
Key points
• When comparing two designs or products, you need to account for chance differences between sample data by generating a p-value from the appropriate statistical test.
• To understand the likely range of the difference between designs or products, you should compute a confidence interval around the difference.
• To determine which statistical test you need to use, you need to identify whether your outcome measure is binary or continuous and whether you have the same users in each group (within-subjects) or a different set of users (between-subjects).
• For comparing data from two continuous means such as questionnaire data or task times:
• For between-subjects: Use the two-sample t-test if different users are in each sample. The procedure can handle non-normal data and unequal variances. Compute a t-confidence interval around the difference between means.
• For within-subjects: Use the paired t-test if the same users are in each sample. The procedure can handle non-normal data. Compute a t-confidence interval around the difference between means.
• There is surprisingly little agreement in the statistics literature on the best statistical approach for comparing binary measures. Our recommendations appear the most promising given the current research.
• For comparing a binary outcome measure such as task completion rates or conversion rate (as used in A/B testing):
• For between-subjects: Use the N−1 two-proportion test if different users are in each sample and compute an adjusted-Wald confidence interval around the difference in the proportions.
• For within-subjects: Use the McNemar exact test (using the mid-probability variant) if the same users are in each sample. Compute an adjusted-Wald confidence interval around the difference in the matched proportions.
• Table 5.21 provides a list of the formulas used in this chapter.
Table 5.21
Formulas Used in this Chapter
| Name of Formula | Formula | Notes |
| Paired t-test (dependent means) |

|
Used for all sample sizes when the same users are used in both groups. |
| Confidence interval around the difference between paired means |

|
Used for all sample sizes. |
| Two-sample t-test (independent means) |
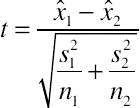
|
Used for all sample sizes when different users are in each sample. It is robust to violations of normality and unequal variances especially when using the Welch–Satterthwaite procedure to adjust the degrees of freedom. |
| Welch–Satterthwaite adjustment to degrees of freedom |

|
Adjusts the degrees of freedom used in a two-sample t-test which makes the test more robust to violations of normality and unequal variances. |
| Confidence interval around two independent means |

|
Used for all sample sizes. |
| N−1 chi-square test for comparing two independent proportions (equal to the N−1 two-proportion test) |

|
The test is the same as the standard chi-square test except it is adjusted by multiplying the numerator by N−1. The test is algebraically equivalent to the N−1 two proportion test. It works well as long as the expected cell counts are greater than 1 (otherwise use the Fisher exact test). |
| N−1 two-proportion test for comparing two independent proportions |

|
The test is the same as the standard two-proportion test except it is adjusted by multiplying the numerator by
 . The test is algebraically equivalent to the N−1 chi-square test. It works well as long as the expected cell counts are greater than 1 (otherwise use the Fisher exact test).
. The test is algebraically equivalent to the N−1 chi-square test. It works well as long as the expected cell counts are greater than 1 (otherwise use the Fisher exact test). |
| Fisher exact test on two independent proportions |

|
Only recommended when expected cell counts are less than 1 (which doesn’t happen a lot). Software computes the p-values by finding all possible combinations of tables equal to or more extreme than the marginal totals observed. |
| Adjusted-Wald confidence interval for the difference between independent proportions |
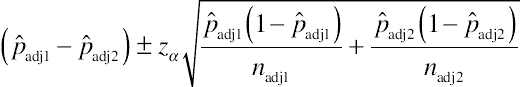
|
The adjustment is to add a quarter of a squared z-critical value to the numerator and half a squared z-critical value to the denominator when computing each proportion. |
| McNemar exact test for matched proportions |

|
This is the binomial probability formula which is used on the proportion of discordant pairs. See the chapter for the process of using this and the mid-p value. |
| Adjusted-Wald confidence interval for difference between matched proportions |

|
The interval is adjusted by adding
|

![]()
Chapter review questions
1. Ten users completed the task to find the best priced nonstop roundtrip ticket on JetBlue.com. A different set of 14 users attempted the same task on AmericanAirlines.com. After each task attempt, the users answered the seven-point Single Ease Question (SEQ, see Sauro, 2011b). Higher responses indicate an easier task. The mean response of JetBlue was 6.1 (sd = .88) and the mean response on American Airlines was 4.86 (sd = 1.61). Is there enough evidence from the sample to conclude that users think booking a flight on American Airlines is more difficult than on JetBlue? What is the likely range of the difference between mean ratings using a 90% level of confidence?
2. Two designs were tested on a website to see which would convert more users to register for a webinar. Is there enough evidence to conclude one design is better?
Design A: 4 out of 109 converted
Design B: 0 out of 88 converted
Compute a 90% confidence interval around the difference.
3. A competitive analysis of travel websites was conducted. One set of 31 users completed tasks on Expedia.com and another set of 25 users completed the same tasks on Kayak.com. Users rated how likely they would be to recommend the website to a friend on an 11-point scale (0 to 10) with 10 being extremely likely. The mean score on Expedia.com was 7.32 (sd = 1.87) and the mean score on Kayak.com was 5.72 (sd = 2.99). Is there evidence that more people would likely recommend Expedia over Kayak.com? What is the likely range for the difference between means using a 95% confidence level?
4. Using the same set of data from question 3, the responses were segmented into promoters, passives, and detractors as shown in Table 5.22. This process degrades a continuous measure into a discrete binary one (which is the typical approach when computing the Net Promoter Score).
Table 5.22
Data for Review Question 4
| Website | Segment | Response Range | No. of Responses |
| Expedia | Promoters | 9–10 | 7 |
| Passive | 7–8 | 14 | |
| Detractors | 0–6 | 10 | |
| Kayak | Promoters | 9–10 | 5 |
| Passive | 7–8 | 8 | |
| Detractors | 0–6 | 12 |

Is there evidence to conclude that there is a difference in the proportion of promoters (the top-2-box scores) between websites?
5. The same 14 users attempted to rent a car on two rental car websites: Budget.com and Enterprise.com. The order of presentation of the websites was counterbalanced, so half of the users worked with Budget first, and the other half with Enterprise. Table 5.23 shows which users were successful on which website. Is there enough evidence to conclude that the websites have different completion rates? How much of a difference, if any, likely exists between the completion rates (use a 90% level of confidence)?
Table 5.23
Data for Review Question 5
| User | Budget.com | Enterprise.com |
| 1 | 1 | 1 |
| 2 | 1 | 1 |
| 3 | 1 | 0 |
| 4 | 1 | 0 |
| 5 | 0 | 1 |
| 6 | 1 | 1 |
| 7 | 1 | 1 |
| 8 | 0 | 0 |
| 9 | 1 | 1 |
| 10 | 1 | 1 |
| 11 | 1 | 1 |
| 12 | 1 | 0 |
| 13 | 1 | 1 |
| 14 | 1 | 1 |
| Comp rate | 86% | 71% |
6. After completing five tasks on both Budget.com and Enterprise.com, the 14 users from question 5 completed the SUS (Table 5.24). The mean SUS scores were 80.4 (sd = 11) for Budget.com and 63.5 (sd = 15) for Enterprise.com. Is there enough evidence to conclude that the SUS scores are different? How large of a difference likely exists in the entire user population using a 95% confidence interval?
Table 5.24
Data for Review Question 6
| User | Budget | Enterprise | Difference |
| 1 | 90.0 | 65.0 | 25 |
| 2 | 85.0 | 82.5 | 2.5 |
| 3 | 80.0 | 55.0 | 25 |
| 4 | 92.5 | 67.5 | 25 |
| 5 | 82.5 | 82.5 | 0 |
| 6 | 80.0 | 37.5 | 42.5 |
| 7 | 62.5 | 77.5 | −15 |
| 8 | 87.5 | 67.5 | 20 |
| 9 | 67.5 | 35.0 | 32.5 |
| 10 | 92.5 | 62.5 | 30 |
| 11 | 65.0 | 57.5 | 7.5 |
| 12 | 70.0 | 85.0 | −15 |
| 13 | 75.0 | 55.0 | 20 |
| 14 | 95.0 | 60.0 | 35 |
| Mean (sd) | 80 (11) | 64 (15) | 16.8 (18) |

Answers to chapter review questions
1. A two-sample t-test should be conducted using the following formula:

The degrees of freedom for this test are as follows:

Looking up the test statistic in a t-table with 20 degrees of freedom we get a p-value of 0.025. There is sufficient evidence for us to conclude that users find completing the task on American Airlines more difficult. For a 90% level of confidence with 20 degrees of freedom, the t-critical value is 1.72 and the formula is

So we can be 90% confident the difference between mean ratings is 0.36–2.12 between the two airline websites.
2. Conduct an N−1 two-proportion test.
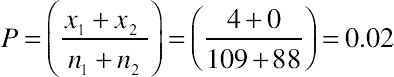

Looking up the test statistic 1.81 in a normal table we get a two-tailed p-value of 0.07. This means there is about a 93% chance the designs are different, which is probably strong enough evidence for almost all circumstances. The 90% confidence interval around the difference is computed using the adjusted-Wald formula. First compute the adjustment for each proportion. The critical value of z for a 90% level of confidence is 1.64.


Then insert this adjustment into the confidence interval formula:

The 90% interval is 0.00 to 0.07, which means we can be 90% confident the difference between conversion rates favors Design A somewhere between 0.0% and 7.0%.
3. Use a two-sample t-test because we have independent samples and a continuous response variable. Using the two-sample t-test formula we get
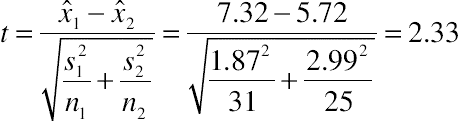
With the following degrees of freedom:
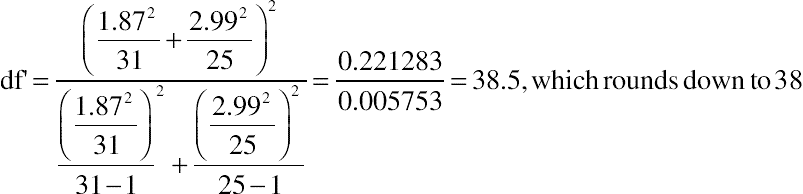
Looking up the test statistic 2.33 using a t-table with 38 degrees of freedom shows a p-value of 0.025. Thus, there is only a 2.5% probability that the difference between means is due to chance. Put another way, there is a 97.5% probability that the mean score on Expedia.com is higher than on Kayak.com. The t-critical value for a 95% confidence level with 38 degrees of freedom (http://www.usablestats.com/calcs/tinv) is 2.02.

We can be 95% confident the difference between mean scores on the likelihood-to-recommend question is between 0.2 and 3.0 in favor of the Expedia.com website.
4. We have two independent proportions, so we use the N−1 two-proportion test.


Looking up the test statistic of 0.232 in a normal (z) table, we get a two-sided p-value of 0.817. Given this sample there is only an 18.3% chance that the proportion of promoters is different between Expedia.com and Kayak.com. Note how the evidence for a difference has dropped when examining top-2-box scores compared to the difference between means in question 3. When we compared the means in question 3 we found a statistical difference. This illustrates that when you reduce a continuous measure to a binary outcome measure, you lose information. The result in this case is little evidence for a difference in top-2-box scores, an example of the loss of sensitivity due to the reduction of multipoint scale data to binary.
5. We need to conduct a McNemar exact test. First set up the 2 × 2 table, as shown in Table 5.25.
Table 5.25
Arrangement of Concordant and Discordant Data for Review Question 5
| Enterprise.com Pass | Enterprise.com Fail Pass | Total | |
| Budget.com Pass | 9 (a) | 3 (b) | 12 (m) |
| Budget.com Fail | 1 (c) | 1 (d) | 2 (n) |
| Total | 10 (r) | 4 (s) | 14 (N) |

We can see that four users had different outcomes (discordant pairs) between websites (from cells b and c). The minus signs in Table 5.26 indicate worse performance on Enterprise.com.
Table 5.26
Discordant Data for Review Question 5
| User | + or − Difference |
| 3 | − |
| 4 | − |
| 5 | − |
| 6 | + |
Three users performed worse on Enterprise.com and one performed better. To find the probability of having one out of four discordant pairs if the probability is really 0.50, we use the binomial probability formula to find the mid-p value. In Excel, the formula is =2*(BINOMDIST(0,4,0.5,FALSE) + 0.5*BINOMDIST(1,4,0.5,FALSE)), which generates a two-tailed mid-p value of 0.375. That is, there’s only a 62.5% chance the completion rates are different given the data from this sample. Although the observed completion rates are different, they aren’t different enough for us to conclude that Budget.com’s completion rate on this task is significantly different from Enterprise.com’s.
To compute the 90% confidence interval around the difference between proportions, we use the adjusted-Wald procedure. The critical value of z for a 90% level of confidence is 1.64, making the adjustment 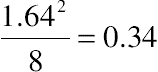 .
.
.We update the 2 × 2 table with the 0.34 adjustment to each cell (Table 5.27).
Table 5.27
Adjusted Data for Review Question 5
| Enterprise.com Pass | Enterprise.com Fail Pass | Total | |
| Budget.com Pass | 9.34 (aadj) | 3.34 (badj) | 12.7 (madj) |
| Budget.com Fail | 1.34 (cadj) | 1.34 (dadj) | 2.7 (nadj) |
| Total | 10.7 (radj) | 4.7 (sadj) | 15.4 (Nadj) |

Finding the component parts of the formula and entering the values we get






The 90% confidence interval is −9.5 to 35.5%. Because the interval crosses 0, this also tells us there’s less than a 90% chance that the completion rates are different.
6. We perform a paired t-test because the same users worked with each website. The test statistic is

Looking up the test statistic of 3.48 in a t-table with 13 degrees of freedom or using the Excel function =TDIST(3.48,13,2), we get the two-sided p-value of 0.004. We have strong evidence to conclude that users think the Budget.com website is easier to use as measured by the SUS. The t-critical value with 13 degrees of freedom for a 95% level of confidence is 2.16, so the resulting 95% confidence interval is


We can be 95% confident the mean difference for the entire user population is between 6.4 and 27.2.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.