
Appendix A. 25 Topic Goodies
As an architect participating in technical and related discussions, I have had my share of awkward moments when I don’t have a clue about specific topics or questions that are discussed. My stress level rises in an uncanny anticipation that I may be asked to throw light on or share my point of view on those topics! Sound familiar?
In this appendix, I have picked 25 topics that I have frequently come across or I feel a software architect needs to have enough understanding and awareness of to be able to contribute to a discussion on such or related topics.
I do not claim that the ones I chose are the top 25 picks because top is a relative term; what seemed top to me may not be the same for you. I focused on topics that appeared to me to be supplemental and related to the overall topics of architecture, technology, and some aspects of analytics (because we dedicated a whole chapter to it in the book).
What Is the Difference Between Architecture and Design?
Architecture deals with the structure or structures of systems that are composed of software components, the external visible properties of those components, and the relationships among them. Design deals with the configuration and customization of components and subcomponents that adhere to an existing system environment and solution requirement.
What Is the Difference Between Architectural Patterns, Design Patterns, and a Framework?
An architectural pattern expresses a fundamental organization schema for software systems. It provides a set of predefined subsystems and components, specifies their responsibilities, and includes rules and guidelines for organizing the relationship between them.
A design pattern, according to the Gang of Four book titled Design Patterns: Elements of Reusable Object-Oriented Software (Gamma, Helm, Johnson, & Vlissides 1994), is the packaging of a set of participating classes and instances, their roles and collaborations, along with the distribution of responsibilities (between the classes and instances) to solve a general design problem in a particular context.
A framework, on the other hand, can be considered an implementation of a collection of architectural or design patterns based on a particular technology. As an example, Spring is a J2EE framework based on the Model View Controller (MVC) pattern implementation in Java.
How Can We Compare a Top-Down Functional Decomposition Technique and an Object-Oriented Analysis and Design (OOAD) Technique?
Top-down functional decomposition is a design methodology that deconstructs the problem from an abstract functional definition of the problem (top) to a detailed solution (bottom). It is a hierarchical approach in which a problem is divided and subdivided into functional subdomains or modules.
In a practical world of software development, no matter how hard you try to achieve completeness, requirements will always contain a varying degree of flux. The challenge with the functional decomposition technique is that it does not let the code be adaptable to possible changes in the future for a graceful evolution. With the focus being on functions and their decomposition into subfunctions, the problems that arise are low cohesion and very tight coupling between the original overarching main functional problem and its functional subdomains. This is a result of the ripple effect, which is quite common in a problem solution using functional decomposition in which the data set that the functions work on is possibly shared among the various functions. Changing a function or the data that is used by a function, hence, will require changes to be made in other pieces of the code, leading to a popular phenomenon in software development called the unwanted side effect. This effect quickly snowballs, and the effect often becomes drastic and unmanageable.
OOAD is a design methodology in which the deconstruction of a problem is in the form of objects. An object, which is an instance of a class, is a mapping of a real-world entity into the software domain. An object, conceptually, is an encapsulation of its own internal state and exposes a set of behaviors (through a set of methods or operations, which work on the object to change its internal state). The intent is to ensure that the only way to change the object’s internal state is through the methods, the collection of which determines its behavior.
In OOAD, unlike top-down functional decomposition, no one single overarching function is responsible. The responsibility is encapsulated into these software building blocks called objects. This leads to a properly encapsulated system in which the data (that is, the object’s state) is tightly integrated with the operations (which define the behavior) that manipulate the data. In turn, this leads to a system that is characterized by low coupling and high cohesion.
OOAD is very adaptable to changes. These changes do not touch the entire system; rather, they are localized in only the set of objects whose behaviors need to change in order to achieve the new functionality.
Note: An object is an instance of a class. While a class defines the entity, an object is an instance of the class. As an example, a Car is defined as class and a BMW is an object that is an instance of (that is, type of) the Car class.
What Is the Difference Between Conceptual, Specified, and Physical Models?
A conceptual model, as it applies to a functional model, represents a set of concepts, represented as entities, that have no affiliation to any technology. The entities represent constructs—for example, people, processes, and software systems, along with depicting their interactions. A conceptual model, as it applies to an operational model, represents only the application-level components that will ultimately need to be placed on a physical topology.
A specification-level model (which is what we have called the “specified” level model in this book), as it applies to a functional model, describes the externally visible aspects of each component (in the model)—for example, their interfaces and ways in which the interfaces interact across components. A specified model, as it applies to an operational model, represents a set of technical components that will ultimately host the application-level components and also support the interconnections and integrations between them; focus shifts into a logical view of the infrastructure.
A physical model, as it applies to a functional model, represents the internal aspects of the components as they relate to the implementation technology or platform—for example, whether a component may be implemented in a J2EE or a .NET technology. A physical model, as it applies to an operational model, defines the hardware configuration for each operational node, the functional components placed on each node, and the network connectivity details of how one physical compute node is interconnected with other nodes or users in the overall system.
How Do Architecture Principles Provide Both Flexibility and Resilience to Systems Architecture?
Architecture principles provide a set of rules, constraints, and guidelines that govern the development, maintenance, and use of a system’s architecture. When a principle is expected to be adopted and followed across the lines of business that use the system, it provides the resilience of the architecture around its adherence. An example of such a principle may be the security mandate for all users, regardless of line of business or persona, to use consistent credentials to access the system. When a principle encourages extensibility, it provides room for the system to be flexible. An example of such a principle may be to adopt a baseline information model but allow for extensions specific to a set of applications used by a line of business.
Why Could the Development of the Physical Operational Model (POM) Be Broken into Iterations?
When you are developing the specified operational model (SOM), you are iteratively refining your understanding of the application-level components and also identifying the technical-level components that will ultimately support the application-level components.
If you have knowledge of the current IT landscape, vendor affinity of the customer, and the evolving architectural blueprint (with its principles and constraints), which are gained during the SOM analysis, you will be able to leverage informed judgment to start identifying the products and technologies required to build the physical operational model (POM). During this phase, a critical understanding of some of the NFRs (for example, availability, disaster recovery, and fault tolerance) may give clues into the final physical topology (for example, which middleware product or component needs to support a hot-cold standby operations mode and which ones will require an on-demand compute ramp-up). However, their detailed configurations may not be required at this point. Hence, it is quite natural to perform the component selection process of the POM in parallel with the SOM activities while leaving the component configuration activities for a later time. Initiating an iterative and parallel (with SOM) development of the POM is quite realistic, often practical, and timely.
What Is a Service-Oriented Architecture?
Service-oriented architecture (SOA) is an architecture style that aims at identifying a set of business-aligned services, each of which is directly aligned to one or more quantifiable business goals. By leveraging a set of techniques, the architecture style identifies one or more granular or atomic services that can be orchestrated in a service dance, so to speak, to realize one or more business services. At its core, the style advocates and fosters the implementation of services that are self-describable, searchable, and reusable (that is, they participate in the implementation of multiple business processes). The focus in SOA is on reusable entities or constructs called a service, which is business aligned.
A suite of technologies supports the implementation and deployment of services. For example, Service registries serve as repositories for services, Web Service Description Language (WSDL) provides a language to specify the metadata for the service descriptions, and Business Process Execution Language (BPEL) provides an orchestration language to invoke and integrate multiple services to implement business processes.
What Is an Event-Driven Architecture?
Event-driven architecture (EDA) was originally proposed by the Gartner analyst firm as a framework to orchestrate behavior around the production, detection, and consumption of events as well as the responses they generate. EDA is an event-centric architecture; the core element of EDA is an event, a first-class entity, that is typically generated asynchronously within or outside the address space of the system under consideration. Events may typically be aggregated, or brokered forms of multiple simpler events correlated both spatially (occurring in different locations) and temporally (occurring at different times) to formulate higher-order events that are relevant and contextual to trigger the execution of a business process.
EDA typically leverages some form of an ESB for the event receipt, event aggregation, and brokering; it also triggers business processes.
There have been philosophical debates regarding the use of SOA versus EDA. One simplified approach that has been tried is the unification of SOA and EDA into SOA 2.0.
What Is a Process Architecture?
There is a class of applications and systems, and arguably a class of enterprises, that is heavily process driven, some more so than others. Consider manufacturing and production companies that typically have to incur heavy operating costs due to design errors. The later these errors are caught in the process, the more costly is the undertaking. Such organizations need a framework to not only reduce the errors at every step of the process but also to be able to rapidly adapt parts of the business process to support dynamic and adaptable changes. A careful analysis of such process-centric enterprises may also reveal a strong causal relationship between a set of events that drive such process-centric systems: the sending and receiving of events triggers parts of or entire operational processes.
A process architecture typically has a business description, in process terms, as well as an underlying technology framework supporting its implementation. The business description provides a high-level specification of the participating set of processes, their interdependencies, and intercommunications. The technology framework not only defines an underlying technology foundation (which supports a set of events for which the receipt and triggering provide the interconnections and intercommunications between processes) but also provides appropriate tooling and a runtime to simulate how new processes may communicate with the existing processes and how new processes may react to events. The technology framework also defines interfaces for processes (a.k.a. process interfaces) defined in terms of events that a process may receive or send as well as how events define the communication conduit between processes—a communication architecture connecting processes with events using a distributed integration middleware.
Process architectures typically fall under the bigger umbrella of enterprise business architectures, the latter defining the enterprise value streams (represented as an outcome-driven collection of activities and tasks) and their relationships to both external and internal business entities and events.
If you look closely, you may be a bit confused as to why and how process architectures are different from EDA. The confusion is quite legitimate. One way to handle any confusion is to consider the perspective and lens through which you are looking at the problem. If you are talking to the business strategy community, it may be worthwhile to put the processes at the center of the conversation. If you are talking to production and operations users, it may be worthwhile to discuss the events that are central to the execution of the processes. As a software architect, you need to be cognizant of the user community you have to deal with and orient yourself to speak the lingo that the intended community is comfortable with. It is important, however, to document the individual business processes as well as their interactions. It is equally important to describe and define the events that enable them to react to anything that is external to the processes. In technology speak, it is critical to define the integration architecture that ties the processes to the events and their interconnections. As long as you are not perturbed by so many different architecture terms and instead focus on what needs to be solved and how to define an architecture to solve the “what,” you can keep the confusion at bay.
What Is a Technology Architecture?
Architectures have multiple views and viewpoints and also have multiple renditions as they go through various phases of maturity—from concept to realization. One of the critical architecture formulation phases requires the functional architecture views to be mapped on to the operational architecture views. During such a mapping, the middleware software products, the hardware compute and its specifications, and the network topology need to be designed and defined; all these need to come together.
The technology architecture of a system defines the set of middleware products, their placement on well-specified hardware configurations, and the network topology that interconnects the servers to other parts of the system. A system’s POM may be a good phase in the design to formulate and formalize the technology architecture.
What Is an Adapter?
In any nontrivial enterprise system, connectivity between multiple, possibly disparate systems is quite common. Such disparate systems may be built in different technologies, supporting different data formats and connectivity protocols. Data and information exchange between such disparate systems requires some means to adapt to each of those systems so that their language can be understood, so to speak.
An adapter is typically a piece of custom or packaged code that connects to such systems so as to streamline data and information exchange while abstracting the specificities of the particular (often proprietary or archaic) protocol and formats from the adapter’s consumers. The adapter does all the magic of hiding those specificities while exposing an easy-to-use facade (interface) for communication and data exchange.
The adapter exposes a set of APIs used to interact with the underlying systems, which makes enterprise application integration (EAI) simpler!
What Is a Service Registry?
A service registry is a software component that provides a simple service registration capability, allowing service developers and service registrars to easily register new or existing business services into a service catalog. The component allows developers to browse the catalog to find a suitable service and then easily request to consume it by registering the application (which would consume the service).
Among others, the component may also optionally provide the following capabilities:
• Service-level requirements supporting a set of service-level agreements (SLAs)
• A service management profile for service governance and life-cycle management
• Bulk loading of services into the registry from various common sources (for example, Excel sheets and flat files)
• A simplified user interface to browse the metadata and specifications for the services
What Is a Network Switch Block?
A switch block is a collection of Access and Distribution layer network devices (refer to Chapter 10, “Infrastructure Matters”) that connect multiple Access layer switches to a pair of Distribution layer devices. It is essentially a block of switches consisting of multiple Access layer switches, along with a pair of Distribution layer devices.
What Are Operational Data Warehouses?
Traditional data warehouses (a.k.a. enterprise data warehouses or EDWs) are designed for very efficient reads, for executing analytical queries on large data sets with a quick query response turnaround, and for aggregating data from multiple transactional and referential data sources. Their strength is in building a trusted source of enterprise data, typically across different lines of businesses and answering strategic after-the-fact business questions that span across multiple lines of businesses on data that is kept over relatively long periods of time such as multiple years. Such data warehouses are typically refreshed infrequently, perhaps once a day.
In the current era of big data, the volume at which data is being generated is staggering to say the least and, as per projections, is only going to grow exponentially. The need to harness analytical insights from data, in real time, requires a different paradigm. Data needs to be streamed from transactional systems into a data warehouse in near real time. Such data needs to be analytically processed and persisted into the data warehouse at the rate at which it is ingested. Analytics on the newly arrived data need to be generated immediately. An operational data warehouse involves technologies that allow a traditional data warehouse to preserve its traditional capabilities and areas of strengths but also support the following:
• Ingesting data at a high frequency or in a continuous steady-state stream (also known as trickle feeds)
• Writing data at a high frequency without compromising the performance of reads and analytical queries
• Generating analytics on the combination of high-frequency incoming data and the existing data sets
In essence, an operational data warehouse is a traditional high-performing enterprise data warehouse that can support very high-frequency refreshes with new data without compromising the strengths of the en’terprise data warehouse.
What Is the Difference Between Complex Event Processing (CEP) and Stream Computing?
To understand complex event processing (CEP), you need to first understand complex events. Complex events detect causal and temporal relationships and memberships of simpler individual or homogeneous events. Causal relationships between events can be horizontal or vertical in nature. Horizontal causality implies triggering of events at the same level (for example, one business meeting outcome being the decision to arrange another follow-up meeting), whereas vertical causality relates to how, in a hierarchy of events, higher-level events are traceable to one or more lower-level events and vice versa.
CEP is a set of techniques, packaged into a technology framework, used to detect patterns of complex events, actively monitor and trace their causal relationships (both horizontally and vertically) in real time, define the relationships of complex events to autonomous business processes, and take appropriate actions through the triggering of business processes upon complex event detection. CEP primarily deals with the real-time analysis of discrete business events.
Stream computing is a relatively newer concept and technology that can be traced back to the initial maturity timelines of big data. Stream computing is a programming paradigm, supported by a runtime platform, that supports the ingestion of a continuous stream of data (in discrete data packets); it performs complex and computationally intensive advanced analytics on the data in motion and in real time (that is, at the rate in which data is generated and is ingested into the stream computing platform).
While the vendor-specific product literature of both technologies claims to support real-time and ultra-low latency computations, the difference is in their quantitative degrees in rates of data processing and their qualitative nature of support for advanced analytics. The differences may include
• CEP engines expect discrete business events as data packets; stream computing supports a continuous stream of data packets.
• Stream computing is expected to support an order of scale higher volume of data processing in real time.
• Stream computing typically supports a wider variety of data (both structured and unstructured); CEP typically functions on structured data sets.
• CEP mostly leverages rules-based correlations of events; stream computing is expected to support simple to very complex and advanced analytics (for example, time series analysis, image and video analytics, complex mathematical techniques such as integrals and Fourier transforms on numerical data, data mining, and data filtering).
What Is the Difference Between Schema at Read and Schema at Write Techniques?
Schema at read and schema at write techniques have become discussion topics with the advent of Big Data processing. With the proliferation of unstructured data and its tremendous value as it pertains to analytical decision making, the need to persist data that is primarily unstructured in nature has gained a lot of importance.
Structured data has been around for more than four decades: using schema definitions to store structured data has been the most common technique to store data in database systems. A lot of upfront design work goes into the design and realization of the structured data, primarily because of the inherent structure in the data that requires it to be modeled before data persistence (that is, design of data schemas before data is written), and hence the name schema at write. The inherent nature of unstructured data implies that it carries no predefined structure; the variety of unstructured data (for example, text, images, videos) makes the investment of any effort to come up with a predefined structure quite impractical and cost prohibitive. Therefore, storage for unstructured data may be realized without any a priori schema definitions; it can be persisted in its native form. Processing (that is, retrieving, interpreting, and analyzing) unstructured data after its persistence requires significantly more investment in time and effort primarily because the nature, and more importantly the intended usage, of the unstructured data has to be known when it is retrieved for analysis—hence, the name schema at read.
Schema at write requires significant investment of time upfront to define the data schema before the data can be persisted but makes up for that time with fast and efficient reads. Schema at read requires a significant effort to understand the nature of the data at the time it is retrieved but makes up for that time with very fast and efficient data persistence. You give some, you get some!
What Is a Triple Store?
A Triple Store is a special type of database that stores data in a way that is more generic than a normal relational database. Its purpose is to store triples, which are short statements that associate two entities in the form subject-predicate-object—for example, Ants (subject) are destroying (predicate) the garden (object). The Triple Store can store semantic relationships between any pair of entities and record the nature of those relationships when they are stored. Triple stores are primarily used to store textual information after it undergoes lexical parsing, the outcome of which is a set of tuples.
One major advantage of a Triple Store database is that it does not need any structural changes to accommodate new entity types or new relationship types.
What Is a Massively Parallel Processing (MPP) System?
MPP is a technique in which a complex job is processed, in a coordinated manner, on multiple parallel and dedicated compute nodes (that is, processors that have their own hardware, memory, and storage, with the array of processors communicating with each other through a high-speed interconnection). The interconnection works as a data path to allow information exchange between the processor bank (that is, the array of processors). Owing to the nature of each processor dedicating its entire compute power to the assigned workload, MPP is also considered a shared nothing architecture.
MPP typically requires a coordinator that deconstructs a complex task into a set of subtasks and distributes the subtasks to an array of dedicated processors. They, in turn, process at extreme speeds (often in the hardware) and return the subtasks to the coordinator. The coordinator processes the subresults to form a single response. Check out IBM PureData® for Analytics and Oracle’s Teradata as two popular MPPs.
IBM Watson Is Built on DeepQA Architecture. What Is DeepQA?
DeepQA, which stands for Deep Question Answer, is the foundation on which IBM Watson systems were originally built. The DeepQA project at IBM was intended to illustrate how the wide and growing body of natural language content, together with the integration and advancement of natural language processing, information retrieval, machine learning, knowledge representation, and reasoning techniques, plus massively parallel computation can drive open-domain autonomic Question Answering technology to a point where it clearly and consistently assists and will ultimately rival the best human performance.
DeepQA architecture is built on advanced natural language processing (NLP) techniques. NLP, by its very nature, is ambiguous and polysemous (having multiple meanings), with its meaning often being highly contextual. A system like IBM Watson needs to consider many possible meanings, attempting to find the inference paths that are most confidently supported by the data.
The primary computational principle supported by the DeepQA architecture is to assume and maintain multiple interpretations of the question, to generate many plausible answers or hypotheses for each interpretation, and to collect and process many different evidence streams that might support or refute those hypotheses. Each component in the system adds assumptions about what the question means or what the content means or what the answer might be or why it might be correct. “Candidate answers” are then formed. The candidate answers are scored, independently of any additional evidence, by deeper analysis algorithms. In cases in which the original question was deconstructed into smaller questions, which were independently subjected to the evidence-based hypothesis technique to generate the best possible answers, the answers to the question subparts are synthesized (using advanced synthesis algorithms) to form coherent final answers. In the final step, trained machine-learning techniques and algorithms are applied to rank the final answers. The entire technique is working on a corpus of data that surpasses the capacity of a human brain to hold and to process in a timely manner.
What Is the Difference Between Supervised and Unsupervised Learning Techniques?
The clue to understanding the difference between supervised and unsupervised learning lies in their names. Supervised implies there is some element of supervision; that is, the learning model is trained based on historical data in which every instance of a set of input events has a corresponding outcome, and the learned model is then expected to predict a future event based on what it learned from the correlation between the input events and the outcome (the target variable). Unsupervised implies that the learning model does not enjoy any prior supervision; that is, there is no associated outcome for a set of input events, and the model is expected to determine and derive a set of clusters or groups in the data set.
In supervised modeling, a model is trained with a set of historical data that has the form y = Ω (x1, x2, ..., xn), where ![]() is a vector represented by (x1, x2, ..., xn); that is,
is a vector represented by (x1, x2, ..., xn); that is, ![]() = (x1, x2, ..., xn) and for every instance of the
= (x1, x2, ..., xn) and for every instance of the ![]() vector, there is a known value of y (the response or target variable); Ω is the mapping function. The trained model is expected to predict the value of y given a new and unknown instance of the
vector, there is a known value of y (the response or target variable); Ω is the mapping function. The trained model is expected to predict the value of y given a new and unknown instance of the ![]() vector. Classification and regression are two classes of modeling techniques that use supervised learning techniques. Decision trees, neural networks, and regression are examples of supervised machine-learning techniques.
vector. Classification and regression are two classes of modeling techniques that use supervised learning techniques. Decision trees, neural networks, and regression are examples of supervised machine-learning techniques.
Unsupervised modeling lacks any response variable; therefore, it cannot be trained with historical data. The goal of unsupervised modeling is to understand the relationships between the elements of the ![]() vector (x1, x2, ..., xn) and try to determine whether and how some subsets of the
vector (x1, x2, ..., xn) and try to determine whether and how some subsets of the ![]() vector fall into relatively distinct groups. Stated in a different way, unsupervised modeling tries to identify clusters of variables that tend to display similar characteristics that are different from other such clusters. Unsupervised modeling is also called cluster analysis. Segmentation of a user population based on certain attributes (for example, income, race, address, and so on) can cluster users into high income brackets and medium income brackets. K-means clustering, Kohonen clustering, and Outlier analysis are examples of unsupervised machine-learning techniques.
vector fall into relatively distinct groups. Stated in a different way, unsupervised modeling tries to identify clusters of variables that tend to display similar characteristics that are different from other such clusters. Unsupervised modeling is also called cluster analysis. Segmentation of a user population based on certain attributes (for example, income, race, address, and so on) can cluster users into high income brackets and medium income brackets. K-means clustering, Kohonen clustering, and Outlier analysis are examples of unsupervised machine-learning techniques.
What Is the Difference Between Taxonomy and Ontology?
Taxonomies model a hierarchical tree-like structure representing elements and their containment or constituents (that is, a parent-to-child relationship). Traversal of the tree results in narrowing down the domain of description. For example, Universe -> Milky Way -> Solar System -> Sun -> Earth -> Mountains is a taxonomy representation. Taxonomies often leave the meaning of the relationships between the parent and child elements loosely defined, owing to the inherent inability to depict relationships between the elements.
Ontologies, on the other hand, are taxonomies that are associated with rules on how elements are related semantically. The rules are expressed in the form of tuples: a subject-object-predicate relationship (for example, Barack Obama is the US President). The tuples offer different perspective meanings to a subject based on the context (the tuple itself) in which it is used. The well-ordered tuples form the basis of knowledge induction; that is, the tuples form the basis from which the relationships can be reasoned and inferred.
What Is Spark and How Does It Work?
Spark, an Apache project, is a fast, general-purpose shared nothing MPP engine leveraging highly optimized runtime architecture of a cluster computing system for large-scale data processing. It supports fast startup times and leverages aggressively cached in-memory distributed computing and dedicated processes that are available even when no jobs are running.
The general-purpose Spark platform covers a wide range of workloads—for example, SQL, stream computing, machine learning, graph-based data processing, as well as leveraging the capabilities of Hadoop (although it is expected to be higher performing than Hadoop’s Map Reduce).
The Spark platform is very flexible because it is written in Scala, an object-oriented programming language, and also easier to use than, for example, programming in Map Reduce. It has support for Scala, Java, and Python APIs. As of this writing, it is a significant advancement over the traditional Hadoop ecosystem, primarily gaining a significant edge over Map Reduce, through the availability of powerful interactive shells to analyze data dynamically and in real time.
The anatomy of the current Spark platform can be described by the following concepts of Spark:
• Context represents a connection to the Spark cluster. An application can initiate a context before submitting one or more jobs. The jobs can be either sequential or parallel, batch mode or interactive, or may also be long running, thereby serving continuous requests.
• Driver represents a program or a process running the Spark context that is responsible for running the jobs over the cluster and converting the application processing into a set of tasks.
• Job, represented by a query or a query plan, is a piece of code that will take some input from the application, perform some computations (transformations and actions), and generate some output.
• Tasks are the constituents of a stage. Each task is executed on one partition (of the data) and processed by one executor.
• Executor is the process that is responsible for executing a task on a worker node.
Figure A.1 provides a visual depiction of the various components of Spark.
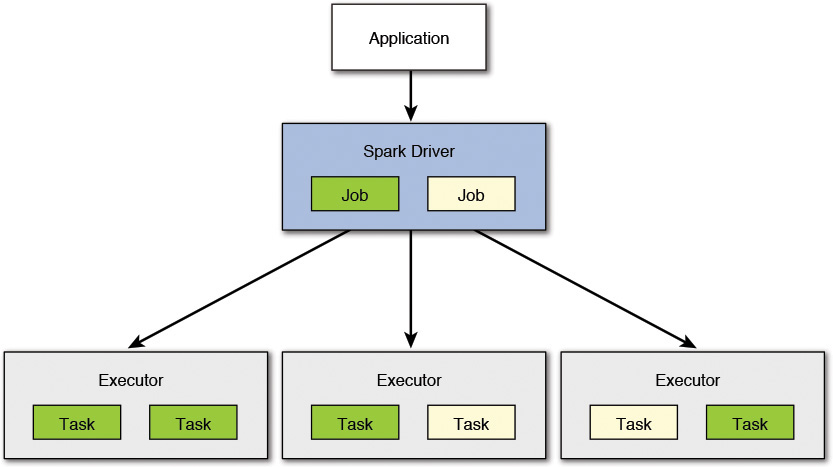
Each Spark application runs as a set of processes coordinated by the Spark context, which is the driver program. Figure A.2 provides a depiction of the same.
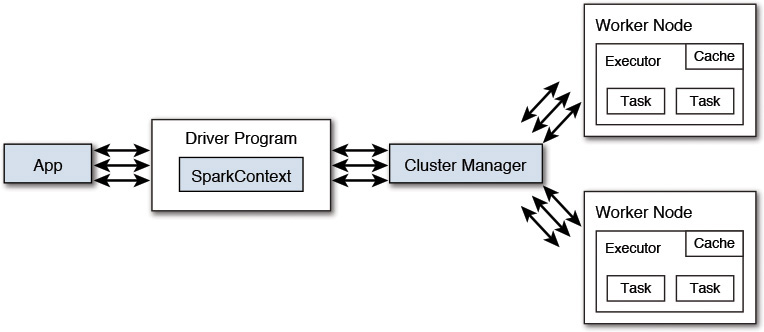
As shown in Figure A.2, each application gets its own executor processes, which stay up for the duration of the whole application and run tasks in multiple threads. This has the benefit of isolating applications from each other on both the scheduling side (each driver schedules its own tasks) and executor side (tasks from different applications running in different execution spaces—for example, different Java Virtual Machines). However, it also means that data cannot be shared across different Spark applications, which are instances of the Spark context, without writing it to an external storage system.
At the time of writing, Spark is gaining tremendous popularity, supported by rapid adoption, and is being touted as the next-generation integrated advanced analytics platform.
What Are Some of the Advantages and Challenges of the Cloud Computing Platform and Paradigm?
Cloud computing is a relatively new paradigm that has caught on immensely quickly in the industry. In fact, any enterprise that has an IT presence is considered to be lagging quite far behind if it does not have some form of a cloud-based infrastructure and computing strategy.
Cloud computing obviously has some distinct advantages, which makes it such a powerful value proposition. Some of the value propositions, but obviously not limited to these, are the following:
• Reduced capital and operational cost—Infrastructure and computational needs can typically be requested and made available on demand with the elasticity to grow or shrink on an as-needed basis. Setting up the infrastructure, regardless of its usage and monitoring and maintaining its usage do not require any upfront locked-in costs. The billing model supports pay per use; the infrastructure is not purchased, thus lowering maintenance; both initial and recurring expenses are much lower than traditional computing.
• Massive data storage—Storage and maintenance of large volumes of data on an elastic compute platform are possible. Sudden workload spikes are also managed effectively and efficiently on the cloud, owing to its dynamic and on-demand scalability.
• Flexibility—Enterprises need to continuously adapt even more rapidly to changing business conditions. Speed to deliver is critical, requiring rapid application development that is made possible by assembling the most appropriate infrastructure, platform, and software building blocks on the cloud platform.
However, some inherent challenges ought to be addressed. Some of the challenges stem from the following:
• Data security is a crucial element because enterprises are skeptical of exposing their data outside their enterprise perimeter; they fear losing data to the competition and failing to protect the data confidentiality of their consumers. While enterprise networks traditionally put the necessary network infrastructures in place to protect the data, the cloud model assumes the cloud service providers to be responsible for maintaining data security on behalf of the enterprises.
• Data recoverability and availability require business applications to support, often stringent, SLAs. Appropriate clustering and failover, disaster recovery, capacity and performance management, systems monitoring, and maintenance become critical. The cloud service provider needs to support all of these elements; their failure could mean severe damage and impact to the enterprise.
• Management capabilities will continue to challenge the current techniques and will require pushing the envelope toward more autonomic scaling and load-balancing features; these requirements for features are far more sophisticated and demanding than what the current cloud providers can support.
• Regulatory and compliance restrictions place stringent laws around making sensitive personal information (SPI) available outside country borders. Pervasive cloud hosting would become a challenge because not all cloud providers have data centers in all countries and regions.
However, the advantages of cloud computing are lucrative enough to outweigh the challenges and hence make cloud computing a significant value proposition to fuel its exponential growth of adoption.
What Are the Different Cloud Deployment Models?
As of this writing, most cloud service providers support essentially three cloud deployment model options. You therefore can determine the right solution for any given enterprise. The three options are public cloud, private cloud, and hybrid cloud.
• Public cloud—Owned and operated by cloud service providers, this option allows service providers to deliver superior economies of scale to their customers primarily because the infrastructure costs are distributed (and hence shared) across a set of enterprises that are hosted in the same physical infrastructure through a multitenancy operating model. The shared cost fosters an attractive low-cost, “pay-as-you-go” cost model. This rental model allows customers to account for their costs as an operational expense (OpEx) spread over multiple years as opposed to an upfront capital expense (CapEx). An added advantage is the extreme elasticity of compute and storage available on demand as and when the system workload demands it. However, in this scenario, a customer’s applications that share the same infrastructure pool do not have too much flexibility for personalized configuration, security protections, and availability.
• Private Cloud—Private clouds are built exclusively for a single enterprise, often owing to regulatory reasons, security policies, the need to protect intellectual property, or simply a client’s desire. They aim to address concerns on data security and offer greater control, which is typically lacking in a public cloud. There are two variations to a private cloud:
• On-premise Private Cloud—Also known as an internal or intranet cloud, it is hosted within an enterprise’s own data center. This model provides a more standardized process and protection, but is limited in its elasticity of size and scalability. IT departments also need to incur both capital and operational costs for the physical resources. This option is best suited for applications that require complete control and configurability of the infrastructure and security.
• Externally Hosted Private Cloud—This type of cloud is hosted externally with a cloud service provider, where the provider facilitates an exclusive cloud environment with a full guarantee of privacy and dedicated infrastructure. This option is best suited for enterprises that do not prefer a public cloud due to sharing of physical resources.
• Hybrid Cloud—This option combines both public and private cloud models. In this model, enterprises can utilize third-party cloud service providers in a full or partial manner, thus increasing the flexibility of computing. The hybrid cloud environment can be offered on an on-demand, externally provisioned scale and hence supports compute elasticity. In this hybrid setup, the private cloud capacity model may be augmented with the resources of a public cloud to manage any unexpected surges in workload. Applications and systems that require strict compliance can operate on the private cloud instance, whereas the suite of applications that can run under lesser constrained environments can operate on the public cloud instance with a dedicated interconnection between the private and public cloud environments.
What Is Docker Technology?
Docker is technology that was developed as a part of the Apache Open Source consortium. As of this writing, Docker is built as a portable, lightweight application runtime and packaging tool that is built on top of the core Linux container primitives. It also extends Linux’s common container format called Linux Containers (LXC). The Docker container comes with tools that can package an application and all its dependencies into a virtual container that can be deployed on servers supporting most, if not all, Linux distributions. Once packaged, the self-contained application can run anywhere without any additional effort.
The virtualization in Docker is lightweight because it does not package its own version of the operating system; rather, it leverages the same instance of the underlying OS. This is different from standard virtualization techniques in which each virtual machine has its own instance of OS, which highlights one perceived advantage of standard virtual machines: each VM can have a different OS, implying one VM can be on Linux, whereas the other can be on Windows server.
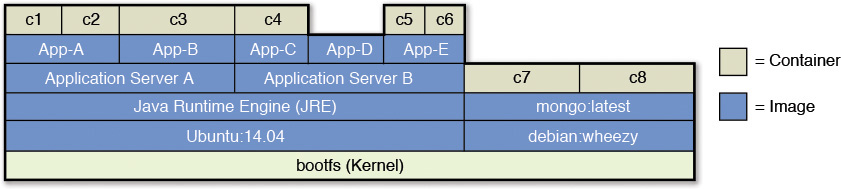
A Docker container is an isolated user or application space within a running Linux OS with multiple containers sharing the Linux kernel, and each application (along with its codebase, required packages, and data) has isolated runtimes (saved as file systems). Figure A.3 shows the way containers are isolated and running application instances.
Summary
In this appendix, I discussed a collection of concepts that I have encountered as an architect and modern-day technologist.
I have had my fair share of conversations and meetings in which some of the topics discussed here were not very well known to me, and although I was able to avoid embarrassment, internally, I did not feel too well until I went back to research and learn the concept or technique and got to apply it in real-world engagements.
I realize that discussing just 25 topics is not exhaustive; I easily could have discussed and highlighted another 25 topics. However, that would have distorted the main theme of the book a bit too much.