
Chapter 27. From Sparse Mocap to Highly Detailed Facial Animation
Bernd Bickel and Manuel Lang
The face conveys the most relevant visual characteristics of human identity and expression. Hence, realistic facial animations or interactions with virtual avatars are important for storytelling and gameplay. However, current approaches are either computationally expensive, require very specialized capture hardware, or are extremely labor intensive. In our article, we present a method for real-time animation of highly detailed facial expressions based on sparse motion capture data and a limited set of static example poses. This data can be easily obtained by traditional capture hardware. The proposed in-game algorithm is fast. It also is easy to implement and maps well onto programmable GPUs.
27.1. System Overview
Our method for real-time animation of highly detailed facial expressions decomposes geometry into large-scale motion and fine-scale details, such as expression wrinkles.
First, large-scale deformations are computed with a fast and simple linear deformation model, which is intuitively and accurately controlled by a sparse set of motion-capture markers or user-defined handle points. Our GPU implementation for this step is only a couple of lines long and already results in a convincing facial animation by exactly interpolating the given marker points.
In the second step, fine-scale facial details, like wrinkles, are incorporated using a pose-space deformation technique. In a precomputation step, the correlation of wrinkle formation to sparsely measured skin strain is learned. At runtime, given an arbitrary facial expression, our algorithm computes the skin strain from the relative distance between marker points and derives fine-scale corrections for the large-scale deformation. During gameplay only the sparse set of marker-point positions is transmitted to the GPU. The face animation is entirely computed on the GPU where the resulting mesh can directly be used as input for the rendering stages.
Our method features real-time animation of highly detailed faces with realistic wrinkle formation and allows both large-scale deformations and fine-scale wrinkles to be edited intuitively. Furthermore, our pose-space representation enables the transfer of facial details to novel expressions or other facial models. Both large- and fine-scale deformation algorithms run entirely on the GPU, and our implementation based on CUDA achieves an overall performance of about 30fps on an NVIDIA 8800GTX graphics card for a mesh of 530,000 vertices and more than a million faces.
Modeling, acquisitions, and animation of the human face are topics largely explored in computer graphics and related fields like computer vision. We will quickly review and compare the current state-of-the-art methods for real-time facial animation before we dive into the specifics of our method.
One large family of face animation methods evolved around a technique called blend shapes. As the name suggests, a facial expression is obtained by linearly combining (“blending”) a set of example shapes. As demonstrated by Lorach
[6]
, this operation can be performed very efficiently on the GPU. Blend shapes are a very flexible and powerful tool, but the example shapes have to be created and selected very carefully because the method is able to produce only facial expressions spanned by those examples. Therefore, the number of required input poses tends to be high. All of these input poses have to be modeled or scanned. Our two-scale approach allows a significant reduction in the required number of example poses. In contrast to blend shapes, we start with a single pose. Using a simple, but powerful deformation technique, we obtain the large-scale deformation. The method ensures that given motion capture marker positions are exactly matched; therefore, we obtain already in the first step an accurate overall pose approximation, which has to be enriched only by the specific fine-scale details distinctive for the given pose. This is done by our fine-scale enrichment. A few example input poses are sufficient for learning the formation of high-resolution details based on local skin strain.
Alternatively, Borshukov
et al
.
[7]
presents a stunning method for reproducing realistic animated faces called Playable Universal Capture. In addition to a marker-based motion capture system, they use high-definition color cameras to record an animated texture. The animated texture contains fine details and “baked-in” ambient occlusion. Although this technique is already successfully applied in various computer games, it requires very specialized capture hardware and is restricted to playback of captured sequences. When the animation is split in three parts, a single mesh in undeformed state, the large-scale, and the fine-scale deformation allow us to perform editing operations on each of them independently and even reuse fine-scale details on different facial models. This gives artists and animators the freedom to combine any facial model with any other dataset of facial details and even enrich artificial characters with real-life captured wrinkle data. For a storage-critical application, this may also allow reduction of the number of different facial details and save memory by reusing the same details on multiple characters.
27.3. Core Technology and Algorithms
We start with an overview of the input data and the workflow of our face animation pipeline, depicted in
Figure 27.1
, before describing the large-scale and fine-scale deformations in more detail in the following sections. In contrast to blend shapes, which linearly combine several facial poses, we use a single high-resolution face mesh of the rest pose (∼1 M triangles), and generate all frames of the animation by deforming this mesh from its rest pose.
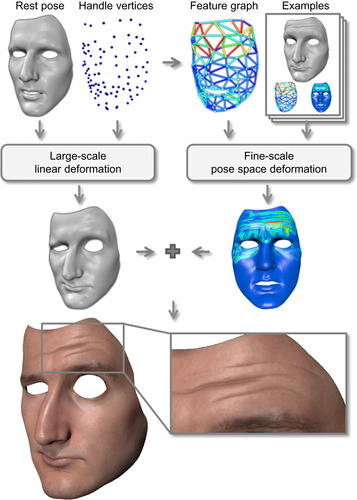 |
| Figure 27.1
Our animation pipeline computes the large-scale facial motion from a linear deformation model and adds fine-scale details from a set of example poses. Image from Bickel et al., 2008.
|
We compute the large-scale facial motion using a linear thin shell model. Figuratively, it approximates the face as a rubber shell and minimizes bending and stretching energies. Its deformation is controlled through a set of approximately 100 handle vertices, which may correspond to a set of face points tracked during an actor's performance or may be interactively controlled by an animator.
The resulting large-scale deformation successfully captures the overall facial expression, but lacks fine-scale facial details such as expression wrinkles.
The nonlinear behavior that goes beyond the linear large-scale motion is learned in a preprocess from a set of example poses. These examples are represented by high-resolution triangle meshes in full-vertex correspondence with the rest pose mesh. In practice, example poses can, for instance, be created manually by an artist or by capturing an actor's face with a high-resolution scanner. Given the example poses, the corresponding fine-scale details are extracted per-vertex as the difference between the examples and the results of the large-scale deformation for the same poses.
In order to synthesize the fine-scale corrections for an arbitrary facial pose, we learn the correlation of skin strain to the formation of skin details such as wrinkles. The skin strain is approximated by the relative distance change of neighboring marker points. These discrete measurements are sufficient for locally controlling the fine-scale corrections on a per-vertex basis (Figure 27.1
, right).
27.3.1. Large-Scale Deformation
For the large-scale face deformation we employ the method of Bickel
et al
.
[1]
, which demonstrates that the displacements of a set of sparse handle vertices provides sufficient geometric constraints for capturing the large-scale facial motion in a plausible way. Given as input constraints the 3-D displacements
u
H
∈
R
H
× 3
of the
H
handle vertices, the large-scale deformation is computed by minimizing a simplified quadratic thin shell energy. The deformation is represented as a vector
u
, containing the displacement of all free vertices from their rest pose position. A comprehensive overview of linear surface deformation methods can be found in Botsch and Sorkine
[2]
.
Setting Up the Equations
This amounts to solving the equations
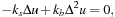 under the constraints
u
H
imposed by handle vertices. In this equation,
k
s
and
k
b
denote the stiffness for surface stretching and bending, respectively, and Δ is the Laplace-Beltrami operator. It can be discretized using the following form:
under the constraints
u
H
imposed by handle vertices. In this equation,
k
s
and
k
b
denote the stiffness for surface stretching and bending, respectively, and Δ is the Laplace-Beltrami operator. It can be discretized using the following form:
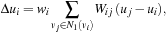 where
u
i
is the displacement of the
i
'th vertex
v
i
, and
v
i
∈
N
1
(v
i
) are its incident one-ring neighbors. For the per-vertex normalization weights and the edge weights, we are using the de facto standard cotangent discretization
[2]
.
where
u
i
is the displacement of the
i
'th vertex
v
i
, and
v
i
∈
N
1
(v
i
) are its incident one-ring neighbors. For the per-vertex normalization weights and the edge weights, we are using the de facto standard cotangent discretization
[2]
.
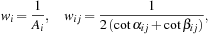 where
α
ij
and
β
ij
are the two angles opposite to the edge (v
i
, v
j
), and
A
i
is the Voronoi area of vertex
v
i
as shown in
Figure 27.2
.
where
α
ij
and
β
ij
are the two angles opposite to the edge (v
i
, v
j
), and
A
i
is the Voronoi area of vertex
v
i
as shown in
Figure 27.2
.
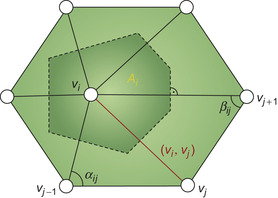 |
| Figure 27.2
The cotangent discretization. The weights of the Laplacian operator at a vertex
v
i
are computed by considering the Voronoi area
A
i
and the edge weights
W
ij
based on the cotangents of the angles
α
ij
and
β
ij
opposite to the edge.
|
Setting up this equation at every free vertex yields the linear system
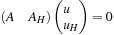 to be solved for the unknown displacements
u
∈
R
(V − H) × 3
of the (V
−
H
) free vertices. The matrix
A
is of size (V
−
H
) × (V
−
H
), and
A
H
is of size (V
−
H
) ×
H
.
to be solved for the unknown displacements
u
∈
R
(V − H) × 3
of the (V
−
H
) free vertices. The matrix
A
is of size (V
−
H
) × (V
−
H
), and
A
H
is of size (V
−
H
) ×
H
.
Implementation — Solving It in Real Time
The standard way of computing the displacements would be directly solving the preceding linear equation system. However, we found that precomputing a “basis function” matrix
Bu
H
=
u
allows a very
efficient evaluation of the large-scale deformation during runtime on the GPU. Basically, the required computation during runtime boils down to a simple matrix-vector multiplication of the basis function matrix
B
with the handle positions
u
H
.
The basis function matrix
B
= −
A
−1
A
H
depends only on the rest pose mesh and the selection of handle vertices. Each column
b
i
of
B
is computed by solving a sparse linear system
Ab
i
=
h
i
involving
A
and the corresponding column
h
i
of
A
H
.
At runtime, the large-scale deformation
u
is obtained from the handle displacement
u
H
by the matrix product
Bu
H
=
u
, which can efficiently be computed in a parallel GPU implementation. The kernel for the matrix multiplication is given in
Listing 27.1
.
 |
| Listing 27.1. |
| The large-scale deformation can be implemented as a matrix vector multiplication.
|
Before starting the animation sequence, we load all required static data to GPU memory. In the case of the large-scale deformation, this comprises the position of all vertices in their rest pose (float4 *in) and the basis function matrix
B
T
(float *basis). During animation only the current handle displacements
u
H
have to be copied to the GPU (float3 *handles) and the
LargeScaleKernel
kernel function has to be invoked for all face vertices in parallel. The function first copies the commonly accessed handles to fast on-chip shared memory. After that step is completed, the matrix vector multiplication can be carried out in a simple for-loop, and the resulting displacements can be added to rest pose positions. Please note that matrix
B
is stored transposed to achieve a coalesced memory access pattern.
27.3.2. Fine-Scale Deformation
The linear deformation model described in the last section approximates the facial motion well at a large scale. However, nonlinear fine-scale effects, such as the bulging produced by expression wrinkles, cannot be reproduced. These fine-scale deformations are highly nonlinear with respect to the positions of the handle vertices. However, they vary smoothly as a function of facial pose; hence, we have opted for learning, as a preprocess, the fine-scale displacement
d
from a set of example poses, and then at runtime compute it by interpolation in a suitable facial pose space.
We first define a facial pose space based on a rotation-invariant feature vector of skin strain and formulate the learning problem as scattered-data interpolation in this pose space. We extend the basic
method to weighted pose-space deformation, segmenting the face implicitly into individual regions and thereby allowing for a more compact basis.
Skin Strain Is a Good Descriptor for Facial Pose
We require a suitable space and descriptor that controls the interpolation of fine-scale displacements from a set of example poses. At each animation frame, the raw input data describing a pose consists of the positions of the handle vertices. These data are not invariant under rigid transformations; hence, it does not constitute an effective pose descriptor.
As everybody can observe, bulging effects of wrinkles appear due to lateral compression of skin patches. Therefore, we suggest a feature vector that measures skin strain between various points across the face. We define a set of
F
edges between handle vertices, which yields an
F
-dimensional feature vector
f
= [
f
1
…
f
F
] of a pose. The entry
f
i
represents the relative stretch of the
i
'th feature edge, which can be regarded as a measure of strain. Specifically, given the positions of the end points
p
i
, 1
and
p
i
, 2
and the rest length
l
i
, we define
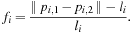
Figure 27.3
shows the correlation between the feature vector and wrinkle formation.
 |
| Figure 27.3
Wrinkle formation and skin strain. Close-up of the forehead for three input examples (bottom) and the corresponding strain on the feature edges (top), showing the correlation between skin strain and wrinkle formation. Image from Bickel et al., 2008.
|
Mathematical Background — Blending in High-Resolution Details
Our goal is to use a data-driven approach and learn the connection of skin strain to wrinkle formation. We represent each facial expression by its rotation-invariant feature vector
f
as described in the last section. Hence, each facial expression corresponds to a point in an
F
-dimensional pose space, which constitutes the domain of the function we want to learn. Its range is the fine-scale detail correction
d
, represented as well in a rotation-invariant manner by storing it in per-vertex local frames.
Each of the
P
example poses corresponds to a feature vector
f
with its associated fine-scale displacement
d
. Our goal is now to come up with a function that fulfills the following properties:
• Given an arbitrary facial pose, compute efficiently the fine-scale displacements by smart interpolation and extrapolation of the details contained in the example poses.
• Given an input facial pose, it should accurately reproduce the corresponding input detail.
• It should vary smoothly and should not contain any discontinuities.
This corresponds to a scattered data interpolation problem, for which we employ radial basis functions (RBFs). Hence, the function
d
:
R
F
→
R
3
V
, mapping a facial pose to 3-D fine-scale displacement, has the form
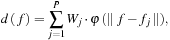 where
φ
is a scalar basis function, and
w
j
∈
R
3
V
and
f
j
are the weight and feature vectors for the
j
'th example pose. We employ the biharmonic RBF kernel
φ
(r
) =
r
, because it allows for smooth interpolation of sparsely scattered example poses and does not require any additional parameter tuning. More information on smooth scattered data interpolation using RBFs can be found in Carr
et al
.
[5]
.
where
φ
is a scalar basis function, and
w
j
∈
R
3
V
and
f
j
are the weight and feature vectors for the
j
'th example pose. We employ the biharmonic RBF kernel
φ
(r
) =
r
, because it allows for smooth interpolation of sparsely scattered example poses and does not require any additional parameter tuning. More information on smooth scattered data interpolation using RBFs can be found in Carr
et al
.
[5]
.
In our basic definition of a function for blending in details, every input example influences all vertices of the face mesh in the same manner because we compute a single feature distance
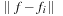 per example pose
j
. This feature distance is constant over the whole face. Consequently, the set of example poses is required to grow exponentially to sufficiently sample the combinations of independent deformations (e.g., raising both eyebrows versus raising just one eyebrow). As an answer to this problem, we follow the idea of
[4]
. We break the face into several overlapping areas. Every vertex will be affected only by a small set of nearby strain measurements. This requires us to redefine the function
d
(f
) to compute feature distances in a per-vertex manner, replacing the global Euclidean metric
per example pose
j
. This feature distance is constant over the whole face. Consequently, the set of example poses is required to grow exponentially to sufficiently sample the combinations of independent deformations (e.g., raising both eyebrows versus raising just one eyebrow). As an answer to this problem, we follow the idea of
[4]
. We break the face into several overlapping areas. Every vertex will be affected only by a small set of nearby strain measurements. This requires us to redefine the function
d
(f
) to compute feature distances in a per-vertex manner, replacing the global Euclidean metric
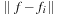 with a weighted distance metric per vertex
v
:
with a weighted distance metric per vertex
v
:
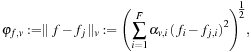 where
f
j,i
is the strain of the
i
'th strain edge in the
j
'th pose. We exploit the fact that every edge measures a local property (i.e., relative stretch of feature edges), and therefore, assign weights
α
v,i
based on proximity to the edges. Specifically, for a vertex
v
we define the weight of the
i
'th feature edge as a exponentially decaying weight
where
f
j,i
is the strain of the
i
'th strain edge in the
j
'th pose. We exploit the fact that every edge measures a local property (i.e., relative stretch of feature edges), and therefore, assign weights
α
v,i
based on proximity to the edges. Specifically, for a vertex
v
we define the weight of the
i
'th feature edge as a exponentially decaying weight
 where
l
i
is the rest length of the feature edge, and
L
v,i
is the sum of rest pose distances from vertex
v
to the edge end points. This weight is 1 on the edge and decays smoothly everywhere else, as shown in
Figure 27.4
. The parameter
β
can be used to control the rate of decay, based on the local density of handle vertices. In our experiments we discard weights
where
l
i
is the rest length of the feature edge, and
L
v,i
is the sum of rest pose distances from vertex
v
to the edge end points. This weight is 1 on the edge and decays smoothly everywhere else, as shown in
Figure 27.4
. The parameter
β
can be used to control the rate of decay, based on the local density of handle vertices. In our experiments we discard weights
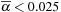 , and set
β
so that a vertex is influenced by at most 16 edges.
, and set
β
so that a vertex is influenced by at most 16 edges.
 |
| Figure 27.4
For three edges, the exponentially dropping local influence weight
α
v,i
is shown. The weights decay in a way such that every face vertex is influenced by at most 16 feature edges.
|
Precomputation
As a preprocess, the RBF weights
w
j
have to be computed. We compute the weights so that the displacements of the example poses are interpolated exactly; that is,
d
(f
i
) =
d
i
. This reduces to solving 3 ·
V
linear
P
×
P
systems, which differ in their right-hand side only.
27.3.3. Implementation — Synthesizing High-Resolution Details on the GPU
Calculating the high-resolution details during runtime is done by evaluating
d
(f
) for every vertex independently, as shown in
Listing 27.2
. First, the scalar basis function
φ
f,v
is evaluated and multiplied with the corresponding precomputed weight
w
j
. The sum of those yields the displacement correction in the local tangent frame. These are transformed into global coordinates and applied to the vertex positions.
 |
| Listing 27.2. |
| This CUDA kernel computes the fine-scale details for a given a set of approximated local skin strain measurements.
|
Evaluating
φ
f,v
efficiently is done by precomputing the
α
v,i
's and storing them on GPU memory
(alphas_v)
. To achieve real-time performance, we consider only the 16
(alpha_size = 16)
closest strain measurements. Therefore, for every vertex, we store the
alpha_size
non-zero
α
v,i
values. We utilize another
alpha_size
large array
(alpha_indices_v)
per vertex to store the indices pointing to the corresponding feature vector
(poses_f)
entries. The feature vector of all example poses is stored in the
arrayposes_f
. This data structure is randomly accessed from all vertices and fits into fast shared
memory. After we have calculated the weighted distance
φ
f,v
(phi_fv)
, we multiply it with
w
j
's of each vertex. Because
w
j
's
(poses_w)
is large and the entries are accessed only once per vertex, we store it in a way that coalesced reads are used.
Now, the computed fine-scale displacements
d
(f
) have to be applied onto the vertex positions
(vertex)
resulting from the previous large-scale deformation.
d
(f
) is represented in a local coordinate frame at each vertex. We defined the local coordinate frame by assigning each mesh vertex a specific neighbor vertex. This neighbor vertex position, together with the vertex normal, is sufficient to span a consistent local coordinate frame. Based on the local frame, we compute and apply the global high-resolution details.
27.3.4. Results and Evaluation
Our method is designed for parallel GPU computation. All computations are carried out on the GPU, and the resulting geometry is directly passed to the rendering stage, without transferring a large amount of data. During runtime, the animation is controlled by the motion-capture marker position, and only these data have to be sent to the GPU.
The significant speedup compared with a single-core CPU (about a factor of 80, factor of 10 on an eight core) is possible because our method is parallelized over the large number of vertices of the face mesh. The position and displacement of vertices can be computed independently from each other. We need three CUDA kernels to perform the animation. First, the large-scale kernel computes new positions for all face vertices; these positions are simply obtained by three dot products (for
x
,
y
,
z
coordinates) of weights with handle positions. Then, the normals of the face vertices have to be updated. This is done in one kernel with the help of a simple data structure enumerating one ring of vertices around every vertex. Then, the fine-scale enrichment kernel calculates the local displacement for each vertex and computes all new vertex positions in parallel. This is followed by a second final vertex normal update for rendering. In our current implementation, we utilize the CPU to synchronize the kernel invokes of the aforementioned steps.
27.3.6. Memory Access Strategy
We found that an optimized memory access pattern is crucial to achieve the required interactive performance. In the following, we will quickly summarize the applied strategies. Most of them will be very familiar to experienced GPU programmers, and some of them are less important on newer hardware (compute capability 2.0).
Large-Scale Deformation
For the large-scale deformation, it is important to note that the same handle position is accessed simultaneously by all threads. Therefore, the handle positions should be either placed in shared memory or in constant memory. Because all threads address the same location at the same time, both methods will be almost as fast as accessing a register (after caching).
Furthermore, every element in the basis matrix is accessed only once per kernel invocation; therefore, it is not helpful to copy it first into shared memory. Only a neighborhood-aware caching could improve performance. This would be exactly what texture-caching units could achieve. However, our large-scale deformation basis matrix is too large to fit into a CUDA array (texture). It is also too big to fit into cached constant memory. Therefore, we can optimize only the access pattern for global memory. Luckily, this is straightforward. The matrix is stored transposed so that the information for each thread (vertex) is next to each other. This way, the number of rows in the matrix is equal to the number of handles. It is also important to use a correct padding between the rows to achieve coalesced memory access also on older GPUs. In this context, one can also benefit from NVIDA GF100's L1 cache that enhances memory locality.
Fine-Scale Deformation
Finding the right memory access patterns for the fine-scale deformation kernel is a bit more involved. The per-frame input of this stage is the feature vector composed out of approximately 250 scalar float values (the strain measurements). In contrast to the large-scale deformation, not all input components are accessed exactly once by all vertices. Multiple threads in one block will likely access some of the components multiple times. Therefore, these reads should be cached. In this case we opt in for shared memory. We assume that simultaneously running threads will randomly access 16 of the feature vector components. By placing them into shared memory, we observed that random bank conflicts are not too
frequent. The other option would be constant memory, but because threads will likely not access the same address at the same time, a bank-conflict-free shared memory access is faster. We apply the same strategy for the feature vectors of all example poses. Luckily, all feature vectors together fit into shared memory.
All other data in this kernel is accessed only once per vertex, and therefore, we just utilized coalesced memory reads.
Normal Updates
We have to update all vertex normals twice in our algorithm. The data accessed by the normal update kernel are the vertex positions and a list of indices per vertex to help finding the first ring of neighbor vertices (the list is terminated with a-1 index). For older computing architectures it is beneficial to interleave the neighbor list so that vertices running in the same warp will have a coalesced access pattern.
27.3.7. Performance
We tested the performance of our method with a detailed facial model. The face model is composed from 530,000 vertices and more than one million triangles. To achieve convincing animation results we required only six example poses. The animation sequence was captured by motion capturing with 89 mocap markers that were directly painted on the actor's face. The 89 markers were directly used to drive the large-scale deformation and additionally they were used to compute 243 discrete local strain measurements. These 243 float values were used as per-frame input to the fine-scale kernel. Overall, we stored 137 floats and 24 integers per face vertex on the GPU memory. For this setup we obtained an overall performance of about 30fps on an NVIDIA 8800 GTX graphics card on Windows XP. The large-scale deformation required about 4 ms and fine-scale deformation was performed in 13 ms. Additionally, we had to update the vertex normals twice (one after large-scale deformation and one before rendering). This was also done in CUDA and required about 5 ms per update. A subsequent simple untextured Gouraud shading in OpenGL required 4 ms. With an additional skin rendering providing real-time subsurface scattering, as described by D'Eon
et al
.
[8]
, the final rendering took about 36 ms/frame for our highly detailed mesh.
Table 27.1
shows a comparison of performance numbers. Our algorithm was 10 times faster than an OpenMP CPU implementation. The CPU implementation would also require an additional copy of the entire face onto the GPU every frame before rendering (+ 2ms GTX480, not included in the measured timings). We also observed that the user space driver model in Windows 7 influenced our
timings significantly. One solution to reduce the kernel invocation overhead would be to implement everything in a single kernel and use global GPU synchronization techniques. However, those features are only available on newer architectures.
| *
The CPU implementation uses OpenMP to utilize eight logical cores
.
| |||
| GTX8800 Windows XP | GTX480 Windows 7 | CPU i7920 QuadCore * | |
|---|---|---|---|
| Large-scale kernel | 4 ms | 6 ms | 65 ms |
| Medium-scale kernel | 13 ms | 11 ms | 80 ms |
 |
| Figure 27.5. |
| Results. The first row shows the six example poses used. The second row shows the intermediate large-scale result and the final result. The third and fourth rows show some additional results with asymmetric deformations not present in the input examples. Image from Bickel et al., 2008.
|
27.4. Future Directions
Although we focused on animating human faces, the presented algorithms are not inherently limited to this application area. Theoretically, our approach can be applied for deforming arbitrary surfaces, but large local rotations would require special handling owing to linearization artifacts that we do not address in this chapter.
There is room for further speeding up of the algorithm. All timings were measured on a dense, uniformly sampled mesh. Although in regions such as the forehead and around the eyes, complex wrinkle structures might show up, other regions, such as the cheek or chin, are less affected. Adaptive mesh decimation depending on the frequency of the high-resolution features could lead to significant speedups.
CUDA is a perfect environment to implement the algorithms presented in this chapter in a highly parallelized way on a GPU without being limited by the API of a traditional graphics pipeline. However, future work could investigate how the algorithms could be mapped onto traditional shader architectures. Large-scale and fine-scale deformation are both parallelized over the vertices; therefore, a vertex shader could be a natural choice for both. The large-scale deformation could be implemented in vertex shader straightforward, but extra care has to be given to the large basis matrix. A single texture (often restricted to 8
k
× 8
k
) might not be able to store the entire matrix for a large face with many handles. Also a high number of handles may not fit into an available number of uniform registers. Modern extensions to graphics APIs, like DirectCompute or OpenCL, could also be an alternative for a GPU vendor-independent implementation, as often required for commercial products.
Acknowledgments
This chapter is based on the paper “Pose-Space Animation and Transfer of Facial Details” by Bickel et al., 2008.
Figure 27.1
and
Figure 27.3
, Eurographics Association 2008. Reproduced by kind permission of the Eurographics Association.
References
[1]
B. Bickel, M. Lang, M. Botsch, M. Otaduy, M. Gross,
Pose-space animation and transfer of facial details
,
In: (Editors: M. Gross, D. James)
Proceedings of the 2008 ACM SIGGRAPH/Eurographics Symposium on Computer Animation, July 7–9, 2008
Dublin, Ireland
. (2008
), pp.
57
–
66
.
[2]
M. Meyer, M. Desbrun, P. Schröder, A.H. Barr,
Discrete differential-geometry operators for triangulated 2-manifolds
,
In:
Visualization and Mathematics III
(2003
)
Springer-Verlag
, pp.
35
–
57
.
[3]
J.P. Lewis, M. Cordner, N. Fong,
Pose spaced deformations: a unified approach to shape interpolation and skeleton-driven deformation
,
In: (Editor: K. Akeley)
Proceedings of SIGGRAPH 00, New Orleans
(2000
), pp.
165
–
172
.
[4]
T. Rhee, J.P. Lewis, U. Neumann,
Real-time weighted pose-space deformation on the GPU
,
In:
Proceedings of Eurographics, Comput. Graph. Forum
,
25
(2006
), pp.
439
–
448
;
(3)
.
[5]
J.C. Carr, R.K. Beatson, J.B. Cherrie, T.J. Mitchell, W.R. Fright, B.C. McCallum,
et al.
,
Reconstruction and representation of 3D objects with radial basis functions
,
In: (Editor: E. Fiume)
Proceedings of SIGGRAPH 01
Los Angeles, CA
. (2001
), pp.
67
–
76
.
[6]
T. Lorach, K. Akeley (Eds.), DirectX10 blend shapes: breaking the limit
In: (Editor: H. Nguyen)
GPU Gems 3
(2007
)
Addison Wesley
,
Boston, MA
, pp.
53
–
67
.
[7]
G. Borshukov, J. Montgomery, J. Hable, K. Akeley (Eds.), Playable universal capture
In: (Editor: H. Nguyen)
GPU Gems 3
(2007
)
Addison Wesley
,
Boston, MA
, pp.
349
–
371
.
[8]
E. D’eon, D. Luebke, E. Enderton,
Efficient rendering of human skin
,
In: (Editors: J. Kautz, S. Pattanaik)
Proceedings of Eurographics Symposium on Rendering
Grenoble, France
. (2007
), pp.
147
–
157
.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.