 13–18 and 22–31), truncate the “other” snapshot (lines 33–35), pull the rows from the master and stick them into our empty table (lines 37–48), flip the view to look at our fresh snapshot (lines 50–53), and commit (line 55). The script takes the tables to snapshot as additional arguments to the script itself.
Again, although this script is functional, a production version should leverage the database vendor-specific extensions for bulk data loading to reduce overall load on the slave node. In my personal experience doing this from Oracle to MySQL, we used the LOAD DATA INFILE with success, and when performing snapshots from Oracle to PostgreSQL we used the pl/perl procedural language in combination with dbi-link to perform all aspects of the snapshot procedure from within PostgreSQL itself.
Anyone who has set up Oracle to Oracle or MySQL to MySQL master-slave replication will know that it is a well-documented and straightforward process. So, why go through a laborious example of how to replicate from one vendor to another? There is a good reason—thanks for hanging in there!
When an architecture relies on a specific vendor at the core, people tend to narrow their vision. This isn’t limited to developers alone, but developers in particular always attempt to solve problems with the tools they best understand—regardless of the tools’ suitability for the job at hand.
We should make it very clear that if you are using Product X at the core of the architecture and you are in the position of needing similar or related functionality elsewhere in the architecture, it makes the most sense to use the same Product X. The reasons for this should be obvious, but here are just a few:
-
Limiting the number of different products in the architecture reduces the overall set of expertise needed by staff.
-
Each product has its own bugs, release cycles, and life cycles, all of which must be accounted for in operational planning.
-
You’d be out of your mind to manage and maintain two separate tools to do the exact same job.
With that said, similar or related functionality is often poorly assessed. Often, the reason for needing a database replica is due to a performance concern or a different usage pattern on the existing database that would negatively impact existing operations. If the new task at hand causes a performance issue or demonstrates a different usage pattern, clearly the functionality will not be the same on the new slave nodes as on the current master.
It takes some experience, but the ultimate goal is to evaluate how different the demands on the new database architecture will be from the current ones. If they are indeed different, it is worth the time to step back from the architecture for some serious deliberation. You should be asking yourself several questions. Why doesn’t my current database serve this new purpose well? Are there specific features of functions that are missing from this product that exist in a different RDBMS? Could I solve my problem without a database at all?
After answering these questions (without specific products in mind!), you may find that it makes the most sense to have the new portions of your architecture built on the same database (and go buy a replication book for Product X), have a different vendor’s database (this chapter should make that a little less intimidating), or don’t have a database at all (which is why there is Chapter 10, “The Right Tool for the Job,” in this book).