
Hash Functions
Introduction
Secure one-way hash functions are recurring tools in cryptosystems just like the symmetric block ciphers. They are highly flexible primitives that can be used to obtain privacy, integrity and authenticity. This chapter deals solely with the integrity aspects of hash functions.
A hash function (formally known as a pseudo random function or PRF) maps an arbitrary sized input to a fixed size output through a process known as compression. This form of compression is not your typical data compression (as you would see with a .zip file), but a noninvertible mapping. Loosely speaking, checksum algorithms are forms of “hash functions,” and in many independent circles they are called just that. For example, mapping inputs to hash buckets is a simple way of storing arbitrary data that is efficiently searchable. In the cryptographic sense, hash functions must have two properties to be useful: they must be one-way and must be collision resistant. For these reasons, simple checksums and CRCs are not good hash functions for cryptography.
Being one-way implies that given the output of a hash function, learning anything useful about the input is nontrivial. This is an important property for a hash, since they are often used in conjunction with RNG seed data and user passwords. Most trivial checksums are not one-way, since they are linear functions. For short enough inputs, deducing the input from the output is often a simple computation.
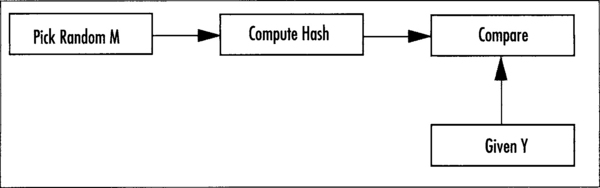
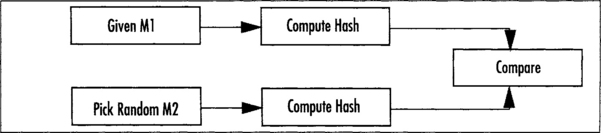
Being collision resistant implies that given an output from the hash, finding another input that produces the same output (called a collision) is nontrivial. There are two forms of collision resistance that we require from a useful hash function. Pre-image collision resistance (Figure 5.1) states that given an output Y, finding another input M’ such that the hash of M’ equals Y is nontrivial. This is an important property for digital signatures since they apply their signature to the hash only. If collisions of this form were easy to find, an attacker could substitute one signed message for another message. Second pre-image collision resistance (Figure 5.2) states that finding two messages M1 (given) and M2 (chosen at random), whose hatches match is nontrivial.
Throughout the years, there have been multiple proposals for secure hash functions. The reader may have even heard of algorithms such as MD4, MD5, or HAVAL. All of these algorithms have held their place in cryptographic tools and all have been broken.
MD4 and MD5 have shown to be fairly insecure as they are not collision resistant. HAVAL is suffering a similar fate, but the designers were careful enough to over design the algorithm. So far, it is still secure to use. NIST has provided designs for what it calls the Secure Hash Standard (FIPS 180-2), which includes the older SHA-1 hash function and newer SHA-2 family of hashes (SHA stands for Secure Hash Algorithm). We will refer to these SHS algorithms only in the rest of the text.
SHA-1 was the first family of hashes proposed by NIST. Originally, it was called SHA, but a flaw in the algorithm led to a tweak that became known as SHA-1 (and the old standard as SHA-0). NIST only recommends the use of SHA-1 and not SHA-0.
SHA-1 is a 160-bit hash function, which means that the output, also known as the digest, is 160 bits long. Like HAVAL, there are attacks on reduced variants of SHA-1 that can produce collisions, but there is no attack on the full SHA-1 as of this writing. The current recommendation is that SHA-1 is not insecure to use, but people instead use one of the SHA-2 algorithms.
SHA-2 is the informal name for the second round of SHS algorithms designed by NIST. They include the SHA-224, SHA-256, SHA-384, and SHA-512 algorithms. The number preceding SHA indicates the digest length. In the SHA-2 series, there are actually only two algorithms. SHA-224 uses SHA-256 with a minor modification and truncates the output to 224 bits. Similarly, SHA-384 uses SHA-512 and truncates the output. The current recommendation is to use at least SHA-256 as the default hash algorithm, especially if you are using AES-128 for privacy (as we shall see shortly).
Hash Digests Lengths
You may be wondering where all these sizes for hash digests come from. Why did SHA-2 start at 256 bits and go all the way up to 512 (SHA-224 was added to the SHS specification after the initial release)?
It turns out the resistance of a hash to collision is not as linear as one would hope. For example, the probability of a second pre-image collision in SHA-256 is not 1/2256 as one may think; instead, it is only at least 1/2128. An observation known as the birthday paradox states (roughly) that the probability of 23 people in a room sharing a birthday is roughly 50 percent.
This is because there are 23C2 = 253 (that is read as “23 choose 2”) unique pairs. Each pair has a chance of 364/365 that the birthday is not the same. The chance that all the pairs are not the same is given by raising the fraction to the power of 253. Noticing the probability of an event and its negation must sum to one, we take this last result and deduct it from one to get a decent estimate for the probability that any birthdays match. It turns out to be fractionally over 50 percent.
As the number n grows, the nC2 operation is closely approximated by n2, so with 2128 hashes we have 2256 pairs and expect to find a collision.
In effect, our hashes have half of their digest size in strength. SHA-256 takes 2128 work to find collisions; SHA-512 takes 2256 work; and so on. One important design guideline is to ensure that all of your primitives have equal “bit strength.” There is no sense using AES-256 with SHA-1 (at least directly), as the hash only emits 160 bits; birthday paradoxes play less into this problem. They do, however, affect digital signatures, as we shall see.
SHA-1 output size of 160 bits actually comes from the (then) common use of RSA-1024 (see Chapter 9, “Public Key Algorithms”). Breaking a 1024-bit RSA key takes roughly 286 work, which compares favorably to the difficulty of finding a hash collision of 280 work. This means that an attacker would spend about as much time trying to find another document that collides with the victim’s document, then breaking the RSA key itself.
What one should avoid is getting into a situation where you have a mismatch of strength. Using RSA-1024 with SHA-256 is not a bad idea, but you should be clearly aware that the strength of the combination is only 86 bits and not 128 bits. Similarly, using RSA-2048 (112 bits of strength) with SHA-1 would imply the attacker would only have to find a collision and not break the RSA key (which is much harder).
Table 5.1 indicates which standards apply to a given bit strength desired. It is important to note that the column indicating which SHS to use is only a minimum suggestion. You can safely use SHA-256 if your target is only 112 bits of security. The important thing to note is you do not gain strength by using a larger hash. For instance, if you are using ECC-192 and choose SHA-512, you still only have at most 96 bits of security (provided all else is going right). Choose your primitives wisely.
Table 5.1
Bit Strength and Hash Standard Matching

*Technically, ECC-192 requires 296 work to break, but it is the smallest standard ECC curve NIST provides.
Many (smart) people have written volumes on what key size to strive for. We will simplify it for you. Aim for at least 128 bits and use more if your application can tolerate it. Usually, larger keys mean slower algorithms, so it is important to take timing constraints in consideration. Smaller keys just mean you are begging for someone to put a cluster together and break your cryptography. In the end, if you are worried more about the key sizes you use and less about how the entire application works together, you are not doing a good job as a cryptographer.
A common way to find a collision in a fixed function without actually storing a huge list of values and comparing is cycle finding. The attack works by iterating the function on its output. You start with two or more different initial values and cycle until two of them collide; for example, if user A starts with A[–1] and user B starts with B[–1] such that A[–1] does not equal B[–1], we compute
![]()
Until A[i] equals B[i], Clearly, comparing online is annoying if you want to distribute this attack. However, storing the entire list of A[i] and B[i] for comparison is very inefficient. A clever optimization is to store distinguished points. Usually, they are distinguished by a particular bit pattern. For example, only store the hash values for which the first I-bits are zero.
Now, if they collide they will produce colliding distinguished points as well. The value of I provides a tradeoff between memory on the collection side and efficiency. The more bits, the smaller your tables, but the longer it takes users to report distinguished points. The fewer bits you use, the larger the tables, and the slower the searches.
Designs of SHS and Implementation
As mentioned earlier, SHS FIPS 180-2 is comprised of three distinct algorithms: SHA-1, SHA-256, and SHA-512. From the last two, the alternate algorithms SHA-224 and SHA-384 can be constructed. We will first consider the three unique algorithms.
All three algorithms follow the same basic design flow. A block of the message is extracted, expanded, and then passed through a compression function that updates an internal state (which is the size of the message digest). All three algorithms employ padding to the message using a technique known as MD strengthening.
In Figure 5.3, we can see the flow of how the hash of the two block message M[0,1] is computed. M[0] is first expanded, and then compressed along with the existing hash state. The output of this is the new hash state. Next, we apply the Message Digest (MD) strengthening padding to M[1], expand it, and compress it with the hash state. Since this was the last block, the output of the compression is the hash digest.
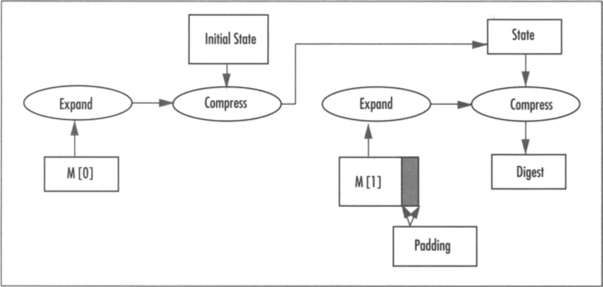
All three hashes are fairly easy to describe in terms of block cipher terminology. The message block (key) is expanded to a set of round keys. The round keys are then used to encrypt the current hash state, which performs a compression of the message to the smaller hash state size. This construction can turn a normal block cipher into a hash as well. In terms of AES, for example, we have
![]()
where AES(M[i], S[i–1]) is the encryption of the previous state S[i–1] under the key M[i]. We use a fixed known value for S[–1], and by padding the message with MD strengthening we have constructed a secure hash. The problem with using traditional ciphers for this is that the key and ciphertext output are too small. For example, with AES-256 we can compress 32 bytes per call and produce a 128-bit digest. SHA–1, on the other hand, compresses 64 bytes per call and produces a 160-bit digest.
MD Strengthening
The process of MD strengthening was originally invented as part of the MD series of hashes by Dr. Rivest. The goal was to prevent a set of prefix and suffix attacks by encoding the length as part of the message.
1. Append a single one bit to the message.
2. Append enough zero bits so the length of the message is congruent to w-l modulo w.
3. Append the length of the message in big endian format as an l-bit integer.
Where w is the block size of the hash function and l is the number of bits to encode the maximum message size. In the case of SHA-1, SHA-224, and SHA-256, we have w = 512 and l = 64. In the case of SHA-384 and SHA-512, we have w = 1024 and l = 128.
SHA-1 Design
SHA-1 is by far the most common hash function next to the MD series. At the time when it was invented, it was among the only hashes that provided a 160-bit digest and still maintained a decent level of efficiency. We will break down the SHA-1 design into three components: the state, the expansion function, and compression function.
SHA-1 State
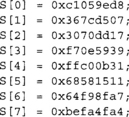
The SHA-1 state is an array of five 32-bit words denoted as S[0 … 4], which hold the initial values of
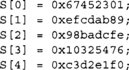
Each invocation of the compression function updates the SHA-1 state. The final value of the SHA-1 state is the hash digest.
SHA-1 Expansion
SHA-1 processes the message in blocks of 64 bytes. Regardless of which block we are expanding (the first or the last with padding), the expansion process is the same. The expansion makes use of an array of 80 32-bit words denoted as W[0 … 79]. The first 16 words are loaded in big endian fashion from the message block.
The next 64 words are produced with the following code.
![]()
Where ROL(x, 1) is a left cyclic 32-bit rotation by 1 bit. At this point, we have fully expanded the 64-byte message block into round keys required for the compression function. The curious reader may wish to know that SHA-0 was defined without the rotation. Without the rotation, the hash function does not have the desired 80 bits’ worth of strength against collision searches.
SHA–1 Compression
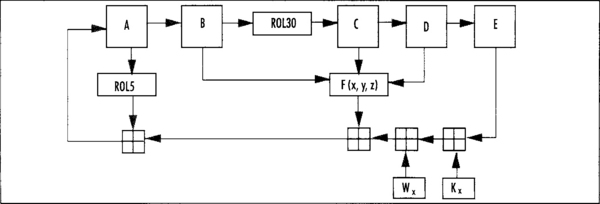
The compression function is a type of Feistel network (do not worry if you do not know what that is) with 80 rounds. In each round, three of the words from the state are sent through a round function and then combined with the remaining two words. SHA-1 uses four types of rounds, each iterated 20 times for a total of 80 rounds.
The hash state must first be copied from the S[] array to some local variables. We shall call them {a,b,c,d,e}, such that a = S[0], b = S[1], and so on. The round structure resembles the following.
![]()
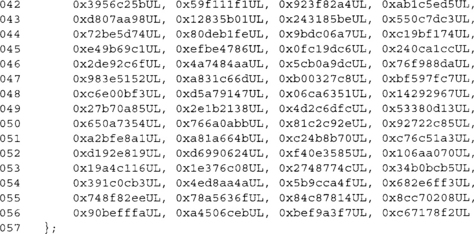
where Fx(x,y,z) is the round function for the x’th grouping. After each round, the words of the state are swapped such that e becomes d, d becomes c, and so on. Kx denotes the round constant for the x’th round. Each group of rounds has its own constant. The four round functions are given by the following code.
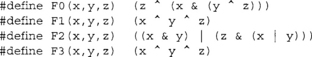
The round constants are the following.
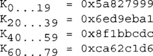
After 20 rounds of each type of round, the five words of {a,b,c,d,e} are added (as integers modulo 232) to their counterparts in the hash state. Another view of the round function is in Figure 5.4.
SHA-1 Implementation
Our SHA-1 implementation is a direct translation of the standard and avoids a couple common optimizations that we will mention inline with the source.

Our familiar macros come up again in this implementation. These macros are a lifesaver in portable coding, as they totally eliminate any endianess issues we may have had.
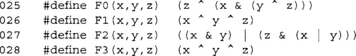
These are the SHA-1 round functions.

This structure holds an SHA-1 state. It allows us to process messages with multiple calls to sha1_process. For example, if we are hashing a message that is streaming or too large to fit in memory at once, we can use multiple calls to the process function to handle the entire message.
![]()

This function initializes the SHA-1 state to the default state. We set the S[] array to the SHA-1 defaults and set the buffer and message lengths to zero. The buffer length (buflen) variable counts how many bytes in the current block we have so far. When it reaches 64, we have to call the compression function to compress the data. The message length (msglen) variable counts the size of the entire message. In our case, we are counting bytes, which means that this routine is limited to 232–l byte messages.

This function expands and compresses the message block into the state. This first loop loads the 64-byte block into W[0..15] in big endian format using the LOAD32H macro.
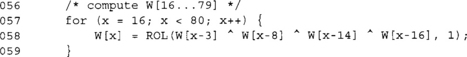
This loop produces the rest of the W[] array entries. Like the AES key schedule (see Chapter 4, “Advanced Encryption Standard”), it is a form of shift register.

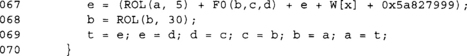
This loop implements the first 20 rounds of the SHA-1 compression function. Here we have rolled the loop up to save space. There are two other common ways to implement it. One is partially to unroll it by copying the body of the loop five times. This allows us to use register renaming instead of the swaps (line 69). With a macro such as
![]()
the loop could be implemented as follows.

This saves on all of the swaps and is more efficient (albeit five times larger) to execute. The next level of optimization is that we can unroll the entire loop replacing the “x++” with the constant round numbers. This level of unrolling rarely produces much benefit on modern processors (with good branch prediction) and solely serves to pollute the instruction cache.

These three loops implement the last 60 rounds of the SHA-1 compression. We can unroll them with the same style of code as the first round for extra performance.

This last bit of code updates the SHA-1 state by adding the copies of the state to the state itself. The additions are meant to be modulo 232. We do not have to reduce the results, as are rotate macros explicitly mask bits in the 32-bit range.

This function is what the caller will use to add message bytes to the SHA-1 hash. The function copies message bytes from buf to the internal buffer and then proceeds to compress them when 64 bytes have accumulated.

Our buffer is only 64 bytes long, so we must prevent copying too much into it. After this point, x contains the number of bytes we have to copy to proceed.

After copying the bytes, we check if our buffer has 64 bytes, and if so we call the compression function. After compression, we reset the buffer length and update the message length. There is an optimization we can apply to this process function, which is a method of performing zero-copy compression.
Suppose you enter the function with buflen equal to zero and you want to hash more than 63 bytes of data. Why does the data have to be copied to the buf[] array before the hash compresses it? By hashing out of the user supplied buffer directly, we avoid the costly double buffering that would otherwise be required. The optimization can be applied further. Suppose buflen was not zero, but we were hashing more than 64 bytes. We could double buffer until we fill buflen; then, if enough bytes remain we could zero-copy as many 64 byte blocks as remained.
This trick is fairly simple to implement and can easily give a several percentage point boost in performance.
![]()
This function terminates the hash and outputs the digest to the caller in the dst buffer.

Technically, SHA-1 supports messages up to 264–1 bits; however, as a matter of practicality we limit ourselves to 232–1 bytes. Before we can encode the length, however, we have to encode it as the number of bits. We extract the upper bits of the message length (line 131) and then shift up by three, emulating a multiplication by 8. At this point, the 64-bit value l2*232 + l1 represents the message length in bits as required for the padding scheme.
![]()
This is the leading padding bit. Since we are dealing with byte units, we are always aligned on a byte boundary. SHA-1 is big endian, so the one bit turns into 0x80 (with seven padding zero bits).

If our current block is too large to accommodate the 64-bit length, we must pad with zero bytes until we hit 64 bytes. We compress and reset the buffer length counter.

At this point, buflen < 56 is guaranteed. We pad with enough zero bytes until we hit position 56.
![]()
![]()
We store the length of the message as a 64-bit big endian number. We are emulating this by performing two big endian 32-bit stores.
![]()
A final compression including the padding terminates the hash.

Now we extract the digest, which is the five 32-bit words of the SHA-1 state. At this point, dst[0 … 19] contains the message digest of the message that was hashed.

This function is a nice helper function to have around. It hashes a complete message and outputs the digest in a single function call. This is useful if you are hashing small buffers that can fit in memory—for example, for hashing passwords and salts.


Our demo program uses two standard SHA-1 test vectors to try to determine if our code actually works. There are a few corner cases we are missing from the test suite (which are not part of the FIPS standard anyway). They:
1. A zero length (null) message.
2. A message that is exactly 64 bytes long.
The FIPS 800-2 standard provides three test vectors, two of which we used in our example. The third is a million a’s, which should result in the digest 34aa973c d4c4daa4 f61eeb2b dbad2731 6534016f.
As we will see with other NIST standards, it is not uncommon for their test vectors to lack thoroughness. As an aside, how much do FIPS validation certificates cost these days anyway?
SHA-256 Design
SHA-256 follows a similar design (overall) as SHA-1. It uses a 256-bit state divided into eight 32-bit words denoted as S[0 … 7]. While it has the same expansion and compression feel as SHA-1, the actual operations are more complicated. SHA-256 uses a single round function that is repeated 64 times.
SHA-256 makes use of a set of eight simple functions defined as follows.
![]()
These are the nonlinear functions used within the SHA-256 round function. They provide the linear complexity to the design required to ensure the function is one way and differences are hard to control. Without these functions, SHA-256 would be entirely linear (with the exception of the integer additions we will see shortly) and collisions would be trivial to find.
![]()
These are a right cyclic shift and a right logical shift, respectively. A curious reader may note that the S() macro performs a rotation and the R() macro performs a shift. These were macros based off the early drafts of the SHA-256 design. We left them like this partially because it’s amusing and partially because it is what LibTomCrypt uses.
![]()
These two functions are used within the round function to promote diffusion. They replace the rotations by 5 and 30 bits used in SHA-1. Now, a single bit difference in the input will spread to two other bits in the output. This helps promote rapid diffusion through the design by being placed at just the right spot. If we examine the SHA-256 block diagram (Figure 5.5), we can see that the output of Sigma0 and Sigma1 eventually feeds back into the same word of the state the input came from. This means that after one round, a single bit affects three bits of the neighboring word. After two rounds, it affects at least nine bits, and so on. This feedback scheme has so far proven very effective at making the designs immune to cryptanalysis.
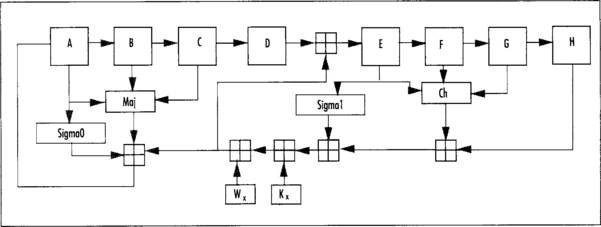
![]()
These two functions are used within the expansion phase to promote collision resistance. Within the SHA-256 (and FIPS 180-2 in general) standard, they use the upper- and lowercase Greek sigma for the Sigma and Gamma functions. We renamed the lowercase sigma functions to Gamma to prevent confusion in the source code.
SHA-256 State
The initial state of SHA-256 is 8 32-bit words denoted as S[0 … 7], specified as follows.

SHA-256 Expansion
Like SHA-1, the message block is expanded before it is used. The message block is expanded to 64 32-bit words. The first 16 words are loaded in big endian format from the 64 bytes of the message block. The next 48 words are computed with the following recurrence.

SHA-256 Compression
Compression begins by making a copy of the SHA-256 state from S[0 … 7] to {a,b,c,d,e,f,g,h}. Next, 64 identical rounds are executed. The x’th round structure is as follows.

After each round, the words are rotated such that h becomes g, g becomes f, f becomes e, and so on. The K array is a fixed array of 64 32-bit words (see the Implementation section). After the 64th round, the words {a,b,c,d,e,f,g,h} are added to the hash state in their respective locations. The hash state of after compressing the last message block is the message digest.
Comparing this diagram to that of SHA-1 (Figure 5.4), we can see that they apply two parallel nonlinear functions, two more complicated diffusion primitives (Sigma0 and Sigma1), and more feedback (into the A and E words). These changes make the new SHS algorithms have much higher diffusion and are less likely to be susceptible to the same class of attacks that are plaguing the MD5 and SHA-1 algorithms currently.
SHA-256 Implementation
Our SHA-256 implementation is directly adopted from the framework of the SHA-1 implementation. In a way, it highlights the similarities between the two hashes. It also highlights the fact that we did not want to write two different hash interfaces, partly out of laziness and partly because it would make the code harder to use.
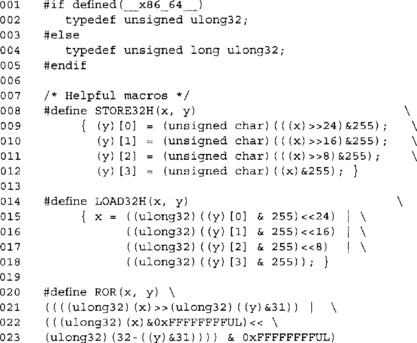
So far, very familiar with the exception we use a right cyclic rotation, not left.

These are our SHA-256 macros for the expansion and compression phases.

Our SHA-256 state with the longer S[] array. The variables otherwise have the same purposes as in the SHA-1 code.
![]()
This is the complete K[] array required by the compression function. NIST states they are the 32 bits of the fractional part of the cube root of the first 32 primes. For example, 21/3 truncated to just the fractional part is 0.2599210498948731647672106072782, which when multiplied by 232 is 1116352408.8404644807431890114033, and rounded down produces our first table entry 0x428A2F98.
We guess NIST never thought it may be a good idea to be able to generate the K[] values on the fly. In their defense, they chose such an odd table generation function so they could claim there are no “trap doors” in the table.

This initializes the state to the default SHA-256 state.

![]()
At this point, we have fully expanded the message block to W[0 … 63] and can begin compressing the data. Note that the additions are modulo 232, but as it turns out, we do not have to explicitly reduce them, as the round function only uses the rotation macros. Like SHA-1, we can expand the block on the fly and in place if memory is tight.

Like the SHA-1 implementation, we have fully rolled the loop. We can unroll it either eight times or fully to gain a boost in speed. Unrolling it fully also allows us to embed the K[] constants in the code, which avoids a table lookup during the round function. The benefits of fully unrolling depend on the platform. On most x86 platforms, the gains are slight (if any) and the code size increase can be dramatic.
By defining a round macro, we could perform the unrolling nicely.

This will perform the SHA-256 compression without performing all of the swaps of the previous routine. Note that we increment i after the macro, as it is used multiple times before we hit a sequence point in the source.

Like SHA-1, we add the copies to the SHA-256 state to terminate the compression function.

This is a direct copy of the SHA-1 function, with the sha1_compress function swapped for sha256_compress.

This function is also copied from the SHA-1 implementation with the function name changes and we store eight 32-bit words instead of five.


Our test program to ensure our SHA-256 implementation is working correctly.
SHA-512 Design
SHA-512 was designed after the SHA-256 algorithm. It differs in the message block size, round constants, number of rounds, and the Sigma/Gamma functions. It has a state comprised of eight 64-bit words and follows the same expansion and compression workflow as the other hashes. SHA-512 uses 128-byte blocks instead of the 64-byte blocks SHA-1 and SHA-256 use. The new macros are the following.
![]()
These are the round function macros; note that the rotations and shifts are of 64-bit words, not 32-bit words as in the case of SHA-256.
![]()
These are the expansion function macros; again, they are 64-bit operations.
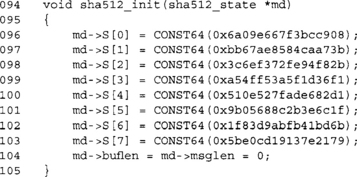
SHA-512 State

The SHA-512 state is eight 64-bit words denoted as S[0 … 7], initially set to the following values.
SHA-512 Expansion
SHA-512 expansion works the same as SHA-256 expansion, except it uses the 64-bit macros and we must produce 80 words instead. The first 16 64-bit words are loaded from the 128-byte message block as big endian format. The next 64 words are generated with the following recurrence.

SHA-512 Compression
SHA-512 compression is similar to SHA-256 compression. It uses the same pattern for the round function, except there are 80 rounds instead of 64. It also uses 80 64-bit constant words denoted K[0 … 79], which are derived in much the same manner as the 64 words used in the SHA-256 algorithm.
SHA-512 Implementation
Following is our implementation of SHA-512 derived from the SHA-256 source code. It has the same calling conventions as the SHA-1 and SHA-256 implementation, with the exception that it produces a 64-byte message digest instead of a 20- or 32-byte message.
![]()

First, we need a way to use 64-bit data types. SHA-512 is for the most part an adaptation of SHA-256 with 64-bit words instead of 32-bit words. In C99, a data type that is at least 64-bits was defined to be unsigned long long, which works well with most UNIX CC and the GNU CC. Unfortunately, Microsoft’s compiler does not support C99 and implements this differently.
Our CONST64 macro gives us a reasonably portable manner of defining 64-bit constants. Our ulong64 typedef allows us to use 64-bit words in an efficient fashion.

These are the SHA macros for the 512-bit hash. Note that we are performing 64-bit operations here (including the shifts and rotations).

This is our SHA-512 state. Note that SHA-512 uses a 128-byte block so our buffer is now larger. There are still eight chaining variables, but they are now 64 bits.

These are the 80 64-bit round constants for the compression function. Note we are using our CONST64 macro for portability.
This function initializes our SHA-512 state to the default state.

At this point, we have expanded the 128 bytes of message input into 80 64-bit words. Just like the SHA-1 and SHA-256 functions, we can compute the expanded words on the fly.

This performs the compression round functions. We can unroll this either eight times or fully. Usually, eight times will net a sizeable performance boost, while unrolling fully will not pay off as much. On the AMD64 series, unrolling fully does not improve performance and wastes cache space.

The process function resembles the process functions from SHA-1 and SHA-256, with the exception that we use 128-byte blocks. As in the other algorithms, we can use a zero-copy mechanism here as well, and it is highly recommended.


This function terminates the hash and outputs the digest. Note we have to store a 128-bit length. Since our block size is 128 bytes, we have to pad until our message is 112 modulo 128 bytes long.

This is our familiar helper function to perform a SHA-512 compression of an inmemory buffer.


This is our demo application that tests the implementation. We have only implemented the first two of three NIST standard test vectors.
SHA-224 Design
SHA-224 is a hash that produces a 224-bit message digest and uses SHA-256 to perform the hashing. SHA-224 begins by initializing the state with eight different words listed here.
SHA-224 uses the SHA-256 expansion and compression function on all the message blocks. The final digest as produced by SHA-256 is truncated by copying the first 28 bytes to the caller.
From a performance point of view, SHA-224 is no faster than SHA-256, and from a security standpoint, it is less secure. There are times when truncating a hash is a good idea, as we will see with digital signatures, but there are simpler ways to accomplish it than modifying an existing hash.
SHA-224 is a useful choice if your application is working with ECC-224, as it produces an output that has roughly the same size as the order of the curve—a property that will be shown to be useful in Chapter 9.
For completeness, here are the test vectors for SHA-224 similar to those from SHA-256.

SHA-384 Design
Like SHA-224, SHA-384 was designed after an SHS algorithm. In this case, SHA-384 is based on SHA-512. Like SHA-224, we begin with a modified state.

SHA-384 uses the SHA-512 algorithm to perform the actual message hashing. The output of SHA-384 is the output of SHA-512 truncated by copying the first 48 bytes of the output to the caller. SHA-384 is a useful choice of hash when working with the ECC-384 curve.
For completeness, here are the test vectors for SHA-384.

Zero-Copying Hashing
Earlier we alluded to a zero-copying technique to boost hash algorithm throughput. We shall now present this technique as applied to the SHA-1 process function. We shall only present the modified code to save space.

We first have to modify the compression function to accept the message block from the caller, instead of implicitly from the SHA-1 state.


This is our newly modified process function. Inside the inner loop, we perform the zero-copy optimization by passing 64-byte blocks directly to the compression function without first copying it to the internal state. We can only do this if the SHA-1 state is empty (buflen is zero) and there are at least 64 bytes of message bytes left to process.
This optimization may not seem like much on a processor like the AMD Opteron with its huge L1 data cache. However, on much more compact processors such as the ARM series, extra data movement over, say, a 16-MHz data bus can mean a real performance loss.


For completeness, this is the modified done function with the new calls to the compression function.
PKCS #5 Key Derivation
Hash functions can be used for many different problems, from integrity and authenticity (see Chapter 6, “Message Authentication Code Algorithms”) to pseudo random number generation (see Chapter 3, “Random Number Generation”) and key derivation. Now we shall explore the latter property.
Key derivation functions (KDF) derive key material from another source of entropy while preserving the entropy of the input and being one-way. Key derivation is often used for more than generating key material. It is also used to derive initial values (IV) and nonces (see Chapter 6) for cryptographic sessions. The typical usage of a key derivation function is to take a secret such as a password or a shared secret (see Chapter 9) and a salt to produce a key and IV. The salt is generated at random when the session is first created to prevent dictionary attacks. It’s not as important when a random shared secret is being used, as a dictionary attack will not apply.
PKCS #5 (ftp://ftp.rsasecurity.com/pub/pkcs/pkcs-5v2/pkcs5v2-0.pdf) is a standard put forth by the former RSA Data Security Corporation as one of a series of standards of public key cryptography. It defines two KDF algorithms called PBKDF1 and PBKDF2. The former is an old standard that was originally meant to be used with DES, and as such has fixed size inputs. PBKDF2 is more flexible and the recommended KDF from the PKCS #5 standard
The algorithm we are going to present uses an algorithm known as HMAC (hash message authentication code), which we have not discussed yet. Confused readers are encouraged to read the discussion of HMAC in Chapter 6 first before coming back to this algorithm (Figure 5.6).

The value of blkNo is appended to the salt as a 32-bit big endian number. The algorithm begins by computing the HMAC of the salt with the blkNo value appended. This gives us our starting value for this pass of the algorithm. We make a copy of this value into U and then repeatedly HMAC the value of T, XORing the output to U in each iteration. The purpose of the iterations count is to make dictionary and exhaustive search attacks even slower. For example, if it is set to 1024, we are effectively adding 10 bits to our secret key.
The data generated by this function is meant to be used as both cipher keys and session initial values such as IVs and nonces. For example, to use AES-128 in CTR mode, the caller would use this KDF to generate 32 bytes of data. The first 16 bytes could be the AES key, and the second 16 bytes could be the CTR initial value. If we used SHA-256 as the hash for the HMAC, we would loop only once, as at step 4 we would have generated the required 32 bytes. Had we used SHA-1, for example, we would have to loop twice, producing 40 bytes that would then be truncated to 32 bytes.
The function requires that the secret be unpredictable from an attacker. The salt should be random, but cannot be a secret, as the recipient will need to know it to generate the same session values. The salt can be any length. In practice, it should be no larger than secret and no smaller than eight bytes.
A curious reader may wish to use the often mistaken construction of hash (secret | | data) as a message authentication like primitive. However, as we shall see in Chapter 6, this is not a secure construction and should be avoided. As it applies to PKCS #5, it may very well be secure; however, for the purposes of interoperability, one should choose to use a proper HMAC construction.
Putting It All Together
As we have seen, the SHS algorithms are easy to implement, and as we have hinted at, are convenient to have around. What we will now consider are more concrete examples of using hashes in fielded systems. What not to use them for, how to optimize them for space and time, and finally give a concrete example of using PKCS #5 with our previous AES CTR example (see Chapter 4).
It is easy to use a hash as the tool it was meant to be if we simply keep in mind it is a pseudo-random function (PRF). Just as how ciphers are pseudo random permutations (PRP) and have their own usage limitations, so do hashes.
What Hashes Are For
Hashes are pseudo-random functions. What this means is that they pseudo randomly map the input to the output. Unlike ciphers, which are PRPs, the input (domain) and output (co-domain) are not the same size. The typical hash algorithm can allow inputs as large as 264–l bits and produce fixed size outputs of hundreds of bits. The pseudo-random mapping suggests one useful feature, one-wayness. It also suggests the capability of being collision resistant if the mapping is hard to control.
One-Wayness
A function is considered one-way if computing the function is trivial in one sense and nontrivial in the reverse sense. In terms of hash functions, this means that the message digest is trivial to compute. Finding the message given only the message digest is nontrivial.
Passwords
Working with user passwords and pass phrases is one example of using this property. Ideally, a network application that requires users to authenticate themselves will ask for a credential such as a password. Sending the password in the clear would mean attackers could read it. Similarly, a password list for a multi-user environment (e.g., school network) would need to store something to compare against user credentials. Hash algorithms provide a way of proving ownership of the credential without leaking the credential itself.
Random Number Generators
Another useful task that takes advantage of this property is random number generators, and the pseudo random variety. By hashing seeding data, the output does not leak the seed data the generator is privy to. This seed data often will contain private information such as network traffic or keystrokes.
Collision Resistance
Hashes must also be collision resistant to be cryptographically useful. Often, this property is exploited in the process of performing digital signatures (see Chapter 9). Typical public key signature algorithms are slower by magnitudes of cycles than the typical hash function. To optimize the signature process, a cryptosystem could choose to sign a hash of the message instead of the full message itself.
This procedure can be as effectively secure as signing the message, provided the hash algorithm has two properties. It must be collision resistant and it must produce a digest of respective size. Recall the discussion of the birthday paradox earlier in this chapter. If you are using a public key algorithm that takes, say, 280 work (“work” often refers to the number of operations required; in this sense, work could mean public key operations or hash operations) to break, your hash should produce no less than 160 bits of message digest.
File Manifests
Collision resistance is useful for integrity tasks as well. In the most innocent of cases, computing the message digest of files offered for download helps ensure users download the file correctly. This assumes, of course, the absence of an attacker. There is an often cited defense that because the message digest would be stored on a secure server, the attackers would have to modify it there. This is not correct. An attacker would only have to get between the client and server to perform the attack. This is typically far easier than breaking into a secured server.
Intrusion Detection
Hashes are also in intrusion detection software (IDS), which scans for modifications to files as a sign of an intruder. They compute the message digest of executables and compare on the fly against the cached value. This works well provided the IDS software itself has not been exploited. However, one can never be too vigilant. In 2005, MD5 (the most common hash for this task) was broken. Various people, including Dan Kaminsky, championed the Trojan payload attack.
Their attack is both clever and effective. They produce a program that has two payloads attached. Then, they insert a block of data that will collide with MD5. They can then swap the block out depending on whether they want to activate the payload. The program works by first checking which block was included and acting differently accordingly. The two files would have the same MD5 message digest, but they would act very differently.
Many Linux distributions have moved to using multiple hashes as a result. Gentoo Linux, for example, checks MD5, RMD-160, and SHA-256 checksums on all files in their Portage repository. While this is at best as strong as a perfect 256-bit hash (we will not assume SHA-256 is perfect), it has the durability that in case SHA-256 is broken, at least checking the RMD-160 hash is a good fallback. ((RMD (also RIPEMD) stands for RIPE-Message Digest, where RIPE (RACE Integrity Primitives Evaluation) is a European standards process. The original RIPEMD algorithm was generally not considered strong and was broken in 2004. The RIPEMD-160, 256, and 320 algorithms are mostly based off of the MD4 design and are not competitively efficient.)
What Hashes Are Not For
We have seen some clear examples of what hashes can be safely used for. There is also a variety of tasks that crop up and are mistakenly used in fielded systems. Part of the problem stems from the fact that people think that hashes are universally magical random functions. They often forget that we can prefix data, append data, and pre-compute things.
Unsalted Passwords
This is one of the cases where a little salt is healthy (sorry, we could not resist the pun). As we will see in more detail shortly (we are almost there), password hashing is a tricky business. Suppose we want to store your password for future comparison.
Clearly, we cannot store the password on its own, as an attacker who can see the password list will own the system. The logical solution that pops to mind is to hash the passwords. After all, it is one-way. What could possibly go wrong?
Hashes Make Bad Ciphers
It’s often tempting to turn a hash into a cipher. Hashes are actually ciphers in disguise if you look at them. For example, SHACAL is a 160-bit block cipher that uses SHA-1. It treats the W[] array as the cipher key and the state as the plaintext (or ciphertext). You can also just use a hash in CTR mode to create a stream cipher.
While technically sound and most likely secure, neither construction is part of a standard. They are also slower than block ciphers. For example, MD5 routinely clocks in at eight cycles per byte hashes on an AMD Opteron. That means eight cycles per byte of input not output. MD5 has 64-byte blocks; therefore, the compression takes at least 512 cycles, which would produce a CTR key stream at a rate of 32 cycles per byte. AES CTR requires slightly over 17 cycles per byte.
It gets no better for the other hashes. SHA-512 requires 12 cycles per byte of input on the Opteron, which translates into 24 cycles per byte of output. SHA-1 requires 18 cycles per byte on an Intel Pentium 4 (to give examples from other processors), which translates into 58 cycles per byte of output (over twice as slow as AES on this processor).
The lack of standards and the fact it is inefficient to do so makes ciphering with a hash a bad idea in general. About the only place it would make sense is where you are limited for software or hardware space.
Hashes Are Not MACs
Hashes are not message authentication code algorithms. The most common construction that is not actually secure is to make the MAC as follows.
![]()
The attack takes advantage of the fact that an attacker does not have to start with the same initial value as the standard specifies. In the preceding case, we are effectively hashing the message blocks: key, message, MD-strengthening. This produces a tag that is effectively the hash state after hashing all the data. An attacker could append a block (and then another MD-strengthening block) and use the tag as the initial state. The computed hash would appear to be a valid message from a victim with the key.
The fix is often to use the following combination:
![]()
which does not leak the internal state of the inner hash. However, it violates one of the goals of MAC algorithms. It is attackable in an offline sense, as we will see in the discussion of HMAC in Chapter 6.
Hashes Don’t Double
A common trick to double the size of the message digest is to concatenate two message digests of slightly different messages. For instance,
![]()
The problem with this technique is that a collision in the first message block will immediately make any following blocks collide. For example, consider the input as 1 | | block | | message, where 1 | | block fits in one message block in the hash (e.g., 64 bytes for SHA-1). If we can find a block for which hash(l | | block) equals hash(2 | | block), we would only have to find two message values that collide through the remainder of the hash.
Hashes Don’t Mingle
Failing the double-up trick, the next idea is to concatenate two message digests from different hashes. For instance,
![]()
Unfortunately, this is no better than the strongest hash in the mix—at least not with the typical hash construction. Suppose M and M’ collide in hash1. Then, M | | Q and M’ | | Q will collide since their hash states collide after M (M′, respectively). Thus, an attacker would only have to find a pair M and M’ and proceed to attack the second hash. It is conceivable that two properly constructed hashes offer more security as a pair; however, with the common MD style hash this is not believed to be the case.
Working with Passwords
As we have mentioned, hashes are good when working with passwords. They do not allow determining the input from the output and are collision resistant. In effect, if users can produce the correct message digest, chances are they know the correct input.
Using this nice property securely is a tricky challenge. First, let us consider the offline world, and then we shall explore the online world.
Offline Passwords
Offline password verification is what you may find on an account login (say, locally to your machine). The goal is to compare what you produce against a proof stored locally. The proof is essentially producible only by someone in possession of the credential required.
In the offline world, we are typically dealing with a privileged process such as login (typical to UNIX-like platforms), so the proof generation process is tamper safe.
If we simply stored the hash of the password, we would prevent an attacker from directly finding out the password. Unfortunately, we do not stop a practical and often fruitful attack—the dictionary attack. Users tend to pick passwords and pass phrases that are easy to memorize. This means they pick dictionary words, and occasionally mix two or more together. A dictionary attack literally runs through a dictionary, hashes the generated strings, and compares it against the password list.
If we simply hash the passwords, if two or more users choose the same password this will immediately be revealed. What is worse is that an attacker could pre-compute a hash list (another use of the word hash) that associates hashes with passwords. The entire “attack” could take only seconds on the victim’s machine.
Salts
The most common and satisfactory solution (letting aside educating the users) is to salt the passwords. Salting means we “add flavor” to the hash specific for the user. In terms of cryptography, it means we add random digits to the string we hash. Those random digits, the salt, become associated with the user for the given credential proof list. If a user moves to another system, he should have a different salt totally unrelated to the previous instance. What the salt prevents the attacker from doing is pre-computing a dictionary list. The attacker would to compute it only after learning the user’s salt, and would have to re-compute it for every user he chooses to attack.
Salt Sizes
Now that we are salting our passwords, what size should the salt be? Typically, it does not have to be large. It should be unique for all the users in the given credential list. A safe guideline is to use salts no less than 8 bytes and no larger than 16 bytes. Even 8 bytes is overkill, but since it is not likely to hurt performance (in terms of storage space or computation time), it’s a good low bound to use.
Technically, you need at least the square of the number of credentials you plan to store. For example, if your system is meant to accommodate 1000 users, you need a 20-bit salt. This is due to the birthday paradox.
Our suggestion of eight bytes would allow you to have slightly over four billion credentials in your list.
Rehash
Another common trick is to not use the hash output directly, but instead re-apply the hash to the hash output a certain number of times. For example:
![]()
While not highly scientific, it is a valid way of making dictionary attacks slower. If you apply the hash, say 1024 times, then you make a brute force search 1024 times harder. In practice, the user will not likely notice. For example, on an AMD Opteron, 1024 invocations of SHA-1 will take roughly 720,000 CPU cycles. At the average clock rate of 2.2GHz, this amounts to a mere 0.32 milliseconds. This technique is used by PKCS #5 for the same purpose.
Online Passwords
Online password checking is a different problem from the offline word. Here we are not privileged, and attackers can intercept and modify packets between the client and server.
The most important first step is to establish an anonymous secure session. An SSL session between the client and server is a good example. This makes password checking much like the offline case. Various protocols such as IKE and SRP (Secure Remote Passwords: http://srp.stanford.edu/) achieve both password authentication and channel security (see Chapter 9).
In the absence of such solutions, it is best to use a challenge-response scheme on the password. The basic challenge response works by having the server send a random string to the client. The client then must produce the message digest of the password and challenge to pass the test. It is important to always use random challenges to prevent replay attacks. This approach is still vulnerable to meet in the middle attacks and is not a safe solution.
Two-Factor Authentication
Two-factor authentication is a user verification methodology where multiple (at least two in this case) different forms of credentials are used for the authentication process.
A very popular implementation of this are the RSA SecurID tokens. They are small, keychain size computers with a six-to-eight digit LCD. The computer has been keyed to a given user ID. Every minute, it produces a new number on the LCD that only the token and server will now. The purpose of this device is to make guessing the password insufficient to break the system.
Effectively, the device is producing a hash of a secret (which the server knows) and time. The server must compensate for drift (by allowing values in the previous, current, and next minutes) over the network, but is otherwise trivial to develop.
Performance Considerations
Hashes typically do not use as many table lookups or complicated operations as the typical block cipher. This makes implementation for performance (or space) a rather nice and short job.
All three (distinct) algorithms in the SHS portfolio are subject to the same performance tweaks.
Inline Expansion
The expanded values (the W[] arrays) do not have to be fully computed before compression. In each case, only 16 of the values are required at any given time. This means we can save memory by only storing them and compute 16 new expanded values as required.
In the case of SHA-1, this saves 256 bytes; SHA-256 saves 192 bytes; and SHA-512 saves 512 bytes of memory by using this trick.
Compression Unrolling
All three algorithms employ a shift register like construction. In a fully rolled loop, this requires us to manually shift data from one word to another. However, if we fully unroll the loops, we can perform renaming to avoid the shifts. All three algorithms have a round count that is a multiple of the number of words in the state. This means we always finish the compression with the words in the same spot they started in.
In the case of SHA-1, we can unroll each of the four groups either 5-fold or the full 20-fold. Depending on the platform, the performance gains of 20-fold can be positive or negative over the 5-fold unrolling. On most desktops, it is not faster, or faster by a large enough margin to be worth it.
In SHA-256 and SHA-512, loop unrolling can proceed at either the 8-fold or the full 64-fold (80, resp.) steps. Since SHA-256 and SHA-512 are a bit more complicated than SHA-1, the benefits differ in terms of unrolling. On the Opteron, process unrolling SHA-256 fully usually pays off better than 8-fold, whereas SHA-512 is usually better off unrolled only 8-fold.
Unrolling in the latter hashes also means the possibility of embedding the round constants (the K[] array) into the code instead of performing a table lookup. This pays off less on platforms like the ARM, which cannot embed 32-bit (or 64-bit for that matter) constants in the instruction flow.
Zero-Copy Hashing
Another useful optimization is to zero-copy the data we are hashing. This optimization basically loads the message block directly from the user-passed data instead of buffering it internally. This hash is most important on platforms with little to no cache. Data in these cases is usually going over a relatively slower data bus, often competing for system devices for traffic.
For example, if a 32-bit load or store requires (say) six cycles, which is typical for the average low power embedded device, then storing a message block will take 96 cycles. A compression may only take 1000 to 2000 cycles, so we are adding between 4.5% and 9 percent more cycles to the operation that we do not have to.
This optimization usually adds little to the code size and gives us a cheap boost in performance.
PKCS #5 Example
We are now going to consider the example of AES CTR from Chapter 4. The reader may be a bit upset at the comment “somehow fill secretkey and IV …” found in the code with that section missing. We now show one way to fill it in.
The reader should keep in mind that we are putting in a dummy password to make the example work. In practice, you would fetch the password from the user, or by first turning off the console echo and so on.
Our example again uses the LibTomCrypt library. This library also provides a nice and handy PKCS #5 function that in one call produces the output from the secret and salt.

This is a handy debugging function for dumping arrays. Often in cryptographic protocols, it is useful to see intermediate outputs before the final output. In particular, in multistep protocols, it will let us debug at what point we deviated from the test vectors. That is, provided the test vectors list such things.

Similar list of variables from the CTR example. Note we now have a salt[] array and a buflen integer.
![]()
Now we have registered SHA-256 in the crypto library. This allows us to use SHA-256 by name in the various functions (such as PKCS #5 in this case). Part of the benefit of the LibTomCrypt approach is that many functions are agnostic to which cipher, hash, or other function they are actually using. Our PKCS #5 example would work just as easily with SHA-1, SHA-256, or even the Whirlpool hash functions.
![]()
In this case, we read the RNG instead of setting up a PRNG. Since we are only reading eight bytes, this is not likely to block on Linux or BSD setups. In Windows, it will never block.

This function call invokes PKCS #5. We pass the dummy password “passwd” instead of a properly entered one from the user. Please note that this is just an example and not the type of password scheme you should employ in your application.
The next line specifies our salt and its length—in this case, eight bytes. Follow by the number of iterations desired. We picked 1024 simply because it’s a nice round nontrivial number.
The find_hash() function call may be new to some readers unfamiliar with the LibTomCrypt library. This function searches the tables of registered hashes for the entry matching the name provided. It returns an integer that is an index into the table. The function (PKCS #5 in this case) can then use this index to invoke the hash algorithm.
The tables LibTomCrypt uses are actually an array of a C “struct” type, which contains pointers to functions and other parameters. The functions pointed to implement the given hash in question. This allows the calling routine to essentially support any hash without having been designed around it first.
The last line of the function call specifies where to store it and how much data to read. LibTomCrypt uses a “caller specified” size for buffers. This means the caller must first say the size of the buffer (in the pointer to an unsigned long), and then the function will update it with the number of bytes stored.
This will become useful in the public key and ASN. 1 function calls, as callers do not always know the final output size, but do know the size of the buffer they are passing.
![]()
At this point, buf[0..31] contains 32 pseudo random bytes derived from our password and salt. We copy the first 16 bytes as the secret key and the second 16 bytes as the IV for the CTR mode.

The example can be built, provided LibTomCrypt has already been installed, with the following command.
![]()
The example output would resemble the following.

Each run should choose a different salt and respectively produce a different ciphertext. As the demonstration states, we would only have to be given the salt and ciphertext to be able to decrypt it (provided we knew the password). We do not have to send the IV bytes since they are derived from the PKCS #5 algorithm.
The following Frequently Asked Questions, answered by the authors of this book, are designed to both measure your understanding of the concepts presented in this chapter and to assist you with real-life implementation of these concepts. To have your questions about this chapter answered by the author, browse to www.syngress.com/solutions and click on the “Ask the Author” form.
A: A hash function accepts as input an arbitrary length string of bits and produces as output a fixed size string of bits known as the message digest. The goal of a cryptographic hash function is to perform the mapping as if the function were a random function.
A: A message digest is the output of a hash function. Usually, it is interpreted as a representative of the message.
Q: What does one-way and collision resistant mean?
A: A function that is one-way implies that determining the output given the input is a hard problem to solve. In this case, given a message digest, finding the input should be hard. An ideal hash function is one-way. Collision resistant implies that finding pairs of unique inputs that produce the same message digest is a hard problem. There are two forms of collision resistance. The first is called pre-image collision resistance, which implies given a fixed message we cannot find another message that collides with it. The second is simply called second pre-image collision resistance and implies that finding two random messages that collide is a hard problem.
Q: What are hash functions used for?
A: Hash functions form what are known as Pseudo Random Functions (PRFs). That is, the mapping from input to output is indistinguishable from a random function. Being a PRF, a hash function can be used for integrity purposes. Including a message digest with an archive is the most direct way of using a hash. Hashes can also be used to create message authentication codes (see Chapter 6) such as HMAC. Hashes can also be used to collect entropy for RNG and PRNG designs, and to produce the actual output from the PRNG designs.
A: Currently, NIST only specifies SHA-1 and the SHA-2 series of hash algorithms as standards. There are other hashes (usually unfortunately) in wide deployment such as MD4 and MD5, both of which are currently considered broken. The NESSIE process in Europe has provided the Whirlpool hash, which competes with SHA-512.
Q: Where can I find implementations of these hashes?
A: LibTomCrypt currently supports all NIST standard hashes (including the newer SHA-224), and the NESSIE specifies Whirlpool hash. LibTomCrypt also supports the older hash algorithms such as RIPEMD, MD2, MD4, and so on, but generally users are warned to avoid them unless they are trying to implement an older standard (such as the NT hash). OpenSSL supports SHA-1 and RIPEMD, and Crypto++ supports a variety of hashes including the NIST standards.
Q: What are the patent claims on these hashes?
A: SHA-0 (the original SHA) was patented by the NSA, but irrevocably released to the public for all purposes. SHA-2 series and Whirlpool are both public domain and free for all purposes.
Q: What length of digest should I use? What is the birthday paradox?
A: In general, you should use twice the number of bits in your message digest as the target bit strength you are looking for. If, for example, you want an attacker to spend no less than 2128 work breaking your cryptography, you should use a hash that produces at least a 256-bit message digest. This is a result of the birthday paradox, which states that given roughly the square root of the message digest’s domain size of outputs, one can find a collision. For example, with a 256-bit message digest, there are 2256 possible outcomes. The square root of this is 2128, and given 2128 pairs of inputs and outputs from the hash function, an attacker has a good probability of finding a collision among the entries of the set.
A: MD (Message Digest) strengthening is a technique of padding a message with an encoding of the message length to avoid various prefix and extension attacks.
A: Key derivation is the process of taking a shared secret key and producing from it various secret and public materials to secure a communication session. For instance, two parties could agree on a secret key and then pass that to a key derivation function to produce keys for encryption, authentication, and the various IV parameters. Key derivation is preferable over using shared secrets directly, as it requires sharing fewer bits and also mitigates the damages of key discovery. For example, if an attacker learns your authentication key, he should not learn your encryption key.
A: PKCS #5 is the RSA Security Public Key Cryptographic Standard that addresses password-based encryption. In particular, their updated and revised algorithm PBEKDF2 (also known as PKCS #5 Alg2) accepts a secret salt and then expands it to any length required by the user. It is very useful for deriving session keys and IVs from a single (shorter) shared secret. Despite the fact that the standard was meant for password-based cryptography, it can also be used for randomly generated shared secrets typical of public key negotiation algorithms.