
Chapter 5. Refactoring

In 1999, I read Refactoring1 by Martin Fowler. It is a classic, and I encourage you to get a copy and read it. He has recently published a second edition,2 which has been considerably rewritten and modernized. The first edition presents examples in Java; the second edition presents examples in JavaScript.
1 Martin Fowler, Refactoring: Improving the Design of Existing Code, 1st ed. (Addison-Wesley, 1999).
2 Martin Fowler, Refactoring: Improving the Design of Existing Code, 2nd. ed. (Addison-Wesley, 2019).
At the time that I was reading the first edition, my twelve-year-old son, Justin, was on a hockey team. For those of you who are not hockey parents, the games involve five minutes of your child playing on the ice and ten to fifteen minutes off the ice so that they can cool down.
While my son was off the ice, I read Martin’s wonderful book. It was the first book I had ever read that presented code as something malleable. Most other books of the period, and before, presented code in final form. But this book showed how you could take bad code and clean it.
As I read it, I would hear the crowd cheer for the kids on the ice, and I would cheer along with them—but I was not cheering for the game. I was cheering for what I was reading in that book. In many ways, it was the book that put me on the path to writing Clean Code.3
3 Robert C. Martin, Clean Code (Addison-Wesley, 2009).
Nobody said it better than Martin:
Any fool can write code that a computer can understand. Good programmers write code that humans can understand.
This chapter presents the art of refactoring from my personal point of view. It is not intended as a replacement for Martin’s book.
What Is Refactoring?
This time, I paraphrase Martin with my own quote:
Refactoring is a sequence of small changes that improve the structure of the software without changing its behavior—as proven by passing a comprehensive suite of tests after each change in the sequence.
There are two critical points in this definition.
First, refactoring preserves behavior. After a refactoring, or a sequence of refactorings, the behavior of the software remains unchanged. The only way I know to prove the preservation of behavior is to consistently pass a suite of comprehensive tests.
Second, each individual refactoring is small. How small? I have a rubric: small enough that I won’t have to debug.
There are many specific refactorings, and I describe some of them in the pages that follow. There are many other changes to code that are not part of the refactoring canon but that are still behavior-preserving changes to structure. Some refactorings are so formulaic that your IDE can do them for you. Some are simple enough that you can do them manually without fear. Some are a bit more involved and require significant care. For those in the latter case, I apply my rubric. If I fear that I will wind up in a debugger, I break the change down into smaller, safer pieces. If I wind up in a debugger anyway, I adjust my fear threshold in favor of caution.
Rule 15: Avoid using debuggers.
The purpose of refactoring is to clean the code. The process for refactoring is the red → green → refactor cycle. Refactoring is a constant activity, not a scheduled and planned activity. You keep the code clean by refactoring it every time around the red → green → refactor loop.
There will be times when larger refactorings are necessary. You will inevitably find that the design for your system needs updating, and you’ll want to make that design change throughout the body of the code. You do not schedule this. You do not stop adding features and fixing bugs to do it. You simply add a bit of extra refactoring effort to the red → green → refactor cycle and gradually make the desired changes as you also continuously deliver business value.
The Basic Toolkit
I use a few refactorings much more than any of the others. They are automated by the IDE that I use. I urge you to learn these refactorings by heart and understand the intricacies of your IDE’s automation of them.
Rename
A chapter in my Clean Code book discusses how to name things well. There are many other references4 for learning to name things well. The important thing is . . . to name things well.
4 Another good reference is Domain-Driven Design: Tackling Complexity in the Heart of Software by Eric Evans (Addison-Wesley, 2013).
Naming things is hard. Finding the right name for something is often a process of successive, iterative improvements. Do not be afraid to pursue the right name. Improve names as often as you can when the project is young.
As the project ages, changing names becomes increasingly difficult. Increasing numbers of programmers will have committed the names to memory and will not react well if those names are changed without warning. As time goes on, renaming important classes and functions will require meetings and consensus.
So, as you write new code, and while that code is not too widely known, experiment with names. Rename your classes and methods frequently. As you do, you’ll find that you’ll want to group them differently. You’ll move methods from one class to another to remain consistent with your new names. You’ll change the partitioning of functions and classes to correspond to the new naming scheme.
In short, the practice of searching for the best names will likely have a profoundly positive effect on the way you partition the code into classes and modules.
So, learn to use the Rename refactoring frequently and well.
Extract Method
The Extract Method refactoring may be the most important of all the refactorings. Indeed, this refactoring may be the most important mechanism for keeping your code clean and well organized.
My advice is to follow the extract ’til you drop discipline.
This discipline pursues two goals. First, every function should do one thing.5 Second, your code should read like well-written prose.6
5 Martin, Clean Code, p. 7.
6 Martin, p. 8.
A function does one thing when no other function can be extracted from it. Therefore, in order that your functions all do one thing, you should extract and extract and extract until you cannot extract any more.
This will, of course, lead to a plethora of little tiny functions. And this may disturb you. You may feel that so many little tiny functions will obscure the intent of your code. You may worry that it would be easy to get lost within such a huge swarm of functions.
But the opposite happens. The intent of your code becomes much more obvious. The levels of abstraction become crisp and the lines between them clear.
Remember that languages nowadays are rich with modules, classes, and namespaces. This allows you to build a hierarchy of names within which to place your functions. Namespaces hold classes. Classes hold functions. Public functions refer to private functions. Classes hold inner and nested classes. And so on. Take advantage of these tools to create a structure that makes it easy for other programmers to locate the functions you have written.
And then choose good names. Remember that the length of a function’s name should be inversely proportional to the scope that contains it. The names of public functions should be relatively short. The names of private functions should be longer.
As you extract and extract, the names of the functions will get longer and longer because the purpose of the function will become less and less general. Most of these extracted functions will be called from only one place, so their purpose will be extremely specialized and precise. The names of such specialized and precise functions must be long. They will likely be full clauses or even sentences.
These functions will be called from within the parentheses of while loops and if statements. They will be called from within the bodies of those statements as well, leading to code that looks like this:
if (employeeShouldHaveFullBenefits()) AddFullBenefitsToEmployee();
It will make your code read like well-written prose.
Using the Extract Method refactoring is also how you will get your functions to follow the stepdown rule.7 We want each line of a function to be at the same level of abstraction, and that level should be one level below the name of the function. To achieve this, we extract all code snippets within a function that are below the desired level.
7 Martin, p. 37.
Extract Variable
If Extract Method is the most important of refactorings, Extract Variable is its ready assistant. It turns out that in order to extract methods, you often must extract variables first.
For example, consider this refactoring from the bowling game in Chapter 2, “Test-Driven Development.” We started with this:
@Test
public void allOnes() throws Exception {
for (int i=0; i<20; i++)
g.roll(1);
assertEquals(20, g.score());
}And we ended up with this:
private void rollMany(int n, int pins) {
for (int i = 0; i < n; i++) {
g.roll(pins);
}
}
@Test
public void allOnes() throws Exception {
rollMany(20, 1);
assertEquals(20, g.score());
}The sequence of refactorings was as follows:
1. Extract Variable: The 1 in g.roll(1) was extracted into a variable named pins.
2. Extract Variable: The 20 in assertEquals(20, g.score()); was extracted into a variable named n.
3. The two variables were moved above the for loop.
4. Extract Method: The for loop was extracted into the rollMany function. The names of the variables became the names of the arguments.
5. Inline: The two variables were inlined. They had served their purpose and were no longer needed.
Another common usage for Extract Variable is to create an explanatory variable.8 For example, consider the following if statement:
8 Kent Beck, Smalltalk Best Practice Patterns (Addison-Wesley, 1997), 108.
if (employee.age > 60 && employee.salary > 150000)
ScheduleForEarlyRetirement(employee);This might read better with an explanatory variable:
boolean isEligibleForEarlyRetirement = employee.age > 60 &&
employee.salary > 150000
if (isEligibleForEarlyRetirement)
ScheduleForEarlyRetirement(employee);Extract Field
This refactoring can have a profoundly positive effect. I don’t use it often, but when I do, it puts the code on a path to substantial improvement.
It all begins with a failed Extract Method. Consider the following class, which converts a CSV file of data into a report. It’s a bit of a mess.
public class NewCasesReporter {
public String makeReport(String countyCsv) {
int totalCases = 0;
Map<String, Integer> stateCounts = new HashMap<>();
List<County> counties = new ArrayList<>();
String[] lines = countyCsv.split("
");
for (String line : lines) {
String[] tokens = line.split(",");
County county = new County();
county.county = tokens[0].trim();
county.state = tokens[1].trim();
//compute rolling average
int lastDay = tokens.length - 1;
int firstDay = lastDay - 7 + 1;
if (firstDay < 2)
firstDay = 2;
double n = lastDay - firstDay + 1;
int sum = 0;
for (int day = firstDay; day <= lastDay; day++)
sum += Integer.parseInt(tokens[day].trim());
county.rollingAverage = (sum / n);
//compute sum of cases.
int cases = 0;
for (int i = 2; i < tokens.length; i++)
cases += (Integer.parseInt(tokens[i].trim()));
totalCases += cases;
int stateCount = stateCounts.getOrDefault(county.state, 0);
stateCounts.put(county.state, stateCount + cases);
counties.add(county);
}
StringBuilder report = new StringBuilder("" +
"County State Avg New Cases
" +
"====== ===== =============
");
for (County county : counties) {
report.append(String.format("%-11s%-10s%.2f
",
county.county,
county.state,
county.rollingAverage));
}
report.append("
");
TreeSet<String> states = new TreeSet<>(stateCounts.keySet());
for (String state : states)
report.append(String.format("%s cases: %d
",
state, stateCounts.get(state)));
report.append(String.format("Total Cases: %d
", totalCases));
return report.toString();
}
public static class County {
public String county = null;
public String state = null;
public double rollingAverage = Double.NaN;
}
}Fortunately for us, the author was kind enough to have written some tests. These tests aren’t great, but they’ll do.
public class NewCasesReporterTest {
private final double DELTA = 0.0001;
private NewCasesReporter reporter;
@Before
public void setUp() throws Exception {
reporter = new NewCasesReporter();
}
@Test
public void countyReport() throws Exception {
String report = reporter.makeReport("" +
"c1, s1, 1, 1, 1, 1, 1, 1, 1, 7
" +
"c2, s2, 2, 2, 2, 2, 2, 2, 2, 7");
assertEquals("" +
"County State Avg New Cases
" +
"====== ===== =============
" +
"c1 s1 1.86
" +
"c2 s2 2.71
" +
"s1 cases: 14
" +
"s2 cases: 21
" +
"Total Cases: 35
",
report);
}
@Test
public void stateWithTwoCounties() throws Exception {
String report = reporter.makeReport("" +
"c1, s1, 1, 1, 1, 1, 1, 1, 1, 7
" +
"c2, s1, 2, 2, 2, 2, 2, 2, 2, 7");
assertEquals("" +
"County State Avg New Cases
" +
"====== ===== =============
" +
"c1 s1 1.86
" +
"c2 s1 2.71
" +
"s1 cases: 35
" +
"Total Cases: 35
",
report);
}
@Test
public void statesWithShortLines() throws Exception {
String report = reporter.makeReport("" +
"c1, s1, 1, 1, 1, 1, 7
" +
"c2, s2, 7
");
assertEquals("" +
"County State Avg New Cases
" +
"====== ===== =============
" +
"c1 s1 2.20
" +
"c2 s2 7.00
" +
"s1 cases: 11
" +
"s2 cases: 7
" +
"Total Cases: 18
",
report);
}
}The tests give us a good idea of what the program is doing. The input is a CSV string. Each line represents a county and has a list of the number of new covid cases per day. The output is a report that shows the seven-day rolling average of new cases per county and provides some totals for each state along with a grand total.
Clearly, we want to start extracting methods from this big horrible function. Let’s begin with that loop up at the top. That loop does all the math for all the counties, so we should probably call it something like calculateCounties.
However, selecting that loop and trying to extract a method produces the dialog shown in Figure 5.1.
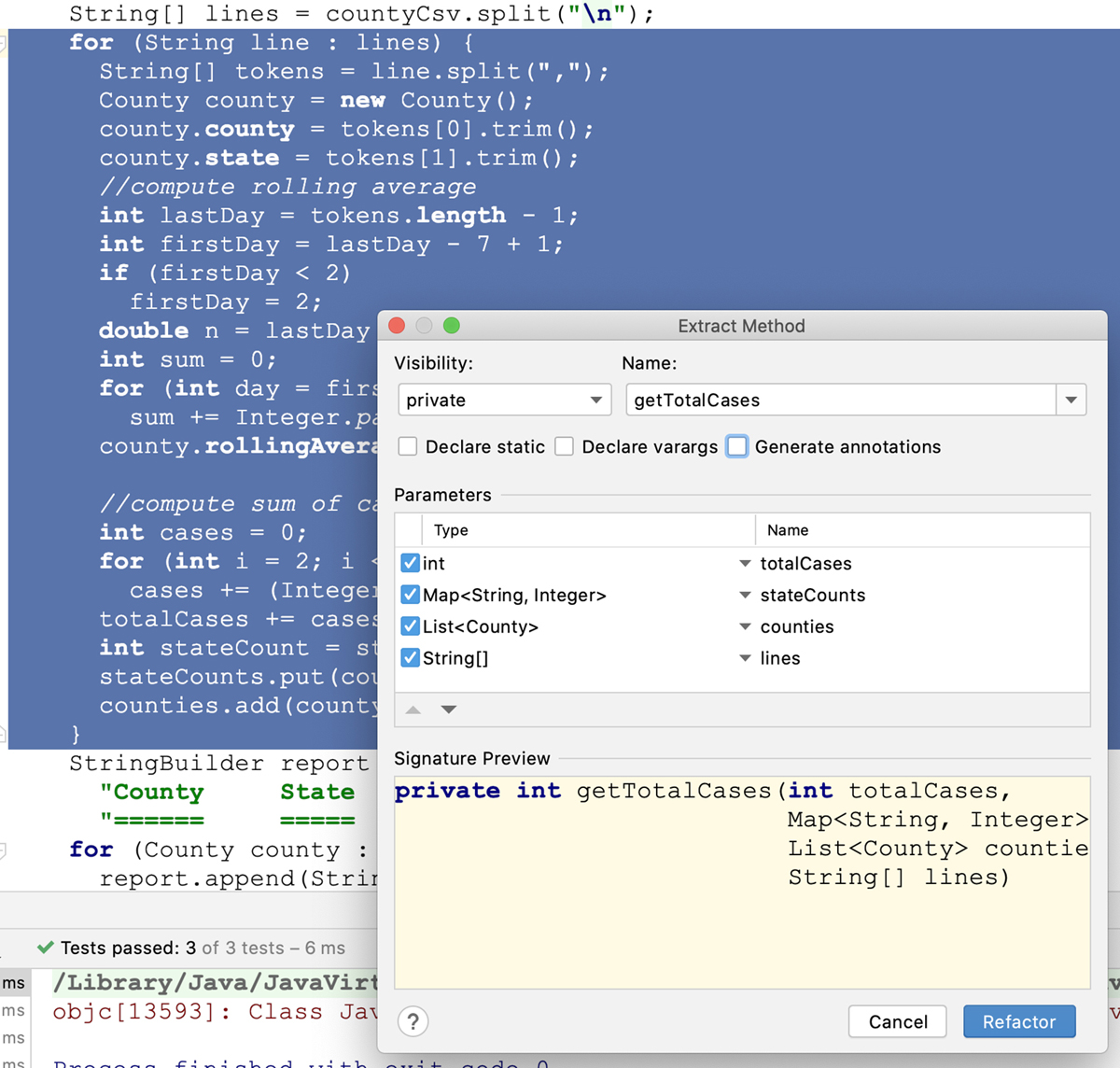
Figure 5.1 Extract Method dialog
The IDE wants to name the function getTotalCases. You’ve got to hand it to the IDE authors—they worked pretty hard to try to suggest names. The IDE decided on that name because the code after the loop needs the number of new cases and has no way to get it if this new function doesn’t return it.
But we don’t want to call the function getTotalCases. That’s not our intent for this function. We want to call it calculateCounties. Moreover, we don’t want to pass in those four arguments either. All we really want to pass in to the extracted function is the lines array.
So let’s hit Cancel and look again.
To refactor this properly, we need to extract some of the local variables within that loop into fields of the surrounding class. We use the Extract Field refactoring to do this:
public class NewCasesReporter {
private int totalCases;
private final Map<String, Integer> stateCounts = new HashMap<>();
private final List<County> counties = new ArrayList<>();
public String makeReport(String countyCsv) {
totalCases = 0;
stateCounts.clear();
counties.clear();
String[] lines = countyCsv.split("
");
for (String line : lines) {
String[] tokens = line.split(",");
County county = new County();Note that we initialize the values of those variables at the top of the makeReport function. This preserves the original behavior.
Now we can extract out the loop without passing in any more variables than we want and without returning the totalCases:
public class NewCasesReporter {
private int totalCases;
private final Map<String, Integer> stateCounts = new HashMap<>();
private final List<County> counties = new ArrayList<>();
public String makeReport(String countyCsv) {
String[] countyLines = countyCsv.split("
");
calculateCounties(countyLines);
StringBuilder report = new StringBuilder("" +
"County State Avg New Cases
" +
"====== ===== =============
");
for (County county : counties) {
report.append(String.format("%-11s%-10s%.2f
",
county.county,
county.state,
county.rollingAverage));
}
report.append("
");
TreeSet<String> states = new TreeSet<>(stateCounts.keySet());
for (String state : states)
report.append(String.format("%s cases: %d
",
state, stateCounts.get(state)));
report.append(String.format("Total Cases: %d
", totalCases));
return report.toString();
}
private void calculateCounties(String[] lines) {
totalCases = 0;
stateCounts.clear();
counties.clear();
for (String line : lines) {
String[] tokens = line.split(",");
County county = new County();
county.county = tokens[0].trim();
county.state = tokens[1].trim();
//compute rolling average
int lastDay = tokens.length - 1;
int firstDay = lastDay - 7 + 1;
if (firstDay < 2)
firstDay = 2;
double n = lastDay - firstDay + 1;
int sum = 0;
for (int day = firstDay; day <= lastDay; day++)
sum += Integer.parseInt(tokens[day].trim());
county.rollingAverage = (sum / n);
//compute sum of cases.
int cases = 0;
for (int i = 2; i < tokens.length; i++)
cases += (Integer.parseInt(tokens[i].trim()));
totalCases += cases;
int stateCount = stateCounts.getOrDefault(county.state, 0);
stateCounts.put(county.state, stateCount + cases);
counties.add(county);
}
}
public static class County {
public String county = null;
public String state = null;
public double rollingAverage = Double.NaN;
}
}Now, with those variables as fields, we can continue to extract and rename to our heart’s delight.
public class NewCasesReporter {
private int totalCases;
private final Map<String, Integer> stateCounts = new HashMap<>();
private final List<County> counties = new ArrayList<>();
public String makeReport(String countyCsv) {
String[] countyLines = countyCsv.split("
");
calculateCounties(countyLines);
StringBuilder report = makeHeader();
report.append(makeCountyDetails());
report.append("
");
report.append(makeStateTotals());
report.append(String.format("Total Cases: %d
", totalCases));
return report.toString();
}
private void calculateCounties(String[] countyLines) {
totalCases = 0;
stateCounts.clear();
counties.clear();
for (String countyLine : countyLines)
counties.add(calcluateCounty(countyLine));
}
private County calcluateCounty(String line) {
County county = new County();
String[] tokens = line.split(",");
county.county = tokens[0].trim();
county.state = tokens[1].trim();
county.rollingAverage = calculateRollingAverage(tokens);
int cases = calculateSumOfCases(tokens);
totalCases += cases;
incrementStateCounter(county.state, cases);
return county;
}
private double calculateRollingAverage(String[] tokens) {
int lastDay = tokens.length - 1;
int firstDay = lastDay - 7 + 1;
if (firstDay < 2)
firstDay = 2;
double n = lastDay - firstDay + 1;
int sum = 0;
for (int day = firstDay; day <= lastDay; day++)
sum += Integer.parseInt(tokens[day].trim());
return (sum / n);
}
private int calculateSumOfCases(String[] tokens) {
int cases = 0;
for (int i = 2; i < tokens.length; i++)
cases += (Integer.parseInt(tokens[i].trim()));
return cases;
}
private void incrementStateCounter(String state, int cases) {
int stateCount = stateCounts.getOrDefault(state, 0);
stateCounts.put(state, stateCount + cases);
}
private StringBuilder makeHeader() {
return new StringBuilder("" +
"County State Avg New Cases
" +
"====== ===== =============
");
}
private StringBuilder makeCountyDetails() {
StringBuilder countyDetails = new StringBuilder();
for (County county : counties) {
countyDetails.append(String.format("%-11s%-10s%.2f
",
county.county,
county.state,
county.rollingAverage));
}
return countyDetails;
}
private StringBuilder makeStateTotals() {
StringBuilder stateTotals = new StringBuilder();
TreeSet<String> states = new TreeSet<>(stateCounts.keySet());
for (String state : states)
stateTotals.append(String.format("%s cases: %d
",
state, stateCounts.get(state)));
return stateTotals;
}
public static class County {
public String county = null;
public String state = null;
public double rollingAverage = Double.NaN;
}
}This is much better, but I don’t like the fact that the code that formats the report is in the same class with the code that calculates the data. That’s a violation of the single responsibility principle because the format of the report and the calculations are very likely to change for different reasons.
In order to pull the calculation portion of the code out into a new class, we use the Extract Superclass refactoring to pull the calculations up into a superclass named NewCasesCalculator. NewCasesReporter will derive from it.
public class NewCasesCalculator {
protected final Map<String, Integer> stateCounts = new HashMap<>();
protected final List<County> counties = new ArrayList<>();
protected int totalCases;
protected void calculateCounties(String[] countyLines) {
totalCases = 0;
stateCounts.clear();
counties.clear();
for (String countyLine : countyLines)
counties.add(calcluateCounty(countyLine));
}
private County calcluateCounty(String line) {
County county = new County();
String[] tokens = line.split(",");
county.county = tokens[0].trim();
county.state = tokens[1].trim();
county.rollingAverage = calculateRollingAverage(tokens);
int cases = calculateSumOfCases(tokens);
totalCases += cases;
incrementStateCounter(county.state, cases);
return county;
}
private double calculateRollingAverage(String[] tokens) {
int lastDay = tokens.length - 1;
int firstDay = lastDay - 7 + 1;
if (firstDay < 2)
firstDay = 2;
double n = lastDay - firstDay + 1;
int sum = 0;
for (int day = firstDay; day <= lastDay; day++)
sum += Integer.parseInt(tokens[day].trim());
return (sum / n);
}
private int calculateSumOfCases(String[] tokens) {
int cases = 0;
for (int i = 2; i < tokens.length; i++)
cases += (Integer.parseInt(tokens[i].trim()));
return cases;
}
private void incrementStateCounter(String state, int cases) {
int stateCount = stateCounts.getOrDefault(state, 0);
stateCounts.put(state, stateCount + cases);
}
public static class County {
public String county = null;
public String state = null;
public double rollingAverage = Double.NaN;
}
}
=======
public class NewCasesReporter extends NewCasesCalculator {
public String makeReport(String countyCsv) {
String[] countyLines = countyCsv.split("
");
calculateCounties(countyLines);
StringBuilder report = makeHeader();
report.append(makeCountyDetails());
report.append("
");
report.append(makeStateTotals());
report.append(String.format("Total Cases: %d
", totalCases));
return report.toString();
}
private StringBuilder makeHeader() {
return new StringBuilder("" +
"County State Avg New Cases
" +
"====== ===== =============
");
}
private StringBuilder makeCountyDetails() {
StringBuilder countyDetails = new StringBuilder();
for (County county : counties) {
countyDetails.append(String.format("%-11s%-10s%.2f
",
county.county,
county.state,
county.rollingAverage));
}
return countyDetails;
}
private StringBuilder makeStateTotals() {
StringBuilder stateTotals = new StringBuilder();
TreeSet<String> states = new TreeSet<>(stateCounts.keySet());
for (String state : states)
stateTotals.append(String.format("%s cases: %d
",
state, stateCounts.get(state)));
return stateTotals;
}
}This partitioning separates things out very nicely. Reporting and calculation are accomplished in separate modules. And all because of that initial Extract Field.
Rubik’s Cube
So far, I’ve tried to show you how powerful a small set of refactorings can be. In my normal work, I seldom use more than the ones I’ve shown you. The trick is to learn them well and understand all the details of the IDE and the tricks for using them.
I have often compared refactoring to solving a Rubik’s cube. If you’ve never solved one of these puzzles, it would be worth your time to learn how. Once you know the trick, it’s relatively easy.
It turns out that there are a set of “operations” that you can apply to the cube that preserve most of the cube’s positions but change certain positions in predictable ways. Once you know three or four of those operations, you can incrementally manipulate the cube into a solvable position.
The more operations you know and the more adept you are at performing them, the faster and more directly you can solve the cube. But you’d better learn those operations well. One missed step and the cube melts down into a random distribution of cubies, and you have to start all over.
Refactoring code is a lot like this. The more refactorings you know and the more adept you are at using them, the easier it is to push, pull, and stretch the code in any direction you desire.
Oh, and you’d better have tests too. Without them, meltdowns are a near certainty.
The Disciplines
Refactoring is safe, easy, and powerful if you approach it in a regular and disciplined manner. If, on the other hand, you approach it as an ad hoc, temporary, and sporadic activity, that safety and power can quickly evaporate.
Tests
The first of the disciplines, of course, is tests. Tests, tests, tests, tests, and more tests. To safely and reliably refactor your code, you need a test suite that you trust with your life. You need tests.
Quick Tests
The tests also need to be quick. Refactoring just doesn’t work well if your tests take hours (or even minutes) to run.
In large systems, no matter how hard you try to reduce test time, it’s hard to reduce it to less than a few minutes. For this reason, I like to organize my test suite such that I can quickly and easily run the relevant subset of tests that check the part of the code I am refactoring at the moment. This usually allows me to reduce the test time from minutes to sub-seconds. I run the whole suite once per hour or so just to make sure no bugs leaked out.
Break Deep One-to-One Correspondences
Creating a test structure that allows relevant subsets to be run means that, at the level of modules and components, the design of your tests will mirror the design of your code. There will likely be a one-to-one correspondence between your high-level test modules and your high-level production code modules.
As we learned in the previous section, deep one-to-one correspondences between tests and code lead to fragile tests.
The speed benefit of being able to run relevant subsets of tests is much greater than the cost of one-to-one coupling at that level. But in order to prevent fragile tests, we don’t want the one-to-one correspondence to continue. So, below the level of modules and components, we purposely break that one-to-one correspondence.
Refactor Continuously
When I cook a meal, I make it a rule to clean the preparation dishes as I proceed.9 I do not let them pile up in the sink. There’s always enough time to clean the used utensils and pans while the food is cooking.
9 My wife disputes this claim.
Refactoring is like that too. Don’t wait to refactor. Refactor as you go. Keep the red → green → refactor loop in your mind, and spin around that loop every few minutes. That way, you will prevent the mess from building so large that it starts to intimidate you.
Refactor Mercilessly
Merciless refactoring was one of Kent Beck’s sound bites for Extreme Programming. It was a good one. The discipline is simply to be courageous when you refactor. Don’t be afraid to try things. Don’t be reluctant to make changes. Manipulate the code as though it is clay and you are the sculptor. Fear of the code is the mind-killer, the dark path. Once you start down the dark path, forever will it dominate your destiny. Consume you it will.
Keep the Tests Passing!
Sometimes you will realize that you’ve made a structural error and that a large swath of code needs to change. This can happen when a new requirement that invalidates your current design comes along. It can also happen out of the blue when, one day, you suddenly realize that there’s a better structure for the future of your project.
You must be merciless, but you must also be smart. Never break the tests! Or rather, never leave them broken for more than a few minutes at a time.
If the restructuring is going to take hours or days to complete, then do the restructuring in small chunks while you keep everything passing and while you continue to do other activities.
For example, let’s say that you realize that you need to change a fundamental data structure in the system—a data structure that large swathes of the code use. If you were to change that data structure, those swaths would stop working and many tests would break.
Instead, you should create a new data structure that mirrors the content of the old data structure. Then, gradually, move each portion of the code from the old data structure to the new data structure while keeping the tests passing.
While this is going on, you may also be adding new features and fixing bugs according to your regular schedule of work. There is no need to ask for special time to perform this restructuring. You can keep on doing other work while you opportunistically manipulate the code until the old data structure is no longer used and can be deleted.
This may take weeks or even months, depending on how significant the restructuring is. Even so, at no time would the system be down for deployment. Even while the restructuring is only partially complete, the tests still pass and the system can be deployed into production.
Leave Yourself an Out
When flying into an area where the weather might not be so good, pilots are taught to always make sure they leave an avenue of escape. Refactoring can be a bit like that. Sometimes you start a series of refactorings that, after an hour or two, leads you to a dead end. The idea you started with just didn’t pan out for some reason.
In situations like this, git reset --hard can be your friend.
So, when beginning such a sequence of refactorings, make sure to tag your source repository so you can back out if you need to.
Conclusion
I kept this chapter intentionally brief because there were only a few ideas that I wanted to add to Martin Fowler’s Refactoring. Again, I urge you to refer to that book for an in-depth understanding.
The best approach to refactoring is to develop a comfortable repertoire of refactorings that you use frequently and to have a good working knowledge of many others. If you use an IDE that provides refactoring operations, make sure you understand them in detail.
Refactoring makes no sense without tests. Without tests, the opportunities for error are just too common. Even the automated refactorings that your IDE provides can sometimes make mistakes. So always back up your refactoring efforts with a comprehensive suite of tests.
Finally, be disciplined. Refactor frequently. Refactor mercilessly. And refactor without apology. Never, ever ask permission to refactor.