
2
Mutual Exclusion
Mutual exclusion is perhaps the most prevalent form of coordination in multiprocessor programming. This chapter covers classical mutual exclusion algorithms that work by reading and writing shared memory. Although these algorithms are not used in practice, we study them because they provide an ideal introduction to the kinds of algorithmic and correctness issues that arise in every area of synchronization. The chapter also provides an impossibility proof. This proof teaches us the limitations of solutions to mutual exclusion that work by reading and writing shared memory, and will help to motivate the real-world mutual exclusion algorithms that appear in later chapters. This chapter is one of the few that contains proofs of algorithms. Though the reader should feel free to skip these proofs, it is very helpful to understand the kind of reasoning they present, because we can use the same approach to reason about the practical algorithms considered in later chapters.
2.1 Time
Reasoning about concurrent computation is mostly reasoning about time. Sometimes we want things to happen simultaneously, and sometimes we want them to happen at different times. We need to reason about complicated conditions involving how multiple time intervals can overlap, or, sometimes, how they cannot. We need a simple but unambiguous language to talk about events and durations in time. Everyday English is too ambiguous and imprecise. Instead, we introduce a simple vocabulary and notation to describe how concurrent threads behave in time.
In 1689, Isaac Newton stated “absolute, true and mathematical time, of itself and from its own nature, flows equably without relation to anything external.” We endorse his notion of time, if not his prose style. Threads share a common time (though not necessarily a common clock). A thread is a state machine, and its state transitions are called events.
Events are instantaneous: they occur at a single instant of time. It is convenient to require that events are never simultaneous: distinct events occur at distinct times. (As a practical matter, if we are unsure about the order of two events that happen very close in time, then any order will do.) A thread A produces a sequence of events a0, a1, … Threads typically contain loops, so a single program statement can produce many events. We denote the j-th occurrence of an event ai by ![]() . One event a precedes another event b, written a → b, if a occurs at an earlier time. The precedence relation “→” is a total order on events.
. One event a precedes another event b, written a → b, if a occurs at an earlier time. The precedence relation “→” is a total order on events.
Let a0 and a1 be events such that a0 → a1. An interval (a0, a1) is the duration between a0 and a1. Interval IA = (a0, a1) precedes IB = (b0, b1), written IA → IB, if a1 → b0 (that is, if the final event of IA precedes the starting event of IB). More succinctly, the → relation is a partial order on intervals. Intervals that are unrelated by → are said to be concurrent. By analogy with events, we denote the j-th execution of interval IA by ![]() .
.
2.2 Critical Sections
In an earlier chapter, we discussed the Counter class implementation shown in Fig. 2.1. We observed that this implementation is correct in a single-thread system, but misbehaves when used by two or more threads. The problem occurs if both threads read the value field at the line marked “start of danger zone,” and then both update that field at the line marked “end of danger zone.”

Figure 2.1 The Counter class.
We can avoid this problem if we transform these two lines into a critical section: a block of code that can be executed by only one thread at a time. We call this property mutual exclusion. The standard way to approach mutual exclusion is through a Lock object satisfying the interface shown in Fig. 2.2.
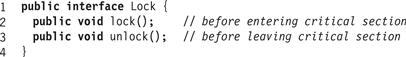
Figure 2.2 The Lock interface.
For brevity, we say a thread acquires (alternately locks) a lock when it executes a lock() method call, and releases (alternately unlocks) the lock when it executes an unlock() method call. Fig. 2.3 shows how to use a Lock field to add mutual exclusion to a shared counter implementation. Threads using the lock() and unlock() methods must follow a specific format. A thread is well formed if:
1. each critical section is associated with a unique Lock object,
2. the thread calls that object’s lock() method when it is trying to enter the critical section, and
3. the thread calls the unlock() method when it leaves the critical section.

Figure 2.3 Using a lock object.
Pragma 2.2.1
In Java, these methods should be used in the following structured way.
1 mutex.lock();
2 try {
3 … // body
4 } finally {
5 mutex.unlock();
6 }
This idiom ensures that the lock is acquired before entering the try block, and that the lock is released when control leaves the block, even if some statement in the block throws an unexpected exception.
We now formalize the properties that a good Lock algorithm should satisfy. Let ![]() be the interval during which A executes the critical section for the j-th time. Let us assume, for simplicity, that each thread repeatedly acquires and releases the lock, with other work taking place in the meantime.
be the interval during which A executes the critical section for the j-th time. Let us assume, for simplicity, that each thread repeatedly acquires and releases the lock, with other work taking place in the meantime.
Mutual Exclusion Critical sections of different threads do not overlap. For threads A and B, and integers j and k, either ![]() or
or ![]() .
.
Freedom from Deadlock If some thread attempts to acquire the lock, then some thread will succeed in acquiring the lock. If thread A calls lock() but never acquires the lock, then other threads must be completing an infinite number of critical sections.
Freedom from Starvation Every thread that attempts to acquire the lock eventually succeeds. Every call to lock() eventually returns. This property is sometimes called lockout freedom.
Note that starvation freedom implies deadlock freedom.
The mutual exclusion property is clearly essential. Without this property, we cannot guarantee that a computation’s results are correct. In the terminology of Chapter 1, mutual exclusion is a safety property. The deadlock-freedom property is important. It implies that the system never “freezes.” Individual threads may be stuck forever (called starvation), but some thread makes progress. In the terminology of Chapter 1, deadlock-freedom is a liveness property. Note that a program can still deadlock even if each of the locks it uses satisfies the deadlock-freedom property. For example, consider threads A and B that share locks ![]() 0 and
0 and ![]() 1. First, A acquires
1. First, A acquires ![]() 0 and B acquires
0 and B acquires ![]() 1. Next, A tries to acquire
1. Next, A tries to acquire ![]() 1 and B tries to acquire
1 and B tries to acquire ![]() 0. The threads deadlock because each one waits for the other to release its lock.
0. The threads deadlock because each one waits for the other to release its lock.
The starvation-freedom property, while clearly desirable, is the least compelling of the three. Later on, we will see practical mutual exclusion algorithms that fail to be starvation-free. These algorithms are typically deployed in circumstances where starvation is a theoretical possibility, but is unlikely to occur in practice. Nevertheless, the ability to reason about starvation is essential for understanding whether it is a realistic threat.
The starvation-freedom property is also weak in the sense that there is no guarantee for how long a thread waits before it enters the critical section. Later on, we will look at algorithms that place bounds on how long a thread can wait.
2.3 2-Thread Solutions
We begin with two inadequate but interesting Lock algorithms.
2.3.1 The LockOne Class
Fig. 2.4 shows the LockOne algorithm. Our 2-thread lock algorithms follow the following conventions: the threads have ids 0 and 1, the calling thread has i, and the other j = 1 − i. Each thread acquires its index by calling Thread ID.get().

Figure 2.4 The LockOne algorithm.
Pragma 2.3.1
In practice, the Boolean flag variables in Fig. 2.4, as well as the victim and label variables in later algorithms must all be declared volatile to work properly. We explain the reasons in Chapter 1 and Appendix B. We will begin declaring the appropriate variables as volatile in Chapter 7.
We use writeA (x = v) to denote the event in which A assigns value v to field x, and readA (x == v) to denote the event in which A reads v from field x. Sometimes we omit v when the value is unimportant. For example, in Fig. 2.4 the event writeA (flag[i] = true) is caused by Line 7 of the lock() method.
Lemma 2.3.1
The LockOne algorithm satisfies mutual exclusion.
Proof
Suppose not. Then there exist integers j and k such that ![]() and
and ![]() . Consider each thread’s last execution of the lock() method before entering its k-th (j-th) critical section.
. Consider each thread’s last execution of the lock() method before entering its k-th (j-th) critical section.
Inspecting the code, we see that
![]() (2.3.1)
(2.3.1)
![]() (2.3.2)
(2.3.2)
![]() (2.3.3)
(2.3.3)
Note that once flag[B] is set to true it remains true. It follows that Eq. 2.3.3 holds, since otherwise thread A could not have read flag[B] as false. Eq. 2.3.4 follows from Eqs. 2.3.1–2.3.3, and the transitivity of the precedence order.
![]() (2.3.4)
(2.3.4)
It follows that writeA (flag [A] = true) → readB (flag [A] == false) without an intervening write to the flag[] array, a contradiction.
The LockOne algorithm is inadequate because it deadlocks if thread executions are interleaved. If writeA (flag [A] = true) and writeB (flag [B] = true) events occur before readA (flag [B]) and readB (flag [A]) events, then both threads wait forever. Nevertheless, LockOne has an interesting property: if one thread runs before the other, no deadlock occurs, and all is well.
2.3.2 The LockTwo Class
Fig. 2.5 shows an alternative lock algorithm, the LockTwo class.

Figure 2.5 The LockTwo algorithm.
Lemma 2.3.2
The LockTwo algorithm satisfies mutual exclusion.
Proof
Suppose not. Then there exist integers j and k such that ![]() and
and ![]() . Consider as before each thread’s last execution of the lock() method before entering its k-th (j-th) critical section.
. Consider as before each thread’s last execution of the lock() method before entering its k-th (j-th) critical section.
Inspecting the code, we see that
![]() (2.3.5)
(2.3.5)
![]() (2.3.6)
(2.3.6)
Thread B must assign B to the victim field between events writeA (victim = A) and readA (victim = B) (see Eq. 2.3.5). Since this assignment is the last, we have
![]() (2.3.7)
(2.3.7)
Once the victim field is set to B, it does not change, so any subsequent read returns B, contradicting Eq. 2.3.6.
The LockTwo class is inadequate because it deadlocks if one thread runs completely ahead of the other. Nevertheless, LockTwo has an interesting property: if the threads run concurrently, the lock() method succeeds. The LockOne and LockTwo classes complement one another: each succeeds under conditions that cause the other to deadlock.
2.3.3 The Peterson Lock
We now combine the LockOne and LockTwo algorithms to construct a starvation-free Lock algorithm, shown in Fig. 2.6. This algorithm is arguably the most succinct and elegant two-thread mutual exclusion algorithm. It is known as “Peterson’s Algorithm,” after its inventor.

Figure 2.6 The Peterson lock algorithm.
Lemma 2.3.3
The Peterson lock algorithm satisfies mutual exclusion.
Proof
Suppose not. As before, consider the last executions of the lock() method by threads A and B. Inspecting the code, we see that
![]() (2.3.8)
(2.3.8)
![]() (2.3.9)
(2.3.9)
Assume, without loss of generality, that A was the last thread to write to the victim field.
![]() (2.3.10)
(2.3.10)
Equation 2.3.10 implies that A observed victim to be A in Eq. 2.3.8. Since A nevertheless entered its critical section, it must have observed flag[B] to be false, so we have
![]() (2.3.11)
(2.3.11)
Eqs. 2.3.9–2.3.11, together with the transitivity of →, imply Eq. 2.3.12.
![]() (2.3.12)
(2.3.12)
It follows that ![]() . This observation yields a contradiction because no other write to flag[B] was performed before the critical section executions.
. This observation yields a contradiction because no other write to flag[B] was performed before the critical section executions.
Lemma 2.3.4
The Peterson lock algorithm is starvation-free.
Proof
Suppose not. Suppose (without loss of generality) that A runs forever in the lock() method. It must be executing the while statement, waiting until either flag[B] becomes false or victim is set to B.
What is B doing while A fails to make progress? Perhaps B is repeatedly entering and leaving its critical section. If so, however, then B sets victim to B as soon as it reenters the critical section. Once victim is set to B, it does not change, and A must eventually return from the lock() method, a contradiction.
So it must be that B is also stuck in its lock() method call, waiting until either flag[A] becomes false or victim is set to A. But victim cannot be both A and B, a contradiction.
Corollary 2.3.1
The Peterson lock algorithm is deadlock-free.
2.4 The Filter Lock
We now consider two mutual exclusion protocols that work for n threads, where n is greater than 2. The first solution, the Filter lock, is a direct generalization of the Peterson lock to multiple threads. The second solution, the Bakery lock, is perhaps the simplest and best known n-thread solution.
The Filter lock, shown in Fig. 2.7, creates n − 1 “waiting rooms,” called levels, that a thread must traverse before acquiring the lock. The levels are depicted in Fig. 2.8. Levels satisfy two important properties:
![]() At least one thread trying to enter level
At least one thread trying to enter level ![]() succeeds.
succeeds.
![]() If more than one thread is trying to enter level
If more than one thread is trying to enter level ![]() , then at least one is blocked (i.e., continues to wait at that level).
, then at least one is blocked (i.e., continues to wait at that level).

Figure 2.7 The Filter lock algorithm.
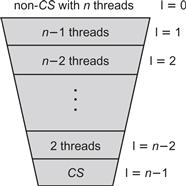
Figure 2.8 There are n − 1 levels threads pass through, the last of which is the critical section. There are at most n threads that pass concurrently into level 0, n − 1 into level 1 (a thread in level 1 is already in level 0), n − 2 into level 2 and so on, so that only one enters the critical section at level n − 1.
The Peterson lock uses a two-element boolean flag array to indicate whether a thread is trying to enter the critical section. The Filter lock generalizes this notion with an n-element integer level[] array, where the value of level[A] indicates the highest level that thread A is trying to enter. Each thread must pass through n − 1 levels of “exclusion” to enter its critical section. Each level ![]() has a distinct victim[
has a distinct victim[![]() ] field used to “filter out” one thread, excluding it from the next level.
] field used to “filter out” one thread, excluding it from the next level.
Initially a thread A is at level 0. We say that A is at level j for j > 0, when it last completes the waiting loop in Line 17 with level[A] ≥ j. (So a thread at level j is also at level j − 1, and so on.)
Lemma 2.4.1
For j between 0 and n − 1, there are at most n − j threads at level j.
Proof
By induction on j. The base case, where j = 0, is trivial. For the induction step, the induction hypothesis implies that there are at most n − j + 1 threads at level j − 1. To show that at least one thread cannot progress to level j, we argue by contradiction: assume there are n − j + 1 threads at level j.
Let A be the last thread at level j to write to victim[j]. Because A is last, for any other B at level j:
![]()
Inspecting the code, we see that B writes level[B] before it writes to victim[j], so
![]()
Inspecting the code, we see that A reads level[B] after it writes to victim[j], so
![]()
Because B is at level j, every time A reads level[B], it observes a value greater than or equal to j, implying that A could not have completed its waiting loop in Line 17, a contradiction.
Entering the critical section is equivalent to entering level n − 1.
Corollary 2.4.1
The Filter lock algorithm satisfies mutual exclusion.
Lemma 2.4.2
The Filter lock algorithm is starvation-free.
Proof
We argue by reverse induction on the levels. The base case, level n − 1, is trivial, because it contains at the most one thread. For the induction hypothesis, assume that every thread that reaches level j + 1 or higher, eventually enters (and leaves) its critical section.
Suppose A is stuck at level j. Eventually, by the induction hypothesis, there are no threads at higher levels. Once A sets level[A] to j, then any thread at level j − 1 that subsequently reads level[A] is prevented from entering level j. Eventually, no more threads enter level j from lower levels. All threads stuck at level j are in the waiting loop at Line 17, and the values of the victim and level fields no longer change.
We now argue by induction on the number of threads stuck at level j. For the base case, if A is the only thread at level j or higher, then clearly it will enter level j + 1. For the induction hypothesis, we assume that fewer than k threads cannot be stuck at level j. Suppose threads A and B are stuck at level j. A is stuck as long as it reads victim[j] = A, and B is stuck as long as it reads victim[j] = B. The victim field is unchanging, and it cannot be equal to both A and B, so one of the two threads will enter level j + 1, reducing the number of stuck threads to k − 1, contradicting the induction hypothesis.
Corollary 2.4.2
The Filter lock algorithm is deadlock-free.
2.5 Fairness
The starvation-freedom property guarantees that every thread that calls lock() eventually enters the critical section, but it makes no guarantees about how long this may take. Ideally (and very informally) if A calls lock() before B, then A should enter the critical section before B. Unfortunately, using the tools at hand we cannot determine which thread called lock() first. Instead, we split the lock() method into two sections of code (with corresponding execution intervals):
1. A doorway section, whose execution interval DA consists of a bounded number of steps, and
2. a waiting section, whose execution interval WA may take an unbounded number of steps.
The requirement that the doorway section always finish in a bounded number of steps is a strong requirement. We will call this requirement the bounded wait-free progress property. We discuss systematic ways of providing this property in later chapters.
Here is how we define fairness.
Definition 2.5.1
A lock is first-come-first-served if, whenever, thread A finishes its doorway before thread B starts its doorway, then A cannot be overtaken by B:
![]()
for threads A and B and integers j and k.
2.6 Lamport’s Bakery Algorithm
The Bakery lock algorithm appears in Fig. 2.9. It maintains the first-come-first-served property by using a distributed version of the number-dispensing machines often found in bakeries: each thread takes a number in the doorway, and then waits until no thread with an earlier number is trying to enter it.

Figure 2.9 The Bakery lock algorithm.
In the Bakery lock, flag[A] is a Boolean flag indicating whether A wants to enter the critical section, and label[A] is an integer that indicates the thread’s relative order when entering the bakery, for each thread A.
Each time a thread acquires a lock, it generates a new label[] in two steps. First, it reads all the other threads' labels in any order. Second, it reads all the other threads' labels one after the other (this can be done in some arbitrary order) and generates a label greater by one than the maximal label it read. We call the code from the raising of the flag (Line 13) to the writing of the new label[] (Line 14) the doorway. It establishes that thread’s order with respect to the other threads trying to acquire the lock. If two threads execute their doorways concurrently, they may read the same maximal label and pick the same new label. To break this symmetry, the algorithm uses a lexicographical ordering << on pairs of label[] and thread ids:
 (2.6.13)
(2.6.13)
In the waiting part of the Bakery algorithm (Line 15), a thread repeatedly rereads the labels one after the other in some arbitrary order until it determines that no thread with a raised flag has a lexicographically smaller label/id pair.
Since releasing a lock does not reset the label[], it is easy to see that each thread’s labels are strictly increasing. Interestingly, in both the doorway and waiting sections, threads read the labels asynchronously and in an arbitrary order, so that the set of labels seen prior to picking a new one may have never existed in memory at the same time. Nevertheless, the algorithm works.
Lemma 2.6.1
The Bakery lock algorithm is deadlock-free.
Proof
Some waiting thread A has the unique least (label[A], A) pair, and that thread never waits for another thread.
Lemma 2.6.2
The Bakery lock algorithm is first-come-first-served.
Proof
If A’s doorway precedes B’s, DA → DB, then A’s label is smaller since
![]()
so B is locked out while flag[A] is true.
Note that any algorithm that is both deadlock-free and first-come-first-served is also starvation-free.
Lemma 2.6.3
The Bakery algorithm satisfies mutual exclusion.
Proof
Suppose not. Let A and B be two threads concurrently in the critical section. Let labelingA and labelingB be the last respective sequences of acquiring new labels prior to entering the critical section. Suppose that (label[A], A) << (label [B], B). When B successfully completed the test in its waiting section, it must have read that flag[A] was false or that (label[B], B) << (label [A], A). However, for a given thread, its id is fixed and its label[] values are strictly increasing, so B must have seen that flag[A] was false. It follows that
![]()
which contradicts the assumption that (label[A], A) << (label[B], B).
2.7 Bounded Timestamps
Notice that the labels of the Bakery lock grow without bound, so in a long-lived system we may have to worry about overflow. If a thread’s label field silently rolls over from a large number to zero, then the first-come-first-served property no longer holds.
Later on, we will see constructions where counters are used to order threads, or even to produce unique identifiers. How important is the overflow problem in the real world? It is difficult to generalize. Sometimes it matters a great deal. The celebrated “Y2K” bug that captivated the media in the last years of the twentieth century is an example of a genuine overflow problem, even if the consequences were not as dire as predicted. On January 18, 2038, the Unix time_t data structure will overflow when the number of seconds since January 1, 1970 exceeds 232. No one knows whether it will matter. Sometimes, of course, counter overflow is a nonissue. Most applications that use, say, a 64-bit counter are unlikely to last long enough for roll-over to occur. (Let the grandchildren worry!)
In the Bakery lock, labels act as timestamps: they establish an order among the contending threads. Informally, we need to ensure that if one thread takes a label after another, then the latter has the larger label. Inspecting the code for the Bakery lock, we see that a thread needs two abilities:
A Java interface to such a timestamping system appears in Fig. 2.10. Since our principal application for a bounded timestamping system is to implement the doorway section of the Lock class, the timestamping system must be wait-free. It is possible to construct such a wait-free concurrent timestamping system (see the chapter notes), but the construction is long and rather technical. Instead, we focus on a simpler problem, interesting in its own right: constructing a sequential timestamping system, in which threads perform scan-and-label operations one completely after the other, that is, as if each were performed using mutual exclusion. In other words, consider only executions in which a thread can perform a scan of the other threads' labels, or a scan, and then an assignment of a new label, where each such sequence is a single atomic step. The principles underlying a concurrent and sequential timestamping systems are essentially the same, but they differ substantially in detail.

Figure 2.10 A timestamping system interface.
Think of the range of possible timestamps as nodes of a directed graph (called a precedence graph). An edge from node a to node b means that a is a later time-stamp than b. The timestamp order is irreflexive: there is no edge from any node a to itself. The order is also antisymmetric: if there is an edge from a to b, then there is no edge from b to a. Notice that we do not require that the order be transitive: there can be an edge from a to b and from b to c, without necessarily implying there is an edge from a to c.
Think of assigning a timestamp to a thread as placing that thread’s token on that timestamp’s node. A thread performs a scan by locating the other threads' tokens, and it assigns itself a new timestamp by moving its own token to a node a such that there is an edge from a to every other thread’s node.
Pragmatically, we would implement such a system as an array of single-writer multi-reader fields, where array element A represents the graph node where thread A most recently placed its token. The scan() method takes a “snapshot” of the array, and the label() method for thread A updates the A-th array element.
Fig. 2.11 illustrates the precedence graph for the unbounded timestamp system used in the Bakery lock. Not surprisingly, the graph is infinite: there is one node for each natural number, with a directed edge from node a to node b whenever a > b.
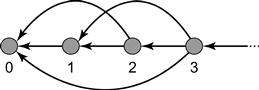
Figure 2.11 The precedence graph for an unbounded timestamping system. The nodes represent the set of all natural numbers and the edges represent the total order among them.
Consider the precedence graph T2 shown in Fig. 2.12. This graph has three nodes, labeled 0, 1, and 2, and its edges define an ordering relation on the nodes in which 0 is less than 1, 1 is less than 2, and 2 is less than 0. If there are only two threads, then we can use this graph to define a bounded (sequential) timestamping system. The system satisfies the following invariant: the two threads always have tokens located on adjacent nodes, with the direction of the edge indicating their relative order. Suppose A’s token is on Node 0, and B’s token on Node 1 (so B has the later timestamp). For B, the label() method is trivial: it already has the latest timestamp, so it does nothing. For A, the label() method “leapfrogs” B’s node by jumping from 0 to 2.
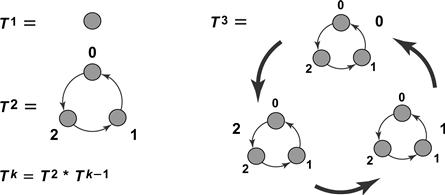
Figure 2.12 The precedence graph for a bounded timestamping system. Consider an initial situation in which there is a token A on Node 12 (Node 2 in subgraph 1) and tokens B and C on Nodes 21 and 22 (Nodes 1 and 2 in subgraph 2) respectively. Token B will move to 20 to dominate the others. Token C will then move to 21 to dominate the others, and B and C can continue to cycle in the T2 subgraph 2 forever. If A is to move to dominate B and C, it cannot pick a node in subgraph 2 since it is full (any Tk subgraph can accommodate at most k tokens). Instead, token A moves to Node 00. If B now moves, it will choose Node 01, C will choose 10 and so on.
Recall that a cycle1 in a directed graph is a set of nodes n0, n1, …, nk such that there is an edge from n0 to n1, from n1 to n2, and eventually from nk − 1 to nk, and back from nk to n0.
The only cycle in the graph T2 has length three, and there are only two threads, so the order among the threads is never ambiguous. To go beyond two threads, we need additional conceptual tools. Let G be a precedence graph, and A and B subgraphs of G (possibly single nodes). We say that A dominates B in G if every node of A has edges directed to every node of B. Let graph multiplication be the following noncommutative composition operator for graphs (denoted G ![]() H):
H):
Replace every node v of G by a copy of H (denoted Hv), and let Hv dominate Hu in G ![]() H if v dominates u in G.
H if v dominates u in G.
Define the graph Tk inductively to be:
For example, the graph T3 is illustrated in Fig. 2.12.
The precedence graph Tn is the basis for an n-thread bounded sequential timestamping system. We can “address” any node in the Tn graph with n − 1 digits, using ternary notation. For example, the nodes in graph T2 are addressed by 0, 1, and 2. The nodes in graph T3 are denoted by 00, 01, …, 22, where the high-order digit indicates one of the three subgraphs, and the low-order digit indicates one node within that subgraph.
The key to understanding the n-thread labeling algorithm is that the nodes covered by tokens can never form a cycle. As mentioned, two threads can never form a cycle on T2, because the shortest cycle in T2 requires three nodes.
How does the label() method work for three threads? When A calls label(), if both the other threads have tokens on the same T2 subgraph, then move to a node on the next highest T2 subgraph, the one whose nodes dominate that T2 subgraph. For example, consider the graph T3 as illustrated in Fig. 2.12. We assume an initial acyclic situation in which there is a token A on Node 12 (Node 2 in subgraph 1) and tokens B and C, respectively, on Nodes 21 and 22 (Nodes 1 and 2 in subgraph 2). Token B will move to 20 to dominate all others. Token C will then move to 21 to dominate all others, and B and C can continue to cycle in the T2 subgraph 2 forever. If A is to move to dominate B and C, it cannot pick a node in subgraph 2 since it is full (any Tk subgraph can accommodate at most k tokens). Token A thus moves to Node 00. If B now moves, it will choose Node 01, C will choose 10 and so on.
2.8 Lower Bounds on the Number of Locations
The Bakery lock is succinct, elegant, and fair. So why is it not considered practical? The principal drawback is the need to read and write n distinct locations, where n (which may be very large) is the maximum number of concurrent threads.
Is there a clever Lock algorithm based on reading and writing memory that avoids this overhead? We now demonstrate that the answer is no. Any deadlock-free Lock algorithm requires allocating and then reading or writing at least n distinct locations in the worst case. This result is crucially important, because it motivates us to add to our multiprocessor machines, synchronization operations stronger than read-write, and use them as the basis of our mutual exclusion algorithms.
In this section, we observe why this linear bound is inherent before we discuss practical mutual exclusion algorithms in later chapters. We will observe the following important limitation of memory locations accessed solely by read or write instructions (in practice these are called loads and stores): any information written by a thread to a given location could be overwritten (stored-to) without any other thread ever seeing it.
Our proof requires us to argue about the state of all memory used by a given multithreaded program. An object’s state is just the state of its fields. A thread’s local state is the state of its program counters and local variables. A global state or system state is the state of all objects, plus the local states of the threads.
Definition 2.8.1
A Lock object state s is inconsistent in any global state where some thread is in the critical section, but the lock state is compatible with a global state in which no thread is in the critical section or is trying to enter the critical section.
Lemma 2.8.1
No deadlock-free Lock algorithm can enter an inconsistent state.
Proof
Suppose the Lock object is in an inconsistent state s, where some thread A is in the critical section. If thread B tries to enter the critical section, it must eventually succeed because the algorithm is deadlock-free and B cannot determine that A is in the critical section, a contradiction.
Any Lock algorithm that solves deadlock-free mutual exclusion must have n distinct locations. Here, we consider only the 3-thread case, showing that a deadlock-free Lock algorithm accessed by three threads must use three distinct locations.
Definition 2.8.2
A covering state for a Lock object is one in which there is at least one thread about to write to each shared location, but the Lock object’s locations “look” like the critical section is empty (i.e., the locations' states appear as if there is no thread either in the critical section or trying to enter the critical section).
In a covering state, we say that each thread covers the location it is about to write.
Theorem 2.8.1
Any Lock algorithm that, by reading and writing memory, solves deadlock-free mutual exclusion for three threads, must use at least three distinct memory locations.
Proof
Assume by way of contradiction that we have a deadlock-free Lock algorithm for three threads with only two locations. Initially, in state s, no thread is in the critical section or trying to enter. If we run any thread by itself, then it must write to at least one location before entering the critical section, as otherwise it creates an inconsistent state.
It follows that every thread must write at least one location before entering. If the shared locations are single-writer locations as in the Bakery lock, then it is immediate that three distinct locations are needed.
Now consider multiwriter locations such as the victim location in Peterson’s algorithm (Fig. 2.6). Lets assume that we can bring the system to a covering Lock state s where A and B respectively cover distinct locations. Consider this possible execution starting from state s as depicted in Fig. 2.13:
Let C run alone. Because the Lock algorithm satisfies the deadlock-free property, C enters the critical section eventually. Then let A and B respectively update their covered locations, leaving the Lock object in state s′.
The state s′ is inconsistent because no thread can tell whether C is in the critical section, so a lock with two locations is impossible.
It remains to be shown how to maneuver threads A and B into a covering state. Consider an execution in which B runs through the critical section three times. Each time around, it must write some location, so consider the first location it writes when trying to enter the critical section. Since there are only two locations, B must “write first” to the same location twice. Call that location LB.
Let B run until it is poised to write location LB for the first time. If A runs now, it would enter the critical section, since B has not written anything. A must write LA before entering the critical section. Otherwise, if A writes only LB, then let A enter the critical section, let B write to LB(obliterating A’s last write). The result is an inconsistent state: B cannot tell whether A is in the critical section.
Let A run until it is poised to write LA. This state is not a covering state, because A could have written something to LB indicating to thread C that it is trying to enter the critical section. Let B run, obliterating any value A might have written to LB, entering and leaving the critical section at most three times, and halting just before its second write to LB. Notice that every time B enters and leaves the critical section, whatever it wrote to the locations is no longer relevant.
In this state, A is about to write LA, B is about to write LB, and the locations are consistent with no thread trying to enter or in the critical section, as required in a covering state. Fig. 2.14 illustrates this scenario.
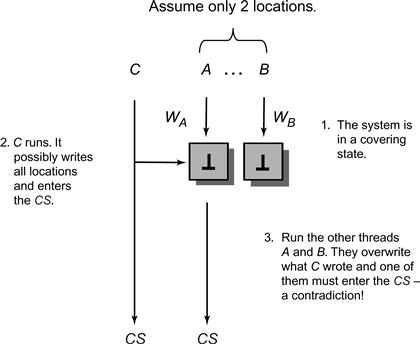
Figure 2.13 Contradiction using a covering state for two locations. Initially both locations have the empty value ⊥.
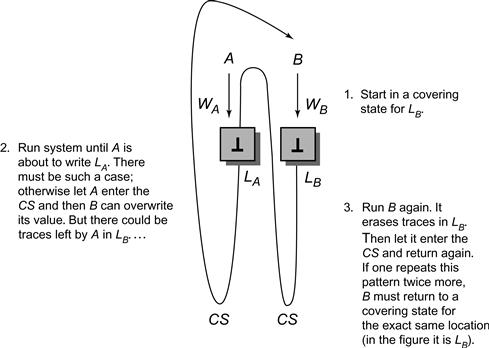
Figure 2.14 Reaching a covering state. In the initial covering state for LB both locations have the empty value ⊥.
The same line of argument can be extended to show that n-thread deadlock-free mutual exclusion requires n distinct locations. The Peterson and Bakery locks are thus optimal (within a constant factor). However, as we note, the need to allocate n locations per Lock makes them impractical.
This proof shows the inherent limitation of read and write operations: information written by a thread may be overwritten without any other thread ever reading it. We will remember this limitation when we move on to design other algorithms.
In later chapters, we will see that modern machine architectures provide specialized instructions that overcome the “overwriting” limitation of read and write instructions, allowing n-thread Lock implementations that use only a constant number of memory locations. We will also see that making effective use of these instructions to solve mutual exclusion is far from trivial.
2.9 Chapter Notes
Isaac Newton’s ideas about the flow of time appear in his famous Principia [121]. The “→” formalism is due to Leslie Lamport [89]. The first three algorithms in this chapter are due to Gary Peterson, who published them in a two-page paper in 1981 [124]. The Bakery lock presented here is a simplification of the original Bakery Algorithm due to Leslie Lamport [88]. The sequential time-stamp algorithm is due to Amos Israeli and Ming Li [77], who invented the notion of a bounded timestamping system. Danny Dolev and Nir Shavit [34] invented the first bounded concurrent timestamping system. Other bounded timestamping schemes include Sibsankar Haldar and Paul Vitányi [51], and Cynthia Dwork and Orli Waarts [37]. The lower bound on the number of lock fields is due to Jim Burns and Nancy Lynch [23]. Their proof technique, called a covering argument, has since been widely used to prove lower bounds in distributed computing. Readers interested in further reading can find a historical survey of mutual exclusion algorithms in a classic book by Michel Raynal [131].
Exercise 9. Define r-bounded waiting for a given mutual exclusion algorithm to mean that if ![]() then
then ![]() . Is there a way to define a doorway for the Peterson algorithm such that it provides r-bounded waiting for some value of r?
. Is there a way to define a doorway for the Peterson algorithm such that it provides r-bounded waiting for some value of r?
Exercise 10. Why do we need to define a doorway section, and why cannot we define FCFS in a mutual exclusion algorithm based on the order in which the first instruction in the lock() method was executed? Argue your answer in a case-by-case manner based on the nature of the first instruction executed by the lock(): a read or a write, to separate locations or the same location.
Exercise 11. Programmers at the Flaky Computer Corporation designed the protocol shown in Fig. 2.15 to achieve n-thread mutual exclusion. For each question, either sketch a proof, or display an execution where it fails.

Figure 2.15 The Flaky lock used in Exercise 11.
Exercise 12. Show that the Filter lock allows some threads to overtake others an arbitrary number of times.
Exercise 13. Another way to generalize the two-thread Peterson lock is to arrange a number of 2-thread Peterson locks in a binary tree. Suppose n is a power of two. Each thread is assigned a leaf lock which it shares with one other thread. Each lock treats one thread as thread 0 and the other as thread 1.
In the tree-lock’s acquire method, the thread acquires every two-thread Peterson lock from that thread’s leaf to the root. The tree-lock’s release method for the tree-lock unlocks each of the 2-thread Peterson locks that thread has acquired, from the root back to its leaf. At any time, a thread can be delayed for a finite duration. (In other words, threads can take naps, or even vacations, but they do not drop dead.) For each property, either sketch a proof that it holds, or describe a (possibly infinite) execution where it is violated.
Is there an upper bound on the number of times the tree-lock can be acquired and released between the time a thread starts acquiring the tree-lock and when it succeeds?
Exercise 14. The ![]() -exclusion problem is a variant of the starvation-free mutual exclusion problem. We make two changes: as many as
-exclusion problem is a variant of the starvation-free mutual exclusion problem. We make two changes: as many as ![]() threads may be in the critical section at the same time, and fewer than
threads may be in the critical section at the same time, and fewer than ![]() threads might fail (by halting) in the critical section.
threads might fail (by halting) in the critical section.
An implementation must satisfy the following conditions:
![]() -Exclusion: At any time, at most
-Exclusion: At any time, at most ![]() threads are in the critical section.
threads are in the critical section.
![]() -Starvation-Freedom: As long as fewer than
-Starvation-Freedom: As long as fewer than ![]() threads are in the critical section, then some thread that wants to enter the critical section will eventually succeed (even if some threads in the critical section have halted).
threads are in the critical section, then some thread that wants to enter the critical section will eventually succeed (even if some threads in the critical section have halted).
Modify the n-process Filter mutual exclusion algorithm to turn it into an ![]() -exclusion algorithm.
-exclusion algorithm.
Exercise 15. In practice, almost all lock acquisitions are uncontended, so the most practical measure of a lock’s performance is the number of steps needed for a thread to acquire a lock when no other thread is concurrently trying to acquire the lock.
Scientists at Cantaloupe-Melon University have devised the following “wrapper” for an arbitrary lock, shown in Fig. 2.16. They claim that if the base Lock class provides mutual exclusion and is starvation-free, so does the FastPath lock, but it can be acquired in a constant number of steps in the absence of contention. Sketch an argument why they are right, or give a counterexample.

Figure 2.16 Fast path mutual exclusion algorithm used in Exercise 15.
Exercise 16. Suppose n threads call the visit() method of the Bouncer class shown in Fig. 2.17. Prove that—

Figure 2.17 The Bouncer class implementation.
Note that the last two proofs are not symmetric.
Exercise 17. So far, we have assumed that all n threads have unique, small indexes. Here is one way to assign unique small indexes to threads. Arrange Bouncer objects in a triangular matrix, where each Bouncer is given an id as shown in Fig. 2.18. Each thread starts by visiting Bouncer zero. If it gets STOP, it stops. If it gets RIGHT, it visits 1, and if it gets DOWN, it visits 2. In general, if a thread gets STOP, it stops. If it gets RIGHT, it visits the next Bouncer on that row, and if it gets DOWN, it visits the next Bouncer in that column. Each thread takes the id of the Bouncer object where it stops.

Figure 2.18 Array layout for Bouncer objects.
![]() Prove that each thread eventually stops at some Bouncer object.
Prove that each thread eventually stops at some Bouncer object.
![]() How many Bouncer objects do you need in the array if you know in advance the total number n of threads?
How many Bouncer objects do you need in the array if you know in advance the total number n of threads?
Exercise 18. Prove, by way of a counterexample, that the sequential time-stamp system T3, started in a valid state (with no cycles among the labels), does not work for three threads in the concurrent case. Note that it is not a problem to have two identical labels since one can break such ties using thread IDs. The counterexample should display a state of the execution where three labels are not totally ordered.
Exercise 19. The sequential time-stamp system T3 had a range of O(3n) different possible label values. Design a sequential time-stamp system that requires only ![]() labels. Note that in a time-stamp system, one may look at all the labels to choose a new label, yet once a label is chosen, it should be comparable to any other label without knowing what the other labels in the system are. Hint: think of the labels in terms of their bit representation.
labels. Note that in a time-stamp system, one may look at all the labels to choose a new label, yet once a label is chosen, it should be comparable to any other label without knowing what the other labels in the system are. Hint: think of the labels in terms of their bit representation.
Exercise 20. Give Java code to implement the Timestamp interface of Fig. 2.10 using unbounded labels. Then, show how to replace the pseudocode of the Bakery lock of Fig. 2.9 using your Timestamp Java code [82].
1 The word “cycle” comes from the same Greek root as “circle.”