
Chapter 1 Introducing Model Implementation with the Building Block Method
This chapter introduces the building block approach. Any known financial instrument from the most simple to the most complex and esoteric can be put together from a small set of atomic components. With traditional data models you need to extend your data model every time you get a new unexpected combination of features. Then you need to develop new valuation and risk models for the new type of instrument. With the building block approach neither of the two steps are needed. All you need to do is to compose the new instrument from predefined building blocks that cover all imaginable features.
The fact that building blocks can be added easily and all instruments can be composed from a small set of building blocks means that a small number of building block valuation and risk models can handle an endless variety of actual financial instruments, rule sets can be built from simple components and configured to validate specific combinations of features dynamically, and data base, modelling, and portal software are not impacted by new instrument types but instead support them as soon as they arise.
1.1 Why Use a Building Block Approach?
Financial instruments come in a bewildering variety. There are virtually limitless possibilities to create new instruments by combining even just the more mainstream features in different combinations in order to match constantly changing market conditions and needs of investors. It is hence impossible to create a unique off-the-shelf valuation model for each combination of features used in the market. While most instruments are specimens of the pure plain vanilla variety of common instrument types like money market discount instruments, zero coupon bonds, fixed or variable coupon bonds, equity as well as derivatives make up a large fraction of all instruments in use at any point in time, this still leaves a large set of instruments that are more complex and often unique in one or more aspects.
However, help is at hand. Nearly two millennia before modern physics discovered the real atoms, Greek philosophers used the word atomos, meaning that which is indivisible, to describe the basic substance from which they thought all material things were constructed.
When you take on the task of valuing financial instruments with a comprehensive set of atomic instruments, it will allow you to split up more complex investments into combinations of simpler ones. This means that you will need a much smaller set of tools than you would have otherwise.
Robust and sophisticated tools whose behaviour is well known can be constructed to allow you to determine the value, risk, and profitability of the atomic parts of any instrument and ultimately that of the instrument of which they form a part. In addition, the smaller set of tools will be more manageable to learn and master.
Figure 1.1 illustrates how you can quickly build actual financial instruments by dragging common building blocks from a palette onto the instrument definition. In the example a Fixed Coupon Bond is composed from two building blocks: a Fixed Coupon and a Bullet Style Fixed Redemption building block. In Figure 1.2 you can see the details for the Fixed Coupon building block of the example Fixed Coupon Bond.

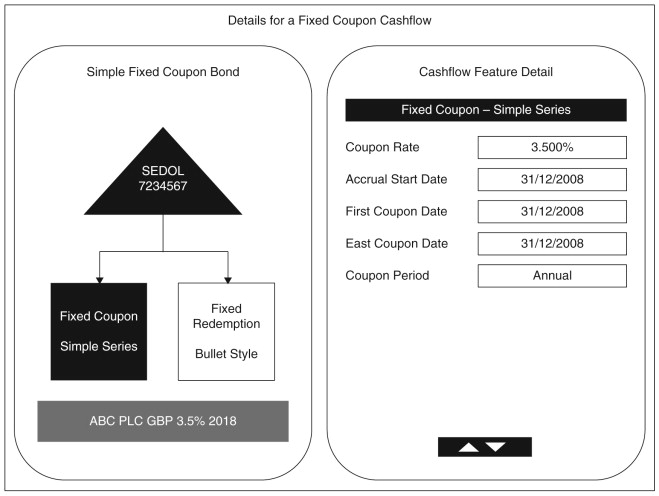
Fixed Coupon Bonds of course are handled easily by more conventional models, but there are many structured products that combine endless combinations of different plain vanilla and exotic features into different unique products. One of the big attractions of the building block approach is that you can easily create instruments of any complexity using a graphical drag-and-drop wizard tool (such as the one on the companion web site).
This is where the building block approach starts to pay off. With traditional data models or approaches you would need to extend your data model every time you get or want to use a new unexpected combination of features. You would now need to develop new valuation and risk models for the new type of instrument. With the building block approach neither of the two steps are needed. All you need to do is to compose the new instrument from predefined building blocks that cover all the separate features.
Very occasionally a new building block will be needed but this usually can be added without any data model changes again since the underlying data frame for all building blocks—called the Cash Flow Element—already has a super set of attributes that allows the definition of a near limitless variety of new building block types.
The fact that building blocks can be added easily and all instruments can be composed from a small set of building blocks not only allows very intuitive user interfaces for the creation of new instruments such as the Graphical Instrument Wizard from Fincore Financial, but it also means that a small number of building block valuation and risk models can handle an endless variety of actual financial instruments. Rule sets can be built from simple components and configured to validate specific combinations of features dynamically. Data base, modelling, and portal software is not impacted by new types of instruments but instead supports them as soon as they arise.
1.2 An Implementation Framework
Implementing valuation, risk, and performance measurement models is a complex task even in the simplest cases. Fortunately the task can be broken down into many smaller steps that are much easier to complete. To do this successfully you will need a framework and methodology to hold all the smaller steps together. In this chapter we introduce such a framework. This framework has been derived from a framework set out in Innmon, Zachman, and Geiger, 1997. In Figure 1.3 we outline the model implementation framework. Figure 1.4 provides an overview diagram for a generic methodology for implementing models.


In the remainder of this chapter we will look at how to apply the implementation framework and methodology. Because implementing models is such a complex endeavour, only the most simple ones can be implemented in one go from the first identification of a need right through to ongoing use of the model for decision making.
As a first step we will therefore look at the role of iterative cycles in the implementation process. The pattern we suggest to use is the iterative fountain model with short parallel planning and delivery cycles. Then we will look at each perspective in the framework and methodology starting with the methodology perspective. Although it might appear surprising to cover the task of methodology definition in an iterative and practical approach, there are good reasons to do so. The usefulness and reliability of risk modelling efforts in a particular context are highly dependent on the way the models are developed, implemented, and operated. What may have worked well in one context may well prove of little value or downright dangerous in another.
Next we will look at the requirements perspective. It may seem an obvious step but it is often underestimated. The results of modelling are highly dependent on the question we try to answer. It is important to ensure that the questions we try to answer with a set of risk models are really the ones that need to be answered to make the right decisions for a successful outcome from a business perspective.
Following the requirements perspective comes the architecture perspective. Any nontrivial risk model implementation is a complex (software) engineering task and will produce a nontrivial software (engineering) system as a result. To ensure that the overall system will fulfil the expectations placed on it when it is first delivered, and likewise years later after accommodating many changes, it is vital that it is built on the basis of blueprints that ensure its overall efficiency and effectiveness as much as its resilience in the face of change.
The system perspective will complete the sequence of steps necessary for the development of particular implementations of risk models. This is the sharp end where we need to make decisions about all the details that determine the best way to realise risk models as working software components. Beyond the models themselves we also need to ensure we have or create the right components that feed our models with the right input at the right time, and allow us to distribute and analyse our modelling results to support the decision-making processes for which we built the models in the first place.
Finally we will cover the operations perspective. Again this may be a surprise since a model is operated only once its development has been completed. However as we initially noted, only very few models can be successfully implemented in a single go without the need to elaborate them or at least adapt them in the wake of change in the environment and user needs. In this logic the operations phase becomes an integral part of the model development lifecycle.
1.2.1 The Iterative Process of Implementing Risk Models
Implementing risk models requires many decisions and assumptions whose impact can usually be assesed only by reviewing the perfomance of the resulting implementation in practical use. This makes an iterative implementation approach a necessity for all but the most trivial projects.
The iterative approach works best with short, well-defined iteration cycles such as one month. Weekly cycles also may be appropriate in some cases, and maybe six or even eight weeks in others. Shorter cycles tend to work better if the major focus is on modelling itself, whereas slightly longer cycles may be more appropriate to very large-scale projects focussed predominantly on software development where the actual models are already well known, tried and tested for the given circumstances.
The iteration approach we recommend as part of the Building Block implementation methodology is illustrated in Figure 1.5. It has two parallel streams for each cycle and a review between cycles: The first stream, Planning, is concerned with preparing the ground for the implementation work in the following iteration.

The second stream, Delivery, is concerned with creating the deliverables that are needed to realise the models both as working software but also as real-life business processes delivering the required results in a given organisational context.
Every time one iteration ends and another one starts it is also very beneficial to review the lessons from the iteration just finished and feed it back into the forthcoming iterations.
Let us now briefly review the role of each of the three elements of the iteration approach in the context of model implementations.
1.2.1.1 Iteration Planning Cycle
With risk model implementations numerous problems will arise and have an impact also via interdependencies at many different levels, from governance all the way to day-to-day operations. Making changes in response to perceived gaps or issues often requires input from people having different perspectives, different backgrounds and qualifications in order to tackle the same gap or issue at different levels of our implementation framework.
The purpose of the planning cycle is to give time and provide a structure for the vital dialogue that needs to occur before any commitments are to be made to address a gap or issue in a particular way.
The iteration planning cycle is therefore not a project management activity focussed on crafting schedules or waterfall-type paint-by-number dead specifications. It is instead a process that aims at efficiently tackling gaps or issues through a structured dialogue. This dialogue gives relevant participants from each of the five perspectives the opportunity to contribute.
Iteration Planning should not be a weighty or bureaucratic process. Often it is best done through joint review workshops carried out after participants have had a chance to review the original gap or issue in writing and put forward brief written comments setting out alternative solutions or highlighting interactions or constraints.
At the end of the dialogue each gap or issue should either have an agreed solution or should be referred to a future iteration. The solutions should ideally be small enough to be developed or otherwise created in less than a week by one or two participants, but this may well vary somewhat depending on circumstances. Before the solutions are handed over to the delivery cycle they should also be prioritised and fitted into a suitable place in a roadmap so that it is clear what needs to be done now and what later, and which things need to be carried out together.
1.2.1.2 Iteration Delivery Cycle
The iteration delivery cycle is the workhorse of model implementation. If the planning cycle is working well the planning activities will leave the majority of time of all participants to be devoted to the delivery cycle itself. If the solutions, priorities, and the roadmap of the planning cycle are “fit for purpose”, then project participants can focus on implementing as many solutions as possible in priority order without much additional overhead to coordinate the delivery work any further.
Model implementation involves many different qualifications. By splitting the solution dialogue and coordination effort from the actual delivery work itself, it becomes possible to maintain communication overhead at a minimum while ensuring that necessary communication does really take place and dialogue time really contributes to better solutions.
1.2.1.3 Iteration Reviews and Roadmaps
Iteration Reviews and maintaining an implementation roadmap are not a separate stream but should be done as part of the planning cycle. They are, however, a key backbone that ties the planning and delivery cycles together.
Iteration reviews are best built up by recording gaps, issues, and observations as they occur during delivery and then feeding them into the planning cycle after they have been reviewed by participants and any observations or responses have been recorded by participants.
At the other end of the planning cycle we should see a clear roadmap emerge that ties together different solutions into logical groups that should be or must be delivered together. It further visualises the priorities that are assigned to different solutions.
The roadmap allows the delivery work to proceed at an optimal pace and provides, together with the solution description, the information needed to create quality results delivered when they can make the biggest possible contribution.
1.2.2 Modelling Methodology Perspective
Model implementation and ongoing model operations almost always are and should be deeply woven into an organisation’s fabric. This means that the goals and schedules need to be aligned with an organisation’s wider goals and schedules with respect to risk management, including those set externally by regulators or voluntary codes.
The organisation of risk modelling projects and ongoing operations also needs to be aligned to both the complexity of the task itself and the organisational, regulatory or governance framework in which they take place.
Finally the selection of models, data, and processes also needs to fit both regulatory and governance constraints and be in line with both the organisation’s actual capabilities and the organisation’s tolerance to errors in any particular risk modelling efforts.
At the risk modelling methodology or governance level you therefore need to address this alignment between your project and the wider organisation. As you plan your next iteration or the roadmap beyond, you will need to bring in the necessary expertise and involve the right stakeholders to ensure that the alignment with the wider organisation and beyond can take place.
Thus, you should include not only the key project participants and the business sponsor for the project, but also any additional experts as well as other key stakeholders such as those with a governance responsibility that includes the business units directly involved in the project.
As part of the planning cycle, at this level you should agree on any modifications to the overall planning and delivery approach for the forthcoming planning and delivery cycles, and, where possible, for stages of the roadmap beyond the current iteration cycles.
Risk modelling projects, because of their complexity, rely strongly on an appropriate approach for good results. What is appropriate can vary tremendously over time and in different situations. It is therefore important to check in each iteration whether the approach needs to be adapted and, if so, ensure that the right modifications are made and actually work.
This helps to break down the methodology and guidelines into the different perspectives: Goals, Organisation, Schedules, Models, Data, Process.
1.2.3 Modelling Requirements Perspective
Risk Models are never created or implemented just for their own sake. It is therefore paramount to establish the true Modelling Requirements for the project from a business perspective before each iteration. If a project is broken down into sufficiently small and frequent iterations then the requirements can be refined and elaborated from iteration to iteration. The modelling effort from earlier iterations will help throw light on constraints such as the available experience of model developers and model operators; the availability, reliability, and timeliness of required data; the performance and accuracy of models, and so on.
It helps breaking down the requirements into different perspectives: Goals, Organisation, Schedules, Models, Data, and Process. Let us now look at Modelling Requirements from each of the six perspectives.
GOALS: Why Are We Really Doing This?
The first perspective to consider should be the ultimate goals of the project from a business perspective, because these requirements are fundamental to all the others. Goal requirements are concerned with the question, “why are we doing this?”
It is very tempting to answer this question with little introspection and just repeat whatever may have been the apparent trigger for the project. With a risk management project this is particularly dangerous as it leaves a large number of assumptions that will have to be made both unarticulated and untested.
Not properly clarifying the underlying goals of the project will vastly increase the potential for misunderstanding both within the project and between the project and external stakeholders. It will also make it difficult or even impossible to check whether the project is delivering results that are fit for purpose or not.
The question you should consider is “why are we really doing this?” Thus a goal such as “we need to know our VAR / ETL at 99%” should be carefully investigated and if left standing only be there to supplement the real reasons. The kind of questions you should ask to get to the real requirements are, who will be using the information, for what purpose, and in what context?
Once you have elaborated the real goals sufficiently it is also important to consider if the set of goals is consistent and achievable.
ORGANISATION: Who Will Need to Be Involved?
The next perspective is to look at the organisation of the project; in other words, who will need to be involved, and how, in order to
- Contribute from a governance point of view
- Contribute knowledge and expertise
- Plan and execute the project
- Implement the models and supporting data and process infrastructure
- Supply the inputs and infrastructure for the models
- Operate the resulting models
- Use the information generated by the models once in operation
In Risk Modelling projects the significance of who needs to be involved and how is of high significance. The complexity of the modelling task and the difficulty of visualising the fit of the models as implemented, with the needs and constraints of those involved once they are operational, makes it imperative that you have a robust plan for who to involve and how.
SCHEDULES: When Will We Need to Reach Certain Milestones?
Model implementations are usually tightly linked to other projects and organisational objectives. It is therefore imperative that you get a clear view of the interdependencies and agree on a realistic roadmap flexible enough to accommodate inevitable changes.
MODELS: Are There Constraints on How We Can Model Risks in the Project?
Even the most ambitious well-endowed greenfield project will face a range of constraints on which models can be used and how they can be implemented. The constraints come from a variety of sources such as regulatory requirements and your organisation’s capabilities and resources.
DATA: What Inputs Do We Have Available for Driving the Models?
Data is a key aspect when planning to implement models. Even the most sophisticated and robust model will produce unreasonable results if fed with corrupt or wrong information, and will stop working altogether if certain inputs are unavailable. A realistic roadmap for what data will be available, and when, is critical for a successful implementation. Often an implementation must devote considerable efforts to obtaining data hitherto unavailable and you need to factor this into your plans.
PROCESS: Where and With Which Resources Will the Models Be Operating?
This final dimension must take into account both project resources and the resources that will be available for operating the models you deliver once they have moved into production. It is no good to deliver an ideal model that trumps other alternatives but requires twice as many resources to run on an ongoing basis than what the user of your model results can afford to pay. It is critical to your success that you know as early as possible when there is a conflict between what is affordable and what is required in terms of ultimate goals.
1.2.4 Modelling Architecture, Systems, and Operations Perspectives
The architecture, systems, and operations perspectives again cover the dimensions: Goals, Organisation, Schedules, Models, Data, and Process. Each is a gradual refinement and stepwise instantiation of the requirements within the bounds of the methodology. You will find more information about these perspectives on the companion web site (http://modelbook.bancstreet.com/).
To help you work through each of those perspectives, go to the companion web site and work through Lab Exercise 1.1.