
8. Adventures in Functions
In this chapter you’ll learn about the following:
• Inline functions
• Reference variables
• How to pass function arguments by reference
• Default arguments
• Function overloading
• Function templates
• Function template specializations
With Chapter 7, “Functions: C++’s Programming Modules,” under your belt, you now know a lot about C++ functions, but there’s much more to come. C++ provides many new function features that separate C++ from its C heritage. The new features include inline functions, by-reference variable passing, default argument values, function overloading (polymorphism), and template functions. This chapter, more than any other you’ve read so far, explores features found in C++ but not C, so it marks your first major foray into plus-plussedness.
C++ Inline Functions
Inline functions are a C++ enhancement designed to speed up programs. The primary distinction between normal functions and inline functions is not in how you code them but in how the C++ compiler incorporates them into a program. To understand the distinction between inline functions and normal functions, you need to peer more deeply into a program’s innards than we have so far. Let’s do that now.
The final product of the compilation process is an executable program, which consists of a set of machine language instructions. When you start a program, the operating system loads these instructions into the computer’s memory so that each instruction has a particular memory address. The computer then goes through these instructions step-by-step. Sometimes, as when you have a loop or a branching statement, program execution skips over instructions, jumping backward or forward to a particular address. Normal function calls also involve having a program jump to another address (the function’s address) and then jump back when the function terminates. Let’s look at a typical implementation of that process in a little more detail. When a program reaches the function call instruction, the program stores the memory address of the instruction immediately following the function call, copies function arguments to the stack (a block of memory reserved for that purpose), jumps to the memory location that marks the beginning of the function, executes the function code (perhaps placing a return value in a register), and then jumps back to the instruction whose address it saved.1 Jumping back and forth and keeping track of where to jump means that there is an overhead in elapsed time to using functions.
C++ inline functions provide an alternative. In an inline function, the compiled code is “in line” with the other code in the program. That is, the compiler replaces the function call with the corresponding function code. With inline code, the program doesn’t have to jump to another location to execute the code and then jump back. Inline functions thus run a little faster than regular functions, but they come with a memory penalty. If a program calls an inline function at ten separate locations, then the program winds up with ten copies of the function inserted into the code (see Figure 8.1).
Figure 8.1. Inline functions versus regular functions.
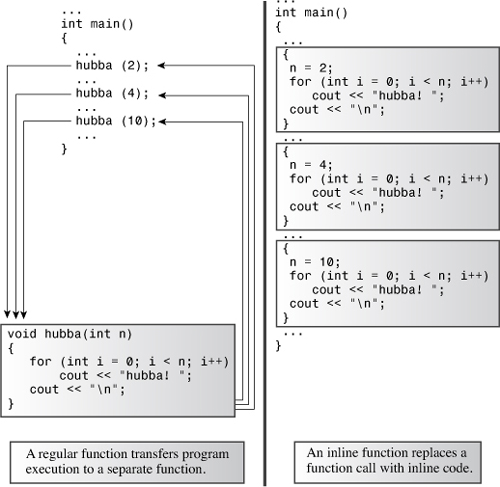
You should be selective about using inline functions. If the time needed to execute the function code is long compared to the time needed to handle the function call mechanism, then the time saved is a relatively small portion of the entire process. If the code execution time is short, then an inline call can save a large portion of the time used by the non-inline call. On the other hand, you are now saving a large portion of a relatively quick process, so the absolute time savings may not be that great unless the function is called frequently.
To use this feature, you must take at least one of two actions:
• Preface the function declaration with the keyword inline.
• Preface the function definition with the keyword inline.
A common practice is to omit the prototype and to place the entire definition (meaning the function header and all the function code) where the prototype would normally go.
The compiler does not have to honor your request to make a function inline. It might decide the function is too large or notice that it calls itself (recursion is not allowed or indeed possible for inline functions), or the feature might not be turned on or implemented for your particular compiler.
Listing 8.1 illustrates the inline technique with an inline square() function that squares its argument. Note that the entire definition is on one line. That’s not required, but if the definition doesn’t fit on one or two lines (assuming you don’t have lengthy identifiers), the function is probably a poor candidate for an inline function.
// inline.cpp -- using an inline function
#include <iostream>
// an inline function definition
inline double square(double x) { return x * x; }
int main()
{
using namespace std;
double a, b;
double c = 13.0;
a = square(5.0);
b = square(4.5 + 7.5); // can pass expressions
cout << "a = " << a << ", b = " << b << "
";
cout << "c = " << c;
cout << ", c squared = " << square(c++) << "
";
cout << "Now c = " << c << "
";
return 0;
}
Here’s the output of the program in Listing 8.1:
a = 25, b = 144
c = 13, c squared = 169
Now c = 14
This output illustrates that inline functions pass arguments by value just like regular functions do. If the argument is an expression, such as 4.5 + 7.5, the function passes the value of the expression—12 in this case. This makes C++’s inline facility far superior to C’s macro definitions. See the “Inline Versus Macros” sidebar.
Even though the program doesn’t provide a separate prototype, C++’s prototyping features are still in play. That’s because the entire definition, which comes before the function’s first use, serves as a prototype. This means you can use square() with an int argument or a long argument, and the program automatically type casts the value to type double before passing it to the function.
Reference Variables
C++ adds a new compound type to the language—the reference variable. A reference is a name that acts as an alias, or an alternative name, for a previously defined variable. For example, if you make twain a reference to the clemens variable, you can use twain and clemens interchangeably to represent that variable. Of what use is such an alias? Is it to help people who are embarrassed by their choice of variable names? Maybe, but the main use for a reference variable is as a formal argument to a function. If you use a reference as an argument, the function works with the original data instead of with a copy. References provide a convenient alternative to pointers for processing large structures with a function, and they are essential for designing classes. Before you see how to use references with functions, however, let’s examine the basics of defining and using a reference. Keep in mind that the purpose of the following discussion is to illustrate how references work, not how they are typically used.