
Until now, we have seen only simple directory architectures. We had a single directory server holding the whole directory and serving a number of clients. However, life is rarely so simple, and you probably have a somewhat more difficult implementation in place.
A single directory server is not always sufficient to meet your requirements. Sometimes it is necessary to keep a copy of the same data at different locations to optimize access speed. There are many good reasons to do so, and we will discuss them later in greater detail. For now, let us review a few without further comment. For example, one reason could be to bring the server closer to the clients. This is helpful in the case of a wide-area network (WAN) with slow network connections between the different local-area networks (LANs) that make up the network. Another reason could be load balancing, where an overloaded directory server is distributed over two or more machines to increase throughput. Whatever the reason for distributing the directory over several physical servers, the pieces should form a single logical directory server.
The LDAP protocol running over TCP/IP is well suited for running in a distributed architecture. You can even design your LDAP architecture to cross enterprise boundaries. In this chapter, we will learn how.
Let us begin with a familiar example, the Web browser. The HTTP protocol running also over TCP/IP is indeed a very well known example of such a distributed architecture. Consider the myriad of Web servers holding a wealth of data; it is clear that not all the data can be held on a single server. Furthermore, it happens that the same data may be available from different places. This redundancy allows the user to choose the nearest location. It furthermore allows the user to contact another server should the first server become unavailable. You can design the architecture so that the search for the available server becomes automatic (round-robin architecture or proxy). You can also cross enterprise boundaries, with your links pointing to Web servers outside your enterprise boundary, if the configuration of the firewall allows this. The underlying concepts are the same for LDAP.
Data distribution is closely coupled with the protocol nature of LDAP. Indeed, directory services is one piece of the distributed computing environment (DCE), which was developed by the Open Systems Foundation (OSF) that converged in the Open Group. DCE version 1.0 was released in 1992 and contained the following major services:
■ Distributed time services
■ Distributed file services
■ Remote procedure call (RPC)
■ Directory services
The distributed computing environment has the goal of coordinating resources and applications in large heterogeneous networks. A heterogeneous network is made up of computers on different hardware platforms running different operating systems. The TCP/IP and OSI protocol suites provide the basis of the communication between these computers.
The administration of such a DCE requires standards for making a number of services available over the whole network. One such service is the time service. Timing is very important when a large number of computers are linked together. Another very important service is our directory service. As we have seen in previous chapters, directory services are used to hold very different information. Naming services (e.g., domain name services [DNS]), network information services (NIS), and the distribution of configuration data (for example, alias maps for sendmail) are examples of information that should be administered at one point only but made available all over the network. To distribute directory services effectively, reliably, and efficiently, you must have the tools of replication and partitioning.
It frequently happens that a company’s intranet has a number of different data repositories on different platforms. The reason is mostly historical and derives from the way applications were born. It is quite common for each application to uses its own repository. It is also common for these applications to store the same or similar data. These applications normally have grown up separately from each other and have a life of their own. In this way, a number of information islands are created in the enterprise, each of them using different hardware and software. It happens, therefore, that almost the same data is held on different systems in a different way. This not only keeps administration efforts high; it also makes it difficult to obtain a unique and consistent view of the data. The installation of a directory could potentially solve this problem, but it is not always possible to migrate all application to use a directory for data storage.
If you have such a distributed system — for whatever reason — you will need to optimize the management of and access to the data. What you have to do is to find a way of consolidating the data. This chapter addresses the issue of how to “hold together” such distributed systems. It consists of two parts, corresponding to the two reasons for why systems are distributed:
1. To divide (partition) the same architecture for a gain in performance or availability or both. The division is planned and optimized for a given situation.
2. To have the same data on different architectures (replication) for application needs. The division has historical reasons, slows down performance, and increases administration efforts. Sometimes you have to live with this situation, even if it is not optimized. However, we will see that there are strategies for improving this situation too.
Introduction to Replication and Partitioning
There are two concepts supporting the distribution of directory data over multiple directory servers: replication and partitioning.
Partitioning distributes a database over two or more LDAP servers. As mentioned previously, you cannot hold an infinite amount of data on the same server. For one thing, the amount of disk space is limited. Despite the ever-increasing capacity of hard disks, it is not possible to continue adding more disks or substituting the existing disks with larger ones. Very large databases become cumbersome for the backup procedures. The time it takes to make a backup increases with the amount of data you have to back up. Furthermore, the larger the database is, the slower will be search and access operations. Add, update, and modify operations are all affected by the size of the database. Remember that LDAP repositories are optimized for access speed, not for update speed. Therefore, with the growth of database volume, the time required for update processes increases much more than the time required for search processes.
The more data your directory holds, the more often clients will contact it. This means increased network traffic, which will slow down the response time of your server. There is also an upper limit of parallel requests supported by a directory server. If you reach this limit, you will have to think about distributing the directory over more servers.
Data ownership is another reason for holding the data on different servers. Assume that two departments need to have a directory administration of their own. Furthermore, it may be that the requirements of these two departments to the directory service are quite different. Therefore, the configuration of their servers would be different. In this case, it is convenient to install and maintain the directory on two different servers.
Replication puts the same data onto two or more other directory servers. There are several good reasons to do so. Having more servers that offer directory services, you can distribute the client requests among these servers. This increases the performance on execution of the requests. More requests can be elaborated in parallel. Thus performance increases. If your directory server installation has reached the limit of parallel requests that it can handle, it could be a good idea to put two directory servers in place, each a replication of the other.
You can also configure your clients to use the directory server nearest to them. If this server does not respond, the client can then contact an alternative server. This strategy keeps network traffic low and results in a huge performance boost.
If the servers are located on different LANs, the clients on each LAN will continue to work even if the connection between the LANs is down. This means a gain in availability of directory services on your network in case of network failure. In the event of a server crash, clients still have the option of switching to another directory server so that they can continue to work. This is a gain in availability in case of server failure. Thus replication can protect your enterprise from both server and network failures.
Many sites also use replication for backup procedures. Imagine that you have a master LDAP server and a slave LDAP server. (We will discuss the master and slave server further in the following section.) As a backup procedure, you take the slave offline and make an offline backup. Use the master for the LDAP traffic. It will, therefore, answer the queries and accept updates of the directory. The updates cannot be transferred to the slave until the slave is down, but as soon as the backup procedure finishes and you put the slave online again, the master server will push all modifications made in the meantime onto the slave server.
In the next two sections we will cover both partitioning and replication. First we will look at how we can partition a directory and which type of partitioning is allowed. When a directory server receives a request that it cannot answer because it lacks the requisite data, it responds by telling the client that it cannot answer to its request. However, this answer is connected with a hint telling the client who it should contact to get the information it needs. It is then up to the client to decide whether to follow the suggestion of the directory server or give up and inform the user of the failure. We will see that a referral is a special object type that informs the client that it has to contact another server. It is then up to the client to follow the referral or not. There is also an alternative possibility to the referral, called “chaining.” In this case, the server does not transfer the request it received from a client to another server. Instead, it acts upon the client’s request and contacts the server it thinks should handle the request. Once it gets the result back, it sends it on to the client as if it had answered the request. The client, however, has no idea at all what really happened. It sees only that its request was answered. If the server contacted by the LDAP server does not hold the information, it could contact yet another server.
Once we have done with this interesting concept, we will see the different replication scenarios. The easiest form of replication is the master-slave replication. At configurable intervals, a replication process copies the data that has been modified from the master to the slave. The multimaster replication is somewhat more complicated because you have several servers that accept update operations from clients. You have to configure a policy that allows resolving potential conflicts.
Now a word about standards: The only concept supported by standards at the time of this writing is the referral. There is also the alias, which we saw in Chapter 3. However, nearly every directory implementation supports replication. Most support chaining as well. Still, there is not yet a standard definition, which is the reason why two different implementations of a directory server cannot replicate between each other. Work is under way to define standards regarding replication. At this time, the working group called LDUP (LDAP duplication/replication/update protocols) is finishing its efforts to define a minimal standard for replication. You can learn more about what is going on at the Web site of the Internet Engineering Task Force (IETF), following the link “working groups” (http://www.ietf.org). There are several working groups for issues other than replication. Choose the ones beginning with LDAP.
Data Distribution between LDAP and Non-LDAP Systems
In the last section of this chapter, you will see that there are a number of possibilities to integrate different data sources. The most flexible of these possibilities is a broker between the different data sources and the LDAP server. This broker, however, has to be written and maintained.
The most frequent repositories you will find in an enterprise are databases of users and groups defined to access system resources. The same users, however, are defined only in the enterprise directory. We will see briefly a couple of examples of how these user databases can be integrated into the directory.
The last method to integrate different repositories into the company directory is to use the metadirectory technology. A metadirectory can integrate different information sources produced by different applications to provide one consistent view of all the available data. Nearly all suppliers of directory servers offer metadirectory solutions.
All of these issues are works in progress, because nearly all suppliers continue to provide diverse solutions to meet the requirements of the market. Because work on LDAP is far from being completed, the work on integrating directories with other important repositories required in every enterprise also has to continue.
Partitioning is the action of dividing one large directory into two or more smaller and therefore more easily manageable pieces that combine to form a complete, logical unit. Once divided, the clients can continue accessing the directories as if they were on the same directory server. The ability to access the directories as one logical directory can be achieved through the use of referrals or by chaining.
We will see what partitioning is and learn how to partition a directory. In the introduction we learned about the benefits of partitioning. We will learn more about this in Chapter 9, which addresses the topics of planning and design of directory services. In this chapter, we will concentrate on the technical aspects of partitioning.
Once we have an understanding of partitioning, we will look at referrals. We will learn how to create a referral and understand what happens when the directory server sends back a referral. We will also see the different kinds of referrals.
We then move on to have a look at chaining and discuss the differences between referrals and chaining. Note, however, that chaining is not yet standardized, and therefore not all directory servers support chaining.
Let us consider a very basic situation, as shown in Exhibit 1. Our enterprise Ldap_abc.de has grown up and now it is ldap_abc.org. The org extension indicates a change in the organization’s status, but that is not the point. The point for us is that the organization now spans more than one country, with each of these countries having a directory server of its own.
For the moment, let us assume that besides the server in Germany, we now have a server in the United Kingdom, too. Exhibit 1 shows that we hold the German part of the directory on the German server, while the U.K. directory points to the U.K. server, managed completely in the United Kingdom. The main server is still in Germany and holds also the referral to the U.K. server. If a client asks for ou = UK, ldap_abc.de, it refers to the United Kingdom. I presume that users are more likely to use their own data, i.e., users in the United Kingdom are more likely to need the data held on the U.K. directory server, while users in Germany are more likely to use data held on the German directory server. But if a German user needs data from the U.K. directory server, she can access the data, if she is authorized to do so.
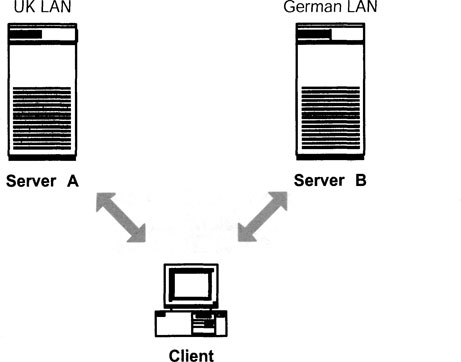
Exhibit 1. Partitioning of a Directory
Partitioning also refers to a situation where a piece of the directory tree is removed and put on a different directory server. Exhibit 2 illustrates this more complicated example. This architecture has a number of advantages. Users on the LAN in the United Kingdom do not need to use the network link between the United Kingdom and Germany. This means better performance and greater availability. Should the network link between Germany and the United Kingdom be down, both sites still have access to their local data. On the other hand, if users on the U.K. LAN need access to the German data, they can still do so using the network link if the link is up and running. However, the clients in the United Kingdom have to be configured to use the U.K. server, and the clients in Germany to use the German server. Both directory servers will send a referral to the other server if they are unable to provide the requested information. The client then decides whether to follow the referral and try to contact the server holding the desired information. We previously said that the two directories build a complete logical unit, but this is not exactly the whole truth. Using referrals, clients notice very well that a piece of the directory is on another directory server. Thus it is more accurate to say that clients can navigate seamlessly in the directory spanned by the two directory servers.
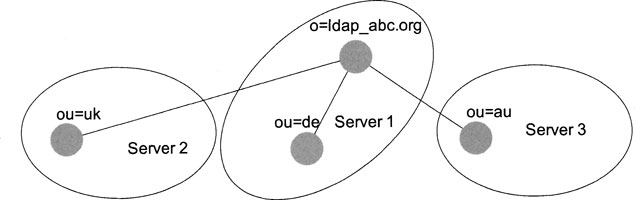
Exhibit 2. Directory Divided into Three Partitions
In the next example, we add a new organizational unit on a new server. Let us assume that we decide to locate all organizational units outside of the main server, which now has a simple dispatch function only. Exhibit 3 depicts this scenario. Using this setup, we can divide a large directory into a number of smaller partitions. Note, however, that each partition has to be a real directory tree. Exhibit 4 shows an invalid partition, where the two organizational units of the partition on server 2 do not have a common ancestor lying inside the partition. The directory on server 2 does not build a tree, and therefore the partition lying on server 2 is not a legal subtree of the root partition on server 0.
Exhibit 5 shows another example of an invalid partition. The partition on server 0 is illegal because the partition contains a hole. For example, there is no element between the object type “inetOrgPerson” with RDN uid = JParker and the organization “o = ldap_abc.org.” To make the partition legal, we could move the organizational unit in the partition on Server 0 or move the person with RDN uid = JParker into the partition on server 1.
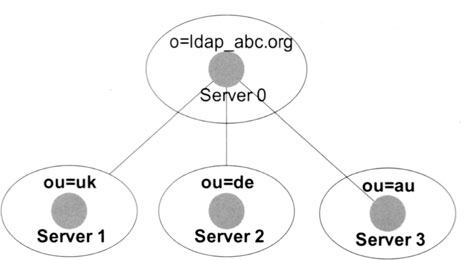
Exhibit 3. A Main Server with Three Organizational Units on Different Partitions
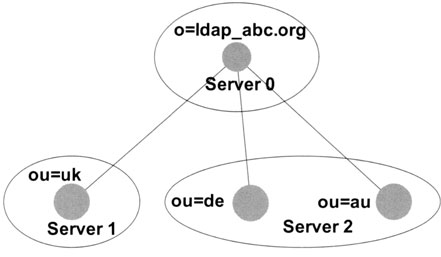
Exhibit 4. Example of an Illegal Partition
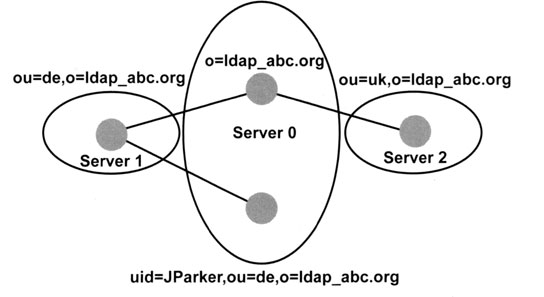
Exhibit 5. Example of Illegal Partition, Ancestor Missing
Gluing the Directories Together
Now assume we have partitioned our directory servers and want to get them up and running. However, there is still one point missing. Look again at Exhibit 3. How does directory server 0 know that the subtree “ou = de” is located on directory server 2? And how, in turn, does directory server 1 know that its ancestor is located on directory server 0?
These details are held in the “knowledge information.” The “superior knowledge information” points to the directory server containing the ancestor of the current directory root. The “subordinate knowledge information” points from the ancestor to its child. Most directory server implementations hold this information in the root DSE (DSA specific entry). Recall that DSA is the name used in the X.500 protocol for the directory server (directory server agent).
Note that there is still no standardization. Work is under way, but you can learn more about the knowledge information and other questions about referrals in a draft report available from IETF (draftietf-asid-ldapv3-referral-xx.txt).
This is the only concept in LDAP (v3) now defined as a standard by an RFC. If a client asks a directory server for an entry it does not contain, the server sends the referral information back. Its function is to tell the client that the desired entry is not available on this server and suggest where to find the desired information. The referral has the following structure:
■ The host name of the directory server
■ The port number of the directory server
■ The base DN of the new target. If omitted, the client tries the same DN it searched on this server.
There are two types of referrals: The smart referral implements the “subordinate knowledge information,” and the “superior knowledge information” is implemented by the global referral. The referral that implements the subordinate information is sometimes identified in the literature as a “smart referral,” and the global referral is simply called a “referral.” In any case, the global referral refers to another directory server if the server you are querying does not have the requested information. In the case of a superior knowledge information, the referenced server does have this information and delivers it to the client. In this way, the directory server could be thought of as a kind of proxy server. All requests it is not able to resolve are forwarded to another directory server that may contain smart referrals to the directory server containing this information. The client has to express explicitly that it wishes to follow the referral. The analogy to the proxy server is, however, not to be considered strict. A proxy server works more as a chaining server than as a referral. The client using a proxy server has no idea that the one that actually holds the data and elaborates the query is not the proxy itself but another server.
Until now, the discussion may have been interesting, but an example will explain much more than an entire chapter of theory. So let us change our example slightly to see data distribution at work. This time, let us assume that we have a brand-new directory server installed in the United States. This directory server will be used to administer all information regarding the United States. Clients located in the United States will use this directory server, while clients located in Germany will use the German one. Exhibit 6 shows this scenario. In our example, one directory server is running on the standard port, and the other directory server is running on Port 700. This example is not presented to show that it is easy to listen at a nonstandard port. No, the objective is to allow you to try out this example even if you own only one server for test purposes.
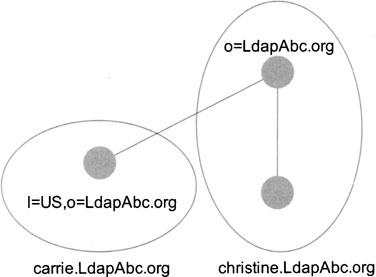
Exhibit 6. New Location in United States Will Need a New Directory Server
The machine called christine.LdapAbc.org is running the directory server with directory root:
“o=LdapAbc.org”
On this directory server, we will find the entire directory information tree except the subtree:
“1=US, o=LdapAbc.org.”
On the server called “carrie.LdapAbc.org,” we find the directory server containing information regarding the U.S. location. This directory server has the directory root entry:
“1=US, o=LdapAbc.org”
Once the two directory servers are configured and running, everything seems to work quite nicely. If we query Christine, it will report any data located on its directory server. If we query Carrie, its directory server will do the same. If we want to have information from Carrie regarding the search base:
“ou=IT, 1=US, o=LdapAbc.org”
we will get a “no such object” message. If we ask Christine about entries not contained in the 1 = US subtree, the server cannot answer us.
First we will explain to the LDAP server mounted on Carrie how to retrieve the information in the 1 = US subtree. This we can achieve via the referral object. The next line shows our first attempt to find a Mister Seidl, working in the United States, on our directory server.
ldapsearch −b “o=LdapAbc.org” −h christine.LdapAbc.org “(&(1=US)(sn=Seidl))”
The server will not report any result. Then we add the referral that explains how to arrive at the subtree where Mister Seidl is located.
The distinct name of the referral is just the mount point between the two servers. The object class is “referral,” which inherits from “extensibleObject.” The last attribute in the referral entry is the LDAP URL where you can find the subtree. Now the search should work fine. But, as you note, we do not get the information. We get instead from the server a hint to look at the directory server
ldap://christine.LdapAbc.org/l=US, o=LdapAbc.org
using the distinct name:
1=US, o=LdapAbc.org
If we want to get all of the information in one step, we have to tell the client to follow automatically all referrals. With the command line we are using, it is enough to specify the −c flag.
So one part of our job is done. The client asking the central server for information on the U.S. site gets a referral or gets the data directly. If a person in the United States connects with the directory on her site now, she still gets “no such object.” You have to tell the server Christine to contact the server Carrie if it does not contain the requested information, by setting up a global referral to the server Carrie. The specific command depends on the implementation of the directory server. In the OpenLDAP configuration file, all you have to do is to add this line:
referral ldap://Carrie.LdapAbc.org
to set up a global referral to the server Carrie.
And Now … from the Client Point of View
Concluding the discussion about referrals, it is worthwhile to have a look at the previous example from the client point of view. We will use the example mentioned above.
The LDAP Server A with the root DN “o = LdapAbc.org” has the organizational unit ou = US. This entry in reality does not live on server A, but is a referral pointing to Server B with root DN “ou = US, o = LdapAbc.org.” Since not everybody has two machines to test out the example, this exercise uses two LDAP servers listening on two different ports: one on the standard port and one on port 700. For this experiment, you should create a configuration file equal to server A, but with root DN ou = US, o = LdapAbc.org, and start it on port 700. Look at the documentation shipped with your directory server software to learn how to do that.
Furthermore, you should create some entries. I suggest creating the same entries as in server A, only with different root DN and different surnames/given names to test out queries on both servers. You have to configure two things:
■ The subordinate knowledge information on server A:
ref: ldap://12 7.0.0.1:700/ou=US,o=LdapAbc.org
■ The superior knowledge information on server B:
referral ldap://127.0.0.1
After configuring and restarting the server, we can try it out using the LDAP command-line tools as well as a Java program to test our implementation.
Let us first search an entry on the first server using the command-line tool. The entry with sn = Voglmaier resides on server A. The command shown in Exhibit 7 does the job. The response to our request gives the hint that there could be further information available using the reported URL. It is now the job of the client software to decide if it should follow the LDAP URL
ldapsearch −LLL −b “o=LdapAbc.org” −h localhost −p 700 “(sn=Voglmaier)”
Exhibit 7. Search Command to Find Entry on Server A: Its Output
ldapsearch −LLL −b “o=LdapAbc.org” −h localhost −p 389 “(sn=Voglmaier)”
dn: uid=RVoglmaier,ou=IT,o=LdapAbc.org
objectClass: top
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
cn: Reinhard Erich Voglmaier
sn: Voglmaier
givenName: Reinhard Erich
ou: IT
uid: RVoglmaier
mail: [email protected]
# refldap://127.0.0.1:700/ou=US,o=LdapAbc.org??sub
or instead deliver the following result:
Referral (10)
Referral : ldap://127.0.0.l/o=LdapAbc.org??sub
Again, we see the hint to have a look at the localhost that could contain further information.
The query:
ldapsearch −LLL −b “ou=US, o=LdapAbc.org” −h localhost −p 700“(sn=King)”
results in the output shown in Exhibit 8, which shows as the entry of Stephen King. Here the directory server knows that only itself has information about the base ou = US.
ldapsearch −LLL −b “ou=US, o=LdapAbc.org” −h localhost −p 700“(sn=Voglmaier)”
The search for Voglmaier, which does not exist in ou = US, does not deliver anything because Voglmaier resides in Italy. Leave out “ou=US” and you should get back the referral.
Exhibit 9 shows a brief program in Java that does the same thing.
Exhibit 10 shows the concept of chaining in action. The concept is nearly the same as for referrals. The objective of chaining is to keep the directories together in a logical unit.
If a client in the United Kingdom wishes information located in Germany, it will first ask the directory server in the United Kingdom. The directory server checks to see if it contains the requested data. If it does not, it will search to identify the server that contains the information required. In the case of a referral, the directory server would send this information back to the client, which then decides whether to follow the referral or not. In the case of chaining, however, the server does not report anything to the client. Instead, it contacts the server it thinks contains the information on the behalf of the client. Once it has the information, the server sends it back to the client. In the meantime, the client waits.
Exhibit 8. Output from Search Command against Host B
dn: uid=SKing,ou=Marketing,ou=US,o=LdapAbc.org
objectClass: top
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
cn: Stephen King
sn: King
givenName: Stephen
ou: Marketing uid: SKing
mail: [email protected]
Exhibit 9. Java Program following Referrals
1 import netscape.ldap.* ;
2 import java.util.* ;
3
4 /**
5 * Simple example of referral usage
6 */
7
8 public class Referrall {
9
10 public static void main(String args[]) {
11
12 String name = args[0] ;
13 String baseDN = args[l] ;
14 String host = args[2] ;
15 int port = Integer.parselnt( args[3]);
16
17 int searchScope=LDAPConnection.SCOPE_SUB;
18 String searchFilter = “(sn=” + name +”)”;
19 String getAttrs[] = {“cn,” “mail,” “uid”};
20
21 LDAPConnection Id = new LDAPConnection () ;
22
23 try {
24 Id.connect(host,port);
25 Id.getSearchConstraints().setReferrals( true );
26 LDAPSearchResults res = Id.search( baseDN,
27 searchScope,
28 searchFilter,
29 getAttrs,
30 false ) ;
31 while ( res.hasMoreElements() ) {
32 LDAPEntry Entry = null ;
33 Entry = (LDAPEntry) res.next();
34 System.out.println(“DN:” + Entry.getDN()) ;
35 }
36 ld.disconnect();
37 } catch ( LDAPReferralException e) {
38 LDAPUrl refUrls[] = e.getURLs();
39 for ( int i=0 ; i < refUrls.length; i++ ) {
40 System.out.println(refUrIs[i].getUrl() ) ;
41 }
42 } catch ( LDAPException e ) {
43 System.out.println( e.toString() );
44 }
45
46 }
47 }
In this case, too, the knowledge information is stored in the server. There is not yet a standard defining the chaining process, so check your vendor’s documentation for guidance.
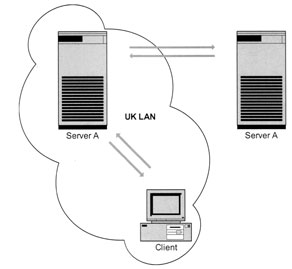
Exhibit 10. Chaining Client Requests
Security Aspects Using Chaining
Look again at Exhibit 10. The client contacts server A. Server A does not hold the information required by the client and therefore asks Server B, which does hold the information. Server B then sends the information to server A, and server A relays it back to the client. This is okay if the information exchanged is public. However, if the information can only be accessed upon previous authentication, things get slightly more complicated. In this case, when server A asks for the information from server B on behalf of the client, server A must also pass the user credentials to Server B.
Such an authentication scheme may be good enough for an intranet environment. In an insecure environment like the Internet, things get even more complicated. In this environment, the client must have assurance that server A really is server A and not an impostor running an LDAP server. This impostor could then steal the user’s credentials and use them to gain access to the system. Thus when communicating over the Internet, it is absolutely necessary to use certificates to ensure that communicating parties really are who they claim to be.
Difference between Chaining and Referrals
Chaining and referrals are both used to contact another server if one server cannot provide an answer. However, referrals and chaining are two very different concepts as seen from the client’s and the server’s points of view. Using the referral strategy, the server simply sends a referral back to the client if it cannot execute the operation requested by the client. With the referral, the server also sends back a message identifying the server where the requested information resides. Thus the server acts nearly as it would upon receiving a request for data that it actually holds. The server does its job by informing the client, and then it is the client’s job to handle the situation from there. In this case, the client has to do the work of interpreting the answer it got from the original server and then constructing the new address and distinguished name so that it can request the information from the new server identified in the referral. The client also has to decide whether to follow the request automatically or allow the user to decide what to do. In the case of a referral, the burden of work lies on the client and, consequently, on the client programmer.
In the case of chaining, the client knows nothing about these server transactions. Now the server has to do the work, and the vendor implementing the LDAP server has to invest much more work in the programming of the server software. In a chaining scheme, the originally contacted server handles all of the traffic from the final server holding the requested information as well as the directory client that made the request. Because a single request can result in more than one response, the original server may have to collect multiple responses and send them to the client. The client programmer has no direct control of the information flow between client, which is speaking with a kind of broker and not with the server itself.
A last difference between chaining and referrals lies in network performance. Obviously, performance is affected by the number of requests arriving at a server. If the server does not hold the requested information and thus must redirect the requests to other servers, the effect on performance is even greater. Because the client knows nothing about the chained transactions among the servers, it continues to send subsequent information to the original server, generating even more server-to-server transactions. Depending on the number of requests traveling this way and on the network architecture, this could have a negative effect on network performance. If the client is configured to recognize that the original server cannot execute the desired operation, it may be possible to switch its focus to the relevant server that can execute the requests directly. However, this feature is not available in all applications.
You may decide to duplicate a part of the directory or the whole directory on two or more other directory servers. This action of duplicating the directory is called “replication.” The LDAP literature uses the terms “consumer” and “supplier.” These expressions come in handy when describing the data flow. The server that sends the data is called the supplier. The server that receives the data from the supplier is called the consumer. These roles are not exclusive. The consumer server can be a supplier server for other servers, as we will see in the next section, “replication scenarios.”
Furthermore, there are master servers and slave servers. The slave server runs in a read-only mode, getting its data from a master. The clients, therefore, cannot update the data on a slave server. Only the master server can modify data on the slave server, whose only function is to serve clients for search operations. Of course, the master server can also modify the data in the directory it contains. A directory application can have more than one master. However, the so-called multimaster replication is more difficult to implement. In this first section we will speak about master-slave replication only. In the section on multimaster replication, we will have a look at what is different in a configuration with more than one master directory server.
Replication has a number of advantages. It can improve:
■ Availability: Upon the failure of one server, another can continue to provide information to the clients.
■ Performance: Distribution of the workload among multiple servers increases efficiency by dividing the type of work each one performs. For example, you could have one server dedicated to data updates and another for data retrieval.
■ Bandwidth: Efficient configuration increases bandwidth. Most enterprises have a large geographical extension and thus a geographically extended WAN. In this situation, it may be convenient to bring the directory closer to the clients by putting a directory server on every LAN and keeping these directory servers synchronized. The main advantage is a gain in bandwidth that you can use for other applications.
■ Maintenance: Organizations that span multiple time zones must always have an active server. If each time zone has its own directory server, directory servers that are not being used can be safely taken offline. If you offer 24/7 service, you can take a server offline for maintenance as long as there are enough servers to respond to client requests. As mentioned before, a master-slave pair can also be used for offline backup. While the offline backup of the slave is active, the master continues its work. Once the backup is finished, you can put the slave online again.
Note, however, that there are no formal standards for replication or for a replication protocol at the time of this writing. Work is under way, and the workgroup is now releasing an important milestone of its work, but it will still take some time to create a standard. You can monitor the state of the art at the Web site of IETF (http://www.ietf.org). We will discuss this in greater detail in the section called “Work in Progress.” The lack of a standard combined with vendors’ desire to meet the needs of the market has led to the current situation where every LDAP implementation has it own replication solution.
Let us see how OpenLDAP is implementing replication. In Appendix D you will find a detailed discussion of the configuration of OpenLDAP for replication. You have to configure one server as master and one server as slave. The master server maintains a replication log. This log describes the changes to the directory the master server has applied. The slave server has to be configured to accept modifications of the master server. OpenLDAP delivers a replication server that does nothing else but communicate to the slave server the changes in the directory the master server has applied. Replication server and master server are two different programs. If I want to be precise, I should have stated the following: the slave server has to be configured to accept modifications from the replication server. That’s enough, however, for the sake of this example. More in Appendix D.
Previously I said that ever vendor has its own solution for replication, and these single solutions, unfortunately, are not compatible with each other, so you cannot set up a replication between directory servers of different suppliers.
You can replicate the whole directory or one part of the directory, and you can replicate one server to more servers. There are a number of possibilities for implementing replication, and you can also combine these implementations. You can even combine replication with partitioning. We will address these subjects in Chapter 9, where we consider design questions.
However, bear in mind that not all implementations support all of the features that we have mentioned. It is best to check the documentation of the various LDAP implementations while you are still in the planning phase. Of course, most users are not in the fortunate position of choosing their LDAP software based on its replication options. In most cases, replication does not become an issue until the directory services system is successfully deployed and the workload increases. At this point you have to live with the options that your implementation offers. The reason for underestimating the workload is simple. When the directory services are up and running, more and more application programmers will use them. The real use of directory services is typically far greater than expected. We will address this issue later. For now, we will have a look at the different replication scenarios.
In this section, we will briefly look at a few of the possible replication scenarios. We will return to this topic in Chapter 9, when we examine the design of directory services.
Exhibit 11 depicts the most basic scenario: a simple master-slave replication. The master server A replicates to the slave server B. The replication in this case has the goal of increasing the availability of directory services. If server A is down, then the clients can use still directory services through server B.
Exhibit 12 shows a different scenario. We still have master-slave replication, but the main scope here is to make the data available in a different subnet. If the connection between the two networks is down, the clients on the location of either the slave or the master still have directory information, although the information on the slave side may be out of date. The main advantage in this configuration, however, is that the traffic on the network link caused by the directory servers is kept as low as possible. Server A sends only the data that has been modified to server B. Both sites use their own directory server. The network link is used only for replication updates. The bandwidth that otherwise would be used by the clients is now available for use by other applications. Both sites can continue to use the directory, even if one of the servers is unavailable, because in this case its replication partner takes over its workload.
Exhibit 13 shows an example of a cascading replication, where the replicated server replicates furthermore on a second slave server. Not all directory server implementations support this architecture. In the case of OpenLDAP, where you have a dedicated consumer server, a cascading architecture would not be possible.
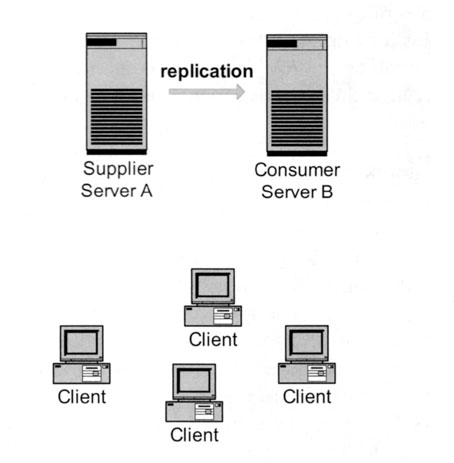
Exhibit 11. Simple Master–Slave Replication
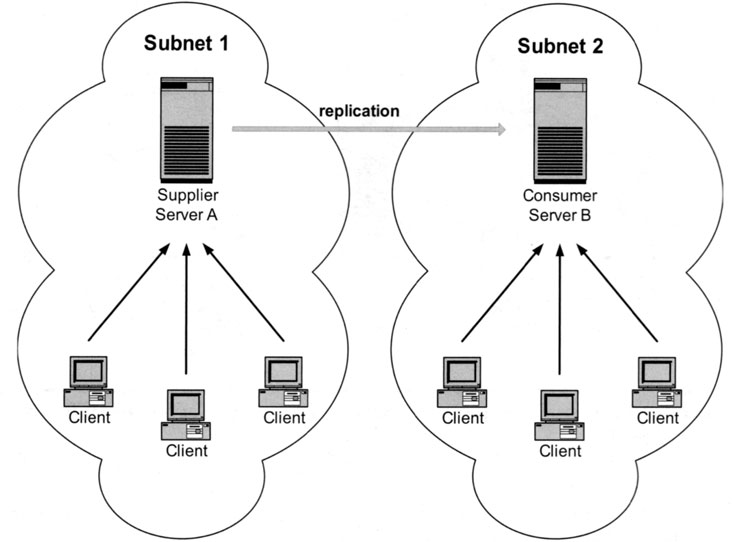
Exhibit 12. Simple Master-Slave Replication between Subnets
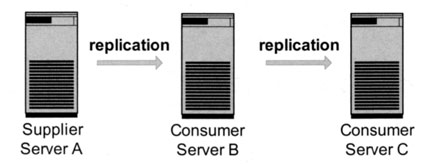
Exhibit 13. Cascading Replication
Exhibit 14 depicts a somewhat more complex configuration. The master server holds the database, and all changes (insert, modify, delete operations) are made on this server. There are four consumer servers, each serving one subnet. These four servers can be put much closer to the clients they are serving than the master server. The master replication server in this configuration has two functions. First, it speaks with the clients requesting a directory update. Then it distributes these updates to the single consumer servers.
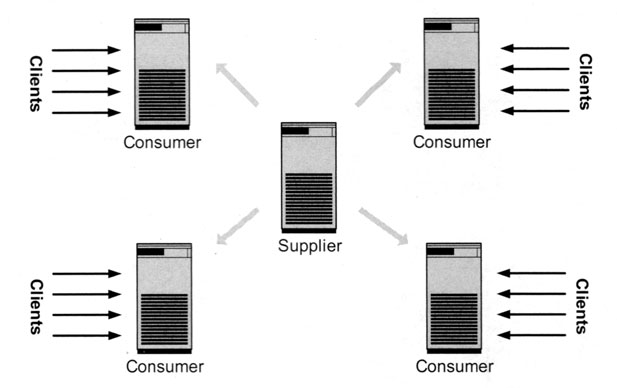
Exhibit 14. Supplier Server with Several Consumer Servers in Different Subnets
Performance can be improved even more by putting a further replicating server between the master replication server and the slaves, working practically as a hub. In this configuration, the supplier server leaves the distribution of the updates to the hub and concentrates on its job as LDAP server. It receives the messages from the clients and executes the necessary steps on the directory.
In LDAP (v3), schema information should be held in the form of a subschemaSubentry object. Some implementations use this mechanism to propagate changes in the schema from the supplier to the consumer. Because the exact syntax for the representation of the schema in the subschemaSubentry is not yet defined in a standard, every supplier uses its own. Thus it is best to have a common schema for both the supplier and consumer and to avoid changing the schema.
Since there is no standard defining access control lists (ACLs), some directory server implementations hold the ACL in the configuration files, and others keep it where the data is, in the directory. When the ACL is part of the directory, updates in the ACL can be propagated through replication.
Work is under way to define a standard for both mechanisms. A major goal of this effort is to allow directory servers from different suppliers to exchange information. Once these standards are defined, it will still take some time until the first suppliers implement the standards.
Single Master versus Multimaster
Until now we have seen only configurations featuring a single master server. Updates of the directory are made on the master server, which replicates them on the slaves or slave. In all these cases, the access is to slave servers running in read-only mode, which means that they cannot modify any entry. The only one who can do this is the master server. However, this does not mean that a client connected to the slave server cannot modify an entry. Indeed, the client can ask the slave server to update or delete an entry, and the request is handled like a referral. Upon the request to the slave server, the client receives from the slave server the location of the master server and its IP number. With this information, the client submits its request to update information to the master server. Normally, the client software handles this automatically, and the transaction is hidden from the user. Alternatively, the update request could also be handled using chaining. The client asks the slave server to update an entry. The slave server asks the master server to make the update. After the master server sends the return code in the form of a message object, the slave server informs the client.
There are also situations where you may wish to have more than one master server. In this case of multimaster replication, more than one directory server has write access to the directory. This obviously complicates the situation. Clients in such an architecture can submit update requests to any of these master servers. If in a master-slave solution the master is no longer available, you can read the directory, but you cannot update it anymore. Whether this is acceptable depends on the particular application. If you have two masters, though, you continue to work both in read and update, even if one of the masters is not available. As soon as the disabled master becomes available again, it will be updated.
This solution has its advantages, but it also introduces a big problem. If more than one server accepts updates from the clients, the same entry can be updated on two different servers. An entry might be updated with one value on server A and another value on server B. Exhibit 15 depicts such a situation. The server software has to have some sort of policy to resolve such conflicts. The servers could use the time stamp of the update action to decide which update to keep and which one to discard. Using Exhibit 15, imagine that a client in the United States updates the room number to 512 at 4:01 p.m. and one minute later a client in the United Kingdom updates the room number to 528. Most directory servers keep the most recent update and discard the previous one. This obviously requires that the time between the servers is perfectly synchronized. Note, however, that there is no correct way to handle this situation because, for the directory server, no client’s update is better or worse than the other.
Again, how these details are handled depends on the implementation because there is no standard yet. Check the documentation shipped with your software. Given the lack of a standard, it is clear that replication cannot be implemented between software from different suppliers. It is not only the multimaster replication that does not work between products of different suppliers. It is the replication protocol between the directory servers that has not yet been standardized.
Exhibit 15 shows a very interesting scenario of replication. This architecture is particularly interesting because it is a thing between multimaster and single-master replication. Two directory servers (server A and server B) share a common directory. The goal is that if server A is unavailable, server B can continue its work. Because both directory servers use a common directory, you need not replicate it to keep both servers aligned. If the client wants to connect with the directory server, it gets the IP number from the DNS and then connects with the directory server. If server A should answer, the DNS gives the address of server A. If server B should answer, the DNS gives the address of server B. The switch from server A to server B is therefore achieved by the DNS server that resolves the names. Let me make the example clearer. The client asks the address ldap.abc.de from the DNS server. If we want server A to respond, the DNS says to the client: “Look, the address of ldap.abc.de is 245.94.37.2.” If we want server B to respond, we tell to the client: “The address of ldap.abc.de is 245.94.37.7.”.
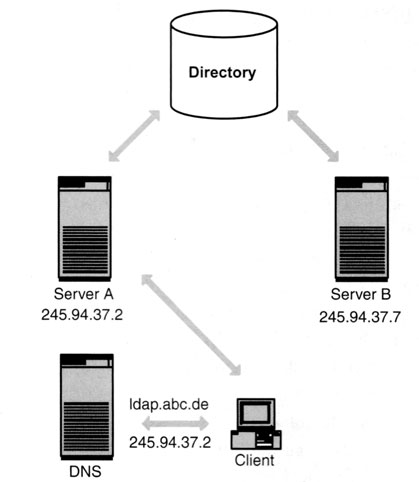
Exhibit 15. Two Servers Sharing One Directory
Once the architecture is established, replication still has to be set up to work properly. You set up replication by defining a handful of agreements between supplier and consumer servers. These are the arguments the server has to agree upon:
■ Supplier- or consumer-initiated replication
■ Frequency of replication
■ Unit of replication
■ Incremental or total replication
■ Replication account
We will have a brief look at each of these points. Please keep in mind, however, that each directory server handles replication in a different manner, so some points may be just configured and you cannot change them. Refer to the documentation delivered with your directory server.
Supplier- or Consumer-Initiated Replication
This describes which of the partners initiates the replication. In a supplier-initiated replication the supplier contacts the consumer and pushes all the data changed since the last replication to the consumer. In a consumer-initiated replication, the consumer contacts the supplier and pulls down all data changed since the last replication. The end result for both replication types is the same. The choice of which to use depends on the particular architecture. The supplier-initiated replication can push an update to the consumer as soon as the data in the supplier changes, thus minimizing the delay between the update of supplier and consumer. Using this strategy, the consistency between supplier and consumer is strong. The consumer-initiated replication is used when the connection to the consumer is not very stable, for example in a dial-up connection. When the consumer connects to the LAN, it can request the supplier to begin the replication.
The frequency of replication depends on the degree of consistency required between consumer and supplier. As the divergence between consumer and supplier becomes more critical, replication should occur more frequently. However, the more frequently the server is busy with replication, the greater is the loss of performance against connections to the clients.
You can also decide which part of the DIT you will replicate. Some implementations only allow you to replicate the whole directory.
Incremental or Total Replication
This defines whether you replicate the whole directory or just the part that has actually changed. Total replication is used when you set up replication for the first time or if you reload the entire directory on the supplier. For normal operation, you will normally use incremental replication between supplier and consumer.
You must define an account that the supplier and the consumer can use for the replication process. The replication account must have sufficient rights to achieve the operation on the partner server.
Replication has different objectives, one of which is load sharing. We have already seen two possible methods of load sharing. The first possibility is to use two or more directory servers and distribute accesses to these directory servers via DNS. The client asks for the directory server “directory.Ldap_Abc.org.” The DNS server gives an IP number, and the client then contacts the directory server with this IP number. When the next request arrives at the DNS, it delivers another IP number. Thus, the requests are distributed among all directory servers. Exhibit 16 shows this architecture. The disadvantage of this architecture is that the DNS does not speak LDAP and therefore does not understand if one of the LDAP servers does not answer. Furthermore, the distribution among the directory servers is not guided by the nature of the requests.
Another possibility is to use a gateway, as noted in the previous section on “replication scenarios.” Every directory server in this schema is specialized on a particular activity. Exhibit 17 shows the architecture. One or more supplier servers accept all the data maintenance operations. Remember that data maintenance operations are more resource consuming than read operations. The supplier pushes the changes onto the gateway, which distributes the data to the consumer servers. The consumer servers, in turn, handle the read operations for the clients.
A last possibility is to use an LDAP proxy server, as shown in Exhibit 18. Because the proxy server speaks LDAP, it understands the requests made by the clients. Therefore, the LDAP proxy can decide on a configurable and “intelligent” way to distribute the requests. It can furthermore decide to hide certain attributes from the client or to put together two data sources and make them appear as a unique data source to the client. Most of the commercial vendors also offer an LDAP proxy server. However, this is a very expensive solution. Fortunately, the OpenLDAP implementation can be compiled to work as a proxy server. We previously mentioned the need to compile OpenLDAP in a particular way to get it work as a proxy. Chapter 7, “LDAP Directory Server Administration,” provides more information about the installation of LDAP, and Appendix D tells you how to compile and configure the OpenLDAP proxy server.
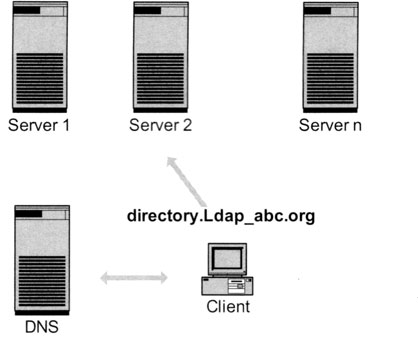
Exhibit 16. LDAP Load Balancing Using DNS
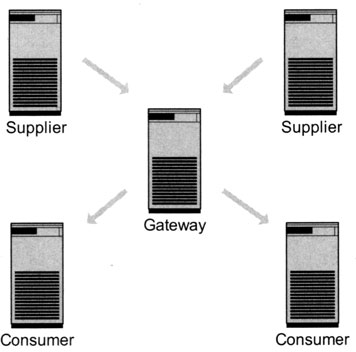
Exhibit 17. LDAP Gateway
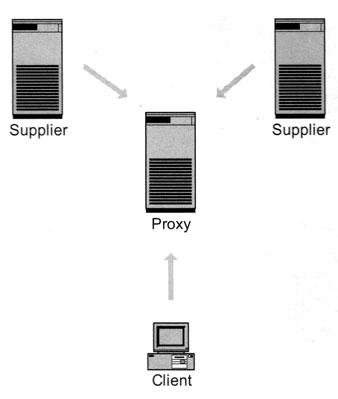
Exhibit 18. LDAP Proxy
The security considerations for the conversation between a consumer and supplier server are the same as for a conversation between a client and server. Most server implementations offer a variety of options to secure this conversation. Your choice of method depends on your particular requirements.
In an insecure environment like the Internet, it is very important that both the supplier and the consumer servers are sure about the identity of the partner. However, even in an intranet environment, security issues should be a concern. Many intranet administrators assume that the “bad guys” are outside the network. Unfortunately, experience has shown that “bad guys” could also be inside the system.
As mentioned before, directory servers can exchange schema information and ACLs. In a so-called man-in-the-middle attack, this information can be forged if transmitted in the clear without encryption. Thus such information should be encrypted before transmission. The same holds true for user data. User data stored in the directory contains the users’ passwords. When this information is transmitted between consumer and supplier servers, anyone listening on the network can capture it.
The available security options depend on the implementation you are using. Refer to the documentation delivered with your software to understand which options are appropriate for your application. Again, there is no standard, and every software vendor has a solution of its own. A number of suppliers offer an LDAP proxy. For example, Sun has one in its Sun One server suite that also includes an LDAP proxy server.
The replication process, like much of LDAP, is a work in progress. A working group called LDUP (LDAP Duplication/Replication/Update Protocol) is in the process of standardizing master-slave (also called single-master) and multimaster replication. You can learn more about their work from the IETF Web site at http://www.ietf.org/html.charters/ldup-charter.html.
The following lists reflect the latest information drawn from the workgroup’s Web site at the time of this writing. Given the time lag in publishing, you would be wise to refer to the Web site for recent updates. The LDUP working group has divided its activities into seven areas, each of which is documented by one or more papers:
1. LDAP (v3) replication architecture: Describes the overall architecture of the LDUP protocol, i.e., the LDUP components and how these components work together.
2. LDAP (v3) replication information model: Defines the schema information necessary for replication to work. It includes replication agreements, consistency models, replication topologies, management of deleted objects, and administration. This information has to be maintained by the replicating servers.
3. LDAP (v3) replication information transport protocol: Defines extended operations that allow LDAP itself to propagate the information to be replicated
4. LDAP (v3) mandatory replica management: Management protocol to administer replication.
5. LDAP (v3) update reconciliation procedures: Procedures for the detection and resolution of replication conflicts. Replication may try to update the same element from different information sources. These procedures should resolve conflicts.
6. LDAP (v3) profiles: LDAP (v3) replication architecture, information model, protocol extensions, and update reconciliation procedures
7. LDAP (v3) client update: Enables the client to synchronize with update in the LDAP server and receive notification about modifications in the database.
At the time of this writing, the work of the LDAP group has produced the following documentation:
■ RFC 3384, “LDAPv3 Replication Requirements”
■ “General Usage Profile for LDAPv3 Replication,” draft available from http://www.ietf.org/internet-drafts/draft-ietf-ldup-usage-profile-03.txt
■ “LDAP Client Update Protocol,” draft available from http://www.ietf.org/internet-drafts/draft-ietf-ldup-lcup-03.txt
Data Distribution between LDAP and Non-LDAP Systems
What should you do if part of the data resides in non-LDAP systems, like relational databases, applications, or flat files? The first thing to consider is moving all of the data into one common LDAP repository. However, it is not always possible to migrate existing applications to another architecture. Nor is it always a good idea to convert everything into LDAP. There are many different factors that might hamper your efforts to move disparate data to a common repository. For example, an application might not be available in an LDAP-enabled version. Other reasons could be of a political nature. For example, a data “owner” might want to continue to maintain his repository using his familiar software without having to go through the enterprise directory to maintain the data. There are also cases where it is simply impossible for one reason or another to migrate the database to LDAP.
The most flexible way to create a common platform for all data sources is to design a broker that can put all the systems in contact, allowing you to maintain and query the data in a consistent way. Exhibit 19 shows an example of such a mixed-up environment.
Before we look at commercial implementations, let us first have a brief look at the requirements for a broker connecting different repositories. These requirements depend very much on the particular implementation. As mentioned previously, the directory can be interconnected with a number of different repositories. Thus, the first thing to do is to understand the different repositories holding the data and the types of data they hold.
For each of the repositories (LDAP, RDBMS, application, flat file, etc.), you need to build a connector to regulate the data flow. This connector is specialized to keep a connection between the data source and the directory. As such, it has to know the direction of the data flow, i.e., it has to know which of the two partners is the master and which is the slave.
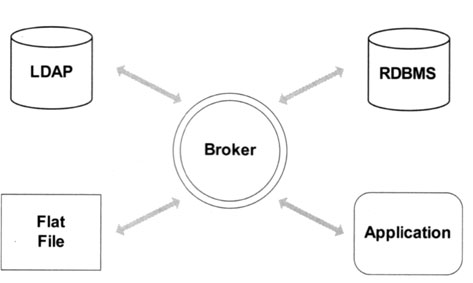
Exhibit 19. Connecting Different Repositories
If both of the partners accept modifications, there must be a strategy module to decide which of the modifications should be kept in the event that both sources receive an update. The strategy module also has other jobs to do. A data source that accepts modifications is called a “data producer.” There is usually more than one data producer. The strategy module therefore has to decide on a sequence for the different data producers so that they are synchronized with the directory. If two or more data producers can update the same data, there is a possibility of generating conflicting data. The strategy module has to be configured to resolve such conflicts. (The conflicts are the same as those that can occur with multimaster replication of LDAP servers.)
Conflicts are mostly a sign that there are problems in the data flow. A conflict indicates that there is more than one source responsible for the maintenance of the same data. In most cases, it is good to review the business logic that requires this redundant maintenance and find a solution of a master-slave relationship. We will discuss this further in Chapter 9 when we learn more about LDAP server design.
Security is another important consideration. You have to determine what types of user credentials should be used to pass information between different systems. You may also need to set up the exchange of certificates to allow conversing partners to verify each other’s authenticity.
The broker centrally controls all of these connections and the data flow between the different repositories. The frequency of the update between the repositories is yet another important consideration. You need to define how much time it should take for the different repositories to become aligned. It is also important to decide which of the repositories should be considered as the authoritative data source.
It is not overly difficult to set up an environment connecting different repositories so that they can communicate with each other. However, as the saying goes, the devil is in the details. This means that the framework needs to be carefully designed and implemented. Needless to say, a home-grown implementation has the advantage of exactly meeting your particular application and security requirements. However, you will need the skills of people who can design, develop, and maintain the software. Most of the commercial directory servers offer a solution that sits on top of their directory server, a metadirectory. We will learn more about metadirectories in the next section.
If you do not want to develop your own solution for data distribution, you can adopt a ready-to-use product called a “metadirectory.” The function of a metadirectory is to synchronize a central directory with the different repositories on different systems. The way a commercial product performs this task is similar to the theoretical approach described in the previous section. One central strategy module (that can also be called a broker) looks around at the various repositories and tries to keep the central directory in sync with the repositories. The central strategy module can be configured to describe the locations of the various repositories, the update frequencies, the interrogation sequence for the different data sources, and the authoritative data source.
The number of vendors of metadirectory solutions is constantly growing. The major names are Siemens with its DirX 6.0 product, Sun One metadirectory, Microsoft metadirectory, and many others. Metadirectories are a relatively new area, and vendor brochures have created high customer expectations.
As previously noted, behind the problems a companywide metadirectory should solve, there are mostly organizational or design problems. The tool will not solve these problems. However, the tool may be helpful in uncovering these problems and may lead to a change in the business logic, thereby avoiding data inconsistencies.
One interesting means of exchanging directory information is the DSML standard. The directory services markup language DSML is a dialect of extended markup language (XML). DSML takes advantage of the XML syntax, enabling applications to share data using a simple human-readable format.
A thorough explanation of XML is beyond the scope of this book. For our purposes, it is enough to say that XML is a standard of representing Web content in ASCII format. As opposed to HTML, it allows the user to define her own tags and thus extend the language. As such, XML can be put on any Web server and transferred like any other Web document.
DSML was created initially by Bowstreet Inc. in July 1999. It is intended as an open standard and is maintained on the Web site of OASIS http://www.oasis-open.org/committees/dsml. OASIS is sponsored by Netscape, Sun Microsystems, Oracle, Novell, Microsoft, IBM, and other enterprises. At the time of this writing, DSML is in version 2. DSML (v1) provides a means of representing directory content in XML. DSML (v2) extends the functionality to allow a client to formulate queries, delete, insert, and modify actions as XML documents. Perhaps obviously, the results of these operations are sent back in XML format.
The big advantage of DSML is that it is an ASCII format markup language and therefore the directory content can be made available via a Web server. This means that you can distribute directory content across enterprise boundaries, for example in your extranet, or even make it available to customers over the Internet. Since it is ASCII, you can export your directory content in DSML and import it into a completely different repository, for example a directory server from a different supplier. This means that even a client unable to speak LDAP can access a directory. This could, for example, be an application developed using XML tools and then be integrated in a directory-driven environment.
At this point, a few examples are very helpful to get a basic understanding of how all this works. These examples are drawn from the DSML draft available from OASIS. First, Exhibit 20 shows you how to formulate a search using DSML. As you may notice, the request is included in the <searchRequest> and </searchRequest> tags. Meanwhile, the filter is defined in <filter> and </filter> tags. Exhibit 21 instead shows the result. As you can imagine, using a style sheet you can easily format this XML code into a pretty good-looking HTML page.
Finally, Exhibit 22 and Exhibit 23 show an example of adding an entry to a directory. Exhibit 22 shows the request the client has to produce, and Exhibit 23 the response the client gets. Exhibits 20 and 21 and Exhibits 22 and 23 are taken from the DSML draft document.
There is a handy tool set written in Java that helps to export directory content to DSML and import it into an LDAP database. The tools are named LDAPtoDSML and DSMLtoLDAP. The software has been developed by Gervase Markham and is available at http://www.dsml-tools.org.
These tools make it easy to export and reimport LDAP data. The following line exports data from our LDAP repository:
LDAPtoDSML
To import data into an LDAP repository, use the following line:
DSMLtoLDAP
Exhibit 20. Example of Search Request in DSML
<searchRequest dn=“ou=Marketing,dc=Microsoft, dc=com” scope=“singleLevel” derefAliases=“neverDerefAliases” sizeLimit=“1000”>
<filter>
<substrings name=“sn”><final>john</final></substrings>
</filter>
</searchRequest>
Exhibit 21. Example of Search Result in DSML
<searchResponse>
<searchResultEntry dn=“OU=Development,DC=Example,DC=COM”>
<attr name=“allowedAttributeEffective”>
<value>description</value>
<value>ntSecurityDescriptor</value>
<value>www.Homepage</value>
</attr>
</searchResultEntry>
<searchResultEntry dn=“CN=David,OU=HR,DC=Example,DC=COM”>
<attr name=“objectclass”><value>person</value></attr>
<attr name=“sn”><value>Johnson</value></attr>
<attr name=“givenName”><value>David</value></attr>
<attr name=“title”><value>Program Manager</value></attr>
</searchResultEntry>
<searchResultEntry dn=“CN=JSmith, OU=Finance,DC=Example,DC=COM”>
<attr name=“objectclass”><value>top</value></attr>
<attr name=“objectclass”><value>person</value></attr>
<attr name=“objectclass”><value>organizationalPerson</value></attr>
<attr name=“sn”><value>Smith</value></attr>
</searchResultEntry>
<searchResultDone>
<control type=“1.2.840.113556.1.4.621” criticality=“false”>
<controlValue xsi:type=“xsd:base64Binary”>
U2VhcmNoIFJlcXVlc3QgRXhhbXBsZQ==
</controlValue>
</control>
<resultCode code=“0”/>
</searchResultDone>
</searchResponse>
As we close the DSML section, we should briefly mention the Castor framework, which provides data binding. Castor is developed by Exolab, an organization working in the development of open-source software based on Java and XML.
Data binding facilitates the transfer of one data model into another. For example, Castor can map an XML data model into Java classes by generating Java classes from an XML document. It can also use instances of these classes to store data in XML form. Castor is also capable of binding data from Java classes to tables, rows, and columns of a RDBMS. One of the functionalities being investigated at the time of this writing is the development of mapping from LDAP to Java and finally to XML.
Exhibit 22. Example of Adding an Entry in DSML: Request
<addRequest dn=“CN=Alice,OU=HR,DC=Example,DC=COM”>
<attr name=“objectclass”><value>top</value></attr>
<attr name=“objectclass”><value>person</value></attr>
<attr name=“objectclass”><value>organizationalPerson</value></attr>
<attr name=“sn”><value>Johnson</value></attr>
<attr name=“givenName”><value>Alice</value></attr>
<attr name=“title”><value>Software Design Engineer</value></attr>
</addRequest>
Exhibit 23. Example of Adding an Entry in DSML: Response
<addResponse>
<resultCode code=“0”/>
<errorMessage>completed</errorMessage>
</addResponse>
Castor DSML remains (at the time of this writing) a work in progress. You can learn more about the Castor project at the Castor home page: http://castor.exolab.org.
In this chapter, we have seen a number of interesting distributed architectures for data maintenance. The previous chapters assumed that there is only one directory holding all the data in our enterprise. However, life is rarely so simple. There are many situations where it makes sense to divide the directory over more than one server, assigning each of these directory servers the responsibility for one part of the directory information tree. The user, however, should be able to get the whole picture, retrieving information held on the different directory servers as if the data was held on a single server.
We furthermore have seen how to replicate data from the directory on other directory servers. There are many reasons to replicate a directory, including availability, performance, and administrative issues.
We also learned how to integrate data from different sources into a directory server to form one unique architecture using metadirectories.
The last part of this chapter showed how to use the markup language XML and the directory standard LDAP, thus allowing access to your directory via XML. The advantage of this technique is that applications developed in XML have the ability to use the enterprise directory without the need of an LDAP-enabled client.