
Chapter 1
Introducing Security Operations and the SOC
The journey of a thousand miles begins with one step.
—Lao Tzu
Security is a simple concept: protect something from threats. Although this sounds easy, many organizations, from small government agencies to Fortune 500 businesses, do not know how to transform their current efforts into a formal security operations center (SOC). As a result, the security teams within these organizations have trouble obtaining the proper support and funding to improve their capabilities. Having static SOC capacities leads to failures in how the SOC functions because too much time is spent on reactive and manual efforts with no clear path for improvement of any SOC service. The combination of these challenges causes organizations to experience breaches of security, loss of talent, large fines, and other negative outcomes, possibly including the complete failure of the business.
In this chapter, you learn about fundamental security and SOC concepts. I cover why it is important to build a mature security operations center that combines people, processes, and technology. Security topics include how to develop a defense-in-depth security architecture using industry recommendations found within standards, guidelines, and frameworks. I show you how to better understand potential threats using threat models and vulnerability assessments. I introduce the eight fundamental services I find in mature SOCs around the world and show you how to assess yourself against those services. This chapter is the foundation for everything covered in this book.
Introducing the SOC
The security operations center, more commonly called “the SOC,” is a centralized unit that deals with security issues on both an organizational level and a technical level. This occurs through the use of people, process, and capabilities to deliver one or more services. Services could include identifying and reducing risk, addressing vulnerabilities, adhering to compliance requirements, responding to incidents, collecting forensic evidence, and performing other tasks deemed essential to the security posture of the organization. Which services any particular SOC offers depends on the nature of the business the SOC is protecting. Some SOCs might outsource services using on-demand or external service providers to fill the need for a capability. Other SOCs might accept the risk and ignore services or pass on responsibilities to other groups within the organization. An example is handing off vulnerability management to the desktop support team. Chapter 3, “SOC Services,” covers all of the services typically offered in mature SOCs around the world.
Every organization can have a SOC, regardless of the services and capabilities that it offers. The size or type of the business shouldn’t matter, because every organization has one or more business goals that are threatened by various elements ranging from cybercriminals to poor IT practices. There are some exceptions to this rule, such as a small firm or organization with a small IT footprint; however, many such organizations will leverage more technology in the future, leading to the need for a SOC. The massive growth in the Internet of Things (IoT) represents the impact from many nontechnical markets leveraging technology.
Whether you are the sole person responsible for protecting the security of your organization or you are part of a large team with the same responsibility, you essentially are operating as a SOC, even though you might not be labeled as such. How you are viewed by your organization depends on how you (and your group, if applicable) are organized and present your job responsibilities to the organization. For example, imagine that a team of two IT administrators who also are responsible for the security of their organization grows into a dedicated security team of ten administrators with the quality technology and authority to enforce proper practices even if the person violating a process is the CEO. I have assisted with this type of change by helping security professionals mature their security job roles into a documented practice that is backed by leadership and given the authority to make strategic decisions and obtain budget for growth. This is the foundation of a mature SOC practice.
Factors Leading to a Dysfunctional SOC
Several factors can lead to a SOC becoming dysfunctional. The first problem is a lack of educated security professionals to meet demand. Many organizations have trouble finding and retaining the right people for SOC-related work. There are a lot of job opportunities in the cybersecurity marketspace and not enough skilled professionals to meet the demand. That has become even more acute during the pandemic, as reported in a September 2020 article published on CNBC.com by Kate Rogers and Betsy Spring titled “We are outnumbered – cybersecurity pros face a huge staffing shortage as attacks surge during the pandemic” (https://www.cnbc.com/2020/09/05/cyber-security-workers-in-demand.html). Citing a report by (ISC)2, the article states “2.8 million professionals work in cybersecurity jobs globally, but the industry would need another 4 million trained workers in order to properly defend organizations and close the skills gap. That includes about half a million workers needed in the U.S. to meet demand.” The skills gap is also a moving target, as technology shifts toward the need for skills in programming and development versus traditional management of security tools.
The second factor that may lead to a dysfunctional SOC is the cybersecurity industry’s hyperfocus on preventing compromises. Preventing a compromise from happening is ideal, but the more realistic approach is to prepare for when a compromise does occur. Organizations should defend against all parts of the attack process rather than assuming the SOC will prevent exploitation 100% of the time. Lacking capabilities to detect adversaries that have compromised a network will lead to nefarious actions taking place within an organization that go unnoticed.
A third issue that may cause a SOC to become dysfunctional is that it cannot be scaled to meet the current demand, resulting in poor reporting, dysfunctional tools, and analyst burnout. Many drivers such as cloud computing, data transfer and storage, and IoT increase bandwidth requirements, necessitating that security tools increase in size and power to accommodate the increase in data that must be monitored. As data increases, the backlog of events requiring an analyst to sift through becomes 12 to 18 months’ worth of continuous review, leading to analyst burnout. The combination of underestimating technology and overwhelming workload demand can quickly bring a SOC to a grinding halt.
Finally, a SOC may become dysfunctional if the organization moves to cloud services without consideration for proper security. Cloud computing offers new challenges to securing data, including leveraging cloud resources that the organization is not permitted to manage or have visibility into. Also, some traditional security vendors might not offer cloud options of their technology that the organization is already familiar with, forcing the organization to acquire new technology that needs new skillsets and has additional costs. Recent technology trends, such as software defended networking (SDN) and work-from-anywhere strategies, are further driving the need for cloud technology.
Any of these challenges can cause the breakdown of how an organization runs its SOC. These challenges can lead to uneducated decisions, gaps in security capabilities, and ineffective procedures. Uneducated decisions include seeing the impact of a problem but not correctly addressing the issue due to a lack of understanding regarding what should be done. There are hundreds of sources claiming “best practices,” ranging from vendor publications to industry guidelines, yet different teams will have different missions they are trying to accomplish and, hence, different views of any particular problem. This in turn leads to running the SOC as various siloed groups responding to events with no plan to improve how the security practice operates. A dysfunctional SOC puts an organization at high risk of being compromised by adversaries, and being compromised can lead to the end of an organization.
Cyberthreats
A SOC that is dysfunctional for any or all of the reasons outlined in the previous section will eventually fail to secure the organization, giving cyber adversaries an opportunity to abuse an exposed vulnerability. An effective SOC, on the other hand, is aware of the wide range of cyberthreats and knows how to protect the organization from them. This section outlines the various cyberthreats as a foundation for subsequent discussion of how to defend against them.
One type of cyberthreat is a malicious actor attempting to compromise a network. An essential element of defending against such attacks is to understand who would do this and what motivates them. According to “Data Thieves: The Motivations of Cyber Threat Actors and Their Use and Monetization of Stolen Data” (a RAND Corp. publication documenting the March 15, 2018 testimony of RAND associate Lillian Ablon before the U.S. House of Representatives Committee on Financial Services Subcommittee on Terrorism and Illicit Finance), there are four categories of cyberthreat actors: cybercriminals, hacktivists, state-sponsored actors, and cyberterrorists.
Cybercriminals: These threat actors focus on making money. They typically are members of organized crime groups or small-time criminals trying to capitalize on using technology to steal data and then sell it to make money. The key to preventing cybercriminals is to make their actions more costly than profitable so that they move on to another target. The key points to consider for this category of cyberthreat actors are as follows:
Cybercriminals are driven by profit. Reducing potential profit reduces this adversary’s interest in investing time into an attack strategy.
Many cybercriminals operate as independent contractors taking work on a for-hire term. Cybercriminals can be recruited by nation states, organizations, or other parties that need to outsource their criminal activity.
Larger cybercriminal organizations are essentially the mafia. Rather than robbing banks physically, organized crime groups have shifted their focus to cybercrime as it involves less risk of being caught and very high profit possibilities.
Some cybercriminal organizations set up call centers dedicated to specific attacks including making phone calls to deliver social engineering attacks, packing malware to bypass host-based security, and sending phishing emails. These call centers function similarly to any legitimate business, providing full- or part-time jobs for employees and providing the benefits an employee would expect from any employer.
Hacktivists: These threat actors are people driven by belief in a cause. Anonymous is an infamous hacktivist group that targets people or organizations they feel have violated human rights or other political agendas and need to be punished. Figure 1-1 shows a screen capture from a video featuring a person in the typical mask worn by Anonymous members. Defending against hacktivists is different from defending against typical cybercriminals because hacktivists are not driven by making money. The key points to consider for this category of cyberthreat actors are as follows:
Because hacktivists are motivated by a cause rather than profit, they are likely to target a specific entity much more persistently than would a financially driven adversary.
It is common for hacktivists to be associated with conspiracy theories, including those involving anti-government concepts
Hacktivists have caused major breaches, including the takedown of the PlayStation network and the takedown of HBGary and its CEO Aaron Barr by publishing 68,000 private emails when Barr announced he would reveal the names of some “leaders” of Anonymous.
Hacktivists can contract cybercriminals to help with their mission as well as for burst support based on the issue they are addressing.

FIGURE 1-1 Video Posted by Anonymous on YouTube
State-sponsored actors: These threat actors are similar to hacktivists in that they are driven by a cause based on the state that sponsors them. It isn’t a secret that most governments are investing in cyberwarfare. Any large-scale war will include disruption of technology using cyber-exploitation tactics. This means if you are responsible for your government’s critical infrastructure or other key services, you are a potential target for this adversary. The key points to consider for this category of cyberthreat actors are as follows:
State-sponsored cybercrime tends to be very well funded and elite.
Many organizations do not have the capabilities to prevent a state-sponsored attack.
Most technologically advanced countries are continuously growing their cyberattack capabilities in secret. No country really knows precisely what other countries have in regard to cyber-offense capabilities, creating a cyber cold war based on an ongoing silent military race.
It is extremely difficult to track, document evidence of, and enforce laws against international-based crime.
State-sponsored cybercrime typically represents very targeted attacks commonly referred to as advanced persistent threats (APTs)
Cyberterrorists: These threat actors can be anybody who is motivated to intimidate, coerce, or influence an audience, cause fear, or physically harm. Basically, these are terrorists using technology. Some cyberterrorists are very skilled and are responsible for developing malware never seen until it is used, known as zero-day threats since all known detection signatures will not be effective. Other times cyberterrorists are leveraging pre-built scripts to launch attacks making it easy to perform largescale damage to systems. They just point the tool at a target and execute the attack. The key points to consider for this category of cyberthreat actors are as follows:
Cyberterrorists can be contracted the same way cybercriminals are obtained, meaning cyberterrorists can operate as independent contractors with skills specializing in causing destruction.
Cyberterrorists are not the only adversary that can use a zero-day exploit.
The impact of cyberterrorists has changed the cybersecurity industry, prompting requirements for multifactor authentication, improved password policies, and the use of digital certificates to reduce the risk of global events caused by cyberterror.
The compromised systems of some unwitting victims of cyberterrorists become part of an attack. Examples include spreading malware through a compromised system, leveraging a compromised system as a gateway into a network, and pushing emails through a compromised system during a phishing attack.
Note
The specific motivation for a threat actor can vary from passion about supporting a cause to being involved only if the pay is right. The threat actor marketplace functions similarly to other marketplaces, with hackers for hire, hackers that treat their work as a 9 to 5 job, and hackers willing to spend months or even years to execute an attack without any pay based on whatever is driving them to be involved with cybercrime.
In addition to the categories of threat actors in the previous list, another category is insider threats. An insider threat could be someone with malicious intent, such as an employee about to leave the company with sensitive data or a security, or it could be an accident, such as an administrator making an honest mistake that exposes the organization to additional risk or being compromised. As an example of the latter scenario, I have seen security administrators accidentally misconfigure security tools such as honeypots and sandboxes, turning these tools into gateways for malware to infect the environment.
One final threat that your organization must be prepared for is change. The industry has seen continuous change in how threats operate over the last few decades. In the late 1980s and early 1990s, threat actors primarily attacked computer operating systems. As the operating systems became more secure, threat actors turned their attention to attacking the Internet browsers installed on operating systems. As Internet browsers became more secure, threat actors began attacking browser plugins such as Java and Flash. Looking at security tools, when defenders invented the sandbox to detect malware, malware writers purchased the sandbox, learned how it functioned, and configured malware to bypass the sandbox. When bitcoin technology made it effective for adversaries to remain anonymous while requesting payment from users infected with ransomware, bitcoin became the method to obtain payment from victims of ransomware. Some ransomware creators found it more lucrative to infect systems with crypto-mining software rather than ransomware, so those ransomware writers gravitated toward creating crypto-mining tools.
The cyber battlefield is a constantly changing environment, which means you need to expect constantly changing variations of exploitation against your organization from different types of threat actors. If you do not continue to invest in your security program, it will quickly become obsolete. If you focus all of your energy at defending the attack of the month, the next change will bypass your security. The following is a great axiom to keep in mind: “Security is a journey, not a destination.” You don’t become secure; you continue your security journey as you run the security operations center.
This quick overview of cyberthreats should help you to understand what is out there waiting for your SOC to slip up in defending its people, technology, and data. This leads us to the next topic, which is how you can defend against cyberthreats. Let’s next look at the concept of security.
Investing in Security
What is the proper investment to improve security within an organization? Some people believe security is all about having the latest or “best of breed” technology and that obtaining such technology should be the highest budget priority. Others think success depends on the quality of the people within the security team and therefore money is best spent on highly skilled IT personnel. A third idea is that the best security comes from well-defined and executed policies that include how to restrict risky behavior as well as respond to threats. The truth is that best practice is a combination of these concepts representing investments in people, process, and technology. There are many industry models and certification programs that reference the ingredients to security using these or very similar terms. For example, the U.S. National Security Agency (NSA) substitutes “operations” for “process” in its information assurance and defense-in-depth strategy, as shown in Figure 1-2.
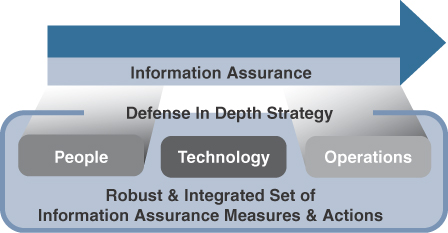
FIGURE 1-2 NSA Information Assurance and Defense-in-Depth Strategy
Figure 1-2 includes some key terms to explore, as they will be important underlying themes for many of the concepts in this book:
Information assurance: The practice of assuring the confidentiality, integrity and availability (CIA) of information and managing risks related to the use, processing, storage, and transmission of information and the systems and processes used for those purposes. Essentially, information assurance means protecting data. Data represents the crown jewels of an organization and is very valuable both to the organization and on the black market.
Defense in depth strategy: To protect data, a SOC uses a combination of people, processes, and technology to create different layers of defenses, which ensures that when one layer of defense fails, another layer steps in, making it harder for a cyberthreat to accomplish its goal. For example, when a firewall fails to prevent an open port from being exposed, an intrusion protection system (IPS) can monitor the traffic through the open port for exploitation behavior. If the IPS fails to see the exploitation behavior, a host-based anti-malware tool can evaluate which files successfully made it through the open firewall port and were not blocked by the IPS.
A SOC creates and enforces a defense-in-depth strategy to protecting data by following high-level polices supported by detailed procedures, which all make up the instructions that guide the success of securing data, hence providing information insurance. Pay attention to the language being used throughout this book, as it aligns with how the industry speaks about cybersecurity concepts.
The Impact of a Breach
Why does developing a mature security operations center even matter to an organization? The answer is apparent by measuring the impact of incurring a cyberbreach. The impact includes a wide variety of pain to an organization, starting with potentially huge financial losses. According to the IBM Security Cost of a Data Breach Report 2020, based on independent research conducted by the Ponemon Institute, the average total cost of a data breach is $3.86 million and the average cost per lost or stolen record is $148. Many organizations would not be able to recover from this level of cost, and even larger Fortune 500 organizations would go out of business if a few incidents of this level of cost would occur, assuming they have not invested in cybersecurity insurance. This cost can span across a long period of time based on what is required to do post incident in terms of services, discounts, new tools, and other damages.
Another cost of a breach besides the direct financial impact is the loss of trust in the organization. This could result, for example, in customers not wanting to buy certain technology from the organization or even being afraid to pay for a service through its website due to a fear that their credit card information may get stolen. Depending on the location of where a breach occurs, there could be breach notification laws that require an organization to inform the public of potential losses. For example, some laws require an organization to alert all record owners about a breach based not on whether the adversary actually accessed their records but on the length of exposure and existing forensic evidence indicating the possibility that their records were accessed. An example is the Target breach that Kevin McCoy stated “the data breach that affected 41 million customers.” It’s hard to say that 41 million customers were directly impacted by this breach; however, because the potential existed for those records to be accessed, Target was forced to release that number to the public and alert all of those 41 million customers of the incident.
A third impact of a cyberbreach is potential fines and loss of staff. Some services such as leveraging credit card information (industry regulation) or people’s private data (government regulation) include requirements that must be addressed to protect such data. If a violation is found within a government regulation, fines will be issued and parties responsible for the violation could serve time in jail. Outside of required punishment, many organizations respond internally to a cyberbreach by assigning blame, which may lead to the termination of one or more employees or their reassignment to a different role within the organization. This tends to compound the stressfulness of a security event because the organization then has to replace critical staff in an industry that is limited in qualified talent.
One final potential impact of a cyberbreach is the loss of data. The loss of data could lead to hefty fines and loss of trust, as covered earlier, but there are also other negative outcomes from losing data. The loss of company proprietary data could give competitors an advantage. For example, a breach of sales contacts or documentation on future technology would be devastating to some businesses if their competitors had access to such information. The loss of data can expose employees to identity theft and cause a loss of staff or loss of partnerships with other businesses (for example, according to a 2014 article in the Wall Street Journal, the Sony Pictures hack exposed personal data, including Social Security numbers, of 47,000 Sony employees and Hollywood stars including Sylvester Stallone, Judd Apatow, and Rebel Wilson.”
Any of the previously discussed outcomes will cause a tremendous negative impact on any organization, from small businesses to Fortune 500 companies. Smaller businesses that run on a tighter margin have less resources and can be driven to bankruptcy. Larger organizations might not go out of business; however, they will experience losses leading to stock devaluation and huge costs to return business back to an operational state. It is for these and other reasons that running a mature SOC is critical to the safety and sustainability of any business. Small business can’t live by the concept “we are not important enough to be a target” and larger organizations can’t believe “we have enough resources to handle the blowback from a security incident.” Actions must be taken to reduce the risk of having to deal with a breach. Those actions are the responsibility of the SOC.
Establishing a Baseline
Before you can make any improvements to your security practice, you need to assess the maturity of your current practice. This is an evaluation of everything from how your practice aligns with the goals of your business to your specific capabilities and processes. Consider this a baseline of your existing capabilities and services, which enables you to determine when and where improvements are made or lost. Having a baseline permits the SOC to develop goals for future capabilities and services as well as establish milestones leading to those goals. If you don’t know how to establish your baseline, you can consult frameworks such as the Cybersecurity Framework from NIST and self-assessment strategies, covered later in this chapter, to help develop your baseline. SOC leadership can give rewards and recognition to SOC staff for meeting milestones toward accomplishing development goals as a way to encourage improvements that enhance the SOC atmosphere. SOC members can align requests for resources to specific goals to help justify those requests to non-SOC parties, typically members of nontechnical leadership teams that control the budget. Chapter 2, “Developing a Security Operations Center,” walks you through how to align your SOC to the business.
Note
Details on the NIST Cybersecurity Framework version 1 can be found at https://www.nist.gov/cyberframework/framework. I will reference this and other guidelines throughout this book, as they are great resources for establishing a SOC baseline.
The Impact of Change
Improving the maturity of your security practice comes from making changes. Know that it is close to impossible to receive 100% benefit from any change, because changes also introduce some form of complexity. For example, a new tool might provide value, but there will be complexity involved with setting it up and operationalizing it to obtain any benefit. Sometimes, the tools are so complex that they require many additional steps to use properly, pulling resources and time away from other areas of security, essentially hurting your security capabilities rather than helping them. If this is likely to occur, you should recognize that the complexity outweighs the benefit and avoid the change.
An example of a decision that requires comparing the impact of change is the choice between a free, open-source option and an enterprise option for a specific tool. The open-source tool might not have a cost to acquire it, but it will have a cost to install, configure, learn, and maintain. The enterprise option has an upfront acquisition cost, but it could offer simpler deployment and configuration options as well as include features and support from a vendor that would not be provided with the open-source option. It is important to weigh all of these factors before determining the true cost of a change. You will learn more about comparing investments in building your own tools, using open-source tools, and purchasing enterprise options in more detail in Chapter 10, “Data Orchestration.”
A good change is one where the capability outweighs the complexity. An example of this is improving the SOC’s capability to identify and remediate vulnerabilities, a practice that many organizations find extremely difficult due to a lack of visibility regarding what is on the network and what types of vulnerabilities the known and unknown devices introduce. One method to simplify a SOC’s vulnerability management practice is to leverage network access control and vulnerability management solutions. Network access control (NAC) solutions are designed to automate control of what can and cannot connect to a network. Vulnerability management solutions are designed to identify any known vulnerability, including details based on a Common Vulnerability Scoring System (CVSS) score. A CVSS score provides a way to capture the principal characteristics of a vulnerability and produce a numerical score reflecting its severity. The numerical score can then be translated into a qualitative representation (such as low, medium, high, and critical) to help organizations properly assess and prioritize their vulnerability management processes. Chapter 9, “Vulnerability Management,” covers vulnerability management in much greater detail.
Integrating NAC and vulnerability scanning technologies can automate identification of what is connecting to the network and scanning any device for vulnerabilities upon connection. Many NAC technologies can even limit access to systems that are found to have a critical vulnerability, such as a CVSS of 8.0 or higher. Figure 1-3 is a SANS Institute concept model for vulnerability management best practices that reflects this concept.

FIGURE 1-3 SANS Vulnerability Management Best Practices Concept Model
Automating vulnerability management using these tools and processes is something every organization should consider; however, remember that every change introduces its own level of complexity. Technologies such as NAC and integration with vulnerability management solutions can be complex to deploy. The question that should be asked is whether the benefit of the capability outweighs the complexity. For many medium to large organizations, the answer is yes, due to the existing risk of not having an effective automated vulnerability management program as well as existing efforts used to function in a manual reactive manner. Smaller organizations may not need this level of automation since it would be overcomplicating something that could be controlled at the desktop level by a small IT support team. This is why the capabilities and complexity associated with change will always be specific to the organization to which it is being applied.
It might be hard to recognize the complexity that comes with a capability or service. Many vendors love to promote how easy their technology is to implement and use and they tend to oversell the effectiveness (after all, they are in the business of selling products and services). It will be up to the SOC or an external audit to judge the effectiveness of your capabilities and what could be done to increase your organization’s security effectiveness. I will cover how to audit your security capabilities and services later in this chapter. Before looking at how to audit capabilities, we need to first review the concept of capabilities.
Fundamental Security Capabilities
What are capabilities in regard to security? They are your ability to identify and respond to a threat. Managing risk caused by threats is a key service most SOCs address, which is a topic covered in Chapter 3. What is important in understanding risk is the likelihood that a threat could exploit a vulnerability. Simply put, threats exploit vulnerabilities, and the SOC’s job is to attempt to detect and prevent this from happening. Detection and prevention involve different security capabilities. The security industry is notorious for claiming that security tools can offer complex capabilities such as using human-like behavior (artificial intelligence) to make decisions about whether something is a risk, leveraging cloud resources to further evaluate potential threats, or having layers of different “checks” to catch the stealthiest malware. Some of these claims are true; however, the truth is that there are three fundamental detection capabilities that are used by security tools. Security tools are designed to leverage one or more of three fundamental capabilities: the capability to detect known attacks, the capability to detect known bad behavior, and the capability to detect anomalies (such as unusual behavior by a new type of attack). Industry capabilities can be boiled down to these fundamental detection concepts. Figure 1-4 represents this concept of the three core security capabilities used by security tools to detect and prevent threats.

FIGURE 1-4 Security Detection Capabilities
Signature Detection
Let’s start with the capability to detect known attacks, which relies on signature-based technology. One way to look for known threats is by using signatures that represent detection of specific threats that have been identified before in the security industry. For example, antivirus solutions have many signatures for known malware and will compare files against a list that is continuously updated with signatures of recent threats. Detecting malware could be based on various characteristics, such as a hash of file, but it isn’t as simple as it may seem. There are challenges associated with creating and managing signatures. The more specific a signature is, the easier it is for an attacker to modify an attack to the point of avoiding detection. The more general a signature is, the more likely it could generate false positives, meaning triggering against things that are not actual threats. It is common for adversaries to modify existing malware in a way that changes the look of the file, known as encoding the file. They do this so that the malicious object is seen by an antivirus solution as something different from what is found within its list of known bad files. There are other methods of avoiding detection, including encrypting files, adding useless lines of code, or adding no operations (NOPs). Adversaries can test malware against public signature lists such as VirusTotal to see if malware could possibly be triggered by popular security tools. (If you have never heard of VirusTotal, check it out at https://www.virustotal.com.)
Note
Open-source penetration testing tools such as Metasploit by Rapid7 offer various methods to hide files. For example, you can use Metasploit to encode test payloads and see if your security tools can detect your encoded threat. The creators of Kali Linux, Offensive Security, posted a great article explaining this concept at https://www.offensive-security.com/metasploit-unleashed/generating-payloads/.
Behavior Detection
The concept of detecting known bad behavior is based on actions seen rather than scanning for specific things (pattern matching). Malicious behavior could be anything from a computer scanning the network to a file attempting to gain root access to a system. Returning to my malicious file example, assume the adversary encoded the file so that it is not detected by an antivirus signature. Antivirus software can monitor the file’s behavior to identify it as malicious. Let’s say for this example the file is ransomware, which means it would attempt to encrypt the hard drive of the system it has infected. If ransomware is configured to use asymmetric encryption, it would need to reach out to an external source on the Internet to perform the key exchange before the encryption process can be completed. This means the file will beacon out a web source owned by the threat actor to complete the encryption process. Any of these actions caused by a file should trigger a security tool to prevent the file from proceeding with these actions. This makes behavior rules ideal for validating that threats are not bypassing signature rules.
Anomaly Detection
What happens when a threat is unknown by signature and behavior detection capabilities? This is where anomaly detection can be extremely beneficial. Although detecting anomalies might seem similar to detecting known bad behavior, they are different. Anomaly detection is based on baselining a network and flagging anything that is unusual. For example, some organizations might permit employees to send email from their corporate email accounts to their personal email accounts. Although this activity may occur all of the time in an organization with hundreds of employees, the SOC could configure an anomaly rule that flags when a corporate email account sends an unusual amount of emails to a personal email address. Why would an organization want to implement this rule? This activity could indicate that an employee is about to quit the organization and is emailing a load of sensitive internal material to their personal mailbox before they resign and turn in their computer. For this use case, the rule could be either behavior-based (meaning a set number of emails during a specific time would trigger the alarm) or anomaly based (look at the user’s average email activity and flag an unusual spike based on that specific user). Some users might have a higher average of email activity based on their role, making anomaly detection capable to adjust to real-world activity. One key point that is shown in this example is how anomaly detection isn’t as accurate as other methods. For this example, the email rule could trigger if a legit reason is occurring to send an unusual amount of email from a corporate email account to a personal account. Legit reasons could include a user sending out tons of email for an authorized email campaign or performing a backup of their email.
Note
I experienced the email anomaly detection alarm in my career when I was upgrading my computer. I spent a few minutes sending files over email from my corporate email account to my personal account because it was quicker than connecting an external hard drive or using a cloud hard drive to move files over. My goal was to quickly move files from my old computer to my new computer, which both were connected to the Internet, because I needed to clean my old computer so I could return it to my employer. After I sent around 15 to 20 emails to my personal Gmail account, I received a phone call from human resources asking if I was satisfied with my current position. Based on my unusual email activity, my employer had concerns that I could be leaving the organization. I simply explained I was migrating to a new computer, and that was the end of that conversation. Also note that this rule was not put in place for data loss prevention purposes. If I had sent only a few emails, I wouldn’t have received the call from HR or the data security team since the actual data wasn’t being evaluated. That means the anomaly rule was only designed for a spike in data being sent targeting potential employee flight risk.
Another example of an ideal use of anomaly detection capability is to monitor home appliances that are being connected to the IoT. Imagine a thermostat connected to the network that periodically downloads small updates from the manufacturer’s website. An anomaly alarm should go off if this thermostat starts exporting large amounts of data from the corporate network. Anomaly detection could be combined with behavior detection, meaning the risk in the thermostat example could be increased if the thermostat also starts performing port scanning for the first time, indicating this IoT device is potentially being leveraged by an external party to survey the inside network. Once again, it is important to point out that anomaly detection isn’t always accurate. For this example, the IoT device might be downloading a very large firmware update or might have a new feature enabled that has it send large amounts of data to the vendor.
Note
To avoid false positives, you need to configure security tools to ignore devices that will trigger your security capabilities. For example, you will want to add a vulnerability scanner to an ignore list; otherwise, every time it performs a vulnerability scan, it will trigger reconnaissance alarms in your detection tools.
It is common at a security event to hear a vendor claim their security tool can do a lot more than the three detection capabilities I just covered. Hopefully, knowing how to boil capabilities down to their core concepts will help you understand the true value of tools you are considering for your environment. I point this out because it is absolutely critical to understand which capability you are evaluating so that you can understand what it protects, what it doesn’t protect, and how to maintain it for maximum return on investment.
Best of Breed vs. Defense in Depth
What is the best approach for using the available security capabilities? Is it better to have one very strong capability, known as best-of-breed capability, or to layer different capabilities, known as a defense-in-depth strategy? Best practice is to layer different capabilities rather than using the same type of detection. For example, a firewall permits or denies traffic based on rules. Having multiple firewalls wouldn’t provide any additional defense against an exploit targeting a system over port 80 if all firewalls have port 80 open. What is more ideal is to have an IPS and some form of breach detection layered so that if the firewall permits the traffic, the IPS can analyze the traffic for exploitation. If the attack goes unnoticed, bypassing the firewall and IPS, the breach detection technology, such as an anomaly-based tool, can identify the unusual change to the target and flag it as being exploited. By following this strategy, an attacker has to beat different forms of detection in order to accomplish his or her goal. The more layers with different capabilities, the less likely an attacker will be successful. Figure 1-5 represents the concept of layering capabilities.
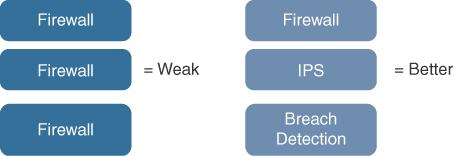
FIGURE 1-5 Best of Breed vs. Defense in Depth
Note
It is important to point out that purchasing multiple firewalls is not a bad investment. Different parts of your network will need their own firewall, hence would be their own string of technology capabilities that include a firewall. Each string of capabilities would be graded independently from the rest of the network’s capabilities, including other firewalls. An example of this is comparing the edge of a company’s network against the security within its private cloud or internal datacenter. It is ideal for organizations to have separate firewall, IPS, and breach solutions for the datacenter and the network edge.
Evaluating Technology
The security market can be confusing with regard to understanding whether the technology you are considering is offering a best-of-breed option or a defense-in-depth option. Vendors often claim their stack of defense-in-depth technology is the best of breed based on how the different capabilities work together. There are resources such as Gartner Magic Quadrants that attempt to categorize a security product and compare multiple vendors within that category based on who they believe is the closest to best of breed. The results of some resources are not technically accurate either because the ranking is influenced by nontechnical data such as customer feedback or vendor financial endorsements or because the tools are tested subjectively. An example of the latter case is a vendor who sponsors a test and rigs the testing criteria in favor of its own product. I once saw testing results for the “IPS Category” show that one vendor had a 100% detection rate while others did not. After further reviewing the testing criteria, I found the test was based on searching for a customized signature that only the tool of the vendor sponsoring the test had enabled! This type of test is obviously not a representation of a real-world use case and is only done as a way to develop a report used to generate sales. My recommendation is to question any report that ranks technology based on the following items:
How is the testing performed?
Who set up the vendor technology?
Who conducted the test?
Is the latest version of each vendor technology being evaluated?
Has the vendor confirmed its tools were properly configured?
Is the test based on real-world situations and based on vendor-neutral concepts?
Are there nontechnical factors such as vendor sponsorship or other potential bias in the results?
Do the associated vendors agree with the results?
Were some vendors given access to the testing criteria before the tests were performed?
Basically, you are looking to see whether all tools were tested in a fair manner. I recommend to always question the results of these types of tests rather than trust them at face value. While I was employed for one security vendor that was involved with all of the leading third-party evaluation reports, I was shocked to find how much effort was required to participate with groups such as Gartner and NSS Labs (no longer in business). Effort included hundreds of hours of top engineering time, travel between testing facilities, providing hundreds of thousands of dollars of free equipment, countless hours involved with analyzing alpha/beta results, and responding to questions from the third-party evaluation team. There are smaller vendors with great technology that can’t endure the financial burden associated with some third-party tests, leading to poor results that are not truly accurate as to how the tool actually performs against competitive technology.
Researching Technology
My recommendation regarding determining what is the best solution for your organization is to use a combination of external resources, align what you find to your business goals, and test. Testing can be challenging based on the capabilities involved as well as general performance concepts such as providing the promised traffic throughput when capabilities are enabled. One example of a common challenge security tools deal with is encrypted traffic. One workaround is having the capability of decrypting traffic so it can be evaluated by a security tool and encrypted before sending it on to its destination. This decryption/encryption process will impact performance and is important to consider as a tool is evaluated. I have seen performance losses as high as 60 to 80% when certain security capabilities are enabled. Make sure to start your testing criteria with how the tool should be sized for your needs and if your desired capabilities will still deliver the expected performance.
When testing capabilities, it is common to use testing tools to speed up the process as well as to provide a third-party, vendor-agnostic view of the testing process being delivered. BreakingPoint is an example of a tool that can apply stress to a tool to evaluate how it performs under real-world conditions. Tools such as BreakingPoint also can provide templates for common attacks, sometimes called a strike pack, which can be used to test how a security tool detects and prevents attacks. To avoid obtaining inaccurate results, it is absolutely critical to consider how close to real-world conditions a strike pack is designed to represent. Using an outdated strike pack would mean testing security tools for threats that might not exist anymore or have been patched; hence, the security tools may no longer be blocking certain attacks launched by the strike pack, resulting in a reported miss even though the threat really doesn’t exist since a patch would mean the vulnerability has been mitigated. Consultants such as technology resellers that have access to different vendors can help with building a lab to test different vendor capabilities as well as provide their experience with different tools.
One common question I often receive is, “I understand how to test security tools when I know what I’m looking for; however, how do I know what security capability my organization needs based on our existing investments and, more importantly, which tool should I buy first?” Essentially, the question is asking what materials should be referenced prior to researching what is best of breed for a specific security capability. My answer to this question is to not rely solely on the advice of a specific vendor or even a third-party consultant. Both parties can evaluate your organization and provide recommendations; however, both parties could also be financially motivated to recommend specific technology, hence offering biased advice. To truly obtain a vendor-neutral view of what security tools you need to consider for your organization, you should leverage industry standards, guidelines, and frameworks.
Standards, Guidelines, and Frameworks
Many organizations look to industry standards, guidelines, and frameworks for help with developing security architectures for their environment. With the exception of industry standards such as PCI DSS, standards, guidelines, and frameworks provide recommendations and guidance that organizations can choose to follow, not mandatory practices that they are required to follow for compliance reasons. Many organizations will turn industry recommendations into corporate policies, which could have both advantages and disadvantages. Benefits of standards, guidelines, and frameworks come from how they are typically developed by industry experts and tested against common threats such as using threat modeling, which is a topic I cover shortly. Recommendations from standards, guidelines, and frameworks are usually vendor-agnostic and focus on capabilities and services generic enough to provide value to any type of organization.
The downside of these resources is that they take time to develop and update, during which time threats continue to rapidly change. I have seen situations where technology is found to be vulnerable and the manufacturer has developed a fix, but the customer will not install the fix until the version of software meets an industry standard, guideline, or framework. This exposes the customer to unnecessary risk during the time it takes for industry recommendations to catch up with the change in the threat landscape. Recommendations from these sources can also be too generic to address threats that are specific to an organization. As an example, suppose an organization has an HR employee who will open any resume file without considering security. The risk of the employee exposing the organization to malware infection could be reduced by following generic framework recommendations for implementing segmentation and anti-malware; however, to fully address this situation effectively, the organization also needs to directly educate the user of the malware risk and develop a specific process to sanitize files before they are sent to the user. The key point of this example is that you should use standards, guidelines, and frameworks only as a baseline for your security architecture rather than as an all-encompassing blueprint for implementing security in your specific environment. Organizations need to develop their own maturity-grading structure and work on improving security based on what matters to their specific organization, which will extend well beyond the average standard, guideline, and framework.
Note
Many of these external security resources now include self-assessment procedures to help an organization more closely align the recommendations with what the organization actually needs to implement. As a result, fewer adjustments are needed to be made outside of what is being recommended by the specific guidance the organization needs to incorporate. I believe that this trend of including self-assessment capabilities within standards, guidelines, and frameworks will continue and the capabilities will get even better.
Some examples of commonly used standards, guidelines, and frameworks are NIST, ISO, and frameworks from FIRST.org. Chapter 6, “Reducing Risk and Exceeding Compliance,” will cover each of these in greater detail. For now, let’s take a quick look at each of these resources, starting with what NIST has to offer your SOC.
NIST Cybersecurity Framework
The National Institute of Standards and Technology (NIST) developed the NIST Cybersecurity Framework (CSF), one of the most popular frameworks consisting of standards, guidelines, and best practices related to dealing with cybersecurity-related risk. The latest version, CSF Version 1.1 (https://www.nist.gov/cyberframework), presents a Framework Core based on the following five Functions, as depicted in Figure 1-6 (from NIST):
Identify applies to managing systems, people, assets, data, and capabilities.
Protect focuses on defending services.
Detect covers how to identify that a specific event has occurred.
Respond is what actions are taken when an incident is detected.
Recover applies to how an organization attempts to be resilient during the attack as well as how to restore services impacted by the event.

FIGURE 1-6 NIST Cybersecurity Framework Core
Within this Core Framework are Categories, Subcategories, and Informative References, which all are methods to further divide the five functions into more focused topics. For example, the Protect Function includes a Category named Identity Management and Access Control (PR.AC), which has a Subcategory labeled PR.AC-7 that specifies that users, devices, and other assets must be authenticated commensurate with the risk of the transaction. The industry references 802.1X as a leading method for providing access control with multi-factor authentication, meaning it isn’t required but highly suggested by the industry. Figure 1-7 shows the structure of the 2018 NIST Framework Core as presented by NIST in CSF Version 1.1.

FIGURE 1-7 NIST Framework Core Structure
Using NIST
Many SOCs will review NIST recommendations and develop requests for capabilities they feel will improve their security based on how NIST grades the maturity of that specific Category or Subcategory within the Framework Core. Returning to the example of the PR.AC Category within the Protect Function, it includes best practices for controlling physical access to assets, handling identities and credentials, provisioning remote access, and so forth. Best practices found within this category include controlling physical access to assets, how identities and credentials are handled, and how remote access is provisioned. The NIST CSF also includes references to other industry guidelines to back up its recommendations. The Informative References section of the PR.AC Category includes references to ISO/IEC 27001:2013, COBIT 5, ISA 62443, and CIS CSC, including specific section references, confirming how the NIST CSF document aligns directly with other industry guidelines.
Recommend practice dictates that you download the latest version of the NIST CSF and validate your existing capabilities against each Category NIST covers. Doing so not only can help you identify areas of improvement but also can give you a list of Informative References to back up why you are requesting a people, process, or technology change. I have seen customers achieve success using the NIST CSF in this manner. An example is a member of the SOC team presenting to executives within the organization the risk of not having access control before requesting budget to purchase technology, services, and training for the access control capability. The SOC can back up the request by citing the recommendations of the NIST CSF and the other authoritative resources it supplies. Validating your budget request by citing best practices issued by well-regarded third parties can go a long way toward convincing decision makers who don’t understand the technology!
Some organizations treat NIST recommendations as mandatory policy, making budget request conversations much easier. For example, U.S. military organizations use NIST documentation for many of their policies. I see that organizations which follow NIST in this fashion will identify any published NIST requirement, and if they don’t have whatever technology is being suggested by NIST, they buy it. No questions asked. It is also important to point out that NIST has many other publications for areas outside IT that can provide value to your organization.
Note
If you have not explored the vast array of NIST documentation, visit https://www.nist.gov/publications
ISO 3100:2018
Another source of popular guidelines is the International Organization for Standardization, more commonly known as ISO. Like NIST, ISO is made up of vendor-agnostic industry experts that provide industry best practices. ISO is a worldwide federation and is well respected in the IT industry. Some organizations will even talk about being ISO certified even though ISO does not certify organizations meaning the certification part is developed by third parties. The most that an organization can legally claim is that its product or system has been certified to a specific ISO standard by an accredited certification body, such as marketing a product as “ISO 9001:2015 certified.” People and organizations talk about being ISO certified as a means to show they take cybersecurity seriously, so they can win over customer trust.
ISO 3100:2018, Risk management – Guidelines, helps organizations to deal with risk. The 2018 version replaces the 2009 standard and, like any guideline, is voluntary. There are three risk management focus areas for ISO, which are based on Principles, Frameworks, and Processes. Risk Management Principles targets how to develop an approach that is structured and comprehensive. This will take into consideration many factors such as what is valuable to the company, culture elements, how to ensure improvement, and so on. The end goal is to ensure the risk management approach is effective, dynamic, and customized to your organization’s needs.
The risk management framework attempts to identify business goals and establish a formal framework that is sponsored by leadership. Having leadership’s buy-in is critical and is a concept you will find not only in ISO but also many other guidelines covering SOC mission statements and business objectives. The ISO framework has five parts that are designed to be repeated, with the last step as Improvement, emphasizing that security needs to continue to improve. I will cover ISO in much more detail in Chapter 6.
Note
Learn more about ISO standards at https://www.iso.org/standards.html
FIRST Service Frameworks
FIRST.org is a nonprofit that brings together incident response and security teams from every country across the world to develop best practices for cybersecurity. One very useful guideline provided by FIRST is the FIRST Services Framework. The FIRST Computer Security Incident Response Team (CSIRT) Services Framework (version 2.1.0 at the time of writing) provides recommendations for areas of services used by CSIRT teams around the world. Those service areas include Information Security Event Management, Information Security Incident Management, Vulnerability Management, Situational Awareness, Communication, and Knowledge Transfer. Recommendations are broken down into service area, service, and function. For example, the service of Information Security Management provides the service of monitoring and detection, which has multiple functions including log and sensor management, detection use case management, and contextual data management. The CSIRT Services Framework explains what is expected from each function to help guide other CSIRT operations on what expectations would exist within these services.
FIRST also offers a similar framework for product incident response teams (PSIRT). The PSIRT Services Framework defines the scope and operational activities of a PSIRT without the change actions an organization needs to take with regard to the specific products impacted at the organization. This is critical to provide value to any organization regardless of which products that organization is responsible to protect. Activities are specific to the PSIRT rather than what an entire organization would do. Figure 1-8 is a high-level diagram of what general PSIRT activities would entail.

FIGURE 1-8 General PSIRT Activities
Applying Frameworks
As previously discussed, you can use a NIST, ISO, or FIRST framework to validate your security capabilities and services based on industry best practices and reference that framework to request budget for change in people, process, and technology. Other industry standards, guidelines, and frameworks provide similar value, such as what is offered by SANS, ISACA’s COBIT, and the Center for Internet Security (CIS) control, each of which gives another take on what experts consider are best practices. Just be mindful of the concepts pointed out earlier regarding how any of these reference materials have limitations based on how often they are released, how they must be generic enough to apply to most organizations, and many other factors that could lead to hurting your security posture if not leveraged properly. Frameworks are a core focus of Chapter 6.
The best way to use the recommendations from standards, guidelines, and frameworks is to apply them based on the specific areas of risk and threats your organization wants to be prepared for, identified from the results of using threat modeling and tabletop exercises. This will make the results of using standards, guidelines, and frameworks more accurate to what needs to be protected with your organization and why it matters. For example, let’s look at comparing the security requirements for two schools. One school may permit teachers to access the network only while on campus, while the other school may permit teachers to use remote-access technology to work from home. This means the school permitting remote access would need to consider the associated risks of attacks over VPN, malware that could be introduced by systems connecting over VPN, and the whole process behind implementing and enforcing security for VPN users. The other school would not have to worry about this threat vector. For this example, the school looking for recommendations to secure the VPN service could seek guidance from NIST or ISO for best practices for people, process, and technology in the area of VPN security.
There is a difference between security concepts and the reality of security you need to provide to your organization. Industry standards, guidelines, and frameworks are great isolated use cases for referencing how you should design your security, but as shown in the previous example of comparing two schools, every business is going to function differently, leading to different security needs. Your security needs today will be different tomorrow, meaning you need to accommodate ongoing changes as you manage your security practice. Part of the focus of Chapter 6, “Reducing Risk and Exceeding Compliance,” is how to build policies, which provide very high-level guidance and don’t change often, and procedures, which are more specific than policies and constantly change. The bigger challenge is to understand why change is needed and when it should occur. The answer to this challenge is not only understanding what is considered security best practice, but also understanding your potential threats. One popular method used to evaluate how a threat could attack different parts of a network is the use of threat modeling. Threat modeling can also help with developing your criteria for the security technology you plan to acquire. Next, I will look deeper into the concept of threat models.
Industry Threat Models
The security industry uses threat models to represent attack and defend concepts. The purpose of these models is to help organizations understand the type of capabilities they need as they develop a defense-in-depth architecture. For example, it is common for gateway or edge technologies, such as firewall/IPS and host-based firewall/IPS, to be heavily focused on preventing exploitation by using signature-based capabilities. The reason is that these are the first line of defense technology, which will see the most malicious traffic. When the first line of defense fails, the next phase of the attack is to establish a foothold and do things with the newly compromised system. The goals for the capabilities to counter this stage of the attack are different because these capabilities assume the gateway tools have failed. It is common for breach detection tools to be more behavior- and anomaly-based because the failed gateway tools tend to be more signature-based. In the real world, the gateway and breach detection tools can have a combination of all three capabilities, but what is key to understand is that different steps of an attack will have different types of objectives for the associated defense. The same concept applies based on different areas or types of devices, meaning email defense is different from network defense, and web application defense is different from network defense.
As organizations pile on all the possibilities for the types of tools potentially needed, they become overwhelmed and need industry threat models to help them understand what tools and technology apply to their business needs based on the types of threats they expect to encounter.
The Cyber Kill Chain Model
One of the most popular threat models used in the industry is the Cyber Kill Chain created by Lockheed Martin. Figure 1-9 is an example of the Cyber Kill Chain showcasing the lifecycle of a common cyberattack, which is an external party exploiting and gaining keyboard access to a victim’s system.

FIGURE 1-9 Generic Cyber Kill Chain Threat Model
The best way to understand the Cyber Kill Chain is to analyze each step of the attack lifecycle, starting with preparing the attack and ending with full-blown keyboard access to the exploited system.
Reconnaissance: The attacker researches the target by probing and assessing publicly available content. This can also include harvesting login credentials or scanning for open ports on Internet-accessible systems. This step is critical for the attacker to learn what is the easiest and more effective method to compromise the target.
Weaponization: Using data found during the reconnaissance phase, the attacker develops an attack technique or tool based on the easiest and most effective route to compromise the target network or system. This could be wrapping software with malware, building an exploit using a tool like Metasploit, creating a phishing email that asks for data, or linking a file to a malicious website. This step could also include testing the attack against known security tools like VirusTotal.
Delivery: The attacker makes contact with the target and delivers the exploit that was built in the weaponization step. This is the first step in which the attacker interacts with the victim. This could be the result of a user clicking the wrong link, for example, exposing the system to the attacker’s malicious tool.
Exploitation: The cyberweapon is delivered and abuses a vulnerability within the target. This causes unwanted behavior such as opening a backdoor on the system or taking down security defenses so that the attacker can install a payload. This could harm the system, but the real damage is what follows this step.
Installation: Once the victim’s system is compromised, the attacker can use the exploit to install malware on the target. Installation is the result of a successful exploitation of a system. Malware can be anything from ransomware to crypto mining to a remote access tool (RAT).
Command and Control: One common step that follows the successful installation of malware is beaconing back to the attacker to inform them that the victim’s system is available to control. Once the attacker knows the system is available to access, he or she can remotely connect and take control of the compromised asset. This is common for attacks that are not targeted, meaning they exploit any victim that can be attacked and wait to see which victim is successfully exploited through the call back from the compromised system.
Actions and Objectives: The final step could be anything from stealing data to taking down the victim. In the real world, many cyberattacks are a combination of multiple attacks, meaning multiple kill chains are executed. For example, if an attacker was targeting the datacenter of an organization, they would need to breach systems on the network edge and pivot between internal systems to eventually make their way to the environment that contains the datacenter servers.
Know that all attacks do not have to follow this particular attack flow, meaning sometimes the attack situation does not apply to this model. A user logging into a fake website and having their password stolen would be a different attack model. The threat caused by user error that takes down the network would be a completely different model. The Cyber Kill Chain model is specific to a threat actor attempting to compromise a network by gaining direct control of the compromised system, typically using a tool that provides keyboard access, which can be any of a variety of types of exploitation, such as browser injection or software abuse, or any type of endpoint compromise, such as installing a RAT or dropper.
Using the Cyber Kill Chain
When would you use the Cyber Kill Chain model, and why consider a model based on only one type of attack? It can be beneficial to understand how your capabilities and services match up to the steps associated with the Cyber Kill Chain threat model based on the range of exploitation and malware that could be used in this fashion. Keeping the model generic allows for change in attack behavior, such as ransomware moving to crypto mining, or flash exploitation changing to using an EternalBlue exploit (Microsoft vulnerability). The specifics don’t matter since you are measuring layered capabilities and services against the entire lifecycle of the attack, not just a specific step of the attack. Preventing the attack at any point is a win for the defender. The earlier the prevention occurs, the bigger the win it is for the defender.
The first step of the Cyber Kill Chain model represents how malicious actors research and prepare an attack based on what they find using various forms of reconnaissance. Defense strategies include methods to limit how a system is exposed to outside parties and preventing access to high-risk external resources. Think about how to prevent an attack before it happens by reducing the exposure of being attacked. If an outsider can scan your systems for vulnerabilities, attackers will do that as a way to find your weaknesses. If your employees can access any website regardless of its potential risk, employees are going to connect to websites that will attempt to exploit their systems (commonly referred to as exploit kits). If your physical network ports are not performing any form of access control, you are at a high risk of the wrong person plugging something into your network. In summary, if you use technology and best practices for limiting exposure, attackers will have a harder time identifying your weaknesses and, hopefully, will either attack somebody else or attempt to exploit you where you are monitoring and better prepared for attacks. One common saying in the industry is that your weakest link is your highest level of security. This translates to attackers will find where you are most vulnerable and hit you there.
The middle part of the Cyber Kill Chain looks at how the attacker abuses a vulnerability to gain access to the system. Common exploitation includes abusing out-of-date Java or Flash software or tricking somebody into installing malicious software. Security strategies should prevent the exploitation by identifying the attack and blocking it or quarantining the malicious software before it can install. Capability examples include intrusion prevention, antivirus, and other signature-based detection technology.
Note
As you will read in Chapter 3, many signature-based detection tools leveraging known threat signature lists are filled with enabled signatures that do not apply to what they are supposed to be protecting. Huh, that doesn’t sound right. Think about the different types of customers that use a vendor’s technology. How could a vendor automatically know what to protect for a large retail store, oil company, school, and casino using a default signature category shared by these different organizations? The truth is, it’s impossible! Instead, vendors provide a best guess at what all customers will need protection from. This means that a significant number of signatures enabled by default on many vendor solutions are looking for things that don’t exist on your network. This also means there are things on only your network that signatures are not enabled for using default signature settings. This is why tuning security solutions is so important. Tuning can only happen if you understand what you are trying to protect through the use of vulnerability management, understanding how the tool operates, understanding what capabilities the tool leverages, and threat modeling.
Many customers I speak with have some form of signature-based security, and many employees in those organizations are hyper-focused on monitoring detection-based alarms. This can be a bad thing if all security capabilities and services are designed to prevent the exploitation part of the Cyber Kill Chain model. Every organization needs to prepare for a threat breaching their defenses based on the likelihood that either the organization will miss securing a vulnerability or malware will use a method that will go undetected by the organization’s existing security defenses.
The final steps of the Cyber Kill Chain look at the result of a successful attack. Attackers can use an exploit to push malware to systems, disable security features, take down systems, and perform many other nefarious actions that will negatively impact your business. An example of the results of an attack is the attacker overloading a switch to cause it to become a hub, essentially opening up the ability for an attacker to hop between networks. Another example of the result of a successful exploitation of a system is exploiting a server and installing a backdoor, permitting the attacker to gain remote control of that system. With control, the attacker can accomplish his or her goal, which may be repeating the kill chain within the target’s network to compromise internal systems, remove data, or shut down the system.
It is critical to use some form of breach detection and continuous monitoring capabilities to validate that previously covered capabilities and services are effective. An example of a breach detection technology is baselining the network and looking for anomalies. Another example is placing vulnerable decoy systems, or honeypots, on the network that will alarm the SOC when attacked. These tools could also be bypassed if the attacker knows how to beat them, but the goal of these capabilities is to be different than other capabilities to provide another layer of detection beyond what is at the perimeter of a network or first layer of defense on a host system.
Different Kill Chain Models
One key concept to consider is where you apply a threat model. For example, before using the Cyber Kill Chain threat model, you need to determine what part of the network you want to evaluate. A host laptop has a different kill chain than a datacenter. Both environments may have antivirus and an IPS, but a laptop’s traffic is based on a single user and would require different tactics to attack than attempting to exploit a datacenter monitored by a SOC within a company’s network. It is important to evaluate different parts of your organization using the Cyber Kill Chain principles while also considering the specifics to the environment. Your goal as the defender is to “break the kill chain” as early as possible; hence, this threat model helps you to prepare for hypothetical cyberattack behavior so that you can evaluate your defenses against each step of the attack. (I will touch more on how to perform a capabilities assessment later in the chapter in the “SOC Capabilities Assessment” section, which looks at what capabilities and services you could use to break the kill chain.) Figure 1-10 represents different parts of the network that could be targeted by an attacker. Each part of the network should be assessed by its own version of the Cyber Kill Chain threat model.

FIGURE 1-10 Various Network Targets
The Diamond Model
The Cyber Kill Chain threat model is a very effective method to evaluate one specific type of attack behavior; however, there are many other ways an adversary could attack your organization. I’m not downplaying leveraging the Cyber Kill Chain, as it is extremely valuable to assess your capabilities against the threats represented during each step of the Cyber Kill Chain. The challenge is considering scenarios in which the attacker approaches your defenses in a different method than represented by the Cyber Kill Chain. Rather than collecting multiple threat models that play through all of the different potential attacks, other threat models review attack behavior from a more holistic viewpoint, providing a way to accommodate any type of attack. One popular threat model that uses more of a broad look at potential threats is the Diamond Model of Intrusion Analysis, commonly known simply as the Diamond Model.
The Diamond Model is designed to represent a security incident made up of four parts, as shown in Figure 1-11. Active intrusions start with an adversary who is targeting a victim. The adversary uses various capabilities along some form of infrastructure to launch an attack against the victim. Capabilities used by the attacker are various forms of tools, techniques, and procedures (TTPs), while the infrastructure is what connects the adversary and victim. The lines connecting each part of the model depict a mapping of how one point reaches another. For example, a SOC analyst could see how a capability such as a phishing attack is being used over an infrastructure such as email and then relate the capabilities back to the adversary. All concepts represented in the Diamond Model are high level by design to accommodate different types of threats, making this model much more general in its approach than the Cyber Kill Chain.

FIGURE 1-11 The Diamond Model of Intrusion
Moving between each part of an attack is called analytic pivoting and is key for modeling the event. The Diamond Model also includes additional meta-features of an event (see Figure 1-11), such as a timestamp, kill chain phase, result of the attack, direction of the attack, attack method, and resources used. An example of a meta-features list might show a timestamp of 1:05 p.m., a kill chain phase of exploitation, a result of success, a direction of adversary to victim, an attack method of spear phishing, and resources related to a specific vulnerability on the victim’s host system. Meta-features provide useful context but are not core to the model, so they can be disregarded and augmented as necessary.
Extended Diamond Model
The Diamond Model can be further expanded by adding two additional meta-features that establish connections between relations. The technology meta-feature connects capabilities and infrastructure by describing the technology used between these two parts of the model. An example of a technology meta-feature could be the Domain Name System (DNS) if it is used by malware to determine its command-and-control point. The social-political meta-feature represents the relationship between the adversary and victim. This is critical to determine the intent behind the attack so that the analyst can understand the reason the victim was selected and the value the adversary sees in the victim, as well as sometimes identify a shared threat space, meaning a situation where multiple victims link back to the same adversaries. A shared threat space is similar to threat intelligence insofar as it is a way of understanding threat actors in a specific space to potentially forecast and react to future malicious activity. An example might be threat actors identified for launching an attack campaign against schools. Figure 1-12 represents the extended version of the Diamond Model.

FIGURE 1-12 The Extended Diamond Model of Intrusion
Diamond Model for Incident Management
Each incident is considered a diamond using this threat modeling approach. An incident management practice should use the Diamond Model as the basis for grouping and organizing incidents. The goal would be to review multiple diamonds and identify a common adversary. For example, let’s consider an attack where the adversary is delivering ransomware to a victim. The first part of the attack could involve the adversary using a malicious email message to trick the victim into accessing a website. The goal is to have the website scan the victim for vulnerabilities and deliver ransomware by exploiting one of those weaknesses. The first stage of the attack could be represented as one diamond, as shown in Figure 1-13.

FIGURE 1-13 Diamond Model for Stage 1 of Ransomware Attack
Stage 2 of the attack follows the phishing email that redirected the victim’s system to the malicious website. Now that the victim’s system has accessed the website, the malicious website will push down the ransomware by exploiting a vulnerability. The adversary is still the same attacker; however, the capabilities and infrastructure involved with the second part of the security incident have changed, which is common when identifying all stages of an attack according to the kill chain concept. Figure 1-14 showcases a diamond for stage 2 of this attack.

FIGURE 1-14 Diamond Model for Stage 2 of Ransomware Attack
Instances of the same event occurring over the course of a few weeks could be linked together through multiple diamonds and then linked back to the same adversary. Linking the spear-phishing attack to the delivery of ransomware can give an analyst a method to diagram the attack and all associated adversaries. The incident response team can create an activity group based on the various connected diamonds and attempt to define what combinations of elements are criteria for grouping diamonds together. As new diamonds appear, activity groups can grow as diamonds are grouped together based on newly available data. The relationships between diamonds are known as activity threads, which can spread across the same attack as well as connect other attacks, depending on intelligence gathered that meets activity group requirements. Figure 1-15 provides an example of building an activity thread based on the previous sample attack data.

FIGURE 1-15 Developing an Activity Thread
Figure 1-15 shows an adversary is linked to two different attacks against the same victim as well as possibly another victim, represented with the dashed line. There is also another possible adversary attacking a similar victim as the previously identified adversary. This visibility into the attack data gives analysts the ability to integrate any hypotheses that can be tested as additional evidence is gathered. The activity thread process displays the current research status, which can help an analyst identify knowledge gaps and adversary campaigns through documentation and testing proposed attack hypotheses.
Diamond Model Attack Graph
Once the incident management team builds a decent-sized activity group mapping out multiple incidents, the team can better analyze the data to fill in missing knowledge gaps and potentially start to predict future attack paths. This threat intelligence data can be built into a graph, known as an attack graph, representing the paths an adversary could take against the victim. Within the attack graph are activity threads, which are paths the adversary has already taken. Combining the attack and activity data gives the team an activity-attack graph, which is useful for highlighting the attacker’s preferences for attacking the victim as well as alternative paths that could be used. This gives the incident response team a way to focus efforts on defending against the adversary, by knowing where to likely expect the attack as well as being aware of other possible risks to the victim. Figure 1-16 is an example of an activity-attack graph for my ransomware example.

FIGURE 1-16 Activity-Attack Graph Example
If the analyst was concerned that this was a persistent attack, using the activity-attack graph could show not only where defenses should be considered for the identified active attack but also additional areas that could be used by the adversary and therefore should be secured proactively. By grouping common malicious events, adversary processes, and threads, the analyst can create activity groups. Figure 1-16 would help the analyst determine which combination of events makes up an activity group based on similar characteristics. Activity groups can then be grouped into activity group families used to model the organizations behind the various incidents, such as identifying a particular organized crime syndicate. The end result could be the identification of a particular group out of Ukraine attempting to plant ransomware at a specific U.S.-based hospital through the analyst grouping together various events against multiple hosts linked to the hospital.
The Diamond Model is a broader view of attack modeling that allows you to accommodate different attack types as well as identify association between attacks that can represent a larger attack campaign. The Diamond Model also includes the flexibility to add details about the attacker to better understand intent, leading to better decisions based on predicting behavior. This approach to threat modeling lacks some details regarding how an attack is carried out but offers a lot of value regarding general planning against attack behavior.
One final model to consider is a hybrid approach between the value seen from the Cyber Kill Chain and Diamond threat models: the MITRE ATT&CK model.
MITRE ATT&CK Model
Another globally accessible resource for modeling adversary tactics and techniques based on real-world observations is the MITRE ATT&CK knowledge base. This can be used for development of specific threat models and methodologies based on common adversary behavior for emulation and intrusion detection research. Customized threat models based on continuously updated real-world data can be more accurate than the Cyber Kill Chain and Diamond models, which can lead to a better view of detection of post-compromise cyber-adversary behavior.
ATT&CK organizes the ecosystem an adversary operates within as technology domains. Adversaries must circumvent or take advantage of the ecosystem in order to accomplish a set of objectives. The two ATT&CK domains are enterprise networks and mobile devices. Within these domains are the platforms representing the systems the adversary operates within. Adversaries apply techniques to one or more platforms, which is how the adversary attempts to accomplish its goal. This approach is similar to the broad view of an attack offered by the Diamond Model but offers tons of details, such as describing the technique, which platforms apply to the technique, system requirements for the technique, permission requirements, data sources, examples, detection strategies, and even mitigation recommendations. Figure 1-17 shows a high-level view of how ATT&CK represents an attack model relationship. Notice that the goal or end result of an ATT&CK model is labeled as a tactic, which explains why the adversary is performing the previous actions.

FIGURE 1-17 ATT&CK Model Relationships
PRE-ATT&CK Research
ATT&CK also includes behavior beyond what occurs during an attack within the PRE-ATT&CK research. PRE-ATT&CK covers documentation of adversarial behavior during requirements gathering, reconnaissance, and weaponization, before exploitation leading to access to an unauthorized network is identified. This is similar to the first few stages of the Cyber Kill Chain, but the results from PRE-ATT&CK are much more specific and based on recent real-world data. Figure 1-18 shows a matrix representing many of the steps of a potential attack against an enterprise.

FIGURE 1-18 Part of the MITRE ATT&CK Matrix for Enterprise
Using MITRE ATT&CK
Common use cases for using ATT&CK details shown in Figure 1-18 include improving an organization’s ability for detection and analytics based on threat modeling, providing a form of threat intelligence, emulating adversary behavior, and assessing existing security capabilities. This can occur based on working through the ATT&CK matrix and chaining together tactics, leading to a very powerful visual of the process that was taken by an adversary. Remember that a single attack will have multiple steps; the ATT&CK threat model offers a way to collect all of those steps and “chain” them into one larger attack. Figure 1-19 provides an example of how this chaining of attack steps could look as the ATT&CK model is leveraged to better understand the attack behavior of an adversary.

FIGURE 1-19 Chaining Together Attack Behavior Using ATT&CK Modeling
Note
Learn more about the MITRE ATT&CK model at https://attack.mitre.org/.
Choosing a Threat Model
The ATT&CK approach to threat modeling can seem overwhelming based on the level of provided detail, which is why simpler threat models such as the Cyber Kill Chain and Diamond models are still being used today. The best way to choose a threat model is to be outcome-focused and match the best approach based on obtaining your desired outcome. There are other industry models that can also be used to represent hypothetical attack and defend concepts. I highlighted the Cyber Kill Chain, Diamond, and ATT&CK models because they are very popular threat models used by many industry professionals, and each model offers a different approach to threat modeling leading to different types of value.
One challenge with these threat models is that they might be too hypothetical for some use cases, such as deciding which specific capability or service should be selected to respond to a potential threat or risk. Performing tabletop exercises is a more common practice used by many SOCs to hypothetically test security capabilities. These are meetings that walk through various attack situations without actually performing the attack and defend behavior. For example, a company could gather the head of desktop support, management, human resources, and the SOC team to go over what should occur if a cyberbreach such as one from the Cyber Kill Chain example is detected. Each team member could act out their role with the goal of testing if a process is in place and how it could work for that situation. I will cover how to perform a tabletop exercise in Chapter 4, “People and Process.”
Threat models are useful for understanding what threats and risks could impact your organization. One key point to take away is how threats abuse vulnerabilities; without vulnerabilities, the threats are no longer a risk. This means that in order to deliver strong security, you must understand not only what are best practices for security and the potential threats, but also where you are vulnerable. The next topic to introduce is vulnerabilities and risk, which will also be the focus of Chapter 9.
Vulnerabilities and Risk
Vulnerabilities are weaknesses that can be exploited by an attacker. For example, a vulnerability could be a door that is unlocked, opening the possibility of an intruder walking through it. A vulnerability could be a system missing a security patch, exposing a weakness that an attacker could digitally leverage to cause unwanted behavior. A vulnerability could even be an oversight in a business policy, such as setting a password policy that requires passwords to be a minimum of six characters and a maximum of eight characters and have a special character at the end. Why could this password policy be considered a vulnerability? If an attacker discovers this policy is being used by a specific organization, the attacker can adjust brute-force tools to search only for passwords that are six to eight characters and include a special character as the last character, dramatically reducing the complexity of guessing the password. Essentially, the brute-force attack does not have to attempt any passwords shorter than six characters or longer than eight characters and can assume that the last character is one of only a handful of special characters.
Looking back at the Cyber Kill Chain model, the hypothetical attacker in that threat model is exploiting a vulnerability to deliver a payload. This means that if a vulnerability doesn’t exist, the attacker can’t deliver the exploit. An example of removing a vulnerability is applying a patch that fixes the known weakness in code. The attacker can also be prevented from exploiting the vulnerability by using a defense tactic. That means the vulnerability continues to exist but the attacker can’t exploit it to accomplish his or her goal. An example of this is using a security tool such as an IPS to block exploitation behavior against a vulnerable system.
Endless Vulnerabilities
It is important to realize that all organizations have vulnerabilities and that there will never be a point when all vulnerabilities can be identified and patched. One reason for this is that networks and systems are constantly changing, which continues to introduce new vulnerabilities. Another reason is that technology changes cause errors to occur as new versions or capabilities are introduced. An even more common cause of vulnerabilities is how technology is used by people. The technology might not be vulnerable if used a certain way; however, people could misconfigure or misuse technology outside of how it was intended to be used, causing a vulnerability. An example of a misuse of technology is placing a honeypot within the network and configuring an external connection. This is a bad idea because a honeypot is designed to be so vulnerable that it would attract a malicious element. Including an external connection would mean sources outside the network could use the honeypot to access the internal network, essentially turning the honeypot into a gateway for threat actors to breach the network.
Security tools are ideal for identifying and preventing threats from exploiting vulnerabilities. It would be ideal to fix all vulnerabilities; however, that will not happen for the previously described reasons. This means security tools can identify and prevent exploitation of a vulnerability until the organization is able to fix the vulnerability. In some cases, such as the IoT examples previously covered, a fix may not exist or be possible.
In many organizations, the SOC is responsible for managing vulnerabilities or partners with system support to oversee vulnerability management to ensure risk of exposure is reduced and ensure security technology and services are protecting where the most critical vulnerabilities exist. The key focus here is that vulnerability management is a risk reduction effort, meaning that it falls under the risk management services because vulnerabilities are a subset of the many things the make up what a risk is to an organization. Chapter 6 covers risk management concepts in more detail, while Chapter 9 provides a more focused conversation around vulnerability management best practices.
Technical vulnerabilities are not the only challenges a SOC is responsible to deal with in regard to risk management priorities. There are many business challenges and threats that introduce risk into an organization, which should be included under a SOC’s risk management practice. Let’s look at some of those business-related risks.
Business Challenges
Earlier in this chapter you learned about the challenges that organizations face that lead to a future compromise regardless of having a security program and security tools in place. Those challenges include the rapidly changing landscape, lack of experienced security professionals, difficulty understanding which tools to choose, lack of security capabilities with some types of devices like IoT, and the list goes on. There are even more challenges to consider that relate to the business the organization is involved in. Examples of such challenges include adapting to changes in technology, complying with regulation requirements, and finding the right people to fill security roles.
A very common example of challenges with adapting to technology is how to leverage cloud services in a secure manner. There is a challenge to secure users accessing the cloud, which may require a secure Internet gateway. There is a challenge for software as a service (SaaS) cloud application, which may require a cloud access security broker (CASB). There are public cloud offerings such as Amazon Web Services (AWS) and Microsoft Azure, commonly referred to as infrastructure as a service (IaaS), that should be treated like datacenters within your environment, meaning they need to include their own layered security capabilities and services. Many organizations I meet with have a cloud-first business objective, yet they lack an understanding of how to move forward using cloud services in a secure manner. Technologies such as software-defined networks (SDNs) are pushing cloud business to new levels of interest across all organizations.
An example of a regulation challenge is meeting compliance requirements. Many organizations must comply with industry-specific regulations or risk incurring large fines and potential legal action if they are found out of acceptable compliance levels. For example, any organization leveraging credit card data must comply with the requirements of the Payment Card Industry Data Security Standard (PCI DSS), and any organization within the United States with access to healthcare records must comply with the requirements of the Health Insurance Portability and Accountability Act (HIPAA). Certain countries have compliance requirements such as only the government can own phone lines, which means it is against the law to have a private phone line. This requirement also means technologies such as voice over IP (VoIP) would be considered a violation of the government’s ownership of communication. Chapter 6 covers compliance in much more detail.
People will always be a business challenge for every organization. Today’s market has more security jobs available than people with the right skills that can fill them. This means filling job requirements and employee retention is a major business challenge for organizations. It is becoming uncommon for security professionals to stay with an organization more than a few years, causing concerns for data privacy and increasing the need for job rotation to ensure there is always somebody ready to fill in when a key member leaves the organization. Chapter 4 dives into people challenges and best practices in more detail.
There are other business challenges that are specific business sectors. Organizations responsible for utility services and other critical infrastructure have to deal with being targeted by other countries’ cyber militaries. Banks are responsible for keeping transactions secure and extremely fast, as milliseconds lost could cost hundreds of thousands of dollars to customers. Smaller churches have budget challenges for investing in proper security solutions since the majority of their profits are based on donation and volunteer work. You will not be able to cover every business challenge your organization will face; however, it is best practice to assign a team to deal with identifying and managing risk. That team should be the SOC. Risk management, however, should just be one of the handful of services a SOC can offer.
At this point, I have introduced the security operations center and covered at a high level the security capabilities designed to reduce the risk of threats. The rest of this book delves much deeper into all of these topics. To help you understand how a SOC can improve security, this book takes the approach of focusing on outcome, which means a focus on the services provided by the SOC. The next topic to address is what I find are the security capabilities offered by mature SOCs around the world. Each of these services will be the focus for the chapters ahead.
In-House vs. Outsourcing
While I have talked about threats and security capabilities, how does this all relate back to a security operations center? I defined a SOC as a centralized unit that deals with security issues on an organizational and technical level. This is accomplished through various types of services, which are directly handled by the SOC or outsourced. There are advantages and disadvantages both to using in-house SOC services and outsourcing SOC services. The best decision for going either way will depend on your business needs. Some organizations may outsource using an on-demand or ad hoc approach, meaning they don’t have the service internally but may add it if a situation ever demands it. Other times, services are ongoing, such as hiring an external company to handle any calls related to potential security incidents. A common example of using an on-demand approach would be an immediate need for digital forensics following a major security event. It is important to point out that most ad hoc approaches are the least effective and most expensive option versus the cost and value from dedicated or preplanned services. That decision will depend on your organization’s need for each SOC service.
Table 1-1 shows a comparison of the advantages of using in-house SOC services and the advantages of outsourcing SOC services.
TABLE 1-1 Advantages of In-House SOC Services and Outsourcing SOC Services
In-House Advantages |
Outsourcing Advantages |
Knowledge of business |
OPEX costs that can be spread out |
Data stored internally |
No conflict of interest |
Cross-department correlation |
Scalability and flexibility |
Tailored requirements |
Leverage other customer trends |
Services Advantages
To summarize the advantages of in-house SOC services, it is all about having more control over and ability to customize the service being performed by the SOC. Members performing the service know the environment as well as all people involved with the incident. Having this knowledge can be extremely helpful for responding quickly and dealing with any internal politics. Using in-house services also builds a roadmap for growing the SOC by offering training and career development as the organization makes investments in security. In-house services can simplify compliance requirements for protecting sensitive data and are flexible to adjustments in service goals and procedures. The reason for this flexibility is that in-house services are more familiar with the data, data owners, and business purpose of the data compared to an outsourced service that is just responsible for monitoring for security incidents. If changes need to be made to the outsourced service that are outside of the agreed-upon contract, meetings and changes in cost will be necessary before anything can be accomplished. In-house resources don’t have these limitations regarding adapting to change.
While offering in-house SOC services is ideal for many organizations, sometimes the business model makes it cost-prohibitive to achieve. Advantages of outsourcing services might include a reduction in cost because the organization doesn’t have to hire and pay employees, provide benefits such as healthcare insurance, or provide workspace and equipment. People are the most expensive asset for a business, and finding and retaining the right people that specialize in specific SOC services can be challenging in today’s market. In my experience, many organizations that outsource SOC services have chosen to do so based on comparing the cost to build a team with the right skills and/or train internal employees to be part of a SOC against the cost of plugging in outside services that can provide impact much faster as well as have additional value like experience with other customer events. Other customer data can be a form of threat intelligence, meaning the service provider sees incidents with other organizations that help it to proactively prepare for future attacks against your organization.
Some organizations are required to outsource some SOC services due to conflict-of-interest situations. For example, an organization could have in-house digital forensics experts, but because those experts know the parties involved in any internal investigation, they may not be permitted to testify in court if the judge determines their relationship with the impacted parties might have influenced their investigation or might influence their testimony. In this situation, the organization should hand off the investigation to an outsourced digitals forensic team, so the results are considered an unbiased opinion.
Services Disadvantages
As indicated in the previous discussion of the advantages of outsourcing, the primary disadvantage of in-house SOC services is the cost to properly create and maintain them and the corresponding challenge of obtaining the required budget. Determining the cost to create an in-house SOC service is challenging because many uncertainties exist, such as the cost to find the right people, unforeseen changes in business, required training, and time needed to stand up the practice. This is why having an executive sponsoring the SOC is so important. Without this level of support, any of these cost hurdles may not be addressed, causing a SOC’s service to become dysfunctional. I will provide recommendations for obtaining leadership support for the SOC in Chapter 2.
In situations where the total expected cost to stand up a SOC team is difficult to translate into dollar values, selling the idea to leadership is very difficult because you essentially are asking for a blank check. There are some formulas you can use to overcome this concern. One formula I will cover in Chapter 6 is used to calculate the likelihood of an incident and identify the cost to the organization if an event occurred. The formula will look at how to spread that cost over a period of time. The end result will be a hypothetical dollar amount of the cost of an incident and how its cost can be spread over time, giving leadership a value to compare against the risk based on how likely it will occur compared as well as how often it will occur. If that value is very high, such as millions of dollars for every security incident that could occur, it will make sense to price out SOC services to reduce the chance of a devastating incident occurring. If the per-incident cost is low, other options such as contracted or ad hoc services may be the best option for the business. These computations are typically hypothetical, whereas most contracted and on-demand services have much clearer associated costs, which makes outsourcing a much more attractive approach to parties responsible for funding the reduction of risk. If you plan to attain CISSP or CompTIA CySA+ certification, you will be required to know the formulas for calculating security costs.
As previously indicated, the largest disadvantages of outsourcing services are the limitations in the service provider’s knowledge about the organization and the lack of flexibility because outsourced services are tied to a set contract. Changes to contracts have a cost, and it is possible the provider doesn’t have resources available to support the changes being requested. Another disadvantage of outsourcing is that it is common for external services to use tools that sit outside the network or place technology within the network in order to monitor the environment, limiting the organization’s visibility of where those tools are installed. Further, many outsourced services also swap around personnel, meaning the resource assigned to a contract is not dedicated and not very knowledgeable of the environment he or she is assigned to protect. Finally, outsourced services commonly offer different tiers of coverage, the result of which is that if a top-tier organization experiences an incident, it will consume the top talent from the service provider, leaving limited support for other customers with lower-tier coverage. Table 1-2 outlines the disadvantages of in-house SOC services and outsourcing SOC services.
TABLE 1-2 Disadvantages of In-House SOC Services and Outsourcing SOC Services
In-House Disadvantages |
Outsourcing Disadvantages |
Cost |
Limited business knowledge |
People (hire/maintain) |
External tools and data flow |
Potential conflict of interest |
Lack of communication |
ROI concerns |
Usually not dedicated people |
Limited customization |
|
Services are limited based on cost (e.g., tiered Gold, Silver, and Bronze services) |
Hybrid Services
It is common for organizations to use a hybrid approach to obtain the maximum benefit of both in-house and outsourced SOC service approaches. I’ve encountered a lot of companies that outsource tier one support and train specialists within the organization to handle anything that is escalated above tier one’s capabilities. The value of this process is having generic requests outsourced, reducing the workload for the higher-cost internal assets. Internal assets know the environment and internal politics and have access to all internal tools. Tier one has a limited view of the organization, but that is sufficient for handling many of the first-level calls for support. This hybrid example also gives an organization the opportunity to grow its internal assets so eventually those people can handle the tier one support requirements and the organization can dissolve future outsourcing needs. The same approach can be used for specific services, such as first outsource incident response services until internal members are required or trained to cover this responsibility. Services can also be outsourced during demanding times such as during a major incident potentially requiring specific expertise.
SOC Services
Mature SOCs around the world tend to have in common a core set of security services. Those services might be in-house, outsourced, or even on demand, enabling the SOC to pull desired services when needed. On demand could be a contract that retains the services if they are ever needed or as simple as a saved services quote that can be executed upon at some future point. Regardless of the approach of delivery, there are services that every SOC needs to offer. To summarize those common SOC services, they can be defined as the following offerings:
Risk management: Identifying and making decisions to deal with organizational risk. This pertains to managing any type of risk, from physically securing assets to patching digital vulnerabilities that exist within software. This can also apply to remediating weak policies and lack of education regarding security awareness within members of an organization.
Vulnerability management: Identifying and managing risk from technical vulnerabilities. This commonly involves targeting vulnerabilities within software found on servers, laptops, and IoT devices. Most SOCs use vulnerability scanners and outside threat intelligence to identify vulnerabilities.
Incident management: Responding to security-related events. This covers what actions the SOC takes when certain events occur, such as isolating systems, alerting team members, and implementing remediation steps to resolve the issue. Other subcategories that fall under incident management include incident response, incident investigation, and other incident-related topics. Technologies such as orchestration tools, artificial intelligence, and playbooks are becoming extremely popular to help assist SOCs with incident response services.
Analysis: Analyzing various types of artefacts. This includes identifying characteristics, reverse engineering, vulnerability/exploitation analysis, root-cause analysis, remediation, and mitigation analysis. What separates an analyst focusing on analysis versus incident response is the type of required skills. Analysis uses tools such as IDA Pro to disassemble malware and understand how it functions. An analysis engineer can answer the question “Is this file malicious?” by running it in a sandbox to learn about its behavior. These skills are different from those of a SOC analyst responding to a potential breach.
Compliance: Assessing and maintaining organizational compliance requirements. This can include legally obligated requirements such as HIPAA and PCI DSS compliance as well as organization-driven goals such as meeting a NIST or ISO standard, which are not required by law but could be seen as a required policy by the organization or its customers. The compliance service also prepares the organization for assessments and assists with gathering required information for outside parties validating an organization’s compliance.
Digital forensics: Gathering evidence post incident to determine the cause of the incident and prepare for legal action. There is some overlap in digital forensics, incident response, and analysis skillsets since all three include some form of understanding what malware or a malicious party has done. What separates digital forensics is the legal aspect regarding how evidence is collected. For example, if you manipulate a file during your investigation, you ruin any chance of using that evidence in a court of law (based on the concept of evidence contamination). Chapter 8, “Threat Hunting and Incident Response,” addresses digital forensic concepts in more detail.
Situational and security awareness: Providing the organization with awareness of its operational environment and potential threats. This includes education about critical elements that could impact the organization’s goals, potential threats, and actions to reduce risk against operational risk and threats.
Research and development: Researching the ever-evolving threat landscape, developing new tools and techniques, and modifying existing tools to improve effectiveness.
You might have some form of all of these services within your SOC, whether outsourced or covered using in-house employees. If your SOC lacks one of these services, I recommend at least obtaining quotes for on-demand services so that you have an option if that service is ever required. I already gave an example of how some organizations do not have digital forensics covered in-house and are sometimes forced to use an ad hoc approach following a major incident. It would be wise to know who to call before this service is needed versus trying to figure out who to contact while also dealing with the major incident.
Note
Regarding digital forensics, time is critical to success, meaning evidence will quickly be lost or contaminated if a proper investigation isn’t launched. Imagine the time that would be lost if you had to start researching forensics services after normal business hours or on the weekend when most businesses are closed. According to the Ponemon Institute 2018 Cost of Data Breach Study report, sponsored by IBM, in a consolidated sample of companies in various countries and regions, the mean time to identify (MTTI) a breach was 197 days and the mean time to contain (MTTC) a breach was 69 days. These numbers represent identifying and containing breaches, not the time to perform forensics post-incident response!
One important exercise is determining which of these SOC services your organization currently has and doesn’t have. It is also important to figure out how effective are the services that exist within the SOC. If those services are not effective, your organization can decide whether to improve those services based on the cost of the change compared against the business need. Remember that simply having a service doesn’t mean it provides value to the organization. Just because you purchase a vulnerability scanner doesn’t mean you have a formidable vulnerability practice. The best way to not only understand what services you currently have but also evaluate how effective they are is by using maturity models.
SOC Maturity Models
One common question I receive when speaking with SOCs is how effective they are compared to the industry. This is hard to answer since the goal of the SOC should be supporting the business objectives of its own organization rather than measuring itself based on the type of technology or processes SOCs in other organizations are using. My answer is that a better approach is to validate how effective the SOC is in supporting the goals of the business rather than how other businesses are running their SOCs. This leads to a conversation about SOC maturity and business relevance.
Assessing SOC maturity is the process of determining characteristics and features of the SOC, such as specific technologies and processes. The goal of creating SOC maturity models is to establish an understanding of the quality of SOC services as they currently exist and develop a roadmap with milestones for improvement. The results of a SOC maturity model can be used to predict and request budget for SOC services, establish criteria for rewarding improvement, and tracking the success of each SOC service as change is made. Assessing the maturity of the SOC is a critical step to running a successful SOC program and is a process all SOCs need to do on a regular basis.
SOC Maturity Assessment
How does assessing a SOC’s maturity work? A basic maturity assessment evaluates how each SOC service is functioning. For example, consider a SOC service that is used only when needed. Suppose a particular SOC has an incident response service that only a few people know how to do. They don’t share knowledge about how they do it; they just do it when an incident occurs. Those incident responders don’t perform the same steps for each investigation, and if they were to leave the company, that service would be lost. In this example, this SOC service would be considered acting in a low maturity state. To improve the maturity of this service, they first would need to formalize the steps they perform in their incident response service, so that it becomes a repeatable service with expected results. As the service matures, the process can be documented so others can follow the same steps to produce similar results. Eventually, certain steps could be automated and optimized with tools and processes to improve the speed and effectiveness of the incident response service. Each improvement milestone can be seen as an increase in maturity based on the maturity model being used. Figure 1-20 is CMMI Institute’s view of modeling maturity. The CMMI Institute example uses five levels of maturity for assessing people, process, and technology.

FIGURE 1-20 CMMI Institute Standardized Definitions of Maturity
SOC-CMM Model
Another SOC maturity model is the SOC-CMM model created by the master program of Lulea University of Technology (LTU). This model consists of five domains. The first three domains, Business, People, and Process, are all evaluated for maturity, while the remaining two domains, Technology and Services, are evaluated for both maturity and capabilities. The SOC-CMM model ranks maturity based on similar categories as NIST. The categories are non-existent, initial, defined, managed, quantitatively managed, and optimizing and will vary depending on the type of domain being evaluated. Figure 1-21 shows each of the five SOC-CCM domains and the 25 associated aspects.

FIGURE 1-21 SOC-CCM Model Diagram
What is really beneficial about the SOC-CCM model is that it includes references to other standards, guidelines, and frameworks for its recommendations to enhance maturity of a SOC service or capability. For example, the subcategory for ID.AM-1: Physical devices and systems within the organization are inventoried, includes references to CCS CSC1, COBIT 5, ISA, and NIST. The SOC-CCM model is free to use and can be downloaded from https://www.soc-cmm.com.
ISACA COBIT 5 Process Assessment Model
Another popular industry maturity model by ISACA is the COBIT 5 Process Assessment Model (PAM) based on the ISO/IEC 15504 standard for performing a process assessment (COBIT). According to COBIT, there is a six-point system of scoring, 0 through 5. Level 0 means a service doesn’t exist or is incomplete. A level 1 service represents an ad hoc capability, meaning that it at least achieves its purpose even though it is not an effective approach for the business. Once that capability is repeatable, it moves to level 2. This requires the capability to be managed with expected results. Once the repeatable capability is fully documented and defined as a formal process, it moves to a level 4. This means the process can be used throughout the organization rather than just by a specific group or individual. As the process is executed, it can be measured and managed for improvement. Once checkpoints for success and failure are established and maintained, the maturity becomes level 4. Finally, the process can start to be optimized for ongoing improvement, making it a level 5.
This model should look similar to the CMMI Institute model. Figure 1-22 breaks down the COBIT scoring model. The details of how to perform a COBIT assessment can be found on the ISACA.org website.

FIGURE 1-22 COBIT Capability Scoring
SOC Program Maturity
The NIST, SOC-CMM, and COBIT models are great resources for evaluating the maturity of specific features of a SOC service. A more general approach to modeling the maturity of the SOC is to evaluate the entire SOC program. Using this approach consolidates the associated people, process, and technology for the entire SOC rather than breaking up each SOC service as is done in the NIST, SOC-CCM, and COBIT models. This approach starts with defining the most basic SOC maturity level:
First-generation SOC: This level is a SOC that just monitors device logs, which means it has limited coverage based on the data that is monitored. A basic SOC has limited data retention capabilities and is not effective at responding to security incidents. The basic SOC has a few security tools sending event logs to a centralized tool such as a security information and event management (SIEM) system, which is what the SOC uses for all security awareness. The services expected from a first-generation SOC are some form of risk management and limited continuous monitoring for security incidents.
Second-generation SOC: A second-generation SOC leverages data correlation and consolidation to turn log data into security events. This simplifies monitoring, dramatically improving incident response. This can also lead to developing a tracking system to manage events and eventually playbooks that represent the proper response to a specific type of incident. A second-generation SOC offers more advanced risk management and a more mature incident response service. This level of SOC can be effective but is still very reactive based.
Third-generation SOC: A third-generation SOC has more experience with SOC capabilities and is able to offer more services, such as vulnerability management and compliance. This level of SOC has assessment services looking for potential weaknesses and areas that violate policy as well as required compliance. A key point is that a third-generation SOC has moved from reactive to proactive security practices, because it has services that are designed to prepare for attacks before they happen by reducing potential risk. This also means the SOC can develop better playbooks and perform lessons learned exercises to better prepare for future attacks following a security incident.
Fourth-generation SOC: A fourth-generation SOC leverages the latest SOC technologies and services. This level of SOC further tunes tools and expands visibility to other networks through threat intelligence, reputation security, and cloud services. It enhances data correlation by using artificial intelligence, not only improving decision making but also supporting development of new security rules and playbooks based on live data. A fourth-generation SOC uses data sources such as NetFlow and packet captures to deliver network forensics services. It not only is proactive but also continuously measures results and sets growth and maturity goals. I provide recommendations and guidance throughout this book to help you increase your overall SOC maturity to become a fourth-generation SOC.
Figure 1-23 represents the overall SOC maturity breakdown.

FIGURE 1-23 SOC Maturing Models
Within each SOC generation are services that can be broken down and evaluated using the CSSI Institute, SOC-CCM, or COBIT models or other standards, guidelines, or frameworks. You may find that your SOC has a basic forensics service that you would grade as a first-generation SOC service because it is ad hoc, while the incident response program is much more mature based on how your SOC has invested in that service. You may find that your SOC works with a different vulnerability management team rather than running the vulnerability management program within the SOC. This approach to vulnerability management means the first-generation SOC service is combining its resources with the desktop support team to move its capabilities and services to the third-generation performance arena. I recommend grading your SOC as an operation as well as evaluating each of the common SOC services (described earlier in this chapter) in this fashion using a standard, framework, or guideline such as NIST, SOC-CCM, or COBIT.
Establishing the maturity of your SOC services and developing milestones for improvement are critical steps to formalizing your SOC program. By understanding the status of maturity, your SOC program can assess what level of improvement is required for the business. This provides a foundation for requests for resources and developing a reward behavior to encourage a healthy SOC environment. Roadmaps lead to change, which is how a group of people responsible for security can develop their practice into a responsible SOC.
One challenge regarding assessing the maturity of a SOC is assessing the specific security capabilities that exist within the network of the organization protected by the SOC. Network standards, guidelines, and frameworks can be helpful, but in the next section I provide a methodology that I have used to develop customized capability assessment maps and goal ranking. This approach helps with making decisions about what is the best security capability and/or service to invest effort for improvement of the organization security posture and SOC’s services.
SOC Goals Assessment
As you have read, there are very useful standards, guidelines, and frameworks available in the industry that provide recommendations for best practice for security. I highlighted some of the most popular options in this chapter as well as identified some limitations to using those resources. Those limitations include the fact that they are not updated at the same pace as technology changes, they are generic by design to accommodate various types of industries, and they don’t provide a method to prioritize which changes are most important to your specific business. This leaves decisions such as prioritizing which investment in security capabilities and services to make first and where consolidation of existing security capabilities could occur up to the organization. Imagine an organization that has a budget for one security tool but needs both a next-generation firewall (NGFW) and a web application firewall (WAF). Which one should the organization invest in first?
I have collaborated with some fantastic security architects at Cisco to develop a methodology that complements the value of standards, guidelines, and frameworks by providing a customized list of goals with capability assessment diagrams showcasing gaps in security as well as potential areas for consolidation. Having a list of goals simplifies where investments could be made if those goals align with the focus of the business. Ranking the goal list against how important each goal is to the business provides a clear view of how important each goal is so decisions can be focused on top-priority goals. Developing capability maps provides a clear viewpoint of where a gap or overlapping capability exists so technical and nontechnical people can understand why a change is needed. You may be wondering, why not just jump into assessing your security capabilities? Why first review the goals of an organization and SOC? Consider again the scenario where an organization with a limited budget has a need for multiple security tools but does not know the order in which to invest its money and time. By first establishing and ranking the goals of the business and SOC, the organization can align security tools to that list to provide a roadmap for how each security need should be addressed and in what order.
Defining Goals
The first step to the SOC assessment methodology is to define the goals of the business. This is critical to ensure that all other goals for the SOC align directly to the goal of the business. If a business is focused on delivering online video games, for example, the goal for the SOC should target supporting delivering games in a secure manner as well as protecting all systems associated with delivering the online gaming service. If the business is a school whose primary focus is to offer the most modern online learning environment, then the goal of the SOC should be to provide a reliable network and digital learning resources. Determining the goals for the organization should be done at the executive level. The SOC then builds its IT goals based on the goals of the organization. It is important to have an executive sponsor validate that the business goals are correct, to ensure all goal planning for the SOC is relevant for the organization. The business goals can also be seen in the SOC’s mission and scope statements, which I will cover in Chapter 2.
Note
I highly recommend confirming the SOC team’s understanding of the business goals with their SOC executive sponsor or other executive to ensure the SOC’s goals are properly aligned with the business.
Once the business goal(s) are established and validated by leadership, you can develop the goals for the SOC based on meeting the business goals. These goals will be based on the people, process, and technology offered by the SOC and part of one or more SOC services. I call these the IT goals for the SOC. IT goals align with business goals, meaning the technology helps accomplish the business goals. Revisiting the previous examples, an obvious IT goal for the online gaming company would be to protect the online gaming service from external threats, because the online gaming service is needed for the business to be profitable. An IT goal for the school offering online classes would be to provide a reliable network and identify any systems that could impact the network’s performance. Once again, this should make sense, because a business goal for the school is to provide a modern learning environment, which would heavily depend on a reliable network. IT goals can be documented and transformed into company policy, making them a requirement to follow. IT goals should be very high level and explain the vision for the goal without explaining details on how to accomplish the goal. This helps keep the goal relevant regardless of specific changes to people, process, and technology. The aim of IT goals is to provide the vision for the SOC.
Because IT goals are high level, the details for delivering each goal are defined in one or more IT processes. An IT process establishes the step-by-step approach to delivering a goal. A process for the online gaming company would be to monitor for spikes in online requests with the intent to identify potential denial-of-service (DoS) attacks. All of the steps and tools used to accomplish the IT goal to protect the online service, as well as who is responsible to ensure this occurs, would be explained within one or more IT processes. If somebody asks why a process exists, it could be explained by showing how the process directly aligns with an IT goal that also aligns with a business goal. An IT process for the school would be the steps used to monitor for network outages. This could include what tools are used to monitor network traffic usage, what to do when an outage occurs, and which people are responsible for providing this service. In both examples, these could be one or more IT processes aligned to a specific IT goal or more than one IT goal. Figure 1-24 represents how business goals, IT goals, and processes should align. This model is similar to the CompTIA CySA+ view of policies, standards, and procedures alignment.

FIGURE 1-24 Business Goals, IT Goals, and Process Alignment
The following is a short summary of the SOC goal assessment process:
Meet with the SOC executive sponsor or business leadership to confirm business goals.
Develop SOC goals, also called IT goals, that support the mission for the business goals. IT goals must align to the business goals.
Create IT processes representing the more detailed documentation of how to execute an IT goal properly.
Identify any missing people, process, or technology within an IT process.
SOC Goals Ranking
Looking back at my examples, I mentioned the IT goal of the online gaming company would include protecting online resources, which will require DoS and web exploitation defense technology capabilities and services. I mentioned the goal of the online school would be to protect the performance of the network, which would require IT goals for vulnerability management, incident response, and continuous monitoring of the network. Assessing a SOC in this manner helps justify the specific tools and processes that are put in place, which later can be evaluated for maturity using any of the standards, guidelines, or frameworks previously reviewed. Table 1-3 and Table 1-4 outline examples of the high-level business and technology goal mappings of the online school and online gaming company, respectively.
Note
The following examples are similar to results from customers I have performed this work for in the past. Every organization will have different goals and priority ranking.
TABLE 1-3 Online School Goal Mapping
Policy Goal |
Priority |
Data privacy |
1 |
Support learning environment |
1 |
Services for students and faculty |
2 |
Reduce time to detect and correct events |
3 |
Learning outside of walls |
3 |
Reputation of school |
4 |
Road warrior support |
5 |
TABLE 1-4 Online Gaming Company Goal Mapping
Policy Goal |
Priority |
Providing 99.9% uptime |
1 |
Company reputation |
2 |
Quick software release and updates |
3 |
Protect customer data |
3 |
Remote worker support |
4 |
Employee retention |
5 |
Vendor partnerships |
6 |
Notice in Tables 1-3 and 1-4 that some of the policy goals are ranked with the same priority. This is ok as long as all goals are not ranked as a top priority. The reason behind the ranking is to determine how to prioritize goals. It is recommended to first list out all business goals and rank them based on input from various parties, which could include desktop support, legal, finance, facilities, security, HR, and leadership, so everybody is on the same page regarding how important each goal is to the organization. I recommend validating the results of how business goals are ranked with the executive sponsor of the SOC.
Table 1-5 and Table 1-6 demonstrate performing a technology goal assessment for the online school and online gaming company, respectively. Notice that the technology goals align with how the business goals are ranked. If the school ranks data privacy as a top concern, data loss prevention technology should also be a top technology goal. Technology goals are just one example of an IT goal. Other examples could focus on people and process elements of the SOC.
TABLE 1-5 Online School Technology Mapping
Technology Goal |
Priority |
Data loss prevention |
1 |
Network uptime |
1 |
High availability |
2 |
Segmentation |
2 |
Endpoint security enforcement |
3 |
Authorized vs. unauthorized cloud services |
4 |
User training |
4 |
Least privilege enforcement |
5 |
Vulnerability management |
6 |
Configuration management |
7 |
TABLE 1-6 Online Gaming Company Technology Mapping
Technology Goal |
Priority |
Denial of service defense |
1 |
High availability |
1 |
Network monitoring |
1 |
Application and WAF needs |
2 |
Configuration validation |
3 |
Data loss prevention |
3 |
Least privilege enforcement |
4 |
VPN and remote routing |
5 |
Endpoint security enforcement |
6 |
Internal segmentation |
7 |
Developing the technology goals and ranking them should be much easier than performing the same process for the business goals, since the previously created business goals influence and narrow the scope of the technology goal conversation. It is critical that the business goals are developed and ranked first for this purpose. The order of how goals are assessed matters! I have performed these assessments for hundreds of customers and many times find, for example, that the organization believes they need a new firewall before the assessment but discover through the assessment that their business goals highlight a larger need for investment in areas where they completely lack capabilities and services. In the example of the online gaming system, a WAF and DoS technology should be a higher priority than a new NGFW or segmentation technology. I opened this section with posing the question of whether a company should choose a WAF or an NGFW. For the online gaming company example, the answer would be a WAF, based on the results of the business goal and IT goal ranking. If another organization went through this process, they may find the NGFW is the better investment based on the results they come up with.
Note
You might be wondering why the SOC would be involved with purchasing security tools (some customers I speak with think of a SOC as only being responsible for responding to security incidents). Among the SOC services I commonly find in mature SOCs around the world, one key service is research and development. This service focuses on researching and evaluating security tools so that the expected security experts within the organization, the SOC, are choosing the best technology match for the organization rather than another team within the organization. I highly recommend the SOC’s involvement in any evaluation of a tool that will be used by the SOC. I have seen hundreds of times an organization procurement office holding full responsibility for acquiring tools and selecting a tool only based on price. Trust me when I say that approach tends to lead to a poor decision. Chapter 10 covers evaluating whether to create your own tools, take advantage of open source tools, or step up and pay for enterprise options.
IT goals should be high level, while IT processes should be specific to which people, process, or technology is being offered. An IT process should include step-by-step instructions for how something is performed, the details about the tools involved, and who is responsible for doing the service. One or more IT processes can align to a single IT goal. For example, one IT process may be the specifics around how the WAF is configured, while another IT process may cover how the WAF is monitored. In both IT processes, details about who does the work, when the work is done, and how the work is done are just some of the information that should be included. IT processes can also be ranked similarly to how IT goals were ranked in the previous examples.
Threats Ranking
A third aspect that can be evaluated outside of goals is looking at top threats to the organization. This can complement the threat modeling exercise I covered earlier in this chapter. Ranking threats can justify how the technology goals align to the business goals as well as validate if capabilities and processes exist to combat a situation of high concern. The types of threats and expected action of threats can be pulled from threat modeling exercises. Looking at the online gaming company example, it would make sense to consider threats against their goal of 99.9% uptime to be a top priority for the business. This means threats that can take down their service would be ranked at a 1. Table 1-7 and Table 1-8 show examples of doing this for my example online school and online gaming company.
TABLE 1-7 Online School Threat Mapping
Threat Concern |
Priority |
Denial of service |
1 |
Data compromise |
1 |
Lack of visibility |
2 |
Exploitation |
3 |
Stolen accounts |
3 |
Lateral movement |
3 |
Malware |
4 |
User error/Layer 8 |
4 |
Unauthorized devices (hubs/routers) |
5 |
Process violations |
6 |
TABLE 1-8 Online Gaming Company Threat Mapping
Threat Concern |
Priority |
Denial of service |
1 |
Stolen user accounts |
1 |
Website exploitation |
2 |
Software compromise |
2 |
Stolen accounts |
3 |
Configuration errors |
4 |
Endpoint malware |
5 |
Internal threats |
6 |
Unauthorized devices (hubs/routers) |
7 |
Partner risk |
7 |
Having these ranking and alignment results provides a solid foundation for understanding what goals and processes are important to the SOC based on how they align with the overall business. Keep in mind that if certain groups are not involved with the process of creating and ranking goals, you may have to repeat the assessment with the missing parties to get a true balanced opinion of the goals and ranking. I have seen situations where desktop support was not involved with these decisions and later pulled away their part of budget due to not supporting what was being proposed as the next step for the organization’s security investments. I highly recommend including at least a director or higher to represent business goals and managers from each key service within the organization to obtain maximum impact from this exercise. Typically, this person is the executive sponsor of the SOC.
SOC Goals Assessment Summarized
Once this work is complete, your organization will have a good idea of what parts of the organization are top targets for investing for SOC services and capabilities in relation to accomplishing goals. What is still missing is identifying specific gaps in capabilities as well as areas where consolidation could occur to create new budget. In the next section, I will focus on a methodology used to evaluate security capabilities based on capability models.
The following steps summarize the ranking of goals:
Establish the business goals and align SOC/IT goals and IT processes.
Rank the business goals and IT goals according to their importance.
Debate ranking and validate with different groups within the organization to ensure all voices are heard.
Apply gap analysis against each item ranked, starting with the most critical.
Turn gap analysis into a three- to five-year plan to enhance SOC capabilities.
The two assessment programs I just covered will result in a list of goals that align with business. The next step of assessing the SOC and developing a roadmap for improvement is identifying gaps or overlapping capabilities within an IT goal. For example, if an IT goal is to reduce the risk of vulnerabilities, how do you know which capabilities exist to accomplish that goal? To assess people and processes, you will need to do a tabletop exercise, covered in Chapter 4. To assess technology capabilities, I recommend using a SOC capabilities assessment.
SOC Capabilities Assessment
The previous section discussed assessing SOC business goals, IT goals, and IT processes. You learned how to rank those goals to get an idea of how to prioritize focus for investments into the SOC services and capabilities. What I haven’t looked at is how to validate what SOC capabilities exist so specific areas of investment can be identified. For example, what capabilities does the online gaming company have to accomplish its goal of 99.9% uptime for its games and services? What capabilities could the online school use to ensure the student network is performing properly? Should the focus be on the edge, within the network, or on the hosts? What are the best investments to make, assuming there is limited budget to use for the SOC?
In this section, I will look at developing capability maps that can be used for consolidation of similar capabilities as well as identifying gaps. Consolidation leads to having more budget for future tools, people, and services. Identifying gaps helps SOC and non-SOC members understand what types of services and capabilities need to exist to improve maturity of a SOC service. Industry standards, guidelines, and frameworks can also provide recommendations for improvements, but, as previously discussed, they will not be specific to your organization. Capability maps are customized to your environment, but they can include missing capabilities that are found within industry standards, guidelines, and frameworks if desired.
Capability Maps
Creating capability maps involves identifying the different parts of your network and mapping how users and systems interact within that environment. To better understand this, let’s walk through mapping an average organization’s branch network. I will start with the end user and attempt to define what security capabilities or services exist to protect that user’s laptop. Does the organization standardize on the same hardware and software or do employees bring their own technology? Do the employees have rights to install or modify software? You may or may not care about the level of detail depending on your business requirements and what you want to include in your capability map. Looking at the online school example, let’s say the school does not care which operating system is used by students, meaning students are permitted to bring their own system. This would be different from an organization such as the online gaming system that requires all employees to only use their corporate-issued device on the company network.
Capability Map Example: Endpoint Security
For this capability map example, I am going to disregard system and host details so that I can purely focus on security technology capabilities. Capability maps could include other concepts, such as services running on a host, but to keep this example simple and focused, I will look only at security capabilities. Starting with a focus on end-user systems, those computers will have antivirus software to prevent known malicious files. What about anti-malware that is used for more advanced unknown threats, which has the ability to detect threats based on behavior that bypasses antivirus? Is there any content filtering or reputation security installed on the host for protecting users from accessing external known malicious sources? Do host systems have firewalls enabled or host-based intrusion prevention (HIPS)? You can use industry standards, guidelines, or frameworks covered earlier in this chapter as a method to identify industry best practices for security capabilities for endpoint protection and compare those recommendations against existing capabilities. For example, NIST has a set of recommendations for what security capabilities should exist on a host system. Which specific standard, guideline, or framework you use should be based on which you find the most useful for your organization.
The key to this example is to list capabilities that are different or at least provide additional checkpoints for threats. This leads to a defense-in-depth approach to security. Redundant capabilities such as two antivirus programs can be identified as being a repetitive capability, represented by the same icon twice in the capability map. Figure 1-25 is an example of mapping out host-based security capabilities. Remember that for this example, I am only focusing on the capabilities that exist within the host. SOC services such as endpoint vulnerability scanning and managing user privileges are not covered but are just as important as IT capabilities.

FIGURE 1-25 Host Capabilities
Capability Map Example: Endpoint OS Security
You might want to dive deeper into assessing capabilities within an endpoint because the last capability map shown in Figure 1-25 glossed over it. For the next example, a desktop support member might be concerned about security for the operating system and want to assess the host OS for capabilities and services. You could develop a separate capability map for the host OS to serve this purpose. Once the host OS capability map is complete, it could be referenced by other capability maps, so you don’t have to repeat the process every time a host OS is listed in a capability map. Figure 1-26 is an example of creating a host-specific defense security diagram. These host OS capability suggestions come from NIST SP 800-30, Guide for Conducting Risk Assessments.

FIGURE 1-26 Host-Specific Defense Diagram
Note
I recommend starting the capability mapping at a high level to establish a general understanding of information flow and how it interacts with existing capabilities. As you identify areas of interest, you can create more detailed capability maps for that specific area. For example, you can first group “gateway security capabilities” as a single checkpoint and later map out all of the capabilities that would be within a secured gateway such as firewall, IPS, WAF, etc.
Capability Map Example: Network Security
For the next part of this capability mapping exercise, I will look at how users connect to the network. I need to think about how any user connects to the network and what the network does to reduce the risk of compromise. I should also think about any associated processes and policies, such as requiring any device that connects to be scanned for vulnerabilities before being permitted access. Here are some questions to consider for this part of the assessment exercise:
Is there a form of access control in place?
How is authentication handled?
What is the policy for permitting certain levels of access to people and systems?
How are systems monitored that can connect to the network?
Is the hardware profiled and are certain hardware types granted more access than others?
Is segmentation enforced based on device and user types?
What happens once the system is granted online services?
Is user behavior monitored for malicious behavior?
Who is responsible for these services?
What security is in place as traffic leaves the user’s system and goes out to the Internet?
What is key is understanding the flow of traffic and different capabilities that are in place. It is recommended to not turn this process into a product conversation, but rather focus on the capabilities and services regardless of how they are provided. For example, one product such as a “Next-Generation Firewall” could have multiple capabilities. Many “Next-Generation Firewalls” found in the industry are providing multiple capabilities including firewall, application firewall, intrusion prevention, anti-malware, and so on. Figure 1-27 is an example of a NGFW broken down into a capability flow. Notice that traffic is first going to hit the firewall capability and then be filtered through the application controls if traffic is permitted through. That traffic will next be scanned by the IPS for threat behavior. Finally, any files that are permitted through will be evaluated for malware. The flow is important, so you understand at what part of the kill chain the defense should be taking effect. Once again for this example I am just focusing on capabilities. Factors such as who should manage this, what policies should be enforced such as what content should be filtered, and many other items are not included for simplicity purposes.

FIGURE 1-27 Next-Generation Firewall Capabilities Flow
Note
You can create boxes around capabilities that are included in a single existing product to improve the understanding of what is being documented. I find confusion can occur regarding the number of products needed or existing if the reader believes each capability represents a product. The reality is that most of the capabilities will be grouped into different products, meaning a few multifeatured products will make up all of the capabilities represented in a capabilities map.
Capability Map Example: Branch Network
I recommend that you keep mapping of capabilities vendor agnostic, but you could label them for documentation purposes if desired. The key is to develop a diagram of what capabilities and services exist even if more than one technology is providing the same capability. An example could be an NGFW with application-layer firewall capabilities and web proxy both having the capability to filter traffic. Figure 1-28 is an example of what an organization’s branch network could look like after mapping out capabilities from a user to how that user’s traffic goes out to the Internet. This example isn’t focused on only what actually exists but looks at all of the possible capabilities, including what doesn’t exist but should be part of the map, based on industry standards, guidelines, and frameworks like NIST and ISO. In this example, I am only focusing on technical capabilities for simplicity purposes.

FIGURE 1-28 Branch Office Capabilities Example
SOC Capabilities Gaps Analysis
Once you create a capability map, you evaluate it based on gaps and overlapping capabilities and services. I suggest marking areas of competent capabilities in green shading or with a check mark and identifying unsatisfactory capabilities in yellow shading or with a slash. An example of a weak capability could be an organization using manual port security to enforce access control versus using automated network access control. Manual port security means to configure a network switch to only permit one or more devices access to the network. When any device not within the approved list attempts to connect to the network, the network switch will disable the port. Although this provides port security, it can be tedious to manage the approved list of devices and respond when network ports become disabled. Manual port security is also known to be vulnerable to spoofing attacks since adversaries can spoof an authorized system’s MAC address if they can determine what type of system should be plugged into a port. An example could be spoofing the MAC address of a printer that is connected to a specific point, unplugging the printer, and plugging into that port with the printer’s spoofed MAC address.
I suggest marking capabilities and services that do not exist in red shading or with an X. The lack of a capability or service doesn’t mean it must be added. There may be business or technical reasons for not having a capability or service. You may find that industry guidelines, standards, and frameworks suggest more capabilities and services than you can invest in or need for your particular business and IT goals. Figure 1-29 shows the previous capability map marked up with how it applies to an example customer. For this example, a check mark represents an existing effective capability, a slash represents an existing capability that is not effective, and an X represents a capability that is missing.

FIGURE 1-29 Capabilities Evaluation Example
This approach to performing a capabilities gap analysis does not show how capabilities will prevent specific threats. The purpose of this approach is to develop an understanding of the organization’s defense-in-depth architecture regardless of the type of threats it will encounter. Remember that threats that are a major problem today will be replaced by another threat tomorrow. Using a defense-in-depth approach accommodates for such change by layering different capabilities. Maybe a threat today will exploit a vulnerability that your IPS isn’t aware of using signature-based detection. If that attack is successful at exploiting a target, now the threat must deal with the next layer of defense, which will analyze the files being installed on the target. If the attacker can plant malware on the target, the next layer of defense will evaluate if the file is functioning in an unusual behavior based on how all files of the same type are supposed to function. As you layer more defense capabilities, you reduce the risk of an attacker having the ability to bypass all of the layers of security that need to be beat in order for the attacker to accomplish his or her goal. If you want to align a test of capabilities to this approach of assessing the organization’s security capabilities, you can apply a threat model such as MITRE ATT&CK.
Note
At some point, the conversation of which vendor should be chosen will come up during these different assessment meetings. It is ideal to postpone vendor-specific conversations until after all assessment work has been done, to keep the focus purely on capabilities and business goals.
Capability Map Next Steps
There are a couple of next steps that could follow developing a capability map. First, you might find that you have overlapping capabilities and/or services, which could be consolidated to simplify data streams, simplify management of tools, and reduce cost to the organization to maintain vendor contracts. Second, when presenting to nontechnical parties, you can identify gaps in capabilities and services by using the visual diagram(s) you just created. This data can be applied against business goals, technology goals, and threat ranking to determine which area of concern should be addressed first. For example, if your capability map shows a lack of insider threat capabilities and business priorities point to this being an area of concern, that would be the first place to invest future people, process, and technology improvements. Looking back at the online gaming company example, its capability map would show a missing capability for next-generation firewall and web application firewall. The company’s business goal and IT goal ranking can help with the decision of what to invest in if only one tool could be purchased due to budget constraints. For this example, the WAF would be the best one based on web-based attacks being a high priority.
Note
Having overlapping capabilities is not always a bad thing. It may represent an opportunity to consolidate and acquire new capabilities to further expand the defense-in-depth architecture. For example, why have a proxy and application-layer firewall both performing content filtering when either approach can accomplish that goal for the organization? Maybe there are political or operational reasons to maintain this approach or maybe by consolidating that responsibility to one tool, an additional license, product, or job function could be repurposed to a capability that doesn’t exit.
This exercise can be performed in a similar manner for other parts of the network, such as the datacenter, wireless network, headquarters, remote offices, and so on. Figure 1-30 is an example of mapping out a datacenter focusing only on IT capabilities. In this example, I first looked at clients accessing the network, which will access an inside firewall segmenting off the network from the datacenter network. Inside that datacenter network are suggested insider threat or east/west-based security. I find many organizations put most of the security on the edge of a datacenter even though the majority of the traffic exists within the datacenter. This means that if the datacenter is compromised, it may go unnoticed until malicious actions occur across the edge, such as stolen data going out the door! If that was the case, this diagram would show X’s representing a lack of capabilities beyond the datacenter edge firewall.

FIGURE 1-30 Datacenter Capabilities Example
Performing a SOC capabilities and services assessment will take time and require somebody with a decent understanding of security as well as industry best practices to properly capture the right data points. If you are not sure what capabilities should exist, look to industry standards, guidelines and frameworks for recommendations.
SOC Development Milestones
Developing a mature SOC is a journey with key milestones. The first milestone is to identify one or more executive sponsors. The purpose of a sponsor is to have an authoritative figure help the SOC enforce its policies as they are created. The sponsor can also validate the true business goal(s) of the organization and help align any SOC IT goals to the business. Together, the SOC and the sponsor can work toward the second milestone, which is establishing the SOC program. Establishing the program includes various development milestones such as developing what budget would be needed for the SOC, what talent should be recruited, and what types of technology should be acquired. These milestones are dependent on each other. The budget needs to be established before talent can be targeted. Higher-quality talent will require a higher cost than entry-level positions, but the latter will require more training. Technology shouldn’t be acquired until the staff is in place and can be assessed for skills as well as asked which type of technology they prefer to use. Once the people and technology are acquired based on the program goals, processes can be developed that consist of the steps that should be taken to accomplish each goal. Processes might start off in an ad hoc fashion; however, over time they can be improved based on the maturity models covered in this chapter. As maturity is established, collaboration can occur between other teams. An example is the SOC taking on some responsibilities for vulnerability management while the desktop support team is responsible for desktop vulnerability remediation. Figure 1-31 represents a high-level diagram showcasing each of the SOC development milestones.

FIGURE 1-31 Developing a Successful SOC
The strategy shown in Figure 1-31 should seem straightforward when evaluating how to develop a SOC from a high level. The key to success, however, will be how to execute the steps within each milestone. I will dive into the details of each of these milestones in the following chapters. You will learn how to approach executives and obtain proper sponsorship for the SOC. You will learn about best practices for recruiting and retaining people. I will also cover security tools, capabilities, and services in much more detail, and I will explain the processes seen within effective fourth-generation SOCs. Your journey to an effective SOC starts with the next chapter, where I will look deeper into building a SOC and how to choose what services you plan to offer.
Summary
This chapter kicked off with a review of the basics behind cyberthreats and vulnerabilities. Next, you learned the purpose of the SOC and what capabilities could be used by a SOC to identify and respond to cyberthreats. Next, the chapter dove deeper into understanding cyberthreat behavior by reviewing threat models. You also learned about industry best practices for defending against cyberthreats using standards, guidelines, and procedures. You looked at business and technical challenges as well as common SOC services. The chapter wrapped up with a review of how to assess a SOC using maturity models, goal assessments, and capabilities assessment exercises.
Many of the concepts in this chapter were high level and designed to establish a fundamental understanding of how to develop a SOC. The following chapters will provide the details for the concepts covered, so you improve the capabilities and services of your SOC. Maturing a SOC will lead to less vulnerabilities, effective SOC services and more support from the organization.
References
Ablon, L. (2018, March 15). Data Thieves. Rand Corporation. https://www.rand.org/content/dam/rand/pubs/testimonies/CT400/CT490/RAND_CT490.pdf
Caltagirone, S., Pendergast, A., & Betz, C. (2013, July 5). The Diamond Model of Intrusion Analysis. U.S. Department of Defense. http://www.activeresponse.org/wp-content/uploads/2013/07/diamond.pdf
Cimpanu, C. (2019, December 12). A Decade of Hacking: The Most Notable Cyber-security Events of the 2010s. ZDNet. https://www.zdnet.com/article/a-decade-of-hacking-the-most-notable-cyber-security-events-of-the-2010s/
Cisco. (2018). Figure 37: Patching Behavior Before and After WannaCry Campaign. Cisco 2018 Annual Cybersecurity Report (pp. 41). Cisco. https://www.cisco.com/c/dam/m/hu_hu/campaigns/security-hub/pdf/acr-2018.pdf
Fritz, B., & Yadron D. (2014, December 5). Sony Hack Exposed Personal Data of Hollywood Stars. Wall Street Journal. https://www.wsj.com/articles/sony-pictures-hack-reveals-more-data-than-previously-believed-1417734425
IBM Security. (2020). Cost of a Data Breach Report 2020. IBM Security. https://www.ibm.com/security/data-breach
International Organization for Standardization (2018, February). ISO 31000:2018: Risk management – Guidelines. ISO. https://www.iso.org/standard/65694.html
ISACA. (2019). COBIT 2019 Framework (various publications). ISACA. https://www.isaca.org/resources/cobit
Joint Task Force Transformation Initiative. (2012, September). SP 800-30 Rev. 1: Guide for Conducting Risk Assessments. NIST. https://csrc.nist.gov/publications/detail/sp/800-30/rev-1/final
Kaspersky. (2018, June 27). Ransomware and Malicious Crypto Miners in 2016–2018. Securelist. https://securelist.com/ransomware-and-malicious-crypto-miners-in-2016-2018/86238/
McKay, B., & McKay, K. (2014, September 15). The Tao of Boyd: How to Master the OODA Loop. The Art of Manliness. https://www.artofmanliness.com/articles/ooda-loop/
National Institute of Standards and Technology. (2018, August 10). The Five Functions. NIST. https://www.nist.gov/cyberframework/online-learning/five-functions
National Security Agency. (2010). Defense in Depth. NSA. https://citadel-information.com/wp-content/uploads/2010/12/nsa-defense-in-depth.pdf
Ponemon Institute. (2018, October). 2018 Cost of a Data Breach Study: Impact of Business Continuity Management. IBM. https://www.ibm.com/downloads/cas/AEJYBPWA
Proffitt, T. (2009, March). Achievements and Pitfalls of Creating and Maintaining Vulnerability Assessment Programs. SlidePlayer. https://slideplayer.com/slide/5705807/
Quote Investigator. (2013, February 10). I Rob Banks Because That’s Where the Money Is. Quote Investigator. https://quoteinvestigator.com/2013/02/10/where-money-is/
Robertson, A. (2018, September 28). California Just Became the First State with an Internet of Things Cybersecurity Law. The Verge. https://www.theverge.com/2018/9/28/17874768/california-iot-smart-device-cybersecurity-bill-sb-327-signed-law
Rogers, K., & Spring, B. (2020, September 6). ‘We Are Outnumbered’ – Cybersecurity Pros Face a Huge Staffing Shortage as Attacks Surge During the Pandemic. CNBC. https://www.cnbc.com/2020/09/05/cyber-security-workers-in-demand.html
van Os, R. (n.d.). SOC-CCM Model. SOC-CCM. https://www.soc-cmm.com/