
Chapter 18. Planning the Multiple-Team Project
“Do the planning, but throw out the plans.”
—Mary Poppendieck
Agile teams are often described as having no more than seven to ten developers. Teams of this size can accomplish quite a bit, especially with an agile process that allows and encourages them to become more productive. However, there are some projects in which we’d like to bring a larger team to bear on the project. Rather than establishing a single 100-person team, the agile approach is to create multiple smaller teams. An agile project may have a dozen smaller teams instead of a single 100-person team.
In this chapter, we will take what we’ve learned in previous chapters and apply it to the challenge of planning a project comprising multiple teams. Planning a large, multiple team project may require
1. Establishing a common basis for estimates.
2. Adding detail to their user stories sooner.
3. Performing lookahead planning.
4. Incorporating feeding buffers into the plan.
A project may require some or all of these techniques, depending on how many subteams are involved, as well as how often and intensely they need to coordinate. In general, I advise teams to incorporate only as many of these additional techniques as necessary, starting with establishing a common basis and working in order toward introducing feeding buffers.
Establishing a Common Basis for Estimates
Although it would be nice to let each individual subteam choose whether to estimate in story points or ideal days, most projects with multiple teams will benefit from estimating in a common unit and establishing a baseline meaning for that unit. Imagine the difficulty of predicting how much longer is needed to complete a set of user stories if some of them are estimated in ideal days and some are estimated in story points. Worse, imagine how much harder it would be if one team estimated a set of stories as 20 points but another team estimated the same work as 100 story points.
At the start of a project, the teams should meet and choose between story points and ideal days. They should then establish a common baseline for their estimates so that an estimate by one team will be similar to that of another team if the other team had estimated the work instead. Each user story needs to be estimated by only one team, but the estimates should be equivalent regardless of which team estimated the work.
There are two good ways to establish a common baseline. The first approach works only if the teams have worked together on a past project. In that case, they can select some user stories from the past project and agree on the estimates for them. Suppose they are estimating in ideal days; they should find two or three stories they consider as one ideal-day each. Then they should find a few they consider to be two ideal-day stories, and so on. They may identify twenty or so old stories, agreeing upon a new estimate for each, knowing what they now know about the stories. Once these baseline stories are agreed upon, the teams may separately estimate stories by comparing them with the baseline stories (that is, estimating them by analogy).
The second approach is similar but involves collaboratively estimating an assortment of new user stories. A variety of stories planned for the new release are selected. The stories should span a variety of sizes and should be in areas of the system that most of the estimators can relate to. Either the entire large team—or representatives of each subteam, if the entire team is too big—meet and agree upon an estimate for these stories. As with the first approach, these estimates are then used as baselines against which future estimates are compared.
The only time separate teams should consider estimating in different units without a common baseline is when the products being built are truly separate and there is absolutely no opportunity for developers from one team to move onto another. Even then, my recommendation is to establish a common baseline, as it facilitates communicating about the project.
Adding Detail to User Stories Sooner
Ideally, an agile team begins an iteration with vaguely defined requirements and turns those vague requirements into functioning, tested software by the end of the iteration. Going from vague requirement to working software in one iteration is usually easier on a single-team project than it is when there are multiple teams. On a multiple-team project, it is often appropriate and necessary to put more thought into the user stories before the start of the iteration. The additional detail allows multiple teams to coordinate work.
To achieve this, larger teams often include dedicated analysts, user interaction designers, and others who spend a portion of their time during a given iteration preparing the work of the next iteration. In general, I do not advise having analysts, interaction designers, and others work a full iteration ahead. Rather, their primary responsibility should remain the work of the current iteration, but in planning the current iteration, they should include some tasks related to preparing for the next iteration.
What I’ve found to be the most useful outcome of work done in advance of the iteration is the identification of the product owner’s conditions of satisfaction for the user stories that are likely to be developed during the iteration. A product owner’s conditions of satisfaction for a user story are the high-level acceptance tests that she would like to see applied to the story before considering it finished. A user story is finished when it can be demonstrated to meet all of the conditions of satisfaction identified by the product owner.
Although it is extremely helpful to know the conditions of satisfaction for a user story before an iteration begins, it is unlikely (and unnecessary) that a team identify them for all user stories in advance of the iteration. Realistically, the exact set of stories that will be undertaken in the next iteration are not known until the end of the iteration planning meeting that kicks off the iteration. In most cases, however, the product owner and team can make a reasonable guess at the stories that will most likely be prioritized into the next iteration. Conditions of satisfaction can be identified for these stories in advance of the iteration.
Lookahead Planning
Most teams with either moderately complex or frequent interdependencies will benefit from maintaining a rolling lookahead window during release and iteration planning. Suppose two teams are working on the SwimStats application. Part of SwimStats involves displaying static information such as practice times, the addresses of and directions to pools, and so on. However, SwimStats must also provide database-driven dynamic information, including results from all meets over the past fifteen years and personal records for all swimmers in all events.
National and age-group records are stored in a database at the remote facility of the national swimming association. Accessing the database isn’t as simple as the teams would like, and the national association is planning to change database vendors in the next year or two. For these reasons, the product owner and development teams agree that they want to develop an API (application programming interface) for accessing the database. This will make a later change to a different database vendor much simpler. The initial user stories and the estimates for each are shown in Table 18.1.
Table 18.1. The Initial User Stories and Estimates for SwimStats
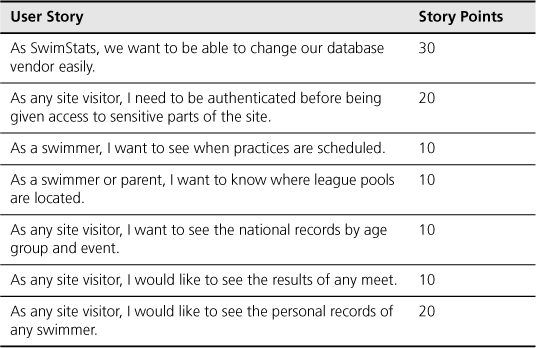
Velocity is estimated to be twenty points per iteration for each team. Because there are 110 points of work, this means the teams should be able to deliver all functionality in three iterations. However, thirty of the points are for developing the API, and another forty (the last three stories in Table 18.1) can be done only after the API. To finish these seventy points in three iterations, both teams will need to use the API. This leads them to an allocation of work as shown in Figure 18.1, which shows the team interdependency as an arrow between the API work of the first team and the personal records work done by the second.
Figure 18.1. Coordinating the work of two teams.
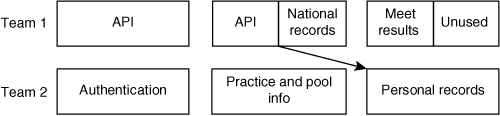
You may recall that in Chapter 13, “Release Planning Essentials,” I advised that the release plan show detail only for the next couple of iterations. This is because that is often enough to support the interdependencies encountered by many teams. When multiple teams need to coordinate work, the release plan should be updated to show and coordinate the work of the next two or three iterations. The exact number of iterations will, of course, depend on the frequency and significance of the dependencies among teams. As iterations are completed, details about them are dropped from the plan. The release plan then becomes a rolling lookahead plan that always outlines expectations about the new few iterations. Laufer (1996) refers to this as “peering forward.”
Figure 18.1 shows the situation in which a handoff between teams occurs between iterations. This is safer than planning on a handoff occurring during an iteration. At the start of each iteration, each team identifies the work they can complete and commits to finishing it. In the case of Figure 18.1, at the start of the third iteration, Team 2 was able to make a meaningful commitment to completing the personal records user story because they knew that the API was finished. Suppose instead that when Team 2 planned its third iteration the API was not done but was expected to be finished in a few days. Even if Team 2 could finish the personal-records story without having the API on the first day, it is a much more tenuous commitment, and the overall schedule is at greater risk. Teams will often need to make commitments based on miditeration deliverables. However, to the extent possible, they should limit commitments to work completed before the start of the iteration.
Incorporating Feeding Buffers into the Plan
For most teams in most situations, a rolling lookahead plan is adequate. There are situations, however, in which the interdependencies between teams are so complex or frequent that the simple rolling lookahead planning of the preceding section is not enough. In these cases, your first recourse should be to try to find a way to reduce the number of interdependencies so that a rolling lookahead plan is adequate. If that cannot be done, consider including a feeding buffer in iterations that deliver capabilities needed by other teams. A feeding buffer, like the schedule buffer of the previous chapter, protects the on-time delivery of a set of new capabilities. This is a somewhat complicated way of saying that if your team needs something from my team tomorrow at 8:00 a.m., my team shouldn’t plan on finishing it at 7:59. That is, we’d like a plan that looks like Figure 18.2.
Figure 18.2. Adding a feeding buffer.
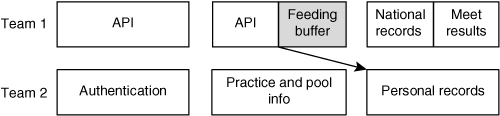
In Figure 18.2, a feeding buffer has been inserted between Team 1’s completion of the API and the beginning of Team 2’s work using the API on the personal records user story. The feeding buffer protects the start date on the personal-records story against delays in the completion of the API.
To include a feeding buffer in a release plan, all you need to do is plan temporarily for a lower velocity for the team that is delivering a capability to another team. In the case of Figure 18.2, Team 1’s effort is evenly split between finishing the API and a feeding buffer so that we can be sure Team 2 is able to start on the personal records at the beginning of the third iteration. This does not mean that Team 1 gets to take it easy during the second iteration. In fact, the expectation is that they will complete ten points on the API, need only a portion of the buffer, and begin work on the national-records user story during the second iteration.
What Gets Buffered?
In the case shown in Figure 18.2, adding a feeding buffer did not extend the length of the overall project, because Team 1’s third iteration was not already full. In many cases, however, adding feeding buffers will extend the expected duration of a project. But it usually does so in a way that represents a realistic expectation of the likely schedule, not in a “let’s pad the schedule so we don’t have to work hard” way. Because feeding buffers can prolong a schedule, you want to add them only when necessary.
To determine where feeding buffers are necessary, first allocate user stories among teams and iterations. Then look for critical dependencies between iterations and teams. Finally, add a feeding buffer only between these critical dependencies. That is, add a feeding buffer only if a team will be unable to do planned, high-priority work without the deliverables of another team. Even so, if the team can easily swap in other highly valuable work, a feeding buffer is unnecessary. Similarly, do not add a feeding buffer if the second team will be able to start making progress with a partial deliverable from the first team. If your team can start its work even if my team delivers only half of the planned functionality, a feeding buffer is not needed.
Sizing a Feeding Buffer
To size the feeding buffer, you can use the guidelines provided in Chapter 17, “Buffering Plans for Uncertainty.” Fortunately, however, most interteam dependencies are based on no more than a handful of stories or features at a time. Because of this, you usually won’t have enough stories to use the square root of the sum of the squares approach described in that chapter effectively. In these cases, set the size of the feeding buffer as a percentage of the stories creating the interdependency. You can use 50% as a default buffer size, but this should be adjusted based on team judgment.
It is possible to have a feeding buffer that is longer than a full iteration. However, it is rarely advisable to use a feeding buffer that long. A feeding buffer that is longer than an iteration is usually the result of planning to pass a large chunk of functionality on to another team. There are two reasons why a project probably doesn’t need a large feeding buffer in these cases. First, the handoff from one team to another should almost certainly be divided so that the functionality is delivered incrementally. This will allow the second team to get started as soon as they receive the initial set of functionality from the first team. Second, rather than consume an extremely large feeding buffer, the teams would probably find ways of splitting the work or of making other adjustments between iterations as soon as they noticed one team slipping behind. Having the receiving team act as a product owner or customer of the delivering team will usually allow the two teams to work out an incremental delivery sequence that works for both teams.
I’ve never had to use a feeding buffer that was larger than a full iteration and have rarely used one longer than half an iteration. Whenever I encounter the possible need to do so, I question my assumptions and review the plan to see what I can do to shorten the chain of deliverables being passed from one team to another.
But This Is So Much Work
Well, yes, but so is a large, multiple-team project. Keep in mind that you don’t need to do any of this if you’ve got a single team. You probably don’t even need to do this if you have just three or four approximately seven-person teams as long as those teams communicate often.
However, many large projects need to announce and commit to deadlines many months in advance, and many large projects do have interteam dependencies like those shown in this chapter. When faced with a project like that, it is useful to spend a few more hours planning the project. Doing so will allow you to more confidently and accurately estimate a target completion date at the outset and will also provide some protection against easily avoided schedule delays.
Summary
Agile projects tend to avoid large teams instead using teams of teams to develop large projects. When multiple teams are working on one project, they need to coordinate their work. This chapter described four techniques that are useful in helping multiple teams work on the same project.
First, teams should establish a common basis for their estimates. All teams should agree to estimate in the same unit: story points or ideal days. They should further agree on the meaning of those units by agreeing upon the estimates for a small set of stories.
Second, when multiple teams need to work together, it is often useful to add detail to their user stories sooner. The best way to do this is to identify the product owner’s conditions of satisfaction for a story. These are the things that can be demonstrated as true about a story once it is fully implemented.
Third, multiple teams benefit from incorporating a rolling lookahead plan into their release planning process. A rolling lookahead plan simply looks forward a small number of iterations (typically, only two or three) and allows teams to coordinate work by sharing information about what each will be working on in the near future.
Fourth, on highly complex projects with many interteam dependencies, it can be helpful to incorporate feeding buffers into the plan. A feeding buffer is an amount of time that prevents the late delivery by one team causing the late start of another.
These techniques are generally introduced to a project in the order described. They can, however, be introduced in any order desired.
Discussion Questions
1. How would you choose to establish a common baseline for your estimates on a project with multiple teams?
2. How significant are team interdependencies on your project? Which of the techniques introduced in this chapter would be most beneficial?