
8
Memory and I/O Systems

8.1 Introduction
A computer’s ability to solve problems is influenced by its memory system and the input/output (I/O) devices – such as monitors, keyboards, and printers – that allow us to manipulate and view the results of its computations. This chapter investigates these practical memory and I/O systems.
Computer system performance depends on the memory system as well as the processor microarchitecture. Chapter 7 assumed an ideal memory system that could be accessed in a single clock cycle. However, this would be true only for a very small memory—or a very slow processor! Early processors were relatively slow, so memory was able to keep up. But processor speed has increased at a faster rate than memory speeds. DRAM memories are currently 10 to 100 times slower than processors. The increasing gap between processor and DRAM memory speeds demands increasingly ingenious memory systems to try to approximate a memory that is as fast as the processor. The first half of this chapter investigates memory systems and considers trade-offs of speed, capacity, and cost.
The processor communicates with the memory system over a memory interface. Figure 8.1 shows the simple memory interface used in our multicycle MIPS processor. The processor sends an address over the Address bus to the memory system. For a read, MemWrite is 0 and the memory returns the data on the ReadData bus. For a write, MemWrite is 1 and the processor sends data to memory on the WriteData bus.
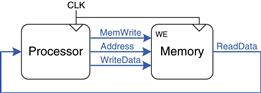
Figure 8.1 The memory interface
The major issues in memory system design can be broadly explained using a metaphor of books in a library. A library contains many books on the shelves. If you were writing a term paper on the meaning of dreams, you might go to the library1 and pull Freud’s The Interpretation of Dreams off the shelf and bring it to your cubicle. After skimming it, you might put it back and pull out Jung’s The Psychology of the Unconscious. You might then go back for another quote from Interpretation of Dreams, followed by yet another trip to the stacks for Freud’s The Ego and the Id. Pretty soon you would get tired of walking from your cubicle to the stacks. If you are clever, you would save time by keeping the books in your cubicle rather than schlepping them back and forth. Furthermore, when you pull a book by Freud, you could also pull several of his other books from the same shelf.
This metaphor emphasizes the principle, introduced in Section 6.2.1, of making the common case fast. By keeping books that you have recently used or might likely use in the future at your cubicle, you reduce the number of time-consuming trips to the stacks. In particular, you use the principles of temporal and spatial locality. Temporal locality means that if you have used a book recently, you are likely to use it again soon. Spatial locality means that when you use one particular book, you are likely to be interested in other books on the same shelf.
The library itself makes the common case fast by using these principles of locality. The library has neither the shelf space nor the budget to accommodate all of the books in the world. Instead, it keeps some of the lesser-used books in deep storage in the basement. Also, it may have an interlibrary loan agreement with nearby libraries so that it can offer more books than it physically carries.
In summary, you obtain the benefits of both a large collection and quick access to the most commonly used books through a hierarchy of storage. The most commonly used books are in your cubicle. A larger collection is on the shelves. And an even larger collection is available, with advanced notice, from the basement and other libraries. Similarly, memory systems use a hierarchy of storage to quickly access the most commonly used data while still having the capacity to store large amounts of data.

Memory subsystems used to build this hierarchy were introduced in Section 5.5. Computer memories are primarily built from dynamic RAM (DRAM) and static RAM (SRAM). Ideally, the computer memory system is fast, large, and cheap. In practice, a single memory only has two of these three attributes; it is either slow, small, or expensive. But computer systems can approximate the ideal by combining a fast small cheap memory and a slow large cheap memory. The fast memory stores the most commonly used data and instructions, so on average the memory system appears fast. The large memory stores the remainder of the data and instructions, so the overall capacity is large. The combination of two cheap memories is much less expensive than a single large fast memory. These principles extend to using an entire hierarchy of memories of increasing capacity and decreasing speed.
Computer memory is generally built from DRAM chips. In 2012, a typical PC had a main memory consisting of 4 to 8 GB of DRAM, and DRAM cost about $10 per gigabyte (GB). DRAM prices have declined at about 25% per year for the last three decades, and memory capacity has grown at the same rate, so the total cost of the memory in a PC has remained roughly constant. Unfortunately, DRAM speed has improved by only about 7% per year, whereas processor performance has improved at a rate of 25 to 50% per year, as shown in Figure 8.2. The plot shows memory (DRAM) and processor speeds with the 1980 speeds as a baseline. In about 1980, processor and memory speeds were the same. But performance has diverged since then, with memories badly lagging.2
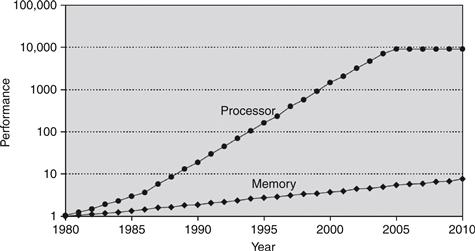
Figure 8.2 Diverging processor and memory performance
Adapted with permission from Hennessy and Patterson, Computer Architecture: A Quantitative Approach, 5th ed., Morgan Kaufmann, 2012.
DRAM could keep up with processors in the 1970s and early 1980’s, but it is now woefully too slow. The DRAM access time is one to two orders of magnitude longer than the processor cycle time (tens of nanoseconds, compared to less than one nanosecond).
To counteract this trend, computers store the most commonly used instructions and data in a faster but smaller memory, called a cache. The cache is usually built out of SRAM on the same chip as the processor. The cache speed is comparable to the processor speed, because SRAM is inherently faster than DRAM, and because the on-chip memory eliminates lengthy delays caused by traveling to and from a separate chip. In 2012, on-chip SRAM costs were on the order of $10,000/GB, but the cache is relatively small (kilobytes to several megabytes), so the overall cost is low. Caches can store both instructions and data, but we will refer to their contents generically as “data.”
If the processor requests data that is available in the cache, it is returned quickly. This is called a cache hit. Otherwise, the processor retrieves the data from main memory (DRAM). This is called a cache miss. If the cache hits most of the time, then the processor seldom has to wait for the slow main memory, and the average access time is low.
The third level in the memory hierarchy is the hard drive. In the same way that a library uses the basement to store books that do not fit in the stacks, computer systems use the hard drive to store data that does not fit in main memory. In 2012, a hard disk drive (HDD), built using magnetic storage, cost less than $0.10/GB and had an access time of about 10 ms. Hard disk costs have decreased at 60%/year but access times scarcely improved. Solid state drives (SSDs), built using flash memory technology, are an increasingly common alternative to HDDs. SSDs have been used by niche markets for over two decades, and they were introduced into the mainstream market in 2007. SSDs overcome some of the mechanical failures of HDDs, but they cost ten times as much at $1/GB.
The hard drive provides an illusion of more capacity than actually exists in the main memory. It is thus called virtual memory. Like books in the basement, data in virtual memory takes a long time to access. Main memory, also called physical memory, holds a subset of the virtual memory. Hence, the main memory can be viewed as a cache for the most commonly used data from the hard drive.
Figure 8.3 summarizes the memory hierarchy of the computer system discussed in the rest of this chapter. The processor first seeks data in a small but fast cache that is usually located on the same chip. If the data is not available in the cache, the processor then looks in main memory. If the data is not there either, the processor fetches the data from virtual memory on the large but slow hard disk. Figure 8.4 illustrates this capacity and speed trade-off in the memory hierarchy and lists typical costs, access times, and bandwidth in 2012 technology. As access time decreases, speed increases.
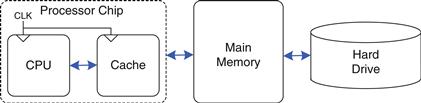
Figure 8.3 A typical memory hierarchy
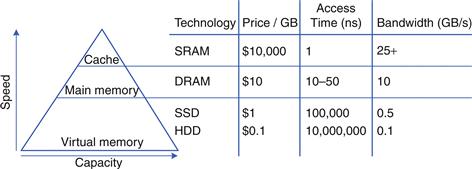
Figure 8.4 Memory hierarchy components, with typical characteristics in 2012
Section 8.2 introduces memory system performance analysis. Section 8.3 explores several cache organizations, and Section 8.4 delves into virtual memory systems. To conclude, this chapter explores how processors can access input and output devices, such as keyboards and monitors, in much the same way as they access memory. Section 8.5 investigates such memory-mapped I/O. Section 8.6 addresses I/O for embedded systems, and Section 8.7 describes major I/O standards for personal computers.
8.2 Memory System Performance Analysis
Designers (and computer buyers) need quantitative ways to measure the performance of memory systems to evaluate the cost-benefit trade-offs of various alternatives. Memory system performance metrics are miss rate or hit rate and average memory access time. Miss and hit rates are calculated as:
 (8.1)
(8.1)
Example 8.1 Calculating Cache Performance
Suppose a program has 2000 data access instructions (loads or stores), and 1250 of these requested data values are found in the cache. The other 750 data values are supplied to the processor by main memory or disk memory. What are the miss and hit rates for the cache?
Solution
The miss rate is 750/2000 = 0.375 = 37.5%. The hit rate is 1250/2000 = 0.625 = 1 − 0.375 = 62.5%.
Average memory access time (AMAT) is the average time a processor must wait for memory per load or store instruction. In the typical computer system from Figure 8.3, the processor first looks for the data in the cache. If the cache misses, the processor then looks in main memory. If the main memory misses, the processor accesses virtual memory on the hard disk. Thus, AMAT is calculated as:
![]() (8.2)
(8.2)
where tcache, tMM, and tVM are the access times of the cache, main memory, and virtual memory, and MRcache and MRMM are the cache and main memory miss rates, respectively.
Example 8.2 Calculating Average Memory Access Time
Suppose a computer system has a memory organization with only two levels of hierarchy, a cache and main memory. What is the average memory access time given the access times and miss rates in Table 8.1?
Table 8.1 Access times and miss rates
| Memory Level | Access Time (Cycles) | Miss Rate |
| Cache | 1 | 10% |
| Main Memory | 100 | 0% |
Solution
The average memory access time is 1 + 0.1(100) = 11 cycles.
Gene Amdahl, 1922–

Most famous for Amdahl’s Law, an observation he made in 1965. While in graduate school, he began designing computers in his free time. This side work earned him his Ph.D. in theoretical physics in 1952. He joined IBM immediately after graduation, and later went on to found three companies, including one called Amdahl Corporation in 1970.
Example 8.3 Improving Access Time
An 11-cycle average memory access time means that the processor spends ten cycles waiting for data for every one cycle actually using that data. What cache miss rate is needed to reduce the average memory access time to 1.5 cycles given the access times in Table 8.1?
Solution
If the miss rate is m, the average access time is 1 + 100m. Setting this time to 1.5 and solving for m requires a cache miss rate of 0.5%.
As a word of caution, performance improvements might not always be as good as they sound. For example, making the memory system ten times faster will not necessarily make a computer program run ten times as fast. If 50% of a program’s instructions are loads and stores, a tenfold memory system improvement only means a 1.82-fold improvement in program performance. This general principle is called Amdahl’s Law, which says that the effort spent on increasing the performance of a subsystem is worthwhile only if the subsystem affects a large percentage of the overall performance.
8.3 Caches
A cache holds commonly used memory data. The number of data words that it can hold is called the capacity, C. Because the capacity of the cache is smaller than that of main memory, the computer system designer must choose what subset of the main memory is kept in the cache.
When the processor attempts to access data, it first checks the cache for the data. If the cache hits, the data is available immediately. If the cache misses, the processor fetches the data from main memory and places it in the cache for future use. To accommodate the new data, the cache must replace old data. This section investigates these issues in cache design by answering the following questions: (1) What data is held in the cache? (2) How is data found? and (3) What data is replaced to make room for new data when the cache is full?
Cache: a hiding place especially for concealing and preserving provisions or implements.
– Merriam Webster Online Dictionary. 2012. www.merriam-webster.com
When reading the next sections, keep in mind that the driving force in answering these questions is the inherent spatial and temporal locality of data accesses in most applications. Caches use spatial and temporal locality to predict what data will be needed next. If a program accesses data in a random order, it would not benefit from a cache.
As we explain in the following sections, caches are specified by their capacity (C), number of sets (S), block size (b), number of blocks (B), and degree of associativity (N).
Although we focus on data cache loads, the same principles apply for fetches from an instruction cache. Data cache store operations are similar and are discussed further in Section 8.3.4.
8.3.1 What Data is Held in the Cache?
An ideal cache would anticipate all of the data needed by the processor and fetch it from main memory ahead of time so that the cache has a zero miss rate. Because it is impossible to predict the future with perfect accuracy, the cache must guess what data will be needed based on the past pattern of memory accesses. In particular, the cache exploits temporal and spatial locality to achieve a low miss rate.
Recall that temporal locality means that the processor is likely to access a piece of data again soon if it has accessed that data recently. Therefore, when the processor loads or stores data that is not in the cache, the data is copied from main memory into the cache. Subsequent requests for that data hit in the cache.
Recall that spatial locality means that, when the processor accesses a piece of data, it is also likely to access data in nearby memory locations. Therefore, when the cache fetches one word from memory, it may also fetch several adjacent words. This group of words is called a cache block or cache line. The number of words in the cache block, b, is called the block size. A cache of capacity C contains B = C/b blocks.
The principles of temporal and spatial locality have been experimentally verified in real programs. If a variable is used in a program, the same variable is likely to be used again, creating temporal locality. If an element in an array is used, other elements in the same array are also likely to be used, creating spatial locality.
8.3.2 How is Data Found?
A cache is organized into S sets, each of which holds one or more blocks of data. The relationship between the address of data in main memory and the location of that data in the cache is called the mapping. Each memory address maps to exactly one set in the cache. Some of the address bits are used to determine which cache set contains the data. If the set contains more than one block, the data may be kept in any of the blocks in the set.
Caches are categorized based on the number of blocks in a set. In a direct mapped cache, each set contains exactly one block, so the cache has S = B sets. Thus, a particular main memory address maps to a unique block in the cache. In an N-way set associative cache, each set contains N blocks. The address still maps to a unique set, with S = B/N sets. But the data from that address can go in any of the N blocks in that set. A fully associative cache has only S = 1 set. Data can go in any of the B blocks in the set. Hence, a fully associative cache is another name for a B-way set associative cache.
To illustrate these cache organizations, we will consider a MIPS memory system with 32-bit addresses and 32-bit words. The memory is byte-addressable, and each word is four bytes, so the memory consists of 230 words aligned on word boundaries. We analyze caches with an eight-word capacity (C) for the sake of simplicity. We begin with a one-word block size (b), then generalize later to larger blocks.
Direct Mapped Cache
A direct mapped cache has one block in each set, so it is organized into S = B sets. To understand the mapping of memory addresses onto cache blocks, imagine main memory as being mapped into b-word blocks, just as the cache is. An address in block 0 of main memory maps to set 0 of the cache. An address in block 1 of main memory maps to set 1 of the cache, and so forth until an address in block B − 1 of main memory maps to block B − 1 of the cache. There are no more blocks of the cache, so the mapping wraps around, such that block B of main memory maps to block 0 of the cache.
This mapping is illustrated in Figure 8.5 for a direct mapped cache with a capacity of eight words and a block size of one word. The cache has eight sets, each of which contains a one-word block. The bottom two bits of the address are always 00, because they are word aligned. The next log28 = 3 bits indicate the set onto which the memory address maps. Thus, the data at addresses 0x00000004, 0x00000024, …, 0xFFFFFFE4 all map to set 1, as shown in blue. Likewise, data at addresses 0x00000010, …, 0xFFFFFFF0 all map to set 4, and so forth. Each main memory address maps to exactly one set in the cache.
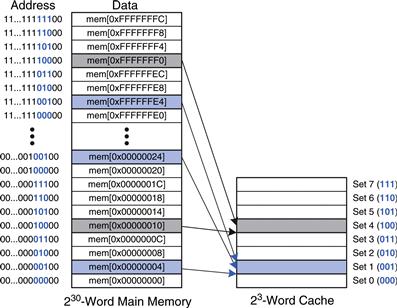
Figure 8.5 Mapping of main memory to a direct mapped cache
Example 8.4 Cache Fields
To what cache set in Figure 8.5 does the word at address 0x00000014 map? Name another address that maps to the same set.
Solution
The two least significant bits of the address are 00, because the address is word aligned. The next three bits are 101, so the word maps to set 5. Words at addresses 0x34, 0x54, 0x74, …, 0xFFFFFFF4 all map to this same set.
Because many addresses map to a single set, the cache must also keep track of the address of the data actually contained in each set. The least significant bits of the address specify which set holds the data. The remaining most significant bits are called the tag and indicate which of the many possible addresses is held in that set.
In our previous examples, the two least significant bits of the 32-bit address are called the byte offset, because they indicate the byte within the word. The next three bits are called the set bits, because they indicate the set to which the address maps. (In general, the number of set bits is log2S.) The remaining 27 tag bits indicate the memory address of the data stored in a given cache set. Figure 8.6 shows the cache fields for address 0xFFFFFFE4. It maps to set 1 and its tag is all l’s.
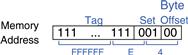
Figure 8.6 Cache fields for address 0xFFFFFFE4 when mapping to the cache in Figure 8.5
Example 8.5 Cache Fields
Find the number of set and tag bits for a direct mapped cache with 1024 (210) sets and a one-word block size. The address size is 32 bits.
Solution
A cache with 210 sets requires log2(210) = 10 set bits. The two least significant bits of the address are the byte offset, and the remaining 32 − 10 – 2 = 20 bits form the tag.
Sometimes, such as when the computer first starts up, the cache sets contain no data at all. The cache uses a valid bit for each set to indicate whether the set holds meaningful data. If the valid bit is 0, the contents are meaningless.
Figure 8.7 shows the hardware for the direct mapped cache of Figure 8.5. The cache is constructed as an eight-entry SRAM. Each entry, or set, contains one line consisting of 32 bits of data, 27 bits of tag, and 1 valid bit. The cache is accessed using the 32-bit address. The two least significant bits, the byte offset bits, are ignored for word accesses. The next three bits, the set bits, specify the entry or set in the cache. A load instruction reads the specified entry from the cache and checks the tag and valid bits. If the tag matches the most significant 27 bits of the address and the valid bit is 1, the cache hits and the data is returned to the processor. Otherwise, the cache misses and the memory system must fetch the data from main memory.
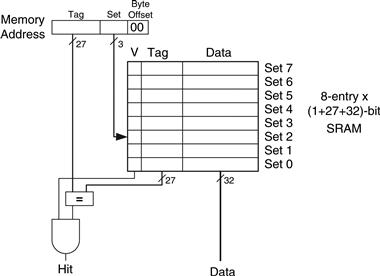
Figure 8.7 Direct mapped cache with 8 sets
Example 8.6 Temporal Locality with a Direct Mapped Cache
Loops are a common source of temporal and spatial locality in applications. Using the eight-entry cache of Figure 8.7, show the contents of the cache after executing the following silly loop in MIPS assembly code. Assume that the cache is initially empty. What is the miss rate?
addi $t0, $0, 5
loop: beq $t0, $0, done
lw $t1, 0x4($0)
lw $t2, 0xC($0)
lw $t3, 0x8($0)
addi $t0, $t0, −1
j loop
done:
Solution
The program contains a loop that repeats for five iterations. Each iteration involves three memory accesses (loads), resulting in 15 total memory accesses. The first time the loop executes, the cache is empty and the data must be fetched from main memory locations 0x4, 0xC, and 0x8 into cache sets 1, 3, and 2, respectively. However, the next four times the loop executes, the data is found in the cache. Figure 8.8 shows the contents of the cache during the last request to memory address 0x4. The tags are all 0 because the upper 27 bits of the addresses are 0. The miss rate is 3/15 = 20%.
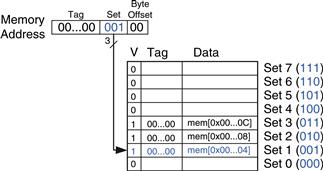
Figure 8.8 Direct mapped cache contents
When two recently accessed addresses map to the same cache block, a conflict occurs, and the most recently accessed address evicts the previous one from the block. Direct mapped caches have only one block in each set, so two addresses that map to the same set always cause a conflict. Example 8.7 on the next page illustrates conflicts.
Example 8.7 Cache Block Conflict
What is the miss rate when the following loop is executed on the eight-word direct mapped cache from Figure 8.7? Assume that the cache is initially empty.
addi $t0, $0, 5
loop: beq $t0, $0, done
lw $t1, 0x4($0)
lw $t2, 0x24($0)
addi $t0, $t0, –1
j loop
done:
Solution
Memory addresses 0x4 and 0x24 both map to set 1. During the initial execution of the loop, data at address 0x4 is loaded into set 1 of the cache. Then data at address 0x24 is loaded into set 1, evicting the data from address 0x4. Upon the second execution of the loop, the pattern repeats and the cache must refetch data at address 0x4, evicting data from address 0x24. The two addresses conflict, and the miss rate is 100%.
Multi-way Set Associative Cache
An N-way set associative cache reduces conflicts by providing N blocks in each set where data mapping to that set might be found. Each memory address still maps to a specific set, but it can map to any one of the N blocks in the set. Hence, a direct mapped cache is another name for a one-way set associative cache. N is also called the degree of associativity of the cache.
Figure 8.9 shows the hardware for a C = 8-word, N = 2-way set associative cache. The cache now has only S = 4 sets rather than 8. Thus, only log24 = 2 set bits rather than 3 are used to select the set. The tag increases from 27 to 28 bits. Each set contains two ways or degrees of associativity. Each way consists of a data block and the valid and tag bits. The cache reads blocks from both ways in the selected set and checks the tags and valid bits for a hit. If a hit occurs in one of the ways, a multiplexer selects data from that way.
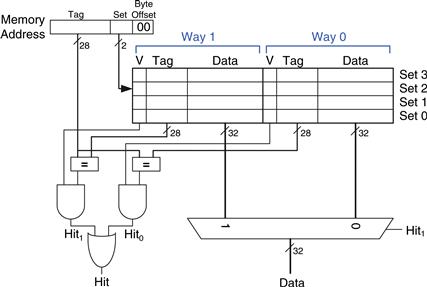
Figure 8.9 Two-way set associative cache
Set associative caches generally have lower miss rates than direct mapped caches of the same capacity, because they have fewer conflicts. However, set associative caches are usually slower and somewhat more expensive to build because of the output multiplexer and additional comparators. They also raise the question of which way to replace when both ways are full; this is addressed further in Section 8.3.3. Most commercial systems use set associative caches.
Example 8.8 Set Associative Cache Miss Rate
Repeat Example 8.7 using the eight-word two-way set associative cache from Figure 8.9.
Solution
Both memory accesses, to addresses 0x4 and 0x24, map to set 1. However, the cache has two ways, so it can accommodate data from both addresses. During the first loop iteration, the empty cache misses both addresses and loads both words of data into the two ways of set 1, as shown in Figure 8.10. On the next four iterations, the cache hits. Hence, the miss rate is 2/10 = 20%. Recall that the direct mapped cache of the same size from Example 8.7 had a miss rate of 100%.
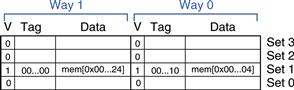
Figure 8.10 Two-way set associative cache contents
Fully Associative Cache
A fully associative cache contains a single set with B ways, where B is the number of blocks. A memory address can map to a block in any of these ways. A fully associative cache is another name for a B-way set associative cache with one set.
Figure 8.11 shows the SRAM array of a fully associative cache with eight blocks. Upon a data request, eight tag comparisons (not shown) must be made, because the data could be in any block. Similarly, an 8:1 multiplexer chooses the proper data if a hit occurs. Fully associative caches tend to have the fewest conflict misses for a given cache capacity, but they require more hardware for additional tag comparisons. They are best suited to relatively small caches because of the large number of comparators.
![]()
Figure 8.11 Eight-block fully associative cache
Block Size
The previous examples were able to take advantage only of temporal locality, because the block size was one word. To exploit spatial locality, a cache uses larger blocks to hold several consecutive words.
The advantage of a block size greater than one is that when a miss occurs and the word is fetched into the cache, the adjacent words in the block are also fetched. Therefore, subsequent accesses are more likely to hit because of spatial locality. However, a large block size means that a fixed-size cache will have fewer blocks. This may lead to more conflicts, increasing the miss rate. Moreover, it takes more time to fetch the missing cache block after a miss, because more than one data word is fetched from main memory. The time required to load the missing block into the cache is called the miss penalty. If the adjacent words in the block are not accessed later, the effort of fetching them is wasted. Nevertheless, most real programs benefit from larger block sizes.
Figure 8.12 shows the hardware for a C = 8-word direct mapped cache with a b = 4-word block size. The cache now has only B = C/b = 2 blocks. A direct mapped cache has one block in each set, so this cache is organized as two sets. Thus, only log22 = 1 bit is used to select the set. A multiplexer is now needed to select the word within the block. The multiplexer is controlled by the log24 = 2 block offset bits of the address. The most significant 27 address bits form the tag. Only one tag is needed for the entire block, because the words in the block are at consecutive addresses.

Figure 8.12 Direct mapped cache with two sets and a four-word block size
Figure 8.13 shows the cache fields for address 0x8000009C when it maps to the direct mapped cache of Figure 8.12. The byte offset bits are always 0 for word accesses. The next log2b = 2 block offset bits indicate the word within the block. And the next bit indicates the set. The remaining 27 bits are the tag. Therefore, word 0x8000009C maps to set 1, word 3 in the cache. The principle of using larger block sizes to exploit spatial locality also applies to associative caches.
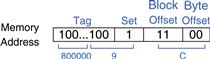
Figure 8.13 Cache fields for address 0x8000009C when mapping to the cache of Figure 8.12
Example 8.9 Spatial Locality with a Direct Mapped Cache
Repeat Example 8.6 for the eight-word direct mapped cache with a four-word block size.
Solution
Figure 8.14 shows the contents of the cache after the first memory access. On the first loop iteration, the cache misses on the access to memory address 0x4. This access loads data at addresses 0x0 through 0xC into the cache block. All subsequent accesses (as shown for address 0xC) hit in the cache. Hence, the miss rate is 1/15 = 6.67%.

Figure 8.14 Cache contents with a block size b of four words
Putting it All Together
Caches are organized as two-dimensional arrays. The rows are called sets, and the columns are called ways. Each entry in the array consists of a data block and its associated valid and tag bits. Caches are characterized by
Table 8.2 summarizes the various cache organizations. Each address in memory maps to only one set but can be stored in any of the ways.
Table 8.2 Cache organizations
| Organization | Number of Ways (N) | Number of Sets (S) |
| Direct Mapped | 1 | B |
| Set Associative | 1 < N < B | B/N |
| Fully Associative | B | 1 |
Cache capacity, associativity, set size, and block size are typically powers of 2. This makes the cache fields (tag, set, and block offset bits) subsets of the address bits.
Increasing the associativity N usually reduces the miss rate caused by conflicts. But higher associativity requires more tag comparators. Increasing the block size b takes advantage of spatial locality to reduce the miss rate. However, it decreases the number of sets in a fixed sized cache and therefore could lead to more conflicts. It also increases the miss penalty.
8.3.3 What Data is Replaced?
In a direct mapped cache, each address maps to a unique block and set. If a set is full when new data must be loaded, the block in that set is replaced with the new data. In set associative and fully associative caches, the cache must choose which block to evict when a cache set is full. The principle of temporal locality suggests that the best choice is to evict the least recently used block, because it is least likely to be used again soon. Hence, most associative caches have a least recently used (LRU) replacement policy.
In a two-way set associative cache, a use bit, U, indicates which way within a set was least recently used. Each time one of the ways is used, U is adjusted to indicate the other way. For set associative caches with more than two ways, tracking the least recently used way becomes complicated. To simplify the problem, the ways are often divided into two groups and U indicates which group of ways was least recently used. Upon replacement, the new block replaces a random block within the least recently used group. Such a policy is called pseudo-LRU and is good enough in practice.
Example 8.10 LRU Replacement
Show the contents of an eight-word two-way set associative cache after executing the following code. Assume LRU replacement, a block size of one word, and an initially empty cache.
lw $t0, 0x04($0)
lw $t1, 0x24($0)
lw $t2, 0x54($0)
Solution
The first two instructions load data from memory addresses 0x4 and 0x24 into set 1 of the cache, shown in Figure 8.15(a). U = 0 indicates that data in way 0 was the least recently used. The next memory access, to address 0x54, also maps to set 1 and replaces the least recently used data in way 0, as shown in Figure 8.15(b). The use bit U is set to 1 to indicate that data in way 1 was the least recently used.
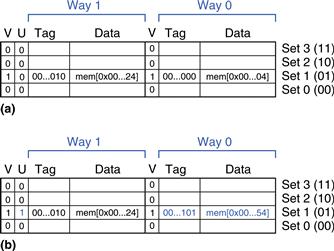
Figure 8.15 Two-way associative cache with LRU replacement
8.3.4 Advanced Cache Design*
Modern systems use multiple levels of caches to decrease memory access time. This section explores the performance of a two-level caching system and examines how block size, associativity, and cache capacity affect miss rate. The section also describes how caches handle stores, or writes, by using a write-through or write-back policy.
Multiple-Level Caches
Large caches are beneficial because they are more likely to hold data of interest and therefore have lower miss rates. However, large caches tend to be slower than small ones. Modern systems often use at least two levels of caches, as shown in Figure 8.16. The first-level (L1) cache is small enough to provide a one- or two-cycle access time. The second-level (L2) cache is also built from SRAM but is larger, and therefore slower, than the L1 cache. The processor first looks for the data in the L1 cache. If the L1 cache misses, the processor looks in the L2 cache. If the L2 cache misses, the processor fetches the data from main memory. Many modern systems add even more levels of cache to the memory hierarchy, because accessing main memory is so slow.
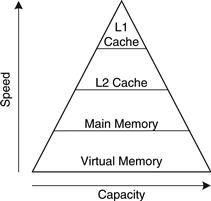
Figure 8.16 Memory hierarchy with two levels of cache
Example 8.11 System with an L2 Cache
Use the system of Figure 8.16 with access times of 1, 10, and 100 cycles for the L1 cache, L2 cache, and main memory, respectively. Assume that the L1 and L2 caches have miss rates of 5% and 20%, respectively. Specifically, of the 5% of accesses that miss the L1 cache, 20% of those also miss the L2 cache. What is the average memory access time (AMAT)?
Solution
Each memory access checks the L1 cache. When the L1 cache misses (5% of the time), the processor checks the L2 cache. When the L2 cache misses (20% of the time), the processor fetches the data from main memory. Using Equation 8.2, we calculate the average memory access time as follows: 1 cycle + 0.05[10 cycles + 0.2(100 cycles)] = 2.5 cycles
The L2 miss rate is high because it receives only the “hard” memory accesses, those that miss in the L1 cache. If all accesses went directly to the L2 cache, the L2 miss rate would be about 1%.
Reducing Miss Rate
Cache misses can be reduced by changing capacity, block size, and/or associativity. The first step to reducing the miss rate is to understand the causes of the misses. The misses can be classified as compulsory, capacity, and conflict. The first request to a cache block is called a compulsory miss, because the block must be read from memory regardless of the cache design. Capacity misses occur when the cache is too small to hold all concurrently used data. Conflict misses are caused when several addresses map to the same set and evict blocks that are still needed.
Changing cache parameters can affect one or more type of cache miss. For example, increasing cache capacity can reduce conflict and capacity misses, but it does not affect compulsory misses. On the other hand, increasing block size could reduce compulsory misses (due to spatial locality) but might actually increase conflict misses (because more addresses would map to the same set and could conflict).
Memory systems are complicated enough that the best way to evaluate their performance is by running benchmarks while varying cache parameters. Figure 8.17 plots miss rate versus cache size and degree of associativity for the SPEC2000 benchmark. This benchmark has a small number of compulsory misses, shown by the dark region near the x-axis. As expected, when cache size increases, capacity misses decrease. Increased associativity, especially for small caches, decreases the number of conflict misses shown along the top of the curve. Increasing associativity beyond four or eight ways provides only small decreases in miss rate.
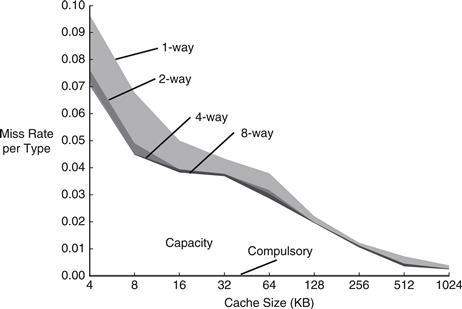
Figure 8.17 Miss rate versus cache size and associativity on SPEC2000 benchmark
Adapted with permission from Hennessy and Patterson, Computer Architecture: A Quantitative Approach, 5th ed., Morgan Kaufmann, 2012.
As mentioned, miss rate can also be decreased by using larger block sizes that take advantage of spatial locality. But as block size increases, the number of sets in a fixed-size cache decreases, increasing the probability of conflicts. Figure 8.18 plots miss rate versus block size (in number of bytes) for caches of varying capacity. For small caches, such as the 4-KB cache, increasing the block size beyond 64 bytes increases the miss rate because of conflicts. For larger caches, increasing the block size beyond 64 bytes does not change the miss rate. However, large block sizes might still increase execution time because of the larger miss penalty, the time required to fetch the missing cache block from main memory.
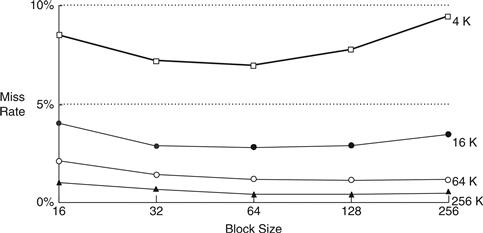
Figure 8.18 Miss rate versus block size and cache size on SPEC92 benchmark
Adapted with permission from Hennessy and Patterson, Computer Architecture: A Quantitative Approach, 5th ed., Morgan Kaufmann, 2012.
Write Policy
The previous sections focused on memory loads. Memory stores, or writes, follow a similar procedure as loads. Upon a memory store, the processor checks the cache. If the cache misses, the cache block is fetched from main memory into the cache, and then the appropriate word in the cache block is written. If the cache hits, the word is simply written to the cache block.
Caches are classified as either write-through or write-back. In a write-through cache, the data written to a cache block is simultaneously written to main memory. In a write-back cache, a dirty bit (D) is associated with each cache block. D is 1 when the cache block has been written and 0 otherwise. Dirty cache blocks are written back to main memory only when they are evicted from the cache. A write-through cache requires no dirty bit but usually requires more main memory writes than a write-back cache. Modern caches are usually write-back, because main memory access time is so large.
Example 8.12 Write-Through Versus Write-Back
Suppose a cache has a block size of four words. How many main memory accesses are required by the following code when using each write policy: write-through or write-back?
sw $t0, 0x0($0)
sw $t0, OxC($0)
sw $t0, 0x8($0)
sw $t0, 0x4($0)
Solution
All four store instructions write to the same cache block. With a write-through cache, each store instruction writes a word to main memory, requiring four main memory writes. A write-back policy requires only one main memory access, when the dirty cache block is evicted.
8.3.5 The Evolution of MIPS Caches*
Table 8.3 traces the evolution of cache organizations used by the MIPS processor from 1985 to 2010. The major trends are the introduction of multiple levels of cache, larger cache capacity, and increased associativity. These trends are driven by the growing disparity between CPU frequency and main memory speed and the decreasing cost of transistors. The growing difference between CPU and memory speeds necessitates a lower miss rate to avoid the main memory bottleneck, and the decreasing cost of transistors allows larger cache sizes.
Table 8.3 MIPS cache evolution*
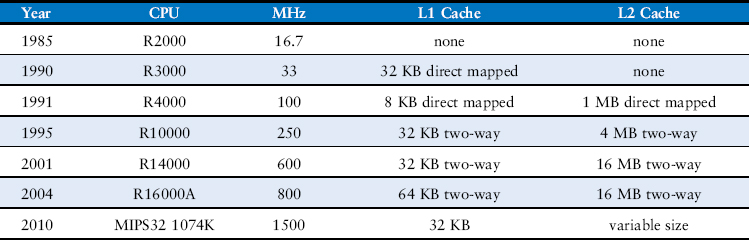
* Adapted from D. Sweetman, See MIPS Run, Morgan Kaufmann, 1999.
8.4 Virtual Memory
Most modern computer systems use a hard drive made of magnetic or solid state storage as the lowest level in the memory hierarchy (see Figure 8.4). Compared with the ideal large, fast, cheap memory, a hard drive is large and cheap but terribly slow. It provides a much larger capacity than is possible with a cost-effective main memory (DRAM). However, if a significant fraction of memory accesses involve the hard drive, performance is dismal. You may have encountered this on a PC when running too many programs at once.
Figure 8.19 shows a hard drive made of magnetic storage, also called a hard disk, with the lid of its case removed. As the name implies, the hard disk contains one or more rigid disks or platters, each of which has a read/write head on the end of a long triangular arm. The head moves to the correct location on the disk and reads or writes data magnetically as the disk rotates beneath it. The head takes several milliseconds to seek the correct location on the disk, which is fast from a human perspective but millions of times slower than the processor.

Figure 8.19 Hard disk
The objective of adding a hard drive to the memory hierarchy is to inexpensively give the illusion of a very large memory while still providing the speed of faster memory for most accesses. A computer with only 128 MB of DRAM, for example, could effectively provide 2 GB of memory using the hard drive. This larger 2-GB memory is called virtual memory, and the smaller 128-MB main memory is called physical memory. We will use the term physical memory to refer to main memory throughout this section.
A computer with 32-bit addresses can access a maximum of 232 bytes = 4 GB of memory. This is one of the motivations for moving to 64-bit computers, which can access far more memory.
Programs can access data anywhere in virtual memory, so they must use virtual addresses that specify the location in virtual memory. The physical memory holds a subset of most recently accessed virtual memory. In this way, physical memory acts as a cache for virtual memory. Thus, most accesses hit in physical memory at the speed of DRAM, yet the program enjoys the capacity of the larger virtual memory.
Virtual memory systems use different terminologies for the same caching principles discussed in Section 8.3. Table 8.4 summarizes the analogous terms. Virtual memory is divided into virtual pages, typically 4 KB in size. Physical memory is likewise divided into physical pages of the same size. A virtual page may be located in physical memory (DRAM) or on the hard drive. For example, Figure 8.20 shows a virtual memory that is larger than physical memory. The rectangles indicate pages. Some virtual pages are present in physical memory, and some are located on the hard drive. The process of determining the physical address from the virtual address is called address translation. If the processor attempts to access a virtual address that is not in physical memory, a page fault occurs, and the operating system loads the page from the hard drive into physical memory.
Table 8.4 Analogous cache and virtual memory terms
| Cache | Virtual Memory |
| Block | Page |
| Block size | Page size |
| Block offset | Page offset |
| Miss | Page fault |
| Tag | Virtual page number |
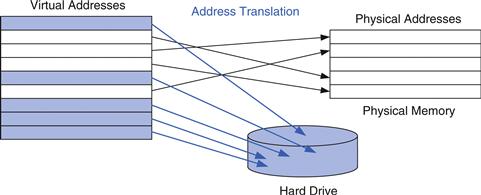
Figure 8.20 Virtual and physical pages
To avoid page faults caused by conflicts, any virtual page can map to any physical page. In other words, physical memory behaves as a fully associative cache for virtual memory. In a conventional fully associative cache, every cache block has a comparator that checks the most significant address bits against a tag to determine whether the request hits in the block. In an analogous virtual memory system, each physical page would need a comparator to check the most significant virtual address bits against a tag to determine whether the virtual page maps to that physical page.
A realistic virtual memory system has so many physical pages that providing a comparator for each page would be excessively expensive. Instead, the virtual memory system uses a page table to perform address translation. A page table contains an entry for each virtual page, indicating its location in physical memory or that it is on the hard drive. Each load or store instruction requires a page table access followed by a physical memory access. The page table access translates the virtual address used by the program to a physical address. The physical address is then used to actually read or write the data.
The page table is usually so large that it is located in physical memory. Hence, each load or store involves two physical memory accesses: a page table access, and a data access. To speed up address translation, a translation lookaside buffer (TLB) caches the most commonly used page table entries.
The remainder of this section elaborates on address translation, page tables, and TLBs.
8.4.1 Address Translation
In a system with virtual memory, programs use virtual addresses so that they can access a large memory. The computer must translate these virtual addresses to either find the address in physical memory or take a page fault and fetch the data from the hard drive.
Recall that virtual memory and physical memory are divided into pages. The most significant bits of the virtual or physical address specify the virtual or physical page number. The least significant bits specify the word within the page and are called the page offset.
Figure 8.21 illustrates the page organization of a virtual memory system with 2 GB of virtual memory and 128 MB of physical memory divided into 4-KB pages. MIPS accommodates 32-bit addresses. With a 2-GB = 231-byte virtual memory, only the least significant 31 virtual address bits are used; the 32nd bit is always 0. Similarly, with a 128-MB = 227-byte physical memory, only the least significant 27 physical address bits are used; the upper 5 bits are always 0.

Figure 8.21 Physical and virtual pages
Because the page size is 4 KB = 212 bytes, there are 231/212 = 219 virtual pages and 227/212 = 215 physical pages. Thus, the virtual and physical page numbers are 19 and 15 bits, respectively. Physical memory can only hold up to 1/16th of the virtual pages at any given time. The rest of the virtual pages are kept on the hard drive.
Figure 8.21 shows virtual page 5 mapping to physical page 1, virtual page 0x7FFFC mapping to physical page 0x7FFE, and so forth. For example, virtual address 0x53F8 (an offset of 0x3F8 within virtual page 5) maps to physical address 0x13F8 (an offset of 0x3F8 within physical page 1). The least significant 12 bits of the virtual and physical addresses are the same (0x3F8) and specify the page offset within the virtual and physical pages. Only the page number needs to be translated to obtain the physical address from the virtual address.
Figure 8.22 illustrates the translation of a virtual address to a physical address. The least significant 12 bits indicate the page offset and require no translation. The upper 19 bits of the virtual address specify the virtual page number (VPN) and are translated to a 15-bit physical page number (PPN). The next two sections describe how page tables and TLBs are used to perform this address translation.
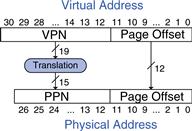
Figure 8.22 Translation from virtual address to physical address
Example 8.13 Virtual Address to Physical Address Translation
Find the physical address of virtual address 0x247C using the virtual memory system shown in Figure 8.21.
Solution
The 12-bit page offset (0x47C) requires no translation. The remaining 19 bits of the virtual address give the virtual page number, so virtual address 0x247C is found in virtual page 0x2. In Figure 8.21, virtual page 0x2 maps to physical page 0x7FFF. Thus, virtual address 0x247C maps to physical address 0x7FFF47C.
8.4.2 The Page Table
The processor uses a page table to translate virtual addresses to physical addresses. The page table contains an entry for each virtual page. This entry contains a physical page number and a valid bit. If the valid bit is 1, the virtual page maps to the physical page specified in the entry. Otherwise, the virtual page is found on the hard drive.
Because the page table is so large, it is stored in physical memory. Let us assume for now that it is stored as a contiguous array, as shown in Figure 8.23. This page table contains the mapping of the memory system of Figure 8.21. The page table is indexed with the virtual page number (VPN). For example, entry 5 specifies that virtual page 5 maps to physical page 1. Entry 6 is invalid (V = 0), so virtual page 6 is located on the hard drive.

Figure 8.23 The page table for Figure 8.21
Example 8.14 Using the Page Table to Perform Address Translation
Find the physical address of virtual address 0x247C using the page table shown in Figure 8.23.
Solution
Figure 8.24 shows the virtual address to physical address translation for virtual address 0x247C. The 12-bit page offset requires no translation. The remaining 19 bits of the virtual address are the virtual page number, 0x2, and give the index into the page table. The page table maps virtual page 0x2 to physical page 0x7FFF. So, virtual address 0x247C maps to physical address 0x7FFF47C. The least significant 12 bits are the same in both the physical and the virtual address.

Figure 8.24 Address translation using the page table
The page table can be stored anywhere in physical memory, at the discretion of the OS. The processor typically uses a dedicated register, called the page table register, to store the base address of the page table in physical memory.
To perform a load or store, the processor must first translate the virtual address to a physical address and then access the data at that physical address. The processor extracts the virtual page number from the virtual address and adds it to the page table register to find the physical address of the page table entry. The processor then reads this page table entry from physical memory to obtain the physical page number. If the entry is valid, it merges this physical page number with the page offset to create the physical address. Finally, it reads or writes data at this physical address. Because the page table is stored in physical memory, each load or store involves two physical memory accesses.
8.4.3 The Translation Lookaside Buffer
Virtual memory would have a severe performance impact if it required a page table read on every load or store, doubling the delay of loads and stores. Fortunately, page table accesses have great temporal locality. The temporal and spatial locality of data accesses and the large page size mean that many consecutive loads or stores are likely to reference the same page. Therefore, if the processor remembers the last page table entry that it read, it can probably reuse this translation without rereading the page table. In general, the processor can keep the last several page table entries in a small cache called a translation lookaside buffer (TLB). The processor “looks aside” to find the translation in the TLB before having to access the page table in physical memory. In real programs, the vast majority of accesses hit in the TLB, avoiding the time-consuming page table reads from physical memory.
A TLB is organized as a fully associative cache and typically holds 16 to 512 entries. Each TLB entry holds a virtual page number and its corresponding physical page number. The TLB is accessed using the virtual page number. If the TLB hits, it returns the corresponding physical page number. Otherwise, the processor must read the page table in physical memory. The TLB is designed to be small enough that it can be accessed in less than one cycle. Even so, TLBs typically have a hit rate of greater than 99%. The TLB decreases the number of memory accesses required for most load or store instructions from two to one.
Example 8.15 Using the TLB to Perform Address Translation
Consider the virtual memory system of Figure 8.21. Use a two-entry TLB or explain why a page table access is necessary to translate virtual addresses 0x247C and 0x5FB0 to physical addresses. Suppose the TLB currently holds valid translations of virtual pages 0x2 and 0x7FFFD.
Solution
Figure 8.25 shows the two-entry TLB with the request for virtual address 0x247C. The TLB receives the virtual page number of the incoming address, 0x2, and compares it to the virtual page number of each entry. Entry 0 matches and is valid, so the request hits. The translated physical address is the physical page number of the matching entry, 0x7FFF, concatenated with the page offset of the virtual address. As always, the page offset requires no translation.

Figure 8.25 Address translation using a two-entry TLB
The request for virtual address 0x5FB0 misses in the TLB. So, the request is forwarded to the page table for translation.
8.4.4 Memory Protection
So far, this section has focused on using virtual memory to provide a fast, inexpensive, large memory. An equally important reason to use virtual memory is to provide protection between concurrently running programs.
As you probably know, modern computers typically run several programs or processes at the same time. All of the programs are simultaneously present in physical memory. In a well-designed computer system, the programs should be protected from each other so that no program can crash or hijack another program. Specifically, no program should be able to access another program’s memory without permission. This is called memory protection.
Virtual memory systems provide memory protection by giving each program its own virtual address space. Each program can use as much memory as it wants in that virtual address space, but only a portion of the virtual address space is in physical memory at any given time. Each program can use its entire virtual address space without having to worry about where other programs are physically located. However, a program can access only those physical pages that are mapped in its page table. In this way, a program cannot accidentally or maliciously access another program’s physical pages, because they are not mapped in its page table. In some cases, multiple programs access common instructions or data. The operating system adds control bits to each page table entry to determine which programs, if any, can write to the shared physical pages.
8.4.5 Replacement Policies*
Virtual memory systems use write-back and an approximate least recently used (LRU) replacement policy. A write-through policy, where each write to physical memory initiates a write to the hard drive, would be impractical. Store instructions would operate at the speed of the hard drive instead of the speed of the processor (milliseconds instead of nanoseconds). Under the writeback policy, the physical page is written back to the hard drive only when it is evicted from physical memory. Writing the physical page back to the hard drive and reloading it with a different virtual page is called paging, and the hard drive in a virtual memory system is sometimes called swap space. The processor pages out one of the least recently used physical pages when a page fault occurs, then replaces that page with the missing virtual page. To support these replacement policies, each page table entry contains two additional status bits: a dirty bit D and a use bit U.
The dirty bit is 1 if any store instructions have changed the physical page since it was read from the hard drive. When a physical page is paged out, it needs to be written back to the hard drive only if its dirty bit is 1; otherwise, the hard drive already holds an exact copy of the page.
The use bit is 1 if the physical page has been accessed recently. As in a cache system, exact LRU replacement would be impractically complicated. Instead, the OS approximates LRU replacement by periodically resetting all the use bits in the page table. When a page is accessed, its use bit is set to 1. Upon a page fault, the OS finds a page with U = 0 to page out of physical memory. Thus, it does not necessarily replace the least recently used page, just one of the least recently used pages.
8.4.6 Multilevel Page Tables*
Page tables can occupy a large amount of physical memory. For example, the page table from the previous sections for a 2 GB virtual memory with 4 KB pages would need 219 entries. If each entry is 4 bytes, the page table is 219 × 22 bytes = 221 bytes = 2 MB.
To conserve physical memory, page tables can be broken up into multiple (usually two) levels. The first-level page table is always kept in physical memory. It indicates where small second-level page tables are stored in virtual memory. The second-level page tables each contain the actual translations for a range of virtual pages. If a particular range of translations is not actively used, the corresponding second-level page table can be paged out to the hard drive so it does not waste physical memory.
In a two-level page table, the virtual page number is split into two parts: the page table number and the page table offset, as shown in Figure 8.26. The page table number indexes the first-level page table, which must reside in physical memory. The first-level page table entry gives the base address of the second-level page table or indicates that it must be fetched from the hard drive when V is 0. The page table offset indexes the second-level page table. The remaining 12 bits of the virtual address are the page offset, as before, for a page size of 212 = 4 KB.
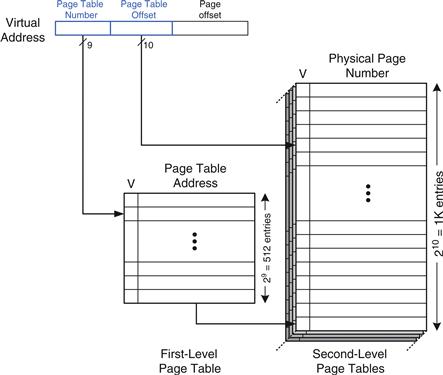
Figure 8.26 Hierarchical page tables
In Figure 8.26 the 19-bit virtual page number is broken into 9 and 10 bits, to indicate the page table number and the page table offset, respectively. Thus, the first-level page table has 29 = 512 entries. Each of these 512 second-level page tables has 210 = 1 K entries. If each of the first- and second-level page table entries is 32 bits (4 bytes) and only two second-level page tables are present in physical memory at once, the hierarchical page table uses only (512 × 4 bytes) + 2 × (1 K × 4 bytes) = 10 KB of physical memory. The two-level page table requires a fraction of the physical memory needed to store the entire page table (2 MB). The drawback of a two-level page table is that it adds yet another memory access for translation when the TLB misses.
Example 8.16 Using a Multilevel Page Table for Address Translation
Figure 8.27 shows the possible contents of the two-level page table from Figure 8.26. The contents of only one second-level page table are shown. Using this two-level page table, describe what happens on an access to virtual address 0x003FEFB0.
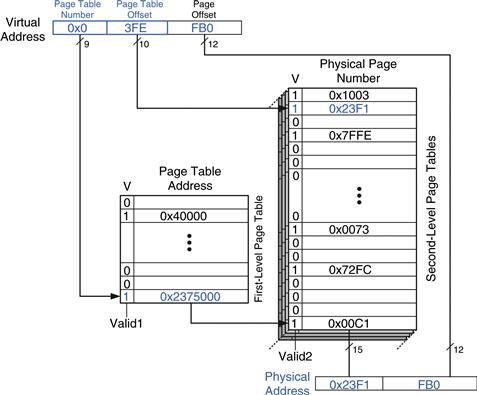
Figure 8.27 Address translation using a two-level page table
Solution
As always, only the virtual page number requires translation. The most significant nine bits of the virtual address, 0x0, give the page table number, the index into the first-level page table. The first-level page table at entry 0x0 indicates that the second-level page table is resident in memory (V = 1) and its physical address is 0x2375000.
The next ten bits of the virtual address, 0x3FE, are the page table offset, which gives the index into the second-level page table. Entry 0 is at the bottom of the second-level page table, and entry 0x3FF is at the top. Entry 0x3FE in the second-level page table indicates that the virtual page is resident in physical memory (V = 1) and that the physical page number is 0x23F1. The physical page number is concatenated with the page offset to form the physical address, 0x23F1FB0.
8.5 I/O Introduction
Input/Output (I/O) systems are used to connect a computer with external devices called peripherals. In a personal computer, the devices typically include keyboards, monitors, printers, and wireless networks. In embedded systems, devices could include a toaster’s heating element, a doll’s speech synthesizer, an engine’s fuel injector, a satellite’s solar panel positioning motors, and so forth. A processor accesses an I/O device using the address and data busses in the same way that it accesses memory.
Embedded systems are special-purpose computers that control some physical device. They typically consist of a microcontroller or digital signal processor connected to one or more hardware I/O devices. For example, a microwave oven may have a simple microcontroller to read the buttons, run the clock and timer, and turn the magnetron on and off at the appropriate times. Contrast embedded systems with general-purpose computers, such as PCs, which run multiple programs and typically interact more with the user than with a physical device. Systems such as smart phones blur the lines between embedded and general-purpose computing.
A portion of the address space is dedicated to I/O devices rather than memory. For example, suppose that addresses in the range 0xFFFF0000 to 0xFFFFFFFF are used for I/O. Recall from Section 6.6.1 that these addresses are in a reserved portion of the memory map. Each I/O device is assigned one or more memory addresses in this range. A store to the specified address sends data to the device. A load receives data from the device. This method of communicating with I/O devices is called memory-mapped I/O.
In a system with memory-mapped I/O, a load or store may access either memory or an I/O device. Figure 8.28 shows the hardware needed to support two memory-mapped I/O devices. An address decoder determines which device communicates with the processor. It uses the Address and MemWrite signals to generate control signals for the rest of the hardware. The ReadData multiplexer selects between memory and the various I/O devices. Write-enabled registers hold the values written to the I/O devices.
Some architectures, notably x86, use specialized instructions instead of memory-mapped I/O to communicate with I/O devices. These instructions are of the following form, where device1 and device2 are the unique ID of the peripheral device:
lwio $t0, device1
swio $t0, device2
This type of communication with I/O devices is called programmed I/O.
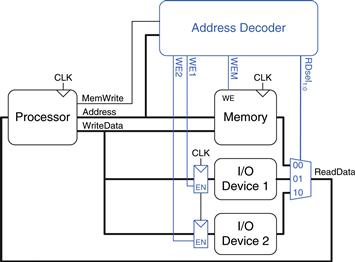
Figure 8.28 Support hardware for memory-mapped I/O
Example 8.17 Communicating with I/O Devices
Suppose I/O Device 1 in Figure 8.28 is assigned the memory address 0xFFFFFFF4. Show the MIPS assembly code for writing the value 7 to I/O Device 1 and for reading the output value from I/O Device 1.
Solution
The following MIPS assembly code writes the value 7 to I/O Device 1.
addi $t0, $0, 7
sw $t0, 0xFFF4($0) # FFF4 is sign-extended to 0xFFFFFFF4
The address decoder asserts WE1 because the address is 0xFFFFFFF4 and MemWrite is TRUE. The value on the WriteData bus, 7, is written into the register connected to the input pins of I/O Device 1.
To read from I/O Device 1, the processor performs the following MIPS assembly code.
lw $t1, 0xFFF4($0)
The address decoder sets RDsel1:0 to 01, because it detects the address 0xFFFFFFF4 and MemWrite is FALSE. The output of I/O Device 1 passes through the multiplexer onto the ReadData bus and is loaded into $t1 in the processor.
Software that communicates with an I/O device is called a device driver. You have probably downloaded or installed device drivers for your printer or other I/O device. Writing a device driver requires detailed knowledge about the I/O device hardware. Other programs call functions in the device driver to access the device without having to understand the low-level device hardware.
The addresses associated with I/O devices are often called I/O registers because they may correspond with physical registers in the I/O device like those shown in Figure 8.28.
The next sections of this chapter provide concrete examples of I/O devices. Section 8.6 examines I/O in the context of embedded systems, showing how to use a MIPS-based microcontroller to control many physical devices. Section 8.7 surveys the major I/O systems used in PCs.
8.6 Embedded I/O Systems
Embedded systems use a processor to control interactions with the physical environment. They are typically built around microcontroller units (MCUs) which combine a microprocessor with a set of easy-to-use peripherals such as general-purpose digital and analog I/O pins, serial ports, timers, etc. Microcontrollers are generally inexpensive and are designed to minimize system cost and size by integrating most of the necessary components onto a single chip. Most are smaller and lighter than a dime, consume milliwatts of power, and range in cost from a few dimes up to several dollars. Microcontrollers are classified by the size of data that they operate upon. 8-bit microcontrollers are the smallest and least expensive, while 32-bit microcontrollers provide more memory and higher performance.
For the sake of concreteness, this section will illustrate embedded system I/O in the context of a commercial microcontroller. Specifically, we will focus on the PIC32MX675F512H, a member of Microchip’s PIC32-series of microcontrollers based on the 32-bit MIPS microprocessor. The PIC32 family also has a generous assortment of on-chip peripherals and memory so that the complete system can be built with few external components. We selected this family because it has an inexpensive, easy-to-use development environment, it is based on the MIPS architecture studied in this book, and because Microchip is a leading microcontroller vendor that sells more than a billion chips a year. Microcontroller I/O systems are quite similar from one manufacturer to another, so the principles illustrated on the PIC32 can readily be adapted to other microcontrollers.
Approximately $16B of microcontrollers were sold in 2011, and the market continues to grow by about 10% a year. Microcontrollers have become ubiquitous and nearly invisible, with an estimated 150 in each home and 50 in each automobile in 2010. The 8051 is a classic 8-bit microcontroller originally developed by Intel in 1980 and now sold by a host of manufacturers. Microchip’s PIC16 and PIC18-series are 8-bit market leaders. The Atmel AVR series of microcontrollers has been popularized among hobbyists as the brain of the Arduino platform. Among 32-bit microcontrollers, Renesas leads the overall market, while ARM is a major player in mobile systems including the iPhone. Freescale, Samsung, Texas Instruments, and Infineon are other major microcontroller manufacturers.
The rest of this section will illustrate how microcontrollers perform general-purpose digital, analog, and serial I/O. Timers are also commonly used to generate or measure precise time intervals. The section concludes with other interesting peripherals such as displays, motors, and wireless links.
8.6.1 PIC32MX675F512H Microcontroller
Figure 8.29 shows a block diagram of a PIC32-series microcontroller. At the heart of the system is the 32-bit MIPS processor. The processor connects via 32-bit busses to Flash memory containing the program and SRAM containing data. The PIC32MX675F512H has 512 KB of Flash and 64 KB of RAM; other flavors with 16 to 512 KB of FLASH and 4 to 128 KB of RAM are available at various price points. High performance peripherals such as USB and Ethernet also communicate directly with the RAM through a bus matrix. Lower performance peripherals including serial ports, timers, and A/D converters share a separate peripheral bus. The chip also contains timing generation circuitry to produce the clocks and voltage sensing circuitry to detect when the chip is powering up or about to lose power.

Figure 8.29 PIC32MX675F512H block diagram
© 2012 Microchip Technology Inc.; reprinted with permission.
Figure 8.30 shows the virtual memory map of the microcontroller. All addresses used by the programmer are virtual. The MIPS architecture offers a 32-bit address space to access up to 232 bytes = 4 GB of memory, but only a small fraction of that memory is actually implemented on the chip. The relevant sections from address 0xA0000000-0xBFC02FFF include the RAM, the Flash, and the special function registers (SFRs) used to communicate with peripherals. Note that there is an additional 12 KB of Boot Flash that typically performs some initialization and then jumps to the main program in Flash memory. On reset, the program counter is initialized to the start of the Boot Flash at 0xBFC00000.

Figure 8.30 PIC32 memory map
© 2012 Microchip Technology Inc.; reprinted with permission.
Figure 8.31 shows the pinout of the microcontroller. Pins include power and ground, clock, reset, and many I/O pins that can be used for general-purpose I/O and/or special-purpose peripherals. Figure 8.32 shows a photograph of the microcontroller in a 64-pin Thin Quad Flat Pack (TQFP) with pins along the four sides spaced at 20 mil (0.02 inch) intervals. The microcontroller is also available in a 100-pin package with more I/O pins; that version has a part number ending with an L instead of an H.
Figure 8.31 PIC32MX6xxFxxH pinout. Black pins are 5 V-tolerant.
© 2012 Microchip Technology Inc.; reprinted with permission.

Figure 8.32 PIC32 in 64-pin TQFP package
Figure 8.33 shows the microcontroller connected in a minimal operational configuration with a power supply, an external clock, a reset switch, and a jack for a programming cable. The PIC32 and external circuitry are mounted on a printed circuit board; this board may be an actual product (e.g. a toaster controller), or a development board facilitating easy access to the chip during testing.
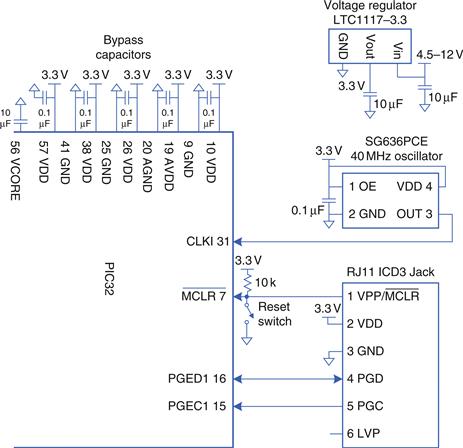
Figure 8.33 PIC32 basic operational schematic
The LTC1117-3.3 regulator accepts an input of 4.5-12 V (e.g., from a wall transformer, battery, or external power supply) and drops it down to a steady 3.3 V required at the power supply pins. The PIC32 has multiple VDD and GND pins to reduce power supply noise by providing a low-impedance path. An assortment of bypass capacitors provide a reservoir of charge to keep the power supply stable in the event of sudden changes in current demand. A bypass capacitor also connects to the VCORE pin, which serves an internal 1.8 V voltage regulator. The PIC32 typically draws 1–2 mA/MHz of current from the power supply. For example, at 80 MHz, the maximum power dissipation is P = VI = (3.3 V)(120 mA) = 0.396 W. The 64-pin TQFP has a thermal resistance of 47°C/W, so the chip may heat up by about 19°C if operated without a heat sink or cooling fan.
An external oscillator running up to 50 MHz can be connected to the clock pin. In this example circuit, the oscillator is running at 40.000 MHz. Alternatively, the microcontroller can be programmed to use an internal oscillator running at 8.00 MHz ± 2%. This is much less precise in frequency, but may be good enough. The peripheral bus clock, PBCLK, for the I/O devices (such as serial ports, A/D converter, timers) typically runs at a fraction (e.g., half) of the speed of the main system clock SYSCLK. This clocking scheme can be set by configuration bits in the MPLAB development software or by placing the following lines of code at the start of your C program.
#pragma config FPBDIV = DIV_2 // peripherals operate at half
// sysckfreq (20 MHz)
#pragma config POSCMOD = EC // configure primary oscillator in
// external clock mode
#pragma config FNOSC = PRI // select the primary oscillator
The peripheral bus clock PBCLK can be configured to operate at the same speed as the main system clock, or at half, a quarter, or an eighth of the speed. Early PIC32 microcontrollers were limited to a maximum of half-speed operation because some peripherals were too slow, but most current products can run at full speed. If you change the PBCLK speed, you’ll need to adjust parts of the sample code in this section such as the number of PBCLK ticks to measure a certain amount of time.
It is always handy to provide a reset button to put the chip into a known initial state of operation. The reset circuitry consists of a push-button switch and a resistor connected to the reset pin, ![]() . The reset pin is active-low, indicating that the processor resets if the pin is at 0. When the button is not pressed, the switch is open and the resistor pulls the reset pin to 1, allowing normal operation. When the button is pressed, the switch closes and pulls the reset pin down to 0, forcing the processor to reset. The PIC32 also resets itself automatically when power is turned on.
. The reset pin is active-low, indicating that the processor resets if the pin is at 0. When the button is not pressed, the switch is open and the resistor pulls the reset pin to 1, allowing normal operation. When the button is pressed, the switch closes and pulls the reset pin down to 0, forcing the processor to reset. The PIC32 also resets itself automatically when power is turned on.
The easiest way to program the microcontroller is with a Microchip In Circuit Debugger (ICD) 3, affectionately known as a puck. The ICD3, shown in Figure 8.34, allows the programmer to communicate with the PIC32 from a PC to download code and to debug the program. The ICD3 connects to a USB port on the PC and to a six-pin RJ-11 modular connector on the PIC32 development board. The RJ-11 connector is the familiar connector used in United States telephone jacks. The ICD3 communicates with the PIC32 over a 2-wire In-Circuit Serial Programming interface with a clock and a bidirectional data pin. You can use Microchip’s free MPLAB Integrated Development Environment (IDE) to write your programs in assembly language or C, debug them in simulation, and download and test them on a development board by means of the ICD.

Figure 8.34 Microchip ICD3
Most of the pins of the PIC32 microcontroller default to function as general-purpose digital I/O pins. Because the chip has a limited number of pins, these same pins are shared for special-purpose I/O functions such as serial ports, analog-to-digital converter inputs, etc., that become active when the corresponding peripheral is enabled. It is the responsibility of the programmer to use each pin for only one purpose at any given time. The remainder of Section 8.6 explores the microcontroller I/O functions in detail.
Microcontroller capabilities go far beyond what can be covered in the limited space of this chapter. See the manufacturer’s datasheet for more detail. In particular, the PIC32MX5XX/6XX/7XX Family Data Sheet and PIC32 Family Reference Manual from Microchip are authoritative and tolerably readable.
8.6.2 General-Purpose Digital I/O
General-purpose I/O (GPIO) pins are used to read or write digital signals. For example, Figure 8.35 shows eight light-emitting diodes (LEDs) and four switches connected to a 12-bit GPIO port. The schematic indicates the name and pin number of each of the port’s 12 pins; this tells the programmer the function of each pin and the hardware designer what connections to physically make. The LEDs are wired to glow when driven with a 1 and turn off when driven with a 0. The switches are wired to produce a 1 when closed and a 0 when open. The microcontroller can use the port both to drive the LEDs and to read the state of the switches.
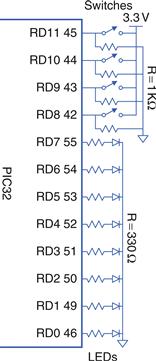
Figure 8.35 LEDs and switches connected to 12-bit GPIO port D
The PIC32 organizes groups of GPIOs into ports that are read and written together. Our PIC32 calls these ports RA, RB, RC, RD, RE, RF, and RG; they are referred to as simply port A, port B, etc. Each port may have up to 16 GPIO pins, although the PIC32 doesn’t have enough pins to provide that many signals for all of its ports.
Each port is controlled by two registers: TRISx and PORTx, where x is a letter (A-G) indicating the port of interest. The TRISx registers determine whether the pin of the port is an input or an output, while the PORTx registers indicate the value read from an input or driven to an output. The 16 least significant bits of each register correspond to the sixteen pins of the GPIO port. When a given bit of the TRISx register is 0, the pin is an output, and when it is 1, the pin is an input. It is prudent to leave unused GPIO pins as inputs (their default state) so that they are not inadvertently driven to troublesome values.
Each register is memory-mapped to a word in the Special Function Registers portion of virtual memory (0xBF80000-BF8FFFF). For example, TRISD is at address 0xBF8860C0 and PORTD is at address 0xBF8860D0. The p32xxxx.h header file declares these registers as 32-bit unsigned integers. Hence, the programmer can access them by name rather than having to look up the address.
Example 8.18 GPIO for Switches and LEDs
Write a C program to read the four switches and turn on the corresponding bottom four LEDs using the hardware in Figure 8.35.
Solution
Configure TRISD so that pins RD[7:0] are outputs and RD[11:8] are inputs. Then read the switches by examining pins RD[11:8], and write this value back to RD[3:0] to turn on the appropriate LEDs.
#include <p32xxxx.h>
int main(void) {
int switches;
TRISD = 0xFF00; // set RD[7:0] to output,
// RD[11:8] to input
while (1) {
switches = (PORTD >> 8) & 0xF; // Read and mask switches from
// RD[11:8]
PORTD = switches; // display on the LEDs
}
}
Example 8.18 writes the entire register at once. It is also possible to access individual bits. For example, the following code copies the value of the first switch to the first LED.
PORTDbits.RD0 = PORTDbits.RD8;
Each port also has corresponding SET and CLR registers that can be written with a mask indicating which bits to set or clear. For example, sets the first and third bits of PORTD and clears the fourth bit. If the bottom four bits of PORTD had been 1110, they would become 0111.
In the context of bit manipulation, “setting” means writing to 1 and “clearing” means writing to 0.
PORTDSET = 0b0101;
PORTDCLR = 0b1000;
The number of GPIO pins available depends on the size of the package. Table 8.5 summarizes which pins are available in various packages. For example, a 100-pin TQFP provides pins RA[15:14], RA[10:9], and RA[7:0] of port A. Beware that RG[3:2] are input only. Also, RB[15:0] are shared as analog input pins, and the other pins have multiple functions as well.
Table 8.5 PIC32MX5xx/6xx/7xx GPIO pins
| Port | 64-pin QFN/TQFP | 100-pin TQFP, 121-pin XBGA |
| RA | None | 15:14, 10:9, 7:0 |
| RB | 15:0 | 15:0 |
| RC | 15:12 | 15:12, 4:0 |
| RD | 11:0 | 15:0 |
| RE | 7:0 | 9:0 |
| RF | 5:3, 1:0 | 13:12, 8, 5:0 |
| RG | 9:6, 3:2 | 15:12, 9:6, 3:0 |
The logic levels are LVCMOS-compatible. Input pins expect logic levels of VIL = 0.15VDD and VIH = 0.8VDD, or 0.5 V and 2.6 V assuming VDD of 3.3V. Output pins produce VOL of 0.4 V and VOH of 2.4 V as long as the output current Iout does not exceed a paltry 7 mA.
8.6.3 Serial I/O
If a microcontroller needs to send more bits than the number of free GPIO pins, it must break the message into multiple smaller transmissions. In each step, it can send either one bit or several bits. The former is called serial I/O and the latter is called parallel I/O. Serial I/O is popular because it uses few wires and is fast enough for many applications. Indeed, it is so popular that multiple standards for serial I/O have been established and the PIC32 has dedicated hardware to easily send data via these standards. This section describes the Serial Peripheral Interface (SPI) and Universal Asynchronous Receiver/Transmitter (UART) standard protocols.
Other common serial standards include Inter-Integrated Circuit (I2C), Universal Serial Bus (USB), and Ethernet. I2C (pronounced “I squared C”) is a 2-wire interface with a clock and a bidirectional data pin; it is used in a fashion similar to SPI. USB and Ethernet are more complex, high-performance standards described in Sections 8.7.1 and 8.7.4, respectively.
Serial Peripheral Interface (SPI)
SPI (pronounced “S-P-I”) is a simple synchronous serial protocol that is easy to use and relatively fast. The physical interface consists of three pins: Serial Clock (SCK), Serial Data Out (SDO), and Serial Data In (SDI). SPI connects a master device to a slave device, as shown in Figure 8.36(a). The master produces the clock. It initiates communication by sending a series of clock pulses on SCK. If it wants to send data to the slave, it puts the data on SDO, starting with the most significant bit. The slave may simultaneously respond by putting data on the master’s SDI. Figure 8.36(b) shows the SPI waveforms for an 8-bit data transmission.
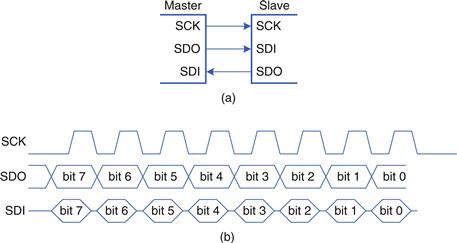
Figure 8.36 SPI connection and master waveforms
The PIC32 has up to four SPI ports unsurprisingly named SPI1-SPI4. Each can operate as a master or slave. This section describes master mode operation, but slave mode is similar. To use an SPI port, the PIC® program must first configure the port. It can then write data to a register; the data is transmitted serially to the slave. Data received from the slave is collected in another register. When the transmission is complete, the PIC32 can read the received data.
Each SPI port is associated with four 32-bit registers: SPIxCON, SPIxSTAT, SPIxBRG, and SPIxBUF. For example, SPI1CON is the control register for SPI port 1. It is used to turn the SPI ON and set attributes such as the number of bits to transfer and the polarity of the clock. Table 8.6 lists the names and functions of all the bits of the CON registers. All have a default value of 0 on reset. Most of the functions, such as framing, enhanced buffering, slave select signals, and interrupts are not used in this section but can be found in the datasheet. STAT is the status register indicating, for example, whether the receive register is full. Again, the details of this register are also fully described in the PIC32 datasheet.
Table 8.6 SPIxCON register fields
| Bits | Name | Function |
| 31 | FRMEN | 1: Enable framing |
| 30 | FRMSYNC | Frame sync pulse direction control |
| 29 | FRMPOL | Frame sync polarity (1 = active high) |
| 28 | MSSEN | 1: Enable slave select generation in master mode |
| 27 | FRMSYPW | Frame sync pulse width bit (1 = 1 word wide, 0 = 1 clock wide) |
| 26:24 | FRMCNT[2:0] | Frame sync pulse counter (frequency of sync pulses) |
| 23 | MCLKSEL | Master clock select (1 = master clock, 0 = peripheral clock) |
| 22:18 | unused | |
| 17 | SPIFE | Frame sync pulse edge select |
| 16 | ENHBUF | 1: Enable enhanced buffering |
| 15 | ON | 1: SPI ON |
| 14 | unused | |
| 13 | SIDL | 1: Stop SPI when CPU is in idle mode |
| 12 | DISSDO | 1: disable SDO pin |
| 11 | MODE32 | 1: 32-bit transfers |
| 10 | MODE16 | 1: 16-bit transfers |
| 9 | SMP | Sample phase (see Figure 8.39) |
| 8 | CKE | Clock edge (see Figure 8.39) |
| 7 | SSEN | 1: Enable slave select |
| 6 | CKP | Clock polarity (see Figure 8.39) |
| 5 | MSTEN | 1: Enable master mode |
| 4 | DISSDI | 1: disable SDI pin |
| 3:2 | STXISEL[1:0] | Transmit buffer interrupt mode |
| 1:0 | SRXISEL[1:0] | Receive buffer interrupt mode |
The serial clock can be configured to toggle at half the peripheral clock rate or less. SPI has no theoretical limit on the data rate and can readily operate at tens of MHz on a printed circuit board, though it may experience noise problems running above 1 MHz using wires on a breadboard. BRG is the baud rate register that sets the speed of SCK relative to the peripheral clock according to the formula:
![]() (8.3)
(8.3)
BUF is the data buffer. Data written to BUF is transferred over the SPI port on the SDO pin, and the received data from the SDI pin can be found by reading BUF after the transfer is complete.
To prepare the SPI in master mode, first turn it OFF by clearing bit 15 of the CON register (the ON bit) to 0. Clear anything that might be in the receive buffer by reading the BUF register. Set the desired baud rate by writing the BRG register. For example, if the peripheral clock is 20 MHz and the desired baud rate is 1.25 MHz, set BRG to [20/(2 × 1.25)] – 1 = 7. Put the SPI in master mode by setting bit 5 of the CON register (MSTEN) to 1. Set bit 8 of the CON register (CKE) so that SDO is centered on the rising edge of the clock. Finally, turn the SPI back ON by setting the ON bit of the CON register.
Baud rate gives the signaling rate, measured in symbols per second, whereas bit rate gives the data rate, measured in bits per second. The signaling we’ve discussed in this text is 2-level signaling, where each symbol represents a bit. However, multi-level signaling can send multiple bits per symbol; for example, 4-level signaling sends two bits per symbol. In that case, the bit rate is twice the baud rate. In a simple system where each symbol is a bit and each symbol represents data, the baud rate is equal to the bit rate. Some signaling conventions require overhead bits in addition to the data (see Section 8.6.3.2 on UARTs). For example, a two-level signaling system that uses two overhead bits for each 8 bits of data with a baud rate of 9600 has a bit rate of (9600 symbols/second) × (8 bits/10 symbols) = 7680 bits/second.
To send data to the slave, write the data to the BUF register. The data will be transmitted serially, and the slave will simultaneously send data back to the master. Wait until bit 11 of the STAT register (the SPIBUSY bit) becomes 0 indicating that the SPI has completed its operation. Then the data received from the slave can be read from BUF.
SPI always sends data in both directions on each transfer. If the system only needs unidirectional communication, it can ignore the unwanted data. For example, if the master only needs to send data to the slave, the byte received from the slave can be ignored. If the master only needs to receive data from the slave, it must still trigger the SPI communication by sending an arbitrary byte that the slave will ignore. It can then read the data received from the slave.
The SPI port on a PIC32 is highly configurable so that it can talk to a wide variety of serial devices. Unfortunately, this leads to the possibility of incorrectly configuring the port and getting garbled data transmissions. The relative timing of the clock and data signals are configured with three CON register bits called CKP, CKE, and SMP. By default, these bits are 0, but the timing in Figure 8.36(b) uses CKE = 1. The master changes SDO on the falling edge of SCK, so the slave should sample the value on the rising edge using a positive edge-triggered flip-flop. The master expects SDI to be stable around the rising edge of SCK, so the slave should change it on the falling edge, as shown in the timing diagram. The MODE32 and MODE16 bits of the CON register specify whether a 32- or 16-bit word should be sent; these both default to 0 indicating an 8-bit transfer.
Example 8.19 Sending and Receiving Bytes Over SPI
Design a system to communicate between a PIC® master and an FPGA slave over SPI. Sketch a schematic of the interface. Write the C code for the microcontroller to send the character ’A’ and receive a character back. Write HDL code for an SPI slave on the FPGA. How could the slave be simplified if it only needs to receive data?
Solution
Figure 8.37 shows the connection between the devices using SPI port 2. The pin numbers are obtained from the component datasheets (e.g., Figure 8.31). Notice that both the pin numbers and signal names are shown on the diagram to indicate both the physical and logical connectivity. These pins are also used by GPIO port RG[8:6]. When the SPI is enabled, these bits of port G cannot be used for GPIO.
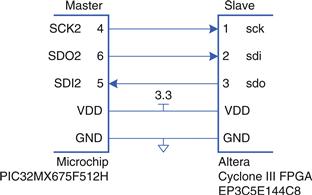
Figure 8.37 SPI connection between PIC32 and FPGA
The C code below initializes the SPI and then sends and receives a character.
#include <p32xxxx.h>
void initspi(void) {
char junk;
SPI2CONbits.ON = 0; // disable SPI to reset any previous state
junk = SPI2BUF; // read SPI buffer to clear the receive buffer
SPI2BRG = 7;
SPI2CONbits.MSTEN = 1; // enable master mode
SPI2CONbits.CKE = 1; // set clock-to-data timing
SPI2CONbits.ON = 1; // turn SPI on
}
char spi_send_receive(char send) {
SPI2BUF = send; // send data to slave
while (SPI2STATbits.SPIBUSY); // wait until SPI transmission complete
return SPI2BUF; // return received data
}
int main(void) {
char received;
initspi(); // initialize the SPI port
received = spi_send_receive(’A’); // send letter A and receive byte
// back from slave
}
The HDL code for the FPGA is listed below and a block diagram with timing is shown in Figure 8.38. The FPGA uses a shift register to hold the bits that have been received from the master and the bits that remain to be sent to the master. On the first rising sck edge after reset and each 8 cycles thereafter, a new byte from d is loaded into the shift register. On each subsequent cycle, a bit is shifted in on the FPGA’s sdi and a bit is shifted out of the FPGA’s sdo. sdo is delayed until the falling edge of sck so that it can be sampled by the master on the next rising edge. After 8 cycles, the byte received can be found in q.

Figure 8.38 SPI slave circuitry and timing
module spi_slave(input logic sck, // from master
input logic sdi, // from master
output logic sdo, // to master
input logic reset, // system reset
input logic [7:0] d, // data to send
output logic [7:0] q); // data received
logic [2:0] cnt;
logic qdelayed;
// 3-bit counter tracks when full byte is transmitted
always_ff @(negedge sck, posedge reset)
if (reset) cnt = 0;
else cnt = cnt + 3’ b1;
// loadable shift register
// loads d at the start, shifts sdi into bottom on each step
always_ff @(posedge sck)
q <= (cnt == 0) ? {d[6:0], sdi} : {q[6:0], sdi};
// align sdo to falling edge of sck
// load d at the start
always_ff @(negedge sck)
qdelayed = q[7];
assign sdo = (cnt == 0) ? d[7] : qdelayed;
endmodule
If the slave only needs to receive data from the master, it reduces to a simple shift register given in the following HDL code.
module spi_slave_receive_only(input logic sck, // from master
input logic sdi, // from master
output logic [7:0] q); // data received
always_ff @(posedge sck)
q <= {q[6:0], sdi}; // shift register
endmodule
Sometimes it is necessary to change the configuration bits to communicate with a device that expects different timing. When CKP = 1, SCK is inverted. When CKE = 0, the clocks toggle half a cycle earlier relative to the data. When SAMPLE = 1, the master samples SDI half a cycle later (and the slave should ensure it is stable at that time). These modes are shown in Figure 8.39. Be aware that different SPI products may use different names and polarities for these options; check the waveforms carefully for your device. It can also be helpful to examine SCK, SDO, and SDI on an oscilloscope if you are having communication difficulties.