
Chapter 8. API design
When a block of code grows too complex, you should decompose it, as implied by figure 8.1. The previous chapter discussed where to take things apart. In this chapter, you’ll learn how to design the new parts.
Figure 8.1: Decompose a block of code into smaller blocks when it becomes too complex. How should the new blocks look? You’ll learn some principles of API design in this chapter.
You can decompose code in many ways. There isn’t a single correct way to do it, but there are more wrong ways than good ways. Staying on the narrow path of good API design requires skill and taste. Fortunately, the skill can be learned. Congruent with the theme of this book, you can apply heuristics to API design, as you will see in this chapter.
8.1 Principles of API design
The acronym API means Application Programming Interface, that is: an interface against which you can write client code. You have to be careful with these words, because their meanings are overloaded.
8.1.1 Affordance
How do you understand the word interface? You might think of it as a language keyword, as in listing 6.5. In the context of APIs, we use it in a broader sense. An interface is an affordance. It’s the set of methods, values, functions, and objects you have at your disposal to interact with some other code. With good encapsulation, the interface is the set of operations that preserve the invariants of the objects involved. In other words, the operations guarantee that the object states are all valid.
An API enables you to interact with an encapsulated package of code, just like a door handle enables you to interact with a door. Donald A. Norman uses the term affordance to describe such a relationship.
“The term affordance refers to the relationship between a physical object and a person (or for that matter, any interacting agent, whether animal or human, or even machines and robots). An affordance is a relationship between the properties of an object and the capabilities of the agent that determine just how the object could be possibly be used. A chair affords (“is for”) support and, therefore, affords sitting. Most chairs can also be carried by a single person (they afford lifting), but some can only be lifted by a strong person or by a team of people. If young or relatively weak people cannot lift a chair, then for these people, the chair does not have that affordance, it does not afford lifting.”[71]
I find that this notion translates well to API design. An API like IReservationsRepository in listing 6.5 affords reading reservations related to a certain date, as well as adding a new reservation. You can only call the methods if you can supply the required input arguments. The relationship between client code and an API is akin to the relationship between caller and a properly-encapsulated object. The object only affords its capabilities to client code that fulfils the required preconditions.
As Norman also writes:
“Every day we encounter thousands of objects, many of them new to us. Many of the new objects are similar to ones we already know, but many are unique, yet we manage quite well. How do we do this? Why is it that when we encounter many unusual natural objects, we know how to interact with them? Why is this true with many of the artificial human-made objects we encounter? The answer lies with a few basic principles. Some of the most important of these principles come from a consideration of affordances.”[71]
When you encounter a chair for the first time, it’s clear from the shape how you can use it. Office chairs come with extra capabilities: You can adjust their height, and so on. With some models, you can easily find the appropriate lever, while with other models, this is harder. All the levers look the same, and the one you thought would adjust the height instead adjusts the seat angle.
How does a an API advertise its affordances? When you’re working with a compiled statically typed language, you can use the type system. Development environments can use type information to display the operations available on a given object, as you’re typing, like shown in figure 8.2.
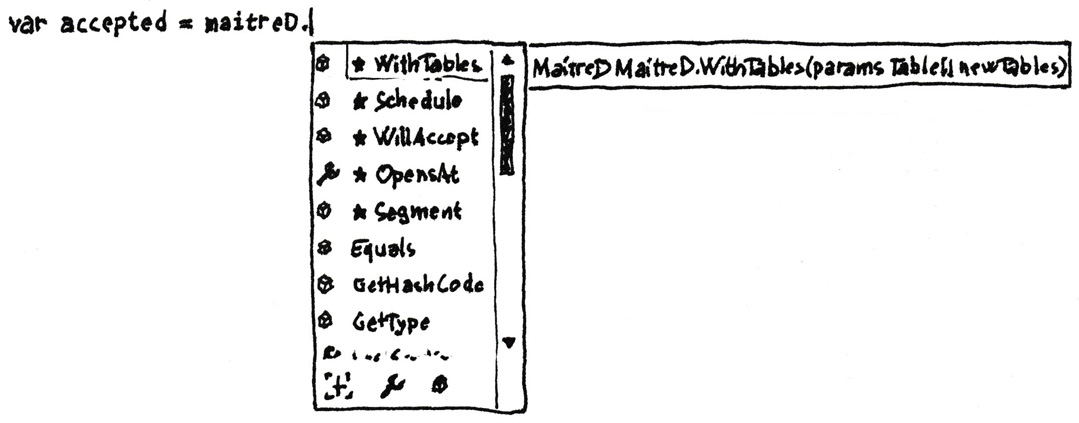
Figure 8.2: An IDE can show available methods on an object as you type. In Visual Studio this is called IntelliSense.
This offers a degree of discoverability called dot-driven development1, because once you type the dot (period) after an object, you’re presented with a selection of methods you can call.
1 I first heard this term in a talk by Phil Trelford at the 2012 GOTO Copenhagen conference. I’ve found no earlier definition of the term.
8.1.2 Poka-yoke
A common error is to design a Swiss Army knife. I’ve met many developers who think that a good API is one that enables as many activities as possible. Like a Swiss Army knife, such an API may collect many capabilities in one place, but none are as fit for their purpose as a specialised tool (figure 8.3). At the end of this design road lies the God Class2.
2 God Class[15] is an antipattern that describes classes with dozens of members implemented in thousands of lines of code in a single file.

Figure 8.3: A Swiss Army knife can be handy in a bind, but is no substitute for proper tools. Figures not to scale.
Good interface design considers not only what’s possible, but also what should be deliberately impossible - the affordances. The members exposed by an API advertise its capabilities, but the operations not supplied communicate what you’re not supposed to do.
Design APIs so that it’s difficult to misuse them. An important concept in lean software development is to build quality in[81] - that is, mistake-proof both your artefacts and processes, instead of waiting until the end to detect and fix defects. In lean manufacturing this is known by the Japanese word poka-yoke, which means mistake-proofing. It translates well to software engineering[1].
Poka-yoke comes in two flavours: active and passive. Active mistake-proofing involves inspecting new artefacts as soon as they come into being. Test-driven development is the prime example[1]. You should run automated tests all the time.
I am, however, particularly enamoured with the notion of passive mistake-proofing. In the physical world you can find many examples of this. Cable connectors like USB and HDMI can only be inserted the correct way. Height restriction barriers, as in figure 8.4, warn drivers that their vehicle is not going to fit. Such systems require no active inspection to work.

Figure 8.4: A height restriction barrier. Light-weight bars hang from chains. A truck too tall for what’s up ahead will first hit these bars, with much noise but little damage.
Likewise, design APIs so that they make illegal states unrepresentable[69]. If a state is invalid, it’s best to design the API so that it’s impossible to express it in code. Capture the absence of a capability in the API’s design, so that something that should be impossible doesn’t even compile3. A compiler error gives you faster feedback than a runtime exception[98].
3 This is trivial to do in programming languages with sum types. These include Haskell and F#. In object-oriented design, the direct equivalent is the more verbose Visitor design pattern[106].
8.1.3 Write for readers
If you recall your school days, you probably remember writing essays. Your teacher insisted that you should consider the context, sender, receiver, and so on. Recall that the sender is the person who ostensibly ‘writes’ the text, and the receiver is the person who reads it. Your teacher instructed you to explicitly consider the relationship between sender and receiver.
I’ve met more than one software developer who recall those days with loathing; who are happy that they are now programmers, literary analysis far behind them.
I’ve got bad news for you.
All this is still relevant in your professional life. There’s a reason schools teach these skills. Sender and receiver matter when you compose an email. That relationship matters when you write documentation. And it matters when you write code.
Code is read more than it’s written.
Write code for future readers. It may be yourself.
8.1.4 Favour well-named code over comments
You’ve probably heard that you should write clean code instead of comments[61]. Comments may deteriorate as the code evolves around them.
What was once a correct comment becomes misleading as time passes. Ultimately, the only artefact you can trust is the code. Not the comments in the code, but the actual instructions and expressions that are compiled to working software. Listing 8.1 shows a typical example.
// Reject reservation if it's outside of opening hours if (candidate.At.TimeOfDay < OpensAt || LastSeating < candidate.At.TimeOfDay) return false;
Listing 8.1: A comment explaining the intent of code. Don’t do that. Replace it with a well-named method, as shown in listing 8.2. (Restaurant/81b3348/Restaurant.RestApi/MaitreD.cs)
If possible, replace the comment with a method with a helpful name[61], as in listing 8.2.
if (IsOutsideOfOpeningHours(candidate)) return false;
Listing 8.2: A method call replaces a comment. Compare with listing 8.1. (Restaurant/f3cd960/Restaurant.RestApi/MaitreD.cs)
Not all comments are bad[61], but favour well-named methods over comments.
8.1.5 X out names
Don’t rest on your laurels, though. Just as comments can grow stale and misleading over time, so can method names. Hopefully you pay more attention to method names than comments, but it still happens that someone changes the implementation of a method, but forgets to update the name.
Fortunately, with a statically typed language, you can use types to keep you honest. Design APIs so that they advertise their contracts with types. Consider the updated version of IReservationsRepository shown in listing 8.3. It has a third method named ReadReservation. It’s a descriptive name, but is it sufficiently self-documenting?
One question I often find myself asking when I explore an unfamiliar API is: should I check the return value for null? How do you communicate that in a durable and consistent way?
public interface IReservationsRepository { Task Create(Reservation reservation); Task<IReadOnlyCollection<Reservation>> ReadReservations( DateTime dateTime); Task<Reservation?> ReadReservation(Guid id); }
Listing 8.3: IReservationsRepository with an additional ReadReservation method compared to listing 6.5. (Restaurant/ee3c786/Restaurant.RestApi/IReservationsRepository.cs)
You could try to communicate with descriptive naming. For example, you might call the method GetReservationOrNull. This works, but is vulnerable to changes in behaviour. You might later decide to change the API design so that null is no longer a valid return value, but forget to change the name.
Notice, however, that with C#’s nullable reference types feature, that information is already included in the method’s type signature4. Its return type is Task<Reservation?>. Recall that the question mark indicates that the Reservation object could be null.
4 If your language doesn’t make the distinction between nullable and non-nullable reference types explicit, you can instead adopt the Maybe concept described on page 129. In that case, the signature of the ReadReservation method would be Task<Maybe<Reservation>> ReadReservation(Guid id).
As an exercise in API design, try to x out the method names and see if you can still figure out what they do:
public interface IReservationsRepository { Task Xxx(Reservation reservation); Task<IReadOnlyCollection<Reservation>> Xxx(DateTime dateTime); Task<Reservation?> Xxx(Guid id); }
What does it look like Task Xxx(Reservation reservation) does? It takes a Reservation object as input, but it doesn’t return anything5. Since there’s no return value, it must perform some sort of side effect. What might it be?
5 Strictly speaking, it returns a Task, but that object contains no additional data. Regard Task as the asynchronous equivalent of void.
It could be that it saves the reservation. It might also conceivably transform it to an email and send it. It could log the information. This is where the defining object comes into play. When you know that the object that defines the method is called IReservationsRepository, the implied context is one of persistence. This enables you to eliminate logging and emailing as alternatives.
Still, it’s not clear whether that method creates a new row in the database, or it updates an existing. It might even do both. It’s also technically possible that it deletes a row, although a better candidate signature for a delete operation would be Task Xxx(Guid id).
What about Task<IReadOnlyCollection<Reservation>> Xxx(DateTime dateTime)? This method takes a date as input and returns a collection of reservations as output. It doesn’t take much imagination to guess that this is a date-based query.
Finally, Task<Reservation?> Xxx(Guid id) takes an id as input, and may or may not return a single reservation. That’s unambiguously an id-based lookup.
This technique works as long as objects afford only few interactions. The example has only three members, and they all have different types. When you combine method signatures with the name of the class or interface, you can often guess what a method does.
Notice, though, how it took more guesswork to reason about the anonymised Create method. Since there’s effectively no return type, you have to reason about its intent based exclusively on the input type. With the queries, you have both input types and output types to hint at the method’s intent.
X’ing out method names can be a useful exercise, because it helps you empathise with future readers of your code. You may think that the method name you just coined is descriptive and helpful, but it may not be to someone with a different context.
Names are still helpful, but you don’t have to repeat what the types already state. This gives you room to tell the reader something he or she can’t divine from the types.
Notice the importance of keeping the tools sharp, so to speak. This is another reason to favour specialised APIs over Swiss Army knifes. When an object only exposes three or four methods, each method tends to have a type distinct from the other methods in that context. When you have dozens of methods on the same object, this is less likely to work well.
The method types are most likely to be helpful when the types alone disambiguate them from each other. If all methods return string or int, their types are less likely to be helpful. That’s another reason to eschew stringly typed[3] APIs.
8.1.6 Command Query Separation
When you X out names the role that static types can play come into focus. Consider a method signature like void Xxx(). This tells you hardly anything about what the method does. All you can say is that it must have some sort of side effect, because it doesn’t return anything, and what other reason for existence could it have?
Clearly, if you give the method a name, it’s easier to guess what it does. It might be void MoveToNextHoliday() or void Repaint(). The possibilities are endless.
With a method structure like void Xxx(), the only way you can communicate with the reader is by choosing a good name. As you add types, you get more design options. Consider a signature like void Xxx(Email x). It’s still not clear exactly what’s being done to the Email argument, but some side effect must be involved. What could it be?
An obvious side effect involving an email is to send it. It’s hardly unambiguous, though. The method might also delete the email.
What’s a side effect? It’s when a procedure changes the state of something. This could be a local effect, like changing the state of an object, or a global effect, like changing the state of the application as a whole. This could include deleting a row from a database, editing a file on disk, repainting a graphical user interface, or sending an email.
The goal of good API design is to factor code so that it fits in our brains. Recall that the purpose of encapsulation is to hide implementation details. Thus, the code that implements a method could make use of local state changes, and you shouldn’t regard those as side effects. Consider the helper method shown in listing 8.4.
This method creates the local variable availableTables, which it then proceeds to modify before returning it. You might think that this counts as a side effect because the state of availableTables changes. On the other hand, the Allocate method doesn’t change the state of the object that defines it, and it returns availableTables as a read-only collection6.
6 IEnumerable<T> is the standard .NET implementation of the Iterator[39] design pattern.
When you write code that calls the Allocate method, all you need to know is that if you supply it a collection of reservations, you receive a collection of tables. As far as you’re concerned, there’s no side effect that you can observe.
private IEnumerable<Table> Allocate( IEnumerable<Reservation> reservations) { List<Table> availableTables = Tables.ToList(); foreach (var r in reservations) { var table = availableTables.Find(t => t.Fits(r.Quantity)); if (table is { }) { availableTables.Remove(table); if (table.IsCommunal) availableTables.Add(table.Reserve(r.Quantity)); } } return availableTables; }
Listing 8.4: A method with local state change, but no observable side effects. (Restaurant/9c134dc/Restaurant.RestApi/MaitreD.cs)
Methods with side effects should return no data. In other words, their return type should be void. That makes it trivial to recognise them. When you see a method that returns no data, you know that its raison d’etre is to carry out a side effect. Such methods are called Commands[67].
To distinguish between procedures with and without side effects, then, methods that do return data should have no side effects. Thus, when you see a method signature like IEnumerable<Table> Allocate(IEnumerable<Reservation> reservations), you ought to realise that it has no side effects because it has a return type. Such methods are called Queries[67]7.
7 Careful: A Query doesn’t have to be a database query, although it can be. The distinction between Commands and Queries was made by Bertrand Meyer in or before 1988[67]. At that time, relational databases weren’t as pervasive as they are now, so the term query didn’t come with as strong an association to database operations as may be the case today.
It’s much easier to reason about APIs if you keep Commands and Queries separate. Don’t return data from methods with side effects, and don’t cause side effects from methods that return data. If you follow that rule, you can distinguish between these two types of functions without having to read the implementation code.
This is known as Command Query Separation (CQS8). As most other techniques in this book, this isn’t something that just happens automatically. The compiler doesn’t need or enforce this rule9, so it’s your responsibility. You could make a checklist out of this rule, if need be.
8 Be careful to not confuse CQS with CQRS (Command Query Responsibility Segregation). This is an architectural style that takes its terminology from CQS (hence the acronym resemblance), but takes the notion much further.
9 Unless the compiler is the Haskell or PureScript compiler.
As you saw in subsection 8.1.5, it’s easier to reason about Queries than it is to reason about Commands, so favour Queries over Commands.
To be clear, it’s trivially technically possible to write a method that both has a side effect and returns data. That’s neither a Command nor a Query. The compiler doesn’t care, but when you follow Command Query Separation, this combination isn’t legal. You can always apply this principle, but it may require some practice before you figure out how to deal with various knotty situations10.
10 The thorniest problem people commonly run into is how to add a row to a database and return the generated ID to the caller. This, too, can be solved with adherence to CQS[94].
8.1.7 Hierarchy of communication
Just as comments can grow stale, so can names. It seems that there’s a generalisable rule:
Don’t say anything with a comment that you can say with a method name. Don’t say anything with a method name you can say with a type.
In priority, from most important to least important:
1. Guide the reader by giving APIs distinct types.
2. Guide the reader by giving methods helpful names.
3. Guide the reader by writing good comments.
4. Guide the reader by providing illustrative examples as automated tests.
5. Guide the reader by writing helpful commit messages in Git.
6. Guide the reader by writing good documentation.
The types are part of the compilation process. If you make a mistake with the types of your API, your code will likely not compile. None of the other alternatives for communicating with the reader has that quality.
Good method names are still part of the code base. You look at those every day. They’re also a good way to communicate your intent to the reader.
There are matters that you can’t easily communicate with good naming. These may include the reason you decide to write the implementation code in a particular way. That’s still a legitimate reason to include a comment[61].
Likewise, there are considerations that relate to a particular change you make to the code. These should be documented as commit messages.
Finally, a few high-level questions are best answered by documentation. These include how to set up the development environment, or the overall mission of the code base. You can document such things in a readme file or another kind of documentation.
Notice that while I don’t dismiss old-fashioned documentation, I consider it the least effective way to communicate with other developers. The code never grows stale. By definition, this is the only artefact that is always current. Everything else (names, comments, documentation) easily stagnates.
8.2 API design example
How do you apply such API design principles to code? What does it look like when used to solve a non-trivial problem? You’ll see an example in this section.
The logic so far implemented in ReservationsController is trivial. Consider listing 7.6. The restaurant has a hard-coded capacity of ten seats. The decision rule doesn’t take into account the size of each party of guests, so the implication is that all guests are seated at the same table. A typical configuration at hipster restaurants is bar-style seating with a view to the kitchen.
The logic in listing 7.6 also doesn’t take into account the time of day of the reservation. The implication is that there’s only a single seating per day.
Granted, I’ve dined at restaurants like that, but they are rare. Most places have more than one table, and they may have second seatings. This is when guests are allotted a given duration to finish their meal. If you’ve made a reservation for 18:30, someone else may have a reservation for your table for 21:00. You have ![]() hours to finish your meal.
hours to finish your meal.
The reservation system should also take opening hours into account. If the restaurant opens at 18:00, a reservation for 17:30 should be rejected. Likewise, the system should reject reservations in the past.
All of that (table configurations, second seatings, and opening hours) should be configurable. These requirements clearly are complex enough that you’ll have to factor the code to stay within the constraints suggested in this book. The cyclomatic complexity should be seven or less, the methods shouldn’t be too big, or involve too many variables.
You’ll need to delegate that business decision to a separate object.
8.2.1 Maître d’
Only two lines of code in listing 7.6 handle the business logic. These two lines of code are repeated in listing 8.5 for clarity.
int reservedSeats = reservations.Sum(r => r.Quantity); if (10 < reservedSeats + r.Quantity)
Listing 8.5: The only two lines of code from listing 7.6 that actually make a business decision. (Restaurant/a0c39e2/Restaurant.RestApi/ReservationsController.cs)
With the new requirements, the decision is going to be significantly more complex. It makes sense to define a Domain Model[33]. What should you call the class? If you want to adopt a ubiquitous language[26] that the domain experts already speak, you could call it maître d’. In formal restaurants, the maître d’hôtel is the head waiter who oversees the guest area of a restaurant (as opposed to the chef de cuisine, who manages the kitchen).
Taking reservations and assigning tables is among a maître d’s responsibilities. Adding a MaitreD class sounds like proper domain-driven design[26].
Contrary to previous chapters, I’ll skip the iterative development to instead show you the results. If you’re interested in the unit tests I wrote, and the small steps I took, they’re all visible as commits in the Git repository that accompanies the book. You can see the MaitreD API I arrived at in listings 8.6 and 8.7. Take a moment to consider them. Which conclusions do you arrive at?
Listings 8.6 and 8.7 only show the publicly visible API. I’ve hidden the implementation code from you. This is the point of encapsulation. You should be able to interact with MaitreD objects without knowing implementation details. Can you?
How does one create a new MaitreD object? If you start typing new MaitreD(, as soon as you type the left bracket, your IDE will display what is needed in order to continue, as shown in figure 8.5. You’ll need to supply opensAt, lastSeating, seatingDuration, and tables arguments. All are required. None can be null.

Figure 8.5: IDE displaying the requirements of a constructor, based on static type information.
public MaitreD( TimeOfDay opensAt, TimeOfDay lastSeating, TimeSpan seatingDuration, IEnumerable<Table> tables)
Listing 8.6: The MaitreD constructor. Another overload that takes a params array also exists. (Restaurant/62f3a56/Restaurant.RestApi/MaitreD.cs)
public bool WillAccept( DateTime now, IEnumerable<Reservation> existingReservations, Reservation candidate)
Listing 8.7: Signature of the WillAccept instance method on MaitreD. (Restaurant/62f3a56/Restaurant.RestApi/MaitreD.cs)
Can you figure out what to do here? What should you put in place of opensAt? A TimeOfDay value is required. This is a custom type created for the purpose, but I hope that I made a good job naming it. If you wonder how to create instances of TimeOfDay, you can look at its public API. The lastSeating parameter works the same way.
Can you figure out what seatingDuration is for? I hope that this, too, is sufficiently self-explanatory.
What do you think the tables parameter is for? You’ve never seen the Table class before, so you’ll have to learn the public API of that class as well. I’m going to skip further exegesis. The point isn’t that I should talk you through the API. The point is to give you a sense for how to reason about an API.
You can put the WillAccept method in listing 8.7 through the same kind of analysis. If I’ve done my job well, it should be clear how to interact with it. If you give it the arguments it requires, it’ll tell you whether it will accept the candidate reservation.
Does the method perform any side effects? It returns a value, so it looks like a Query. According to Command Query Separation, then, it must have no side effects. This is indeed the case. This means that you can call the method without worrying about what’s going to happen. The only thing that’s going to happen is that it’ll use some CPU cycles and return a Boolean value.
8.2.2 Interacting with an encapsulated object
You should be able to interact with a well-designed API without knowing the implementation details. Can you do that with a MaitreD object?
The WillAccept method requires three arguments. Refer to the method signature in listing 8.7. You’ll need a valid instance of the MaitreD class, as well as a DateTime representing now, a collection of existingReservations, and the candidate reservation.
Assuming that the ReservationsController already has a valid MaitreD object, you can replace the two lines of code in listing 8.5 with a single call to WillAccept, as shown in listing 8.8. Despite the increased complexity of the total system, the size and complexity of the Post method remains low. All the new behaviour is in the MaitreD class.
if (!MaitreD.WillAccept(DateTime.Now, reservations, r))
Listing 8.8: You can replace the two lines of business logic shown in listing 8.5 with a single call to WillAccept. (Restaurant/62f3a56/Restaurant.RestApi/ReservationsController.cs)
The Post method of ReservationsController uses DateTime.Now to supply the now argument. It already has a collection of existing reservations from its injected Repository as well as the validated candidate reservation r (see listing 7.6). The conditional expression uses a Boolean negation (!) so that the Post method rejects the reservation when WillAccept returns false.
How is the MaitreD object in listing 8.8 defined? It’s a read-only property initialised via the ReservationsController constructor, shown in listing 8.9.
This looks like Constructor Injection[25], apart from the fact that MaitreD isn’t a polymorphic dependency. Why did I decide to do it that way? Is it a good idea to take a formal dependency on MaitreD? Isn’t it just an implementation detail?
public ReservationsController( IReservationsRepository repository, MaitreD maitreD) { Repository = repository; MaitreD = maitreD; } public IReservationsRepository Repository { get; } public MaitreD MaitreD { get; }
Listing 8.9: ReservationsController constructor. (Restaurant/62f3a56/Restaurant.RestApi/ReservationsController.cs)
Consider the alternative: pass all configuration values one-by-one via ReservationsController’s constructor, as you can see in listing 8.10.
public ReservationsController( IReservationsRepository repository, TimeOfDay opensAt, TimeOfDay lastSeating, TimeSpan seatingDuration, IEnumerable<Table> tables) { Repository = repository; MaitreD = new MaitreD(opensAt, lastSeating, seatingDuration, tables); }
Listing 8.10: ReservationsController constructor with exploded configuration values for MaitreD. Compared to listing 8.9 this doesn’t seem like a better alternative. (Restaurant/0bb8068/Restaurant.RestApi/ReservationsController.cs)
This seems like an odd design. Granted, ReservationsController no longer has an publicly visible dependency on MaitreD, but it’s still there. If you change the constructor of MaitreD, you’ll also have to change the constructor of ReservationsController. The design choice shown in listing 8.9 causes less maintenance overhead, because if you change the MaitreD constructor, you only have to edit the places where the injected MaitreD object is created.
This happens in the Startup class’ ConfigureServices method, as shown in listing 8.11. MaitreD is an immutable class; once created, it can’t change. This is by design. One of the many benefits of such a stateless service is that it’s thread-safe, so that you can register it with Singleton lifetime[25].
var settings = new Settings.RestaurantSettings(); Configuration.Bind("Restaurant", settings); services.AddSingleton(settings.ToMaitreD());
Listing 8.11: Load restaurant settings from the application configuration and register a MaitreD object containing those values. The ToMaitreD method is shown in listing 8.12. (Restaurant/62f3a56/Restaurant.RestApi/Startup.cs)
You can see the ToMaitreD method in listing 8.12. The OpensAt, LastSeating, SeatingDuration, and Tables properties belongs to a RestaurantSettings object with poor encapsulation. Due to the way ASP.NET’s configuration system works, you’re expected to define configuration objects in such a way that they can be populated with values read from a file. In a sense, such objects are like Data Transfer Objects[33] (DTOs).
internal MaitreD ToMaitreD() { return new MaitreD( OpensAt, LastSeating, SeatingDuration, Tables.Select(ts => ts.ToTable())); }
Listing 8.12: The ToMaitreD method converts values read from the application configuration to a MaitreD object. (Restaurant/62f3a56/Restaurant.RestApi/Settings/RestaurantSettings.cs)
Contrary to DTOs that arrive as JSON documents while the service is running, there’s little you can do if parsing of configuration values fails. In that case, the application can’t start. For that reason, the ToMaitreD method doesn’t check the values it passes to the MaitreD constructor. If the values are invalid, the constructor will throw an exception and the application will crash, leaving a log entry on the server.
8.2.3 Implementation details
It’s good to know that you can use a class like MaitreD without knowing all of the implementation details. Sometimes, however, your task involves changing the behaviour of an object. When that’s your task, you’ll need to go a level deeper in the fractal architecture. You’ll have to read the code.
Listing 8.13 shows the WillAccept implementation. It stays within the bounds of humane code. Its cyclomatic complexity is 5, it has twenty lines of code, stays within 80 characters in width, and activates seven objects.
public bool WillAccept( DateTime now, IEnumerable<Reservation> existingReservations, Reservation candidate) { if (existingReservations is null) throw new ArgumentNullException(nameof(existingReservations)); if (candidate is null) throw new ArgumentNullException(nameof(candidate)); if (candidate.At < now) return false; if (IsOutsideOfOpeningHours(candidate)) return false; var seating = new Seating(SeatingDuration, candidate); var relevantReservations = existingReservations.Where(seating.Overlaps); var availableTables = Allocate(relevantReservations); return availableTables.Any(t => t.Fits(candidate.Quantity)); }
Listing 8.13: The WillAccept method. (Restaurant/62f3a56/Restaurant.RestApi/MaitreD.cs)
It’s not the whole implementation. The way to stay within the bounds of code that fits in your brain is to aggressively delegate pieces of the implementation to other parts. Take a moment to look at the code and see if you get the gist of it.
You’ve never seen the Seating class before. You don’t know what the Fits method does. Still, hopefully you can get a sense of where to look next, depending on your motivation for looking at the code. If you need to change the way the method allocates tables, where would you look? If there’s a bug in the seating overlap detection, where do you go next?
You could decide to look at the Allocate method. You’ve already seen it. It’s in listing 8.4. When you look at that code, you can forget about the WillAccept method. Looking at Allocate is another zoom-in operation in the fractal architecture. Remember that what you see is all there is[51]. What you need to know should be right there in the code.
The Allocate method does a good job of that. It activates six objects. Apart from the object property Tables, all are declared and used inside the method. This means that you don’t need to keep in your head any other context that impacts how the method works. It fits in your brain.
It still delegates some of its implementation to other objects. It calls Reserve on table, and the Fits method makes another appearance. If you’re curious about the Fits method, you could go and look at that as well. You can see it in listing 8.14.
internal bool Fits(int quantity) { return quantity <= Seats; }
Listing 8.14: The Fits method. Seats is a read-only int property. (Restaurant/62f3a56/Restaurant.RestApi/Table.cs)
This is not even close to the limits of our brains’ capacity, but it still abstracts two chunks (Seats and quantity) into one. It represents yet another zoom-in operation in the fractal architecture. When you read the source code of Fits, you only need to keep track of Seats and quantity. You don’t have to care about the code that calls the Fits method in order to understand how it works. It fits in your brain.
I haven’t shown you the Reserve method, or the Seating class, but they follow the same design principles. All implementations respect our cognitive constraints. All are Queries. If you’re interested in these implementation details, you can consult the Git repository that accompanies the book.
8.3 Conclusion
Write code for readers. As Martin Fowler put it:
“Any fool can write code that a computer can understand. Good programmers write code that humans can understand.”[34]
Obviously, the code must result in working software, but that’s the low bar. That’s what Fowler means by ‘code that a computer can understand.’ It’s not a sufficiently high bar. For code to be sustainable, you must write it so that humans understand it.
Encapsulation is an important part of this endeavour. It involves designing APIs so that the implementation details are irrelevant. Recall Robert C. Martin’s definition of abstraction:
“Abstraction is the elimination of the irrelevant and the amplification of the essential”[60]
The implementation details should stay irrelevant until you actually need to change them. Thus, design APIs so that they afford reasoning about them from the outside. This chapter covered some fundamental design principles that help push API design in that direction.