
If you’re at all aware of Internet security, you’ve probably heard the term buffer overflow, followed by shudders, groans, and swearing. But if you’re unclear on what exactly a buffer is, let alone what would make it overflow, don’t worry. We explain the whole thing in this chapter. Once we nail down exactly what buffer overflows are, we talk about how to prevent them.
Buffer overflow attacks are particularly vicious because they allow attackers to do just about anything they want with your server. They can run remote applications, gain root access to your server, or simply cause the entire system to crash.
The good news is, buffer overflow vulnerabilities are difficult to find and deceptively trivial to prevent. Then why are they such a big problem in the Internet security field? Preventing buffer overflow vulnerabilities requires you as a programmer to write code defensively, and for most of us that’s a completely different mind-set from what we’re used to. Programmers like to create working systems from grand ideas. Most have a hard time looking at their own creations and thinking up ways to break them. But that’s exactly what you have to do in order to harden your application against buffer overflow attacks.
You may have heard that PHP isn’t vulnerable to buffer overflow attacks. In fact, that may even have been one of the reasons you chose to write your application in PHP rather than in one of the other languages used for Web development. That’s true, up to a point. Unfortunately, there are two major problems with the idea that you as a programmer can ignore buffer overflows because you write in PHP:
• The fallibility of each programmer on the PHP development team
• The underlying foundation on which PHP is built
We’ll talk about the underlying foundation later in this chapter. You’ll need a basic idea of what buffers are and how they overflow before we can get into PHP’s foundations. The next section will explain the basics of buffers, stacks, heaps, and memory allocation. Before we get into the hard-core computer science, let’s discuss fallibility for a moment.
Anytime you read or hear that a given technology can’t be broken in one way or another, don’t believe it. No matter how careful programmers are when they create their applications, they miss things. Your application will never be 100 percent secure. None of the applications and systems we’ve ever worked with—our own or those of our colleagues in the Web development and Internet security fields—have ever been 100 percent secure. The same goes for the work of the PHP development team. They’re a great group of programmers, and the fact that they’ve produced such a widely used programming language speaks very highly of their abilities. But they’re still human, and humans miss things sometimes. That’s just reality. You can’t catch every single bug, every possible security hole. Remember, the Titanic was supposed to be unsinkable, and look how that worked out.
PHP was designed to make buffer overflow attacks obsolete (we’ll get into how that works later in the chapter, after you know how buffers work), but they have still crept in. The good news is, as soon as they’re found, the PHP development team has fixed the problem areas and released a new version of PHP. The bad news is, if you’re in a shared hosting environment or don’t control your own Web server, it may not have the most up-to-date version of PHP. This is something you’ll simply have to check on and ask your system administrator to update if necessary. We get into that in more detail in Chapter 13, “Securing PHP on the Server.” But that’s not the real bad news. The real issue here is that if buffer overflow vulnerabilities were found in one version of PHP, they may still exist in later versions and simply haven’t been found and exploited—yet. And let’s just say, hypothetically, that PHP as it exists today is 100 percent invulnerable to buffer overflow attacks. There’s no guarantee that the next version won’t accidentally introduce a bug that allows for buffer overflows. The members of the PHP development team, like any other group of programmers, are just human and they make mistakes just like the rest of us.
Just because you can’t trust the statement that PHP is invulnerable to buffer overflows doesn’t mean the code you write in PHP is hopelessly insecure. It simply means that you don’t get the luxury of ignoring the problem, so you’ll have to write code that defends against this type of attack. Before we get into how to do that, read the next section for a brief overview of exactly what a buffer overflow is.
In order to understand how buffer overflow attacks work, you have to understand how computers store programs and data in memory, so before we can get into how to prevent buffer overflow attacks, we’re going to have to delve into some computer science. This isn’t something you’ll ever have to work with directly (unless you decide to write a low-level code library), but it does affect the PHP interpreter and the libraries your application relies on, so it’s a good idea to have a general understanding of what’s going on. You’ll probably never design a new engine for your car either, but if you plan to do your own maintenance, it helps to have a basic understanding of how the internal combustion engine works. The same thing applies to programming. If you want to write your own high-level applications, it helps to have a general idea of what’s going on under the hood. It’s safest to assume that the hackers who attack your code have a better understanding of the inner workings of PHP, the underlying C libraries, and the operating system it all runs on than you do. Figure 4.1 shows how the low-level code in the operating system and the C libraries PHP relies on affects your application.

The hackers who will attack your application have a very good understanding of this relationship and will use their knowledge of low-level programming against you. If you ignore buffer overflows simply because PHP is supposed to be invulnerable to them, you’re basically leaving your front door unlocked. Maybe no one will come along and try an attack. But if someone does, your application, and the Web server it runs on, will come crashing down. The rest of this chapter is all about how to lock the door.
When a program is loaded, the program instructions are stored in memory. Other sections of memory, called buffers, are also set aside to hold the program’s data (stored in global variables), any libraries the program refers to, and two data structures: the stack and the heap. The memory allocation for a single program is shown in Figure 4.2.
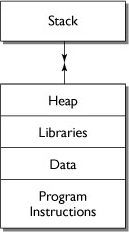
The stack is like an array that stores information relevant to the specific subroutine currently executing. For example, when our guestbook application calls the moveFile() function (which we defined in Chapter 3, “System Calls”), some context information is stored at the top of the stack. When moveFile() calls the exec() function, exec’s context information is stored above the information for moveFile(), as shown in Figure 4.3.
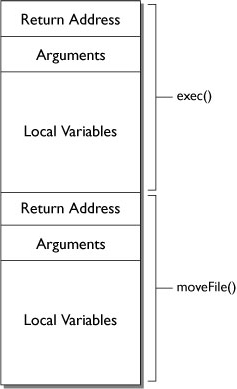
The heap functions in a very similar way to the stack. It is laid out differently, but essentially it stores the same information:
• Return address: The address in memory where the calling program instructions are stored. This tells the computer where to look for its next instruction, once the immediate subroutine is finished.
• Arguments: The area where data passed to the subroutine is stored before it is moved into a local variable.
• Local variables: The area where any local variables are stored. Any data stored in this area becomes unavailable once execution control passes out of the current subroutine and back to the calling program.
Remember, the stack is filled from the bottom up. This is crucial for understanding buffer overflows. To exploit a program that is vulnerable to buffer overflows, a hacker simply has to pass in more data than the argument buffer is prepared to store. The computer stores as much information as it can in the argument buffer, then overwrites the next available memory address—the return address buffer.
At best, this will cause the program to behave erratically and probably crash the application, if not the whole server. A skilled hacker can carefully set up his or her exploit so that the return address buffer isn’t overwritten with random data but rather a specific address that contains the hacker’s own malicious code. This address could be another memory location on the same server or instructions stored on a remote server.
If all this sounds ominous, it should. But just in case you’re not thoroughly convinced that buffer overflow attacks are an unmitigated bad thing, take a look at some of the more common consequences of buffer overflows:
• Injection attacks, which enable hackers to insert code, SQL statements, or just about anything else into your application
• Arbitrary code attacks, in which hackers can gain direct, root-level access to the server’s operating system, allowing them to completely take over the server
• Denial-of-service attacks, which cause the server to get so bogged down in executing malicious code (usually an infinite loop or other meaningless instructions) that it doesn’t have the resources to perform normal tasks
• Remote exploits, where your server is used as a staging point to attack other servers
How does all this happen, when PHP is supposedly immune to buffer overflows? We’ll get into the nuts and bolts in the next section.
Hackers overflow the buffer by passing large strings into your application through an input field. Your application takes that input and stores it in a variable—which is stored in the stack. If the input is larger than the space allotted for it, you have a buffer overflow.
PHP itself doesn’t set limits on how much data a variable can hold. This is the basis of PHP’s theoretical invulnerability to buffer overflow attacks. If there’s no size limit on variables, it’s impossible to send a string that’s too large for the variable to hold, right? It works on paper, but in reality there’s no such thing as an infinitely large variable. There are limits to how large a variable can be. These limits are imposed by the amount of memory available on the server, and by the underlying C code that the PHP interpreter and its libraries are built on.
In late October of 2006, the Hardened-PHP Project (www.hardened-php.net) found a buffer overflow vulnerability in the htmlentities() and htmlspecialchars() functions that are built into PHP. Those two functions are built with the idea that HTML characters are never more than eight characters long. Most of the time this is true. Unfortunately, if you use UTF-8 encoding with Greek characters, this assumption fails.
UTF-8 is a variable-length character-encoding scheme that allows for characters outside the typical Roman alphabet. The benefit to using UTF-8 is that it allows your application to handle international data, typically in Asian or Middle Eastern languages. To handle these characters, UTF-8 allots 4 bytes to each character:
• The 128 ASCII characters require only 1 byte to encode. These are the characters most commonly used online because for much of the existence of computing, work was done primarily in English. Politically incorrect? Possibly. But computer programmers—especially those who deal with low-level operating system functions like character encodings—aren’t widely known for their social graces. UTF-8 was created to solve the limitations of English-based ASCII while maintaining backward compatibility. The UTF-8 encoding of the letter A, for example, would be only 1 byte long, just like its ASCII equivalent.
• Latin, Greek, Cyrillic, Armenian, Hebrew, Arabic, Syriac, and Thaana alphabets require 2 bytes to encode. This is where htmlentities() runs into trouble, because it assumes a 1-byte character.
• Three bytes are required for the Basic Multilingual Plane in Unicode, which includes virtually all characters in use today.
• Four bytes are reserved for other Unicode planes, which are rarely used. This, however, doesn’t mean you can assume the fourth byte in a UTF-8-encoded character is empty or harmless.
The htmlentities() and htmlspecialchars() functions assume an 8-character entity. Most of the time this isn’t a problem. As we noted above, the vast majority of computing is done in English, although this is changing as the Internet becomes more widely available outside of North America and Western Europe. What happens when a user (or a hacker, depending purely upon motivations) inserts a Greek UTF-8-encoded character into your Web form, which you then pass to htmlentities() for sanitization before displaying it in the browser? When the HTML entity encoder in PHP encounters this Greek HTML entity that is larger than the current 8-character buffer, PHP will simply increase the size of the buffer by 2 characters. Unfortunately, if the HTML entity is 11 characters long, the buffer will overflow and allow for arbitrary code to be executed. Figure 4.4 shows how PHP handles a normal, English-language HTML entity. Figure 4.5 shows how this vulnerability is exploited with a Greek character.


There are two important points to take from this exploit:
• First, buffer overflows do happen in PHP. The only solution to the htmlentities() and htmlspecialchars() exploit is to upgrade PHP to version 5.2.0 or greater, so it’s crucial to keep PHP (and its underlying libraries, and the operating system) up to date.
• Second, if a buffer overflow vulnerability occurred once, it can—and will—occur again. Just because one hole was closed does not imply that no other holes exist, nor does it imply that new holes won’t be introduced in the next version of the language, or its underlying libraries. Before the htmlentities() and htmlspecialchars() buffer overflow vulnerability was discovered, the same vulnerability was found and fixed in the wordwrap() function. There will certainly be vulnerabilities discovered in the future. You simply can’t assume that because one vulnerability was found and resolved, another doesn’t exist or won’t be introduced later.
The moral of this story is, don’t rely on PHP to keep your application safe from buffer overflows. You have to defend your own code and your own data against this type of attack. The rest of this chapter deals with how to go about protecting your application from buffer overflows.
Your server may be as secure as you can make it today, but that does not imply that it will be secure tomorrow. New exploits and vulnerabilities are being discovered constantly, and the only way to know whether your systems are affected is to watch the security alerts. Luckily for us all, there are a few organizations that collect and distribute the latest security information. Take a look at the list in the Appendix, “Online Resources,” for each organization’s Web site and mailing list information.
Figure 4.6 shows a sample security alert from SecurityFocus.
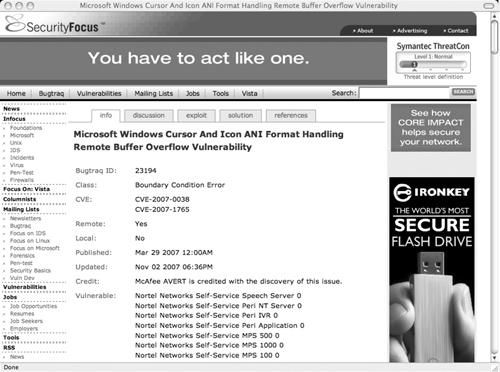
This looks like a lot of meaningless information, but we’ll go through it and pick out the most important points. On the first tab, “info,” you see the following information (as well as some other things, but these are the most important):
• Class: This tells you what type of problem the alert addresses. In this case a Boundary Condition Error is another way of saying buffer overflow.
• Remote: This tells you whether or not the vulnerability can be exploited to give an attacker remote access to the system. If a vulnerability can be exploited remotely, that’s bad. Well, any vulnerability is bad, but remote ones are worse.
• Local: This is the opposite of remote; someone must be physically connected to the system in order to exploit it. Some vulnerabilities can be exploited both locally and remotely.
• Published and Updated: These tell you how recent the alert is. Unfortunately, you can’t necessarily assume that alerts from 1999 are obsolete, but you should certainly pay attention to the ones published or updated within the past few months.
• Vulnerable: This is a list of systems and versions that are vulnerable to the problem described in the alert.
SecurityFocus isn’t the only security watchdog. CERT and the Hardened-PHP Project also release security information. Figure 4.7 shows a CERT advisory. It includes much of the same information as the SecurityFocus advisory.
Figure 4.8 shows an advisory from the Hardened-PHP Project.
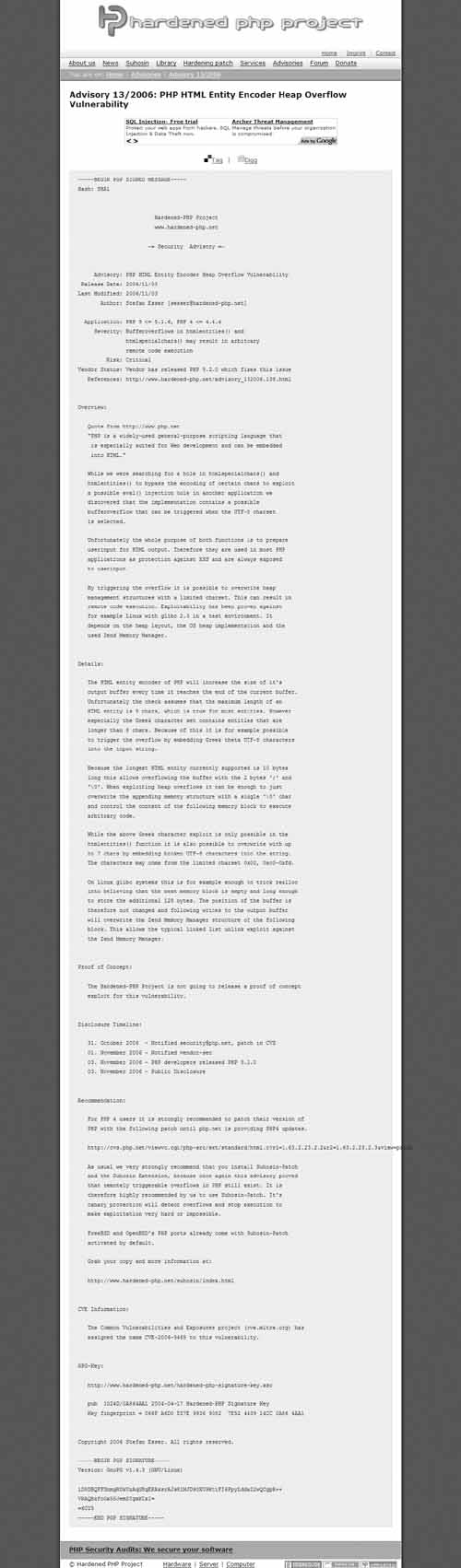
Why do you need to watch more than one security advisory source, when they all give the same basic information? First, it’s just a good idea to cross-reference your information to be sure it’s accurate. Second, each group has its own team of exploit researchers. Often one group will find a vulnerability that the others aren’t aware of. In order to get the most complete and up-to-date information, you need to keep an eye on all the security alerts. Luckily, they all allow you to subscribe to a feed that delivers information to your desktop via e-mail or RSS, so you don’t need to visit each Web site separately.
Buffer overflow attacks exist because hackers can put their own data into specific parts of the computer’s memory. The only way to do that is to sneak data into the application. You can prevent malicious users from sneaking data into your application by sanitizing, or verifying, the data in your variables.
The first place to start sanitizing variables is with user inputs. If you assume that all data coming in from users is malicious, you’ll verify it before you use it. (See Chapter 5, “Input Validation,” for more details on how to verify data.)
Unfortunately, even if you sanitize every single piece of data coming in from users, you’re not completely safe from buffer overflow attacks. Users aren’t the only source of data coming into your application.
There are three primary sources of data for any application:
• The users
• Outside data sources, such as remote databases, RSS, data feeds, or even the command line
• System functions
User input is the most obvious source, and the most dangerous, but that doesn’t mean you can ignore outside data sources and system functions. They can be exploited, too; it’s just a little harder. If your application uses data pulled from an external database or other data feed mechanism, you have no way of knowing firsthand how secure that data, or the server it resides upon, really is. For all you know, that server was compromised at some point, giving hackers an opening to attack other servers, including yours. If Joe Hacker’s goal this week is to see how much havoc he can wreak, what better way to bring down thousands of servers than to slip a few Greek characters into a popular RSS feed? You should assume that any data coming in from an external source could be altered and intended to cause a buffer overflow condition.
System functions are a lot harder to corrupt, but it can be done if a malicious user already has access to the server. This is usually the case with disgruntled employees or contractors—since they have access to the server, they can replace a regular system function with exploit code. If you are the only person with direct access to the server, you probably don’t have to worry about this type of vandalism, but if you are on shared hosting or in a corporate environment where access to the server is relatively open, you should validate any data coming from a system function as well—just in case. It is relatively rare that this type of attack will occur, but it really doesn’t take much effort to validate data. It’s simply a matter of maintaining a healthy sense of distrust while you write your code.
Chapter 5, “Input Validation,” goes into more detail on how to sanitize data, so we’ll just deal with one facet of sanitization here. The most important check for preventing buffer overflow condition is data length. If you’re expecting a string, use the strlen() function (as shown in the following) to make sure it’s not longer than your variable can hold:
if(strlen($incoming_html_char) > 10) {
//Reject the data
} //otherwise continue processing
$safe_html .= htmlentities($incoming_html_char);
In this case, we’ve chosen an arbitrary length that we assume is smaller than the underlying buffer. As application programmers, we are several layers removed from the actual buffer code, so unfortunately we don’t usually know exactly how large the limit is, at least not until it’s been exploited. Sure, we could dig through the code for the PHP interpreter and all its built-in functions and libraries to figure out if there are assumed variable size limits (as in the htmlentities() and htmlspecialchars() vulnerability). Once we’re done there, we’d have to do the same thing with all the C libraries that PHP is built on. If you have that kind of time, go for it. For most of us, that’s just not realistic, so we make educated guesses about what a reasonable length for our variables is.
Of course, if you’ve created an API to handle all system calls, as discussed in Chapter 3, “System Calls,” sanitizing data coming in from those system calls is even easier. Simply add the check to the API function and return only data that is of the expected length.
To add buffer overflow prevention to the guestbook application, we’ll need to perform two tasks:
• Verify that we’re running the latest stable version of the operating system, PHP, and database.
• Add length checks to all data coming into the application.
On average, this should take a couple of hours of time—not a bad investment to prevent one of the most vicious types of attacks.
Our guestbook is running on a shared hosting account on a Red Hat Linux server, so the first step in verifying that the server is up to date is to check the control panel and user agreement for our shared hosting account. If that doesn’t give us the version numbers we need, we’ll send off an e-mail to our host’s technical support crew, explaining that we’re hardening a custom application against buffer overflow attacks and would like to verify that the server is running the latest stable versions of the operating system, PHP language, and database server. It’s always helpful to do a little research and include the version numbers for each system. After all, if we make it as easy as possible for tech support to get us the information we need, odds are in our favor that they’ll get back to us quickly.
To check the version numbers for this system, we’ll need to visit the following Web sites:
• Linux kernel: www.kernel.org/
• Red Hat Linux: www.redhat.com/rhel/server/details/
Scroll about halfway down the page until you see the section on “Kernel,” as shown in Figure 4.9.

What you want to verify is that the kernel version listed on the Red Hat site is within a few minor releases of the official latest kernel release. As of this writing, the latest stable version of the Linux kernel is 2.6.23.9. Red Hat is using 2.6.18. As long as the first two sets of digits match, you’re probably fine. The digits in the version number are progressively more minor.
The first digit, 2, is the major release number. You should always avoid using a system that is a major release behind. The second digit is a minor release number. It’s a good idea to keep up with the minor releases as well. The last two digits are usually very minor releases—bug fixes, changes to documentation, that sort of thing. Although it’s a good idea to stay current, it’s really not necessary to install every single bug fix release, unless the bug fix is something that actively affects your environment.
• MySQL: http://dev.mysql.com/
Look for the GA, or “Generally Available” version. RC versions or alpha versions are still in development or testing and aren’t recommended for production environments.
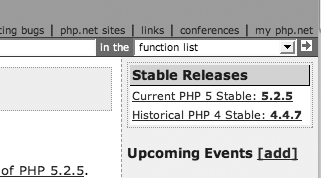
• PHP: www.php.net
The latest version is listed right on the front page. If you don’t see it there, look on the right-hand side under “Stable Releases” as shown in Figure 4.10.
While we wait for tech support to get back to us confirming the version numbers, we’ll get started on variable sanitation. The first thing we’ll tackle is the system calls API we created in Chapter 3, “System Calls.” Since we’re working with shared hosting, we really can’t afford to trust the data that comes in from anywhere, not even from the underlying operating system.
As the application stands, the system calls API looks like this:
function moveFile($tainted_filename) {
// Set up our variables
if(strlen($tainted_filename) > 256) {
//return FALSE; //Bail
}
$filename = NULL; // This will hold the validated filename
$tempPath = '/www/uploads/';
$finalPath = '/home/guestbook/uploads/';
// Validate filename
if(preg_match("/^[A-Za-z0-9].*.[a-z]{0,3}$/", $tainted_filename)) {
$filename = $tainted_filename;
} else {
return FALSE; // Bail
}
// At this point, we can safely assume that $filename is legitimate
exec("mv $tempPath.$filename $finalPath.$filename");
}
All we’ve added is the simple if() statement checking the length of the tainted variable. If it’s too long, we stop processing and return FALSE, which lets the application know that something went wrong. We’ll go through the rest of the application and repeat the process. Once we’ve covered all user input and system calls (we can ignore external data sources, since we don’t use them in this application), we can be reasonably assured that the application is safe from buffer overflow attacks.
We covered some pretty heavy computer science in this chapter, explaining what a buffer is and how it allows hackers to inject their own code into your application. We also talked about how to stop any hacker from exploiting the buffers your program runs upon by implementing some basic server security and presuming that any data coming into your application is guilty until proven innocent.