
Although computers are famous for their “number-crunching” capabilities, the truth is that most computer systems process character data far more often than numbers. Given the importance of character manipulation in modern software, a thorough understanding of character and string data is necessary if you’re going to write great code.
The term character refers to a human or machine-readable symbol that is typically a nonnumeric entity. In general, a character is any symbol that you can type on a keyboard or display on a video display. Note that in addition to alphabetic characters, character data includes punctuation symbols, numeric digits, spaces, tabs, carriage returns (the enter key), other control characters, and other special symbols.
This chapter looks at how we represent characters, strings, and character sets within a computer system. This chapter also discusses various operations on these data types.
Most computer systems use a 1- or 2-byte binary sequence to encode the various characters. Windows and Linux certainly fall into this category, using the ASCII or Unicode character sets, whose members can all be represented using 1- or 2-byte binary sequences. The EBCDIC character set, in use on IBM mainframes and minicomputers, is another example of a single-byte character code.
I will discuss all three of these character sets, and their internal representations, in this chapter. I will also describe how to create your own custom character sets later in this chapter.
The ASCII (American Standard Code for Information Interchange) character set maps 128 characters to the unsigned integer values 0..127 ($0..$7F). Although the exact mapping of characters to numeric values is arbitrary and unimportant, a standardized mapping allows you to communicate between programs and peripheral devices. The standard ASCII codes are useful because nearly everyone uses them. Therefore, if you use the ASCII code 65 to represent the character A, then you know that some peripheral device (such as a printer) will correctly interpret this value as the character A.
Because the ASCII character set provides only 128 different characters, an interesting question arises: “What do we do with the additional 128 values ($80..$FF) that we can represent with a byte?” One answer is to ignore those extra values. That will be the primary approach of this book. Another possibility is to extend the ASCII character set by an additional 128 characters. Of course, unless you can get everyone to agree upon one particular extension of the character set,[18] the whole purpose of having a standardized character set will be defeated. And getting everyone to agree is a difficult task.
Despite some major shortcomings, ASCII data is the standard for data interchange across computer systems and programs. Most programs can accept ASCII data, and most programs can produce ASCII data. Because you will probably be dealing with ASCII characters in your programs, it would be wise to study the layout of the character set and memorize a few key ASCII codes (such as those for 0, A, a, and so on). Table A-1 in Appendix A lists all the characters in the standard ASCII character set.
The ASCII character set is divided into four groups of 32 characters. The first 32 characters, ASCII codes $0 through $1F (0 through 31), form a special set of nonprinting characters called the control characters. We call them control characters because they perform various printer and display control operations rather than displaying actual symbols. Examples of control characters include carriage return, which positions the cursor at the beginning of the current line of characters;[19] line feed, which moves the cursor down one line on the output device; and backspace, which moves the cursor back one position to the left. Unfortunately, different control characters perform different operations on different output devices. There is very little standardization among output devices. To find out exactly how a particular control character affects a particular device, you will need to consult its manual.
The second group of 32 ASCII character codes comprises various punctuation symbols, special characters, and the numeric digits. The most notable characters in this group include the space character (ASCII code $20) and the numeric digits (ASCII codes $30..$39).
The third group of 32 ASCII characters contains the uppercase alphabetic characters. The ASCII codes for the characters A through Z lie in the range $41..$5A. Because there are only 26 different alphabetic characters, the remaining six codes hold various special symbols.
The fourth and final group of 32 ASCII character codes represents the lowercase alphabetic symbols, five additional special symbols, and another control character (delete). Note that the lowercase character symbols use the ASCII codes $61..$7A. If you convert the codes for the upper- and lowercase characters to binary, you will notice that the uppercase symbols differ from their lowercase equivalents in exactly one bit position. For example, consider the character codes for E and e appearing in Figure 5-1.
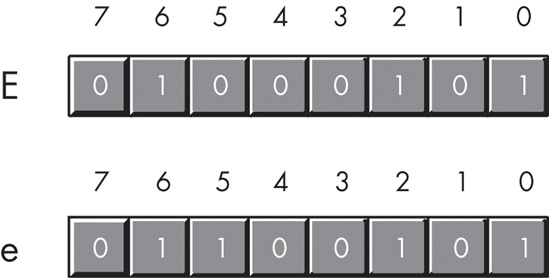
The only place these two codes differ is in bit five. Uppercase alphabetic characters always contain a zero in bit five; lowercase alphabetic characters always contain a one in bit five. You can use this fact to quickly convert an alphabetic character between upper- and lowercase by simply inverting bit five. If you have an uppercase character, you can force it to lowercase by setting bit five to one. If you have a lowercase character and you wish to force it to uppercase, you can do so by setting bit five to zero.
Bits five and six determine the character’s group (see Table 5-1). Therefore, you can convert any upper- or lowercase (or special) character to its corresponding control character by setting bits five and six to zero.
Consider, for a moment, the ASCII codes of the numeric digit characters in Table 5-2. The decimal representations of these ASCII codes are not very enlightening. However, the hexadecimal representation of these ASCII codes reveals something very important — the LO nibble of the ASCII code is the binary equivalent of the represented number. By stripping away (setting to zero) the HO nibble of the ASCII code, you obtain the binary representation of that digit. Conversely, you can convert a binary value in the range 0..9 to its ASCII character representation by simply setting the HO nibble to %0011, or the decimal value 3. Note that you can use the logical AND operation to force the HO bits to zero; likewise, you can use the logical OR operation to force the HO bits to %0011 (decimal 3). For more information on string-to-numeric conversions, see Chapter 2.
Table 5-2. ASCII Codes for the Numeric Digits
Character | Decimal | Hexadecimal |
|---|---|---|
0 | 48 | $30 |
1 | 49 | $31 |
2 | 50 | $32 |
3 | 51 | $33 |
4 | 52 | $34 |
5 | 53 | $35 |
6 | 54 | $36 |
7 | 55 | $37 |
8 | 56 | $38 |
9 | 57 | $39 |
Despite the fact that it is a “standard,” simply encoding your data using ASCII characters does not guarantee compatibility across systems. While it’s true that an A on one machine is most likely an A on another system, there is very little standardization across machines with respect to the use of the control characters. Indeed, of the 32 control codes in the first group of ASCII codes, plus the delete code in the last group, there are only 4 control codes commonly supported by most devices and applications — backspace (BS), tab, carriage return (CR), and line feed (LF). Worse still, different machines often use these “supported” control codes in different ways. End-of-line is a particularly troublesome example. Windows, MS-DOS, CP/M, and other systems mark end-of-line by the two-character sequence CR/LF. The Apple Macintosh, and many other systems, mark end-of-line by a single CR character. Linux, BeOS, and other Unix systems mark end-of-line with a single LF character.
Attempting to exchange simple text files between such different systems can be an experience in frustration. Even if you use standard ASCII characters in all your files on these systems, you will still need to convert the data when exchanging files between them. Fortunately, such conversions are rather simple, and many text editors automatically handle files with different line endings (there are also many available freeware utilities that will do this conversion for you). Even if you have to do this in your own software, all that the conversion involves is copying all characters except the end-of-line sequence from one file to another, and then emitting the new end-of-line sequence whenever you encounter an old end-of-line sequence in the input file.
Although the ASCII character set is, unquestionably, the most popular character representation, it is certainly not the only format available. For example, IBM uses the EBCDIC code on many of its mainframe and mini-computer lines. Because EBCDIC appears mainly on IBM’s big iron and you’ll rarely encounter it on personal computer systems, we’ll only consider it briefly in this book.
EBCDIC (pronounced EB-suh-dic) is an acronym that stands for Extended Binary Coded Decimal Interchange Code. If you’re wondering if there was an unextended version of this character code, the answer is yes. Earlier IBM systems and keypunch machines used a character set known as BCDIC (Binary Coded Decimal Interchange Code). This was a character set based on punched cards and decimal representation (for IBM’s older decimal machines).
The first thing to note about EBCDIC is that it is not a single character set; rather, it is a family of character sets. While the EBCDIC character sets have a common core (for example, the encodings for the alphabetic characters are usually the same), different versions of EBCDIC (known as code pages) have different encodings for punctuation and special characters. Because there are a limited number of encodings available in a single byte, different code pages reuse some of the character encodings for their own special set of characters. So, if you’re given a file that contains EBCDIC characters and someone asks you to translate it to ASCII, you’ll quickly discover that this is not a trivial task.
Before you ever look at the EBCDIC character set, you should first realize that the forerunner of EBCDIC (BCDIC) was in existence long before modern digital computers. BCDIC was born on old-fashioned IBM keypunches and tabulator machines. EBCDIC was simply an extension of that encoding to provide an extended character set for IBM’s computers. However, EBCDIC inherited several peculiarities from BCDIC that seem strange in the context of modern computers. For example, the encodings of the alphabetic characters are not contiguous. This is probably a direct result of the fact that the original character encodings really did use a decimal (BCD) encoding. Originally (in BCD/decimal), the alphabetic characters probably did have a sequential encoding. However, when IBM expanded the character set, they used some of the binary combinations that are not present in the BCD format (values like %1010..%1111). Such binary values appear between two otherwise sequential BCD values, which explains why certain character sequences (such as the alphabetic characters) do not use sequential binary codes in the EBCDIC encoding.
Unfortunately, because of the weirdness of the EBCDIC character set, many common algorithms that work well on ASCII characters simply don’t work with EBCDIC. This chapter will not consider EBCDIC beyond a token mention here or there. However, keep in mind that EBCDIC functional equivalents exist for most ASCII characters. Check out the IBM literature for more details.
Because of the encoding limitations of an 8-bit byte (which has a maximum of 256 characters) and the need to represent more than 256 characters, some computer systems use special codes to indicate that a particular character consumes two bytes rather than a single byte. Such double-byte character sets (DBCSs) do not encode every character using 16 bits — instead, they use a single byte for most character encodings and use two-byte codes only for certain characters.
A typical double-byte character set utilizes the standard ASCII character set along with several additional characters in the range $80..$FF. Certain values in this range are extension codes that tell the software that a second byte immediately follows. Each extension byte allows the DBCS to support another 256 different character codes. With three extension values, for example, the DBCS can support up to 1,021 different characters. You get 256 characters with each of the extension bytes, and you get 253 (256 – 3) characters in the standard single-byte set (minus three because the three extension byte values each consume one of the 256 combinations, and they don’t count as characters).
Back in the days when terminals and computers used memory-mapped character displays, double-byte character sets weren’t very practical. Hardware character generators really want each character to be the same size, and they want to process a limited number of characters. However, as bitmapped displays with software character generators became prevalent (Windows, Macintosh, and Unix/XWindows machines), it became possible to process DBCSs.
Although DBCSs can compactly represent a large number of characters, they demand more computing resources in order to process text in a DBCS format. For example, if you have a zero-terminated string containing DBCS characters (typical in the C/C++ languages), then determining the number of characters in the string can be considerable work. The problem is that some characters in the string consume two bytes while most others consume only one byte. A string length function has to scan byte-by-byte through each character of the string to locate any extension values that indicate that a single character consumes two bytes. This extra comparison more than doubles the time a high-performance string length function takes to execute. Worse still, many common algorithms that people use to manipulate string data fail when they apply them to DBCSs. For example, a common C/C++ trick to step through characters in a string is to either increment or decrement a pointer to the string using expressions like ++ptrChar or −−ptrChar. Unfortunately, these tricks don’t work with DBCSs. While someone using a DBCS probably has a set of standard C library routines available that work properly on DBCSs, it’s also quite likely that other useful character functions they’ve written (or that others have written) don’t work properly with the extended characters in a DBCS. For this and other reasons, you’re far better off using the Unicode character set if you need a standardized character set that supports more than 256 characters. For all the details, keep reading.
A while back, engineers at Apple Computer and Xerox realized that their new computer systems with bitmapped displays and user-selectable fonts could display far more than 256 different characters at one time. Although DBCSs were a possibility, those engineers quickly discovered the compatibility problems associated with double-byte character sets and sought a different route. The solution they came up with was the Unicode character set. Unicode has since become an international standard adopted and supported by nearly every major computer manufacturer and operating system provider (Mac OS, Windows, Linux, Unix, and many other operating systems support Unicode).
Unicode uses a 16-bit word to represent each character. Therefore, Unicode supports up to 65,536 different character codes. This is obviously a huge advance over the 256 possible codes we can represent with an 8-bit byte. Furthermore, Unicode is upward compatible from ASCII; if the HO 9 bits[20] of a Unicode character’s binary representation contain zero, then the LO 7 bits use the standard ASCII code. If the HO 9 bits contain some nonzero value, then the 16 bits form an extended character code (extended from ASCII, that is). If you’re wondering why so many different character codes are necessary, simply note that certain Asian character sets contain 4,096 characters (at least, in their Unicode character subset). The Unicode character set even provides a set of codes you can use to create an application-defined character set. At the time of this writing, approximately half of the 65,536 possible character codes have been defined; the remaining character encodings are reserved for future expansion.
Today, many operating systems and language libraries provide excellent support for Unicode. Microsoft Windows, for example, uses Unicode internally.[21] So operating system calls will actually run faster if you pass them Unicode strings rather than ASCII strings. (When you pass an ASCII string to a modern version of Windows, the OS first converts the string from ASCII to Unicode and then proceeds with the OS API function.) Likewise, whenever Windows returns a string to an application, that string is in Unicode form; if the application needs it in ASCII form, then Windows must convert the string from Unicode to ASCII before returning.
There are two big disadvantages to Unicode, however. First, Unicode character data requires twice as much memory to represent as ASCII or other single-byte encodings do. Although machines have far more memory today (both in RAM and on disk where text files usually reside), doubling the size of text files, databases, and in-memory strings (such as those for a text editor or word processor) can have a significant impact on the system. Worse, because strings are now twice as long, it takes almost twice as many instructions to process a Unicode string as it does to process a string encoded with single-byte characters. This means that string functions may run at half the speed of those functions that process byte-sized character data.[22] The second disadvantage to Unicode is that most of the world’s data files out there are in ASCII or EBCDIC form, so if you use Unicode within an application, you wind up spending considerable time converting between Unicode and those other character sets.
Although Unicode is a widely accepted standard, it still is not seeing widespread use (though it is becoming more popular every day). Quite soon, Unicode will hit “critical mass” and really take off. However, that point is still in the future, so most of the examples in this text will continue to use ASCII characters. Still, at some point in the not-too-distant future, it wouldn’t be unreasonable to emphasize Unicode rather than ASCII in a book like this.
After integers, character strings are probably the most common type in use in modern programs. In general, a character string is a sequence of characters that possesses two main attributes: a length and the character data.
Character strings may also possess other attributes, such as the maximum length allowable for that particular variable or a reference count that specifies how many different string variables refer to the same character string. We’ll look at these attributes and how programs can use them in the following sections, which describe various string formats and some of the possible string operations.
Different languages use different data structures to represent strings. Some string formats use less memory, others allow faster processing, some are more convenient to use, and some provide additional functionality for the programmer and operating system. To better understand the reasoning behind the design of character strings, it is instructive to look at some common string representations popularized by various high-level languages.
Without question, zero-terminated strings are probably the most common string representation in use today, because this is the native string format for C, C++, Java, and several other languages. In addition, you’ll find zero-terminated strings in use in programs written in languages that don’t have a specific native string format, such as assembly language.
A zero-terminated ASCII string is a sequence containing zero or more 8-bit character codes ending with a byte containing zero (or, in the case of Unicode, a sequence containing zero or more 16-bit character codes ending with a 16-bit word containing zero). For example, in C/C++, the ASCII string “abc” requires four bytes: one byte for each of the three characters a, b, and c, followed by a zero byte.
Zero-terminated strings have a couple of advantages over other string formats:
Zero-terminated strings can represent strings of any practical length with only one byte of overhead (two bytes in Unicode).
Given the popularity of the C/C++ programming languages, high-performance string processing libraries are available that work well with zero-terminated strings.
Zero-terminated strings are easy to implement. Indeed, except for dealing with string literal constants, the C/C++ programming languages don’t provide native string support. As far as the C and C++ languages are concerned, strings are just arrays of characters. That’s probably why C’s designers chose this format in the first place — so they wouldn’t have to clutter up the language with string operators.
This format allows you to easily represent zero-terminated strings in any language that provides the ability to create an array of characters.
However, despite these advantages, zero-terminated strings also have disadvantages — they are not always the best choice for representing character string data. These disadvantages are as follows:
String functions often aren’t very efficient when operating on zero-terminated strings. Many string operations need to know the length of the string before working on the string data. The only reasonable way to compute the length of a zero-terminated string is to scan the string from the beginning to the end. The longer your strings are, the slower this function runs. Therefore, the zero-terminated string format isn’t the best choice if you need to process long strings.
Though this is a minor problem, with the zero-terminated string format you cannot easily represent any character whose character code is zero (such as the ASCII NUL character).
With zero-terminated strings there is no information contained within the string data itself that tells you how long a string can grow beyond the terminating zero byte. Therefore, some string functions, like concatenation, can only extend the length of an existing string variable and check for overflow if the caller explicitly passes in the maximum length.
A second string format, length-prefixed strings, overcomes some of the problems with zero-terminated strings. Length-prefixed strings are common in languages like Pascal; they generally consist of a single byte that specifies the length of the string, followed by zero or more 8-bit character codes. In a length-prefixed scheme, the string “abc” would consist of four bytes: the length byte ($03), followed by a, b, and c.
Length-prefixed strings solve two of the problems associated with zero-terminated strings. First, it is possible to represent the NUL character in a length-prefixed string, and second, string operations are more efficient. Another advantage to length-prefixed strings is that the length is usually sitting at position zero in the string (when viewing the string as an array of characters), so the first character of the string begins at index one in the array representation of the string. For many string functions, having a one-based index into the character data is much more convenient than a zero-based index (which zero-terminated strings use).
Length-prefixed strings do suffer from their own drawbacks, the principal drawback being that they are limited to a maximum of 255 characters in length (assuming a 1-byte length prefix). One can remove this limitation by using a 2- or 4-byte length value, but doing so increases the amount of overhead data from one to two or four bytes.
An interesting string format that works for 7-bit codes like ASCII involves using the HO bit to indicate the end of the string. All but the last character code in the string would have their HO bit clear (or set, your choice) and the last character in the string would have its HO bit set (or clear, if all the other HO bits are set).
This 7-bit string format has several disadvantages:
However, the big advantage of 7-bit strings is that they don’t require any overhead bytes to encode the length. Assembly language (using a macro to create literal string constants) is probably the best language to use when dealing with 7-bit strings — because the advantage of 7-bit strings is their compactness, and assembly language programmers tend to be the ones who worry most about compactness, this is a good match. Here’s an HLA macro that will convert a literal string constant to a 7-bit string:
#macro sbs( s );
// Grab all but the last character of the string:
(@substr( s, 0, @length(s) − 1) +
// Concatenate the last character with its HO bit set:
char( uns8( char( @substr( s, @length(s) − 1, 1))) | $80 ))
#endmacro
. . .
byte sbs( "Hello World" );As long as you’re not too concerned about a few extra bytes of overhead per string, it’s quite possible to create a string format that combines the advantages of both length-prefixed and zero-terminated strings without their disadvantages. The HLA language has done this with its native string format.[23]
The biggest drawback to the HLA character string format is the amount of overhead required for each string (which can be significant, percentage-wise, if you’re in a memory-constrained environment and you process many small strings). HLA strings contain both a length prefix and a zero-terminating byte, as well as some other information, that costs nine bytes of overhead per string.[24]
The HLA string format uses a 4-byte length prefix, allowing character strings to be just over four billion characters long (obviously, this is far more than any practical application will use). HLA also sticks a zero byte at the end of the character string data, so HLA strings are upward compatible with string functions that reference (but do not change the length of) zero-terminated strings. The additional four bytes of overhead in an HLA string contain the maximum legal length for that string. Having this extra field allows HLA string functions to check for string overflow, if necessary. In memory, HLA strings take the form shown in Figure 5-2.
The four bytes immediately before the first character of the string contain the current string length. The four bytes preceding the current string length contain the maximum string length. Immediately following the character data is a zero byte. Finally, HLA always ensures that the string data structure’s length is a multiple of four bytes long (for performance reasons), so there may be up to three additional bytes of padding at the end of the object in memory (note that the string appearing in Figure 5-2 requires only one byte of padding to ensure that the data structure is a multiple of four bytes in length).
HLA string variables are actually pointers that contain the byte address of the first character in the string. To access the length fields, you would load the value of the string pointer into a 32-bit register. You’d access the Length field at offset −4 from the base register and the MaxLength field at offset −8 from the base register. Here’s an example:
static
s :string := "Hello World";
. . .
mov( s, esi ); // Move the address of 'H' in "Hello World"
// into esi.
mov( [esi-4], ecx ); // Puts length of string (11 for "Hello World")
// into ECX.
. . .
mov( s, esi );
cmp( eax, [esi-8] ); // See if value in EAX exceeds the maximum
// string length.
ja StringOverflow;One nice thing about HLA string variables is that (as read-only objects) HLA strings are compatible with zero-terminated strings. For example, if you have a function written in C or some other language that’s expecting you to pass it a zero-terminated string, you can call that function and pass it an HLA string variable, like this:
someCFunc( hlaStringVar );
The only catch is that the C function must not make any changes to the string that would affect its length (because the C code won’t update the Length field of the HLA string). Of course, you can always call a C strlen function upon returning to update the length field yourself, but generally, it’s best not to pass HLA strings to a function that modifies zero-terminated strings.
The string formats we’ve considered up to this point have kept the attribute information (the lengths and terminating bytes) for a string in memory along with the character data. Perhaps a slightly more flexible scheme is to maintain information like the maximum and current lengths of a string in a record structure that also contains a pointer to the character data. We call such records descriptors. Consider the following Pascal/Delphi/Kylix data structure:
type
dString :record
curLength :integer;
strData :^char;
end;Note that this data structure does not hold the actual character data. Instead, the strData pointer contains the address of the first character of the string. The curLength field specifies the current length of the string. Of course, you could add any other fields you like to this record, like a maximum length field, though a maximum length isn’t usually necessary because most string formats employing a descriptor are dynamic (as will be discussed in the next section). Most string formats employing a descriptor just maintain the length field.
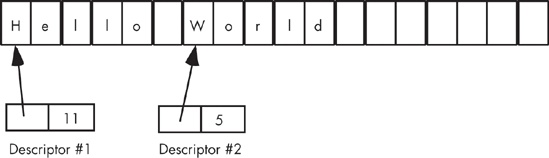
An interesting attribute of a descriptor-based string system is that the actual character data associated with a string could be part of a larger string. Because there are no length or terminating bytes within the actual character data, it is possible to have the character data for two strings overlap. For example, take a look at Figure 5-3. In this example, there are two strings: one representing the string “Hello World” and the second representing “World.” Notice that the two strings overlap. This can save memory and make certain functions (like substring) very efficient. Of course, when strings overlap as these ones do, you cannot modify the string data because that could wipe out part of some other string.
Based on the various string formats covered thus far, we can now define three string types according to when the system allocates storage for the string. There are static strings, pseudo-dynamic strings, and dynamic strings.
Pure static strings are those whose maximum size a programmer chooses when writing the program. Pascal (and Delphi “short” strings) fall into this category. Arrays of characters that you will use to hold zero-terminated strings in C/C++ also fall into this category. Consider the following declaration in Pascal:
(* Pascal static string example *) var pascalString :string(255); // Max length will always be 255 characters.
And here’s an example in C/C++:
// C/C++ static string example:
char cString[256]; // Max length will always be 255 characters
// (plus zero byte).While the program is running, there is no way to increase the maximum sizes of these static strings. Nor is there any way to reduce the storage they will use. These string objects will consume 256 bytes at run time, period. One advantage to pure static strings is that the compiler can determine their maximum length at compile time and implicitly pass this information to a string function so it can test for bounds violations at run time.
Pseudo-dynamic strings are those whose length the system sets at run time by calling a memory-management function like malloc to allocate storage for the string. However, once the system allocates storage for the string, the maximum length of the string is fixed. HLA strings generally operate in this manner.[25] An HLA programmer would typically call the stralloc function to allocate storage for a string variable. Once created via stralloc, however, that particular string object has a fixed length that cannot change.[26]
Dynamic string systems, which typically use a descriptor-based format, will automatically allocate sufficient storage for a string object whenever you create a new string or otherwise do something that affects an existing string. Operations like string assignment and substring are relatively trivial in dynamic string systems — generally they only copy the string descriptor data, so such operations are fast. However, as the section on descriptor strings notes, when using strings this way, one cannot store data back into a string object, because it could modify data that is part of other string objects in the system.
The solution to this problem is to use a technique known as copy on write. Whenever a string function needs to change some characters in a dynamic string, the function first makes a copy of the string and then makes whatever modifications are necessary to the copy of the data. Research with typical programs suggests that copy-on-write semantics can improve the performance of many applications because operations like string assignment and substring are far more common than the modification of character data within strings. The only drawback to this mechanism is that after several modifications to string data in memory, there may be sections of the string heap area that contain character data that are no longer in use. To avoid a memory leak, dynamic string systems employing copy-on-write usually provide garbage collection code that scans through the string area looking for stale character data in order to recover that memory for other purposes. Unfortunately, depending on the algorithms in use, garbage collection can be slow.
Consider the case where you have two string descriptors (or just pointers) pointing at the same string data in memory. Clearly, you cannot deallocate (that is, reuse for a different purpose) the storage associated with one of these pointers while the program is still using the other pointer to access the same data. One (alas, common) solution is to make the programmer responsible for keeping track of such details. Unfortunately, as applications become more complex, relying on the programmer to keep track of such details often leads to dangling pointers, memory leaks, and other pointer-related problems in the software. A better solution is to allow the programmer to deallocate the storage for the character data in the string, and to have the deallocation process hold off on the actual deallocation until the programmer releases the last pointer referencing the character data for the string. To accomplish this, a string system can use reference counters to track the pointers and their associated data.
A reference counter is an integer that counts the number of pointers that reference a string’s character data in memory. Every time you assign the address of the string to some pointer, you increment the reference counter by one. Likewise, whenever you wish to deallocate the storage associated with the character data for the string, you decrement the reference counter. Deallocation of the storage for the actual character data doesn’t happen until the reference counter decrements to zero.
Reference counting works great when the language handles the details of string assignment automatically for you. If you try to implement reference counting manually, the only difficulty is ensuring that you always increment the reference counter when you assign a string pointer to some other pointer variable. The best way to do this is to never assign pointers directly but to handle all string assignments via some function (or macro) call that updates the reference counters in addition to copying the pointer data. If your code fails to update the reference counter properly, you’ll wind up with dangling pointers or memory leaks.
Although Delphi and Kylix provide a “short string” format that is compatible with the length-prefixed strings in earlier versions of Delphi, later versions of Delphi (4.0 and later) and Kylix use dynamic strings for their string data. Although this string format is unpublished (and, therefore, subject to change), experiments with Delphi at the time of this writing indicate that Delphi’s string format is very similar to HLA’s. Delphi uses a zero-terminated sequence of characters with a leading string length and a reference counter (rather than a maximum length as HLA uses). Figure 5-4 shows the layout of a Delphi string in memory.
Just like HLA, Delphi/Kylix string variables are pointers that point to the first character of the actual string data. To access the length and reference-counter fields, the Delphi/Kylix string routines use a negative offset of −4 and −8 from the character data’s base address. However, because this string format is not published, applications should never access the length or reference counter fields directly. Delphi/Kylix provides a length function that extracts the string length for you, and there really is no need for your applications to access the reference counter field because the Delphi/Kylix string functions maintain this field automatically.
Typically, you will use the string format your language provides, unless you have special requirements. When you do have such requirements, you will find that most languages provide user-defined data-structuring capabilities that allow you to create your own custom string formats.
About the only problem you’ll run into is that the language will probably insist on a single string format for literal string constants. However, you can usually write a short conversion function that will translate the literal strings in your language to whatever format you choose.
Like strings, character sets are another composite data type built upon the character data type. A character set is a mathematical set of characters. Membership in a set is a binary relation. A character is either in the set or it is not in the set; you cannot have multiple copies of the same character in a character set. Furthermore, the concept of sequence (whether one character comes before another, as in a string) is foreign to a character set. If two characters are members of a set, their order in the set is irrelevant.
Table 5-3 lists some of the more common character set functions to give you an idea of the types of operations applications typically perform on character sets.
Table 5-3. Common Character Set Functions
Function/Operator | Description |
|---|---|
Membership (IN) | Checks to see if a character is a member of a character set (returns true/false). |
Intersection | Returns the intersection of two character sets (that is, the set of characters that are members of both sets). |
Union | Returns the union of two character sets (that is, all the characters that are members of either set or both sets). |
Difference | Returns the difference of two sets (that is, those characters in one set that are not in the other). |
Extraction | Extracts a single character from a set. |
Subset | Returns true if one character set is a subset of another. |
Proper subset | Returns true if one character set is a proper subset of another. |
Superset | Returns true if one character set is a superset of another. |
Proper superset | Returns true if one character set is a proper superset of another. |
Equality | Returns true if one character set is equal to another. |
Inequality | Returns true if one character set is not equal to another. |
There are many different ways to represent character sets. Several languages implement character sets using an array of Boolean values (one Boolean value for each possible character code). Each Boolean value determines whether its corresponding character is or is not a member of the character set: true indicates that the specified character is a member of the set; false indicates that the corresponding character is not a member of the set. To conserve memory, most character set implementations allocate only a single bit for each character in the set; therefore, such character sets consume 16 bytes (128 bits) of memory when supporting 128 characters, or 32 bytes (256 bits) when supporting up to 256 possible characters. This representation of a character set is known as a powerset.
The HLA language uses an array of 16 bytes to represent the 128 possible ASCII characters. This array of 128 bits is organized in memory, as shown in Figure 5-5.

Bit zero of byte zero corresponds to ASCII code zero (the NUL character). If this bit is one, then the character set contains the NUL character; if this bit is zero, then the character set does not contain the NUL character. Likewise, bit one of byte eight corresponds to ASCII code 65, an uppercase A. Bit 65 will contain a one if A is a current member of the character set, it will contain zero if A is not a member of the set.
Pascal (for example, Delphi/Kylix) uses a similar scheme to represent character sets. Delphi allows up to 256 characters in a character set, so Delphi/Kylix character sets consume 256 bits (or 32 bytes) of memory.
While there are other possible ways to implement character sets, this bit vector (array) implementation has the advantage that it is very easy to implement set operations like union, intersection, difference comparison, and membership tests.
Sometimes a powerset bitmap just isn’t the right representation for a character set. For example, if your sets are always very small (no more than three or four members), using 16 or 32 bytes to represent such a set can be overkill. For very small sets, using a character string to represent a list of characters is probably the best way to go.[27] If you rarely have more than a few characters in a set, scanning through a string to locate a particular character is probably efficient enough for most applications.
On the other hand, if your character set has a large number of possible characters, then the powerset representation for the character set could become quite large (for example, Unicode character sets would require 8,192 bytes of memory to implement them as powersets). For these reasons (and more), the powerset representation isn’t always the best. A list or character string representation could be more appropriate in such situations.
There is very little that is sacred about the ASCII, EBCDIC, and Unicode character sets. Their primary advantage is that they are international standards to which many systems adhere. If you stick with one of these standards, chances are good you’ll be able to exchange information with other people. That is the whole purpose of these standardized codes.
However, these codes were not designed to make various character computations easy. ASCII and EBCDIC were designed with now-antiquated hardware in mind. In particular, the ASCII character set was designed to correspond to the mechanical teletypewriters’ keyboards, and EBCDIC was designed with old punched-card systems in mind. Given that such equipment is mainly found in museums today, the layout of the codes in these character sets has almost no benefit in modern computer systems. If we could design our own character sets today, they’d probably be considerably different from ASCII or EBCDIC. They’d probably be based on modern keyboards (so they’d include codes for common keys, like left arrow, right arrow, PgUp, and PgDn). The codes would also be laid out to make various common computations a whole lot easier.
Although the ASCII and EBCDIC character sets are not going away any time soon, there is nothing stopping you from defining your own application-specific character set. Of course, an application-specific character set is, well, application-specific, and you won’t be able to share text files containing characters encoded in your custom character set with applications that are ignorant of your private encoding. But it is fairly easy to translate between different character sets using a lookup table, so you can convert between your application’s internal character set and an external character set (like ASCII) when performing I/O operations. Assuming you pick a reasonable encoding that makes your programs more efficient overall, the loss of efficiency during I/O can be worthwhile. But how do you choose an encoding for your character set?
The first question you have to ask yourself is, “How many characters do you want to support in your character set?” Obviously, the number of characters you choose will directly affect the size of your character data. An easy choice is 256 possible characters, because bytes are the most common primitive data type that software uses to represent character data. Keep in mind, however, that if you don’t really need 256 characters, you probably shouldn’t try to define that many characters in your character set. For example, if you can get by with 128 characters or even 64 characters in your custom character set, then “text files” you create with such character sets will compress better. Likewise, data transmissions using your custom character set will be faster if you only have to transmit six or seven bits for each character instead of eight. If you need more than 256 characters, you’ll have to weigh the advantages and disadvantages of using multiple code pages, double-byte character sets, or 16-bit characters. And keep in mind that Unicode provides for user-defined characters. So if you need more than 256 characters in your character set, you might consider using Unicode and the user-defined points (character sets) to remain “somewhat standard” with the rest of the world.
However, in this section, we’ll define a character set containing 128 characters using an 8-bit byte. For the most part, we’re going to simply rearrange the codes in the ASCII character set to make them more convenient for several calculations, and we’re going to rename a few of the control codes so they make sense on modern systems instead of the old mainframes and teletypes for which they were created. However, we will add a few new characters beyond those defined by the ASCII standard. Again, the main purpose of this exercise is to make various computations more efficient, not create new characters. We’ll call this character set the HyCode character set.
Note
The development of HyCode in this chapter is not an attempt to create some new character set standard. HyCode is simply a demonstration of how you can create a custom, application-specific, character set to improve your programs.
We should think about several things when designing a new character set. For example, do we need to be able to represent strings of characters using an existing string format? This can have a bearing on the encoding of our strings. For example, if you want to be able to use function libraries that operate on zero-terminated strings, then you need to reserve encoding zero in your custom character set for use as an end-of-string marker. Do keep in mind, however, that a fair number of string functions won’t work with your new character set, no matter what you do. For example, functions like stricmp only work if you use the same representation for alphabetic characters as ASCII (or some other common character set). Therefore, you shouldn’t feel hampered by the requirements of some particular string representation, because you’re going to have to write many of your own string functions to process your custom characters. The HyCode character set doesn’t reserve code zero for an end-of-string marker, and that’s okay because, as we’ve seen, zero-terminated strings are not very efficient.
If you look at programs that make use of character functions, you’ll see that certain functions occur frequently, such as these:
Check a character to see if it is a digit.
Convert a digit character to its numeric equivalent.
Convert a numeric digit to its character equivalent.
Check a character to see if it is alphabetic.
Check a character to see if it is a lowercase character.
Check a character to see if it is an uppercase character.
Compare two characters (or strings) using a case-insensitive comparison.
Sort a set of alphabetic strings (case-sensitive and case-insensitive sorting).
Check a character to see if it is alphanumeric.
Check a character to see if it is legal in an identifier.
Check a character to see if it is a common arithmetic or logical operator.
Check a character to see if it is a bracketing character (that is, one of (, ), [, ], {, }, <, or >).
Check a character to see if it is a punctuation character.
Check a character to see if it is a whitespace character (such as a space, tab, or newline).
Check a character to see if it is a cursor control character.
Check a character to see if it is a scroll control key (such as PgUp, PgDn, home, and end).
Check a character to see if it is a function key.
We’ll design the HyCode character set to make these types of operations as efficient and as easy as possible. A huge improvement we can make over the ASCII character set is to assign contiguous character codes to characters belonging to the same type, such as alphabetic characters and control characters. This will allow us to do any of the tests above by using a pair of comparisons. For example, it would be nice if we could determine that a particular character is some sort of punctuation character by comparing against two values that represent upper and lower bounds of the entire range of such characters. While it’s not possible to satisfy every conceivable range comparison this way, we can design our character set to accommodate the most common tests with as few comparisons as possible. Although ASCII does organize some of the character sequences in a reasonable fashion, we can do much better. For example, in ASCII, it is not possible to check for a punctuation character with a pair of comparisons because the punctuation characters are spread throughout the character set.
Consider the first three functions in the previous list — we can achieve all three of these goals by reserving the character codes zero through nine for the characters 0 through 9. First, by using a single unsigned comparison to check if a character code is less than or equal to nine, we can see if a character is a digit. Next, converting between characters and their numeric representations is trivial, because the character code and the numeric representation are one and the same.
Dealing with alphabetic characters is another common character/string problem. The ASCII character set, though nowhere near as bad as EBCDIC, just isn’t well designed for dealing with alphabetic character tests and operations. Here are some problems with ASCII that we’ll solve with HyCode:
The alphabetic characters lie in two disjoint ranges. Tests for an alphabetic character, for example, require four comparisons.
The lowercase characters have ASCII codes that are greater than the uppercase characters. For comparison purposes, if we’re going to do a case-sensitive comparison, it’s more intuitive to treat lowercase characters as being less than uppercase characters.
All lowercase characters have a greater value than any individual uppercase character. This leads to counterintuitive results such as a being greater than B even though any school child who has learned their ABCs knows that this isn’t the case.
HyCode solves these problems in a couple of interesting ways. First, HyCode uses encodings $4C through $7F to represent the 52 alphabetic characters. Because HyCode only uses 128 character codes ($00..$7F), the alphabetic codes consume the last 52 character codes. This means that if we want to test a character to see if it is alphabetic, we only need to compare whether the code is greater than or equal to $4C. In a high-level language, you’d write the comparison like this:
if( c >= 76) . . .
Or if your compiler supports the HyCode character set, like this:
if( c >= 'a') . . .
In assembly language, you could use a pair of instructions like the following:
cmp( al, 76 );
jnae NotAlphabetic;
// Execute these statements if it's alphabetic
NotAlphabetic:Another advantage of HyCode (and another big difference from other character sets) is that HyCode interleaves the lowercase and uppercase characters (that is, the sequential encodings are for the characters a, A, b, B, c, C, and so on). This makes sorting and comparing strings very easy, regardless of whether you’re doing a case-sensitive or case-insensitive search. The inter-leaving uses the LO bit of the character code to determine whether the character code is lowercase (LO bit is zero) or uppercase (LO bit is one). HyCode uses the following encodings for alphabetic characters:
a:76, A:77, b:78, B:79, c:80, C:81, . . . y:124, Y:125, z:126, Z:127
Checking for an uppercase or lowercase alphabetic using HyCode is a little more work than checking whether a character is alphabetic, but when working in assembly it’s still less work than you’ll need for the equivalent ASCII comparison. To test a character to see if it’s a member of a single case, you effectively need two comparisons; the first test is to see if it’s alphabetic, and then you determine its case. In C/C++ you’d probably use statements like the following:
if( (c >= 76) && (c & 1))
{
// execute this code if it's an uppercase character
}
if( (c >= 76) && !(c & 1))
{
// execute this code if it's a lowercase character
}Note that the subexpression (c & 1) evaluates true (1) if the LO bit of c is one, meaning we have an uppercase character if c is alphabetic. Likewise, !(c & 1) evaluates true if the LO bit of c is zero, meaning we have a lowercase character. If you’re working in 80x86 assembly language, you can actually test a character to see if it is uppercase or lowercase by using three machine instructions:
// Note: ROR(1, AL) maps lowercase to the range $26..$3F (38..63)
// and uppercase to $A6..$BF (166..191). Note that all other characters
// get mapped to smaller values within these ranges.
ror( 1, al );
cmp( al, $26 );
jnae NotLower; // Note: must be an unsigned branch!
// Code that deals with a lowercase character.
NotLower:
// For uppercase, note that the ROR creates codes in the range $A8..$BF which
// are negative (8-bit) values. They also happen to be the *most* negative
// numbers that ROR will produce from the HyCode character set.
ror( 1, al );
cmp( al, $a6 );
jge NotUpper; // Note: must be a signed branch!
// Code that deals with an uppercase character.
NotUpper:Unfortunately, very few languages provide the equivalent of an ror operation, and only a few languages allow you to (easily) treat character values as signed and unsigned within the same code sequence. Therefore, this sequence is probably limited to assembly language programs.
The HyCode grouping of alphabetic characters means that lexicographical ordering (i.e., “dictionary ordering”) is almost free, no matter what language you’re using. As long as you can live with the fact that lowercase characters are less than the corresponding uppercase characters, sorting your strings by comparing the HyCode character values will give you lexicographical order. This is because, unlike ASCII, HyCode defines the following relations on the alphabetic characters:
a < A < b < B < c < C < d < D < . . . < w < W < x < X < y < Y < z < Z
This is exactly the relationship you want for lexicographical ordering, and it’s also the intuitive relationship most people would expect.
Case-insensitive comparisons only involve a tiny bit more work than straight case-sensitive comparisons (and far less work than doing case-insensitive comparisons using a character set like ASCII). When comparing two alphabetic characters, you simply mask out their LO bits (or force them both to one) and you automatically get a case-insensitive comparison.
To see the benefit of the HyCode character set when doing case-insensitive comparisons, let’s first take a look at what the standard case-insensitive character comparison would look like in C/C++ for two ASCII characters:
if( toupper( c ) == toupper( d ))
{
// do code that handles c==d using a case-insensitive comparison.
}This code doesn’t look too bad, but consider what the toupper function (or, usually, macro) expands to:[28]
#define toupper(ch) ((ch >= 'a' && ch <= 'z') ? ch & 0x5f : ch )
With this macro, you wind up with the following once the C preprocessor expands the former if statement:
if
(
((c >= 'a' && c <= 'z') ? c & 0x5f : c )
== ((d >= 'a' && d <= 'z') ? d & 0x5f : d )
)
{
// do code that handles c==d using a case-insensitive comparison.
}This example expands to 80x86 code similar to this:
// assume c is in cl and d is in dl.
cmp( cl, 'a' ); // See if c is in the range 'a'..'z'
jb NotLower;
cmp( cl, 'z' );
ja NotLower;
and( $5f, cl ); // Convert lowercase char in cl to uppercase.
NotLower:
cmp( dl, 'a' ); // See if d is in the range 'a'..'z'
jb NotLower2;
cmp( dl, 'z' );
ja NotLower2;
and( $5f, dl ); // Convert lowercase char in dl to uppercase.
NotLower2:
cmp( cl, dl ); // Compare the (now uppercase if alphabetic)
// chars.
jne NotEqual; // Skip the code that handles c==d if they're
// not equal.
// do code that handles c==d using a case-insensitive comparison.
NotEqual:When using HyCode, case-insensitive comparisons are much simpler. Here’s what the HLA assembly code would look like:
// Check to see if CL is alphabetic. No need to check DL as the comparison
// will always fail if DL is non-alphabetic.
cmp( cl, 76 ); // If CL < 76 ('a') then it's not alphabetic
jb TestEqual; // and there is no way the two chars are equal
// (even ignoring case).
or( 1, cl ); // CL is alpha, force it to uppercase.
or( 1, dl ); // DL may or may not be alpha. Force to
// uppercase if it is.
TestEqual:
cmp( cl, dl ); // Compare the uppercase versions of the chars.
jne NotEqual; // Bail out if they're not equal.
TheyreEqual:
// do code that handles c==d using a case-insensitive comparison.
NotEqual:As you can see, the HyCode sequence uses half the instructions for a case- insensitive comparison of two characters.
Because alphabetic characters are at one end of the character-code range and numeric characters are at the other, it takes two comparisons to check a character to see if it’s alphanumeric (which is still better than the four comparisons necessary when using ASCII). Here’s the Pascal/Delphi/Kylix code you’d use to see if a character is alphanumeric:
if( ch < chr(10) or ch >= chr(76)) then . . .
Several programs (beyond compilers) need to efficiently process strings of characters that represent program identifiers. Most languages allow alphanumeric characters in identifiers, and, as you just saw, we can check a character to see if it’s alphanumeric using only two comparisons.
Many languages also allow underscores within identifiers, and some languages, such as MASM and TASM, allow other characters like the at character (@) and dollar sign ($) to appear within identifiers. Therefore, by assigning the underscore character the value 75, and by assigning the $ and @ characters the codes 73 and 74, we can still test for an identifier character using only two comparisons.
For similar reasons, the HyCode character set groups several other classes of characters into contiguous character-code ranges. For example, HyCode groups the cursor control keys together, the whitespace characters, the bracketing characters (parentheses, brackets, braces, and angle brackets), the arithmetic operators, the punctuation characters, and so on. Table 5-4 lists the complete HyCode character set. If you study the numeric codes assigned to each of these characters, you’ll discover that their code assignments allow efficient computation of most of the character operations described earlier.
Table 5-4. The HyCode Character Set
Binary | Hex | Decimal | Character | Binary | Hex | Decimal | Character |
|---|---|---|---|---|---|---|---|
0000_0000 | 00 | 0 | 0 | 0001_1110 | 1E | 30 | End |
0000_0001 | 01 | 1 | 1 | 0001_1111 | 1F | 31 | Home |
0000_0010 | 02 | 2 | 2 | 0010_0000 | 20 | 32 | PgDn |
0000_0011 | 03 | 3 | 3 | 0010_0001 | 21 | 33 | PgUp |
0000_0100 | 04 | 4 | 4 | 0010_0010 | 22 | 34 | left |
0000_0101 | 05 | 5 | 5 | 0010_0011 | 23 | 35 | right |
0000_0110 | 06 | 6 | 6 | 0010_0100 | 24 | 36 | up |
0000_0111 | 07 | 7 | 7 | 0010_0101 | 25 | 37 | down/linefeed |
0000_1000 | 08 | 8 | 8 | 0010_0110 | 26 | 38 | nonbreaking space |
0000_1001 | 09 | 9 | 9 | 0010_0111 | 27 | 39 | paragraph |
0000_1010 | 0A | 10 | keypad | 0010_1000 | 28 | 40 | carriage return |
0000_1011 | 0B | 11 | cursor | 0010_1001 | 29 | 41 | newline/enter |
0000_1100 | 0C | 12 | function | 0010_1010 | 2A | 42 | tab |
0000_1101 | 0D | 13 | alt | 0010_1011 | 2B | 43 | space |
0000_1110 | 0E | 14 | control | 0010_1100 | 2C | 44 | ( |
0000_1111 | 0F | 15 | command | 0010_1101 | 2D | 45 | ) |
0001_0000 | 10 | 16 | len | 0010_1110 | 2E | 46 | [ |
0001_0001 | 11 | 17 | len128 | 0010_1111 | 2F | 47 | ] |
0001_0010 | 12 | 18 | bin128 | 0011_0000 | 30 | 48 | { |
0001_0011 | 13 | 19 | EOS | 0011_0001 | 31 | 49 | } |
0001_0100 | 14 | 20 | EOF | 0011_0010 | 32 | 50 | < |
0001_0101 | 15 | 21 | sentinel | 0011_0011 | 33 | 51 | > |
0001_0110 | 16 | 22 | break/interrupt | 0011_0100 | 34 | 52 | = |
0001_0111 | 17 | 23 | escape/cancel | 0011_0101 | 35 | 53 | ^ |
0001_1000 | 18 | 24 | pause | 0011_0110 | 36 | 54 | | |
0001_1001 | 19 | 25 | bell | 0011_0111 | 37 | 55 | & |
0001_1010 | 1A | 26 | back tab | 0011_1000 | 38 | 56 | − |
0001_1011 | 1B | 27 | backspace | 0011_1001 | 39 | 57 | + |
0001_1100 | 1C | 28 | delete | ||||
0001_1101 | 1D | 29 | Insert | ||||
0011_1010 | 3A | 58 | * | 0101_1101 | 5D | 93 | I |
0011_1011 | 3B | 59 | / | 0101_1110 | 5E | 94 | j |
0011_1100 | 3C | 60 | % | 0101_1111 | 5F | 95 | J |
0011_1101 | 3D | 61 | ˜ | 0110_0000 | 60 | 96 | k |
0011_1110 | 3E | 62 | ! | 0110_0001 | 61 | 97 | K |
0011_1111 | 3F | 63 | ? | 0110_0010 | 62 | 98 | l |
0100_0000 | 40 | 64 | , | 0110_0011 | 63 | 99 | L |
0100_0001 | 41 | 65 | . | 0110_0100 | 64 | 100 | m |
0100_0010 | 42 | 66 | : | 0110_0101 | 65 | 101 | M |
0100_0011 | 43 | 67 | ; | 0110_0110 | 66 | 102 | n |
0100_0100 | 44 | 68 | “ | 0110_0111 | 67 | 103 | N |
0100_0101 | 45 | 69 | ’ | 0110_1000 | 68 | 104 | o |
0100_0110 | 46 | 70 | ' | 0110_1001 | 69 | 105 | O |
0100_0111 | 47 | 71 | 0110_1010 | 6A | 106 | p | |
0100_1000 | 48 | 72 | # | 0110_1011 | 6B | 107 | P |
0100_1001 | 49 | 73 | $ | 0110_1100 | 6C | 108 | q |
0100_1010 | 4A | 74 | @ | 0110_1101 | 6D | 109 | Q |
0100_1011 | 4B | 75 | _ | 0110_1110 | 6E | 110 | r |
0100_1100 | 4C | 76 | a | 0110_1111 | 6F | 111 | R |
0100_1101 | 4D | 77 | A | 0111_0000 | 70 | 112 | s |
0100_1110 | 4E | 78 | b | 0111_0001 | 71 | 113 | S |
0100_1111 | 4F | 79 | B | 0111_0010 | 72 | 114 | t |
0101_0000 | 50 | 80 | c | 0111_0011 | 73 | 115 | T |
0101_0001 | 51 | 81 | C | 0111_0100 | 74 | 116 | u |
0101_0010 | 52 | 82 | d | 0111_0101 | 75 | 117 | U |
0101_0011 | 53 | 83 | D | 0111_0110 | 76 | 118 | v |
0101_0100 | 54 | 84 | e | 0111_0111 | 77 | 119 | V |
0101_0101 | 55 | 85 | E | 0111_1000 | 78 | 120 | w |
0101_0110 | 56 | 86 | f | 0111_1001 | 79 | 121 | W |
0101_0111 | 57 | 87 | F | 0111_1010 | 7A | 122 | x |
0101_1000 | 58 | 88 | g | 0111_1011 | 7B | 123 | X |
0101_1001 | 59 | 89 | G | 0111_1100 | 7C | 124 | y |
0101_1010 | 5A | 90 | h | 0111_1101 | 7D | 125 | Y |
0101_1011 | 5B | 91 | H | 0111_1110 | 7E | 126 | z |
0101_1100 | 5C | 92 | i | 0111_1111 | 7F | 127 | Z |
ASCII, EBCDIC, and Unicode are all international standards. You can find out more about the EBCDIC character set families on IBM’s website (http://www.ibm.com). ASCII and Unicode are both ISO standards, and ISO provides reports for both character sets. Generally, those reports cost money, but you can also find out lots of information about the ASCII and Unicode character sets by searching for them by name on the Internet. You can also read about UNICODE at http://www.unicode.org.
Those who are interested in more information about character, string, and character set functions should consider reading references on the following languages:
The Awk programming language
The Perl programming language
The SNOBOL4 programming language
The Icon programming language
The SETL programming language
The High Level Assembly (HLA) language
In particular, the HLA programming language provides a wide set of character, string, character set, and pattern matching functions. Check out the HLA Standard Library Reference Manual, usually found at http://webster.cs.ucr.edu, for more details.
[18] Back before Windows became popular, IBM supported an extended 256-element character set on its text displays. Though this character set is “standard” even on modern PCs, few applications or peripheral devices continue to use the extended characters.
[19] Historically, carriage return refers to the paper carriage used on typewriters. A carriage return consisted of physically moving the carriage all the way to the right so that the next character typed would appear at the left-hand side of the paper.
[20] ASCII is a 7-bit code. If the HO 9 bits of a 16-bit Unicode value are all zero, the remaining 7 bits are an ASCII encoding for a character.
[21] The Windows CE variant only supports Unicode. You don’t even have the option of passing ASCII strings to a Win CE function.
[22] Some might argue that it shouldn’t take any longer to process a Unicode string using instructions that process words versus processing byte strings using machine instructions that manipulate bytes. However, high-performance string functions tend to process double words (or more) at one time. Such string functions can process half as many Unicode characters at one time, so they’ll require twice as many machine instructions to do the same amount of work.
[23] Note that HLA is an assembly language, so it’s perfectly possible, and easy in fact, to support any reasonable string format. HLA’s native string format is the one it uses for literal string constants, and this is the format that most of the routines in the HLA standard library support.
[24] Actually, because of memory alignment restrictions, there can be up to 12 bytes of overhead, depending on the string.
[25] Though, being assembly language, of course it’s possible to create static strings and pure dynamic strings in HLA, as well.
[26] Actually, you could call strrealloc to change the size of an HLA string, but dynamic string systems generally do this automatically, something that the existing HLA string functions will not do for you if they detect a string overflow.
[27] Though it is up to you to ensure that the character string maintains set semantics. That is, you never allow duplicate characters in such a string.
[28] Actually, it’s worse than this because most C standard libraries use lookup tables to map ranges of characters, but we’ll ignore that issue here.