
Chapter 8
Software Development Security
This chapter covers the following subjects:
Software Development Concepts: Concepts discussed include software architectures and languages used to implement them.
Security in the System and Software Development Life Cycle: Concepts discussed include the System Development Life Cycle; the Software Development Life Cycle; software development methods and maturity models; operation and maintenance; change management; and the integrated product team.
Security Controls in Development: Concepts discussed include software development security best practices, software environment security, source code issues, source code analysis tools, code repository security, application programming interface security, software threats, and software protection mechanisms.
Assess Software Security Effectiveness: Concepts discussed include auditing and logging, risk analysis and mitigation, and regression and acceptance testing.
Security Impact of Acquired Software: Concepts discussed include the acquired software life cycle and the security impact of acquired software.
Secure Coding Guidelines and Standards: Concepts discussed include security weaknesses and vulnerabilities at the source code level, security of application programming interfaces, and secure coding practices.
Software development security covers all the security issues and controls that security professionals must understand when dealing with commercial or in-house-developed software. They should understand the software development life cycle and be able to assess software security effectiveness and the impact of software.
Software is at the heart of all functionality in computer systems. Various types of software, including operating systems, applications, and utilities, work together to deliver instructions from a human to hardware. All these instructions are created with the intent of making some operation possible.
When software is written and developed, the focus can be placed on its functionality and ease of use or on its security. In many cases, the two goals might work at cross purposes. Giving inadequate attention to the security of a piece of software results in software that can introduce security issues to both the application and the systems on which it is run. Moreover, some types of software are intentionally developed to create security openings in a network or system. This chapter discusses software development methodology, best practices for secure development, and types of malware and methods of mitigating the effects of malware.
Foundation Topics
Software Development Concepts
Software comprises the written instructions that allow humans to communicate with the computer hardware. These instructions are written in various programming languages. As programming has evolved over the years, each successive language has delivered more functionality to programmers. Programming languages can be classified in categories based on the types of instructions they create and to which part of the system they speak. The following sections cover the main categories.
Machine Languages
Machine languages are those that deliver instructions directly to the processor. This was the only type of programming done in the 1950s and uses basic binary instructions without a compiler or interpreter (programs that convert higher language types to a form that can be executed by the processor). This type of programming is both time-consuming and prone to errors. Most of these programs were very rudimentary due to the need to keep a tight rein on their length.
Assembly Languages and Assemblers
Considered to be “one step above” machine languages, assembly languages use symbols or mnemonics to represent sections of complicated binary code. Consequently, these languages use an assembler to convert the code to machine level. Although this tool greatly simplifies and shortens the code, it still requires extensive knowledge of the computer’s architecture. It also means that any code written in these languages will be hardware specific. Although assembly language is simpler to write than machine language, it is not as easy to create as the high-level languages discussed next.
High-Level Languages, Compilers, and Interpreters
In the 1960s, a third level of language emerged, called high-level languages. These instructions use abstract statements (for example, IF–THEN–ELSE) and are processor independent. They are easier to work with, and their syntax is more similar to human language. This code uses either assemblers or compilers to convert the instructions into machine code. The end result is a decrease in the total number of code writers required for a particular project.
A fourth generation of languages, called very-high-level languages, focuses on abstract algorithms that hide some of the complexity from the programmer. These algorithms free programmers to focus on the real-world problems they are trying to solve rather than the details that go on behind the scenes.
Finally, in the 1990s, a fifth generation of languages began to emerge, called natural languages. The goal is to use these languages to create software that can solve problems on its own rather than require a programmer to create code to deal with the problem. Although this goal is not fully realized, using knowledge-based processing and artificial intelligence is worth pursuing.
A significant distinction exists with respect to security between compiled programs and interpreted programs. Because a compiled program has already been translated to binary language (machine code), detecting malicious code inside an application is very difficult. Interpreted code, on the other hand, uses a language interpreter, which is a piece of software that translates high-level code, line-by-line, each time a program is executed (run). In this case, spotting malicious code is somewhat easier because the code is a bit more readable by humans.
Object-Oriented Programming
In classic software development, data is input into a program, the program manages the data from beginning to end, and a result is returned. Object-oriented programming (OOP) supplies the same functionality, but it is more efficiently introduced through different techniques. In OOP, objects are organized in a hierarchy of classes with characteristics called attributes attached to each class. OOP emphasizes the employment of objects and methods rather than types or transformations.
The programmer creates the classes of objects but not necessarily the objects themselves. Software in the program allows for objects to be created on demand when needed through requests. When a request comes in, usually from an existing object for a new object to carry out some function, it is built (instantiated) with necessary code. It does not matter whether objects are written in a different programming language as long as the objects have the ability to communicate with one another, a process usually made possible through an application programming interface (API).
Moreover, because objects are organized in hierarchical classes, object methods (functionalities or procedures) can be passed from a class to a subclass through a process called inheritance. The objects contain or encapsulate attribute values. Objects communicate with messages sent to another object’s API. Different objects might react differently to the same message, which is called the object’s behavior. The code that defines how an object will behave with respect to a message is called its method.
Some parts of an object can be defined as private, which means its internal data and operation are not visible to other objects. This privacy is provided through the encapsulation process and is sometimes called data hiding. Abstraction is the ability to suppress these unnecessary internal details. Other objects, subjects, and applications can make use of objects’ functionality through standardized interfaces without worrying about the details of the functionality.
OOP uses data types with defined ranges. Programmers must identify all data objects and their relationships through a process called data modeling. The object is then generalized into an object class and is defined as part of a logic sequence, also called a method, used to manipulate the object. An object can be used in different applications.
Examples of OOP languages are C++, Java, Simula 67, and Smalltalk. The many advantages to this OOP include
Modularity in design through autonomous objects
Definition of internal components without impacting other parts of the system
Reusability of components
The capability to more readily map to business needs
Polymorphism
In an object-oriented system, polymorphism denotes objects of many different classes that are related by some common superclass; thus, any object denoted by this name can respond to some common set of operations in a different way. Polymorphism is the ability of different objects with a common name to react to the same message or input and produce a different output. For example, three objects can be created to receive the string “Toyota Corolla” as input. One object’s output might be “subcompact”, another’s might be “uses regular fuel”, and another’s might be “costs $18,000”. In some cases, these differences derive from the fact that the objects have inherited different characteristics from their parent classes.
Polyinstantiation
Polyinstantiation prevents low-level objects from gaining information from a higher security level. Objects may act differently depending on the data they contain. For this reason, it may be difficult to determine whether inherited security properties are valid. Polyinstantiation prevents inference database attacks.
Encapsulation
Encapsulation protects objects by preventing direct access to data that is in the object. It ensures that private data is protected. However, encapsulation makes it hard to apply the appropriate security policies to an object because it is hard to determine what the object contains.
Cohesion
Cohesion is a term used to describe program organization. It is the degree to which elements of a module are related functionally. If it is limited to a small number or a single function, it is said to have high cohesion. High cohesion is good in that changes can be made to the model without affecting other modules. It also makes reusing the module easier. The highest cohesion is provided by limiting the scope of a module’s operation.
Coupling
Coupling describes how much interaction one module requires from another module to function the overall programming function. Low or loose coupling indicates that a module does not need much help from other modules, whereas high coupling indicates the opposite. If Module A needs to wait on results from messages it sent to three other modules before it can proceed, it is said to have high coupling. Low coupling, in other words, indicates how independent a class is from other classes. The best programming provides high cohesion and low coupling.
Data Structures
Data structure refers to the logical relationship between elements of data. It describes the extent to which elements, methods of access, and processing alternatives are associated and the organization of data elements. These relationships can be simple or complex. From a security standpoint, these relationships or the way in which various software components communicate and the data formats that they use must be well understood to understand the vulnerabilities that might be exposed by these data structures.
Distributed Object-Oriented Systems
When an application operates in a client/server framework, as many do, the solution is performing distributed computing. This means that components on different systems must be able to both locate each other and communicate on a network. Typically, the bulk of the solution is on the server, and a smaller piece is located on the client. Therefore, some architecture is required to support this process-to-process communication. Several distributed object-oriented systems can be used, as discussed in the next sections.
CORBA
Common Object Request Broker Architecture (CORBA) is an open object-oriented standard developed by the Object Management Group (OMG). This standard uses a component called the Object Request Broker (ORB) to implement exchanges among objects in a heterogeneous, distributed environment.
The ORB manages all communication between components. It accepts requests for service from the client application, directs the request to the server, and then relays the response back to the client application. The ORB makes communication possible locally or remotely. This communication is even possible between components that are written in different languages because they use a standard interface to communicate with the ORB.
The ORB is responsible for enforcing the security policy, which describes what the users and system are allowed to do and what actions are restricted. It provides four types of policies: access control, data protection, nonrepudiation, and auditing.
COM and DCOM
Component Object Model (COM) is a model for communication between processes on the same computer, whereas, as its name implies, the Distributed Component Object Model (DCOM) is a model for communication between processes in different parts of the network. DCOM works as the middleware between these remote processes (called interprocess communication [IPC]).
DCOM provides the same services as those provided by the ORB in the CORBA framework—that is, data connectivity, message service, and distributed transaction service. All of these functions are integrated into one technology that uses the same interface as COM.
OLE
Object Linking and Embedding (OLE) is a method for sharing objects on a local computer that uses COM (Component Object Model) as its foundation. In fact, OLE is sometimes described as the predecessor of COM. It allows objects to be embedded in documents (spreadsheets, graphics, and so on). The term linking refers to the relationship between one program and another, and the term embedding refers to the placement of data into a foreign program or document. One example of OLE is including an Excel worksheet in a Microsoft Word document.
Java
Java Platform, Enterprise Edition (Java EE), is another distributed component model that relies on the Java programming language. It is a framework used to develop software that provides APIs for networking services and uses an interprocess communication process that is based on Common Object Request Broker Architecture (CORBA). Its goal is to provide a standardized method of providing back-end code that carries out business logic for enterprise applications.
SOA
A newer approach to providing a distributed computing model is the service-oriented architecture (SOA). It operates on the theory of providing web-based communication functionality without each application requiring redundant code to be written per application. It uses standardized interfaces and components called service brokers to facilitate communication among web-based applications.
Mobile Code
Mobile code is a type of code that can be transferred across a network and then executed on a remote system or device. The security concerns with mobile code revolve around preventing the execution of malicious code without the knowledge of the user. The following sections cover the two main types of mobile code, Java applets and ActiveX applets, and the way they operate.
Java Applets
A Java applet is a small application written in Java that is run from a web page. It is platform independent and compiles to bytecode that is not processor-specific. When the applet downloads to the computer, the Java virtual machine (JVM), which must be present on the destination computer, converts the byte code to machine code.
The JVM executes the applet in a protected environment called a sandbox. This critical security feature, called the Java Security Model (JSM), helps mitigate the extent of damage that could be caused by the applet if it has any malicious code. However, it does not eliminate the problem with hostile applets (also called active content modules), so Java applets should still be regarded with suspicion because they might launch an intentional attack after being downloaded from the Internet. Java applets have largely been phased out.
ActiveX
ActiveX is a Microsoft technology that uses OOP (object-oriented programming) and is based on the COM and DCOM. These self-sufficient programs, called controls, become a part of the operating system after they’re downloaded. The problem is that these controls execute under the security context of the current user, which in many cases has administrator rights without knowing and by default. This means that a malicious ActiveX control will download and automatically run with administrative privileges and could do some serious damage.
ActiveX uses Authenticode technology to digitally sign the controls. This system has been shown to have significant flaws, and ActiveX controls are generally regarded with more suspicion than Java applets. ActiveX is being phased out and is not supported by Microsoft’s Edge web browser.
NIST SP 800-163
NIST SP 800-163 Rev. 1, “Vetting the Security of Mobile Applications,” was written to help organizations (1) understand the process for vetting the security of mobile applications, (2) plan for the implementation of an application (app) vetting process, (3) develop app security requirements, (4) understand the types of app vulnerabilities and the testing methods used to detect those vulnerabilities, and (5) determine whether an app is acceptable for deployment on the organization’s mobile devices.
To provide software assurance for apps, organizations should develop security requirements that specify, for example, how data used by an app should be secured, the environment in which an app will be deployed, and the acceptable level of risk for an app. To help ensure that an app conforms to such requirements, a process for evaluating the security of apps should be performed. This process is referred to as an app vetting process. An app vetting process is a sequence of activities that aims to determine whether an app conforms to the organization’s security requirements. This process is performed on an app after the app has been developed and released for distribution but prior to its deployment on an organization’s mobile device. Thus, an app vetting process is distinguished from software assurance processes that may occur during the software development life cycle of an app. Note that an app vetting process typically involves analysis of an app’s compiled, binary representation but can also involve analysis of the app’s source code if it is available.
An app vetting process comprises a sequence of two main activities: app testing and app approval/rejection.
According to NIST SP 800-163 Rev. 1, an app vetting process begins when an app is submitted by a mobile device administrator to one or more analyzers for testing. Apps that are submitted by an administrator for testing will typically be acquired from an app store or an app developer, each of which may be internal or external to the organization. An analyzer is a service, tool, or human that tests an app for specific software vulnerabilities and may be internal or external to the organization. After an app has been received and preprocessed by an analyzer, the analyzer then tests the app for the presence of software vulnerabilities. Such testing may include a wide variety of tests including static and dynamic analyses and may be performed in an automated or manual fashion. Note that the tests performed by an analyzer are aimed at identifying software vulnerabilities that may be common across different apps. After testing an app, an analyzer generates a report that identifies detected software vulnerabilities. In addition, the analyzer generates a risk assessment that estimates the likelihood that a detected vulnerability will be exploited and the impact that the detected vulnerability may have on the app or its related device or network. Risk assessments are typically represented as ordinal values indicating the severity of the risk (for example, low-, moderate-, and high-risk).
After the report and risk assessment are generated by an analyzer, they are made available to one or more auditors of the organization. The auditor inspects reports and risk assessments from one or more analyzers to ensure that an app meets the security requirements of the organization. The auditor also evaluates additional criteria to determine whether the app violates any organization-specific security requirements that could not be ascertained by the analyzers. After evaluating all reports, risk assessments, and additional criteria, the auditor then collates this information into a single report and risk assessment and derives a recommendation for approving or rejecting the app based on the overall security posture of the app. This recommendation is then made available to an approver. An approver uses the recommendations provided by one or more auditors that describe the security posture of the app as well as other non-security-related criteria to determine the organization’s official approval or rejection of an app. If an app is approved it is then permitted to deploy the app on the organization’s mobile devices. If, however, the app is rejected, the organization will follow specified procedures for identifying a suitable alternative app or rectifying issues with the problematic app.
According to NIST SP 800-163 Rev. 1, before an organization can implement an app vetting process, it is necessary for the organization to (1) develop app security requirements, (2) understand the limitations of app vetting, and (3) procure a budget and staff for supporting the app vetting process.
A general requirement is an app security requirement that specifies a software characteristic or behavior that an app should exhibit to be considered secure. General app security requirements include
Enabling authorized functionality: The app must work as described; all buttons, menu items, and other interfaces must work. Error conditions must be handled gracefully, such as when a service or function is unavailable (for example, disabled, unreachable, and so on).
Preventing unauthorized functionality: Unauthorized functionality, such as data exfiltration performed by malware, must not be supported.
Limiting permissions: Apps should have only the minimum permissions necessary and should grant other applications only the necessary permissions.
Protecting sensitive data: Apps that collect, store, and transmit sensitive data should protect the confidentiality and integrity of sensitive data. This category includes preserving privacy, such as asking permission to use personal information and using it only for authorized purposes.
Securing app code dependencies: If the app has any dependencies, such as on libraries, they should be used in a reasonable manner and not for malicious purposes.
Testing app updates: New versions of the app must also be tested to identify any new weaknesses. The implication is that when an existing app is updated, the updated app is not automatically approved.
A context-sensitive requirement is an app security requirement that specifies how the organization should use apps to ensure that organization’s security posture. For an app, the satisfaction or violation of context-sensitive requirements cannot be determined by analyzers but instead must be determined by an auditor using organization-specific vetting criteria. Such criteria include
Requirements: The pertinent requirements, security policies, privacy policies, acceptable use policies, and social media guidelines that are applicable to the organization.
Provenance: The identity of the developer, the developer’s organization, the developer’s reputation, date received, marketplace/app store consumer reviews, and so on.
Data sensitivity: The relative sensitivity of the data collected, stored, and/or transmitted by the app.
App criticality: How critical the app is to the organization’s business processes.
Target users: The intended set of users of the app.
Target hardware: The intended hardware platform and configuration on which the app will be deployed.
Target environment: The intended operational environment of the app (e.g., general public use versus sensitive military environment).
Digital signature: Digital signatures applied to the app binaries or packages.
App documentation:
User guide: When available, the app’s user guide assists testing by specifying the expected functionality and expected behaviors. This guide is simply a statement from the developer describing what they claim their app does and how it does it.
Test plans: Reviewing the developer’s test plans may help focus app vetting by identifying any areas that have not been tested or were tested inadequately. A developer could opt to submit a test oracle in certain situations to demonstrate its internal test effort.
Testing results: Code review results and other testing results will indicate which security standards were followed. For example, if an application threat model was created, this model should be submitted. It will list weaknesses that were identified and should have been addressed during design and coding of the app.
Service-level agreement: If an app was developed for an organization by a third party, a service-level agreement (SLA) may have been included as part of the vendor contract. This contract should require the app to be compatible with the organization’s security policy.
Security in the System and Software Development Life Cycle
When writing code for new software, developers must ensure that the appropriate security controls are implemented and that the code is properly secured. The following sections cover the System Development Life Cycle; the Software Development Life Cycle; software development methods and maturity models; operation and maintenance; change management; and the integrated product team.
System Development Life Cycle
When an organization defines new functionality that must be provided either to its customers or internally, it must create systems to deliver that functionality. Many decisions have to be made, and a logical process should be followed in making those decisions. This process is called the System Development Life Cycle (SDLC). Rather than being a haphazard approach, the SDLC provides clear and logical steps to follow to ensure that the system that emerges at the end of the development process provides the intended functionality with an acceptable level of security.
SP 800-37 Rev. 2, “Risk Management Framework for Information Systems and Organizations: A System Life Cycle Approach for Security and Privacy” is an important publication for security professionals to review. This paper provides guidance on managing security and privacy risk as it relates to the SDLC.
The System Development Life Cycle includes the following phases:

Initiate
Acquire/Develop
Implement
Operate/Maintain
Dispose
Next, we explain these five phases in the SDLC.
Initiate
In the Initiate phase, the realization is made that a new feature or functionality is desired or required in an existing piece of software. This new feature might constitute an upgrade to an existing product or the development of a whole new piece of software. In either case, the Initiate phase includes making a decision on whether to purchase or develop the product internally.
In this stage, an organization must also give thought to the security requirements of the solution. A preliminary risk assessment can be created to detail the confidentiality, integrity, and availability (CIA) requirements and concerns. Identifying these issues at the outset is important so these considerations can guide the purchase or development of the solution. The earlier in the System Development Life Cycle that the security requirements are identified, the more likely that the issues can be successfully addressed in the final product.
Acquire/Develop
In the Acquire/Develop stage of the System Development Life Cycle, a series of activities take place that provide input to facilitate making a decision about acquiring or developing the solution; the organization then makes a decision on the solution. The activities are designed to get answers to the following questions:
What functions does the system need to perform?
What are the potential risks to CIA exposed by the solution?
What protection levels must be provided to satisfy legal and regulatory requirements?
What tests are required to ensure that security concerns have been mitigated?
How do various third-party solutions address these concerns?
How do the security controls required by the solution affect other parts of the company security policy?
What metrics will be used to evaluate the success of the security controls?
The answers to these questions should guide the acquisition or develop the decision as well as the steps that follow this stage of the System Development Life Cycle.
Implement
In the Implement stage, the solution is introduced to the live environment but not without its completing both certification and accreditation. Certification is the process of technically verifying the solution’s effectiveness and security. The accreditation process involves a formal authorization to introduce the solution into the production environment by management.
Operate/Maintain
After the system is operating in the environment, the process does not end. Doing a performance baseline is important so that continuous monitoring can take place. The baseline ensures that performance issues can be quickly determined. Any changes over time (addition of new features, patches to the solution, and so on) should be closely monitored with respect to the effects on the baseline.
Instituting a formal change management process ensures that all changes are both approved and documented. Because changes can affect both security and performance, special attention should be given to monitoring the solution after any changes.
Finally, vulnerability assessments and penetration testing after the solution is implemented can help discover any security or performance problems that might either be introduced by a change or arise as a result of a new threat.
Dispose
The Dispose stage consists of removing the solution from the environment when it reaches the end of its usefulness. When this situation occurs, an organization must consider certain issues. They include
Does removal or replacement of the solution introduce any security holes in the network?
How can the system be terminated in an orderly fashion so as not to disrupt business continuity?
How should any residual data left on any systems be removed?
How should any physical systems that were a part of the solution be disposed of safely?
Are there any legal or regulatory issues that would guide the destruction of data?
Software Development Life Cycle
The Software Development Life Cycle (SDLC) can be seen as a subset of the System Development Life Cycle in that any system under development could (but does not necessarily) include the development of software to support the solution. The goal of the SDLC is to provide a predictable framework of procedures designed to identify all requirements with regard to functionality, cost, reliability, and delivery schedule and ensure that each is met in the final solution. Here, we break down the steps in the Software Development Life Cycle and describe how each step contributes to this ultimate goal. Keep in mind that steps in the Software Development Life Cycle can vary based on the provider, and this is but one popular example.
The following sections outline the SDLC steps in detail:
Plan/Initiate Project
Gather Requirements
Design
Develop
Test/Validate
Release/Maintain
Certify/Accredit
Change Management and Configuration Management/Replacement
Plan/Initiate Project
In the Plan/Initiate Project phase of the Software Development Life Cycle, the organization decides to initiate a new software development project and formally plans the project. Security professionals should be involved in this phase to determine whether information involved in the project requires protection and whether the application needs to be safeguarded separately from the data it processes. Security professionals need to analyze the expected results of the new application to determine whether the resultant data has a higher value to the organization and, therefore, requires higher protection.
Any information that is handled by the application needs a value assigned by its owner, and any special regulatory or compliance requirements need to be documented. For example, healthcare information is regulated by several federal laws and must be protected. The classification of all input and output data of the application needs to be documented, and the appropriate application controls should be documented to ensure that the input and output data are protected.
Data transmission must also be analyzed to determine the types of networks used. All data sources must also be analyzed. Finally, the effects of the application on organizational operations and culture need to be analyzed.
Gather Requirements
In the Gather Requirements phase of the Software Development Life Cycle, both the functionality and the security requirements of the solution are identified. These requirements could be derived from a variety of sources, such as evaluating competitor products for a commercial product or surveying the needs of users for an internal solution. In some cases, these requirements could come from a direct request from a current customer. There are also user requirements, functional requirements, and security requirements.
From a security perspective, an organization must identify potential vulnerabilities and threats. When this assessment is performed, the intended purpose of the software and the expected environment must be considered. Moreover, the data that will be generated or handled by the solution must be assessed for its sensitivity. Assigning a privacy impact rating to the data to help guide measures intended to protect the data from exposure might be useful.
Design
In the Design phase of the Software Development Life Cycle, an organization develops a detailed description of how the software will satisfy all functional and security goals. It attempts to map the internal behavior and operations of the software to specific requirements to identify any requirements that have not been met prior to implementation and testing.
During this process, the state of the application is determined in every phase of its activities. The state of the application refers to its functional and security posture during each operation it performs. Therefore all possible operations must be identified. This is done to ensure that at no time does the software enter an insecure state or act in an unpredictable way.
Identifying the attack surface is also a part of this analysis. The attack surface describes what is available to be leveraged by an attacker. The amount of attack surface might change at various states of the application, but at no time should the attack surface provided violate the security needs identified in the Gather Requirements stage.
Develop
The Develop phase involves writing the code or instructions that make the software work. The emphasis of this phase is strict adherence to secure coding practices. Some models that can help promote secure coding are covered later in this chapter, in the section “Software Development Security Best Practices.”
Many security issues with software are created through insecure coding practices, such as lack of input validation or data type checks. Organizations need to identify these issues in a code review that attempts to assume all possible attack scenarios and their impact on the code. Not identifying these issues can lead to attacks such as buffer overflows and injection and to other error conditions, which are covered later in this chapter, in the section “Security Weaknesses and Vulnerabilities at the Source Code Level.”
Test/Validate
In the Test/Validate phase, several types of testing should occur, including ways to identify both functional errors and security issues. The auditing method that assesses the extent of the system testing and identifies specific program logic that has not been tested is called the test data method. This method tests not only expected or valid input but also invalid and unexpected values to assess the behavior of the software in both instances. An active attempt should be made to attack the software, including attempts at buffer overflows and denial-of-service (DoS) attacks. Some goals of testing performed at this time are
Verification testing: Determines whether the original design specifications have been met.
Validation testing: Takes a higher-level view and determines whether the original purpose of the software has been achieved.
Software is typically developed in pieces or modules of code that are later assembled to produce the final product. Each module should be tested separately, in a procedure called unit testing. Having development staff carry out this testing is critical, but using a different group of engineers than the ones who wrote the code can ensure that an impartial process occurs. This is a good example of the concept of separation of duties.
The following should be characteristics of the unit testing:
The test data is part of the specifications.
Testing should check for out-of-range values and out-of-bounds conditions.
Correct test output results should be developed and known beforehand.
Live or actual field data is not recommended for use in the unit testing procedures.
Additional testing that is recommended includes
Integration testing: Assesses the way in which the modules work together and determines whether functional and security specifications have been met.
Acceptance testing: Ensures that the customer (either internal or external) is satisfied with the functionality of the software.
Regression testing: Takes place after changes are made to the code to ensure the changes have reduced neither functionality nor security.
Release/Maintenance
The Release/Maintenance phase includes the implementation of the software into the live environment and the continued monitoring of its operation. Finding additional functional and security problems at this point, as the software begins to interface with other elements of the network, is not unusual.
In many cases, vulnerabilities are discovered in the live environments for which no current fix or patch exists. Such a vulnerability is referred to as a zero-day vulnerability. It is, of course, better for an organization to have supporting development staff discover these issues than to have people who are looking to exploit vulnerabilities find them.
Certify/Accredit
Certification is the process of evaluating software or a system for its security effectiveness with regard to the customer’s needs. Ratings can certainly be an input to this but are not the only consideration. Accreditation is the formal acceptance of the adequacy of a system’s overall security by the management. Provisional accreditation is given for a specific amount of time and lists required changes to applications, systems, or accreditation documentation. Full accreditation grants accreditation without any required changes. Provisional accreditation becomes full accreditation after all the changes are completed, analyzed, and approved by the certifying body.
Although certification and accreditation are related, they are not considered to be two steps in a process.
Change Management and Configuration Management/Replacement
After a solution is deployed in a live production environment, additional changes inevitably must be made to the software due to security issues. In some cases, the software might have to be altered to enhance or increase its functionality. In either case, changes must be handled through a formal change and configuration management process.
The purpose of this process is to ensure that all changes to the configuration of the source code and the source code itself are approved by the proper personnel and are implemented in a safe and logical manner. This process should always ensure continued functionality in the live environment, and changes should be documented fully, including all changes to hardware and software.
In some cases, it may be necessary to completely replace applications or systems. Although some failures may be fixed with enhancements or changes, a failure may occur that can be solved only by completely replacing the application.
DevSecOps
DevSecOps is short for development, security, operations, which is a methodology that focuses on integrating security during each stage of the Software Development Life Cycle. Prior to DevSecOps, security was added in the latter stages of the development life cycle. When security is integrated at all stages, it becomes a shared responsibility for developers, operations, and IT security. Ultimately, the goal is to deliver more secure code faster.
Static Application Security Testing (SAST) and Dynamic Application Security Testing (DAST)
Application testing is a critical part of software development, with the goal of identifying security vulnerabilities. As you have just learned from DevSecOps, security testing should be integrated in every phase of the development life cycle, which means that application security testing should begin early in application development.
Static Application Security Testing (SAST), also referred to as white-box testing, is the analysis of code at rest. This type of security testing goes through the code line-by-line to identify security vulnerabilities. Unlike SAST, DAST does not have access to the source code during security testing.
Dynamic Application Security Testing (DAST), also referred to as black-box testing, refers to application testing by simulating attacks on the application while the application is running. DAST is often associated with web application vulnerability scanning. Much of this testing checks for vulnerabilities that have been publicized by organizations such as OWASP (Open Web Application Security Project) and CISA (Cybersecurity & Infrastructure Security Agency). An example of an application vulnerability that DAST may identify is SQL injection. Again, the goal is to identify security vulnerabilities that may be related to application configuration or authentication protocols.
DAST can occur when the application is in production, but more commonly this security testing takes place during the quality assurance phase of development.
Security Orchestration and Automated Response (SOAR)
Security Orchestration and Automated Response (SOAR) integrates a series of different security tools to collect data and security alerts and bring all of that information into one platform, which is referred to as security orchestration. These security tools (or applications) can include firewalls and intrusion detection systems.
The second part of SOAR refers to the automated response to security incidents. SOAR benefits both a security operations center (SOC) and incident response (IR) by producing a faster response than a person or a team can produce through automation. Furthermore, a SOC and IR face continuous challenges with hiring and maintaining skilled staff; therefore, SOAR can alleviate the demands of these functional areas. SOAR can automate threat intelligence, malware analysis, vulnerability management, and responses to phishing attacks, to name but a few. Machine learning (ML) can benefit incident response by learning from historical data and providing an automated response to security threats.
SOAR can also be beneficial to organizations by providing a comprehensive dashboard of security threats and generating reports for various organizational stakeholders.
Software Development Methods and Maturity Models
In the course of creating software in the past, developers learned many things about the development process. As development projects have grown from a single developer to small teams to now large development teams working on massive projects with many modules that must securely interact, development models have been created to increase the efficiency and success of these projects. A new “lessons learned” phase has been incorporated into these models and methods. The following sections cover some of the common models, along with concepts and practices that must be understood to implement them.
Next, we discuss the following software development methods and maturity models:
Build and Fix Model
Waterfall Model
V-shaped Model
Prototype Model
Modified Prototype Model
Incremental Model
Spiral Model
Agile Model
Continuous Integration and Continuous Delivery (CI/CD)
Rapid Application Development (RAD) Model
Joint Analysis Development (JAD) Model
Cleanroom Model
Structured Programming Development Model
Exploratory Model
Computer-Aided Software Engineering (CASE) Model
Component-Based Development Model
CMMI
ISO 9001:2015/90003:2014
IDEAL Model
Build and Fix Model
Although it’s not a formal model, the Build and Fix approach describes a method that, while certainly used in the past, has been largely discredited and is now used as a template for how not to manage a development project. Simply put, in this method, the software is developed as quickly as possible and released.
No formal control mechanisms are used to provide feedback during the process. The product is rushed to market, and problems are fixed on an as-discovered basis with patches and service packs. Although this approach gets the product to market faster and cheaper, in the long run the costs involved in addressing problems and the collateral damage to the product in the marketplace outweigh any initial cost savings.
Despite the fact that this model still seems to be in use today, most successful developers have learned to implement one of the other models discussed here so that the initial product, though not necessarily perfect, comes much closer to meeting all the functional and security requirements of the design. Moreover, using these models helps to identify and eliminate as many bugs as possible without using the customer as “quality control.”
In this simplistic model of the software development process, certain unrealistic assumptions are made, including
Each step of development can be completed and finalized without affecting later stages that might require rework.
Iteration (reworking and repeating) among the steps in the process that is typically called for in other models is not stressed in this model.
Phases are not seen as individual milestones as in some other models discussed here.
Waterfall Model
The original Waterfall model breaks the development process into distinct phases. Although this model uses somewhat of a rigid approach, the basic process is as a sequential series of steps that are followed without going back to earlier steps. This approach is called incremental development. Figure 8-1 is a representation of the Waterfall process.
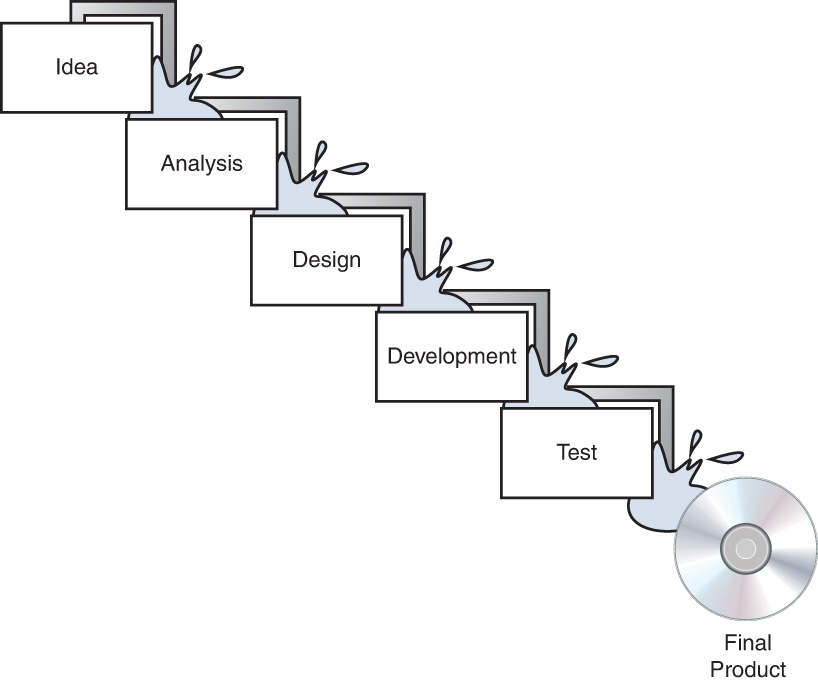
Figure 8-1 Waterfall Model
In the modified Waterfall model, each phase in the development process is considered its own milestone in the project management process. Unlimited backward iteration (returning to earlier stages to address problems) is not allowed in this model. However, product verification and validation are performed in this model. Problems that are discovered during the project do not initiate a return to earlier stages but rather are dealt with after the project is complete.
V-Shaped Model
The V-shaped model is also somewhat rigid but differs primarily from the Waterfall method in that verification and validation are performed at each step. Although this model can work when all requirements are well understood up front (frequently not the case) and potential scope changes are small, it does not provide for handling events concurrently because it is also a sequential process like the Waterfall. It does build in a higher likelihood of success because it performs testing at every stage. Figure 8-2 is a representation of this process.
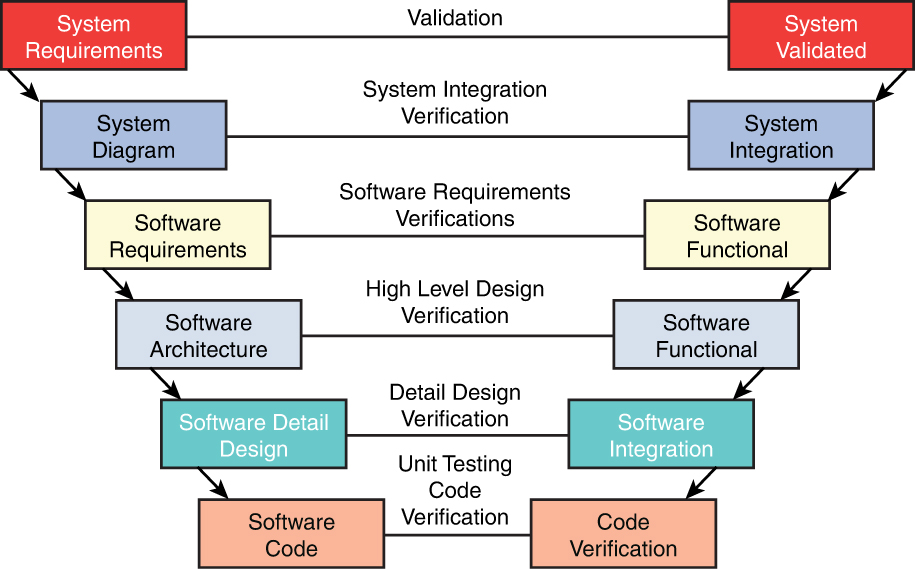
Figure 8-2 V-Shaped Model
Prototyping
Although it’s not a formal model unto itself, prototyping is the use of a sample of code to explore a specific approach to solving a problem before extensive time and cost have been invested in the approach. This technique allows the team to both identify the utility of the sample code and identify design problems with the approach. Prototype systems can provide significant time and cost savings because the whole final product does not have to be made to begin testing it.
Modified Prototype Model (MPM)
MPM is a prototyping method that is used with minimal requirements. The client provides feedback, and then a fully functioning prototype is developed and used as the basis for the final product.
Incremental Model
The Incremental model is a refinement to the basic Waterfall model, which states that software should be developed in increments of functional capability. In this model, a working version or iteration of the solution is produced, tested, and redone until the final product is completed. You could think of it as a series of waterfalls. After each iteration or version of the software is completed, testing occurs to identify gaps in functionality and security from the original design. Then the gaps are addressed by proceeding through the same analysis, design, code, and test stages again. When the product is deemed to be acceptable with respect to the original design, it is released. Figure 8-3 is a representation of this process.
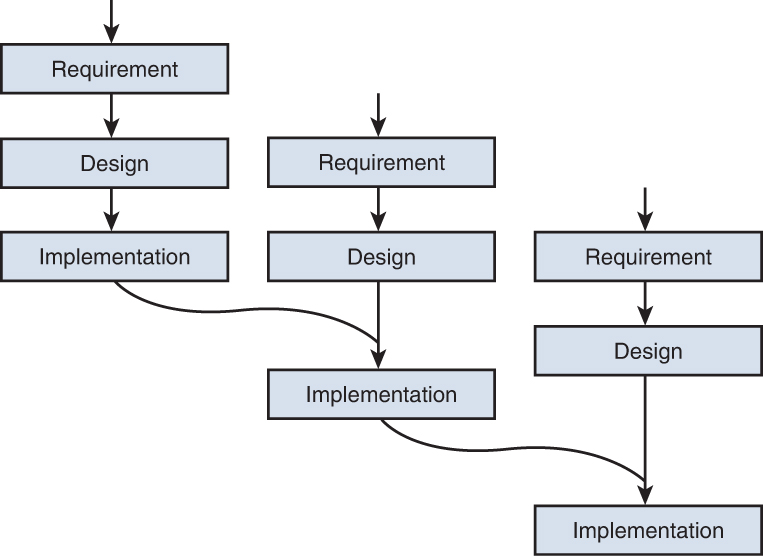
Figure 8-3 Incremental Model
Spiral Model
The Spiral model is actually a meta-model that incorporates a number of the software development models. It is also an iterative approach but places more emphasis on risk analysis at each stage. Prototypes are produced at each stage, and the process can be seen as a loop that keeps circling back to take a critical look at risks that have been addressed while still allowing visibility into new risks that might have been created in the last iteration.
This model assumes that knowledge will be gained at each iteration and should be incorporated into the design as it evolves. Some cases even involve the customer making comments and observations at each iteration. Figure 8-4 is a representation of this process. The radial dimension of the diagram represents cumulative cost, and the angular dimension represents progress made in completing each cycle.
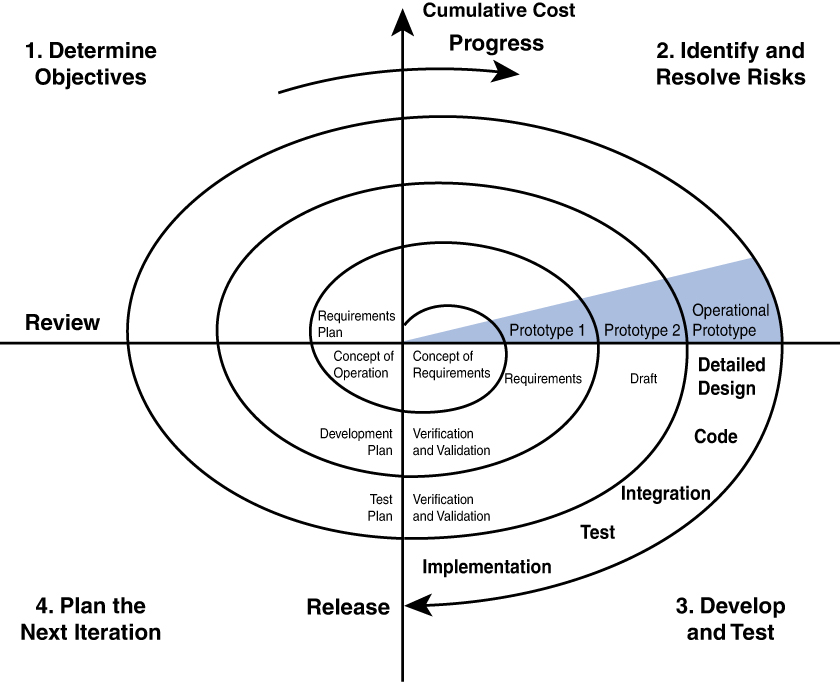
Figure 8-4 Spiral Model
Agile Model
Many of the processes or models discussed thus far rely on rigid adherence to process-oriented models. In many cases, the focus is more on following procedural steps than on reacting to changes quickly and increasing efficiency. The Agile model puts more emphasis on continuous feedback and cross-functional teamwork.
This model attempts to be nimble enough to react to situations that arise during development. Less time is spent on the upfront analysis and more emphasis is placed on learning from the process and incorporating lessons learned in real time. There is also regular and active interaction with the customer throughout the process. Figure 8-5 compares the Agile model with the Waterfall model.
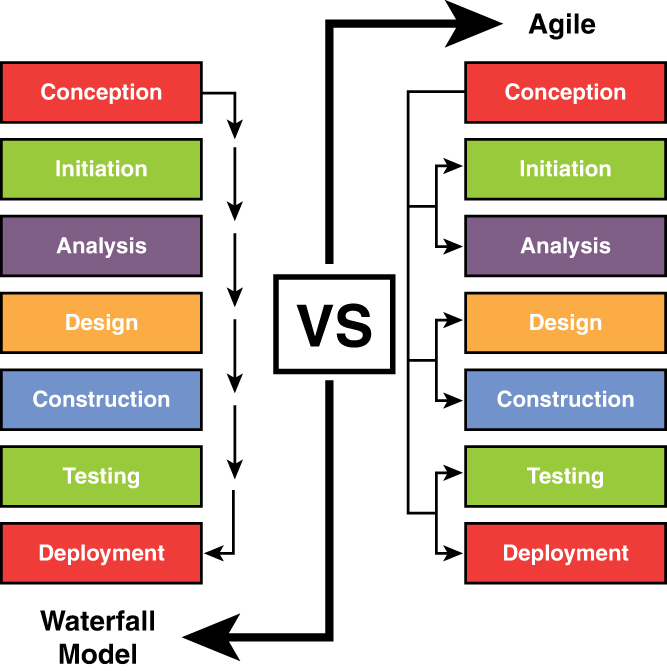
Figure 8-5 Agile and Waterfall Model Comparison
Continuous Integration and Continuous Delivery (CI/CD)
Continuous integration (CI) refers to the process of frequently integrating code changes and updates, provided by the development team, during software development. These changes may occur several times a day. Automated testing of the code is built into the CI process. Continuous delivery (CD) refers to the frequent transfer of changes to production. These changes may include bug fixes or configuration changes. During the CD process, code can be deployed at any time, provided that automated test cases were successful.
Rapid Application Development (RAD)
In the Rapid Application Development (RAD) model, less time is spent up front on design, and emphasis is placed on rapidly producing prototypes with the assumption that crucial knowledge can be gained only through trial and error. This model is especially helpful when requirements are not well understood at the outset and are developed as issues and challenges arise during the building of prototypes. Figure 8-6 compares the RAD model to traditional models, where the project is completed fully and then verified and validated.
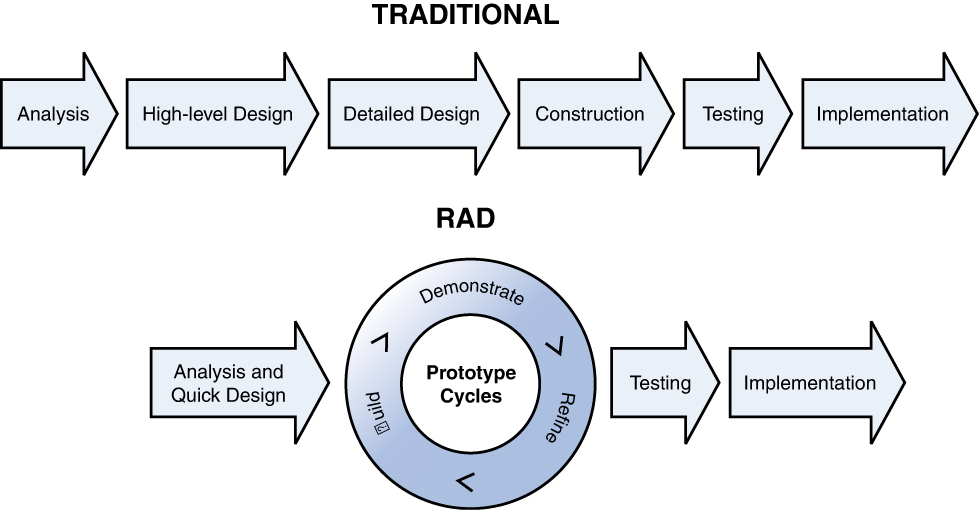
Figure 8-6 Traditional and RAD Models
Joint Analysis Development (JAD)
The Joint Analysis Development (JAD) model uses a team approach. It uses workshops to both agree on requirements and resolve differences. JAD is based on the theory that bringing all parties together at all stages usually results in a better product to emerge at the end of the process.
Cleanroom Model
In contrast to the JAD model, the Cleanroom model strictly adheres to formal steps and a more structured method. It attempts to prevent errors and mistakes through extensive testing. This method works well in situations where high quality is a must, the application is mission critical, or the solution must undergo a strict certification process.
Structured Programming Development Model
In the Structured Programming Development model, programmers write programs while allowing influence on the quality of the finished products. It is one of the most widely known development models and requires defined processes. The product is reviewed at the end of each phase for approval. Security is added in a formalized, structured manner.
Exploratory Model
In the Exploratory model, requirements are based on what is currently available. Assumptions are documented about how the system might work. To create a usable system, other insights and suggestions are incorporated as they are discovered. In this model, security will probably not have priority over enhancements. As a result, security controls are often added on an ad hoc basis.
Computer-Aided Software Engineering (CASE)
The CASE method uses computers and computer utilities to help analyze, design, develop, implement, and maintain software. It requires that you build and maintain software tools and training for developers. CASE tools are divided into the following categories:
Business and analysis modeling
Development
Verification and validation
Configuration management
Metrics and measurement
Project management
Component-Based Development
The Component-Based Development method uses building blocks to assemble an application rather than building the application itself from scratch. The advantage of this method in regards to security is that the components are tested for security prior to being used in the application.
CMMI
The Capability Maturity Model Integration (CMMI) is a comprehensive set of guidelines that addresses all phases of the Software Development Life Cycle. It describes a series of stages or maturity levels that a development process can advance through as it goes from the ad hoc (Build and Fix) model to one that incorporates a budgeted plan for continuous improvement. Figure 8-7 shows its five maturity levels and explains each one.
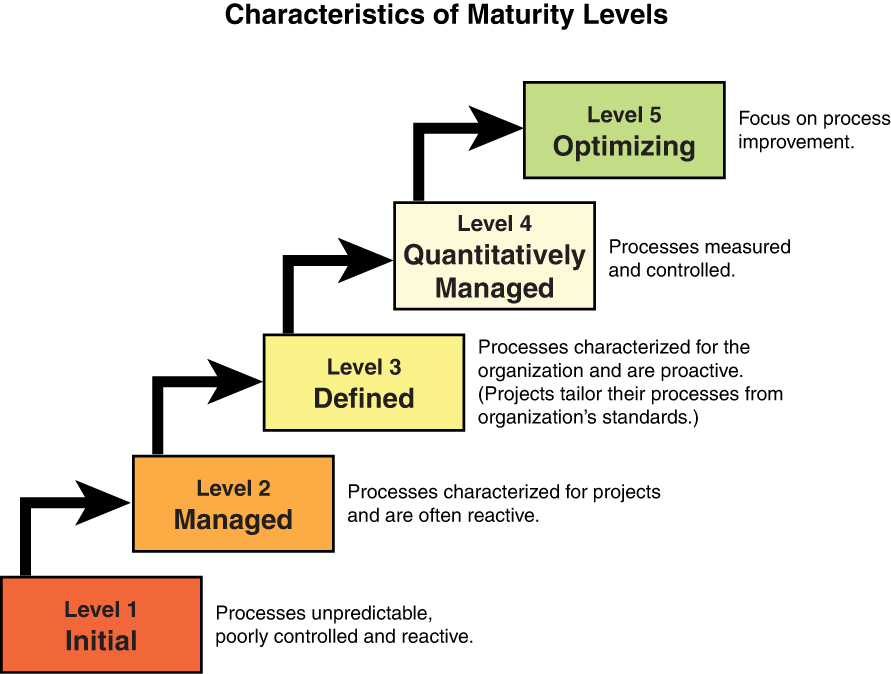
Figure 8-7 CMMI Maturity Levels
ISO 9001:2015/90003:2014
ISO 9001:2015 is a quality management systems standard. It specifies requirements for a quality management system when an organization (1) needs to demonstrate its ability to consistently provide products and services that meet customer and applicable statutory and regulatory requirements, and (2) aims to enhance customer satisfaction through the effective application of the system, including processes for improvement of the system and the assurance of conformity to customer and applicable statutory and regulatory requirements.
All the requirements of ISO 9001:2015 are generic and are intended to be applicable to any organization, regardless of its type or size and regardless of what products and services it provides.
ISO 90003:2014 guides organizations in the application of ISO 9001:2015 in terms of the acquisition, supply, development, operation, and maintenance of computer software and related support services. It does not add to or otherwise change the requirements of ISO 9001:2015.
The application of ISO/IEC 90003:2014 is appropriate to software that is part of a commercial contract with another organization, a product available for a market sector, used to support the processes of an organization, embedded in a hardware product, or related to software services. Some organizations may be involved in all of these activities; others may specialize in one area. Whatever the situation, the organization’s quality management system should cover all aspects (software related and non-software related) of the business.
ISO/IEC 90003:2014 identifies the issues that should be addressed and is independent of the technology, life cycle models, development processes, sequence of activities, and organizational structure used by an organization. Additional guidance and frequent references to the ISO/IEC JTC 1/SC 7 software engineering standards are provided to assist in the application of ISO 9001:2015, in particular ISO/IEC 12207:2017. ISO 9001:2015 is about quality management systems, and ISO/IEC 12207:2017 is about systems and software engineering and software life cycle processes. The entire scope of these two standards is not important for security professionals. However, security professionals should ensure that the software development team understands and follows these standards.
IDEAL Model
The IDEAL model was developed by the Software Engineering Institute to provide guidance on software development. Its name is an acronym that stands for the five phases:
Initiate: Outline the business reasons behind the change, build support for the initiative, and implement the infrastructure needed.
Diagnose: Analyze the current organizational state and make change recommendations.
Establish: Take the recommendations from the previous phase and use them to develop an action plan.
Act: Develop, test, refine, and implement the solutions according to the action plan from the previous phase.
Learn: Use the quality improvement process to determine whether goals have been met and develop new actions based on the analysis.
Figure 8-8 shows the steps involved in each of the phases of the IDEAL model.
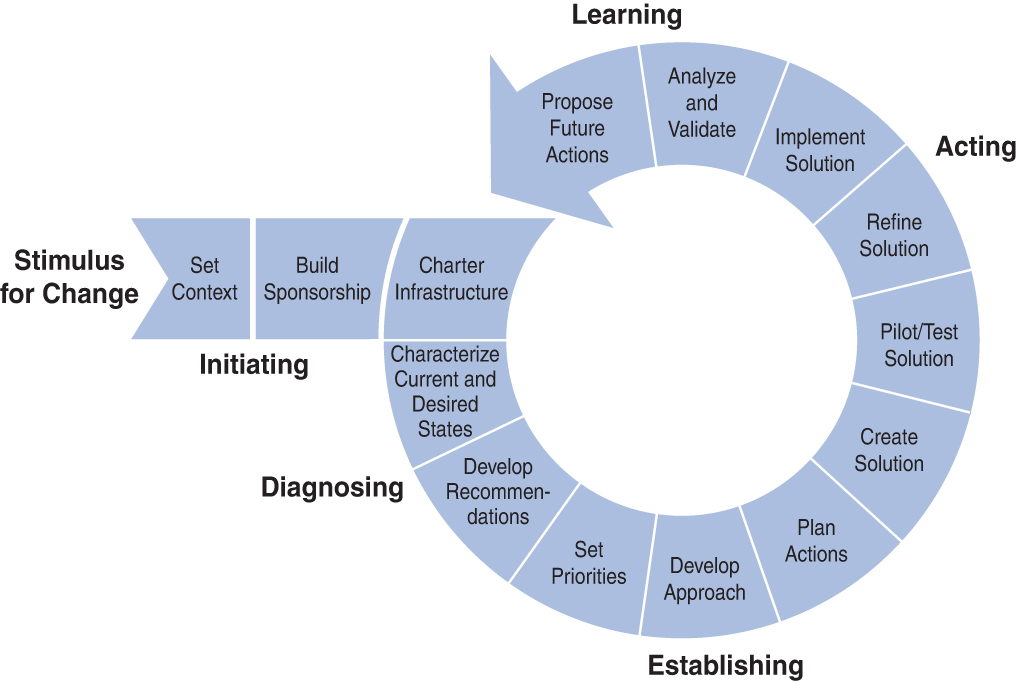
Figure 8-8 Phases and Steps of the IDEAL Model
Operation and Maintenance
Operation and maintenance ensure that the information system is fully functional and performs optimally until the system reaches its end of life. This process includes managing changes to the system to support end users, monitoring system performance, performing required security activities (such as backups, contingency planning, and audits), and providing end-user support through training and documentation.
This process often includes the development of the following deliverables:
Standard operating procedures: Defines the business processes related to the operations and maintenance of the system.
Performance reports: Tracks routine metrics to act as system performance indicators.
Issue reports: Provides details regarding system incidents.
Integrated Product Team
Integrated Product and Process Development (IPPD) integrates all essential acquisition activities through the use of multidisciplinary teams to optimize the design, manufacturing, and supportability processes. IPPD facilitates meeting cost and performance objectives from product conception through production, including field support. One of the key IPPD tenets is multidisciplinary teamwork through integrated product teams (IPTs). It is based on a U.S. Department of Defense (DoD) handbook.
The acquisition process is typically divided into five stages, with the first four formal phases separated by milestone decision points. These are the five stages:
Phase 0: Concept Exploration (CE)
Phase I: Program Definition and Risk Reduction (PDRR)
Phase II: Engineering and Manufacturing Development (EMD)
Phase III: Production, Fielding/Deployment, and Operational Support (PFDOS)
Demilitarization and Disposal (DD)
The DoD handbook says the IPT should function efficiently and effectively. The important point to remember is that each IPT in IPPD has a mission to develop and deliver a product and its associated processes. At the program level, IPT characteristics include
Responsibility for a defined product or process
Authority over the resources and personnel
An agreed schedule for delivery of the defined product
An agreed level of risk to deliver the defined product
An agreed-upon set of measurable metrics
IPTs are an integral part of the acquisition oversight and review process. There are generally two levels of IPTs: the working-level integrated product team (WIPT) and the overarching integrated product team (OIPT). Each program should have one OIPT and at least one WIPT. A WIPT should focus on a particular topic, such as cost/performance, program baseline, acquisition strategy, test and evaluation (or contracting). An integrating integrated product team (IIPT), which is a type of a WIPT, should coordinate WIPT efforts and cover all program topics, including those not otherwise assigned to another IPT. IPT participation is the primary way for any organization to be part of the acquisition program. IIPTs are essential in that they facilitate staff-level program insight into programs at the program level and provide the requisite input to the OIPT.
DevOps (development operations) emphasizes the collaboration and communication of both software developers and other IT professionals while automating the process of software delivery and infrastructure changes. It aims to ensure that building, testing, and releasing software can happen more quickly, more often, and more reliably.
Security Controls in Development
Security controls in software development must be properly implemented to ensure that security issues with software do not become problematic for the organization. To provide security controls, developers must
Understand current industry’s best practices for software development security and software environment security.
Recognize source code issues and know which source code analysis tools are available and what they do to resolve source code issues.
Provide code repository security.
Implement application programming interface security.
Understand software threats and software protection mechanisms.
Software Development Security Best Practices
To support the goal of ensuring that software is soundly developed with regard to both functionality and security, a number of organizations have attempted to assemble a set of software development best practices. First, we look at some of those organizations, and then we look at a number of their most important recommendations.
WASC
The Web Application Security Consortium (WASC) is an organization that provides best practices for web-based applications along with a variety of resources, tools, and information that organizations can make use of in developing web applications.
One of the functions undertaken by WASC is continual monitoring of attacks leading to the development and maintenance of an up-to-date list of top attack methods that are currently known. This list can aid in ensuring that organizations not only are aware of the latest attack methods and how widespread these attacks are but also can make the proper precautions and care to their web applications to mitigate these attack types.
OWASP
The Open Web Application Security Project (OWASP) is another group that monitors attacks, specifically web attacks. OWASP maintains a list of top 10 attacks on an ongoing basis. This group also holds regular meetings at chapters throughout the world, providing resources and tools including testing procedures, code review steps, and development guidelines.
BSI
The Department of Homeland Security (DHS) also has become involved in promoting software security best practices. The Build Security In (BSI) initiative promotes a process-agnostic approach that makes security recommendations with regard to architectures, testing methods, code reviews, and management processes. The DHS Software Assurance program addresses ways to reduce vulnerabilities, mitigate exploitations, and improve the routine development and delivery of software solutions. Although the BSI initiative is considered defunct, security professionals should still be aware of its existence.
ISO/IEC 27000
The International Organization for Standardization (ISO) and the International Electrotechnical Commission (IEC) created the 27034 standard, which is part of a larger body of standards called the ISO/IEC 27000 series. These standards provide guidance to organizations in integrating security into the development and maintenance of software applications. These suggestions are relevant not only to the development of in-house applications but also to the safe deployment, distribution, and management of third-party solutions in an enterprise.
Software Environment Security
The software environment, also referred to as a software library, includes code, classes, procedures, scripts, configuration data, subroutines, macro definitions, global variables, and templates. Software libraries must be built using safe coding practice and implemented properly. Also, they must be kept up to date with updates and security patches. Finally, they must include a feedback feature to address any identified issues. Common programming language libraries include C, C++, Java Class Library (JCL), and the Ruby standard.
Security professionals do not always have the skills necessary to ensure that developed software has the appropriate security implemented. For this reason, they should work to improve security awareness and identify experts who can ensure that secure programming practices are followed.
Source Code Analysis Tools
Source code analysis tools analyze source code or compiled versions of code to locate security flaws. While these tools do not usually find every security flaw, and often tag as flaws some elements that are not actually flaws, they still provide help to programmers in targeting the security-relevant code. Security professionals should work closely with programmers to ensure that source code analysis tools are used throughout the Software Development Life Cycle.
Source code analysis tools work with many kinds of software and can be run often. They are very good at detecting common issues, such as buffer overflows and SQL injections. They also highlight the exact source files and line numbers where the possible flaws are located. However, they may not always find all security issues because many issues are hard to detect. These tools often report a high number of false positives and frequently may not be able to identify configuration issues. Importantly, many source code analysis tools cannot analyze code that cannot be compiled.
Common open-source code analysis tools include .NET analyzers for Microsoft, CodeSearchDiggity for Google, and FindBugs for Java. Commercial tools are also available.
Code Repository Security
Security professionals must be concerned with the security of code while it is being developed, used, and stored in the enterprise. Security professionals should establish security measures to provide physical, system, operational, and software security. In addition, guidelines for communication should be established, including guidelines for the use of encryption. Backups should be performed regularly and securely stored. A limited number of employees should be given access to the code repository.
Software Threats
Software threats, or malicious software, can also be created in the way software is coded or developed. Following development best practices can help prevent this inadvertent creation of security issues when creating software. Software threats also can be introduced through malware. In the following sections, we discuss malware and software coding issues as well as options to mitigate the threat. Some of these topics are discussed in Chapter 5, “Identity and Access Management (IAM),” and they are covered more extensively in this chapter.
Malware
Malicious software (or malware) is any software that intends to harm a computer, modifies/corrupts/deletes data, or takes actions the user did not authorize. It includes a wide array of malware types, including ones you have probably heard of, such as viruses, and many you might not have heard of but of which you should be aware.
Some of the malware that security professionals need to understand includes the following:
Virus
Boot sector virus
Parasitic virus
Stealth virus
Polymorphic virus
Macro virus
Multipartite virus
Worm
Trojan horse
Logic bomb
Spyware/adware
Botnet
Rootkit
Ransomware
Keylogger
Mobile Malware
Virus
A virus is a software program that infects and causes the other genuine software to malfunction. It uses a host application to reproduce and deliver its payload and typically attaches itself to a file. It differs from a worm in that it usually requires some action on the part of the user to help it spread to other computers.
Following are the virus types along with a brief description of each:
Boot sector virus: This type of malware infects the boot sector of a computer and either overwrites files or installs code into the sector so the virus initiates at startup.
Parasitic virus: This type of virus attaches itself to a file, usually an executable file, and then delivers the payload when the program is used.
Stealth virus: This type of virus is difficult for a system to detect.
Polymorphic virus: This type of virus makes copies of itself, and then makes changes to those copies. It does so in hopes of avoiding detection from antivirus software.
Macro virus: This type of virus infects programs written in Word, Basic, Visual Basic, or VBScript that are used to automate functions. These viruses infect Microsoft Office files and are easy to create because the underlying language is simple and intuitive to apply. They are especially dangerous in that they infect the operating system itself. They also can be transported between different operating systems because the languages are platform independent.
Multipartite virus: Originally, this type of virus could infect both program files and boot sectors. This term now means that the virus can infect more than one type of object or can infect in more than one way.
File or system infector: File infectors program files, and system infectors infect system program files.
Companion virus: This type of virus does not physically touch the target file. It is also referred to as a spawn virus.
Email malware: This type of malware specifically uses an email system to spread itself because it is aware of the email system functions. Knowledge of such email system functions allows this virus to take advantage of all email system capabilities.
Script malware: This type of malware is a stand-alone file that can be executed by an interpreter.
Worm
A worm is a type of malware that can spread without the assistance of the user. It is a small program that, like a virus, is used to deliver a payload. One way to help mitigate the effects of worms is to place limits on sharing, writing, and executing programs.
Trojan Horse
A Trojan horse is a program or rogue application that appears to, or is purported to do, one thing but actually does another when executed. For example, what appears to be a screensaver program might really be a Trojan horse. When the user unwittingly uses the program, it executes its payload, which in turn could delete files or create backdoors. Backdoors are alternative ways to access the computer undetected in the future.
One type of Trojan targets and attempts to access and make use of smart cards. A countermeasure to prevent this attack is to use “single-access device driver” architecture. Using this approach, the operating system allows only one application to have access to the serial device (and thus the smart card) at any given time. Another way to prevent the attack is by using a smart card that enforces a “one private key usage per PIN entry” policy model. In this model, the user must enter a PIN every single time the private key is used, and therefore, the Trojan horse would not have access to the key.
Logic Bomb
A logic bomb is a type of malware that executes when a particular event takes place. For example, that event could be a time of day or a specific date, or it could be the first time you open notepad.exe. Some logic bombs execute when digital forensics is being conducted, and in that case the bomb might delete all digital evidence.
Spyware/Adware
Adware doesn’t actually steal anything, but it tracks Internet usage in an attempt to tailor ads and junk email to a user’s interests. Spyware also tracks activities and can also gather personal information that could lead to identity theft. In some cases, spyware can even direct the computer to install software and change settings.
Botnet
A bot is a type of malware that installs itself on large numbers of computers through infected emails, downloads from websites, Trojan horses, and shared media. After it’s installed, the bot can connect back to the hacker’s computer. After a connection is successfully established, the hacker’s server controls all the bots located on these machines. At a set time, the hacker might direct the bots to take some action, such as direct all the machines to send out spam messages, initiate a distributed denial-of-service (DDoS) attack, send phishing emails, or do any number of malicious acts. The collection of computers that act together is called a botnet, and the individual computers are called zombies. The attacker’s computer that manages the botnet is often referred to as the bot herder or bot master. Figure 8-9 shows this relationship.
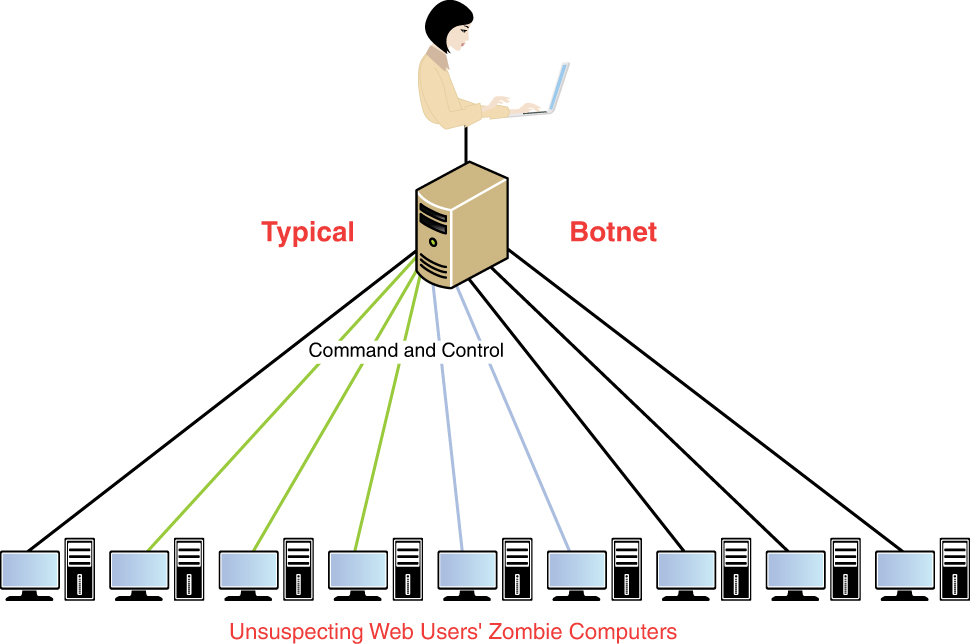
Figure 8-9 Botnet
Rootkit
A rootkit is a set of tools that a hacker can use on a computer after managing to gain access and elevating privileges to administrator. It gets its name from the root account, the most powerful account in UNIX-based operating systems. The rootkit tools might include a backdoor for the hacker to access. This is one of the hardest types of malware to remove, and in many cases only a reformat of the hard drive will completely remove it.
The following are some of the actions a rootkit can take:
Install a backdoor.
Remove all entries from the security log (log scrubbing).
Replace default tools with compromised versions (Trojaned programs).
Make malicious kernel changes.
Ransomware
Ransomware is malware that prevents or limits users from accessing their systems. It is called ransomware because it forces its victims to pay a ransom through certain online payment methods to be given access to their systems again or to get their data back. Generally, the hacker will demand a ransom (or payment) in cryptocurrency within a short space of time; after the deadline, the ransom goes up, thereby forcing an organization to make a quick decision. An organization should view the resources available at nomoreransom.org first in case an existing solution is available to remove the ransomware. The organization should also consider cyber insurance to prepare for a potential ransomware or other major cyberattack.
Keylogger
A keylogger is malware that records a user’s keystrokes. After these keystrokes are sent back to the hacker, the hacker can in turn use those recorded keystrokes to the user’s credentials into a website.
Mobile Malware
The huge growth in mobile devices, such as smartphones, has meant that there has been tremendous growth in mobile malware. Mobile malware can include mobile banking Trojans—that is, a link to a mobile application installation, which is malicious. The majority of mobile malware is found on Android devices.
Malware Protection
Organizations and individuals are not totally helpless in the fight against malware. Programs and practices can help to mitigate the damage malware can cause. Here, we discuss some of the ways to protect a network from malware.
Antivirus Software
The first line of defense is antivirus software. This software is designed to identify viruses, Trojans, and worms and delete them, or at least quarantine them until they can be removed. This identification process requires that the software’s definition files, the files that make it possible for the software to identify the latest viruses, are updated frequently. If a new virus is created that has not yet been identified in the list, the computer will not be protected until the virus definition is added and the new definition file is downloaded.
Anti-malware Software
Closely related to antivirus software and in some cases part of the same software package, anti-malware software focuses on other types of malware, such as adware and spyware. An important way to help prevent malware infection is to train users on appropriate behavior when using the Internet. For that reason, user education in safe practices is a necessary part of preventing malware. This practice should be a part of security policies.
Scanning Types
Three major types of scanning for malware or viruses occur: known signature scanning, activity monitoring, and change detection. With known signature scanning, a database of malware signatures is maintained. When scans occur, they are looking for matches to a signature in the database. With activity monitoring, the monitor watches for suspicious activity. With change detection, the detector examines files and configuration, stores the information, and compares the stored information against the configuration at a later date. It usually involves checksum values.
Security Policies
Security policies are covered in detail in Chapter 1, “Security and Risk Management,” but it is important to mention here that encouraging or requiring safe browsing and data handling practices should be formalized into the security policy of the organization. Some of the items to stress in this policy and perhaps include in training for users are the importance of the following:
Antivirus and anti-malware updates
Reporting any error message concerning an update failure on the user machine
Reporting any strange computer behavior that might indicate a virus infection
Software Protection Mechanisms
In 1972, the U.S. government commissioned the Computer Security Technology Planning Study to outline the basic and foundational security requirements of systems purchased by the government. This study eventually led to the Trusted Computer System Evaluation Criteria, or Orange Book (discussed in more detail in Chapter 3, “Security Architecture and Engineering”). This section defines some of the core tenets in the Orange Book:
Trusted computer base (TCB): The TCB comprises the components (hardware, firmware, and/or software) that are trusted to enforce the security policy of the system and that, if compromised, jeopardize the security properties of the entire system. The reference monitor is a primary component of the TCB. This term is derived from the Orange Book. All changes to the TCB should be audited and controlled, which is an example of a configuration management control.
Security perimeter: This is the dividing line between the trusted parts of the system and the parts that are untrusted. According to security design best practices, components that lie within this boundary (which means they lie within the TCB) should never permit untrusted components to access critical resources in an insecure manner.
Reference monitor: A reference monitor is a system component that enforces access controls on an object. It is an access control concept that refers to an abstract machine that mediates all accesses to objects by subjects. It was introduced for circumventing difficulties in classic approaches to computer security by limiting damages produced by malicious programs. The security risk created by a covert channel is that it bypasses the reference monitor functions. The reference monitor should exhibit isolation, completeness, and verifiability. Isolation is required because of the following:
The reference monitor can’t be available for public access. The less access, the better.
The reference monitor must have a sense of completeness to provide the whole information and process cycles.
The reference monitor must be verifiable, to provide security, audit, and accounting functions.
Security kernel: A security kernel is the hardware, firmware, and software elements of a TCB that implements the reference monitor concept. It is an access control concept, not an actual physical component. The security kernel should be as small as possible so that it can be easily verified. The security kernel implements the authorized access relationship between subjects and objects of a system as established by the reference monitor. While it is performing this role, all accesses must be meditated, protected from modification, and verifiable.
Assess Software Security Effectiveness
Regardless of whether a software program is purchased from a third party or developed in-house, being able to verify and prove how secure the application is can be useful. The two ways to approach this task are auditing the program’s actions and determining whether it performs any insecure actions, or assessing it through a formal process.
Auditing and Logging
One approach, and a practice that should continue after the software has been introduced to the environment, is continual auditing of its actions and regular reviewing of the audit data. By monitoring the audit logs, a security professional can identify security weaknesses that might not have been apparent in the beginning or that might have gone unreported until now. In addition, any changes that are made are recorded by the audit log and then can be checked to ensure that no security issues were introduced with the change.
Risk Analysis and Mitigation
Risk analysis and management were covered thoroughly in Chapter 1. Because risk management is an ongoing process, it must also be incorporated as part of any software development. Risk analysis determines the risks that can occur, whereas risk mitigation takes steps to reduce the effects of the identified risks. Security professionals should do the following as part of a software development risk analysis and mitigation strategy:
Integrate risk analysis and mitigation in the Software Development Life Cycle.
Use qualitative, quantitative, and hybrid risk analysis approaches based on standardized risk analysis methods.
Track and manage weaknesses that are discovered throughout risk assessment, change management, and continuous monitoring.
Because software often contains vulnerabilities that are not discovered until the software is operational, security professionals should ensure that a patch management process is documented and implemented when necessary to provide risk mitigation. This task includes using a change control process, testing any newly released patches, keeping a working backup, scheduling production downtime to apply the new patches, and establishing a back-out plan. Prior to deploying any patches, security professionals should notify helpdesk personnel and key user groups. When patches are deployed, the least critical computers and devices should receive the patch first, moving up through the hierarchy until the most critical computers and devices are patched.
When mitigations (patches) are deployed, the mitigations must be tested and verified, usually as part of quality assurance and testing. Any risk mitigation that has been completed must be verified by an independent party that is not the developer or system owner. Developers should be encouraged to use code signing to ensure code integrity, to determine who developed code, and to determine the code’s purpose. Code-signing certificates are digital certificates which ensure that code has not been changed. By signing code, organizations can determine whether the code has been modified by an entity other than the signer. Code signing primarily covers running code, not stored code. While code signing verifies code integrity, it cannot guarantee freedom from security vulnerabilities or that an app will not load unsafe or unaltered code during execution.
Regression and Acceptance Testing
Any changes or additions to software must undergo regression and acceptance testing. Regression testing verifies that the software behaves the way it should. Regression testing may identify bugs that may have been accidentally introduced into the new build or release candidate. Acceptance testing verifies whether the software is doing what the end user expects it to do. Acceptance testing is more formal in nature and actually tests the functionality for users based on a user story.
Security Impact of Acquired Software
Organizations often purchase commercial software or contract with other organizations to develop customized software. Security professionals should ensure that organizations understand the security impact of any acquired software.
The process to acquire software has the following four phases:
Planning: During this phase, the organization performs a needs assessment, develops the software requirements, creates the acquisition strategy, and develops evaluation criteria and a plan.
Contracting: Once planning has been completed, the organization creates a request for proposal (RFP) or other supplier solicitation forms, evaluates the supplier proposals, and negotiates the final contract with the selected seller.
Monitoring and accepting: After a contract is in place, the organization establishes the contract work schedule, implements change control procedures, and reviews and accepts the software deliverables. Somewhere around this step, the organization downloads the software, tests on an isolated machine, and certifies for use.
Follow-up: When the software is in place, the organization must sustain the software, including managing risks and changes. At some point, the organization may need to decommission or upgrade the software.
A security professional should be involved in the software assurance process to ensure that unintentional errors, malicious code, information theft, and unauthorized product changes or inserted agents are detected.
Secure Coding Guidelines and Standards
Security professionals must ensure that developers within their organization understand secure coding guidelines and standards. This includes understanding security weaknesses and vulnerabilities at the source code level, security of application programming interfaces, and secure coding practices. A major risk today is that developers will often reuse existing code and functionality, or third-party libraries, that may have untested, unknown security vulnerabilities.
Security Weaknesses and Vulnerabilities at the Source Code Level
Many security issues with software have their roots in poor development practices. A number of threats can be minimized by following certain established software coding principles. Here, we discuss source code issues, along with some guidelines for secure development processes.
Buffer Overflow
As discussed in Chapter 5, a buffer is an area of memory where commands and data are placed until they can be processed by the CPU. A buffer overflow occurs when too much data is accepted as input to a specific process. Hackers can take advantage of this phenomenon by submitting too much data, which can cause an error or, in some cases, execute commands on the machine if the hackers can locate an area where commands can be executed. Not all attacks are designed to execute commands. Some just lock up the computer and are used as DoS attacks.
A packet containing a long string of no-operation instructions (NOPs) followed by a command is usually indicative of a type of buffer overflow attack called an NOP slide. The purpose is to get the CPU to locate where a command can be executed. The following is an example of a packet as seen from a sniffer, showing a long string of 90s in the middle of the packet that pads the packet and causes it to overrun the buffer:
TCP Connection Request
---- 14/03/2018 15:40:57.910
68.144.193.124 : 4560 TCP Connected ID = 1
---- 14/03/2018 15:40:57.910
Status Code: 0 OK
68.144.193.124 : 4560 TCP Data In Length 697 bytes
MD5 = 19323C2EA6F5FCEE2382690100455C17
---- 14/03/2018 15:40:57.920
0000 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0010 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0020 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0030 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0040 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0050 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0060 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0070 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0080 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0090 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
00A0 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
00B0 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
00C0 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
00D0 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
00E0 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
00F0 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0100 90 90 90 90 90 90 90 90 90 90 90 90 4D 3F E3 77 ............M?.w
0110 90 90 90 90 FF 63 64 90 90 90 90 90 90 90 90 90 .....cd.........
0120 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0130 90 90 90 90 90 90 90 90 EB 10 5A 4A 33 C9 66 B9 ..........ZJ3.f.
0140 66 01 80 34 0A 99 E2 FA EB 05 E8 EB FF FF FF 70 f..4...........p
0150 99 98 99 99 C3 21 95 69 64 E6 12 99 12 E9 85 34 .....!.id......4
0160 12 D9 91 12 41 12 EA A5 9A 6A 12 EF E1 9A 6A 12 ....A....j....j.
0170 E7 B9 9A 62 12 D7 8D AA 74 CF CE C8 12 A6 9A 62 ...b....t......b
0180 12 6B F3 97 C0 6A 3F ED 91 C0 C6 1A 5E 9D DC 7B .k...j?.....^..{
0190 70 C0 C6 C7 12 54 12 DF BD 9A 5A 48 78 9A 58 AA p....T....ZHx.X.
01A0 50 FF 12 91 12 DF 85 9A 5A 58 78 9B 9A 58 12 99 P.......ZXx..X..
01B0 9A 5A 12 63 12 6E 1A 5F 97 12 49 F3 9A C0 71 E5 .Z.c.n._..I...q.
01C0 99 99 99 1A 5F 94 CB CF 66 CE 65 C3 12 41 F3 9D ...._...f.e..A..
01D0 C0 71 F0 99 99 99 C9 C9 C9 C9 F3 98 F3 9B 66 CE .q............f.
01E0 69 12 41 5E 9E 9B 99 9E 24 AA 59 10 DE 9D F3 89 i.A^....$.Y.....
01F0 CE CA 66 CE 6D F3 98 CA 66 CE 61 C9 C9 CA 66 CE ..f.m...f.a...f.
0200 65 1A 75 DD 12 6D AA 42 F3 89 C0 10 85 17 7B 62 e.u..m.B......{b
0210 10 DF A1 10 DF A5 10 DF D9 5E DF B5 98 98 99 99 .........^......
0220 14 DE 89 C9 CF CA CA CA F3 98 CA CA 5E DE A5 FA ............^...
0230 F4 FD 99 14 DE A5 C9 CA 66 CE 7D C9 66 CE 71 AA ........f.}.f.q.
0240 59 35 1C 59 EC 60 C8 CB CF CA 66 4B C3 C0 32 7B Y5.Y.`....fK..2{
0250 77 AA 59 5A 71 62 67 66 66 DE FC ED C9 EB F6 FA w.YZqbgff.......
0260 D8 FD FD EB FC EA EA 99 DA EB FC F8 ED FC C9 EB ................
0270 F6 FA FC EA EA D8 99 DC E1 F0 ED C9 EB F6 FA FC ................
0280 EA EA 99 D5 F6 F8 FD D5 F0 FB EB F8 EB E0 D8 99 ................
0290 EE EA AB C6 AA AB 99 CE CA D8 CA F6 FA F2 FC ED ................
02A0 D8 99 FB F0 F7 FD 99 F5 F0 EA ED FC F7 99 F8 FA ................In many cases, the key to preventing buffer overflow attacks is input validation. This method requires that any input be checked for format and length before it is used. Buffer overflows and boundary errors (when input exceeds the boundaries allotted for the input) are considered to be a family of error conditions called input validation errors.
Malformed input is the category in which all buffer overflow attacks fit. Malformed input is any attack in which the input is configured in an unusual way.
Escalation of Privileges
Privilege escalation is the process of exploiting a bug or weakness in an operating system to allow users to receive privileges to which they are not entitled. These privileges can be used to delete files, view private information, or install unwanted programs such as viruses.
Backdoor
Backdoors and trapdoors have been mentioned in passing several times in this book (for example, Chapter 5). A backdoor is a piece of software installed by hackers, using one of the delivery mechanisms previously discussed, that allows them to return later and connect to the computer without going through the normal authentication process. A backdoor normally bypasses access control measures. Some commercial applications inadvertently include backdoors because programmers forget to remove them before release to market. In many cases, the backdoor program is listening on a specific port number, and when attackers attempt to connect to that port, they are allowed to connect without authentication. An example is Back Orifice 2000 (BO2K), an application-level Trojan horse used to give an attacker backdoor network access.
Rogue Programmers
It is becoming commonplace for regular computer users to create utilities and scripts for performing their day-to-day duties. Unfortunately, these rogue programmers do not fully understand the security issues that can arise with the use of such tools. If possible, an organization should forbid the usage of any utilities or scripts that are not created by trained programmers. However, if an organization allows casual programming, security professionals should ensure that the people who are writing utilities and scripts receive the appropriate training in system development practices.
Covert Channel
A covert channel occurs when two processes transfer information in a manner that violates a system’s security policy. Two types of covert channels can occur:
Storage: Involves direct or indirect storage location reading by multiple processes. It usually occurs at a memory location or disk sector shared by two subjects at different security levels.
Timing: Involves one process being able to influence the rate at which another process can acquire CPU, memory, or I/O resources.
Object Reuse
Memory is allocated to a process, de-allocated to a process, and then allocated to another process. Sometimes data from an old process remains behind, and this old data causes a security violation. If the memory is not zeroed out or overwritten by the operating system, this remaining data is carried over into a new process and may be reused. Object reuse can also occur on a hard drive or a paging or swap file.
Mobile Code
As previously mentioned, mobile code is executable content that transmits across a network from a remote source to a local host and is executed on the local host. Mobile code can come from a variety of sources, including web pages and email messages.
Local execution of remotely sourced code is a security concern for every organization today. Mobile code presents a unique security issue because often one subject is acting on behalf of another or itself. Security controls must be implemented to define which of these requests will be allowed or denied.
Time of Check/Time of Use (TOC/TOU)
A TOC or TOU attack occurs when a control changes between the time when a variable’s contents are changed and the time when the variable is actually used. For example, say that a user logs on in the morning and is given all the permissions needed at login. Later in the day, the user is moved to another position in the company, and that user’s permissions are changed in the system. However, the user does not log out and therefore still has the old permissions, based on the original login. To prevent this type of problem, security professionals should implement periodic mandatory authentication to ensure that users and systems are re-authenticated at regular intervals throughout the day.
Security of Application Programming Interfaces
Even the most secure devices have some sort of application programming interface (API) that is used to perform tasks. Unfortunately, untrustworthy people use those same APIs to perform unscrupulous tasks. APIs are used in the Internet of Things (IoT) so that devices can speak to each other without users even knowing they are there. APIs are used to control and monitor things people use every day, including fitness bands, home thermostats, lighting, and automobiles. Comprehensive security must protect the entire spectrum of devices in the digital workplace, including apps and APIs. API security is critical for an organization that is exposing digital assets.
Guidelines for providing API security include
Use the same security controls for APIs as for any web application in the enterprise.
Use Hash-based Message Authentication Code (HMAC).
Use encryption when passing static keys.
Use a framework or an existing library to implement security solutions for APIs.
Implement password encryption instead of single key-based authentication.
Secure Coding Practices
Developers should follow secure coding practices. Earlier in this chapter, we covered software development security best practices. In addition to those best practices, developers should keep in mind the secure coding best practices covered in the following sections.
Validate Input
Developers should be sure to validate any input into an application from all untrusted data sources. Proper input validation can eliminate the vast majority of software vulnerabilities. Most external data sources, including command-line arguments, network interfaces, environmental variables, and user-controlled files, should be considered untrusted.
Heed Compiler Warnings
When developers use a compiler, they should compile the code using the highest warning level available in the compiler. Then they should work to eliminate any warnings they receive by modifying the code. Both static and dynamic analysis tools should be used to detect and eliminate additional security flaws.
Design for Security Policies
Developers should design software to implement and enforce security policies. The design should be kept as simple and small as possible. The likelihood that errors exist in implementation, configuration, and use increases when developers use complex designs. As security mechanisms become more complex, the developer effort needed to achieve an appropriate level of assurance increases dramatically.
Implement Default Deny
Security professionals should ensure that, by default, access is denied and the protection scheme identifies conditions under which access is permitted.
Adhere to the Principle of Least Privilege, and Practice Defense in Depth
Every software action should execute with the least set of privileges necessary to complete the job. Any elevated permission should be granted for a minimum period of time necessary. This approach reduces the chance that an attacker can execute arbitrary code with elevated privileges.
Implement multiple defensive strategies, also known as defense in depth. Doing so ensures that if one layer of defense turns out to be inadequate, another layer of defense can prevent a security flaw from becoming an exploitable vulnerability and/or limit the consequences of a successful exploit.
Sanitize Data Prior to Transmission to Other Systems
Sanitize all data passed to other systems, including command shells, processes, relational databases, and application components. Attackers may be able to invoke unused functionality in these systems using SQL, command, or other injection attacks. This is not necessarily an input validation problem because the system being invoked does not understand the context in which the call is made.
Exam Preparation Tasks
As mentioned in the section “About the CISSP Cert Guide, Fourth Edition” in the Introduction, you have a couple of choices for exam preparation: the exercises here, Chapter 9, “Final Preparation,” and the exam simulation questions in the Pearson Test Prep Software Online.
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topic icon in the outer margin of the page. Table 8-1 lists a reference of these key topics and the page numbers on which each is found.
Table 8-1 Key Topics for Chapter 8
Key Topic Element | Description | Page Number |
List | System Development Life Cycle | 743 |
List | Software Development Life Cycle | 746 |
List | Software development methods and maturity models | 751 |
Agile and Waterfall Model Comparison | 757 | |
CMMI Maturity Levels | 760 | |
Phases and Steps of the IDEAL Model | 762 | |
List | Malware | 767 |
List | Acquired software life cycle | 775 |
Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
Capability Maturity Model Integration (CMMI)
Common Object Request Broker Architecture (CORBA)
Continuous Integration and Continuous Delivery (CI/CD)
Distributed Component Object Model (DCOM)
distributed object-oriented systems
Dynamic Application Security Testing (DAST)
Java Platform, Enterprise Edition (Java EE)
Joint Analysis Development (JAD) model
Object Linking and Embedding (OLE)
object-oriented programming (OOP)
Open Web Application Security Project (OWASP)
Rapid Application Development (RAD)
Security Orchestration and Automated Response (SOAR)
service-oriented architecture (SOA)
Software Development Life Cycle
Static Application Security Testing (SAST)
System Development Life Cycle (SDLC)
Answer Review Questions
1. Which of the following is the last step in the System Development Life Cycle?
Operate/Maintain
Dispose
Acquire/Develop
Initiate
2. In which of the following stages of the Software Development Life Cycle is the software actually coded?
Gather Requirements
Design
Develop
Test/Validate
3. Which of the following initiatives was developed by the Department of Homeland Security?
WASC (Web Application Security Consortium)
BSI (Build Security In)
OWASP (Open Web Application Security Project)
ISO (International Organization for Standardization)
4. Which of the following development models includes no formal control mechanisms to provide feedback?
Waterfall
V-shaped
Build and Fix
Spiral
5. Which language type delivers instructions directly to the processor?
Assembly languages
High-level languages
Machine languages
Natural languages
6. Which term describes the degree to which elements in a module are related to one another?
Polymorphism
Cohesion
Coupling
Data structures
7. Which term describes a standard for communication between processes on the same computer?
CORBA (Common Object Request Broker Architecture)
DCOM (Distributed Component Object Model)
COM (Component Object Model)
SOA (service-oriented architecture)
8. Which of the following is a Microsoft technology?
ActiveX
Java
SOA (service-oriented architecture)
CORBA (Common Object Request Broker Architecture)
9. Which of the following is the dividing line between the trusted parts of the system and those that are untrusted?
Security perimeter
Reference monitor
Trusted computer base (TCB)
Security kernel
10. Which of the following is a system component that enforces access controls on an object?
Security perimeter
Reference monitor
Trusted computer base (TCB)
Security kernel
11. Which of the following tests ensures that the customer (either internal or external) is satisfied with the functionality of the software?
Integration testing
Acceptance testing
Regression testing
Accreditation
12. In which of the following software development models is less time spent on the upfront analysis and more emphasis placed on learning from the process feedback and incorporating lessons learned in real time?
Agile Development
Rapid Application Development
Cleanroom Model
Modified Waterfall
13. Which of the following software development risk analysis and mitigation strategy guidelines should security professionals follow? (Choose all that apply.)
Integrate risk analysis and mitigation in the Software Development Life Cycle.
Use qualitative, quantitative, and hybrid risk analysis approaches based on standardized risk analysis methods.
Track and manage weaknesses that are discovered throughout risk assessment, change management, and continuous monitoring.
Encapsulate data to make it easier to apply the appropriate policies to objects.
14. Which of the following are valid guidelines for providing application programming interface (API) security? (Choose all that apply.)
Use the same security controls for APIs as for any web application in the enterprise.
Use Hash-based Message Authentication Code (HMAC).
Use encryption when passing static keys.
Implement password encryption instead of single key-based authentication.
15. Which of the following is not one of the four phases of acquiring software?
Planning
Contracting
Development
Monitoring and accepting
16. Which of the following are considered secure coding best practices that developers and security professionals should adhere to? (Choose all that apply.)
Sanitize all data passed to other systems.
Implement default deny.
Validate input.
Heed compiler warnings.
17. Which of the following is a sequence of activities that aims to determine whether an application conforms to the organization’s security requirements?
Component-Based Development
Change management process
IDEAL (Initiate, Diagnose, Establish, Act, Learn) phases
Application vetting process
Answers and Explanations
1. b. The five steps in the System Development Life Cycle are as follows:
Initiate
Acquire/Develop
Implement
Operate/Maintain
Dispose
2. c. The Develop stage involves writing the code or instructions that make the software work. The emphasis of this phase is strict adherence to secure coding practices.
3. b. The Department of Homeland Security (DHS) is involved in promoting software security best practices. The Build Security In (BSI) initiative promotes a process-agnostic approach that makes security recommendations with regard to architectures, testing methods, code reviews, and management processes.
4. c. Though it’s not a formal model, the Build and Fix approach describes a method that has been largely discredited and is now used as a template for how not to manage a development project. Simply put, in this method, the software is developed as quickly as possible and released.
5. c. Machine languages deliver instructions directly to the processor. This was the only type of programming done in the 1950s and uses basic binary instructions, compiler or interpreter. (These programs convert higher language types to a form that can be executed by the processor.)
6. b. Cohesion describes how many different tasks a module can carry out. If a module is limited to a small number or a single function, it is said to have high cohesion. Coupling describes how much interaction one module requires from another module to do its job. Low or loose coupling indicates that a module does not need much help from other modules, whereas high coupling indicates the opposite.
7. c. Component Object Model (COM) is a model for communication between processes on the same computer, while, as the name implies, the Distributed Component Object Model (DCOM) is a model for communication between processes in different parts of the network.
8. a. ActiveX is a Microsoft technology that uses object-oriented programming (OOP) and is based on the COM and DCOM.
9. a. The security perimeter is the dividing line between the trusted parts of the system and those that are untrusted. According to security design best practices, components that lie within this boundary (which means they lie within the TCB) should never permit untrusted components to access critical resources in an insecure manner.
10. b. A reference monitor is a system component that enforces access controls on an object. It is an access control concept that refers to an abstract machine that mediates all accesses to objects by subjects.
11. b. Acceptance testing ensures that the customer (either internal or external) is satisfied with the functionality of the software. Integration testing assesses how the modules work together and determines whether functional and security specifications have been met. Regression testing takes place after changes are made to the code to ensure that the changes have reduced neither functionality nor security. Accreditation is the formal acceptance of the adequacy of a system’s overall security by management.
12. a. With the Agile model, less time is spent on upfront analysis, and more emphasis is placed on learning from the process and incorporating lessons learned in real time. There is also more interaction with the customer throughout the process. In the Rapid Application Development (RAD) model, less time is spent up front on design, while emphasis is placed on rapidly producing prototypes with the assumption that crucial knowledge can only be gained through trial and error. In contrast to the JAD model, the Cleanroom model strictly adheres to formal steps and a more structured method. It attempts to prevent errors and mistakes through extensive testing. In the modified Waterfall model, each phase in the development process is considered its own milestone in the project management process. Unlimited backward iteration (returning to earlier stages to address problems) is not allowed in this model.
13. a, b, c. Security professionals should ensure that the software development risk analysis and mitigation strategy follows these guidelines:
Integrate risk analysis and mitigation in the Software Development Life Cycle.
Use qualitative, quantitative, and hybrid risk analysis approaches based on standardized risk analysis methods.
Track and manage weaknesses that are discovered throughout risk assessment, change management, and continuous monitoring.
14. a, b, c, d. Comprehensive security must protect the entire spectrum of devices in the digital workplace, including apps and APIs. API security is critical for an organization that is exposing digital assets. Guidelines for providing API security include
Use the same security controls for APIs as for any web application in the enterprise.
Use Hash-based Message Authentication Code (HMAC).
Use encryption when passing static keys.
Use a framework or an existing library to implement security solutions for APIs.
Implement password encryption instead of single key-based authentication.
15. c. In the Software Development Life Cycle, the code or instructions that make the software work are written in the Develop phase. The process of acquiring software has the following four phases:
Planning: During this phase, the organization performs a needs assessment, develops the software requirements, creates the acquisition strategy, and develops evaluation criteria and a plan.
Contracting: When planning is complete, the organization creates a request for proposal (RFP) or other supplier solicitation forms, evaluates the supplier proposals, and negotiates the final contract with the selected seller.
Monitoring and accepting: When a contract is in place, the organization establishes the contract work schedule, implements change control procedures, and reviews and accepts the software deliverables.
Follow-up: When the software is in place, the organization must sustain the software, including managing risks and changes. At some point, the organization may need to decommission the software.
16. a, b, c, d. Developers and security professionals should adhere to the following secure coding best practices:
Sanitize all data passed to other systems, including command shells, processes, relational databases, and application components.
Security professionals should ensure that, by default, access is denied and the protection scheme identifies conditions under which access is permitted.
Developers should validate any input into an application from all untrusted data sources.
When developers use a compiler, they should compile the code using the highest warning level available in the compiler.
Design software to implement and enforce security policies.
Adhere to the principle of least privilege, and practice defense in depth.
17. d. An app vetting process is a sequence of activities that aims to determine whether an app conforms to the organization’s security requirements. An app vetting process comprises a sequence of two main activities: app testing and app approval/rejection. The Component-Based Development method uses building blocks to assemble an application instead of build it. The advantage of this method in regard to security is that the components are tested for security prior to being used in the application. The purpose of the change management process is to ensure that all changes to the configuration of the source code and to the source code itself are approved by the proper personnel and are implemented in a safe and logical manner. The IDEAL model was developed by the Software Engineering Institute to provide guidance on software development. Its name is an acronym that stands for the five phases:
Initiate: Outline the business reasons behind the change, build support for the initiative, and implement the infrastructure needed.
Diagnose: Analyze the current organizational state and make change recommendations.
Establish: Take the recommendations from the previous phase and use them to develop an action plan.
Act: Develop, test, refine, and implement the solutions according to the action plan from the previous phase.
Learn: Use the quality improvement process to determine whether goals have been met and develop new actions based on the analysis.