
Appendix G. The STL Methods and Functions
The Standard Template Library (STL) aims to provide efficient implementations of common algorithms. It expresses these algorithms in general functions that can be used with any container that satisfies the requirements for the particular algorithm and in methods that can be used with instantiations of particular container classes. This appendix assumes that you have some familiarity with the STL, such as might be gained from reading Chapter 16, “The string Class and the Standard Template Library.” For example, this chapter assumes that you know about iterators and constructors.
Members Common to All Containers
All containers define the types in Table G.1. In this table, X is a container type, such as vector<int>, and T is the type stored in the container, such as int. The examples following the table clarify the meanings.
Table G.1. Types Defined for All Containers
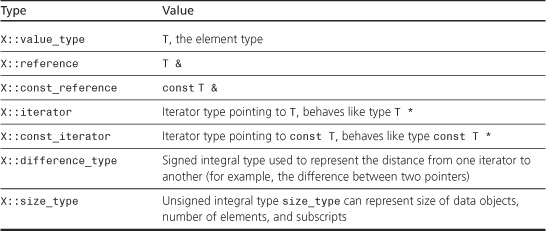
The class definition uses a typedef to define these members. You can use these types to declare suitable variables. For example, the following code uses a roundabout way to replace the first occurrence of "bonus" in a vector of string objects with "bogus" in order to show how you can use member types to declare variables:
vector<string> input;
string temp;
while (cin >> temp && temp != "quit")
input.push_back(temp);
vector<string>::iterator want=
find(input.begin(), input.end(), string("bonus"));
if (want != input.end())
{
vector<string>::reference r = *want;
r = "bogus";
}
This code makes r a reference to the element in input to which want points. Similarly, continuing with the preceding example, you can write code like the following:
vector<string>::value_type s1 = input[0]; // s1 is type string
vector<string>::reference s2 = input[1]; // s2 is type string &
This results in s1 being a new string object that’s a copy of input[0] and in s2 being a reference to input[1]. In this example, given that you already know that the template is based on the string type, it would be simpler to write the following code, which is equivalent in its effect:
string s1 = input[0]; // s1 is type string
string & s2 = input[1]; // s2 is type string &
However, the more elaborate types from Table G.1 can also be used in more general code in which the type of container and element are generic. For example, suppose you want a min() function that takes as its argument a reference to a container and returns the smallest item in the container. This assumes that the < operator is defined for the value type used to instantiate the template and that you don’t want to use the STL min_element() algorithm, which uses an iterator interface. Because the argument could be vector<int> or list<string> or deque<double>, you use a template with a template parameter, such as Bag, to represent the container. (That is, Bag is a template type that might be instantiated as vector<int>, list<string>, or some other container type.) So the argument type for the function is const Bag & b. What about the return type? It should be the value type for the container—that is, Bag::value_type. However, at this point, Bag is just a template parameter, and the compiler has no way of knowing that the value_type member is actually a type. But you can use the typename keyword to clarify that a class member is a typedef:
vector<string>::value_type st; // vector<string> a defined class
typename Bag::value_type m; // Bag an as yet undefined type
For the first definition here, the compiler has access to the vector template definition, which states that value_type is a typedef. For the second definition, the typename keyword promises that, whatever Bag may turn out to be, the combination Bag::value_type is the name of a type. These considerations lead to the following definition:

You then could use this template function as follows:
vector<int> temperatures;
// input temperature values into the vector
int coldest = min(temperatures);
The temperatures parameter would cause Bag to be evaluated as vector<int> and typename Bag::value_type to be evaluated as vector<int>::value_type, which, in turn, is int.
All containers also contain the member functions or operations listed in Table G.2. Again, X is a container type, such as vector<int>, and T is the type stored in the container, such as int. Also, a and b are values of type X.
Table G.2. Methods Defined for All Containers
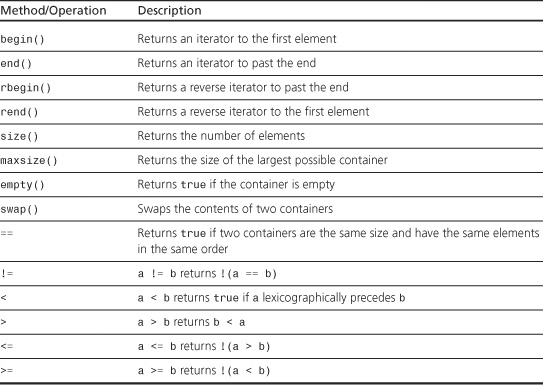
The > operator for a container assumes that the > operator is defined for the value type. A lexicographic comparison is a generalization of alphabetical sorting. It compares two containers, element-by-element, until it encounters an element in one container that doesn’t equal the corresponding element in the other container. In that case, the containers are considered to be in the same order as the noncorresponding pair of elements. For example, if two containers are identical through the first 10 elements, but the 11th element in the first container is less than the 11th element in the second container, the first container precedes the second. If two containers compare equally until one runs out of elements, the shorter container precedes the longer.
Additional Members for Vectors, Lists, and Deques
Vectors, lists, and deques are all sequences, and they all have the methods listed in Table G.3. Again, X is a container type, such as vector<int>, and T is the type stored in the container, such as int, a is a value of type X, t is a value of type X::value_type, i and j are input iterators, q2 and p are iterators, q and q1 are dereferenceable iterators (that is, you can apply the * operator to them), and n is an integer of X::size_type.
Table G.3. Methods Defined for Vectors, Lists, and Deques
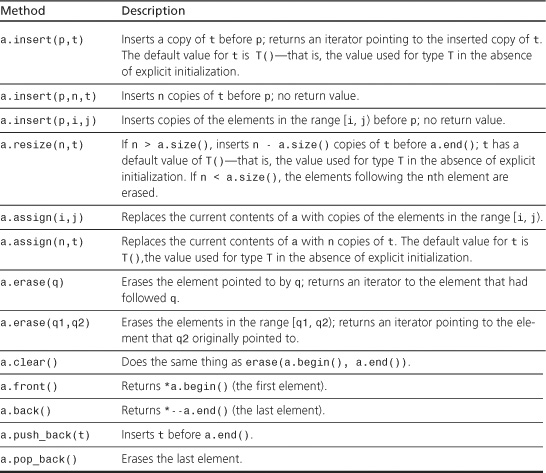
Table G.4 lists methods common to two of the three sequence classes (vector, list, and deque).
Table G.4. Methods Defined for Some Sequences

The vector template additionally has the methods in Table G.5. Here, a is a vector container and n is an integer of X::size_type.
Table G.5. Additional Methods for Vectors

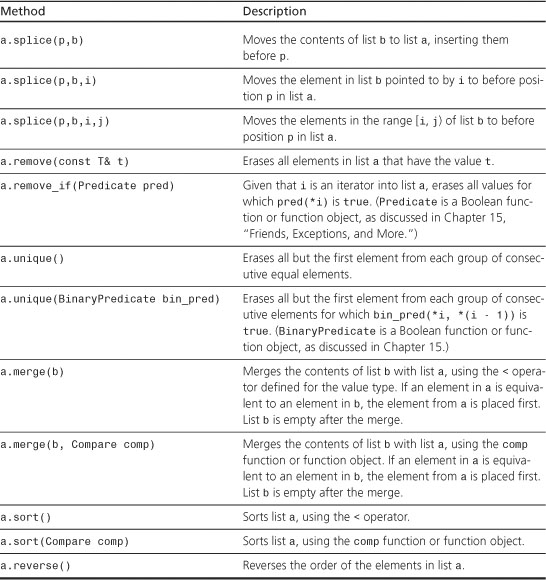
The list template additionally has the methods in Table G.6. Here, a and b are list containers, and T is the type stored in the list, such as int, t is a value of type T, i and j are input iterators, q2 and p are iterators, q and q1 are dereferenceable iterators, and n is an integer of X::size_type. The table uses the standard STL notation [i, j), meaning the range from i up to, but not including, j.
Table G.6. Additional Methods for Lists
Additional Members for Sets and Maps
Associative containers, of which sets and maps are models, have a Key template parameter and a Compare template parameter, which indicate, respectively, the type of the key used to order the contents and the function object, termed a comparison object, used to compare key values. For the set and multiset containers, the stored keys are the stored values, so the key type is the same as the value type. For the map and multimap containers, the stored values of one type (template parameter T) are associated with a key type (template parameter Key), and the value type is pair<const Key, T>. Associative containers have additional members to describe these features, as listed in Table G.7.
Table G.7. Types Defined for Associative Containers

Associative containers provide the methods listed in Table G.8. In general, the comparison object need not require that values with the same key be identical; the term equivalent keys means that two values, which may or may not be equal, have the same key. In the table, X is a container class, and a is an object of type X. If X uses unique keys (that is, is set or map), a_uniq is an object of type X. If X uses multiple keys (that is, is multiset or multimap), a_eq is an object of type X. As before, i and j are input iterators referring to elements of value_type, [i, j) is a valid range, p and q2 are iterators to a, q and q1 are dereferenceable iterators to a, [q1, q2) is a valid range, t is a value of X::value_type (which may be a pair), and k is a value of X::key_type.
Table G.8. Methods Defined for Sets, Multisets, Maps, and Multimaps
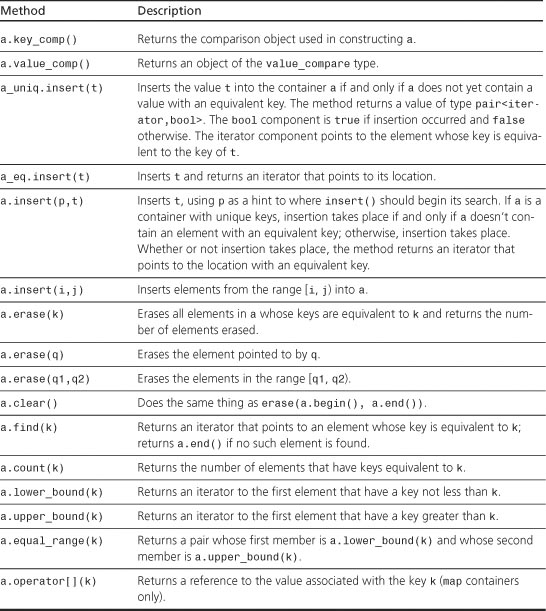
STL Functions
The STL algorithm library, supported by the algorithm and numeric header files, provides a large number of nonmember, iterator-based template functions. As discussed in Chapter 16, the template parameter names are chosen to indicate what concept particular parameters should model. For example, ForwardIterator is used to indicate that a parameter should, at the minimum, model the requirements of a forward iterator, and Predicate is used to indicate a parameter that should be a function object with one argument and a bool return value. The C++ Standard divides the algorithms into four groups: nonmodifying sequence operations, mutating sequence operations, sorting and related operators, and numeric operations. The term sequence operation indicates that the function takes a pair of iterators as arguments to define a range, or sequence, to be operated on. The term mutating means the function is allowed to alter the container.
Nonmodifying Sequence Operations
Table G.9 summarizes the nonmodifying sequence operations. Arguments are not shown, and overloaded functions are listed just once. A fuller description, including the prototypes, follows the table. Thus, you can scan the table to get an idea of what a function does and then look up the details if you find the function appealing.
Table G.9. Nonmodifying Sequence Operations
Now let’s take a more detailed look at these nonmodifying sequence operations. For each function, the discussion shows the prototype(s), followed by a brief explanation. Pairs of iterators indicate ranges, with the chosen template parameter name indicating the type of iterator. As usual a range in the form [first, last) goes from first up to, but not including, last. Some functions take two ranges, which need not be in the same kind of container. For example, you can use equal() to compare a list to a vector. Functions passed as arguments are function objects, which can be pointers (of which function names are an example) or objects for which the () operation is defined. As in Chapter 16, a predicate is a Boolean function with one argument, and a binary predicate is a Boolean function with two arguments. (The functions need not be type bool, as long as they return 0 for false and a nonzero value for true.)
for_each()
template<class InputIterator, class Function>
Function for_each(InputIterator first, InputIterator last, Function f);
The for_each() function applies function object f to each element in the range [first, last). It also returns f.
find()
template<class InputIterator, class T>
InputIterator find(InputIterator first, InputIterator last, const T& value);
The find() function returns an iterator to the first element in the range [first, last) that has the value value; it returns last if the item is not found.
find_if()
template<class InputIterator, class Predicate>
InputIterator find_if(InputIterator first, InputIterator last,
Predicate pred);
The find_if() function returns an iterator it to the first element in the range [first, last) for which the function object call pred(*i) is true; it returns last if the item is not found.
find_end()
template<class ForwardIterator1, class ForwardIterator2>
ForwardIterator1 find_end(ForwardIterator1 first1, ForwardIterator1 last1,
ForwardIterator2 first2, ForwardIterator2 last2);
template<class ForwardIterator1, class ForwardIterator2,
class BinaryPredicate>
ForwardIterator1 find_end(ForwardIterator1 first1, ForwardIterator1 last1,
ForwardIterator2 first2, ForwardIterator2 last2,
BinaryPredicate pred);
The find_end() function returns an iterator it to the last element in the range [first1, last1) that marks the beginning of a subsequence that matches the contents of the range [first2, last2). The first version uses the == operator for the value type to compare elements. The second version uses the binary predicate function object pred to compare elements. That is, elements pointed to by it1 and it2 match if pred(*it1, *it2) is true. Both return last1 if the item is not found.
find_first_of()
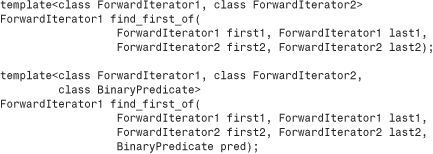
The find_first_of() function returns an iterator it to the first element in the range [first1, last1) that matches any element of the range [first2, last2). The first version uses the == operator for the value type to compare elements. The second version uses the binary predicate function object pred to compare elements. That is, elements pointed to by it1 and it2 match if pred(*it1, *it2) is true. Both return last1 if the item is not found.
adjacent_find()

The adjacent_find() function returns an iterator it to the first element in the range [first1, last1) such that the element matches the following element. The function returns last if no such pair is found. The first version uses the == operator for the value type to compare elements. The second version uses the binary predicate function object pred to compare elements. That is, elements pointed to by it1 and it2 match if pred(*it1, *it2) is true.
count()
![]()
The count() function returns the number of elements in the range [first, last) that match the value value. The == operator for the value type is used to compare values. The return type is an integer type that is large enough to contain the maximum number of items the container can hold.
count_if()
![]()
The count if() function returns the number of elements in the range [first, last) for which the function object pred returns a true value when passed the element as an argument.
mismatch()

Each of the mismatch() functions finds the first element in the range [first1, last1) that doesn’t match the corresponding element in the range beginning at first2 and returns a pair holding iterators to the two mismatching elements. If no mismatch is found, the return value is pair<last1, first2 + (last1 - first1)>. The first version uses the == operator to test matching. The second version uses the binary predicate function object pred to compare elements. That is, elements pointed to by it1 and it2 don’t match if pred(*it1, *it2) is false.
equal()

The equal() function returns true if each element in the range [first1, last1) matches the corresponding element in the sequence beginning at first2 and false otherwise. The first version uses the == operator for the value type to compare elements. The second version uses the binary predicate function object pred to compare elements. That is, elements pointed to by it1 and it2 match if pred(*it1, *it2) is true.
search()

The search() function finds the first occurrence in the range [first1, last1) that matches the corresponding sequence found in the range [first2, last2). It returns last1 if no such sequence is found. The first version uses the == operator for the value type to compare elements. The second version uses the binary predicate function object pred to compare elements. That is, elements pointed to by it1 and it2 match if pred(*it1, *it2) is true.
search_n()

The search_n() function finds the first occurrence in the range [first1, last1) that matches the sequence consisting of count consecutive occurrences of value. It returns last1 if no such sequence is found. The first version uses the == operator for the value type to compare elements. The second version uses the binary predicate function object pred to compare elements. That is, elements pointed to by it1 and it2 match if pred(*it1, *it2) is true.
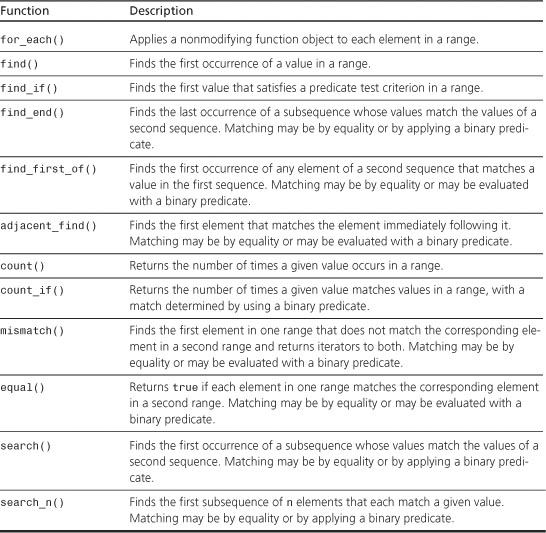
Mutating Sequence Operations
Table G.10 summarizes the mutating sequence operations. Arguments are not shown, and overloaded functions are listed just once. A fuller description, including the prototypes, follows the table. Thus, you can scan the table to get an idea of what a function does and then look up the details if you find the function appealing.
Table G.10. Mutating Sequence Operations
Now let’s take a more detailed look at these mutating sequence operations. For each function, the discussion shows the prototype(s), followed by a brief explanation. As you saw earlier, pairs of iterators indicate ranges, with the chosen template parameter name indicating the type of iterator. As usual, a range in the form [first, last) goes from first up to, but not including, last. Functions passed as arguments are function objects, which can be function pointers or objects for which the () operation is defined. As in Chapter 16, a predicate is a Boolean function with one argument, and a binary predicate is a Boolean function with two arguments. (The functions need not be type bool, as long as they return 0 for false and a nonzero value for true.) Also, as in Chapter 16, a unary function object is one that takes a single argument, and a binary function object is one that takes two arguments.
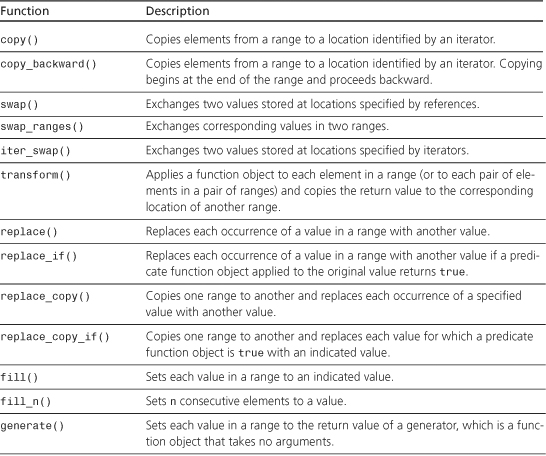
copy()
template<class InputIterator, class OutputIterator>
OutputIterator copy(InputIterator first, InputIterator last,
OutputIterator result);
The copy() function copies the elements in the range [first, last) into the range [result, result + (last - first)). It returns result + (last - first)—that is, an iterator pointing one past the last copied-to location. The function requires that result not be in the range [first, last)—that is, the target can’t overlap the source.
copy_backward()
template<class BidirectionalIterator1, class BidirectionalIterator2>
BidirectionalIterator2 copy_backward(BidirectionalIterator1 first,
BidirectionalIterator1 last, BidirectionalIterator2 result);
The copy_backward() function copies the elements in the range [first, last) into the range [result -(last - first), result). Copying begins with the element at last -1 being copied to location result - 1 and proceeds backward from there to first. It returns result - (last - first)—that is, an iterator pointing one past the last copied-to location. The function requires that result not be in the range [first, last). However, because copying is done backward, it is possible for the target and source to overlap.
swap()
template<class T> void swap(T& a, T& b);
The swap() function exchanges values stored at two locations specified by references.
swap_ranges()
template<class ForwardIterator1, class ForwardIterator2>
ForwardIterator2 swap_ranges(
ForwardIterator1 first1, ForwardIterator1 last1,
ForwardIterator2 first2);
The swap_ranges() function exchanges values in the range [first1, last1) with the corresponding values in the range beginning at first2. The two ranges should not overlap.
template<class ForwardIterator1, class ForwardIterator2>
void iter_swap(ForwardIterator1 a, ForwardIterator2 b);
The iter_swap() function exchanges values stored at two locations specified by iterators.
transform()
template<class InputIterator, class OutputIterator, class UnaryOperation>
OutputIterator transform(InputIterator first, InputIterator last,
OutputIterator result, UnaryOperation op);
template<class InputIterator1, class InputIterator2, class OutputIterator,
class BinaryOperation>
OutputIterator transform(InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, OutputIterator result,
BinaryOperation binary_op);
The first version of transform() applies the unary function object op to each element in the range [first, last) and assigns the return value to the corresponding element in the range beginning at result. So *result is set to op(*first), and so on. It returns result + (last - first)—that is, the past-the-end value for the target range.
The second version of transform() applies the binary function object op to each element in the range [first1, last1) and to each element in the range [first2, last2) and assigns the return value to the corresponding element in the range beginning at result. So *result is set to op(*first1, *first2), and so on. It returns result + (last - first), the past-the-end value for the target range.
replace()
template<class ForwardIterator, class T>
void replace(ForwardIterator first, ForwardIterator last,
const T& old_value, const T& new_value);
The replace() function replaces each occurrence of the value old_value in the range [first, last) with the value new_value.
replace_if()
template<class ForwardIterator, class Predicate, class T>
void replace_if(ForwardIterator first, ForwardIterator last,
Predicate pred, const T& new_value);
The replace()_if function replaces each value old in the range [first, last) for which pred(old) is true with the value new_value.
replace_copy()
template<class InputIterator, class OutputIterator, class T>
OutputIterator replace_copy(InputIterator first, InputIterator last,
OutputIterator result,const T& old_ value, const T& new_ value);
The replace_copy() function copies the elements in the range [first, last) to a range beginning at result but substituting new_value for each occurrence of old_value. It returns result + (last - first), the past-the-end value for the target range.
replace_copy_if()
template<class Iterator, class OutputIterator, class Predicate, class T>
OutputIterator replace_copy_if(Iterator first, Iterator last,
OutputIterator result, Predicate pred, const T& new_ value);
The replace_copy_if() function copies the elements in the range [first, last) to a range beginning at result but substituting new_value for each value old for which pred(old) is true. It returns result + (last - first), the past-the-end value for the target range.
fill()
template<class ForwardIterator, class T>
void fill(ForwardIterator first, ForwardIterator last, const T& value);
The fill() function sets each element in the range [first, last) to value.
fill_n()
template<class OutputIterator, class Size, class T>
void fill_n(OutputIterator first, Size n, const T& value);
The fill_n() function sets each of the first n elements beginning at location first to value.
generate()
template<class ForwardIterator, class Generator>
void generate(ForwardIterator first, ForwardIterator last, Generator gen);
The generate() function sets each element in the range [first, last) to gen(), where gen is a generator function object—that is, one that takes no arguments. For example, gen can be a pointer to rand().
generate_n()
template<class OutputIterator, class Size, class Generator>
void generate_n(OutputIterator first, Size n, Generator gen);
The generate_n() function sets each of the first n elements in the range beginning at first to gen(), where gen is a generator function object—that is, one that takes no arguments. For example, gen can be a pointer to rand().
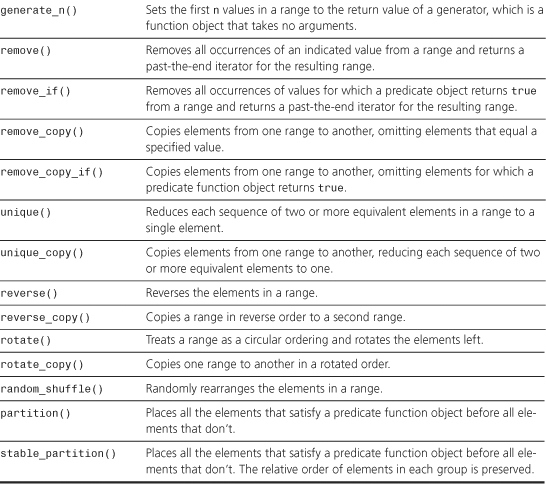
remove()
template<class ForwardIterator, class T>
ForwardIterator remove(ForwardIterator first, ForwardIterator last,
const T& value);
The remove() function removes all occurrences of value from the range [first, last) and returns a past-the-end iterator for the resulting range. The function is stable, meaning that the order of the unremoved elements is unaltered.
Note
![]()
Because the various remove() and unique() functions are not member functions, and also because they aren’t restricted to STL containers, they can’t reset the size of a container. Instead, they return an iterator that indicates the new past-the-end location. Typically, the removed items are simply shifted to the end of the container. However, for STL containers, you can use the returned iterator and one of the erase() methods to reset end().
remove_if()
template<class ForwardIterator, class Predicate>
ForwardIterator remove_if(ForwardIterator first, ForwardIterator last,
Predicate pred);
The remove_if() function removes all occurrences of values val for which pred(val) is true from the range [first, last) and returns a past-the-end iterator for the resulting range. The function is stable, meaning that the order of the unremoved elements is unaltered.
remove_copy()
template<class InputIterator, class OutputIterator, class T>
OutputIterator remove_copy(InputIterator first, InputIterator last,
OutputIterator result, const T& value);
The remove_copy() function copies values from the range [first, last) to the range beginning at result, skipping instances of value as it copies. It returns a past-the-end iterator for the resulting range. The function is stable, meaning that the order of the unremoved elements is unaltered.
remove_copy_if()
template<class InputIterator, class OutputIterator, class Predicate>
OutputIterator remove_copy_if(InputIterator first, InputIterator last,
OutputIterator result, Predicate pred);
The remove_copy_if() function copies values from the range [first, last) to the range beginning at result, skipping instances of val for which pred(val) is true as it copies. It returns a past-the-end iterator for the resulting range. The function is stable, meaning that the order of the unremoved elements is unaltered.
unique()

The unique() function reduces each sequence of two or more equivalent elements in the range [first, last) to a single element and returns a past-the-end iterator for the new range. The first version uses the == operator for the value type to compare elements. The second version uses the binary predicate function object pred to compare elements. That is, elements pointed to by it1 and it2 match if pred(*it1, *it2) is true.
unique_copy()

The unique_copy() function copies elements from the range [first, last) to the range beginning at result, reducing each sequence of two or more identical elements to a single element. It returns a past-the-end iterator for the new range. The first version uses the == operator for the value type to compare elements. The second version uses the binary predicate function object pred to compare elements. That is, elements pointed to by it1 and it2 match if pred(*it1, *it2) is true.
template<class BidirectionalIterator>
void reverse(BidirectionalIterator first, BidirectionalIterator last);
The reverse() function reverses the elements in the range [first, last) by invoking swap(first, last - 1), and so on.
reverse_copy()
template<class BidirectionalIterator, class OutputIterator>
OutputIterator reverse_copy(BidirectionalIterator first,
BidirectionalIterator last,
OutputIterator result);
The reverse copy() function copies the elements in the range [first, last) to the range beginning at result in reverse order. The two ranges should not overlap.
rotate()
template<class ForwardIterator>
void rotate(ForwardIterator first, ForwardIterator middle,
ForwardIterator last);
The rotate() function performs a left rotation on the elements in the range [first, last). The element at middle is moved to first, the element at middle + 1 is moved to first + 1, and so on. The elements preceding middle are wrapped around to the end of the container so that the element at first follows the element formerly at last - 1.
rotate_copy()
template<class ForwardIterator, class OutputIterator>
OutputIterator rotate_copy(ForwardIterator first, ForwardIterator middle,
ForwardIterator last, OutputIterator result);
The rotate_copy() function copies the elements in the range [first, last) to the range beginning at result, using the rotated sequence described for rotate().
replace()
template<class RandomAccessIterator>
void random_shuffle(RandomAccessIterator first, RandomAccessIterator last);
This version of the random_shuffle() function shuffles the elements in the range [first, last). The distribution is uniform; that is, each possible permutation of the original order is equally likely.
random_shuffle()
template<class RandomAccessIterator, class RandomNumberGenerator>
void random_shuffle(RandomAccessIterator first, RandomAccessIterator last,
RandomNumberGenerator& random);
This version of the random_shuffle() function shuffles the elements in the range [first, last). The function object random determines the distribution. Given n elements, the expression random(n) should return a value in the range [0,n).
partition()
template<class BidirectionalIterator, class Predicate>
BidirectionalIterator partition(BidirectionalIterator first,
BidirectionalIterator last,
Predicate pred);
The partition() function places each element whose value val is such that pred(val) is true before all elements that don’t meet that test. It returns an iterator to the position following that last position, holding a value for which the predicate object function was true.
stable_partition()
template<class BidirectionalIterator, class Predicate>
BidirectionalIterator stable_partition(BidirectionalIterator first,
BidirectionalIterator last,
Predicate pred);
The stable_partition() function places each element whose value val is such that pred(val) is true before all elements that don’t meet that test. This function preserves the relative ordering within each of the two groups. It returns an iterator to the position following that last position, holding a value for which the predicate object function was true.
Sorting and Related Operations
Table G.11 summarizes the sorting and related operations. Arguments are not shown, and overloaded functions are listed just once. Each function has a version that uses < for ordering elements and a version that uses a comparison function object for ordering elements. A fuller description, including the prototypes, follows the table. Thus, you can scan the table to get an idea of what a function does and then look up the details if you find the function appealing.
Table G.11. Sorting and Related Operations
The functions in this section determine the order of two elements by using the < operator defined for the elements or by using a comparison object designated by the template type Compare. If comp is an object of type Compare, then comp(a,b) is a generalization of a < b and returns true if a precedes b in the ordering scheme. If a < b is false and b < a is also false, a and b are equivalent. A comparison object must provide at least strict weak ordering. This means the following:
• The expression comp(a,a) must be false, a generalization of the fact that a value can’t be less than itself. (This is the strict part.)
• If comp(a,b) is true and comp(b,c) is true, then comp(a,c) is true (that is, comparison is a transitive relationship).
• If a is equivalent to b and b is equivalent to c, then a is equivalent to c (that is, equivalency is a transitive relationship).
If you think of applying < to integers, then equivalency implies equality, but this doesn’t have to hold for more general cases. For example, you could define a structure with several members describing a mailing address and define a comp comparison object that orders the structures according to zip code. Then any two addresses with the same zip code would be equivalent but not equal.
Now let’s take a more detailed look at these sorting and related operations. For each function, the discussion shows the prototype(s), followed by a brief explanation. This section is divided into several subsections. As you saw earlier, pairs of iterators indicate ranges, with the chosen template parameter name indicating the type of iterator. As usual, a range in the form [first, last) goes from first up to, but not including, last. Functions passed as arguments are function objects, which can be pointers or objects for which the () operation is defined. As you learned in Chapter 16, a predicate is a Boolean function with one argument, and a binary predicate is a Boolean function with two arguments. (The functions need not be type bool, as long as they return 0 for false and a nonzero value for true.) Also, as in Chapter 16, a unary function object is one that takes a single argument, and a binary function object is one that takes two arguments.
Sorting
First, let’s examine the sorting algorithms.
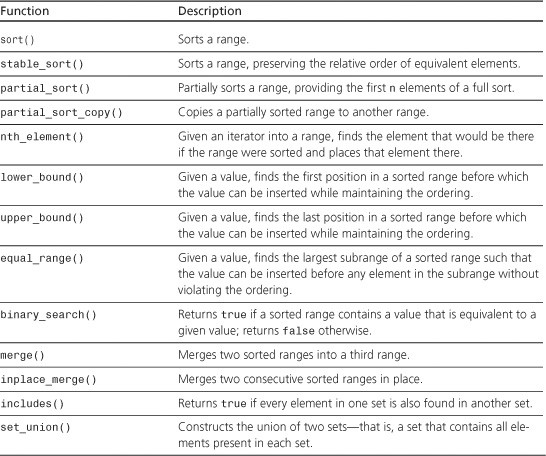
sort()

The sort() function sorts the range [first, last) in increasing order, using the value type < operator for comparison. The first version uses <, and the second version uses the comparison object comp to determine the order.
stable_sort()

The stable_sort() function sorts the range [first, last), preserving the relative order of equivalent elements. The first version uses <, and the second version uses the comparison object comp to determine the order.
partial_sort()

The partial_sort() function partially sorts the range [first, last). The first middle - first elements of the sorted range are placed in the range [first, middle), and the remaining elements are unsorted. The first version uses <, and the second version uses the comparison object comp to determine the order.
partial_sort_copy()

The partial_sort_copy() function copies the first n elements of the sorted range [first, last) to the range [result_first, result_first + n). The value of n is the lesser of last - first and result_last - result_first. The function returns result_first + n. The first version uses <, and the second version uses the comparison object comp to determine the order.
nth_element()

The nth_element() function finds the element in the range [first, last) that would be at position nth were the range sorted, and it places that element at position nth. The first version uses <, and the second version uses the comparison object comp to determine the order.
Binary Searching
The algorithms in the binary searching group assume that the range is sorted. They only require a forward iterator but are most efficient for random iterators.
lower_bound()

The lower_bound() function finds the first position the a sorted range [first, last) in front of which value can be inserted without violating the order. It returns an iterator that points to this position. The first version uses <, and the second version uses the comparison object comp to determine the order.
upper_bound()

The upper_bound() function finds the last position in the sorted range [first, last) in front of which value can be inserted without violating the order. It returns an iterator that points to this position. The first version uses <, and the second version uses the comparison object comp to determine the order.
equal_range()

The equal_range() function finds the largest subrange [it1, it2) in the sorted range [first, last) such that value can be inserted in front of any iterator in this range without violating the order. The function returns a pair formed of it1 and it2. The first version uses <, and the second version uses the comparison object comp to determine the order.
binary_search()

The binary_search() function returns true if the equivalent of value is found in the sorted range [first, last); it returns false otherwise. The first version uses <, and the second version uses the comparison object comp to determine the order.
Note
![]()
Recall that if < is used for ordering, the values a and b are equivalent if both a < b and b < a are false. For ordinary numbers, equivalency implies equality, but this is not the case for structures sorted on the basis of just one member. Thus, there may be more than one location where a new value can be inserted and still keep the data ordered. Similarly, if the comparison object comp is used for ordering, equivalency means both comp(a,b) and comp(b,a) are false. (This is a generalization of the statement that a and b are equivalent if a is not less than b and b is not less than a.)
Merging
The merging functions assume that ranges are sorted.
merge()

The merge() function merges elements from the sorted range [first1, last1) and from the sorted range [first2, last2), placing the result in a range starting at result. The target range should not overlap either of the merged ranges. When equivalent elements are found in both ranges, elements from the first range precede elements of the second. The return value is the past-the-end iterator for the resulting merge. The first version uses <, and the second version uses the comparison object comp to determine the order.
inplace_merge()

The inplace_merge() function merges two consecutive sorted ranges—[first, middle) and [middle, last)—into a single sorted sequence stored in the range [first, last). Elements from the first range precede equivalent elements from the second range. The first version uses <, and the second version uses the comparison object comp to determine the order.
Working with Sets
Set operations work with all sorted sequences, including set and multiset. For containers that hold more than one instance of a value, such as multiset, definitions are generalized. A union of two multisets contains the larger number of occurrences of each element, and an intersection contains the lesser number of occurrences of each element. For example, suppose Multiset A contains the string "apple" seven times and Multiset B contains the same string four times. Then the union of A and B will contain seven instances of "apple", and the intersection will contain four instances.
includes()

The includes() function returns true if every element in the range [first2, last2) is also found in the range [first1, last1); it returns false otherwise. The first version uses <, and the second version uses the comparison object comp to determine the order.
set_union()

The set_union() function constructs the set that is the union of the ranges [first1, last1) and [first2, last2) and copies the result to the location pointed to by result. The resulting range should not overlap either of the original ranges. The function returns a past-the-end iterator for the constructed range. The union is the set that contains all elements found in either or both sets. The first version uses <, and the second version uses the comparison object comp to determine the order.
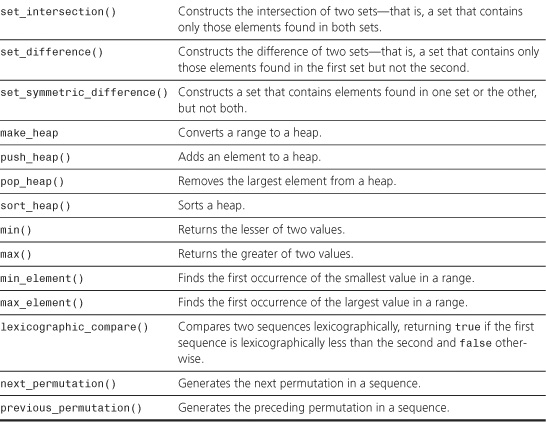
set_intersection()

The set_intersection() function constructs the set that is the intersection of the ranges [first1, last1) and [first2, last2) and copies the result to the location pointed to by result. The resulting range should not overlap either of the original ranges. The function returns a past-the-end iterator for the constructed range. The intersection is the set that contains the elements that are common to both sets. The first version uses <, and the second version uses the comparison object comp to determine the order.
set_difference()

The set_difference() function constructs the set that is the difference between the ranges [first1, last1) and [first2, last2) and copies the result to the location pointed to by result. The resulting range should not overlap either of the original ranges. The function returns a past-the-end iterator for the constructed range. The difference is the set that contains the elements found in the first set but not in the second. The first version uses <, and the second version uses the comparison object comp to determine the order.

The set_symmetric_difference() function constructs the set that is the symmetric difference between the ranges [first1, last1) and [first2, last2) and copies the result to the location pointed to by result. The resulting range should not overlap either of the original ranges. The function returns a past-the-end iterator for the constructed range. The symmetric difference is the set that contains the elements found in the first set but not in the second and the elements found in the second set but not the first. It’s the same as the difference between the union and the intersection. The first version uses <, and the second version uses the comparison object comp to determine the order.
Working with Heaps
A heap is a common data form with the property that the first element in a heap is the largest. Whenever the first element is removed or any element is added, the heap may have to be rearranged to maintain that property. A heap is designed so that these two operations are done efficiently.
make_heap()

The make_heap() function makes a heap of the range [first, last). The first version uses < to determine the ordering, and the second version uses the comp comparison object.
push_heap()

The push_heap() function assumes that the range [first, last - 1) is a valid heap, and it adds the value at location last - 1 (that is, one past the end of the heap that is assumed to be valid) into the heap, making [first, last) a valid heap. The first version uses < to determine the ordering, and the second version uses the comp comparison object.
pop_heap()

The pop_heap() function assumes that the range [first, last) is a valid heap. It swaps the value at location last - 1 with the value at first and makes the range [first, last - 1) a valid heap. The first version uses < to determine the ordering, and the second version uses the comp comparison object.
sort_heap()

The sort_heap() function assumes that the range [first, last) is a heap and sorts it. The first version uses < to determine the ordering, and the second version uses the comp comparison object.
Finding Minimum and Maximum Values
The minimum and maximum functions return the minimum and maximum values of pairs of values and of sequences of values.
min()

The min() function returns the lesser of two values. If the two values are equivalent, it returns the first value. The first version uses < to determine the ordering, and the second version uses the comp comparison object.
max()

The max() function returns the greater of two values. If the two values are equivalent, it returns the first value. The first version uses < to determine the ordering, and the second version uses the comp comparison object.
min_element()

The min_element() function returns the first iterator it in the range [first, last) such that no element in the range is less than *it. The first version uses < to determine the ordering, and the second version uses the comp comparison object.
max_element()

The max_element() function returns the first iterator it in the range [first, last) such that there is no element that *it is less than. The first version uses < to determine the ordering, and the second version uses the comp comparison object.
lexicographical_compare()

The lexicographical_compare() function returns true if the sequence of elements in the range [first1, last1) is lexicographically less than the sequence of elements in the range [first2, last2); it returns false otherwise. A lexicographic comparison compares the first element of one sequence to the first of the second—that is, it compares *first1 to *first2. If *first1 is less than *first2, the function returns true. If *first2 is less than *first1, the function returns false. If the two are equivalent, comparison proceeds to the next element in each sequence. This process continues until two corresponding elements are not equivalent or until the end of a sequence is reached. If two sequences are equivalent until the end of one is reached, the shorter sequence is less. If the two sequences are equivalent and of the same length, neither is less, so the function returns false. The first version of the function uses < to compare elements, and the second version uses the comp comparison object. The lexicographic comparison is a generalization of an alphabetic comparison.
Working with Permutations
A permutation of a sequence is a reordering of the elements. For example, a sequence of three elements has six possible orderings because you have a choice of three elements for the first element. Choosing a particular element for the first position leaves a choice of two for the second, and one for the third. For example, the six permutations of the digits 1, 2, 3 are as follows:
123 132 213 232 312 321
In general, a sequence of n elements has n × (n-1) × ... × 1, or n! possible permutations.
The permutation functions assume that the set of all possible permutations can be arranged in lexicographic order, as in the previous example of six permutations. That means, in general, that there is a specific permutation that precedes and follows each permutation. For example, 213 immediately precedes 232, and 312 immediately follows it. However, the first permutation (123 in the example) has no predecessor, and the last permutation (321 in the example) has no follower.
next_permutation()

The next_permutation() function transforms the sequence in the range [first, last) to the next permutation in lexicographic order. If the next permutation exists, the function returns true. If it doesn’t exist (that is, the range contains the last permutation in lexicographic order), the function returns false and transforms the range to the first permutation in lexicographic order. The first version uses < to determine the ordering, and the second version uses the comp comparison object.
prev_permutation()

The previous_permutation() function transforms the sequence in the range [first, last) to the previous permutation in lexicographic order. If the previous permutation exists, the function returns true. If it doesn’t exist (that is, the range contains the first permutation in lexicographic order), the function returns false and transforms the range to the last permutation in lexicographic order. The first version uses < to determine the ordering, and the second version uses the comp comparison object.
Numeric Operations
Table G.12 summarizes the numeric operations, which are described by the numeric header file. Arguments are not shown, and overloaded functions are listed just once. Each function has a version that uses < for ordering elements and a version that uses a comparison function object for ordering elements. A fuller description, including the prototypes, follows the table. Thus, you can scan the table to get an idea of what a function does and then look up the details if you find the function appealing.
Table G.12. Sorting and Related Operations
Now let’s take a more detailed look at these numeric operations. For each function, the discussion shows the prototype(s), followed by a brief explanation.
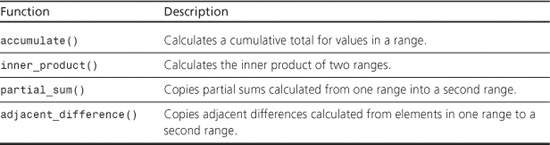
accumulate()

The accumulate() function initializes a value acc to init; then it performs the operation acc = acc + *i (first version) or acc = binary_op(acc, *i) (second version) for each iterator i in the range [first, last), in order. It then returns the resulting value of acc.
inner_product()

The inner_product() function initializes a value acc to init; then it performs the operation acc = *i * *j (first version) or acc = binary_op(*i, *j) (second version) for each iterator i in the range [first1, last1), in order, and each corresponding iterator j in the range [first2, first2 + (last1 - first1)). That is, it calculates a value from the first elements from each sequence, then from the second elements of each sequence, and so on, until it reaches the end of the first sequence. (Hence the second sequence should be at least as long as the first.) The function then returns the resulting value of acc.
partial_sum()

The partial_sum() function assigns *first to *result or *first + *(first + 1) to *(result + 1) (first version) or it assigns binary_op(*first, *(first + 1)) to *(result + 1) (second version), and so on. That is, the nth element of the sequence beginning at result contains the sum (or binary_op equivalent) of the first n elements of the sequence beginning at first. The function returns the past-the-end iterator for the result. The algorithm allows result to be first—that is, it allows the result to be copied over the original sequence, if desired.
adjacent_difference()

The adjacent_difference() function assigns *first to the location result (*result = *first). Subsequent locations in the target range are assigned the differences (or binary_op equivalent) of adjacent locations in the source range. That is, the next location in the target range (result + 1) is assigned *(first + 1) - *first (first version) or binary_op(*(first + 1), *first) (second version), and so on. The function returns the past-the-end iterator for the result. The algorithm allows result to be first—that is, it allows the result to be copied over the original sequence, if desired.