
Chapter 7. Decomposition
No-one deliberately decides to write legacy code. Code bases gradually deteriorate.
Why is that? Everyone seems to understand that a file with thousands of lines of code is a bad idea; that methods spanning hundreds of lines are difficult to work with. Programmers suffer when they have to work with such code bases.
If everyone understands that, though, then why do they allow the situation to become so bad?
7.1 Code rot
Code gradually becomes more complicated because each change seems small, and no-one pays attention to the overall quality. It doesn’t happen overnight, but one day you realise that you’ve developed a legacy code base, and by then, it’s too late to do anything about it.
At the beginning, a method has low complexity, but as you fix defects and add features, the complexity increases, as shown in figure 7.1. If you don’t pay attention to, say, cyclomatic complexity, you pass 7 without noticing it. You pass 10 without noticing it. You pass 15 and 20 without noticing it.

Figure 7.1: Gradual decay of a code base. Early on, things begin to go wrong as a complexity measure crosses a threshold. No-one, however, pays attention to the metric, so you only discover that you have a problem much later, when the metric has become so great that it may be impossible to salvage.
One day you discover that you have a problem - not because you finally look at a metric, but because the code has now become so complicated that everyone notices. Alas, now it’s too late to do anything about it.
Code rot sets in a little at a time; it works like boiling the proverbial frog.
7.1.1 Thresholds
Agreeing on a threshold can help curb code rot. Institute a rule and monitor a metric. For example, you could agree to keep an eye on cyclomatic complexity. If it exceeds seven, you reject the change.
Such rules work because they can be used to counteract gradual decay. It’s not the specific value 7 that contributes to better code quality; it’s the automatic activation of a rule based on a threshold. If you decide that the threshold should be 10 instead, that’ll also make a difference, but I find seven a good number, even if it’s more symbolic than a strict limit. Recall from subsection 3.2.1 that seven is a token for your brain’s working memory capacity.
Notice that figure 7.2 suggests that exceeding the threshold is still possible. Rules are in the way if you must rigidly obey them. Situations arise where breaking a rule is the best response. Once you’ve responded to the situation, however, find a way to bring the offending code back in line. Once a threshold is exceeded, you don’t get any further warnings, and there’s a risk that that particular code will gradually decay.
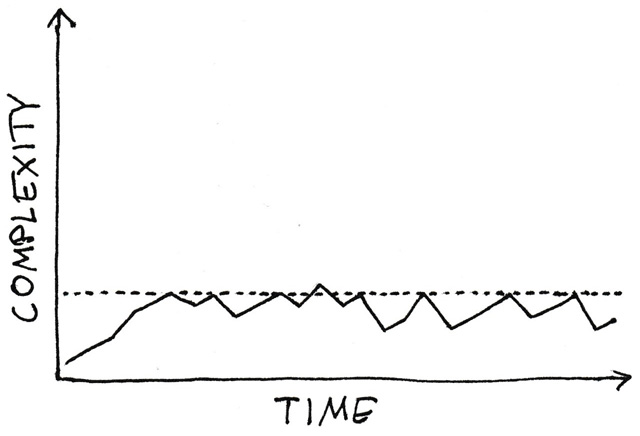
Figure 7.2: A threshold can help keep gradual decay in check.
You could automate the process. Imagine running cyclomatic complexity analysis as part of a Continuous Integration build and rejecting changes that exceed a threshold. This is, in a way, a deliberate attempt to hack the management effect where you get what you measure. With emphasis on a metric like cyclomatic complexity, you and your colleagues will pay attention to it.
Be aware, however, of the law of unintended consequences1. Be careful with instituting hard rules.
1 For an entertaining introduction to the world of unintended consequences and perverse incentives, see Freakonomics[57] and SuperFreakonomics[58]. While the titles sound silly, as a university-educated economist, I can vouch for them.
I’ve had success with introducing threshold rules because they increase awareness. It can help a technical leader shift emphasis to the qualities that he or she wishes to improve. Once the team’s mindset has changed, the rule itself becomes redundant.
7.1.2 Cyclomatic complexity
You’ve already encountered the term cyclomatic complexity here and there in the book. It’s one of the rare code metrics that I find useful in practice.
You’d expect a book about software engineering to be full of metrics. By now you’ve realised that this isn’t the case. You can invent myriad code metrics2, but most have little practical value. Preliminary research suggests that the simplest metric of all, lines of code, is the most pragmatic predictor of complexity[43]. I think that’s a good point that we should return to, but I want to make sure all readers get the message.
2 See e.g. Object-Oriented Metrics in Practice[56].
The more lines of code, the worse the code base. Lines of code is only a productivity metric if you measure lines of code deleted. The more lines of code you add, the more code other people have to read and understand.
While lines of code may be a pragmatic indicator of complexity, cyclomatic complexity is useful for other reasons. It’s a useful analysis tool because it not only informs you about complexity, but also guides you when it comes to unit testing.
Think of cyclomatic complexity as a measure of the number of pathways through a piece of code.
Even the simplest body of code affords a single pathway, so the minimum cyclomatic complexity is 1. You can easily ‘calculate’ the cyclomatic complexity of a method or function. You start at one, and then count how many times if and for occurs. For each of these keywords, you increment the number (which started at 1).
The specifics are language-dependent. The idea is to count branching and looping instructions. In C#, for example, you’d also have to include foreach, while, do, and each case in a switch block. In other languages, the keywords to count will differ.
What’s the cyclomatic complexity of the Post method in the restaurant reservation system? Try to count all branching instructions in listing 6.9, starting with the number 1.
Which number did you arrive at?
The cyclomatic complexity of listing 6.9 is 7. Did you arrive at 6? 5?
Here’s how you arrive at 7. Remember to start with 1. For each branching instruction you find, increment by one. There are five if statements. 5 plus the starting number 1 is 6. The last one is harder to spot. It’s the ?? null-coalescing operator, which represents two alternative branches: one where dto.Name is null and one where it isn’t. That’s another branching instruction3. There’s a total of seven pathways through the Post method.
3 If you aren’t used to thinking about C#’s null operators as branching instructions, this may not convince you, but maybe this will: Visual Studio’s built-in code metrics calculator also arrives at a cyclomatic complexity of 7.
Recall from section 3.2.1 that I use the number seven as a symbolic value that represents the limit of the brain’s short-term memory. If you adopt a threshold of seven, the Post method in listing 6.9 is right at the limit. You could leave it as is. That’s fine, but has the consequence that if you need to add an eighth branch in the future, you should first refactor. Perhaps at that time, you don’t have time to do that, so if you have time now, it might be better to do it prophylactically.
Hold that thought. We return to the Post method in section 7.2.2 to refactor it. Before we do that, however, I think we should cover some other guiding principles.
7.1.3 The 80/24 rule
What about the notion that lines of code is a simpler predictor for complexity?
We shouldn’t forget about that. Don’t write long methods. Write small blocks of code.
How small?
You can’t give a universally good answer to that question. Among other things, it depends on the programming language in question. Some languages are much denser than others. The densest language I’ve ever programmed in is APL.
Most mainstream languages, however, seem to be verbose to approximately the same order of magnitude. When I write C# code, I become uncomfortable when my method size approaches twenty lines of code. C# is, however, a fairly wordy language, so it sometimes happens that I have to allow a method to grow larger. My limit is probably somewhere around 30 lines of code.
That’s an arbitrary number, but if I have to quote one, it would be around that size. Since it’s arbitrary anyway, let’s make it 24, for reasons that I’ll explain later.
The maximum line count of a method, then, should be 24.
To repeat the point from before, this depends on the language. I’d consider a 24-line Haskell or F# function to be so huge that if I received it as a pull request, I’d reject it on the grounds of size alone.
Most languages allow for flexibility in layout. For example, C-based languages use the ; character as a delimiter. This enables you to write more than one statement per line:
var foo = 32; var bar = foo + 10; Console.WriteLine(bar);
You could attempt to avoid the 24-line-height rule by writing wide lines. That would, however, defeat the purpose.
The purpose of writing small methods is to nudge yourself towards writing readable code; code that fits in your brain. The smaller, the better.
For completeness sake, let’s institute a maximum line width as well. If there’s any accepted industry standard for maximum line width, it’s 80 characters. I’ve used that maximum for years, and it’s a good maximum.
The 80-character limit has a long and venerable history, but what about the 24-line limit? While both are, ultimately, arbitrary, both fit the size of the popular VT100 terminal, which had a display resolution of 80x24 characters.
A box of 80x24 characters thus reproduces the size of an old terminal. Does that mean that I suggest that you should write programs on terminals? No, people always misunderstand this. That should be the maximum size of a method4. On larger screens, you’d be able to see multiple small methods at the same time. For example, you could view a unit test and its target in a split screen configuration.
4 I feel the need to stress the point that this particular limit is arbitrary. The point is to have a threshold[96]. If your team is more comfortable with a 120x40 box, then that’s fine, too. Just to prove the point, though, I wrote the entire example code base that accompanies this book using the 80x24 box as a threshold. It’s possible, but I admit that it’s a close fit for C#.
The exact sizes are arbitrary, but I think that there’s something fundamentally right about such continuity with the past.
You can keep your line width in check with the help of code editors. Most development environments come with an option to paint vertical lines in the edit windows. You can, for example, put a line at the 80 character mark.
If you’ve been wondering why the code in this book is formatted as it is, one of the reasons is that it stays within the 80 character width limit.
Not only does the code in listing 6.9 have a cyclomatic complexity of 7, it’s also exactly 24 lines high. That’s one more reason to refactor it. It’s right at the limit, and I don’t think it’s done yet.
7.2 Code that fits in your brain
Your brain can only keep track of seven items at the same time. It’s a good idea to take this into account when designing the architecture of the code base.
7.2.1 Hex flower
When you look at a piece of code, your brain runs an emulator. It tries to interpret what the code will do when you execute it. If there’s too much to keep track of, the code is no longer immediately comprehensible. It doesn’t fit in your short-term memory. Instead, you must painstakingly work to commit the structure of the code to long-term memory. Legacy code is close at hand.
I posit the following rule, then:
No more than seven things should be going on in a single piece of code.
There’s more than one way to measure that, but one option is to use cyclomatic complexity. You could diagram the capacity of your short-term memory like figure 7.3.
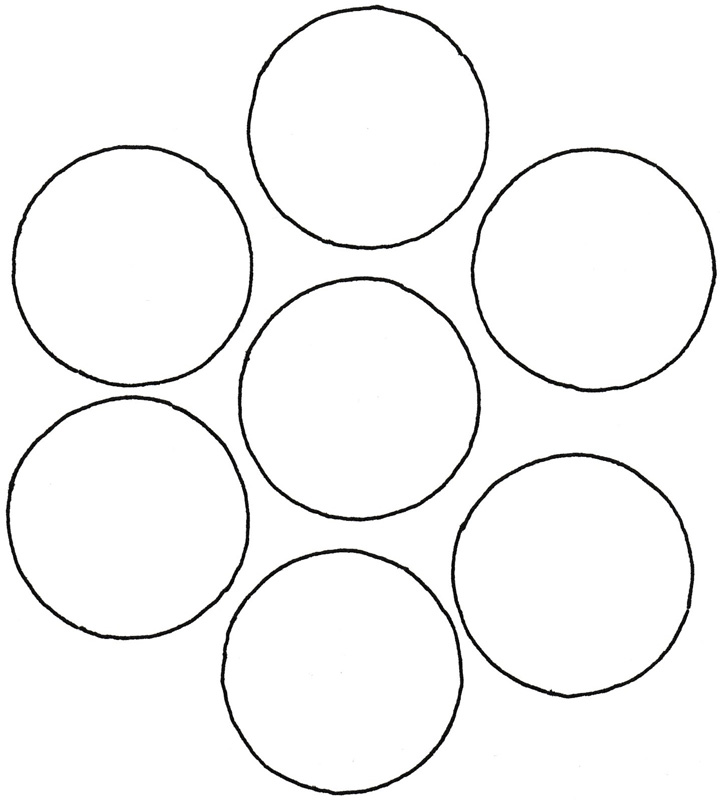
Figure 7.3: The capacity of human short-term memory illustrated as seven ‘registers’.
Think of each of these circles as a ‘memory slot’ or ‘register’. Each can hold a single chunk[79] of information.
If you squeeze the above bubbles together and also imagine that they’re surrounded by other bubbles, the most compact representation is as figure 7.4.
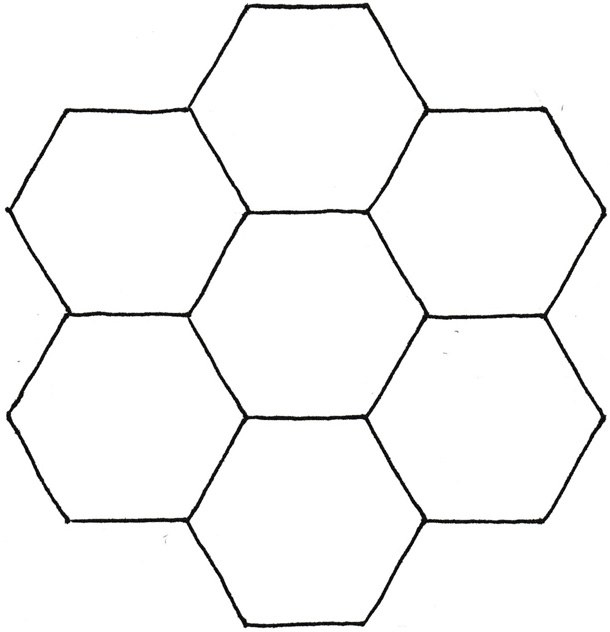
Figure 7.4: Seven ‘registers’ arranged in compact form. While hexagons could be arranged like this in an infinite grid, this particular shape looks like a stylised flower. For that reason, I’ll refer to such diagrams as ‘hex flowers’.
Conceptually, you should be able to describe what’s going on in a piece of code by filling out the seven hexagons in that figure. What would the contents be for the code in listing 6.9?
It might look like figure 7.5.
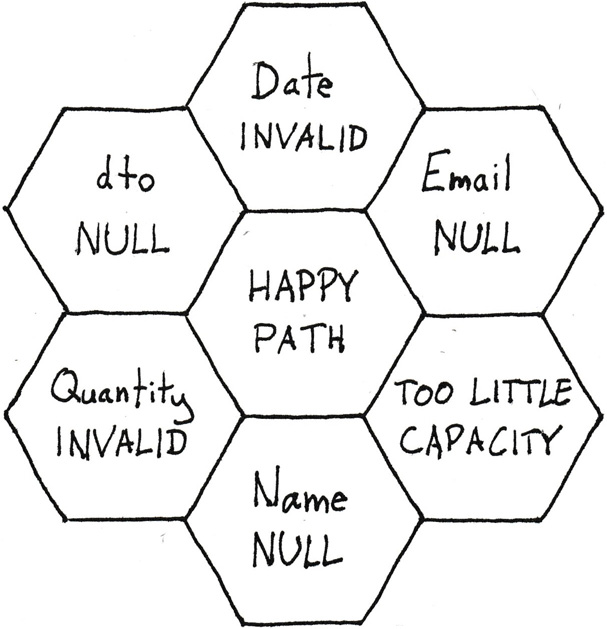
Figure 7.5: Hex flower diagram of the the branches of the Post method in listing 6.9.
In each slot, I’ve plotted an outcome related to a branch in the code. From the cyclomatic complexity metric you know that listing 6.9 has seven pathways through the code. Those are the chunks I’ve filled into the hexagons.
All ‘slots’ are filled. If you treat the number seven as a hard limit5, then you can’t add more complexity to the Post method. The problem is that in the future, you’re going to have to add more complex behaviour. For example, you may want to reject all reservations in the past. Also, the business rule only works for hipster restaurants with communal tables and single seatings. A more sophisticated reservation system should be able to handle tables of different sizes, second seatings, and so on.
5 The number seven isn’t really a hard limit. Nothing in the line of reasoning presented here relies on that exact number, but the visualisation, on the other hand, does.
You’ll have to decompose the Post method to move forward.
7.2.2 Cohesion
How, or where, should you decompose the Post method in listing 6.9?
Perhaps it helps that the code is already organised into sections by a few blank lines6. There seems to be four sections; the first is a sequence of Guard Clauses[7]. This section is the best candidate for refactoring.
6 This book doesn’t go into every little detail about how and why you lay out general source code, including how you should use blank lines. This is already covered in Code Complete[65]. I consider my use of blank lines to be consistent with it.
How can you tell?
The first section uses no instance members of the owning ReservationsController class. The second and third sections both use the Repository property. The fourth section is only a single return expression, so there’s little to improve there.
That the second and third sections use an instance member doesn’t preclude them from being extracted into helper methods, but the first section is more conspicuous. This relates to a central concept in object-oriented design: cohesion. I like the way that Kent Beck puts it:
“Things that change at the same rate belong together. Things that change at different rates belong apart.”[8]
Consider how instance fields of a class are used. Maximum cohesion is when all methods use all class fields. Minimum cohesion is when each method uses its own disjoint set of class fields.
Blocks of code that don’t use any class fields at all look even more suspicious in that light. That’s the reason I find that the best refactoring candidate is the first section of the code.
Your first attempt might resemble listing 7.1. This small method has only six lines of code and a cyclomatic complexity of 3. According to the metrics we’ve discussed so far, it looks great.
private static bool IsValid(ReservationDto dto) { return DateTime.TryParse(dto.At, out _) && !(dto.Email is null) && 0 < dto.Quantity; }
Listing 7.1: Helper method to determine if a reservation DTO is valid. (Restaurant/f8d1210/Restaurant.RestApi/ReservationsController.cs)
Notice, however, that it’s marked static. This is necessary because a code analyser rule7 has detected that it doesn’t use any instance members. That could be a code smell. We’ll return to that in a moment.
7 CA1822: Mark members as static.
Did the introduction of the IsValid helper method improve the Post method? Listing 7.2 shows the result.
At first glance, that looks like an improvement. The line count is down to 22 and the cyclomatic complexity to 5.
Did it surprise you that cyclomatic complexity decreased?
public async Task<ActionResult> Post(ReservationDto dto) { if (dto is null) throw new ArgumentNullException(nameof(dto)); if (!IsValid(dto)) return new BadRequestResult(); var d = DateTime.Parse(dto.At!, CultureInfo.InvariantCulture); var reservations = await Repository.ReadReservations(d).ConfigureAwait(false); int reservedSeats = reservations.Sum(r => r.Quantity); if (10 < reservedSeats + dto.Quantity) return new StatusCodeResult( StatusCodes.Status500InternalServerError); var r = new Reservation(d, dto.Email!, dto.Name ?? "", dto.Quantity); await Repository.Create(r).ConfigureAwait(false); return new NoContentResult(); }
Listing 7.2: The Post method using the new IsValid helper method. (Restaurant/f8d1210/Restaurant.RestApi/ReservationsController.cs)
After all, when you consider the combined behaviour of the Post method and its IsValid helper method, it hasn’t changed. Shouldn’t we count the complexity of IsValid into the complexity of the Post method?
That’s a fair question, but it’s not how the measure works. This way of viewing a method call represents both a danger and an opportunity. If you need to keep track of the details of how IsValid behaves, then nothing is gained. If, on the other hand, you can treat it as a single operation, then the corresponding hex flower (figure 7.6) looks better.

Figure 7.6: Hex flower diagram plotting the complexity of listing 7.2. Two empty ‘registers’ illustrates extra capacity of your short-term memory. In other words, the code fits in your brain.
Three fine-grained chunks has been replaced with a single slightly larger chunk.
“Short-term memory is measured in chunks [...] because each item can be a label that points to a much bigger information structure in long-term memory”[79]
The key to such replacement is the ability to replace many things with one thing. You can do that if you can abstract the essence of the thing. Does that sound familiar?
That’s Robert C. Martin’s definition of abstraction:
“Abstraction is the elimination of the irrelevant and the amplification of the essential”[60]
The IsValid method amplifies that it validates a Data Transfer Object while it eliminates the exact details about how it does that. We can draw another hexagonal short-term memory layout for it (figure 7.7).

Figure 7.7: Hex flower diagram plotting the complexity of listing 7.1.
When you look at the code for IsValid you don’t have to know anything about the surrounding context. The calling code doesn’t influence the IsValid method, beyond passing an argument to it. Both IsValid and Post fit in your brain.
7.2.3 Feature Envy
While complexity decreased with the above refactoring, the change introduced other problems.
The most evident problem is the code smell that the IsValid method is static8. It takes a ReservationDto parameter, but uses no instance members of the ReservationsController class. That’s a case of the Feature Envy[34] code smell. As Refactoring[34] suggests, try moving the method to the object it seems ‘envious’ of.
8 It’s not always a problem that a method is static, but in object-oriented design, it could be. It’s worthwhile paying attention to your use of static.
Listing 7.3 shows the method moved to the ReservationDto class. For now I decided to keep it internal, but I might consider changing that decision later.
I also chose to implement the member as a property9 instead of a method. The previous method was ‘envious’ of the features of ReservationDto, but now that the member is a part of that class, it needs no further parameters. It could have been a method that took no input, but in this case a property seems like a better choice.
9 A property is just C# syntactic sugar for a ‘getter’ (and/or ‘setter’) method.
It’s a simple operation without preconditions, and it can’t throw exceptions. That fits the .NET framework guidelines’ rules for property getters[23].
internal bool IsValid { get { return DateTime.TryParse(At, out _) && !(Email is null) && 0 < Quantity; } }
Listing 7.3: IsValid method moved to the ReservationDto class. (Restaurant/0551970/Restaurant.RestApi/ReservationDto.cs)
Listing 7.4 shows the part of the Post method where it checks whether the dto is valid.
if (!dto.IsValid) return new BadRequestResult();
Listing 7.4: Code fragment from the Post method. This is where it calls the IsValid method shown in listing 7.3. (Restaurant/0551970/Restaurant.RestApi/ReservationsController.cs)
All tests pass. Don’t forget to commit the changes to Git and push them through your deployment pipeline[49].
7.2.4 Lost in translation
Even a small block of code can exhibit multiple problems. Fixing one issue doesn’t guarantee that there are no more of them. That’s the case with the Post method.
The C# compiler can no longer see that At and Email are guaranteed to be non-null. We have to tell it to turn off its static flow analysis for these references with the null-forgiving ! operator. Otherwise, the code doesn’t compile. You’re essentially suppressing the nullable reference types compiler feature. That’s not a step in the right direction.
Another problem with listing 7.2 is that it effectively parses the At property twice - once in the IsValid method, and once again in the Post method.
It seems that too much is lost in the translation. It turns out that, after all, IsValid isn’t a good abstraction. It eliminates too much and amplifies too little.
This is a typical problem with object-oriented validation. A member like IsValid produces a Boolean flag, but not all the information that downstream code might need - for example the parsed date. This compels other code to repeat the validation. The result is code duplication.
A better alternative is to capture the validated data. How do you represent validated data?
Recall the discussion about encapsulation in chapter 5. Objects should protect their invariants. That includes pre- and postconditions. A properly initialised object is guaranteed to be in a valid state - if it’s not, encapsulation is broken because the constructor failed to check a precondition.
This is the motivation for a Domain Model. The classes that model the domain should capture its invariants. This is in contrast to Data Transfer Objects that model the messy interactions with the rest of the world.
In the restaurant reservation system, the domain model of a valid reservation already exists. It’s the Reservation class, last glimpsed in listing 5.13. Return such an object instead.
7.2.5 Parse, don’t validate
Instead of an IsValid member that returns a Boolean value, translate Data Transfer Objects[33] to domain objects if the preconditions hold. Listing 7.5 shows an example.
internal Reservation? Validate() { if (!DateTime.TryParse(At, out var d)) return null; if (Email is null) return null; if (Quantity < 1) return null; return new Reservation(d, Email, Name ?? "", Quantity); }
Listing 7.5: The Validate method returns an encapsulated object. (Restaurant/a0c39e2/Restaurant.RestApi/ReservationDto.cs)
The Validate method uses Guard Clauses[7] to check the preconditions of the Reservation class. This includes parsing the At string into a proper DateTime value. Only if all preconditions are fulfilled does it return a Reservation object. Otherwise, it returns null.
public async Task<ActionResult> Post(ReservationDto dto) { if (dto is null) throw new ArgumentNullException(nameof(dto)); Reservation? r = dto.Validate(); if (r is null) return new BadRequestResult(); var reservations = await Repository .ReadReservations(r.At) .ConfigureAwait(false); int reservedSeats = reservations.Sum(r => r.Quantity); if (10 < reservedSeats + r.Quantity) return new StatusCodeResult( StatusCodes.Status500InternalServerError); await Repository.Create(r).ConfigureAwait(false); return new NoContentResult(); }
Listing 7.6: The Post method calls the Validate method on the dto and branches on whether or not the returned value is null. (Restaurant/a0c39e2/Restaurant.RestApi/ReservationsController.cs)
Notice that this solves all the problems introduced by the static IsValid method shown in listing 7.1. The Post method doesn’t have to suppress the compiler’s static flow analyser, and it doesn’t have to duplicate parsing the date.
The Post method’s cyclomatic complexity is now down to 4. This fits in your brain, as figure 7.8 illustrates.
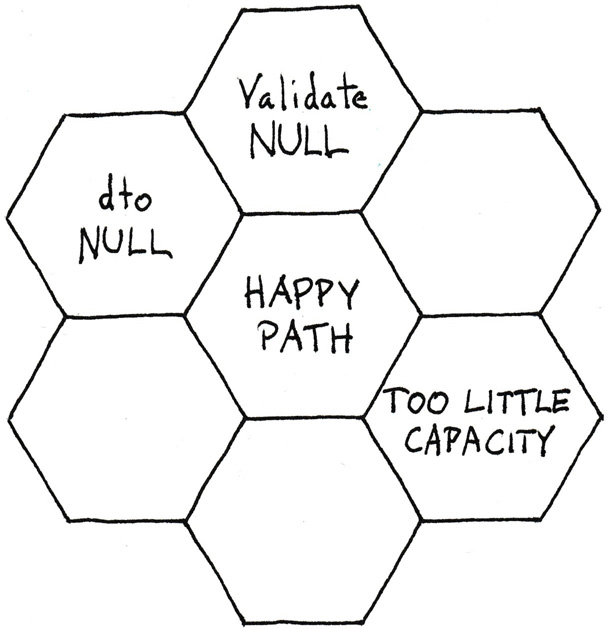
Figure 7.8: Hex flower diagram for the Post method shown in listing 7.6.
The Validate method is a better abstraction because it amplifies the essentials: does dto represent a valid reservation? It does that by projecting the input data into a stronger representation of the same data.
Alexis King calls this technique parse, don’t validate.
“Consider: what is a parser? Really, a parser is just a function that consumes less-structured input and produces more-structured output. By its very nature, a parser is a partial function - some values in the domain do not correspond to any value in the range - so all parsers must have some notion of failure. Often, the input to a parser is text, but this is by no means a requirement”[54]
The Validate method is actually a parser: it takes the less-structured ReservationDto as input and produces the more-structured Reservation as output. Perhaps the Validate method ought to be named Parse, but I was concerned it might confuse readers with more narrow views on parsing.
7.2.6 Fractal architecture
Consider a diagram like figure 7.8 that depicts the Post method. Only four of the seven slots are occupied by chunks.
You know, however, that the chunk representing the Validate method amplifies the essentials while it eliminates some complexity. While you don’t have to think about the complexity hidden by the chunk, it’s still there, as suggested by figure 7.9.
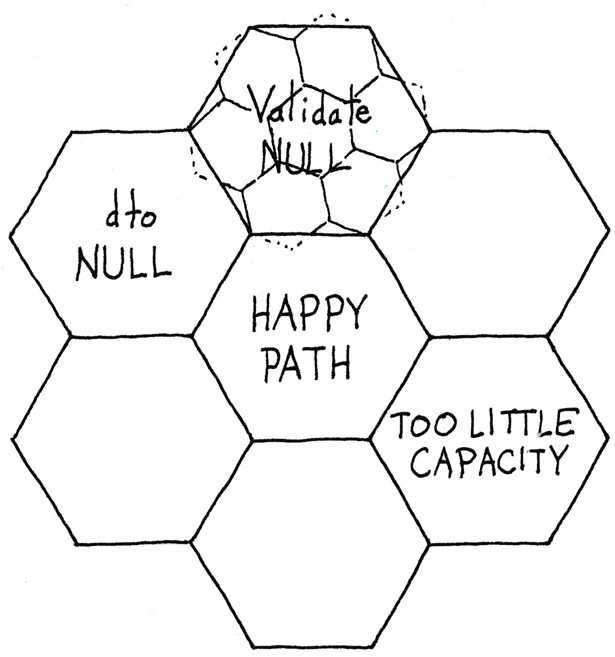
Figure 7.9: Hex flower hinting that each chunk can hide other complexity.
You can zoom in on the Validate chunk. Figure 7.10 shows that the structure is the same.
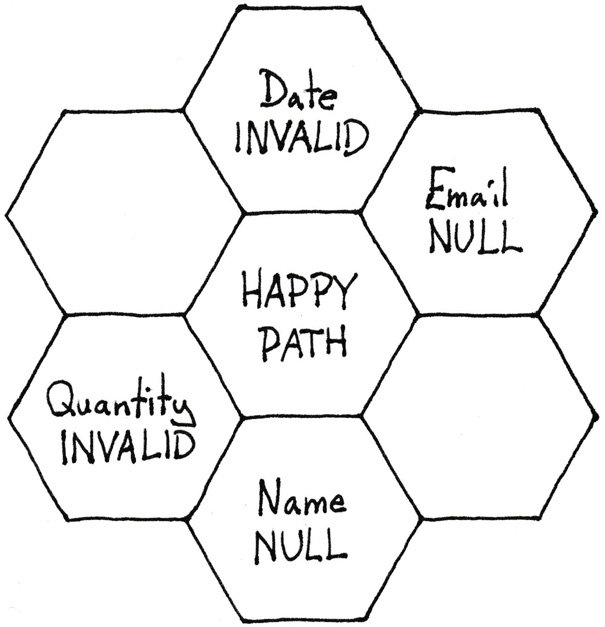
Figure 7.10: Hex flower for the Validate method shown in listing 7.5.
The cyclomatic complexity of the Validate method is 5, so if you use that as a yardstick for complexity, it makes sense to fill out five of the seven slots with chunks.
By now you’ll have noticed that when you zoom in on a detail, it has the same shape as the caller. What happens if you zoom out?
The Post method doesn’t have any direct callers. The ASP.NET framework calls Controller methods based on the configuration in the Startup class. How does that class measure up?
It hasn’t changed since listing 4.20. The cyclomatic complexity of the entire class is as low as 5. You can easily plot it in the a hex flower like figure 7.11.
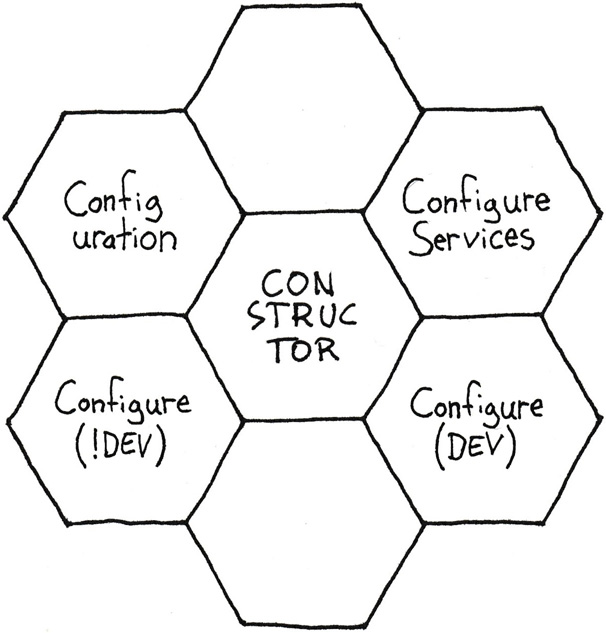
Figure 7.11: All complexity elements of the Startup class. Most class members have a cyclomatic complexity of 1, so they take up only one hexagon. The Configure method has a cyclomatic complexity of 2, so it takes up two hexagons: one where IsDevelopment is true, and one where it’s false.
Even the overall definition of the application fits in your brain. It should stay that way.
Imagine that you’re a new team member, and this is the first time you’re looking at the code base. A good place to start, if you’re trying to understand how the application works, is the entry point. That’s the Program class, which hasn’t changed since listing 2.4. If you know ASP.NET you quickly realise that nothing unexpected is going on here. To understand the application, you should look at the Startup class.
When you open the Startup class, you’re pleasantly surprised to learn that it fits in your brain. From the Configure method you quickly learn that the system uses ASP.NET’s standard Model View Controller[33] system, as well as its regular routing engine.
From the ConfigureServices method you learn that the application reads a connection string from its configuration system and uses it to register a SqlReservationsRepository object with the framework’s Dependency Injection Container[25]. This should suggest to you that the code uses Dependency Injection and a relational database.
This is a high-level view of the system. You don’t learn any details, but you learn where to look if you’re interested in details. If you want to know about the database implementation, you can navigate to the SqlReservationsRepository code. If you want to see how a particular HTTP request is handled, you find the associated Controller class.
When you navigate to those parts of the code base, you also learn that each class, or each method, fits in your brain at that level of abstraction. You can diagram the chunks of the code in a ‘hex flower’, like you’ve repeatedly seen throughout this chapter.
Regardless of the ‘zoom level’, the ‘complexity structure’ looks the same. This quality is reminiscent of mathematical fractals, which made me name this style of architecture fractal architecture. At all levels of abstraction, the code should fit in your brain.
In contrast to mathematical fractals, you can’t keep zooming indefinitely in a code base. Sooner or later, you’ll reach the highest level of resolution. That’ll be methods that call none of your other code. For example, the methods in the SqlReservationsRepository class (see e.g. listing 4.19) don’t call any other user code.
Another way to illustrate this style of architecture is as a tree, with the leaf nodes representing the highest level of resolution.
In general, you could illustrate an architecture that fits in your brain as a fractal tree, like in figure 7.12. At the trunk, your brain can handle up to seven chunks, represented by seven branches. At each branch, your brain can again handle seven more branches, and so on. A mathematical fractal tree is conceptually infinite, but when drawing it, you sooner or later have to stop rendering the branches.
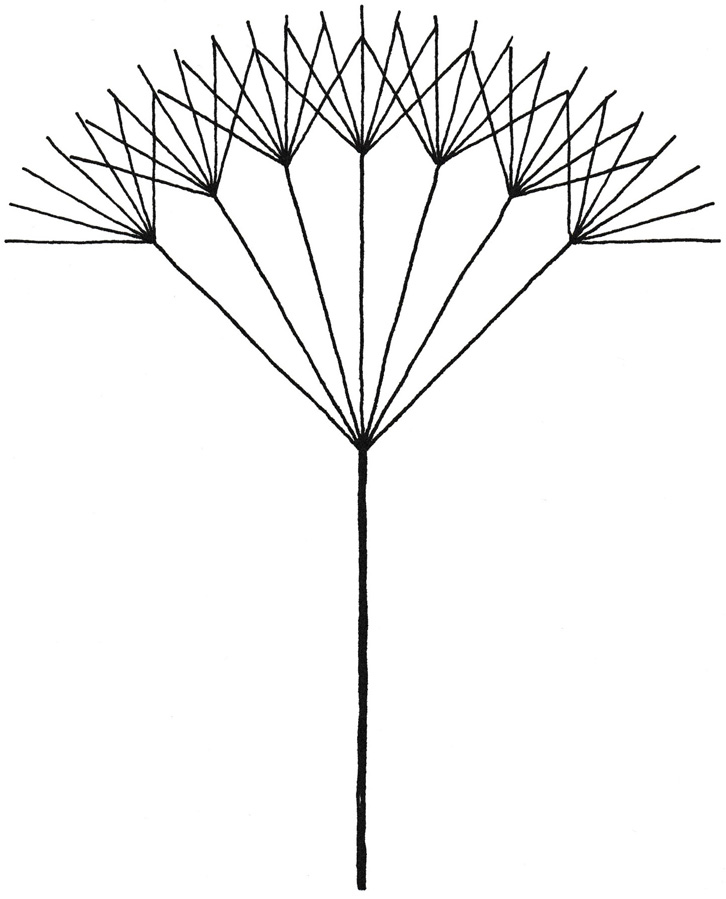
Figure 7.12: Seven-way fractal tree.
A fractal architecture is a way to organise code so that wherever you look, it fits in your brain. Lover-level details should be represented as a single abstract chunk, and higher-level details should be either irrelevant at that level of zoom, or otherwise explicitly visible as method parameters or injected dependencies. Keep in mind that what you see is all there is[51].
A fractal architecture doesn’t happen by itself. You have to explicitly consider the complexity of each block of code you write. You can calculate cyclomatic complexity, keep an eye on lines of code, or count the number of variables involved in a method. Exactly how you evaluate complexity is less important than keeping it low.
Chapter 16 takes you on a tour of the finished example code base. The completed system is more complex than you’ve so far seen, but it still meet the requirements of a fractal architecture.
7.2.7 Count the variables
As implied above, you can get another perspective on complexity by counting the number of variables in a method. I sometimes do that just to get another view on things.
If you decide to do that, make sure that you count all the involved objects. That includes local variables, method arguments, and class fields.
For example, the Post method in listing 7.6 involves five variables: dto, r, reservations, Repository, and reservedSeats. Three of those are local variables while dto is a parameter and Repository is a property (which is backed by an implicit, auto-generated class field). That’s five things that you have to keep track of. Your brain can do that, so this is fine.
I mostly do this when I consider if it’s okay to add another parameter to a method. Are four parameters too many? It sounds like four parameters are well within the limit of seven, but if those four arguments interact with five local variables and three class fields, then too much is probably going on. One way out of such a situation is to introduce a Parameter Object[34].
Obviously, this type of complexity analysis doesn’t work with interfaces or abstract methods, since there’s no implementation.
7.3 Conclusion
Code bases aren’t born as legacy code. They degrade over time. They accumulate cruft so gradually that it’s difficult to notice.
High-quality code is like an unstable equilibrium, as pointed out by Brian Foote and Joseph Yoder:
“Ironically, comprehensibility can work against an artifact’s preservation, by causing it to mutate more rapidly than artifacts that are harder to understand [...] An object with a clear interface and hard to understand internals may remain relatively intact.”[28]
You must actively prevent code from rotting. You can pay attention by measuring various metrics, such as lines of code, cyclomatic complexity, or just counting the variables.
I’ve no illusions about the universality of these metrics. They can be useful guides, but ultimately, you must use your own judgment. I find, however, that monitoring metrics like these can raise awareness of code rot.
When you combine metrics with aggressive thresholds, you establish a culture that actively pays attention to code quality. This tells you when to decompose a code block into smaller components.
Complexity metrics don’t tell you which parts to decompose. This is a big subject that’s already covered by many other books[60][27][34], but a few things to look for is cohesion, Feature Envy, and validation.
You should aim for an architecture of your code base so that regardless of where you look, the code fits in your head. At a high level, there’s seven or fewer things going on. In the low-level code, there’s at most seven things you have to keep track of. At the intermediary level, this still holds.
At every zoom level, the complexity of the code remains within humane bounds. This self-similarity at different levels of resolution looks enough like fractals that I call this fractal architecture.
It doesn’t happen by itself, but if you can achieve it, the code is orders of magnitude easier to understand than legacy code because it’ll mostly involve your short-term memory.
In chapter 16 you get a tour of the ‘completed’ code base, so that you can see how the concept of fractal architecture plays out in a realistic setting.