
Introduction
Abstract
With the rapid advances in multimedia, communication, and Internet technology, today there is an ever-increasing amount of multimedia content with rich metadata tags on the Web. Of this massive multimedia data, image and video data represent major proportions and contain rich content information, which is very accessible for human observation and manipulation. Image and video datasets are also widely used in medical analysis, digital libraries, computer vision, and intelligent vehicles. Consequently, how to organize such digital media toward effective indexing and search is recognized as one of the fundamental challenges in the above fields, with a bright future in both academic and industrial research. Consequently, due to the incomplete annotations of multimedia data on the Web, there is a huge semantic gap between the image/video content and its textual/semantic description, which has been the core problem in multimedia analysis research thus far. Generally speaking, photographing operation from a real-world three-dimensional scene into a two-dimensional RGB image is an irreversible process that introduces problems in image and video content understanding, as well as visual search and recognition applications. Therefore, the representation, indexing and search techniques of image and video data has been a longstanding focus in research fields such as computer vision, multimedia analysis, and information retrieval, while serving as an emerging demand to improve the multimedia search services for big companies such as Google and Yahoo!.
1.1 Background and Significance
Computerized visual representation aims to leverage computer analysis techniques to allow machines to “see” the environment, such that the appearances and structures of physical scenes can be obtained. In this scenario, discriminative information representations (visual features) are extracted for the subsequent visual inference and recognition tasks. The main intelligence of computer vision lies in its ability to obtain the informative “knowledge” from images or videos, which is further used to make “decisions” as in traditional artificial intelligence systems. It simulates the key functionality of human visual systems. The human visual system is widely acknowledged as one of the most powerful biological vision systems, with the ability to not only passively receive information, but also actively “sense” information. The computerized simulation of the human visual system has a long story such as visual content receiving, interpretation, and response to visual stimulus, with help from fields such as signal processing, machine learning, and pattern recognition.
The main trend of current visual search and matching techniques lies in the visual dictionary model, which is built based on local feature representations. Compared to traditional global feature representation, local feature representation has been demonstrated to be more robust in terms of photographing variances in image viewing angles, lightings, scale changes, etc. On the other hand, as a result of the large success of document retrieval, models such as bag-of-words or hashing have been introduced to generate image signatures. These efficient and effective image representations are widely used in image search, object recognition, and multimedia event-detection systems. For example, bag-of-words is used to quantize the local features extracted from images into corresponding frequency histograms of visual words. On this basis, traditional techniques in documentation retrieval (like TF-IDF, pLSI, and LDA) can be directly applied to improve multimedia search and recognition performance.
Visual content representation is the core problem in multimedia analysis, retrieval, and computer vision research. During the last decade, the major research focus in visual content representation has switched from global and regional features to local features that are extracted from local image blobs or corners. Serving as the basis of visual content representation, the idea of extracting and describing local features was inspired by the study of motion tracking and analysis. For instance, Hannah et al. proposed the first algorithm for corner detection in images [1]. Subsequently, Harris et al. adopted the ratios of eigenvalues of the second-order matrix of the surrounding region to detect and describe interest points [2]. Upon this basis, different corner detectors were proposed [3–5]. Recently, more theoretical analysis and formulations about corner detector have been given in [6]. To cope with the demand for invariances of small image regions in rotations, scales, and affine transforms, Schmid et al. [7] proposed the Hessian affine local feature detector. Among them, one of the most representative methods is the SIFT (Scale-Invariant Feature Transform) proposed by D. G. Lowe, [8, 9] which handles the invariances of scale and partial affine transform from the perspective of scale space theory. A detailed review of related work in local feature detectors up to 2005 can be found at [10]. Another origin of local feature comes from the inspiration of biological research. The biological vision system serves as a natural local visual system. For instance, Hubel and Wiesel have discovered that the visual receptive field is a natural local feature detector and processor [11]. Marr proposed to summarize low-level image processing problems as a sort of local feature extraction, which includes extracting edge, bar, blob and terminator [12]. Zhu and Poggio et al. have shown that, based on such local feature extractions, almost all information for each individual image can be represented based upon image-edge features [13, 14].
A subsequent problem after local feature extraction is how to describe these local features in an effective and efficient manner. The current methods used either visual dictionary or hashing techniques with inverted file indexing to overcome the matching deficiency between two sets of local features. Furthermore, to handle the scalability, the visual dictionary is typically learnt by hierarchical k-means to accelerate both the offline dictionary construction and the online local feature quantization. However, quantization procedures such as k-means would bias the clustering procedures to be concentrated into the densest regions in the local feature space, resulting in discriminability degeneration in the resulting bag-of-visual-words histogram. In addition, for the visual dictionary-based representations, current approaches still output a high-dimensional sparse representation in the bag-of-words histogram, which is indeed less efficient as the content signature. Finally, how to integrate the learning mechanism into different levels of local feature quantization is still unclear; however, this is one of the major functionalities in the learning procedure of human visual systems.
So far, existing works in visual local representation are still based on the visual statistics of local features. Although such representation offers sufficient robustness for traditional visual matching problems, the semantic gap between low-level visual content representation and high-level semantic understanding remains, which has slowed progress in related fields such as visual object detection, recognition, and multimedia content tagging. Such a gap serves as the main bottleneck in existing visual local representation research. In contrast, during the evolution of the human visual system, its corresponding visual representation mechanism has been largely affected and influenced by its environment, in terms of learning its optimal representation strategy to effectively characterize scene contents. In other words, the learning mechanism plays an important role in the feature detection and representation of human vision systems, which indeed is one of the most important reasons the human vision system is able to obtain meaningful visual representation through limited and sparse observations from outer scenes.
This book provides a systematic introduction to how the machine learning mechanism can be used in local feature representation and indexing. By integrating learning components, the goal is to build a more effective and efficient visual local representation to benefit computer vision research. In particular, this book focuses on how machine learning can be used to build the components of local feature detection, quantization, and representation, as well as its scalability to deal with massive data. It begins with learning-based semi-local interest-point detection, connected by unsupervised visual dictionary optimization and supervised visual dictionary learning, and finally builds upon higher-level visual pattern representation. More specifically, this book reviews work in the following perspectives:
• The book first focuses on how to extract a semi-local interest point that is more semantic-aware and with a larger spatial scale to use as the basis of the subsequent visual dictionary construction. To this end, a context-aware semi-local feature detector (CASL) is proposed, which combines (1) the spatial context of nearby local features and (2) the semantic labels of the targeted image to carry out the real “interest”-point detection at a higher level.
• The book then focuses on how to improve the hierarchical local feature quantization procedure from an unsupervised perspective. To this end, a density-based metric learning (DML) is proposed to refine the distance metric distortion during hierarchical k-means based visual dictionary construction.
• Thirdly, improving the visual dictionary from a supervised manner is proposed, which is achieved by exploring the readily available social tags from reference images, based on a proposed generative embedding of supervised tag information. This is achieved by a hidden Markov random field to supervise the dictionary building as well as modeling the tag similarity and correlation.
• Finally, based on the learned optimized dictionary, this book further exploits its potential usage for visual pattern generation, together with its potential to improve the traditional bag-of-visual-words model. To achieve this goal, a gravity-distance based co-location pattern mining approach is proposed to extend the traditional transaction-based co-location pattern mining scheme.
1.2 Literature Review of the Visual Dictionary
The visual dictionary serves as one of the most important and fundamental components in the research of visual local representation. Different from the traditional global features or filter-based features, the visual dictionary can be regarded as a sort of data-driven feature extractor, whose performance therefore highly influences the subsequent bag-of-words representation. From a higher perspective, visual local representation and indexing involve multi-disciplinary research fields including computer vision, pattern recognition, signal processing, information retrieval, machine learning, and cognition science. The visual dictionary together with the local feature extraction serves as a key component in image and video retrieval, scene recognition, object detection, image classification, video surveillance, image matching, three-dimensional reconstruction, as well as robotic navigation.
In the past decade, local features and the visual dictionary have been widely studied in computer vision. For instance, the Visual Computing Group at Oxford University led by A. Zisserman has done a lot of pioneering work in visual dictionary-based image/video search and scene matching. For example, the Video Google system uses k-means clustering to build the visual dictionary together with the inverted indexing structure for large-scale near-duplicate video retrieval. In terms of object recognition, Fei-Fei Li et al. at Princeton and Stanford universities have done quite a lot of work on local feature-based object modeling and scene recognition [15]. To cope with the construction and search deficiency, D. Nister et al. from the Center for Visualization and Virtual Environments at the University of Kentucky have proposed the so-called Vocabulary Tree model [16], which exploits the hierarchical k-means clustering-based strategy to build the visual dictionary. For mobile-based location search, the Photo2Search system [17] developed by the Web Search and Mining Group at Microsoft Research Asia is one of the pioneering works.
There has been active research on visual local representation and indexing as reported in academic publications, especially at the competitive peer-review conferences worldwide such as the IEEE International Conference on Computer Vision, IEEE International Conference on Computer Vision and Pattern Recognition, European Conference on Computer Vision, and ACM Multimedia. For example, when searching with the keywords “local feature” in the Proceedings of CVPR 2009, over 100 papers resulted (in total about 250). In addition, there are many related tutorial and workshops at these conferences. Beyond conference proceedings, papers concerning visual local representation and indexing are also well published in major peer-review journals such as the International Journal of Computer Vision, IEEE Transactions on Pattern Analysis and Machine Intelligence, IEEE Transactions on Image Processing, IEEE Transactions on Multimedia, Pattern Recognition, and Computer Vision and Image Understanding, with many special issues.
1.2.1 Local Interest-Point Extraction
Local feature detector and descriptor: Generally speaking, obtaining local features from a target image refers to both the detection and description phases. The task of local-feature extraction is to discover and locate the salient regions (or so-called interest points), such as corners or conjunctions within a given image. Such interest points are supposed to have a strong response to a series of filters in either spatial or frequency domains, e.g., difference of Gaussians filters, while their description should be robust to a series of photographing variances such as viewing angle changes, lighting condition changes, rotations, affine transforms, and partial occlusions. There have been many representative interest-point detectors proposed in recent years, such as SIFT [9], PCA-SIFT [18], GLOH [10], Shape Context [19], RIFT [20], MOP [21], and the learning-based MSR descriptor [22, 23]. Among them is the concept of combining the difference of Gaussians-based interest-point detection with SIFT-based interest-point description. As one of the most popular local feature extractor, the SIFT (scale invariant feature transform) [9] descriptor adopts scale–space theory to achieve the invariant description of the local interest point with respect to the scale and rotation changes. In [9], local minimal and maximal in the scale space are first detected, subsequently the detected regions are rotated into its main gradient direction. As described, the corresponding pixel region is subdivided into 4 × 4 blocks, within each of which an 8-dimensional histogram is extracted, resulting in a 128-dimensional descriptor in total. To further accelerate the extraction and reduce the descriptor size, Ke et al. further proposed to do dimension reduction based on this extracted 128-dimensional vector, resulting in the so-called PCA-SIFT [18]. There is no doubt that the SIFT descriptor and its variances are the most common interest-point descriptors used in the literature, with good invariances to the photographing variances in rotations, scales, and affiance transforms, providing sufficient robustness for matching images captured from different perspectives.
Using the SIFT feature as an example, the local feature extraction and description contains the following two stages: The first stage is the difference of Gaussians or dense sampling based interest-point detection, which includes the following three detailed steps:
1. Scale space construction and local maximal/minimal point detection, to locate the initial locations of interest points and their corresponding scales.
2. Filter out the edge points with a one-directional gradient response, based on Hessian matrix-based operations (the ratio between the matrix trace and determinant).
3. Rotate the region of each interest point, based on its main gradient direction, which ensures the subsequent descriptor is rotation invariant.
The second stage is the aforementioned SIFT descriptor extraction.
1.2.2 Visual-Dictionary Generation and Indexing
Working mechanism of the visual dictionary: Most existing visual dictionaries, such as the vocabulary tree model [16], the approximate k-means clustering [24], the locality sensitive hashing [25], and the hamming embedding [26], are built based upon the quantization of the local feature space, aiming to subdivide the local reference features extracted from the image database into visual word regions. Then, for a given image to be searched or matched, the algorithm extracts a variant number of local features and then uses the learnt visual dictionary to quantize these local features into a bag-of-words histogram. Such a histogram offers good robustness against partial occlusions and further invariances to heavier affine transforms. Another advantage comes from the capability to leverage traditional techniques in document retrieval that have been proven to be very effective in visual search problems, such as TF-IDF, pLSI, and LDA.
Hierarchical structure: With the increasing size of the image/video corpus, there are challenges for the traditional visual search and matching techniques. For instance, the system needs to process a massive amount of visual local features (e.g., there are two to three million SIFT features extracted from 30,000 images). In an online query there is no way to store such massive data in the memory or to do a real-time online search within such a gigantic dataset. Although the traditional k-d tree indexing can process the massive data, it typically fails in handling high-dimensional data such as 128-dimensional SIFT feature space, where the matching efficiency would occasionally degenerate to linear scanning. On the contrary, the visual dictionary adequately addresses these challenges with the principle of (hierarchical) local descriptor quantization with inverted indexing, which ensures the search time cost is unrelated to the scale of the image dataset.
As one of the most representative schemes used to build the visual dictionary, the vocabulary tree (VT) model [16] adopts hierarchical k-means clustering to do quantization definition of “hierarchy” is subdividing a given set of local features into k-clusters at each layer (k is the branching factor, and k = 3 in this example), which results in Voronoi region divisions, typically implemented in a recursive manner. To search a large-scale high-dimensional dataset, the vocabulary tree serves as a very effective and efficient model structure. The clustering stops either when the current tree structure has achieved the maximal hierarchical layer, or when the number of local interest points to be clustered is smaller than a given threshold. From the above definition, the vocabulary tree finally outputs a tree structure with depth L and branch k, containing approximately kL nodes. The finite nodes (without any children) can be regarded as visual words, each of which contains the local features that are closest to this word centroid rather than the other words.
Online query involves comparing each extracted local feature to the visual dictionary to find a more similar visual word. Again, in the case of a hierarchical dictionary structure, this is done by querying the local feature with the centroids in each layer to decide which subtree to go to in the next layer. Finally, when locating the best matched words, images that are inverted indexed in this word are picked up and pushed to a similarity list, where the IDF-based weighting might also help to differentiate the votings of this word.
The data structure of the tree-based quantization can be categorized into two parts: (1) the feature-based partition tree, which is based on subdividing the data in individual dimensions, with subsequent mapping of the data subset to its corresponding subregion (representative approaches include the K-D tree, R-tree, and Ball-tree); and (2) the data-based partition tree (metric tree), which is based on directly subdividing the data within its original feature space, for which there are representative works like k-means, approximated k-means, and hierarchical k-means.
Visual dictionaries commonly exist in current visual search and recognition systems. Their structure plays an important role in the subsequent visual search and recognition performance [16, 27]. The vocabulary tree is a metric tree, where the resulting visual word subdivisions can be visualized as 2-D Voronoi regions.
Similar to the TF-IDF in the document retrieval, each image j can be represented as a vector ![]() , in which nt is the number of visual words in the visual dictionary. Each dimension in this vector is weighted by its term frequency and inverted document frequency (TF-IDF) together to represent its discriminativity (relative importance) to the bag-of-words histogram. The calculation of TF-IDF is:
, in which nt is the number of visual words in the visual dictionary. Each dimension in this vector is weighted by its term frequency and inverted document frequency (TF-IDF) together to represent its discriminativity (relative importance) to the bag-of-words histogram. The calculation of TF-IDF is:
where the TF (term frequency) [28] reveals the importance of this word in the target image and is obtained by calculating the occurrence frequency of this word in the target image as:
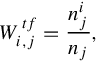
where ![]() is the time that the ith visual word appears in the jth image and nj is the total number of visual words appearing in the jth image.
is the time that the ith visual word appears in the jth image and nj is the total number of visual words appearing in the jth image.
For IDF, intuitively, if a given word appears in too many images, it has little to add to the corresponding image representation. On the contrary, if the word appears in only a few images, it is of great importance to the corresponding image representation. Such importance is opposite to the frequency of this word appearing in different images, which is revealed as IDF (inverted document frequency) [28], as:
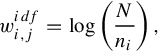
where N is the number of images in the data and ni is the number of images that are inverted indexed in the ith visual word. Based on the aforementioned TF-IDF weights, the image similarity between the two images is the weighted Cosine distance of their corresponding bag-of-words vectors.
Quantization error: The building of a visual dictionary introduces many important issues that influence the subsequent visual search and recognition performances, which is mainly due to the process of quantizing continuous local feature descriptors into discrete subregions in the local descriptor feature space [9, 15, 27, 29, 30]. Nister et al. [16] investigate the combination of multiple layers to build a hierarchical bag-of-words model, which aims to improve the finest quantization errors by embedding its higher-level node similarity. Jurie et al. [31] adopt adaptive distance metrics to improve the mean shift effect in the k-means clustering. Yang et al. [32] investigate the factors of dictionary size, soft quantization strategy, and different pooling methods, IDF weightings, and stop-word removal techniques to the final retrieval and classification performance. There are also existing works that focus on the learning-based visual word selection to build a better bag-of-words histogram representation. For instance, boosting-based codeword selection with mutual information maximization criterion is proposed in [33] and [34]. The bottleneck of such methods lies in the dependency of the training phase as well the ignoring of the middle-level dictionary representation in the dictionary hierarchy. For instance, works in [31] and [35] do not consider the case of hierarchical structure to the final retrieval performance; and work in [32] cannot guarantee the resulting codebook construction is optimal, with a certain random style to build an optimal codebook. Finally, the works in [33] and [10] heavily rely on supervised labels, which therefore prevent their potential extension to large-scale settings (Figure 1.1).

Inspirations from the text domain: In document retrieval, there is not a clear definition of textual word hierarchy. On the contrary, in visual words, especially in the vocabulary tree-based model, the hierarchical structure highly affects the subsequent visual search and recognition performance. During the hierarchical quantization of visual words, not only the finest level of leaf nodes (visual words) but also their middle-level representation are built. In other words, such a hierarchical dictionary structure not only provides the lower-level bag-of-words representation but also their higher-level abstraction. The works in [31] and [36] have shown that the k-means clustering can show bias to the dense regions in the local feature space, called the mean shift effect [37], and therefore the feature-space division is not bias. Furthermore, the hierarchical subdivision can amplify this unbiased mean shift effect, which results in a very unbalanced feature-space division. One significant effect is that, the more discriminative the region (i.e., it appears in fewer images and hence is more sparse) the more coarsely quantized and a low IDF is obtained, while the less discriminative region (i.e., it appears in more images and hence is more dense) would be heavily quantized and a high IDF would be obtained. This book will show that this problem is the exact reason previous works [30, 32] reported that the IDF was not as good as expected. From this point, the book will further propose an unsupervised feature-space quantization scheme to alleviate the above unbalanced feature-space hierarchical subdivision.
Supervised dictionary learning: Despite the branch of works in unsupervised distance metric learning, recently supervised or semi-supervised dictionary optimization has also received increasing research focus. For example, the work in [38] proposed a Markov random field model with must-link and cannot-link to do supervised data clustering. Mairal et al. proposed a sparse coding-based discriminative, supervised visual codebook construction strategy [39], which has been validated in the tasks of visual object recognition. Lazebnik et al. proposed a mutual information minimization-based supervised codebook learning [40], which requires supervised labels on the exact local descriptor level. Moosmann et al. proposed an ERC-Forest model [41] to leverage the descriptor level supervision to guide the indexing tree construction. The works in [42–44] also proposed to subdivide or merge the original codewords learned from the originally unsupervised dictionary construction, so as to build a category (or image)-specific codebook to refine the subsequent classifier training or image search. One of the major limitations of [42–44] lies in the fact that their computation complexity is at least linear to the category number, and are therefore unable to scale up to massive amount of Web images with tens of thousands of semantic labels.
It is worth mentioning that learning-based quantization has also been included in the research of data compression, as in [45–47]. To this end, models such as self-organized map [46] or regress loss minimization model [47] have been adopted to minimize the reconstruction loss between the local features and the quantized codewords. Also, works in [48, 49] proposed to combine the spatial constraint into the clustering of textual regions to produce the texton dictionary. However, the aforementioned works in supervised dictionary learning do not take into account the semantic correlation, and therefore can not handle the label correlations well. However, this is the main limitation if the algorithm need to learn from the Web. In addition, the existing learning-based visual representation [15, 39–44, 50] only considers the case where the supervised labels are on the local feature level rather than the global (image) level, so the learning effectiveness is also limited.
Feature hashing: In addition to the visual dictionary models based on feature-space quantization, the Approximate Nearest Neighbor Search can be also used to handle the large-scale feature matching problem in the high-dimensional feature space. In such a setting, the Locality Sensitive Hashing (LSH) approach and its variants [51–53] has been widely used. LSH is a sort of hashing technique to ensure the neighborhood hashing results are meaningful and represent similarity. Its main idea is to leverage a group of independently calculated hashing functions to project the high-dimensional space into low-dimensional space for search and indexing, such that the finding of the nearest neighborhood can be guaranteed. This property enables a direct comparison of the hashing code to come up with a similarity measurement of the two local features. The recent works have also demonstrated that the Hamming distance can be further used to provide a good approximate of the distance metric [54, 55] when comparing two hashing codes. Moreover, kernel-based similarity metrics are also proposed in [40, 56, 57] and have been shown to have good effectiveness and large acceleration in large-scale visual matching problems.
Multi-tree based indexing: Another technique beyond hashing for fast nearest neighborhood searching is multi-tree based indexing. One of the most well-known examples is the k-d tree and k-d forest, whose main idea is to iteratively find the best dimension in the feature space to subdivide the reference dataset. There are different criteria used to guide the division within individual dimensions, such as maximizing the information gain after division. To further extend this idea, the work in [58] adopts a best bin first (BBF) search strategy to efficiently find the best matching under a given threshold. Other related works include [59–61]. For instance, Nene and Nayar et al. proposed a slicing technique in [62], which adopts a series of two-dimensional binary search techniques to sort data within each dimension to reduce the nearest neighborhood search complicity. Grauman and Darrell et al. in [63] proposed to reweight the matchings at different tree dimensions to further reduce the matching errors. Muja and Lowe et al. [64] proposed to compare not only one dimension each time in the feature tree indexing structure, and improves the randomized k-d tree based visual similarity search.
Visual pattern mining: Due to the ignoring of spatial correlation between different visual words in the reference image, there are many mismatches caused by visual dictionary-based quantization [10, 29, 65]. In recent works [66–68], spatial combinations of visual words (called visual phrases) have been used to replace traditional bag-of-words based non-spatial representations. For instance, the work in [29] proposed a constellation model to model the joint spatial distribution of visual words for a given object category for object classification and detection. However, the constellation model is generative and typically involves adjusting lots of parameters so is unfeasible for handling large-scale data. The work in [65] proposed a middle-level model representation built upon the geometric constellation of visual words to learn different parts of a given object, while the parameter ordering problem in [29] is handled to a certain degree. However, due to the requirement of strong geometric constraint as a prior, the work in [29] cannot be scaled up to the problem of large-scale visual matching.
Following the idea of visual pattern/phase discovery, there are many related works devoted to mining the representative spatial combination of visual words in the recent literature [69–72]. These works [69–72] can be mainly categorized as transaction-based co-location pattern mining, which depends on the modeling of spatial co-location statistics of visual words into transactions. Compared to the previous works that rely on strong prior knowledge, these works [69–72] advance in their unsupervised manner of feature representation.
In [69], Sivic et al. proposed to use viewpoint invariant features to build the initial visual words by k-means clustering, with a frequent item set mining technique to discover the most frequently found spatial combinations of word pairs or subsets. In [70], Quack et al. proposed to discovered the most frequent objects in a given scene in an unsupervised manner, where the candidate objects are detected by mining the frequently appeared spatial combinations of visual words. In [71], Yuan et al. proposed a visual phase mining model and used the mined visual phase to refine the original similarity metric of bag-of-words. The work in [72] further leveraged the mined visual patterns to filter out the initial visual words extracted from dense sampling.
Geometric verification: Beyond visual pattern or phase-based mining, the spatial cues also play an important role in visual search, as the information used to do spatial verification-based post-processing, e.g., the RANSAC [9, 24, 30, 73] operator. However, due to its low efficiency, RANSAC-based methods [9, 24, 30, 73] are typically used to do post-processing. As an alternative, the work in [30, 74] proposed to do a spatial voting of nearby matching pairs for a given local feature, and the bundled-based features are proposed in [75] to further improve the search accuracy.
Visual word correlations: Another direction for visual dictionary post-processing is to analyze the visual words as well as the target images. For instance, Jing et al. proposed to simulate the visual feature matching between images as hyperlinks between webpages, based on a PageRank-like mechanism [76] to achieve the selection of representative images. In addition, many widely used models in topical analysis in document retrieval, such as latent semantic analysis (LSA), can be further leveraged for extracting middle-level image representation from visual words. LSA needs pre-defined topical numbers, which are used to carry out singular value decomposition (SVD) for the topical feature extraction. Such a fixed-number topical setting is given in [77, 78] by adopting latent topical models like pLSA [77] or latent Dirichlet analysis (LDA) [78].
1.3 Contents of this Book
A scale beyond local: The first work introduced in this book is to challenge the independent assumption among the local interest-point detection procedures [8, 29, 79–81]. In the previous setting, each interest point is assumed to be conditional independent, and therefore their detection processes do not influence each other. However, in many multimedia analysis and computer vision tasks, the detected local features are treated as a whole in the subsequent processing. For example, adopting a support vector machine to map the bag-of-words histogram into a high-dimensional space where the separated hyperplane is found. From this perspective, the performance of interest-point detectors not only depends on the detection repetitiveness, but also depends on whether the ensemble of all detected local features are discriminative enough for the subsequent feature mapping or classification. The same conclusion also comes from observations of the human visual system [82], where the V1 cortex in the human brain (which can be simulated as Gabor-like local filter bands) generates a spatial context that is further processed by the V2 cortex [83] by its complex cells, resulting in a so-called semi-local stimulus for the further processing. Therefore, a natural question is: Can we make use of the spatial and semantic context of local descriptors to discover more discriminative “semi-local” interest points?
Unsupervised dictionary optimization: The visual dictionary contains not only the finest-level visual words but also their higher-level abstraction. Therefore, such structural abstraction provides natural cues to improve the search performance by combining the middle-level bag-of-words with the finest-level bag-of-words. However, the study in [16] has found that such a hierarchical weighted (with IDF weights) combination does not achieve significant performance gain as expected. In this book, we further argue that this performance deficiency can be further saved based upon an optimized dictionary hierarchy learned in an unsupervised manner. To this end, a distance-based metric learning (DML) approach is proposed to improve the hierarchical k-means clustering. Consequently, a hierarchical recognition chain is proposed to simulate the coarse-to-fine decision in the Boosting chain classifier [84] for high efficiency retrieval.
Supervised dictionary learning: The existing works concerning the visual dictionary are mainly based on unsupervised local feature-space quantization, based upon the visual contents as introduced in [16, 24–26]. However, some recent works have started to exploit supervised dictionary learning [39–41] and semantic labels, especially the correlative image tags from the Web. Semantic tags are widely used in classifier training tasks. In this book, a supervised dictionary learning scheme is introduced based upon the generative Markov random field, with the help of image tag correlation modeling to achieve a better supervised dictionary learning from imprecise and correlative semantic labels.
This approach aims to address two main challenges in large-scale supervised dictionary learning: (1) How to obtain large-scale precise local feature supervision if only the image (global) supervision is available, when in such a case manual annotation is unfeasible. This is addressed by leveraging the readily available image tags from social media websites such as Flickr and Facebook together with a global-to-local tag propagation scheme; and (2) how to model such correlative and numerous tags, which is achieved by proposing a hidden Markov random field-based generative semantic embedding scheme.
Visual pattern mining: Finally, the book proposes to further mine meaningful visual words into visual patterns, and subsequently study its potential improvement to the traditional bag-of-words based visual search paradigm. We have discovered that the traditional transaction-based co-location pattern mining scheme typically tends to discover texture regions. To handle this problem, a distance-based co-location mining is further proposed. Meanwhile, to better handle the drawback in the traditional Euclidean distance measure in visual pattern mining schemes, a gravity distance is further proposed in the distance-based co-location mining scheme.