
Visual Pattern Mining
Abstract
Visual patterns, i.e., high-order combinations of visual words, have provided a discriminative abstraction of the high-dimensional bag-of-words image representation. However, the existing visual pattern mining schemes are built upon the ill-posed 2D photographic concurrences of visual words, rather than their real-world 3D concurrences, which incorrectly bind words from different objects/depth into an identical pattern to degenerate the mining precision. On the other hand, how to build a compact yet discriminative image representation from the mined patterns is left open, which is however highly demanded for many emerging applications like mobile visual search. In this paper, we propose a novel compact bag-of-patterns (CBoP) descriptor to address both issues, with application to low bit rate mobile landmark search. First, to overcome the ill-posed 2D photographic configuration, we build a 3D point cloud from the reference images of each target, based on which extract accurate pattern candidates from the 3D concurrences of visual words. Then, we introduce a novel gravity distance metric for pattern mining, which models the relative frequency between the concurrent words as “gravity” to mine more discriminative visual patterns. Finally, we build a CBoP descriptor toward a compact yet discriminative image representation, which conducts sparse coding over the mined patterns to maximally reconstruct the original bag-of-words histogram with a minimal coding length. The proposed CBoP paradigm is deployed in a large-scale low bit rate mobile landmark search prototype, where compact visual descriptors are directly extracted and sent from the mobile end to reduce the query delivery latency. We quantize our performance in several large-scale public benchmarks with comparisons to the state-of-the-art compact descriptors [112, 113], 2D visual patterns [71, 72], topic features [114, 115] and Hashing descriptors [116]. We have reported superior performance, e.g., comparable accuracy to the million-scale bag-of-words histogram with an 1:160,000 descriptor compression rate (approximately 100-bit per descriptor).
5.1 Introduction
Most existing scalable visual search systems are built based upon visual vocabulary models with inverted indexing structures [16, 24, 27, 30]. In such a case, the local features extracted from a reference image are quantized into visual words, whose ensemble constitutes a bag-of-words histogram and the image is inverted indexed into every nonzero words correspondingly. This bag-of-words representation offers sufficient robustness against photographing variances in occlusions, viewpoints, illuminations, scales, and backgrounds. And the image search problem is transferred into a document retrieval problem, where several well-used techniques like TF-IDF [28], pLSA [117], and LDA [78] can be further deployed.
Motivation. Although bag-of-words representation well handles the photographic variances, one significant drawback comes from ignoring the spatial layouts of words. To a certain degree, this can be compensated by predefined spatial embedding strategies to group neighborhood words, for instance feature bundling [75] and max/min pooling [118]. Or alternatively, a more time-consuming solution is to carry out spatial verification, such as RANdom SAmple Consensus (RANSAC) and neighborhood voting [30].
Nevertheless, the discriminability of pairing or grouping words within each image are not alone, but in turn highly depends on the overall spatial layout statistics of word combinations in the reference image collection. To this end, rather than designing the spatial embedding for individual images independently [75, 118], a more data driven alternative is to discover such discriminative pairing or grouping of visual words from the image corpus. This is referred as “visual patterns” or “visual phrases” [69–72] as from the information retrieval literature, and typically involves techniques like colocation mining [99].
More formally speaking, a visual pattern is a meaningful spatial combination of visual words, which can be regarded as a semifully geometrical dependency model, where the geometry of each part depends only on its neighbors. Comparing to previous works in class-driven spatial modeling where restrictive priors and parameters are demanded [67, 119], visual patterns have been well advocated by their parameter-free intrinsic, i.e., all structures within visual patterns are obtained by data mining with class or category supervision. This intrinsic is of fundamental importance for the scalability, which on the opposite is the key restriction for the previous works [67, 119].
Problem. Two important problems are left open in the existing visual pattern mining paradigm:
• The existing visual patterns are built on the 2D word concurrences within individual images. It suffers from the ill-posed 2D photographic degeneration to capture their real-world 3D layouts. For instance words from different depth or different foreground/background objects can be nearby under certain 2D perspectives, but such spatial concurrence is not robust and discriminative enough with un controlled viewpoint variations. Figure 5.1 shows several examples of these incorrect configurations.

• Given the mined patterns, how to design a compact yet discriminative image representation is left unexploited in the literature. To this end, visual patterns are typically treated as compensative dimensions appended the bag-of-words histogram [69–72], which simply follows the standard usage of textual patterns in the traditional document retrieval endeavor. We argue that the purely pattern-level representation can be also discriminative enough, given a well-design pattern selection approach as in Section 5.2.1.1 This pattern-level compact descriptor well suits for several emerging applications like low bit rate mobile visual search [120], as detailed in Section 5.4.
Approach. We propose a compact bag-of-patterns (CBoP) descriptor to address both issues toward a compact yet discriminative image representation. Figure 5.2 outlines the workflow of our CBoP descriptor, which is built based upon the popular bag-of-words representation. In preliminary, we assume that each target (e.g., object or landmark instance) in the dataset contains multiple reference images captured at different viewing angles. Using these images, a 3D point cloud is built for this target by structure-from-motion [121]. Then, we present a 3D sphere coding scheme to construct the initial pattern candidates, which eliminates the ill-posed 2D spatial layout in individual images by binding visual word concurrence within their 3D point cloud.

In visual pattern mining, we introduce a “gravity distance” to measure the closeness between two words to better captures their relative importance. This “gravity” incorporates the mutual information between the frequencies (or so-called saliencies) of both words into the subsequent a priori-based frequent itemset mining [122] procedure.
The mined patterns are further pooled together to build a CBoP histogram. This pooling operation seeks an optimal tradeoff between the descriptor compactness and its discriminability, which is achieved by sparse coding to minimize the number of selected patterns, typically at hundreds of bits, under a given distortion between the resulted CBoP histogram and the originally bag-of-words histogram. Finally, supervised labels can be also incorporated into the above formulation to further improve the performance.
Application. The mined CBoP descriptor has potentials in multidisciplinary applications such as object recognition, visual search, and image classification. In this paper, we demonstrate its usage in the emerging low bit rate mobile visual search application, where visual descriptors are directly extracted and sent instead of the query image to reduce the query delivery latency in mobile visual search [112, 113, 120]. In such a scenario, the extracted descriptor is expected to be compact, discriminative, and computationally efficient. While most state-of-the-art works target at abstracting or compressing the high-dimensional bag-of-words histogram [112, 120], the pattern-level abstraction is a natural choice but left unexploited in the literature. We provide two additional arguments to support such patter-level descriptor:
• First, previous works are deployed based on the linear combination of visual words for instance boosting [120], which selects one word in each round into the compact descriptor. It is a natural extension to look at their higher-oder combinations, i.e., patterns, to further improve the compression rate.
• Second, we argue that a pattern-level descriptor benefits in both memory cost and extraction time, i.e., only word combination/selection operations over the initial bag-of-words histogram, which is memory light and almost real-time comparing to other alternatives like topic features [114, 115, 123].
In practice, our CBoP has achieved almost identical search accuracy comparing to the million scale bag-of-words histogram, with an approximate 100-bit descriptor size. This performance significantly beats the state-of-the-art alternatives like 2D visual patterns [71, 72], topic features [114, 115, 123], and Hashing-based descriptors [116].
Outline. The rest of this chapter is organized as follows: Section 5.2 introduces our discriminative 3D visual pattern mining and CBoP extraction scheme. Section 5.3 shows its application in the low bit rate mobile landmark search prototype, and Section 5.4 details quantitative comparisons to the state-of-the-art works [16, 71, 72, 114–116]. For more details of this chapter, please refer to our publication in IEEE Transactions on Image Processing (2013).
5.2 Discriminative 3D Pattern Mining
In this section, the proposed CBoP descriptor generation is presented. Our 3D pattern mining and CBoP descriptor construction are deployed based on the bag-of-words image representation. Suppose we have M target of interest (ToI) in total, each of which could be an object instance, a scene, a landmark, or a product. For each ToI, we also have a set of reference images captured from different viewpoints. For the sake of generality, we assume these reference images do not have tags to identify the viewing angles, e.g., inter- and intracamera parameters.2 For each ToI, we first introduce a 3D sphere coding scheme to build the initial pattern candidate collection, following by a novel gravity distance-based pattern mining algorithm in Section 5.2.1. Finally, patterns from individual ToIs are pooled together to extract the CBoP histogram as detailed in Section 5.2.2.
5.2.1 The Proposed Mining Scheme
3D sphere coding. Formally speaking, for each reference image Ii(i ∈ [1,nt]) of the tth ToI (t ∈ [1,M]), suppose there are J local descriptors L(i) = [L1(i),…,LJ(i)] extracted from Ii, which is quantized into an m-dimensional bag-of-words histogram V(i) = [V1(i),…,Vm(i)]. We denote the spatial positions of L(i) as S(i) = [S1(i),…,SJ(i)], where each Sj(i) (j ∈ [1,J]) is the 2D or 3D spatial position of the jth local descriptor. For each Sj(i), we scan its spatial k-nearest neighborhood to identify all concurrent words
where Tj(i) (if any) is called an “transaction” built for Sj(i) in Ii. We denote all transactions in Ii with order K as:
All k-order transactions found for images ![]() in the tth ToI is defined as Tk(ToIt) = {Tk(1),…,Tk(nt)}. The goal of pattern mining is to mine nt patterns from
in the tth ToI is defined as Tk(ToIt) = {Tk(1),…,Tk(nt)}. The goal of pattern mining is to mine nt patterns from ![]() , i.e.,
, i.e., ![]() form each tth ToI and ensemble them together as
form each tth ToI and ensemble them together as ![]() .3
.3
While the traditional pattern candidates are built based on the coding the 2D concurrences of visual words within individual reference images, we propose to search the k-nearest neighbors in the 3D point cloud of each tth ToI. Such a point cloud is constructed by structure-from-motion over the reference images with bundle adjustment [121]. Figure 5.3 shows several 3D sphere coding examples in the 3D point clouds of representative landmarks as detailed in Section 5.4.

Distance-based pattern mining. Previous works in visual pattern mining mainly resort to Transaction-based Colocation pattern Mining (TCM). For instance, works in [69–71] built transaction features by coding the k-nearest words in 2D.4 A transaction in TCM can be defined by coding the 2D spatial layouts of neighborhood words. Then frequent itemset mining algorithms like a Priori [122] are deployed to discover meaningful word combinations as patterns, which typically check the pattern candidates from orders 1 to K.
TCM can be formulated as follows: Let {V1,V2,…,Vm} be the set of all potential items, each of which corresponds to a visual word in our case. Let D = {T1,T2,…,Tn} be all possible transactions extracted as above, each is a possible combination of several items within V after spatial coding. Here for simplification, we use i ∈ [1,n] to denote all transactions discovered with orders 1 to K and in ToIs 1 to M. Let A be an “itemset” for the a given transaction T, we define the support of an itemset as
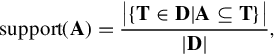
If and only if support(A) ≥ s, the itemset A is defined as a frequent itemset of D, where s is the threshold to restrict the minimal support rate. Note that any two Ti and Tj are induplicated.
We then define the confidence of each frequent itemset as:
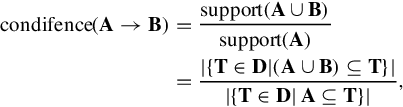
where A and B are two itemsets. The confidence in Equation (5.4) is defined as the maximal likelihood that B is correct in the case that A is also correct. Confidence-based restriction is to guarantee that the found patterns can discover the minimal item subsets, which are most helpful in representing the visual features at order k ∈ [2,K].
To give a minimal association hyperplane to bound A, an Association Hyperedge of each A is defined as:
Finally, by checking all possible itemset combinations in D from order 2 to K, the itemsets with support() ≥ s and AH ≥ γ are defined as frequent patterns.
One crucial issue lies in TCM would generate repeated patterns in texture regions containing dense words. To address this issue, distance-based Colocation pattern mining (DCM) is proposed with two new measures named participation ratio (pr) and participation index (pi).
First, a R-reachable measure is introduced as the basis of both pi and pr: Two words Vi and Vj are R-reachable when
where dis() is the distance metric such as Euclidean and dthres is the distance threshold. Subsequently, for a given word Vi, we define its partition rate pr(V,Vi) as the percentage of subset V −{Vi} that are R-reachable:
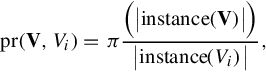
where π is the relational projection operation with deduplication. The participation index pi is defined as:
where pi describes the frequency of subset V − Vi in the neighborhood. Note that only item subsets with pi larger than a give threshold is defined as patterns in DCM.
Gravity distance R-reachable: In many cases, the Euclidean distance cannot discriminatively describe the colocation visual patterns, which is due to it ignores the word discriminability and scale in building items. Intuitively, words from the same scale tend to share more commonsense in building items, and more discriminative words also produce more meaningful items. We then proposed a novel gravity distance R-reachable (GD R-reachable) to incorporate both cues. Two words Vi and Vj are GD R-reachable once Ri,j < Crirj in the traditional DCM model, where ri and rj are the local feature scales of Vi and Vj, respectively, C is the fixed parameter, and Ri,j = dis(Vi,Vj) is the Euclidean distance of two words.
For interpretation, we can image that every word has a certain “gravity” to the other words, which is proportional to the square of its local feature scale. If this gravity is larger than a minimal threshold Fmin, we denote these two words as GD R-reachable:
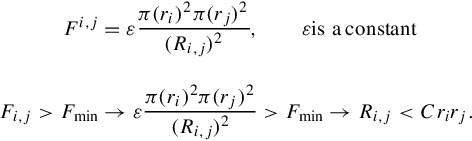
Similar to DCM, the input of the gravity distance-based mining is all instances of visual words. Each instance contains the following attributes: original local features, visual word ID, location, and scale of this local feature (word instance). To unify the description, we embed the word ID of each feature with its corresponding location into the mining. Then, we run the similar procedure as in DCM to mine colocation patterns. Algorithm 5.1 outlines the workflow of our gravity distance-based visual pattern mining. Figure 5.4 shows some case studies of the mined patterns between the gravity-based pattern mining and the Euclidean distance-based pattern mining.

Algorithm 5.1
Gravity distance based visual pattern mining

5.2.2 Sparse Pattern Coding
Sparse coding formulation. Given the mined pattern collection P, not all patterns are equivalently important and discriminative in terms of feature representation. Indeed, there are typically redundancy and noise in this initial pattern mining results. However, how to come up with a compact yet discriminative pattern-level features are left unexploited in the literature. In this section, we formulate the pattern-level representation as a sparse pattern coding problem, aiming to maximally reconstruct the original bag-of-words histogram using a minimal number of patterns.
Formally speaking, let P = {P1,…,PL} be the mined patterns with maximal order K. In online coding, given the bag-of-words histogram V(q) = [V1(q),…,Vm(q)] extracted from image Iq, we aim to encode V(q) by using a compact yet discriminative subset of patterns, say ![]() . We formulate this target as seeking an optimal tradeoff between the maximal reconstruction capability and the minimal coding length:
. We formulate this target as seeking an optimal tradeoff between the maximal reconstruction capability and the minimal coding length:
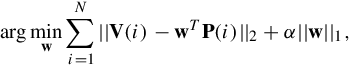
where P is the patterns mined previously, from which a minimal set is selected to lossy reconstruct each bag-of-words histogram V(i) as close as possible. w serves as a weighted linear combination of all nonzero patterns in P, which pools patterns to encode each V(i) as:
where [w1,,wm] is the weighted vector learned to reconstruct V(i) in Equation (5.10). Each wj is assigned either 0 or 1, performing a binary pattern selection.
Learning with respect to Equations (5.10) and (5.13) are achieved by spare coding over the pattern pool P. While guaranteeing the real sparsity through ![]() is intractable, we approximate a sparse solution for the coefficients w using
is intractable, we approximate a sparse solution for the coefficients w using ![]() penalty, which results in a Lasso-based effective solution [124].
penalty, which results in a Lasso-based effective solution [124].
Finally, we denote the selected pattern subset as Qselected, which contains nselected patterns as ![]() . nselected is typically very small, say 100. Therefore, each reference or query image is represented as an nselected-bin pattern histogram.
. nselected is typically very small, say 100. Therefore, each reference or query image is represented as an nselected-bin pattern histogram.
Supervised coding. Once the supervised labels ![]() (e.g., category label or prediction from a compensative source) for reference image
(e.g., category label or prediction from a compensative source) for reference image ![]() are also available, we can further incorporate Li to refine the coding of Equation (5.10) as:
are also available, we can further incorporate Li to refine the coding of Equation (5.10) as:
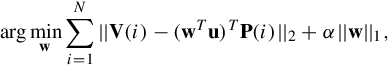
where we integrate the supervised label ![]() into the coding function of P for I(i) as:
into the coding function of P for I(i) as:
[u1,…,um] adds the prior distribution of patterns to bias the selection of [w1,…,wm], where uj is the discriminability of the jth pattern based on its information gain to Li:
Here, H(Li) is the prior of label Li given Ii, H(Li|Pj) is the conditional entropy of label Li given Pj, which is obtained by averaging the intraclass observation of Pj divided by the interclass distribution of Pj:
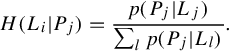
In this sense, the definition of supervised label Li is quite flexible, e.g., category labels or positive/negative tags, which also allows the case of missing labels.
In terms of compact visual descriptor, CBoP preserves the higher order statistics comparing to the transitional nonzero coding scheme [112] as well as the state-of-the-art boosting-based codeword selection scheme [120]. Different from all previous unsupervised descriptor learning schemes [69–72, 112], CBoP further provides a supervised coding alternative as an optional choice, which yet differs from the work in [120] that demands online side information from the query.
5.3 CBoP for Low Bit Rate Mobile Visual Search
We demonstrate the advances of the proposed CBoP descriptor in the emerging low bit rate mobile visual search scenario, with application to a large-scale mobile landmark search prototype. In such a scenario, different from sending the query image to cost a large query delivery latency, compact descriptors are directly extracted and sent from the mobile end. Such descriptor(s) is expected to be compact, discriminative, and meanwhile efficient for extraction, so as to reduce the overall query delivery latency.
Search pipeline: Figure 5.5 shows the workflow of using our CBoP descriptor in this prototype: The algorithm extracts local features from the query image, quantize them into a bag-of-words histogram, scan 2D spatial nearby words into potential patterns, and encode the discovered patterns into a CBoP descriptor.5 We further compress this descriptor into a bin occurrence (hit/nonhit) histogram with residual coding.

In the remote server, the decoding procedure is performed: First, a difference decoding is conducted to obtain CBoP histogram, which is then recovered into a bag-of-words histogram by weighted summing up all nonzero patterns using their original word combinations:
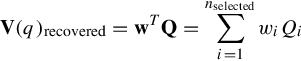
The decompressed BoW is subsequently sent to the vocabulary tree-based inverted indexing system where the ranking is conducted. Note that the spatial layouts of words can be also sent to do spatial reranking.
Efficiency. In our current implementation, given a query image, we only need approximately 2 s to extract the CBoP descriptor. By using techniques such as visual word pruning (e.g., only maintains the visual word centroid features as well as an approximate radius of each word), the storage cost of the vocabulary tree is also very limited.
Contextual learning: There is cheaply available side information in the mobile end, such as GPS tags, compass direction, and base station identity tag. Exploiting the above side information with our supervised coding (Section 5.2.2), the extracted CBoP can be further refined, as detailed in the subsequent experiments (Section 5.4).
5.4 Quantitative Results
5.4.1 Data Collection
PhotoTourism. First, we validate on the image patch correspondence benchmark. It contains over 100,000 image patches with correspondence labels generated from the point clouds of Trevi Fountain (Rome), Notre Dame (Paris), and Half Dome (Yosemite), all of which are produced by the PhotoTourism system [121]. Each patch correspondence consists of a set of local patches, which is obtained by projecting a given 3D point from the point cloud back to multiple reference images and cropping the corresponding salienct regions.6 Some exemplar patches obtained through the above procedure are shown in Figure 5.6.

10M landmark photos. To validate our CBoP descriptor in the scalable image retrieval application, we have also collected over 10 million geo-tagged photos from both Flickr and Panoramio websites. We crawled photos tagged within five cities, i.e., Beijing, New York City, Lhasa, Singapore, and Florence. This dataset is named as 10M landmarks. Some exemplar photos are shown in Figure 5.7.

We use k-means clustering to partition photos of each city into multiple regions based on their geographical tags. For each city, we select the top 30 densest regions as well as 30 random regions. We then ask a group of volunteers to identify one or more dominant landmark views for each of these 60 regions. For an identified dominant view, all their near-duplicate photos are manually labeled in its belonged region and nearby regions. Eventually, we have 300 queries as well as their ground truth labels (corrected matched photos) as our test set.
PKUBench. We also evaluate on several typical mobile visual search scenario using PKUBench, which is a public available mobile visual search benchmark. This benchmark contains 13,179 scene photos organized into 198 landmark locations, captured by both digital and phone cameras. There are in total 6193 photos captured from digital cameras and 6986 from phone cameras respectively. We recruited 20 volunteers in data acquisition. Each landmark is captured by a pair of volunteers with a portable GPS device (one using digital camera and the other using phone camera). Especially, this benchmark includes four groups of exemplar mobile query scenarios (in total 118 images):
• Occlusive query set: 20 mobile queries and 20 corresponding digital camera queries, occluded by foreground cars, people, and buildings.
• Background cluttered query set: 20 mobile queries and 20 corresponding digital camera queries, captured far away from a landmark, where GPS search yields worse results due to the signal bias of nearby buildings.
• Night query set: 9 mobile phone queries and 9 digital camera queries, where the photo quality heavily depends on the lighting conditions.
• Blurring and shaking query set: 20 mobile queries with blurring or shaking and 20 corresponding digital camera queries without any blurring or shaking.
5.4.2 Evaluation Criteria
Effectiveness: We use mean Average Precision (mAP) to evaluate our performance, which is also widely used in the state-of-the-art works [24, 27, 30, 113, 125]. mAP reveals the position-sensitive ranking precision by the returning list:
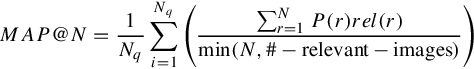
where Nq is the number of queries, r is the rank, N is the number of related images for query i, rel(r) is a binary function on the relevance of r, and P(r) is the precision at the cut-off rank of r.
Note that here we have a min operation between the top N returning and #-relevant-images. In a large-scale search system, there are always over hundreds of ground truth relevant images to each query. Therefore, dividing by #-relevant-images would result in a very small MAP. Alternatively, a better choice is the division by the number of returning images. We use min(N, #-relevant-images) to calculate MAP@N.7
Efficiency: We use the descriptor compactness, i.e., the size of the descriptor stored in the memory or hard disk (for instance 1KB per descriptor etc.).
5.4.3 Baselines
• Bag-of-words: Transmitting the entire BoW has the lowest compression rate. However, it provides an mAP upper bound to the other BoW compression strategies.
• 2D patterns: Instead of obtaining the initial pattern candidates through 3D sphere coding, using the point cloud, we adopt the traditional 2D spatial coding from individual reference images as initially proposed in [72]. This baseline validates the effectiveness of our proposed 3D sphere coding strategy.
• LDA [115]: One straightforward alternative in abstracting compact features from the bag-of-words histogram is the topic model features [78, 114, 115]. In this paper, we implement the well-used Latent Direchellet Allocation (LDA)-based feature in [115] as our baseline.
• CHoG [113]: We also compare our CBoP descriptor to the CHoG local descriptor, which is a state-of-the-art alternative as introduced in [113].
• Tree histogram coding [112]: In terms of image-level compact descriptor, we further implement the tree histogram coding scheme proposed by Chen et al. [112], which is a lossless BoW compression that uses residual coding to compress the BoW histogram.
• LDVC [120]: Finally, we compare our CBoP descriptor with the state-of-the-art compact descriptor to the best of our knowledge [120], which adopts location discriminative coding to boost a very compact subset of words. To compare to our unsupervised CBoP, we used reference images from the entire dataset (i.e., landmark photos from the entire city) to train the LDVC descriptor. To compare to our supervised CBoP, we adopt the location label to train a location sensitive descriptor as in [120].
5.4.4 Quantitative Performance
Efficiency analysis. We deploy the low bit rate mobile visual search prototype on HTC Desire G7 as a software application. The HTC DESIRE G7 is equipped with an embedded camera with maximal 2592 × 1944 resolution, a Qualcomm MSM7201A processor at 528 MHz, a 512M ROM + 576M RAM memory, 8G extended storage and an embedded GPS. Table 5.1 shows the time cost with comparisons to state-of-the-arts in [112, 120, 125]. In our CBoP descriptor extraction, the most time-consuming part is the local feature extraction, which can be further accelerated by random sampling, instead of using the interest point detectors [9, 113].
Table 5.1
Time (Second) requirements for CBoP and other alternatives on the mobile end
| Compression methods | Local feature(S) | Descriptor coding(S) |
| BoW histogram | 1.25 | 0.14 |
| Aggregate local descriptors [125] | 1.25 | 164 |
| Tree histogram coding [112] | 1.25 | 0.14 |
| Vocabulary Boosting[120] | 1.25 | 0.14 |
| CBoP |
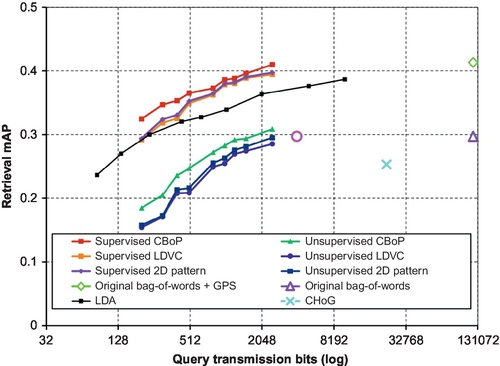
Rate distortion analysis. To compare our CBoP descriptors to the baselines [112, 113, 125], we give the rate distortion analysis in Figure 5.9, where the compression rates correspond to the descriptor lengths of our CBoP descriptor and the alternatives, while the search distortions correspond to the mAP drops of different methods, respectively. As shown in Figure 5.9, our CBoP descriptor has achieved the best tradeoff in the rate distortion evaluation. It reports the highest compression rate with a comparable distortion (by viewing Figure 5.9 horizontally), as well as the highest ranking performance with a comparable compression rate (by viewing Figure 5.9 vertically). In addition, without supervised learning, our CBoP descriptor can still achieve better performance comparing to all alternatives and state-of-the-arts [112, 113, 125]. Figure 5.8 shows some examples in the extreme mobile query scenarios for more intuitive understanding.

5.5 Conclusion
In this chapter, we propose to mine discriminative visual patterns from 3D point clouds, based on which learn a CBoP descriptor. Our motivations are twofold: On one hand, while the visual patterns can offer a higher-level abstraction of the bag-of-words representation, the existing mining schemes are misled by the ill-posed pattern configurations from the 2D photographic statistics of individual images. On the other hand, the existing pattern-level representation lacks the capability to offer a compact yet discriminative visual representation, which in turn is crucial for many emerging applications such as low bit rate mobile visual search.
The proposed CBoP descriptor addresses both issues in a principled way: To build a more precise pattern configurations in the real world, we propose to reconstruct 3D point clouds of the target by using structure-from-motion with bundle adjustment, based on which adopt a 3D sphere coding to precisely capture the colocation statistics among words in 3D. To mine more discriminative patterns, a gravity-based distance is introduced into our colocation pattern mining, which embeds the word discriminability into their spatial distances to highlight patterns that contains more discriminative words. Based upon the mined pattern, we further propose to build a compact yet discriminative image representation at the pattern level, named CBoP. CBoP adopts a sparse pattern coding to pursuit a maximal reconstruction of the original bag-of-words histograms with a minimal pattern coding length. Finally, supervised labels can be further incorporated to improve the discriminability of CBoP descriptor.
We have validated the proposed CBoP descriptor in a low bit rate mobile landmark search prototype. We quantitatively demonstrate our advances on both benchmark datasets and a 10-million landmark photo collection. Our CBoP descriptor has shown superior performance over the state-of-the-art pattern mining schemes [72], topic features [115], and compact descriptors [112, 113, 120].