
2.5. Data Models
Before You Reached Here ...
![]() Easiest and
Easiest and ![]() Promenade: Chapter 2.4 Data Viewpoint has discussed how to understand a system by looking at its memory or its stored data. This chapter discusses the technicalities of building such a model.
Promenade: Chapter 2.4 Data Viewpoint has discussed how to understand a system by looking at its memory or its stored data. This chapter discusses the technicalities of building such a model.
![]() More Difficult: This chapter deals with how to build a model, and your trail bypasses it. As you are here, take the time now to look through this chapter. You may find some new variations on the data modeling technique. If you want to rejoin your own trail, turn to Chapter 1.3 What About the Business Data?
More Difficult: This chapter deals with how to build a model, and your trail bypasses it. As you are here, take the time now to look through this chapter. You may find some new variations on the data modeling technique. If you want to rejoin your own trail, turn to Chapter 1.3 What About the Business Data?
![]() Most Difficult: You should be at Chapter 1.3 What About the Business Data? but feel free to stay here to review this material. A guide at the end of this chapter will steer you back to your chosen trail.
Most Difficult: You should be at Chapter 1.3 What About the Business Data? but feel free to stay here to review this material. A guide at the end of this chapter will steer you back to your chosen trail.
Role of Data Models
A fundamental task of information systems is to store and retrieve data. Regardless of whether the system uses computerized files or manual ledgers to keep its data, the system must remember facts about subjects that are important to the system.
Without knowing what the system remembers, you cannot know what the system does.
So far in the Piccadilly Project, you have modeled only the processes that transform and/or store data. Apart from adding data stores to the data flow diagrams, you have not modeled any of the data. This is like forgetting to breathe because you happen to be eating. It is necessary in systems analysis to model both the data and the processes, and to model them at the same time. If the stored data are not understood, there is little chance of understanding the processes that store the data.
To build the data model, you use the idea of partitioning as you did for the data flow diagram. However, instead of using flows and processes, you use entities and relationships to partition the system. Data models are also known as entity-relationship diagrams, Chen diagrams, and information models, among other aliases.
In this chapter, we’ll demonstrate how to build a data model to reflect the system’s business policy. We’ll also discuss how definitions of the existing stored data may help you to build a data model. Neither of these methods is perfect. After we have taken you through event partitioning, we’ll show you another strategy. However, you first need to understand the role of the data model and how it represents the policy of the system.
Entities
An entity is a rational collection of data elements. It describes something from the real world that is important to the business.
For an example of a business, let’s look at an annual event held at the Richmond Arms. The Richmond Arms is a public house built beside the millstream at West Ashling in the county of Sussex. Each year, the pub’s landlord raises money for charity by holding a duck race.
“Foul!” cry the readers (pun intended). “Ducks are not orderly enough for organized racing!” This fact of nature was indeed apparent to the landlord at the time of the inaugural race. So he hit upon the idea of using wooden ducks.
The ducks are placed in the millstream, and they float on the current from the starting gate to the far side of the Southbrook Bridge. Customers of the pub who wish to enter a duck in the race (the landlord calls them “sponsors”) must pledge a sum of money before the duck is handed over. The duck must float in a proper upright position, and it has to be modified below the waterline for this to happen. Modifications to improve floating and use of the current are encouraged, with the exception of any form of motorization or other power.
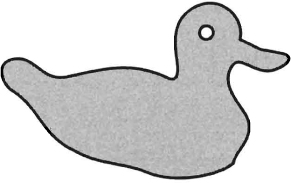
Figure 2.5.1: A Richmond Arms duck. Made of wood, the ducks are available in the public bar of the Richmond Arms in return for pledging money to charity.
The sponsor may not handle the duck during the race. The landlord very sensibly introduced this rule after several over-enthusiastic, and possibly over-inebriated, sponsors entered the water to assist their ducks without realizing they were unable to swim (the sponsors, not the ducks). They (the sponsors) were rescued, safe but not exactly sound, on the downstream side of Oakwood Weir. The ducks are still missing.
The sponsorship money, the total of all the pledges, is presented to the charity of the winner’s choice during post-race ceremonies in the public bar.*
*This is not fiction. There actually is an annual West Ashling Duck Race. Skeptical readers are invited to attend the event at the Richmond Arms, West Ashling, Chichester, West Sussex, England. One or two details of the race rules have been altered for technical reasons, and the rule about the ducks entering the oil drum was omitted.
What entities can you find in the above description of the business? First, recall that an entity is a rational collection of data elements that describes something important to the business. The landlord has to remember who the sponsors are, as they play an important role. Sponsors pledge money to enter the race. The system has to remember such facts as the sponsor’s name and telephone number. (The term “remember” here means that the system stores that data. It doesn’t matter if the landlord writes the information in a book, keeps it in his head, or uses a computer. The point is that the system retains the information.) Because the system has to remember each sponsor, you can say that SPONSOR is an entity.
The landlord also keeps information about each duck and charity. The sponsors may independently raise money to increase their pledges. This means that a duck, charity, and pledge are all real-world things, and the system needs to remember them. DUCK, CHARITY, and PLEDGE, thus, become entities.
An entity has a unique purpose and a definable role in the enterprise. For example, a SPONSOR promises a PLEDGE and nominates the CHARITY that he wants a duck to represent. The DUCK is an entrant in the race. The PLEDGE is an amount of money that may be increased from time to time. A CHARITY is the beneficiary of all the money raised by the event. Every entity in a data model must have a clearly stated purpose. If you cannot state the purpose, the proposed entity is not an entity at all; it is probably data that describe some other entity.
Every entity must have a unique and definable role in the business.
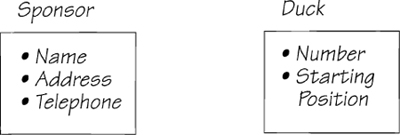
Each of the entities—SPONSOR, DUCK, PLEDGE, and CHARITY—represents a collection of data elements. For example, the name of the sponsor is recorded along with the address and telephone number. The DUCK entity contains its identifying number and the starting position. (Ducks are assigned their starting position from a draw. One side of the gate is released at the start. Ducks drawing low-numbered positions are on the advantageous side.)
An entity must have at least one attribute to describe it.
Each entity stores data. It is like a container in which you put data elements that are all about the same subject. Each container must have at least one data element. These elements, or attributes as they are known, describe one entity and no other.
An entity is the subject of some data. It is not the data itself. For instance, SPONSOR is an entity. You cannot give a value to SPONSOR, but you can have attributes to describe it. NAME is an attribute of SPONSOR, for example. On the other hand, NAME has a value but no attributes.
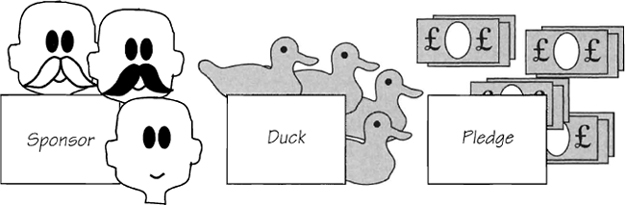
Figure 2.5.4: Each entity type represents all occurrences of the entity. For example, the entity SPONSOR represents all the sponsors taking part in the event.
There can be many occurrences of each type of entity. For example, there are many ducks. The race rules allow up to fifty of them. Similarly, there are many sponsors, many charities, and so on. Each entity type in the data model is not a single instance, but rather it represents every occurrence of the entity.
You may prefer to think of this situation by using a table in which each column represents one of the entity’s attributes, and each row an occurrence of the entity. Figure 2.5.5 is an example of such a table.

Figure 2.5.5: This table represents all occurrences of the entity SPONSOR. The column headings are the attributes, and each row contains the unique data values for each sponsor. Extra rows are added as each new sponsor enters the race.
Each of the entities DUCK and PLEDGE also has such a table. If there are many occurrences of the entity, the table becomes quite long and unwieldy. So for the purposes of this book, we’ll represent the system’s entities using a rectangle on the data model, with its attributes listed in a data dictionary. If you prefer to use the table notation, that is your choice.
Because there are many occurrences of an entity, each one must be uniquely identified. For example, the entity SPONSOR has an attribute NAME that distinguishes a specific instance of sponsor from all the others. Each DUCK has a unique number, and so on.

Entities are uniquely identifiable.
While entities have numbers, names, and so on to identify them, they do not have codes that alter the business role of the entity. For example, at the moment, sponsors are people who frequent the Richmond Arms pub. Suppose that we change the system a little, and we now wish to include information about the course marshals who organize the race and oversee its correct running. Both the marshals and sponsors are customers, but it wouldn’t be correct to model an entity CUSTOMER and give it a code to indicate which role it is playing. Although they both happen to be customers, marshals and sponsors play different parts in the system and have different attributes. If you only had a CUSTOMER entity, some of the marshal’s attributes would not be relevant to a sponsor, and vice versa. So you must ensure that each entity is a unique collection of attributes.
Each attribute applies to every occurrence of its entity.
The entities you have seen so far are not connected to each other. Each one contains data that are relevant only to that entity. For example, the SPONSOR entity holds only data that directly pertain to someone willing to pledge money and float a duck. It does not contain anything else. The DUCK entity contains only attributes that describe a wooden duck. How do you know which DUCK belongs to which SPONSOR? You know because of the relationship.
Relationships
A relationship connects entities and, through the connection, expresses the business policy of the data model. In the duck race, the landlord needs to know which ducks are being sponsored by which sponsor. He also needs to know which sponsors have promised a pledge. By using a relationship to connect ducks to the relevant sponsor, and another to connect a sponsor to his pledges, the landlord can keep track of all the entities.
Figure 2.5.6 shows the relationships that connect the duck race entities. The relationship is not just the simple association of entities; there must be some business policy that describes the circumstances for making the connection. You’ll find the policy for these relationships in the rules for the race:
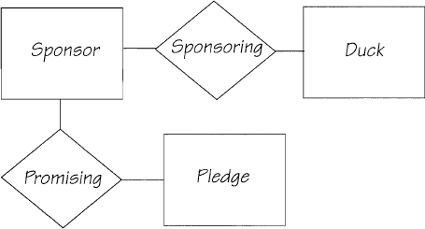
Figure 2.5.6: The relationship describes a business association between the entities. The relationship’s name reflects the reason for the association.
The relationship is a business connection between entities. There must be some business policy to establish the connection.
Looking through the rules, you can see that a pub customer may sponsor a duck if he promises to hand over at least £100 (which goes to charity), and agrees to modify and number the duck in the approved manner. Of course, a duck must be available in order to be sponsored. So for each willing sponsor, the landlord writes down the sponsor’s details and the number of the duck being sponsored. By associating two entities according to the business rules, the landlord establishes the relationship.
You must be able to write the rules for associating the entities. If you can’t, there may be no reason for the association. Normally, the processes that store or retrieve data make use of the relationships. Mini specifications describe processes (the topic of Chapter 2.12 Mini Specifications), and it is here that you describe each specific circumstance under which the relationships and entities are created, referenced, updated, and deleted.
The rules for relating entities must be definable business rules. They are part of the mini specifications for the processes handling the entities.
Some relationships have attributes. For example, the landlord at the Richmond Arms records the date, time, and a witness’ name when one of his customers asks to sponsor a duck. (He does this so that he can remind sponsors of their obligations if they forget to pick up their ducks on the day of the race.) However, the attributes of the relationship must be data that exist because the relationship exists. For example, the date, time, and witness’ name are only important to the business because a sponsor has a SPONSORING relationship with a duck. Note also that you cannot attribute these pieces of data to either the duck or the sponsor, but only to the SPONSORING relationship.
The relationship may contain attributes provided they describe the relationship itself, and not the participating entities.
To make the model more informative, you must give each relationship a unique name to describe the reason for the relationship’s existence. While you are thinking of a suitable name for a relationship (it’s not always easy), try to remember that a relationship is not directional. It simply indicates which entities participate in the relationship and the reason for their participation. For example, Figure 2.5.6 shows a SPONSORING relationship between a duck and a sponsor.
While verbs in business descriptions tend to become relationships in data models, do not read the relationship as a verb. Do not say, “A sponsor is sponsoring a duck” because it doesn’t work the other way. Wooden ducks don’t have the money to sponsor one of the pub’s customers. Instead, read “sponsoring” as the noun form of the verb (or gerund, as is its proper grammatical term). In other words, “The sponsor and the duck have a sponsoring relationship.” There is a business link that the system needs to remember because of an act of sponsorship.
Similarly, the sponsor and the pledge have a PROMISING relationship: The pledge is promised, and the sponsor promises. Pledges are donated to a charity, the charity receives a donation, so a DONATING relationship is appropriate. The money raised by the duck race goes to the charity that is represented by the winning duck. Alternatively, the winning duck represents a charity. To call the relationship REPRESENTING describes the reason that the system needs to remember the relationship between a duck and a charity.
We suggested that when you name relationships you use the noun form of the verb. Typically, relationship names end with “ing,” “ment,” “tion,” or “ance.” Remember that you are describing why the relationship exists, not the action of one of the entities.
We built the model in Figure 2.5.7 by putting together everything we know about the West Ashling Duck Race. Since the data model is a reflection of the system’s business policy, before continuing, be sure that it is as accurate as possible at this stage of the analysis. The model in Figure 2.5.7 seems to have all the necessary entities, and there is nothing else in the race rules to suggest other data that need to be stored. The system doesn’t have to remember its owner (the landlord), its place of business (the Richmond Arms), or other information regarding the internal workings of the system.
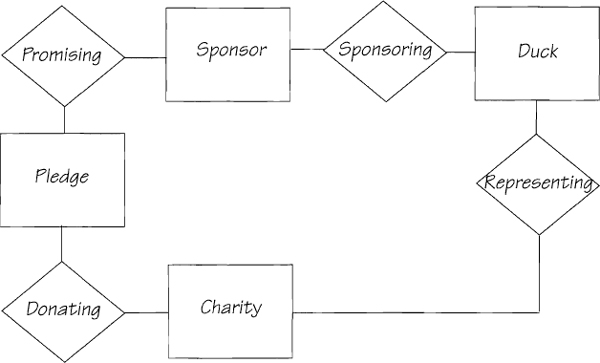
Do you understand the necessary relationships? There is always a tendency when building data models to relate every entity to every other. However, show only the relationships that are necessary for the business in the model. For example, should the SPONSOR relate to the CHARITY? While a sponsor may be an avid supporter of one or more charities, it is of little interest to the system because it is the DUCK that determines whether the charity benefits (all the money goes to the charity represented by the winning duck). The model shows only the direct and important relationships.
Similarly, should there be a connection between the DUCK and the PLEDGE? All the money raised by the pledges is given to a charity after the race. This means that the system has no interest in how much money has been pledged for any given duck, so there is no need to show a relationship between those entities.
No Foreign Keys
Before going on, we wish to exorcise a common misconception about relationships. The misconception concerns foreign keys.
Foreign keys are a way of implementing a relationship. They are not the relationship.
A foreign key is one or more attributes that are included in one entity for the purpose of identifying another. For example, a SPONSOR has an attribute NAME to identify it. If the DUCK also held the sponsor’s NAME and, on the other side of the relationship, the SPONSOR contained the duck’s NUMBER, the two entities would be linked using foreign keys. The term “foreign” signifies that the attribute really belongs to another entity besides the one holding it.
So consider the purpose of the data model. It is a model of the system’s business policy, not its implementation. A relationship between entities is a business connection and deliberately avoids representing any possible implementation of this connection. In other words, this is not a model of a database, nor of any other data storage system. Foreign keys break the rule about each entity containing only data that describe that entity, and no other.
The data model does not include foreign keys.
If you don’t have foreign keys, how do you know which DUCK belongs to which SPONSOR or, given a DUCK, who is the SPONSOR? The relationship shows that there is a requirement to connect the entities. In other words, it is the existence of a relationship in the data model that says, “I have a need to be able to remember that this entity has a connection to that one.” Remember that you are dealing with an abstract model of the data used by the system and you are not designing a database. If you include foreign keys in the entities at either end of the relationship, you are saying that there is a business requirement to include those data elements in the database. That’s not true: Foreign keys are one technological solution for the implementation of a relationship. They may or may not be applicable to the particular database management system (DBMS) or other storage technology chosen for your system. Right now, you need to focus on analyzing the business requirements for a system to be able to determine who has sponsored a particular duck. Later, after you’ve modeled the associated processes and you know the navigational requirements, you can design the appropriate implementation for the connection.
Cardinality
Cardinality tells you how many entities of each type participate in a relationship. For example, a sponsor may choose to sponsor several ducks. This happens when the sponsor is unsure whether a deep or shallow draught will be most effective at catching the stream’s current. To increase his chances of being the sponsor of the winning duck, he opts to enter several ducks, each with a different modification below the waterline. To show this aspect of the policy, you add cardinal operators to the model.
The operators in the model in Figure 2.5.8 show that for one instance of SPONSOR, there may be many instances of DUCK. The operator N (sometimes M) is used to symbolize one or more than one. This relationship is known as a one-to-many relationship. Note the way to read the cardinality: “For any one sponsor, there may be one or many ducks. For one instance of duck, there may be only one sponsor.” To determine the cardinality, you have to ask this question from the entities at both ends of the model: “If I have a single instance of this entity, how many are there at the other end of the relationship?”

One-to-many is by far the most common type of cardinality, though you will come across others. For example, if the rules of the race are changed to limit a sponsor to a single duck, and a duck may have only one sponsor (as at present), the cardinality in Figure 2.5.8 would be changed to show a one-to-one relationship.
Sometimes, many-to-many relationships arise. For instance, suppose the rules were again changed to allow several sponsors to be involved with one duck, and each of those sponsors could sponsor several ducks. In this case, the sponsoring relationship would have a many-to-many cardinality. However, this rule change is unlikely to occur, as the landlord of the Richmond Arms does not want to chase more people than necessary to collect their pledges and certainly does not want to have to deal with multiple sponsors for each duck.
A final word on cardinality: The cardinal operators should be added to the data model as soon as you come across the cardinal policy. Note that in your models, you needn’t be concerned about the exact location of the operators—above, below, left, right, or in the line—just make sure their placement is clear and unambiguous. Use cardinality as a way of raising constructive questions about your model. Eventually, to understand all your data, you will need to define all the cardinal operators.
As we’ve said, the data model represents the policy of the business being studied by partitioning whatever the system remembers into entities and relationships. Is the model in Figure 2.5.9 an accurate statement of the business policy? We have already examined the relationships to see if the business needed to remember any other links between the data. So now let us turn our attention to examining the meaning of the cardinality.
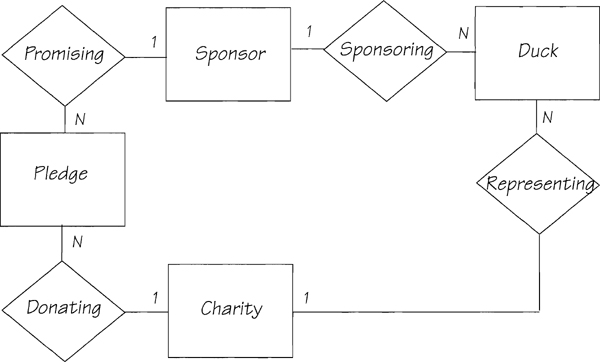
Figure 2.5.9: This shows the Duck Race model with the cardinality added. It now states the complete policy of the race.
The relationship REPRESENTING says that several pub customers favor a CHARITY, and so it is represented by more than one DUCK. Note that each DUCK races on behalf of a single CHARITY. The cardinality for the relationship PROMISING says that any SPONSOR may make more than one PLEDGE. This is probably because he is sponsoring several ducks. We have already discussed and dismissed a relationship between DUCK and PLEDGE, and the model is saying that there is no way to tell which pledge is for which duck. So how does the system know which charities get which pledges?
It doesn’t have to. All the money generated by the race is donated to the charity represented by the winning duck. The winning sponsor (the system can identify him from the SPONSORING relationship) officially gets nothing, but the landlord always stands him a few pints.
Building a Data Model
Let’s look at how you go about building a model of the system’s data. First, keep in mind that data modeling and process modeling are not exclusive, nor are they serial, activities. The book you are reading is a serial device; you read one chapter and presumably finish it before starting the next. In this book, we present the models in the order that we think is appropriate for most analysis projects. But the order of the book’s chapters does not mean that one activity is completed before the other is started. That is not how it works. Data modeling and process modeling are done in parallel. Each model helps you to build the other by giving you different views of the same system, and thereby to build a complete and accurate model.
Finding Entities
You can build the first cut of a data model from the information that is usually available at the beginning of an analysis project. Remember the definition of an entity: a rational collection of data elements that describes something from the real world that is important to the business.
The definition helps you get started in your search for the entities. One or more of these rules of thumb will help you to recognize candidate entities:
• An entity has a defined business purpose. If you can’t say what it means, you don’t need to remember it.
• An entity holds at least one, and preferably more than one, attribute.
• An entity has more than one instance. If there is only one instance, it is probably a piece of constant information that is part of the policy of a process.
• Each entity must be uniquely identifiable. The identifier may be made up of one or a number of attributes, or it may be a specially generated code. For example, a person’s name can be a satisfactory identifier, or in the case of the ducks, the landlord generated a number to tell them apart.
• An entity doesn’t have a value. For example, a telephone number is not an entity, but is an attribute of an entity.
• A terminator from the context diagram may be an entity. If the system sends data to a terminator, it must at least remember the terminator’s address.
• A report is rarely an entity.
• Column headings and names in reports often are entities. So are rows and columns in spreadsheets. But remember that entities are not calculated or derived.
• Nouns in business descriptions are often entities.
• Products (toasters, tomatoes, services, and so on) often are entities, providing there is more than one such product.
• Roles (such as the sponsor in the duck race) are usually entities.
• A repeating group in a data flow or data store is usually an entity or a collection of entities.
Where do you start looking for entities that are important to the business? The context diagram is a good place to start. All the data that enter and leave the system appear as data flows in this diagram. By analyzing these boundary data flows, you discover all the attributes that the system must store. By determining which entity each one rightfully belongs to, you identify all the entities. This process is called attribution, and is discussed later in this chapter.
Where else can you discover things that are important to the business? The documents used by the business are often good sources of entities and attributes. In most reports, the entities usually appear as names or headings, but remember the rule of thumb that says entities are not usually calculated or derived.
Users’ descriptions of the business reveal entities. As the users discuss their business, note the things they use in their business. The rule of thumb says that nouns are potential entities. Documents such as procedural manuals, job descriptions, and existing business forms all usually contain nouns that are potential entities.
Finding Relationships
The rule of thumb for finding the relationship between entities says that a relationship exists when a verb is used in a description of a business. Consider the following statement from the landlord of the Richmond Arms:

“The sponsors put a lot of effort into decorating their ducks, so we have a number of decoration categories, such as historical, topical, local humor, and so on. Local businesses have donated prizes for the different categories, and we award the prizes to worthy sponsors during the post-race ceremonies.”
Not every verb you hear is a suitable candidate to become a relationship. A verb must describe some action that needs to be remembered, and it must describe some activity that includes two entities that form the subject and the object of the verb. Because both the subject and the object are involved in the action (“The prizes are awarded to the sponsors”), there must be a business reason to remember the link between them. The name of the relationship should reflect why the connection exists.
Verbs are not always reliable indicators of relationships. For example, the relationship DECORATING? linking the duck and the sponsor in the model shown in Figure 2.5.11 is probably not interesting to the business. It is unlikely that the landlord cares who decorated the duck, and if the duck has not been decorated, it will not win a prize in any of the decoration categories. You could omit this relationship from your model. Besides, you already know that there is a SPONSORING relationship between these two entities. However, if the DECORATING relationship is important to the business, and if it differs in meaning from SPONSORING, you could have both relationships between SPONSOR and DUCK.
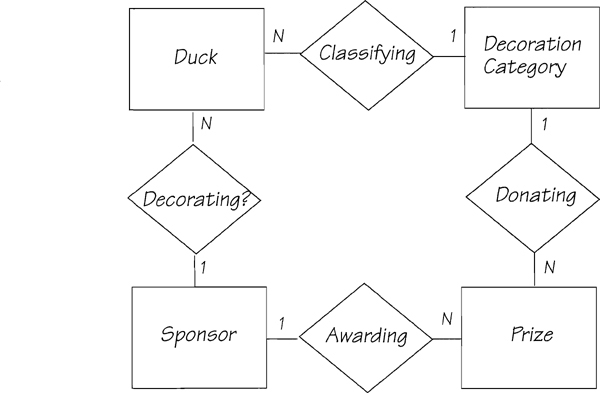
Figure 2.5.11: Verbs reveal relationships. The relationships in this model can be traced to the landlord’s policy statement.
The following rules of thumb can be useful when considering relationships:
• A relationship is an interaction between two (or more) entities that the system needs to remember.
• A verb often indicates a relationship.
• For a relationship to exist, there must be some business policy stating the circumstances under which it is established and used.
• A relationship’s name reflects the reason for the association.
• A relationship may contain attributes, but it doesn’t have to.
• If a data element describes an action, it may be an attribute of a relationship. For example, SPONSORING DATE cannot be attributed to either the DUCK or the SPONSOR. Therefore, it is an attribute of the relationship between them.
• A relationship may be needed if there are two adjacent attributes in a form or in a file, and if the attributes belong to different entities.
• Consider only those relationships that are necessary for the business within your context. Ignore those that are outside the scope of your system.
• A relationship is the requirement for a connection between entities; it is not the implementation of the connection.
• Relationships are usually of the one-to-many type. If you have a one-to-one relationship, there may be no need for the second entity. If you have a many-to-many relationship, you may have missed an entity.
• Relationships should not be directional. The noun form of the verb (or gerund) often works.
Keep in mind that these rules of thumb will only guide, but won’t lead, you.
Subtypes and Supertypes
Most systems contain entities that are very similar to one another. In some cases, the characteristics of the entities suggest that perhaps there ought to be one entity instead of several. For example, earlier in this chapter, we talked about how customers could be either sponsors or marshals. Our rule said that their respective roles and attributes made them separate entities.
However, suppose you come across entities that have some identical and some different attributes. To illustrate, let’s expand the West Ashling Duck Race to allow corporate sponsors. While both corporate and individual sponsors have the same relationship to a duck, the information the system needs to keep about each of them may be somewhat different. The corporate sponsor has a name and address that corresponds to the individual’s name and address, and, in addition, has a contact name and an authorizing officer. Alternatively, let’s now say that the system has to keep a record of the individual’s favorite pint. This attribute cannot possibly apply to a corporation.
An entity must be a unique collection of attributes, and must not have a code to say, for any given occurrence, whether it is a corporate or an individual sponsor. As a data modeler, you want to have it both ways. You want to show the similarities between these entities, but you also want to preserve the differences. You can do this by using supertypes and subtypes. A supertype is a generalized entity. Its business role and its attributes apply to all its subtypes. A subtype is a specialized case in which the entity has its own unique characteristic as well as the characteristics of its supertype entity. An example of a supertype-subtype relationship is shown in Figure 2.5.12.
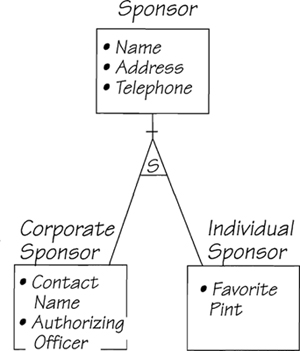
Figure 2.5.12: The supertype SPONSOR relates to DUCK as before. The two subtypes, CORPORATE SPONSOR and INDIVIDUAL SPONSOR, carry attributes that are unique to their specialized roles. The “S” in the triangle indicates the supertype-subtype relationship in the model.
The arrangement in Figure 2.5.12 shows SPONSOR as the supertype. This entity has a relationship with DUCK, and the relationship exists for any kind of sponsor. The attributes of SPONSOR are needed for any kind of sponsor. The subtypes CORPORATE SPONSOR and INDIVIDUAL SPONSOR are specialized kinds of sponsors and have their individual data requirements. There is no theoretical limit to the number of subtypes, and you could add FOREIGN SPONSOR as another subtype to the model.
Sometimes, supertype-subtype relationships are confusing. Keep in mind that you can describe the true sub-supertype relationship as “is a.” For example, the individual sponsor “is a” sponsor. The corporate sponsor “is a” sponsor. You must distinguish between this and a relationship that is an accumulation or composition. For example, TRANSMISSION, ENGINE, and BODY are not subtypes of an entity CAR. A transmission is not a car, nor is an engine. However, it may be useful to model the transmission, the engine, and the body as subtypes of CAR COMPONENT.
Existing Files and Stores
The data model specifies the requirement for the system’s stored data. This suggests that the files and data stores belonging to any current implementation may be a useful source of information. After all, if the data are currently being stored, there may be a reason for keeping the data as part of your new system.
Let’s have a look at another example. Say there is an existing computer system that processes a file about animals in a zoo. If we write a definition of the file, we might learn about the system’s need for stored data. Look at our definition in Figure 2.5.13. (The caption explains the notation. If this brief explanation is too brief for you, read through the relevant parts of Chapter 2.9 Data Dictionary; then return here.)
Animal File = {Species + Gender + Animal Weight + Date Of Birth
+ {Pen Number + Pen Location
+ {Keeper Identity + Pen Key Number}}
+ {Food Type + Food Schedule}}
Figure 2.5.13: The definition of an existing file. The notation, in brief, is as follows: The file is made up of everything following the =. The + means “together with,” and anything enclosed in {} is repeating. Thus, the file is made up of repetitions of everything, while for one animal there is a number of pens, each having a number of keepers. The information about food applies to an animal.
In this example, braces { } enclose a repeating group, a collection of data items that occur more than once. Typically, the group repeats because its data items have a different subject than whatever preceded it, and the group therefore is a potential entity. The data elements within the repeating group are potentially the attributes of that entity.
In the definition in Figure 2.5.13, you can break out a new entity for each repeating group. The first lot of data elements applies to an animal, and there are several pens for each animal. This reveals two entities, with a relationship between them. Similarly, there will be a number of keeper entities that relate to the pen. The double right braces }} after the keeper information indicate that the repeating has ended, and that the next lot of data refers to the animal.
The data model in Figure 2.5.14 was translated directly from an existing file. You have no way of knowing whether the design of the file was based on logical groupings of data or not, and so you must regard it with suspicion. The cardinality resulting from this translation looks very suspicious. For example, an animal is relating to many pens, but an animal can’t possibly be in more than one place at any one time. This may be historical information, so that the system keeps track of where the animal has lived. If so, the file doesn’t appear to keep any information about when an animal was moved into or out of a pen. This may be deliberate, or it may be poor file design. A pen may be attended by several keepers, but do you need to know which keepers look after which pens?
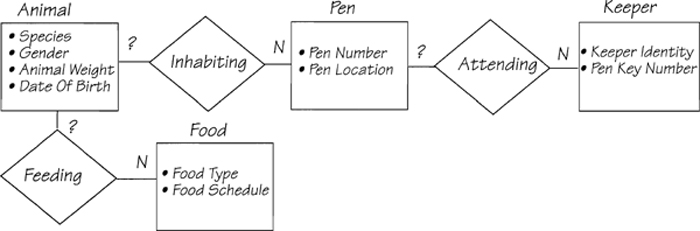
Figure 2.5.14: This model is derived from the data dictionary entry for ANIMAL FILE. Note that some of the attributes do not appear to be in the correct entity. The question marks are used to signify the unknown cardinality.
The problem with using existing files is that if they are poorly designed, they may not always reveal the precise nature of the stored data, and you will need a lot of information from your users. However, such files do provide you with an alternative strategy for starting your data model.
Put your questions aside for the moment, and let’s continue with the animal file. You now need to examine each of the attributes to determine if it is in the proper place.
Attribution
Attribution is best described as assigning data elements to the appropriate entity. An attribute is a data element that describes an entity or a relationship. For each data element, ask, “What entity or relationship does this element describe?” If it is describing the entity to which it is attached, then well and good, leave it alone. Otherwise, you need to find the entity that this element describes, or, to give the process its correct name, you attribute the element to another entity or relationship. Sometimes, there is no suitable entity or relationship in the data model for an attribute. In that case, you must create a new one. Let’s revisit the animal data model for an example of attribution.
Every data element stored by the system must be attributed to one, and only one, entity or relationship.
Keeper
• Keeper Identity
• Pen Key Number
Note the attribute PEN KEY NUMBER. The existing computer file stores this next to the identity of the keeper. The file designer did this to keep track of which keepers held keys to which pens. In other words, the physical placement of PEN KEY NUMBER is a way of implementing a relationship. However, an element called PEN KEY NUMBER cannot be an attribute of KEEPER. An attribute called PEN KEY NUMBER is describing something other than a keeper. What to do? Simply attribute it to the appropriate entity, in this case PEN. You also create a relationship that reflects the reason why PEN KEY NUMBER and KEEPER IDENTITY are adjacent in the physical file. In this case, there is already an ATTENDING relationship between KEEPER and PEN. If this relationship captures the required meaning, it will suffice (let’s say it does in this case). If it did not serve the purpose, you would then add a relationship between the two types of entities. The rearranged fragment of the model is shown in Figure 2.5.15.
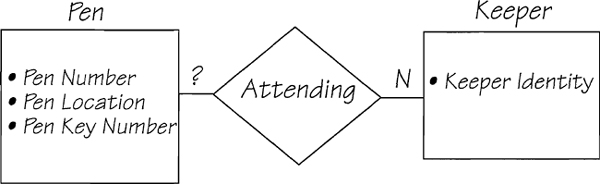
Sometimes, after attributing all the elements, you are left with an entity that has no attributes. When this happens, remove the entity from your data model. As our rule of thumb suggests, if there is no data to describe the entity, it is not an entity that your system needs.
A Sample Data Model
We will now show you a data model under construction with the aid of a travel agency example. Mallard Travel is a London-based company that provides low-cost flights to holiday and vacation destinations. Part of the business involves selling flights to the more obscure summer destinations in Europe. Our data model will be for this part of Mallard’s business.
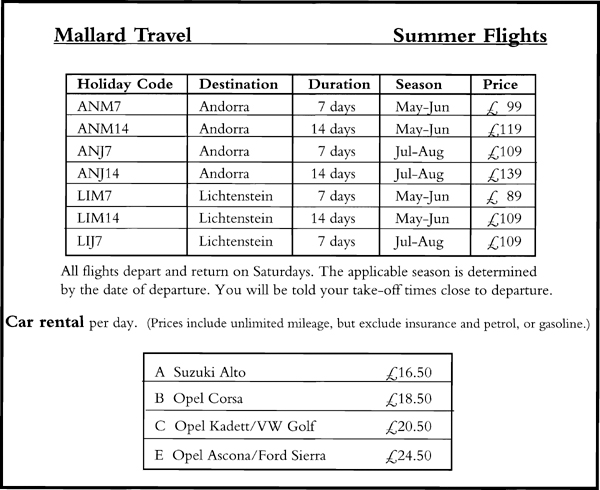
A fragment of the context diagram for this booking, or reservation, system is shown in Figure 2.5.16. There are other boundary data flows, but the two shown will give us enough information about the system’s stored data for our purposes. Most of the incoming data from BOOKING FORM is remembered by the system. The outgoing flow BROCHURE is made up of data from the system’s memory. By analyzing these flows, and understanding the business policy they represent, you can build the data model. Instead of giving you a definition of the flows, we’ve taken some pages from the Mallard Travel brochure and partially reproduced them in Figures 2.5.17 and 2.5.18. Assume that all the data making up the two data flows are in these figures. The goal is to define the business policy in the form of a data model.
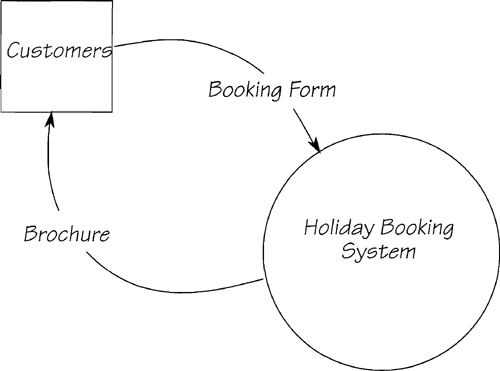
Figure 2.5.16: Part of the context diagram for the Mallard Travel system. The flow BROCHURE is constructed from stored data held within the system. The data from BOOKING FORM are remembered by the system.

A data model is a statement of business policy. Building a data model from information about the business is a translation process. You first understand the business policy, then translate it into data model terminology. However, before you start interpreting this policy, you must disregard any knowledge of travel booking policy you’ve acquired from any other system. It is irrelevant because you are studying a different system. In this exercise, you’ll have to interpret what you read about Mallard’s business. Since there will be no users available to answer questions, this exercise will not produce a conclusive statement of business policy, but it will adequately demonstrate the process.
Begin with the booking form shown in Figure 2.5.18. Let’s start with the obvious. This system is all about booking holidays, so there is a potential entity called BOOKING and one called HOLIDAY. HOLIDAY CODE and BOOKING REFERENCE GIVEN ON TELEPHONE are unique identifiers. One of the rules for entities says that they must be uniquely identified. Therefore, a unique identifier indicates the existence of an entity. Mallard Travel wants to know which bookings are reserving which holidays, so it is reasonable that they have a RESERVING relationship.
Figure 2.5.17 tells you that the company is offering flights to various destinations; so, you guessed it, FLIGHT is the next potential entity. When we add it to the model, the result is shown in Figure 2.5.19.
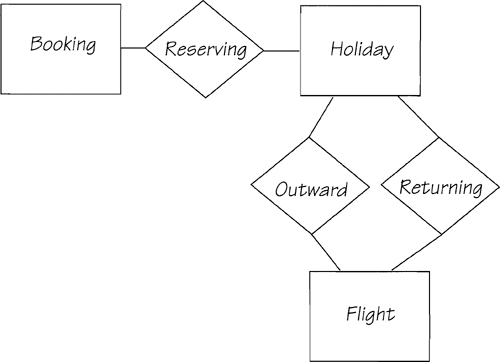
The relationships between HOLIDAY and FLIGHT are interesting. It is correct to model this as a single relationship with a one-to-many cardinality. One instance of the FLIGHT entity represents the outward flight, and another the returning flight. However, we feel that having an outward and a returning relationship demonstrates the system’s policy far more effectively.
Next, let’s look at the attributes of each of these entities. You know already that BOOKING REFERENCE GIVEN ON TELEPHONE is a unique identifier for BOOKING. The booking form also collects other information about the passenger. A reasonable definition of the booking entity’s attributes is
Booking = Booking Reference + Passenger Title + Passenger Initials
+ Passenger Name
+ (Passenger Age)
+ Passenger Address + Day Telephone + Night Telephone
The underscoring indicates the unique identifier, or key field, of the entity. Note that the passenger details are attributed to BOOKING. Each passenger is required to make a separate booking. The company does not keep information about passengers except when they make a booking, so there is no requirement for a passenger entity.
Some of the data in the forms could be attributed to the other entities. Take a moment to consider what attribution you would make.
There are more entities to add to the model. The summer flights brochure gives details concerning renting a car should one be required. Since the form has data that apply only to renting a car, it is feasible to make CAR RENTAL a potential entity. Note that the person making the reservation on the booking form can specify dates for the car rental that are different from the flight dates. As they are separate, you must say that these are attributes of the entity CAR RENTAL, and are not reused attributes from FLIGHT. The updated model is shown in Figure 2.5.20.
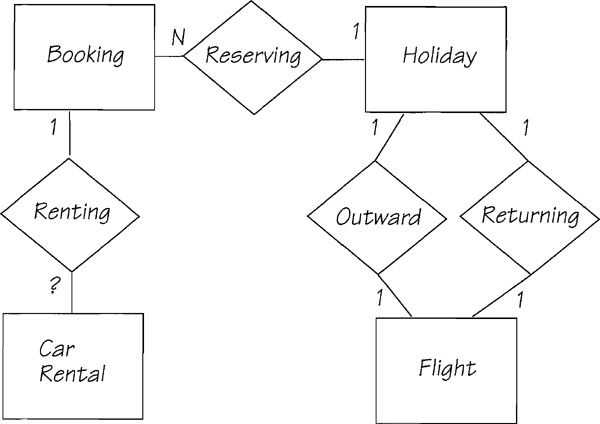
Figure 2.5.20: The data model to date. Cardinality has been added to provide additional information. We are uncertain whether a booking can be involved in renting more than one car. The form indicates only one, but that seems to be unreasonable business policy.
Passengers may pay by credit card or check. If there are two types of payment, each with its own data requirement, the model should show a supertype called PAYMENT with two subtypes: CHECK PAYMENT and CREDIT CARD PAYMENT. PAYMENT relates to BOOKING, since that is what is being paid for. The PAYMENT entities are shown in Figure 2.5.21.
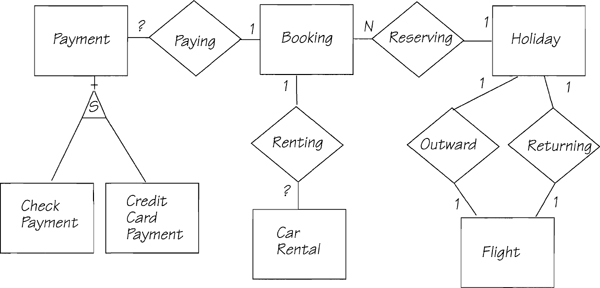
Before going too far, you should write down whatever information you have about the known attributes. We suggest these sample definitions:
Booking = Booking Reference + Passenger Title + Passenger Initials
+ Passenger Name
+ (Passenger Age)
+ Passenger Address + Day Telephone + Night Telephone
Car Rental = Car Group + Date From + Date To + Car Type + Price
Check Payment = Check Number
Credit Card Payment = Credit Card Number + Expiration Date
Flight = Flight Number + Departure Date + Departure Time + Arrival Date?
+ Arrival Time
Holiday = Holiday Code + Duration + Destination + Price
Payment = Payment Number + Payment Date + Payment Amount
The data model is still only a preliminary model. We constructed it using the information from the brochure and the booking form. There must be more business policy for the system. For example, most charter flight operators book blocks of seats for certain flights. They get a discount from the airlines and make their profit by selling the seats to their own customers. So there is probably an entity called BLOCK BOOKING OUTWARD (or something similar) to hold details of how many seats are available. This would relate to the FLIGHT entity. There is a similar entity for the block booking for return flights. Naturally, as you talk to the users and model their business, you can expect to find more and more policy to add to the data model.
This approach to data modeling results in a rather fuzzy first-cut data model. Note that we referred to most of the entities and relationships in the model as “potential” entities and relationships, because you still have to confirm their existence with the users. At this stage, the model helps you to understand the nature of the problem. Later, when you model the event-responses for Piccadilly, we will show you a way to confirm your model. Event-response modeling, which we will discuss later, also provides an alternative way to build data models.
The Mallard Travel model is intended as a demonstration of how you can build a data model from the data flows and the policy that you can determine from looking at existing brochures and forms.
Participation
We want to explain another requirement that you will eventually need to specify. As you have learned, building a data model leads you to a more and more detailed understanding of the data. Before finishing your Project, you will check the entities and relationships against the processes that create, reference, update, and delete them. At that stage, you will specify the rules for participation for each connection between an entity and a relationship. We have postponed mentioning this until now because the subject of data modeling is complex and you have had enough to think about. But now that you have built some data models, just spend a few minutes to think about how you will eventually define answers to the questions that may occur to you.
Looking back at the West Ashling Duck Race (Figure 2.5.8), you see the cardinal operators specify that any one sponsor may have more than one duck in the race. Now we discover that the ducks are owned by the Richmond Arms and kept in the back parlor when they are not being sponsored in a race. Stated formally, the DUCK entity has optional participation in the SPONSORING relationship. When we ask questions about the sponsor’s participation in the relationship, we discover that the Richmond Arms is only interested in sponsors if they participate in a sponsoring relationship. The SPONSOR entity has mandatory participation in the SPONSORING relationship.
Participation is specified by including the participation rules in the relationship definition in the data dictionary:
Sponsoring = * Relationship. Keeps track of which ducks are being sponsored by which sponsor. Cardinality: for each Sponsor, there are many Ducks; for each Duck, there is one Sponsor. Participation: Sponsor mandatory, Duck optional.*
When you have learned more about the Piccadilly Project, you will be concerned with specifying the participation rules.
Summary
Well, that’s it for building data models from policy statements and existing data. If you are not feeling slightly confused and uncertain, either you are indeed remarkable, or you have done this before. Building data models from policy statements is difficult, and by no means precise. Our intention in taking you through this chapter is to expose you to the thinking that lies behind this model, the information that the model shows you, and its contribution to the analysis of the system.
We mentioned several times in the chapter that you first have to understand why you need the data model. Then, when you build event-response models, you can make a more precise definition of the stored data.
Exercise: The Barbican Data Model
The Barbican Centre is a large theater and arts complex in London. Figures 2.5.22 and 2.5.23 are two extracts from a monthly program of events. From these samples and the following user’s description, derive the data model for the policy being used at the Barbican.

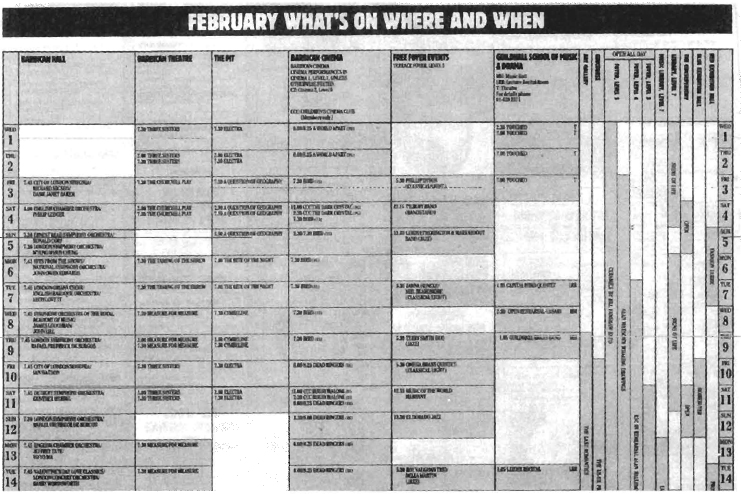
Here’s the user statement by Molly Aire about the Barbican’s policy: “People can book for performances at the Barbican by coming to the box office in person, by telephoning and using a credit card, or by mailing in the form with either a check or a credit card number and signature.
“We have a number of venues or performance areas in the complex. People can book in advance for any of them, except of course for the free events we hold in the lobby. The pricing policy is a little different for each of the venues. In the Hall, where we have orchestral music, the price of the seat depends upon the area of the Hall. I have given you a seating plan (Figure 2.5.22). Each performance has its own prices depending on the chosen seating area. We print these prices in the program. (See Figure 2.5.22.) There is never more than one performance a day, so there are no matinée prices.
“The Theatre is where plays are presented. The prices here are the same regardless of the play, but they vary depending on the area inside the Theatre. We also have different prices for matinees and evenings. They are

“In the Pit, where we have smaller plays, all seats are £10 in the evenings and £8.50 for matinees. School children and senior citizens can get a £5 ticket for matinees only.
“Cinema prices are £3.50 for adults. Senior citizens and children pay £2.50.
“We accept bookings from our mailing list subscribers as soon as they receive their program through the mail. Our program covers one calendar month of events, and we mail it about three months in advance. Other people can book as soon as we release the program one month after mailing.”
Trail Guide
![]() Easiest: Now that you know how to build data models, it’s time to do one for Piccadilly. The task is in Chapter 1.3 What About the Business Data?
Easiest: Now that you know how to build data models, it’s time to do one for Piccadilly. The task is in Chapter 1.3 What About the Business Data?
![]() More Difficult and
More Difficult and ![]() Most Difficult: Although this was not officially part of your trail, we’re glad you made it through the chapter. Your next task is to build a data model for the Piccadilly Project. It’s waiting for you in Chapter 1.3 What About the Business Data?
Most Difficult: Although this was not officially part of your trail, we’re glad you made it through the chapter. Your next task is to build a data model for the Piccadilly Project. It’s waiting for you in Chapter 1.3 What About the Business Data?
![]() Promenade: By now you have seen different types of system models, and read about viewpoints that are useful when building system models. Your trail to this point may have been a little disjointed, but there is method to this madness. We wanted to present the views and models in a way that we felt would be most comfortable for you. We also wanted you to have the correct preparation for the next important topic: the essential viewpoint of the system’s process. This is in Chapter 2.10 Essential Viewpoint.
Promenade: By now you have seen different types of system models, and read about viewpoints that are useful when building system models. Your trail to this point may have been a little disjointed, but there is method to this madness. We wanted to present the views and models in a way that we felt would be most comfortable for you. We also wanted you to have the correct preparation for the next important topic: the essential viewpoint of the system’s process. This is in Chapter 2.10 Essential Viewpoint.