
A typical program has three basic tasks: input, computation, and output. This book has so far concentrated on the computational aspects of the computer system, but now it is time to discuss input and output.
This chapter will focus on the primitive input and output activities of the CPU, rather than on the abstract file or character input/output (I/O) that high-level applications usually employ. It will discuss how the CPU transfers bytes of data to and from the outside world, paying special attention to the performance issues behind I/O operations. As all high-level I/O activities are eventually routed through the low-level I/O systems, you must understand how low-level input and output works on a computer system if you want to write programs that communicate efficiently with the outside world.
The first thing to learn about the I/O subsystem is that I/O in a typical computer system is radically different from I/O in a typical high-level programming language. At the primitive I/O levels of a computer system, you will rarely find machine instructions that behave like Pascal’s writeln, C++’s cout, C’s printf, or even like the HLA stdin and stdout statements. In fact, most I/O machine instructions behave exactly like the 80x86’s mov instruction. To send data to an output device, the CPU simply moves that data to a special memory location, and to read data from an input device, the CPU moves data from the device’s address into the CPU. I/O operations behave much like memory read and write operations, except that there are usually more wait states associated with I/O operations.
We can classify I/O ports into five categories based on the CPU’s ability to read and write data at a given port address. These five categories of ports are read-only, write-only, read/write, dual I/O, and bidirectional.
A read-only port is obviously an input port. If the CPU can only read the data from the port, then the data must come from some source external to the computer system. The hardware typically ignores any attempt to write data to a read-only port, but it’s never a good idea to write to a read-only port because some devices may fail if you do so. A good example of a read-only port is the status port on a PC’s parallel printer interface. Data from this port specifies the current status of the printer, while the hardware ignores any data written to this port.
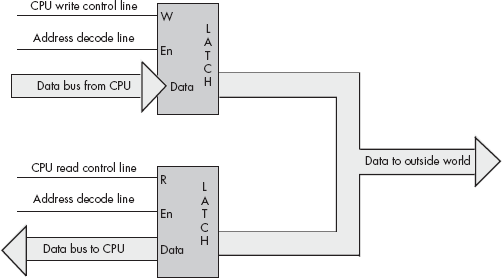
A write-only port is always an output port. Writing data to such a port presents the data for use by an external device. Attempting to read data from a write-only port generally returns whatever garbage value happens to be on the data bus. You generally cannot depend on the meaning of any value read from a write-only port. An output port typically uses a latch device to hold data to be sent to the outside world. When a CPU writes to a port address associated with an output latch, the latch stores the data and makes it available on an external set of signal lines (see Figure 12-1).

A perfect example of an output port is a parallel printer port. The CPU typically writes an ASCII character to a byte-wide output port that connects to the DB-25F connector on the back of the computer’s case. A cable transmits this data to the printer, where it arrives on the printer’s input port (from the printer’s perspective, it is reading the data from the computer system). A processor inside the printer typically converts this ASCII character to a sequence of dots that it prints on the paper.
Note that output ports can be write-only or read/write. The port in Figure 12-1, for example, is a write-only port. Because the outputs on the latch do not loop back to the CPU’s data bus, the CPU cannot read the data the latch contains. Both the address decode line (En) and the write control line (W) must be active for the latch to operate. If the CPU tries to read the data located at the latch’s address the address decode line is active but the write control line is not, so the latch does not respond to the read request.
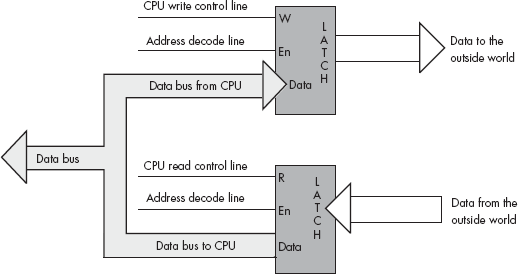
A read/write port is an output port as far as the outside world is concerned. However, the CPU can read as well as write data to such a port. Whenever the CPU reads data from a read/write port, it reads the data that was last written to the port allowing a programmer to retrieve that value. The act of reading data from the port does not affect the data presented to the external peripheral device.[46]
Figure 12-2 shows how to create a port that you can both read from and write to. The data written to the output port loops back to a second latch. Placing the address of these two latches on the address bus asserts the address decode lines on both latches. Therefore, to select between the two latches, the CPU must also assert either the read line or the write line. Asserting the read line (as will happen during a read operation) will enable the lower latch. This places the data previously written to the output port on the CPU’s data bus, allowing the CPU to read that data.
Note that the port in Figure 12-2 is not an input port — true input ports read data from external pins. Although the CPU can read data from this latch, the organization of this circuit simply allows the CPU to read the data it previously wrote to the port, thus saving the program from maintaining this value in a separate variable if the application needs to know what was written to the port. The data appearing on the external connector is output only, and one cannot connect realworld input devices to these signal pins.
A dual I/O port is also a read/write port, but when you read a dual I/O port, you read data from an external input device rather than the last data written to the output side of the port’s address. Writing data to a dual I/O port transmits data to some external output device, just as writing to a write-only port does. Figure 12-3 shows how you could interface a dual I/O port with the system.
Note that a dual I/O port is actually created using two ports — a read-only port and a write-only port — that share the same port address. Reading from the address accesses the read-only port, and writing to the address accesses the write-only port. Essentially, this port arrangement uses the read and write (R/W) control lines to provide an extra address bit that specifies which of the two ports to use.
A bidirectional port allows the CPU to both read and write data to an external device. To function properly, a bidirectional port must pass various control lines, such as read and write enable, to the peripheral device so that the device can change the direction of data transfer based on the CPU’s read/write request. In effect, a bidirectional port is an extension of the CPU’s bus through a bidirectional latch or buffer.
Generally, a given peripheral device will utilize multiple I/O ports. The original PC parallel printer interface, for example, uses three port addresses: a read/write I/O port, a read-only input port, and a write-only output port. The read/write port is the data port on which the CPU can read the last ASCII character written through that port. The input port returns control signals from the printer, which indicate whether the printer is ready to accept another character, is offline, is out of paper, and so on. The output port transmits control information to the printer. Later model PCs substituted a bidirectional port for the data port, allowing data transfer from and to a device through the parallel port. The bidirectional data port improved performance for various devices such as disk and tape drives connected to the PC’s parallel port.
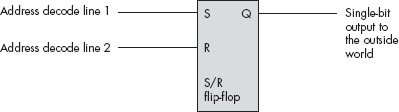
The examples given thus far may leave you with the impression that the CPU always reads and writes peripheral data using the data bus. However, while the CPU generally transfers the data it has read from input ports across the data bus, it does not always use the data bus when writing data to output ports. In fact, a very common output method is to simply access a port’s address directly without writing any data to it. Figure 12-4 illustrates a very simple example of this technique using a set/reset (S/R) flip-flop. In this circuit, an address decoder decodes two separate addresses. Any read or write access to the first address sets the output line high; any read or write access to the second address clears the output line. This circuit ignores the data on the CPU’s data lines, and it also ignores the status of the read and write lines. The only thing that matters is that the CPU accesses one of these two addresses.
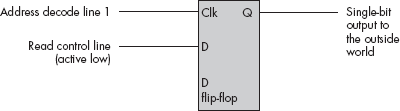
Another possible way to connect an output port to a system is to connect the read/write status lines to the data input of a D flip-flop. Figure 12-5 shows how you could design such a device. In this diagram, any read of the port sets the output bit to zero, while any write to this port sets the output bit to one.
These examples of connecting peripheral devices directly to the CPU are only two of an amazing number of different designs that engineers have devised to avoid using the data bus. However, unless otherwise noted, the remaining examples in this chapter presume that the CPU reads and writes data to an external device using the data bus.
There are three basic I/O mechanisms that computer systems can use to communicate with peripheral devices: memory-mapped input/output, I/O-mapped input/output, and direct memory access (DMA). Memory-mapped I/O uses ordinary locations within the CPU’s memory address space to communicate with peripheral devices. I/O-mapped input/output uses an address space separate from memory, and it uses special machine instructions to transfer data between that special I/O address space and the outside world. DMA is a special form of memory-mapped I/O where the peripheral device reads and writes data located in memory without CPU intervention. Each I/O mechanism has its own set of advantages and disadvantages, which we will discuss in the following sections.
How a device connects to a computer system is usually determined by the hardware system engineer at design time, and programmers have little control over this choice. While some devices may present two different interfaces to the system, software engineers generally have to live with whatever interface the hardware designers provide. Nevertheless, by paying attention to the costs and benefits of the I/O mechanism used for communication between the CPU and the peripheral device, you can choose different code sequences that will maximize the performance of I/O within your applications.
A memory-mapped peripheral device is connected to the CPU’s address and data lines exactly like regular memory, so whenever the CPU writes to or reads from the address associated with the peripheral device, the CPU transfers data to or from the device. This mechanism has several benefits and only a few disadvantages.
The principle advantage of a memory-mapped I/O subsystem is that the CPU can use any instruction that accesses memory, such as mov, to transfer data between the CPU and a peripheral. For example, if you are trying to access a read/write or bidirectional port, you can use an 80x86 read/modify/write instruction, like add, to read the port, manipulate the value, and then write data back to the port, all with a single instruction. Of course, if the port is read-only or write-only, an instruction that reads from the port address, modifies the value, and then writes the modified value back to the port will be of little use.
The big disadvantage of memory-mapped I/O devices is that they consume addresses in the CPU’s memory map. Every byte of address space that a peripheral device consumes is one less byte available for installing actual memory. Generally, the minimum amount of space you can allocate to a peripheral (or block of related peripherals) is a page of memory (4,096 bytes on an 80x86). Fortunately, a typical PC has only a couple dozen such devices, so this usually isn’t much of a problem. However, it can become a problem with some peripheral devices, like video cards, that consume a large chunk of the address space. Some video cards have 32 MB of on-board memory that they map into the memory address space and this means that the 32 MB address range consumed by the card is not available to the system for use as regular RAM memory.
It goes without saying that the CPU cannot cache values intended for memory-mapped I/O ports. Caching data from an input port would mean that subsequent reads of the input port would access the value in the cache rather than the data at the input port, which could be different. Similarly, with a write-back cache mechanism, some writes might never reach an output port because the CPU might save up several writes in the cache before sending the last write to the actual I/O port. In order to avoid these potential problems, there must be some mechanism to tell the CPU not to cache accesses to certain memory locations.
The solution is found in the virtual memory subsystem of the CPU. The 80x86’s page table entries, for example, contain information that the CPU can use to determine whether it is okay to map data from a page in memory to cache. If this flag is set one way, the cache operates normally; if the flag is set the other way, the CPU does not cache up accesses to that page.
I/O-mapped input/output differs from memory-mapped I/O, insofar as it uses a special I/O address space separate from the normal memory space, and it uses special machine instructions to access device addresses. For example, the 80x86 CPUs provide the in and out instructions specifically for this purpose. These 80x86 instructions behave somewhat like the mov instruction except that they transmit their data to and from the special I/O address space rather than the normal memory address space. Although the 80x86 processors (and other processors that provide I/O-mapped input/output capabilities, most notably various embedded microcontrollers) use the same physical address bus to transfer both memory addresses and I/O device addresses, additional control lines differentiate between addresses that belong to the normal memory space and those that belong to the special I/O address space. This means that the presence of an I/O-mapped input/output system on a CPU does not preclude the use of memory-mapped I/O in the system. Therefore, if there is an insufficient number of I/O-mapped locations in the CPU’s address space, a hardware designer can always use memory-mapped I/O instead (as a video card does on a typical PC).
In modern 80x86 PC systems that utilize the PCI bus (or later variants), special peripheral chips on the system’s motherboard remap the I/O address space into the main memory space, allowing programs to access I/O-mapped devices using either memory-mapped or I/O-mapped input/output. By placing the peripheral port addresses in the standard memory space, high-level languages can control those I/O devices even though those languages might not provide special statements to reference the I/O address space. As almost all high-level languages provide the ability to access memory, but most do not allow access to the I/O space, having the PCI bus remap the I/O address space into the memory address space provides I/O access to those high-level languages.
Memory-mapped I/O subsystems and I/O-mapped subsystems both require the CPU to move data between the peripheral device and memory. For this reason, we often call these two forms of I/O programmed I/O. For example, to store into memory a sequence of ten bytes taken from an input port, the CPU must read each value from the input port and store it into memory.
For very high-speed I/O devices the CPU may be too slow to process this data one byte (or one word or double word) at a time. Such devices generally have an interface to the CPU’s bus so they can directly read and write memory, which is known as direct memory access because the peripheral device accesses memory directly, without using the CPU as an intermediary. This often allows the I/O operation to proceed in parallel with other CPU operations, thereby increasing the overall speed of the system. Note, however, that the CPU and the DMA device cannot both use the address and data buses at the same time. Therefore, concurrent processing only occurs if the bus is free for use by the I/O device, which happens when the CPU has a cache and is accessing code and data in the cache. Nevertheless, even if the CPU must halt and wait for the DMA operation to complete before beginning a different operation, the DMA approach is still much faster because many of the bus operations that occur during I/O-mapped input/output or memory-mapped I/O consist of instruction fetches or I/O port accesses that are not present during DMA operations.
A typical DMA controller consists of a pair of counters and other circuitry that interfaces with memory and the peripheral device. One of the counters serves as an address register, and this counter supplies an address on the address bus for each transfer. The second counter specifies the number of data transfers. Each time the peripheral device wants to transfer data to or from memory, it sends a signal to the DMA controller, which places the value of the address counter on the address bus. In coordination with the DMA controller, the peripheral device places data on the data bus to write to memory during an input operation, or it reads data from the data bus, taken from memory, during an output operation.[47] After a successful data transfer, the DMA controller increments its address register and decrements the transfer counter. This process repeats until the transfer counter decrements to zero.
Different peripheral devices have different data transfer rates. Some devices, like keyboards, are extremely slow when compared to CPU speeds. Other devices, like disk drives, can actually transfer data faster than the CPU can process it. The appropriate programming technique for data transfer depends strongly on the transfer speed of the peripheral device involved in the I/O operation. Therefore, in order to understand how to write the most appropriate code, it first makes sense to invent some terminology to describe the different transfer rates of peripheral devices.
- Low-speed devices
Devices that produce or consume data at a rate much slower than the CPU is capable of processing. For the purposes of discussion, we’ll assume that low-speed devices operate at speeds that are two or more orders of magnitude slower than the CPU.
- Medium-speed devices
Devices that transfer data at approximately the same rate as, or up to two orders of magnitude slower than, the CPU.
- High-speed devices
Devices that transfer data faster than the CPU is capable of handling using programmed I/O.
The speed of the peripheral device will determine the type of I/O mechanism used for the I/O operation. Clearly, high-speed devices must use DMA because programmed I/O is too slow. Medium- and low-speed devices may use any of the three I/O mechanisms for data transfer (though low-speed devices rarely use DMA because of the cost of the extra hardware involved).
With typical bus architectures, personal computer systems are capable of one transfer per microsecond or better. Therefore, high-speed devices are those that transfer data more rapidly than once per microsecond. Medium-speed transfers are those that involve a data transfer every 1 to 100 micro-seconds. Low-speed devices usually transfer data less often than once every 100 microseconds. Of course, these definitions for the speed of low-, medium-, and high-speed devices are system dependent. Faster CPUs with faster buses allow faster medium-speed operations.
Note that one transfer per microsecond is not the same thing as a 1-MB-per-second transfer rate. A peripheral device can actually transfer more than one byte per data transfer operation. For example, when using the 80x86 in( dx, eax ); instruction, the peripheral device can transfer four bytes in one transfer. Therefore, if the device is reaching one transfer per micro-second, the device can transfer 4 MB per second using this instruction.
Earlier in this book, you saw that the CPU communicates with memory and I/O devices using the system bus. If you’ve ever opened up a computer and looked inside or read the specifications for a system, you’ve probably seen terms like PCI, ISA, EISA, or even NuBus mentioned when discussing the computer’s system bus. In this section, we’ll discuss the relationship between the CPU’s bus and these different system buses, and describe how these different computer system buses affect the performance of a system.
Although the choice of the hardware bus is made by hardware engineers, not software engineers, many computer systems will actually employ multiple buses in the same system. Therefore, software engineers can choose which peripheral devices they use based upon the bus connections of those peripherals. Furthermore, maximizing performance for a particular bus may require different programming techniques than for other buses. Finally, although a software engineer may not be able to choose the buses available in a particular computer system, that engineer can choose which system to write their software for, based on the buses available in the system they ultimately choose.
Computer system buses like PCI (Peripheral Component Interconnect) and ISA (Industry Standard Architecture) are definitions for physical connectors inside a computer system. These definitions describe the set of signals, physical dimensions (i.e., connector layouts and distances from one another), and a data transfer protocol for connecting different electronic devices. These buses are related to the CPU’s local bus, which consists of the address, data, and control lines, because many of the signals on the peripheral buses are identical to signals that appear on the CPU’s bus.
However, peripheral buses do not necessarily mirror the CPU’s bus — they often contain several lines that are not present on the CPU’s bus. These additional lines let peripheral devices communicate with one another without having to go through the CPU or memory. For example, most peripheral buses provide a common set of interrupt control signals that let I/O devices communicate directly with the system’s interrupt controller, which is also a peripheral device. Nor do the peripheral buses include all the signals found on the CPU’s bus. For example, the ISA bus only supports 24 address lines compared with the Pentium IV’s 36 address lines.
Different peripheral devices are designed to use different peripheral buses. Figure 12-6 shows the organization of the PCI and ISA buses in a typical computer system.
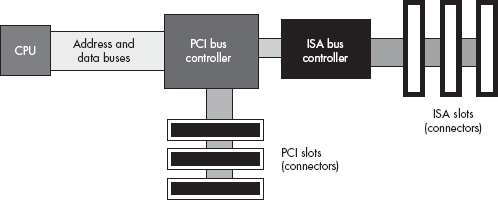
Notice how the CPU’s address and data buses connect to a PCI bus controller peripheral device, but not to the PCI bus itself. The PCI bus controller contains two sets of pins, providing a bridge between the CPU’s local bus and the PCI bus. The signal lines on the local bus are not connected directly to the corresponding lines on the PCI bus; instead, the PCI bus controller acts as an intermediary, rerouting all data transfer requests between the CPU and the PCI bus.
Another interesting thing to note is that the ISA bus controller is not directly connected to the CPU. Instead, it is usually connected to the PCI bus controller. There is no logical reason why the ISA controller couldn’t be connected directly to the CPU’s local bus. However, in most modern PCs, the ISA and PCI controllers appear on the same chip, and the manufacturer of this chip has chosen to interface the ISA bus through the PCI controller for cost or performance reasons.
The CPU’s local bus usually runs at some submultiple of the CPU’s frequency. Typical local bus frequencies are currently 66 MHz, 100 MHz, 133 MHz, 400 MHz, 533 MHz, and 800 MHz, but they may become even faster. Usually, only memory and a few selected peripherals like the PCI bus controller sit on the CPU’s bus and operate at this high frequency.
Because a typical CPU’s bus is 64 bits wide and because it is theoretically possible to achieve one data transfer per clock cycle, the CPU’s bus has a maximum possible data transfer rate of eight bytes times the clock frequency, or 800 MB per second for a 100-MHz bus. In practice, CPUs rarely achieve the maximum data transfer rate, but they do achieve some percentage of it, so the faster the bus, the more data can move in and out of the CPU (and caches) in a given amount of time.
The PCI bus comes in several configurations. The base configuration has a 32-bit-wide data bus operating at 33 MHz. Like the CPU’s local bus, the PCI bus is theoretically capable of transferring data on each clock cycle. This means that the bus has a theoretical maximum data transfer rate of 4 bytes times 33 MHz, or 132 MB per second. In practice, though, the PCI bus doesn’t come anywhere near this level of performance except in short bursts.
Whenever the CPU wishes to access a peripheral on the PCI bus, it must negotiate with other peripheral devices for the right to use the bus. This negotiation can take several clock cycles before the PCI controller grants the CPU access to the bus. If a CPU writes a sequence of values to a peripheral device at a rate of a double word per bus transfer, you can see that the negotiation time actually causes the transfer rate to drop dramatically. The only way to achieve anywhere near the maximum theoretical bandwidth on the bus is to use a DMA controller and move blocks of data in burst mode. In this burst mode, the DMA controller negotiates just once for the bus and then makes a large number of transfers without giving up the bus between each one.
There are a couple of enhancements to the PCI bus that improve performance. Some PCI buses support a 64-bit wide data path. This, obviously, doubles the maximum theoretical data transfer rate from four bytes per transfer to eight bytes per transfer. Another enhancement is running the bus at 66 MHz, which also doubles the throughput. With a 64-bit-wide 66-MHz bus you would quadruple the data transfer rate over the performance of the baseline configuration. These optional enhancements to the PCI bus allow it to grow with the CPU as CPUs increase their performance. As this is being written, a high-performance version of the PCI bus, PCI-X, is starting to appear with expected bus speeds beginning at 133 MHz and other enhancements to improve performance.
The ISA bus is a carry-over from the original PC/AT computer system. This bus is 16 bits wide and operates at 8 MHz. It requires four clock cycles for each bus cycle. For this and other reasons, the ISA bus is capable of about only one data transmission per microsecond. With a 16-bit-wide bus, data transfer is limited to about 2 MB per second. This is much slower than the speed at which both the CPU’s local bus and the PCI bus operate. Generally, you would only attach low-speed devices, like an RS-232 communications device, a modem, or a parallel printer interface, to the ISA bus. Most other devices, like disks, scanners, and network cards, are too fast for the ISA bus. The ISA bus is really only capable of supporting low-speed and medium-speed devices.
Note that accessing the ISA bus on most systems involves first negotiating for the PCI bus. The PCI bus is so much faster than the ISA bus that the negotiation time has very little impact on the performance of peripherals on the ISA bus. Therefore, there is very little difference to be gained by connecting the ISA controller directly to the CPU’s local bus.
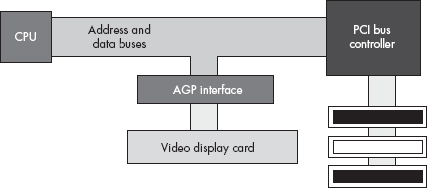
Video display cards are very special peripherals that need maximum bus performance to ensure quick screen updates and fast graphic operations. Unfortunately, if the CPU has to constantly negotiate with other peripherals for the use of the PCI bus, graphics performance can suffer. To overcome this problem, video card designers created the AGP (Accelerated Graphics Port) interface between the CPU’s local bus and the video display card, which provides various control lines and bus protocols specifically designed for video display cards.
The AGP connection lets the CPU quickly move data to and from the video display RAM (see Figure 12-7). Because there is only one AGP port per system, only one card can use the AGP slot at a time. The upside of this is that the system never has to negotiate for access to the AGP bus.
If a particular I/O device produces or consumes data faster than the system is capable of transferring data to or from that device, the system designer has two choices: provide a faster connection between the CPU and the device, or slow down the rate of transfer between the two.
If the peripheral device is connected to a slow bus like ISA, a faster connection can be created by using a different, faster bus. Another way to increase the connection speed is by switching to a wider bus like the 64-bit PCI bus, a bus with a higher frequency, or a higher performance bus like PCI-X. System designers can also sometimes create a faster interface to the bus as they have done with the AGP connection. However, once you exhaust these possibilities for improving performance, it can be very expensive to create a faster connection between peripherals and the system.
The other alternative available when a peripheral device is capable of transferring data faster than the system is capable of processing it, is to slow down the transfer rate between the peripheral and the computer system. This isn’t always as bad an option as it might seem. Most high-speed devices don’t transfer data at a constant rate to the system. Instead, devices typically transfer a block of data rapidly and then sit idle for some length of time. Although the burst rate is high and is faster than what the CPU or memory can handle, the average data transfer rate is usually lower than this. If you could average out the high-bandwidth peaks and transfer some of the data when the peripheral was inactive, you could easily move data between the peripheral and the computer system without resorting to an expensive, high-bandwidth bus or connection.
The trick is to use memory on the peripheral side to buffer the data. The peripheral can rapidly fill this buffer with data during an input operation, and it can rapidly extract data from the buffer during an output operation. Once the peripheral device is inactive, the system can proceed at a sustainable rate either to empty or refill the buffer, depending on whether the buffer is full or empty at the time. As long as the average data transfer rate of the peripheral device is below the maximum bandwidth the system supports, and the buffer is large enough to hold bursts of data going to and from the peripheral, this scheme lets the peripheral communicate with the system at a lower average data transfer rate.
Often, to save costs, the buffering takes place in the CPU’s address space rather than in memory local to the peripheral device. In this case, it is often the software engineer’s responsibility to initialize the buffer for a peripheral device. Therefore, this buffering isn’t always transparent to the software engineer. In some cases, neither the peripheral device nor the OS provide a buffer for the peripheral’s data and it becomes the application’s responsibility to buffer up this data in order to maintain maximum performance and avoid loss of data. In other cases, the device or OS may provide a small buffer, but the application itself might not process the data often enough to avoid data overruns — in such situations, an application can create a larger buffer that is local to the application to avoid the data overruns.
Many I/O devices cannot accept data at just any rate. For example, a Pentium-based PC is capable of sending several hundred million characters per second to a printer, but printers are incapable of printing that many characters each second. Likewise, an input device such as a keyboard will never transmit several million keystrokes per second to the system (because it operates at human speeds, not computer speeds). Because of the difference in capabilities between the CPU and many of the system peripherals, the CPU needs some mechanism to coordinate data transfer between the computer system and its peripheral devices.
One common way to coordinate data transfers is to send and receive status bits on a port separate from the data port. For example, a single bit sent by a printer could tell the system whether it is ready to accept more data. Likewise, a single status bit in a different port could specify whether a keystroke is available at the keyboard data port. The CPU can test these bits prior to writing a character to the printer, or reading a key from the keyboard.
Using status bits to indicate that a device is ready to accept or transmit data is known as handshaking. It gets this name because the protocol is similar to two people agreeing on some method of transfer by a handshake.
To demonstrate how handshaking works, consider the following short 80x86 assembly language program segment. This code fragment will continuously loop while the HO bit of the printer status register (at input port $379) contains zero and will exit once the HO bit is set (indicating that the printer is ready to accept data):
mov( $379, dx ); // Initialize DX with the address of the status port.
repeat
in( dx, al ); // Get the parallel port status into the AL register.
and( $80, al ); // Clear Z flag if the HO bit is set.
until( @nz ); // Repeat until the HO bit contains a one.
// Okay to write another byte to the printer data port here.One problem with the repeat..until loop in the previous section is that it could spin indefinitely as it waits for the printer to become ready to accept additional input. If someone turns the printer off, or if the printer cable becomes disconnected, the program could freeze up, forever waiting for the printer to become available. Usually, it’s a better idea to inform the user when something goes wrong rather than allowing the system to hang. Typically, great programmers handle this problem by including a time-out period in the loop, which once exceeded causes the program to alert the user that something is wrong with the peripheral device.
You can expect some sort of response from most peripheral devices within a reasonable amount of time. For example, even in the worst case, most printers will be ready to accept additional character data within a few seconds of the last transmission. Therefore, something is probably wrong if 30 seconds or more have passed without the printer accepting a new character. If the program is written to detect this kind of problem, it can pause, asking the user to check the printer and tell the program to resume printing once the problem is resolved.
Choosing a good time-out period is not an easy task. In doing so, you must carefully balance the irritation of possibly having the program incorrectly claim that something is wrong, with the pain of having the program lock up for long periods when there actually is something wrong. Both situations are equally annoying to the end user.
An easy way to create a time-out period is to count the number of times the program loops while waiting for a handshake signal from a peripheral. Consider the following modification to the repeat..until loop of the previous section:
mov( $379, dx ); // Initialize DX with the address of the status port.
mov( 30_000_000, ecx ); // Time-out period of approximately 30 seconds,
// assuming port access time is about 1 microsecond.
HandshakeLoop:
in( dx, al ); // Get the parallel port status into the AL register.
and( $80, al ); // Clear Z flag if the HO bit is set.
loopz HandshakeLoop; // Decrement ECX and loop while ECX <> 0 and
// the HO bit of AL contains a zero.
if( ecx <> 0 ) then
// Okay to write another byte to the printer data port here.
else
// We had a time-out condition if we get here.
endif;This code will exit once the printer is ready to accept data or when approximately 30 seconds have expired. You might question the 30-second figure, after all, a software-based loop (counting down ECX to zero) should run at different speeds on different processors. However, don’t miss the fact that there is an in instruction inside this loop. The in instruction reads a port on the ISA bus and that means this instruction will take approximately one microsecond to execute (about the fastest operation on the ISA bus). Hence, one million times through the loop will take about a second (plus or minus 50 percent, but close enough for our purposes). This is true almost regardless of the CPU frequency.
Polling is the process of constantly testing a port to see if data is available. The handshaking loops of the previous sections provide good examples of polling — the CPU waits in a short loop, testing the printer port’s status value until the printer is ready to accept more data, and then the CPU can transfer more data to the printer. Polled I/O is inherently inefficient. If the printer in this example takes ten seconds to accept another byte of data, the CPU spins doing nothing productive for those ten seconds.
In early personal computer systems, this is exactly how a program would behave. When a program wanted to read a key from the keyboard, it would poll the keyboard status port until a key was available. These early computers could not do other processing while waiting for the keyboard.
The solution to this problem is to use what is called an interrupt mechanism. An interrupt is triggered by an external hardware event, such as the printer becoming ready to accept another character, that causes the CPU to interrupt its current instruction sequence and call a special interrupt service routine (ISR). Typically, an interrupt service routine runs through the following sequence of events:
It preserves the current values of all machine registers and flags so that the computation that is interrupted can be continued later.
It does whatever operation is necessary to service the interrupt.
It restores the registers and flags to the values they had before the interrupt.
It resumes execution of the code that was interrupted.
In most computer systems, typical I/O devices generate an interrupt whenever they make data available to the CPU, or when they become able to accept data from the CPU. The ISR quickly processes the interrupt request in the background, allowing some other computation to proceed normally in the foreground.
Though interrupt service routines are usually written by OS designers or peripheral device manufacturers, most OSes provide the ability to pass an interrupt to an application via signals or some similar mechanism. This allows you to include interrupt service routines directly within an application. You could use this facility, for example, to have a peripheral device notify your application when its internal buffer is full and the application needs to copy data from the peripheral’s buffer to an application buffer to prevent data loss.
If you’re working on Windows 95 or 98, you can write assembly code to access I/O ports directly. The assembly code shown earlier as an example of hand-shaking is a good example of this. However, recent versions of Windows and all versions of Linux employ a protected mode of operation. In this mode, direct access to devices is restricted to the OS and certain privileged programs. Standard applications, even those written in assembly language, are not so privileged. If you write a simple program that attempts to send data to an I/O port, the system will generate an illegal access exception and halt your program.
Linux does not allow just any program to access I/O ports as it pleases. Only programs with “super-user” (root) privileges may do so. For limited I/O access, it is possible to use the Linux ioperm system call to make certain I/O ports accessible from user applications. For more details, Linux users should read the “man” page on “ioperm.”
If Linux and Windows don’t allow direct access to peripheral devices, how does a program communicate with these devices? Clearly, this can be done, because applications interact with real-world devices all the time. It turns out that specially written modules, known as device drivers, are able to access I/O ports by special permission from the OS. A complete discussion of writing device drivers is well beyond the scope of this book, but an understanding of how device drivers work may help you understand the possibilities and limitations of I/O under a protected-mode OS.
A device driver is a special type of program that links with the OS. A device driver must follow some special protocols, and it must make some special calls to the OS that are not available to standard applications. Furthermore, in order to install a device driver in your system, you must have administrator privileges, because device drivers create all kinds of security and resource allocation problems, and you can’t have every hacker in the world taking advantage of rogue device drivers running on your system. Therefore, “whipping out a device driver” is not a trivial process and application programs cannot load and unload drivers at will.
Fortunately, there are only a limited number of devices found on a typical PC, so you only need a limited number of device drivers. You would typically install a device driver in the OS at the same time you install the device, or, if the device is built into the PC, at the same time you install the OS. About the only time you’d really need to write your own device driver is when building your own device, or in special cases when you need to take advantage of some device’s capabilities that standard device drivers don’t handle.
The device driver model works well with low-speed devices, where the OS and device driver can respond to the device much more quickly than the device requires. The model is also great for use with medium- and high-speed devices where the system transmits large blocks of data to and from the device. However, the device driver model does have a few drawbacks, and one is that it does not support medium- and high-speed data transfers that require a high degree of interaction between the device and the application.
The problem is that calling the OS is an expensive process. Whenever an application makes a call to the OS to transmit data to the device, it can potentially take hundreds of microseconds, if not milliseconds, before the device driver actually sees the application’s data. If the interaction between the device and the application requires a constant flurry of bytes moving back and forth, there will be a big delay if each transfer has to go through the OS. The important point to note is that for applications of this sort, you will need to write a special device driver that can handle the transactions itself rather than continually returning to the application.
For the most part, communicating with a peripheral device under a modern OS is exactly like writing data to a file or reading data from a file. In most OSes, you open a “file” using a special file name like COM1 (the serial port) or LPT1 (the parallel port) and the OS automatically creates a connection to the specified device. When you are finished using the device, you “close” the associated file, which tells the OS that the application is done with the device so other applications can use it.
Of course, most devices do not support the same semantics that do disk files do. Some devices, like printers or modems, can accept a long stream of unformatted data, but other devices may require that you preformat the data into blocks and write the blocks to the device with a single write operation. The exact semantics depend upon the particular device. Nevertheless, the typical way to send data to a peripheral is to use an OS “write” function to which you pass a buffer containing some data, and the way to read data from a device is to call an OS “read” function to which you pass the address of some buffer into which the OS will place the data it reads.
Of course, not all devices conform to the stream-I/O data semantics of file I/O. Therefore, most OSes provide a device-control API that lets you pass information directly to the peripheral’s device driver to handle the cases where a stream-I/O model fails.
Because it varies by OS, the exact details concerning the OS API interface are a bit beyond the scope of this book. Though most OSes use a similar scheme, they are different enough to make it impossible to describe them in a generic fashion. For more details, consult the programmer’s reference for your particular OS.
This chapter has so far introduced I/O in a very general sense, without spending too much time discussing the particular peripheral devices present in a typical PC. It some respects, it’s dangerous to discuss real devices on modern PCs because the traditional (“legacy”) devices that are easy to understand are slowly disappearing from PC designs. As manufacturers introduce new PCs, they are removing many of the legacy peripherals like parallel and serial ports that are easy to program, and they are replacing these devices with complex peripherals like USB and FireWire. Although a detailed discussion on programming these newer peripheral devices is beyond the scope of this book, you need to understand their behavior in order to write great code that accesses these devices.
Because of the nature of the peripheral devices appearing in the rest of this chapter, the information presented applies only to IBM-compatible PCs. There simply isn’t enough space in this book to cover how particular I/O devices behave on different systems. Other systems support similar I/O devices, but their hardware interfaces may be different from what’s presented here. Nevertheless, the general principles still apply.
The PC’s keyboard is a computer system in its own right. Buried inside the keyboard’s case is an 8042 microcontroller chip that constantly scans the switches on the keyboard to see if any keys are held down. This processing occurs in parallel with the normal activities of the PC, and even though the PC’s 80x86 is busy with other things, the keyboard never misses a keystroke.
A typical keystroke starts with the user pressing a key on the keyboard. This closes an electrical contact in a switch, which the keyboard’s micro-controller can sense. Unfortunately, mechanical switches do not always close perfectly clean. Often, the contacts bounce off one another several times before coming to rest with a solid connection. To a microcontroller chip that is reading the switch constantly, these bouncing contacts will look like a very quick series of keypresses and releases. If the microcontroller registers these as multiple keystrokes, a phenomenon known as keybounce may result, a problem common to many cheap and old keyboards. Even on the most expensive and newest keyboards, keybounce can be a problem if you look at the switch a million times a second, because mechanical switches simply cannot settle down that quickly. A typical inexpensive key will settle down within five milliseconds, so if the keyboard scanning software polls the key less often than this, the controller will effectively miss the keybounce. The practice of limiting how often one scans the keyboard in order to eliminate keybounce is known as debouncing.
The keyboard controller must not generate a new key code sequence every time it scans the keyboard and finds a key held down. The user may hold a key down for many tens or hundreds of milliseconds before releasing it, and we don’t want this to register as multiple keystrokes. Instead, the keyboard controller should generate a single key code value when the key goes from the up position to the down position (a down key operation). In addition to this, modern keyboards provide an autorepeat capability that engages once the user has held down a key for a given time period (usually about half a second), and it treats the held key as a sequence of keystrokes as long as the user continues to hold the key down. However, even these autorepeat keystrokes are regulated to allow only about ten keystrokes per second rather than the number of times per second the keyboard controller scans all the switches on the keyboard.
Upon detecting a down keystroke, the microcontroller sends a keyboard scan code to the PC. The scan code is not related to the ASCII code for that key; it is an arbitrary value IBM chose when the PC’s keyboard was first developed. The PC keyboard actually generates two scan codes for every key you press. It generates a down code when you press a key down and an up code when you release the key. Should you hold the key down long enough for the autorepeat operation to begin, the keyboard controller will send a sequence of down codes until you release the key, at which time the keyboard controller will send a single up code.
The 8042 microcontroller chip transmits these scan codes to the PC, where they are processed by an interrupt service routine for the keyboard. Having separate up and down codes is important because certain keys (like shift, ctrl, and alt) are only meaningful when held down. By generating up codes for all the keys, the keyboard ensures that the keyboard ISR knows which keys are pressed while the user is holding down one of these modifier keys. Exactly what the system does with these scan codes depends on the OS, but usually the OS’s keyboard device driver will translate the scan code sequence into an appropriate ASCII code or some other notation that applications can work with.
The original IBM PC design provided support for three parallel printer ports that IBM designated LPT1:, LPT2:, and LPT3:. With laser and ink jet printers still a few years in the future, IBM probably envisioned machines that could support a standard dot matrix printer, a daisy wheel printer, and maybe some other auxiliary type of printer for different purposes. Surely, IBM did not anticipate the general use that parallel ports have received or they would probably have designed them differently. Today, the PC’s parallel port controls keyboards, disk drives, tape drives, SCSI adapters, Ethernet (and other network) adapters, joystick adapters, auxiliary keypad devices, other miscellaneous devices, and, oh yes, printers.
The current trend is to eliminate the parallel port from systems because of connector size and performance problems. Nevertheless, the parallel port remains an interesting device. It’s one of the few interfaces that hobbyists can use to connect the PC to simple devices they’ve built themselves. Therefore, learning to program the parallel port is a task many hardware enthusiasts take upon themselves.
In a unidirectional parallel communication system, there are two distinguished sites: the transmitting site and the receiving site. The transmitting site places its data on the data lines and informs the receiving site that data is available; the receiving site then reads the data lines and informs the transmitting site that it has taken the data. Note how the two sites synchronize their access to the data lines — the receiving site does not read the data lines until the transmitting site tells it to, and the transmitting site does not place a new value on the data lines until the receiving site removes the data and tells the transmitting site that it has the data. In other words, this form of parallel communications between the printer and computer system relies on hand-shaking to coordinate the data transfer.
The PC’s parallel port implements handshaking using three control signals in addition to the eight data lines. The transmitting site uses the strobe (or data strobe) line to tell the receiving site that data is available. The receiving site uses the acknowledge line to tell the transmitting site that it has taken the data. A third handshaking line, busy, tells the transmitting site that the receiving site is busy and that the transmitting site should not attempt to send data. The busy signal differs from the acknowledge signal, insofar as acknowledge tells the system that the receiving site has accepted the data just sent and processed it. The busy line tells the system that the receiving site cannot accept any new data just yet; the busy line does not imply that the last character sent has been processed (or even that a character was sent).
From the perspective of the transmitting site, a typical data transmission session looks something like the following:
The transmitting site checks the busy line to see if the receiving site is busy. If the busy line is active, the transmitter waits in a loop until the busy line becomes inactive.
The transmitting site places its data on the data lines.
The transmitting site activates the strobe line.
The transmitting site waits in a loop for the acknowledge line to become active.
The transmitting site sets the strobe inactive.
The transmitting site waits in a loop for the receiving site to set the acknowledge line inactive, indicating that it recognizes that the strobe line is now inactive.
The transmitting site repeats steps 1–6 for each byte it must transmit.
From the perspective of the receiving site, a typical data transmission session looks something like the following:
The receiving site sets the busy line inactive when it is ready to accept data.
The receiving site waits in a loop until the strobe line becomes active.
The receiving site reads the data from the data lines.
The receiving site activates the acknowledge line.
The receiving site waits in a loop until the strobe line goes inactive.
The receiving site (optionally) sets the busy line active.
The receiving site sets the acknowledge line inactive.
The receiving site processes the data.
The receiving site sets the busy line inactive (optional).
The receiving site repeats steps 2–9 for each additional byte it receives.
By carefully following these steps, the receiving and transmitting sites coordinate their actions so that the transmitting site doesn’t attempt to put several bytes on the data lines before the receiving site consumes them, and so the receiving site doesn’t attempt to read data that the transmitting site has not sent.
The RS-232 serial communication standard is probably the most popular serial communication scheme in the world. Although it suffers from many drawbacks, speed being the primary one, its use is widespread, and there are thousands of devices you can connect to a PC using an RS-232 serial interface. Though the use of the serial port is rapidly being eclipsed by USB use, many devices still use the RS-232 standard.
The original PC system design supports concurrent use of up to four RS-232 compatible devices connected through the COM1:, COM2:, COM3:, and COM4: ports. For those who need to connect additional serial devices, you can buy interface cards that let you add 16 or more serial ports to the PC.
In the early days of the PC, DOS programmers had to directly access the 8250 Serial Communications Chip (SCC) to implement RS-232 communications in their applications. A typical serial communications program would have a serial port ISR that read incoming data from the SCC and wrote outgoing data to the chip, as well as code to initialize the chip and to buffer incoming and outgoing data. Though the serial chip is very simple compared to modern peripheral interfaces, the 8250 is sufficiently complex that many programmers would have difficulty getting their serial communications software working properly. Furthermore, because serial communications was rarely the main purpose of the application being written, few programmers added anything beyond the basic serial communications features needed for their applications.
Fortunately, today’s application programmers rarely program the SCC directly. Instead, OSes such as Windows or Linux provide sophisticated serial communications device drivers that application programmers can call. These drivers provide a consistent feature set that all applications can use, and this reduces the learning curve needed to provide serial communication functionality. Another advantage to the OS device driver approach is that it removes the dependency on the 8250 SCC. Applications that use an OS device driver will automatically work with different serial communication chips. In contrast, an application that programs the 8250 directly will not work on a system that uses a USB to RS-232 converter cable. However, if the manufacturer of that USB to RS-232 converter cable provides an appropriate device driver for an OS, applications that do serial communications via that OS will automatically work with the USB/serial device.
An in-depth examination of RS-232 serial communications is beyond the scope of this book. For more information on this topic, consult your OS programmer’s guide or pick up one of the many excellent texts devoted specifically to this subject.
Almost all modern computer systems include some sort of disk drive unit to provide online mass storage. At one time, certain workstation vendors produced diskless workstations, but the relentless drop in price and increasing storage space of fixed (aka “hard”) disk units has all but obliterated the diskless computer system. Disk drives are so ubiquitous in modern systems that most people take them for granted. However, for a programmer to take a disk drive for granted is a dangerous thing. Software constantly interacts with the disk drive as a medium for application file storage, so a good understanding of how disk drives operate is very important if you want to write efficient code.
Floppy disks are rapidly disappearing from today’s PCs. Their limited storage capacity (typically 1.44 MB) is far too small for modern applications and the data those applications produce. It is hard to believe that barely 25 years ago a 143 KB (that’s kilobytes, not megabytes or gigabytes) floppy drive was considered a high-ticket item. However, except for floptical drives (discussed in 12.15.4 Zip and Other Floptical Drives), floppy disk drives have failed to keep up with technological advances in the computer industry. Therefore, we’ll not consider these devices in this chapter.
The fixed disk drive, more commonly known as the hard disk, is without question the most common mass storage device in use today. The modern hard drive is truly an engineering marvel. Between 1982 and 2004, the capacity of a single drive unit has increased over 50,000-fold, from 5 MB to over 250 GB. At the same time, the minimum price for a new unit has dropped from $2,500 (U.S.) to below $50. No other component in the computer system has enjoyed such a radical increase in capacity and performance along with a comparable drop in price. (Semiconductor RAM probably comes in second, and paying the 1982 price today would get you about 4,000 times the capacity.)
While hard drives were decreasing in price and increasing in capacity, they were also becoming faster. In the early 1980s, a hard drive subsystem was doing well to transfer 1 MB per second between the drive and the CPU’s memory; modern hard drives transfer more than 50 MB per second. While this increase in performance isn’t as great as the increase in performance of memory or CPUs, keep in mind that disk drives are mechanical units on which the laws of physics place greater limitations. In some cases, the dropping costs of hard drives has allowed system designers to improve their performance by using disk arrays (see 12.15.3 RAID Systems, for details). By using certain hard disk subsystems like disk arrays, it is possible to achieve 320-MB-per-second transfer rates, though it’s not especially cheap to do so.
“Hard” drives are so named because their data is stored on a small, rigid disk that is usually made out of aluminum or glass and is coated with a magnetic material. The name “hard” differentiates these disks from floppy disks, which store their information on a thin piece of flexible Mylar plastic.
In disk drive terminology, the small aluminum or glass disk is known as a platter. Each platter has two surfaces, front and back (or top and bottom), and both sides contain the magnetic coating. During operation, the hard drive unit spins this platter at a particular speed, which these days is usually 3,600; 5,400; 7,200; 10,000; or 15,000 revolutions per minute (RPM). Generally, though not always, the faster you spin the platter, the faster you can read data from the disk and the higher the data transfer rate between the disk and the system. The smaller disk drives that find their way into laptop computers typically spin at much slower speeds, like 2,000 or 4,000 RPM, to conserve battery life and generate less heat.
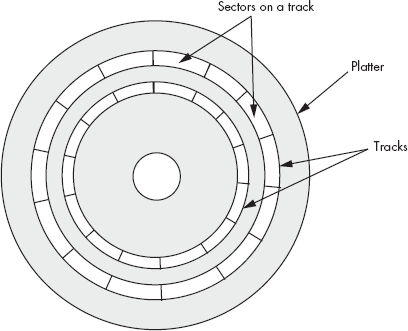
A hard disk subsystem contains two main active components: the disk platter(s) and the read/write head. The read/write head, when held stationary, floats above concentric circles, or tracks, on the disk surface (see Figure 12-8). Each track is broken up into a sequence of sections known as sectors or blocks. The actual number of sectors varies by drive design, but a typical hard drive might have between 32 and 128 sectors per track (again, see Figure 12-8). Each sector typically holds between 256 and 4,096 bytes of data, and many disk drive units let the OS choose between several different sector sizes, the most common choices being 512 bytes and 4,096 bytes.
The disk drive records data when the read/write head sends a series of electrical pulses to the platter, which translates those electrical pulses into magnetic pulses that the platter’s magnetic surface retains. The frequency at which the disk controller can record these pulses is limited by the quality of the electronics, the read/write head design, and the quality of the magnetic surface.
The magnetic medium is capable of recording two adjacent bits on its disk surface and then differentiating between those two bits during a later read operation. However, as you record bits closer and closer together, it becomes harder and harder to differentiate between them in the magnetic domain. Bit density is a measure of how closely a particular hard disk can pack data into its tracks — the higher the bit density, the more data you can squeeze onto a single track. However, to recover densely packed data requires faster and more expensive electronics.
The bit density has a big impact on the performance of the drive. If the drive’s platters are rotating at a fixed number of revolutions per minute, then the higher bit density, the more bits will rotate underneath the read/write head during a fixed amount of time. Larger disk drives tend to be faster than smaller disk drives because they often employ a higher bit density.
By moving the disk’s read/write head in a roughly linear path from the center of the disk platter to the outside edge, the system can position a single read/write head over any one of several thousand tracks. Yet the use of only one read/write head means that it will take a fair amount of time to move the head among the disk’s many tracks. Indeed, two of the most often quoted hard disk performance parameters are the read/write head’s average seek time and track-to-track seek time.
A typical high-performance disk drive will have an average seek time between five and ten milliseconds, which is half the amount of time it takes to move the read/write head from the edge of the disk to the center, or vice versa. Its track-to-track seek time, on the other hand, is on the order of one or two milliseconds. From these numbers, you can see that the acceleration and deceleration of the read/write head consumes a much greater percentage of the track-to-track seek time than it consumes of the average seek time. It only takes 20 times longer to traverse 1,000 tracks than it does to move to the next track. And because moving the read/write heads from one track to the next is usually the most common operation, the track-to-track seek time is probably a better indication of the disk’s performance. Regardless of which metric you use, however, keep in mind that moving the disk’s read/write head is one of the most expensive operations you can do on a disk drive so it’s something you want to minimize.
Because most hard drive subsystems record data on both sides of a disk platter, there are two read/write heads associated with each platter — one for the top of the platter and one for the bottom. And because most hard drives incorporate multiple platters in their disk assembly in order to increase storage capacity (see Figure 12-9), a typical drive will have multiple read/write heads (two heads for each platter).
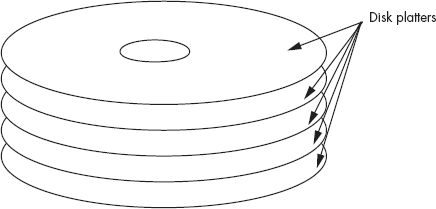
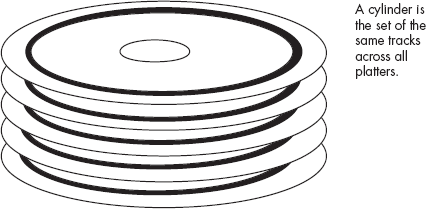
The various read/write heads are physically connected to the same actuator. Therefore, each head sits above the same track on its respective platter, and all the heads move across the disk surfaces as a unit. The set of all tracks over which the read/write heads are currently sitting is known as a cylinder (see Figure 12-10).
Although using multiple heads and platters increases the cost of a hard disk drive, it also increases the performance. The performance boost occurs when data that the system needs is not located on the current track. In a hard disk subsystem with only one platter, the read/write head would need to move to another track to locate the data. But in a disk subsystem with multiple platters, the next block of data to read is usually located within the same cylinder. And because the hard disk controller can quickly switch between read/write heads electronically, doubling the number of platters in a disk subsystem nearly doubles the track seek performance of the disk unit because it winds up doing half the number of seek operations. Of course, increasing the number of platters also increases the capacity of the unit, which is another reason why high-capacity drives are often higher-performance drives as well.
With older disk drives, when the system wants to read a particular sector from a particular track on one of the platters, it commands the disk to position the read/write heads over the appropriate track, and the disk drive then waits for the desired sector to rotate underneath. But by the time the head settles down, there’s a chance that the desired sector has just passed under the head, meaning the disk will have to wait for almost one complete rotation before it can read the data. On the average, the desired sector appears halfway across the disk. If the disk is rotating at 7,200 RPM (120 revolutions per second), it requires 8.333 milliseconds for one complete rotation of the platter, and, if on average the desired sector is halfway across the disk, 4.2 milliseconds will pass before the sector rotates underneath the head. This delay is known as the average rotational latency of the drive, and it is usually equivalent to the time needed for one rotation, divided by two.
To see how this can be a problem, consider that an OS usually manipulates disk data in sector-sized chunks. For example, when reading data from a disk file, the OS will typically request that the disk subsystem read a sector of data and return that data. Once the OS receives the data, it processes the data and then very likely makes a request for additional data from the disk. But what happens when this second request is for data that is located on the next sector of the current track? Unfortunately, while the OS is processing the first sector’s data, the disk platters are still moving underneath the read/write heads. If the OS wants to read the next sector on the disk’s surface and it doesn’t notify the drive immediately after reading the first sector, the second sector will rotate underneath the read/write head. When this happens, the OS will have to wait for almost a complete disk rotation before it can read the desired sector. This is known as blowing revs (revolutions). If the OS (or application) is constantly blowing revs when reading data from a file, file system performance suffers dramatically. In early “single-tasking” OSes running on slower machines, blowing revs was an unpleasant fact. If a track had 64 sectors, it would often take 64 revolutions of the disk in order to read all the data on a single track.
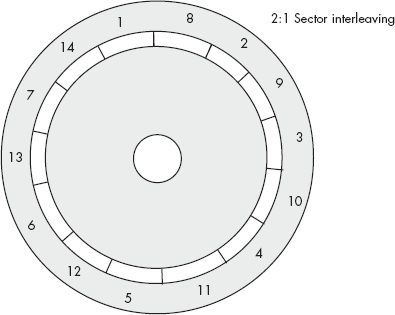
To combat this problem, the disk-formatting routines for older drives allow the user to interleave sectors. Interleaving sectors is the process of spreading out sectors within a track so that logically adjacent sectors are not physically adjacent on the disk surface (see Figure 12-11).
The advantage of interleaving sectors is that once the OS reads a sector, it will take a full sector’s rotation time before the logically adjacent sector moves under the read/write head. This gives the OS time to do some processing and to issue a new disk I/O request before the desired sector moves underneath the head. However, in modern multitasking OSes, it’s difficult to guarantee that an application will gain control of the CPU so that it can respond before the next logical sector moves under the head. Therefore, interleaving isn’t very effective in such multitasking OSes.
To solve this problem, as well as improve disk performance in general, most modern disk drives include memory on the disk controller that allows the controller to read data from an entire track. By avoiding interleaving the controller can read an entire track into memory in one disk revolution, and once the track data is cached in the controller’s memory, the controller can communicate disk read/write operations at RAM speed rather than at disk rotation speeds, which can dramatically improve performance. Reading the first sector from a track still exhibits rotational latency problems, but once the disk controller reads the entire track, the latency is all but eliminated for that track.
A typical track may have 64 sectors of 512 bytes each, for a total of 32 KB per track. Because newer disks usually have between 512 KB and 8 MB of on-controller memory, the controller can buffer as many as 100 or so tracks in its memory. Therefore, the disk-controller cache not only improves the performance of disk read/write operations on a single track, it also improves overall disk performance. And the disk-controller cache not only speeds up read operations, but write operations as well. For example, the CPU can often write data to the disk controller’s cache memory within a few micro-seconds and then return to normal data processing while the disk controller moves the disk read/write heads into position. When the disk heads are finally in position at the appropriate track, the controller can write the data from the cache to the disk surface.
From an application designer’s perspective, advances in disk subsystem design have attempted to reduce the need to understand how disk drive geometries (track and sector layouts) and disk-controller hardware affect the application’s performance. Despite these attempts to make the hardware transparent to the application, though, software engineers wanting to write great code must always remain cognizant of the underlying operation of the disk drive. For example, sequential file operations are usually much faster than random-access operations because sequential operations require fewer head seeks. Also, if you know that a disk controller has an on-board cache, you can write file data in smaller blocks, doing other processing between the block operations, to give the hardware time to write the data to the disk surface. Though the techniques early programmers used to maximize disk performance don’t apply to modern hardware, by understanding how disks operate and how they store their data, you can avoid various pitfalls that produce slow code.
Because a modern disk drive typically has between 8 and 16 heads, you might wonder if it is possible to improve performance by simultaneously reading or writing data on multiple heads. While this is certainly possible, few disk drives utilize this technique. The reason is cost. The read/write electronics are among the most expensive, bulky, and sensitive circuitry on the disk drive controller. Requiring up to 16 sets of the read/write electronics would be prohibitively expensive and would require a much larger disk-controller circuit board. Also, you would need to run up to 16 sets of cables between the read/write heads and the electronics. Because cables are bulky and add mass to the disk head assembly, adding so many cables would affect track seek time. However, the basic concept of improving performance by operating in parallel is sound. Fortunately, there is another way to improve disk drive performance using parallel read and write operations: the redundant array of inexpensive disks (RAID) configuration.
The RAID concept is quite simple: you connect multiple hard disk drives to a special host controller card, and that adapter card simultaneously reads and writes the various disk drives. By hooking up two disk drives to a RAID controller card, you can read and write data about twice as fast as you could with a single disk drive. By hooking up four disk drives, you can almost improve average performance by a factor of four.
RAID controllers support different configurations depending on the purpose of the disk subsystem. So-called Level 0 RAID subsystems use multiple disk drives simply to increase the data transfer rate. If you connect two 150-GB disk drives to a RAID controller, you’ll produce the equivalent of a 300-GB disk subsystem with double the data transfer rate. This is a typical configuration for personal RAID systems — those systems that are not installed on a file server.
Many high-end file server systems use Level 1 RAID subsystems (and other higher-numbered RAID configurations) to store multiple copies of the data across the multiple disk drives, rather than to increase the data transfer rate between the system and the disk drive. In such a system, should one disk fail, a copy of the data is still available on another disk drive. Some even higher-level RAID subsystems combine four or more disk drives to increase the data transfer rate and provide redundant data storage. This type of configuration usually appears on high-end, high-availability file server systems.
RAID systems provide a way to dramatically increase disk subsystem performance without having to purchase exotic and expensive mass storage solutions. Though a software engineer cannot assume that every computer system in the world has a fast RAID subsystem available, certain applications that could not otherwise be written can be created using RAID. When writing great code, you shouldn’t specify a fast disk subsystem like RAID from the beginning, but it’s nice to know you can always fall back to its specification if you’ve optimized your code as much as possible and you still cannot get the data transfer rates your application requires.
One special form of floppy disk is the floptical disk. By using a laser to etch marks on the floppy disk’s magnetic surface, floptical manufacturers are able to produce disks with 100 to 1,000 times the storage of normal floppy disk drives. Storage capacities of 100 MB, 250 MB, 750 MB, and more, are possible with the floptical devices. The Zip drive from Iomega is a good example of this type of media. These floptical devices interface with the PC using the same connections as regular hard drives (IDE, SCSI, and USB), so they look just like a hard drive to software. Other than their reduced speed and storage capacity, software can interact with these devices as it does with hard drives.
An optical drive is one that uses a laser beam and a special photosensitive medium to record and play back digital data. Optical drives have a couple of advantages over hard disk subsystems that use magnetic media:
They are more shock resistant, so banging the disk drive around during operation won’t destroy the drive unit as easily as a hard disk.
The media is usually removable, allowing you to maintain an almost unlimited amount of offline or near-line storage.
The capacity of an individual optical disk is fairly high compared to other removable storage solutions, such as floptical drives or cartridge hard disks.
At one time, optical storage systems appeared to be the wave of the future because they offered very high storage capacity in a small space. Unfortunately, they have fallen out of favor in all but a few niche markets because they also have several drawbacks:
While their read performance is okay, their write speed is very slow: an order of magnitude slower than a hard drive and only a few times faster than a floptical drive.
Although the optical medium is far more robust than the magnetic medium, the magnetic medium in a hard drive is usually sealed away from dirt, humidity, and abrasion. In contrast, optical media is easily accessible to someone who really wants to do damage to the disk’s surface.
Seek times for optical disk subsystems are much slower than for magnetic disks.
Optical disks have limited storage capacity, currently less than a couple gigabytes.
One area where optical disk subsystems still find use is in near-line storage subsystems. An optical near-line storage subsystem typically uses a robotic jukebox to manage hundreds or thousands of optical disks. Although one could argue that a rack of high-capacity hard disk drives would provide a more space efficient storage solution, such a hard disk solution would consume far more power, generate far more heat, and require a more sophisticated interface. An optical jukebox, on the other hand, usually has only a single optical drive unit and a robotic disk selection mechanism. For archival storage, where the server system rarely needs access to any particular piece of data in the storage subsystem, a jukebox system is a very cost-effective solution.
If you wind up writing software that manipulates files on an optical drive subsystem, the most important thing to remember is that read access is much faster than write access. You should try to use the optical system as a “read-mostly” device and avoid writing data as much as possible to the device. You should also avoid random access on an optical disk’s surface, as the seek times are very slow.
CD and DVD drives are also optical drives. However, their widespread use and their sufficiently different organization and performance when compared with standard optical drives means that they warrant a separate discussion.
CD-ROM was the first optical drive subsystem to achieve wide acceptance in the personal computer market. CD-ROM disks were based on the audio CD digital recording standard, and they provided a large amount of storage (650 MB) when compared to hard disk drive storage capacities at the time (typically 100 MB). As time passed, of course, this relationship reversed. Still, CD-ROMs became the preferred distribution vehicle for most commercial applications, completely replacing the floppy disk medium for this purpose. Although a few of the newer applications contain so much data that it is inconvenient to ship them on one or two CD-ROM disks, the vast majority of applications can be delivered just fine on CD-ROM, so this will probably remain the preferred software distribution medium for most applications.
Although the CD-ROM format is a very inexpensive distribution medium in large quantities, often only costing a few cents per disk, it is not an appropriate distribution medium for small production runs. The problem is that it typically costs several hundreds or thousands of dollars to produce a disk master (from which the run of CD-ROMs are made), meaning that CD-ROM is usually only a cost-effective distribution medium when the quantity of disks being produced is at least in the thousands.
The solution was to invent a new CD medium, CD-Recordable (CD-R), which allowed the production of one-off CD-ROMs. CD-R uses a write-once optical disk technology, known euphemistically as WORM (write-once, read-many). When first introduced, CD-R disks cost about $10–$15. However, once the drives reached critical mass and media manufacturers began pro-ducing blank CD-R disks in huge quantities, the bulk retail price of CD-Rs fell to about $0.25. As a result, CD-R made it possible to distribute a fair amount of data in small quantities.
One obvious drawback to CD-R is the “write-once” limitation. To overcome this limitation, the CD-Rewriteable (CD-RW) drive and medium were created. CD-RW, as its name suggests, supports both reading and writing. Unlike optical disks, however, you cannot simply rewrite a single sector on CD-RW. Instead, to rewrite the data on a CD-RW disk you must first erase the whole disk.
Although the 650 MB of storage on a CD seemed like a gargantuan amount when CDs were first introduced, the old maxim that data and programs expand to fill up all available space certainly held true. Though CDs were ultimately expanded from 650 MB to 700 MB, various games (with embedded video), large databases, developer documentation, programmer development systems, clip art, stock photographs, and even regular applications reached the point where a single CD was woefully inadequate. The DVD-ROM (and later, DVD-R, DVD-RW, DVD+RW, and DVD-RAM) disk reduced this problem by offering between 3 GB and 17 GB of storage on a single disk. Except for the DVD-RAM format, one can view the DVD formats as faster, higher-capacity versions of the CD formats. There are some clear technical differences between the two formats, but most of them are transparent to the software.
The CD and DVD formats were created for reading data in a continuous stream from the storage medium, called streaming data. The track-to-track head movement time required when reading data stored on a hard disk, creates a big gap in the streaming sequence that is unacceptable for audio and video applications. Therefore, CDs and DVDs record information on a single, very long track that forms a spiral across the surface of the whole disk. This allows the CD or DVD player to continuously read a stream of data by simply moving the laser beam along the disk’s single spiral track at a continuous rate.
Although having a single track is great for streaming data, it does make it a bit more difficult to locate a specific sector on the disk. The CD or DVD drive can only approximate a sector’s position by mechanically repositioning the laser beam to some point on the disk. Once the drive approximates the position, it must actually read data from the disk surface to determine where the laser is positioned, and then do some fine-tuning adjustments of the laser position in order to find the desired sector. As a result, searching for a specific sector on a CD or DVD disk can take an order of magnitude longer than searching for a specific sector on a hard disk.
From the programmer’s perspective, the most important thing to remember when writing code that interacts with CD or DVD media is that random-access is verboten. These media were designed for sequential streaming access, and seeking for data on such media will have a negative impact on application performance. If you are using these disks to deliver your application and its data to the end user, you should have the user copy the data to a hard disk before use if high-performance random access is necessary.
Tape drives are also popular mass storage devices. Traditionally, personal computer owners have used tape drives to back up data stored on hard disk drives. For many years, tape storage was far more cost-effective than hard disk storage on a cost-per-megabyte basis. Indeed, at one time there was an order of magnitude difference in cost per megabyte between tape storage and magnetic disk storage. And because tape drives held more data than most hard disk drives, they were more space-efficient too.
However, because of competition and technological advances in the hard disk drive marketplace, tapes have lost these advantages. Hard disk drives are now exceeding 250 GB in storage, and the optimum price point for hard disks is about $0.50 per gigabyte. Tape storage today costs far more per megabyte than hard disk storage. Plus, only a few tape technologies allow one to store 250 GB on a single tape, and those that do (such as Digital Linear Tape, or DLT) are extremely expensive. It’s not surprising that tape drives are seeing less and less use these days in home PCs and are typically found only in larger file server machines.
Back in the days of mainframes, application programs interacted with tape drives in much the same way that today’s applications interact with hard disk drives. A tape drive, however, is not an efficient random access device. That is, although software can read a random set of blocks from a tape, it cannot do so with acceptable performance. Of course, in the days when most applications ran on mainframes, applications generally were not interactive, and the CPUs were much slower. As such, the standard for “acceptable performance” was different.
In a tape drive, the read/write head is fixed, and the tape transport mechanism moves the tape past the read/write head linearly, from the beginning of the tape to the end of the tape, or vice versa. If the beginning of the tape is currently positioned over the read/write head and you want to read data at the end of the tape, you have to move the entire tape past the read/write head to get to the desired data. This can be very slow, requiring tens or even hundreds of seconds, depending on the length and format of the tape. Compare this with the tens of milliseconds it takes to reposition a hard disk’s read/write head. Therefore, to perform well on a tape drive, software has to be written with special awareness of the limitations of a sequential access device. In particular, data should be read or written sequentially on a tape to produce the highest performance.
Originally, data was written to tapes in blocks (much like sectors on a hard disk), and the drives were designed to allow quasi-random access to the tape’s blocks. If you’ve ever seen an old science fiction movie with the old-style reel-to-reel drives, with the reels constantly stopping, starting, stopping, reversing, stopping, and continuing, you were seeing “random access” in action. Such tape drives were very expensive because they required powerful motors, finely tooled tape-path mechanisms, and so on. As hard drives became larger and less expensive, applications stopped using tape as a data manipulation medium and used tape only for offline storage. Using a tape drive was simply too slow for normal application work. As a result, most systems started using tape drives only in sequential mode for backing up data from hard disks.
Because sequential data access on tape does not require the heavy-duty mechanics of the original tape drives, the tape drive manufactures sought to make a lower-cost product suitable for sequential access only. Their solution was the streaming tape drive, which was designed to keep the data constantly moving from the CPU to the tape, or vice versa. For example, while backing up the data from a hard disk to tape, a streaming tape drive treats the data like a video or audio recording and just lets the tape run, constantly writing the data from the hard disk to the tape. Because of the way streaming tape drives work, very few applications deal directly with the tape unit. Today, it’s very rare for anything other than a tape backup utility program, run by the system administrator, to access the tape hardware.
An interesting storage medium that has recently become popular because of its compact form factor [48] is flash storage media. The flash medium is actually a semiconductor device, based on the electrically erasable programmable read-only memory (EEPROM) technology, which, despite its name, is both readable and writable. Unlike regular semiconductor memory, flash storage is non-volatile, meaning that it maintains its data even in the absence of power. Like other semiconductor technologies, flash storage is purely electronic and doesn’t require any motors or other electro-mechanical devices for proper operation. Therefore, flash storage devices are more reliable and shock resistant, and they use far less power than mechanical storage solutions such as disk drives. This makes flash storage solutions especially valuable in portable battery-powered devices like PDAs, electronic cameras, MP3 playback devices, and portable recorders.
Flash storage modules now provide between 2 MB and several gigabytes of storage, and their optimal price point is at about $0.25 per megabyte. This makes them far more expensive per bit than hard disk storage, which means that their use as a storage medium is diminished.
Flash devices are sold in many different form factors. OEMs (original equipment manufacturers) can buy flash storage devices that look like other semiconductor chips and then mount these devices directly on their circuit boards. However, most flash memory devices sold today are built into one of several standard forms including PC Cards, CompactFlash cards, smart memory modules, memory sticks, or USB/flash modules. For example, a digital camera user might remove a CompactFlash card from their camera, insert it into a special CompactFlash card reader on their PC, and access their photographs just as they would files on a disk drive.
Memory in a flash storage module is organized in blocks of bytes, not unlike sectors on a hard disk. Unlike regular semiconductor memory, or RAM, you cannot write individual bytes in a flash storage module. Although you can generally read an individual byte from a flash storage device, to write to a particular byte you must first erase the entire block on which it resides. The block size varies by device, but most OSes will treat these flash blocks like a disk sector for the purposes of reading and writing. Although the basic flash storage device itself could connect directly to the CPU’s memory bus, most common flash storage packages (such as Compact Flash cards and Memory Sticks) contain electronics that simulate a hard disk interface, and you access the flash device just as you would a hard disk drive.
One interesting aspect to flash memory devices, and EEPROM devices in general, is that they have a limited write lifetime. That is, you may only write to a particular memory cell in a flash memory module a certain number of times before that cell begins to have problems retaining the information. In early EEPROM/flash devices, this was a big concern because the average number of write cycles before failures would begin occurring was around 10,000. That is, if some software wrote to the same memory block 10,000 times in a row, the EEPROM/flash device would probably develop a bad memory cell in that block, effectively rendering the entire chip useless. On the other hand, if the software wrote just once to 10,000 separate blocks, the device could still take 9,999 additional writes to each memory cell. Therefore, the OSes of these early devices would try to spread out write operations across the entire device to minimize damage. Although modern flash devices still exhibit this problem, technological advances have reduced it almost to the point where we can ignore it. A modern flash memory cell supports an average of about a million write cycles before it will go bad. Furthermore, today’s OSes simply mark bad flash blocks, the same way they mark bad sectors on a disk, and will skip a block once they determine that it has gone bad.
Being electronic, flash devices do not exhibit rotational latency times at all, and they don’t exhibit much in the way of seek times. There is a tiny amount of time needed to write an address to a flash memory module, but it is nothing compared to the head seek times on a hard disk. Despite this, flash memory is generally nowhere near as fast as typical RAM. Reading data from a flash device itself usually takes microseconds (rather than nanoseconds), and the interface between the flash memory device and the system may require additional time to set up a data transfer. Worse still, it is common to interface a flash storage module to a PC using a USB flash reader device, and this often reduces the average read time per byte to hundreds of micro-seconds.
Write performance is even worse. To write a block of data to flash, you must write the data, read it back, compare it to the original data, and rewrite it if they don’t match. Writing a block of data to flash can take several tens or even hundreds of milliseconds.
As a result, flash memory modules are generally quite a bit slower than high-performance hard disk subsystems. Technological advances are improving their performance, a process that is mainly being driven by high-end digital camera users who want to be able to snap as many pictures as possible in a short time. Though flash memory performance will probably not catch up with hard disk performance any time soon, it should steadily improve as time passes.
Another pair of interesting mass storage devices you’ll find are the RAM and semiconductor disks. A RAM disk is just an application that treats a large block of the computer system’s memory as though it were a disk drive, simulating blocks and sectors using memory arrays. A semiconductor disk is a device consisting of RAM memory and a controller that interfaces with the system using a traditional disk interface. Semiconductor disks usually have their own power supply (including a battery backup system) so that they maintain memory integrity when you turn off the PC. The use of a standard disk interface and a separate, uninterruptible, power supply are what differentiate true semiconductor disks from software-based RAM disks.
The advantage of memory-based disks is that they are very high performance. RAM disks and semiconductor disks do not exhibit the time delays associated with head seek time and rotational latency that you find on hard, optical, and floppy drives. Their interface to the CPU is also much faster, so data transfer times are very high, often running at the maximum bus speed. It is hard to imagine a faster storage technology than a RAM or semiconductor disk.
RAM and semiconductor disks, however, have two disadvantages: cost and volatility. The cost per byte of storage in a semiconductor disk system is very high. Indeed, byte-for-byte, semiconductor storage is as much as 1,000 times more expensive than magnetic hard disk storage. Because of the high cost of semiconductor storage, semiconductor disks usually have low storage capacities, typically no more than a couple of gigabytes. And, semiconductor disks are volatile — they lose their memory unless they are powered at all times. A battery-backed, uninterruptible power supply can help prevent memory loss during power failures, but you cannot disconnect a semiconductor disk from the power line for an extended period of time and expect the data to persist. This generally means that semiconductor disks are great for storing temporary files and files you’ll copy back to some permanent storage device before shutting down the system. Because of their low-latency, high data transfer rates, and relatively low storage capacity, semiconductor disks are excellent for use as swap storage for a virtual memory subsystem. They are not particularly well suited for maintaining important information over long periods of time.
The popularity of semiconductor disks tends to rise and fall with mother-board and CPU designs. Semiconductor disks tend to be more popular when it is physically impossible to extend the amount of memory in a given computer system. Semiconductor disks tend to be less popular when a computer system allows memory expansion. The reason for this is simple: It is far less expensive to increase the RAM in a typical computer system and use a soft-ware-based RAM disk than it is to add a semiconductor disk to the system. A software-based RAM disk is usually faster than a semiconductor disk because the system can access the RAM disk at memory bus speeds rather than at disk controller speeds. In fact, there are only two disadvantages to RAM disks: their memory is volatile, and every byte you allocate to a RAM disk is one less byte available for your applications. In a few systems, these two disadvantages prevent the use of RAM disks. For most uses, however, if there is a little extra unused RAM in the system, and the user is careful to copy important data from the RAM disk to nonvolatile storage before shutting off the system, a software-based RAM disk can be a very cost-effective solution.
The problems with software-based RAM disk solutions begin when you have added all the RAM your system can support, and your applications require most of the memory in the system. Back when CPUs had a 16-bit address space, users quickly reached the point where they had installed as much as 64 KB of memory on their machines (216 bytes is 64 KB). When the 8088/8086 rolled around with a 20-bit address bus, it wasn’t long before users had installed the maximum amount of memory in those machines too. Ditto for CPUs with a 24-bit address bus, allowing a maximum of 16 MB of memory. Once CPUs started supporting 32-bit address buses, it seemed like the amount of memory one could install in the system had hit infinity, but today we’re once again bumping up against that limit. It’s not uncommon now to find machines with the maximum amount of memory already installed, particularly since motherboards often limit the amount of RAM that can be installed on a system even though the system CPU can address a much larger amount of RAM.
Semiconductor disks become practical when you’ve installed the maximum amount of RAM in your system and the applications or OS are making use of that memory, so that there isn’t a large block of memory lying around that you can use for a RAM disk. Because the semiconductor disk’s memory exists outside the CPU’s address space, it does not impact the memory limits that apply to motherboard designs.
The Small Computer System Interface (SCSI, pronounced “scuzzy”) is a peripheral interconnection bus used to connect high-speed peripheral devices to personal computer systems. Designed in the early 1980s, the SCSI bus was popularized by its introduction on the Apple Macintosh computer system in the middle 1980s. The original SCSI interface supported an 8-bit bidirectional data bus and was capable of transferring 5 MB of data per second, which was considered “high-performance” for hard disk subsystems of that era. Although the performance of that early SCSI interface is quite slow by modern standards, SCSI has gone through several revisions over the years and remains a high-performance peripheral interconnection system. Today’s SCSI devices are capable of transferring 320 MB per second.
Although the SCSI interconnection system is most commonly used for disk drive subsystems, SCSI was designed to support a whole host of PC peripherals using a cable connection. Indeed, as SCSI became popular during the late 1980s and into the 1990s, you could find printers, scanners, imaging machines, phototypesetters, network, and display adapters, and many other devices interfacing with the SCSI bus. However, the popularity of the SCSI bus as a general-purpose peripheral bus has diminished since the appearance of the USB and FireWire peripheral connection systems. Except for very high performance disk drive subsystems and some very specialized peripheral devices, few new peripherals use the SCSI interface.
To understand why SCSI’s popularity is waning, one must consider the problems SCSI users have faced over the years. When SCSI was first introduced, the SCSI bus supported concurrent connection of the SCSI adapter card and up to seven actual peripheral devices. To connect multiple devices, one first ran a cable from the host controller card to the first peripheral device. To connect a second device, one ran a cable from a second connector on the first device to the second device. To connect a third device, one ran a cable from a separate connector on the second device to the third device, and so on. At the end of this “daisy chain” of devices, one attached a special terminating device to the last connector of the last peripheral device. Without the special “terminator” at the end of the SCSI chain, many SCSI systems would work unreliably, if at all.
As a “convenience” to their customers, many peripheral manufacturers built the terminating circuitry into their devices. Unfortunately, connecting multiple terminators in the middle of the SCSI chain was just as bad as not having a terminator in the SCSI system. Though most manufacturers who designed the terminating circuitry into their peripherals often provided an option to disable the terminator, some did not. Ensuring that those devices with the active terminator circuitry were at the end of the SCSI chain was often cumbersome, and even if a device provided an option to enable or disable the terminator, knowing the appropriate “dip-switch” settings was a problem if the documentation wasn’t handy. As a result, many computer owners had problems with a chain of SCSI devices not working properly in their system.
On the original SCSI bus, the computer system owner had to assign each device one of eight numeric “addresses” from zero to seven, with address seven generally reserved for the host controller card. If two devices in the SCSI chain had the same address, they wouldn’t operate properly. This made moving SCSI peripherals from one computer system to another somewhat difficult, because the address of the device being moved was usually already taken by another device on the new system.
The original SCSI bus had other limitations as well. First, it only supported seven peripheral devices. When SCSI was first designed, this wasn’t usually a problem because common SCSI peripherals like hard drives and scanners were very expensive, costing thousands of dollars each. Connecting more than seven devices wasn’t something your average computer owner would have done back then. But, as the price of hard drives and other SCSI peripherals came down, the seven-peripheral limit became burdensome. Second, SCSI was not, and still is not, hot swappable. That is, you cannot unplug a peripheral device while power is applied to the system, nor may you connect a new peripheral to the SCSI bus while the power is on. Doing so could cause electrical damage to the SCSI controller, the peripheral, or even some other peripheral on the SCSI bus. As SCSI peripherals came down in price and people began connecting multiple devices to their computer systems, the desire to unplug a device from one system and plug it into another grew, but SCSI did not support this mode of operation.
Despite all these bad features, SCSI’s popularity grew. To maintain that popularity, SCSI was modified over time to improve its functionality. SCSI-2, the first modification, doubled the speed from 5 MHz to 10 MHz, thus doubling the data transfer rate on the bus. This was necessary because the speed of high-performance devices like disk drives increased so much that the original SCSI interface was actually slowing them down. The next improvement was to increase the size of the bidirectional SCSI data bus from 8 bits to 16 bits. This not only doubled the data transfer rate from 10 MB per second to 20 MB per second, it also increased the number of peripherals one could place on the bus from 7 to 15. Variations of SCSI-2 were known as Fast SCSI (10 MHz), Wide SCSI (16 bits), and Fast and Wide SCSI (16 bits at 10 MHz).
It should come as no surprise that SCSI-3 followed SCSI-2. SCSI-3 offers a veritable smorgasbord of different connection options while maintaining compatibility with the older standards. Although SCSI-3 (using names like Ultra, Ultra Wide, Ultra2, Wide Ultra2, Ultra3, and Ultra320) still operates as a 16-bit bus in the parallel cable mode, and it still supports a maximum of 15 peripherals, it is vastly improved. SCSI-3 increased the operating speed of the bus and the maximum permissible physical distance across which SCSI peripherals could be chained. To make a long story short, SCSI-3 operates at speeds of up to 160 MHz, allowing the SCSI bus to transfer data in bursts up to 320 MB per second (that is, faster than many PCI bus interconnects!).
SCSI was originally a parallel interface. Today, SCSI supports three different interconnection standards: SCSI Parallel Interface (SPI), Serial SCSI across FireWire, and Fibre Channel Arbitrated Loop. The SPI is the original definition that most people associate with the SCSI interface. SCSI parallel cables contain either 8 or 16 data lines, depending on the type of SCSI interface in use. This makes SCSI cables bulky, heavy, and expensive. The parallel SCSI interface also limits the maximum length of the SCSI chain in the system to just a few meters. These concerns, especially the economic ones, are why modern computer systems only use SCSI peripherals when extremely high performance is necessary.
An important fact to note about SCSI is that it is not a master/slave interconnection system. That is, the computer system does not own the bus and doesn’t necessarily direct the traffic between various peripherals on the bus. SCSI is a true peer-to-peer bus, and any two peripherals on the bus may communicate with one another. Indeed, it’s possible (though unusual) for two computer systems to share the same SCSI bus. This peer-to-peer operation can improve the performance of the overall system tremendously. To illustrate this point, consider a tape backup system. In practice, most tape backup programs read a block of data from a disk drive into the computer’s memory and then write that block of data from the computer’s memory to the tape drive. On the SCSI bus (in theory, at least), it is possible to have the tape and disk drives communicate directly with one another. The tape backup software would send two commands, one to the disk drive and one to the tape drive, telling the disk drive to transfer the block of data directly to the tape drive rather than going through the computer system. Not only does this reduce the number of transfers across the SCSI bus by half, speeding up the transfer, but it also frees up the computer’s CPU to do other things. In reality, few tape backup systems work this way, but there are many examples where two peripherals communicate with one another across the SCSI bus without using the computer as an intermediary. Software that programs SCSI peripherals to operate this way (rather than running the data through the computer’s memory) is a good example of great programming.
SCSI is interesting insofar as it is not only an electrical interconnection, but a protocol as well. One does not communicate with a SCSI peripheral device by writing some data to a couple of registers on the SCSI interface card, causing that data to travel down the SCSI cable to the peripheral device. Although SCSI is a parallel interface like the parallel printer port, it doesn’t communicate with SCSI peripheral devices like the parallel port communicates with printer devices. To use SCSI, you build up a data structure in memory containing a SCSI command, command parameters, any data you may want to send to the SCSI peripheral, and possibly a pointer with the memory address where the SCSI controller should store any data the peripheral device returns. Once you construct this data structure, you normally provide the SCSI controller with the data structure’s address, and the SCSI controller then fetches the command from system memory and sends it to the appropriate peripheral device on the SCSI bus.
As SCSI hardware has evolved over the years, so has the SCSI protocol, the SCSI command set. SCSI was never intended to serve as just a hard disk interface, and the breadth of peripherals that SCSI supports has steadily increased over the years along with the advent of new types of computer peripherals. To accommodate these new and unanticipated uses for the SCSI bus, SCSI’s designers created a device-independent command protocol that could be easily extended as new devices were invented. Contrast this with certain device interfaces such as the original Integrated Disk Electronics (IDE) interface, which was suitable only for disk drives.
The SCSI protocol transmits a packet containing the peripheral’s address, the command, and the command’s data. The SCSI-3 standard has roughly grouped these commands into the following classes:
Controller commands for RAID arrays (SCC)
Enclosure services commands (SES)
Graphics commands for printers (SGC)
Hard disk interface commands (the SCSI block commands, or SBC)
Management server commands (MSC)
Multimedia commands for devices such as DVD drives (MMC)
Object-based storage commands (OSD)
Primary commands (SPC)
Reduced block commands for simplified hard drive subsystems (RBC)
Stream commands for tape drives (SSC)
What do these commands look like? Unlike traditional interfaces such as serial and parallel, one does not necessarily write SCSI “commands” to registers on the SCSI controller chip. Indeed, SCSI commands are generally intended for devices on the SCSI bus, not for the SCSI host controller (which is often called the SCSI host adapter). The job of the host controller, from the programmer’s perspective, is to place SCSI commands onto the SCSI bus for use by other peripherals and to fetch commands and data from the SCSI bus intended for the host system. Although the SCSI commands themselves are standardized, the actual interface to the SCSI host controller is not. Different host controller manufacturers use different hardware to connect their SCSI controller chips to the host computer system, so how you talk to a SCSI controller chip is different, depending on the particular host controller device. Because SCSI controllers are very complex and difficult to program, and because there is no “standard” SCSI interface chip, programmers are faced with having to write several different variants of their software to control SCSI devices.
To correct this situation, SCSI host controller manufacturers like Adaptec have created specialized device driver modules that provide a uniform interface to their devices. Rather than writing data directly to a SCSI chip, a programmer creates an in-memory data structure with SCSI commands to be placed on the SCSI bus, calls the device driver software, and lets the device driver transfer the SCSI commands to the SCSI bus. There are several nice things about this approach:
It frees the programmer from having to learn the complexities of each particular host controller.
It allows different manufacturers to provide a compatible interface to their SCSI controller devices.
It allows manufacturers to create a single optimized driver that properly supports the capabilities of their device, rather than allowing individual programmers to write possibly mediocre code for the device.
It allows manufacturers to change the hardware of future versions of their device without destroying compatibility with existing software.
This concept was carried forward into modern OSes. Today, SCSI host controller manufacturers write SCSI miniport drivers for OSes like Windows. These miniport drivers provide a hardware-independent interface to the host controller so that the OS can simply say, “Here is a SCSI command. Put it on the SCSI bus.”
One big advantage of the SCSI interface is that it provides parallel processing of SCSI commands. That is, a host system can place several different SCSI commands on the bus, and different peripheral devices can process those commands simultaneously. Some devices, like disk drives, can even accept multiple commands at once and process those commands in the order that is most efficient. As an example, suppose that a disk drive is currently near block 1,000. If the system sends block read requests for blocks 5,000; 4,560; 3,000; and 8,000; the disk controller can rearrange these requests and satisfy them in the most efficient order (probably 3,000; 4,560; 5,000; and then 8,000) as it moves the read/write head across the surface of the disk. This results in a big performance improvement on multitasking OSes that process requests for disk I/O from several different applications simultaneously.
SCSI is also a great interface for RAID systems because SCSI is one of the few disk controller interfaces that supports a large number of drives on the same interface. Indeed, because no modern hard drive is capable of equaling SCSI data transfer rates, the only way to achieve SCSI’s 320-MB-per-second transfer rate is with a RAID subsystem. Very high performance drives are capable of sustaining only about 80-MB-per-second data transfer rates, and that’s only in burst mode. In an ideal world where the SCSI protocol did not consume any overhead, you would have to connect four such drives to a RAID/SCSI controller to achieve the theoretical maximum data transfer rate on the SCSI bus.[49] A very high performance RAID controller would sit between the SCSI bus and the actual hard drives. Lower-cost RAID systems can be created by connecting the disks directly to the SCSI bus and using special software to send disk I/O operations to different disks on the SCSI bus. Such systems don’t require special hardware, but they don’t achieve the maximum throughput that is possible on SCSI either; not that they run particularly slowly, mind you.
The SCSI command set is very powerful, and it is designed for high-performance applications. It is sufficiently large and complex that space limitations prevent its inclusion here. Readers interested in a deeper look at SCSI programming should refer to The Book of SCSI (by Gary Field, Peter M. Ridge, et al., published by No Starch Press). The complete SCSI specifications appear at various sites on the Web. A quick search for “SCSI specifications” on AltaVista, Google, or any other decent Web search engine should turn up several copies of the specifications.
Although the SCSI interface is very high performance, it is also expensive. A SCSI device requires a sophisticated and fast processor in order to handle all the operations that are possible on the SCSI bus. Furthermore, because SCSI devices can operate on a peer-to-peer basis (that is, one peripheral may talk to another without intervention from a host computer system), each SCSI device must carry around a considerable amount of sophisticated software in ROM on the device’s controller board. Adding all the extra functionality needed to support full SCSI when all you want to do is to attach a single hard disk to a personal computer system is a bit of overkill. During the middle to late 1980’s, several computer and disk manufacturers got together to discuss a less expensive, though standardized, interface that would let them connect inexpensive disk drives to personal computers. The result of this initiative was the IDE (Integrated Drive Electronics) interface.
The point behind SCSI was to off load as much work as was reasonably possible to the device controller, freeing up the host computer to do other activities. But all this extra complexity and cost to improve system performance was going to waste because in typical personal computer systems the host computer was usually waiting for the data transfer to complete. So the computer was sitting idle while the SCSI disk drive was busy processing the SCSI command. The idea behind the IDE interface was to lower the cost of the disk drive by using the host computer’s CPU to do the processing. Because the CPU was usually idle (during SCSI transfers) anyway, this seemed like a good use of resources. IDE drives, because they were often hundreds of dollars less than SCSI drives, became incredibly popular on personal computer systems.
The original IDE drive specification was very limited compared to the SCSI interface. First, it supported only two drives chained together (modern systems provide two IDE interfaces, a primary channel and a secondary channel, that support up to four devices). Second, the IDE specification was created only for disk drives; it was not a general-purpose peripheral interface bus like SCSI. And third, cable lengths for the IDE interface effectively limited IDE devices to residing in the same case as the CPU. Nevertheless, the much lower cost of the IDE interface and of IDE drives ensured its popularity.
Soon after the introduction of the IDE interface, peripheral manufacturers discovered that there were other devices that they’d like to connect to the IDE interface. Though the IDE interface was designed specifically for mass storage devices, and wouldn’t work well with non-storage devices like scanners and printers, there were many types of storage devices other than hard disks (such as CD-ROMs, tape drives, and Zip drives) for which the IDE interface represented a cheap alternative to SCSI. Furthermore, because most PCs were being shipped with IDE interfaces, manufacturers of non-hard-disk mass storage devices were drooling over the possibility of connecting to an interface found on all new personal computer systems. Because the original IDE specification was geared specifically to hard disk drives and was not particularly well suited for other types of storage devices, the committee that designed the IDE interface went back to work and developed the AT Attachment with Packet Interface (IDE/ATAPI), which is usually shortened to ATA (Advanced Technology Attachment). Like SCSI, the ATA standard has gone through several revisions and improvements over the years.
Originally, IDE was designed to work on a 33-MHz PCI bus and was theoretically capable of transferring 33 MB per second. Later revisions of the ATA standard (ATA-66, ATA-100, and ATA-133) were capable of transferring data at 66 MB, 100 MB, and 133 MB per second. One might think that with these speeds (which far outstrip the speed of the physical disk drives) the ATA interface would be comparable to SCSI in performance. However, there are two reasons why the ATA interface is still slower than SCSI. First, the host processor is still involved in many of the operations, and it may take several host computer operations across the IDE/ATA interface to accomplish what a SCSI device could do on its own. Second, SCSI supports RAID much better than the ATA interface does. For the average home user, though, the modern IDE/ATA interface provides very good performance. One easy way to compare ATA and SCSI is to note that the most recent ATA specification tends to have performance equal to the previous SCSI generation.
The ATAPI specification (in its sixth version as of December 2001) extends the IDE specification to support a wide range of mass storage devices, including tape drives, Zip drives, CD-ROMs, DVDs, removable cartridge drives, and more. In order to extend the IDE interface to support all these different storage devices, the designers of the ATAPI specification adopted a packet command format that is very similar to, and in some cases is identical to, the SCSI packet command format. One big difference between SCSI and ATA is the fact that the hardware interface for ATA is far more standardized. This allows, for example, a single BIOS routine to boot from an IDE device regardless of who manufactured the interface chip. Indeed, the major differences between various IDE/ATAPI interface chips are simply the particular ATAPI specification to which the chip adheres: ATAPI-2, ATAPI-3, ATAPI-4, ATAPI-5, or ATAPI-6. So, in theory at least, it’s possible for application programmers to communicate directly with the IDE/ATAPI interface and control the mass storage device directly.
In modern protected-mode OSes like Windows or Linux, however, an application programmer is never allowed to talk directly to the hardware. In theory, it would be possible to write a miniport driver for IDE to simulate the way the SCSI interface works. In practice, however, the OS vendor generally supplies a software library that provides an API (application programming interface) to the IDE/ATAPI devices. The application programmer can then make function calls to the API, passing appropriate parameters, and the underlying library routines take care of the remaining tasks associated with actually talking to the hardware.
Programming ATAPI devices in a modern system is quite similar to programming SCSI devices. You load up a memory-based data structure with a command code and a set of parameters, and then pass the memory structure to a driver library function that passes the data across the ATAPI interface to the target storage device. If such a low-level library is not available, and your OS allows it, you can program the ATAPI interface device to grab this data (generally using DMA on modern systems). The full ATAPI-6 specification is almost 500 pages long; obviously, we do not have sufficient space to cover the specification in any kind of detail. If you are interested in a more detailed look at the IDE/ATAPI specifications, search for “ATAPI specifications” with your favorite Internet search engine.
Modern machines use a serial ATA (SATA) controller. This is a high-performance serial version of the venerable IDE/ATAPI parallel interface. However, to the programmer, SATA looks exactly like ATAPI.
Very few applications access mass storage devices directly. That is, applications do not generally read and write tracks, sectors, or blocks on a mass storage device. Instead, most applications open, read, write, and otherwise manipulate files on the mass storage device. The OS’s file manager is responsible for abstracting away the physical configuration of the underlying storage device and providing a convenient storage facility for multiple independent files on a single device.
On the earliest computer systems, application software was responsible for tracking the physical position of data on a mass storage device because there was no file manager available to handle this function for them. Such applications were able to maximize their performance by carefully considering the layout of data on the disk. For example, software could manually interleave data across various sectors on a track to give the CPU time to process data between reading and writing those sectors on the track. Such software was often many times faster than comparable software using a generic file manager. Later, when file managers were commonly available, some application authors still managed their files on a storage device for performance reasons. This was especially true back in the days of floppy disks, when low-level software written to manipulate data at the track and sector level often ran ten times faster than the same application using a file manager system.
In theory, today’s software could benefit from this as well, but you rarely see such low-level disk access in modern software for several reasons. First, writing software that manipulates a mass storage device at such a low level locks you into using that one particular device. That is, if your software manipulates a disk with 48 sectors per track, 12 tracks per cylinder, and 768 cylinders per drive, that same software will not work optimally (if at all) on a drive with a different sector, track, and cylinder layout. Second, accessing the drive at a low level makes it difficult to share the device among different applications, something that can be especially costly on a multitasking system that may have multiple applications sharing the device at once. For example, if you’ve laid out your data on various sectors on a track to coordinate computation time with sector access, your work is lost when the OS interrupts your program and gives some other application its timeslice, thus consuming the time you were counting on to do any computations prior to the next data sector rotating under the read/write head. Third, some of the features of modern mass storage devices, such as on-board caching controllers and SCSI interfaces that present a storage device as a sequence of blocks rather than as something with a given track and sector geometry, eliminate any advantage such low-level software might have had at one time. Fourth, modern OSes typically contain file buffering and block caching algorithms that provide good file system performance, obviating the need to operate at such a low level. Finally, low-level disk access is very complex and writing such software is difficult.
The earliest file manager systems stored files sequentially on the disk’s surface. That is, if each sector/block on the disk held 512 bytes and a file was 32 KB long, that file would consume 64 consecutive sectors/blocks on the disk’s surface. In order to access that file at some future time, the file manager only needed to know the file’s starting block number and the number of blocks it occupied. Because the file system had to maintain these two pieces of information somewhere in nonvolatile storage, the obvious place was on the storage media itself, in a data structure known as the directory. A disk directory is an array of values starting at a specific location on the disk that the OS can reference when an application requests a specific file. The file manager can search through the directory for the file’s name and extract its starting block and length. With this information, the file system can provide the application with access to the file’s data.
One advantage of the sequential file system is that it is very fast. The OS can read or write a single file’s data very rapidly if the file is stored in sequential blocks on the disk’s surface. But a sequential file organization has some big problems, too. The biggest and most obvious drawback is that you cannot extend the size of a file once the file manager places another file at the next block on the disk. Disk fragmentation is another big problem. As applications create and delete many small and medium-sized files, the disk fills up with small sequences of unused sectors that, individually, are too small for most files. It was common on sequential file systems to find disks that had sufficient free space to hold some data, but that couldn’t use that free space because it was spread all over the disk’s surface in small pieces. To solve this problem, users had to run disk compaction programs to coalesce all the free sectors and move them to the end of the disk by physically rearranging files on the disk’s surface. Another solution was to copy files from one full disk to another empty disk, thereby collecting the many small, unused sectors together. Obviously, this was extra work that the user had to do, work that the OS should be doing.
The sequential-file storage scheme really falls apart when used with multitasking OSes. If two applications attempt to write file data to the disk concurrently, the file system must place the starting block of the second application’s file beyond the last block required by the first application’s file. As the OS has no way of determining how large the files can grow, each application has to tell the OS the maximum length of the file when the application first opens the file. Unfortunately, many applications cannot determine, beforehand, how much space they will need for their files. So the applications have to guess the file size when opening a file. If the estimated file size is too small, either the program will have to abort with a “file full” error, or the application will have to create a larger file, copy the old data from the “full” file to the new file, and then delete the old file. As you can imagine this is horribly inefficient, and definitely not great code.
To avoid such performance problems, many applications grossly over-estimate the amount of space they need for their files. As a result, they wind up wasting disk space when the files don’t actually use all the data allocated to them, a form of internal fragmentation. Furthermore, if applications truncate their files when closing them, the resulting free sections returned to the OS tend to fragment the disk into small, unusable blocks of free space, a problem known as external fragmentation. For these reasons, sequential storage on the disk was replaced by more sophisticated storage-management schemes in modern OSes.
Most modern file-allocation strategies allow files to be stored across arbitrary blocks on the disk. Because the file system can now place bytes of the file in any free block on the disk, the problems of external fragmentation and the limitation on file size are all but eliminated. As long as there is at least one free block on the disk, you can expand the size of any file. However, along with this flexibility comes some extra complexity. In a sequential file system, it was easy to locate free space on the disk — by noting the starting block numbers and sizes of the files in a directory, it was possible to easily locate a free block large enough to satisfy the current disk allocation request, if such a block was available. But with a file system that stores files across arbitrary blocks, scanning the directory and noting which blocks a file uses is far too expensive to compute, so the file system has to keep track of the free and used blocks. Most modern OSes use one of three data structures — a set, a table (array), or a list — to keep track of which sectors are free and which are not. Each of these schemes has its advantages and disadvantages, and you’ll find all three schemes in use in modern OSes.
The free-space bitmap scheme uses a set data structure to maintain a set of free blocks on the disk drive. If a block is a member of the free-block set, the file manager can remove that block from the set whenever it needs another block for a file. Because set membership is a Boolean relationship (you’re either in the set or you’re not), it takes exactly one bit to specify the set membership of each block.
Typically, a file manager will reserve a certain section of the disk to hold a bitmap that specifies which blocks on the disk are free. The bitmap will consume some integral number of blocks on the disk, with each block consumed being able to represent a specific number of other blocks on the disk, which can be calculated by multiplying the block size (in bytes) by 8 (bits per byte). For example, if the OS uses 4,096-byte blocks on the disk, a bit map consisting of a single block can track up to 32,768 other blocks on the disk. To handle larger disks, you need a larger bitmap. The disadvantage of the bitmap scheme is that as disks get large, so does the bitmap. For example, on a 120-gigabyte drive with 4,096-byte blocks, the bitmap will be almost four megabytes long. While this is a small percentage of the total disk capacity, accessing a single bit in a bitmap this large can be clumsy. To find a free block, the OS has to do a linear search through this four-megabyte bitmap. Even if you keep the bitmap in system memory (which is a bit expensive, considering that you have to do it for each drive), searching through the bitmap every time you need a free sector is an expensive proposition. As a result, you don’t see this scheme used much on larger disk drives.
One advantage (and also a disadvantage) of the bitmap scheme is that the file manager only uses it to keep track of the free space on the disk, but it does not use this data to track which sectors belong to a given file. As a result, if the free sector bitmap is damaged somehow, nothing is permanently lost. It’s easy to reconstruct the free-space bitmap by searching through all the directories on the disk and computing which sectors are in use by the files in those directories (with the remaining sectors, obviously, being the free ones). Although such a computation is somewhat time consuming, it’s nice to have this ability when disaster strikes.
Another way to track disk sector usage is with a table of sector pointers. In fact, this scheme is the most common one in use today because it is the scheme employed by MS-DOS and various versions of Microsoft Windows. An interesting facet of the file allocation table (FAT) scheme is that it combines both free-space management and file-sector allocation management into the same data structure, ultimately saving space when compared to the bitmap scheme, which uses separate data structures for free-space management and file-sector allocation. Furthermore, unlike the bitmap scheme, FAT doesn’t require an inefficient linear search to find the next available free sector.
The FAT is really nothing more than an array of self-relative pointers (or indexes, if you prefer) into itself, setting aside one pointer for each sector/block on the storage device. When a disk is first initialized, the first several blocks on the disk’s surface are reserved for objects like the root directory and the FAT itself, and then the remaining blocks on the disk are the free space. Somewhere in the root directory is a free-space pointer that specifies the next available free block on the disk. Assuming the free-space pointer initially contains the value 64, implying that the next free block is block 64, the FAT entries at indexes 64, 65, 65, and so on, would contain the following values, assuming there are n blocks on the disk, numbered from zero to n −1:
FAT Index | FAT Entry Value |
|---|---|
. . . | . . . |
64 | 65 |
65 | 66 |
66 | 67 |
67 | 68 |
. . . | . . . |
n−2 | n−1 |
n−1 | 0 |
The entry at block 64 tells you the next available free block on the disk, 65. Moving on to entry 65, you’ll find the value of the next available free block on the disk, 66. The last entry in the FAT contains a zero (block zero contains meta-information for the entire disk partition and is never available).
Whenever an application needs one or more blocks to hold some new data on the disk’s surface, the file manager grabs the free-space pointer value and then continues going through the FAT entries for however many blocks are required to store the new data. For example, if each block is 4,096 bytes long and the current application is attempting to write 8,000 bytes to a file, the file manager will need to remove two blocks from the free-block list. To do so, the file manager needs to go through the following steps:
Get the value of the free-space pointer.
Save the value of the free-space pointer so that the file manager will know the first free sector it can use.
Continue going through the FAT entries for the number of blocks required to store the application’s data.
Extract the FAT entry value of the last block where the application needs to store its data, and set the free-space pointer to this value.
Store a zero over the FAT entry value of the last block that the application uses, thus marking the end to the list of blocks that the application needs.
Return the original value of the free-space pointer (as it was prior to these steps) into the FAT as the pointer to the list of blocks in the FAT that are now allocated for the application.
After the block allocation scheme in our earlier example, the application has blocks 64 and 65 at its disposal, the free-space pointer contains 66, and the FAT looks like this:
FAT Index | FAT Entry Value |
|---|---|
. . . | . . . |
64 | 65 |
65 | 0 |
66 | 67 |
67 | 68 |
. . . | . . . |
n- 2 | n- 1 |
n- 1 | 0 |
Don’t get the impression that entries in the FAT always contain the index of the next entry in the table. As the file manager allocates and deallocates storage for files on the disk, these numbers tend to become scrambled. For example, if an application winds up returning block 64 to the free list but holds on to block 65, the free-space pointer would contain the value 64, and the FAT would wind up having the following values:
FAT Index | FAT Entry Value |
|---|---|
. . . | . . . |
64 | 66 |
65 | 0 |
66 | 67 |
67 | 68 |
. . . | . . . |
n- 2 | n- 1 |
n- 1 | 0 |
As noted earlier, one advantage of the FAT data structure is that it combines both the free-space management and the file block lists into a single data structure. This means that each file doesn’t have to carry around a list of the blocks its data occupies. Instead, a file’s directory entry needs to have only a single pointer value that specifies an index into the FAT where the first block of the file’s data can be found. The remaining blocks that the file’s data consumes can be found by simply stepping through the FAT. One important advantage that the FAT scheme has over the set (bitmap) scheme is that once the disk using a FAT file system is full, no blocks on the disk are used to maintain information about which blocks are free. Even when there are no free blocks available, the bitmap scheme still consumes space on the disk to track the free space. But the FAT scheme replaces the entries originally used to track free blocks with the file-block pointers. When the disk is full, none of the values that originally maintained the free-block list are consuming space on the disk because all of those values are now tracking blocks in files. In that case, the free-space pointer would contain zero (to denote an empty free space list) and all the entries in the FAT would contain chains of block indexes for file data.
However, the FAT scheme does have a couple of disadvantages. First, unlike the bitmap in a set scheme file system, the table in a FAT file system represents a single point of failure. If the FAT is somehow destroyed, it can be very difficult to repair the disk and recover files; losing some free space on a disk is a problem, but losing track of where one’s files are on the disk is a major problem. Furthermore, because the disk head tends to spend more time in the FAT area of a storage device than in any other single area on the disk, the FAT is the most likely part of a hard disk to be damaged by a head crash, or the most likely part of a floppy or optical drive to exhibit excessive wear. This has been a sufficiently big concern that some FAT file systems provide an option to maintain an extra copy of the file allocation table on the disk.
Another problem with the FAT is that it’s usually located at a fixed place on the disk, usually at some low block number. In order to determine which block or blocks to read for a particular file, the disk heads must move to the FAT, and if the FAT is at the beginning of the disk, the disk heads will constantly be seeking to and from the FAT across large distances. This massive head movement is slow, and, in fact, tends to wear out the mechanical parts of the disk drive sooner. In newer versions of Microsoft OSes, the FAT-32 scheme eliminates part of this problem by allowing the FAT to be located somewhere other than the beginning of the disk, though still at a fixed location. Application file I/O performance can be quite low with a FAT file system unless the OS caches the FAT in main memory, which can be dangerous if the system crashes, because you could lose track of all file data whose FAT entries have not been written to disk.
The FAT scheme is also inefficient when doing random access on a file. To read from offset m to offset n in a file, the file manager must divide n by the block size to obtain the block offset into the file containing the byte at offset n, divide m by the block size to obtain its block offset, and then sequentially search through the FAT chain between these two blocks to find the sector(s) containing the desired data. This linear search can be expensive if the file is a large database with many thousands of blocks between the current block position and the desired block position.
Yet another problem with the FAT file system, though this one is rather esoteric, is that it doesn’t support sparse files. That is, you cannot write to byte 0 and byte 1,000,000 of a file without also allocating every byte of data in between the two points on the disk surface. Some non-FAT file managers will only allocate the blocks where an application has written data. For example, if an application only writes data to bytes 0 and 1,000,000 of a file, the file manager would only allocate two blocks for the file. If the application attempts to read a block that has not been previously allocated (for example, if the application in the current example attempts to read the byte at byte offset 500,000 without first writing to that location), the file manager will simply return zeros for the read operation without actually using any space on the disk. The way a FAT is organized, it is not possible to create sparse files on the disk.
To overcome the limitations of the FAT file system, advanced OSes such as Windows NT/2000/XP and various flavors of Unix use a list-of-blocks scheme rather than a FAT. Indeed, the list scheme enjoys all the advantages of a FAT system (such as efficient, nonlinear free-block location, and efficient storage of the free-block list), and it solves many of FAT’s problems.
The list scheme begins by setting aside several blocks on the disk for the purpose of keeping (generally) 32-bit pointers to each of the free blocks on the disk. If each block on the disk holds 4,096 bytes, a block can hold 1,024 pointers. Dividing the number of blocks on the disk by 1,024 determines the number of blocks the free-block list will initially consume. As you’ll soon see, the system can actually use these blocks to store data once the disk fills up, so there is no storage overhead associated with the blocks consumed by the free-block list.
If a block in the free-block list contains 1,024 pointers, then the first 1,023 pointers contain the block numbers of free blocks on the disk. The file manager maintains two pointers on the disk: one that holds the block number of the current block containing free-block pointers, and one that holds an index into that current block. Whenever the file system needs a free block, it obtains the index for one from the free list block by using these two pointers. Then the file manager increments the index into the free-block list to the next available entry in the list. When the index increments to 1,023 (the 1,024th item in the free-block list), the OS does not use the pointer entry value at index 1,023 to locate a free block. Instead, the file manager uses this pointer as the address of the next block containing a list of free-block pointers on the disk, and it uses the current block, containing a now-empty list of block pointers, as the free block. This is how the file manager reuses the blocks originally designated to hold the free-block list. Unlike the FAT, the file manager does not reuse the pointers in the free-block list to keep track of the blocks belonging to a given file. Once the file manager uses up all the free-block pointers in a given block, the file manager uses that block for actual file data.
Unlike the FAT, the list scheme does not merge the free-block list and the file list into the same data structure. Instead, a separate data structure for each file holds the list of blocks associated with that file. Under typical Unix and Linux file systems, the directory entry for the file actually holds the first 8 to 16 entries in the list (see Figure 12-12). This allows the OS to track short files (up to 32 KB or 64 KB) without having to allocate any extra space on the disk.
OS research on various flavors of Unix suggests that the vast majority of files are small, and embedding several pointers into the directory entry provides an efficient way to access small files. Of course, as time passes, the average file size seems to increase. But as it turns out, block sizes tend to increase as well. When this average file size research was first done, the typical block size was 512 bytes, but today a typical block size is 4,096 bytes. During that time, then, average file sizes could have increased by a factor of eight without, on average, requiring any extra space in the directory entries.
For medium sized files up to about 4 MB, the OS will allocate a single block with 1,024 pointers to the blocks that store the file’s data. The OS continues to use the pointers found in the directory entry for the first few blocks of the file, and then it uses a block on the disk to hold the next group of block pointers. Generally, the last pointer in the directory entry holds the location of this block (see Figure 12-13).
For files larger than about 4 MB, the file system switches to a three-tiered block scheme, which works for file sizes up to 4 GB. In this scheme, the last pointer in the directory entry stores the location of a block of 1,024 pointers, and each of the pointers in this block holds the location of an additional block of 1,024 pointers, with each pointer in this block storing the location of a block that contains actual file data. See Figure 12-14 for the details.
One advantage to this tree structure is that it readily supports sparse files. That is, an application can write to block 0 and block 100 of a file without having to allocate data blocks for every block in between those two points. By placing a special block pointer value (typically zero) in the intervening entries in the block list, the OS can determine whether a block is not present in the file. Should an application attempt to read such a missing block in the file, the OS can simply return all zeros for the empty block. Of course, once the application writes data to a block that hadn’t been previously allocated, the OS must copy the data to the disk and fill in the appropriate block pointer in the block list.
As disks became larger, the 4 GB file limit imposed by this scheme began to create some problems for certain applications, such as video editors, large database applications, and Web servers. One could easily extend this scheme 1,000 times — to 4 terabytes (TB) — by adding another level to the block-list tree. The only problem with this approach is that the more levels of indirection you have, the slower random file access becomes, because the OS may have to read several blocks from the disk in order to get a single block of data. (When it has one level, it is practical to cache the block-pointer list in memory, but with two and three levels, it is impractical to do this for every file). Another way to extend the maximum value size 4 GB at a time is to use multiple pointers to second-tier file blocks (for example, take the original 8 to 16 pointers in the directory and have all or most of them point at second-tier block list entries rather than directly at file data blocks). Although there is no current standard way to extend beyond three levels, rest assured that as the need arises, OS designers will develop schemes they can use to access large files in an efficient manner.
Understanding how different mass storage devices behave is important if you want to write high-performance software that manipulates files on these devices. Although modern OSes attempt to isolate applications from the physical realities of mass storage, an OS can only do so much for you. Furthermore, an OS cannot predict how your particular application will access files on a mass storage device, so the OS cannot optimize access for your specific application; instead, the OS optimizes file access for applications that exhibit typical file-access patterns. The less typical your application’s file I/O is, the less likely you’ll get the best performance out of the system. In this section, we’ll look at how you can coordinate your file access activities with the OS to achieve the best performance.
Although disk drives and most other mass storage devices are often thought of as “random access” devices, the fact is that mass storage access is usually more efficient when done in a sequential fashion. Sequential access on a disk drive is relatively efficient because the OS can move the read/write head one track at a time (assuming the file appears in sequential blocks on the disk). This is much faster than accessing one block on the disk, moving the read/write head to some other track, accessing another block, moving the head again, and so on. Therefore, you should avoid random file access in an application if it is possible to do so.
You should also attempt to read or write large blocks of data on each file access rather than reading or writing small amounts more frequently. There are two reasons for this. First, OS calls are not fast, so if you make half as many calls by reading or writing twice as much data on each access, the application will often run twice as fast. Second, the OS must read or write whole disk blocks. If your block size is 4,096 bytes, but you just write 2,000 bytes to some block and then seek to some other position in the file outside that block, the OS will actually have to read the entire 4,096-byte block from the disk, merge in the 2000 bytes, and then finally write the entire 4,096 bytes back to the disk. This happens because the OS must read and write entire blocks; it cannot transfer partial blocks between the disk and memory. Contrast this with a write operation that writes a full 4,096 bytes — in this case, the OS wouldn’t have to read the data from the disk first; it would only have to write the block. Writing full blocks improves disk access performance by a factor of two because writing partial blocks requires the OS to first read the block, merge the data, and then write the block; by writing whole blocks the read operation is unnecessary. Even if your application doesn’t write data in increments that are even multiples of the disk’s block size, writing large blocks improves performance. If you write 16,000 bytes to a file in one write operation, the OS will still have to write the last block of those 16,000 bytes using a read-merge-write operation, but it will write the first three blocks using only write operations.
If you start with a relatively empty disk, the OS will generally attempt to write the data for new files in sequential blocks. This organization is probably most efficient for future file access. However, as the system’s users create and delete files on the disk, the blocks of data for individual files may start to be spread out in a nonsequential fashion. In a very bad case, the OS may wind up allocating a few blocks here and a few blocks there all across the disk’s surface. As a result, even sequential file access can behave like slow random file access. This situation, known as file fragmentation, can dramatically decrease file system performance. Unfortunately, there is no way for an application to determine if its file data is fragmented across the disk surface and, even if it could, there would be little that it could do about the situation. Although utilities exist to defragment the blocks on the disk’s surface, an application generally cannot request the execution of these utilities. Furthermore, “defragger” utilities are generally quite slow.
Although applications rarely get the opportunity to defragment their data files during normal program execution, there are some rules you can follow to reduce the probability that your data files will become fragmented. The best advice you can follow is to always write file data in large chunks. Indeed, if you can write the whole file in a single write operation, do so. In addition to speeding up access to the OS, writing large amounts of data tends to cause sequential blocks to be allocated for the data. When you write small blocks of data to the disk, other applications in a multitasking environment could also be writing to the disk concurrently. In such a case, the OS may interleave the block allocation requests for the files being written by several different applications making it unlikely that a particular file’s data will be written in sequential blocks on the disk’s surface. It is important to try to write a file’s data in sequential blocks, even if you plan to access portions of that data randomly, since searching for random records in a file that is written to contiguous blocks generally requires far less head movement than searching for random records in a file whose blocks are scattered all over the place.
If you’re going to create a file and then access its blocks of data repeatedly, whether randomly or sequentially, it’s probably a good idea to preallocate the blocks on the disk if you have an idea about how large the file will grow. If you know, for example, that your file’s data will not exceed one megabyte, you could write a block of one million zeros to the disk before your application starts manipulating the file. By doing so, you help ensure that the OS will write your file to sequential blocks on the disk. Though you pay a price to write all those zeros to begin with (an operation you wouldn’t normally do, presumably), the savings in read/write head-seek times could easily make up for the time spent preallocating the file. This scheme is especially useful if an application is reading or writing two or more files concurrently (which would almost guarantee the interleaving of the blocks for the various files).
Because most mass storage devices are mechanical, and, therefore, subject to mechanical delays, applications that make extensive use of such devices are going to have to wait for them to complete read/write operations. Most disk I/O operations are synchronous, meaning that an application that makes a call to the OS will wait until that I/O request is complete before continuing subsequent operations.
However, most modern OSes also provide an asynchronous I/O capability, in which the OS begins the application’s request and then returns control to the application without waiting for the I/O operation to complete. While the I/O operation proceeds, the application promises not to do anything with the data buffer specified for the I/O request. Then, when the I/O operation completes, the OS somehow notifies the application. This allows the application to do additional computation while waiting for the I/O operation to complete, and it also allows the application to schedule additional I/O operations while waiting for the first operation to complete. This is especially useful when accessing files on multiple disk drives in the system, which is usually only possible with SCSI and other high-end drives.
Another important consideration when writing software that manipulates mass storage devices is the type of I/O you’re performing. Binary I/O is usually faster than formatted text I/O. The difference between the two has to do with the format of the data written to disk. For example, suppose you have an array of 16 integer values that you want to write to a file. To achieve this, you could use either of the following two C/C++ code sequences:
FILE *f;
int array[16];
. . .
// Sequence #1:
fwrite( f, array, 16 * sizeof( int ));
. . .
// Sequence #2:
for( i=0; i < 16; ++i )
fprintf( f, "%d ", array[i] );The second sequence looks like it would run slower than the first because it uses a loop to step through each element of the array, rather than a single call. But although the extra execution overhead of the loop does have a small negative impact on the execution time of the write operation, this efficiency loss is minor compared to the real problem with the second sequence. Whereas the first code sequence writes out a 64-byte memory image consisting of 16 32-bit integers to the disk, the second code sequence converts each of the 16 integers to a string of characters and then writes each of those strings to the disk. This integer-to-string conversion is relatively slow and will greatly impact the performance of the code. Furthermore, the fprintf function has to interpret the format string ("%d") at run time, thus incurring an additional delay.
The advantage of formatted I/O is that the resulting file is both human readable and easily read by other applications. However, if you’re using a file to hold data that is only of interest to your application, you can improve the efficiency of your software by writing data as a memory image, rather than first converting it to human-readable text.
Some OSes allow you to use what are known as memory-mapped files. Memory-mapped files use the OS’s virtual memory capabilities to map memory addresses in the application space directly to blocks on the disk. Because modern OSes have highly optimized virtual memory subsystems, piggy-backing file I/O on top of the virtual memory subsystem can produce very efficient file access. Furthermore, memory-mapped file access is very easy. When you open a memory-mapped file, the OS returns a memory pointer to some block of memory. By simply accessing the memory locations referenced by this pointer, just as you would any other in-memory data structure, you can access the file’s data. This makes file access almost trivial, while often improving file-manipulation performance, especially when file access is random.
One of the reasons that memory-mapped files are so much more efficient than regular files is that the OS only reads the list of blocks belonging to memory-mapped files once. It then sets up the system’s memory-management tables to point at each of the blocks belonging to the file. After opening the file, the OS rarely has to read any file metadata from the disk. This greatly reduces superfluous disk access during random file access. It also improves sequential file access, though to a lesser degree. Memory-mapped file access is very efficient because the OS doesn’t constantly have to copy data between the disk, internal OS buffers, and application data buffers.
Memory-mapped file access does have some disadvantages. First, you cannot map gigantic files entirely into memory, at least on contemporary PCs that have a 32-bit address bus and set aside a maximum of 4 GB per application. Generally, it is not practical to use a memory-mapped access scheme for files larger than 256 MB, though this will change as more CPUs with 64-bit addressing capabilities become available. It is also not a good idea to use memory-mapped files when an application already uses an amount of memory that approaches the amount of RAM physically present in the system. Fortunately, these two situations are not typical, so they don’t limit the use of memory-mapped files much.
However, there is another problem with memory-mapped files that is rather significant. When you first create a memory-mapped file, you have to tell the OS the maximum size of that file. If it is impossible to determine the file’s final size, you’ll have to overestimate it and then truncate the file when you close it. Unfortunately, this wastes system memory while the file is open. Memory-mapped files work well when you’re manipulating files in read-only fashion or you’re simply reading and writing data within an existing file without extending the file’s size. Fortunately, you can always create a file using traditional file-access mechanisms and then use memory-mapped file I/O to access the file later.
Finally, almost every OS does memory-mapped file access differently, and there is little chance that memory-mapped file I/O code will be portable between OSes. Nevertheless, the code to open and close memory-mapped files is quite short, and it’s easy enough to provide multiple copies of the code for the various OSes you need to support. Of course, actually accessing the file’s data consists of simple memory accesses, and that’s independent of the OS. For more information on memory-mapped files, consult your OS’s API reference. Given the convenience and performance of memory-mapped files, you should seriously consider using them whenever possible in your applications.
The Universal Serial Bus (USB) is not a peripheral port in the traditional sense (like an RS-2323 serial communications controller). Rather than using it to connect your computer to some peripheral device, USB is a mechanism that allows you to use a single interface to connect a wide variety of different peripheral devices to a PC, similar to SCSI. The USB supports hot-pluggable devices, meaning that you can plug and unplug devices without shutting down the power or rebooting your machine, and it supports plug-and-play devices, meaning that the OS will automatically load a device driver, if available, once you plug in a device. This flexibility comes at a cost, however. Programming devices on the USB is considerably more complex than programming a serial or parallel port. You cannot communicate with USB peripherals by reading or writing a few device registers.
To understand the motivation behind USB, consider the situation PC users faced when Windows 95 first arrived, nearly 14 years after the introduction of the IBM PC. The IBM PC’s designers provided the PC with a variety of peripheral interconnects that were common on personal computers and minicomputers in the late 1970s. However, they did not anticipate, nor did they particularly allow for, the wide variety of peripheral devices that people would invent to attach to PCs in the following decades. They also did not count on any individual PC owners connecting more than a few different peripheral devices to their machines. Certainly three parallel ports, four serial ports, and a single hard disk drive should have been sufficient!
By the time Windows 95 was introduced, people were connecting their PCs to all kinds of crazy devices, including sound cards, video digitizers, digital cameras, advanced gaming devices, scanners, telephones, mice, digitizing tablets, SCSI devices, and literally hundreds of other devices the original PC’s designers hadn’t dreamed of. The creators of these devices interfaced their hardware to the PC using peripheral I/O port addresses, interrupts, and DMA channels that were originally intended for other devices. The problem with this approach was that there were a limited number of port addresses, interrupts, and DMA channels, and there were a large number of devices that competed for these resources. In an attempt to alleviate conflicts between devices, the device manufacturers added “jumpers” to their cards that would allow the purchaser to select from a small set of different port addresses, interrupts, and DMA channels, so as not to conflict with other devices. Creating a conflict-free system was a complex process, and it was impossible to achieve with some combinations of peripherals. In fact, one of the big selling points of the Apple Macintosh during this period was that you could easily connect multiple peripheral devices without worrying about device conflicts. What was needed was a new peripheral connection system that supported a large number of devices without conflicts. USB was the answer.
USB allows the connection of up to 127 devices simultaneously by using a 7-bit address. USB reserves the 128th slot, address zero, for auto-configuration purposes. In real life, it’s doubtful that one would ever successfully connect so many devices to a single PC, but it’s good to know that USB has a fair amount of potential for growth, unlike the original PC’s design.
Despite the name, USB isn’t a true “bus” in the sense of allowing several devices to communicate with one another. The USB is a master-slave connection, with the PC always acting as master and the peripherals acting as slaves. This means, for example, that a camera cannot talk directly to a printer across the USB. To transmit information from a digital camera to a printer, both of which are connected to a PC, the camera must first send its data to the PC before the PC can pass the data along to the printer. The PCI, ISA, and FireWire (IEEE 1394) buses allow two devices to communicate with one another in a peer-to-peer fashion, independent of the host’s CPU, but USB wasn’t designed to allow this method of communication (to keep down the cost of peripherals and the USB interface chips in those peripheral devices).[50]
USB also keeps peripheral costs down by moving as much complexity as possible to the host (PC) side of the connection. The thinking here is that the PC’s CPU will offer much higher performance than the low-cost micro-controllers found in most USB peripheral devices. This means that writing software to be embedded in a USB peripheral isn’t much more work than using another interface. On the other hand, writing USB software on the host (PC) side is very complex. So complex, in fact, that it isn’t realistic to expect programmers to write software that directly communicates over the USB. Instead, the OS supplier must provide a USB host controller stack that enables communication with USB devices and most application programmers talk to those devices using the OS’s device driver interface. Even those programmers who need to write custom USB device drivers for their particular device don’t talk directly to the USB hardware. Instead, they make OS calls to the USB host controller stack with requests for their particular device. Because a typical USB host controller stack is generally around 20,000 to 50,000 lines of C code and requires several years of development, there is little chance of programming USB devices on a system that does not provide a native USB stack (such as MS-DOS).
The initial USB design supported two different types of peripherals — slow and fast. Slow devices could transfer up to 1.5 Mbps (megabits per sec) across the USB, while fast devices were capable of transferring up to 12 Mbps. The reason for supporting two speeds was cost. Cost-sensitive devices could be built inexpensively as low-speed devices. Non–cost-sensitive devices could use the 12 Mbps data rate. The USB 2.0 specifications added a high-speed mode supporting up to 480 Mbps data transfer rates, at considerable extra complexity and cost.
USB will not dedicate the entire 1.5 Mbps, 12 Mbps, or 480 Mbps available bandwidth to one peripheral. Instead, the host controller stack multi-plexes the data on the USB, effectively giving each peripheral a “time slice” of the bus. The USB operates with a one-millisecond clock. At the start of each millisecond period, the USB host controller begins a new USB frame, and during a frame, each peripheral may transmit or receive a packet of data. Packets vary in size, depending on the speed of the device and the transmission time, but a typical packet size contains between 4 and 64 bytes of data. If you’re transferring data between four peripherals at an equal rate, you’d typically expect the USB stack to transmit one packet of data between the host and each peripheral in a round-robin fashion, taking care of the first peripheral first, the second peripheral second, and so on. Like time slicing in a multitasking OS, this data transfer mechanism gives the appearance of transferring data concurrently between the host and every USB peripheral, even though there can be only one transmission on the USB at a time.
Although USB provides a very flexible and expandable system, keep in mind that as you add more peripherals to the bus, you reduce the maximum amount of bandwidth available to each device. For example, if you connect two disk drives to the USB and access both drives simultaneously, the two drives must share the available bandwidth on the USB. For USB 1.x devices, this produces a noticeable speed degradation. For USB 2.x devices, the available bandwidth is sufficiently high (typically higher than what two disk drivers can sustain) that you will not notice the performance degradation. Theoretically, you could use multiple host controllers to provide multiple USB buses in a system (with full bandwidth available on each bus). But this addresses only part of the performance problem.
Another performance consideration is the overhead of the USB host controller stack. Although the USB 1.x hardware may be capable of 12 Mbps bandwidth, there is some “dead” time during which no transmission takes place on the USB because the host controller stack consumes a fair amount of time setting up data transfers. In some USB systems, achieving half the theoretical USB bandwidth is the best you can hope for, because the host controller stack uses so much of the available CPU time setting up the transfer and moving data around. On some embedded systems using slower processors (such as 486, StrongArm, or MIPS) running an embedded USB 1.x host controller device, this can be a real problem. Fortunately, on modern PCs with USB 2.x controllers, the host controller only consumes a small percentage of the USB bandwidth.
If a particular host controller stack is incapable of maintaining the full USB bandwidth, it usually means that the CPU can’t process USB information as fast as the USB produces it. This generally implies that the CPU’s processing capabilities are saturated, and no time is available for other computations, either. Remember, USB leaves all the complex computations for the host controller on the USB, and executing code in the USB stack on the host requires CPU cycles. It is quite possible for the host controller to get so involved processing USB traffic that overall system performance for non-USB traffic suffers.
The USB supports four different types of data transmissions: control, bulk, interrupt, and isochronous. Note that it is the peripheral manufacturer, not the application programmer, that determines the data transfer mechanism between the host and a given peripheral device. That is, if a device uses the isochronous data transfer mode to communicate with the host PC, a programmer cannot decide to use bulk transfers instead. Indeed, the application program may not even be aware of the underlying transmission scheme, as long as the software can handle the rate at which the device produces or consumes the data.
USB generally uses control transmissions to initialize a peripheral device. In theory, you could use control transmissions to pass data between the peripheral and the host, but very few devices use control transmissions for that purpose. USB guarantees correct delivery of control transmissions and also guarantees that at least 10 percent of the USB bandwidth is available for control transmissions to prevent starvation, a situation where a particular transmission never occurs because some higher-priority transmission is always taking place. USB control transmissions are generally used to read and write data from and to a peripheral’s registers. For example, if you have a USB-to-serial converter device, you would typically use control transfers to set the baud rate, number of data bits, parity, number of stop bits, and so on, just as you would store data into the 8250 SCC’s register set.
As the name implies, USB bulk transmissions are used to transmit large blocks of data between the host and a peripheral device. Bulk transmissions are available only on full-speed (12 Mbps) and high-speed (480 Mbps) devices, not on low-speed ones. On full-speed devices, a bulk transmission generally carries between 4 and 64 bytes of data per packet; on high-speed devices you can transmit up to 1,023 bytes per packet. USB guarantees correct delivery of a bulk packet between the host and the peripheral device, but it does not guarantee timely delivery. If the USB is handling a large number of other transmissions, it may take a while for a bulk transmission to complete. In fact, theoretically, a bulk transmission might never occur if the USB is sufficiently busy with the right combination of isochronous, interrupt, and control transmissions. In practice, however, most USB stacks do set aside a small amount of guaranteed bandwidth for bulk transmissions (generally about 2 to 2.5 percent) so that starvation doesn’t occur.
USB intends bulk transmissions to be used by devices that transmit a fair amount of data that must transfer correctly yet doesn’t necessarily need to be transferred quickly. For example, when transferring data to a printer or between a computer and a disk drive, correct transfer is far more important than is a timely transfer. Sure, it may be annoying to wait what seems like forever to save a file to a USB disk drive, but operating slowly is much better than operating quickly and writing incorrect data to the disk file.
Some devices require both correct data transmission and a timely delivery of the data. The interrupt transfer type provides this capability. Despite the name, interrupt transfers do not involve interrupts on the computer system. In fact, with only two exceptions (initial connection and power-up notification), peripheral devices never communicate with the host across USB unless the host explicitly requests information from the device. The host polls all devices on the USB — the devices do not interrupt the host when they have data available. A peripheral device may request how often the host polls it, choosing an interval from 1 to 255 milliseconds, but the host may legally poll the device more often than the device requests.
In order to guarantee correct and timely delivery of interrupt transmissions between a host and a peripheral device, the USB host controller stack must reserve a portion of the USB bandwidth whenever an application opens a device for interrupt transmission. For example, if a particular device wants to be serviced every millisecond and needs to transmit 16 bytes per packet, the USB host controller stack must reserve a little bit more than 128 Kbps (kilobits per second) of bandwidth (16 bytes × 8 bits per byte × 1,000 packets per second) from the total bandwidth available. You need to reserve a little bit more than this because there is some protocol overhead on the bus as well. We’ll not worry about the actual figure here other than to suggest that the overhead is probably at least 10 to 20 percent and could be more depending upon how the USB stack is written.
Because there is a limited amount of bandwidth available on the USB, and because interrupt transmissions consume a fixed amount of that bandwidth whenever you open a device for use, it is clearly not possible to have an arbitrary number of interrupt transmissions active at any one time. Once the USB bandwidth (minus the 10 percent that USB reserves for control transmissions) is consumed, the stack refuses to allow the activation of any new interrupt transmissions.
Interrupt transmission packets are between 4 and 64 bytes long, though most of the time they fall into the low end of this range. Many devices use interrupt transmissions to notify the host CPU that some data is available, and then the host can read the actual data from the device using a bulk transmission. Of course, if the amount of data to be transmitted between the host and the peripheral is small, then the peripheral may transmit the data as part of the interrupt’s data payload to avoid a second transmission. Keyboards, mice, joysticks, and similar devices are examples of peripherals that typically transmit their data as part of the interrupt packet payload. Disk drives, scanners, and other such devices are good examples of peripherals that use interrupt transmissions to notify the host that data is available and then use bulk transfers to actually move the data around.
Isochronous transfers are the fourth transfer type that USB supports. Like interrupt transfers, isochronous transfers (or just iso transfers) require a timely delivery. Like bulk transfers, iso transfers generally involve larger data packets. However, unlike the other three transfer types, iso transfers do not guarantee correct delivery between the host and the peripheral device. Timely delivery is so important for iso transfers that if a packet arrives late, it may as well not arrive at all. Peripheral devices such as audio input (microphones) and output (speakers) and video cameras use isochronous transmissions. If you lose a packet, or if a packet is transmitted incorrectly between the peripheral and host, you’ll get a momentary glitch on the video display or in the audio signal, but the results are not disastrous as long as such problems don’t occur too frequently.
Like interrupt transfers, isochronous transfers consume USB bandwidth. Whenever you open a connection to an isochronous USB peripheral device, that device requests a certain amount of bandwidth. If the bandwidth is available, the USB host controller stack reserves that amount of bandwidth for the device until the application is finished with the device. If sufficient bandwidth is not available, the USB stack notifies the application that it cannot use the desired device until more bandwidth is available, and the user will have to stop using other iso and interrupt devices to free up some bandwidth.
Most OSes that provide a USB stack support dynamic loading and unloading of USB device drivers, also known as client drivers in USB terminology. Whenever you attach a USB device to the USB, the host system gets a signal that tells it that the bus topology has changed (that is, there is a new device on the USB). The host controller scans for the new device, a process known as enumeration, and then reads some configuration information from the peripheral. Among other things, this configuration information tells the USB stack the type of the device, the manufacturer, and model information. The USB host stack uses this information to determine which device driver to load into memory. If the USB stack cannot find a suitable driver, it will generally open up a dialog box requesting help from the user; if the user cannot provide the path to an appropriate driver, the system will simply ignore the new device. Similarly, when the user unplugs a device, the USB stack will unload the appropriate device driver from memory if it’s not also being used for some other device.
To simplify device-driver implementation for many common devices, such as keyboards, disk drives, mice, and joysticks, the USB standard defines certain device classes. Peripheral manufacturers who create devices that adhere to one of these standardized device classes don’t have to supply a device driver with their equipment. Instead, the class drivers that come with the USB host controller stack provide the only interface necessary. Examples of class drivers include HID (Human Interface Devices, such as keyboards, mice, and joysticks), STORAGE (disk, CD, and tape drives), COMMUNICATIONS (modems and serial converters), AUDIO (speakers, microphones, and telephony equipment), and PRINTERS. A peripheral manufacturer always has the option of supplying their own specialized features that add several bells and whistles to their product, but a customer can often get basic functionality with some existing class driver by simply plugging in the device without installing a device driver specifically for the new peripheral.
Along with disk drives, keyboards, and display devices, pointing devices are probably the most common peripherals you’ll find on modern personal computers. Pointing devices are actually among the more simple peripheral devices, providing a very simple data stream to the computer. Pointing devices generally come in two categories: those that return the relative position of the pointer and those that return the absolute position of the pointing device. A relative position is simply the change in position since the last time the system read the device; an absolute position is some set of coordinate values within a fixed coordinate system. Mice, trackpads, and trackballs are examples of devices that return relative coordinates; touch screens, light pens, pressure-sensitive tablets, and joysticks are examples of devices that return absolute coordinates. Generally, it’s easy to translate an absolute coordinate system to a relative one, but a bit more problematic to convert a relative coordinate system to an absolute one. This latter conversion requires a constant reference point that may become meaningless if, for example, someone lifts a mouse off the surface and sets it down elsewhere. Fortunately, most windowing systems work with relative coordinate values from pointing devices, so the limitations of pointing devices that return relative coordinates are not a problem.
Early mice were typically opto-mechanical devices that rotated two encoding wheels that were oriented along the X- and Y-axes of the mouse body. Usually, both of these wheels were encoded to send 2-bit pulses whenever they would move a certain distance. One bit told the system that the wheel had moved a certain distance, and the other bit told the system which direction the wheel had moved.[51] By constantly tracking the four bits (two bits for each axis) from the mouse, the computer system could determine the mouse’s distance and direction traveled, and keep a very accurate calculation of the mouse’s position in between application requests for that position.
One problem with having the CPU track each mouse movement is that when moved quickly, mice can generate a constant and high-speed stream of data. If the system is busy with other computations, it might miss some of the incoming mouse data and would therefore lose track of the mouse’s position. Furthermore, using the host CPU to keep track of the mouse position consumes CPU time that could be put to better use doing application computations.
As a result, mouse manufacturers decided early on to incorporate a simple microcontroller in the mouse package. This simple microcontroller keeps track of the physical mouse movements and responds to system requests for mouse coordinate updates, or at the very least generates interrupts on a periodic basis when the mouse position changes. Most modern mice connect to the system via the USB and respond with positional updates to system requests that occur about every eight milliseconds.
Because of the wide acceptance of the mouse as a GUI pointing device, computer manufacturers have created many other devices that serve the same purpose. The motivation behind developing most of these devices has been to increase portability — mice aren’t the most convenient pointing devices to attach to a laptop computer system on the road. Trackballs, strain gauges (the little “stick” you’ll find between the G and H keys on many laptops), trackpads, trackpoints, and touch screens are all examples of devices that manufacturers have attached to portable computers and PDAs to create more portable pointing devices. Though these devices vary with respect to their convenience to the end user, to the OS they can all look like a mouse. So, from a software perspective, there is little difference between these devices.
In modern OSes, the application rarely interfaces with a pointing device directly. Instead, the OS is responsible for tracking the mouse position and updating cursors and other mouse effects in the system. The OS typically notifies an application when some sort of pointing device event occurs that the application should consider. Though applications may query the pointing device’s status, as a normal state of affairs they don’t manage the pointing device’s position. In response to a query from an application, the OS will return the position of the system cursor and the state of the buttons on the pointing device. The OS may also notify the application whenever a pointer device event, such as a button press, occurs.
The analog game adapter created for the IBM PC allowed users to connect up to four resistive potentiometers and four digital switch connections to the PC. The design of the PC’s game adapter was obviously influenced by the analog input capabilities of the Apple II computer, the most popular computer available at the time the PC was developed. IBM’s analog input design, like Apple’s, was designed to be dirt-cheap. Accuracy and performance were not a concern at all. In fact, you can purchase the electronic parts to build your own version of the game adapter, at retail, for less than three dollars. Unfortunately, IBM’s low-cost design in 1981 produces some major performance problems for high-speed machines and high-performance game software in the 2000s.
Few modern systems incorporate the original electronics of the IBM PC game controller because of the inherent inefficiencies of reading them. Rather, most modern game controllers contain the analog electronics that convert physical position into a digital value directly inside the controller, and then interface to the system via USB. Microsoft Windows and other modern OSes provide a special game-controller device-driver interface that allows applications to determine what facilities the game controller has and also sends the data to those applications in a standardized form. This allows game-controller manufacturers to provide many special features that were not possible when using the original PC game-controller interface. Modern applications read game-controller data just as though they were reading data from a file or some other character-oriented device like a keyboard. This vastly simplifies the programming of such devices while improving overall system performance.
Microsoft Windows also provides a special game controller API that provides a high-performance interface to various types of game controllers on the system. Similar library modules exist for other OSes as well. Some “old-time” game programmers feel that calling such code is inherently inefficient and that great code always controls the hardware directly. This concept is a bit outdated. First, most modern OSes don’t allow applications direct access to hardware even if the programmer wants such access. Second, software that talks directly to the hardware won’t work with as wide a variety of devices as software that lets the OS handle the hardware for it. Back in the days when there were a small number of standardized peripherals for the PC, it was possible for a single application to directly program all the different devices the program would access. In modern systems, however, there are far too many devices for an individual program to deal with. This is just as true for game-controller devices as it is for other types of devices. Finally, keep in mind that most OS device drivers are probably going to be written more efficiently by the manufacturer’s programmers or the OS developer’s programmers than you could write them yourself.
Because newer game controllers are no longer constrained by the design of the original IBM PC game-controller card, they provide a wide range of capabilities. Refer to the relevant game controller and OS documentation for information on how to program the API for the device.
The original IBM PC included a built-in speaker that the CPU could program using an on board timer chip that could produce a single frequency tone. To produce a wide range of sound effects required programming a single bit connected directly to the speaker, something which consumed nearly all available CPU time. Within a couple of years of the PC’s arrival, various manufacturers like Creative Labs created a special interface board that provided higher quality PC audio output that didn’t consume anywhere near the CPU resources.
The first sound cards to appear for the PC didn’t follow any standards because no such standards existed at the time. Creative Labs’ Sound Blaster card became the defacto standard because it had reasonable capabilities and sold in very high volumes. At the time, there was no such thing as a device driver for sound cards, so most applications were programming the registers directly on the sound card. Initially, the fact that so many applications were written for the Sound Blaster card meant that anyone wanting to use most audio applications also had to purchase Creative Labs’ sound card. However, before too long this advantage was negated, as other sound card manufacturers quickly copied the Sound Blaster design. All of these manufacturers became stuck with their designs, for they knew that any new features added to their designs would not be supported by any of the available audio software.
Sound card technology stagnated until Microsoft introduced multimedia support into Windows. Once Windows fully supported audio cards in a device-independent fashion, sound card technology improved dramatically. The original audio cards were capable of mediocre music synthesis, suitable only for cheesy video game sound effects. Some boards supported 8-bit telephone-quality audio sampling, but the audio was definitely not high fidelity. Once Windows provided a standardized interface for audio, the sound card manufacturers began producing high-quality sound cards for the PC. Immediately, “CD-quality” cards appeared that were capable of recording and playing back audio at 44.1 KHz and 16 bits. Higher-quality sound cards began adding “wave table” synthesis hardware that produced realistic synthesis of musical instruments. Synthesizer manufacturers like Roland and Yamaha produced sound cards with the same electronics found in their high-end synthesizers. Today, professional recording studios use PC-based digital audio recording systems to record original music with 24-bit resolution at 96 KHz, arguably producing better results than all but the finest analog recording systems. Of course, such systems are not cheap, costing many thousands of dollars. They’re definitely not your typical sound card that retails for under $100.
Modern audio interface peripherals[52] generally produce sound in one of three different fashions: analog (FM synthesis), digital-wave-table synthesis, or digital playback. The first two schemes produce musical tones and are the basis for most computer-based synthesizers, while the third scheme is used to play back audio that was digitally recorded.
The FM-synthesis scheme is an older, lower-cost, music-synthesis mechanism that creates musical tones by controlling various oscillators and other sound-producing circuits on the sound card. The sound produced by such devices is usually very low quality, reminiscent of the types of sounds associated with early video games; there is no mistaking such sound synthesis for an actual musical instrument. While some very low-end sound cards still use FM synthesis as their main sound-producing mechanism, few modern audio peripherals continue to provide this form of synthesis for anything other than producing “synthetic” sounds.
Modern sound cards that provide musical synthesis capabilities tend to use what has become known as wave table synthesis. With wave-table synthesis, the audio manufacturer will typically record and digitize several notes from an actual musical instrument. They program these digital recordings into read-only memory (ROM) that they assemble into the audio interface circuit. When an application requests that the audio interface play some note on a given musical instrument, the audio hardware will play back the recording from ROM producing a very realistic sound. To someone who is not intimately familiar with what the actual instrument sounds like, wave-table synthesis can produce some extremely realistic sounds.
However, wave table synthesis is not simply a digital playback scheme. To record over 100 different instruments, each with a several octave range, would require a tremendous amount of ROM storage. Although ROM isn’t outrageously expensive, providing hundreds of megabytes of ROM with an audio synthesizer device for a PC would be prohibitively expensive. Therefore, most manufacturers of such devices will actually resort to using software embedded on the audio interface card to take a small number of digitized waveforms stored in ROM and raise or lower them by some integral number of octaves. This allows manufacturers to record and store only a single octave (12 notes) for each instrument. In fact, it is theoretically possible to use software to convert only a single recorded note into any other note, and some synthesizers do exactly that to reduce costs. However, in practice, the more notes the manufacturer records, the better the quality of the resulting sound. Some of the higher-end audio boards will record several octaves on complex musical instruments (like a piano) but record only a few notes on some lesser-used, less-complex sound-producing objects. This is especially true for sound effects like gunshots, explosions, crowd noise, and other less-critical sounds.
Pure digital playback is used for two purposes: playing back arbitrary audio recordings and performing very high-end musical synthesis, known as sampling. A sampling synthesizer is, effectively, a RAM-based version of a wave-table synthesizer. Rather than storing digitized instruments in ROM, a sampling synthesizer stores them in system RAM. Whenever an application wants to play a given note from a musical instrument, the system fetches the recording for that note from system RAM and sends it to the audio circuitry for playback. Like wave-table synthesis methods, a sampling synthesizer can convert digitized notes up and down octaves, but because the system doesn’t have the cost-per-byte constraints associated with ROM, the audio manufacturer can usually record a wider range of samples from real-world musical instruments. Generally, sampling synthesizers provide a microphone input to create your own samples. This allows you, for example, to play a song by recording a barking dog and generating a couple octaves of “dog bark” notes on the synthesizer. Third parties often sell “sound fonts” containing high-quality samples of popular musical instruments.
The other use for pure digital playback is as a digital audio recorder. Almost every modern sound card has an audio input that will theoretically record “CD-quality” sound in stereo.[53] This allows the user to record an analog signal and play it back verbatim, like a tape recorder. With sufficient outboard gear, it’s even possible to make your own musical recordings and burn your own music CDs, though to do so you’d want something a little bit fancier than a typical Sound Blaster card — something at least as advanced as the DigiDesign Digi-001 or M-Audio system.
There are two standard mechanisms for playing back sound in a modern PC: audio file playback and MIDI file playback. Audio files contain digitized samples of the sound to play back. While there are many different audio file formats (for example, WAV and AIF), the basic idea is the same — the file contains some header information that specifies the recording format (such as 16-bit 44.1 KHz, or 8-bit 22 KHz) and the number of samples, followed by the actual sound samples. Some of the simpler file formats allow you to dump the data directly to a typical sound card after proper initialization of the card; other formats may require a minor data translation prior to having the sound card process the data. In either case, the audio file format is essentially a hardware-independent version of the data one would normally feed to a generic sound card.
One problem with sound files is that they can grow rather large. One minute of stereo CD-quality audio requires just less than 10 MB of storage. A typical three- to four-minute song requires between 25 MB and 40 MB. Not only would such a file take up an inordinate amount of RAM, but it consumes a fair amount of storage on the software’s distribution CD as well. If you’re playing back a unique audio sequence that you’ve had to record, you have no choice but to use this space to hold the sequence. However, if you’re playing back an audio sequence that consists of a series of repeated sounds, you can use the same technique that sampling synthesizers use and store only one instance of each sound, then use some sort of index value to indicate which sound you want to play. This can dramatically reduce the size of a music file.
This is exactly the idea behind the MIDI (Musical Instrument Digital Interface) file format. MIDI is a standard protocol for controlling music synthesis and other equipment. Rather than holding audio samples, a MIDI file simply specifies the musical notes to play, when to play them, how long to play them, which instrument to play them on, and so on. Because it only takes a few bytes to specify all this information, a MIDI file can represent an entire song very compactly. High-quality MIDI files generally range from about 20 KB to 100 KB for a typical three- to four-minute song. Contrast this with the 20 MB to 45 MB an audio file of the same length would require. Most sound cards today are capable of playing back General MIDI (GM) files using an on-board wave-table synthesizer or FM synthesis. General MIDI is a standard that most synthesizer manufacturers use to control their equipment, so its use is very widespread and GM files are easy to obtain. If you want to play back music that doesn’t contain vocals or other nonmusical elements, MIDI can be very efficient.
One problem with MIDI is that the quality of the playback is dependent upon the quality of the sound card the end user provides. Some of the more expensive audio boards do a very good job of playing back MIDI files. Some of the lower-cost boards, including, unfortunately, a large number of systems that have the audio interface built on to the motherboard, produce cartoonish sounding recordings. Therefore, you need to carefully consider using MIDI in your applications. On the one hand, MIDI offers the advantages of smaller files and faster processing. On the other hand, on some systems the audio quality will be quite low, making your application sound bad. You have to balance the pros and cons of these approaches for your particular application.
Because most modern audio cards are capable of playing back “CD-quality” recordings, you might wonder why the sound card manufacturers don’t collect a bunch of samples and simulate one of these sampling synthesizers. Well, they do. Roland, for example, provides a program it calls the Virtual Sound Canvas that does a good simulation of its hardware Sound Canvas module in software. These virtual synthesizers produce very high quality output. However, that quality comes at a price — CPU cycles. Virtual synthesizer programs consume a large percentage of the CPU’s capability, thus leaving less power for your applications. If your applications don’t need the full power of the CPU, these virtual synthesizers provide a very high-quality, low-cost solution to this problem.
Another solution is to connect an outboard synthesizer module to your PC via a MIDI interface port and send the MIDI data to a synthesizer to play. This solution is acceptable if you know your target audience will have such a device, but few people outside of musicians would own one, so requiring the hardware severely limits your customer base.
One of the best things about audio in modern applications is that there has been a tremendous amount of standardization. File formats and audio hardware interfaces are very easy to use in modern applications. Like most other peripheral interface issues, few modern programs will control audio hardware directly, because OSes like Windows and Linux provide device drivers that handle this chore for you. To produce sound in a typical Windows application requires little more than reading data from a file that contains the sound information, and writing that data to another file that transmits the data to the device driver that interfaces with the actual audio hardware.
One other issue to consider when writing audio-based software is the availability of multimedia extensions in the CPU you’re using. The Pentium and later 80x86 CPUs provide the MMX instruction set. Other CPU families provide comparable instruction set extensions (such as the AltaVec instructions on the PowerPC). Although the OS probably uses these extended instructions in the device driver, it’s quite possible to employ these multimedia instructions in your own applications as well. Unfortunately, using these extended instructions usually involves assembly language programming, because few high-level languages provide efficient access to them. Therefore, if you’re going to be doing high-performance multimedia programming, assembly language is probably something you want to learn. See my book The Art of Assembly Language for additional details on the Pentium’s MMX instruction set.
To program a particular peripheral device, you will need to obtain the data sheets for that device directly from its manufacturer. Most manufacturers maintain their data sheets on the Web these days, so getting the information is usually a simple matter of finding their Web page. Some manufacturers do consider the interface to their devices to be proprietary and refuse to share this information (this is particularly true of video card manufacturers), but by and large it’s relatively easy to get the information you need.
Semiconductor manufacturers are especially generous with the information they supply on their websites. Furthermore, common peripheral devices like the 8250 serial communications chip have dozens of websites dedicated to programming them. A quick search on the Net will turn up considerable information for the more common interface devices.
For USB, FireWire, and TCP/IP (network) protocol stacks, there is considerable information available on the Net. For example, http://www.usb.org contains all the technical specifications for the USB protocol as well as programming information for various common USB host controller chip sets. Similar information exists for FireWire.
You’ll be able to find considerable example code that controls most peripheral devices on the Net as well. This even includes some complex protocols such as USB, FireWire, and TCP/IP. For example, the open source Linux OS provides complete TCP/IP and USB host controller stacks in source form. This code is not easy reading and is tens of thousands of lines long, but if you’re dead-set on creating this kind of code, the Linux (and other open source) offerings make a good starting point.
[46] Historically, “peripheral” meant any device external to the computer system itself. This book will use the modern form of this term to simply imply any device that is not part of the CPU or memory.
[47] Don’t forget that “input” and “output” are from the perspective of the computer system, not the device. Hence, the device writes data during an input operation and reads data during an output operation.
[48] In this context, “form factor” means shape and size.
[49] In reality, of course, there is some overhead consumed by the SCSI protocol itself. Hence, the SCSI bus would actually be saturated with fewer than 20 high-performance drives.
[50] Recently, the USB Interface Group (or USB-IF) has defined an extension to the USB known as USB On-The-Go that allows a limited amount of pseudo-peer-to-peer operation. However, this scheme doesn’t truly support peer-to-peer operation; what it really does is allow different peripherals to take turns being the master on the USB.
[51] Actually, this is a bit of a simplification, but we will ignore that fact here.
[52] The term “sound card” hardly applies anymore because many personal computers include the audio controller directly on the motherboard, and many high-end audio interface systems interface via USB or FireWire, or require multiples boxes and interface cards.
[53] “CD quality” simply means that the board’s digitizing electronics are capable of capturing 44,100 16-bit samples every second. Usually the analog circuitry on the board does not have sufficiently high quality to pass this audio quality through to the digitizing circuitry. Hence, very few PC sound cards today are truly capable of “CD-quality” recording.