
A. Yes. They are automatically set to 0 for numeric types, false for the boolean type, and the special value null for all reference types. These values are consistent with the way Java automatically initializes array elements. This automatic initialization ensures that every instance variable always stores a legal (but not necessarily meaningful) value. Writing code that depends on these values is controversial: some experienced programmers embrace the idea because the resulting code can be very compact; others avoid it because the code is opaque to someone who does not know the rules.
Q. What is null?
A. It is a literal value that refers to no object. Using the null reference to invoke an instance method is meaningless and results in a NullPointerException. Often, this is a sign that you failed to properly initialize an object’s instance variables or an array’s elements.
Q. Can I initialize an instance variable to a value other than the default value when I declare it?
A. Normally, you initialize instance variables to nondefault values in the constructor. However, you can specify initial values for an instance variables when you declare them, using the same conventions as for inline initialization of local variables. This inline initialization occurs before the constructor is called.
Q. Must every class have a constructor?
A. Yes, but if you do not specify a constructor, Java provides a default (no-argument) constructor automatically. When the client invokes that constructor with new, the instance variables are auto-initialized as usual. If you do specify a constructor, then the default no-argument constructor disappears.
Q. Suppose I do not include a toString() method. What happens if I try to print an object of that type with StdOut.println()?
A. The printed output is an integer that is unlikely to be of much use to you.
Q. Can one instance method call another instance method in the same class?
A. Yes, for example the following is an alternative implementation of plus() in Complex (PROGRAM 3.2.6):
public Complex plus(Complex b)
{
double real = re() + b.re();
double imag = im() + b.im();
return new Complex(real, imag);
}
The code re() calls the instance method of the invoking object; the code b.re() calls the instance method of the object referenced by b.
Q. Can I have a static method in a class that implements a data type?
A. Of course. For example, all of our classes have main(). But it is easy to get confused when static methods and instance methods are mixed up in the same class. For example, it is natural to consider using static methods for operations that involve multiple objects where none of them naturally suggests itself as the one that should invoke the method. For example, we write z.abs() to get | z |, but writing a.plus(b) to get the sum is perhaps not so natural. Why not b.plus(a)? An alternative is to define a static method like the following within Complex:
public static Complex plus(Complex a, Complex b)
{
return new Complex(a.re + b.re, a.im + b.im);
}
We generally avoid such usage and live with expressions that do not mix static methods and instance methods to avoid having to write code like this:
z = Complex.plus(Complex.times(z, z), z0)
Instead, we would write:
z = z.times(z).plus(z0)
Q. These computations with plus() and times() seem rather clumsy. Is there some way to use symbols like + and * in expressions involving objects where they make sense, such as Complex and Vector, so that we could write more compact expressions like z = z * z + z0 instead?
A. Some languages (notably C++ and Python) support this feature, which is known as operator overloading, but Java does not do so. As usual, this is a decision of the language designers that we just live with, but many Java programmers do not consider this to be much of a loss. Operator overloading makes sense only for types that represent numeric or algebraic abstractions, a small fraction of the total, and many programs are easier to understand when operations have descriptive names such as plus() and times(). The APL programming language of the 1970s took this issue to the opposite extreme by insisting that every operation be represented by a single symbol (including Greek letters).
Q. Are there other kinds of variables besides argument, local, and instance variables in a class?
A. If you include the keyword static in a variable declaration (outside of any method), it creates a completely different type of variable, known as a static variable or class variable. Like instance variables, static variables are accessible to every method in the class; however, they are not associated with any object—there is one variable per class. In older programming languages, such variables are known as global variables because of their global scope. In modern programming, we focus on limiting scope, so we rarely use such variables.
Q. Mandelbrot creates tens of millions of Complex objects. Doesn’t all that object-creation overhead slow things down?
A. Yes, but not so much that we cannot generate our plots. Our goal is to make our programs readable and easy to maintain—limiting scope via the complex number abstraction helps us achieve that goal. You certainly could speed up Mandelbrot by bypassing the complex number abstraction or by using a different implementation of Complex.
Exercises
3.2.1 Consider the following data-type implementation for axis-aligned rectangles, which represents each rectangle with the coordinates of its center point and its width and height:
public class Rectangle
{
private final double x, y; // center of rectangle
private final double width; // width of rectangle
private final double height; // height of rectangle
public Rectangle(double x0, double y0, double w, double h)
{
x = x0;
y = y0;
width = w;
height = h;
}
public double area()
{ return width * height; }
public double perimeter()
{ /* Compute perimeter. */ }
public boolean intersects(Rectangle b)
{ /* Does this rectangle intersect b? */ }
public boolean contains(Rectangle b)
{ /* Is b inside this rectangle? */ }
public void draw(Rectangle b)
{ /* Draw rectangle on standard drawing. */ }
}

Write an API for this class, and fill in the code for perimeter(), intersects(), and contains(). Note: Consider two rectangles to intersect if they share one or more common points (improper intersections). For example, a.intersects(a) and a.contains(a) are both true.
3.2.2 Write a test client for Rectangle that takes three command-line arguments n, min, and max; generates n random rectangles whose width and height are uniformly distributed between min and max in the unit square; draws them on standard drawing; and prints their average area and perimeter to standard output.
3.2.3 Add code to your test client from the previous exercise code to compute the average number of rectangles that intersect a given rectangle.
3.2.4 Develop an implementation of your Rectangle API from EXERCISE 3.2.1 that represents rectangles with the x- and y-coordinates of their lower-left and upper-right corners. Do not change the API.
3.2.5 What is wrong with the following code?
public class Charge
{
private double rx, ry; // position
private double q; // charge
public Charge(double x0, double y0, double q0)
{
double rx = x0;
double ry = y0;
double q = q0;
}
...
}
Answer: The assignment statements in the constructor are also declarations that create new local variables rx, ry, and q, which go out of scope when the constructor completes. The instance variables rx, ry, and q remain at their default value of 0. Note: A local variable with the same name as an instance variable is said to shadow the instance variable—we discuss in the next section a way to refer to shadowed instance variables, which are best avoided by beginners.
3.2.6 Create a data type Location that represents a location on Earth using latitudes and longitudes. Include a method distanceTo() that computes distances using the great-circle distance (see EXERCISE 1.2.33).
3.2.7 Implement a data type Rational for rational numbers that supports addition, subtraction, multiplication, and division.
|
||
|
|
|
|
|
sum of this number and |
|
|
difference of this number and |
|
|
product of this number and |
|
|
quotient of this number and |
|
|
string representation |
Use Euclid.gcd() (PROGRAM 2.3.1) to ensure that the numerator and the denominator never have any common factors. Include a test client that exercises all of your methods. Do not worry about testing for integer overflow (see EXERCISE 3.3.17).
3.2.8 Write a data type Interval that implements the following API:
|
||
|
|
|
|
|
is |
|
|
do this interval and |
|
|
string representation |
An interval is defined to be the set of all points on the line greater than or equal to min and less than or equal to max. In particular, an interval with max less than min is empty. Write a client that is a filter that takes a floating-point command-line argument x and prints all of the intervals on standard input (each defined by a pair of double values) that contain x.
3.2.9 Write a client for your Interval class from the previous exercise that takes an integer command-line argument n, reads n intervals (each defined by a pair of double values) from standard input, and prints all pairs of intervals that intersect.
3.2.10 Develop an implementation of your Rectangle API from EXERCISE 3.2.1 that takes advantage of the Interval data type to simplify and clarify the code.
3.2.11 Write a data type Point that implements the following API:
|
||
|
|
|
|
|
Euclidean distance between this point and |
|
|
string representation |
3.2.12 Add methods to Stopwatch that allow clients to stop and restart the stopwatch.
3.2.13 Use Stopwatch to compare the cost of computing harmonic numbers with a for loop (see PROGRAM 1.3.5) as opposed to using the recursive method given in SECTION 2.3.
3.2.14 Develop a version of Histogram that uses Draw, so that a client can create multiple histograms. Add to the display a red vertical line showing the sample mean and blue vertical lines at a distance of two standard deviations from the mean. Use a test client that creates histograms for flipping coins (Bernoulli trials) with a biased coin that is heads with probability p, for p = 0.2, 0.4, 0.6. and 0.8, taking the number of flips and the number of trials from the command line, as in PROGRAM 3.2.3.
3.2.15 Modify the test client in Turtle to take an odd integer n as a command-line argument and draw a star with n points.
3.2.16 Modify the toString() method in Complex (PROGRAM 3.2.6) so that it prints complex numbers in the traditional format. For example, it should print the value 3 – i as 3 - i instead of 3.0 + -1.0i, the value 3 as 3 instead of 3.0 + 0.0i, and the value 3i as 3i instead of 0.0 + 3.0i.
3.2.17 Write a Complex client that takes three floating-point numbers a, b, and c as command-line arguments and prints the two (complex) roots of ax2 + bx + c.
3.2.18 Write a Complex client RootsOfUnity that takes two double values a and b and an integer n from the command line and prints the nth roots of a + b i. Note: Skip this exercise if you are not familiar with the operation of taking roots of complex numbers.
3.2.19 Implement the following additions to the Complex API:
|
|
phase (angle) of this number |
|
|
difference of this number and |
|
|
conjugate of this number |
|
|
result of dividing this number by |
|
|
result of raising this number to the |
Write a test client that exercises all of your methods.
3.2.20 Suppose you want to add a constructor to Complex that takes a double value as its argument and creates a Complex number with that value as the real part (and no imaginary part). You write the following code:
public void Complex(double real)
{
re = real;
im = 0.0;
}
But then the statement Complex c = new Complex(1.0); does not compile. Why? Solution: Constructors do not have return types, not even void. This code defines a method named Complex, not a constructor. Remove the keyword void.
3.2.21 Find a Complex value for which mand() returns a number greater than 100, and then zoom in on that value, as in the example in the text.
3.2.22 Implement the valueOf() and save() methods for StockAccount (PROGRAM 3.2.8).
Creative Exercises
3.2.23 Electric potential visualization. Write a program Potential that creates an array of charged particles from values given on standard input (each charged particle is specified by its x-coordinate, y-coordinate, and charge value) and produces a visualization of the electric potential in the unit square. To do so, sample points in the unit square. For each sampled point, compute the electric potential at that point (by summing the electric potentials due to each charged particle) and plot the corresponding point in a shade of gray proportional to the electric potential.

3.2.24 Mutable charges. Modify Charge (PROGRAM 3.2.1) so that the charge value q is not final, and add a method increaseCharge() that takes a double argument and adds the given value to the charge. Then, write a client that initializes an array with
Charge[] a = new Charge[3]; a[0] = new Charge(0.4, 0.6, 50); a[1] = new Charge(0.5, 0.5, -5); a[2] = new Charge(0.6, 0.6, 50);
and then displays the result of slowly decreasing the charge value of a[i] by wrapping the code that computes the images in a loop like the following:
for (int t = 0; t < 100; t++)
{
// Compute the picture.
picture.show();
a[1].increaseCharge(-2.0);
}

3.2.25 Complex timing. Write a Stopwatch client that compares the cost of using Complex to the cost of writing code that directly manipulates two double values, for the task of doing the calculations in Mandelbrot. Specifically, create a version of Mandelbrot that just does the calculations (remove the code that refers to Picture), then create a version of that program that does not use Complex, and then compute the ratio of the running times.
3.2.26 Quaternions. In 1843, Sir William Hamilton discovered an extension to complex numbers called quaternions. A quaternion is a 4-tuple a = (a0, a1, a2, a3) with the following operations:
• Magnitude:
• Conjugate: the conjugate of a is (a0, –a1, –a2, –a3)
• Inverse: a–1 = (a0/|a|2, –a1/|a|2, –a2/|a|2, –a3/|a|2)
• Sum: a + b = (a0 + b0, a1 + b1, a2 + b2, a3 + b3)
• Product: a × b = (a0 b0 – a1 b1 – a2 b2 – a3 b3, a0 b1 – a1 b0 + a2 b3 – a3 b2, a0 b2 – a1 b3 + a2 b0 + a3 b1, a0 b3 + a1 b2 – a2 b1 + a3 b0)
• Quotient: a / b = ab–1
Create a data type Quaternion for quaternions and a test client that exercises all of your code. Quaternions extend the concept of rotation in three dimensions to four dimensions. They are used in computer graphics, control theory, signal processing, and orbital mechanics.
3.2.27 Dragon curves. Write a recursive Turtle client Dragon that draws dragon curves (see EXERCISE 1.2.35 and EXERCISE 1.5.9).

Answer: These curves, which were originally discovered by three NASA physicists, were popularized in the 1960s by Martin Gardner and later used by Michael Crichton in the book and movie Jurassic Park. This exercise can be solved with remarkably compact code, based on a pair of mutually recursive methods derived directly from the definition in EXERCISE 1.2.35. One of them, dragon(), should draw the curve as you expect; the other, nogard(), should draw the curve in reverse order. See the booksite for details.
3.2.28 Hilbert curves. A space-filling curve is a continuous curve in the unit square that passes through every point. Write a recursive Turtle client that produces these recursive patterns, which approach a space-filling curve that was defined by the mathematician David Hilbert at the end of the 19th century.

Partial answer: Design a pair of mutually recursive methods: hilbert(), which traverses a Hilbert curve, and treblih(), which traverses a Hilbert curve in reverse order. See the booksite for details.
3.2.29 Gosper island. Write a recursive Turtle client that produces these recursive patterns.

3.2.30 Chemical elements. Create a data type ChemicalElement for entries in the Periodic Table of Elements. Include data-type values for element, atomic number, symbol, and atomic weight, and accessor methods for each of these values. Then create a data type PeriodicTable that reads values from a file to create an array of ChemicalElement objects (you can find the file and a description of its formation on the booksite) and responds to queries on standard input so that a user can type a molecular equation like H2O and the program responds by printing the molecular weight. Develop APIs and implementations for each data type.
3.2.31 Data analysis. Write a data type for use in running experiments where the control variable is an integer in the range [0, n) and the dependent variable is a double value. (For example, studying the running time of a program that takes an integer argument would involve such experiments.) Implement the following API:
|
||
|
|
create a new data analysis object for the |
|
|
add a data point ( |
|
|
plot all the data points |
Use the static methods in StdStats to do the statistical calculations and draw the plots. Write a test client that plots the results (percolation probability) of running experiments with Percolation as the grid size n increases.
3.2.32 Stock prices. The file DJIA.csv on the booksite contains all closing stock prices in the history of the Dow Jones Industrial Average, in the comma-separated-value format. Create a data type DowJonesEntry that can hold one entry in the table, with values for date, opening price, daily high, daily low, closing price, and so forth. Then, create a data type DowJones that reads the file to build an array of DowJonesEntry objects and supports methods for computing averages over various periods of time. Finally, create interesting DowJones clients to produce plots of the data. Be creative: this path is well trodden.
3.2.33 Biggest winner and biggest loser. Write a StockAccount client that builds an array of StockAccount objects, computes the total value of each account, and prints a report for the accounts with the largest and smallest values. Assume that the information in the accounts is kept in a single file that contains the information for the accounts, one after the other, in the format given in the text.
3.2.34 Chaos with Newton’s method. The polynomial f (z) = z4 – 1 has four roots: at 1, –1, i, and –i. We can find the roots using Newton’s method in the complex plane: zk+1 = zk – f (zk) / f ′(zk). Here, f (z) = z4 – 1 and f ′(z) = 4z3. The method converges to one of the four roots, depending on the starting point z0. Write a Complex and Picture client NewtonChaos that takes a command-line argument n and creates an n-by-n picture corresponding to the square of size 2 centered at the origin. Color each pixel white, red, green, or blue according to which of the four roots the corresponding complex number converges (black if no convergence after 100 iterations).
3.2.35 Color Mandelbrot plot. Create a file of 256 integer triples that represent interesting Color values, and then use those colors instead of grayscale values to plot each pixel in Mandelbrot. Read the values to create an array of 256 Color values, then index into that array with the return value of mand(). By experimenting with various color choices at various places in the set, you can produce astonishing images. See mandel.txt on the booksite for an example.
3.2.36 Julia sets. The Julia set for a given complex number c is a set of points related to the Mandelbrot function. Instead of fixing z and varying c, we fix c and vary z. Those points z for which the modified Mandelbrot function stays bounded are in the Julia set; those for which the sequence diverges to infinity are not in the set. All points z of interest lie in the 4-by-4 box centered at the origin. The Julia set for c is connected if and only if c is in the Mandelbrot set! Write a program ColorJulia that takes two command-line arguments a and b, and plots a color version of the Julia set for c = a + bi, using the color-table method described in the previous exercise.
3.3 Designing Data Types
The ability to create data types turns every programmer into a language designer. You do not have to settle for the types of data and associated operations that are built into the language, because you can create your own data types and write client programs that use them. For example, Java does not have a predefined data type for complex numbers, but you can define Complex and write client programs such as Mandelbrot. Similarly, Java does not have a built-in facility for turtle graphics, but you can define Turtle and write client programs that take immediate advantage of this abstraction. Even when Java does include a particular facility, you might prefer to create separate data types tailored to your specific needs, as we do with Picture, In, Out, and Draw.
The first thing that we strive for when creating a program is an understanding of the types of data that we will need. Developing this understanding is a design activity. In this section, we focus on developing APIs as a critical step in the development of any program. We need to consider various alternatives, understand their impact on both client programs and implementations, and refine the design to strike an appropriate balance between the needs of clients and the possible implementation strategies.
If you take a course in systems programming, you will learn that this design activity is critical when building large systems, and that Java and similar languages have powerful high-level mechanisms that support code reuse when writing large programs. Many of these mechanisms are intended for use by experts building large systems, but the general approach is worthwhile for every programmer, and some of these mechanisms are useful when writing small programs.
In this section we discuss encapsulation, immutability, and inheritance, with particular attention to the use of these mechanisms in data-type design to enable modular programming, facilitate debugging, and write clear and correct code.
At the end of the section, we discuss Java’s mechanisms for use in checking design assumptions against actual conditions at run time. Such tools are invaluable aids in developing reliable software.
Designing APIs
In SECTION 3.1, we wrote client programs that use APIs; in SECTION 3.2, we implemented APIs. Now we consider the challenge of designing APIs. Treating these topics in this order and with this focus is appropriate because most of the time that you spend programming will be writing client programs.
Often the most important and most challenging step in building software is designing the APIs. This task takes practice, careful deliberation, and many iterations. However, any time spent designing a good API is certain to be repaid in time saved during debugging or with code reuse.
Articulating an API might seem to be overkill when writing a small program, but you should consider writing every program as though you will need to reuse the code someday—not because you know that you will reuse that code, but because you are quite likely to want to reuse some of your code and you cannot know which code you will need.

Standards
It is easy to understand why writing to an API is so important by considering other domains. From railroad tracks, to threaded nuts and bolts, to MP3s, to radio frequencies, to Internet standards, we know that using a common standard interface enables the broadest usage of a technology. Java itself is another example: your Java programs are clients of the Java virtual machine, which is a standard interface that is implemented on a wide variety of hardware and software platforms. By using APIs to separate clients from implementations, we reap the benefits of standard interfaces for every program that we write.
Specification problem
Our APIs are lists of methods, along with brief English-language descriptions of what the methods are supposed to do. Ideally, an API would clearly articulate behavior for all possible inputs, including side effects, and then we would have software to check that implementations meet the specification. Unfortunately, a fundamental result from theoretical computer science, known as the specification problem, says that this goal is actually impossible to achieve. Briefly, such a specification would have to be written in a formal language like a programming language, and the problem of determining whether two programs perform the same computation is known, mathematically, to be unsolvable. (If you are interested in this idea, you can learn much more about the nature of unsolvable problems and their role in our understanding of the nature of computation in a course in theoretical computer science.) Therefore, we resort to informal descriptions with examples, such as those in the text surrounding our APIs.
Wide interfaces
A wide interface is one that has an excessive number of methods. An important principle to follow in designing an API is to avoid wide interfaces. The size of an API naturally tends to grow over time because it is easy to add methods to an existing API, whereas it is difficult to remove methods without breaking existing clients. In certain situations, wide interfaces are justified—for example, in widely used systems libraries such as String. Various techniques are helpful in reducing the effective width of an interface. One approach is to include methods that are orthogonal in functionality. For example, Java’s Math library includes trigonometric functions for sine, cosine, and tangent but not secant and cosecant.
Start with client code
One of the primary purposes of developing a data type is to simplify client code. Therefore, it makes sense to pay attention to client code from the start. Often, it is wise to write the client code before working on an implementation. When you find yourself with some client code that is becoming cumbersome, one way to proceed is to write a fanciful simplified version of the code that expresses the computation the way you are thinking about it. Or, if you have done a good job of writing succinct comments to describe your computation, one possible starting point is to think about opportunities to convert the comments into code.
Avoid dependence on representation
Usually when developing an API, we have a representation in mind. After all, a data type is a set of values and a set of operations on those values, and it does not make much sense to talk about the operations without knowing the values. But that is different from knowing the representation of the values. One purpose of the data type is to simplify client code by allowing it to avoid details of and dependence on a particular representation. For example, our client programs for Picture and StdAudio work with simple abstract representations of pictures and sound, respectively. The primary value of the APIs for these abstractions is that they allow client code to ignore a substantial amount of detail that is found in the standard representations of those abstractions.
Pitfalls in API design
An API may be too hard to implement, implying implementations that are difficult or impossible to develop, or too hard to use, creating client code that is more complicated than without the API. An API might be too narrow, omitting methods that clients need, or too wide, including a large number of methods not needed by any client. An API may be too general, providing no useful abstractions, or too specific, providing abstractions so detailed or so diffuse as to be useless. These considerations are sometimes summarized in yet another motto: provide to clients the methods they need and no others.
When you first started programming, you typed in HelloWorld.java without understanding much about it except the effect that it produced. From that starting point, you learned to program by mimicking the code in the book and eventually developing your own code to solve various problems. You are at a similar point with API design. There are many APIs available in the book, on the booksite, and in online Java documentation that you can study and use, to gain confidence in designing and developing APIs of your own.
Encapsulation
The process of separating clients from implementations by hiding information is known as encapsulation. Details of the implementation are kept hidden from clients, and implementations have no way of knowing details of client code, which may even be created in the future.
As you may have surmised, we have been practicing encapsulation in our data-type implementations. In SECTION 3.1, we started with the mantra you do not need to know how a data type is implemented to use it. This statement describes one of the prime benefits of encapsulation. We consider it to be so important that we have not described to you any other way of designing a data type. Now, we describe our three primary reasons for doing so in more detail. We use encapsulation for the following purposes:
• To enable modular programming
• To facilitate debugging
• To clarify program code
These reasons are tied together (well-designed modular code is easier to debug and understand than code based entirely on primitive types in long programs).
Modular programming
The programming style that we have been developing since CHAPTER 2 has been predicated on the idea of breaking large programs into small modules that can be developed and debugged independently. This approach improves the resiliency of our software by limiting and localizing the effects of making changes, and it promotes code reuse by making it possible to substitute new implementations of a data type to improve performance, accuracy, or memory footprint. The same idea works in many settings. We often reap the benefits of encapsulation when we use system libraries. New versions of the Java system often include new implementations of various data types, but the APIs do not change. There is strong and constant motivation to improve data-type implementations because all clients can potentially benefit from an improved implementation. The key to success in modular programming is to maintain independence among modules. We do so by insisting on the API being the only point of dependence between client and implementation. You do not need to know how a data type is implemented to use it. The flip side of this mantra is that a data-type implementation can assume that the client knows nothing about the data type except the API.
Example
For example, consider Complex (PROGRAM 3.3.1). It has the same name and API as PROGRAM 3.2.6, but uses a different representation for the complex numbers. PROGRAM 3.2.6 uses the Cartesian representation, where instance variables x and y represent a complex number x + i y. PROGRAM 3.3.1 uses the polar representation, where instance variables r and theta represent a complex number in the form r(cos θ + i sin θ). The polar representation is of interest because certain operations on complex number (such as multiplication and division) are more efficient using the polar representation. The idea of encapsulation is that we can substitute one of these programs for the other (for whatever reason) without changing client code. The choice between the two implementations depends on the client. Indeed, in principle, the only difference to the client should be in different performance properties. This capability is of critical importance for many reasons. One of the most important is that it allows us to improve software constantly: when we develop a better way to implement a data type, all of its clients can benefit. You take advantage of this property every time you install a new version of a software system, including Java itself.
Private
Java’s language support for enforcing encapsulation is the private access modifier. When you declare an instance variable (or method) to be private, you are making it impossible for any client (code in another class) to directly access that instance variable (or method). Clients can access the data type only through the public methods and constructors—the API. Accordingly, you can modify the implementation to use different private instance variables (or reorganize the private instance method) and know that no client will be directly affected. Java does not require that all instance variables be private, but we insist on this convention in the programs in this book. For example, if the instance variables re and im in Complex (PROGRAM 3.2.6) were public, then a client could write code that directly accesses them. If z refers to a Complex object, z.re and z.im refer to those values. But any client code that does so becomes completely dependent on that implementation, violating a basic precept of encapsulation. A switch to a different implementation, such as the one in PROGRAM 3.3.1, would render that code useless. To protect ourselves against such situations, we always make instance variables private. Next, we examine some ramifications of this convention.
Program 3.3.1 Complex number (alternate)
public class Complex
{
private final double r;
private final double theta;
public Complex(double re, double im)
{
r = Math.sqrt(re*re + im*im);
theta = Math.atan2(im, re);
}
public Complex plus(Complex b)
{ // Return the sum of this number and b.
double real = re() + b.re();
double imag = im() + b.im();
return new Complex(real, imag);
}
public Complex times(Complex b)
{ // Return the product of this number and b.
double radius = r * b.r;
double angle = theta + b.theta;
// See Q&A.
}
public double abs()
{ return r; }
public double re() { return r * Math.cos(theta); }
public double im() { return r * Math.sin(theta); }
public String toString()
{ return re() + " + " + im() + "i"; }
public static void main(String[] args)
{
Complex z0 = new Complex(1.0, 1.0);
Complex z = z0;
z = z.times(z).plus(z0);
z = z.times(z).plus(z0);
StdOut.println(z);
}
}
r | radius theta | angle

This data type implements the same API as PROGRAM 3.2.6. It uses the same instance methods but different instance variables. Since the instance variables are private, this program might be used in place of PROGRAM 3.2.6 without changing any client code.
Planning for the future
There have been numerous examples of important applications where significant expense can be directly traced to programmers not encapsulating their data types.
• Y2K problem. In the last millennium, many programs represented the year using only two decimal digits to save storage. Such programs could not distinguish between the year 1900 and the year 2000. As January 1, 2000, approached, programmers raced to fix such rollover errors and avert the catastrophic failures that were predicted by many technologists.
• ZIP codes. In 1963, The United States Postal Service (USPS) began using a five-digit ZIP code to improve the sorting and delivery of mail. Programmers wrote software that assumed that these codes would remain at five digits forever, and represented them in their programs using a single 32-bit integer. In 1983, the USPS introduced an expanded ZIP code called ZIP+4, which consists of the original five-digit ZIP code plus four extra digits.
• IPv4 versus IPv6. The Internet Protocol (IP) is a standard used by electronic devices to exchange data over the Internet. Each device is assigned a unique integer or address. IPv4 uses 32-bit addresses and supports about 4.3 billion addresses. Due to explosive growth of the Internet, a new version, IPv6, uses 128-bit addresses and supports 2128 addresses.
In each of these cases, a necessary change to the internal representation meant that a large amount of client code that depended on the current standard (because the data type was not encapsulated) simply would not function as intended. The estimated costs for the changes in each of these cases ran to hundreds of millions of dollars! That is a huge cost for failing to encapsulate a single number. These predicaments might seem distant to you, but you can be sure that every individual programmer (that’s you) who does not take advantage of the protection available through encapsulation risks losing significant amounts of time and effort fixing broken code when conventions change.
Our convention to define all of our instance variables with the private access modifier provides some protection against such problems. If you adopt this convention when implementing a data type for a year, ZIP code, IP address, or whatever, you can change the representation without affecting clients. The data-type implementation knows the data representation, and the object holds the data; the client holds only a reference to the object and does not know the details.
Limiting the potential for error
Encapsulation also helps programmers ensure that their code operates as intended. As an example, we consider yet another horror story: In the 2000 presidential election, Al Gore received negative 16,022 votes on an electronic voting machine in Volusia County, Florida. The counter variable was not properly encapsulated in the voting machine software! To understand the problem, consider Counter (PROGRAM 3.3.2), which implements a simple counter according to the following API:
|
||
|
|
create a counter, initialized to |
|
|
increment the counter unless its value is |
|
|
return the value of the counter |
|
|
string representation |
API for a counter data type (see PROGRAM 3.3.2) |
||
This abstraction is useful in many contexts, including, for example, an electronic voting machine. It encapsulates a single integer and ensures that the only operation that can be performed on the integer is increment by 1. Therefore, it can never go negative. The goal of data abstraction is to restrict the operations on the data. It also isolates operations on the data. For example, we could add a new implementation with a logging capability so that increment() saves a timestamp for each vote or some other information that can be used for consistency checks. But without the private modifier, there could be client code like the following somewhere in the voting machine:
Counter c = new Counter("Volusia", VOTERS_IN_VOLUSIA_COUNTY);
c.count = -16022;
With the private modifier, code like this will not compile; without it, Gore’s vote count was negative. Using encapsulation is far from a complete solution to the voting security problem, but it is a good start.
public class Counter
{
private final String name;
private final int maxCount;
private int count;
public Counter(String id, int max)
{ name = id; maxCount = max; }
public void increment()
{ if (count < maxCount) count++; }
public int value()
{ return count; }
public String toString()
{ return name + ": " + count; }
public static void main(String[] args)
{
int n = Integer.parseInt(args[0]);
int trials = Integer.parseInt(args[1]);
Counter[] hits = new Counter[n];
for (int i = 0; i < n; i++)
hits[i] = new Counter(i + "", trials);
for (int t = 0; t < trials; t++)
hits[StdRandom.uniform(n)].increment();
for (int i = 0; i < n; i++)
StdOut.println(hits[i]);
}
}
name | counter name maxCount | maximum value count | value
This class encapsulates a simple integer counter, assigning it a string name and initializing it to 0 (Java’s default initialization), incrementing it each time the client calls increment(), reporting the value when the client calls value(), and creating a string with its name and value in toString().
% java Counter 6 600000
0: 100684
1: 99258
2: 100119
3: 100054
4: 99844
5: 100037
Code clarity
Precisely specifying a data type is also good design because it leads to client code that can more clearly express its computation. You have seen many examples of such client code in SECTIONS 3.1 and 3.2, and we already mentioned this issue in our discussion of Histogram (PROGRAM 3.2.3). Clients of that program are clearer with it than without it because calls on the instance method addDataPoint() clearly identify points of interest in the client. One key to good design is to observe that code written with the proper abstractions can be nearly self-documenting. Some aficionados of object-oriented programming might argue that Histogram itself would be easier to understand if it were to use Counter (see EXERCISE 3.3.3), but that point is perhaps debatable.
We have stressed the benefits of encapsulation throughout this book. We summarize them again here, in the context of designing data types. Encapsulation enables modular programming, allowing us to:
• Independently develop client and implementation code
• Substitute improved implementations without affecting clients
• Support programs not yet written (any client can write to the API)
Encapsulation also isolates data-type operations, which leads to the possibility of:
• Adding consistency checks and other debugging tools in implementations
• Clarifying client code
A properly implemented data type (encapsulated) extends the Java language, allowing any client program to make use of it.
Immutability
As defined at the end of Section 3.1, an object from a data type is immutable if its data-type value cannot change once created. An immutable data type is one in which all objects of that type are immutable. In contrast, a mutable data type is one in which objects of that type have values that are designed to change. Of the data types considered in this chapter, String, Charge, Color, and Complex are all immutable, and Turtle, Picture, Histogram, StockAccount, and Counter are all mutable. Whether to make a data type immutable is an important design decision and depends on the application at hand.
Immutable types
The purpose of many data types is to encapsulate values that do not change so that they behave in the same way as primitive types. For example, a programmer implementing a Complex client might reasonably expect to write the code z = z0 for two Complex variables, in the same way as for double or int variables. But if Complex objects were mutable and the value of z were to change after the assignment z = z0, then the value of z0 would also change (they are both references to the same object)! This unexpected result, known as an aliasing bug, comes as a surprise to many newcomers to object-oriented programming. One very important reason to implement immutable types is that we can use immutable objects in assignment statements (or as arguments and return values from methods) without having to worry about their values changing.
immutable |
mutable |
|
|
|
|
|
|
|
|
|
|
|
Java arrays |
Mutable types
For many data types, the very purpose of the abstraction is to encapsulate values as they change. Turtle (PROGRAM 3.2.4) is a prime example. Our reason for using Turtle is to relieve client programs of the responsibility of tracking the changing values. Similarly, Picture, Histogram, StockAccount, Counter, and Java arrays are all data types for which we expect values to change. When we pass a Turtle as an argument to a method, as in Koch, we expect the value of the Turtle object to change.
Arrays and strings
You have already encountered this distinction as a client programmer, when using Java arrays (mutable) and Java’s String data type (immutable). When you pass a String to a method, you do not need to worry about that method changing the sequence of characters in the String, but when you pass an array to a method, the method is free to change the values of the elements in the array. The String data type is immutable because we generally do not want string values to change, and Java arrays are mutable because we generally do want array values to change. There are also situations where we want to have mutable strings (that is the purpose of Java’s StringBuilder data type) and where we want to have immutable arrays (that is the purpose of the Vector data type that we consider later in this section).
Advantages of immutability
Generally, immutable types are easier to use and harder to misuse because the scope of code that can change their values is far smaller than for mutable types. It is easier to debug code that uses immutable types because it is easier to guarantee that variables in the client code that uses them will remain in a consistent state. When using mutable types, you must always be concerned about where and when their values change.

Cost of immutability
The downside of immutability is that a new object must be created for every value. For example, the expression z = z.times(z).plus(z0) involves creating a new object (the return value of z.times(z)), then using that object to invoke plus(), but never saving a reference to it. A program such as Mandelbrot (PROGRAM 3.2.7) might create a large number of such intermediate orphans. However, this expense is normally manageable because Java garbage collectors are typically optimized for such situations. Also, as in the case of Mandelbrot, when the point of the calculation is to create a large number of values, we expect to pay the cost of representing them. Mandelbrot also creates a large number of (immutable) Color objects.
Final
You can use the final modifier to help enforce immutability in a data type. When you declare an instance variable as final, you are promising to assign it a value only once, either in an inline initialization statement or in the constructor. Any other code that could modify the value of a final variable leads to a compile-time error. In our code, we use the modifier final with instance variables whose values never change. This policy serves as documentation that the value does not change, prevents accidental changes, and makes programs easier to debug. For example, you do not have to include a final variable in a trace, since you know that its value never changes.
Reference types
Unfortunately, final guarantees immutability only when instance variables are primitive types, not reference types. If an instance variable of a reference type has the final modifier, the value of that instance variable (the object reference) will never change—it will always refer to the same object. However, the value of the object itself can change. For example, if you have a final instance variable that is an array, you cannot change the array (to change its length or type, say), but you can change the values of the individual array elements. Thus, aliasing bugs can arise. For example, this code does not implement an immutable data type:
public class Vector
{
private final double[] coords;
public Vector(double[] a)
{
coords = a;
}
...
}
A client program could create a Vector by specifying the elements in an array, and then (bypassing the API) change the elements of the Vector after construction:
double[] a = { 3.0, 4.0 };
Vector vector = new Vector(a);
a[0] = 17.0; // coords[0] is now 17.0
The instance variable coords[] is private and final, but Vector is mutable because the client holds a reference to the same array. When the client changes the value of an element in its array, the change also appears in the corresponding coords[] array, because coords[] and a[] are aliases. To ensure immutability of a data type that includes an instance variable of a mutable type, we need to make a local copy, known as a defensive copy. Next, we consider such an implementation.
Immutability needs to be taken into account in any data-type design. Ideally, whether a data type is immutable should be specified in the API, so that clients know that object values will not change. Implementing an immutable data type can be a burden in the presence of reference types. For complicated data types, making the defensive copy is one challenge; ensuring that none of the instance methods change values is another.
Example: spatial vectors
To illustrate these ideas in the context of a useful mathematical abstraction, we now consider a vector data type. Like complex numbers, the basic definition of the vector abstraction is familiar because it has played a central role in applied mathematics for more than 100 years. The field of mathematics known as linear algebra is concerned with properties of vectors. Linear algebra is a rich and successful theory with numerous applications, and plays an important role in all fields of social and natural science. Full treatment of linear algebra is certainly beyond the scope of this book, but several important applications are based upon elementary and familiar calculations, so we touch upon vectors and linear algebra throughout the book (for example, the random-surfer example in SECTION 1.6 is based on linear algebra). Accordingly, it is worthwhile to encapsulate such an abstraction in a data type.
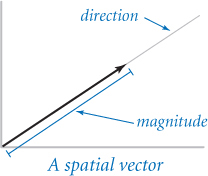
A spatial vector is an abstract entity that has a magnitude and a direction. Spatial vectors provide a natural way to describe properties of the physical world, such as force, velocity, momentum, and acceleration. One standard way to specify a vector is as an arrow from the origin to a point in a Cartesian coordinate system: the direction is the ray from the origin to the point and the magnitude is the length of the arrow (distance from the origin to the point). To specify the vector it suffices to specify the point.
This concept extends to any number of dimensions: a sequence of n real numbers (the coordinates of an n-dimensional point) suffices to specify a vector in n-dimensional space. By convention, we use a boldface letter to refer to a vector and numbers or indexed variable names (the same letter in italics) separated by commas within parentheses to denote its value. For example, we might use x to denote the vector (x0, x1, ..., xn–1) and y to denote the vector ( y0, y1, ..., yn–1).
API
The basic operations on vectors are to add two vectors, scale a vector, compute the dot product of two vectors, and compute the magnitude and direction, as follows:
• Addition: x + y = ( x0 + y0, x1 + y1, ..., xn–1 + yn–1 )
• Vector scaling: α x = (α x0, α x1, ..., α xn–1)
• Dot product: x · y = x0y0 + x1y1 + ... + xn–1yn–1
• Magnitude: |x| = (x02 + x12 +... + xn–12)1/2
• Direction: x / |x| = ( x0 / |x|, x1 / |x|, ..., xn–1 / |x| )
The result of addition, vector scaling, and the direction are vectors, but the magnitude and the dot product are scalar quantities (real numbers). For example, if x = (0, 3, 4, 0), and y = (0, –3, 1, –4), then x + y = (0, 0, 5, –4), 3x = (0, 9, 12, 0), x · y = –5, |x| = 5, and x / |x| = (0, 3/5, 4/5, 0). The direction vector is a unit vector: its magnitude is 1. These definitions lead immediately to an API:
|
||
|
|
create a vector with the given Cartesian coordinates |
|
|
sum of this vector and |
|
|
difference of this vector and |
|
|
this vector, scaled by |
|
|
dot product of this vector and |
|
|
magnitude |
|
|
unit vector with same direction as this vector |
|
|
|
|
|
string representation |
API for spatial vectors (see PROGRAM 3.3.3) |
||
As with the Complex API, this API does not explicitly specify that this type is immutable, but we know that client programmers (who are likely to be thinking in terms of the mathematical abstraction) will certainly expect that.
Representation
As usual, our first choice in developing an implementation is to choose a representation for the data. Using an array to hold the Cartesian coordinates provided in the constructor is a clear choice, but not the only reasonable choice. Indeed, one of the basic tenets of linear algebra is that other sets of n vectors can be used as the basis for a coordinate system: any vector can be expressed as a linear combination of a set of n vectors, satisfying a certain condition known as linear independence. This ability to change coordinate systems aligns nicely with encapsulation. Most clients do not need to know about the internal representation at all and can work with Vector objects and operations. If warranted, the implementation can change the coordinate system without affecting any client code.
public class Vector
{
private final double[] coords;
public Vector(double[] a)
{ // Make a defensive copy to ensure immutability.
coords = new double[a.length];
for (int i = 0; i < a.length; i++)
coords[i] = a[i];
}
public Vector plus(Vector that)
{ // Sum of this vector and that.
double[] result = new double[coords.length];
for (int i = 0; i < coords.length; i++)
result[i] = this.coords[i] + that.coords[i];
return new Vector(result);
}
public Vector scale(double alpha)
{ // Scale this vector by alpha.
double[] result = new double[coords.length];
for (int i = 0; i < coords.length; i++)
result[i] = alpha * coords[i];
return new Vector(result);
}
public double dot(Vector that)
{ // Dot product of this vector and that.
double sum = 0.0;
for (int i = 0; i < coords.length; i++)
sum += this.coords[i] * that.coords[i];
return sum;
}
public double magnitude()
{ return Math.sqrt(this.dot(this)); }
public Vector direction()
{ return this.scale(1/this.magnitude()); }
public double cartesian(int i)
{ return coords[i]; }
}
coords[] | Cartesian coordinates
This implementation encapsulates the mathematical spatial-vector abstraction in an immutable Java data type. Sketch (PROGRAM 3.3.4) and Body (PROGRAM 3.4.1) are typical clients The instance methods minus() and toString() are left for exercises (EXERCISE 3.3.4 and EXERCISE 3.3.14), as is the test client (EXERCISE 3.3.5).
Implementation
Given the representation, the code that implements all of these operations (Vector, in PROGRAM 3.3.3) is straightforward. The constructor makes a defensive copy of the client array and none of the methods assign values to the copy, so that the Vector data type is immutable. The cartesian() method is easy to implement in our Cartesian coordinate representation: return the i th coordinate in the array. It actually implements a mathematical function that is defined for any Vector representation: the geometric projection onto the i th Cartesian axis.

The this reference
Within an instance method (or constructor), the this keyword gives us a way to refer to the object whose instance method (or constructor) is being called. You can use this in the same way you use any other object reference (for example, to invoke a method, pass as an argument to a method, or access instance variables). For example, the magnitude() method in Vector uses the this keyword in two ways: to invoke the dot() method and as an argument to the dot() method. Thus, the expression vector.magnitude() is equivalent to Math.sqrt(vector.dot(vector)). Some Java programmers always use this to access instance variables. This policy is easy to defend because it clearly indicates when you are referring to an instance variable (as opposed to a local or parameter variable). However, it leads to a surfeit of this keywords, so we take the opposite tack and use this sparingly in our code.
Why go to the trouble of using a Vector data type when all of the operations are so easily implemented with arrays? By now the answer to this question should be obvious to you: to enable modular programming, facilitate debugging, and clarify code. A double array is a low-level Java mechanism that admits all kinds of operations on its elements. By restricting ourselves to just the operations in the Vector API (which are the only ones that we need, for many clients), we simplify the process of designing, implementing, and maintaining our programs. Because the Vector data type is immutable, we can use it in the same way we use primitive types. For example, when we pass a Vector to a method, we are assured its value will not change (but we do not have that assurance when passing an array). Writing programs that use the Vector data type and its associated operations is an easy and natural way to take advantage of the extensive amount of mathematical knowledge that has been developed around this abstract concept.
Java provides language support for defining relationships among objects, known as inheritance. Software developers use these mechanisms widely, so you will study them in detail if you take a course in software engineering. Generally, effective use of such mechanisms is beyond the scope of this book, but we briefly describe the two main forms of inheritance in Java—interface inheritance and implementation inheritance—here because there are a few situations where you are likely to encounter them.
Interface inheritance (subtyping)
Java provides the interface construct for declaring a relationship between otherwise unrelated classes, by specifying a common set of methods that each implementing class must include. That is, an interface is a contract for a class to implement a certain set of methods. We refer to this arrangement as interface inheritance because an implementing class inherits a partial API from the interface. Interfaces enable us to write client programs that can manipulate objects of varying types, by invoking common methods from the interface. As with most new programming concepts, it is a bit confusing at first, but will make sense to you after you have seen a few examples.
Defining an interface
As a motivating example, suppose that we want to write code to plot any real-valued function. We have previously encountered programs in which we plot one specific function by sampling the function of interest at evenly spaced points in a particular interval. To generalize these programs to handle arbitrary functions, we define a Java interface for real-valued functions of a single variable:
public interface Function
{
public abstract double evaluate(double x);
}
The first line of the interface declaration is similar to that of a class declaration, but uses the keyword interface instead of class. The body of the interface contains a list of abstract methods. An abstract method is a method that is declared but does not include any implementation code; it contains only the method signature, terminated by a semicolon. The modifier abstract designates a method as abstract. As with a Java class, you must save a Java interface in a file whose name matches the name of the interface, with a .java extension.
Implementing an interface
An interface is a contract for a class to implement a certain set of methods. To write a class that implements an interface, you must do two things. First, you must include an implements clause in the class declaration with the name of the interface. You can think of this as signing a contract, promising to implement each of the abstract methods declared in the interface. Second, you must implement each of these abstract methods. For example, you can define a class for computing the square of a real number that implements the Function interface as follows:
public class Square implements Function
{
public double evaluate(double x)
{ return x*x; }
}
Similarly, you can define a class for computing the Gaussian probability density function (see PROGRAM 2.1.2):
public class GaussianPDF implements Function
{
public double evaluate(double x)
{ return Math.exp(-x*x/2) / Math.sqrt(2 * Math.PI); }
}
If you fail to implement any of the abstract methods specified in the interface, you will get a compile-time error. Conversely, a class implementing an interface may include methods not specified in the interface.
Using an interface
An interface is a reference type. You can use an interface name in the same way that you use any other data-type name. For example, you can declare the type of a variable to be the name of an interface. When you do so, any object you assign to that variable must be an instance of a class that implements the interface. For example, a variable of type Function may store an object of type Square or GaussianPDF, but not of type Complex.
Function f1 = new Square();
Function f2 = new GaussianPDF();
Function f3 = new Complex(1.0, 2.0); // compile-time error
A variable of an interface type may invoke only those methods declared in the interface, even if the implementing class defines additional methods.
When a variable of an interface type invokes a method declared in the interface, Java knows which method to call because it knows the type of the invoking object. For example, f1.evaluate() would call the evaluate() method defined in the Square class, whereas f2.evaluate() would call the evaluate() method defined in the GaussianPDF class. This powerful programming mechanism is known as polymorphism or dynamic dispatch.
To see the advantages of using interfaces and polymorphism, we return to the application of plotting the graph of a function f in the interval [a, b]. If the function f is sufficiently smooth, we can sample the function at n + 1 evenly spaced points in the interval [a, b] and display the results using StdStats.plotPoints() or StdStats.plotLines().
public static void plot(Function f, double a, double b, int n)
{
double[] y = new double[n+1];
double delta = (b - a) / n;
for (int i = 0; i <= n; i++)
y[i] = f.evaluate(a + delta*i);
StdStats.plotPoints(y);
StdStats.plotLines(y);
}
The advantage of declaring the variable f using the interface type Function is that the same method call f.evaluate() works for an object f of any data type that implements the Function interface, including Square or GaussianPDF. Consequently, we don’t need to write overloaded methods for each type—we can reuse the same plot() function for many types! This ability to arrange to write a client to plot any function is a persuasive example of interface inheritance.

Computing with functions
Often, particularly in scientific computing, we want to compute with functions: we want differentiate functions, integrate functions, find roots of functions, and so forth. In some programming languages, known as functional programming languages, this desire aligns with the underlying design of the language, which uses computing with functions to substantially simplify client code. Unfortunately, methods are not first-class objects in Java. However, as we just saw with plot(), we can use Java interfaces to achieve some of the same objectives.
As an example, consider the problem of estimating the Riemann integral of a positive real-valued function f (the area under the curve) in an interval (a, b). This computation is known as quadrature or numerical integration. A number of methods have been developed for quadrature. Perhaps the simplest is known as the rectangle rule, where we approximate the value of the integral by computing the total area of n equal-width rectangles under the curve. The integrate() function defined below evaluates the integral of a real-valued function f in the interval (a, b), using the rectangle rule with n rectangles:
public static double integrate(Function f,
double a, double b, int n)
{
double delta = (b - a) / n;
double sum = 0.0;
for (int i = 0; i < n; i++)
sum += delta * f.evaluate(a + delta * (i + 0.5));
return sum;
}

The indefinite integral of x2 is x3/3, so the definite integral between 0 and 10 is 1,000/3. The call to integrate(new Square(), 0, 10, 1000) returns 333.33324999999996, which is the correct answer to six significant digits of accuracy. Similarly, the call to integrate(new GaussianPDF(), -1, 1, 1000) returns 0.6826895727940137, which is the correct answer to seven significant digits of accuracy (recall the Gaussian probability density function and PROGRAM 2.1.2).
Quadrature is not always the most efficient or accurate way to evaluate a function. For example, the Gaussian.cdf() function in PROGRAM 2.1.2 is a faster and more accurate way to integrate the Gaussian probability density function. However, quadrature has the advantage of being useful for any function whatsoever, subject only to certain technical conditions on smoothness.
Lambda expressions
The syntax that we have just considered for computing with functions is a bit unwieldy. For example, it is awkward to define a new class that implements the Function interface for each function that we might want to plot or integrate. To simplify syntax in such situations, Java provides a powerful functional programming feature known as lambda expressions. You should think of a lambda expression as a block of code that you can pass around and execute later. In its simplest form, a lambda expression consists of the three elements:
• A list of parameters variables, separated by commas, and enclosed in parentheses
• The lambda operator ->
• A single expression, which is the value returned by the lambda expression
For example, the lambda expression (x, y) -> Math.sqrt(x*x + y*y) implements the hypotenuse function. The parentheses are optional when there is only one parameter. So the lambda expression x -> x*x implements the square function and x -> Gaussian.pdf(x) implements the Gaussian probability density function.

Our primary use of lambda expressions is as a concise way to implement a functional interface (an interface with a single abstract method). Specifically, you can use a lambda expression wherever an object from a functional interface is expected. For example, you can integrate the square function with the call integrate(x -> x*x, 0, 10, 1000), thereby bypassing the need to define the Square class. You do not need to declare explicitly that the lambda expression implements the Function interface; as long as the signature of the single abstract method is compatible with the lambda expression (same number of arguments and types), Java will infer it from context. In this case, the lambda expression x -> x*x is compatible with the abstract method evaluate().

Built-in interfaces
Java includes three interfaces that we will consider later this book. In SECTION 4.2, we will consider Java’s java.util.Comparable interface, which contains a single abstract method compareTo(). The compareTo() method defines a natural order for comparing objects of the same type, such as alphabetical order for strings and ascending order for integers and real numbers. This enables us to write code to sort arrays of objects. In SECTION 4.3, we will use interfaces to enable clients to iterate over the items in a collection, without relying on the underlying representation. Java supplies two interfaces—java.util.Iterator and java.lang.Iterable—for this purpose.
Event-based programming
Another powerful example of the value of interface inheritance is its use in event-based programming. In a familiar setting, consider the problem of extending Draw to respond to user input such as mouse clicks and keystrokes. One way to do so is to define an interface to specify which method or methods Draw should call when user input happens. The descriptive term callback is sometimes used to describe a call from a method in one class to a method in another class through an interface. You can find on the booksite an example interface DrawListener and information on how to write code to respond to user mouse clicks and keystrokes within Draw. You will find it easy to write code that creates a Draw object and includes a method that the Draw method can invoke (callback your code) to tell your method the character typed on a user keystroke event or the mouse position on a mouse click. Writing interactive code is fun but challenging because you have to plan for all possible user input actions.
Interface inheritance is an advanced programming concept that is embraced by many experienced programmers because it enables code reuse, without sacrificing encapsulation. The functional programming style that it supports is controversial in some quarters, but lambda expressions and similar constructs date back to the earliest days of programming and have found their way into numerous modern programming languages. The style has passionate proponents who believe that we should be using and teaching it exclusively. We have not emphasized it from the start because the preponderance of code that you will encounter was built without it, but we introduce it here because every programmer needs to be aware of the possibility and on the watch for opportunities to exploit it.
Implementation inheritance (subclassing)
Java also supports another inheritance mechanism known as subclassing. The idea is to define a new class (subclass, or derived class) that inherits instance variables (state) and instance methods (behavior) from another class (superclass, or base class), enabling code reuse. Typically, the subclass redefines or overrides some of the methods in the superclass. We refer to this arrangement as implementation inheritance because one class inherits code from another class.
Systems programmers use subclassing to build so-called extensible libraries—one programmer (even you) can add methods to a library built by another programmer (or, perhaps, a team of systems programmers), effectively reusing the code in a potentially huge library. This approach is widely used, particularly in the development of user interfaces, so that the large amount of code required to provide all the facilities that users expect (windows, buttons, scrollbars, drop-down menus, cut-and-paste, access to files, and so forth) can be reused.

The use of subclassing is controversial among systems programmers because its advantages over subtyping are debatable. In this book, we avoid subclassing because it works against encapsulation in two ways. First, any change in the superclass affects all subclasses. The subclass cannot be developed independently of the superclass; indeed, it is completely dependent on the superclass. This problem is known as the fragile base class problem. Second, the subclass code, having access to instance variables in the superclass, can subvert the intention of the superclass code. For example, the designer of a class such as Vector may have taken great care to make the Vector immutable, but a subclass, with full access to those instance variables, can recklessly change them.
Java’s Object superclass
Certain vestiges of subclassing are built into Java and therefore unavoidable. Specifically, every class is a subclass of Java’s Object class. This structure enables implementation of the “convention” that every class includes an implementation of toString(), equals(), hashCode(), and several other methods. Every class inherits these methods from Object through subclassing. When programming in Java, you will often override one or more of these methods.
|
||
|
|
string representation of this object |
|
|
is this object equal to |
|
|
hash code of this object |
|
|
class of this object |
Methods inherited by all classes (used in this book) |
||
String conversion
Every Java class inherits the toString() method, so any client can invoke toString() for any object. As with Java interfaces, Java knows which toString() method to call (polymorphically) because it knows the type of the invoking object. This convention is the basis for Java’s automatic conversion of one operand of the string concatenation operator + to a string whenever the other operand is a string. For example, if x is any object reference, then Java automatically converts the expression "x = " + x to "x = " + x.toString(). If a class does not override the toString() method, then Java invokes the inherited toString() implementation, which is normally not helpful (typically a string representation of the memory address of the object). Accordingly, it is good programming practice to override the toString() method in every class that you develop.
Equality
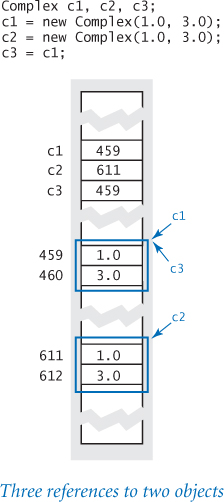
What does it mean for two objects to be equal? If we test equality with (x == y), where x and y are object references, we are testing whether they have the same identity: whether the object references are equal. For example, consider the code in the diagram at right, which creates two Complex objects (PROGRAM 3.2.6) referenced by three variables c1, c2, and c3. As illustrated in the diagram, c1 and c3 both reference the same object, which is different from the object referenced by c2. Consequently, (c1 == c3) is true but (c1 == c2) is false. This is known as reference equality, but it is rarely what clients want.
Typical clients want to test whether the data-type values (object state) are the same. This is known as object equality. Java includes the equals() method—which is inherited by all classes—for this purpose. For example, the String data type overrides this method in a natural manner: If x and y refer to String objects, then x.equals(y) is true if and only if the two strings correspond to the same sequence of characters (and not depending on whether they reference the same String object).
Java’s convention is that the equals() method must implement an equivalence relation by satisfying the following three natural properties for all object references x, y, and z:
• Reflexive: x.equals(x) is true.
• Symmetric: x.equals(y) is true if and only if y.equals(x) is true.
• Transitive: if x.equals(y) is true and y.equals(z) is true, then x.equals(z) is true.
In addition, the following two properties must hold:
• Multiple calls to x.equals(y) return the same truth value, provided neither object is modified between calls.
• x.equals(null) returns false.
Typically, when we define our own data types, we override the equals() method because the inherited implementation is reference equality. For example, suppose we want to consider two Complex objects equal if and only if their real and imaginary components are the same. The implementation at the top of the next page gets the job done:
public boolean equals(Object x)
{
if (x == null) return false;
if (this.getClass() != x.getClass()) return false;
Complex that = (Complex) x;
return (this.re == that.re) && (this.im == that.im);
}
This code is unexpectedly intricate because the argument to equals() can be a reference to an object of any type (or null), so we summarize the purpose of each statement:
• The first statement returns false if the arguments is null, as required.
• The second statement uses the inherited method getClass() to return false if the two objects are of different types.
• The cast in the third statement is guaranteed to succeed because of the second statement.
• The last statement implements the logic of the equality test by comparing the corresponding instance variables of the two objects.
You can use this implementation as a template—once you have implemented one equals() method, you will not find it difficult to implement another.
Hashing
We now consider a fundamental operation related to equality testing, known as hashing, which maps an object to an integer, known as a hash code. This operation is so important that it is handled by a method named hashCode(), which is inherited by all classes. Java’s convention is that the hashCode() method must satisfy the following two properties for all object references x and y:
• If x.equals(y) is true, then x.hashCode() is equal to y.hashCode().
• Multiple calls of x.hashCode() return the same integer, provided the object is not modified between calls.
For example, in the following code fragment, x and y refer to equal String objects—x.equals(y) is true—so they must have the same hash code; x and z refer to different String objects, so we expect their hash codes to be different.
String x = new String("Java"); // x.hashCode() is 2301506
String y = new String("Java"); // y.hashCode() is 2301506
String z = new String("Python"); // z.hashCode() is -1889329924
In typical applications, we use the hash code to map an object x to an integer in a small range, say between 0 and m-1, using this hash function:
private int hash(Object x)
{ return Math.abs(x.hashCode() % m); }
The call to Math.abs() ensures that the return value is not a negative integer, which might otherwise be the case if x.hashCode() is negative. We can use the hash function value as an integer index into an array of length m (the utility of this operation will become apparent in PROGRAM 3.3.4 and PROGRAM 4.4.3). By convention, objects whose values are equal must have the same hash code, so they also have the same hash function value. Objects whose values are not equal can have the same hash function value but we expect the hash function to divide n typical objects from the class into m groups of roughly equal size. Many of Java’s immutable data types (including String) include implementations of hashCode() that are engineered to distribute objects in a reasonable manner.
Crafting a good implementation of hashCode() for a data type requires a deft combination of science and engineering, and is beyond the scope of this book. Instead, we describe a simple recipe for doing so in Java that is effective in a wide variety of situations:
• Ensure that the data type is immutable.
• Import the class java.util.Objects.
• Implement equals() by comparing all significant instance variables.
• Implement hashCode() by using all significant instance variables as arguments to the static method Objects.hash().
The static method Objects.hash() generates a hash code for its sequence of arguments. For example, the following hashCode() implementation for the Complex data type (PROGRAM 3.2.1) accompanies the equals() implementation that we just considered:
public int hashCode()
{ return Objects.hash(re, im); }

Wrapper types
One of the main benefits of inheritance is code reuse. However, this code reuse is limited to reference types (and not primitive types). For example, the expression x.hashCode() is legal for any object reference x, but produces a compile-time error if x is a variable of a primitive type. For situations where we wish want to represent a value from a primitive type as an object, Java supplies built-in reference types known as wrapper types, one for each of the eight primitive types. For example, the wrapper types Integer and Double correspond to int and double, respectively. An object of a wrapper type “wraps” a value from a primitive type into an object, so that you can use instance methods such as equals() and hashCode(). Each of these wrapper types is immutable and includes both instance methods (such as compareTo() for comparing two objects numerically) and static methods (such as Integer.parseInt() and Double.parseDouble() for converting from strings to primitive types).
primitive type |
wrapper type |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Autoboxing and unboxing
Java automatically converts between an object from a wrapper type and the corresponding primitive data-type value—in assignment statements, method arguments, and arithmetic/logic expressions—so that you can write code like the following:
Integer x = 17; // Autoboxing (int -> Integer) int a = x; // Unboxing (Integer -> int)
In the first statement, Java automatically casts (autoboxes) the int value 17 to be an object of type Integer before assigning it to the variable x. Similarly, in the second statement, Java automatically casts (unboxes) the Integer object to be a value of type int before assigning that value to the variable a. Autoboxing and unboxing can be convenient features when writing code, but involves a significant amount of processing behind the scenes that can affect performance.
For code clarity and performance, we use primitive types for computing with numbers whenever possible. However, in CHAPTER 4, we will encounter several compelling examples (particularly with data types that store collections of objects), for which wrapper types and autoboxing/unboxing enable us to develop code for use with reference types and reuse that same code (without modification) with primitive types.
Application: data mining
To illustrate some of the concepts discussed in this section in the context of an application, we next consider a software technology that is proving important in addressing the daunting challenges of data mining, a term that describes the process of discovering patterns by searching through massive amounts of information. This technology can serve as the basis for dramatic improvements in the quality of web search results, for multimedia information retrieval, for biomedical databases, for research in genomics, for improved scholarship in many fields, for innovation in commercial applications, for learning the plans of evildoers, and for many other purposes. Accordingly, there is intense interest and extensive ongoing research on data mining.
You have direct access to thousands of files on your computer and indirect access to billions of files on the web. As you know, these files are remarkably diverse: there are commercial web pages, music and video, email, program code, and all sorts of other information. For simplicity, we will restrict our attention to text documents (though the method we will consider applies to images, music, and all sorts of other files as well). Even with this restriction, there is remarkable diversity in the types of documents. For reference, you can find these documents on the booksite:
file name |
description |
sample text |
|
legal document |
|
|
American novel |
|
|
American novel |
|
|
English novel |
|
|
Java code |
|
|
financial data |
|
|
web page source |
|
|
virus genome |
|
Some text documents |
||
Our interest is in finding efficient ways to search through the files using their content to characterize documents. One fruitful approach to this problem is to associate with each document a vector known as a sketch, which is a function of its content. The basic idea is that the sketch should characterize a document, so that documents that are different have sketches that are different and documents that are similar have sketches that are similar. You probably are not surprised to learn that this approach can enable us to distinguish among a novel, a Java program, and a genome, but you might be surprised to learn that content searches can tell the difference between novels written by different authors and can be effective as the basis for many other subtle search criteria.
To start, we need an abstraction for text documents. What is a text document? Which operations do we want to perform on text documents? The answers to these questions inform our design and, ultimately, the code that we write. For the purposes of data mining, it is clear that the answer to the first question is that a text document is defined by a string. The answer to the second question is that we need to be able to compute a number to measure the similarity between a document and any other document. These considerations lead to the following API:
|
||
|
|
|
|
|
similarity measure between this sketch and |
|
|
string representation |
API for sketches (see PROGRAM 3.3.4) |
||
The arguments of the constructor are a text string and two integers that control the quality and size of the sketch. Clients can use the similarTo() method to determine the extent of similarity between this Sketch and any other Sketch on a scale from 0 (not similar) to 1 (similar). The toString() method is primarily for debugging. This data type provides a good separation between implementing a similarity measure and implementing clients that use the similarity measure to search among documents.
Computing sketches
Our first challenge is to compute a sketch of the text string. We will use a sequence of real numbers (or a Vector) to represent a document’s sketch. But which information should go into computing the sketch and how do we compute the Vector sketch? Many different approaches have been studied, and researchers are still actively seeking efficient and effective algorithms for this task. Our implementation Sketch (PROGRAM 3.3.4) uses a simple frequency count approach. The constructor has two arguments: an integer k and a vector dimension d. It scans the document and examines all of the k-grams in the document—that is, the substrings of length k starting at each position. In its simplest form, the sketch is a vector that gives the relative frequency of occurrence of the k-grams in the string; it is an element for each possible k-gram giving the number of k-grams in the content that have that value. For example, suppose that we use k = 2 in genomic data, with d = 16 (there are 4 possible character values and therefore 42 = 16 possible 2-grams). The 2-gram AT occurs 4 times in the string ATAGATGCATAGCGCATAGC, so, for example, the vector element corresponding to AT would be 4. To build the frequency vector, we need to be able to convert each of the 16 possible k-grams into an integer between 0 and 15 (this function is known as a hash value). For genomic data, this is an easy exercise (see EXERCISE 3.3.28). Then, we can compute an array to build the frequency vector in one scan through the text, incrementing the array element corresponding to each k-gram encountered. It would seem that we lose information by disregarding the order of the k-grams, but the remarkable fact is that the information content of that order is lower than that of their frequency. A Markov model paradigm not dissimilar from the one that we studied for the random surfer in SECTION 1.6 can be used to take order into account—such models are effective, but much more work to implement. Encapsulating the computation in Sketch gives us the flexibility to experiment with various designs without needing to rewrite Sketch clients.
|
|
|
|
||
2-gram |
hash |
count |
unit |
count |
unit |
AA |
0 |
0 |
0 |
2 |
.139 |
AC |
1 |
0 |
0 |
1 |
.070 |
AG |
2 |
3 |
.397 |
2 |
.139 |
AT |
3 |
4 |
.530 |
1 |
.070 |
CA |
4 |
2 |
.265 |
2 |
.139 |
CC |
5 |
0 |
0 |
2 |
.139 |
CG |
6 |
1 |
.132 |
6 |
.417 |
CT |
7 |
0 |
0 |
4 |
.278 |
GA |
8 |
1 |
.132 |
2 |
.139 |
GC |
9 |
4 |
.530 |
6 |
.417 |
GG |
10 |
0 |
0 |
2 |
.139 |
GT |
11 |
0 |
0 |
4 |
.278 |
TA |
12 |
3 |
.397 |
0 |
0 |
TC |
13 |
0 |
0 |
5 |
.348 |
TG |
14 |
1 |
.132 |
4 |
.278 |
TT |
15 |
0 |
0 |
6 |
.417 |
Profiling genomic data |
|||||
Hashing
For ASCII text strings there are 128 different possible values for each character, so there are 128k possible k-grams, and the dimension d would have to be 128k for the scheme just described. This number is prohibitively large even for moderately large k. For Unicode, with more than 65,536 characters, even 2-grams lead to huge vector sketches. To ameliorate this problem, we use hashing, a fundamental operation related to search algorithms that we just considered in our discussion of inheritance. Recall that all objects inherit a method hashCode() that returns an integer between –231 and 231–1. Given any string s, we use the expression Math.abs(s.hashCode() % d) to produce an integer hash value between 0 and d-1, which we can use as an index into an array of length d to compute frequencies. The sketch that we use is the direction of the vector defined by frequencies of these values for all k-grams in the document (the unit vector with the same direction). Since we expect different strings to have different hash values, text documents with similar k-gram distributions will have similar sketches and text documents with different k-gram distributions will very likely have different sketches.
public class Sketch
{
private final Vector profile;
public Sketch(String text, int k, int d)
{
int n = text.length();
double[] freq = new double[d];
for (int i = 0; i < n-k-1; i++)
{
String kgram = text.substring(i, i+k);
int hash = kgram.hashCode();
freq[Math.abs(hash % d)] += 1;
}
Vector vector = new Vector(freq);
profile = vector.direction();
}
public double similarTo(Sketch other)
{ return profile.dot(other.profile); }
public static void main(String[] args)
{
int k = Integer.parseInt(args[0]);
int d = Integer.parseInt(args[1]);
String text = StdIn.readAll();
Sketch sketch = new Sketch(text, k, d);
StdOut.println(sketch);
}
}
profile | unit vector
name | document name k | length of gram d | dimension text | entire document n | document length freq[] | hash frequencies hash | hash for k-gram
This Vector client creates a d-dimensional unit vector from a document’s k-grams that clients can use to measure its similarity to other documents (see text). The toString() method appears as EXERCISE 3.3.15.
% more genome20.txt ATAGATGCATAGCGCATAGC % java Sketch 2 16 < genome20.txt (0.0, 0.0, 0.0, 0.620, 0.124, 0.372, ..., 0.496, 0.372, 0.248, 0.0)
Comparing sketches
The second challenge is to compute a similarity measure between two sketches. Again, there are many different ways to compare two vectors. Perhaps the simplest is to compute the Euclidean distance between them. Given vectors x and y, this distance is defined by
|x – y| = ((x0 – y0)2 + (x1 – y1)2 + ... + (xd–1 – yd–1)2)1/2
You are familiar with this formula for d = 2 or d = 3. With Vector, the Euclidean distance is easy to compute. If x and y are two Vector objects, then x.minus(y).magnitude() is the Euclidean distance between them. If documents are similar, we expect their sketches to be similar and the distance between them to be low. Another widely used similarity measure, known as the cosine similarity measure, is even simpler: since our sketches are unit vectors with non-negative coordinates, their dot product
x · y = x0 y0 + x1 y1 + ... + xd–1 yd–1
is a real number between 0 and 1. Geometrically, this quantity is the cosine of the angle formed by the two vectors (see EXERCISE 3.3.10). The more similar the documents, the closer we expect this measure to be to 1.
Comparing all pairs
CompareDocuments (PROGRAM 3.3.5) is a simple and useful Sketch client that provides the information needed to solve the following problem: given a set of documents, find the two that are most similar. Since this specification is a bit subjective, CompareDocuments prints the cosine similarity measure for all pairs of documents on an input list. For moderate-size k and d, the sketches do a remarkably good job of characterizing our sample set of documents. The results say not only that genomic data, financial data, Java code, and web source code are quite different from legal documents and novels, but also that Tom Sawyer and Huckleberry Finn are much more similar to each other than to Pride and Prejudice. A researcher in comparative literature could use this program to discover relationships between texts; a teacher could also use this program to detect plagiarism in a set of student submissions (indeed, many teachers do use such programs on a regular basis); and a biologist could use this program to discover relationships among genomes. You can find many documents on the booksite (or gather your own collection) to test the effectiveness of CompareDocuments for various parameter settings.
% more documents.txt
Consititution.txt
TomSawyer.txt
HuckFinn.txt
Prejudice.txt
Picture.java
DJIA.csv
Amazon.html
ATCG.txt
Program 3.3.5 Similarity detection
public class CompareDocuments
{
public static void main(String[] args)
{
int k = Integer.parseInt(args[0]);
int d = Integer.parseInt(args[1]);
String[] filenames = StdIn.readAllStrings();
int n = filenames.length;
Sketch[] a = new Sketch[n];
for (int i = 0; i < n; i++)
a[i] = new Sketch(new In(filenames[i]).readAll(), k, d);
StdOut.print(" ");
for (int j = 0; j < n; j++)
StdOut.printf("%8.4s",filenames[j]);
StdOut.println();
for (int i = 0; i < n; i++)
{
StdOut.printf("%.4s", filenames[i]);
for (int j = 0; j < n; j++)
StdOut.printf("%8.2f", a[i].similarTo(a[j]));
StdOut.println();
}
}
}
k | length of gram d | dimension n | number of documents a[] | the sketches
This Sketch client reads a document list from standard input, computes sketches based on k-gram frequencies for all the documents, and prints a table of similarity measures between all pairs of documents. It takes two arguments from the command line: the value of k and the dimension d of the sketches.
% java CompareDocuments 5 10000 < documents.txt Cons TomS Huck Prej Pict DJIA Amaz ATCG Cons 1.00 0.66 0.60 0.64 0.20 0.18 0.21 0.11 TomS 0.66 1.00 0.93 0.88 0.12 0.24 0.18 0.14 Huck 0.60 0.93 1.00 0.82 0.08 0.23 0.16 0.12 Prej 0.64 0.88 0.82 1.00 0.11 0.25 0.19 0.15 Pict 0.20 0.12 0.08 0.11 1.00 0.04 0.39 0.03 DJIA 0.18 0.24 0.23 0.25 0.04 1.00 0.16 0.11 Amaz 0.21 0.18 0.16 0.19 0.39 0.16 1.00 0.07 ATCG 0.11 0.14 0.12 0.15 0.03 0.11 0.07 1.00
Searching for similar documents
Another natural Sketch client is one that uses sketches to search among a large number of documents to identify those that are similar to a given document. For example, web search engines uses clients of this type to present you with pages that are similar to those you have previously visited, online book merchants use clients of this type to recommend books that are similar to ones you have purchased, and social networking websites use clients of this type to identify people whose personal interests are similar to yours. Since In can take web addresses instead of file names, it is feasible to write a program that can surf the web, compute sketches, and return links to web pages that have sketches that are similar to the one sought. We leave this client for a challenging exercise.
This solution is just a sketch. Many sophisticated algorithms for efficiently computing sketches and comparing them are still being invented and studied by computer scientists. Our purpose here is to introduce you to this fundamental problem domain while at the same time illustrating the power of abstraction in addressing a computational challenge. Vectors are an essential mathematical abstraction, and we can build a similarity search client by developing layers of abstraction: Vector is built with the Java array, Sketch is built with Vector, and client code uses Sketch. As usual, we have spared you from a lengthy account of our many attempts to develop these APIs, but you can see that the data types are designed in response to the needs of the problem, with an eye toward the requirements of implementations. Identifying and implementing appropriate abstractions is the key to effective object-oriented programming. The power of abstraction—in mathematics, physical models, and computer programs—pervades these examples. As you become fluent in developing data types to address your own computational challenges, your appreciation for this power will surely grow.

Design by contract
To conclude, we briefly discuss Java language mechanisms that enable you to verify assumptions about your program while it is running. For example, if you have a data type that represents a particle, you might assert that its mass is positive and its speed is less than the speed of light. Or if you have a method to add two vectors of the same dimension, you might assert that the dimension of the resulting vector is the same.
Exceptions
An exception is a disruptive event that occurs while a program is running, often to signal an error. The action taken is known as throwing an exception. We have already encountered exceptions thrown by Java system methods in the course of learning to program: ArithmeticException, IllegalArgumentException, NumberFormatException, and ArrayIndexOutOfBoundsException are typical examples.
You can also create and throw your own exceptions. Java includes an elaborate inheritance hierarchy of predefined exceptions; each exception class is a subclasses of java.lang.Exception. The diagram at the bottom of this page illustrates a portion of this hierarchy.

Perhaps the simplest kind of exception is a RuntimeException. The following statement creates a RuntimeException; typically it terminates execution of the program and prints a custom error message
throw new RuntimeException("Custom error message here.");
It is good practice to use exceptions when they can be helpful to the user. For example, in Vector (PROGRAM 3.3.3), we should throw an exception in plus() if the two Vectors to be added have different dimensions. To do so, we insert the following statement at the beginning of plus():
if (this.coords.length != that.coords.length)
throw new IllegalArgumentException("Dimensions disagree.");
With this code, the client receives a precise description of the API violation (calling the plus() method with vectors of different dimensions), enabling the programmer to identify and fix the mistake. Without this code, the behavior of the plus() method is erratic, either throwing an ArrayIndexOutOfBoundsException or returning a bogus result, depending on the dimensions of the two vectors (see EXERCISE 3.3.16).
Assertions
An assertion is a boolean expression that you are affirming is true at some point during the execution of a program. If the expression is false, the program will throw an AssertionError, which typically terminates the program and reports an error message. Errors are like exceptions, except that they indicate catastrophic failure; StackOverflowError and OutOfMemoryError are two examples that we have previously encountered.
Assertions are widely used by programmers to detect bugs and gain confidence in the correctness of programs. They also serve to document the programmer’s intent. For example, in Counter (PROGRAM 3.3.2), we might check that the counter is never negative by adding the following assertion as the last statement in increment():
assert count >= 0;
This statement would identify a negative count. You can also add a custom message
assert count >= 0 : "Negative count detected in increment()";
to help you locate the bug. By default, assertions are disabled, but you can enable them from the command line by using the -enableassertions flag (-ea for short). Assertions are for debugging only; your program should not rely on assertions for normal operation since they may be disabled.
When you take a course in systems programming, you will learn to use assertions to ensure that your code never terminates in a system error or goes into an infinite loop. One model, known as the design-by-contract model of programming, expresses this idea. The designer of a data type expresses a precondition (the condition that the client promises to satisfy when calling a method), a postcondition (the condition that the implementation promises to achieve when returning from a method), invariants (any condition that the implementation promises to satisfy while the method is executing), and side effects (any other change in state that the method could cause). During development, these conditions can be tested with assertions. Many programmers use assertions liberally to aid in debugging.
The language mechanisms discussed throughout this section illustrate that effective data-type design takes us into deep water in programming-language design. Experts are still debating the best ways to support some of the design ideas that we are discussing. Why does Java not allow functions as arguments to methods? Why does Python not include language support for enforcing encapsulation? Why does Matlab not support mutable data types? As mentioned early in CHAPTER 1, it is a slippery slope from complaining about features in a programming language to becoming a programming-language designer. If you do not plan to do so, your best strategy is to use widely available languages. Most systems have extensive libraries that you certainly should use when appropriate, but you often can simplify your client code and protect yourself by building abstractions that can easily be transferred to other languages. Your main goal is to develop data types so that most of your work is done at a level of abstraction that is appropriate to the problem at hand.
Q&A
Q. What happens if I try to access a private instance variable or method from a class in another file?
A. You get a compile-time error that says the given instance variable or method has private access in the given class.
Q. The instance variables in Complex are private, but when I am executing the method plus() for a Complex object with a.plus(b), I can access not only a’s instance variables but also b’s. Shouldn’t b’s instance variables be inaccessible?
A. The granularity of private access is at the class level, not the instance level. Declaring an instance variable as private means that it is not directly accessible from any other class. Methods within the Complex class can access (read or write) the instance variables of any instance in that class. It might be nice to have a more restrictive access modifier—say, superprivate—that would impose the granularity at the instance level so that only the invoking object can access its instance variables, but Java does not have such a facility.
Q. The times() method in Complex (PROGRAM 3.3.1) needs a constructor that takes polar coordinates as arguments. How can we add such a constructor?
A. You cannot, since there is already a constructor that takes two floating-point arguments. An alternative design would be to have two factory methods createRect(x, y) and createPolar(r, theta) in the API that create and return new objects. This design is better because it would provide the client with the capability to create objects by specifying either rectangular or polar coordinates. This example demonstrates that it is a good idea to think about more than one implementation when developing a data type.
Q. Is there a relationship between the Vector (PROGRAM 3.3.3) data type defined in this section and Java’s java.util.Vector data type?
A. No. We use the name because the term vector properly belongs to linear algebra and vector calculus.
Q. What should the direction() method in Vector (PROGRAM 3.3.3) do if invoked with the all zero vector?
A. A complete API should specify the behavior of every method for every situation. In this case, throwing an exception or returning null would be appropriate.
Q. What is a deprecated method?
A. A method that is no longer fully supported, but kept in an API to maintain compatibility. For example, Java once included a method Character.isSpace(), and programmers wrote programs that relied on using that method’s behavior. When the designers of Java later wanted to support additional Unicode whitespace characters, they could not change the behavior of isSpace() without breaking client programs. To deal with this issue, they added a new method Character. isWhiteSpace() and deprecated the old method. As time wears on, this practice certainly complicates APIs.
Q. What is wrong with the following implementation of equals() for Complex?
public boolean equals(Complex that)
{
return (this.re == that.re) && (this.im == that.im);
}
A. This code overloads the equals() method instead of overriding it. That is, it defines a new method named equals() that takes an argument of type Complex. This overloaded method is different from the inherited method equals() that takes an argument of type Object. There are some situations—such as with the java.util. HashMap library that we consider in SECTION 4.4—in which the inherited method gets called instead of the overloaded method, leading to puzzling behavior.
Q. What is wrong with the following of hashCode() for Complex?
public int hashCode()
{ return -17; }
A. Technically, it satisfies the contract for hashCode(): if two objects are equal, they have the same hash code. However, it will lead to poor performance because we expect Math.abs(x.hashCode() % m) to divide n typical Complex objects into m groups of roughly equal size.
Q. Can an interface include constructors?
A. No, because you cannot instantiate an interface; you can instantiate only objects of an implementing class. However, an interface can include constants, method signatures, default methods, static methods, and nested types, but these features are beyond the scope of this book.
Q. Can a class be a direct subclass of more than one class?
A. No. Every class (other than Object) is a direct subclass of one and only one superclass. This feature is known as single inheritance; some other languages (notably, C++) support multiple inheritance, where a class can be a direct subclass of two or more superclasses.
Q. Can a class implement more than one interface?
A. Yes. To do so, list each of the interfaces, separated by commas, after the keyword implements.
Q. Can the body of a lambda expression consist of more than a single statement?
A. Yes, the body can be a block of statements and can include variable declarations, loops, and conditionals. In such cases, you must use an explicit return statement to specify the value returned by the lambda expression.
Q. In some cases a lambda expression does nothing more than call a named method in another class. Is there any shorthand for doing this?
A. Yes, a method reference is a compact, easy-to-read lambda expression for a method that already has a name. For example, you can use the method reference Gaussian::pdf as shorthand for the lambda expression x -> Gaussian.pdf(x). See the booksite for more details.
Exercises
3.3.1 Represent a point in time by using an int to store the number of seconds since January 1, 1970. When will programs that use this representation face a time bomb? How should you proceed when that happens?
3.3.2 Create a data type Location for dealing with locations on Earth using spherical coordinates (latitude/longitude). Include methods to generate a random location on the surface of the Earth, parse a location “25.344 N, 63.5532 W”, and compute the great circle distance between two locations.
3.3.3 Develop an implementation of Histogram (PROGRAM 3.2.3) that uses Counter (PROGRAM 3.3.2).
3.3.4 Give an implementation of minus() for Vector solely in terms of the other Vector methods, such as direction() and magnitude().
Answer:
public Vector minus(Vector that)
{ return this.plus(that.scale(-1.0)); }
The advantage of such implementations is that they limit the amount of detailed code to check; the disadvantage is that they can be inefficient. In this case, plus() and times() both create new Vector objects, so copying the code for plus() and replacing the minus sign with a plus sign is probably a better implementation.
3.3.5 Implement a main() method for Vector that unit-tests its methods.
3.3.6 Create a data type for a three-dimensional particle with position (rx, ry, rz), mass (m), and velocity (vx, vy, vz). Include a method to return its kinetic energy, which equals 1/2 m (vx2 + vy2 + vz2). Use Vector (PROGRAM 3.3.3).
3.3.7 If you know your physics, develop an alternate implementation for your data type from the previous exercise based on using the momentum (px, py, pz) as an instance variable.
3.3.8 Implement a data type Vector2D for two-dimensional vectors that has the same API as Vector, except that the constructor takes two double values as arguments. Use two double values (instead of an array) for instance variables.
3.3.9 Implement the Vector2D data type from the previous exercise using one Complex value as the only instance variable.
3.3.10 Prove that the dot product of two two-dimensional unit-vectors is the cosine of the angle between them.
3.3.11 Implement a data type Vector3D for three-dimensional vectors that has the same API as Vector, except that the constructor takes three double values as arguments. Also, add a cross-product method: the cross-product of two vectors is another vector, defined by the equation
a × b = c |a| |b| sin θ
where c is the unit normal vector perpendicular to both a and b, and θ is the angle between a and b. In Cartesian coordinates, the following equation defines the cross-product:
(a0, a1, a2) × (b0, b1, b2) = (a1 b2 –a2 b1, a2 b0 –a0 b2, a0 b1 –a1 b0)
The cross-product arises in the definition of torque, angular momentum, and vector operator curl. Also, |a × b| is the area of the parallelogram with sides a and b.
3.3.12 Override the equals() method for Charge (PROGRAM 3.2.6) so that two Charge objects are equal if they have identical position and charge value. Override the hashCode() method using the Objects.hash() technique described in this section.
3.3.13 Override the equals() and hashCode() methods for Vector (PROGRAM 3.3.3) so that two Vector objects are equal if they have the same length and the corresponding coordinates are equal.
3.3.14 Add a toString() method to Vector that returns the vector components, separated by commas, and enclosed in matching parentheses.
3.3.15 Add a toString() method to Sketch that returns a string representation of the unit vector corresponding to the sketch.
3.3.16 Describe the behavior of the method calls x.add(y) and y.add(x) in Vector (PROGRAM 3.3.3) if x corresponds to the vector (1, 2, 3) and y corresponds to the vector (5, 6).
3.3.17 Use assertions and exceptions to develop an implementation of Rational (see EXERCISE 3.2.7) that is immune to overflow.
3.3.18 Add code to Counter (PROGRAM 3.3.2) to throw an IllegalArgumentException if the client tries to construct a Counter object using a negative value for max.
Data-Type Design Exercises
This list of exercises is intended to give you experience in developing data types. For each problem, design one or more APIs with API implementations, testing your design decisions by implementing typical client code. Some of the exercises require either knowledge of a particular domain or a search for information about it on the web.
3.3.19 Statistics. Develop a data type for maintaining statistics for a set of real numbers. Provide a method to add data points and methods that return the number of points, the mean, the standard deviation, and the variance. Develop two implementations: one whose instance values are the number of points, the sum of the values, and the sum of the squares of the values, and another that keeps an array containing all the points. For simplicity, you may take the maximum number of points in the constructor. Your first implementation is likely to be faster and use substantially less space, but is also likely to be susceptible to roundoff error. See the booksite for a well-engineered alternative.
3.3.20 Genome. Develop a data type to store the genome of an organism. Biologists often abstract the genome to a sequence of nucleotides (A, C, G, or T). The data type should support the methods addNucleotide(char c) and nucleotideAt(int i), as well as isPotentialGene() (see PROGRAM 3.1.1). Develop three implementations. First, use one instance variable of type String, implementing addCodon() with string concatenation. Each method call takes time proportional to the length of the current genome. Second, use an array of characters, doubling the length of the array each time it fills up. Third, use a boolean array, using two bits to encode each codon, and doubling the length of the array each time it fills up.
3.3.21 Time. Develop a data type for the time of day. Provide client methods that return the current hour, minute, and second, as well as toString(), equals(), and hashCode() methods. Develop two implementations: one that keeps the time as a single int value (number of seconds since midnight) and another that keeps three int values, one each for seconds, minutes, and hours.
3.3.22 VIN number. Develop a data type for the naming scheme for vehicles known as the Vehicle Identification Number (VIN). A VIN describes the make, model, year, and other attributes of cars, buses, and trucks in the United States.
3.3.23 Generating pseudo-random numbers. Develop a data type for generating pseudo-random numbers. That is, convert StdRandom to a data type. Instead of using Math.random(), base your data type on a linear congruential generator. This method traces to the earliest days of computing and is also a quintessential example of the value of maintaining state in a computation (implementing a data type). To generate pseudo-random int values, maintain an int value x (the value of the last “random” number returned). Each time the client asks for a new value, return a*x + b for suitably chosen values of a and b (ignoring overflow). Use arithmetic to convert these values to “random” values of other types of data. As suggested by D. E. Knuth, use the values 3141592621 for a and 2718281829 for b. Provide a constructor allowing the client to start with an int value known as a seed (the initial value of x). This ability makes it clear that the numbers are not at all random (even though they may have many of the properties of random numbers) but that fact can be used to aid in debugging, since clients can arrange to see the same numbers each time.
import java.util.Date;
public class Appointment
{
private Date date;
private String contact;
public Appointment(Date date)
{
this.date = date;
this.contact = contact;
}
public Date getDate()
{ return date; }
}
Answer: No. Java’s java.util.Date class is mutable. The method setDate(seconds) changes the value of the invoking date to the number of milliseconds since January 1, 1970, 00:00:00 GMT. This has the unfortunate consequence that when a client gets a date with date = getDate(), the client program can then invoke date.setDate() and change the date in an Appointment object type, perhaps creating a conflict. In a data type, we cannot let references to mutable objects escape because the caller can then modify its state. One solution is to create a defensive copy of the Date before returning it using new Date(date.getTime()); and a defensive copy when storing it via this.date = new Date(date.getTime()). Many programmers regard the mutability of Date as a Java design flaw. (GregorianCalendar is a more modern Java library for storing dates, but it is mutable, too.)
3.3.25 Date. Develop an implementation of Java’s java.util.Date API that is immutable and therefore corrects the defects of the previous exercise.
3.3.26 Calendar. Develop Appointment and Calendar APIs that can be used to keep track of appointments (by day) in a calendar year. Your goal is to enable clients to schedule appointments that do not conflict and to report current appointments to clients.
3.3.27 Vector field. A vector field associates a vector with every point in a Euclidean space. Write a version of Potential (EXERCISE 3.2.23) that takes as input a grid size n, computes the Vector value of the potential due to the point charges at each point in an n-by-n grid of evenly spaced points, and draws the unit vector in the direction of the accumulated field at each point. (Modify Charge to return a Vector.)
3.3.28 Genome profiling. Write a function hash() that takes as its argument a k-gram (string of length k) whose characters are all A, C, G, or T and returns an int value between 0 and 4k – 1 that corresponds to treating the strings as base-4 numbers with {A, C, G, T} replaced by {0, 1, 2, 3}, respectively. Next, write a function unHash() that reverses the transformation. Use your methods to create a class Genome that is like Sketch (PROGRAM 3.3.4), but is based on exact counting of k-grams in genomes. Finally, write a version of CompareDocuments (PROGRAM 3.3.5) for Genome objects and use it to look for similarities among the set of genome files on the booksite.
3.3.29 Profiling. Pick an interesting set of documents from the booksite (or use a collection of your own) and run CompareDocuments with various values for the command-line arguments k and d, to learn about their effect on the computation.
3.3.30 Multimedia search. Develop profiling strategies for sound and pictures, and use them to discover interesting similarities among songs in the music library and photos in the photo album on your computer.
3.3.31 Data mining. Write a recursive program that surfs the web, starting at a page given as the first command-line argument, looking for pages that are similar to the page given as the second command-line argument, as follows: to process a name, open an input stream, do a readAll(), sketch it, and print the name if its distance to the target page is greater than the threshold value given as the third command-line argument. Then scan the page for all strings that begin with the prefix http:// and (recursively) process pages with those names. Note: This program could read a very large number of pages!
3.4 Case Study: N-Body Simulation
Several of the examples that we considered in CHAPTERS 1 AND 2 are better expressed as object-oriented programs. For example, BouncingBall (PROGRAM 3.1.9) is naturally implemented as a data type whose values are the position and the velocity of the ball and a client that calls instance methods to move and draw the ball. Such a data type enables, for example, clients that can simulate the motion of several balls at once (see EXERCISE 3.4.1). Similarly, our case study for Percolation in SECTION 2.4 certainly makes an interesting exercise in object-oriented programming, as does our random-surfer case study in SECTION 1.6. We leave the former as EXERCISE 3.4.8 and revisit the latter in SECTION 4.5. In this section, we consider a new example that exemplifies object-oriented programming.
Our task is to write a program that dynamically simulates the motion of n bodies under the influence of mutual gravitational attraction. This problem was first formulated by Isaac Newton more than 350 years ago, and it is still studied intensely today.
What is the set of values, and what are the operations on those values? One reason that this problem is an amusing and compelling example of object-oriented programming is that it presents a direct and natural correspondence between physical objects in the real world and the abstract objects that we use in programming. The shift from solving problems by putting together sequences of statements to be executed to beginning with data-type design is a difficult one for many novices. As you gain more experience, you will appreciate the value in this approach to computational problem-solving.
We recall a few basic concepts and equations that you learned in high school physics. Understanding those equations fully is not required to appreciate the code—because of encapsulation, these equations are restricted to a few methods, and because of data abstraction, most of the code is intuitive and will make sense to you. In a sense, this is the ultimate object-oriented program.
N-body simulation
The bouncing ball simulation of SECTION 1.5 is based on Newton’s first law of motion: a body in motion remains in motion at the same velocity unless acted on by an outside force. Embellishing that simulation to incorporate Newton’s second law of motion (which explains how outside forces affect velocity) leads us to a basic problem that has fascinated scientists for ages. Given a system of n bodies, mutually affected by gravitational forces, the n-body problem is to describe their motion. The same basic model applies to problems ranging in scale from astrophysics to molecular dynamics.
In 1687, Newton formulated the principles governing the motion of two bodies under the influence of their mutual gravitational attraction, in his famous Principia. However, Newton was unable to develop a mathematical description of the motion of three bodies. It has since been shown that not only is there no such description in terms of elementary functions, but also chaotic behavior is possible, depending on the initial values. To study such problems, scientists have no recourse but to develop an accurate simulation. In this section, we develop an object-oriented program that implements such a simulation. Scientists are interested in studying such problems at a high degree of accuracy for huge numbers of bodies, so our solution is merely an introduction to the subject. Nevertheless, you are likely to be surprised at the ease with which we can develop realistic animations depicting the complexity of the motion.
Body data type
In BouncingBall (PROGRAM 3.1.9), we keep the displacement from the origin in the double variables rx and ry and the velocity in the double variables vx and vy, and displace the ball the amount it moves in one time unit with the statements:
rx = rx + vx;
ry = ry + vy;
With Vector (PROGRAM 3.3.3), we can keep the position in the Vector variable r and the velocity in the Vector variable v, and then displace the body by the amount it moves in dt time units with a single statement:
r = r.plus(v.times(dt));

In n-body simulation, we have several operations of this kind, so our first design decision is to work with Vector objects instead of individual x- and y-components. This decision leads to code that is clearer, more compact, and more flexible than the alternative of working with individual components. Body (PROGRAM 3.4.1) is a Java class that uses Vector to implement a data type for moving bodies. Its instance variables are two Vector variables that hold the body’s position and velocity, as well as a double variable that stores the mass. The data-type operations allow clients to move and to draw the body (and to compute the force vector due to gravitational attraction of another body), as defined by the following API:
|
||
|
|
|
|
|
apply force |
|
|
draw the ball |
|
|
force vector between this body and |
API for bodies moving under Newton’s laws (see PROGRAM 3.4.1) |
||
Technically, the body’s position (displacement from the origin) is not a vector (it is a point in space, rather than a direction and a magnitude), but it is convenient to represent it as a Vector because Vector’s operations lead to compact code for the transformation that we need to move the body, as just discussed. When we move a Body, we need to change not just its position, but also its velocity.
Force and motion
Newton’s second law of motion says that the force on a body (a vector) is equal to the product of its mass (a scalar) and its acceleration (also a vector): F = m a. In other words, to compute the acceleration of a body, we compute the force, then divide by its mass. In Body, the force is a Vector argument f to move(), so that we can first compute the acceleration vector just by dividing by the mass (a scalar value that is stored in a double instance variable) and then compute the change in velocity by adding to it the amount this vector changes over the time interval (in the same way as we used the velocity to change the position). This law immediately translates to the following code for updating the position and velocity of a body due to a given force vector f and amount of time dt:
Vector a = f.scale(1/mass); v = v.plus(a.scale(dt)); r = r.plus(v.scale(dt));

This code appears in the move() instance method in Body, to adjust its values to reflect the consequences of that force being applied for that amount of time: the body moves and its velocity changes. This calculation assumes that the acceleration is constant during the time interval.
Forces among bodies
The computation of the force imposed by one body on another is encapsulated in the instance method forceFrom() in Body, which takes a Body object as its argument and returns a Vector. Newton’s law of universal gravitation is the basis for the calculation: it says that the magnitude of the gravitational force between two bodies is given by the product of their masses divided by the square of the distance between them (scaled by the gravitational constant G, which is 6.67 × 10-11 N m2 / kg2) and that the direction of the force is the line between the two particles. This law translates into the following code for computing a.forceFrom(b):
double G = 6.67e-11; Vector delta = b.r.minus(a.r); double dist = delta.magnitude(); double magnitude = (G * a.mass * b.mass) / (dist * dist); Vector force = delta.direction().scale(magnitude); return force;

The magnitude of the force vector is the double variable magnitude, and the direction of the force vector is the same as the direction of the difference vector between the two body’s positions. The force vector force is the unit direction vector, scaled by the magnitude.
Program 3.4.1 Gravitational body
public class Body
{
private Vector r;
private Vector v;
private final double mass;
public Body(Vector r0, Vector v0, double m0)
{ r = r0; v = v0; mass = m0; }
public void move(Vector force, double dt)
{ // Update position and velocity.
Vector a = force.scale(1/mass);
v = v.plus(a.scale(dt));
r = r.plus(v.scale(dt));
}
public Vector forceFrom(Body b)
{ // Compute force on this body from b.
Body a = this;
double G = 6.67e-11;
Vector delta = b.r.minus(a.r);
double dist = delta.magnitude();
double magnitude = (G * a.mass * b.mass)
/ (dist * dist);
Vector force = delta.direction().scale(magnitude);
return force;
}
public void draw()
{
StdDraw.setPenRadius(0.0125);
StdDraw.point(r.cartesian(0), r.cartesian(1));
}
}
r | position v | velocity mass | mass
force | force on this body dt | time increment a | acceleration
a | this body b | another body G | gravitational constant delta | vector from b to a dist | distance from b to a magnitude | magnitude of force
This data type provides the operations that we need to simulate the motion of physical bodies such as planets or atomic particles. It is a mutable type whose instance variables are the position and velocity of the body, which change in the move() method in response to external forces (the body’s mass is not mutable). The forceFrom() method returns a force vector.
Universe data type
Universe (PROGRAM 3.4.2) is a data type that implements the following API:
|
||
|
|
initialize universe from |
|
|
simulate the passing of |
|
|
draw the universe |
API for a universe (see PROGRAM 3.4.2) |
||
Its data-type values define a universe (its size, number of bodies, and an array of bodies) and two data-type operations: increaseTime(), which adjusts the positions (and velocities) of all of the bodies, and draw(), which draws all of the bodies. The key to the n-body simulation is the implementation of increaseTime() in Universe. The main part of the computation is a double nested loop that computes the force vector describing the gravitational force of each body on each other body. It applies the principle of superposition, which says that we can add together the force vectors affecting a body to get a single vector representing all the forces. After it has computed all of the forces, it calls move() for each body to apply the computed force for a fixed time interval.

File format
As usual, we use a data-driven design, with input taken from a file. The constructor reads the universe parameters and body descriptions from a file that contains the following information:
• The number of bodies
• The radius of the universe
• The position, velocity, and mass of each body
As usual, for consistency, all measurements are in standard SI units (recall also that the gravitational constant G appears in our code). With this defined file format, the code for our Universe constructor is straightforward.
public Universe(String filename)
{
In in = new In(filename);
n = in.readInt();
double radius = in.readDouble();
StdDraw.setXscale(-radius, +radius);
StdDraw.setYscale(-radius, +radius);
bodies = new Body[n];
for (int i = 0; i < n; i++)
{
double rx = in.readDouble();
double ry = in.readDouble();
double[] position = { rx, ry };
double vx = in.readDouble();
double vy = in.readDouble();
double[] velocity = { vx, vy };
double mass = in.readDouble();
Vector r = new Vector(position);
Vector v = new Vector(velocity);
bodies[i] = new Body(r, v, mass);
}
}
Each Body is described by five double values: the x- and y-coordinates of its position, the x- and y-components of its initial velocity, and its mass.
To summarize, we have in the test client main() in Universe a data-driven program that simulates the motion of n bodies mutually attracted by gravity. The constructor creates an array of n Body objects, reading each body’s initial position, initial velocity, and mass from the file whose name is specified as an argument. The increaseTime() method calculates the forces for each body and uses that information to update the acceleration, velocity, and position of each body after a time interval dt. The main() test client invokes the constructor, then stays in a loop calling increaseTime() and draw() to simulate motion.
Program 3.4.2 N-body simulation
public class Universe
{
private final int n;
private final Body[] bodies;
public void increaseTime(double dt)
{
Vector[] f = new Vector[n];
for (int i = 0; i < n; i++)
f[i] = new Vector(new double[2]);
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
if (i != j)
f[i] = f[i].plus(bodies[i].forceFrom(bodies[j]));
for (int i = 0; i < n; i++)
bodies[i].move(f[i], dt);
}
public void draw()
{
for (int i = 0; i < n; i++)
bodies[i].draw();
}
public static void main(String[] args)
{
Universe newton = new Universe(args[0]);
double dt = Double.parseDouble(args[1]);
StdDraw.enableDoubleBuffering();
while (true)
{
StdDraw.clear();
newton.increaseTime(dt);
newton.draw();
StdDraw.show();
StdDraw.pause(20);
}
}
}
n | number of bodies bodies[] | array of bodies

This data-driven program simulates motion in the universe defined by a file specified as the first command-line argument, increasing time at the rate specified as the second command-line argument. See the accompanying text for the implementation of the constructor.
You will find on the booksite a variety of files that define “universes” of all sorts, and you are encouraged to run Universe and observe their motion. When you view the motion for even a small number of bodies, you will understand why Newton had trouble deriving the equations that define their paths. The figures on the following page illustrate the result of running Universe for the 2-body, 3-body, and 4-body examples in the data files given earlier. The 2-body example is a mutually orbiting pair, the 3-body example is a chaotic situation with a moon jumping between two orbiting planets, and the 4-body example is a relatively simple situation where two pairs of mutually orbiting bodies are slowly rotating. The static images on these pages are made by modifying Universe and Body to draw the bodies in white, and then black on a gray background (see EXERCISE 3.4.9): the dynamic images that you get when you run Universe as it stands give a realistic feeling of the bodies orbiting one another, which is difficult to discern in the fixed pictures. When you run Universe on an example with a large number of bodies, you can appreciate why simulation is such an important tool for scientists who are trying to understand a complex problem. The n-body simulation model is remarkably versatile, as you will see if you experiment with some of these files.
You will certainly be tempted to design your own universe (see EXERCISE 3.4.7). The biggest challenge in creating a data file is appropriately scaling the numbers so that the radius of the universe, time scale, and the mass and velocity of the bodies lead to interesting behavior. You can study the motion of planets rotating around a sun or subatomic particles interacting with one another, but you will have no luck studying the interaction of a planet with a subatomic particle. When you work with your own data, you are likely to have some bodies that will fly off to infinity and some others that will be sucked into others, but enjoy!
planetary scale
% more 2body.txt
2
5.0e10
0.0e00 4.5e10 1.0e04 0.0e00 1.5e30
0.0e00 -4.5e10 -1.0e04 0.0e00 1.5e30
subatomic scale
% more 2bodyTiny.txt
2
5.0e-10
0.0e00 4.5e-10 1.0e-16 0.0e00 1.5e-30
0.0e00 -4.5e-10 -1.0e-16 0.0e00 1.5e-30
Our purpose in presenting this example is to illustrate the utility of data types, not to provide n-body simulation code for production use. There are many issues that scientists have to deal with when using this approach to study natural phenomena. The first is accuracy: it is common for inaccuracies in the calculations to accumulate to create dramatic effects in the simulation that would not be observed in nature. For example, our code takes no special action when bodies (nearly) collide. The second is efficiency: the move() method in Universe takes time proportional to n2, so it is not usable for huge numbers of bodies. As with genomics, addressing scientific problems related to the n-body problem now involves not just knowledge of the original problem domain, but also understanding core issues that computer scientists have been studying since the early days of computation.
For simplicity, we are working with a two-dimensional universe, which is realistic only when we are considering bodies in motion on a plane. But an important implication of basing the implementation of Body on Vector is that a client could use three-dimensional vectors to simulate the motion of bodies in three dimensions (actually, any number of dimensions) without changing the code at all! The draw() method projects the position onto the plane defined by the first two dimensions.
The test client in Universe is just one possibility; we can use the same basic model in all sorts of other situations (for example, involving different kinds of interactions among the bodies). One such possibility is to observe and measure the current motion of some existing bodies and then run the simulation backward! That is one method that astrophysicists use to try to understand the origins of the universe. In science, we try to understand the past and to predict the future; with a good simulation, we can do both.
Q&A
Q. The Universe API is certainly small. Why not just implement that code in a main() test client for Body?
A. Our design is an expression of what most people believe about the universe: it was created, and then time moves on. It clarifies the code and allows for maximum flexibility in simulating what goes on in the universe.
Q. Why is forceFrom() an instance method? Wouldn’t it be better for it to be a static method that takes two Body objects as arguments?
A. Yes, implementing forceFrom() as an instance method is one of several possible alternatives, and having a static method that takes two Body objects as arguments is certainly a reasonable choice. Some programmers prefer to completely avoid static methods in data-type implementations; another option is to maintain the force acting on each Body as an instance variable. Our choice is a compromise between these two.
Exercises
3.4.1 Develop an object-oriented version of BouncingBall (PROGRAM 3.1.9). Include a constructor that starts each ball moving in a random direction at a random velocity (within reasonable limits) and a test client that takes an integer command-line argument n and simulates the motion of n bouncing balls.
3.4.2 Add a main() method to PROGRAM 3.4.1 that unit-tests the Body data type.
3.4.3 Modify Body (PROGRAM 3.4.1) so that the radius of the circle it draws for a body is proportional to its mass.
3.4.4 What happens in a universe in which there is no gravitational force? This situation would correspond to forceTo() in Body always returning the zero vector.
3.4.5 Create a data type Universe3D to model three-dimensional universes. Develop a data file to simulate the motion of the planets in our solar system around the sun.
3.4.6 Implement a class RandomBody that initializes its instance variables with (carefully chosen) random values instead of using a constructor and a client RandomUniverse that takes a single command-line argument n and simulates motion in a random universe with n bodies.
Creative Exercises
3.4.7 New universe. Design a new universe with interesting properties and simulate its motion with Universe. This exercise is truly an opportunity to be creative!
3.4.8 Percolation. Develop an object-oriented version of Percolation (PROGRAM 2.4.5). Think carefully about the design before you begin, and be prepared to defend your design decisions.
3.4.9 N-body trace. Write a client UniverseTrace that produces traces of the n-body simulation system like the static images on page 487.