
Message - Authentication Code Algorithms
Introduction
Message Authentication Code (MAC) algorithms are a fairly crucial component of most online protocols. They ensure the authenticity of the message between two or more parties to the transaction. As important as MAC algorithms are, they are often overlooked in the design of cryptosystems.
A typical mistake is to focus solely on the privacy of the message and disregard the implications of a message modification (whether by transmission error or malicious attacker).
An even more common mistake is for people to not realize they need them. Many people new to the field assume that not being sure of the contents of a message means you cannot change it. The logic goes, “if they have no idea what is in my message, how can they possibly introduce a useful change?”
The error in the logic is the first assumption. Generally, an attacker can get a very good idea of the rough content of your message, and this knowledge is more than enough to mess with the message in a meaningful way. To illustrate this, consider a very simple banking protocol. You pass a transaction to the bank for authorization and the bank sends a single bit back: 0 for declined, 1 for a successful transaction.
If the transmission isn’t authenticated and you can change messages on the communication line, you can cause all kinds of trouble. You could send fake credentials to the merchant that the bank would duly reject, but since you know the message is going to be a rejection, you could change the encrypted zero the bank sends back to a one—just by flipping the value of the bit. It’s these types of attacks that MACs are designed to stop.
MAC algorithms work in much the same context as symmetric ciphers. They are fixed algorithms that accept a secret key that controls the mapping from input to the output (typically called the tag). However, MAC algorithms do not perform the mapping on a fixed input size basis; in this regard, they are also like hash functions, which leads to confusion for beginners.
Although MAC functions accept arbitrary large inputs and produce a fixed size output, they are not equivalent to hash functions in terms of security. MAC functions with fixed keys are often not secure one-way hash functions. Similarly, one-way functions are not secure MAC functions (unless special care is taken).
Purpose of A MAC Function
The goal of a MAC is to ensure that two (or more) parties, who share a secret key, can communicate with the ability (in all likelihood) to detect modifications to the message in transit. This prevents an attacker from modifying the message to obtain undesirable outcomes as discussed previously.
MAC algorithms accomplish this by accepting as input the message and secret key and producing a fixed size MAC tag. The message and tag are transmitted to the other party, who can then re-compute the tag and compare it against the tag that was transmitted. If they match, the message is almost certainly correct. Otherwise, the message is incorrect and should be ignored, or drop the connection, as it is likely being tampered with, depending on the circumstances.
For an attacker to forge a message, he would be required to break the MAC function. This is obviously not an easy thing to do. Really, you want it be just as hard as breaking the cipher that protects the secrecy of the message.
Usually for reasons of efficiency, protocols will divide long messages into smaller pieces that are independently authenticated. This raises all sorts of problems such as replay attacks. Near the end of this chapter, we will discuss protocol design criteria when using MAC algorithms. Simply put, it is not sufficient to merely throw a properly keyed MAC algorithm to authenticate a stream of messages. The protocol is just as important.
Security Guidelines
The security goals of a MAC algorithm are different from those of a one-way hash function. Here, instead of trying to ensure the integrity of a message, we are trying to establish the authenticity. These are distinct goals, but they share a lot of common ground. In both cases, we are trying to determine correctness, or more specifically the purity of a message. Where the concepts differ is that the goal of authenticity tries also to establish an origin for the message.
For example, if I tell you the SHA-1 message digest of a file is the 160-bit string X and then give you the file, or better yet, you retrieve the file yourself, then you can determine if the file is original (unmodified) if the computed message digest matches what you were given. You will not know who made the file; the message digest will not tell you that. Now suppose we are in the middle of communicating, and we both have a shared secret key K. If I send you a file and the MAC tag produced with the key K, you can verify if the message originated from my side of the channel by verifying the MAC tag.
Another way MAC and hash functions differ is in the notion of their bit security. Recall from Chapter 5, “Hash Functions,” that a birthday attack reduces the bit security strength of a hash to half the digest size. For example, it takes 2128 work to find collisions in SHA-256. This is possible because message digests can be computed offline, which allows an attacker to pre-compute a huge dictionary of message digests without involving the victim. MAC algorithms, on the other hand, are online only. Without access to the key, collisions are not possible to find (if the MAC is indeed secure), and the attacker cannot arbitrarily compute tags without somehow tricking the victim into producing them for him.
As a result, the common line of thinking is that birthday attacks do not apply to MAC functions. That is, if a MAC tag is k-bits long, it should take roughly 2k work to find a collision to that specific value. Often, you will see protocols that greatly truncated the MAC tag length, to exploit this property of MAC functions.
IPsec, for instance, can use 96-bit tags. This is a safe optimization to make, since the bit security is still very high at 296 work to produce a forgery.
MAC Key Lifespan
The security of a MAC depends on more than just on the tag length. Given a single message and its tag, the length of the tag determines the probability of creating a forgery. However, as the secret key is used to authenticate more and more messages, the advantage—that is, the probability of a successful forgery—rises.
Roughly speaking, for example, for MACs based on block ciphers the probability of a forgery is 0.5 after hitting the birthday paradox limit. That is, after 264 blocks, with AES an attacker has an even chance of forging a message (that’s still 512 exabytes of data, a truly stupendous quantity of information).
For this reason, we must think of security not from the ideal tag length point of view, but the probability of forgery. This sets the upper bound on our MAC key lifespan. Fortunately for us, we do not need a very low probability to remain secure. For instance, with a probability of 2−40 of forgery, an attacker would have to guess the correct tag (or contents to match a fixed tag) on his first try. This alone means that MAC key lifespan is probably more of an academic discussion than anything we need to worry about in a deployed system
Even though we may not need a very low probability of forgery, this does not mean we should truncate the tag. The probability of forgery only rises as you authenticate more and more data. In effect, truncating the tag would save you space, but throw away security at the same time. For short messages, the attacker has learned virtually nothing required to compute forgeries and would rely on the probability of a random collision for his attack vector on the MAC.
Standards
To help developers implement interoperable MAC functions in their products, NIST has standardized two different forms of MAC functions. The first to be developed was the hash-based HMAC (FIPS 198), which described a method of safely turning a one-way collision resistant hash into a MAC function. Although HMAC was originally intended to be used with SHA-1, it is appropriate to use it with other hash function. (Recent results show that collision resistance is not required for the security of NMAC, the algorithm from which HMAC was derived (http://eprint.iacr.org/2006/043.pdf for more details). However, another paper (http://eprint.iacr.org/2006/187.pdf) suggests that the hash has to behave securely regardless.)
The second standard developed by NIST was the CMAC (SP 800-38B) standard. Oddly enough, CMAC falls under “modes of operations” on the NIST Web site and not a message authentication code. That discrepancy aside, CMAC is intended for message authenticity. Unlike HMAC, CMAC uses a block cipher to perform the MAC function and is ideal in space-limited situations where only a cipher will fit.
Cipher Message Authentication Code
The cipher message authentication code (CMAC, SP 800-38B) algorithm is actually taken from a proposal called OMAC, which stands for “One-Key Message Authentication Code” and is historically based off the three-key cipher block chaining MAC. The original cipher-based MAC proposed by NIST was informally known as CBC-MAC.
In the CBC-MAC design, the sender simply chooses an independent key (not easily related to the encryption key) and proceeds to encrypt the data in CBC mode. The sender discards all intermediate ciphertexts except for the last, which is the MAC tag. Provided the key used for the CBC-MAC is not the same (or related to) the key used to encrypt the plaintext, the MAC is secure (Figure 6.1).

That is, for all fixed length messages under the same key. When the messages are packets of varying lengths, the scheme becomes insecure and forgeries are possible; specifically, when messages are not an even multiple of the cipher’s block length.
The fix to this problem came in the form of XCBC, which used three keys. One key would be used for the cipher to encrypt the data in CBC-MAC mode. The other two would be XOR’ed against the last message block depending on whether it was complete. Specifically, if the last block was complete, the second key would be used; otherwise, the block was padded and the third key used.
The problem with XCBC was that the proof of security, at least originally, required three totally independent keys. While trivial to provide with a key derivation function such as PKCS #5, the keys were not always easy to supply.
After XCBC mode came TMAC, which used two keys. It worked similarly to XCBC, with the exception that the third key would be linearly derived from the first. They did trade some security for flexibility. In the same stride, OMAC is a revision of TMAC that uses a single key (Figures 6.2 and 6.3).
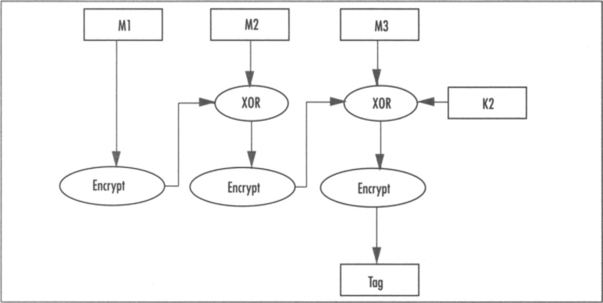

Security of CM AC
To make these functions easier to use, they made the keys dependent on one another. This falls victim to the fact that if an attacker learns one key, he knows the others (or all of them in the case of OMAC). We say the advantage of an attacker is the probability that his forgery will succeed after witnessing a given number of MAC tags being produced.
1. Let AdvMAC represent the probability of a MAC forgery.
2. Let AdvPRP represent the probability of distinguishing the cipher from a random permutation.
3. Let t represent the time the attacker spends.
4. Let q represent the number of MAC tags the attacker has seen (with the corresponding inputs).
5. Let n represent the size of the block cipher in bits.
6. Let m represent the (average) number of blocks per message authenticated.
The advantage of an attacker against OMAC is then (roughly) no more than:
![]()
Assuming that mq is much less than 2n/2, then AdvPRP() is essentially zero. This leaves us with the left-hand side of the equation. This effectively gives us a limit on the CMAC algorithm. Suppose we use AES (n = 128), and that we want a probability of forgery of no more than 2−96. This means that we need
![]()
If we simplify that, we obtain the result
![]()
What this means is that we can process no more than 215 blocks with the same key, while keeping a probability of forgery below 2−96. This limit seems a bit too strict, as it means we can only authenticate 512 kilobytes before having to change the key. Recall from our previous discussion on MAC security that we do not need such strict requirements. The attacker need only fail once before the attack is detected. Suppose we use the upper bound of 2−40 instead. This means we have the following limits:
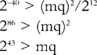
This means we can authenticate 243 blocks (1024 terabytes) before changing the key. An attacker having seen all of that traffic would have a probability of 2−40 of forging a packet, which is fairly safe to say not going to happen. Of course, this does not mean that one should use the same key for that length of traffic.
CMAC Design
CMAC is based off the OMAC design; more specifically, off the OMAC1 design. The designer of OMAC designed two very related proposals. OMAC1 and OMAC2 differ only in how the two additional keys are generated. In practice, people should only use OMAC1 if they intend to comply with the CMAC standard.
CMAC Initialization
CMAC accepts as input during initialization a secret key K. It uses this key to generate two additional keys K1 and K2. Formally, CMAC uses a multiplication by p(x) = x in a GF(2)[x]/v(x) field to accomplish the key generation. Fortunately, there is a much easier way to explain it (Figure 6.4).

The values are interpreted in big endian fashion, and the operations are all on either 64- or 128-bit strings depending on the block size of the block cipher being used. The value of Rb depends on the block size. It is 0x87 for 128-bit block ciphers and 0x1B for 64-bit block ciphers. The value of L is the encryption of the all zero string with the key K.
Now that we have K1 and K2, we can proceed with the MAC. It is important to keep in mind that K1 and K2 must remain secret. Treat them as you would a ciphering key.
CMAC Processing
From the description, it seems that CMAC is only useful for packets where you know the length in advance. However, since the only deviations occur on the last block, it is possible to implement CMAC as a streaming MAC function without advanced knowledge of the data size. For zero length messages, CMAC treats them as incomplete blocks (Figure 6.5).

It may look tempting to give out Ci values as ciphertext for your message. However, that invalidates the proof of security for CMAC. You will have to encrypt your plaintext with a different (unrelated) key to maintain the proof of security for CMAC.
CMAC Implementation
Our implementation of CMAC has been hardcode to use the AES routines of Chapter 4 with 128-bit keys. CMAC is not limited to such decisions, but to better demonstrate the MAC we decided to simplify it. The CMAC routines in LibTomCrypt (under the OMAC directory) demonstrate how to write a very flexible CMAC routine that can accept any 64- or 128-bit block cipher.
![]()
We copied the AES code to our directory for Chapter 6. At this stage, we want to keep the code simple, so to this end, we simply include the AES code directly in our application.
Obviously, in the field the best practice would be to write an AES header and link the two files against each other properly.

This is our CMAC state function. Our implementation will process the CMAC message as a stream instead of a fixed sized block. The L array holds our two keys K1 and K2, which we compute in the cmac_init() function. The C array holds the CBC chaining block. We buffer the message into the C array by XOR’ing the message against it. The buflen integer counts the number of bytes pending to be sent through the cipher.

This function initializes our CMAC state. It has been hard coded to use 128-bit AES keys.
![]()
First, we schedule the input key to the array in the CMAC state. This allows us to invoke the cipher on demand throughout the rest of the algorithm.

At this point, our L[0] array (equivalent to K1) contains the encryption of the zero byte string. We will multiply this by the polynomial x next to compute the final value of K1.

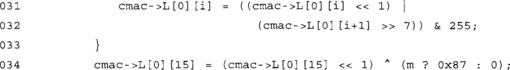
We first grab the MSB of L[0] (into m) and then proceed with the left shift. The shift is equivalent to a multiplication by x. The last byte is shifted on its own and the value of 0x87 XORed in if the MSB was nonzero.

This copies L[0] (K1) into L[1] (K2) and performs the multiplication by x again. At this point, we have both additional keys required to process the message with CMAC.

This final bit of code initializes the buffer and CBC chaining variable. We are now ready to process the message through CMAC.

Our “process” function is much like the process functions found in the implementations of the hash algorithms. It allows the caller to send in an arbitrary length message to be handled by the algorithm.
![]()
This turns off the first block flag telling the CMAC functions that we have processed at least one byte in the function.

If we have filled the CBC chaining block, we must encrypt it and clear the counter. We must do this for every 16 bytes we process, since we assume we are using AES, which has a 16-byte block size.

The last statement XORs a byte of the message against the CBC chaining block. Notice, how we check for a full block before we add the next byte. The reason for this becomes more apparent in the next function.
This loop can be optimized on 32- and 64-bit platforms by XORing larger words of input message against the CBC chaining block. For example, on a 32-bit platform we could use the following:

This loop XORs 32-bit words at a time, and for performance reasons assumes that the input buffer is aligned on a 32-bit boundary. Note that it is endianess neutral and only depends on the mapping of four unsigned chars to a single ulong32. That is, the code is not entirely portable but will work on many platforms. Note that we only process if the CMAC buffer is empty, and we only encrypt if there are more than 16 bytes left.
The LibTomCrypt library uses a similar trick that also works well on 64-bit platforms.
The OMAC routines in that library provide another example of how to optimize CMAC.

This function terminates the CMAC and outputs the MAC tag value.

If we have zero bytes in the message or an incomplete block, we first append a one bit follow by enough zero bits. Since we are byte based, the padding is the 0x80 byte followed by zero bytes. We then XOR K2 against the block.

Otherwise, if we had a complete block we XOR K1 against the block.
![]()
We encrypt the CBC chaining block one last time. The ciphertext of this encryption will be the MAC tag. All that is left is to truncate it as requested by the caller.

This simple function allows the caller to compute the CMAC tag of a message with a single function call. Very handy to have.


These arrays are the standard test vectors for CMAC with AES-128. An implementation must at the very least match these vectors to claim CMAC AES-128 compliance.

This demonstration program computes the CMAC tags for the test messages and compares the tags. Keep in mind this test program only uses AES-128 and not the full AES suite. Although, in general, if you can comply to the AES-128 CMAC test vectors, you should comply with the AES-192 and AES-256 vectors as well.
CMAC Performance
Overall, the performance of CMAC depends on the underlying cipher. With the feedback optimization for the process function (XORing words of data instead of bytes), the overhead can be minimal.
Unfortunately, CMAC uses CBC mode and cannot be parallelized. This means in hardware, the best performance will be achieved with the fastest AES implementation and not many parallel instances.
Hash Message Authentication Code
The Hash Message Authentication Code standard (FIPS 198) takes a cryptographic one-way hash function and turns it into a message authentication code algorithm. Remember how earlier we said that hashes are not authentication functions? This section will tell you how to turn your favorite hash into a MAC.
The overall HMAC design was derived from a proposal called NMAC, which turns any pseudo random function (PRF) into a MAC function with provable security bounds. In particular, the focus was to use a hash function as the PRF. NMAC was based on the concept of prefixing the message with a key smf then hashing the concatenation. For example,
![]()
However, recall from Chapter 5 that we said that such a construction is not secure. In particular, an attacker can extend the message by using the tag as the initial state of the hash. The problem is that the attacker knows the message being hashed to produce the tag. If we could somehow hide that, the attacker could not produce valid tag, Effectively, we have
![]()
Now an attacker who attempts to extend the message by using tag as the initial hash state, the result of the PRF() mapping will not be predictable. In this configuration, an attacker can no longer use tag as the initial state. The only question now is how to create a PRF? It turns out that the original construction is a decent PRF to use. That is, hash functions are by definition pseudo random functions that map their inputs to difficult to otherwise predict outputs. The outputs are also hard to invert (that is, the hash is one-way). Keying the hash function by pre-pending secret data to the message should by definition create a keyed PRF.
The complete construction is then
![]()
Note that NMAC requires two keys, one for in the inner hash and one for the outer hash. While the constructions is simple, it lacks efficiency as it requires two independent keys.
The HMAC construction is based on NMAC, except that the two keys are linearly related. The contribution of HMAC was to prove that the construction with a single key is also secure. It requires that the hash function be a secure PRF, and while it does not have to be collision resistant (New Proofs for NMAC and HMAC: Security without Collision Resistant: http://eprint.iacr.org/2006/043.pdf), it must be resistant to differential cryptanalysis (On The Security of HMAC and NMAC Based on HAVAL, MD4, MD5, SHA-0, and SHA-1: http://eprint.iacr.org/2006/187.pdf).
HMAC Design
Now that we have a general idea of what HMAC is, we can examine the specifics that make up the FIPS 198 standard. HMAC, like CMAC, is not specific to a given algorithm underneath. While HMAC was originally intended to be used with SHA-1 it can safely be used with any otherwise secure hash function, such as SHA-256 and SHA-512.
HMAC derives the two keys from a single secret key by XORing two constants against it. First, before we can do this we have to make sure the key is the size of the hashes compression block size. For instance, SHA-1 and SHA-256 compress 64-byte blocks, whereas SHA-512 compresses 128-byte blocks.
If the secret key is larger than the compression block size, the standard requires the key to be hashed first. The output of the hash is then treated as the secret key. The secret key is padded with zero bytes to ensure it is the size of the compression block input size.
The result of the padding is then copied twice. One copy has all the bytes XORed with 0x36; this is the outer key. The other copy has all its bytes XORed with 0x5C; this is the inner key. For simplicity we shall call the string of 0x36 bytes the opad, and the string of 0x5C bytes the ipad.
You may wonder why the key is padded to be the size of a compression block. Effectively, this turns the hash into a keyed hash by making the initial hash state key dependent. From a cryptographic standpoint, HMAC is equivalent to picking the hashes initial state at random based on a secret key (Figures 6.6 and 6.7).
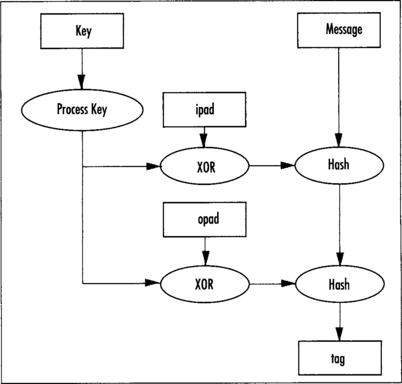

As we can see, HMAC is a simple algorithm to describe. With a handy hash function implementation, it is trivial to implement HMAC. We note that, since the message is only hashed in the inner hash, we can effectively HMAC a stream on the fly without the need for the entire message at once (provided the hash function does not require the entire message at once).
Since this algorithm uses a hash as the PRF, and most hashes are not able to process message blocks in parallel, this will become the significant critical path of the algorithm in terms of performance. It is possible to compute the hash of (opad XOR K) while computing the inner hash, but this will save little time and require two parallel instances of the hash. It is not a worthwhile optimization for messages that are more than a few message blocks in length.
HMAC Implementation
Our implementation of HMAC has been tied to the SHA-1 hash function. Like CMAC, we decided to simplify the implementation to ensure the implementation is easy to absorb.
We directly include the SHA-1 source code to provide our hash function. Ideally, we would include a proper header file and link against SHA-1. However, at this point we just want to show off HMAC working.
![]()
![]()
This is our HMAC state. It is fairly simple, since all of the data buffering is handled internally by the SHA-1 functions. We keep a copy of the outer key K to allow the HMAC implementation to apply the outer hash. Note that we would have to change the size of K to suit the hash. For instance, with SHA-512 it would have to be 128 bytes long. We would have to make that same change to the following function.

This function initializes the HMAC state by processing the key and starting the inner hash.

If the secret key is larger than 64 bytes (the compression block size of SHA-1), we hash it using the helper SHA-1 function. If it is not, we copy it into our local K array. In either case, at this point i will indicate the number of bytes in the array that have been filled in. This is used in the next loop to pad the key.

This pads the keys with zero bytes so that it is 64 bytes long.


The first loop creates the outer key and stores it in the HMAC state. The second loop creates the inner key and stores it locally. We only need it for a short period of time, so there is no reason to copy it to the HMAC state.

At this point we have initialized the HMAC state. We can process data to be authenticated with the following function.

This function processes data we want to authenticate. Take a moment to appreciate the vast complexity of HMAC. Done? This is one of the reasons HMAC is a good standard. It is ridiculously simple to implement.

This function terminates the HMAC and outputs the tag.

The T array stores the message digest from the hash function. You will have to adjust it to match the output size of the hash function.

At this point, we have all the prerequisites to begin using HMAC to process data. We can borrow from our hash implementations a bit to help out here.

As in the case of CMAC, we have provided a simple to use HMAC function that produces a tag with a single function call.



The test vectors in our implementation are from RFC 22021 published in 1997 (HMAC RFC: www.faqs.org/rfcs/rfc2104.html, HMAC Test Cases: www.faqs.org/rfcs/rfc2202.html). The Request for Comments (RFC) publication was the original standard for the HMAC algorithm. We use these vectors since they were published before the test vectors listed in FIPS 198. Strictly speaking, FIPS 198 is not dependent on RFC 2104; that is, to claim standard compliance with FIPS 198, you must pass the FIPS 198 test vectors.
Fortunately, RFC 2104 and FIPS 198 specify the same algorithm. Oddly enough, in the NIST FIPS 198 specification they claim their standard is a “generalization” of RFC 2104. We have not noticed any significant difference between the standards. While HMAC was originally intended to be used with MD5 and SHA-1, the RFC does not state that it is limited in such a way. In fact, quoting from the RFC, “This document specifies HMAC using a generic cryptographic hash function (denoted by H),” we can see clearly the intended scope of the standard was not limited to a given hash function.
Putting It All Together
Now that we have seen two standard MAC functions, we can begin to work on how to use the MAC functions to accomplish useful goals in a secure manner. We will first examine the basic tasks MAC functions are for, and what they are not for. Next, we will compare CMAC and HMAC and give advice on when to use one over the other.
After that point, we will have examined which MAC function to use and why we want you to use them. We will then proceed to examine how to use them securely. It is not enough to simply apply the MAC function to your data; you must also apply it within a given context for the system to be secure.
What MAC Functions Are For?
First and foremost, MAC functions were designed to provide authenticity between parties on a communication channel. If all is working correctly, all of the parties can both send and receive (and verify) authenticated messages between one another—that is, without the significant probability that an attacker is forging messages.
So, what exactly do we use MACs for in real-world situations? Some classic examples include SSL and TLS connections on the Internet. For example, HTTPS connections use either TLS or SSL to encrypt the channel for privacy, and apply a MAC to the data being sent in either direction to ensure its authenticity. SSH is another classic example. SSH (Secure Shell) is a protocol that allows users to remotely log in to other machines in much the same way telnet would. However, unlike telnet, SSH uses cryptography to ensure both the privacy and authentication of the data being sent in both directions. Finally, another example is the GSM cellular standard. It uses an algorithm known as COMP128 to authenticate users on the network. Unlike SSL and SSH, COMP128 is used to authenticate the user by providing a challenge for which the user must provide the correct MAC tag in response. COMP128 is not used to authenticate data in transit.
Consequences
Suppose we had not used MAC authenticators in the previous protocols, what threats would the users face?
In the typical use case of TLS and SSL, users are trying to connect to a legitimate host and transfer data between the two points. The data usually consists of HTTPS traffic; that is, HTML documents and form replies. The consequences of being able to insert or modify replies depends on the application. For instance, if you are reading e-mail, an attacker could re-issue previous commands from the victim to the server. These commands could be innocuous such as “read next e-mail,” but could also be destructive such as “delete current e-mail.” Online banking is another important user of TLS cryptography. Suppose you issued an HTML form reply of “pay recipient $100.” An attacker could modify the message and change the dollar amount, or simpler yet, re-issue the command depleting the bank account.
Modification in the TLS and SSL domains are generally less important, as the attacker is modifying ciphertext, not plaintext. Attackers can hardly make modifications in a protocol legible fashion. For instance, a user connected to SMTP through TLS must send properly formatted commands to have the server perform work. Modifying the data will likely modify the commands.
In the SSH context, without a MAC in place, an attacker could re-issue many commands sent by the users. This is because SSH uses a Nagle-like protocol to buffer out going data. For instance, if SSH sent a packet for every keystroke you made, it would literally be sending kilobytes of data to simply enter a few paragraphs of text. Instead, SSH, like the TCP/IP protocol, buffers outgoing data until a reply is received from the other end. In this way, the protocol is self-clocking and will only give as low latency as the network will allow while using an optimal amount of bandwidth.
With the buffering of input comes a certain problem. For instance, if you typed “rm –f *” at your shell prompt to empty a directory, chances are the entire string (along with the newline) would be sent out as one packet to the SSH server. An attacker who retrieves this packet can then replay it, regardless of where you are in your session.
In the case of GSM’s COMP128 protocol, if it did not exist (and no replacement was used), a GSM client would simply pop on a cellular network, say “I’m Me!” and be able to issue any command he wanted such as dialing a number or initiating a GPRS (data) session.
In short, without a MAC function in place, attackers can modify packets and replay old packets without immediate and likely detection. Modifying packets may seem hard at first; however, on various protocols it is entirely possible if the attacker has some knowledge of the likely characteristics of the plaintext. People tend to think that modifications will be caught further down the line. For instance, if the message is text, a human reading it will notice. If the message is an executable, the processor will throw an exception at invalid instructions. However, not all modifications, even random ones (without an attacker), are that noticeable.
For instance, in many cases on machines with broken memory—that is, memory that is either not storing values correctly, or simply failing to meet timing specifications—errors received by the processor go unnoticed for quite some time. The symptoms of problematic memory could be as simple as a program terminating, or files and directories not appearing correctly. Servers typically employ the use of error correcting code (ECC) based memory, which sends redundant information along with the data. The ECC data is then used to correct errors on the fly. Even with ECC, however, it’s possible to have memory failures that are not correctable.
Message replay attacks can be far more dangerous. In this case, an attacker resends an old valid packet with the hopes of causing harm to the victim. The replayed packets are not modified so the decryption should be valid, and depending on the current context of the protocol could be very dangerous.
What MAC Functions Are Not For?
MAC functions usually are not abused in cryptographic applications, at least not in the same way hash and cipher functions are. Sadly, this is not because of the technical understanding of MAC functions by most developers. In fact, most amateur protocols omit authentication threats altogether. As an aside, that is usually a good indicator of snake oil products. MAC functions are not usually abused by those who know about them, mostly because MAC functions are made out of useful primitives like ciphers and hashes. With that said, we shall still briefly cover some basics.
MACs are not meant to be used as hash functions. Occasionally, people will ask about using CMAC with a fixed key to create a hash function. This construction is not secure because the “compression” function (the cipher) is no longer a PRP. None of the proofs applies at that point. There is a secure way of turning a cipher into a hash:
In this mode, EncryptK(P) means to encrypt the plaintext P with key K. The initial value, H[0], is chosen by encrypting the zero string to make the protocol easier to specify. This method of hashing is not part of any NIST standard, although it has been used in a variety of products. It is secure, provided the cipher itself is immune to differential attacks and the key schedule is immune to related key attacks.
MACs are also not meant for RNG processing or even to be turned into a PRNG. With a random secret key, the MAC function should behave as a PRF to an attacker. This implies that it could be used as a PRNG, which is indeed true. In practice, a properly keyed MAC could make a secure PRNG function if you ran a counter as the input and used the output as the random numbers. However, such a construction is slow and wastes resources. A properly keyed cipher in CTR mode can accomplish the same goal and consume fewer resources.
CMAC versus HMAC
Comparing CMAC against HMAC for useful comparison metrics depends on the problem you are trying to solve, and what means you have to solve it. CMAC is typically a good choice if you already have a cipher lying around (say, for privacy). You can re-use the same code (or hardware) to accomplish authentication. CMAC is also based on block ciphers, which while having small inputs (compared to hashes) can return an output in short order. This reduces the latency of the operation. For short messages, say as small as 16 or 32 bytes, CMAC with AES can often be faster and lower latency than HMAC.
Where HMAC begins to win out is on the larger messages. Hashes typically process data with fewer cycles per byte when compared to ciphers. Hashes also typically create larger outputs than ciphers, which allows for larger MAC tags as required. Unfortunately, HMAC requires you to have a hash function implemented; however, on the upside, the HMAC code that wraps around the hash implementation is trivial to implement.
From a security standpoint, provided the respective underlying primitives (e.g., the cipher or the hash) are secure on their own (e.g., a PRP or PRF, respectively), the MAC construction can be secure as well. While HMAC can typically put out larger MAC tags than CMAC (by using a larger hash function), the security advantage of using larger tags is not significant.
Bottom line: If you have the space or already have a hash, and your messages are not trivially small, use HMAC. If you have a cipher (or want a smaller footprint) and are dealing with smaller messages, use CMAC. Above all, do not re-invent the wheel; use the standard that fits your needs.
Replay Protection
Simply applying the MAC function to your message is not enough to guarantee the system as a whole is safe from replays. This problem arises due to a need for efficiency and necessity. Instead of sending a message as one long chunk of data, a program may divide it into smaller, more manageable pieces and send them in turn. Streaming applications such as SSH essentially demand the use of data packets to function in a useful capacity.
The cryptographic vulnerabilities of using packets, even individually authenticated packets, is that they are meant to form, as a whole, a larger message. That is, the individual packets themselves have to be correct but also the order of the packets over the entire session. An attacker may exploit this venue by replaying old packets or modifying the order of the packets. If the system has no way to authenticate the order of the packets, it could accept the packets as valid and interpret the re-arrangement as the entire message.
The classic example of how this is a problem is a purchase order. For example, a client wishes to buy 100 shares of a company. So he packages up the message M = “I want to buy 100 shares.” The client then encrypts the message and applies a MAC to the ciphertext. Why is this not secure? An attacker who sees the ciphertext and MAC tag can retransmit the pair. The server, which is not concerned with replay attacks, will read the pair, validate the MAC, and interpret the ciphertext as valid. Now an attacker can deplete the victim’s funds by re-issuing the purchase order as often as he desires.
The two typical solutions to replay attacks are timestamps and counters. Both solutions must include extra data as part of the message that is authenticated. They give the packets a context, which helps the receiver interpret their presence in the stream.
Timestamps
Timestamps can come in various shapes and sizes, depending on the precision and accuracy required. The goal of a timestamp is to ensure that a message is valid only for a given period of time. For example, a system may only allow a packet to be valid for 30 seconds since the timestamp was applied. Timestamps sound wonderfully simple, but there are various problems.
From a security standpoint, they are hard to get narrow enough to avoid replay attacks within the window of validity. For instance, if you set the window of validity to (say) five minutes, an attacker can replay the message during a five-minute period. On the other hand, if you make the window only three seconds, you may have a hard time delivering the packet within the window; worse yet, clock drift between the two end points may make the system unusable.
This last point leads to the practical problems with timestamps. Computers are not terribly accurate time keepers. The system time can drift due to inaccuracies in the timing hardware, system crashes, and so on. Usually, most operating systems will provide a mechanism for updating system time, usually via the Network Time Protocol (NTP). Getting two computers, especially remotely, to agree on the current time is a difficult challenge.
Counters
Counters are the more ideal solution against replay attacks. At its most fundamental level, you need a concept of what the “next” value should be. For instance, you could store a LFSR state in one packet and expect the clocked LFSR in the next packet. If you did not see the clocked LFSR value, you could assume that you did not actually receive the packet desired. A simpler approach that is also more useful is to use an integer as the counter. As long as the counter is not reused during the same session (without first changing the MAC key), they can be used to put the packets in to context.
Counter values are agreed upon by both parties and do not have to be random or unique if a new MAC key is used during the session (for example, a MAC key derived from a key derivation function). Each packet sent increments the counter; the counter itself is included in the message and is part of the MAC function input. That is, you MAC both the ciphertext and the counter. You could optionally encrypt the counter, but there is often little security benefit in doing so. The recipient checks the counter before doing any other work. If the counter is less than or equal to the newest packet counter, chances are it is a replay and you should act accordingly. If it is equal, you should proceed to the next step.
Often, it is wise to determine the size of your counter to be no larger than the maximum number of packets you will send. For example, it is most certainly a waste to use a 16-byte counter. For most applications, an 8-byte counter is excessive as well. For most networked applications, a 32-bit counter is sufficient, but as the situation varies, a 40- or 48-bit counter may be required.
Another useful trick with counters in bidirectional mediums is to have one counter for each direction. This makes the incoming counter independent of the outgoing counter. In effect, it allows both parties to transmit at the same time without using a token passing scheme.
Encrypt then MAC?
A common question regarding the use of both encryption and MAC algorithms is which order to apply them in? Encrypt then MAC or MAC then Encrypt? That is, do you MAC the plaintext or ciphertext? Fundamentally, they seem they would provide the same level of security, but there are subtle differences.
Regardless of the order chosen, it is very important that the ciphering and MAC keys are not easily related to one another. The simplest and most appropriate solution is to use a key derivation function to stretch a shared (or known) shared secret into ciphering and MAC keys.
Encrypt then MAC
In this mode, you first encrypt the plaintext and then MAC the ciphertext (along with a counter or timestamp). Since the encryption is a proper random mapping of the plaintext (requires an appropriately chosen IV), the MAC is essentially of a random message. This mode is generally preferred on the basis that the MAC does not leak information about the plaintext. Also, one does not have to decrypt to reject invalid packets.
MAC then Encrypt
In this mode, you first MAC the plaintext (along with a counter or timestamp) and then encrypt the plaintext. Since the input to the MAC is not random and most MAC algorithms (at least CMAC and HMAC) do not use IVs, the output of the MAC will be nonrandom—that is, if you are not using replay protection. The common objection is that the MAC is based on the plaintext, so you are giving an attacker the ciphertext and the MAC tag of the plaintext. If the plaintext remained unchanged, the ciphertext may change (due to proper selection of an IV), but the MAC tag would remain the same.
However, one should always include a counter or timestamp as part of the MAC function input. Since the MAC is a PRF, it would defeat this attack even if the plaintext remained the same. Better yet, there is another way to defeat this attack altogether: simply apply the encryption to the MAC tag as well as the plaintext. This will not prevent replay attacks (you still need some variance in the MAC function input), but will totally obscure the MAC tag value from the attacker.
The one downside to this mode is that it requires a victim to decrypt before he can compare the MAC tag for a forgery. Oddly enough, this downside has a surprisingly useful upside. It does not leak, at least on its own, timing information to the attacker. That is, in the first mode we may stop processing once the MAC fails. This tells the attacker when the forgery fails. In this mode, we always perform the same amount of work to verify the MAC tag. How useful this is to an attacker depends on the circumstances. At the very least, it is an edge over the former mode.
Encryption and Authentication
We will again draw upon LibTomCrypt to implement an example system. The example is meant for bidirectional channels where the threat vectors include privacy and authenticity violations, and stream modifications such as re-ordering and replays.
The example code combats these problems with the use of AES-CTR for privacy, HMAC-SHA256 for authenticity, and numbered packets for stream protection. The code is not quite optimal, but does provide for a useful foundation upon which to improve the code as the situation warrants. In particular, the code is not thread safe. That is, if two treads attempt to send packets at the same time, they will corrupt the state.
![]()
We are using LibTomCrypt to provide the routines. Please have it installed if you wish to attempt to run this demonstration.
![]()
These are our encryption and MAC key lengths. The encrypt key length must be a valid AES key length, as we have chosen to use AES. The MAC key length can be any length, but practically speaking, it might as well be no larger than the encryption key.

These three macros define our per packet sizes. CTRLEN defines the size of the packet counter. The default, four bytes, allows one to send 232 packets before an overflow occurs and the stream becomes unusable. On the upside, this is a simple way to avoid using the same key settings for too long.
MACLEN defines the length of the MAC tag we wish to store. The default, 12 bytes (96 bits), should be large enough to make forgery difficult. Since we are limited to 232 packets, the advantage of a forger will remain fairly minimal.
Together, both values contribute OVERHEAD bytes to each packet in addition to the ciphertext. With the defaults, the data expands by 16 bytes per packet. With a typical packet size of 1024 bytes, this represents a 1.5-percent overhead.

MAC_FAILED indicates when the message MAC tag does not compare to what the recipient generates; for instance, if an attacker modifies the payload or the counter (or both). PKTCTR_FAILED indicates when a counter has been replayed or out of order.

This structure contains all the details we need about a single unidirectional channel. We have the packet counter (PktCTR), encryption key (enckey), and MAC key (mackey). We have also scheduled a key in advance to reduce the processing latency (skey).

This structure simply encapsulates two unidirectional streams into one structure. In our notation, channel[0] is always the outgoing channel, and channel[1] is always the incoming channel. We will see shortly how we can have two peers communicating with this convention.

This function registers AES and SHA256 with LibTomCrypt so we can use them in the plug-in driven functions.

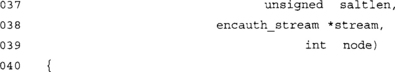
This function initiates a bi-directional stream with a given master key and salt. It uses PKCS #5 key derivation to obtain a pair of key for each direction of the stream.
The node parameter allows us to swap the meaning of the streams. This is used by one of the parties so that their outgoing stream is the incoming stream of the other party (and vice versa for their incoming).

This call derives the bytes required for the two pairs of keys. We use only 16 iterations of PKCS #5 since we will make the assumption that masterkey is randomly chosen.

This snippet extracts the keys from the PKCS #5 output buffer.

With each new session, we start the packet counters at zero.

At this point, we have scheduled the encrypt keys for use. This means as we process keys, we do not have to run the (relatively slow) AES key schedule to initialize the CTR context.

If we are not node 0, we swap the meaning of the streams. This allows two parties to talk to one another.
![]()
Wipe the keys off the stack. Note that we use the LTC zeromem() function, which will not be optimized by the compiler (well at least, very likely will not be) to a no-operation (which would be valid for the compiler).

![]()
This function encodes a frame (or packet) by numbering, encrypting, and applying the HMAC. It stores inlen+OVERHEAD bytes in the out buffer. Note that in and out may not overlap in memory.

We increment our packet counter in big endian format. This coincides with how we initialized the CTR sessions previously and will shortly come in handy.
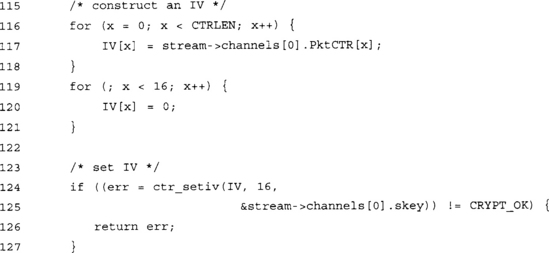
Our packet counter is only CTRLEN bytes long (default: 4), and an AES CTR mode IV is 16 bytes. We pad the rest with 0 bytes, but what does that mean in this context?
Our CTR counters are in big endian mode. The first CTRLEN bytes will be most significant bytes of the CTR IV. The last bytes (where we store the zeroes) are the least significant bytes. This means that while we are encrypting the text, the CTR counter is incremented only in the lower portion of the IV, preventing an overlap.
For instance, if CTRLEN was 15 and inlen was 257 * 16 = 4112, we would run into problems. The last 16 bytes of the first packet would be encrypted with the IV 00000000000000000000000000000100, while the first 16 bytes of the second packet would be encrypted with the same IV.
As we recall from Chapter 4, CTR mode is as secure as the underlying block cipher (assuming it has been keyed and implemented properly) only if the IVs are unique. In this case, they would not be unique and an attacker could exploit the overlap.
This places upper bounds on implementation. With CTRLEN set to 4, we can have only 232 packets, but each could be 2100 bytes long. With CTRLEN set to 8, we can have 264 packets, each limited to 268 bytes. However, the longer the CTRLEN setting, the larger the overhead. Longer packet counters do not always help; on the other hand, short packet counters can be ineffective if there is a lot of traffic.
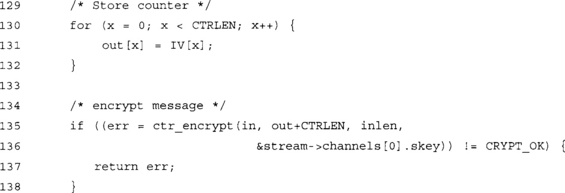
At this point, we have stored the packet counter and the ciphertext in the output buffer. The first CTRLEN bytes are the counter, followed by the ciphertext.

Our ordering of the data is not haphazard. One might wonder why we did not place the HMAC tag after the packet counter. This function call answers this question. In one fell swoop, we can HMAC both the counter and the ciphertext.
LibTomCrypt does provide a hmac_memory_multi() function, which is similar to hmac_memory() except that it uses a va_list to HMAC multiple regions of memory in a single function call (very similar to scattergather lists). That function has a higher caller overhead, as it uses va_list functions to retrieve the parameters.

At this point, we have the entire packet ready to be transmitted. All packets that come in as inlen bytes in length come out as inlen+OVERHEAD bytes in length.

This function decodes and authenticates an encoded frame. Note that inlen is the size of the packet created by encode_frame() and not the original plaintext length.

We restore the plaintext length to make the rest of the function comparable with the encoding. The first check is to ensure that the input length is actually valid. We return –1 if it is not.

At this point, we have verified the HMAC tag and it is valid. We are not out of the woods yet, however. The packet could be a replay or out of order.
There is a choice of how the caller can handle a MAC failure. Very likely, if the medium is something as robust as Ethernet, or the underlying transport protocol guarantees delivery such as TCP, then a MAC failure is a sign of tampering. The caller should look at this as an active attack. On the other hand, if the medium is not robust, such as a radio link or watermark, a MAC failure could just be the result of noise overpowering the signal.
The caller must determine how to proceed based on the context of the application.

This memcmp() operation performs our nice big endian packet counter comparison. It will return a value <= 0 if the packet counter in the packet is not larger than the packet counter in our stream structure. We allow out of order packets, but only in the forward direction. For instance, receiving packets 0, 3, 4, 7, and 8 (in that order) would be valid; however, the packets 0, 3, 4, 1, 2 (in that order) would not be.
Unlike MAC failures, a counter failure can occur for various legitimate reasons. It is valid for UDP packets, for instance, to arrive in any order. While they will most likely arrive in order (especially over traditional IPv4 links), unordered packets are not always a sign of attack. Replayed packets, on the other hand, are usually not part of a transmission protocol.
The reader may wish to augment this function to distinguish between replay and out of order packets (such as using the sliding window trick).
Our test program will initialize two streams (one in either direction) and proceed to try to decrypt the same packet three times. It should work the first time, and fail the second and third times. On the second attempt, it should fail with a PKTCTR_FAILED error as we replayed the packet. On the third attempt, we have modified a byte of the payload and it should fail with a MAC_FAILED error.

This sets up LibTomCrypt for use by our demonstration.

Here we are using the system RNG for our key and salt. In a real application, we need to get our master key from somewhere a bit more useful. The salt should be generated in this manner.
Two possible methods of deriving a master key could be by hashing a user’s password, or sharing a random key by using a public key encryption scheme.

This initializes our incoming stream. Note that we used the value 0 for the node parameter.

This initializes our outgoing stream. Note that we used the value 1 for the node parameter. In fact, it does not matter which order we pick the node values in; as long as we are consistent, it will work fine.
Note also that each side of the communication has to generate only one stream structure to both encode and decode. In our example, we generate two because we are both encoding and decoding data we generate.

Our traditional sample message.

At this point, outbuf[0 … sizeof(inbuf)+OVERHEAD-1] contains the packet. By transmitting the entire buffer to the other party, they can authenticate and decrypt it.

We first clear the inbuf array to show that the routine did indeed decode the data. We decode the buffer using the incoming stream structure. At this point we should see the string
![]()

This represents a replayed packet. It should fail with PKTCTR_FAILED, and we should see
![]()

This represents both a replayed and forged message. It should fail the MAC test before getting to the packet counter check. We should see

This demonstration represents code that is not entirely optimal. There are several methods of improving it based on the context it will be used.
The first useful optimization ensures the ciphertext is aligned on a 16-byte boundary. This allows the LibTomCrypt routines to safely use word-aligned XOR operations to perform the CTR encryption. A simple way to accomplish this is to pad the message with zero bytes between the packet counter and the ciphertext (include it as part of the MAC input).
The second optimization involves knowledge of how LibTomCrypt works; the CTR structure exposes the IV nicely, which means we can directly set the IV instead of using ctr_setiv() to update it.
The third optimization is also a security optimization. By making the code thread safe, we can decode or encode multiple packets at once. This combined with a sliding window for the packet counter can ensure that even if the threads are executed out of order, we are reasonable assured that the decoder will accept them.
The following Frequently Asked Questions, answered by the authors of this book, are designed to both measure your understanding of the concepts presented in this chapter and to assist you with real-life implementation of these concepts. To have your questions about this chapter answered by the author, browse to www.syngress.com/solutions and click on the “Ask the Author” form.
A: A MAC or message authentication code function is a function that accepts a secret key and message and reduces it to a MAC tag.
A: A tag is a short string of bits that is used to prove that the secret key and message were processed together through the MAC function.
Q: What does that mean? What does authentication mean?
A: Being able to prove that the message and secret key were combined to produce the tag can directly imply one Bug: that the holder of the key produced vouches for or simply wishes to convey an unaltered original message. A forger not possessing the secret key should have no significant advantage in producing verifiable MAC tags for messages. In short, the goal of a MAC function is to be able to conclude that if the MAC tag is correct, the message is intact and was not modified during transit. Since only a limited number of parties (typically only one or two) have the secret key, the ownership of the message is rather obvious.
A: There are two NIST standards for MAC functions currently worth considering. The CM AC standard is SP 800-38B and specifies a method of turning a block cipher into a MAC function. The HMAC standard is FIPS-198 and specifies a method of turning a hash function into a MAC. An older standard, FIPS-113, specifies CBC-MAC (a precursor to CMAC) using DES, and should be considered insecure.
A: Both CMAC and HMAC are secure when keyed and implemented safely. CMAC is typically more efficient for very short messages. It is also ideal for instances where a cipher is already deployed and space is limited. HMAC is more efficient for larger messages, and ideal when a hash is already deployed. Of course, you should pick whichever matches the standard you are trying to adhere to.
A: We have seen the term advantage several times in our discussion already. Essentially, the advantage of an attacker refers to the probability of forgery gained by a forger through analysis of previously authenticated messages. In the case of CMAC, for instance, the advantage is roughly approximate to (mq)2/2126 for CMAC-AES—where m is the number of messages authenticated, and q is the number of AES blocks per message. As the ratio approaches one, the probability of a successful forgery approaches one as well.
Advantage is a little different in this context than in the symmetric encryption context. An advantage of 2−40 is not the same as using a 40-bit encryption key. An attack on the MAC must take place online. This means, an attacker has but one chance to guess the correct MAC tag. In the latter context, an attacker can guess encryption keys offline and does not run the risk of exposure.
Q: How do key lengths play into the security of MAC functions?
A: Key lengths matter for MAC functions in much the same way they matter in symmetric cryptography. The longer the key, the longer a brute force key determination will take. If an attacker can guess a message, he can forge messages.
Q: How does the length of the MAC tag play into the security of MAC functions?
A: The length of the MAC tag is often variable (at least it is in HMAC and CMAC) and can limit the security of the MAC function. The shorter the tag, the more likely a forger is to guess it correctly. Unlike hash functions, the birthday paradox attack does not apply. Therefore, short MAC tags are often ideally secure for particular applications.
Q: How do I match up key length, MAC tag length, and advantage?
A: Your key length should ideally be as large as possible. There is often little practical value to using shorter keys. For instance, padding an AES-128 key with 88 bits of zeroes, effectively reducing it to a 40-bit key, may seem like it requires fewer resources. In fact, it saves no time or space and weakens the system. Ideally, for a MAC tag length of w- bits, you wish to give your attacker an advantage of no more than 2−w. For instance, if you are going to send 240 blocks of message data with CMAC-AES, the attacker’s advantage is no less than 2−46. In this case, a tag longer than 46 bits is actually wasteful as you approach the 240th block of message data. On the other hand, if you are sending a trivial amount of message blocks, the advantage is very small and the tag length can be customized to suit bandwidth needs.
Q: Why can I not use hash(key | | message) as a MAC function?
A: Such a construction is not resistant to offline attacks and is also vulnerable to message extension attacks. Forging messages is trivial with this scheme.
A: A replay attack can occur when you break a larger message into smaller independent pieces (e.g., packets). The attacker exploits the fact that unless you correlate the order of the packets, the attacker can change the meaning of the message simply by re-arranging the order of the packets. While each individual packet may be authenticated, it is not being modified. Thus, the attack goes unnoticed.
A: Without replay protection, an attacker can change the meaning of the overall message. Often, this implies the attacker can re-issue statements or commands. An attacker could, for instance, re-issue shell commands sent by a remote login shell.
Q: How do I defeat replay attacks?
A: The most obvious solution is to have a method of correlating the packets to their overall (relative) order within the larger stream of packets that make up the message. The most obvious solutions are timestamp counters and simple incremental counters. In both cases, the counter is included as part of the message authenticated. Filtering based on previously authenticated counters prevents an attacker from re-issuing an old packet or issuing them out of stream order.
Q: How do I deal with packet loss or re-ordering?
A: Occasionally, packet loss and re-ordering are part of the communication medium. For example, UDP is a lossy protocol that tolerates packet loss. Even when packets are not lost, they are not guaranteed to arrive in any particular order (this is often a warning that does not arise in most networks). Out of order UDP is fairly rare on non-congested IPv4 networks. The meaning of the error depends on the context of the application. If you are working with UDP (or another lossy medium), packet loss and re-ordering are usually not malicious acts. The best practice is to reject the packet, possibly issue a synchronization message, and resume the protocol. Note that an attacker may exploit the resynchronization step to have a victim generate authenticated messages. On a relatively stable medium such as TCP, packet loss and reordering are usually a sign of malicious interference and should be treated as hostile. The usual action here is to drop the connection. (Commonly, this is argued to be a denial of service (DoS) attack vector. However, anyone with the ability to modify packets between you and another host can also simply filter all packets anyways.) There is no added threat by taking this precaution. In both cases, whether the error is treated as hostile or benign, the packet should be dropped and not interpreted further up the protocol stack.
Q: What libraries provide MAC functionality?
A: LibTomCrypt provides a highly modular HMAC function for C developers. Crypto++ provides similar functionality for C++ developers. Limited HMAC support is also found in OpenSSL. LibTomCrypt also provides modular support for CMAC. At the time of this writing, neither Crypto++ or OpenSSL provide support for CMAC. By “modular,” we mean that the HMAC and CMAC implementations are not tied to underlying algorithms. For instance, the HMAC code in LibTomCrypt can use any hash function that LibTomCrypt supports without changes to the API. This allows future upgrades to be performed in a more timely and streamlined fashion.
Q: What patents cover MAC functions?
A: Both HMAC and CMAC are patent free and can be used for any purpose. Various other MAC functions such as PMAC are covered by patents but are also not standard.