
Encrypt and Authenticate Modes
Introduction
In Chapter 6, “Message Authentication Code Algorithms,” we saw how we could use message authentication code (MAC) functions to ensure the authenticity of messages between two or more parties. The MAC function takes a message and secret key as input and produces a MAC tag as output. This tag, combined with the message, can be verified by any party who has the same secret key.
We saw how MAC functions are integral to various applications to avoid various attacks. That is, if an attacker can forge messages he could perform tasks we would rather he could not. We also saw how to secure a message broken into smaller packets for convenience. Finally, our example program combined both encryption and authentication into a frame encoder to provide both privacy and authentication. In particular, we use PKCS #5, a key derivation function to accept a master secret key, and produce a key for encryption and another key for the MAC function.
Would it not be nice, if we had some function F(K, P) that accepts a secret key K and message P and returns the pair of (C, T) corresponding to the ciphertext and MAC tag (respectively)? Instead of having to create, or otherwise supply, two secret keys to accomplish both goals, we could defer that process to some encapsulated standard.
Encrypt and Authenticate Modes
This chapter introduces a relatively new set of standards in the cryptographic world known as encrypt and authenticate modes. These modes of operations encapsulate the tasks of encryption and authentication into a single process. The user of these modes simply passes a single key, IV (or nonce), and plaintext. The mode will then produce the ciphertext and MAC tag. By combining both tasks into a single step, the entire operation is much easier to implement.
The catalyst for these modes is from two major sources. The first is to extract any performance benefits to be had from combining the modes. The second is to make authentication more attractive to developers who tend to ignore it. You are more likely to find a product that encrypts data, than to find one that authenticates data.
Security Goals
The security goals of encrypt and authenticate modes are to ensure the privacy and authenticity of messages. Ideally, breaking one should not weaken the other. To achieve these goals, most combined modes require a secret key long enough such that an attacker could not guess it. They also require a unique IV per invocation to ensure replay attacks are not possible. These unique IVs are often called nonces in this context. The term nonce actually comes from Nonce, which means to use N once and only once.
We will see later in this chapter that we can use the nonce as a packet counter when the secret key is randomly generated. This allows for ease of integration into existing protocols.
Standards
Even though encrypt and authenticate modes are relatively new, there are still a few good standards covering their design. In May 2004, NIST specified CCM as SP 800-38C, the first NIST encrypt and authenticate mode. Specified as a mode of operation for block ciphers, it was intended to be used with a NIST block cipher such as AES. CCM was selected as the result of a design contest in which various proposals were sought out. Of the more likely contestants to win were Galois Counter Mode (GCM), EAX mode, and CCM.
GCM was designed originally to be put to use in various wireless standards such as 802.16 (WiMAX), and later submitted to NIST for the contest. GCM is not yet a NIST standard (it is proposed as SP 800-38D), but as it is used through IEEE wireless standards it is a good algorithm to know about. GCM strives to achieve hardware performance by being massively parallelizable. In software, as we shall see, GCM can achieve high performance levels with the suitable use of the processor’s cache.
Finally, EAX mode was proposed after the submission of CCM mode to address some of the shortcomings in the design. In particular, EAX mode is more flexible in terms of how it can be used and strives for higher performance (which turns out to not be true in practice). EAX mode is actually a properly constructed wrapper around CTR encryption mode and CMAC authentication mode. This makes the security analysis easier, and the design more worthy of attention. Unfortunately, EAX was not, and is currently not, considered for standardization. Despite this, EAX is still a worthy mode to know about and understand.
Design and Implementation
We shall consider the design, implementation, and optimization of three popular algorithms. We will first explore the GCM algorithm, which has already found practical use in the IEEE 802 series of standards. The reader should take particular interest in this design, as it is also likely to become a NIST standard. After GCM, we will explore the design of CCM, the only NIST standardized mode at the time of this writing. CCM is both efficient and secure, making it a mode worth using and knowing about.
Additional Authentication Data
All three algorithms include an input known as the additional authentication data (AAD, also known as header data in CCM). This allows the implementer to include data that accompanies the ciphertext, and must be authenticated but does not have to be encrypted; for example, metadata such as packet counters, timestamps, user and host names, and so on.
AAD is unique to these modes and is handled differently in all three. In particular, EAX has the most flexible AAD handling, while GCM and CCM are more restrictive. All three modes accept empty AAD strings, which allows developers to ignore the AAD facilities if they do not need them.
Design of GCM
GCM (Galois Counter Mode) is the design of David McGraw and John Viega. It is the product of universal hashing and CTR mode encryption for security. The original motivation for GCM mode was fast hardware implementation. As such, GCM employs the use of GF(2128) multiplication, which can be efficient in typical FPGA and other hardware implementations.
To properly discuss GCM, we have to unravel an implementer’s worst nightmare—bit ordering. That is, which bit is the most significant bit, how are they ordered, and so on. It turns out that GCM is not one of the most straightforward designs in this respect. Once we get past the Galois field math, the rest of GCM is relatively easy to specify.
GCM GF(2) Mathematics
GCM employs multiplications in the field GF(2128)[x]/v(x) to perform a function it calls GHASH. Effectively, GHASH is a form of universal hashing, which we will discuss next. The multiplication we are performing here is not any different in nature than the multiplications used within the AES block cipher. The only differences are the size of the field and the irreducible polynomial used.
GCM uses a bit ordering that does not seem normal upon first inspection. Instead of storing the coefficients of the polynomials from the least significant bit upward, they store them backward. For example, from AES we would see that the polynomial p(x) = x7 + x3 + x + 1 would be represented by 0x8B. In the GCM notation, the bits are reversed. In GCM notation, x7 would be 0x01 instead of 0x80, so our polynomial p(x) would be represented as 0xD1 instead. In effect, the bytes are in little endian fashion. The bytes themselves are arranged in big endian fashion, which further complicates things. That is, byte number 15 is the least significant byte, and byte number 0 is the most significant byte.
The multiplication routine is then implemented with the following routines:

This performs what GCM calls a right shift operation. Numerically, it is equivalent to a left shift (multiplication by 2), but since we order the bits in each byte in the opposite direction, we use a right shift to perform this. We are shifting from byte 15 down to byte 0.

The mask is a simple way of masking off bits in the byte in reverse order. The poly array is the least significant byte of the polynomial, the first element is a zero, and the second element is the byte of the polynomial. In this case, 0xE1 maps to p(x) = x128 + x7 + x2 + x + 1 where the x128 term is implicit.

This routine accomplishes the operation c = ab in the Galois field chosen by GCM. It effectively is the same algorithm we used for the multiplication in AES, except here we are using an array of bytes to represent the polynomials. We use Z to accumulate the product as we produce it. We use V as a copy of a, which we can double and selectively add to Z based on the bits of b.
This multiplication routine accomplishes numerically what we require, but is horribly slow. Fortunately, there is more than one way to multiply field elements. As we shall see during the implementation phase, a table-based multiplication routine will be far more profitable.
The curious reader may wish to examine the GCM source of LibTomCrypt for the variety of tricks that are optionally used depending on the configuration. In addition to the previous routine, LibTomCrypt provides an alternative to gcm_gf_mult() (see src/encauth/gcm/gcm_gf_mult.c in LibTomCrypt) that uses a windowed multiplication on whole words (Darrel Hankerson, Alfred Menezes, Scott Vanstone, “Guide to Elliptic Curve Cryptography,” p. 50, Algorithm 2.36). This becomes important during the setup phase of GCM, even when we use a table-based multiplication routine for bulk data processing. Before we can show you a table-based multiplication routine, we must show you the constraints on GCM that make this possible.
Universal Hashing
Universal hashing is a method of creating a function f(x) such that for distinct values of x and y, the probability of f(x) = f(y) is that of any proper random function. The simplest example of such a universal hash is the mapping
![]()
for random values of a and b and random primes p and n (n < p). Universal MAC functions, such as those in GCM (and other algorithms such as Daniel Bernstein’s Poly1305) use a variation of this to achieve a secure MAC function
![]()
where the last H[i] value is the tag, K is a unit in a finite field and the secret key, and M[i] is a block of the message. The multiplication and addition must be performed in a finite field of considerable size (e.g., 2128 units or more). In the case of GCM, we will create the MAC functionality, called GHASH, with this scheme using our GF(2128) multiplication routine.
GCM Definitions
The entire GCM algorithm can be specified by a series of equations. First, let us define the various symbols we will be using in the equations (Figure 7.1).

![]() Let K represent the secret key.
Let K represent the secret key.
![]() Let A represent the additional authentication data, there are m blocks of data in A.
Let A represent the additional authentication data, there are m blocks of data in A.
![]() Let P represent the plaintext, there are n blocks of data in P.
Let P represent the plaintext, there are n blocks of data in P.
![]() Let C represent the ciphertext.
Let C represent the ciphertext.
![]() Let Y represent the CTR counters.
Let Y represent the CTR counters.
![]() Let E(K, P) represent the encryption of P with the secret key K and block cipher E (e.g., E = AES).
Let E(K, P) represent the encryption of P with the secret key K and block cipher E (e.g., E = AES).
The first step is to generate the universal MAC key H, which is used solely in the GHASH function. Next, we need an IV for the CTR mode. If the user-supplied IV is 96 bits long, we use it directly by padding it with 31 zero bits and 1 one bit. Otherwise, we apply the GHASH function to the IV and use the returned value as the CTR IV.
Once we have H and the initial Y0 value, we can encrypt the plaintext. The encryption is performed in CTR mode using the counter in big endian fashion. Oddly enough, the bits per byte of the counter are treated in the normal ordering. The last block of ciphertext is not expanded if it does not fill a block with the cipher. For instance, if Pn is 32 bits, the output of E(K, Yn) is truncated to 32 bits, and Cn is the 32-bit XOR of the two values.
Finally, the MAC tag is produced by performing the GHASH function on the additional authentication data and ciphertext. The output of GHASH is then XORed with the encryption of the initial value. Next, we examine the GHASH function (Figure 7.2).

The GHASH function compresses the additional authentication data and ciphertext to a final MAC tag. The multiplication by H is a GF(2128)[x] multiplication as mentioned earlier. The length encodings are 64-bit big endian strings concatenated to one another. The length of A stored in the first 8 bytes and the length of C in the last 8.
Implementation of GCM
While the description of GCM is nice and concise, the implementation is not. First, the multiplication requires careful optimization to get decent performance. Second, the flexibility of the IV, AAD, and plaintext processing requires careful state transitions. Originally, we had planned to write a GCM implementation from scratch for this text. However, we later decided our readers would be better served if we simply used an existing optimized implementation.
To demonstrate GCM, we used the implementation of LibTomCrypt. This implementation is public domain, freely accessible on the project’s Web site, optimized, and easy to follow. We will omit various administrative portions of the code to reduce the size of the code listings. Readers are strongly encouraged to use the routines found in LibTomCrypt (or similar libraries) instead of rolling their own if they can get away with it.
Interface
Our GCM interface has several functions that we will discuss in turn. The high level of abstraction allows us to use the GCM implementation to the full flexibility warranted by the GCM specification. The functions we will discuss are:

These functions all combine to allow a caller to process a message through the GCM algorithm. For any message, the functions 3 through 7 are meant to be called in that order to process the message. That is, one must add the IV before the AAD, and the AAD before the plaintext. GCM does not allow for processing the distinct data elements in other orders. For example, you cannot add AAD before the IV. The functions can be called multiple times as long as the order of the appearance is intact. For example, you can call gcm_add_iv() twice before calling gcm_add_aad() for the first time.
All the functions make use of the structure gcm_state, which contains the current working state of the GCM algorithm. It fully determines how the functions should behave, which allows the functions to be fully thread safe (Figure 7.3).

As we can see, the state has quite a few members. Table 7.1 explains their function.
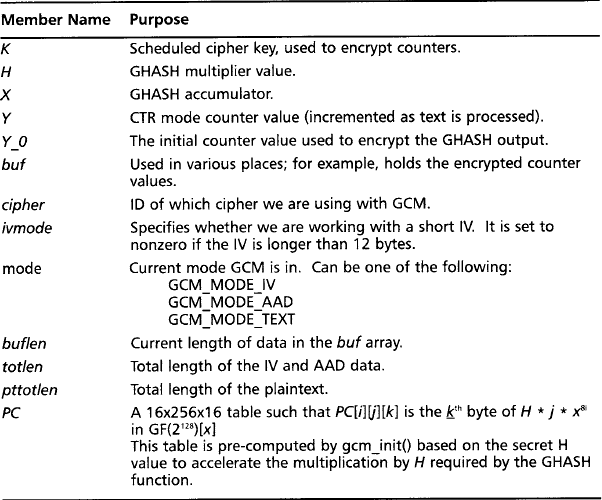
The PC table is an optional table only included if GCM_TABLES was defined at build time. As we will see shortly, it can greatly speed up the processing of data through GHASH; however, it requires a 64 kilobyte table, which could easily be prohibitive in various embedded platforms.
GCM Generic Multiplication
The following code implements the generic GF(2128)[x] multiplication required by GCM. It is designed to work with any multiplier values and is not optimized to the GHASH usage pattern of multiplying by a single value (H).


This table contains the residue of the value of k * x128 mod p(x) for all 256 values of k. Since the value of p(x) is sparse, only the lower two bytes of the residue are nonzero. As such, we can compress the table. Every pair of bytes are the lower two bytes of the residue for the given value of k. For instance, gcm_shift_table[3] and gcm_shift_table[4] are the value of the least significant bytes of 2 * x128 mod p(x).
This table is only used if LTC_FAST is defined. This define instructs the implementation to use a fast parallel XOR operations on words instead of on the byte level. In our case, we can exploit it to perform the generic multiplication much faster.

This function performs the right shift (multiplication by x) using GCM conventions.


This is the slow bit serial approach. We use the LibTomCrypt functions zeromem (similar to memset) and XMEMCPY (defaults to memcpy) for portability issues. Many small C platforms do not have full C libraries. These functions (and macros) allow developers to work around such limitations in a safe manner.

These are some macros we use in the faster generic multiplier. The M() macro maps a four-bit nibble to the GCM convention (e.g., reverse).
The LTC_FAST_TYPE symbol refers to a data type defined in LibTomCrypt that represents an optimal data type that is a multiple of eight bits in length. For example, on 32-bit platforms, it is a unsigned long. The data type has to overlap perfectly with the unsigned char data type. It is used to allow parallel XOR operations.
The BPD macro is the number of bytes per LTC_FAST_TYPE. Clearly, this only works if CHAR_BIT is 8, which is why LTC_FAST is not enabled by default. The WPV macro is the number of words per 128-bit value plus a word.

The B array contains the computed values of ka for k=0 … 15. It allows us to perform a 4x128 multiplication with a table lookup. The tmp array contains the product (before it has been reduced). The pB array contains the loaded and converted copy of b with the appropriate treatment for the GCM order of the bits.

The preceding code loads the bytes of a and b into their respective arrays. A curious reader may note that we load a with a big endian macro and b with a little endian macro. The a value is loaded in big endian fashion to adhere to the GCM specs. The b value is loaded in the opposite fashion so we can use a more straightforward digit extraction expression.
In fact, we could load both as big endian, and merely rewrite the order in which we fetch nibbles to compensate.

This block of code creates the entries for ax, ax2, and ax3. Note that we do not perform any reductions. This is why WPV has an extra word appended to it, since we are dealing with values that have more than 128 bits in them.


These two blocks construct the rest of the entries word per word. We first construct the values that only have two bits set (3, 5, 6, 9, 10, and 12), and then from those we construct the values that have three bits set. Note the use of the M() macro, which evaluates to a constant at compile time.

Here we are extracting a nibble of b to multiply a by. Note the use of (i^1) to extract the nibbles in reverse order since GCM stores bits in each byte in reverse order.

This loop multiplies each nibble of each word of b by a, and adds it to the appropriate offset within tmp. The product of the ith nibble of the jthword is added to tmp [j … j+WPV-1].

After we have added all of the products regarding the ith nibbles of each word, we shift the entire product (tmp) up by four bits.
![]()

This reduction makes use of the fact that for any j > 15, the value of kxj mod p(x) is congruent to (kx16)xj–16. Since we have a nice table for kx16 mod p(x), we can compute (kx16)xj–16 by a table look up and shift. This routine adds the residue of the product from the high byte to the lower bytes.
Each loop of the preceding for loop removes one byte from the product at a time. We perform the shift inline by adding the lookup values to pTmp[i–16] and pTmp[i–15].

Both implementations of gcm_gf_mult() accomplish the same goal and are numerically equivalent. The latter implementation is much faster on 32- and 64-bit processors but is not 100-percent portable. It requires a data type that is a multiple of a unsigned char data type in size, which is not always guaranteed.
Now that we have a generic multiplier, we have to implement an optimized multiplier to be used by GHASH.
GCM Optimized Multiplication
The following multiplication routine is optimized solely for performing a multiplication by the secret H value. It takes advantage of the fact we can precompute tables for the multiplication.

![]()
If GCM_TABLES has been defined, we will use the tables approach. The PC table contains 16 8x128 tables, one for each byte of the input and for each of their respective possible values. The first thing we must do is copy the 0th entry to T (our accumulator). The rest of the lookups will be XORed into this value.

Here we see the use of LTC_FAST to optimize parallel XOR operations. For each byte of I, the input, we look up the 128-bit value and XOR it against the accumulator. Since the entries in the table have already been reduced, our accumulator never grows beyond 128 bits in size.

If we are not using tables, we use the slower gcm_gf_mult() to achieve the operation.
Now that we have both of our multipliers out of the way, we can move on to the rest of the GCM algorithm starting with the initialization routine.
GCM Initialization
The first function is gcm_init(), which accepts a secret key and initializes the GCM state.


This is a simple sanity check to make sure the code will actually work with LTC_FAST defined. It does not catch all error cases, but in practice is enough.

This code schedules the secret key to be used by the GCM code.

We encrypt the zero string to compute our secret multiplier value H.

This block of code initializes the GCM state to the default empty and zero state. After this point, we are ready to process IV, AAD, or plaintext (provided GCM_TABLES was not defined).

If we are using tables, we first compute the lowest table, which is simply yH mod p(x) for all 256 values of y. We use the slower multiplier, since at this point we do not have tables to work with.

This code block generates the 15 other 8x128 tables. Since the only difference between the 0th 8x128 table and the 1st 8x128 table is that we multiplied the values by x8, we can perform this with a simple shift and XOR with the reduction table values (as we saw with the fast gcm_gf_mult() function). We can repeat the process for the 2nd, 3rd, 4th, and so on tables.
Using this shift and reduce trick is much faster than naively using gcm_gf_mult() to produce all 16 * 256 = 4096 multiplications required.

At this point, we are good to go with using GCM to process IV, AAD, or plaintext.
GCM IV Processing
The GCM IV controls the initial value of the CTR value used for encryption, and indirectly the MAC tag value since it is based on the ciphertext. Each packet should have a unique IV if the same key is being used. It is safe to use a packet counter as the IV, as long as it never repeats while using the same key.

This is a bit odd, but we do allow null IVs, which can also have IV = = NULL.

We must be in IV mode to call this function. If we are not, this means we have called the AAD or process function (to handle plaintext).

If we have more than 12 bytes of IV, we set the ivmode flag. The processing of the IV changes based on whether this flag is set.


If we can use LTC_FAST, we will add bytes of the IV to the state a word at a time. We only use this optimization if there are 16 or more bytes of IV to add. Usually, IVs are short, so this should not be invoked, but it does allow a user to base the IV on a larger string if desired.

This block of code handles adding any leftover bytes of the IV to the state. It adds one byte at a time; once we accumulate 16, we XOR them against the state and call gcm_mult_h().
![]()
This function handles add IV data to the state. Note carefully that it does not actually terminate the GHASH or compute the initial counter value. That is handled in the next function, gcm_add_aad().
GCM AAD Processing
Additional Authentication Data (AAD) is metadata you can add to the stream being authenticated that is not encrypted. It must be added after the IV and before the plaintext (or ciphertext) has been processed. The AAD step can be skipped if there is no data to add to the stream. Typically, the AAD would be nonprivacy, but stream or packet related data such as unique identifiers or placement markers.


So far, this is all the same style of error checking. The only reason we do not place this in another function is to make sure the LTC_ARGCHK macros report the correct function name (they work much like the assert macro).
![]()
This block of code finishes processing the IV, if any.
![]()
If we have tripped the IV flag or the IV accumulated length is not 12, we have to apply GHASH to the IV data to produce our starting Y value.

At this point, we have emptied the IV buffer and multiplied the GCM state by the secret H value.
![]()

Next, we append the length of the IV and multiply that by H. The result is the output of GHASH and the starting Y value.

This block of code handles the case that our IV is 12 bytes (because the flag has not been tripped and the buflen is 12). In this case, processing the IV means simply copying it to the GCM state and setting the last 32 bits to the big endian version of “1”.
Ideally, you want to use the 12-byte IV in GCM since it allows fast packet processing. If your GCM key is randomly derived per session, the IV can simply be a packet counter. As long as they are all unique, we are using GCM properly.

At this point, we check that we are indeed in AAD mode and that our buflen is a legal value.

![]()
If we have LTC_FAST enabled, we will process AAD data in 16-byte increments by quickly XORing it into the GCM state. This avoids all the manual single-byte XOR operations.

This is the default processing of AAD data. In the event LTC_FAST has been enabled, it handles any lingering bytes. It is ideal to have AAD data that is always a multiple of 16 bytes in length. This way, we can avoid the slower manual byte XORs.
![]()
GCM Plaintext Processing
Processing the plaintext is the final step in processing a GCM message after processing the IV and AAD. Since we are using CTR to encrypt the data, the ciphertext is the same length as the plaintext.
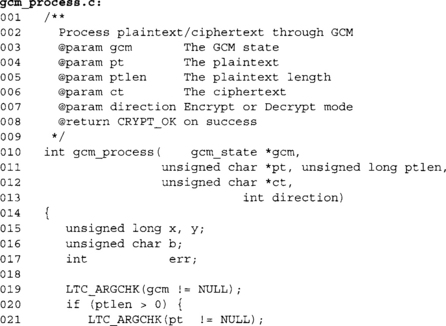

Same error checking code. We can call this function with an empty plaintext just like we can call the previous two functions with empty IV and AAD blocks. GCM is valid with zero length plaintexts and can be used to produce a MAC tag for the AAD data. It is not a good idea to use GCM this way, as CMAC is more efficient for the purpose (and does not require huge tables for efficiency). In short, if all you want is a MAC tag, do not use GCM.

At this point, we have finished processing the AAD. Note that unlike processing the IV, we do not terminate the GHASH.

We increment the initial value of Y and encrypt it to the buf array. This buffer is our CTR key stream used to encrypt or decrypt the message.

At this point, we are ready to process the plaintext. We again will use a LTC_FAST trick to handle the plaintext efficiently. Since the GHASH is applied to the ciphertext, we must handle encryption and decryption differently. This is also because we allow the plaintext and ciphertext buffers supplied by the user to overlap.
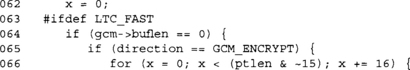
Again, we attempt to process the plaintext 16 bytes at a time. For this reason, ensuring your plaintext is a multiple of 16 bytes is a good idea.

This loop XORs the CTR key stream against the plaintext, and then XORs the ciphertext into the GHASH accumulator. The loop may look complicated, but GCC does a good job to optimize the loop. In fact, the loop is usually fully unrolled and turned into simple load and XOR operations.
![]()
Since we are processing 16-byte blocks, we always perform the multiplication by H on the accumulated data.

We next increment the CTR counter and encrypt it to generate another 16 bytes of key stream.


This second block handles decryption. It is similar to encryption, but since we are shaving cycles, we do not merge them. The code size increase is not significant, especially compared to the time savings.
![]()
This loop handles any remaining bytes for both encryption and decryption. Since we are processing the data a byte at a time, it is best to avoid needing this section of code in performance applications.
![]()
Every 16 bytes, we must accumulate them in the GHASH tag and update the CTR key stream.

![]()
This last bit is seemingly overly complicated but done so by design. We allow ct = pt, which means we cannot overwrite the buffer without copying the ciphertext byte. We could move line 138 into the two cases of the if statement, but that enlarges the code for no savings in time.

At this point, we have enough functionality to start a GCM state, add IV, add AAD, and process plaintext. Now we must be able to terminate the GCM state to compute the final MAC tag.
Terminating the GCM State
Once we have finished processing our GCM message, we will want to compute the GHASH output and retrieve the MAC tag.
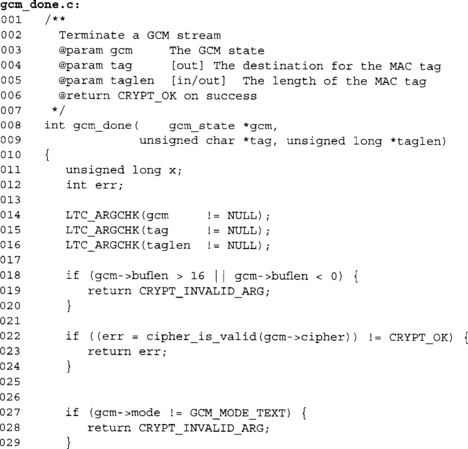
This is again the same sanity checking. It is important that we do this in all the GCM functions, since the context of the state is important in using GCM securely.

This terminates the GHASH of the AAD and ciphertext. The length of the AAD and the length of the ciphertext are added to the final multiplication by H. The output is the GHASH final value, but not the MAC tag.

We encrypt the original Y value and XOR the output against the GHASH output. Since GCM allows truncating the MAC tag, we do so. The user may request any length of MAC tag from 0 to 16 bytes. It is not advisable to truncate the GCM tag.

The last call terminates the cipher state. With LibTomCrypt, the ciphers are allowed to allocate resources during their initialization such as heap or hardware tokens. This call is required to release the resources if any. Upon completion of this function, the user has the MAC tag and the GCM state is no longer valid.
GCM Optimizations
Now that we have seen the design of GCM, and a fielded implementation from the LibTomCrypt project, we have to specifically address how to best use GCM.
The default implementation in LibTomCrypt with the GCM_TABLES macro defined uses 64 kilobytes per GCM state. This may be no problem for a server or desktop application; however, it does not serve well for platforms that may not have 64 kilobytes of memory total. There exists a simple compromise that uses a single 8x128 table, which is four kilobytes in size. In fact, it uses the zero’th table from the 64-kilobyte variant, and we produce a 32-byte product and reduce it the same style as our fast variant of the gcm_gf_mult() function.

We can optimize the nested loop by using word-oriented XOR operations. The final reduction is less amenable to optimization, unfortunately. The fallback position from this algorithm is to use the LTC_FAST variant of gcm_gf_mult(), the generic GF(2) multiplier, to perform the multiply by H function.
Use of SIMD Instructions
Processors such as the recent x86 series and Power PC based G4 and G5 have instructions known as Single Instruction Multiple Data (SIMD). These allow developers to perform multiple parallel operations such as 128-bit wide XORs. This comes in very handy, indeed. For example, consider the function gcm_mult_h() with SSE2 support.


As we can see, the loop becomes much more efficient. Particularly, we are issuing fewer load operations and consuming fewer decoder resources. For example, even though the Opteron FPU issues the 128-bit operations as two 64-bit operations behind the scenes, since we only decode one x86 opcode, the processor can pack the instructions more effectively. Table 7.2 compares the performance of three implementations of GCM on an Opteron and Intel P4 Prescott processors.
Design of CCM
CCM is the current NIST endorsed combined mode (SP 800-38C) based on CBC-MAC and CTR chaining mode. The purpose of CCM is to use a single secret key K and block cipher, to both authenticate and encrypt a message. Unlike GCM, CCM is much simpler and only requires the block cipher to operate. For this reason, it is often a better fit where GF(2) multiplication is too cumbersome.
While CCM is simpler than GCM, it does carry several disadvantages. In hardware, GF(2) multiplication is usually faster than an AES encryption (AES being the usual block cipher paired with GCM). CCM can process AAD (which they call header data), but is less flexible with the order of operations. Where in GCM you can process arbitrary length AAD and plaintext data, CCM must know in advance the length of these elements before initializing the state. This means you cannot use CCM for streaming calls. Fortunately, in practice this is usually not a problem. You simply apply CCM to your individual packets of a known or computable length and everything is fine.
The design of CCM can be split into three distinct phases. First, we must generate a B0 block, which is built out of the user supplied nonce and message length. The B0 block is used as the IV for the CBC-MAC and counter for the CTR chaining mode. Next, the MAC tag generation, which is the CBC-MAC of B0, the header (AAD) data, and finally the plaintext, is performed. Unlike GCM, CCM authenticates the plaintext, which is why a unique nonce is important for security. Finally, the plaintext is encrypted with the CTR chaining mode using a modified B0 block as the counter.
CCM B0 Generation
The B0 block is a special block in CCM mode that is prefixed to the message (before the header data) that is derived from the user supplied nonce value. The layout of the B0 block depends on the length of the plaintext, especially the length of the encoding of the length. For example, if the plaintext is 129 bytes long, it will require one byte to encode the length of the length. We call this length q and the value of the length Q. For example, in our previous example, we would have q= 1 and Q=129.
The nonce data can be up to 13 bytes in length and its contents are represented by N. The length of the desired MAC tag is represented by t, and must be even and larger than 2 (Figure 7.4).

Note how the nonce (N) is truncated due to the length of the plaintext. Usually, this is not a problem in most network protocols where Q is typically smaller than 65536 (leaving us with up to a 13-byte nonce). The flags require a single byte and are packed as shown in Figure 7.5.

The Adata flag is set when there is header (AAD) data present. We encode the MAC tag length by subtracting 2 and dividing it by 2, and t must be an element of the set {4, 6, 8, 10, 12, 14, 16}. MAC lengths that short are usually not a good idea. If you really want to shave a few bytes per packet, try using a MAC tag length no shorter than 12 bytes. The plaintext length is encoded by subtracting one from the length of the plaintext, q must be a member of the set {2, 3, 4, 5, 6, 7, 8}. Zero is not a valid value for either (t–2)/2 or q–1.
CCM MAC Tag Generation
The CCM MAC Tag is generated by the CBC-MAC of B0, any header data (if present), and the plaintext (if any). We prefix the header data with its length. If the header data is less than 65,280 bytes in length, the length is simply encoded as a big endian two-byte value. If the length is larger, the value 0xFF FE is inserted followed by the big endian four-byte encoding of the header length. Technically, CCM supports larger header lengths; however, if you are using more than four gigabytes for your header data, you ought to rethink your application’s used of cryptography.
The header data is padded to a multiple of 16 bytes by inserting zero bytes at the end. The plaintext is similarly padded as required.
After the CBC-MAC output has been generated, it will be pre-pended to the plaintext and encrypted in CTR mode along with the plaintext.
CCM Encryption
Encryption is performed in CTR mode using the B0 block as the counter. The only difference here is that the B0 block will be modified by zeroing the flags and Q parameters (leaving only the nonce). The last q bytes of the B0 block are incremented in big endian fashion for each 16-byte block of Tag and plaintext. The ciphertext is the same length as the plaintext and not padded.
CCM Implementation
We use the CCM implementation from LibTomCrypt as reference. It is a compact and efficient implementation of CCM that performs the entire CCM encoding with a single function call. Since it accepts all the parameters in a single call, it has quite a few parameters. Table 7.3 matches the implementation names with the design variable names.

We allow the caller to schedule a key prior to the call. This is a good idea in practice, as it shaves a fair chunk of cycles per call. Even if you are not using LibTomCrypt, you should provide or use this style of optimization in your code.


We provide a word-oriented optimization later in this implementation. This check is a simple sanity check to make sure it will actually work.

We force the tag length to even and truncate it if it is larger than 16 bytes. We do not error out on excessively long tag lengths, as the caller may simply have passed something such as

In which case, MAXTAGLEN could be larger than 16 if they are supporting more than one algorithm.

We must reject tag lengths less than four bytes per the CCM specification. We have no choice but to error out, as the caller has not indicated we can store at least four bytes of MAC tag.

![]()
LibTomCrypt has the capability to “overload” functions—in this case, CCM. If the pointer is not NULL, the computation is offloaded to it automatically. In this way, a developer can take advantage of accelerators without re-writing their application. This technically is not part of CCM, so you can avoid looking at this chunk if you want.

Here we compute the value of L (q in the CCM design). L was the original name for this variable and is why we used it here. We make sure that L is at least 2 as per the CCM specification.

This resizes the nonce if it is too large and the L parameter as required. The caller has to be aware of the tradeoff. For instance, if you want to encrypt one-megabyte packets, you will need at least three bytes to encode the length, which means the nonce can only be 12 bytes long. One could add a check to ensure that L is never too small for the plaintext length.

If the caller does not supply a key, we must schedule one. We avoid placing the scheduled key structure on the stack by allocating it from the heap. This is important for embedded and kernel applications, as the stacks can be very limited in size.

This section of code creates the B0 value we need for the CBC-MAC phase of CCM. The PAD array holds the 16 bytes of CBC data for the MAC, while CTRPAD, which we see later, holds the 16 bytes of CTR output.
The first byte (line 122) of the block is the flags. We set the Adata flag based on headerlen, encode the tag length by dividing taglen by two, and finally the length of the plaintext length is stored.
Next, the nonce is copied to the block. We use 16 – L + 1 bytes of the nonce since we must store the flags and L bytes of the plaintext length value.
To make things a bit more practical, we only store 32 bits of the plaintext length. If the user specifies a short nonce, the value of L has to be increased to compensate. In this case, we pad with zero bytes before encoding the actual length.

We are using CBC-MAC effectively with a zeroed IV, so the first thing we must do is encrypt PAD. The ciphertext is now the IV for the CBC-MAC of the rest of the header and plaintext data.
![]()
We only get here and do any of the following code if there is header data to process.

The encoding of the length of the header data depends on the size of the header data. If it is less than 65,280 bytes, we use the short two-byte encoding. Otherwise, we emit the escape sequence OxFF FE and then the four-byte encoding. CCM supports larger header sizes, but you are unlikely to ever need to support it.
Note that instead of XORing the PAD (as an IV) against another buffer, we simply XOR the lengths into the PAD. This avoids any double buffering we would otherwise have to use.

This loop processes the entire header data. We do not provide any sort of LTC_FAST optimizations, since headers are usually empty or very short. Every 16 bytes of header data, we encrypt the PAD to emulate CBC-MAC properly.


If we have leftover header data (that is, headerlen is not a multiple of 16), we pad it with zero bytes and encrypt it. Since XORing zero bytes is a no-operation, we simply ignore that step and invoke the cipher.

This code creates the initial counter for the CTR encryption mode. The flags only contain the length of the plaintext length. The nonce is copied much as it is for the CBC-MAC, and the rest of the block is zeroed. The bytes after the nonce are incremented during the encryption.

If we are encrypting, we handle all complete 16-byte blocks of plaintext we have.

The CTR counter is big endian and stored at the end of the ctr array. This code increments it by one.
![]()
![]()
We must encrypt the CTR counter before using it to encrypt plaintext.

This loop XORs 16 bytes of plaintext against the CBC-MAC pad, and then creates 16 bytes of ciphertext by XORing CTRPAD against the plaintext. We do the encryption second (after the CBC-MAC), since we allow the plaintext and ciphertext to point to the same buffer.

Encrypting the CBC-MAC pad performs the required MAC operation for this 16-byte block of plaintext.

We handle decryption similarly, but distinctly, since we allow the plaintext and ciphertext to point to the same memory. Since this code is likely to be unrolled, we avoid having redundant conditional code inside the main loop where possible.

This block performs the CCM operation for any bytes of plaintext not handled by the LTC_FAST code. This could be because the plaintext is not a multiple of 16 bytes, or that LTC_FAST was not enabled. Ideally, we want to avoid needing this code as it is slow and over many packets can consume a fair amount of processing power.
![]()

We finish the CBC-MAC if there are bytes left over. As in the processing of the header, we implicitly pad with zeros by encrypting the PAD as is. At this point, the PAD now contains the CBC-MAC value but not the CCM tag as we still have to encrypt it.

The CTR pad for the CBC-MAC tag is computed by zeroing the last L bytes of the CTR counter and encrypting it to CTRPAD.
![]()
If we scheduled our own key, we will now free any allocated resources.

CCM allows a variable length tag, from 4 to 16 bytes in length in 2-byte increments. We encrypt and store the CCM tag by XORing the CBC-MAC tag with the last encrypted CTR counter.

This block zeroes memory on the stack that could be considered sensitive. We hope the stack has not been swapped to disk, but this routine does not make this guarantee. By clearing the memory, any further potential stack leaks will not be sharing the keys or CBC-MAC intermediate values with the attacker. We only perform this operation if the user requested it by defining the LTC_CLEAN_STACK macro.

Upon successful completion of this function, the user now has the ciphertext (or plaintext depending on the direction) and the CCM tag. While the function may be a tad long, it is nicely bundled up in a single function call, making its deployment rather trivial.
Putting It All Together
This chapter introduced the two standard encrypt and authenticate modes as specified by both NIST and IEEE. They are both designed to take a single key and IV (nonce) and produce a ciphertext and message authentication code tag, thereby simplifying the process for developers by reducing the number of different standards they must support, and in practice the number of functions they have to call to accomplish the same results.
Knowing how to use these modes is a matter of properly choosing an IV, making ideal use of the additional authentication data (AAD), and checking the MAC tag they produce. Neither of these two modes will manage any of these properties for the developer, so they must look after them carefully.
For most applications, it is highly advisable to use these modes over an ad hoc combination of encryption and authentication, if not solely for the reason of code simplicity, then also for proper adherence to cryptographic standards.
What Are These Modes For?
We saw in the previous chapter how we could accomplish both privacy and authentication of data through the combined use of a symmetric cipher and chaining mode with a MAC algorithm. Here, the goal of these modes is to combine the two. This accomplishes several key goals simultaneously. As we alluded to in the previous chapter, CCM and GCM are also meant for small packet messages, ideal for securing a stream of messages between parties. CCM and GCM can be used for offline tasks such as file encryption, but they are not meant for such tasks (especially CCM since it needs the length of the plaintext in advance).
First, combining the modes makes development simpler—there is only one key and one IV to keep track of. The mode will handle using both for both tasks. This makes key derivation easier and quicker, as less session data must be derived. It also means there are fewer variables floating around to keep track of.
These combined modes also mean it’s possible to perform both goals with a single function call. In code where we specifically must trap error codes (usually by looking at the return codes), having fewer functions to call means the code is easier to write safely. While there are other ways to trap errors such as signals and internal masking, making threadsafe global error detection in C is rather difficult.
In addition to making the code easier to read and write, combined modes make the security easier to analyze. CCM, for instance, is a combination of CBC-MAC and CTR encryption mode. In various ways, we can reduce the security of CCM to the security of these modes. In general, with a full length MAC tag, the security of CCM reduces to the security of the block cipher (assuming a unique nonce and random key are used).
What we mean by reduce is that we can make an argument for equivalence. For example, if the security of CTR is reducible to the security of the cipher, we are saying it is as secure as the latter. By this reasoning, if one could break the cipher, he could also break CTR mode. (Strictly speaking, the security of CTR reduces to the determination of whether the cipher is a PRP.)
So, in this context, if we say CCM reduces to the security of the cipher in terms of being a proper pseudo-random permutation (PRP), then if we can break the cipher (by showing it is not a PRP), we can likely break CCM. Similarly, GCM reduces to the security of the cipher for privacy and to universal hashing for the MAC. It is more complicated to prove that it can be secure.
Choosing a Nonce
Both CCM and GCM require a unique nonce (N used once) value to maintain their privacy and authenticity goals. In both cases, the value need not be random, but merely unique for a given key. That is, you can safely use the same nonce (only once, though) between two different keys. Once you use the nonce for a particular key, you cannot use it again.
GCM Nonces
GCM was designed to be most efficient with 12-byte nonce values. Any longer or shorter and GHASH is used to create an IV for the mode. In this case, we can simply use the 12-byte nonce as a packet counter. Since we have to send the nonce to the other party anyway, this means we can double up on the purpose of this field. Each packet would get its own 12-byte nonce (by incrementing it), and the receiver can check for replays and out of order packets by checking the nonce as if it were a 96-bit number.
You can use the 12-byte number as either a big or little endian value, as GCM will not truncate the nonce.
CCM Nonces
CCM was not designed as favorably to the nonces as GCM was. Still, if you know all your packets will be shorter than 65,536 bytes, you can safely assume your nonce is allowed to be up to 13 bytes. Like GCM, you can use it as a 104-bit counter and increment it for every packet you send out.
If you cannot determine the length of your packets ahead of time, it is best to default to a shorter nonce (say 11 bytes, allowing up to four-gigabyte packets) as your counter. Remember, there is no magic property to the length of the nonce other than you have to have a long enough nonce to have unique values for every packet you send out under the same key.
CCM will truncate the nonce if the packet is too long (to have room to store the length), so in practice it is best to treat it as a little endian counter. The most significant bytes would be truncated. It is even better to just use a shorter nonce than worry about it.
Additional Authentication Data
Both CCM and GCM support a sort of side channel known as additional authentication data (AAD). This data is meant to be nonprivate data that should influence the MAC tag output. That is, if the plaintext and AAD are not present together and unmodified, the tag should reflect that.
The usual use for AAD is to store session metadata along with the packet. Things such as username, session ID, and transaction ID are common. You would never use a user credential, since it would not really be something you need on a per-packet basis.
Both protocols support empty AAD strings. Only GCM is optimized to handle AAD strings that are a multiple of 16 bytes long. CCM inserts a four- or six-byte header that offsets the data and makes it harder to optimize for. In general, if you are using CCM, try to have very short AAD strings, preferably less than 10 bytes, as you can cram that into a single encrypt invocation. For GCM, try to have your AAD strings a multiple of 16 bytes even if you have to pad with zero bytes (the implementation cannot do this padding for you, as it would change the meaning of the AAD).
MAC Tag Data
The MAC tag produced by both implementations is not checked internally. The typical usage would involve transmitting the MAC tag with the ciphertext, and the recipient would compare it against the one he generated while decrypting the message.
In theory at least, you can truncate the MAC tag to short lengths such as 80 or 96 bits. However, some evidence points to the contrary with GCM, and in reality the savings are trivial. As the research evolves, it would be best to read up on the latest analysis papers of GCM and CCM to see if short tags are still in fact secure.
In practice, you can save more space if you aggregate packets over a stable channel. For example, instead of sending 128-byte packets, send 196- or 256-byte packets. You will send fewer nonces (and protocol data), and the difference can allow you to use a longer MAC tag. Clearly, this does not work in low latency switching cases (e.g., VoIP), so it is not a bulletproof suggestion.
Example Construction
For our example, we will borrow from the example of Chapter 6, except instead of using HMAC and CTR mode, we will use CCM. The rest of the demo works the same. Again, we will be using LibTomCrypt, as it provides a nice CCM interface that is very easy to use in fielded applications.
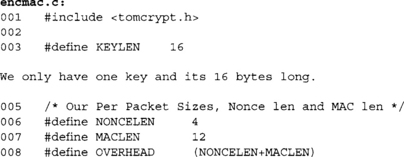
As in the previous example, we have a packet counter length (the length of our nonce), MAC tag length, and the composite overhead. Here we have a 32-bit counter and a 96-bit MAC.


Our encrypted and authenticated channel is similar to the previous example. The differences here are that we are using a generic scheduled key, and we do not have a MAC key.
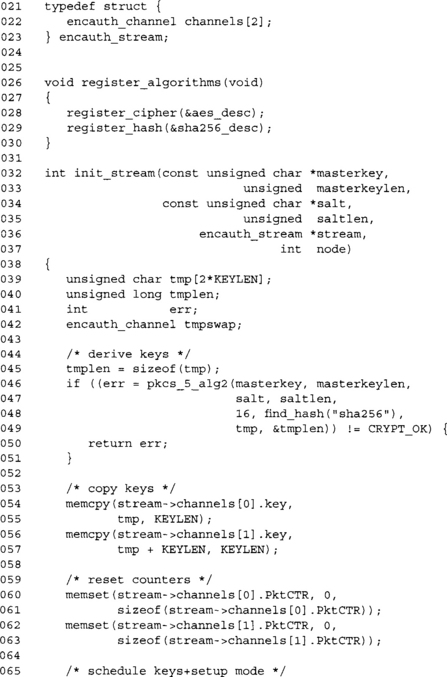

This initialization function is essentially the same. We only change how much PKCS #5 data is to be generated.

We use our packet counter PktCTR as the a method of keeping the packets in order. We also use it as a nonce for the CCM algorithm. The output generated will first consist of the nonce, followed by the ciphertext, and then the MAC tag.
![]()
This function call will generate the ciphertext and MAC tag for us. Libraries are nice.
![]()
First, we need the index of the cipher we want to use. In this case, AES with CCM. We could otherwise use any other 128-bit block cipher such as Twofish, Anubis, or Serpent.
![]()
This is the byte array of the key we want to use and the key length.
![]()
This is the pre-scheduled key. Our CCM routine will use this instead of scheduling the key on the fly. We pass the byte array for completeness (accelerators may need it).
![]()
This is the nonce for the packet.
![]()
This is the AAD; in this case, we are sending none. We pass NULL and 0 to signal this to the library.
![]()
These are the plaintext and ciphertext buffers. The plaintext is always specified first regardless of the direction we are using. It may get a bit confusing for those expecting an “input” and “output” order of arguments.

The ccm_memory() function call produces the ciphertext and MAC tag. The format of our packet contains the nonce, followed by the ciphertext, and then the MAC tag. From a security standpoint, this function provides for the same security goals as the previous chapter’s incarnation of this function. The improvement in this case is that we have shortened the code and removed a few variables from our structure.

![]()
As before, we assume that inlen is the length of the entire packet and not just the plaintext. We first make sure it is a valid length, and then subtract the MAC tag and nonce from the length.
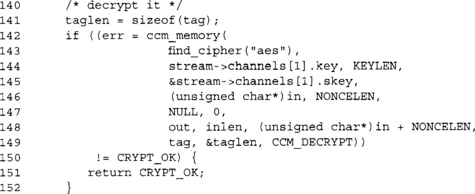
For both encryption and decryption, the ccm_memory() function is used. In decrypt mode, it is used much the same, except our out buffer goes in the plaintext argument position. Therefore, it appears before the input, which seems a bit awkward.
Note that we store the MAC tag locally since we need to compare it next.

These checks are the same as they were in the previous incarnation. The first avoids alterations, and the second avoids replay attacks. We still do not handle out of order packets (e.g., with a window), but that should be trivial to accommodate.
![]()
At this point, our packet is valid, so we copy the nonce out and store it locally, thus preventing future replay attacks.

The rest of our demonstration program is the same as our previous incarnation, as we have not changed the function interfaces.
The following Frequently Asked Questions, answered by the authors of this book, are designed to both measure your understanding of the concepts presented in this chapter and to assist you with real-life implementation of these concepts. To have your questions about this chapter answered by the author, browse to www.syngress.com/solutions and click on the “Ask the Author” form.
Q: What is an Encrypt and Authenticate algorithm?
A: These are algorithms designed to accept a single key and IV, and allow the caller to both encrypt and authenticate his message. Unlike distinct encrypt and authenticate protocols, these modes do not require two independent keys for security.
Q: What are the benefits of these modes over the distinct modes?
A: There are two essential benefits to these modes. First, they are easier to incorporate into cryptosystems, as they require fewer keys, and perform two functions at the same time. This means a developer can accomplish two goals with a single function call. It also means they are more likely to start authenticating traffic. The second benefit is that they are often reducible to the security of the underlying cipher or primitive.
A: When we say one problem is reducable to another, we imply that solving the former involves a solution to the latter. Far instinct, the security of CTR-AES reduces to the problem of whether AES is a true pseudo random permutation (PRP). If AES is not a PRP, CTR-AES is not secure.
Q: What Encrypt and Authenticate modes are standardized?
A: CCM is specified in the NIST publication SP 800-38C. GCM is an IEEE standard and will be specified in the NIST publication SP 800-38D in the future.
Q: Should I use these modes over distinct modes such as AES-CTR and SHA1-HMAC?
A: That depends on whether you are trying to adhere to an older standard. If you are not, most likely GCM or CCM make better use of system resources to accomplish equivalent goals. The distinct modes can be just as secure in practice, but are generally harder to implement and verify in fielded applications. They also rely on more security assumptions, which poses a security risk.
Q: What is a nonce and what is the importance of it?
A: A nonce is a parameter (like an initial value) that is meant to be used only once. Nonces are used to introduce entropy into an otherwise static and fully deterministic process (that is, after the key has been chosen). Nonces must be unique under one key, but may be reused across different keys. Usually, they are simply packet counters. Without a unique nonce, both GCM and CCM have no provable security properties.
Q: What is additional authentication data? AAD? Header data?
A: Additional authentication Data (AAD), also known as header data and associated data (in EAX), is data related to a message, that must be part of the MAC tag computation but not encrypted. Typically, it is simple metadata related to the session that is not private but affects the interpretation of the messages. For instance, an IP datagram encoder could use parts of the IP datagram as part of the header data. That way, if the routing is changed it is detectable, and since the IP header cannot be encrypted (without using another IP standard), it must remain in plaintext form. That is only one example of AAD; there are others. In practice, it is not used much but provided nonetheless.
Q: Which mode should I use? GCM or CCM?
A: That depends on the standard you are trying to comply with (if any). CCM is currently the only NIST standard of the two. If you are working with wireless standards, chances are you will need GCM. Outside of those two cases, it depends on the platform. GCM is very fast, but requires a huge 64-kilobyte table to achieve this speed (at least in software). CCM is a slight bit slower, but is much simpler in design and implementation. CCM also does not require huge tables to achieve its performance claims. If you removed the tables from GCM, it would be much slower than CCM.
Q: Are there any patents on these modes?
A: Neither of GCM and CCM is patented. They are free for any use.
Q: Where can I find implementations?
A: Currently, only LibTomCrypt provides both GCM and CCM in a library form. Brian Gladman has independent copyrighted implementations available. Crypto++ has neither, but the author is aware of this.
Q: What do I do with the MAC tag?
A: If you are encrypting, transmit it along with your ciphertext and AAD data (if any). If you are decrypting, the decryption will generate a MAC tag; compare that with the value stored along with the ciphertext. If they do not compare as equal, the message has been altered or the stored MAC tag is invalid.