
Chapter 4. Estimating Size with Story Points
“In a good shoe, I wear a size six, but a seven feels so good, I buy a size eight.”
—Dolly Parton in Steel Magnolias
Suppose a new restaurant opens nearby, and you decide to try it. For the first course, you can have either a cup or a bowl of soup. You can have the entrée as either a full or half portion. And you can have either a small or a large soda. You’ve probably been to many restaurants like this and can quite easily order about the right amount of food without asking how many ounces are in the cups and bowls of soup and exactly how big the entrée portions are. At most, you may ask the server something like “How big is the salad?” The server will likely respond by holding his hands apart to illustrate the size. In cases such as these, you are ordering by relative rather than measured size. You’re saying, “Give me the large portion” or “I’d like the small serving.” You are not ordering by exact size, such as “I’d like fourteen ounces of soda, six ounces of lasagna, and three ounces of bread.”
It’s possible to estimate an agile project’s user stories or features in the same way. When I’m at an unfamiliar restaurant and order a large soda, I don’t really know how many ounces I’ll get. About all I do know is that a large soda is larger than a small or medium soda and that it’s smaller than an extra-large one. I also know from experience that when I’m about as thirsty as I am now, a large soda at other restaurants has been the right size. Fortunately, this is all the knowledge I need. And on software projects it’s even easier: All I need to know is whether a particular story or feature is larger or smaller than other stories and features.
Story Points Are Relative
Story points are a unit of measure for expressing the overall size of a user story, feature, or other piece of work. When we estimate with story points, we assign a point value to each item. The raw values we assign are unimportant. What matters are the relative values. A story that is assigned a two should be twice as much as a story that is assigned a one. It should also be two-thirds of a story that is estimated as three story points.
The number of story points associated with a story represents the overall size of the story. There is no set formula for defining the size of a story. Rather, a story-point estimate is an amalgamation of the amount of effort involved in developing the feature, the complexity of developing it, the risk inherent in it, and so on.
There are two common ways to get started. The first approach is to select a story that you expect to be one of the smallest stories you’ll work with and say that story is estimated at one story point. The second approach is instead to select a story that seems somewhat medium and give it a number somewhere in the middle of the range you expect to use. Personally, I prefer most of my stories to be in the range of one to ten. (I’ll explain why in Chapter 6, “Techniques for Estimating.”) This means I’ll look for a medium-size story and call it five story points. Once you’ve fairly arbitrarily assigned a story-point value to the first story, each additional story is estimated by comparing it with the first story or with any others that have been estimated.
The best way to see how this works is to try it. Instead of story points, let’s estimate dog points for a moment. Let’s define a dog point as representing the height of the dog at the shoulder. With that in mind, assign dog points to each of these breeds:
• Labrador retriever
• Terrier
• Great Dane
• Poodle
• Dachshund
• German shepherd
• Saint Bernard
• Bulldog
Before reading on, really spend a moment thinking about how many dog points you would assign to each breed. The discussion that follows will be much more clear if you do.
My estimates are shown in Table 4.1. I determined these values by starting with Labrador retriever. This breed seems medium-size to me, so I gave it a five. Great Danes seem about twice as tall, so I gave them a ten. Saint Bernards seem a little less than twice as tall, so I gave them a nine. A dachshund seems about as short as a dog gets and so got a one. Bulldogs are short, so I gave them a three. However, if I had been estimating dog points based on weight, I would have given bulldogs a higher number.
Table 4.1. One Possible Assignment of Dog Points
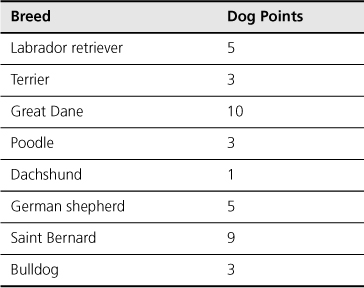
On an agile project it is not uncommon to begin an iteration with incompletely specified requirements, the details of which will be discovered during the iteration. However, we need to associate an estimate with each story, even those that are incompletely defined. You’ve already seen how to do this if you assigned dog points to poodle and terrier. Without more detail, it should have been difficult to assign dog points to poodle and terrier. There are toy, miniature, and standard poodles, each of a different height. Similarly, terrier is a group of more than twenty breeds. Some terriers (West Highland, Norwich, Norfolk) are less than a foot tall; others (Airedale) are nearly two feet tall.
When you’re given a loosely defined user story (or dog), you make some assumptions, take a guess, and move on. In Table 4.1, I took a guess for terrier and poodle, and assigned each three dog points. I reasoned that even the largest are smaller than Labrador retrievers and that the small terriers and poodles would be one- or two-point dogs, so on average a three seemed reasonable.
Velocity
To understand how estimating in unitless story points can possibly work, it is necessary to introduce a new concept: velocity. Velocity is a measure of a team’s rate of progress. It is calculated by summing the number of story points assigned to each user story that the team completed during the iteration.[1] If the team completes three stories each estimated at five story points, their velocity is fifteen. If the team completes two five-point stories, their velocity is ten.
If a team completed ten story points of work last iteration, our best guess is that they will complete ten story points this iteration. Because story points are estimates of relative size, this will be true whether they work on two five-point stories or five two-point stories.
In the introduction to this part of the book, the model in Figure 4.1 was used to show how an estimate of size could be turned into an estimate of duration and a schedule. It should be possible now to see how story points and velocity fit into this model.
Figure 4.1. Estimating the duration of a project begins with estimating its size.
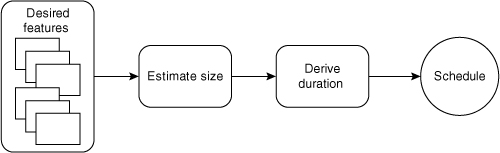
If we sum the story-point estimates for all desired features we come up with a total size estimate for the project. If we know the team’s velocity we can divide size by velocity to arrive at an estimated number of iterations. We can turn this duration into a schedule by mapping it onto a calendar.
A key tenet of agile estimating and planning is that we estimate size but derive duration. Suppose all of the user stories are estimated and the sum of those estimates is 100 story points. This is the estimated size of the system. Suppose further that we know from past experience that the team’s velocity has been ten points per two-week iteration, and that they will continue at the same velocity for this project. From our estimate of size and our known velocity value, we can derive a duration of ten iterations or twenty weeks. We can count forward twenty weeks on the calendar, and that becomes our schedule.
This very simplistic explanation of release planning works for now. It will be extended in Part IV, “Scheduling.” Additionally, this example was made very simple because we used the team’s past velocity. That is not always the case; velocity must sometimes be estimated instead. This can be difficult, but there are ways of doing it, which will be covered in Chapter 16, “Estimating Velocity.”
Velocity Corrects Estimation Errors
Fortunately, as a team begins making progress through the user stories of a project, their velocity becomes apparent over the first few iterations. The beauty of a points-based approach to estimating is that planning errors are self-correcting because of the application of velocity. Suppose a team estimates a project to include 200 points of work. They initially believe they will be able to complete twenty-five points per iteration, which means they will finish in eight iterations. However, once the project begins, their observed velocity is only twenty. Without re-estimating any work they will have correctly identified that the project will take ten iterations rather than eight.
To see how this works, suppose you are hired to paint an unfamiliar house. You are shown the floor plan in Figure 4.2 and are told that all materials will be provided, including a brush, roller, and paint. For your own purposes, you want to know how long this job will take you, so you estimate it. Because all you have is the floor plan, and you cannot see the actual house yet, you estimate based on what you can infer from the floor plan. Suppose that you estimate the effort to paint each of the smaller bedrooms to be five points. The five doesn’t mean anything. It does indicate, however, that the effort will be about the same for each bedroom. Because the master bedroom is about twice the size of the other bedrooms, you estimate it as ten points.
Figure 4.2. How long will it take to paint this house?
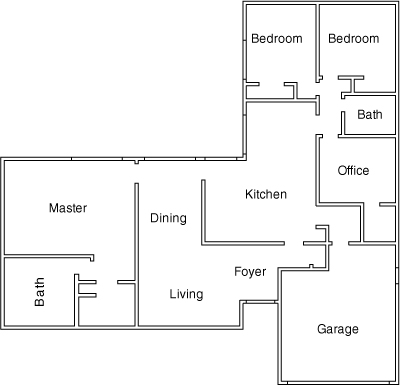
However, look more closely at Figure 4.2 and notice that there are no dimensions given. Are the two bedrooms 8′ × 10′ or 16′ × 20′? It’s impossible to tell from the floor plan. Are the estimates you’ve given completely worthless at this point? No. In fact, your estimates remain useful because they are estimates of the relative effort of painting each room. If you find that the bedrooms are twice the size you thought, the master bedroom is also twice the size you thought. The estimates remain the same, but because the rooms have four times the area you expected, your rate of progress through them will be slower.
The beauty of this is that estimating in story points completely separates the estimation of effort from the estimation of duration. Of course, effort and schedule are related, but separating them allows each to be estimated independently. In fact, you are no longer even estimating the duration of a project; you are computing it or deriving it. The distinction is subtle but important.
Summary
Story points are a relative measure of the size of a user story. A user story estimated as ten story points is twice as big, complex, or risky as a story estimated as five story points. A ten-point story is similarly half as big, complex, or risky as a twenty-point story. What matters are the relative values assigned to different stories.
Velocity is a measure of a team’s rate of progress per iteration. At the end of each iteration, a team can look at the stories they have completed and calculate their velocity by summing the story-point estimates for each completed story.
Story points are purely an estimate of the size of the work to be performed. The duration of a project is not estimated as much as it is derived by taking the total number of story points and dividing it by the velocity of the team.
Discussion Questions
1. What story-point values would you put on some features of your current project?
2. After having assigned dog points to the dogs in this chapter, what estimate would you assign to an elephant if, as your project customer, I told you I misspoke and meant to give you a list of mammals not dogs?
3. It’s fairly easy to estimate that two things of very similar size are the same. Over what range (from the smallest item to the largest) do you think you can reliably estimate? Five times the smallest item? Ten times? A hundred times? A thousand times?