
Validity goes beyond mere well-formedness to ensure that a document is not merely syntactically correct but semantically correct. It promises that only elements and attributes defined in the HTML specification appear so that browsers aren’t taken by surprise. It also promises that they appear only in certain places where their meaning is well defined. For example, in a valid document you won’t find a table in the head or a blockquote in a paragraph.
Validity offers many advantages to site authors and even more advantages to site consumers. First, valid sites are predictable. They show the same content to users with different browsers. Although details regarding font size and positioning can vary from one browser to another, valid pages are more likely to look reasonably similar from one browser to the next.
Valid pages convey the same information to different readers, even readers that use such widely varying interfaces as a graphical browser, an Atom feed reader, or a screen reader. Valid pages are more device-independent.
Because valid pages are more predictable, you waste less time debugging cross-browser idiosyncrasies. Valid pages are much easier to make work reliably.
Valid pages are also more future-proof. They are more likely to work reliably in tomorrow’s browsers, not just today’s. Weird hacks designed for particular browsers sometimes stop working with a new browser release. Invalid pages often depend on the subtle bugs and quirks of a particular browser version. Valid pages are more predictable in browsers you can’t even test yet.
In brief, validity is a solid base for future development. Making a site valid will almost always improve a site’s usability, accessibility, speed, and reliability. Most important, it improves a site’s maintainability. Valid pages are easier to upgrade, easier to style, and easier to improve than invalid pages. Valid pages are simply more robust.
What is true for validity is doubly true for strict validity. Strict validity goes beyond mere validity to also insist that content be separated from presentation. This makes pages smaller, simpler, and more understandable. Furthermore, it enables you to use far more powerful CSS techniques to style pages that go well beyond what you can achieve with simple font tags, spacer GIFs, and table layout.
Validity is not always required. Browsers do build consistent DOMs from merely well-formed documents, and XML tools can still parse an invalid but well-formed document. However, validity does increase the predictability of browser display. Just because you can put a table in the head doesn’t mean you should.
There are, however, times when you need to violate validity. For instance, if you’re adding markup from other applications such as XForms, MathML, or Scalable Vector Graphics (SVG) to your documents, those documents will not be valid. The HTML DTDs do not recognize these elements, but you can use them nonetheless. Similarly, if you’re experimenting with HTML 5, the standard DTDs and browsers won’t recognize your new elements. And there are other reasons you might choose to introduce invalid markup.
That being said, if you can make your documents valid, you should. Valid XHTML will help browsers more closely reflect the author’s intent. If you absolutely must publish invalid documents, I suggest that you carefully control and limit the invalidity. First, make a valid document that leaves out the invalid pieces; then add the minimum number of invalid pieces you need to accomplish your goals.
As a practical matter, you should usually start by making a document well-formed before making it valid. Often the distinction is a little fuzzy. For instance, normalizing the case of all tags to lowercase improves both well-formedness (because start-tags now match end-tags) and validity (because only lowercase element names are valid). Adding a DOCTYPE declaration is optional for well-formedness, but it is required for validity. You can even have valid HTML (though not XHTML) that is not well-formed. In general, though, it is simplest if validity builds on well-formedness.
A document can be invalid in an infinite number of ways. In this chapter, I’ll focus on some of the most common problems you’re likely to need to fix. Once you have valid pages, you will be ready to move on to the next steps, and you can begin to work on improving the appearance, accessibility, and usability of your site.
Insert the XHTML transitional DOCTYPE declaration at the start of each document.
<html xmlns="http://www.w3.org/1999/xhtml"><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml">
The transitional DTD enables you to validate the document while not immediately requiring fully semantic markup. It still allows documents to include deprecated presentational elements such as i, b, and center. Thus, you can find and fix any serious structural problems before moving on to improving the semantics of your document.
Browsers that use the presence or absence of a DOCTYPE to select quirks mode may format the document somewhat differently after you’ve added the DOCTYPE. Although changes should not be major, you should manually inspect pages to make sure nothing too serious has changed. The most likely things to break are any browser-specific hacks you’ve installed, especially ones intended for Internet Explorer.
The first step to making a document valid is to add a document type definition, or DTD. Technically, you don’t add the DTD itself to the document. Rather, you add a DOCTYPE declaration that points to the document type definition. The DOCTYPE declaration will be the first item in the document, even before the root element. For example:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml">
In practice, browsers never actually read the DTD that the DOCTYPE declaration references. They simply check the public identifier to see which variant of HTML they’re dealing with. Thus, you don’t need to worry that this points to an external file on an external server. This will not slow down document display in the browser.
XML parsers and other XML tools do read the DTD, though. If you’re using any of these, you may wish to point to a local copy of the DTD instead. For example, this DOCTYPE asserts that the transitional DTD can be found at the root of the current server in the dtds directory:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "/dtds/xhtml1-transitional.dtd">
You can download the DTDs from the W3C at www.w3.org/TR/2002/REC-xhtml1-20020801/xhtml1.zip and install them wherever convenient. That archive contains the entire XHTML spec. You’ll find the DTDs in the DTD folder.
Pages that define framesets should use the frames DTD instead:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd"> <html xmlns="http://www.w3.org/1999/xhtml">
This is not necessary for pages that merely use an iframe for an ad or two. The transitional DTD works fine for those.
You can automate these fixes fairly easily. TagSoup does not add DOCTYPE declarations, but Tidy does. Unless asked otherwise, it defaults to the transitional DTD when run in XHTML mode.
This is also fairly easy to fix with multifile search and replace. Search for an html start-tag at the beginning of a document, like this:
A<html
You may want to allow for whitespace in front of the start-tag, too:
As*<html
Then replace that with the desired DOCTYPE followed by <html.
Once you’ve added the DOCTYPE, validate all your documents, as discussed in Chapter 2. This will reveal a number of problems to fix. I’ll detail some of the most common problems in subsequent sections in this chapter.
Eliminate bogons.
Modern browsers do not support a lot of the old, deprecated, vendor-proprietary tags such as marquee and multicol introduced in the wild and wooly early days of the Web. If still relevant, these should be replaced by standard tags and CSS stylesheets. If not, they should be deleted to save space and simplify documents.
Older browsers that actually depend on these tags may see a slightly less formatted page. For example, old versions of Netscape will no longer see two columns on a page after you replace a multicol element with CSS. However, today many more browsers don’t support the multicol element than do. You’ll improve the experience for a lot more people than you’ll degrade it.
Regardless of what changes you make, all the actual content of the page should still be present and accessible. It may just be formatted a little differently. This will be improved with CSS later.
Chances are there aren’t a lot of bogons in your documents. However, if one does show up, it’s worth searching for it across more of the site. You’ll usually find the first one by validation. For example, here’s xmllint complaining about an unrecognized multicol element:
$ xmllint --valid --noout document.html
valid.html:18: element multicol: validity error : No
declaration for element multicol
</p></multicol>
^
valid.html:20: element body: validity error : Element body
content does not follow the DTD, expecting (p | h1 | h2 | h3 | h4 | h5 |
h6 | div | ul | ol | dl | pre | hr |
blockquote | address | fieldset | table | form | noscript
| ins | del | script)*, got (h1 multicol )
</body></html>
^Notice that it complains twice: once to tell you that there’s no declaration for the multicol element and once to tell you that multicol is not a legal child of its parent body element.
Where there’s one bogon, there are usually more. Once I noticed that someone had added multicol elements to one page, I’d do a quick search for <multicol across the entire document tree. Any pages where that phrase pops up are worth a closer look. In this case, there’s no good CSS equivalent for multicolumn layouts, so we’ll probably just remove the tags. (They haven’t worked in most browsers for years any-how.) Just replace <multicol> and </multicol> with the empty string. If the multicol elements have attributes, you can search for the regular expression <multicols*[^>]*> instead.
Here are some other elements you may find in your documents that you’ll want to do away with:
marqueeblinkxmpbasefontbgsoundkeygensoundspacerappcommenthtmlpluslayerhypewbr
This isn’t an exhaustive list. There was a time when browser vendors were competing in terms of how many weird tags they could add to HTML. A surprising number of those are still floating around unnoticed on web pages.
A few of these may still work in some browsers. For instance, Firefox supports both marquee and blink. However, neither scrolling nor blinking text is a good idea in the first place. These elements were left out of the official HTML specs for good reason, and you should leave them out of your sites, too. You may want to look at individual occurrences to see what more static styles you might replace these with.
xmp is another bogon that may actually have a raison d’être on your site, especially if the site is dedicated to HTML tutorials or markup languages. It functions much like an XML CDATA section. That is, it interprets everything inside the text as plain text, not markup. You could replace <xmp> with <![CDATA[ and </xmp> with ]]>. However, legacy browsers don’t recognize CDATA sections, so you’re better off just removing the xmp tags and manually escaping everything between them.
You may also occasionally encounter a misspelled tag. For example, you could see <tabel> instead of <table> or <dvi> instead of <div>. These are worth a closer look to figure out just what was intended in the first place. However, because they had no actual effect, you can probably take them out without breaking anything.
Add an alt attribute to every img tag that doesn’t have one.
<img src="right_arrow.gif" width="100" height="50"/> <img src="integral.png" width="75" height="65" /> <img src="logo.png" width="42" height="42" />
The primary reason to add alt text is to assist visually impaired users. Although currently this is a relatively small number of people with visual handicaps, in the near future this class is likely to grow quickly as audio browsers become embedded in cell phones, cars, MP3 players, and other devices aimed at people who may need to keep their visual attention elsewhere.
The second reason is for search engine optimization. Google, especially Google image search, pays a disproportionate amount of attention to the text in alt attributes. If your content is visual—photographs, maps, diagrams, and so forth—you can get quite a bit more high-quality traffic by tagging your images accurately.
Adding alt text requires a lot of time and human intelligence. There are few shortcuts. That being said, the improvements are linear. You can make some of the changes and get some of the return. You don’t have to do it all at once.
Finding images with no alt attributes is straightforward. XHTML requires an alt attribute so that the validator will report all img elements that do not have an alt attribute. You can also do a quick search with a regular expression that matches img tags and all their possible attributes except alt:
<imgs+((height|width|border|class|align|id|src|usemap|hspace|vspace)s
*=s*("[^"]+"|'[^']+')s*)*>This does not match img tags that contain alt attributes and does match every other likely img tag.
However, filling in the missing attributes is not so trivial, and it requires some consideration and human intelligence.
Every image that is part of the content should have a text description that substitutes for the image when used by a screen reader. Sometimes this is simply a description of the image itself. For example, when I posted the picture in Figure 4.1 as part of a story, I used the alt text “30 White Ibis walking across the street in front of a stop sign.”

Or perhaps you’ve embedded a PNG of the equation in a mathematical paper, like so:
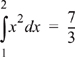
The correct alt text for this would be “The definite integral of x squared between 1 and 2 is seven thirds.”
However, many times the image is not really content. It is iconographic. In this case, choose your words so that the meaning is conveyed rather than the description. For example, on many web sites you’ll see something like this:
<a href="slide67.html"> <img src="right_arrow.gif" width="100" height="50"/> </a>
The correct alt text here is not “blue arrow facing right”. Instead, it is simply the word Next. This conveys the meaning of the image better than a description could.
Finally, many images are simply decorations with no real content at all. These should have empty alt attributes. That is, they should look like this:
<img src="bookcover.png" width="90" height="150" alt=""/>
Consider what happens when every image on your page is replaced with its alt text, because this is exactly what happens for a blind user. The page is likely to be imperfect under these conditions, but try to make it as sensible as possible.
Browsing the Web with a screen reader is challenging at best. Try it sometime yourself if you possibly can. Recruit some blind people to user-test your site while you watch. One thing you can do to improve the experience is remove the number of images whose alt text must be read. Even things that are logically content, such as corporate logos, product photos, and book covers, should often have empty alt text if seeing them is not essential to grasp the content of the page. It takes longer to hear a page than to read it, so anything you can do to compress the page for blind users is appreciated.
There is one trick you can play to speed up the process and reduce the effort of adding alt text. Many images, especially decorative and functional ones, are reused on multiple pages. This makes it possible to do a quick search and replace to add the same alt text to many pages. For example, if you know the file right_arrow.gif is used throughout the site to point to the next page, you can search for src="right-arrow.gif" and replace it with the following:
src="right-arrow.gif" alt="next"
You may even want to just search for right-arrow.gif" and right-arrow.gif' to account for tags in different directories that use different paths to that same file. Literal search is usually sufficient here. You don’t need regular expressions.
Change all embed elements to object elements.
<embed src="banner.swf" quality="high" bgcolor="#006699" width="160" height="600" name="banner" align="middle" allowScriptAccess="sameDomain" type="application/x-shockwave-flash" pluginspage="http://www.macromedia.com/go/getflashplayer" /> <embed src="quicktime_example.mov" width="640" height="480" autoplay="true" controller="false" pluginspage="http://www.apple.com/quicktime/download/" /> <embed src="wicked.rpm" width='200' height='134' />
Netscape invented the embed element to reference any sort of content that would be handled by external plug-ins rather than the browser itself: Flash, RealMedia, QuickTime, PDF, and so on. If this tag were invented today, namespaces would be used, but back then elements were just added to HTML willy-nilly. Netscape figured that one tag for 100 formats would be better than 100 tags for 100 different formats, and they were almost right. However, it did allow the embed element to have an indefinite number of undefined attributes, which makes it impossible to validate.
Consequently, despite its broad adoption and support, embed has never been a part of any HTML specification. However, because it is a nonstandard extension, browser support is inconsistent, even to the level of which attributes browsers recognize and what they mean.
The object element is better documented, more consistently supported in modern browsers, and more agnostic about just what kind of content it loads and who renders it. Most important, whereas embed can have an infinite number of possible attributes, object has just a few. Plug-in-specific parameters can be passed through param child elements, each of which has just two attributes—name and value—to identify the parameter being set. This means object can be validated in a way embed never could be.
Some older browsers, including Netscape 4 and earlier and Internet Explorer for the Mac, do not recognize the object tag. To work around this you can include an embed element inside the object element like so:
<object type="application/x-shockwave-flash"
width="160" height="600" id="banner">
<param name="allowScriptAccess" value="sameDomain" />
<param name="movie" value="banner.swf" />
<param name="quality" value="high" />
<param name="bgcolor" value="#006699" />
<embed src="banner.swf" quality="high" bgcolor="#006699"
width="160" height="600" name="banner"
align="middle" allowScriptAccess="sameDomain"
type="application/x-shockwave-flash"
pluginspage="http://www.macromedia.com/go/getflashplayer" />
</object>Browsers that don’t recognize object will use the embed element. Browsers that do recognize object will ignore it. Such documents are not valid. However, they do work well in browsers. In fact, this is close to what the Flash authoring environment exports.
A somewhat more serious concern is that Internet Explorer will not stream Flash animations embedded like this. It will download and play them, but that can take awhile for a large file. The trick here, named Flash Satay by its discoverer Drew McLellan, is to embed an initial small Flash file whose only purpose is to load and stream the second, actual Flash animation. The minimum you need in the loader movie is this ActionScript on the first frame:
_root.loadMovie(_root.path,0);
The URL to the second, actual animation is in the path variable of the first animation’s query string. Thus, your object element will look like this:
<object type="application/x-shockwave-flash" data="first.swf?path=second.swf" width="300" height="300"> <param name="movie" value="first.swf?path=second.swf" /> </object>
Another noticeable trade-off is one of developer education and convenience. The Flash authoring program generates HTML for authors to include in web pages. However, this HTML is nonstandard and ugly. Using clean, standard markup requires editing a lot of this by hand.
Because the embed element has never been officially included in HTML (though it has been widely supported), any level of validation will find it. Alternatively, you can just do a quick search for <embed to find all the places you have to fix.
Embedded Flash animations usually have the offending embed element wrapped in an object element, because that’s what the Flash authoring environment generates. However, this object element only works for some browsers, and you’ll need to modify it to make it work for all of them.
Usually the object tag you start with looks like this:
<object classid="clsid:d27cdb6e-ae6d-11cf-96b8-444553540000" codebase="http://fpdownload.macromedia.com/pub/shockwave/cabs/flash/ swflash.cab#version=8,0,0,0" width="160" height="600" id="banner" align="middle"> <param name="allowScriptAccess" value="sameDomain" /> <param name="movie" value="banner.swf" /> <param name="quality" value="high" /> <param name="bgcolor" value="#006699" /> </object>
This is suitable for Internet Explorer but not for most other browsers. To make it work elsewhere you need to make these changes.
Add a
type="application/x-shockwave-flash"attribute.Add a
dataattribute that points to the movie—for example,data="banner.swf".Remove the
codebaseattribute.Remove the
alignattribute. Use CSSfloatproperties instead. Add anidattribute for this property to attach to.
The result looks like this:
<object id="flash23" classid="clsid:d27cdb6e-ae6d-11cf-96b8-444553540000" type="application/x-shockwave-flash" width="160" height="600" id="banner"> <param name="allowScriptAccess" value="sameDomain" /> <param name="movie" value="banner.swf" /> <param name="quality" value="high" /> <param name="bgcolor" value="#006699" /> </object>
Other embedded content, such as QuickTime movies, may not be so conveniently wrapped. In this case, you will need to construct your own equivalent object element to replace it. Some of the attributes of the embed element map more or less directly to attributes of the object element or to CSS properties, as shown in Table 4.1.
Table 4.1. Converting Embed to Object
embed Attribute | object Attribute | CSS Property |
|---|---|---|
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
|
|
|
|
|
|
|
|
However, the embed element uses different attributes for different types of content. Embedding a QuickTime movie has one set of attributes. Embedding a Flash animation has a different set of attributes. Embedding a Windows Media Player movie has still another. For example, consider this element that embeds a QuickTime movie:
<embed src="quicktime_example.mov" width="640" height="480"
autoplay="true"
controller="false"
pluginspage="http://www.apple.com/quicktime/download/"
playeveryframe="true"
loop="true"
showlogo="false"
/>When changing embed to object, all attributes except width, height, id, and archive become param elements. The name of each param is the name of the attribute, and the value of the param is the value of the attribute:
<object width="640" height="480" classid="clsid:02BF25D5-8C17-4B23-BC80-D3488ABDDC6B" codebase="http://www.apple.com/qtactivex/qtplugin.cab"> <param name="src" value="quicktime_example.mov"> <param name="controller" value="false"> <param name="autoplay" value="true"> <param name="loop" value="true"> <param name="showlogo" value="false"> </object>
Insert the XHTML strict DOCTYPE declaration at the start of each document.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "DTD/xhtml1-transitional.dtd">
The strict DTD removes deprecated presentational elements such as b, i, and center. You can replace these with semantic elements such as em and strong and CSS styles. This will make your meaning clearer.
It also enables you to move the style information fully into CSS. This reduces bandwidth and makes it much easier to lay out a page, because the markup is not competing with the stylesheet.
The strict DTD is extremely limiting. A lot of elements and attributes you’ve been accustomed to using are no longer allowed. Some changes that may be required involve substantial manual effort.
The counterbalance is that web browsers do not require validity. It is OK to serve documents with the strict DTD even if they still use deprecated elements such as b, i, and iframe. It is OK to have text that is not enclosed in a paragraph. Such documents are not valid, but browsers can handle them. You can gradually increase your conformance by making a series of small changes as time permits.
The first change you need to make is to point to the strict DTD from the DOCTYPE declaration:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
If you’ve already made your documents valid against the transitional DTD, this is a simple search and replace. Search for -//W3C//DTD XHTML 1.0 Transitional//EN and replace it with -//W3C//DTD XHTML 1.0 Strict//EN. Then search for xhtml1-transitional.dtd and replace it with xhtml1-strict.dtd.
Tidy defaults to the transitional DTD when run in XHTML mode, but you can ask it for strict instead using the --doctype option:
$ tidy -asxhtml --doctype strict example.html
Once you’ve added the strict DOCTYPE, validate all your documents once more, as discussed in Chapter 2. This will reveal a number of problems to fix. I’ll detail some of the most common problems in subsequent sections in this chapter.
Change all center elements into divs or the equivalent semantic element; then apply the CSS text-align property.
<h1><center>Martians Invade!</center></h1>
XHTML strict does not allow the center element because centering is about appearance, not meaning. Centering is not possible in non-GUI browsers such as Lynx or screen readers. It should be replaced by more descriptive semantic markup.
Because centering is so purely presentational, it’s often a candidate for style changes when a site is redesigned. If the styles are extracted out into external CSS stylesheets, the updates associated with a redesign are much simpler and faster to implement.
Very old browsers may not recognize the CSS rules, so a few details may not come across, but we’re talking truly ancient browsers here.
In CSS, centering is accomplished by the text-align property with the value center. You can apply this property to all elements of a specific type. For instance, you can center all level 1 headings:
h1 {text-align: center; }Or you can apply it to all elements of a specific class, such as booktitle:
*.booktitle {text-align: center; }You also can center one specific element by referencing its ID:
*#bt1 { text-align: center; }You can apply this rule in one of three places:
A
styleattribute on the element itselfA
styleelement in the document’s headAn external CSS stylesheet
The last option is usually the best. It enables you to share styles across documents, which maintains a consistent look and feel for the site as well as reducing bandwidth requirements. However, we’ll often use the first two as intermediate steps while working up to fully external stylesheets. Furthermore, I will sometimes demonstrate a technique with an inline style here just to keep the examples reasonably short.
Tidy will define replacement CSS classes and rules if you ask it to with the -clean option. Then it will put them in the head. For example, it changes this:
<html>
<head>
<title>Wet Willy's Wonderland!</title>
</head>
<body>
<h1><center>Wet Willy's Wonderland!</center></h1>into this:
<html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>Wet Willy's Wonderland!</title> <style type="text/css"> /*<![CDATA[*/ div.c1 {text-align: center} /*]]>*/ </style> </head> <body> <div class="c1"> <h1>Wet Willy's Wonderland!</h1> </div>
However, the names it chooses aren’t especially meaningful, and it can’t distinguish among different reasons for the center element. Furthermore, it may introduce unnecessary divs, as it did here. What you’d really like in this case is something more like this:
<html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>Wet Willy's Wonderland!</title> <style type="text/css"> /*<![CDATA[*/ h1 {text-align: center} /*]]>*/ </style> </head> <body> <h1>Wet Willy's Wonderland!</h1>
In fact, even this rule should really go into an external stylesheet. Consequently, you’ll probably want to clean up Tidy’s output by hand.
Change all font elements into div, span, or the equivalent semantic element; then apply CSS font properties.
<font face="Tahoma" size="+3" > Camp Edgewood in the Sunny Pines </font> <p><font face="Arial"> Where every boy deserves a week of summer camp. <font size="1">(Not responsible for leeches.)</font> </font> </p>
XHTML strict does not allow the font element because fonts describe appearance, not meaning. They are deprecated in XHTML transitional and even HTML 4. They are the poster child of presentational markup. They do not work in non-GUI browsers such as Lynx or screen readers. In many environments such as screen readers, the whole notion of a font may be meaningless. They should be replaced by more descriptive markup. This can take the form of semantic elements such as cite or h1, or span elements with descriptive class names.
Because fonts are purely presentational, they are frequently changed when a site is redesigned. If the styles are extracted out into external CSS stylesheets, the updates associated with a redesign are much simpler and faster to implement.
Because this refactoring removes elements, your pages will likely be smaller and load faster without font elements, especially if your stylesheets are externalized.
Furthermore, the DOM built for these pages is smaller and simpler. This may improve JavaScript execution speed. It will certainly improve the ease with which you can write JavaScript programs that use the browser’s DOM.
Very old browsers may not recognize the CSS rules, but we’re talking truly ancient browsers here. Even the first and buggiest third-generation browsers that supported CSS at all supported this much.
Finding font elements is simple. Strict validation will sniff them all out, or you can just search for <font or </font>. Once you’ve found them, convert their attributes to CSS properties, as shown in Table 4.2.
The values for face and color attributes are also legal values for the font-family and color properties, respectively. However, for size, one additional change is needed. CSS uses keywords where font uses numbers. Table 4.3 shows the mappings between font numbers and CSS keywords.
You’re likely to encounter two kinds of font tags: those that are nestled snug against other tags and those that appear in the middle of text. The first case is more common. Typically it looks something like this:
<h3><font size="-1">Random Sites Around the Web</font></h3>
Sometimes the font element is wrapped around another element instead of inside it:
<font size="-1"><h3>Random Sites Around the Web</h3></font>
In either case, you simply assign an ID to the semantic element (h3 in this example) and then add a rule to your stylesheet that applies the same style to that ID:
h3#randomsites { font-size: smaller; }
...
<h3 id="randomsites">Random Sites Around the Web</h3>It’s not uncommon to discover the same font applied to several related elements on the page. For instance, if several H3 headers are styled as <font size="-1"> you define a class that all these elements can share and apply the style to that:
h3#sites { font-size: smaller; }
...
<h3 class="sites">Intranet Sites</h3>
<h3 class="sites">Random Sites Around the Web</h3>Less commonly, the font element encloses several elements, so you use class and/or id to apply the style to them too.
On occasion, you may find a font element that neither immediately encloses another element nor is immediately closed inside one. For example:
<p>Sincerely yours,<br /> <font face='Lucida Handwriting'> Harry W. Wacker </font></p>
In this case, you can simply replace the font element with a span or div element, assign an id and/or class to that span or div, and then apply the styling to it.
span#signer { font-family: "Lucida Handwriting"; }
...
<p>Sincerely yours,<br />
<span id='signer'>
Harry W. Wacker
</span></p>Font choices do sometimes convey meaning. For instance, in the preceding fragments, a handwriting font indicates the correspondent’s signature. If this is the case, define a class name that indicates that meaning and use it to attach the equivalent CSS rule. For example:
*.signature { font-family: "Lucida Handwriting"; }
...
<p>Sincerely yours,<br />
<span class='signature'>
Harry W. Wacker
</span></p>The mechanics for replacing font with CSS are much the same as the mechanics for replacing center with CSS. The key difference is that font is an inline element, whereas center is a block element. Thus, if you need to insert an extra element to which to attach the CSS rule, it will be a span rather than a div.
Used with the -clean option, Tidy fixes up font tags as it does center tags. It replaces the font tags with span tags and adds CSS rules to the document’s header to indicate the changes. This comes with the same caveats as it does for center: The names it chooses aren’t especially meaningful, and Tidy can’t distinguish among different reasons for different font elements. Furthermore, it may introduce unnecessary spans when the font is nested directly against an enclosing element. I prefer not to use Tidy for this fix.
Change all i elements into em, span, or the equivalent semantic element.
<i>Literally</i> should <i>not</i> be used to emphasize a phrase. (<i>Strunk and White, Elements of Style, p. 52</i>).
The i element is not allowed in XHTML strict. It describes appearance, not meaning, and it does not work in non-GUI browsers such as Lynx or screen readers. It should be replaced by more descriptive semantic markup. Sometimes that’s an em element, but surprisingly often it’s something else.
The very oldest browsers may not recognize the CSS rules. However, even the first and buggiest browsers that supported CSS at all supported this much. The em element is supported by all browsers back to Mosaic 1.0.
Simple validation with the strict DTD will locate all the i elements. That’s not hard. Alternatively, you can just do a quick search for </i> to find them all.
If you’re willing to assert that the only reason you ever used the i element was for emphasis, you can just replace these with em tags. However, that’s actually not common.
Many sites use the i element purely as a presentational effect, without meaning a whole lot. If this is the case, replace it with CSS. For example, change this:
<li><i>JavaOne</i></li>
into this:
<li style="font-style: italic">JavaOne</li>
You may wish to use a class or id attribute so that you can place the style information in an external stylesheet instead:
<li class="conference" id="javaone07">JavaOne</li>
If necessary, you can introduce an extra span element to hold the style, class, and/or id attributes:
<span class="conference" id="javaone07">JavaOne</span>
Often the i element means something, but not emphasis. One common use is to indicate the title of something: a book, a newspaper, an article, and so on. This is better handled in strict HTML with the underused cite element. For example:
<cite>My Sister Eileen, pg. 9</cite>
Most graphical browsers style the cite element as italic.
Another common use of italics is to indicate foreign words in English text. These can be noted in HTML with the lang or xml:lang attribute. For example:
I greeted Pierre with a hearty <span xml:lang="fr">Bon jour!</span>
There are many other uses of italics in text. Some of the more common include the following.
Names of legal cases, for example, Eldred v. Ashcroft
Epigraphs at the heads of book chapters
Words used as words: It’s hard to spell necessarily
Words that imitate sounds: D’oh!
Genus and species, for example, Aix sponsa
The words see and see also in cross references and indexes for example, see also the Chicago Manual of Style, Section 17.18.
HTML does not have individual elements representing these uses. Instead, they should be indicated by a span or div element whose class attribute indicates the reason for formatting the text as italic:
The drake Wood Duck (<span class="species">Aix sponsa</span>) is the prettiest waterfowl.
Similar techniques should be used for nontraditional uses of italics, such as the earlier conference example or indicating the external links on a page. Indeed, it’s even more important to use external CSS for these elements because you’re even more likely to want to change the style as part of a redesign. If you later decide that conference names should be colored red instead of italicized, it’s relatively hard to find all the conferences in your site. It’s relatively easy to change the one line in a CSS stylesheet that formats elements with class="conference".
Change all b elements into strong elements or span elements.
I'm <b>very</b> certain of this. The triangle inequality states that ||<b>x</b> + <b>y</b>|| ||<b>x</b>|| + ||<b>y</b>||
The b element is not allowed in XHTML strict. It describes appearance, not meaning, and it does not work in non-GUI browsers such as Lynx or screen readers. It should be replaced by more descriptive semantic markup. Usually that’s a strong element, but on occasion it’s something else.
Very old browsers may not recognize the CSS rules. However, even the first and buggiest third-generation browsers that supported CSS at all supported this much. All browsers back to Mosaic 1.0 support the strong element.
Simple validation with the strict DTD will locate all the b elements. Alternatively, a quick search for </b> will find them all.
If you’re willing to assert that the only reason you ever used the b element was to emphasize something, you can just replace these with strong tags.
However, many sites use the b element as a fairly presentational effect, without meaning a whole lot. If this is the case, replace it with CSS. For example, change this:
<a href="72.html"><b>Next Page</b></a>
into this:
<a style="font-weight: bold" href="72.html">Next page</a>
You may wish to use a class or id attribute so that you can place the style information in an external stylesheet instead:
<a class="navigation" id="nextlink" href="72.html">Next page</a>
If necessary, you can introduce an extra span element to hold the style, class, and/or id attributes.
Sometimes the b element does mean something, but what it means is not important. In particular, headlines are often listed in bold, sometimes with accompanying font tags as well. These should be replaced by the appropriate level of header: h1 to h6, and CSS used to reapply the styles. For example, suppose you had this New York Post classic at the top of the page:
<b>Headless Body Found in Topless Bar</b>
<h1>Headless Body Found in Topless Bar</h1>
Other cases you should watch out for where bold may not mean importance include
Vector quantities in mathematics, physics, and engineering
Page numbers of drawings in book indexes
These uses are uncommon, and you can usually ignore them. However, if you encounter any of these cases, turn them into class attributes. For example:
span.vector {font-weight: bold }
...
||<span class='vector'>x</span>
+ <span class='vector'>y</span>||
||<span class='vector'>x</span>||
+ ||<span class='vector'>y</span>||Move all descriptions of color out of the HTML document and into the CSS stylesheet.
<body bgcolor="#FFFFFF" text="#000000"> <h2><font color="#AA0000">Today's News</font></h2>
Color attributes are not allowed in XHTML strict. They describe appearance, not meaning, and they do not work in non-GUI browsers such as Lynx or screen readers. They should be replaced by semantic class attributes mapped to CSS rules.
CSS will make it much easier to maintain a consistent color scheme across a site. It will also make it much easier to update and experiment with new color schemes. In addition, it enables you to provide different but equivalent noncolor styles to be used when the document is printed on a black-and-white printer.
Very old browsers may not recognize the CSS rules, so a few details may not come across, but we’re talking truly ancient browsers here. Even the first and buggiest third-generation browsers that supported CSS at all supported this much.
Moving color from HTML into CSS differs from the last few refactorings because color is always specified with an attribute rather than a specific element. With the partial exception of font, usually an element is already present in an obvious location to which you can attach the styles. At most, you should just have to add an id or class attribute to it so that you can address it from CSS. Sometimes you don’t even have to do that.
Table 4.4 lists the various color attributes you may encounter and the CSS equivalents.
The most common place to see colors set is on the <body> start-tag. For example, some pages specify black text on a white background:
<body bgcolor="#FFFFFF" text="#000000">
This is easily replaced with this CSS rule:
body { color: #000000;
background-color: #FFFFFF; }CSS supports the same hexadecimal values for color properties as HTML does, so you can just copy the old HTML attribute values into the CSS properties. Of course, if you like, feel free to upgrade to HTML 4/CSS named colors instead. For example:
body { color: black;
background-color: white; }You also can specify the vlink, alink, and link attributes of the body element in CSS using the same color property. You simply apply the color to the pseudoclasses :visited, :active, and :link instead of to an element. For example:
*:vlink { color: green; }
*:alink { color: red; }
*:link { color: yellow; }However, in this case I’ll make a strong suggestion that you simply delete these attributes without replacing them in CSS. Standard colors that don’t change from one site to the next help users to recognize links. Changing link colors makes your site harder to navigate. A discontinuity in color schemes between the link colors and everything else on your site is a small price to pay for assisting users with navigating your site.
If a font element specifies the colors, you may need to replace that element with a span element to have someplace to put the color. Follow the instructions in the previous section.
When invoked with the -clean option, Tidy will define replacement CSS classes and insert matching rules in a style element in the head. For example, it changes this:
<body bgcolor="#FFFFFF" text="#000000"> <h2><font color="#AA0000">Today's News</font></h2>
into this:
<style type="text/css">
/*<![CDATA[*/
body {
background-color: #FFFFFF;
color: #000000;
}
h2.c1 {color: #AA0000}
/*]]>*/
</style>
</head>
<body>
<h2 class="c1">Today's News</h2>However, the names Tidy chooses aren’t especially meaningful, and it can’t determine the reasons for the color element. Furthermore, the rules should really go into an external stylesheet. If possible, clean up Tidy’s output by hand.
Remove the align, border, hspace, and vspace attributes from img elements. Replace them with CSS rules.
<img src="/images/newicon.png" alt="New!" width="90" height="54" hspace="5" vspace="5" border="0" align="left" />
XHTML strict moves much of the style for img elements such as align, vspace, hspace, and border into CSS.
Making this change is especially important if you’re doing heavy CSS layout. Adding layout attributes such as these to img elements can interfere with the layout described in the external CSS stylesheet. It’s easier to debug CSS layouts when all the relevant details are in one place, rather than spread out across different files and locations.
As usual, moving the presentation into CSS does cause cosmetic problems in older browsers, and in this case maybe they’re not quite as ancient. However, it’s still true that all current browsers should work just fine with strict markup, and older ones won’t be shut out. They’ll just see a less attractive page.
Validation will find the img elements you need to fix. From that point, though, it’s a bit of a slog. Tidy and TagSoup will not help. Furthermore, many of these attributes have values specific to just one image, so you’ll need to assign an ID to each image and write some rules just for it. Consequently, this is one of the few places where I suspect it often does make sense to use style attributes and inline CSS rather than an external stylesheet.
Table 4.5 lists the attributes you’ll need to change and the CSS properties you’ll replace them with.
For hspace and vspace, notice that CSS gives you more control. You can set the right padding separately from the left padding and the top padding separately from the bottom. When converting to CSS, you’ll need to copy the values from hspace into both padding-left and padding-right. You’ll also need to copy the values from vspace into both padding-top and padding-bottom.
If you’ve modified align, you should also look for any <br clear="all"/> tags that may be lying around. These make sure that the image doesn’t go too far down the screen when the line width is larger than expected. The br element is allowed in strict XHTML, but the clear attribute is not. Instead, you assign the br element a CSS clear property with the value left, right, or both. There’s not a lot of semantics involved here, so I usually just identify these as classes. For example:
br.left { clear: left; }
br.right { clear: right; }
br.all { clear: both; }
...
<br class="left" />
<br class="right"/>
<br class="all" />Tidy will not help with these. You’re on your own.
Change all applet elements to object elements.
<applet code="com.example.Bullseye" codebase="/applets" width="100" height="100" align="left" alt="Bullseye!" name="bullseye"> <param name="rings" value="8" /> <param name="outer" value="red" /> <param name="inner" value="white" /> <p>Bullseye!</p> </applet>
XHTML strict does not allow applet. Instead, it uses the object element. The applet element was removed because it only handles Java applets, not Flash, PDF, HTML, QuickTime, or many other formats authors want to insert in web pages. The object element is simply more generically useful.
In some browsers, the applet element is handled by an outdated Java virtual machine bundled with the browser. However, the object element is handled by the more up-to-date virtual machine in the Java plug-in. Furthermore, the object element allows for near-automatic installation of the current version of Java, whereas the applet element does not.
No one object syntax works for all browsers. To work around this you can nest object elements inside each other and use conditional comments to keep Internet Explorer from seeing the second object element:
<object width="300" height="300"
classid="clsid:8AD9C840-044E-11D1-B3E9-00805F499D93"
codebase="http://java.sun.com/products/plugin/1.4/jinstall-
14-win32.cab#Version=1,4,0,mn">
<param name="codebase" value="/applets">
<param name="archive" value="foo.jar">
<param name="code" value="com.example.applets.BugView">
<!--[if !IE]> -->
<object classid="com.example.applets.BugView"
archive="BugView.jar"
type="application/x-java-applet"
width="300" height="300">
<param name="codebase" value="/applets">
</object>
<!-- <![endif]-->
</object>Browsers fall through these until they find one they recognize. However, IE’s must-ignore behavior is nonconformant, so we have to use special comments to hide markup from it. This is ugly and large, but it is technically valid, and it does seem to work in all modern browsers.
Strict validation will find and report all applet elements that you need to fix. Alternatively, you can just do a quick search for <applet.
You need to change this twice, once for IE and once for other browsers. The IE-specific object element wraps the other object element. We use IE conditional comments to hide the inner object element from IE.
For the outer element:
Change
applettoobjectin both the start- and end-tags.If the value of the
codeattribute ends in.class, remove.class. The value of thecodeattribute should be the fully package-qualified name of the applet, nothing more or less.Add a
classid="clsid:8AD9C840-044E-11D1-B3E9-00805F499D93"attribute.Move the
codebaseattribute (if any) into aparamchild element with aname="codebase"attribute. Thevalueattribute of thisparamelement should have the actual codebase as its value.Add a new
codebaseattributeMove the
archiveattribute (if any) into aparamchild element with aname="archive"attribute. Thevalueattribute of thisparamelement should have the value of the oldarchiveattribute as its value.Change the
objectattribute (if any) to adataattribute with the same value.Add a
codebaseattribute pointing to the version of the Java plug-in you want to use—for instance, http://java.sun.com/products/plugin/1.4/jinstall-14-win32.cab#Version=1,4,0,mn for Java 1.4.
Other attributes and child elements can remain in place.
The resulting object will work in Internet Explorer, but not in most other browsers. For that, we need a second object element. To prevent IE from seeing it and becoming confused, we first have to wrap it in IE conditional comments:
<!--[if !IE]> --> <object ...> ... </object> <!-- <![endif]-->
In this object element we make the following changes:
Change
applettoobjectin both the start- and end-tags.Remove the
codeattribute.Add a
classid="java:fully.package.qualified.classname"attribute.Add a
type="application/x-java-applet"attribute.Move the
codebaseattribute (if any) into aparamchild element with aname="codebase"attribute. Thevalueattribute of thisparamelement should have the actual codebase as its value.Remove the
codebaseattribute.Change the
objectattribute (if any) to adataattribute with the same value.
Finally, put the non-IE object element inside the IE object element and use this to replace the applet element.
This has focused on the Java-specific changes. You may also need to move some presentational attributes into CSS. In particular, the align attribute turns into a CSS float property, and the hspace and vspace attributes are replaced by padding properties. Table 4.6 summarizes.
Table 4.6. Converting applet to object
object Attribute | CSS Property | |
|---|---|---|
|
| |
| ||
|
| |
|
| |
|
| |
| ||
|
| |
|
| |
|
| |
|
|
|
|
|
|
|
|
|
Remove all big, small, strike, s, tt, and u elements and insert equivalent CSS or semantic elements.
<big>All Items A Fraction of Their Usual Price!</big> <small>That fraction is 7/3.</small> <strike>Pick up laundry.</strike> <s>Walk dog.</s> <tt>$ ls *.txt</tt> <u>The Lord of The Rings</u>
XHTML strict does not allow any of these elements either. Usually there’s a good semantic reason for these styles that you can capture with specific elements, such as cite, or with a class attribute.
Very old browsers may not recognize the CSS rules, so a few details may not come across, but we’re talking truly ancient browsers here. Even the earliest browsers that supported CSS at all supported this much.
Validation against the strict DTD finds all of these. Alternatively, you can search for the start-tags <big, <small, <strike, and so on. These elements aren’t as commonly used, so there aren’t likely to be quite as many of them as i and b.
Sometimes these elements are purely presentational. In this case, replace them with a span and attach the necessary CSS to reproduce the styles. The one I’d make an exception for is the u element. Underlining is almost never appropriate for anything except links. It’s used to simulate italics on typewriters, but it has little place in print or on the Web.
Many times, however, these elements do have semantic meaning, and it’s worth capturing that. For example:
<tt>is sometimes used to mark up code. If so, replace it with<code>.<tt>is sometimes used to mark up sample output. If so, replace it with<samp>.<big>is often used for important (<strong>) or headline (<h1>-<h6>) text.<s>and<strike>are used to indicate deleted text. If so, replace them with<del>.
Of course, HTML doesn’t have elements for all the uses to which you might have put these styles. For instance, <small> often indicates legal fine print. You can mark this up with CSS and a semantic class:
<span class="legal"> All users of this web site agree to turn over their first-born children. All legal disputes will be resolved by binding arbitration overseen by an impartial panel chosen from the Board of Directors' spouses, children, and other immediate family members. </span>
Table 4.7 lists the remaining, less common deprecated elements from classic HTML that you’ll want to replace with CSS.
The mechanics of fixing them are much the same as for fixing b and i. If you know that all the occurrences of one of these styles are for the same reason, you can just do a quick regular expression search and replace. However, if they’ve been used inconsistently, you’ll need to inspect them manually. This isn’t as much of a problem here as with the more common b and i tags, though.
Give every inline element a block-level parent, and remove all block-level elements from paragraphs.
Do you like this picture?<br /> <img src="file.gif" alt="Goose" width='100' height='100'/> I think it's really <em>neat</em>.<br />
To be valid, it is not sufficient that all the elements in a document be legal XHTML strict elements. They must also have the right relationships to each other. Browsers and other programs depend on correct placement. For instance, an li element must always be a child of a ul or ol element, and each ul or ol element must have at least one li child. Blockquotes can contain paragraphs, but paragraphs can’t contain blockquotes.
Although browsers will display documents that violate these structure rules, they may interpret them differently. Furthermore, this sort of invalidity can even more seriously confuse editors and other non-browser tools that attempt to work with the HTML. For instance, as I write this, some people are having problems because WordPress is rewriting their markup in unexpected ways to try to fix blockquote/paragraph nesting issues.
When paragraphs or block-level elements are not found where they’re expected, browsers and other tools guess where they should insert extra content to make them fit. They don’t always guess right, and they don’t always guess the same. This causes problems designing cross-browser CSS and JavaScript. Nesting your elements correctly helps browsers and tools to process a document consistently.
None. Browsers deal inconsistently with poorly structured pages. Reorganizing them will give much more consistent behavior across browsers.
The main body of an HTML page consists of several kinds of elements plus text:
Paragraphs:
p,preBlock-level elements:
address,blockquote,center,dir,div,dl,fieldset,form,h1,h2,h3,h4,h5,h6,hr,noscript,ol,table,ulInline elements:
a,abbr,acronym,b,bdo,br,cite,code,dfn,em,img,input,label,q,samp,select,span,strong,sub,sup,textarea,varMiscellaneous elements:
button,del,iframe,ins,map,object,scriptContext-limited elements:
li,dt,dd,tr,th,td,tbody,input,selectRaw text; a.k.a. PCDATA
A block element represents a distinct section that is separated from the elements that precede and follow it. In visual renderings, this separation usually takes the form of a hard line break. In strict XHTML, the body of the page can only contain block elements.
Most block elements can nest. That is, a block can contain other blocks. However, there are a couple of notable exceptions: p and pre.
A p element represents a paragraph. However, unlike other block-level elements, a p may not contain another p or another block element such as blockquote. It can only contain plain text and inline elements. It is in some sense the lowest block-level element.
The pre element is also special in this way. It can contain inline elements, but not other block elements.
Inline elements such as span, strong, img, and a are contained within some block. In transitional XHTML, this block may be implicit, but in strict XHTML, this block must be an explicit block-level element. Inline elements can usually contain other inline elements (though there are exceptions), but they may not contain block elements. Inline elements may wrap from one line to the next, but they do not cause line breaks as long as there’s space left on the current line.
A few miscellaneous elements such as object and ins can be used as either inline or block elements. However, if they’re used as inline elements (i.e., they’re inside a paragraph or pre), they cannot contain a block element.
Finally, a few context-sensitive elements appear in certain parent elements but not others. For instance, an li element must be a child of a ul or ol element. An li element anywhere else is invalid. A td element must be a child of a tr element, which must itself be a child of a tbody or table element. These elements may not appear outside their defined parent elements.
If any elements appear where they don’t belong, the validator will tell you about them. There are actually two styles of error message you may see. Some validators tell you that the parent element has the wrong child. For example, xmllint provides this error message:
example.html:12: element p: validity error : Element div is not declared in p list of possible children
Others tell you that the child has the wrong parent. A few may tell you both. Either way the meaning is the same.
The most common variation of this problem is an inline element without a parent—in particular, raw text that is an immediate child of the body element:
<body> <h1>Welcome to Acme!</h2> Your one-stop source for rockets, explosives, anvils, and portable holes.
In this case, just wrap the excess text in a paragraph or a div as appropriate:
<body> <h1>Welcome to Acme!</h2> <p> Your one-stop source for rockets, explosives, anvils, and portable holes. </p>
Another element that often surprises is img. This is an inline element, and it should be wrapped in a div or possibly a paragraph. For instance, change this:
<img src="cup.gif" width="89" height="67" alt="Cup" />
to this:
<div> <img src="cup.gif" width="89" height="67" alt="Cup"/> </div>
figure Element
HTML 5 may add a figure element specifically for block-level images:
<figure>
<img src="cup.gif" alt="Cup"
width="89" height="67"/>
</figure>It is also a validity error if a p element contains another p or block element. The paragraph is the lowest block-level element. Although a div, blockquote, or table can contain a paragraph, the reverse is not true. For example, this is a problem:
<p>Once upon a time someone famous said,
<blockquote cite="Percy Bysshe Shelley, Ozymandias">
<p>My name is Ozymandias, king of kings</p>
<p>Look on my works, ye mighty, and despair!</p>
</blockquote>
but who it was that said that, I cannot say. He has been
forgotten.
</p>The usual way to fix it is to make two paragraphs—one before the blockquote and one after, like so:
<p>Once upon a time someone famous said,</p>
<blockquote cite="Percy Bysshe Shelley, Ozymandias">
<p>My name is Ozymandias, king of kings</p>
<p>Look on my works, ye mighty, and despair!</p>
</blockquote>
<p>
but who it was that said that, I cannot say. He has been
forgotten.
</p>Similar fixes work for tables, lists, and other block elements you may find in a paragraph.
Blockquotes in Paragraphs
The prohibition on blockquotes within paragraphs is somewhat controversial. Irrespective of HTML, many style manuals do recognize the presence of blockquotes within single paragraphs, and they do treat a construct such as the preceding example as one paragraph that contains a blockquote rather than as a sequence of paragraph-blockquote-paragraph. XHTML 2 has proposed to make it possible to embed blockquotes within paragraphs.
Tidy can fix this if you use the --enclose-block-text yes option:
$ tidy -asxhtml -c --enclose-block-text yes example.html