
4.3 Stacks and Queues
In this section, we introduce two closely related data types for manipulating arbitrarily large collections of objects: the stack and the queue. Stacks and queues are special cases of the idea of a collection. We refer to the objects in a collection as items. A collection is characterized by four operations: create the collection, insert an item, remove an item, and test whether the collection is empty.
4.3.1 Stack of strings (array)
4.3.2 Stack of strings (linked list)
4.3.3 Stack of strings (resizing array)
4.3.6 Generic FIFO queue (linked list)
4.3.8 Load balancing simulation
Programs in this section
When we insert an item into a collection, our intent is clear. But when we remove an item from the collection, which one do we choose? Each type of collection is characterized by the rule used for remove, and each is amenable to various implementations with differing performance characteristics. You have encountered different rules for removing items in various real-world situations, perhaps without thinking about it.
For example, the rule used for a queue is to always remove the item that has been in the collection for the most amount of time. This policy is known as first-in first-out, or FIFO. People waiting in line to buy a ticket follow this discipline: the line is arranged in the order of arrival, so the one who leaves the line has been there longer than any other person in the line.
A policy with quite different behavior is the rule used for a stack: always remove the item that has been in the collection for the least amount of time. This policy is known as last-in first-out, or LIFO. For example, you follow a policy closer to LIFO when you enter and leave the coach cabin in an airplane: people near the front of the cabin board last and exit before those who boarded earlier.
Stacks and queues are broadly useful, so it is important to be familiar with their basic properties and the kind of situation where each might be appropriate. They are excellent examples of fundamental data types that we can use to address higher-level programming tasks. They are widely used in systems and applications programming, as we will see in several examples in this section and in SECTION 4.5.
Pushdown stacks
A pushdown stack (or just a stack) is a collection that is based on the last-in first-out (LIFO) policy.
The LIFO policy underlies several of the applications that you use regularly on your computer. For example, many people organize their email as a stack, where messages go on the top when they are received and are taken from the top, with the most recently received message first (last in, first out). The advantage of this strategy is that we see new messages as soon as possible; the disadvantage is that some old messages might never get read if we never empty the stack.

You have likely encountered another common example of a stack when surfing the web. When you click a hyperlink, your browser displays the new page (and inserts it onto a stack). You can keep clicking on hyperlinks to visit new pages, but you can always revisit the previous page by clicking the back button (remove it from a stack). The last-in first-out policy offered by a pushdown stack provides just the behavior that you expect.
Such uses of stacks are intuitive, but perhaps not persuasive. In fact, the importance of stacks in computing is fundamental and profound, but we defer further discussions of applications to later in this section. For the moment, our goal is to make sure that you understand how stacks work and how to implement them.
Stacks have been used widely since the earliest days of computing. By tradition, we name the stack insert operation push and the stack remove operation pop, as indicated in the following API:
|
||
|
|
create an empty stack |
|
|
is the stack empty? |
|
|
insert a string onto the stack |
|
|
remove and return the most recently inserted string |
API for a pushdown stack of strings |
||
The asterisk indicates that we will be considering more than one implementation of this API (we consider three in this section: ArrayStackOfStrings, LinkedStackOfStrings, and ResizingArrayStackOfStrings). This API also includes a method to test whether the stack is empty, leaving to the client the responsibility of using isEmpty() to avoid invoking pop() when the stack is empty.
This API has an important restriction that is inconvenient in applications: we would like to have stacks that contain other types of data, not just strings. We describe how to remove this restriction (and the importance of doing so) later in this section.
Array implementation
Representing stacks with arrays is a natural idea, but before reading further, it is worthwhile to think for a moment about how you would implement a class ArrayStackOfStrings.
The first problem that you might encounter is implementing the constructor ArrayStackOfStrings(). You clearly need an instance variable items[] with an array of strings to hold the stack items, but how big should the array be? One solution is to start with an array of length 0 and make sure that the array length is always equal to the stack size, but that solution necessitates allocating a new array and copying all of the items into it for each push() and pop() operation, which is unnecessarily inefficient and cumbersome. We will temporarily finesse this problem by having the client provide an argument for the constructor that gives the maximum stack size.
Your next problem might stem from the natural decision to keep the n items in the array in the order they were inserted, with the most recently inserted item in items[0] and the least recently inserted item in items[n-1]. But then each time you push or pop an item, you would have to move all of the other items to reflect the new state of the stack. A simpler and more efficient way to proceed is to keep the items in the opposite order, with the most recently inserted item in items[n-1] and the least recently inserted item in items[0]. This policy allows us to add and remove items at the end of the array, without moving any of the other items in the arrays.
We could hardly hope for a simpler implementation of the stack API than ArrayStackOfStrings (PROGRAM 4.3.1)—all of the methods are one-liners! The instance variables are an array items[] that holds the items in the stack and an integer n that counts the number of items in the stack. To remove an item, we decrement n and then return items[n]; to insert a new item, we set items[n] equal to the new item and then increment n. These operations preserve the following properties:
• The number of items in the stack is n.
• The stack is empty when n is 0.
• The stack items are stored in the array in the order in which they were inserted.
• The most recently inserted item (if the stack is nonempty) is items[n-1].
As usual, thinking in terms of invariants of this sort is the easiest way to verify that an implementation operates as intended. Be sure that you fully understand this implementation. Perhaps the best way to do so is to carefully examine a trace of the stack contents for a sequence of push() and pop() operations. The test client in ArrayStackOfStrings allows for testing with an arbitrary sequence of operations: it does a push() for each string on standard input except the string consisting of a minus sign, for which it does a pop().
|
|
|
|
||||
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Trace of |
|||||||
The primary characteristic of this implementation is that the push and pop operations take constant time. The drawback is that it requires the client to estimate the maximum size of the stack ahead of time and always uses space proportional to that maximum, which may be unreasonable in some situations. We omit the code in push() to test for a full stack, but later we will examine implementations that address this drawback by not allowing the stack to get full (except in an extreme circumstance when there is no memory at all available for use by Java).
Program 4.3.1 Stack of strings (array)
public class ArrayStackOfStrings
{
private String[] items;
private int n = 0;
public ArrayStackOfStrings(int capacity)
{ items = new String[capacity]; }
public boolean isEmpty()
{ return (n == 0); }
public void push(String item)
{ items[n++] = item; }
public String pop()
{ return items[--n]; }
public static void main(String[] args)
{ // Create a stack of specified capacity; push strings
// and pop them, as directed on standard input.
int cap = Integer.parseInt(args[0]);
ArrayStackOfStrings stack = new ArrayStackOfStrings(cap);
while (!StdIn.isEmpty())
{
String item = StdIn.readString();
if (!item.equals("-"))
stack.push(item);
else
StdOut.print(stack.pop() + " ");
}
}
}
items[] | stack items n | number of items items[n-1] | item most recently inserted
Stack methods are simple one-liners, as illustrated in this code. The client pushes or pops strings as directed from standard input (a minus sign indicates pop, and any other string indicates push). Code in push() to test whether the stack is full is omitted (see the text).
% more tobe.txt to be or not to - be - - that - - - is % java ArrayStackOfStrings 5 < tobe.txt to be not that or be
Linked lists
For collections such as stacks and queues, an important objective is to ensure that the amount of memory used is proportional to the number of items in the collection. The use of a fixed-length array to implement a stack in ArrayStackOfStrings works against this objective: when you create a stack with a specified capacity, you are wasting a potentially huge amount of memory at times when the stack is empty or nearly empty. This property makes our fixed-length array implementation unsuitable for many applications. Now we consider the use of a fundamental data structure known as a linked list, which can provide implementations of collections (and, in particular, stacks and queues) that achieve the objective cited at the beginning of this paragraph.
A singly linked list comprises a sequence of nodes, with each node containing a reference (or link) to its successor. By convention, the link in the last node is null, to indicate that it terminates the list. A node is an abstract entity that might hold any kind of data, in addition to the link that characterizes its role in building linked lists. When tracing code that uses linked lists and other linked structures, we use a visual representation where:
• We draw a rectangle to represent each linked-list node.
• We put the item and link within the rectangle.
• We use arrows that point to the referenced objects to depict references.
This visual representation captures the essential characteristic of linked lists and focus on the links. For example, the diagram on this page illustrates a singly linked list containing the sequence of items to, be, or, not, to, and be.
With object-oriented programming, implementing linked lists is not difficult. We define a class for the node abstraction that is recursive in nature. As with recursive functions, the concept of recursive data structures can be a bit mindbending at first.
class Node
{
String item;
Node next;
}

A Node object has two instance variables: a String and a Node. The String instance variable is a placeholder for any data that we might want to structure with a linked list (we can use any set of instance variables). The Node instance variable next characterizes the linked nature of the data structure: it stores a reference to the successor Node in the linked list (or null to indicate that there is no such node). Using this recursive definition, we can represent a linked list with a variable of type Node by ensuring that its value is either null or a reference to a Node whose next field is a reference to a linked list.
To emphasize that we are just using the Node class to structure the data, we do not define any instance methods. As with any class, we can create an object of type Node by invoking the (no-argument) constructor with new Node(). The result is a reference to a new Node object whose instance variables are each initialized to the default value null.
For example, to build a linked list that contains the sequence of items to, be, and or, we create a Node for each item:
Node first = new Node(); Node second = new Node(); Node third = new Node();
and assign the item instance variable in each of the nodes to the desired value:
first.item = "to"; second.item = "be"; third.item = "or";
and set the next instance variables to build the linked list:
first.next = second; second.next = third;
As a result, first is a reference to the first node in a three-node linked list, second is a reference to the second node, and third is a reference to the last node. The code in the accompanying diagram does these same assignment statements, but in a different order.

A linked list represents a sequence of items. In the example just considered, first represents the sequence of items to, be, and or. Alternatively, we can use an array to represent a sequence of items. For example, we could use
String[] items = { "to", "be", "or" };
to represent the same sequence of items. The difference is that it is easier to insert items into the sequence and to remove items from the sequence with linked lists. Next, we consider code to accomplish these two tasks.
Suppose that you want to insert a new node into a linked list. The easiest place to do so is at the beginning of the list. For example, to insert the string not at the beginning of a given linked list whose first node is first, we save first in a temporary variable oldFirst, assign to first a new Node, and assign its item field to not and its next field to oldFirst.
Now, suppose that you want to remove the first node from a linked list. This operation is even easier: simply assign to first the value first.next. Normally, you would retrieve the value of the item (by assigning it to some variable) before doing this assignment, because once you change the value of first, you may no longer have any access to the node to which it was referring. Typically, the Node object becomes an orphan, and the memory it occupies is eventually reclaimed by the Java memory management system.

This code for inserting and removing a node from the beginning of a linked list involves just a few assignment statements and thus takes constant time (independent of the length of the list). If you hold a reference to a node at an arbitrary position in a list, you can use similar (but more complicated) code to remove the node after it or to insert a node after it, also in constant time. However, we leave those implementations for exercises (see EXERCISE 4.3.24 and EXERCISE 4.3.25) because inserting and removing at the beginning are the only linked-list operations that we need to implement stacks.
Implementing stacks with linked lists
LinkedStackOfStrings (PROGRAM 4.3.2) uses a linked list to implement a stack of strings, using little more code than the elementary solution that uses a fixed-length array.
The implementation is based on a nested class Node like the one we have been using. Java allows us to define and use other classes within class implementations in this natural way. The class is private because clients do not need to know any of the details of the linked lists. One characteristic of a private nested class is that its instance variables can be directly accessed from within the enclosing class but nowhere else, so there is no need to declare the Node instance variables as public or private (but there is no harm in doing so).
LinkedStackOfStrings itself has just one instance variable: a reference to the linked list that represents the stack. That single link suffices to directly access the item at the top of the stack and indirectly access the rest of the items in the stack for push() and pop(). Again, be sure that you understand this implementation—it is the prototype for several implementations using linked structures that we will be examining later in this chapter. Using the abstract visual list representation to trace the code is the best way to proceed.
Linked-list traversal
One of the most common operations we perform on collections is to iterate over the items in the collection. For example, we might wish to implement the toString() method that is inherent in every Java API to facilitate debugging our stack code with traces. For ArrayStackOfStrings, this implementation is familiar.
Program 4.3.2 Stack of strings (linked list)
public class LinkedStackOfStrings
{
private Node first;
private class Node
{
private String item;
private Node next;
}
public boolean isEmpty()
{ return (first == null); }
public void push(String item)
{ // Insert a new node at the beginning of the list.
Node oldFirst = first;
first = new Node();
first.item = item;
first.next = oldFirst;
}
public String pop()
{ // Remove the first node from the list and return item.
String item = first.item;
first = first.next;
return item;
}
public static void main(String[] args)
{
LinkedStackOfStrings stack = new LinkedStackOfStrings();
// See Program 4.3.1 for the test client.
}
}
first | first node on list
item | stack item next | next node on list
This stack implementation uses a private nested class Node as the basis for representing the stack as a linked list of Node objects. The instance variable first refers to the first (most recently inserted) Node in the linked list. The next instance variable in each Node refers to the successor Node (the value of next in the final node is null). No explicit constructors are needed, because Java initializes the instance variables to null.

public String toString()
{
String s = "";
for (int i = 0; i < n; i++)
s += a[i] + " ";
return s;
}
This solution is intended for use only when n is small—it takes quadratic time because each string concatenation takes linear time.

Our focus now is just on the process of examining every item. There is a corresponding idiom for visiting the items in a linked list: We initialize a loop-index variable x that references the first Node of the linked list. Then, we find the value of the item associated with x by accessing x.item, and then update x to refer to the next Node in the linked list, assigning to it the value of x.next and repeating this process until x is null (which indicates that we have reached the end of the linked list). This process is known as traversing the linked list, and is succinctly expressed in this implementation of toString() for LinkedStackOfStrings:
public String toString()
{
String s = "";
for (Node x = first; x != null; x = x.next)
s += x.item + " ";
return s;
}
When you program with linked lists, this idiom will become as familiar to you as the idiom for iterating over the items in an array. At the end of this section, we consider the concept of an iterator, which allows us to write client code to iterate over the items in a collection without having to program at this level of detail.
With a linked-list implementation we can write client programs that use large numbers of stacks without having to worry much about memory usage. The same principle applies to collections of any sort, so linked lists are widely used in programming. Indeed, typical implementations of the Java memory management system are based on maintaining linked lists corresponding to blocks of memory of various sizes. Before the widespread use of high-level languages like Java, the details of memory management and programming with linked lists were critical parts of any programmer’s arsenal. In modern systems, most of these details are encapsulated in the implementations of a few data types like the pushdown stack, including the queue, the symbol table, and the set, which we will consider later in this chapter. If you take a course in algorithms and data structures, you will learn several others and gain expertise in creating and debugging programs that manipulate linked lists. Otherwise, you can focus your attention on understanding the role played by linked lists in implementing these fundamental data types. For stacks, they are significant because they allow us to implement the push() and pop() methods in constant time while using only a small constant factor of extra memory (for the links).
Resizing arrays
Next, we consider an alternative approach to accommodating arbitrary growth and shrinkage in a data structure that is an attractive alternative to linked lists. As with linked lists, we introduce it now because the approach is not difficult to understand in the context of a stack implementation and because it is important to know when addressing the challenges of implementing data types that are more complicated than stacks.
The idea is to modify the array implementation (PROGRAM 4.3.1) to dynamically adjust the length of the array items[] so that it is sufficiently large to hold all of the items but not so large as to waste an excessive amount of memory. Achieving these goals turns out to be remarkably easy, and we do so in ResizingArrayStackOfStrings (PROGRAM 4.3.3).
First, in push(), we check whether the array is too small. In particular, we check whether there is room for the new item in the array by checking whether the stack size n is equal to the array length items.length. If there is room, we simply insert the new item with the code items[n++] = item as before; if not, we double the length of the array by creating a new array of twice the length, copying the stack items to the new array, and resetting the items[] instance variable to reference the new array.
Program 4.3.3 Stack of strings (resizing array)
public class ResizingArrayStackOfStrings
{
private String[] items = new String[1];
private int n = 0;
public boolean isEmpty()
{ return (n == 0); }
private void resize(int capacity)
{ // Move stack to a new array of given capacity.
String[] temp = new String[capacity];
for (int i = 0; i < n; i++)
temp[i] = items[i];
items = temp;
}
public void push(String item)
{ // Insert item onto stack.
if (n == items.length) resize(2*items.length);
items[n++] = item;
}
public String pop()
{ // Remove and return most recently inserted item.
String item = items[--n];
items[n] = null; // Avoid loitering (see text).
if (n > 0 && n == items.length/4) resize(items.length/2);
return item;
}
public static void main(String[] args)
{
// See Program 4.3.1 for the test client.
}
}
items[] | stack items n | number of items on stack
This implementation achieves the objective of supporting stacks of any size without excessively wasting memory. It doubles the length of the array when full and halves the length of the array to keep it always at least one-quarter full. On average, all operations take constant time (see the text).
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
||||
|
|
|
|
null |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
null |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
null |
null |
null |
|
|
|
|
|
|
|
|
null |
null |
null |
null |
|
|
|
|
|
|
|
|
|
null |
null |
null |
|
|
|
|
|
|
|
|
null |
null |
null |
null |
|
|
|
|
|
|
|
null |
null |
null |
null |
null |
|
|
|
|
|
|
|
|
null |
null |
null |
null |
|
|
|
|
|
|
|
null |
null |
null |
null |
null |
|
|
|
|
|
|
null |
null |
|
|
|
|
|
|
|
|
|
null |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Trace of |
|||||||||||
Similarly, in pop(), we begin by checking whether the array is too large, and we halve its length if that is the case. If you think a bit about the situation, you will see that an appropriate test is whether the stack size is less than one-fourth the array length. Then, after the array is halved, it will be about half full and can accommodate a substantial number of push() and pop() operations before having to change the length of the array again. This characteristic is important: for example, if we were to use to policy of halving the array when the stack size is one-half the array length, then the resulting array would be full, which would mean it would be doubled for a push(), leading to the possibility of an expensive cycle of doubling and halving.
Amortized analysis
This doubling-and-halving strategy is a judicious tradeoff between wasting space (by setting the length of the array to be too big and leaving empty slots) and wasting time (by reorganizing the array after each insertion). The specific strategy in ResizingArrayStackOfStrings guarantees that the stack never overflows and never becomes less than one-quarter full (unless the stack is empty, in which case the array length is 1). If you are mathematically inclined, you might enjoy proving this fact with mathematical induction (see EXERCISE 4.3.18). More important, we can prove that the cost of doubling and halving is always absorbed (to within a constant factor) in the cost of other stack operations. Again, we leave the details to an exercise for the mathematically inclined, but the idea is simple: when push() doubles the length of the array to n, it starts with n / 2 items in the stack, so the length of the array cannot double again until the client has made at least n / 2 additional calls to push() (more if there are some intervening calls to pop()). If we average the cost of the push() operation that causes the doubling with the cost of those n / 2 push() operations, we get a constant. In other words, in ResizingArrayStackOfStrings, the total cost of all of the stack operations divided by the number of operations is bounded by a constant. This statement is not quite as strong as saying that each operation takes constant time, but it has the same implications in many applications (for example, when our primary interest is in the application’s total running time). This kind of analysis is known as amortized analysis—the resizing array data structure is a prototypical example of its value.
Orphaned items
Java’s garbage collection policy is to reclaim the memory associated with any objects that can no longer be accessed. In the pop() implementation in our initial implementation ArrayStackOfStrings, the reference to the popped item remains in the array. The item is an orphan—we will never use it again within the class, either because the stack will shrink or because it will be overwritten with another reference if the stack grows—but the Java garbage collector has no way to know this. Even when the client is done with the item, the reference in the array may keep it alive. This condition (holding a reference to an item that is no longer needed) is known as loitering, which is not the same as a memory leak (where even the memory management system has no reference to the item). In this case, loitering is easy to avoid. The implementation of pop() in ResizingArrayStackOfStrings sets the array element corresponding to the popped item to null, thus overwriting the unused reference and making it possible for the system to reclaim the memory associated with the popped item when the client is finished with it.
With a resizing-array implementation (as with a linked-list implementation), we can write client programs that use stacks without having to worry much about memory usage. Again, the same principle applies to collections of any sort. For some data types that are more complicated than stacks, resizing arrays are preferred over linked lists because of their ability to access any element in the array in constant time (through indexing), which is critical for implementing certain operations (see, for example, RandomQueue in EXERCISE 4.3.37). As with linked lists, it is best to keep resizing-array code local to the implementation of fundamental data types and not worry about using it in client code.
Parameterized data types
We have developed stack implementations that allow us to build stacks of one particular type (String). But when developing client programs, we need implementations for collections of other types of data, not necessarily strings. A commercial transaction processing system might need to maintain collections of customers, accounts, merchants, and transactions; a university course scheduling system might need to maintain collections of classes, students, and rooms; a portable music player might need to maintain collections of songs, artists, and albums; a scientific program might need to maintain collections of double or int values. In any program that you write, you should not be surprised to find yourself maintaining collections for any type of data that you might create. How would you do so? After considering two simple approaches (and their shortcomings) that use the Java language constructs we have discussed so far, we introduce a more advanced construct that can help us properly address this problem.
Create a new collection data type for each item data type
We could create classes StackOfInts, StackOfCustomers, StackOfStudents, and so forth to supplement StackOfStrings. This approach requires that we duplicate the code for each type of data, which violates a basic precept of software engineering that we should reuse (not copy) code whenever possible. You need a different class for every type of data that you want to put on a stack, so maintaining your code becomes a nightmare: whenever you want or need to make a change, you have to do so in each version of the code. Still, this approach is widely used because many programming languages (including early versions of Java) do not provide any better way to solve the problem. Breaking this barrier is the sign of a sophisticated programmer and programming environment. Can we implement stacks of strings, stacks of integers, and stacks of data of any type whatsoever with just one class?
Use collections of Objects
We could develop a stack whose items are all of type Object. Using inheritance, we can legally push an object of any type (if we want to push an object of type Apple, we can do so because Apple is a subclass of Object, as are all other classes). When we pop the stack, we must cast it back to the appropriate type (everything on the stack is an Object, but our code is processing objects of type Apple). In summary, if we create a class StackOfObjects by changing String to Object everywhere in one of our *StackOfStrings implementations, we can write code like
StackOfObjects stack = new StackOfObjects(); Apple a = new Apple(); stack.push(a); ... a = (Apple) (stack.pop());
thus achieving our goal of having a single class that creates and manipulates stacks of objects of any type. However, this approach is undesirable because it exposes clients to subtle bugs in client programs that cannot be detected at compile time. For example, there is nothing to stop a programmer from putting different types of objects on the same stack, as in the following example:
ObjectStack stack = new ObjectStack();
Apple a = new Apple();
Orange b = new Orange();
stack.push(a);
stack.push(b);
a = (Apple) (stack.pop()); // Throws a ClassCastException.
b = (Orange) (stack.pop());
Type casting in this way amounts to assuming that clients will cast objects popped from the stack to the proper type, avoiding the protection provided by Java’s type system. One reason that programmers use the type system is to protect against errors that arise from such implicit assumptions. The code cannot be type-checked at compile time: there might be an incorrect cast that occurs in a complex piece of code that could escape detection until some particular run-time circumstance arises. We seek to avoid such errors because they can appear long after an implementation is delivered to a client, who would have no way to fix them.
Java generics
A specific mechanism in Java known as generic types solves precisely the problem that we are facing. With generics, we can build collections of objects of a type to be specified by client code. The primary benefit of doing so is the ability to discover type-mismatch errors at compile time (when the software is being developed) instead of at run time (when the software is being used by a client). Conceptually, generics are a bit confusing at first (their impact on the programming language is sufficiently deep that they were not included in early versions of Java), but our use of them in the present context involves just a small bit of extra Java syntax and is easy to understand. We name the generic class Stack and choose the generic name Item for the type of the objects in the stack (you can use any name). The code of Stack (PROGRAM 4.3.4) is identical to the code of LinkedStackOfStrings (we drop the Linked modifier because we have a good implementation for clients who do not care about the representation), except that we replace every occurrence of String with Item and declare the class with the following first line of code:
public class Stack<Item>
public class Stack<Item>
{
private Node first;
private class Node
{
private Item item;
private Node next;
}
public boolean isEmpty()
{ return (first == null); }
public void push(Item item)
{ // Insert item onto stack.
Node oldFirst = first;
first = new Node();
first.item = item;
first.next = oldFirst;
}
public Item pop()
{ // Remove and return most recently inserted item.
Item item = first.item;
first = first.next;
return item;
}
public static void main(String[] args)
{
Stack<String> stack = new Stack<String>();
// See Program 4.3.1 for the test client.
}
}
first | first node on list
item | stack item next | next node on list
This code is almost identical to PROGRAM 4.3.2, but is worth repeating because it demonstrates how easy it is to use generics to allow clients to make collections of any type of data. The keyword Item in this code is a type parameter, a placeholder for an actual type name provided by clients.
% java Stack < tobe.txt
to be not that or be
The name Item is a type parameter, a symbolic placeholder for some actual type to be specified by the client. You can read Stack<Item> as stack of items, which is precisely what we want. When implementing Stack, we do not know the actual type of Item, but a client can use our stack for any type of data, including one defined long after we develop our implementation. The client code specifies the type argument Apple when the stack is created:
Stack<Apple> stack = new Stack<Apple>(); Apple a = new Apple(); ... stack.push(a);
If you try to push an object of the wrong type on the stack, like this:
Stack<Apple> stack = new Stack<Apple>();
Apple a = new Apple();
Orange b = new Orange();
stack.push(a);
stack.push(b); // Compile-time error.
you will get a compile-time error:
push(Apple) in Stack<Apple> cannot be applied to (Orange)
Furthermore, in our Stack implementation, Java can use the type parameter Item to check for type-mismatch errors—even though no actual type is yet known, variables of type Item must be assigned values of type Item, and so forth.
Autoboxing
One slight difficulty with generic code like PROGRAM 4.3.4 is that the type parameter stands for a reference type. How can we use the code for primitive types such as int and double? The Java language feature known as autoboxing and unboxing enables us to reuse generic code with primitive types as well. Java supplies built-in object types known as wrapper types, one for each of the primitive types: Boolean, Byte, Character, Double, Float, Integer, Long, and Short correspond to boolean, byte, char, double, float, int, long, and short, respectively. Java automatically converts between these reference types and the corresponding primitive types—in assignment statements, method arguments, and arithmetic/ logic expressions—so that we can write code like the following:
Stack<Integer> stack = new Stack<Integer>(); stack.push(17); // Autoboxing (int -> Integer). int a = stack.pop(); // Unboxing (Integer -> int).
In this example, Java automatically casts (autoboxes) the primitive value 17 to be of type Integer when we pass it to the push() method. The pop() method returns an Integer, which Java casts (unboxes) to an int value before assigning it to the variable a. This feature is convenient for writing code, but involves a significant amount of processing behind the scenes that can affect performance. In some performance-critical applications, a class like StackOfInts might be necessary, after all.
Generics provide the solution that we seek: they enable code reuse and at the same time provide type safety. Carefully studying Stack (PROGRAM 4.3.4) and being sure that you understand each line of code will pay dividends in the future, as the ability to parameterize data types is an important high-level programming technique that is well supported in Java. You do not have to be an expert to take advantage of this powerful feature.
Stack applications
Pushdown stacks play an essential role in computation. If you study operating systems, programming languages, and other advanced topics in computer science, you will learn that not only are stacks used explicitly in many applications, but they also still serve as the basis for executing programs written in many high-level languages, including Java and Python.
Arithmetic expressions
Some of the first programs that we considered in CHAPTER 1 involved computing the value of arithmetic expressions like this one:
( 1 + ( ( 2 + 3 ) * ( 4 * 5 ) ) )
If you multiply 4 by 5, add 3 to 2, multiply the result, and then add 1, you get the value 101. But how does Java do this calculation? Without going into the details of how Java is built, we can address the essential ideas just by writing a Java program that can take a string as input (the expression) and produce the number represented by the expression as output. For simplicity, we begin with the following explicit recursive definition: an arithmetic expression is either a number or a left parenthesis followed by an arithmetic expression followed by an operator followed by another arithmetic expression followed by a right parenthesis. For simplicity, this definition is for fully parenthesized arithmetic expressions, which specifies precisely which operators apply to which operands—you are a bit more familiar with expressions like 1 + 2 * 3, in which we use precedence rules instead of parentheses. The same basic mechanisms that we consider can handle precedence rules, but we avoid that complication. For specificity, we support the familiar binary operators *, +, and -, as well as a square-root operator sqrt that takes only one argument. We could easily allow more operators to support a larger class of familiar mathematical expressions, including division, trigonometric functions, and exponential functions. Our focus is on understanding how to interpret the string of parentheses, operators, and numbers to enable performing in the proper order the low-level arithmetic operations that are available on any computer.
Arithmetic expression evaluation
Precisely how can we convert an arithmetic expression—a string of characters—to the value that it represents? A remarkably simple algorithm that was developed by Edsger Dijkstra in the 1960s uses two pushdown stacks (one for operands and one for operators) to do this job. An expression consists of parentheses, operators, and operands (numbers). Proceeding from left to right and taking these entities one at a time, we manipulate the stacks according to four possible cases, as follows:
• Push operands onto the operand stack.
• Push operators onto the operator stack.
• Ignore left parentheses.
• On encountering a right parenthesis, pop an operator, pop the requisite number of operands, and push onto the operand stack the result of applying that operator to those operands.
After the final right parenthesis has been processed, there is one value on the stack, which is the value of the expression. Dijkstra’s two-stack algorithm may seem mysterious at first, but it is easy to convince yourself that it computes the proper value: anytime the algorithm encounters a subexpression consisting of two operands separated by an operator, all surrounded by parentheses, it leaves the result of performing that operation on those operands on the operand stack. The result is the same as if that value had appeared in the input instead of the subexpression, so we can think of replacing the subexpression by the value to get an expression that would yield the same result. We can apply this argument again and again until we get a single value. For example, the algorithm computes the same value of all of these expressions:
( 1 + ( ( 2 + 3 ) * ( 4 * 5 ) ) ) ( 1 + ( 5 * ( 4 * 5 ) ) ) ( 1 + ( 5 * 20 ) ) ( 1 + 100 ) 101
Program 4.3.5 Expression evaluation
public class Evaluate
{
public static void main(String[] args)
{
Stack<String> ops = new Stack<String>();
Stack<Double> values = new Stack<Double>();
while (!StdIn.isEmpty())
{ // Read token, push if operator.
String token = StdIn.readString();
if (token.equals("(")) ;
else if (token.equals("+")) ops.push(token);
else if (token.equals("-")) ops.push(token);
else if (token.equals("*")) ops.push(token);
else if (token.equals("sqrt")) ops.push(token);
else if (token.equals(")"))
{ // Pop, evaluate, and push result if token is ")".
String op = ops.pop();
double v = values.pop();
if (op.equals("+")) v = values.pop() + v;
else if (op.equals("-")) v = values.pop() - v;
else if (op.equals("*")) v = values.pop() * v;
else if (op.equals("sqrt")) v = Math.sqrt(v);
values.push(v);
} // Token not operator or paren: push double value.
else values.push(Double.parseDouble(token));
}
StdOut.println(values.pop());
}
}
ops | operator stack values | operand stack token | current token v | current value
This Stack client reads a fully parenthesized numeric expression from standard input, uses Dijkstra’s two-stack algorithm to evaluate it, and prints the resulting number to standard output. It illustrates an essential computational process: interpreting a string as a program and executing that program to compute the desired result. Executing a Java program is nothing other than a more complicated version of this same process.
Evaluate (PROGRAM 4.3.5) is an implementation of this algorithm. This code is a simple example of an interpreter: a program that executes a program (in this case, an arithmetic expression) one step or line at a time. A compiler is a program that translates a program from a higher-level language to a lower-level language that can do the job. A compiler’s conversion is a more complicated process than the step-by-step conversion used by an interpreter, but it is based on the same underlying mechanism. The Java compiler translates code written in the Java programming language into Java bytecode, Originally, Java was based on using an interpreter. Now, however, Java includes a compiler that converts arithmetic expressions (and, more generally, Java programs) into lower-level code for the Java virtual machine, an imaginary machine that is easy to simulate on an actual computer.

Stack-based programming languages
Remarkably, Dijkstra’s two-stack algorithm also computes the same value as in our example for this expression:
( 1 ( ( 2 3 + ) ( 4 5 * ) * ) + )
In other words, we can put each operator after its two operands instead of between them. In such an expression, each right parenthesis immediately follows an operator so we can ignore both kinds of parentheses, writing the expressions as follows:
1 2 3 + 4 5 * * +
This notation is known as reverse Polish notation, or postfix. To evaluate a postfix expression, we use only one stack (see EXERCISE 4.3.15). Proceeding from left to right, taking these entities one at a time, we manipulate the stack according to just two possible cases, as follows:
• Push operands onto the stack.
• On encountering an operator, pop the requisite number of operands and push onto the stack the result of applying the operator to those operands.
Again, this process leaves one value on the stack, which is the value of the expression. This representation is so simple that some programming languages, such as Forth (a scientific programming language) and PostScript (a page description language that is used on most printers) use explicit stacks as primary flow-control structures. For example, the string 1 2 3 + 4 5 * * + is a legal program in both Forth and PostScript that leaves the value 101 on the execution stack. Aficionados of these and similar stack-based programming languages prefer them because they are simpler for many types of computation. Indeed, the Java virtual machine itself is stack based.

Function-call abstraction
Most programs use stacks implicitly because they support a natural way to implement function calls, as follows: at any point during the execution of a function, define its state to be the values of all of its variables and a pointer to the next instruction to be executed. One of the fundamental characteristics of computing environments is that every computation is fully determined by its state (and the value of its inputs). In particular, the system can suspend a computation by saving away its state, then restart it by restoring the state. If you take a course about operating systems, you will learn the details of this process, because it is critical to much of the behavior of computers that we take for granted (for example, switching from one application to another is simply a matter of saving and restoring state). Now, the natural way to implement the function-call abstraction is to use a stack. To call a function, push the state on a stack. To return from a function call, pop the state from the stack to restore all variables to their values before the function call, substitute the function return value (if there is one) in the expression containing the function call (if there is one), and resume execution at the next instruction to be executed (whose location was saved as part of the state of the computation). This mechanism works whenever functions call one another, even recursively. Indeed, if you think about the process carefully, you will see that it is essentially the same process that we just examined in detail for expression evaluation. A program is a sophisticated expression.

The pushdown stack is a fundamental computational abstraction. Stacks have been used for expression evaluation, implementing the function-call abstraction, and other basic tasks since the earliest days of computing. We will examine another (tree traversal) in SECTION 4.4. Stacks are used explicitly and extensively in many areas of computer science, including algorithm design, operating systems, compilers, and numerous other computational applications.
FIFO queues
A FIFO queue (or just a queue) is a collection that is based on the first-in first-out policy.
The policy of doing tasks in the same order that they arrive is one that we encounter frequently in everyday life, from people waiting in line at a theater, to cars waiting in line at a toll booth, to tasks waiting to be serviced by an application on your computer.

One bedrock principle of any service policy is the perception of fairness. The first idea that comes to mind when most people think about fairness is that whoever has been waiting the longest should be served first. That is precisely the FIFO discipline, so queues play a central role in numerous applications. Queues are a natural model for so many everyday phenomena, and their properties were studied in detail even before the advent of computers.
As usual, we begin by articulating an API. Again by tradition, we name the queue insert operation enqueue and the remove operation dequeue, as indicated in the following API:
|
||
|
|
create an empty queue |
|
|
is the queue empty? |
|
|
insert an item into the queue |
|
|
return and remove the item that was inserted least recently |
|
|
number of items in the queue |
API for a generic FIFO queue |
||
As specified in this API, we will use generics in our implementations, so that we can write client programs that safely build and use queues of any reference type. We include a size() method, even though we did not have such a method for stacks because queue clients often do need to be aware of the number of items in the queue, whereas most stack clients do not (see PROGRAM 4.3.8 and EXERCISE 4.3.11).
Applying our knowledge from stacks, we can use linked lists or resizing arrays to develop implementations where the operations take constant time and the memory associated with the queue grows and shrinks with the number of items in the queue. As with stacks, each of these implementations represents a classic programming exercise. You may wish to think about how you might achieve these goals in an implementation before reading further.
Linked-list implementation
To implement a queue with a linked list, we keep the items in order of their arrival (the reverse of the order that we used in Stack). The implementation of dequeue() is the same as the pop() implementation in Stack (save the item in the first linked-list node, remove that node from the queue, and return the saved item). Implementing enqueue(), however, is a bit more challenging: how do we add a node to the end of a linked list? To do so, we need a link to the last node in the linked list, because that node’s link has to be changed to reference a new node containing the item to be inserted. In Stack, the only instance variable is a reference to the first node in the linked list; with only that information, our only recourse is to traverse all the nodes in the linked list to get to the end. That solution is inefficient for long linked lists. A reasonable alternative is to maintain a second instance variable that always references the last node in the linked list. Adding an extra instance variable that needs to be maintained is not something that should be taken lightly, particularly in linked-list code, because every method that modifies the list needs code to check whether that variable needs to be modified (and to make the necessary modifications). For example, removing the first node in the linked list might involve changing the reference to the last node, since when there is only one node remaining, it is both the first one and the last one! (Details like this make linked-list code notoriously difficult to debug.) Queue (PROGRAM 4.3.6) is a linked-list implementation of our FIFO queue API that has the same performance properties as Stack: all of the methods are constant time, and memory usage is proportional to the queue size.

Program 4.3.6 Generic FIFO queue (linked list)
public class Queue<Item>
{
private Node first;
private Node last;
private class Node
{
private Item item;
private Node next;
}
public boolean isEmpty()
{ return (first == null); }
public void enqueue(Item item)
{ // Insert a new node at the end of the list.
Node oldLast = last;
last = new Node();
last.item = item;
last.next = null;
if (isEmpty()) first = last;
else oldLast.next = last;
}
public Item dequeue()
{ // Remove the first node from the list and return item.
Item item = first.item;
first = first.next;
if (isEmpty()) last = null;
return item;
}
public static void main(String[] args)
{ // Test client is similar to Program 4.3.2.
Queue<String> queue = new Queue<String>();
}
}
first | first node on list last | last node on list
item | queue item next | next node on list
This implementation is very similar to our linked-list stack implementation (PROGRAM 4.3.2): dequeue() is almost identical to pop(), but enqueue() links the new node onto the end of the list, not the beginning as in push(). To do so, it maintains an instance variable last that references the last node in the list. The size() method is left for an exercise (see EXERCISE 4.3.11).

Array implementations
It is also possible to develop FIFO queue implementations that use arrays having the same performance characteristics as those that we developed for stacks in ArrayStackOfStrings (PROGRAM 4.3.1) and ResizingArrayStackOfStrings (PROGRAM 4.3.3). These implementations are worthy programming exercises that you are encouraged to pursue further (see EXERCISE 4.3.19).
Random queues
Even though they are widely applicable, there is nothing sacred about the FIFO and LIFO policies. It makes perfect sense to consider other rules for removing items. One of the most important to consider is a data type where dequeue() removes and returns a random item (sampling without replacement), and we have a method sample() that returns a random item without removing it from the queue (sampling with replacement). We use the name RandomQueue to refer to this data type (see EXERCISE 4.3.37).
The stack, queue, and random queue APIs are essentially identical—they differ only in the choice of class and method names (which are chosen arbitrarily). The true differences among these data types are in the semantics of the remove operation—which item is to be removed? The differences between stacks and queues are in the English-language descriptions of what they do. These differences are akin to the differences between Math.sin(x) and Math.log(x), but we might want to articulate them with a formal description of stacks and queues (in the same way as we have mathematical descriptions of the sine and logarithm functions). But precisely describing what we mean by first-in first-out or last-in first-out or random-out is not so simple. For starters, which language would you use for such a description? English? Java? Mathematical logic? The problem of describing how a program behaves is known as the specification problem, and it leads immediately to deep issues in computer science. One reason for our emphasis on clear and concise code is that the code itself can serve as the specification for simple data types such as stacks, queues, and random queues.
Queue applications
In the past century, FIFO queues proved to be accurate and useful models in a broad variety of applications, ranging from manufacturing processes to telephone networks to traffic simulations. A field of mathematics known as queuing theory has been used with great success to help understand and control complex systems of all kinds. FIFO queues also play an important role in computing. You often encounter queues when you use your computer: a queue might hold songs on a playlist, documents to be printed, or events in a game.
Perhaps the ultimate queue application is the Internet itself, which is based on huge numbers of messages moving through huge numbers of queues that have all sorts of different properties and are interconnected in all sorts of complicated ways. Understanding and controlling such a complex system involves solid implementations of the queue abstraction, application of mathematical results of queueing theory, and simulation studies involving both. We consider next a classic example to give a flavor of this process.
M/M/1 queue
One of the most important queueing models is known as an M/M/1 queue, which has been shown to accurately model many real-world situations, such as a single line of cars entering a toll booth or patients entering an emergency room. The M stands for Markovian or memoryless and indicates that both arrivals and services are Poisson processes: both the interarrival times and the service times obey an exponential distribution (see EXERCISE 2.2.8). The 1 indicates that there is one server. An M/M/1 queue is parameterized by its arrival rate λ (for example, the number of cars per minute arriving at the toll booth) and its service rate μ (for example, the number of cars per minute that can pass through the toll booth) and is characterized by three properties:
• There is one server—a FIFO queue.
• Interarrival times to the queue obey an exponential distribution with rate λ per minute.
• Service times from a nonempty queue obey an exponential distribution with rate μ per minute.

The average time between arrivals is 1/λ minutes and the average time between services (when the queue is nonempty) is 1/μ minutes. So, the queue will grow without bound unless μ > λ; otherwise, customers enter and leave the queue in an interesting dynamic process.
Analysis
In practical applications, people are interested in the effect of the parameters λ and μ on various properties of the queue. If you are a customer, you may want to know the expected amount of time you will spend in the system; if you are designing the system, you might want to know how many customers are likely to be in the system, or something more complicated, such as the likelihood that the queue size will exceed a given maximum size. For simple models, probability theory yields formulas expressing these quantities as functions of λ and μ. For M/M/1 queues, it is known that
• The average number of customers in the system L is λ / (μ – λ).
• The average time a customer spends in the system W is 1 / (μ – λ).
For example, if the cars arrive at a rate of λ = 10 per minute and the service rate is μ = 15 per minute, then the average number of cars in the system will be 2 and the average time that a customer spends in the system will be 1/5 minutes or 12 seconds. These formulas confirm that the wait time (and queue length) grows without bound as λ approaches μ. They also obey a general rule known as Little’s law: the average number of customers in the system is λ times the average time a customer spends in the system (L = λW) for many types of queues.
Simulation
MM1Queue (PROGRAM 4.3.7) is a Queue client that you can use to validate these sorts of mathematical results. It is a simple example of an event-based simulation: we generate events that take place at particular times and adjust our data structures accordingly for the events, simulating what happens at the time they occur. In an M/M/1 queue, there are two kinds of events: we have either a customer arrival or a customer service. In turn, we maintain two variables:
• nextService is the time of the next service.
• nextArrival is the time of the next arrival.
To simulate an arrival event, we enqueue nextArrival (the time of arrival); to simulate a service, we dequeue the arrival time of the next customer in the queue, compute that customer’s waiting time wait (which is the time that the service is completed minus the time that the customer entered the queue), and add the wait time to a histogram (see PROGRAM 3.2.3). The shape that results after a large number of trials is characteristic of the M/M/1 queueing system. From a practical point of view, one of the most important characteristics of the process, which you can discover for yourself by running MM1Queue for various values of the parameters λ and μ, is that the average time a customer spends in the system (and the average number of customers in the system) can increase dramatically when the service rate approaches the arrival rate. When the service rate is high, the histogram has a visible tail where the frequency of customers having a given wait time decreases to a negligible duration as the wait time increases. But when the service rate is too close to the arrival rate, the tail of the histogram stretches to the point that most values are in the tail, so the frequency of customers having at least the highest wait time displayed dominates.
Program 4.3.7 M/M/1 queue simulation
public class MM1Queue
{
public static void main(String[] args)
{
double lambda = Double.parseDouble(args[0]);
double mu = Double.parseDouble(args[1]);
Histogram hist = new Histogram(60 + 1);
Queue<Double> queue = new Queue<Double>();
double nextArrival = StdRandom.exp(lambda);
double nextService = nextArrival + StdRandom.exp(mu);
StdDraw.enableDoubleBuffering();
while (true)
{ // Simulate arrivals before next service.
while (nextArrival < nextService)
{
queue.enqueue(nextArrival);
nextArrival += StdRandom.exp(lambda);
}
// Simulate next service.
double wait = nextService - queue.dequeue();
hist.addDataPoint(Math.min(60, (int) Math.round(wait)));
StdDraw.clear();
hist.draw();
StdDraw.show();
StdDraw.wait(20);
if (queue.isEmpty())
nextService = nextArrival + StdRandom.exp(mu);
else
nextService = nextService + StdRandom.exp(mu);
}
}
}
lambda | arrival rate mu | service rate hist | histogram queue | M/M/1 queue wait | time on queue
This simulation of an M/M/1 queue keeps track of time with two variables nextArrival and nextService and a single Queue of double values to calculate wait times. The value of each item on the queue is the (simulated) time it entered the queue. The waiting times are plotted using Histogram (PROGRAM 3.2.3).

As in many other applications that we have studied, the use of simulation to validate a well-understood mathematical model is a starting point for studying more complex situations. In practical applications of queues, we may have multiple queues, multiple servers, multistage servers, limits on queue length, and many other restrictions. Moreover, the distributions of interarrival and service times may not be possible to characterize mathematically. In such situations, we may have no recourse but to use simulations. It is quite common for a system designer to build a computational model of a queuing system (such as MM1Queue) and to use it to adjust design parameters (such as the service rate) to properly respond to the outside environment (such as the arrival rate).
Iterable collections
As mentioned earlier in this section, one of the fundamental operations on arrays and linked lists is the for loop idiom that we use to process each element. This common programming paradigm need not be limited to low-level data structures such as arrays and linked lists. For any collection, the ability to process all of its items (perhaps in some specified order) is a valuable capability. The client’s requirement is just to process each of the items in some way, or to iterate over the items in the collection. This paradigm is so important that it has achieved first-class status in Java and many other modern programming languages (meaning that the language itself has specific mechanisms to support it, not just the libraries). With it, we can write clear and compact code that is free from dependence on the details of a collection’s implementation.
To introduce the concept, we start with a snippet of client code that prints all of the items in a collection of strings, one per line:
Stack<String> collection = new Stack<String>(); ... for (String s : collection) StdOut.println(s); ...
This construct is known as the foreach statement: you can read the for statement as for each string s in the collection, print s. This client code does not need to know anything about the representation or the implementation of the collection; it just wants to process each of the items in the collection. The same foreach loop would work with a Queue of strings or with any other iterable collection of strings.
We could hardly imagine code that is clearer and more compact. However, implementing a collection that supports iteration in this way requires some extra work, which we now consider in detail. First, the foreach construct is shorthand for a while construct. For example, the foreach statement given earlier is equivalent to the following while construct:
Iterator<String> iterator = collection.iterator();
while (iterator.hasNext())
{
String s = iterator.next();
StdOut.println(s);
}
This code exposes the three necessary parts that we need to implement in any iterable collection:
• The collection must implement an iterator() method that returns an Iterator object.
• The Iterator class must include two methods: hasNext() (which returns boolean value) and next() (which returns an item from the collection).
In Java, we use the interface inheritance mechanism to express the idea that a class implements a specific set of methods (see SECTION 3.3). For iterable collections, the necessary interfaces are predefined in Java.
To make a class iterable, the first step is to add the phrase implements Iterable<Item> to its declaration, matching the interface
public interface Iterable<Item>
{
Iterator<Item> iterator();
}
(which is defined in java.lang.Iterable), and to add a method to the class that returns an Iterator<Item>. Iterators are generic; we can use them to provide clients with the ability to iterate over a specified type of objects (and only objects of that specified type).
What is an iterator? An object from a class that implements the methods hasNext() and next(), as in the following interface (which is defined in java.util.Iterator):
public interface Iterator<Item>
{
boolean hasNext();
Item next();
void remove();
}
Although the interface requires a remove() method, we always use an empty method for remove() in this book, because interleaving iteration with operations that modify the data structure is best avoided.
As illustrated in the following two examples, implementing an iterator class is often straightforward for array and linked-list representations of collections.
Making iterable a class that uses an array
As a first example, we will consider all of the steps needed to make ArrayStackOfStrings (PROGRAM 4.3.1) iterable. First, change the class declaration to
public class ArrayStackOfStrings implements Iterable<String>
In other words, we are promising to provide an iterator() method so that a client can use a foreach statement to iterate over the strings in the stack. The iterator() method itself is simple:
public Iterator<String> iterator()
{ return new ReverseArrayIterator(); }
It just returns an object from a private nested class that implements the Iterator interface (which provides hasNext(), next(), and remove() methods):
private class ReverseArrayIterator implements Iterator<String>
{
private int i = n-1;
public boolean hasNext()
{ return i >= 0; }
public String next()
{ return items[i--]; }
public void remove()
{ }
}
Note that the nested class ReverseArrayIterator can access the instance variables of the enclosing class, in this case items[] and n (this ability is the main reason we use nested classes for iterators). One crucial detail remains: we have to include
import java.util.Iterator;
at the beginning of ArrayStackOfStrings. Now, since a client can use the foreach statement with ArrayStackOfStrings objects, it can iterate over the items without being aware of the underlying array representation. This arrangement is of critical importance for implementations of fundamental data types for collections. For example, it frees us to switch to a totally different representation without having to change any client code. More important, taking the client’s point of view, it allows clients to use iteration without having to know any details of the implementation.
Making iterable a class that uses a linked list
The same specific steps (with different code) are effective to make Queue (PROGRAM 4.3.6) iterable, even though it is generic. First, we change the class declaration to
public class Queue<Item> implements Iterable<Item>
In other words, we are promising to provide an iterator() method so that a client can use a foreach statement to iterate over the items in the queue, whatever their type. Again, the iterator() method itself is simple:
public Iterator<Item> iterator()
{ return new ListIterator(); }
As before, we have a private nested class that implements the Iterator interface:
private class ListIterator implements Iterator<Item>
{
Node current = first;
public boolean hasNext()
{ return current != null; }
public Item next()
{
Item item = current.item;
current = current.next;
return item;
}
public void remove()
{ }
}
Again, a client can build a queue of items of any type and then iterate over the items without any awareness of the underlying linked-list representation:
Queue<String> queue = new Queue<String>(); ... for (String s : queue) StdOut.println(s);
This client code is a clearer expression of the computation and therefore easier to write and maintain than code based on the low-level representation.
Our stack iterator iterates over the items in LIFO order and our queue iterator iterates over them in FIFO order, even though there is no requirement to do so: we could return the items in any order whatsoever. However, when developing iterators, it is wise to follow a simple rule: if a data type specification implies a natural iteration order, use it.
Iterable implementations may seem a bit complicated to you at first, but they are worth the effort. You will not find yourself implementing them very often, but when you do, you will enjoy the benefits of clear and correct client code and code reuse. Moreover, as with any programming construct, once you begin to enjoy these benefits, you will find yourself taking advantage of them often.
Making a class iterable certainly changes its API, but to avoid overly complicated API tables, we simply use the adjective iterable to indicate that we have included the appropriate code to a class, as described in this section, and to indicate that you can use the foreach statement in client code. From this point forward we will use in client programs the iterable (and generic) Stack, Queue, and RandomQueue data types described here.

Resource allocation
Next, we examine an application that illustrates the data structures and Java language features that we have been considering. A resource-sharing system involves a large number of loosely cooperating servers that want to share resources. Each server agrees to maintain its own queue of items for sharing, and a central authority distributes the items to the servers (and informs users where they may be found). For example, the items might be songs, photos, or videos to be shared by a large number of users. To fix ideas, we will think in terms of millions of items and thousands of servers.
We will consider the kind of program that the central authority might use to distribute the items, ignoring the dynamics of deleting items from the systems, adding and deleting servers, and so forth.
If we use a round-robin policy, cycling through the servers to make the assignments, we get a balanced allocation, but it is rarely possible for a distributor to have such complete control over the situation: for example, there might be a large number of independent distributors, so none of them could have up-to-date information about the servers. Accordingly, such systems often use a random policy, where the assignments are based on random choice. An even better policy is to choose a random sample of servers and assign a new item to the server that has the fewest items. For small queues, differences among these policies is immaterial, but in a system with millions of items on thousands of servers, the differences can be quite significant, since each server has a fixed amount of resources to devote to this process. Indeed, similar systems are used in Internet hardware, where some queues might be implemented in special-purpose hardware, so queue length translates directly to extra equipment cost. But how big a sample should we take?
LoadBalance (PROGRAM 4.3.8) is a simulation of the sampling policy, which we can use to study this question. This program makes good use of the data structures (queues and random queues) and high-level constructs (generics and iterators) that we have been considering to provide an easily understood program that we can use for experimentation. The simulation maintains a random queue of queues and builds the computation around an inner loop where each new request for service goes on the smallest of a sample of queues, using the sample() method from RandomQueue (EXERCISE 4.3.36) to randomly sample queues. The surprising end result is that samples of size 2 lead to near-perfect balancing, so there is no point in taking larger samples.
Program 4.3.8 Load balancing simulation
public class LoadBalance
{
public static void main(String[] args)
{ // Assign n items to m servers, using
// shortest-in-a-sample policy.
int m = Integer.parseInt(args[0]);
int n = Integer.parseInt(args[1]);
int size = Integer.parseInt(args[2]);
// Create server queues.
RandomQueue<Queue<Integer>> servers;
servers = new RandomQueue<Queue<Integer>>();
for (int i = 0; i < m; i++)
servers.enqueue(new Queue<Integer>());
for (int j = 0; j < n; j++)
{ // Assign an item to a server.
Queue<Integer> min = servers.sample();
for (int k = 1; k < size; k++)
{ // Pick a random server, update if new min.
Queue<Integer> queue = servers.sample();
if (queue.size() < min.size()) min = queue;
} // min is the shortest server queue.
min.enqueue(j);
}
int i = 0;
double[] lengths = new double[m];
for (Queue<Integer> queue : servers)
lengths[i++] = queue.size();
StdDraw.setYscale(0, 2.0 * n / m);
StdStats.plotBars(lengths);
}
}
m | number of servers n | number of items size | sample size servers | queues min | shortest in sample queue | current server
This generic Queue and RandomQueue client simulates the process of assigning n items to a set of m servers. Requests are put on the shortest of a sample of size queues chosen at random.


We have considered in detail the issues surrounding the space and time usage of basic implementations of the stack and queue APIs not just because these data types are important and useful, but also because you are likely to encounter the very same issues in the context of your own data-type implementations.
Should you use a pushdown stack, a FIFO queue, or a random queue when developing a client that maintains collections of data? The answer to this question depends on a high-level analysis of the client to determine which of the LIFO, FIFO, or random disciplines is appropriate.
Should you use an array, a linked list, or a resizing array to structure your data? The answer to this question depends on low-level analysis of performance characteristics. With an array, the advantage is that you can access any element in constant time; the disadvantage is that you need to know the maximum length in advance. A linked list has the advantage that there is no limit on the number of items that it can hold; the disadvantage is that you cannot access an arbitrary element in constant time. A resizing array combines the advantages of arrays and linked lists (you can access any element in constant time but do not need to know the maximum length in advance) but has the (slight) disadvantage that the running time is constant on an amortized basis. Each data structure is appropriate in certain situations; you are likely to encounter all three in most programming environments. For example, the Java class java.util.ArrayList uses a resizing array, and the Java class java.util.LinkedList uses a linked list.
The powerful high-level constructs and new language features that we have considered in this section (generics and iterators) are not to be taken for granted. They are sophisticated programming language features that did not come into widespread use in mainstream languages until the turn of the century, and they are still used mostly by professional programmers. Nevertheless, their use is skyrocketing because they are well supported in Java and C++, because newer languages such as Python and Ruby embrace them, and because many people are learning to appreciate the value of using them in client code. By now, you know that learning to use a new language feature is not so different from learning to ride a bicycle or implement HelloWorld: it seems completely mysterious until you have done it for the first time, but quickly becomes second nature. Learning to use generics and iterators will be well worth your time.
A. As with any other class, you should use new only when you want to create a new Node object (a new node in the linked list). You should not use new to create a new reference to an existing Node object. For example, the code
Node oldFirst = new Node(); oldFirst = first;
creates a new Node object, then immediately loses track of the only reference to it. This code does not result in an error, but it is untidy to create orphans for no reason.
Q. Why declare Node as a nested class? Why private?
A. By declaring the nested class Node to be private, methods in the enclosing class can refer to Node objects, but access from other classes is prohibited. Note for experts: A nested class that is not static is known as an inner class, so technically our Node classes are inner classes, though the ones that are not generic could be static.
Q. When I type javac LinkedStackOfStrings.java to run PROGRAM 4.3.2 and similar programs, I find a file LinkedStackOfStrings$Node.class in addition to LinkedStackOfStrings.class. What is the purpose of that file?
A. That file is for the nested class Node. Java’s naming convention is to use $ to separate the name of the outer class from the nested class.
Q. Should a client be allowed to insert null items into a stack or queue?
A. This question arises frequently when implementing collections in Java. Our implementation (and Java’s stack and queue libraries) do permit the insertion of null values.
Q. Are there Java libraries for stacks and queues?
A. Yes and no. Java has a built-in library called java.util.Stack, but you should avoid using it when you want a stack. It has several additional operations that are not normally associated with a stack, such as getting the ith item. It also allows adding an item to the bottom of the stack (instead of the top), so it can implement a queue! Although having such extra operations might appear to be a bonus, it is actually a curse. We use data types not because they provide every available operation, but rather because they allow us to precisely specify the operations we need. The prime benefit of doing so is that the system can prevent us from performing operations that we do not actually want. The java.util.Stack API is an example of a wide interface, which we generally strive to avoid.
Q. I want to use an array representation for a generic stack, but code like the following will not compile. What is the problem?
private Item[] item = new Item[capacity];
A. Good try. Unfortunately, Java does not permit the creation of arrays of generics. Experts are still vigorously debating this decision. As usual, complaining too loudly about a programming language feature puts you on the slippery slope toward becoming a language designer. There is a way out, using a cast. You can write:
private Item[] item = (Item[]) new Object[capacity];
Q. Why do I need to import java.util.Iterator but not java.lang.Iterable?
A. For historical reasons, the interface Iterator is part of the package java.util, which is not imported by default. The interface Iterable is relatively new and included as part of the package java.lang, which is imported by default.
Q. Can I use a foreach statement with arrays?
A. Yes (even though, technically, arrays do not implement the Iterable interface). The following code prints the command-line arguments to standard output:
public static void main(String[] args)
{
for (String s : args)
StdOut.println(s);
}
Q. When using generics, what happens if I omit the type argument in either the declaration or the constructor call?
Stack<String> stack = new Stack(); // unsafe Stack stack = new Stack<String>(); // unsafe Stack<String> stack = new Stack<String>(); // correct
A. The first statement produces a compile-time warning. The second statement produces a compile-time warning if you call stack.push() with a String argument and a compile-time error if you assign the result of stack.pop() to a variable of type String. As an alternative to the third statement, you can use the diamond operator, which enables Java to infer the type argument to the constructor call from context:
Stack<String> stack = new Stack<>(); // diamond operator
Q. Why not have a single Collection data type that implements methods to add items, remove the most recently inserted item, remove the least recently inserted item, remove a random item, iterate over the items, return the number of items in the collection, and whatever other operations we might desire? Then we could get them all implemented in a single class that could be used by many clients.
A. This is an example of a wide interface, which, as we pointed out in SECTION 3.3, is to be avoided. One reason to avoid wide interfaces is that it is difficult to construct implementations that are efficient for all operations. A more important reason is that narrow interfaces enforce a certain discipline on your programs, which makes client code much easier to understand. If one client uses Stack<String> and another uses Queue<Customer>, we have a good idea that the LIFO discipline is important to the first and the FIFO discipline is important to the second. Another approach is to use inheritance to try to encapsulate operations that are common to all collections. However, such implementations are for experts, whereas any programmer can learn to build generic implementations such as Stack and Queue.
Exercises
4.3.1 Add a method isFull() to ArrayStackOfStrings (PROGRAM 4.3.1) that returns true if the stack size equals the array capacity. Modify push() to throw an exception if it is called when the stack is full.
4.3.2 Give the output printed by java ArrayStackOfStrings 5 for this input:
it was - the best - of times - - - it was - the - -
4.3.3 Suppose that a client performs an intermixed sequence of push and pop operations on a pushdown stack. The push operations insert the integers 0 through 9 in order onto the stack; the pop operations print the return values. Which of the following sequence(s) could not occur?
a. 4 3 2 1 0 9 8 7 6 5
b. 4 6 8 7 5 3 2 9 0 1
c. 2 5 6 7 4 8 9 3 1 0
d. 4 3 2 1 0 5 6 7 8 9
e. 1 2 3 4 5 6 9 8 7 0
f. 0 4 6 5 3 8 1 7 2 9
g. 1 4 7 9 8 6 5 3 0 2
h. 2 1 4 3 6 5 8 7 9 0
4.3.4 Write a filter Reverse that reads strings one at a time from standard input and prints them to standard output in reverse order. Use either a stack or a queue.
4.3.5 Write a static method that reads floating-point numbers one at a time from standard input and returns an array containing them, in the same order they appear on standard input. Hint: Use either a stack or a queue.
4.3.6 Write a stack client Parentheses that reads a string of parentheses, square brackets, and curly braces from standard input and uses a stack to determine whether they are properly balanced. For example, your program should print true for [()]{}{[()()]()} and false for [(]).
4.3.7 What does the following code fragment print when n is 50? Give a high-level description of what the code fragment does when presented with a positive integer n.
Stack<Integer> stack = new Stack<Integer>();
while (n > 0)
{
stack.push(n % 2);
n /= 2;
}
while (!stack.isEmpty())
StdOut.print(stack.pop());
StdOut.println();
Answer: Prints the binary representation of n (110010 when n is 50).
4.3.8 What does the following code fragment do to the queue queue?
Stack<String> stack = new Stack<String>(); while (!queue.isEmpty()) stack.push(queue.dequeue()); while (!stack.isEmpty()) queue.enqueue(stack.pop());
4.3.9 Add a method peek() to Stack (PROGRAM 4.3.4) that returns the most recently inserted item on the stack (without removing it).
4.3.10 Give the contents and length of the array for ResizingArrayStackOfStrings with this input:
it was - the best - of times - - - it was - the - -
4.3.11 Add a method size() to both Stack (PROGRAM 4.3.4) and Queue (PROGRAM 4.3.6) that returns the number of items in the collection. Hint: Make sure that your method takes constant time by maintaining an instance variable n that you initialize to 0, increment in push() and enqueue(), decrement in pop() and dequeue(), and return in size().
4.3.12 Draw a memory-usage diagram in the style of the diagrams in SECTION 4.1 for the three-node example used to introduce linked lists in this section.
4.3.13 Write a program that takes from standard input an expression without left parentheses and prints the equivalent infix expression with the parentheses inserted. For example, given the input
1 + 2 ) * 3 - 4 ) * 5 - 6 ) ) )
your program should print
( ( 1 + 2 ) * ( ( 3 - 4 ) * ( 5 - 6 ) )
4.3.14 Write a filter InfixToPostfix that converts an arithmetic expression from infix to postfix.
4.3.15 Write a program EvaluatePostfix that takes a postfix expression from standard input, evaluates it, and prints the value. (Piping the output of your program from the previous exercise to this program gives equivalent behavior to Evaluate, in PROGRAM 4.3.5.)
4.3.16 Suppose that a client performs an intermixed sequence of enqueue and dequeue operations on a FIFO queue. The enqueue operations insert the integers 0 through 9 in order onto the queue; the dequeue operations print the return values. Which of the following sequence(s) could not occur?
a. 0 1 2 3 4 5 6 7 8 9
b. 4 6 8 7 5 3 2 9 0 1
c. 2 5 6 7 4 8 9 3 1 0
d. 4 3 2 1 0 5 6 7 8 9
4.3.17 Write an iterable Stack client that has a static method copy() that takes a stack of strings as its argument and returns a copy of the stack. See EXERCISE 4.3.48 for an alternative approach.
4.3.18 Write a Queue client that takes an integer command-line argument k and prints the kth from the last string found on standard input.
4.3.19 Develop a data type ResizingArrayQueueOfStrings that implements a queue with a fixed-length array in such a way that all operations take constant time. Then, extend your implementation to use a resizing array to remove the length restriction. Hint: The challenge is that the items will “crawl across” the array as items are added to and removed from the queue. Use modular arithmetic to maintain the array indices of the items at the front and back of the queue.
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4.3.20 (For the mathematically inclined.) Prove that the array in ResizingArrayStackOfStrings is never less than one-quarter full. Then prove that, for any ResizingArrayStackOfStrings client, the total cost of all of the stack operations divided by the number of operations is bounded by a constant.
4.3.21 Modify MM1Queue (PROGRAM 4.3.7) to make a program MD1Queue that simulates a queue for which the service times are fixed (deterministic) at rate of μ. Verify Little’s law for this model.
4.3.22 Develop a class StackOfInts that uses a linked-list representation (but no generics) to implement a stack of integers. Write a client that compares the performance of your implementation with Stack<Integer> to determine the performance penalty from autoboxing and unboxing on your system.
Linked-List Exercises
These exercises are intended to give you experience in working with linked lists. The easiest way to work them is to make drawings using the visual representation described in the text.
4.3.23 Suppose x is a linked-list Node. What is the effect of the following code fragment?
x.next = x.next.next;
Answer: Deletes from the list the node immediately following x.
4.3.24 Write a method find() that takes the first Node in a linked list and a string key as arguments and returns true if some node in the list has key as its item field, and false otherwise.
4.3.25 Write a method delete() that takes the first Node in a linked list and an int argument k and deletes the kth node in the linked list, if it exists.
4.3.26 Suppose that x is a linked-list Node. What is the effect of the following code fragment?
t.next = x.next; x.next = t;
Answer: Inserts node t immediately after node x.
4.3.27 Why does the following code fragment not have the same effect as the code fragment in the previous question?
x.next = t; t.next = x.next;
Answer: When it comes time to update t.next, x.next is no longer the original node following x, but is instead t itself!
4.3.28 Write a method removeAfter() that takes a linked-list Node as its argument and removes the node following the given one (and does nothing if either the argument is null or the next field of the argument is null).
4.3.29 Write a method copy() that takes a linked-list Node as its argument and creates a new linked list with the same sequence of items, without destroying the original linked list.
4.3.30 Write a method remove() that takes a linked-list Node and a string key as its arguments and removes every node in the list whose item field is equal to key.
4.3.31 Write a method max() that takes the first Node in a linked list as its argument and returns the value of the maximum item in the list. Assume that all items are positive integers, and return 0 if the linked list is empty.
4.3.32 Develop a recursive solution to the previous question.
4.3.33 Write a method that takes the first Node in a linked list as its argument and reverses the list, returning the first Node in the result.
4.3.34 Write a recursive method to print the items in a linked list in reverse order. Do not modify any of the links. Easy: Use quadratic time, constant extra space. Also easy: Use linear time, linear extra space. Not so easy: Develop a divide-and-conquer algorithm that takes linearithmic time and uses logarithmic extra space.
4.3.35 Write a recursive method to randomly shuffle the nodes of a linked list by modifying the links. Easy: Use quadratic time, constant extra space. Not so easy: Develop a divide-and-conquer algorithm that takes linearithmic time and uses logarithmic extra memory. See EXERCISE 1.4.40 for the “merging” step.
Creative Exercises
4.3.36 Deque. A double-ended queue or deque (pronounced “deck”) is a collection that is a combination of a stack and a queue. Write a class Deque that uses a linked list to implement the following API:
|
||
|
|
create an empty deque |
|
|
is the deque empty? |
|
|
add |
|
|
add |
|
|
remove and return the item at the beginning |
|
|
remove and return the item at the end |
API for a generic double-ended queue |
||
4.3.37 Random queue. A random queue is a collection that supports the following API:
|
||
|
|
create an empty random queue |
|
|
is the random queue empty? |
|
|
add |
|
|
remove and return a random item (sample without replacement) |
|
|
return a random item, but do not remove (sample with replacement) |
API for a generic random queue |
||
Write a class RandomQueue that implements this API. Hint: Use a resizing array. To remove an item, swap one at a random position (indexed 0 through n-1) with the one at the last position (index n-1). Then, remove and return the last item, as in ResizingArrayStack. Write a client that prints a deck of cards in random order using RandomQueue<Card>.
4.3.38 Random iterator. Write an iterator for RandomQueue<Item> from the previous exercise that returns the items in random order. Different iterators should return the items in different random orders. Note: This exercise is more difficult than it looks.
4.3.39 Josephus problem. In the Josephus problem from antiquity, n people are in dire straits and agree to the following strategy to reduce the population. They arrange themselves in a circle (at positions numbered from 0 to n–1) and proceed around the circle, eliminating every mth person until only one person is left. Legend has it that Josephus figured out where to sit to avoid being eliminated. Write a Queue client Josephus that takes two integer command-line arguments m and n and prints the order in which people are eliminated (and thus would show Josephus where to sit in the circle).
% java Josephus 2 7
1 3 5 0 4 2 6
4.3.40 Generalized queue. Implement a class that supports the following API, which generalizes both a queue and a stack by supporting removal of the ith most recently inserted item:
|
||
|
|
create an empty generalized queue |
|
|
is the generalized queue empty? |
|
|
insert |
|
|
remove and return the |
|
|
number of items on the queue |
API for a generic generalized queue |
||
First, develop an implementation that uses a resizing array, and then develop one that uses a linked list. (See EXERCISE 4.4.57 for a more efficient implementation that uses a binary search tree.)
4.3.41 Ring buffer. A ring buffer (or circular queue) is a FIFO collection that stores a sequence of items, up to a prespecified limit. If you insert an item into a ring buffer that is full, the new item replaces the least recently inserted item. Ring buffers are useful for transferring data between asynchronous processes and for storing log files. When the buffer is empty, the consumer waits until data is deposited; when the buffer is full, the producer waits to deposit data. Develop an API for a ring buffer and an implementation that uses a fixed-length array.
4.3.42 Merging two sorted queues. Given two queues with strings in ascending order, move all of the strings to a third queue so that the third queue ends up with the strings in ascending order.
4.3.43 Nonrecursive mergesort. Given n strings, create n queues, each containing one of the strings. Create a queue of the n queues. Then, repeatedly apply the sorted merging operation from the previous exercise to the first two queues and enqueue the merged queue. Repeat until the queue of queues contains only one queue.
4.3.44 Queue with two stacks. Show how to implement a queue using two stacks. Hint: If you push items onto a stack and then pop them all, they appear in reverse order. Repeating the process puts them back in FIFO order.
4.3.45 Move-to-front. Read in a sequence of characters from standard input and maintain the characters in a linked list with no duplicates. When you read in a previously unseen character, insert it at the front of the list. When you read in a duplicate character, delete it from the list and reinsert it at the beginning. This implements the well-known move-to-front strategy, which is useful for caching, data compression, and many other applications where items that have been recently accessed are more likely to be reaccessed.
4.3.46 Topological sort. You have to sequence the order of n jobs that are numbered from 0 to n-1 on a server. Some of the jobs must complete before others can begin. Write a program TopologicalSorter that takes a command-line argument n and a sequence on standard input of ordered pairs of jobs i j, and then prints a sequence of integers such that for each pair i j in the input, job i appears before job j. Use the following algorithm: First, from the input, build, for each job, (i) a queue of the jobs that must follow it and (ii) its indegree (the number of jobs that must come before it). Then, build a queue of all nodes whose indegree is 0 and repeatedly delete any job with a 0 indegree, maintaining all the data structures. This process has many applications. For example, you can use it to model course prerequisites for your major so that you can find a sequence of courses to take so that you can graduate.
4.3.47 Text-editor buffer. Develop a data type for a buffer in a text editor that implements the following API:
|
||
|
|
create an empty buffer |
|
|
insert |
|
|
delete and return the character at the cursor |
|
|
move the cursor |
|
|
move the cursor |
|
|
number of characters in the buffer |
API for a text buffer |
||
Hint: Use two stacks.
4.3.48 Copy constructor for a stack. Create a new constructor for the linked-list implementation of Stack so that
Stack<Item> t = new Stack<Item>(s);
makes t a reference to a new and independent copy of the stack s. You should be able to push and pop from either s or t without influencing the other.
4.3.49 Copy constructor for a queue. Create a new constructor so that
Queue<Item> r = new Queue<Item>(q);
makes r a reference to a new and independent copy of the queue q.
4.3.50 Quote. Develop a data type Quote that implements the following API for quotations:
|
||
|
|
create an empty quote |
|
|
append |
|
|
insert |
|
|
word at index |
|
|
number of words in the quote |
|
|
the words in the quote |
API for a quote |
||
To do so, define a nested class Card that holds one word of the quotation and a link to the next word in the quotation:
private class Card
{
private String word;
private Card next;
public Card(String word)
{
this.word = word;
this.next = null;
}
}
4.3.51 Circular quote. Repeat the previous exercise but uses a circular linked list. In a circular linked list, each node points to its successor, and the last node in the list points to the first node (instead of null, as in a standard null-terminated linked list).
4.3.52 Reverse a linked list (iteratively). Write a nonrecursive function that takes the first Node in a linked list as an argument and reverses the list, returning the first Node in the result.
4.3.53 Reverse a linked list (recursively). Write a recursive function that takes the first Node in a linked list as an argument and reverses the list, returning the first Node in the result.
4.3.54 Queue simulations. Study what happens when you modify MM1Queue to use a stack instead of a queue. Does Little’s law hold? Answer the same question for a random queue. Plot histograms and compare the standard deviations of the waiting times.
4.3.55 Load-balancing simulations. Modify LoadBalance to print the average queue length and the maximum queue length instead of plotting the histogram, and use it to run simulations for 1 million items on 100,000 queues. Print the average value of the maximum queue length for 100 trials each with sample sizes 1, 2, 3, and 4. Do your experiments validate the conclusion drawn in the text about using a sample of size 2?
4.3.56 Listing files. A folder is a list of files and folders. Write a program that takes the name of a folder as a command-line argument and prints all of the files contained in that folder, with the contents of each folder recursively listed (indented) under that folder’s name. Hint: Use a queue, and see java.io.File.
4.4 Symbol Tables
A symbol table is a data type that we use to associate values with keys. Clients can store (put) an entry into the symbol table by specifying a key–value pair and then can retrieve (get) the value associated with a specified key from the symbol table. For example, a university might associate information such as a student’s name, home address, and grades (the value) with that student’s Social Security number (the key), so that each student’s record can be accessed by specifying a Social Security number. The same approach might be appropriate for a scientist who needs to organize data, a business that needs to keep track of customer transactions, a web search engine that has to associate keywords with web pages, or in countless other ways.
Programs in this section
In this section we consider a basic API for the symbol-table data type. In addition to the put and get operations that characterize a symbol table, our API includes the abilities to test whether any value has been associated with a given key (contains), to remove a key (and its associated value), to determine the number of key–value pairs in the symbol table (size), and to iterate over the keys in the symbol table. We also consider other order-based operations on symbol tables that arise naturally in various applications.
As motivation, we consider two prototypical clients—dictionary lookup and indexing—and briefly discuss the use of each in a number of practical situations. Clients like these are fundamental tools, present in some form in every computing environment, easy to take for granted, and easy to misuse. As with any sophisticated tool, it is important for anyone using a dictionary or an index to understand how it is built to know how to use it effectively. That is the reason that we study symbol tables in detail in this section.
Because of their foundational importance, symbol tables have been heavily used and studied since the early days of computing. We consider two classic implementations. The first uses an operation known as hashing, which transforms keys into array indices that we can use to access values. The second is based on a data structure known as the binary search tree (BST). Both are remarkably simple solutions that serve as the basis for the industrial-strength symbol-table implementations that are found in modern programming environments. The code that we consider for hash tables and binary search trees is only slightly more complicated than the linked-list code that we considered for stacks and queues, but it will introduce you to a new dimension in structuring data that has far-reaching impacts.
API
A symbol table is a collection of key–value pairs. We use a generic type Key for keys and a generic type Value for values—every symbol-table entry associates a Value with a Key. These assumptions lead to the following basic API:
|
||
|
|
create an empty symbol table |
|
|
associate |
|
|
value associated with |
|
|
remove |
|
|
is there a value associated with |
|
|
number of key–value pairs |
|
|
all keys in the symbol table |
API for a generic symbol table |
||
As usual, the asterisk is a placeholder to indicate that multiple implementations might be considered. In this section, we provide two classic implementations: HashST and BST. (We also describe some elementary implementations briefly in the text.) This API reflects several design decisions, which we now enumerate.
Immutable keys
We assume the keys do not change their values while in the symbol table. The simplest and most commonly used types of keys, String and built-in wrapper types such as Integer and Double, are immutable.
Replace-the-old-value policy
If a key–value pair is inserted into the symbol table that already associates another value with the given key, we adopt the convention that the new value replaces the old one (as when assigning a value to an array element with an assignment statement). The contains() method gives the client the flexibility to avoid doing so, if desired.
Not found
The method get() returns null if no value is associated with the specified key. This choice has two implications, discussed next.
Null keys and null values
Clients are not permitted to use null as either a key or a value. This convention enables us to implement contains() as follows:
public boolean contains(Key key)
{ return get(key) != null; }
Remove
We also include in the API a method for removing a key (and its associated value) from the symbol table because many applications require such a method. However, for brevity, we defer implementations of the remove functionality to the exercises or a more advanced course in algorithms and data structures.
Iterating over key–value pairs
The keys() method provides clients with a way to iterate over the key–value pairs in the data structure. For simplicity, it returns only the keys; clients can use get to get the associated value, if desired. This enables client code like the following:
ST<String, Double> st = new ST<String, Double>();
...
for (String key : st.keys())
StdOut.println(key + " " + st.get(key));
Hashable keys
Like many languages, Java includes direct language and system support for symbol-table implementations. In particular, every type of object has an equals() method (which we can use to test whether two keys are the same, as defined by the key data type) and a hashCode() method (which supports a specific type of symbol-table implementation that we will examine later in this section). For the standard data types that we most commonly use for keys, we can depend upon system implementations of these methods. In contrast, for data types that we create, we have to carefully consider implementations, as discussed in SECTION 3.3. Most programmers simply assume that suitable implementations are in place, but caution is advised when working with nonstandard key types.
Comparable keys
In many applications, the keys may be strings, or other data types of data that have a natural order. In Java, as discussed in SECTION 3.3, we expect such keys to implement the Comparable interface. Symbol tables with comparable keys are important for two reasons. First, we can take advantage of key ordering to develop implementations of put and get that can provide performance guarantees. Second, a whole host of new operations come to mind (and can be supported) with comparable keys. A client might want the smallest key, the largest key, the median key, or to iterate over all of the keys in sorted order. Full coverage of this topic is more appropriate for a book on algorithms and data structures, but in this section you will learn about a simple data structure that can easily support the operations detailed in the partial API shown at the top of this page.
|
||
|
|
create an empty symbol table |
|
|
associate |
|
|
value associated with |
|
|
remove |
|
|
is there a value paired with |
|
|
number of key–value pairs |
|
|
all keys in sorted order |
|
|
minimum key |
|
|
maximum key |
|
|
number of keys less than |
|
|
|
|
|
largest key less than or equal to |
|
|
smallest key greater than or equal to |
API for an ordered symbol table |
||
Symbol tables are among the most widely studied data structures in computer science, so the impact of these and many alternative design decisions has been carefully studied, as you will learn if you take later courses in computer science. In this section, our approach is to introduce the most important properties of symbol tables by considering two prototypical client programs, developing efficient implementations of two classic approaches, and studying the performance characteristics of those implementations, to convince you that they can effectively meet the needs of typical clients, even when huge numbers of keys and values need to be processed.
Symbol-table clients
Once you gain some experience with the idea, you will find that symbol tables are broadly useful. To convince you of this fact, we start with two prototypical examples, each of which arises in a large number of important and familiar practical applications.
Dictionary lookup
The most basic kind of symbol-table client builds a symbol table with successive put operations to support get requests. That is, we maintain a collection of data in such a way that we can quickly access the data we need. Most applications also take advantage of the idea that a symbol table is a dynamic dictionary, where it is easy to look up information and to update the information in the table. The following list of familiar examples illustrates the utility of this approach.
• Phone book. When keys are people’s names and values are their phone numbers, a symbol table models a phone book. A very significant difference from a printed phone book is that we can add new names or change existing phone numbers. We could also use the phone number as the key and the name as the value. If you have never done so, try typing your phone number (with area code) into the search field in your browser.
|
key |
value |
phone book |
name |
phone number |
dictionary |
word |
definition |
account |
account number |
balance |
genomics |
codon |
amino acid |
data |
data/time |
results |
Java compiler |
variable name |
memory location |
file share |
song name |
machine |
Internet DNS |
website |
IP address |
Typical dictionary applications |
||
• Dictionary. Associating a word with its definition is a familiar concept that gives us the name “dictionary.” For centuries people kept printed dictionaries in their homes and offices so that they could check the definitions and spellings (values) of words (keys). Now, because of good symbol-table implementations, people expect built-in spell checkers and immediate access to word definitions on their computers.
• Account information. People who own stock now regularly check the current price on the web. Several services on the web associate a ticker symbol (key) with the current price (value), usually along with a great deal of other information (recall PROGRAM 3.1.8). Commercial applications of this sort abound, including financial institutions associating account information with a name or account number and educational institutions associating grades with a student name or identification number.
• Genomics. Symbol tables play a central role in modern genomics. The simplest example is the use of the letters A, C, T, and G to represent the nucleotides found in the DNA of living organisms. The next simplest is the correspondence between codons (nucleotide triplets) and amino acids (TTA corresponds to leucine, TCT to serine, and so forth), then the correspondence between sequences of amino acids and proteins, and so forth. Researchers in genomics routinely use various types of symbol tables to organize this knowledge.
• Experimental data. From astrophysics to zoology, modern scientists are awash in experimental data, and organizing and efficiently accessing this data is vital to understanding what it means. Symbol tables are a critical starting point, and advanced data structures and algorithms that are based on symbol tables are now an important part of scientific research.
• Programming languages. One of the earliest uses of symbol tables was to organize information for programming. At first, programs were simply sequences of numbers, but programmers very quickly found that using symbolic names for operations and memory locations (variable names) was far more convenient. Associating the names with the numbers requires a symbol table. As the size of programs grew, the cost of the symbol-table operations became a bottleneck in program development time, which led to the development of data structures and algorithms like the one we consider in this section.
• Files. We use symbol tables regularly to organize data on computer systems. Perhaps the most prominent example is the file system, where we associate a file name (key) with the location of its contents (value). Your music player uses the same system to associate song titles (keys) with the location of the music itself (value).
• Internet DNS. The domain name system (DNS) that is the basis for organizing information on the Internet associates URLs (keys) that humans understand (such as www.princeton.edu or www.wikipedia.org) with IP addresses (values) that computer network routers understand (such as 208.216.181.15 or 207.142.131.206). This system is the next-generation “phone book.” Thus, humans can use names that are easy to remember and machines can efficiently process the numbers. The number of symbol-table lookups done each second for this purpose on Internet routers around the world is huge, so performance is of obvious importance. Millions of new computers and other devices are put onto the Internet each year, so these symbol tables on Internet routers need to be dynamic.
% more amino.csv TTT,Phe,F,Phenylalanine TTC,Phe,F,Phenylalanine TTA,Leu,L,Leucine TTG,Leu,L,Leucine TCT,Ser,S,Serine TCC,Ser,S,Serine TCA,Ser,S,Serine TCG,Ser,S,Serine TAT,Tyr,Y,Tyrosine TAC,Tyr,Y,Tyrosine TAA,Stop,Stop,Stop ... GCA,Ala,A,Alanine GCG,Ala,A,Alanine GAT,Asp,D,Aspartic Acid GAC,Asp,D,Aspartic Acid GAA,Gly,G,Glutamic Acid GAG,Gly,G,Glutamic Acid GGT,Gly,G,Glycine GGC,Gly,G,Glycine GGA,Gly,G,Glycine GGG,Gly,G,Glycine % more DJIA.csv ... 20-Oct-87,1738.74,608099968,1841.01 19-Oct-87,2164.16,604300032,1738.74 16-Oct-87,2355.09,338500000,2246.73 15-Oct-87,2412.70,263200000,2355.09 ... 30-Oct-29,230.98,10730000,258.47 29-Oct-29,252.38,16410000,230.07 28-Oct-29,295.18,9210000,260.64 25-Oct-29,299.47,5920000,301.22 ... % more ip.csv ... www.ebay.com,66.135.192.87 www.princeton.edu,128.112.128.15 www.cs.princeton.edu,128.112.136.35 www.harvard.edu,128.103.60.24 www.yale.edu,130.132.51.8 www.cnn.com,64.236.16.20 www.google.com,216.239.41.99 www.nytimes.com,199.239.136.200 www.apple.com,17.112.152.32 www.slashdot.org,66.35.250.151 www.espn.com,199.181.135.201 www.weather.com,63.111.66.11 www.yahoo.com,216.109.118.65 ...
Typical comma-separated-value (CSV) files
Despite its scope, this list is still just a representative sample, intended to give you a flavor of the scope of applicability of the symbol-table abstraction. Whenever you specify something by name, there is a symbol table at work. Your computer’s file system or the web might do the work for you, but there is a symbol table behind the scenes.
For example, to build a symbol table that associates amino acid names with codons, we can write code like this:
ST<String, String> amino;
amino = new ST<String, String>();
amino.put("TTA", "leucine");
...
The idea of associating information with a key is so fundamental that many high-level languages have built-in support for associative arrays, where you can use standard array syntax but with keys inside the brackets instead of an integer index. In such a language, you could write amino["TTA"] = "leucine" instead of amino.put("TTA", "leucine"). Although Java does not (yet) support such syntax, thinking in terms of associative arrays is a good way to understand the basic purpose of symbol tables.
Lookup (PROGRAM 4.4.1) builds a set of key–value pairs from a file of comma-separated values (see SECTION 3.1) as specified on the command line and then prints values corresponding to keys read from standard input. The command-line arguments are the file name and two integers, one specifying the field to serve as the key and the other specifying the field to serve as the value.
Program 4.4.1 Dictionary lookup
public class Lookup
{
public static void main(String[] args)
{ // Build dictionary, provide values for keys in StdIn.
In in = new In(args[0]);
int keyField = Integer.parseInt(args[1]);
int valField = Integer.parseInt(args[2]);
String[] database = in.readAllLines();
StdRandom.shuffle(database);
ST<String, String> st = new ST<String, String>();
for (int i = 0; i < database.length; i++)
{ // Extract key, value from one line and add to ST.
String[] tokens = database[i].split(",");
String key = tokens[keyField];
String val = tokens[valField];
st.put(key, val);
}
while (!StdIn.isEmpty())
{ // Read key and provide value.
String s = StdIn.readString();
StdOut.println(st.get(s));
}
}
}
in | input stream (.csv) keyField | key position valField | value position database[] | lines in input st | symbol table (BST) tokens | values on a line key | key val | value s | query
This ST client reads key–value pairs from a comma-separated file, then prints values corresponding to keys on standard input. Both keys and values are strings.
% java Lookup amino.csv 0 3 TTA Leucine ABC null TCT Serine % java Lookup amino.csv 3 0 Glycine GGG
% java Lookup ip.csv 0 1 www.google.com 216.239.41.99 % java Lookup ip.csv 1 0 216.239.41.99 www.google.com % java Lookup DJIA.csv 0 1 29-Oct-29 252.38
Your first step in understanding symbol tables is to download Lookup.java and ST.java (the industrial-strength symbol-table implementation that we consider at the end of this section) from the booksite to do some symbol-table searches. You can find numerous comma-separated-value (.csv) files that are related to various applications that we have described, including amino.csv (codon-to-amino-acid encodings), DJIA.csv (opening price, volume, and closing price of the stock market average, for every day in its history), and ip.csv (a selection of entries from the DNS database). When choosing which field to use as the key, remember that each key must uniquely determine a value. If there are multiple put operations to associate values with the same key, the symbol table will remember only the most recent one (think about associative arrays). We will consider next the case where we want to associate multiple values with a key.
Later in this section, we will see that the cost of the put operations and the get requests in Lookup is logarithmic in the size of the table. This fact implies that you may experience a small delay getting the answer to your first request (for all the put operations to build the symbol table), but you get immediate response for all the others.
Indexing
Index (PROGRAM 4.4.2) is a prototypical example of a symbol-table client that uses an intermixed sequence of calls to get() and put(): it reads a sequence of strings from standard input and prints a sorted list of the distinct strings along with a list of integers specifying the positions where each string appeared in the input. We have a large amount of data and want to know where certain strings of interest occur. In this case, we seem to be associating multiple values with each key, but we are actually associating just one: a queue. Index takes two integer command-line arguments to control the output: the first integer is the minimum string length to include in the symbol table, and the second is the minimum number of occurrences (among the words that appear in the text) to include in the printed index. The following list of indexing applications demonstrates their range and scope:
• Book index. Every textbook has an index where you can look up a word and find the page numbers containing that word. While no reader wants to see every word in the book in an index, a program like Index can provide a starting point for creating a good index.
public class Index
{
public static void main(String[] args)
{
int minlen = Integer.parseInt(args[0]);
int minocc = Integer.parseInt(args[1]);
// Create and initialize the symbol table.
ST<String, Queue<Integer>> st;
st = new ST<String, Queue<Integer>>();
for (int i = 0; !StdIn.isEmpty(); i++)
{
String word = StdIn.readString();
if (word.length() < minlen) continue;
if (!st.contains(word))
st.put(word, new Queue<Integer>());
Queue<Integer> queue = st.get(word);
queue.enqueue(i);
}
// Print words whose occurrence count exceeds threshold.
for (String s : st)
{
Queue<Integer> queue = st.get(s);
if (queue.size() >= minocc)
StdOut.println(s + ": " + queue);
}
}
}
minlen | minimum length minocc | occurrence threshold st | symbol table word | current word queue | queue of positions for current word
This ST client indexes a text file by word position. Keys are words, and values are queues of positions where the word occurs in the file.
% java Index 9 30 < TaleOfTwoCities.txt confidence: 2794 23064 25031 34249 47907 48268 48577 ... courtyard: 11885 12062 17303 17451 32404 32522 38663 ... evremonde: 86211 90791 90798 90802 90814 90822 90856 ... ... something: 3406 3765 9283 13234 13239 15245 20257 ... sometimes: 4514 4530 4548 6082 20731 33883 34239 ... vengeance: 56041 63943 67705 79351 79941 79945 80225 ...
• Programming languages. In a large program that uses a large number of identifiers, it is useful to know where each name is used. A program like Index can be a valuable tool to help programmers keep track of where identifiers are used in their programs. Historically, an explicit printed symbol table was one of the most important tools used by programmers to manage large programs. In modern systems, symbol tables are the basis of software tools that programmers use to manage names of identifiers in programming systems.
|
key |
value |
book |
term |
page numbers |
genomics |
DNA substring |
locations |
web search |
keyword |
websites |
business |
customer name |
transactions |
Typical indexing applications |
||
• Genomics. In a typical (if oversimplified) scenario in genomics research, a scientist wants to know the positions of a given genetic sequence in an existing genome or set of genomes. Existence or proximity of certain sequences may be of scientific significance. The starting point for such research is an index like the one produced by Index, modified to take into account the fact that genomes are not separated into words.
• Web search. When you type a keyword and get a list of websites containing that keyword, you are using an index created by your web search engine. One value (the list of pages) is associated with each key (the query), although the reality is a bit more dynamic and complicated because we often specify multiple keys and the pages are spread through the web, not kept in a table on a single computer.
• Account information. One way for a company that maintains customer accounts to keep track of a day’s transactions is to keep an index of the list of the transactions. The key is the account number; the value is the list of occurrences of that account number in the transaction list.
You are certainly encouraged to download Index from the booksite and run it on various input files to gain further appreciation for the utility of symbol tables. If you do so, you will find that it can build large indices for huge files with little delay, because each put operation and get request is taken care of immediately. Providing this immediate response for huge symbol tables is one of the classic contributions of algorithmic technology.
Elementary symbol-table implementations
All of these examples are persuasive evidence of the importance of symbol tables. Symbol-table implementations have been heavily studied, many different algorithms and data structures have been invented for this purpose, and modern programming environments (such as Java) include one (or more) symbol-table implementations. As usual, knowing how a basic implementation works will help you appreciate, choose among, and more effectively use the advanced ones, or help implement your own version for some specialized situation that you might encounter.
To begin, we briefly consider two elementary implementations, based on two basic data structures that we have encountered: resizing arrays and linked lists. Our purpose in doing so is to establish that we need a more sophisticated data structure, as each implementation uses linear time for either put or get, which makes each of them unsuitable for large practical applications.
Perhaps the simplest implementation is to store the key–value pairs in an unordered linked list (or array) and use sequential search (see EXERCISE 4.4.6). Sequential search means that, when searching for a key, we examine each node (or element) in sequence until either we find the specified key or we exhaust the list (or array). Such an implementation is not feasible for use by typical clients because, for example, get takes linear time when the search key is not in the symbol table.

Alternatively, we might use a sorted (resizing) array for the keys and a parallel array for the values. Since the keys are in sorted order, we can search for a key (and its associated value) using binary search, as in SECTION 4.2. It is not difficult to build a symbol-table implementation based on this approach (see EXERCISE 4.4.5). In such an implementation, search is fast (logarithmic time) but insertion is typically slow (linear time) because we must maintain the resizing array in sorted order. Each time a new key is inserted, larger keys must be shifted one position higher in the array, which implies that put takes linear time in the worst case.

To implement a symbol table that is feasible for use with clients such as Lookup and Index, we need a data structure that is more flexible than either linked lists or resizing arrays. Next, we consider two examples of such data structures: the hash table and the binary search tree.
Hash tables
A hash table is a data structure in which we divide the keys into small groups that can be quickly searched. We choose a parameter m and divide the keys into m groups, which we expect to be about equal in size. For each group, we keep the keys in an unordered linked list and use sequential search, as in the elementary implementation we just considered.
To divide the keys into the m groups, we use a hash function that maps each possible key into a hash value—an integer between 0 and m–1. This enables us to model the symbol table as an array of linked lists and use the hash value as an array index to access the desired list.
Hashing is widely useful, so many programming languages include direct support for it. As we saw in SECTION 3.3, every Java class is supposed to have a hashCode() method for this purpose. If you are using a nonstandard type, it is wise to check the hashCode() implementation, as the default may not do a good job of dividing the keys into groups of equal size. To convert the hash code into a hash value between 0 and m–1, we use the expression Math.abs(x.hashCode() % m).
key |
hash code |
hash value |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Hash codes and hash values for n = 12 strings (m = 5) |
||
Recall that whenever two objects are equal—according to the equals() method—they must have the same hash code. Objects that are not equal may have the same hash code. In the end, hash functions are designed so that it is reasonable to expect the call Math.abs(x.hashCode() % m) to return each of the hash values from 0 to m-1 with equal likelihood.
The table at right above gives hash codes and hash values for 12 representative String keys, with m = 5. Note: In general, hash codes are integers between –231 and 231–1, but for short alphanumeric strings, they happen to be small positive integers.
With this preparation, implementing an efficient symbol table with hashing is a straightforward extension of the linked-list code that we considered in SECTION 4.3. We maintain an array of m linked lists, with element i containing a linked list of all keys whose hash value is i (along with their associated values). To search for a key:
• Compute its hash value to identify its linked list.
• Iterate over the nodes in that linked list, checking for the search key.
• If the search key is in the linked list, return the associated value; otherwise, return null.
To insert a key–value pair:
• Compute the hash value of the key to identify its linked list.
• Iterate over the nodes in that linked list, checking for the key.
• If the key is in the linked list, replace the value currently associated with the key with the new value; otherwise, create a new node with the specified key and value and insert it at the beginning of the linked list.
HashST (PROGRAM 4.4.3) is a full implementation, using a fixed number of m = 1,024 linked lists. It relies on the following nested class that represents each node in the linked list:
private static class Node
{
private Object key;
private Object val;
private Node next;
public Node(Object key, Object val, Node next)
{
this.key = key;
this.val = val;
this.next = next;
}
}
The efficiency of HashST depends on the value of m and the quality of the hash function. Assuming the hash function reasonably distributes the keys, performance is about m times faster than that for sequential search in a linked list, at the cost of m extra references and linked lists. This is a classic space–time tradeoff: the higher the value of m, the more memory we use, but the less time we spend.
public class HashST<Key, Value>
{
private int m = 1024;
private Node[] lists = new Node[m];
private class Node
{ /* See accompanying text. */ }
private int hash(Key key)
{ return Math.abs(key.hashCode() % m); }
public Value get(Key key)
{
int i = hash(key);
for (Node x = lists[i]; x != null; x = x.next)
if (key.equals(x.key))
return (Value) x.val;
return null;
}
public void put(Key key, Value val)
{
int i = hash(key);
for (Node x = lists[i]; x != null; x = x.next)
{
if (key.equals(x.key))
{
x.val = val;
return;
}
}
lists[i] = new Node(key, val, lists[i]);
}
}
m | number of linked lists lists[i] | linked list for hash value i
This program uses an array of linked lists to implement a hash table. The hash function selects one of the m lists. When there are n keys in the table, the average cost of a put() or get() operation is n/m, for suitable hashCode() implementations. This cost per operation is constant if we use a resizing array to ensure that the average number of keys per list is between 1 and 8 (see EXERCISE 4.4.12). We defer implementations of contains(), keys(), size(), and remove() to EXERCISE 4.4.8–11.
The figure below shows the hash table built for our sample keys, inserted in the order given on page 636. First, GGT is inserted in linked list 1, then TTA is inserted in linked list 3, then GCC is inserted in linked list 0, and so forth. After the hash table is built, a search for CAG begins by computing its hash value (2) and then sequentially searching linked list 2. After finding the key CAG in the second node of linked list 2, the method get() returns the value Glutamine.

Often, programmers choose a large fixed value of m (like the 1,024 default we have chosen) based on a rough estimate of the number of keys to be handled. With more care, we can ensure that the average number of keys per list is a constant, by using a resizing array for lists[]. For example, EXERCISE 4.4.12 shows how to ensure that the average number of keys per linked list is between 1 and 8, which leads to constant (amortized) time performance for both put and get. There is certainly opportunity to adjust these parameters to best fit a given practical situation.
The primary advantage of hash tables is that they support the put and get operations efficiently. A disadvantage of hash tables is that they do not take advantage of order in the keys and therefore cannot provide the keys in sorted order (or support other order-based operations). For example, if we substitute HashST for ST in Index, then the keys will be printed in arbitrary order instead of sorted order. Or, if we want to find the smallest key or the largest key, we have to search through them all. Next, we consider a symbol-table implementation that can support order-based operations when the keys are comparable, without sacrificing much performance for put() and get().
Binary search trees
The binary tree is a mathematical abstraction that plays a central role in the efficient organization of information. We define a binary tree recursively: it is either empty (null) or a node containing links to two disjoint binary trees. Binary trees play an important role in computer programming because they strike an efficient balance between flexibility and ease of implementation. Binary trees have many applications in science, mathematics, and computational applications, so you are certain to encounter this model on many occasions.
We often use tree-based terminology when discussing binary trees. We refer to the node at the top as the root of the tree, the node referenced by its left link as the left subtree, and the node referenced by its right link as the right subtree. Traditionally, computer scientists draw trees upside down, with the root at the top. Nodes whose links are both null are called leaf nodes. The height of a tree is the maximum number of links on any path from the root node to a leaf node.
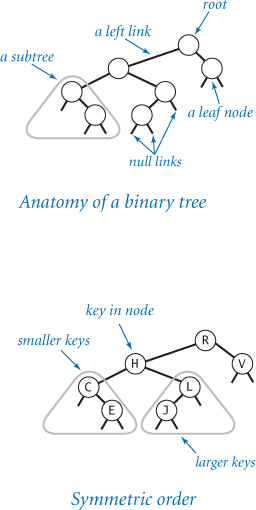
As with arrays, linked lists, and hash tables, we use binary trees to store collections of data. For symbol-table implementations, we use a special type of binary tree known as a binary search tree (BST). A binary search tree is a binary tree that contains a key–value pair in each node and for which the keys are in symmetric order: The key in a node is larger than the key of every node in its left subtree and smaller than the key of every node in its right subtree. As you will soon see, symmetric ordering enables efficient implementations of the put and get operations.
To implement BSTs, we start with a nested class for the node abstraction, which has references to a key, a value, and left and right BSTs. The key type must implement Comparable (to specify an ordering of the keys) but the value type is arbitrary.
private class Node
{
private Key key;
private Value val;
private Node left, right;
}
This definition is like our definition of nodes for linked lists, except that it has two links, instead of one. As with linked lists, the idea of a recursive data structure can be a bit mindbending, but all we are doing is adding a second link (and imposing an ordering restriction) to our linked-list definition.
To (slightly) simplify the code, we add a constructor to Node that initializes the key and val instance variables:
Node(Key key, Value val)
{
this.key = key;
this.val = val;
}

The result of new Node(key, val) is a reference to a Node object (which we can assign to any variable of type Node) whose key and val instance variables are set to the specified values and whose left and right instance variables are both initialized to null.
As with linked lists, when tracing code that uses BSTs, we can use a visual representation of the changes:
• We draw a rectangle to represent each object.
• We put the values of instance variables within the rectangle.
• We depict references as arrows that point to the referenced object.
Most often, we use an even simpler abstract representation where we draw rectangles (or circles) containing keys to represent nodes (suppressing the values) and connect the nodes with arrows that represent links. This abstract representation allows us to focus on the linked structure.
As an example, we consider a BST with string keys and integer values. To build a one-node BST that associates the value 0 with the key it, we create a Node:
Node first = new Node("it", 0);
Since the left and right links are both null, this node represents a BST containing one node. To add a node that associates the value 1 with the key was, we create another Node:
Node second = new Node("was", 1);
(which itself is a BST) and link to it from the right field of the first Node:
first.right = second;
The second node goes to the right of the first because was comes after it in alphabetical order. (Alternatively, we could have chosen to set second.left to first.) Now we can add a third node that associates the value 2 with the key the with the code:
Node third = new Node("the", 2);
second.left = third;
and a fourth node that associates the value 3 with the key best with the code:
Node fourth = new Node("best", 3);
first.left = fourth;
Note that each of our links—first, second, third, and fourth—are, by definition, BSTs (each is either null or refers to a BST, and the ordering condition is satisfied at each node).
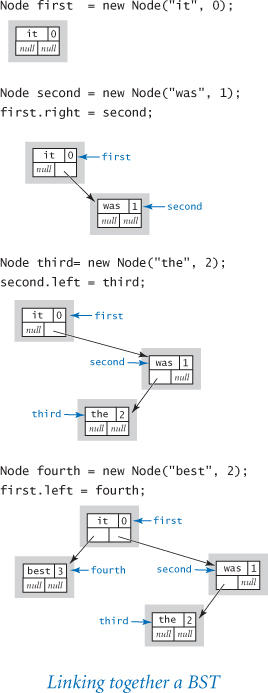
In the present context, we take care to ensure that we always link together nodes such that every Node that we create is the root of a BST (has a key, a value, a link to a left BST with smaller values, and a link to a right BST with a larger value). From the standpoint of the BST data structure, the value is immaterial, so we often ignore it in our figures, but we include it in the definition because it plays such a central role in the symbol-table concept. We slightly abuse our nomenclature, using ST to signify both “symbol table” and “search tree” because search trees play such a central role in symbol-table implementations.
A BST represents an ordered sequence of items. In the example just considered, first represents the sequence best it the was. We can also use an array to represent a sequence of items. For example, we could use
String[] a = { "best", "it", "the", "was" };
to represent the same ordered sequence of strings. Given a set of distinct keys, there is only one way to represent them in an ordered array, but there are many ways to represent them in a BST (see EXERCISE 4.4.7). This flexibility allows us to develop efficient symbol-table implementations. For instance, in our example we were able to insert each new key–value pair by creating a new node and changing just one link. As it turns out, it is always possible to do so. Equally important, we can easily find the node in a BST containing a specified key or find the node whose link must change when we insert a new key–value pair. Next, we consider symbol-table code that accomplishes these two tasks.

Search
Suppose that you want to search for a node with a given key in a BST (or get a value with a given key in a symbol table). There are two possible outcomes: the search might be successful (we find the key in the BST; in a symbol-table implementation, we return the associated value) or it might be unsuccessful (there is no key in the BST with the given key; in a symbol-table implementation, we return null).

A recursive searching algorithm is immediately evident: Given a BST (a reference to a Node), first check whether the tree is empty (the reference is null). If so, then terminate the search as unsuccessful (in a symbol-table implementation, return null). If the tree is nonempty, check whether the key in the node is equal to the search key. If so, then terminate the search as successful (in a symbol-table implementation, return the value associated with the key). If not, compare the search key with the key in the node. If it is smaller, search (recursively) in the left subtree; if it is greater, search (recursively) in the right subtree.
Thinking recursively, it is not difficult to become convinced that this algorithm behaves as intended, based upon the invariant that the key is in the BST if and only if it is in the current subtree. The crucial property of the recursive method is that we always have only one node to examine to decide what to do next. Moreover, we typically examine only a small number of the nodes in the tree: whenever we go to one of the subtrees at a node, we never examine any of the nodes in the other subtree.

Insert
Suppose that you want to insert a new node into a BST (in a symbol-table implementation, put a new key–value pair into the data structure). The logic is similar to searching for a key, but the implementation is trickier. The key to understanding it is to realize that only one link must be changed to point to the new node, and that link is precisely the link that would be found to be null in an unsuccessful search for that key.
If the tree is empty, we create and return a new Node containing the key–value pair; if the search key is less than the key at the root, we set the left link to the result of inserting the key–value pair into the left subtree; if the search key is greater, we set the right link to the result of inserting the key–value pair into the right subtree; otherwise, if the search key is equal, we replace the existing value with the new value. Resetting the left or right link after the recursive call in this way is usually unnecessary, because the link changes only if the subtree is empty, but it is as easy to set the link as it is to test to avoid setting it.

Implementation
BST (PROGRAM 4.4.4) is a symbol-table implementation based on these two recursive algorithms. If you compare this code with our binary search implementation BinarySearch (PROGRAM 4.2.3) and our stack and queue implementations Stack (PROGRAM 4.3.4) and Queue (PROGRAM 4.3.6), you will appreciate the elegance and simplicity of this code. Take the time to think recursively and convince yourself that this code behaves as intended. Perhaps the simplest way to do so is to trace the construction of an initially empty BST from a sample set of keys. Your ability to do so is a sure test of your understanding of this fundamental data structure.
Moreover, the put() and get() methods in BST are remarkably efficient: typically, each accesses a small number of the nodes in the BST (those on the path from the root to the node sought or to the null link that is replaced by a link to the new node). Next, we show that put operations and get requests take logarithmic time (under certain assumptions). Also, put() only creates one new Node and adds one new link. If you make a drawing of a BST built by inserting some keys into an initially empty tree, you certainly will be convinced of this fact—you can just draw each new node somewhere at the bottom of the tree.
Program 4.4.4 Binary search tree
public class BST<Key extends Comparable<Key>, Value>
{
private Node root;
private class Node
{
private Key key;
private Value val;
private Node left, right;
public Node(Key key, Value val)
{ this.key = key; this.val = val; }
}
public Value get(Key key)
{ return get(root, key); }
private Value get(Node x, Key key)
{
if (x == null) return null;
int cmp = key.compareTo(x.key);
if (cmp < 0) return get(x.left, key);
else if (cmp > 0) return get(x.right, key);
else return x.val;
}
public void put(Key key, Value val)
{ root = put(root, key, val); }
private Node put(Node x, Key key, Value val)
{
if (x == null) return new Node(key, val);
int cmp = key.compareTo(x.key);
if (cmp < 0) x.left = put(x.left, key, val);
else if (cmp > 0) x.right = put(x.right, key, val);
else x.val = val;
return x;
}
}
root | root of BST
key | key val | value left | left subtree right | right subtree
This implementation of the symbol-table data type is centered on the recursive BST data structure and recursive methods for traversing it. We defer implementations of contains(), size(), and remove() to EXERCISE 4.4.18–20. We implement keys() at the end of this section.
Performance characteristics of BSTs
The running times of BST algorithms are ultimately dependent on the shape of the trees, and the shape of the trees is dependent on the order in which the keys are inserted. Understanding this dependence is a critical factor in being able to use BSTs effectively in practical situations.
Best case
In the best case, the tree is perfectly balanced (each Node has exactly two non-null children), with about lg n links between the root and each leaf node. In such a tree, it is easy to see that the cost of an unsuccessful search is logarithmic, because that cost satisfies the same recurrence relation as the cost of binary search (see SECTION 4.2) so that the cost of every put operation and get request is proportional to lg n or less. You would have to be quite lucky to get a perfectly balanced tree like this by inserting keys one by one in practice, but it is worthwhile to know the best-case performance characteristics.


Average case
If we insert random keys, we might expect the search times to be logarithmic as well, because the first key becomes the root of the tree and should divide the keys roughly in half. Applying the same argument to the subtrees, we expect to get about the same result as for the best case. This intuition is, indeed, validated by careful analysis: a classic mathematical derivation shows that the time required for put and get in a tree constructed from randomly ordered keys is logarithmic (see the booksite for references). More precisely, the expected number of key compares is ~2 ln n for a random put or get in a tree built from n randomly ordered keys. In a practical application such as Lookup, when we can explicitly randomize the order of the keys, this result suffices to (probabilistically) guarantee logarithmic performance. Indeed, since 2 ln n is about 1.39 lg n, the average case is only about 39% greater than the best case. In an application like Index, where we have no control over the order of insertion, there is no guarantee, but typical data gives logarithmic performance (see EXERCISE 4.4.26). As with binary search, this fact is very significant because of the enormity of the logarithmic–linear chasm: with a BST-based symbol table implementation, we can perform millions of operations per second (or more), even in a huge symbol table.
Worst case
In the worst case, each node (except one) has exactly one null link, so the BST is essentially a linked list with an extra wasted link, where put operations and get requests take linear time. Unfortunately, this worst case is not rare in practice—it arises, for example, when we insert the keys in order.
Thus, good performance of the basic BST implementation is dependent on the keys being sufficiently similar to random keys that the tree is not likely to contain many long paths. If you are not sure that assumption is justified, do not use a simple BST. Your only clue that something is amiss will be slow response time as the problem size increases. (Note: It is not unusual to encounter software of this sort!) Remarkably, some BST variants eliminate this worst case and guarantee logarithmic performance per operation, by making all trees nearly perfectly balanced. One popular variant is known as the red–black tree.
Traversing a BST
Perhaps the most basic tree-processing function is known as tree traversal: given a (reference to) a tree, we want to systematically process every node in the tree. For linked lists, we accomplish this task by following the single link to move from one node to the next. For trees, however, we have decisions to make, because there are two links to follow. Recursion comes immediately to the rescue. To process every node in a BST:
• Process every node in the left subtree.
• Process the node at the root.
• Process every node in the right subtree.
This approach is known as inorder tree traversal, to distinguish it from preorder (do the root first) and postorder (do the root last), which arise in other applications. Given a BST, it is easy to convince yourself with mathematical induction that not only does this approach process every node in the BST, but it also processes them in key-sorted order. For example, the following method prints the keys in the BST rooted at its argument in ascending order of the keys in the nodes:
private void traverse(Node x)
{
if (x == null) return;
traverse(x.left);
StdOut.println(x.key);
traverse(x.right);
}
First, we print all the keys in the left subtree, in key-sorted order. Then we print the root, which is next in the key-sorted order, and then we print all the keys in the right subtree, in key-sorted order.

This remarkably simple method is worthy of careful study. It can be used as a basis for a toString() implementation for BSTs (see EXERCISE 4.4.21). It also serves as the basis for implementing the keys() method, which enables clients to use a Java foreach loop to iterate over the keys in a BST, in sorted order (recall that this functionality is not available in a hash table, where there is no order). We consider this fundamental application of inorder traversal next.
Iterating over the keys
A close look at the recursive traverse() method just considered leads to a way to process all of the key–value pairs in our BST data type. For simplicity, we need only process the keys because we can get the values when we need them. Our goal is implement a method keys() to enable client code like the following:
BST<String, Double> st = new BST<String, Double>(); ... for (String key : st.keys()) StdOut.println(key + " " + st.get(key)); ...
Index (PROGRAM 4.4.2) is another example of client code that uses a foreach loop to iterate over key–value pairs.
The easiest way to implement keys() is to collect all of the keys in an iterable collection—such as a Stack or Queue—and return that iterable to the client.
public Iterable<Key> keys()
{
Queue<Key> queue = new Queue<Key>();
inorder(root, queue);
return queue;
}
private void inorder(Node x, Queue<Key> queue)
{
if (x == null) return;
inorder(x.left, queue);
queue.enqueue(x.key);
inorder(x.right, queue);
}
The first time that one sees it, tree traversal seems a bit magical. Ordered iteration essentially comes for free in a data structure designed for fast search and fast insert. Note that we can use a similar technique (i.e., collecting the keys in an iterable collection) to implement the keys() method for HashST (see EXERCISE 4.4.10). Once again, however, the keys in such an implementation will appear in arbitrary order, since there is no order in hash tables.
Ordered symbol table operations
The flexibility of BSTs and the ability to compare keys enable the implementation of many useful operations beyond those that can be supported efficiently in hash tables. This list is representative; numerous other important operations have been invented for BSTs that are broadly useful in applications. We leave implementations of these operations for exercises and leave further study of their performance characteristics and applications for a course in algorithms and data structures.
Minimum and maximum
To find the smallest key in a BST, follow the left links from the root until null is reached. The last key encountered is the smallest in the BST. The same procedure, albeit following the right links, leads to the largest key in the BST (see EXERCISE 4.4.27).
Size and subtree sizes
To keep track of the number of nodes in a BST, keep an extra instance variable n in BST that counts the number of nodes in the tree. Initialize it to 0 and increment it whenever a new Node is created. Alternatively, keep an extra instance variable n in each Node that counts the number of nodes in the subtree rooted at that node (see EXERCISE 4.4.29).
Range search and range count
With a recursive method like inorder(), we can return an iterable for the keys falling between two given values in time proportional to the height of the BST plus the number of keys in the range (see EXERCISE 4.4.31). If we maintain an instance variable in each node having the size of the subtree rooted at each node, we can count the number of keys falling between two given values in time proportional to the height of the BST (see EXERCISE 4.4.31).
Order statistics and ranks
If we maintain an instance variable in each node having the size of the subtree rooted at each node, we can implement a recursive method that returns the kth smallest key in time proportional to the height of the BST (see EXERCISE 4.4.55). Similarly, we can compute the rank of a key, which is the number of keys in the BST that are strictly smaller than the key (see EXERCISE 4.4.56).
Henceforth, we will use the reference implementation ST that implements our ordered symbol-table API using Java’s java.util.TreeMap, a symbol-table implementation based on red–black trees. You will learn more about red–black trees if you take an advanced course in data structures and algorithms. They support a logarithmic-time guarantee for get(), put(), and many of the other operations just described.
Set data type
As a final example, we consider a data type that is simpler than a symbol table, still broadly useful, and easy to implement with either hash tables or BSTs. A set is a collection of distinct keys, like a symbol table with no values. We could use ST and ignore the values, but client code that uses the following API is simpler and clearer:
|
||
|
|
create an empty set |
|
|
is the set empty? |
|
|
add |
|
|
remove |
|
|
is |
|
|
number of elements in set |
Note: Implementations should also implement the |
||
API for a generic set |
||
As with symbol tables, there is no intrinsic reason that the key type should be comparable. However, processing comparable keys is typical and enables us to support various order-based operations, so we include Comparable in the API. Implementing SET by deleting references to val in our BST code is a straightforward exercise (see EXERCISE 4.4.23). Alternatively, it is easy to develop a SET implementaiton based on hash tables.
DeDup (PROGRAM 4.4.5) is a SET client that reads a sequence of strings from standard input and prints the first occurrence of each string (thereby removing duplicates). You can find many other examples of SET clients in the exercises at the end of this section.
In the next section, you will see the importance of identifying such a fundamental abstraction, illustrated in the context of a case study.
public class DeDup
{
public static void main(String[] args)
{ // Filter out duplicate strings.
SET<String> distinct = new SET<String>();
while (!StdIn.isEmpty())
{ // Read a string, ignore if duplicate.
String key = StdIn.readString();
if (!distinct.contains(key))
{ // Save and print new string.
distinct.add(key);
StdOut.print(key);
}
StdOut.println();
}
}
}
distinct | set of distinct strings on standard input key | current string
This SET client is a filter that reads strings from standard input and writes the strings to standard output, ignoring duplicate strings. For efficiency, it uses a SET containing the distinct strings encountered so far.
% java DeDup < TaleOfTwoCities.txt
it was the best of times worst age wisdom foolishness...
Perspective
Symbol-table implementations are a prime topic of further study in algorithms and data structures. Examples include balanced BSTs, hashing, and tries. Implementations of many of these algorithms and data structures are found in Java and most other computational environments. Different APIs and different assumptions about keys call for different implementations. Researchers in algorithms and data structures still study symbol-table implementations of all sorts.
Which symbol-table implementation is better—hashing or BSTs? The first point to consider is whether the client has comparable keys and needs symbol-table operations that involve ordered operations such as selection and rank. If so, then you need to use BSTs. If not, most programmers are likely to use hashing, because symbol tables based on hash tables are typically faster than those based on BSTs, assuming you have access to a good hash function for the key type.
The use of binary search trees to implement symbol tables and sets is a sterling example of exploiting the tree abstraction, which is ubiquitous and familiar. We are accustomed to many tree structures in everyday life, including family trees, sports tournaments, the organization chart of a company, and parse trees in grammar. Trees also arise in numerous computational applications, including function-call trees, parse trees for programming languages, and file systems. Many important applications of trees are rooted in science and engineering, including phylogenetic trees in computational biology, multidimensional trees in computer graphics, minimax game trees in economics, and quad trees in molecular-dynamics simulations. Other, more complicated, linked structures can be exploited as well, as you will see in SECTION 4.5.
People use dictionaries, indexes, and other kinds of symbol tables every day. Within a short amount of time, applications based on symbol tables replaced phone books, encyclopedias, and all sorts of physical artifacts that served us well in the last millennium. Without symbol-table implementations based on data structures such as hash tables and BSTs, such applications would not be feasible; with them, we have the feeling that anything that we need is instantly accessible online.