
Chapter 2
Developing a Security Operations Center
One great building does not make a great city.
—Thomas Heatherwick
Chapter 1 opened with an introduction to security concepts and covered how to rate the quality of existing capabilities and services against industry best practices. The starting point for your security operations center (SOC) journey may be anywhere between creating a new practice to enhancing a functioning operation. Regardless of the maturity of your operation, it is important to review everything from the high-level mission to the details for each process of each service your SOC is responsible for. This chapter begins with a review of high-level SOC development concepts and works down into the technical details found within highly effective SOCs showcased in later chapters. The absolute first thing any successful organization must define is its purpose, which is captured in the mission statement and scope. Even if you have an existing mission statement or defined purpose, it is worth your time to review it periodically to see if any improvements can be made.
Mission Statement and Scope Statement
It is important for any employee of an organization to know why they come to work every day. If employees don’t know the purpose of the business, they won’t know how to make the most impact with their daily contribution, leading to a lack of career-driven workers. Employees performing job duties without any guidance from leadership regarding why their position exists and how it benefits the mission of the organization become dissatisfied and a flight risk. An example of an employee performing their daily duties without considering the impact to the business can be seen with poor customer service or support. Imagine a situation where a customer calls for support on a product that is no longer covered. If the support representative doesn’t know the business goal, he or she will simply inform the customer that the product is no longer supported, since that is what the rep’s specific job instructs them to do regardless of how it impacts customers. The long-term impact of poor customer service is fewer repeat customers and damage to the brand of the business, leading to diminishing sales. If the goal of the business is to put the customer first and that goal is communicated clearly to customer support representatives, the support reps will prioritize satisfying the customer and provide support based on meeting the business goal for support.
The mission and scope statements of an organization inform employees what the purpose of the organization is. A mission statement is essentially a formal summary of the organization’s core purpose and values. The statement is high level and rarely changes over time, if at all. The mission statement expresses what is important to the business, giving direction to what the organization is looking to accomplish. Any employee should be able to see how their role within the organization impacts the goals found within the mission statement. This accessibility makes the mission statement the ideal starting point for business planning. A scope statement is similar to the mission statement but contains more details. Whereas the mission statement remains the same unless major change to the organization occurs, the purpose of the scope statement is to be more flexible to change.
Developing Mission and Scope Statements
If a SOC is being developed within an organization, its mission and scope statements must relate to the business the SOC is responsible for protecting. The key to creating a successful SOC mission statement is to be crystal clear about what the responsibilities of the SOC are. The mission statement must be a concise explanation of the SOC’s purpose and overall intention. Statements must be long-term goals rather than specifics of what type of services are being offered, because that is covered in the scope statement.
Note
It is common for a SOC mission statement to contain goals similar to those of the organization it protects; however, there are exceptions. Some SOCs are made of a group of SOCs, known as a global SOC (GSOC). Individual SOCs might have their own mission statements or share the overall GSOC mission statement. Some SOCs are outsourced or are isolated from the customer being serviced for compliance or other purposes. This type of SOC has a mission statement that is focused only on its service, rather than considering the mission of its customer.
If you are creating or contributing to a mission statement for a SOC, the key is to ensure that it answers the following questions. Remember to keep mission statement language at a high level representing the vision for the SOC. The specifics are described in the scope statement covered shortly.
Purpose: What is the purpose of the SOC? Why does it exist?
Customers: Who are the SOC’s customers? All employees within the organization or only those in a specific department? Are external customers included?
Alignment to customer’s mission: How does the SOC’s mission align with the organization’s mission? Does the SOC help the organization accomplish its goals along with protecting its assets and data?
Services: What services does the SOC provide? Is it only monitoring or is it also responding to incidents? The services should not be specific, meaning monitoring the network could apply to multiple services such as incident response and vulnerability management. Those details are ideal for the scope statement.
Service availability: When are SOC services available? Is it 24/7 or only during business hours? The mission statement should not provide details that may change for purposes of availability. It should only be a general statement about coverage.
Sample Mission Statements
Here are two sample SOC mission statements. As you read each mission statement, try to identify the answers to the questions provided in the preceding list. (The answers are given in the sublist following each statement.)
Mission Statement 1: The security operations center (SOC) is responsible for monitoring, detecting, and responding to incidents and the management of the organization’s security tools, network technology, end-user devices, and other systems as assigned. The goal of the SOC is to reduce risk from cyberthreats targeting the organization. The function of the SOC is performed seven days a week, 24 hours per day. The SOC is the primary location of the staff and the systems dedicated for this function.
Purpose: Monitoring, detecting, and responding to incidents and managing security tools.
Customers: All end users employed by the organization and guest users.
Alignment to customer’s mission: Reducing the risk from cyberthreats targeting the organization.
Services: Incident management and management of security tools, network technology, end-user devices, and other systems assigned.
Service availability: Seven days a week, 24 hours per day.
Mission Statement 2: The security operations center (SOC) monitors the overall security posture of the IT network. The goal of the SOC is to help the organization identify and respond to security incidents and return impacted systems back to a normal operational state in a timely manner. The security operations center responds and tracks security incidents with the objective of maintaining the overall security posture while reducing risk when possible. The functions are performed around the clock in support of the organization’s operation model.
Purpose: Maintaining the overall security posture of the organization while reducing risk when possible.
Customers: The organization.
Alignment to customer’s mission: Respond to security incidents and return impacted systems back to normal operational state in a timely manner.
Services: Respond and track security incidents.
Service availability: Around the clock in support of the organization’s operation model.
Each of these two sample mission statements represents a single SOC taking on most of the security responsibilities at the organization that it functions within. Statement 1 has more specific details, such as the days of operation and location, while Statement 2 is broader in how it explains its purpose. Both statements are fine; however, relegating items that could change to the scope statement is recommended so that the mission statement can endure relatively unchanged and represent the high-level goals. Statement 1 isn’t bad, but if the SOC changed its hours of operation or location, the mission statement would need to be adjusted. Statement 2 provides broader language for the hours of operation that would be ideal so specific changes in service availability won’t impact the mission statement. Both statements could also have more details regarding how they align to the organization, but are good starting points.
Note
If you do not have a dedicated SOC mission statement or have been using the organization’s mission statement, it is highly recommended to develop a SOC mission statement.
SOC Scope Statement
A SOC scope statement is similar to a SOC mission statement but contains a lot more details about the SOC. The scope statement includes where the SOC is located, which services it provides and does not provide, details about the hours of operation, and what technologies it uses. The scope statement needs to complement the mission statement, but unlike the mission statement, the scope statement can contain items that are subject to more frequent change. Some SOCs combine the scope and mission statements; however, in those situations, changes to the SOC require an update to the combined mission and scope statement rather than just updating the scope statement. For this reason, I recommend keeping the scope and mission statements separate so the scope statement is more flexible to change while the mission statement remains the unchanged vision of the SOC. The scope statement can also accommodate responsibilities for partners and subsidiaries.
Looking back at the mission statement examples, some important topics were not covered. These topics will fall under the scope statement and are subject to change. The ideal topics for a scope statement include the following.
Locations and networks: What parts of the organization will the SOC be responsible for? What physical locations, remote offices, and cloud environments would be in and out of scope for support? What network types are being considered? Will the guest network, datacenter, or wide-area network be part of the SOC’s responsibility?
Ownership: What level of ownership will the SOC have regarding systems and information? Does the SOC have ownership on securing endpoints, or is that a responsibility of desktop support? Does the SOC monitor the datacenter and have responsibility for provisioning access to data, or are access rights managed by a datacenter custodian? It is very likely that the SOC will not be responsible for managing systems or data outside of data within specific security tools. This ownership needs to be clearly listed in the scope statement.
SOC objectives: The SOC’s objectives need to be outlined so that the rest of the organization can understand the SOC’s purpose. This can be explained within the mission statement and referenced within the scope statement or be another mission statement from the organization that aligns with the overall organization’s or GSOC’s mission statement. If a mission statement already exists, the scope statement should be more specific about the objectives, including timelines for accomplishing specific goals. An example could be increasing the maturity of a capability such as responding to incidents or managing vulnerabilities.
Technologies and services: Scope statements can specifically call out what will be used by the SOC. For example, the scope statement can specify “All intrusion prevention appliances,” which would mean other network gear used by the organization would not be a responsibility of the SOC. The scope can also identify services that it offers, such as forensics or incident response. If some services are outsourced, then the scope statement could identify only what the SOC would cover. For example, a scope statement could state that the SOC is responsible for Tier 2 or higher incidents, which would mean another resource would handle Tier 1 support.
Specifics regarding when SOC services are available: This includes the exact start time and ending time each day, if holidays are included, and how non-supported hours are covered.
Let’s look at a few SOC scope statement examples.
Scope Statement 1: The SOC is responsible for every company location across the country that hosts systems and permits systems to connect to the general network. The services that are offered by the SOC include around-the-clock security monitoring of systems, applications, and networks with the objectives of detecting and reacting to all external attacks as well as insider malicious behaviors. The SOC services are also responsible for handling incident response; collecting and correlating the various system events; capturing and analyzing raw packet data; discovering and tracking vulnerabilities; and consuming threat intelligence information received from external sources.
Location and networks: Every company location across the country that hosts systems and permits systems to connect to the general network.
Ownership: Monitoring systems, applications, and networks.
SOC objectives: Detecting and reacting to all external attacks as well as insider malicious behaviors.
Technologies and services: Incident response; collecting and correlating the various system events; capturing and analyzing raw packet data; discovering and tracking vulnerabilities; and consuming threat intelligence information from received external sources.
Specifics regarding services: Around-the-clock monitoring of systems, applications, and networks.
Scope Statement 2: The SOC scope covers all systems that are managed and operated by IT, including those located in national and international offices. The SOC services are offered around the clock and include the collection and correlation of security event messages; detecting internal and external malicious activities; responding to security incidents; and conducting awareness training when required.
Location and networks: National and international offices.
Ownership: All systems that are managed and operated by IT.
SOC objectives: Covering all systems that are managed and operated by IT.
Technologies and services: The collection and correlation of security event messages; detecting internal and external malicious activities; responding to security incidents; and conducting awareness training when required
Specifics regarding services: Around-the-clock services.
What should stand out is how a scope statement contains a lot more details than a mission statement about what the SOC will provide. Every SOC should have a separate mission statement and scope statement (or at least a combination of these statements), even a smaller SOC within a larger GSOC, so that key details such as the services, time of operation, and purpose of the SOC are documented for anybody to reference.
Scope Statement Challenges
A challenge that is common when creating the scope statement is committing to specific services. There might be questions regarding whether the SOC should be responsible for a particular service or another department should handle that service. For example, if the SOC scope statement claims responsibility for identifying vulnerabilities, does that mean desktop support is not responsible for identifying vulnerabilities? Who would handle remediating vulnerabilities? Would that be desktop support and/or the SOC? How would this handoff occur if the SOC does not handle remediating vulnerabilities and hands off systems identified as vulnerable to desktop support? Looking back at the language used in the first example scope statement, the statement points out that the SOC is responsible for only “discovery and tracking vulnerabilities.” The scope statement does not include the responsibility for remediating vulnerabilities, which means the SOC is not responsible for this service.
For this example, another team such as the vulnerability management team can have the responsibility of remediating vulnerabilities. The vulnerability management team can also have a scope statement claiming responsibility for identifying vulnerabilities, which would be an overlap in services offered by the SOC since it also claims responsibility for identifying vulnerabilities. If this situation occurs, both teams need to recognize this overlap in responsibility and develop a plan for how responsibilities are handed off and/or how these teams collaborate. The best approach to this specific example would depend on various factors within the organization. Some organizations might decide to remove vulnerability identification from the SOC’s scope, while other organizations might decide to remove vulnerability identification from the vulnerability management team’s scope, which would mean the SOC would identify vulnerabilities and hand off those findings to the vulnerability management team so the vulnerability management team can handle the remediation.
Governance and Risk Management References
Scope statements can also include concepts related to security governance and/or risk management. The purpose is to provide clarity regarding why specific services are being offered. For example, a scope statement may specify that the reason for providing data control services is to meet HIPAA or PCI DSS compliance. A scope statement can also relate to a business goal, such as to ensure an organization’s product is safe or service is always available to customers. Including clarity regarding the purpose of a SOC service helps leadership better understand the purpose of the service, leading to better support for the SOC. Another benefit of clarity is that those using or impacted by the SOC service will understand and respect why the service exists. Respecting a SOC service leads to less pushback when the SOC has to take actions.
Developing a SOC
Developing a SOC takes more effort than picking the right location and purchasing a bunch of equipment. You must have a process to plan, design, build, and operate the SOC, which can lead to transferring the SOC to another team once the SOC is up and running or help the SOC mature from a small team to a dedicated group within the organization that has its own leadership and funding. SOC planning starts with topics covered in Chapter 1 regarding assessing the SOC’s current state as well as the development of a mission and scope statement.
How you plan and design your SOC will impact it in a positive or negative way, including the cost and time required to develop and improve SOC services. Knowing the expectations of the SOC based on its scope is useful for selecting the type of people to hire and the type of technology to acquire. Figure 2-1 provides a high-level summary of the steps to designing a SOC.

FIGURE 2-1 Phases of Developing a SOC
In Figure 2-1 the planning phase identifies the creation of the mission and scope statements specified as SOC Strategy. These statements are used to develop the SOC strategy made up of policies and processes. Using the assessment tactics from Chapter 1, SOC capability and maturity models are developed in the planning phase. A SOC can compare the existing capability and maturity models against the SOC strategy to develop a design plan that will require people, process, and technology.
In the design and build phase of Figure 2-1, technology is acquired, which involves considering factors such as bandwidth, high availability, and other requirements. Those acquired capabilities lead to services specified in the planning phase that will require processes to be developed and documented. Eventually, those services will go online into the operate phase.
Notice in Figure 2-1 that there is an arrow from the operate phase back to the plan phase. This represents the fact that additional requirements for new services and capabilities will follow the operate phase. As an example, after the SOC is operating, leadership may decide to assign a new responsibility for research and development to the SOC. Even though many of the SOC services are in the operate phase, the new R&D service would start at the plan phase and follow the steps shown in Figure 2-1 before it would be considered operational.
Maintaining the specific people, process, and technology within the SOC might not follow the development process outlined in Figure 2-1. Individual people, process, and technology can have their own quality testing and upgrading processes as shown in Figure 2-2, representing different SOC aspects that are independently developed or acquired. For example, training can be used to onboard a new employee would not follow all four stages shown in Figure 2-2.

FIGURE 2-2 People, Process, and Technology Core Elements
Consider Figures 2-1 and 2-2 as high-level models of the process for developing a SOC. As these steps are completed, procedures are developed by the SOC to represent how the SOC will execute each service it is responsible for. Next we will look at developing SOC procedures.
SOC Procedures
Chapter 1 touched upon common services offered by mature SOCs, which include risk management, vulnerability management, incident management, analysis, compliance, digital forensics, situational and security awareness, and research and development. All of these services are covered in greater detail in Chapter 3, “SOC Services,” and throughout the book. If your SOC is going to offer any of these services, you need to decide what should be outsourced and what will be covered using internal services. Although Chapter 1 covered the benefits and disadvantages of each approach, it did not delve into developing procedures for SOC services.
Procedures are how services are executed by the SOC. Procedures include step-by-step instructions to execute policies, such as the steps to operate a vulnerability scanning tool, how often the tool is run, and what parts of the network or which hosts are scanned by the tool. Each of these procedures is used to enforce a policy for identifying vulnerabilities within the network. Remember that procedures are the details regarding what is done to execute a policy.
Designing Procedures
When designing procedures, there are some important items to consider. The questions in the following list need to be addressed by a SOC procedure:
What is the purpose of the procedure and what policy does it align with?
How should the SOC be involved with this procedure?
How long is the SOC responsible for this procedure?
What other groups or outside elements impact the procedure?
What threat does this procedure deal with?
What resources are required for this procedure?
Are logging or reporting required for this procedure?
What notifications should be included within this procedure?
What is the notification escalation process?
How are notifications delivered (email, mobile, home, chat, etc.)?
Are there any compliance elements involved with this procedure?
The SOC’s involvement with these procedures will vary based on whether the SOC will be responsible for all or part of these actions. For example, a SOC can have another team handle the monitoring and alerting of threats while the SOC is responsible for anything that is escalated. Other times, the complete opposite can occur, having the SOC handle basic incidents and hand off anything escalated to external investigation services.
Here is a list of what are considered common SOC procedures that are used to deliver various types of SOC services:
Monitoring: Surveillance of specific system(s) and network(s)
Alerting: Notification of a threat, problem, or event
Escalation: Passing responsibilities for responding to an event to the next level of support
Investigation: Examining, studying, or inquiring into an event
Incident logging: Case management efforts, which include tracking events that occur and the process of how the events are handled
Compliance: Relating activities and events to meeting compliance requirements
Reporting: Developing and delivering metrics about events that have and have not occurred
Remediation: Returning systems back to operational state and closing vulnerability to reduce future attack
It is critical that any procedure clearly defines the actions required from the SOC so it can develop proper support for people, process, and technology. As procedures mature, recommended practice dictates developing templates so that new team members can easily follow what they are expected to perform. Over time, templates can be automated to improve the efficiency and effectiveness of the SOC services, leading to mature SOC capabilities.
Procedures must define any required communication as well as action. Communication responsibilities include how communication should occur between teams as well as what communication method should be used. This is especially important as SOC tiers are developed.
Procedures Examples
Let’s look at an example of procedures associated with responding to a security incident. Procedures should specify which group is responsible to perform the first response to a security incident. Procedures should include the hours of operation for this team, steps to escalate the problem if it can’t be solved, steps to solve problems that fall within scope of the first responding team, what are the backup options when the team isn’t available, and what the first responding team is authorized to perform. If a new person is recruited to perform the first responder role for an incident, procedures will provide directions for how each of these tasks is performed.
Figure 2-3 is an example of creating a mapping of how a SOC supports a procedure. In this example, the SOC activities include monitoring alerts from three different groups. Tier 1 support handles monitoring, alerting, and escalating to tier 2 when an issue requires more skilled individuals who are authorized to perform such work. Tier 2 can also escalate to a more advanced tier 3 group when such skills are needed. Tier 3 support also includes additional SOC services such as forensics and malware investigation.

FIGURE 2-3 SOC Procedure Example
Figure 2-3 is great for a high-level view of SOC tiers; however, the communication between these teams isn’t defined. For example, how is tier 1 contacted? Who is authorized to escalate an event to a higher tier? Who handles logging and reporting? What if a tier is unavailable when contacted? Figure 2-4 provides a more detailed approach to documenting a procedure. For this example, the procedure diagram covers how customer inbound requests are handled. The helpdesk receives alerts through a phone call or email. Incidents are handed to a SOC tier 1 analyst, who can attempt to close the case or escalate the case through the SOC tier 1 supervisor or team lead. The SOC tier 2 attempts to handle an incident or pull in or hand off an incident to a tier 3 support member. Tier 3 members include external services they can leverage if they are unable to cover the incident with in-house resources. Know that this diagram can include even more details such as the names and locations of parties involved, specific tools available and hours of operation. Many of these details were omitted from the diagram for the purpose of providing a generic example.
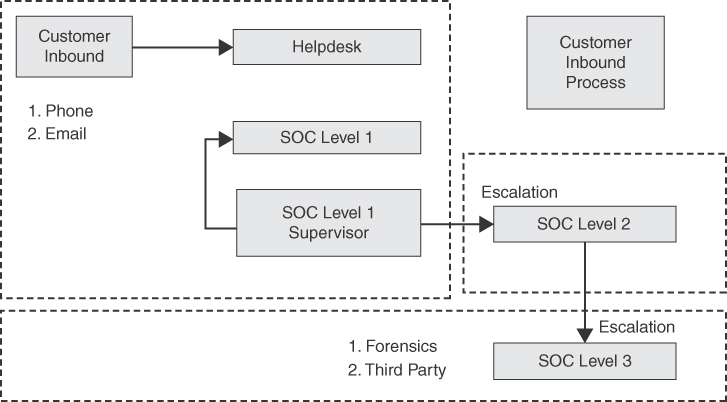
FIGURE 2-4 SOC Contact Flow Example
Security Tools
Chapter 1 pointed out that the best practice for developing a security strategy is to develop capabilities against all of the steps an attacker would take to breach a network. You also learned that those steps will be different for different parts of the network. Let’s now start looking at the different types of tools that a SOC can use to provide a defense-in-depth approach to alerting and responding to security events. All of these tools should have the ability to export logs to the SOC’s security information and event management (SIEM) solution. Chapter 5, “Centralizing Data,” will cover the processes for how that is done in more detail. While many of these tools were touched upon already in the Chapter 1 discussion of protecting the SOC, this section delves into the specific capabilities associated with security tools used by SOCs around the world to deliver various types of services.
Evaluating Vulnerabilities
Chapter 1 pointed out how adversaries exploit vulnerabilities in order to exploit systems. This means as a SOC, it is ideal to have a mature vulnerability management practice. Chapter 9, “Vulnerability Management,” dives deeper into how to build a vulnerability management practice; however, there are some tools you should consider dedicating to your vulnerability management practice. The most obvious tool is something that can assess the network and endpoints for vulnerabilities. Vulnerability scanners serve this purpose by comparing attributes about systems and software being analyzed against known weaknesses. A known vulnerability is classified based on risk impact, which is summarized in its Common Vulnerability Scoring System (CVSS) score (see https://www.first.org/cvss/). A CVSS score provides a way to capture the principal characteristics of a vulnerability and produce a numerical score reflecting its severity. The numerical score can then be translated into a qualitative representation to help organizations properly assess and prioritize their vulnerability management processes.
Active Vulnerability Scanning
In order for a vulnerability scanner to detect and classify system weaknesses in computers, networks, and communications, it must have access to the target being scanned. Access can be from the network or directly on the host. The level of access can be full read-level access, known as authenticated scanning, or no ability to log into the system, known as unauthenticated scanning. Having full read access provides more details about how systems, networks, and communication are vulnerable. Results of authenticated scanning provide a more accurate report, which leads to a better remediation response. Although authenticated scanning provides better results than unauthenticated scanning, it does not realistically represent what a potential adversary will see. Unauthenticated scanning is considered the attacker’s point of view, meaning tools like firewalls will prevent some scanning use cases from providing any useful data. A SOC should use both authenticated and unauthenticated scanning to identify all potential vulnerabilities as well as understand how adversaries would view computers, networks, and communication they could target using the unauthenticated scanning approach.
Figure 2-5 shows an example using Rapid7’s Nexpose vulnerability scanner platform. The dashboard shows a summary of the environment being continuously evaluated for vulnerabilities, which can be broken down into sites or network segments. An example could be scans set up for different parts of the customer and SOC segments. In this example, a summary of the vulnerabilities found within each network segment is presented in two pie charts. The first pie chart rates vulnerabilities based on their CVSS score. The second pie chart ranks vulnerabilities based on the skill level required to exploit them. Below the pie charts are specific vulnerabilities identified by Nexpose. An analyst can click any part of either pie chart or the specific vulnerabilities listed to learn more about what Nexpose discovered.
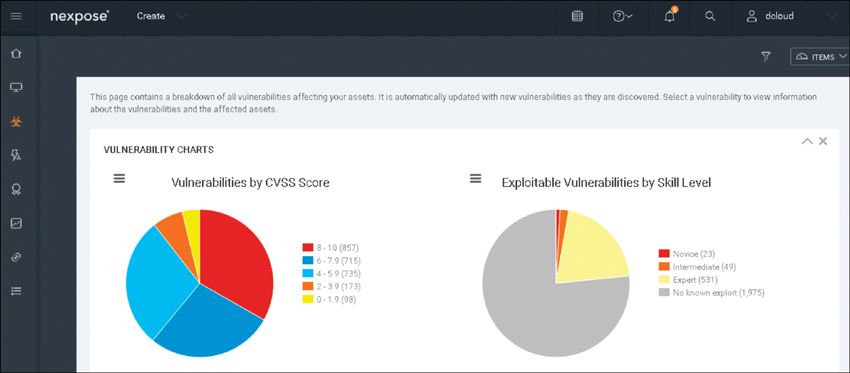
FIGURE 2-5 Rapid7’s Nexpose Vulnerability Scanner
Passive Vulnerability Scanning
Tools such as application-layer firewalls can gather data about endpoints and send that data to vulnerability scanners to perform passive scanning. I am finding that more security solutions are leveraging passive security technology with the intent of adjusting defense capabilities to systems found vulnerable. Figure 2-6 is an example of the Cisco Firepower solution showcasing passive vulnerability scanning information. This approach to passive vulnerability scanning works by leveraging the next-generation firewall’s capability of seeing all layers of traffic. This permits host profiles to be created, which are compared against a database of known vulnerabilities similar to an active vulnerability scanner. The difference between an active vulnerability scanner such as Rapid7’s Nexpose and a passive vulnerability scanner like the Cisco Firepower solution is that a passive scanner only sees what data can be profiled, while an active scanner can be configured to scan any network or host it can access.
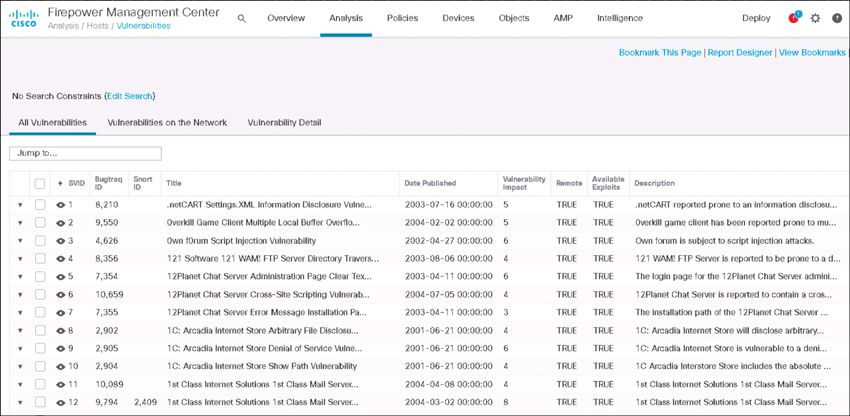
FIGURE 2-6 Cisco Firepower Passive Vulnerability Data
The results of a vulnerability scan (regardless of which approach is used) will produce a handful of vulnerabilities found within computers, networks, and communication on your environment. Analysts will want to identify all systems that are vulnerable and create tickets to assign an engineer to patch these weaknesses. While systems are exposed, the SOC will work to prevent an adversary from exploiting these weaknesses using security tools such as an IDS/IPS and antivirus. Security tools can be tuned using results from vulnerability scanners to help protect computers, networks, and communication that have been identified as being vulnerable. Tuning security tools helps to protect vulnerable computers, networks, and communication from attack while the asset owner is notified to fix the vulnerability.
Note
If you search for a recent threat and don’t see matching signatures within your security product, contact the vendor and ask if you are protected. The vendor might have hidden the rules so that adversaries can’t reverse engineer their defense strategy.
Preventive Technologies
If a system, network, or communication is found to be vulnerable, removing the vulnerability through patching, upgrading, or other method will prevent exploitation from occurring. Unfortunately, remediation cannot always be performed, for a variety of reasons. Some technology such as IoT devices do not offer the ability to fix an identified vulnerability due to limitations in how the technology functions. If a vulnerability can’t be fixed, the SOC needs to find other methods to prevent an adversary from exploiting the vulnerability. One approach is to hide the vulnerability from any potential threat. Another approach is to set up security tools to monitor the vulnerable computer, network, or communication and alert as well as prevent exploitation that is attempted against the vulnerability. Preventive technologies can offer both of these approaches to protecting vulnerable computers, networks, and communication.
There are different types of preventive technologies that the SOC should use to protect vulnerabilities found within the network and system it is responsible for.
Preventive Technology: Firewalls
Firewalls and proxies can perform network segmentation and limit what ports, protocols, and applications are permitted to cross a network segment. Best practice is to enforce least privilege access through each network segment to reduce the risk of exposing vulnerabilities to adversaries outside of network segments. For example, if an organization doesn’t have a business need for permitting Tor traffic, this traffic should be prevented from crossing network segments. Blocking Tor reduces the risk of adversaries and malware communicating between a network segment and Tor network, which is common behavior for threats such as ransomware.
Preventive Technology: Reputation Security
Another preventive technology the SOC should use is reputation security. Reputation security reviews various factors of an external source and judges how trustworthy that source should be seen as. One factor is how long the source has been online. If a source claims to be an online bank but has been online for only a few hours, the source is not a bank. Another factor is the reputation of the domain owner. The current source being evaluated might be seen as safe, but if the domain owner has been flagged as being responsible for other malicious domains, that factor will impact the trustworthiness of the current source being evaluated. Another factor is the type of content that is being presented from the domain. If files that have been downloaded from a domain have been flagged as malicious, that will impact the trustworthiness of the source being evaluated. The list goes on for what factors could be evaluated, and different vendors will have a different approach to how reputation security is evaluated and enforced. An example of reputation security’s value is blocking an adversary from creating a malicious website that looks similar to a trusted site, which is a common tactic associated with phishing attacks. If an adversary attempts to create a fake website representing a trusted bank, factors such as the website only being online for a short time, being hosted from GoDaddy, and the domain owner being associated with other malicious websites would all impact this source’s reputation score. Figure 2-7 is an example of a Cisco block page triggered when accessing a web source with a negative reputation score. Security solutions leveraging reputation security will block the fake bank described in the previous example and display a page such as what is shown in Figure 2-7 based on how the vendor informs users of a source being blocked.
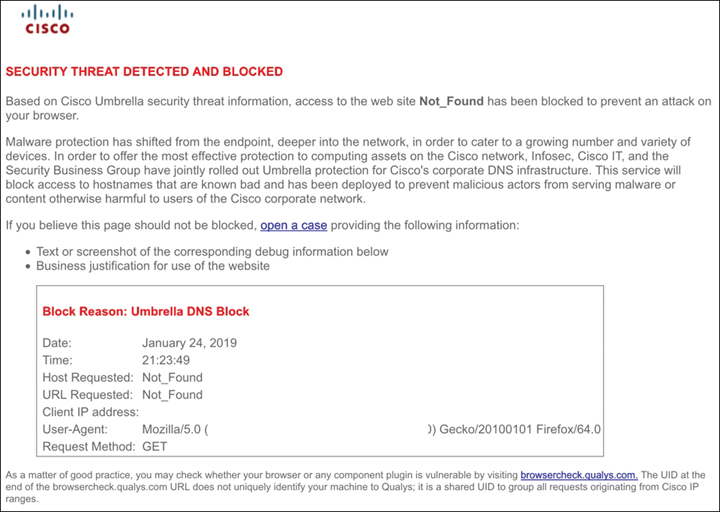
FIGURE 2-7 Cisco Reputation Block Page
Note
You can test if your organization has reputation security by going to www.ihaveabadreputation.com. This website will not harm your computer but has a bad reputation for testing purposes. If you see an image of a ghost rather than a vendor-generated block screen, you do not have reputation security.
Similar reputation security technology can be used on other parts of the network such as host systems and email. Google Gmail is one of the many email services that have adapted reputation security to reduce spam and phishing attacks. Figure 2-8 is an example of a phishing email being flagged by Google as being dangerous based on various factors Goggle uses to flag malicious email. Factors can include the content of the email, the sender of the email, the audience that is receiving the email, and negative results associated with similar emails.
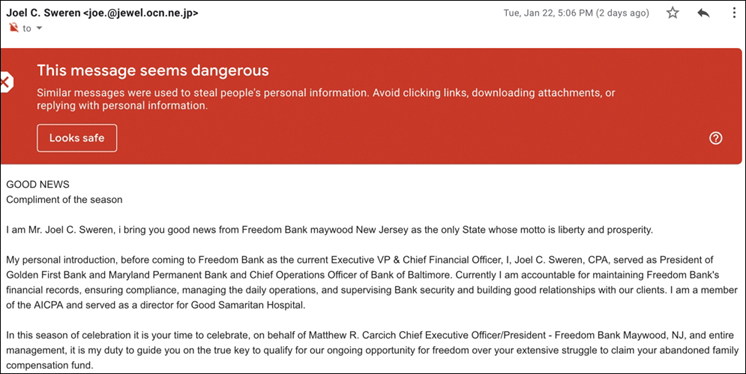
FIGURE 2-8 Google’s Reputation Warning Banner
Note
Reputation security is not 100% effective. That doesn’t mean it isn’t great at reducing the number of attacks due to the increase in effort needed by an adversary to launch an attack. For example, adversaries can compromise a small business or school and pivot from that source using the compromise source’s reputation to bypass this reputation security defense.
Preventive Technology: VPN
Virtual private networking (VPN) is another preventive technology. VPN reduces the risk of man-in-the-middle attacks because all traffic is encrypted. There are different VPN options a SOC can consider. For remote devices requiring access to secured network segments, the SOC can use different options for remote-access VPN such as Secure Sockets Layer (SSL)/TLS or IP Security (IPsec). A SOC can also use VPN to encrypt traffic between different segments such as a SOC headquarters and a branch office. Table 2-1 is a quick summary comparing the differences between remote-access and site-to-site VPN technology.
TABLE 2-1 Comparing Site-to-Site VPN and Remote-Access VPN Technology
Parameter |
Site-to-Site VPN |
Remote-Access VPN |
Concept |
Uses IPsec to build an encrypted tunnel from one customer network (generally HQ or DC) to the customer’s remote site. |
Connects individual remote users to private networks (usually HQ or DC). |
VPN Client on End Devices |
Not required to be set up on each client. |
Every user may (client VPN) or may not (clientless) be required to have own VPN client. |
Tunnel Creation |
Each user is not required to initiate to set up VPN tunnel. |
Each remote-access user needs to initiate to form VPN tunnel. |
Target User |
Office LAN users of branch office need to connect to servers in HQ. |
Roaming users who want to access corporate office resources/servers security. Employees who travel frequently. |
Encryption/Decryption |
The VPN gateway is responsible for encapsulating and encrypting outbound traffic, sending it through a VPN tunnel over the Internet to a peer VPN gateway at the target site. |
The VPN client software encapsulates and encrypts that traffic before sending it over the Internet to the VPN gateway at the edge of the target network. |
Technologies Supported |
IPsec |
IPsec and SSL |
Multiple User/VLAN Traffic Flow |
Allows traffic from multiple users/VLANs to flow through each VPN tunnel. |
Does not allow multiple user traffic to pass through each VPN tunnel. |
Preventive Technology: Network Access Control
Network access control (NAC) is a preventive technology that prevents an unauthorized device from connecting to the network. Because potential attackers don’t have an authorized device, they can’t connect to the network to attempt an attack. NAC can also enforce the principle of least privilege through provisioning predefined access to devices based on various characteristics. Networks for guest users can be limited to only what guest users need, such as only Internet access with limited bandwidth, while trusted employees can be placed on a network with more access capabilities. Controlling access is fundamental to enforcing proper network security.
Preventive Technology: Data at Rest/In Motion
Data at rest and data in motion technology can protect data from unauthorized access. Data at rest technology encrypts files containing sensitive data, preventing adversaries from having access to such data. Data in motion solutions, commonly called data loss prevention (DLP) technology, can prevent sensitive data from leaving the organization using pattern matching, such as identifying data with credit card numbers or other sensitive data. Cloud access security broker (CASB) technology can also perform data in motion capabilities by controlling who can access data within a cloud service to prevent it from being exposed to adversaries.
In summary, preventive means blocking the attack before it happens. Preventive technology can provide value at all stages of the Cyber Kill Chain and needs to be included in your SOC’s defense-in-depth strategy.
Detection Technologies
Preventing any attempt to exploit a computer, network, or communication is ideal, but prevention technologies are not 100% effective due to many factors, including gaps in preventive capabilities as well as how adversaries are continuously changing their tactics. Detection technologies are designed to detect malicious behavior within networks and systems. A SOC needs to include detection technologies for a few reasons:
Detection technologies provide validation that preventive technologies are or are not preventing adversaries from exploiting systems, networks, and communication.
Detection technologies provide another layer of defense, reducing the risk that an adversary can successfully complete all the steps required to exploit an intended target.
Another value of some detection technology is having the ability to learn about exploitation techniques to improve preventive capabilities. For example, if a detection capability identifies a file as being malicious based on its behavior, that security tool can share the hash value of the file with other preventive tools so other security tools can block the file based on the identified hash value.
Detection technologies typically use one or more core capabilities, such as signature-based detection of known threats, malicious behavior detection, and anomaly identification. Antivirus and IDS/IPS are examples of capabilities that attempt to block exploitation behavior. The method used to detect malicious behavior will vary depending on the type of security tool and vendor offering it. For example, some antivirus offerings only scan files for threats. Any threat that doesn’t use files, such as PowerShell exploitation that occurs within memory, would not be detected by a file-based antivirus.
Detection Technology: NetFlow and NBAR
NetFlow and Network-Based Application Recognition (NBAR) can be used to detect threats based on how devices behave on the network as well as deviations from a baseline of those devices’ normal behavior. Both of these approaches offer a lot of value but have limitations in the details they provide about a potential threat. Packet capturing technology can provide more details than NetFlow, such as the specific file that was lost during a potential data loss incident, where NetFlow would only be able to provide records of the parties involved with the event. Records can include who sent the file, what protocols were used, the type of data, and other metrics depending on the technology being used and type of flow being collected.
Detection Technology: Baselines
User behavior can be monitored using detection capabilities. This technology baselines user login trends, what systems are accessing different parts of the network, where the user is located, and what level of access they should have. For example, if a user logs into the network from the United States and moments later logs into the same system from Russia, two different users likely are using the same account, meaning an account login has been compromised. Similar technology is becoming popular for cloud environments, particularly the previously mentioned cloud access security broker (CASB) that monitors access to services such as Dropbox and Salesforce.
Detection Technology: Honeypots
As introduced in Chapter 1, other popular breach detection tools are honeypots, systems designed to attract adversaries and malware. Like bears are attracted to honey, the concept of a honeypot is to attract attackers to a decoy system, diverting their attention and effort from valuable production systems. Malware and adversaries tend to attack what is perceived as the easiest target, and the honeypot system is configured with tons of vulnerabilities to catch their attention. The honeypot is accessible via the network but is firewalled from the rest of the network systems. This tactic can be very effective; however, some malware is designed to target specific behavior rather than exploit the weakest system on a network to avoid compromising a honeypot that would alarm the target of the presence of the adversary within the network. Honeypots also pose a risk to the network if they are not configured properly, such as configuring a honeypot with a public IP address while placing it within a trusted network. Any adversary outside of the trusted network can use this misconfigured honeypot as a gateway into the trusted network.
Chapter 1 covered security capabilities and how a SOC needs to layer different capabilities to develop a defense-in-depth approach to security. Defense in depth includes layering different types of detection and prevention technologies.
Mobile Device Security Concerns
Today, the average employee has more than one device. Many of these devices are mobile and yet contain the same level of sensitive data that an authorized desktop has access to, creating a need for similar levels of security to be enforced between trusted mobile devices and desktops. One popular method to secure mobile devices is to use mobile device management (MDM) technology. SANS Security Awareness, a division of the SANS Institute, provides its recommendations for securing mobile devices in the blog post “Mobile Device Security (https://www.sans.org/security-awareness-training/blog/mobile-device-security). The following list is a shortened version of the security recommendations included in the blog post and features you will want from the MDM technology your SOC chooses to leverage:
Enforce passwords
Screen lock timeout
Remote lock and remote wipe
Password reset
Deployment of settings, policies, and applications
Remote monitoring
Logging for compliance
For the most part, many MDM vendors offer these commonly requested features. Sources such as PCMag that provide evaluation of MDM vendors base their decisions on how users and devices can self-register, how policies and settings can be pushed out to devices, how lost devices are located, and data security. Choosing the right MDM vendor will come down to how their cost and capabilities meet your business requirements.
An alternative to installing clients such as an MDM agent on mobile devices is to create portals that any device can access. This limits exposure of an untrusted mobile device from infecting the network with malware or other threats since the portal is limited to what it has access to. An alternative to a portal is to provide a remote system only keyboard access to a system within a secured network segment. By only providing keyboard access, threats such as malware that have infected the remote host can only see keystrokes to the system within the secured environment. The remote system will never have access to the secured environment, denying the malware the ability to access the secured system and environment.
Planning a SOC
Developing your SOC objectives, defined through a mission statement and scope statement (or a combination mission and scope statement), sets the bar for what your SOC will accomplish. Aligning security tools, policies, and procedures builds a foundation for how your SOC services will be delivered. The next challenge to address is how to support the daily operations of your SOC. Questions such as where analysts will work, how much compute power is needed, and how the SOC will be secured need to be addressed before your SOC can go live. These topics also need to be continuously evaluated to ensure the plumbing and foundation of your SOC keeps up with the increase in demand for various resources.
Capacity Planning
The first SOC foundation planning concept to tackle is understanding the capacity requirements you will need today as well as in the future.
Capacity planning involves developing the physical and technical requirements for building a SOC:
Physical requirements include the location(s) to physically host the SOC employees and technology, power requirements, space to hold equipment, seating arrangement, how trash is handled, physical security considerations, and other items that are used within a SOC.
Technical requirements include network throughput, types of technology, monitors, and other technical SOC needs.
These requirements will be based on supporting the services outlined in the SOC mission and scope statements. For example, if monitoring a local datacenter is part of the scope statement, then physical and technical requirements will include what is required for a SOC analyst to perform that work. If capacity is not properly assessed, you might encounter complications such as lack of network bandwidth or lack of rack space to secure and power the tools needed to perform monitoring. If capacity planning does not take into consideration a healthy SOC layout, problems ranging from a noisy work environment to lack of visibility to monitors displaying critical information will lead to a dysfunctional SOC. For these and many other reasons, it is critical to properly plan the capacity requirements for your SOC.
SOC Goal Alignment
Designing a SOC depends on a handful of factors. First off, the mission statement and scope statement set the boundaries for the location(s) where the SOC will operate. These statements also identify the different services expected from the SOC. Chapter 3 covers SOC services in more detail; however, understand that before a service can be offered, there must be people, process, and technology available to perform the service. That means the people and technology must reside somewhere and there will be expected resources available. Capacity planning ensures that those requirements are met.
Chapter 1 covered how to assess existing capabilities and available technology based on best practices from industry standards, guidelines, and frameworks. Assessing existing capabilities and available technology provides a blueprint of the current state of the SOC. Chapter 1 also covered how to use maturity modeling to develop a plan with milestones to improve SOC services. Those maturity goals include how the future desired SOC will look regarding people, process, and technology:
People goals reflect the number of people for required roles as well as the expected skillsets. Some skillsets might be taught on the job while other skills will be required the day the new hire takes the role.
Process goals impact what is required to deliver services. This includes what policies need to be enforced and how those policies are enforced.
Technology goals complement the people and process goals, acting as an enabler to accomplish goals for SOC services. For example, a goal to monitor the network for threats requires technology that permits monitoring network traffic as well as tools for identifying when malicious activity occurs.
Growth Planning
Maturity goals influence the SOC’s capacity planning requirements. Planning must account for required hardware, number of employees, how teams will collaborate, seating arrangements, and many other factors that are needed to properly deliver a specific SOC service at the expected level of maturity. When considering the physical location for the SOC, one key principle is that choosing a location that the SOC can grow into usually is less expensive than having to move to a larger location at a later date because the SOC has outgrown its initial space. If the SOC capacity planning team is unsure about future requirements for the physical location, it is ideal to predict, at a minimum, a three- to five-year growth percentage and develop the location around those numbers. An example could be viewing the maturity goals for the SOC and target each SOC service to be at a specific state three to five years from the current date. Capacity planning must take into consideration what changes are needed in people, process, and technology to be at the three- to five-year maturity state. Using this approach leads to a SOC design that has a percentage of open seats, growth room for increased bandwidth usage, and available rack space for future technology.
Key Point
Maturity models must be part of capacity planning. More advanced phases of a maturity model will require certain resources in order to be executed properly. This is why before you perform a capacity plan, you first develop your maturity model(s). Then you can align your maturity goals with expected capacity requirements so your SOC sponsor understands your capacity requirements today as well as what they could be in the future.
If your SOC budget does not allow for including future growth in a capacity plan, there are other options that can be used as the SOC outgrows its physical location. Options include permitting teleworking, opening a new branch facility that is connected to the SOC headquarters, and/or outsourcing some services. Any of these options is more ideal than having to migrate an entire SOC and its people and technology to a larger facility while maintaining its services.
Technology Planning
Another capacity planning factor is related to the technologies used by the SOC. As technology capacity planning is performed, it is recommended to set up meetings with vendors of existing equipment within your organization so they can help future-proof their equipment. Vendors will also know the best options for configuration and hardware that meet your SOC maturity goals. It is best to start with existing vendors because they are less likely to have to “sell” against anybody else and they might already understand your environment. Even by doing so, you still might encounter a vendor attempting to upsell or displace other vendors within your organization. For example, if you have products from two different firewall vendors in your environment and invite each vendor to help you with capacity planning, each vendor will offer a future design that replaces the competitive firewall.
Another option for technology capacity planning that captures a vendor-neutral viewpoint is to seek consulting from technology service partners, also called resellers, that broker sales between your organization and vendors. Many enterprise vendors do not sell directly to customers but instead rely on resellers, which can provide the SOC with a comparison between industry leaders and advise on what other SOCs are doing in the specific technology areas of interest. Knowledge is power and there are likely many experts willing to speak with you at no cost regarding the best ways to design different parts of your network.
Before starting conversations with vendors or specialists, you will want to verify all hardware and connectivity requirements based on your SOC maturity goals. Remember that the requirements you develop are a starting point for the design; be prepared for outside specialists to suggest change. For example, some products can include proprietary components or have special requirements such as additional power. It is best practice to lead with technologies that are flexible by supporting application programming interfaces (APIs) and open standards; however, you will want to ensure capacity planning accommodates all requirements, including those systems that are not flexible regarding APIs and open standards. Sometimes you will find that some proprietary technology may be much cheaper and already used within the organization, while other times investing in the effort to convert to a new system will make more sense for your SOC. Chapter 1 provided details on how to assess for capabilities, plan for maturity, and rank which investment would provide the most impact to the organization. The results from these exercises will provide guidance for which technology options are best for your SOC.
SOC Resource Planning
It is important to include all teams that will work with the SOC during the SOC’s capacity planning. There might be areas of cost savings that could be accomplished by leveraging other teams’ resources, including using other teams as designated backup options. For example, another team might agree that its office space could serve as the overflow or emergency workspace for the SOC rather than having to build or rent a redundant location. Having conversations with other teams will involve budget, which can lead to sharing the cost of hardware and service support and consolidation of existing hardware. Working with teams outside of the SOC can help overcome challenges to certain SOC goals. An example is the SOC using the organization’s datacenter to host and manage its technical equipment rather than having the SOC responsible for datacenter management tasks.
Some capacity planning decisions will be influenced by whether in-house or external services are used. Once again, vendors and resellers can advise on the benefits from either approach, but keep in mind that vendors want to sell you something. Rely on your maturity assessments (discussed in Chapter 1) to help keep the conversation nonbiased and in the best interests of the SOC. Reasons for using external services in response to capacity planning are reductions and potential savings in hardware, personnel, required process, and compliance.
Redundancy Planning
Another capacity topic that you must address is the requirement for redundancy. Redundancy decisions are based on the SOC’s risk appetite (for example, backup systems can be configured as active, passive, or on demand) and redundancy plans are developed using in-house services, outsourced services, or both. Chapter 1 covered how to rank the importance of capabilities and services against the goals of the organization. Anything ranked as high importance requires active and more costly redundancy, while lower-ranked services and technology require passive, less expensive redundancy options or just an on-demand option if a backup of a service or technology is needed due to a failure in the primary offering. The section “Disaster Recover,” later in this chapter, looks at disaster planning concepts in greater detail.
Developing a Capacity Plan
To properly perform capacity planning, you should document your capacity plan. Begin by including the time, date, and version of the capacity planning report so readers know how relevant the data is that they are viewing. Next, you need to provide executive statements and/or purpose statements, so readers know why you performed the planning. For example, you want to explain whether the capacity planning is for a new SOC or to future-proof an existing SOC. Another example is explaining that the capacity planning report will define what is needed to improve an existing SOC service to a desired maturity goal. The quality of the executive statement for this report can be the determining factor if executives approve or deny the resources being requested.
When stating capacity specifics in your capacity planning report, you should list the capacity type, current analysis, and any expected growth or changes. You also might want to include other subsections depending on the item being analyzed, but at a minimum, these three capacity specifics must be in the capacity planning report for any items being requested. Once all items are logged, you need to provide details about each item being analyzed. This can include where it is located; what the specific requirements are to operate; what changes are needed to meet the future requirements; any threshold limitations based on hardware, software, or services; and a summary of the strategy that can be implemented to increase the capacity to the desired state. Other details to consider are budget, compliance planning, and an appendix to define key terms or other reference items.
The document in Figure 2-9 is a sample template for capacity planning. You can adjust these questions to meet your SOC’s goals.
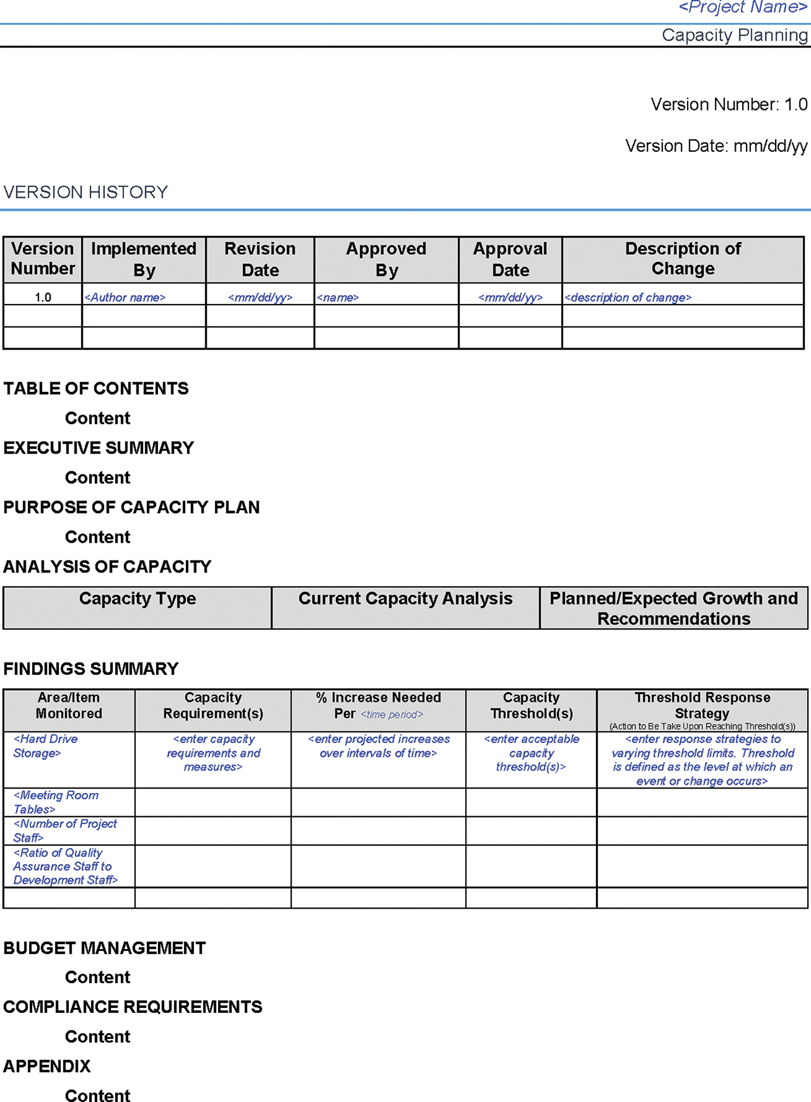
FIGURE 2-9 Capacity Planning Template
There are additional items that you could include with your capacity planning documentation, such as success criteria and a ranking system that is ordered starting with what is most important to the SOC down to what would be a “nice to have.” This additional data will help answer questions such as how to invest limited budget into the SOC, meaning which capacity needs should be addressed now and which should be left for a future budget.
Designing a SOC Facility
This section looks at points of consideration as you develop a new facility or modify an existing facility in which the SOC functions. A great resource for recommendations in this area is the Whole Building Design Guide (WBDG) website (https://www.wbdg.org/) of the National Institute of Building Sciences. A 2017 WBDG article titled “Office Building” identifies the following (among others) as important design considerations (tailored here to SOC facility considerations):
Cost-effective: Assess the performance versus cost of each design element and building component. In some cases, it will be ideal to invest more initially to save on long-term operations and maintenance.
Functional/operational tenant requirements: Consider integrated requirements of the SOC staff. These include the desired image, degree of public access, hours of operation, growth demands, security issues and vulnerability assessment results, and other long-term items.
Flexibility: The office building must easily accommodate frequent renovation and alteration. It must offer easy access for changes, such as using raised floors to permit access to cabling and power distribution.
Urban planning: Consider the value the local neighborhood offers as well as the impact of the SOC to the neighborhood. How far will employees have to travel to purchase lunch? How close is a fire department or a police station? Will building the SOC and associated facilities such as the parking lot negatively impact the surrounding environment?
Productive: Consider worker satisfaction, health, safety, and comfort. Will SOC employees be comfortable and satisfied with the workspace? How easy will it be for the SOC to have meetings with internal and external people?
Technical connectivity: Ensure flexibility for IT infrastructure, allowing technological access and power for SOC equipment. Considerations include wired and wireless options, such as whether wall material permits wireless signals and whether wired network ports are available throughout the building.
The WBDG recommendations apply to an average business developing a workspace. There are some additional key points that should be included with the WBDG list of recommendations based on the needs of a SOC. Additional items include being able to facilitate effective collaboration between SOC members, maintain a secured SOC, adhere to compliance requirements, and accommodate the requirements from your capacity planning reports. Collaboration between SOC members includes how data is shared between individual team members as well as the large screens providing data to the entire SOC floor if a floor monitor is needed. Security for a SOC can depend on the goals of the business. I have seen many SOCs containing classified data require physical lights to be turned off when people without clearance are permitted on the SOC floor.
These examples are just some of the many factors to keep in mind as you consider the capacity planning requirements and building recommendations (such as those from WBDG) while designing the facility for the SOC. Some design features and functions will be mandatory and rank higher in importance than others; however, you should not overlook lower-ranked design features and functions. For example, a comfortable working environment might not be a mandatory requirement, but it will dramatically improve job retention, saving you down the road from having to respond to complaints and employees leaving due to an unsatisfactory work environment. I have seen people leave an organization even after receiving a promotion because they were not offered their own office space. Remember that employees will be spending a large part of their lives in the SOC facility. Investing a little extra into making employees happy can go a long way toward keeping them satisfied.
Physical SOC vs. Virtual SOC
A major factor regarding how much physical space a SOC facility requires is whether you plan to incorporate a virtual SOC design or external consulting services. A virtual SOC might mean that team members are working from various locations that are all connected through collaboration technology. In this example, a physical facility might be needed only for the SOC headquarters or an emergency workspace in the event of a major incident requiring virtual members to meet in a physical location. An example of a major incident could be a security incident that disrupts the organization’s profits, renders employees unable to perform their work, or the loss of company classified data. These situations would demand an “all hands on deck” approach requiring field members to travel to the SOC headquarters to form an ad hoc group, commonly referred to as a “tiger team,” to deal with the situation.
Outsourcing services can mean a virtual SOC design where the SOC analysts work from their own office and only physically show up during a major incident or quarterly meetings. Factors that contribute to whether remote work is allowed include security requirements, policies against data leaving the facility, and technology limitations. As an example, the U.S. government has specific requirements for handling certain levels of classified material. As content is deemed higher in classification, facility security requirements increase, including limiting access to such data as well as where the data is stored.
Chapter 1 covered the advantages and disadvantages of using in-house SOC services and external SOC services. Facility considerations are similar. Table 2-2 provides an overview of the benefits of using an internal facility (i.e., a single physical location for SOC employees to work from) or external facilities (leveraging smaller offices or permitting employees to work from home) for the SOC. This does not take into consideration the benefits and costs associated with outsourcing services, as explained in Chapter 1.
TABLE 2-2 Benefits of In-House and Outsourcing the SOC Facility
Internal |
External |
Face-to-face team interaction |
OPEX savings (office space and resources) |
Direct access to interact with employees |
Further reach for recruitment |
Local support for organization |
Employment in different time zones to accommodate 24/7 support |
Options for live events (team building/lunch and learn) |
Job hour flexibility |
SOC Location
Another decision to consider is where to locate the SOC facility or facilities. Some companies might find value by placing the SOC near the network operations center (NOC) or desktop support team. Smaller organizations might use a shared floorspace and leverage cloud resources for redundancy purposes. The previously referenced WBDG recommendations point out urban considerations, which include the surrounding neighborhood. I have seen organizations located where food, childcare, and other resources that employees need during a workweek were not accessible within an hour’s drive. Employees would have to develop unappealing work schedules to accommodate childcare or take extremely long lunch breaks, which leads to an unhealthy work environment. If a fire department isn’t located within a reasonable distance, the SOC needs to have a fire prevention strategy that doesn’t rely on waiting for the local firefighters.
Outside of the local neighborhood are country-based restrictions to consider. Certain countries have data sovereignty requirements that restrict data from leaving the country. Other country-based restrictions include laws or culture aspects impacting local employees of the organization. Maybe certain procedures that are legally acceptable in one country would not be acceptable in another country and therefore need to be adjusted. For example, could a Dutch-based SOC monitor Chinese citizens? All of these factors must be evaluated as the locations for the SOC facilities are considered.
SOC Interior
There are interior aspects of the SOC facility that need to be considered against the capacity planning report and recommendations such as those from WBDG. The same decision-makers who decide how the SOC is designed need to be responsible for developing the SOC’s mission and scope. This includes SOC managers that will run the SOC, executives that support the SOC, and facility specialists that understand how to create a facility that meets what is being requested for the SOC. Some decisions will concern aesthetics, while others will be based on politics or budgets. Examples of decisions regarding budget and politics are how large a manager’s office should be and what type of workspace SOC analysts should have. Aesthetic considerations include the amount of natural light compared to artificial light. For example, security requirements could influence the decision to not use natural light based on the light ports being a potential vulnerability to physical intrusion.
SOC Interior Design Considerations
The following list highlights key aspects to consider for the SOC’s internal design:
Lighting: Lighting should promote a comfortable working environment permitting the analyst to not only see well in his or her workspace but also the video wall monitors, if applicable. Decisions regarding natural lighting and artificial lighting are made based on the building design, budget, and security requirements. Specialized lighting might also be required for certain SOC functions, such as viewing server rack space or cables under a raised floor.
Acoustics: Poor acoustics can be very disruptive to daily operations. SOC analysts will be collaborating over the phone and within their teams, which will create noise. Noise levels need to be accounted for so that analysts can hear clearly during phone conversations. Also consider noise from equipment, which may necessitate placing it in a separate room such as the computer room rather than in the SOC analyst work area. Soundproof material for the walls could be used to reduce sound levels as well as protect conversations from being heard by unwanted parties. Audio privacy rooms can be built as an escape from noise as well as to ensure privacy of conversations. ISO 17624:2004 also provides guidelines for leveraging acoustical screens as an option to reduce office noise. All of these options can be used to promote a healthy and productive work environment.
Security: Every SOC will have specific requirements about who can and cannot access the operations room. Physical security must be part of the design of the SOC facility. Common options are door locks, common access card (CAC) or other smartcard door locks, video monitoring, and mantraps. Additional specialized lighting might be required for certain situations such as when visitors without clearance are in the SOC facility. I have been in SOCs that use police lights that are enabled when an uncleared person enters the SOC, notifying all analysts to turn off their monitors and the video wall screens while the person is present. External consultants can assist with meeting your SOC’s security requirements and can advise on any constraints such as if CCTV is not permitted within a country.
Secure disposal: People will produce trash that contains sensitive information. A SOC must have requirements for properly shredding and disposing of such trash. Dumpster diving is still a threat to modern organizations. Purchasing professional trash disposable services or tools such as shredders to accommodate securing trash are some options that are available.
Storage: Certain types of data might require specific storage requirements. For example, classified documents or forensic evidence will have to be bagged, tagged, and stored securely. Secure storage needs can require a safe or other storage options, perhaps even a specialized part of the building with armed guards, known as a sensitive compartmented information facility (SCIF), discussed further in the next section.
Video wall: Some SOCs use monitors that enable multiple analysts to view the same data simultaneously. This means having view of multiple dashboards, which will likely need to be placed on a wall so all analysts can see the data. For example, a SOC responsible for various services may display the dashboard for a SIEM or other tools that take into consideration the SOC’s current event workload as well as external data such as global events. Having a centralized monitor allows each SOC analyst to focus on their own responsibility while always having a view of data that applies to the entire organization. To maximize collaboration, analysts should have access to the same data on their personal computer as well as be able to share what they are looking at on a shared video wall. Make sure that the video wall is high enough that all analysts can view it, including if somebody in the front row is taller than an analyst in the back row. Also consider future systems and analysts that might be added according to the capacity planning report. Figure 2-10 shows an example of how to design for these items.
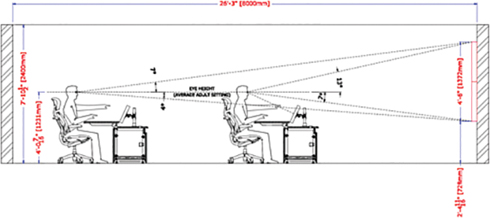
FIGURE 2-10 Video Wall Design Example
Workstations: Consider the workspace for each SOC employee type. For example, should it include a phone, a desktop computer, and possibly a mounted flat-screen monitor? Some analysts will use a laptop only and not need a monitor, while other analysts will prefer having multiple monitors. Consider the number of cable holes that are available to help conceal power and network cables. The layout of how workstations will look can be divided into separate cubical work spaces, grouped into a large workspace, or possibly be a long table that permits open seating. Many office equipment manufactures offer options for configuring workspaces, which is ideal so that the SOC can adjust to the most effective layout (which fulfills the previously discussed WBDG recommendation for flexibility). Speak with an office furniture specialist for more information about workstation furniture options.
Lockers: Providing lockers gives SOC personnel a secure means of storing personal items. There may even be compliance requirements, such as no mobile devices permitted in the SOC, that necessitate provision of lockers. Lockers can also be placed within personal workspaces for storing smaller personal items and documents.
A final factor to consider regarding the value impact of the SOC’s interior design is the SOC’s aesthetic appeal. Do not underestimate the value of a first impression when people walk through a functioning SOC. Many SOCs offer the option to provide tours, enabling non-SOC members to gain awareness of the SOC and its associated activities. Investing extra effort in aesthetics can capture additional funding and support from leadership, who may include the SOC in tours of the company to showcase the company’s investment in security.
SOC Rooms
Another SOC facilities design consideration is the different types of rooms within the facility. These rooms could reside within the SOC headquarters, at a remote branch office, or at some other type of remote facility such as an employee’s home office. The following are room types to consider for your SOC (all of which might not be required for your SOC):
SOC operations room: This is the SOC floor occupied by analysts and other SOC members doing their daily tasks. This room can house various dashboards, incident boards, analyst workspaces, and other operational items. If a video board is being used, this room should offer unrestricted line of sight to the video board for all SOC members. Make sure to size up versus down or you might end up with a crowded floor that ruins the atmosphere of the SOC workspace.
War room/situation room: This room is used for meetings. It should have collaboration technology such as videoconferencing and white boards. Most modern war rooms offer the capability to dial in remote users and share their desktop or the desktop of somebody in the room, so everybody is able to work from the same screen. One aspect to consider is the sensitivity of content that might be covered within the war room. Additional security measures might be required for the walls, door, or collaboration technology based on sensitivity needs.
SOC manager’s office: It is common to design the manager’s office with a clear view of the SOC floor and video wall as well as walls and a door to provide privacy when talking about sensitive topics.
Digital forensics lab/clean room: A room that is dedicated to digital forensics work requires additional security, including documenting any access. This is critical for tracking chain of custody, which requires that all access to evidence be documented; otherwise, it can be considered contaminated from a legal perspective. Other aspects of a digital forensics lab include additional power sources to keep equipment that has been obtained with the system’s power still on and plugged in so it doesn’t power off, fume hoods, space for large lab tables, and higher cleaning standards. Resources for better understanding how to set up a digital forensics lab/clean room include ISO 31000 (risk management), the ISO 14000 family (environmental management systems), the ISO/IEC 27000 family (information security management systems), and OHSAS 18000 (occupational health and safety), depending on the type of lab you are looking to build.
Sensitive compartmented information facility (SCIF): A SCIF (pronounced “skiff”) is required if the SOC plans to work with sensitive compartmented information (SCI). SCI represents resources pertaining to sensitive information that is required by law to protect. Technical specifications for a SCIF take into consideration physical security; heat that radiates from computers, known as tempest; alarms, locks, and safes for containing sensitive information; and storage for all unauthorized devices such as phones, cameras, and computers. These requirements depend on whether the SCIF is for handling British classified data or U.S. classified data and what type of data will be handled. The physical construction, access control, and alarming of the facility has been defined by various government directives, which must be met and audited before sensitive data can be contained with the SCIF.
Computer room: The SOC equipment such as servers and equipment for private networks used for testing need to be hosted somewhere. Sometimes the SOC’s computer room is part of a shared space such as a datacenter, while other times the room is a space dedicated to SOC equipment.
One specific room that is critical for the operation of the SOC is where its technology is housed. This brings us to the next topic of designing computer rooms for the SOC.
SOC Computer Rooms
Developing the computer room includes many requirements to consider. The SOC might or might not be responsible for building the computer room it will use, but it should at least be involved with planning it. There are specific regulatory compliance requirements for versions of hardware and software that are used within the datacenter. Regulatory compliance could also control how a SOC’s data is architected for segmentation as well as require use of certain levels of encryption to protect traffic. Certain specialized equipment may need to be racked, powered, and secured, which must be accounted for.
Computer Room Considerations
The following key topics must be addressed as planning occurs for a computer room that will be used by the SOC:
Power requirements: The first step for planning power requirements is to determine the number of services to install per rack. Some equipment might need special power, such as more current, that would require an electrician to set up. There might be requirements for power strips where large amounts of gear will be located. To avoid blowing fuses or equipment, I recommend gathering your power requirements based on capacity planning reports and speaking with an electrician about what can and cannot be supported. Power redundancy is also an important topic. Impacting factors include the type of redundancy that can be provided, the budget for redundancy options, the available power supplies in equipment, and risk tolerance. One option for power redundancy is a single redundant option, meaning if a primary system powerline goes down, a backup power source takes its place. Grid redundancy is another option, which means to have twice the number of power supplies on the same system, with each power supply using a different AC power source.
Power loads are dependent on the facility input plug. If the power load exceeds the rating on the input plug for a sufficient period of time, the input breaker will be triggered, causing the power to be disrupted. For this reason, power plugs need to be evaluated to ensure they can support expected power requirements based on capacity planning needs. This includes consideration for the different types of plugs used in different countries.
The Uptime Institute offers estimates for the expected power usage of different size computer rooms, which can be helpful for budgeting for power. For example, the Uptime Institute estimates that 1 kilowatt of server capacity costs US$25,000 for a Tier IV datacenter. See https://uptimeinstitute.com/ for a better understanding of estimated costs for powering a computer room and associated equipment.
Temperature and humidity: The American Society of Heating, Refrigeration, and Air Conditioning Engineering (ASHRAE) Technical Committee 9.9 has created a widely accepted set of guidelines for optimal temperature and humidity set points in the datacenter. For example, the ASHRAE guidelines specify acceptable temperature ranges for the datacenter to prevent IT gear from overheating. Cooling options include server racks that have built-in cooling, cooling the server room, and HVAC filters that suck heat out of a computer room or individual server rack space. Warm rooms can produce mold, which is bad for equipment. You might need humidity units, which will require some method to be drained as they collect water. It is best to have a sink that humidifiers can drain in rather than manually having to empty a humidifier.
Table 2-3 represents ASHRAE recommended temperature and humidity ranges for a computer room.
TABLE 2-3 ASHRAE Recommended Temperature and Humidity Ranges
Property
Recommended Value
Lower limit temperature
64.4°F [18°C]
Upper limit temperature
80.6°F [27°C]
Lower limit humidity
40% relative humidity and 41.9°F (5.5°C) dew point
Upper limit humidity
60% relative humidity and 59°F (15°C) dew point
Measuring temperature and humidity needs to be properly done to ensure that accurate readings are taken relating to all systems within the computer room. One side of the computer room may be hotter and moister than another side, so both sides need to be monitored. The design of the computer room can also impact airflow, permitting better control of temperature and humidity. Figure 2-11 is an example of air flowing through a computer room.

FIGURE 2-11 Example Airflow Within a Datacenter
Cisco published a site planning guide titled “Data Center Power and Cooling White Paper” for power and cooling that includes recommendations for the location and use of equipment racks in regard to their impact on temperature and humidity. One recommendation is to consider the arrangement of hot and cold aisles of a server rack. Arranging racks into rows of hot and cold aisles minimizes the mixing of air, reducing temperature and humidity. If two hot aisles are permitted to mix air, cooler air-conditioning requirements will be needed to compensate for the additional heat. Figure 2-12 is an example of how a hot-aisle and cold-aisle layout could look.

FIGURE 2-12 Sample Hot and Cold Aisle Design
The Cisco guide suggests powering the heaviest and most power-dense equipment at the bottom of the rack. This helps lower the rack’s center of mass to reduce the risk of tipping. Power-dense equipment tends to draw more air and need the most cooling. Many datacenters have cooling near the bottom of the rack to give the hottest equipment the coolest air. Cisco also recommends, when possible, to leave unoccupied space in the rack between servers to permit airflow. Unoccupied rack space can be filled with blank panels to keep the airflow within the server space.
Equipment racks: Different types of equipment have different rack requirements. Server racks are different from network gear racks. Make sure to consider what type of gear would need to be stored or racked. Racks that have perforated front and rear doors to maximize air flow are ideal. You might need cable plants that can accommodate different types of connection types such as fiber and CAT6 with booted RJ45 connectors. Optional casters should exist to permit rack mobility if needed. Locks should be available to secure access to the equipment within the rack. Consider removable rack doors to simplify maintenance of systems within the rack as well as the rack itself. Finally, as previously discussed, consider the heat and humidity impact based on how racks are positioned within the computer room as well as the equipment within the racks.
Lighting: Consider how the computer room is lit. Cabling can become extremely difficult to identify in a poorly lit computer room. Make sure your lighting accommodates people and the types of spaces they will have to work out of, meaning that if a tech is expected to go within a rack, there should be lighting that allows the tech to have full visibility of the equipment within that space. Emergency lighting should be available if the primary facility power becomes unavailable.
Redundancy and UPS: The SOC deals with sensitive data that needs to be available even during a power outage. Redundancy can be accomplished through hardware, a backup location, routing, software, and backup power. For example, a dedicated uninterruptable power supply (UPS) or an existing UPS that supports the facility the SOC resides in can provide redundant power options. Backup routing options can be designed so that if a primary system goes out, traffic is routed to another location. Backup systems can sit at branch offices or within the cloud. Software can be configured to fail open or fail closed based on its business function. For example, a network access control solution could be configured to permit all connections (fail open) or deny all connections (fail closed) if a system failure occurs.
Regarding expected costs for UPS support, a good guide is a whitepaper titled “Comparing UPS System Design Configurations” by Kevin McCarthy and Victor Avelar, which suggests potential costs associated with increasing the level of redundancy for a UPS architecture. As more scales of availability are added to the design, the cost per rack increases. McCarthy and Avelar use the following terms for UPS configurations:
Capacity: A single UPS system with no redundancy, meaning no backup system in place.
Isolated redundant: The traditional active standby two-system design where the primary system takes on all the load and the standby system is not used unless an event occurs.
Parallel redundant: Two systems activity sharing the load being used.
Distributed redundant: A few UPS systems are all sharing the load in an active manner.
System plus system: Systems not only are sharing the load but also have an additional local redundant system for backup if the local primary system goes down. An example of a system plus system design is having three facilities sharing the power load as well as each facility having a parallel redundant system.
Table 2-4 represents the estimated costs associated with each UPS design according to the McCarthy and Avelar whitepaper.
TABLE 2-4 Estimated UPS Cost
Configurations
Scale of Availability
Tier Class
Datacenter Scale of Cost (US$)
Capacity (N)
1 = Lowest
Tier 1
$13,500–$18,000/rack
Isolated redundant
2
Tier II
$18,000–$24,000/rack
Parallel redundant (N+1)
3
Distributed redundant
4
Tier III
$24,000–$30,000/rack
System plus system (2N, 2N+1)
5 = Highest
Tier IV
$36,500–$42,000/rack
Grounding: All datacenter equipment needs to be grounded. This can be part of the equipment rack or require additional work. Ensure ground resistance is at least < 1 Ohm. There are many standards and guidelines that can be referenced for grounding best practices. NIST offers recommendations for grounding based on papers titled “Ground Connections for Electrical Systems” (Technologic Papers of the Bureau of Standards No. 108) and “A Consensus on Powering and Grounding Sensitive Electronic Equipment.”
Raised floors: If the SOC plans to host a lot of equipment, that equipment will require cables, which can get really messy. Computer rooms can be built on raised floors to hide cables and power connectors. Figure 2-13 is an example of a raised floor tile. Another option is running cables and power connectors within the ceiling, which requires a ceiling that can support the associated weight. Speak with a facility specialist to confirm that the ceiling or floor option used to host cables will meet your capacity planning requirements.

FIGURE 2-13 Raised Floor Tile
Fire safety: Different countries have different required fire safety codes. Sometimes, fire safety options can put equipment or people at risk when they are released, such as chemicals that can quickly put out fires but are poisonous to humans. Water may be safe to humans but is bad for equipment. You will have to consider all of these factors, including the different types of fires that could occur. For example, an electrical fire is different from a gas fire and requires a different form of fire safety to be put in place. You may need a professional to look at smoke detectors and carbon monoxide detectors to accommodate all of these factors. ISO/TC92, Fire Safety, is one of the many guidelines that you could reference to address the different types of fire safety risk.
Flood protection: The SOC facility could be at risk of flooding based on where it is located. Pumps and drains are countermeasures that can be put in place to handle a certain level of flooding. Water-resistant material and water barriers are also options to reduce the risk of flooding. The WBDG article “Flood Resistance of the Building Envelope” provides methods to evaluate if your facility is located in an area prone to flooding and describes various flooding countermeasures. Table 2-5 is WBDG’s overview of active and passive floodproofing methods.
TABLE 2-5 Examples of Active and Passive Floodproofing Methods for Buildings
Dry
Wet
Active
Temporary flood shields or doors (on building openings)
Temporary relocation of vulnerable contents and equipment prior to a flood, in conjunction with use of flood-resistant materials for the building
Temporary gates or panels (on levees and floodwalls)
Emergency sand bagging
Passive
Waterproof sealants and coatings on walls and floors
Use of flood-resistant materials below design flood elevation (DFE)
Permanently installed, automatic flood shields and doors
Installation of flood vents to permit automatic equalization of water levels
Installation of backflow prevention valves and sump pumps
Elevation of vulnerable equipment above DFE
Monitoring: All electronic equipment needs to be monitored to ensure that accessibility and acceptable performance levels are maintained. It is recommended to have a central monitoring console located outside of the computer room that is monitored 24/7 for this purpose. Some SOCs assign monitoring to the NOC or a third-party consulting company, while other SOCs monitor equipment using in-house resources. Monitoring can include ensuring power is being distributed, systems are reachable, and systems are functioning properly. An example of a network monitoring tool is WhatsUp Gold from Progress (formerly Ipswitch). This tool continuously pings network-based equipment and alarms administrators when a system in found to be unreachable. NetFlow tools can be used to alarm when spikes or drops in network bandwidth are identified. Cisco Secure Network Analytics (formerly Stealthwatch), SolarWinds’ Network Performance Monitor, and Plixer Scrutinizer are examples of NetFlow-based network monitoring solutions.
Locks: Systems in the computer room are critical to the operation of the SOC and need to be physically protected. Locks on the doors and server racks within the datacenter provide physical security and can be lock and key or based on various types of digital systems. Examples of digital systems include smartcards and biometric-based devices. Ensure that access to power and network cables is also secure. You want to avoid scenarios such as a cleaning person unplugging a critical system by accident during a standard cleaning routine. FIPS 140-3, Security Requirements for Cryptographic Modules, also provides guidelines to using locks to enforce proper physical security.
Video and access control: A common requirement for a SOC computer room is the capability to control who accesses the room and monitor what they do while in the room. Access control can be based on physical controls such as mantraps and what type of locks are used on the doors within the SOC and its computer room. Various forms of video surveillance equipment can be used that are always active or triggered when motion is detected. Some SOCs require video surveillance to be recorded and stored for a specific period of time. The specifics of the video and access control requirements will depend on your SOC’s business needs in regard to physical security for the computer room. ISO 22311:2012, Societal security – Video surveillance – Export interoperability, is one of the many guidelines available that can provide recommendations for computer room physical security and monitoring options.
SOC Layouts
Figure 2-14 shows an example of what a SOC layout could look like. This example shows a SOC operation room, war room, and manager’s office. In this example, the computer room is located somewhere else in the building.

FIGURE 2-14 Sample SOC Layout
Figure 2-15 shows a draft for how the analyst area of the operation room could be designed. Notice how the center point for the design is visibility to the video wall. Some SOCs may not require a video wall, which means the design of the analyst area would be completely different from Figure 2-14. Your ideal design will be based on the results of your capacity planning compared against your SOC’s business objectives.
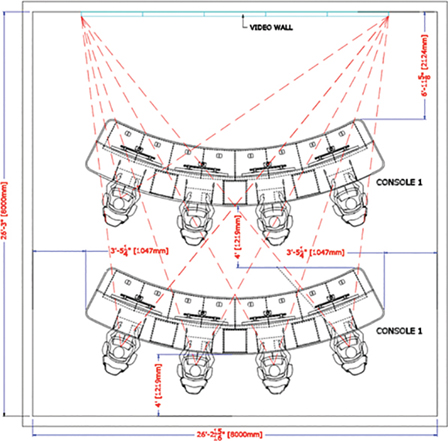
FIGURE 2-15 SOC Floor Layout
Note
For many organizations, other teams outside of the SOC will handle some or all of the topics covered in this section. There might be a dedicated facilities team that handles everything, or the previous tasks might be divided among multiple teams; for example, datacenter operations might handle anything server, power, and cooling related. I covered all of the core concepts in the event your SOC will be responsible for planning and/or building all of the resources it needs.
Network Considerations
The SOC needs a network. Many books are dedicated entirely to developing networks, but for the scope of this book, the following are some key concepts to consider when building a network for a SOC:
Segmentation
Throughput
Connectivity and redundancy
The following sections focus on building a reliable and secure network for your SOC, starting with considerations for segmentation.
Segmentation
Segmentation by definition is to separate things into parts and sections. Regarding technology, segmentation is how systems and users are separated. Segmentation can be accomplished at many layers, starting from physically separating networks to logically separating traffic that is on the same hardware. If you are building a new network, you will want to plan segmentation proactively rather than deploy segmentation after the network is set up. Many organizations have trouble deploying deep segmentation or modifying existing networks once they are operational, causing unwanted disruptions and consuming lots of engineering hours. Being proactive about designing network segmentation will save you a ton of time and money. Figure 2-16 shows an example of the different layers of segmentation that are possible.
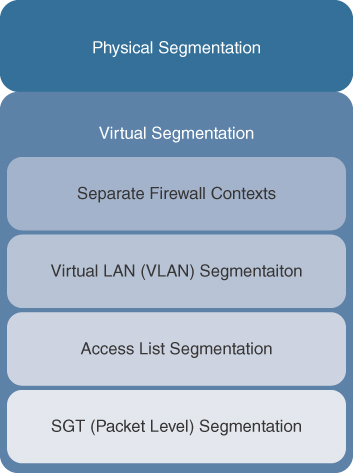
FIGURE 2-16 Different Segmentation Options
The top layer represents providing dedicated network equipment for each network segment, which would include its own routers, switches, and security equipment. This is the most secure and recommended approach, but also the costliest option. Some SOCs require a dedicated network, sometimes referred to as a secure enclave, in which case there is no choice but to invest in dedicated hardware. Reasons for using secure enclaves could be to protect certain types of data, such as a classified network, or to comply with regulatory requirements to keep traffic on a specific network, such as data sovereignty requirements. The secured enclave could also have more security requirements for encryption and other policies for how to control what is connected to the network and the type of hardware or system software that is permitted to run traffic within the network equipment. NIST 800-53 Rev. 5, Security and Privacy Controls for Information Systems and Organizations, is a great resource for learning more about secure enclaves and other segmentation recommendations.
Note
Some SOCs are forced to meet specific regulatory compliance requirements for versions of hardware and software that are used within the network. Regulatory compliance could also control how a SOC’s network is architected for segmentation as well as requirements to use certain levels of encryption to protect network traffic. For example, networks that are in contact with classified data will be required to have government approved technology and encryption. Upgrading to the latest code that isn’t on the approved list can cause the SOC’s network to be in violation of regulatory compliance requirements even though the update fixes known vulnerabilities!
Logical Segmentation
If you are permitted the flexibility of using virtual segmentation tactics, you can save money using the same network equipment by leveraging virtual LANs (VLANs) to logically separate SOC traffic from other traffic. Regarding concerns for VLAN security, there are tactics that can be used to protect traffic that are industry supported and proven to be secure. There is a low risk that an adversary could compromise switch security and tap into the SOC network, depending on whether vulnerabilities exist within the network equipment. An example could be overflowing the content-addressable memory (CAM) table or a switch-spoofing attack with the goal to hop between VLANs. Most modern switches have native security features to defend against these and other switch-based types of threats. This is why I highly recommend investing in proper networking equipment rather than relying on used or cheap equipment that lacks modern network and security capabilities.
The following are settings within most monitor switches that can be enabled to reduce the threat of Layer 2 exploitation in a way to prevent VLAN hopping:
Disable trunking, dynamic desirable, or dynamic auto when not used
Prevent the use of Dynamic Trunking Protocol (DTP) on all trunk and access ports
Prevent double tagging
Shut down all interfaces that are not in use
Logically Segmenting Hardware
Another logical segmentation option is to configure one physical piece of hardware to be recognized logically as more than one solution. An example is configuring a physical firewall to act as multiple logical firewalls. Configuring a physical firewall to be viewed as multiple logical firewalls is known by some vendors as multi-context mode. This feature is great for maximizing an investment in technology because logical separate versions of the same technology can be dedicated for different purposes. Sometimes the segmentation can be at the administration level, meaning administrators can make changes and see everything while other users can only see or change part of the system based on their login rights. Other times, such as in the multi-context firewall example, the firewall hardware views the different logical firewall segments as isolated separate systems that are unaware of each other. Multi-context firewall deployments are popular for service providers that sell access to datacenter services and deploy virtual firewalls dedicated to each customer so that the customer can manage and protect their rented virtual space. The SOC can use a single firewall and virtually dedicate separate firewalls for the analyst network, the testing network, and the management network.
ACL Segmentation
You can use access control lists (ACLs) to filter what can and cannot pass on the same network. An example of using ACLs could be permitting analysts full access to the Internet from the SOC network while limiting network access to guests visiting the SOC based on ACLs denying specific ports and protocols. There are many ways to use ACLs, including dynamic ACLs that can be pushed down by security tools if a policy is triggered. Regardless of your choice for VLANs, ACLs, or security group tags (SGTs), which are yet another way to perform segmentation, I advise not to overcomplicate your network design, or you will create a lot of unnecessary management work that will lead to confusion and unwanted disruption of services.
Note
I highly recommend considering a centralized network access control (NAC) technology for centralizing the management of VLANs, ACLs, and SGTs. NAC will be covered in more detail later in this chapter.
Choosing Segmentation
Which option you should choose for segmentation will depend on how critical the data is within the SOC. This choice essentially boils down to the SOC’s risk appetite based on the risk and the likelihood of an event occurring versus the cost to deploy countermeasures such as implementing segmentation or other security technologies. Be aware that if the SOC shares network gear and that gear is compromised, that will put the SOC’s operational state at risk as well.
Figure 2-17 shows a basic example of segmenting a SOC’s network. The SOC Tools segment is dedicated to the management of various tools. The second network segment is dedicated for analyst tools. The third network segment is set aside for all analyst workstation traffic. The fourth network segment is dedicated to analyzing malware. The purpose of these network segments is to isolate the type of traffic within each network based on the different types of risk they introduce. As an example, if an analyst workstation is compromised, only other analyst workstations could be impacted.
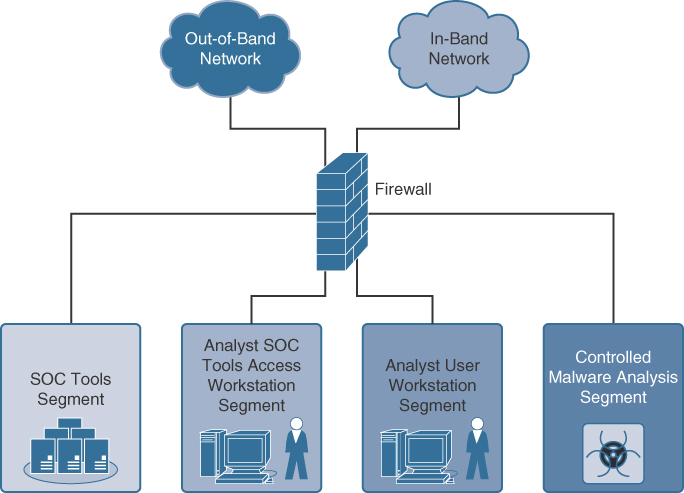
FIGURE 2-17 Logical SOC Network Segmentation
Note
The example shown in Figure 2-17 does not showcase any form of high availability.
Client/Server Segmentation
There are technology options that could run within a network segment that provide another layer of segmentation or access to other segments in a controlled manner, such as thin or fat client/server technology. A client/server architecture is a distributed application structure that partitions tasks or workloads between the server and service requestors, known as clients. Clients can be thin or thick. Thin clients are designed to be small, pushing the bulk of the data processing on the server. Thick clients are much bigger and are capable of performing the bulk of the processing rather than depending on the server. It is common for servers and clients to communicate over a network, which also is used as a way to provision access to a system within a network segment. As an example, referring to Figure 2-17, a SOC network could have a tool located within the SOC Tools network segment that an analyst could not access directly from his or her workstation that is on the Analyst Workstation segment. A thin or thick client can be installed on the analyst’s workstation that is able to access the tool within the SOC Tools network segment, which is a more secure method of providing access to the tool than allowing the analyst’s workstation direct access. Risks such as malware installed on the analyst system would not be able to infect the tool since the workstation does not have direct access to the tool.
Table 2-6 compares the benefits and drawbacks of thin client devices compared to thick client (personal computers).
TABLE 2-6 Comparing Benefits and Drawbacks of Thin Client Devices and Thick Clients
Benefits |
Drawbacks |
Thin client endpoints are less expensive than thick clients. |
Thick clients offer more optimal features than thin clients. |
Thin clients require less power. |
Thick clients require more compute power. |
It is easier to scale a server, client-based technology versus deploying multiple thick clients. |
Some applications will not run on a thin client based on power or other requirements. |
Thin clients can be considered more secured based on being controlled by a centralized computer. |
Thin client centralized management opens the potential for a single point of failure. |
Thin clients are easier to manage based on the centralized management concept. |
|
There is a smaller risk of data loss based on a centralized view of the systems. |
Active Directory Segmentation
Another form of logical segmentation is using an Active Directory (AD) administrative-tier model. This model divides three tiers that create buffer zones to separate administration of high-risk PCs and valuable assets such as domain controllers. Here is a short explanation of each tier:
Tier 0 is the highest level and includes administrative accounts and groups, domain controllers, and domains that have direct or indirect administrative control of the AD forest. Tier 0 administrators can manage and control assets in all tiers but only log in interactively to Tier 0 assets. In other words, a domain administrator should never interactively log in to a Tier 2 asset.
Tier 1 is for domain member servers and applications. Accounts that control these assets have access to sensitive business data. Tier 1 administrators can access Tier 1 or Tier 0 assets (network logon) but can only manage Tier 1 or Tier 2 assets. Tier 1 administrators can only log on interactively to Tier 1 assets.
Tier 2 is for end-user devices. For example, helpdesk staff would be part of this tier. Tier 2 administrators can access all tier assets (network logon) as necessary but can only manage Tier 2 assets. Tier 2 admins can log in interactively to Tier 2 assets.
Just like with traditional network segmentation, the goal of this approach is to add additional layers of segmentation that hackers would need to compromise before they could access a critical system. Also like other segmentation approaches, although it isn’t impossible for a hacker to work from a Tier 2 system up to a Tier 0 system, doing so is much harder. Best practices for security within tier security includes other defenses such as monitoring for malicious activity between tiers. Figure 2-18 is a conceptual diagram showing the Active Directory three-tier model.
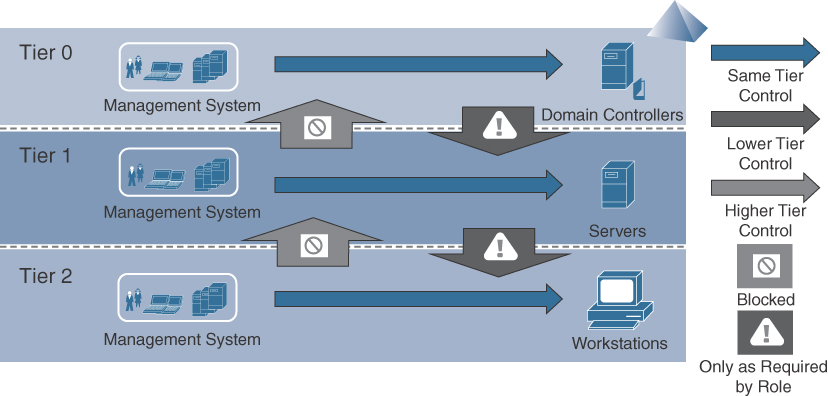
FIGURE 2-18 Active Directory Three-Tier Model
Throughput
Another consideration for the SOC network is throughput requirements. It is recommended to use dedicated circuits to provide services to the SOC. Sharing a network with other, non-SOC network traffic can cause services for all users to go down or be sluggish if the network experiences spikes in usage. There is a higher cost to having a dedicated circuit, which might not be obtainable for all SOCs due to budget constraints.
If your SOC must share a network, you can use configuration and technology to prioritize SOC traffic over other traffic and reduce the risk of a sluggish SOC network. The following items are some options that you can use to provide priority to SOC traffic as well as create an overall faster network for all systems:
Segmentation: Isolate the SOC network logically.
Proper capacity planning: Ensure enough bandwidth exists for the expected workload.
Use wire-speed routing between VLANs: Use the switch, not the router, to route inter-VLAN traffic. A switch’s hardware can do that routing at wire speed, known as static or dynamic IP routing.
Prioritize applications and use traffic shaping: Switches offer the capability to determine the importance of traffic. This can be accomplished using the following methods:
802.1p/Q tagging to prioritize applications
DSCP/type of service (ToS)/Layer 3 switching to prioritize applications by header
Shaping traffic using bandwidth by throttling or rate limiting
Use automatic endpoint parameters: Configure switch endpoint ports using storm control, number of devices, quality of service (QoS), and VLANs. If the smart ports option is available, use that to automate provisioning of endpoint parameter settings.
Leverage switch security: Enable Address Resolution Protocol (ARP) inspection, IP Source Guard, and Dynamic Host Configuration Protocol (DHCP).
MAC layer prioritization: Configure the network to give priority to devices within a specific list of MAC addresses.
Quality of services (QoS): Configure the network to give priority to certain types of time-sensitive and mission-critical data protocols. For example, prioritize audio and video over nonurgent protocols such as SMTP or HTTP.
Note
The organization might have its own requirements for throughput that are different from the throughput needs for your SOC.
Determining Throughput Requirements
One important task in network capacity planning is determining the required amount of throughput for the SOC. Not properly sizing throughput can slow down or even render some SOC services and capabilities unavailable. An example is an interruption in connectivity between a system dedicated to monitoring various SOC tools for availability. If the monitoring tool believes systems are down, it can trigger a failover, which could cause wasted effort to reset all tools back to the primary state. Another example of the impact of not properly sizing the throughput for a SOC could be having the network become extremely slow when a large number of devices connect to the network around the same time. This could occur in the morning when everybody arrives at work or right after lunch when most people return from their break. Capacity planning needs to include a proper method to predict throughput to avoid these situations.
You can measure and predict needed throughput in a few ways. One way is to consider the number of users that will connect to the SOC’s network. Each user will use some level of office Internet bandwidth. The amount of Internet bandwidth can vary from 10 × 1 Mbps to 300 × 20 Mbps depending on the number of users and devices being used. This can depend on whether expectations for each user are for light, moderate, or heavy usage. Light usage would include email and Internet, which may be what a manager would use. Moderate usage includes file downloads, streaming music, Voice over IP (VoIP), and cloud-based resources. Heavy usage includes large file downloads, intense Internet application use, multiple devices, and interactive web conferencing.
The following are some expected bandwidth values associated with common actions that occur on a network:
Opening a webpage: 1 Mbps
Watching a live streaming video at 720p: 5 MB/minute
Skype video calling: 28 Mbps/second
You can use tools to test and validate throughput. Online sources such as Speedtest.net offer a free method to identify current throughput levels. Vendors such as SolarWinds offer network throughput tools that can also provide an estimated report of throughput usage. Whatever estimated throughput requirements you develop, you must also consider other factors beyond your current throughput readings. The following are additional elements that you need to consider in your throughput capacity planning:
Network peak possibilities: Estimate how much throughput would be required in a situation in which the maximum number of users need throughput. An example is accommodating for an event that causes all local and remote employees to connect to the network simultaneously.
Average bandwidth requirements: What is the average usage? Tools such as Speedtest.net and SolarWinds Bandwidth Monitor (free tool) can capture these readings.
Expected growth: What is the expected growth in the number of users and devices. Expected growth in the number of devices should include expectations for Internet of Things (IoT) and other types of devices that are not run by an end user.
System throughput dependencies: All systems expected to connect to the SOC network need to be evaluated for throughput dependencies. The vendor’s website or product documentation can provide this information.
High-availability/failover throughput considerations: Some high-availability configurations will have specific throughput requirements to ensure primary and redundant systems can monitor the status of one another.
Possible traffic shaping options to reduce throughput needs: Consider the configuration options within switches and routers to reduce throughput needs.
As you perform capacity planning for throughput, make sure to consider how traffic will change throughout the year as well as future growth rather than assuming current throughput numbers are good enough for the next three to five years. Getting a feel of what throughput would be needed the next three to five years might require sampling at different times of the year to get a more accurate view of actual bandwidth usage. You need to also consider what new services and capabilities the SOC plans to add based on maturity planning for SOC services. I recommend sizing at least 10–20% room for growth on top of the current throughput needs and expected demands from new SOC services and capabilities. If the SOC experiences bandwidth problems, you can free up bandwidth by using tools and tactics to adjust how the network is used. Best practice is to not depend on filtering tactics for acceptable throughput.
Note
If performance criteria exceed what can be provided with local resources, outsourcing will be a better approach than expanding capacity. For example, if you find that current resources to investigate a single incident take 35 minutes to load and process a query within a security tool, that would lead to a poor SOC response time based on this bottleneck of wasted time waiting for a specific tool to finish its workload. One option to fix this problem is to add more capacity, but the cost to do so may be more expensive than simply removing the tool and using a third-party cloud service or migrating the existing platform to an IaaS or SaaS option. It is critical to weigh all options when capacity planning, including not adding capacity and switching to something else!
Connectivity and Redundancy
One final consideration as you plan the network for the SOC is how systems will connect to the network. Tools that monitor network traffic need to connect inline or out-of-band. Inline monitoring means to force traffic through the technology so that it can read the traffic. A common example is forcing all traffic that is leaving the SOC to travel through a proxy or gateway application-layer firewall to view what applications are used by the SOC. An out-of-band deployment means a mirror or SPAN port is set up so that traffic can be copied and passed over to a tool for evaluation. If a security tool is out-of-band, it will not be able to automatically block traffic because the traffic it is viewing is not live. In the example of using a proxy or gateway application-layer firewall, if either of those tools is configured to view traffic in an out-of-band fashion, it would be able to see if a user is attempting to access Facebook but would not be able to deny access to Facebook (which would require forcing the traffic to travel inline through the application-layer firewall or proxy). Make sure to evaluate whether tools the SOC intends to use will need to evaluate traffic and whether they should be connected inline or configured as an out-of-band connection.
Inline Connectivity Risks
There are risks of having traffic flow inline through a security tool. The first risk is that the security device becomes a bottleneck for network throughput. For example, if a 10 Gigabit Ethernet network flows inline through a 1-gigabit firewall, then the users on the inside network can receive at most only 1 gigabit of traffic because the firewall can’t deliver anything faster. Another concern is that having traffic flow inline through a security tool could create a single point of failure. To resolve this risk, an inline device can be configured in a fail open mode so that if the software fails, traffic can still pass through the device. Doing so essentially turns the device into a hub while the actual security aspects of the product are offline. Use cases might exist that warrant a configuration of a SOC tool to fail closed, meaning disabling the network connection while security is not functioning.
Risk Reduction with Redundancy
You should also consider redundant hardware and networks to reduce the risk caused by an inline device or other network bottlenecks from failing. Include redundancy for all critical systems as well as systems responsible for time, access control, event logging, and any other critical SOC service. Including redundant systems is also useful for performing upgrades that require a system to be rebooted, so that the secondary system can act as the primary is upgraded. You can accomplish redundancy by purchasing duplicate equipment or by using an alternative network path. If devices on one network are found to be unavailable, systems accessing those devices are instructed to go to another network to obtain the same resources.
The following are key terms for understanding redundancy options:
Failover: When a primary system goes down and a second system immediately takes over the primary system role.
Hot standby: When one system acts as the primary while another system waits in a standby inactive mode. If the primary system goes down, the standby system is running and ready to become the primary.
Cold standby: When one system acts as the primary while another system is powered off and assigned as the backup system. If the primary system goes down, the cold standby system must be powered on and set up to take on the role as the primary system.
Subscriber state failover: When a failover occurs, the backup system maintains the subscriber state. An example is if a primary access control system goes down, and the secondary system is capable of taking over the load as well as maintaining awareness/logging of systems that were logged by the primary system.
Failure detect: The method used to determine if a primary system is no longer available.
NIST 800-123, Guide to General Server Security, is one of the main standards, guidelines, and frameworks that can be leveraged to learn more about proper redundancy tactics. Redundancy options will vary depending on the technology you are using.
Note
It is critical not to assume the organization’s existing redundancy meets the risk tolerance for the SOC. Your SOC may need to add additional redundancy on top of what currently exists.
Disaster Recovery
The SOC needs to prepare for the potential loss of systems and people that could be caused by various types of disasters. A disaster recovery plan (DRP) helps eliminate or reduce the potential for economic damage, loss of life, and destruction of property during a disaster. Every business needs to build a disaster recovery team, and it must involve members of the SOC team. There are many industry guidelines, standards, and frameworks that can be used as references to develop a DRP and assign roles for the disaster recovery team. ISO 22301:2019, Security and resilience – Business continuity management systems – Requirements, provides guidance for protecting the organization, while ISO/IEC 27031:2011, Information technology — Security techniques — Guidelines for information and communication technology readiness for business continuity, provides guidance for the technical aspects of ISO 22301. ISO 27031 provides six main categories for business continuity planning:
Key competencies and knowledge: What information is required to run critical systems and services?
Facilities: Where is the facility located, and what concerns exist around how it can resist a potential disaster?
Technology: Which technologies are business critical?
Data: What data is required to restore business activities?
Processes: What processes are in place to deal with an incident?
Suppliers: Which suppliers and supplies are critical to the business?
The disaster recovery team should develop the following documents as part of the DRP:
Backup and recovery policy: The team should document procedures for backup and recovery of any system deemed critical to the business. The details of a backup and recovery policy need to explain how often data is backed up, where it is backed up to, the type of data that is backed up, how to access backed-up data, and who is responsible for the systems and data being backed up. If a disaster occurs, the business will need to restore critical systems and populate those systems with the last known-good version of data. Having the backup and recovery policy documents for every critical system enables anybody within the disaster recovery team to restore systems and obtain critical data post disaster.
Business impact analysis (BIA): The purpose of a BIA is to determine what people, process, and technology must be available to sustain the business. The disaster recovery team can associate values with the loss of people, process, and technology to determine the types of redundancy that should be used as a countermeasure to the risk of loss. For example, a SOC’s datacenter would be critical to the operation of the SOC. A BIA would represent how critical the datacenter is based on the daily loss that would occur if the datacenter were to go down, how the SOC going offline would impact the business, and potential risk reduction items. Including BIA documents within the DRP will inform the team of the impact of losing any person, system, or data due to a disaster.
Step-by-step disaster recovery plan: This plan informs the team where all other disaster recovery data is located as well as the location of the backup of the plan. The DRP also includes contact information for every member of the disaster recovery team, specifies where the team is supposed to meet, and specifies any backups to the meeting location and contacts in case the primary location or any team member is lost or unavailable during a disaster. It is recommended to store a backup of the DRP at a different facility from where the primary plan is stored. Another recommendation is to have a backup facility that is at another location that would likely not be impacted by a disaster that would compromise the primary disaster meeting place. The specifics of how far away the backup facility should be located would be based on your organization’s business requirements and risk tolerance. The steps included in the DRP must accommodate all the items pointed out in ISO/IEC 27031. This includes documenting the knowledge needed to restore the business as well as the facilities, technology, data, and suppliers that are critical to the business.
Note
It is critical that all documentation is dated and tested to ensure the disaster recovery plan is effective and up to date. You do not want to find an out-of-date DRP during a real disaster!
Security Considerations
Another important topic to cover regarding planning the design of a SOC is what security technology and processes will be used to protect the SOC. If a key tool such as the time server or logging system is compromised by an adversary, many of the SOC services will be rendered useless. This type of failure not only could undermine the value of the SOC but also could cause future investment in and trust of the SOC to diminish.
Remember, adversaries know they are up against the defense of their identified target. They know companies install antivirus measures, deploy security tools on the network, and have people responsible for monitoring those tools. Adversaries have labs and develop methods to beat security and hide from administrators.
Some security topics that need to be part of the security planning for the SOC are as follows:
Policy and compliance
Network access control
Encryption
Internal security tools
Note
Security requirements for the SOC will be different than what exist for the organization. The SOC will contain sensitive information about the organization and therefore should not just adopt the organization’s security standards.
Policy and Compliance
The term compliance means to meet some goal. That goal will vary by industry and how an organization operates. Some compliance goals are requirements pushed by local government, which if not followed will lead to fines (or possibly even incarceration in extreme cases) for those responsible for the organization’s compliance. Other compliance goals are mandated by the leadership of an organization, meaning there isn’t any legal obligation; however, the organization has made meeting the compliance goal an obligation for the organization. Some leaders will convert industry recommendations (known as guidelines) into mandated compliance goals with the intent of establishing a baseline of security practices within the organization. Chapter 6, “Reducing Risk and Exceeding Compliance,” covers common forms of mandated and recommended compliance as well as how to enforce compliance goals with policies, procedures, and standards.
Regarding building a SOC, there might be compliance goals that exist or are desired by the organization that must be met before the SOC can move to a go-live status. The most common pre-SOC compliance requirements are those required by local and federal governments as well as those aligned with business operations as stated within an organization’s policies. The Health Insurance Portability and Accountability Act (HIPAA) is an example of a U.S. law that mandates compliance by all organizations (“covered entities”) in the United States that handle protected health information (PHI). The Payment Card Industry Data Security Standard (PCI DSS) is an example of a standard that mandates compliance by all organizations that accept, process, store, or transmit credit card information. It is critical that the SOC identify all required compliance and ensure requirements are met pre-launch. Chapter 6 will cover the most common legal and financial compliance requirements your SOC needs to be aware of.
Policies are high-level requirements the organization must follow and are set by leadership. Procedures contain the details for how to follow policies. Not only will the SOC need to adhere to all policies, but there might be adjustments to how the SOC will be developed and operate in order to be compliant with corporate policies. The SOC will need to verify any pre-launch compliance requirements with the SOC sponsor regardless of whether those requirements are legal or corporate driven. By doing so, the SOC will have executive support that all compliance has been met. I highly recommend ensuring that legal, financial, and other compliance identified by your SOC sponsor is addressed as early in the planning phase as possible to avoid disruption of later steps due to compliance violations. Compliance violations can prevent a SOC from going live!
Note
You will need a SOC sponsor that understands your organization’s compliance requirements. If you are unsure if your SOC sponsor would know all of those requirements, validate with other leadership. Do not assume you have met all compliance requirements without proper validation.
Network Access Control
Network capacity planning and security requirements provide the basic foundation for developing the SOC’s network as well as how the SOC can secure the organization. A foundational security requirement for many modern SOCs is segmentation and controlling access to and between segments. Access control needs to be delivered in a least-privilege design, permitting only necessary services to access or leave a network segment. I recommend isolating device types based on their associated risk and dependencies, but very elaborate segmentation can be complicated to deploy and manage. My most basic device segmentation recommendation is to isolate guest users, employees, administrators, IoT devices, mobile devices, SOC tools, malware testing, and critical systems.
Profiling
A SOC needs a method of validating devices on network segments based on MAC address or more advanced profiling tactics. Without this capability, a SOC network administrator will not be able to determine what type of device has connected to the network. Profiling a device beyond its MAC address is a more ideal approach because it uses various network protocols to ensure the device is authenticated, rather than relying solely on a MAC address, which could be spoofed by an attacker. For example, profiling technologies can determine the difference between an iPhone and iPad even though both products are made by Apple and have similar hardware components. Determining the difference between two different Apple devices can be based on how the DHCP request is seen, what version of Safari is used, or other factors analyzed by the profiling technology. Specific characteristics can also be used to determine not only if the device is what it claims to be but also if it is authorized. A common example is determining if the same device type is company issued versus an unauthorized personally owned asset. MAC addresses can be used for this purpose but, again, could be spoofed. Best practice is to use characteristics within the system such as placing a certificate on the asset that can be validated to ensure the device is issued by the organization.
NAC Value
Leveraging a NAC solution is recommended by many frameworks, including NIST’s Cyber Security Framework and ISO/IEC 27001. One popular choice is to use a centralized policy monitoring and enforcement NAC solution based on the IEEE 802.1X protocol. NAC enables a network administrator to limit certain users or devices to specific access privileges, enforced automatically upon connecting to the network. For example, Anjelica, an administrator, can bring her laptop, printer, and VoIP phone to any office within the SOC’s building and just plug them in. Based on the NAC profile for those devices, her printer would be placed on a dedicated printer network, her VoIP phone would be placed on the IP phone network, and her laptop would be placed on the administrator network. If a guest unplugs any of Anjelica’s devices and plugs in his or her own computer to the network, the network would change that port to the guest network based on how the guest authenticates and the type of device being plugged in. In this example, the guest’s device would not have the company certificate installed on the device connecting to the network and the guest user would not have an employee account within the accounting system. This would cause the guest to have his or her computer automatically placed on the guest network. This is just one of the many deployment options for a NAC solution—the default action the guest experiences could be complete denial of access or possibly provisional access, but an ACL would limit this guest user from administration-level access even though this user is on the same VLAN as Anjelica.
Regardless of how you deploy NAC technology, it is critical to ensure similar security is deployed across all areas and networks, including the LAN, wireless, and VPN networks. I have seen organizations deploy secure wireless while their LAN is open to anybody plugging in any device as long as they can get access to a LAN port. Best practice is to standardize on a network access policy across all access methods.
Additional value can be obtained from using a centralized network access control solution. Many NAC solutions offer the capability to share the database of network-connected devices, which is known as context. This database of connected devices can be used by other solutions, such as a SIEM solution, to match an IP address that the solution sees to what content the NAC solution knows about that IP address. An example is logging into a SOC’s SIEM solution and identifying every device that is on the SOC network by username rather than by IP address. This can occur based on the NAC technology capturing the user’s identity when the user accesses the network and sharing the database of users on the network with the SIEM technology.
Another value of a NAC solution is the capability to remove devices off the network that have violated a policy or are seen as a risk to the organization. Many NAC solutions scan a device as it attempts to access the network and verify that the device has required security features enabled before permitting access. For example, the SOC can use a NAC technology to validate whether a device connecting to the SOC network has antivirus installed and running and, if it doesn’t, deny it network access. NAC technologies can also be integrated with vulnerability scanners. A vulnerability scanner will scan the network and identify any device that has vulnerabilities. Devices that have critical vulnerabilities are labeled with a very high vulnerability score. A NAC technology can be used to automatically remove devices that have very high vulnerability levels. Figure 2-19 is an example of SANS’s recommendations for vulnerability management. Combining the value of a vulnerability scanner and NAC solution can automate the entire process recommended by SANS.

FIGURE 2-19 SANS Recommendations for Vulnerability Management
Note
The SOC must manage its own access control policies even if the NAC solution is a shared resource with the organization. There may be situations such as a forensic investigation led by the SOC that require certain data to be controlled. In the case of a forensic investigation, only the SOC’s forensic team should have access to that data.
Encryption
Traffic needs to be safeguarded between the SOC and customer as well as within SOC segments. This is especially true for traffic sent over wireless networks that anybody within range of the SOC could potentially access as well as for traffic that remote users send over untrusted networks to the SOC network. There are different levels of encryption that can be used to protect the confidentiality and integrity of network traffic, some of which are more trustworthy than others. For example, using WEP to encrypt the SOC’s wireless network is not recommended. WEP is very old and can be easily beaten through known exploitation tactics. WPA2 and WPA3 are more secure options based on the features and security capabilities they offer. Some wireless equipment might not be able to support WPA3, so WPA2 would be the best option. Table 2-7 is a summary of the different types of wireless encryption options.
TABLE 2-7 Comparing Different Wireless Encryption Types
WEP |
WPA |
WPA2 |
WPA3 |
|
Brief Description |
Ensures wired-like privacy in wireless |
Based on 802.11i without requirement for new hardware |
All mandatory 802.11i features and new hardware |
Provides more individualized encryption and WPA3-Enterprise boosting cryptophaic strength for networks transmitting sensitive data. |
Encryption |
RC4 |
TKIP + RC4 |
CCMP/AES |
GCMP-256 |
Authentication |
WEP-Open WEP-Shared |
WPA-PSK WPA-Enterprise |
WPA2-Personal WPA2-Enterprise |
WPA3-Personal WPA3-Enterprise |
Data Integrity |
CRC-32 |
MIC algorithm |
Cipher Block Chaining Message Authentication Code (based on AES) |
256-bit Broadcast/Multicast Integrity Protocol Galois Message Authentication Code (BIP-GMAC-256) |
Key Management |
None |
4-way handshake |
4-way handshake |
Elliptic Curve Diffie-Hellman (ECDH) exchange and Elliptic Curve Digital Signature Algorithm (ECDSA) |
LAN Encryption
The LAN can also use encryption, which could be accomplished using tunneling technology, such as IPsec or SSL encryption, between hosts and servers or specific hardware-encrypting devices that sit between different parts of the network. The difference between encryption options include the following:
Encryption strength
How encryption keys are managed and exchanged
What interfaces, protocols, and ports are used
What OSI layer they run on
Ease of deployment
Speed
A site-to-site VPN can be used to connect two locations together. A SOC can use a site-to-site VPN between a branch office and headquarters to protect traffic as it moves between locations over an untrusted network. A similar concept can be used between a host device and the SOC network, which is ideal for SOC employees that need to access the SOC network remotely. I recommend speaking with the vendor of your network equipment to learn more about what encryption options are available. Table 2-1 from earlier in this chapter provided a quick summary of a site-to-site VPN and remote-access VPN.
Internal Security Tools
SOC security tools must consider all steps an attacker will use to compromise the SOC and its users. Recall the discussion about different threat models in Chapter 1. Threat models are a common approach to understanding what steps an attacker could take as they attempt to exploit your vulnerabilities, deliver unwanted software, and execute unwanted actions. One example of a threat model covered in Chapter 1 is the Cyber Kill Chain represented as Figure 2-20.
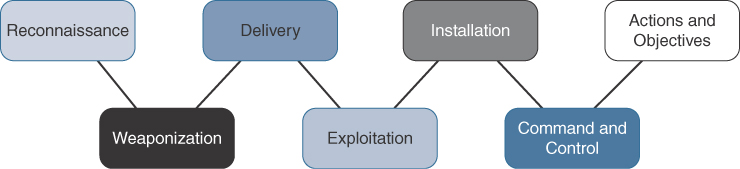
FIGURE 2-20 The Cyber Kill Chain
This particular threat model is used to evaluate different steps an adversary can take to establish a foothold on a network and showcases the need for different types of security capabilities to prevent the attacker’s steps from successfully occurring. For example, the exploitation phase defense capabilities specifically look for attack behavior used for exploiting vulnerabilities and attempts to prevent the exploit from working. The installation step assumes that the attacker’s exploit worked, making security capabilities for prevention in this phase of the attack different, commonly called breach detection capabilities. Breach detection capabilities are designed to detect when an insider is present, alerting the SOC and preventing further expansion into the network. Both exploitation and breach detection have detective and preventive capabilities but they are designed to function differently based on the types of attacks they are expected to defend against.
The goal for the defender is to prevent the attack as early in the Cyber Kill Chain as possible. By combining defenses used for different parts of the Cyber Attack Kill chain, the SOC creates layers of different security capabilities as part of its defense-in-depth strategy.
The rest of this section walks through common security capabilities that are common in mature SOCs around the world. I’ll keep the language vendor agnostic for the most part and focus on capabilities common within a device type category.
Note
The SOC must control polices for all security tools that are used to protect the SOC even when technology is used that is shared by the organization.
Intrusion Detection and Prevention
One option for monitoring internal traffic is to use an intrusion detection system (IDS) deployed off of a monitoring port combination with an intrusion prevention system (IPS) monitoring traffic that travels between network segments. A recommended practice is to tune these tools to be aware of the potential vulnerabilities within assets they are protecting through integration with a vulnerability scanner as well as to perform periodic rule evaluation to maximize their effectiveness. For example, a SOC can run vulnerability scans often to identify and respond to known weaknesses. While those weaknesses are exposed, the IDS and IPS can be tuned to have defense signatures enabled until parties responsible to remediate the vulnerability are able to perform that work. Integrating a vulnerability assessment tool with security tools helps speed up this process. Think of this as defenses against the “exploitation” phase of the Cyber Kill Chain.
Network Flow and Capturing Packets
Baseline tools can be used within the SOC’s network that alarm when they detect an unusual deviation from normal activity. For example, an IoT device can be permitted access to the Internet, but if an unusual amount of traffic is seen from that device, the SOC should be made aware. The increase in traffic could indicate a large firmware update is being installed or it could indicate that an adversary has found a way to use the IoT device as a point of entry to the SOC network! Using NetFlow is one method to detect this type of activity. NetFlow is supported by many common network tools such as network switches. Essentially, NetFlow turns a network into multiple security detection points continuously looking for unusual activity. This dramatically improves visibility compared to deploying specific security tools across a network.
Note
All NetFlow tools are not created equally! Many NetFlow tools only look at peak and valley traffic, meaning they would not be able to determine if activity is malicious.
NetFlow Technology
There are different types of network flow technology options depending on the vendor and version enabled. Examples include sampled flow (sFlow) and Juniper Networks’ J-Flow, to name a few. Comparing the value of a sampled flow such as sFlow against a data-rich option like NetFlow 9 could mean the difference of knowing an event occurred over the last 24 hours (sFlow) versus knowing that a specific action occurred on a specific part of the network from a specific device at a specific point in time (NetFlow). The reason for this difference is that sFlow uses time-based sampling counters while NetFlow uses cached flow entries from the hardware producing it.
NetFlow tools can offer different capabilities based on what the tool can do with the flow that is collected. Many flow tools can alarm for unusual traffic patterns to enable network techs to determine routing problems or areas that are underperforming. This can be useful for detecting network congestion so that alternative routing or other adjustments can be made to improve the overall network performance. Using NetFlow for improving network performance is useful; however, many of these same tools do not have algorithms to detect a port scan or worm activity. Products such as Cisco Stealthwatch and Plixer Scrutinizer are able to convert flow data into security events. Examples of security events include port scanning, worm propagation, data exfiltration, and denial of service.
Note
To see a comprehensive list and descriptions of security events that Cisco Stealthwatch can detect, search the Web for “Stealthwatch Security Events and Alarm Categories” (the current version at the time of writing is version is 7.3).
There is a lot of value from NetFlow if an analyst is able to view all of the records. NetFlow is based on one-way communication, meaning the action of a user connecting to a server and the server responding will equate to multiple NetFlow sessions because each step of the connection will be a single NetFlow record. Multiply each single NetFlow log created as a user continues to use the network by the number of users on the network at any given time and you get a lot of NetFlow records to search through. If a NetFlow tool is only collecting NetFlow records, that tool will quickly fill up with more data than an analyst will be able to review. To deal with this issue, NetFlow tools with deduplication and stitching capabilities can remove duplicate records and stitch the entire session together to simplify mining large amounts of NetFlow data. One user going to a server may create multiple NetFlow records, but a single event can be recorded after all of those NetFlow records are stitched together.
Network-Based Application Recognition (NBAR) is another network protocol that provides intelligent network classification for network infrastructure. NBAR recognizes a wide variety of applications, including web-based applications and client/server applications that dynamically assign TCP and UDP port numbers. Once applications are classified, they can be monitored by security technologies as well as provisioned specific bandwidth through various network policy–based tools. Many NetFlow tools from vendors such as Cisco, SolarWinds, and Plixer also offer the capability to digest NBAR, the results of which complement what is found with NetFlow data.
There is a lot of value from using NetFlow and NBAR; however, these approaches to monitoring data cannot offer the same level of details as using a packet capture technology. Think of the value from the NetFlow approach as giving you the headlines of security events. This includes providing metadata timestamps, senders’ and receivers’ IP addresses, ports used, length of conversation, and amount of data transferred. SOC services such as incident response need accurate details of an event, which NetFlow and NBAR cannot provide. When this need comes up, the SOC must use another source that provides more details.
Packet Capturing Technology
Packet capturing provides the full story, accurately reconstructing what exactly happened and when it happened. The difference between analyzing flow and analyzing a packet capture is analogous to the difference between reviewing a list of phone calls made (flow) and recording the actual calls and listening to them (packet capture).
Packet capturing must store the traffic and a tool must be used to analyze what was captured. This requires large storage systems, leading to a higher cost. Flow can help you to determine where to look, but many flow-based tools lack evidence of whether an event is genuine, meaning you know an IP address violated a policy, but you don’t have the details of what was actually done, as you would if you have a packet-level capture of the activity. An example of details that packet capturing would include that a flow approach would not is the specific files that were exported off the network during a security incident. Having this level of detail would determine the value of the files that were lost, giving the SOC the specifics needed to apply the appropriate response to the incident. If the data was classified or protected by law, the SOC would be required to release to the public what was lost. It would be ideal to use the flow approach to view the network for threats and use the packet capturing approach to investigate a threat, but that is possible only if funding permits acquiring both of these types of tools. Either approach is ideal for monitoring the internal network for threats, but cost will likely cause you to initially invest in only one of these options. The good news is that vendors of either approach are starting to offer hybrid options, which will use flow to baseline the network and launch a packet capture upon seeing an event.
Note
There will be situations that require the details associated with packet capturing technology. Flow technology will not meet these requirements. An example is proving specific types of data were lost during a security event for a forensic investigation.
Change Management
Traffic entering and leaving each SOC network as well as traffic that crosses SOC network segments needs to be controlled using a tool such as an application-layer firewall or proxy because these tools have visibility of all types of traffic. You can configure policies to block specific traffic types but also include a process by which a user can request that traffic be unblocked for a particular service the user needs to use. The process of making exceptions for blocked traffic needs to be part of the SOC’s change management process, requiring at least the following items to be included in the change request:
Requestor
Purpose
Impacted systems
Creation and expiry dates
Change management approval reference number
Best practice is to include change management tools that assist with tracking requests and automate reminders to respond to the expiration of an exception that was granted on a temporary basis. Many organizations fail to use reminders to remove exceptions to firewalls, causing temporary policies to get lost within the configuration, leading to a weak firewall and administrator uncertainty about which traffic they are required to permit or deny. Orchestration technology is becoming popular to assist change management tools with automated remediation of expiring requests using predesigned playbooks.
Note
Over time, poor exception management practices lead to failure in security. An example is how organizations struggle with dealing with expiring access requests. Not addressing expiring access requests leads to exceptions that administrators are afraid to disable because the original purpose of the exception is not documented. As times goes on, the parties involved with the exception are no longer around to explain the need for the exception. Nothing is done and the exception becomes part of the permanent configuration.
Host Systems
Host systems and servers must include security products that provide system-level defense. Computers have different parts that require different types of security capabilities. Security capabilities must protect the firmware, operating system, Internet browsers, and even the plugins within the browsers. Standard signature-based antivirus is a good starting point but cannot be the only security capability installed on a host system. Current malware can operate in ways to avoid antivirus, such as using tactics that function in memory rather than as a file that can be scanned by a traditional antivirus solution.
Figure 2-21 provides an example of host layers and how security can be applied. For this example, the firewall and IPS provide edge defense; however, notice how anti-malware detection sits within the system to monitor activity on the host. Imagine a PDF file with malware that antivirus didn’t flag as malicious and now a user is attempting to open. Ideally, the anti-malware technology is capable of noticing that the PDF is not a known threat, but its actions are not normal and are a concern. I recommend you ask any potential host security vendor about how their solution can look at defending the different host layers shown in Figure 2-21, including host firewalls and IPS options as well as anti-malware capabilities. Also, make sure to question how this software is supported by configuration management, monitoring, and other management tools to avoid being stuck with an isolated management system.

FIGURE 2-21 Defense in Depth for Endpoint Protection
Guidelines and Recommendations for Securing Your SOC Network
There are other security capabilities to consider that can provide more layers to a SOC’s defense-in-depth approach. Honeypots can be used across the network with the intent of luring threats that have breached the SOC’s network. Sandboxes can be used to analyze external files before permitting those files onto a secured SOC network segment or critical system. Vulnerability scanners can be configured to scan the network proactively and identify any potential weaknesses the SOC needs to patch and protect as specified by the earlier SANS recommendation for vulnerability management best practices. Hosts can have agents installed that complement the security technologies previously covered, such as a vulnerability scanner feature within the antivirus or agent that provides host flow data to the network flow collector. As covered in Chapter 1 and earlier in this chapter, there are many sources such as standards, guidelines, procedures, and consultants that you can consult to obtain the best recommendations for securing your SOC network.
Note
There are risks associated with leveraging honeypots and sandboxes. Misconfiguring or misusing these technologies can lead to being compromised. Make sure to use a trusted source for guidance for configuration and proper use of these technologies.
Tool Collaboration
Regardless of the security technology you choose, all of these tools will need a place to send data so the SOC can monitor and analyze it. One popular tool many SOCs use for this purpose is a SIEM solution. Playbooks that are built through developing SOC processes can be automated using orchestration tools and combined with the SIEM solution’s tracking system. This provides a method to enforce actions as instructed by the SOC’s playbook to events identified by the SIEM solution, streamlining the incident response capability offered by the SOC. Many of these topics will be covered later in this book in more detail since they are used by SOCs to monitor the networks they are responsible to protect. The key is that you consider the same tools to protect the SOC network as the SOC would use to protect the network(s) it is responsible for.
There are general industry guidelines that show how many of these security tools can work together. This includes tying network security tools, host tools, and management tools across different parts of the organization. One example guideline is the U.S. Navy CND defense-in-depth strategy shown in Figure 2-22. This example lists different capabilities for each defense segment, which starts with the host layer and works its way out to the outermost network edge. A way to apply this strategy to a SOC’s network design is to replace the LAN in the Navy’s diagram with the SOC’s internal network and replace the outer network with the organization’s network being protected by the SOC. The outer layer in this diagram can be seen as the external network containing the DMZ and other external-facing resources.
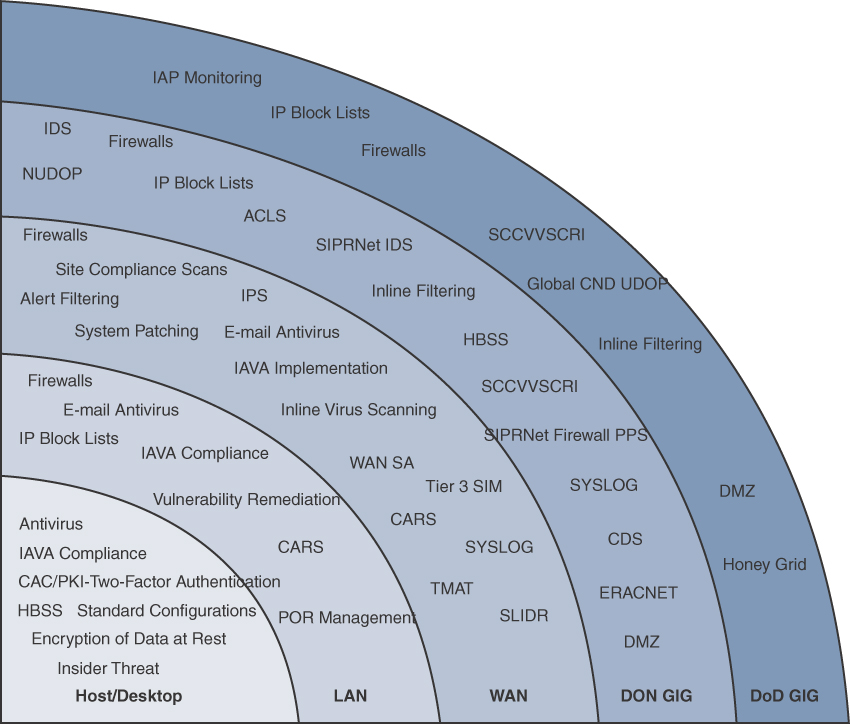
FIGURE 2-22 Department of the Navy Defense-in-Depth Strategy
Note
If you are unsure which technologies to choose, look back to the “SOC Capabilities Assessment” section in Chapter 1 as a method to develop a SOC-focused capabilities map. You can use industry guidelines to help fill in each capability that should exist within your SOC capabilities map. The same approach can be used when choosing security capabilities to secure the organization, which will be a different capabilities map than what is created to show how to protect the SOC.
Building on the Figure 2-17 diagram of an example SOC’s network design, Figure 2-23 shows how a SOC can apply the various security tools covered in this section. Figure 2-23 adds NetFlow, IDS appliances, and packet capture tools to analyze traffic between network segments; adds application-layer firewalls and IPS appliances to secure traffic that travels between each segment; adds antivirus and anti-malware on host systems that support this technology; and adds a sandbox within the malware testing segment to assist with that type of work. This may seem like a lot of security, but as stated at the beginning of this section, the SOC’s security must be a top priority.

FIGURE 2-23 Logical SOC Network Segmentation with Security
SOC Tools
Many SOC procedures require the use of specific tools. I covered tools used to protect a SOC earlier in this chapter. The SOC needs those same tools to protect the SOC’s customer and deliver SOC services, although the SOC may deploy the tools differently or have different expectations from them. Access to tools can be limited based on the role of the SOC member and the type of data within the tool. For example, members responsible for keeping the SOC secure should only see internal SOC data, while an analyst responsible for customer behavior would not be able to see activity regarding fellow SOC analysts. Most security tools offer different views of data based on the type of account that is created for accessing the management interface of the tool. This feature is commonly known as role-based access control because each job role only has a view of the data required for that job role. Best practice is to limit the data seen by a user to least-privilege access using role-based access versus giving administrative access to any user.
Reporting and Dashboards
Reporting and dashboards are other important features available in most SOC tools. I recommend creating reports and dashboards for various parties, including executives and other key members, to provide them a clear value from the SOC. Analysts responsible for monitoring security events will receive reports and have dashboards designed specifically for an analyst role, including IPS logs, Windows security events, and other security tools that fall within the analyst’s area of responsibility. Dashboards and reports for executives will be different than the dashboard for an analyst’s, including how employees use the Internet, what types of devices are connected to the network, or maybe how certain people are using the network. A lot of this data can be captured from next-generation firewall, NAC, and other security tools, and reporting and dashboard options within these technologies can be customized for their intended audience targeting only desired data within the dashboard. SOC-specific dashboards can be created and displayed on the SOC wall, while specific analysts would have additional data available on their own customized dashboards and reports based on their job role. For example, tier 1 analysts will not need access to cases that are handed off to higher-tier support teams.
Note
Reports are a great way to align results with success criteria within SOC functions. Chapter 1 covered using maturity models as a way to measure how effective a SOC service is performing. Part of higher maturity is providing repeatable actions. To prove actions are repeatable, dashboards and reports can be used to show a history of repeatable success.
Note
I highly recommend creating reports for key members of the organization, including the member(s) sponsoring the SOC. This will quickly earn respect and support for the SOC. Providing awareness to the SOC sponsor can lead to more budget, support for decisions made by the SOC, and support for security and policy awareness. Best practice is to interview key executive members and the SOC sponsor(s) regarding the type of data they would find useful and setting up systems to deliver that data on a weekly or monthly basis. An example is meeting with the compliance officer with the goal of assisting him or her with obtaining data needed for compliance reporting.
Throughput and Storage
Other factors that impact a device being used by the SOC are the amount of data the device must consume and store. In the security world, the amount of data thrown at a tool is known as events per second (EPS). Event data could be many things, including alerts, log messages, and flows per second. Chapter 5, “Centralizing Data,” will dive deeper into understanding and tuning tools to accommodate different types of EPS values, but for the purpose of sizing SOC tools, the factors to consider are the amount of storage required for saving events and how ESP impacts licenses. Chatty devices that generate a ton of EPS can quickly consume the storage of security systems. Figure 2-24 shows an example of the different types of data that could be sent to a SOC tool, which would be digested and converted into events an analyst could review.
FIGURE 2-24 Events Digested by a Monitoring System
Note
Factoring the number of devices on a network does not necessarily provide an accurate method to size expected EPS. For example, 10 very chatty systems could generate the same data as 100 non-chatty systems requiring the same amount of storage. See Chapter 5 for more details on understanding how to properly size EPS requirements. When in doubt on ESP numbers, size up to accommodate additional EPS and future growth.
Reducing Events Per Seconds
To reduce the impact from chatty devices, you can implement tuning and storage to reduce the ESP. You can tune devices to generate a log based on the type of event. When debugging a device, you can enable logging for every single event, and when monitoring a device, you can restrict logging to only when a critical action is encountered. Figure 2-25 is an example of alerting levels available in some Cisco products.

FIGURE 2-25 Cisco Alerting Levels Example
Another approach to reducing the impact of EPS is to adjust the amount of data included within an event. Including more details about an event helps the analyst understand why the event occurred but also increases the requirements for storing these types of events. It is recommended to reduce the level of event details to only what an analyst requires to understand the event. Metadata could also be used instead of including the full log message, which would reduce the size of the log message. Some data fields may not provide value, in which case you can configure the tool generating the log to not include data from those fields. Consider all of these factors as you tune how tools will produce events. This will save you time on tuning, save money by enabling you to size monitoring products accurately, and improve the quality of the data being analyzed.
Note
You do not need to have all devices configured at the same severity and log detail level. For example, you can have your edge security tools trigger on less severe alarms while internal tools trigger on more severe logs or vice versa. It is best practice to make these decisions based on the value desired from each tool that is generating logs.
Storage and Data Retention
Another sizing concept to consider for SOC tools is sizing required storage and data retention requirements. For example, if three years’ worth of log data must be stored before records are purged, you will need to look at the impact of EPS on available storage and size accordingly. Sometimes, data retention requirements have different on-box availability needs versus having the data stored and encrypted off box in the event the data is ever required for a future investigation. This could be based on capability goals or required by a regulation such as Sarbanes-Oxley (SOX) or North American Electric Reliability Corporation Critical Information Protection (NERC CIP), to name just a few U.S.-specific examples. It is common for security tools such as SIEMs to carry data for one to three years and export details for anything older to a separate storage system, in a compressed format to save space. If older data is required, there is a process used to identify the record, uncompress it, and upload it back into the SIEM solution. Some security tools such as NGFWs might store data locally only for a short period of time before an off-box storage option is needed. It is important to cover data retention options with the vendors of the products you choose to use and ensure they meet your SOC’s requirements.
General cost can be another factor that determines what data is kept on box and when data is exported to an external storage system. It is common that an organization requires at least a year’s worth of log data that is ready to access, while exporting anything older to an external system. Know that the cost of keeping data on box is higher than storing it. The good news is, the cost of storage continues to decrease as technology advances. According to a March 2017 article published by Computerworld, “in 1967, a 1-megabyte hard drive would have set you back by $1 million. Today, that same megabyte of capacity on a hard disk drive (HDD) costs about two cents.” The specific amount of time before you export data to an external storage system will be based on your SOC’s business objectives. The bad news is, more devices are generating larger amounts of data. increasing the need for more storage. The growth of IoT is causing a major impact on networks. including increasing EPS. Also, different storage options have different costs. Flash memory has a higher cost than magnetic tape or optical discs; however, flash may be worth the higher cost because it performs quicker and can provide stored data faster when requesting it.
Note
SOC data must be protected. I recommend keeping SOC data storage separate from the organization’s data storage whenever possible. If a shared retention source is used, SOC data must be segmented from the organization’s data.
Centralized Data Management
Most SOCs have a centralized tool for digesting events. The most commonly used tool for this purpose is a security information and event management solution. SIEMs specialize in storing events so that they can be mined and analyzed; however, all SIEMs are not created equally. In my experience, some SIEMs focus on SIM, meaning they offer various ways to manage logging and mine data. Splunk is a popular SIEM solution with very advanced log management and mining capabilities. Figure 2-26 is an example of Splunk’s main search field. You can pretty much find anything you want and create various types of dashboards and reports with the results.
FIGURE 2-26 Splunk Dashboard Example
Other SIEMs specialize in SEM, meaning that they offer various event management and event analysis capabilities. IBM QRadar is an example of a SIEM with lots of SEM features. Examples of QRadar event features are the ability to develop various types of dashboards, identify every asset on the network, and even launch native or third-party vulnerability scanners directly from the dashboard. To be clear, Splunk has SEM capabilities and QRadar can be used to mine data as a SIM, but the experience is much different for those specific needs on both of these systems. Figure 2-27 is an example of a QRadar application dashboard known as Pulse. Chapter 5 covers SIEM and data management in more detail.
FIGURE 2-27 QRadar Dashboard Example
Some SIEMs do not offer the capability to take action on events. An example of an action can be blocking an event identified by the SIEM solution. If the ability to take action isn’t available, the analyst would use the SIEM product for event awareness while using a different method to take action. Procedures for taking actions can be documented and converted into playbooks, which later can be automated. This is known as orchestration, which is becoming a feature SIEMs are adapting or partnering with other vendors to offer as a combined solution. We will look deeper at orchestration in Chapter 10, “Data Orchestration.”
SIEMs can also include different approaches for tracking events. One popular approach is a ticketing system. Ticketing could be part of the SIEM or orchestration platform or something dedicated to this purpose. BMC’s Helix ITSM and ServiceNow Security Operations are examples of incident tracking platforms that could service this purpose. Good ticketing tools include collaboration features such as wikis to search for similar cases that occurred in the past. Tools like Tiki Wiki CMS Groupware and MediaWiki are also options for this. I recommend considering all of these needs as you evaluate which solution(s) you use for managing all of the data the SOC will be responsible to monitor and act upon.
Note
It is ideal for the SOC to have its own SIEM, SOAR, and/or XDR used to protect the SOC versus sharing what is used to protect the organization. If a shared system is used, administration between the SOC’s network and organization’s network must be segmented.
Summary
This chapter focused on how to develop a new SOC as well as increase the maturity of an existing SOC. The first concept covered was how to develop mission and scope statements. These form the building blocks for all SOC policies and procedures and are the foundation for why the SOC exists. The next concept covered was the importance of SOC policies and procedures, making up the building blocks for what services the SOC will deliver. This chapter then covered security tool concepts, which are the tools a SOC will use not only to defend the organization it is responsible for, but also to defend the SOC itself from attack.
The remaining chapter topics covered specific details that need to be addressed as you plan and build a security operations center. Topics included everything from how to customize the SOC’s facility to what type of capacity and throughput will be needed to support the SOC services. Many of these planning concepts can also apply to building and protecting an organization, but the focus of this chapter is developing a SOC, which includes keeping the SOC-related data segmented from the organization and secured.
Up until this point, I have provided a high-level overview of building a SOC. In the upcoming chapters, we are going to look deeper at the elements that make a SOC successful. Chapter 3 surveys the variety of services that modern SOCs offer. This includes services offered using in-house resources as well as outsourced services. I highly recommend that every SOC have at least a minimal version of each SOC service covered in the next chapter or at least have an outsourced resource available. The worst situation would be an organization needing a security service that is not offered by the SOC and being unaware of where to look to contract support for the missing service.
References
Bodwell, D. J. (1996, June 23). Team Charter. High Performance Teams. http://www.highperformanceteams.org/hpt_chtr.htm
Cisco. Data Center Power and Cooling White Paper. https://www.cisco.com/c/en/us/solutions/collateral/data-center-virtualization/unified-computing/white_paper_c11-680202.html
Conway, B. (2017, May 12). Office Building. Whole Building Design Guide. https://www.wbdg.org/building-types/office-building
Ferrill, P. (2018, January 8). The Best Mobile Device Management (MDM) Solutions for 2020. PC Magazine. https://www.pcmag.com/article/342695/the-best-mobile-device-management-mdm-software
International Organization for Standardization. (2004, May). ISO 17624:2004: Acoustics – Guidelines for noise control in offices and workrooms by means of acoustical screens. ISO. https://www.iso.org/standard/33148.html
International Organization for Standardization. (2011, March). ISO/IEC 27031:2011: Information technology – Security techniques – Guidelines for information and communication technology readiness for business continuity. ISO. https://www.iso.org/standard/44374.html
International Organization for Standardization. (2012, November). ISO 22311:2012: Societal security – Video surveillance – Export interoperability. ISO. https://www.iso.org/standard/53467.html
ISACA. (2019). COBIT 2019 Framework (various publications). ISACA. https://www.isaca.org/resources/cobit
Jones, C.P. (2017, June 9). Flood Resistance of the Building Envelope. Whole Building Design Guide. https://www.wbdg.org/resources/flood-resistance-building-envelope
Key, T.S., & and Martzloff, F. D. (1986, September). A Consensus on Powering and Grounding Sensitive Electronic Equipment. Conference Record, IEEE/IAS Annual Meeting. https://www.nist.gov/system/files/documents/pml/div684/Consensus.pdf
Kosutic, D. (2015, September 21). Understanding IT Disaster Recovery According to ISO 27031. Advisera. https://advisera.com/27001academy/blog/2015/09/21/understanding-it-disaster-recovery-according-to-iso-27031/
McCarthy, K., & Avelar, V. (n.d.). Comparing UPS System Design Configurations. Schneider Electric – Data Center Science Center. Retrieved from https://www.apc.com/salestools/SADE-5TPL8X/SADE-5TPL8X_R3_EN.pdf
Mearian, L. (2017, March 23). CW@50: Data Storage Goes from $1M to 2 Cents Per Gigabyte. Computerworld. https://www.computerworld.com/article/3182207/cw50-data-storage-goes-from-1m-to-2-cents-per-gigabyte.html
National Security Agency. (2010). Defense in Depth. NSA. https://citadel-information.com/wp-content/uploads/2010/12/nsa-defense-in-depth.pdf
Peters, O.S. (1918, June 20). Technologic Papers of the Bureau of Standards: No. 108. Ground Connections for Electrical Systems. Department of Commerce. https://nvlpubs.nist.gov/nistpubs/nbstechnologic/nbstechnologicpaperT108.pdf
Spitzner, L. (2016, December 14). Mobile Device Security. SANS Security Awareness. https://www.sans.org/security-awareness-training/blog/mobile-device-security
Think Tech Advisors. (2017). PCs vs. Thin Client Devices. Think Tech Advisors. https://thinktechadvisors.com/2020/05/pros-cons-of-thin-client-devices/