
20
Working Collaboratively
To be a successful member of a data science team, you will need to be able to effectively collaborate with others. While this is true for nearly any practice, an additional challenge for collaborative data science is working on shared code for the same project. Many of the techniques for supporting collaborative coding involve writing clear, well-documented code (as demonstrated throughout this book!) that can be read, understood, and modified by others. But you will also need to be able to effectively integrate your code with code written by others, avoiding any “copy-and-pasting” work for collaboration. The best way to do this is to use a version control system. Indeed, one of the biggest benefits of git is its ability to support collaboration (working with other people). In this chapter, you will expand your version control skills to maintain different versions of the same code base using git’s branching model, and familiarize yourself with two different models for collaborative development.
20.1 Tracking Different Versions of Code with Branches
To work effectively with others, you need to understand how git supports nonlinear development on a project through branches. A branch in git is a way of labeling a sequence of commits. You can create labeled commit sequences (branches) that exist side by side within the same project, allowing you to effectively have different “lines” of development occurring in parallel and diverging from each other. That is, you can use git to track multiple different, diverging versions of your code, allowing you to work on multiple versions at the same time.
Chapter 3 describes how to use git when you are working on a single branch (called master) using a linear sequence of commits. As an example, Figure 20.1 illustrates a series of commits for a sample project history. Each one of these commits—identified by its hash (e.g., e6cfd89 in short form)—follows sequentially from the previous commit. Each commit builds directly on the other; you would move back and forth through the history in a straight line. This linear sequence represents a workflow using a single line of development. Having a single line of development is a great start for a work process, as it allows you to track changes and revert to earlier versions of your work.

HEAD—most recent commit—is on the master branch.
In addition to supporting single development lines, git supports a nonlinear model in which you “branch off” from a particular line of development to create new concurrent change histories. You can think of these as “alternate timelines,” which are used for developing different features or fixing bugs. For example, suppose you want to develop a new visualization for your project, but you’re unsure if it will look good and be incorporated. You don’t want to pollute the primary line of development (the “main work”) with experimental code, so instead you branch off from the line of development to work on this code at the same time as the rest of the core work. You are able to commit iterative changes to both the experimental visualization branch and the main development line, as shown in Figure 20.2. If you eventually decide that the code from the experimental branch is worth keeping, you can easily merge it back into the main development line as if it were created there from the start!
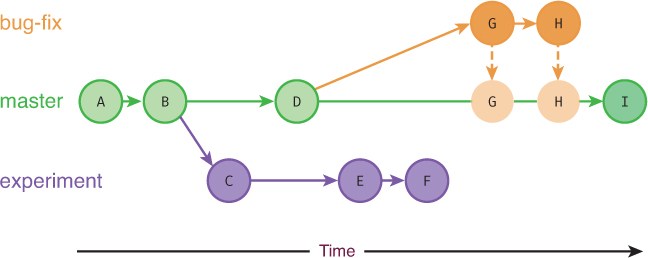
bug-fix branch (labeled G and H) are merged into the master branch, becoming part of that history.
20.1.1 Working with Different Branches
All git repositories have at least one branch (line of development) where commits are made. By default, this branch is called master. You can view a list of current branches in the repo with the git branch command:
# See a list of current branches in the repo
git branch
The line printed with the asterisk (*) is the “current branch” you’re on. You can use the same git branch command to create a new branch:
# Create a new branch called BRANCH_NAME
git branch BRANCH_NAME
This will create a new branch called BRANCH_NAME (replace BRANCH_NAME with whatever name you want; usually not in all caps). For example, you could create a branch called experiment:
# Create a new branch called `experiment`
git branch experiment
If you run git branch again, you will see that this hasn’t actually changed what branch you’re on. In fact, all you have done is create a new branch that starts at the current commit!
Going Further
To switch to a different branch, you use the git checkout command (the same one described in Section 3.5.2).
# Switch to the BRANCH_NAME branch
git checkout BRANCH_NAME
For example, you can switch to the experiment branch with the following command:
# Switch to the `experiment` branch
git checkout experiment
Checking out a branch doesn’t actually create a new commit! All it does is change the HEAD so that it now refers to the latest commit of the target branch (the alternate timeline). HEAD is just an alias for “the most recent commit on the current branch.” It lets you talk about the most recent commit generically, rather than needing to use a particular commit hash.
You can confirm that the branch has changed by running the git branch command and looking for the asterisk (*), as shown in Figure 20.3.
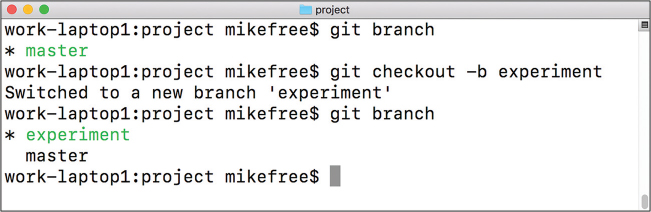
git commands on the command line to display the current branch (git branch), and create and checkout a new branch called experiment (git checkout -b experiment).Alternatively (and more commonly), you can create and checkout a branch in a single step using the -b option with git checkout:
# Create and switch to a branch called BRANCH_NAME
git checkout -b BRANCH_NAME
For example, to create and switch to a new branch called experiment, you would use the following command:
# Create and switch to a new branch called `experiment`
git checkout -b experiment
This effectively does a git branch BRANCH_NAME followed by a git checkout BRANCH_NAME. This is the recommended way of creating new branches.
Once you have checked out a particular branch, any new commits from that point on will occur in the “alternate timeline,” without disturbing any other line of development. New commits will be “attached” to the HEAD (the most recent commit on the current branch), while all other branches (e.g., master) will stay the same. If you use git checkout again, you can switch back to the other branch. This process is illustrated in Figure 20.4.
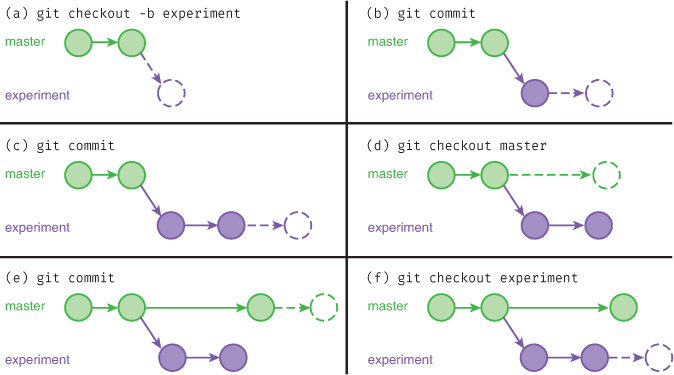
git to commit to multiple branches. A hollow circle is used to represent where the next commit will be added to the history. Switching branches, as in figures (a), (d), and (f), will change the location of the HEAD (the commit that points to the hollow circle), while making new commits, as in figures (b), (c), and (e), will add new commits to the current branch.
Importantly, checking out a branch will “reset” the files and code in the repo to whatever they looked like when you made the last commit on that branch; the code from the other branches’ versions is stored in the repo’s .git database. You can switch back and forth between branches and watch your code change!
For example, Figure 20.5 demonstrates the following steps:
git status: Check the status of your project. This confirms that the repo is on themasterbranch.git checkout -b experiment: Create and checkout a new branch,experiment. This code will branch off of themasterbranch.Make an update to the file in a text editor (still on the
experimentbranch).git commit -am "Update README": This willaddandcommitthe changes (as a single command)! This commit is made only to theexperimentbranch; it exists in that timeline.git checkout master: Switch back to themasterbranch. The file switches to show the latest version of themasterbranch.git checkout experiment: Switch back to theexperimentbranch. The file switches to show the latest version of theexperimentbranch.
Figure 20.5 Switching branches allows you to work on multiple versions of the code simultaneously.
Caution
You can only check out a branch if the current working directory has no uncommitted changes. This means you will need to commit any changes to the current branch before you checkout another branch. If you want to “save” your changes but don’t want to commit to them, you can use git’s ability to temporarily stasha changes.
ahttps://git-scm.com/book/en/v2/Git-Tools-Stashing-and-Cleaning
Finally, you can delete a branch using git branch -d BRANCH_NAME. Note that this command will give you a warning if you might lose work; be sure to read the output message!
Taken together, these commands will allow you to develop different aspects of your project in parallel. The next section discusses how to bring these lines of development together.
Tip
You can also use the git checkout BRANCH_NAME FILE_NAME command to checkout an individual file from a particular branch. This will load the file directly into the current working directory as a file change, replacing the current version of the file (git will not merge the two versions of the file together)! This is identical to checking out a file from a past commit (as described in Chapter 3), just using a branch name instead of a commit hash.
20.1.2 Merging Branches
If you have changes (commits) spread across multiple branches, eventually you will want to combine those changes back into a single branch. This process is called merging: you “merge” the changes from one branch into another. You do this with the (surprise!) git merge command:
# Merge OTHER_BRANCH into the current branch
git merge OTHER_BRANCH
For example, you can merge the experiment branch into the master branch as follows:
# Make sure you are on the `master` branch git checkout master # Merge the `experiment` branch into the current (`master`) branch git merge experiment
The merge command will (in effect) walk through each line of code in the two versions of the files, looking for any differences. Changes to each line of code in the incoming branch will then be applied to the equivalent line in the current branch, so that the current version of the files contains all of the incoming changes. For example, if the experiment branch included a commit that added a new code statement to a file at line 5, changed the code statement at line 9, and deleted the code statement at line 13, then git would add the new line 5 to the file (pushing everything else down), change the code statement that was at line 9, and delete the code statement that was at line 13. git will automatically “stitch” together the two versions of the files so that the current version contains all of the changes.
Tip
When merging, think about where you want the code to “end up”—that is the branch you want to checkout and merge into!
In effect, merging will take the commits from another branch and insert them into the history of the current branch. This is illustrated in Figure 20.6.

experiment branch into the master branch. The committed changes from the experiment branch (labeled C and D) are inserted into the master branch’s history, while also remaining present in the experiment branch.
Note that the git merge command will merge OTHER_BRANCH into the branch you are currently on. For example, if you want to take the changes from your experiment branch and merge them into your master branch, you will need to first checkout your master branch, and merge in the changes from the experiment branch.
Caution
If something goes wrong, don’t panic and close your command shell! Instead, take a breath and look up how to fix the problem you’ve encountered (e.g., how to exit vim). As always, if you’re unsure why something isn’t working with git, use git status to check the current status and to determine which steps to do next.
If the two branches have not edited the same line of code, git will stitch the files together seamlessly and you can move forward with your development. Otherwise, you will have to resolve any conflict that occurs as part of your merge.
20.1.3 Merge Conflicts
If you perform a merge between two branches that have different commits that edit the same lines of code the result will be a merge conflict (so called because the changes are in “conflict”), as demonstrated in Figure 20.7.

git is just a simple computer program, and has no way of knowing which version of the conflicting code it should keep—is the master version or the experiment version better? Since git can’t determine which version of the code to keep, it stops the merge in the middle and forces you to choose what code is correct manually.
To resolve the merge conflict, you will need to edit the files (code) to pick which version to keep. git adds special characters (e.g., <<<<<<<<) to the files to indicate where it encountered a conflict (and thus where you need to make a decision about which code to keep), as shown in Figure 20.8.

To resolve a merge conflict, you need to take the following steps:
Use
git statusto see which files have merge conflicts. Note that multiple files may have conflicts, and each file may have more than one conflict.Choose which version of the code to keep. You do this by editing the files (e.g., in RStudio or Atom). You can make these edits manually, though some IDEs (including Atom) provide buttons that let you directly choose a version of the code to keep (e.g., the “Use me” button in Figure 20.8).
Note that you can choose to keep the “original”
HEADversion from the current branch, the “incoming” version from the other branch, or some combination thereof. Alternatively, you can replace the conflicting code with something new entirely! Think about what you want the “correct” version of the final code to be, and make it so. Remember to remove the<<<<<<<and=======and>>>>>>>characters; these are not legal code in any language.Tip
When resolving a merge conflict, pretend that a cat walked across your keyboard and added a bunch of extra junk to your code. Your task is to fix your work and restore it to a clean, working state. Be sure to test your code to confirm that it continues to work after making these changes!
Once you are confident that the conflicts are all resolved and everything works as it should, follow the instructions shown by
git statustoaddandcommitthe change you made to the code to resolve the conflict:# Check current status: have you edited all conflicting files? git status # Add and commit all updated files git add . git commit -m "Resolve merge conflict"
This will complete the merge! Use
git statusto check that everything is clean again.
Tip
If you want to “cancel” a merge with a conflict (e.g., you initiated a merge, but you don’t want to go through with it because of various conflicts), you can cancel the merge process with the git merge --abort command.
Remember
Merge conflicts are expected. You didn’t do something wrong if one occurs! Don’t worry about getting merge conflicts or try to avoid them: just resolve the conflict, fix the “bug” that has appeared, and move on with your life.
20.1.4 Merging from GitHub
When you push to and pull from GitHub, what you’re actually doing is merging your commits with the ones on GitHub! Because GitHub won’t know which version of your files to keep, you will need to resolve all merge conflicts on your machine. This plays out in two ways:
You will not be able to
pushto GitHub if merging your commits into GitHub’s repo might cause a merge conflict.gitwill instead report an error, telling you that you need topullchanges first and make sure that your version is up to date. “Up to date” in this case means that you have downloaded and merged all the commits on your local machine, so there is no chance of divergent changes causing a merge conflict when you merge by pushing.Whenever you
pullchanges from GitHub, there may be a merge conflict. These are resolved in the exact same way as when merging local branches; that is, you need to edit the files to resolve the conflict, thenaddandcommitthe updated versions.
Thus, when working with GitHub (and especially with multiple people), you will need to perform the following steps to upload your changes:
pull(download) any changes you don’t haveResolve any merge conflicts that occur
push(upload) your merged set of changes
Of course, because GitHub repositories are repos just like the ones on your local machine, they can have branches as well. You gain access to any remote branches when you clone a repo; you can see a list of them with git branch -a (using the “all” option).
If you create a new branch on your local machine, it is possible to push that branch to GitHub, creating a mirroring branch on the remote repo (which usually has the alias name origin). You do this by specifying the branch in the git push command:
# Push the current branch to the BRANCH_NAME branch on the `origin`
# remote (GitHub)
git push origin BRANCH_NAME
where BRANCH_NAME is the name of the branch you are currently on (and thus want to push to GitHub). For example, you could push the experiment branch to GitHub with the following command:
# Make sure you are on the `experiment` branch git checkout experiment # Push the current branch to the `experiment` branch on GitHub git push origin experiment
You often want to create an association between your local branch with the remote one on GitHub. You can establish this relationship by including the -u option in your push:
# Push to the BRANCH_NAME branch on origin, enabling remote tracking
# The -u creates an association between the local and remote branches
git push -u origin BRANCH_NAME
This causes your local branch to “track” the one on GitHub. Then when you run a command such as git status, it will tell you whether one repo has more commits than the other. Tracking will be remembered once set up, so you only need to use the -u option once. It is best to do this the first time you push a local branch to GitHub.
20.2 Developing Projects Using Feature Branches
The main benefit of branches is that they allow you (and others) to simultaneously work on different aspects of the code without disturbing the main code base. Such development is best organized by separating your work across different feature branches—branches that are each dedicated to a different feature (capability or part) of the project. For example, you might have one branch called new-chart that focuses on adding a complex visualization, or another branch called experimental-analysis that tries a bold new approach to processing the data. Importantly, each branch is based on a feature of the project, not a particular person: a single developer could be working on multiple feature branches, and multiple developers could collaborate on a single feature branch (more on this later).
The goal when organizing projects into feature branches is that the master branch should always contain “production-level” code: valid, completely working code that you could deploy or publish (read: give to your boss or teacher) at a whim. All feature branches branch off of master, and are allowed to contain temporary or even broken code (since they are still in development). This way there is always a “working” (if incomplete) copy of the code (master), and development can be kept isolated and considered independent of the whole. Note that this organization is similar to how the earlier example uses an experiment branch.
Using feature branches works like this:
You decide to add a new feature to the project: a snazzy visualization. You create a new feature branch off of
masterto isolate this work:# Make sure you are on the `master` branch git checkout master # Create and switch to a new feature branch (called `new-chart`) git checkout -b new-chart
You then do your coding work while on this branch. Once you have completed some work, you would make a commit to add that progress:
# Add and commit changes to the current (`new-chart`) branch git add . git commit -m "Add progress on new vis feature"
Unfortunately, you may then realize that there is a bug in the
masterbranch. To address this issue, you would switch back to themasterbranch, then create a new branch to fix the bug:# Switch from your `new-chart` branch back to `master` git checkout master # Create and switch to a new branch `bug-fix` to fix the bug git checkout -b bug-fix
(You would fix a bug on a separate branch if it was complex or involved multiple commits, in order to work on the fix separate from your regular work).
After fixing the bug on the
bug-fixbranch, you wouldaddandcommitthose changes, then checkout themasterbranch to merge the fix back intomaster:# Add and commit changes that fix the bug (on the `bug-fix` branch) git add . git commit -m "Fix the bug" # Switch to the `master` branch git checkout master # Merge the changes from `bug-fix` into the current (`master`) branch git merge bug-fix
Now that you have fixed the bug (and merged the changes into
master), you can get back to developing the visualization (on thenew-chartbranch). When it is complete, you willaddandcommitthose changes, then checkout themasterbranch to merge the visualization code back intomaster:# Switch back to the `new-chart` branch from the `master` branch git checkout new-chart # Work on the new chart... # After doing some work, add and commit the changes git add . git commit -m "Finish new visualization" # Switch back to the `master` branch git checkout master # Merge in changes from the `new-chart` branch git merge new-chart
The use of feature branches helps isolate progress on different elements of a project, reducing the need for repeated merging (and the resultant conflicts) of half-finished features and creating an organized project history. Note that feature branches can be used as part of either the centralized workflow (see Section 20.3) or the forking workflow (see Section 20.4).
20.3 Collaboration Using the Centralized Workflow
This section describes a model for working with multiple collaborators on the same project, coordinating and sharing work through GitHub. In particular, it focuses on the centralized workflow,1 in which all collaborators use a single repository on GitHub. This workflow can be extended to support the use of feature branches (in which each feature is developed on a different branch) as described in Section 20.2—the only additional change is that multiple people can work on each feature! Using the centralized workflow involves configuring a shared repository on GitHub, and managing changes across multiple contributors.
1Atlassian: Centralized Workflow: https://www.atlassian.com/git/tutorials/comparing-workflows#centralized-workflow
20.3.1 Creating a Centralized Repository
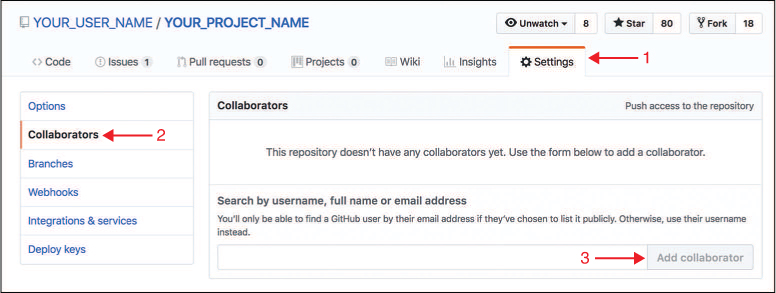
The centralized workflow uses a single repository stored on GitHub—that is, every single member of the collaboration team will push and pull to the same GitHub repo. However, since each repository needs to be created under a particular account, a single member of the team will need to create that repository (e.g., by clicking the “New” button on the “Repositories” tab on the GitHub web portal).
To make sure everyone is able to push to the repository, whoever creates the repo will need to add the other team members as collaborators.2 They can do this under the “Settings” tab of the repo’s web portal page, as shown in Figure 20.9. (The creator will want to give all team members “write” access so they can push changes to the repo.)
2GitHub: Inviting collaborators to a personal repository: https://help.github.com/articles/inviting-collaborators-to-a-personal-repository/
Once everyone has been added to the GitHub repository, each team member will need to clone the repository to their local machines to work on the code individually, as shown in Figure 20.10. Collaborators can then push any changes they make to the central repository, and pull any changes made by others.

push their changes to it.When you are contributing to the same repository along with multiple other people, it’s important to ensure that you are working on the most up-to-date version of the code. This means that you will regularly have to pull changes from GitHub that your team members may have committed. As a result, developing code with the centralized workflow follows these steps:
To begin your work session,
pullin the latest changes from GitHub. For example:# Pull latest changes from `origin` (GitHub's) `master` branch # You could specify a different branch as appropriate git pull origin masterDo your work, making changes to the code. Remember to
addandcommityour work each time you make notable progress!Once you are satisfied with your changes and want to share them with your team, you’ll need to upload the changes back to GitHub. But note that if someone pushes a commit to GitHub before you push your own changes, you will need to integrate those changes into your code (and test them!) before doing your own
pushup to GitHub. Thus you’ll want to firstpulldown any changes that have been made in the interim (there may not be any) so that you are up to date and ready topush:# Pull latest changes from `origin` (GitHub's) `master` branch # You could specify a different branch as appropriate git pull origin master # In case of a merge conflict, fix the changes # Once fixed, add and commit the changes (using default commit message) git add . git commit --no-edit # Push changes to `origin` (GitHub's) `master` branch # You could specify a different branch as appropriate git push origin master
Remember that when you
pullin changes,gitis really merging the remote branch with your local one, which may result in a merge conflict you need to resolve; be sure to fix the conflict and then mark it as resolved. (The--no-editargument used withgit committellsgitto use the default commit message, instead of specifying your own with the-moption.)
While this strategy of working on a single master branch may suffice for small teams and projects, you can spend less time merging commits from different team members if your team instead uses a dedicated feature branch for each feature they work on.
20.3.2 Using Feature Branches in the Centralized Workflow
The centralized workflow supports the use of feature branches for development (often referred to as the feature branch workflow). This is similar to the procedure for working with feature branches described previously. The only additional complexity is that you must push and pull multiple branches to GitHub so that multiple people can work on the same feature.
Remember
In the feature branch workflow, each branch is for a different feature, not a different developer! This means that a developer can work on multiple different features, and a feature can be worked on by multiple developers.
As an example of this workflow, consider the collaboration on a feature occurring between two developers, Ada and Bebe:
Ada decides to add a new feature to the code, a snazzy visualization. She creates a new feature branch off of
master:# Double-check that the current branch is the `master` branch git checkout master # Create and switch to a new feature branch (called `new-chart`) git checkout -b new-chart
Ada does some work on this feature, and then commits that work when she’s satisfied with it:
# Add and commit changes to the current (`new-chart`) branch git add . git commit -m "Add progress on new vis feature"
Happy with her work, Ada decide to takes a break. She pushes her feature branch to GitHub to back it up (and so her team can also contribute to it):
# Push to a new branch on `origin` (GitHub) called `new-chart`, # enabling tracking git push -u origin new-chartAfter talking to Ada, Bebe decides to help finish up the feature. She checks out the feature branch and makes some changes, then pushes them back to GitHub:
# Use `git fetch` to "download" commits from GitHub, without merging # This makes the remote branch available locally git fetch origin # Switch to local copy of the `new-chart` branch git checkout new-chart # Work on the feature is done outside of terminal... # Add, commit, and push the changes back to `origin` # (to the existing `new-chart` branch, which this branch tracks) git add . git commit -m "Add more progress on feature" git push
The
git fetchcommand will “download” commits and branches from GitHub (but without merging them); it is used to get access to branches that were created after the repo was originally cloned. Note thatgit pullis actually a shortcut for agit fetchfollowed by agit merge!Ada then downloads Bebe’s changes to her (Ada’s) machine:
# Download and merge changes from the `new-chart` branch on GitHub # to the current branch git pull origin new-chartAda decides the feature is finished, and merges it back into
master. But first, she makes sure she has the latest version of themastercode:# Switch to the `master` branch, and download any changes git checkout master git pull # Merge the feature branch into the master branch (locally) git merge new-chart # Fix any merge conflicts! # Add and commit these fixes (if necessary) # Push the updated `master` code back to GitHub git push
Now that the feature has been successfully added to the project, Ada can delete the feature branch (using
git branch -d new-chart). She can delete GitHub’s version of the branch through the web portal interface (recommended), or by usinggit push origin -d new-chart.
This kind of workflow is very common and effective for supporting collaboration. Moreover, as projects grow in size, you may need to start being more organized about how and when you create feature branches. For example, the Git Flow3 model organizes feature branches around product releases, and is a popular starting point for large collaborative projects.
3Git Flow: A successful Git branching model: http://nvie.com/posts/a-successful-git-branching-model/
20.4 Collaboration Using the Forking Workflow
The forking workflow takes a fundamentally different approach to collaboration from the centralized workflow. Rather than having a single shared remote repository, each developer has their own repository on GitHub that is forked from the original repository, as shown in Figure 20.11. As discussed in Chapter 3, developers can create their own copy of a repository on GitHub by forking it. This allows the individual to make changes (and contribute) to the repository, without necessarily needing permission to modify the “original” repo. This is particularly valuable when contributing to open source software projects (such as R packages like dplyr) to which you may not have ownership.
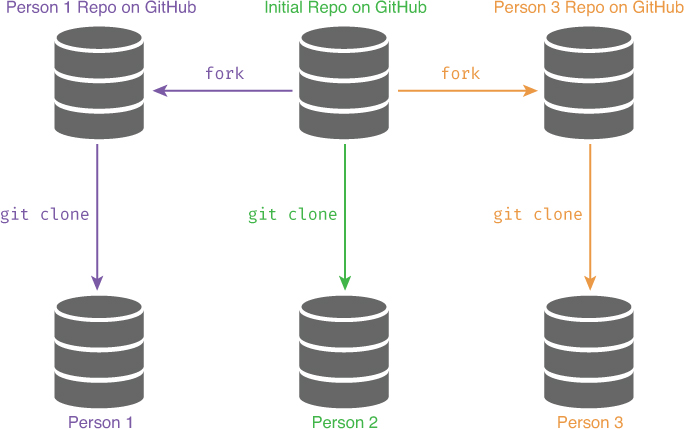
In this model, each person contributes code to their own personal copy of the repository. The changes between these different repos are merged together through a GitHub process called a pull request.4 A pull request (colloquially called a “PR”) is a request for the changes in one version of the code (i.e., a fork or branch) to be pulled (merged) into another. With pull requests, one developer can send a request to another developer, essentially saying “I forked your repository and made some changes: can you integrate my changes into your repo?” The second developer can perform a code review: reviewing the proposed changes and making comments or asking for corrections to anything that appears problematic. Once the changes are made (committed and pushed to the “source” branch on GitHub), the pull request can be accepted and the changes merged into the “target” branch. Because pull requests can be applied across (forked) repositories that share history, a developer can fork an existing professional project, make changes to that fork, and then send a pull request back to the original developer asking that developer to merge in changes.
4GitHub: About pull requests: https://help.github.com/articles/about-pull-requests/
Caution
You should only use pull requests to integrate changes on remote branches (i.e., two different forks of a repo). To integrate commits from different branches of the same repository, you should merge changes on your local machine (not using GitHub’s pull request feature).
To issue a pull request, you will need to make changes to your fork of a repository and push those to GitHub. For example, you could walk through the following steps:
Fork a repository to create your own version on GitHub. For example, you could fork the repository for the
dplyrpackage5 if you wanted to make additions to it, or fix a bug that you’ve identified.5
dplyrPackage GitHub Repository: https://github.com/tidyverse/dplyrYou will need to
cloneyour fork of the repository to your own machine. Be careful that you clone the correct repo (look at the username for the repo in the GitHub web portal—where it saysYOUR_USER_NAMEin Figure 20.12).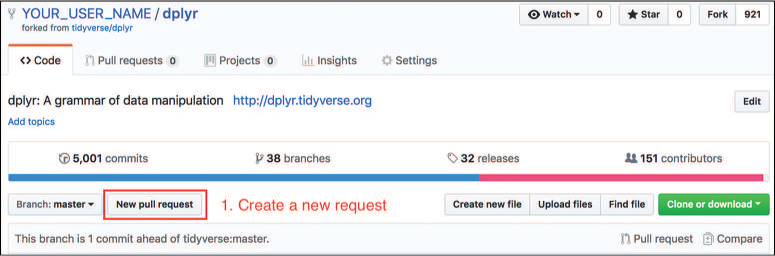
Figure 20.12 Create a new pull request by clicking the “New Pull Request” button on your fork of a repository. After you’ve cloned your fork of the repository to your own machine, you can make any changes desired. When you’re finished,
addandcommitthose changes, thenpushthem up to GitHub.You can use feature branches to make these changes, including pushing the feature branches to GitHub as described earlier.
Once you’ve pushed your changes, navigate to the web portal page for your fork of the repository on GitHub and click the “New Pull Request” button as shown in Figure 20.12.
On the next page, you will need to specify which branches of the repositories you wish to merge. The base branch is the one you want to merge into (often the
masterbranch of the original repository), and the head branch (labeled “compare”) is the branch with the new changes you want to be merged in (often themasterbranch of your fork of the repository), as shown in Figure 20.13.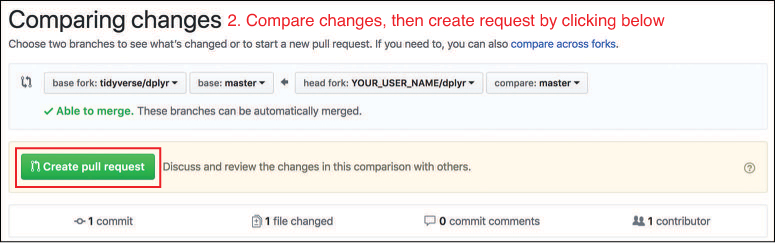
Figure 20.13 Compare changes between the two forks of a repository on GitHub before issuing a pull request. After clicking the “Create Pull Request” button (in Figure 20.13), you will write a title and a description for your pull request (as shown in Figure 20.14). After describing your proposed changes, click the “Create pull request” button to issue the pull request.

Figure 20.14 Write a title and description for your pull request, then issue the request by clicking the “Create Pull Request” button.
Remember
The pull request is a request to merge two branches, not to merge a specific set of commits. This means that you can push more commits to the head (“merge-from”) branch, and they will automatically be included in the pull request—the request is always up to date with whatever commits are on the (remote) branch.
If the code reviewer requests changes, you make those changes to your local repo and just push the changes as normal. They will be integrated into the existing pull request automatically without you needing to issue a new request!
You can view all pull requests (including those that have been accepted) through the “Pull Requests” tab at the top of the repository’s web portal. This view will allow you to see comments that have been left by the reviewer.
If someone (e.g., another developer on your team) sends you a pull request, you can accept that pull request6 through GitHub’s web portal. If the branches can be merged without a conflict, you can do this simply by clicking the “Merge pull request” button. However, if GitHub detects that a conflict may occur, you will need to pull down the branches and merge them locally.7
6GitHub: Merging a pull request: https://help.github.com/articles/merging-a-pull-request/
7GitHub: Checking out pull requests locally: https://help.github.com/articles/checking-out-pull-requests-locally
Note that when you merge a pull request via the GitHub website, the merge is done in the repository on GitHub’s servers. Your copy of the repository on your local machine will not yet have those changes, so you will need to use git pull to download the updates to the appropriate branch.
In the end, the ability to effectively collaborate with others on programming and data projects is one of the biggest benefits of using git and GitHub. While such collaboration may involves some coordination and additional commands, the techniques described in this chapter will enable you to work with others—both within your team and throughout the open source community—on larger and more important projects.
Tip
Branches and collaboration are among the most confusing parts of git, so there is no shortage of resources that aim to help clarify this interaction. Git and GitHub in Plain Englisha is an example tutorial focused on collaboration with branches, while Learn Git Branchingb is an interactive tutorial focused on branching itself. Additional interactive visualizations of branching with git can be found here.c
ahttps://red-badger.com/blog/2016/11/29/gitgithub-in-plain-english
For practice working with collaborative version control methods, see the set of accompanying book exercises.8
8git collaboration exercises: https://github.com/programming-for-data-science/chapter-20-exercises