
Chapter 7. Web Service Evolution
Introduction
Service developers strive to maintain Backward Compatibility whenever a service is changed. This condition exists when the service can successfully process requests from clients that submit older versions of messages or media types. Backward compatibility also means that a client won’t break if the service returns a response using an updated data structure that the client may not fully comprehend. Services can also be Forward Compatible. A client may, for example, send “version 2” of a message, but the service may only know how to process data found in the first version because it hasn’t been altered to work with the newer message structure. This is a common occurrence when structures are defined by external parties. If the service can still process the request without crashing, it may be considered Forward Compatible [Orchard].
Backward and forward compatibility are quite difficult to achieve. A service can only be forward-compatible if it is able to ignore new content. This means that, while the service cannot process data that it is not yet aware of, it should still be able to process the remainder of the request. As a practical matter, service owners tend to spend the majority of their time worrying about backward compatibility. The key problem that all service designers should be aware of is that services can cause clients to break whenever the data structures they receive or send are changed.
While changes to the internal logic of a service can certainly cause clients to break, most of the focus in this chapter is on how changes to a service’s contract (see Chapter 2) affect backward compatibility. We’ll look at the factors that cause breaking changes, and briefly review two common versioning strategies. We’ll also see how RPC APIs (18) can be designed to become less brittle and more flexible, and we’ll review an approach that lets all services, regardless of API style, to be augmented so that they may receive and process new data. Finally, we’ll present an approach that helps all message recipients to become more resilient, and another that ensures services will continue to meet the needs of clients. This chapter concludes with a brief look back at how many of the patterns in this book either support or hinder service evolution. Table 7.1 presents an overview of the patterns in this chapter.
Table 7.1. Patterns for Web Service Evolution
What Causes Breaking Changes?
A breaking change is any change that forces client developers to update their code or change configurations. Clients that fail to makes the necessary changes may experience runtime exceptions. The most common causes for breaking changes include
• Moving services to different domains
• Changing the URI patterns clients use to address services
• Structural changes to media types or messages
• And Service Descriptor (175) changes
Among other things, the section titled How the Patterns Promote Service Evolution at the end of this chapter provides tips on how the first two issues can be mitigated. This section focuses on the last two bullet items.
Structural Changes to Media Types or Messages
Service developers must consider how clients may be affected by changes made to the data structures exchanged with clients. In many cases, the required media types or messages will be formally defined through a meta-language such as XSD or JSON Schema. In other cases, these agreements will simply be listed on a web page. Developers should be aware of what actions on these data structures may cause breaking changes. Several of these are listed below:
• Removing or renaming qualified elements or attributes
• Changing the data types of qualified elements or attributes
• Changing elements or attributes from being optional to being required
• Changing the order in which elements occur in a data structure
• Changing the hierarchical relationships between complex data structures
• Adding elements to the middle of a strict sequence of elements
• Changing the namespace of a data structure or its child structures
• Deprecating data structures
• Changing character encodings
Clients must be able to predict the layout and data types used in service data structures. Changes like those that are listed above can make the processing rules used by clients obsolete and cause them to break. The effect of some of these changes can, however, be mitigated by using the Tolerant Reader pattern (243).
The service’s expectations regarding what information is required and what is optional can be explicitly defined through “machine-readable” meta-languages like XSD and JSON Schema. These expectations might also be described in text-based documents (e.g., Word, HTML, etc.) aimed at developers. Regardless of how these expectations are expressed, once the parties have agreed to “the contract,” and the service has been deployed, they can rarely be changed without causing some disruption. Several common-sense guidelines should therefore be considered. A service should, for example, never change an optional request or response item to become required after it is released. This action usually results in a breaking change. Conversely, a service can usually loosen restrictions and change a required request item to become optional in later releases without incurring breaking changes.
Another factor to consider is whether or not data structure items should occur in a strict sequence. Consider an address structure that contains a street name, city, state or territory, postal code, and country code. The order in which these items occur really shouldn’t matter. Unfortunately, many tools encourage the service designer to define structures that impose a specific sequence. It is worth noting that Data Transfer Objects (94) that use data-binding instructions can map data to or from message structures without imposing such strict sequences. The service designer must, however, be familiar with how to use her platform’s APIs and annotations to enable this outcome. For the greatest degree of flexibility, the Data Transfer Object may avoid data-binding altogether and instead leverage the Tolerant Reader pattern (243).
Some Resource APIs (38) use generic multipurpose media types like Atom Publishing Protocol (APP) or Microformats. These types are relatively static and change infrequently. Some contend that when these structures and protocols are used, the probability of a breaking change is remote. However, generic protocols like APP frequently carry domain-specific structures (e.g., products, customers, inventory, etc.). With APP, one must embed proprietary types within the APP content element. If a breaking change occurs on a type carried in this element, APP cannot insulate the client from the effects.
Service Descriptor Changes
RPC APIs (18) and Message APIs (27) frequently use WSDL as a Service Descriptor (175) to explicitly enumerate related services (i.e., logical operations) and to formally identify the data types received and returned by each operation. Resource APIs (38) may use the Web Application Description Language (WADL) or WSDL 2.0 for similar reasons. Artifacts created with these meta-languages are considered to be backward compatible if the descriptor contains all of the logical operations found in the prior interface, and alterations made to the referenced data structures do not cause breaking changes. New operations may therefore be added without breaking clients.
The following list identifies a few descriptor changes that can cause problems for clients.
• Changing the descriptor’s namespace.
• Removing (i.e., deprecating) or renaming service operations (WSDL) or logical identifiers (e.g., WADL method IDs).
• Changing the order of parameters in a logical operation.
• Removing or renaming operation parameters. This includes changing the service’s response to or from a null response.
• Changing operation input or response types.
• Changing service bindings (WSDL only).
• Changing service addresses.
• Asserting new policies (e.g., requiring a new form of client authentication or message encryption).
One issue with descriptors is caused by the fact that they are meant to group a set of logically related operations. While a consolidated listing of related operations can be useful to clients for code generation, this approach also increases client-service coupling. Problems may arise when a breaking change occurs on a single operation appearing in the descriptor. Such a change may require clients to regenerate their Service Connectors (168) even when they don’t care about the affected operation. Clients can choose to ignore the upgrade if they never call the affected service. However, if they eventually wish to use these services, then the connectors must be regenerated. The degree of client-service coupling for these services can therefore be decreased by minimizing the number of operations appearing in a single descriptor.
It is worth noting that Linked Services (77) provide much of the same information that appears in Service Descriptors, albeit in a “late-bound” fashion at runtime. The client must always be synchronized to know how to search Link Relations and Service Documents (re: Atom Publishing Protocol). It is possible that the service owner could remove or rename relation types or accepted media types and not coordinate these changes with the client. This, of course, may cause clients to break.
Common Versioning Strategies
Services should be expected to change. New services may be added while others are deprecated. The data structures they exchange may be altered as well. As we saw in the preceding section some actions cause breaking changes while others are backward compatible. Services may also be altered in ways that are not immediately apparent. For example, the algorithm a service uses to calculate shipping costs may change. To summarize, some service changes are overt and are related to the Service Contract (see Chapter 2) while others are subtler. Either type may call for a new release and version identifier.
Versioning techniques are used to identify service releases that encompass distinct features and data structures. Versions provide information to help clients decide what release to use. The service owner may decide to support one version at a time, or they might support multiple versions if clients migrate at different rates. In the latter case, the service owner may have to maintain multiple code-bases. This, of course, is a scenario that should be avoided, but is often necessary to support business requirements.
A formal versioning strategy enables clients to clearly identify older versions of service artifacts (e.g., messages, media types, descriptors, etc.) from newer ones. To this end, a variety of techniques may be employed. The traditional approach has been to identify major and minor releases along with revision numbers. Major releases are rolled out when breaking changes occur on the service contract or when the functionality of a service has changed significantly. Minor releases generally correspond to optional upgrades (e.g., new logical service operations) or to significant fixes or additions that do not incur breaking changes [e.g., Dataset Amendments (237)]. Service releases with revision numbers may be used to identify a logical grouping of bug fixes that are less significant than what might be found in a minor release. Clients usually only opt-in to using major or minor service releases. As you might conclude, the decision regarding what should incur a major, minor, or revision release varies per organization. Service owners must therefore create a versioning strategy that is tailored to their needs and the needs of their clients.
Example: A Client That Requests a Specific Version
The following shows how a client using a Resource API (38) may leverage Media Type Negotiation (70) to request a specific version of a proprietary media type.
GET http://acmeCorp.org/products
Accept application/vnd.acmeCorp.product+json;version=2.1
This request indicates that the client would like to receive a product data structure that has a major version of 2 and a minor version of 1. The assumption is that the service is able to produce multiple versions of this media type.
Another common versioning strategy uses dates. The following URI shows how a company might use this approach to version the data structures used by a Message API (27).
http://www.acmeCorp.org/2011/10/14/Messages.xsd
This URI provides a unique identifier for a namespace containing message definitions. It indicates that Messages.XSD was released on October 14, 2011. This technique is typically used to identify a major release; the XSD itself may also incorporate changes for minor releases. This practice provides an effective way to identify schemas that clients and services should use when validating the data structures they exchange.
Single-Message Argument
A web service receives data through an RPC API (18). Service developers are using a Code-First strategy [see the Service Descriptor pattern (175)].
How can a web service with an RPC API (18) become less brittle and easily accommodate new parameters over time without breaking clients?
RPC APIs (18) can be especially brittle. These services often have long parameter lists. If the need ever arises to add or remove parameters, one usually can’t avoid a breaking change. Service operations with these kinds of “flat APIs” are inherently inflexible and fragile. Consider the following service signature.
@WebMethod(operationName = "ReserveRentalCar")
public RentalOptions ReserveRentalCar (
@WebParam(name = "RentalCity") String RentalCity,
@WebParam(name = "PickupMonth") int PickupMonth,
@WebParam(name = "PickupDay") int PickupDay,
@WebParam(name = "PickupYear") int PickupYear,
@WebParam(name = "ReturnMonth") int ReturnMonth,
@WebParam(name = "ReturnDay") int ReturnDay,
@WebParam(name = "ReturnYear") int ReturnYear,
@WebParam(name = "RentalType") String RentalType
)
{
// implementation would appear here
}
Perhaps you might want to offer the renter the ability to supply an airport or postal code as an alternative to selecting the RentalCity. These parameters could be added to the end of this list, and many clients wouldn’t need to be updated because most auto-generated Service Proxies (168) can ignore parameters they don’t recognize as long as they occur at the end of an argument list. Regrettably, the service’s signature starts to become disorganized. It would be better if we could insert new parameters alongside the RentalCity so that the options for the rental location are all kept together. Unfortunately, a breaking change usually occurs whenever new parameters are inserted into the middle of the list. In situations like these, several tough questions must also be answered. Should the service owner create a new service, retire the old one, and coax clients onto the new service? Should he instead create a new service and keep the older one to maintain backward compatibility? Neither option seems appealing.
If we had anticipated the need to add new rental location parameters, we might have moved RentalCity to the end of the argument list so that all new parameters for this topic would follow. However, this shuffling of parameters would do little to alleviate our problems because the same situation would likely occur time and again. How can an RPC API (18) become more flexible and support the introduction of new parameters in a way that is backward compatible?
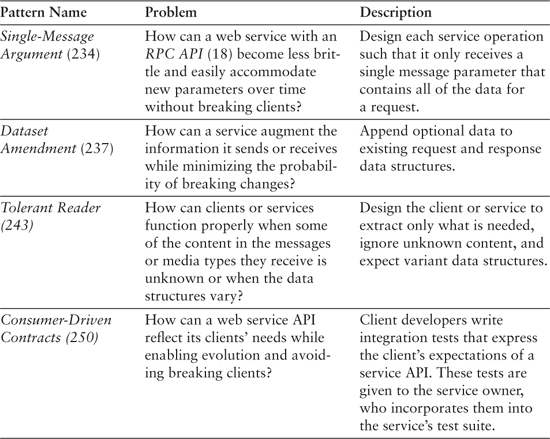
Design each service operation such that it only receives a single message parameter that contains all of the data for a request.
The Single-Message Argument pattern suggests that service developers who use a Code-First strategy [see the Service Descriptor pattern (175)] should refrain from creating signatures with long parameter lists. Signatures like these typically signal the underlying framework to impose a strict ordering of parameters. This, in turn, increases client-service coupling and makes it more difficult to evolve the client and service at different rates. RPC APIs (18) can instead be designed to receive a single message argument. These messages may contain primitive data types (e.g., integers, strings, etc.) or compound structures that may be used to group logically related data. Each child element in the message may be required or may be optional, the allowed values can be constrained or open-ended, and the order in which data is serialized can be explicitly prescribed or be allowed to vary. Each compound structure with the containing message may, of course, contain other structures as well. Their content may be required or not, constrained or open-ended, and the serialization order may vary as well.
By deliberately pushing all arguments down into a single message argument, the service designer has the opportunity to exert a greater degree of control over how the message is formatted and serialized for transmission. Developers can extend messages with ease by applying the Dataset Amendment pattern (237), and may also reuse the structure across multiple services.
Example: An Operation on an RPC API Receives a Single Message
The ReserveRentalCar service can be altered to receive a single message.
@WebMethod(operationName = "ReserveRentalCar")
public RentalOptions ReserveRentalCar (
@WebParam(name = "RentalCriteria") RentalCriteria request
)
{
// implementation would appear here
}
The message received by this service is a RentalCriteria Data Transfer Object (94). Getters and setters were omitted to keep the example brief.
@XmlAccessorType(XmlAccessType.FIELD)
@XmlType(name = "RentalCriteria")
@XmlRootElement(name = "RentalCriteria")
public class RentalCriteria {
@XmlElement(name="RentalLocation",required=true)
public RentalLocation rentalLocation;
@XmlElement(name="PickupDate",required=true)
public PickupDate pickDate;
@XmlElement(name="ReturnDate",required=true)
public ReturnDate returnDate;
@XmlElement(name="VehicleCriteria")
public VehicleCriteria vehicleCriteria;
}
The RentalLocation Data Transfer Object (94) provides a point of extensibility. This structure can be extended by adding new optional parameters without incurring breaking changes (for more information, see the section What Causes Breaking Changes? earlier in this chapter).
@XmlAccessorType(XmlAccessType.FIELD)
@XmlType(name = "RentalLocation")
@XmlRootElement(name = "RentalLocation")
public class RentalLocation {
@XmlElement(name="City") public String city;
@XmlElement(name="AirportCode") public String airportCode;
@XmlElement(name="ZipCode") public String zipCode;
}
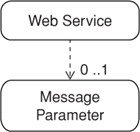
Dataset Amendment
A web service has many clients. The service may define message structures through proprietary protocols, or by using open standards like XML.
How can a service augment the information it sends or receives while minimizing the probability of breaking changes?
Clients often request changes to data structures after a service has been released. In an effort to avoid breaking changes, the service owner may decide to introduce new services (i.e., request handlers) that process client-specific messages or media types (for more on breaking changes, see the section What Causes Breaking Changes? earlier in this chapter). Message APIs (27) and Resource APIs (38) are quite flexible in that they usually can accommodate new structures without breaking clients. A Resource API (38) may, for example, use Media Type Negotiation (70) to route requests to handlers that are capable of processing client-specific data structures. Services that have Message APIs (27) can likewise receive and route client-specific requests to new handlers with minimal impact to existing clients. Unfortunately, service logic is often duplicated when individual services are created for each client application. In an effort to simplify service logic, the service owner might try to encourage all client owners to adopt the data requirements of the requestor. Regrettably, the service owner may encounter resistance if the new structures are irrelevant or incompatible with their needs.
Service owners that use XML to exchange data might consider using Extension Points to allow for Wildcard-Content [Orchard]. This technique makes it possible to add new data structures to existing XML-based messages or media types without having to update published schemas or create additional service handlers to support the new client requirements. Any party (i.e., client or service) that receives a structure with an Extension Point can ignore the data in the extension if it doesn’t recognize its content; otherwise, it can go ahead and process it. The following Java class provides an example of this pattern:
@XmlAccessorType(XmlAccessType.FIELD)
@XmlType(name = "Product",
propOrder = {"CatalogueId", "Extensions"})
@XmlRootElement(name = "Product")
public class Product {
@XmlElement(name="CatalogueId",required=true)
public String CatalogueId;
@XmlElement(name="Extensions",required=false)
public ExtensionElement Extensions;
}
@XmlAccessorType(XmlAccessType.FIELD)
@XmlRootElement(name = "ExtensionElement")
public class ExtensionElement {
@XmlAnyElement(lax=true)
public Object Extensions;
}
The associated XSD for this code looks like this:
<xs:complexType name="Product">
<xs:sequence>
<xs:element name="CatalogueId" type="xs:string" />
<xs:element name="Extensions" type="tns:extensionElement"
minOccurs="0" />
</xs:sequence>
</xs:complexType>
<xs:complexType name="extensionElement">
<xs:sequence>
<xs:any processContents="lax" />
</xs:sequence>
</xs:complexType>
While this practice is common, many have found that it can be problematic. The first issue relates to how the structures within Extension Points are validated. Implementers may constrain the allowed data structures by using the namespace attribute. They may also use the processContents attribute (re: www.w3.org/TR/xmlschema-1/#Wildcards) to prescribe how the content of the extension should be validated. The problem with this approach is that such restrictions tend to trigger many validation exceptions. Consequently, logic which catches and handles each validation error must be created, and this results in a rather inefficient and inelegant way to drive service logic. The service owner may therefore decide to let the content of each extension be unconstrained. This means that the service can’t predict what data types may be found in an extension until it is parsed. Adding to this complexity is the possibility that extensions may contain their own extensions. The service (or client) must therefore parse each extension in turn, figure out what it contains, and have a strategy for dealing with whatever it finds. Strategies to parse and validate Extension Points may be realized in many ways (e.g., programmatic logic, XPath, Schematron) and encapsulated in Request Mappers (109), but other challenges remain.
Another problem with Extension Points pertains to the problem of nondeterminism. This occurs when an XML processor (i.e., client, service, or validating XML parser) can’t figure out when a document or document fragment terminates. A complex type may, for example, define a sequence of elements that contains an optional telephone number element followed by an Extension Point. If the client sends the telephone number, the processor can’t know if that should be the last element or if the wildcard content in the extension might follow. One solution is to make everything that precedes the extension a required element, but this fundamentally alters the rules for how data is exchanged. The parties could instead identify the extension as being a required element and mark it off with Sentry Elements [Obasanjo] that surround the extension and act as delimiters. This means that the sender must always provide an extension, but the contents of it may be left blank. While this solves the problem of nondeterminism, the party receiving this structure still has no way to predict what it might find.
These problems are not unique to data exchange formats like XML. Many of these same issues must be addressed with other formats as well. How can service messages, regardless of the format, support extensibility in a way that is explicit and self-descriptive, yet does not break clients that use older structures?
The Dataset Amendment pattern suggests that service owners should append primitive data or complex data structures to any Data Transfer Object (94) as optional data. Web services can be designed to easily recognize and process amendments when they appear in requests. Since amendments are optional, breaking changes on the client side are generally avoided because most popular service frameworks skip validation of these elements and hide them from the client application. Still, their contents are frequently preserved by the framework (e.g., WCF stores unanticipated data in an ExtensionDataObject). If, for example, the client updates a structure (i.e., message or media type) received from a service, and this structure contains an amendment with content the client doesn’t recognize, the client can send the updated structure back to the originating service or to another service that recognizes the amendment, and the receiver will be able to deserialize and access the preserved amendment with ease.
Amendments to existing messages or media types are often described in a minor release. This makes it possible for services or clients that use validating parsers to deliberately select an appropriate validation scheme (e.g., XSD) for the version they understand.
Considerations
Service developers should consider the following before using the Data Amendment pattern.
• Optional data: The prerequisite for using this pattern is that the client’s data must be optional. The service should be able to successfully process the request whether or not an amendment can be found in the request.
• Doesn’t eliminate client-specific structures: This pattern does not eliminate the need to create and maintain data structures for specific clients. It does, however, provide the opportunity to evaluate how these structures might be consolidated into common messages and media types that are used by all clients.
• Ability to leverage data binding: Since the new structures are explicitly defined as being a part of the parent message or media type, one can take advantage of data-binding technologies to automatically deserialize or serialize information in these structures. This helps to simplify data handling on both the client and service sides.
• Potential for cluttered data structures: This pattern should be used with restraint because it can result in bulkier transmissions that carry data that may be irrelevant to many parties. Service designers may decide to accommodate client-specific needs by using this pattern in between major releases. However, every effort should be made to work with all parties to make the Dataset Amendments a formal part of the next major release. This does not, however, mean that the content in the amendment should be required.
• Use with abstract types: Service owners should be careful about introducing Dataset Amendments that are logically equivalent to other amendments. As an example, the service owner might create two customer Data Transfer Objects (94) which are structurally different in order to appease two different client developer groups. This will, of course, increase service complexity and reduce ease of maintenance. If the service owner cannot sway the clients to adopt a common approach, then the owner may consider using Abstract Data Transfer Objects (105) in the amendment. This variation on the Data Transfer Objects pattern can be used to define “base types” for a family of structures used in requests or responses. For example, whenever an XSD contains a reference to an abstract type, the sender may insert a concrete type derived from that type. This creates an effect similar to polymorphism. New types can be added over time without requiring the client to be updated.
Example: A Data Transfer Object That Supports Amendments
The following C# code shows how a Data Transfer Object can support amendments. The Order attribute on the FlightPreferences DTO is a platform-specific trick that forces it to be appended to the parent DTO. The more important attribute is the IsRequired value.
[DataContract]
public class TripReservation
{
[DataMember]
public string ReservationId{get;set;}
[DataMember]
public ReservationStatus Status{get;set;}
[DataMember]
public TripItinerary Itinerary{get;set;}
//****************************************
// Data Amendment/ Minor release starts here ...
//****************************************
[DataMember(Order = 999, IsRequired = false)]
public FlightPreferences FlightPreferences{get;set;}
// Other amendments would occur here
}
[DataContract]
public class FlightPreferences
{
// An enumerated type indicating
// the traveler's preferences for aisle or window
[DataMember(Name = "SeatPreference", IsRequired = false)]
public SeatPreferences SeatPreference {get;set;}
// An enumerated type indicating the traveler's
// preferences for Economy, Business, or First-Class seating
[DataMember(Name = "TravelClass", IsRequired = false)]
public TravelClass TravelClass {get;set;}
}
Tolerant Reader
A client or service expects changes to occur in a message or media type it receives.
How can clients or services function properly when some of the content in the messages or media types they receive is unknown or when the data structures vary?
Rarely can a single software release produce messages or media types that address all future needs. Indeed, Agile practices have taught us that it is more effective and realistic to adhere to the concept of Emergent Design. The idea is to deliver small incremental pieces of functionality over time, and let the system design evolve naturally. Unfortunately, this introduces the possibility for breaking changes as data items are added to, changed, or removed from the message (for more on breaking changes, refer to the section What Causes Breaking Changes? earlier in this chapter). Message designers can prevent many issues if they understand what causes breaking changes. For example, an optional message element should never become required in future releases. Consumer-Driven Contracts (250) can also help services ensure that client needs will be met when messages change. In any case, message designers must be allowed to make changes. The problem is that client developers may not be able to keep up with these changes. How can a client continue to process service responses when some of the content is unknown or the data structures vary?
Service designers often have to deal with message variability as well. For example, some message structures may be owned and designed by business partners, industry consortiums, or trade groups. In situations like these, service developers may not be able to keep up with client applications that adopt newer message versions. The service must therefore be forward-compatible and accept content that it may not fully understand.
These scenarios suggest that clients should anticipate changes in service responses, and services should, under certain conditions, expect changes in client requests.
Design the client or service to extract only what is needed, ignore unknown content, and expect variant data structures.
Tolerant Readers gracefully handle change and the unknown. This concept was described in the first part of the Robustness Principle [RFC 1122], also known as Postel’s Law:
Be liberal in what you accept
Tolerant Readers extract only what is needed from a message and ignore the rest. Declarative (e.g., XPath) or imperative approaches (i.e., static or dynamic code) can be used to surgically extract the data of interest. It should go without saying, but Tolerant Readers must always know the names and data types of the message items they are interested in.
Schema validators can be overly conservative, and often throw exceptions when the cause of the error can be addressed by the reader. Rather than implementing a strict validation scheme, Tolerant Readers make every attempt to continue with message processing when potential violations are detected. Exceptions are only thrown when the message structure prevents the reader from continuing (i.e., the structure cannot be interpreted) or the content clearly violates business rules (e.g., a money field contains nonmonetary values). Tolerant Readers also ignore new message items (i.e., objects, elements, attributes, structures, etc.), the absence of optional items, and unexpected data values as long as this information does not provide critical input to drive downstream logic.
Considerations
Client and service developers should consider the following issues.
• Data access: Developers should consider when data can be extracted from a message without having to traverse hierarchies. For example, a reader might be able to use an XPath query like //order instead of /orders/order. There will always, of course, be occasions when knowledge of a hierarchy provides the requisite context to process a message. For example, information about a spouse might only make sense in relation to an employee structure (e.g., /employee/spouse). It is worth noting that a reader can also ignore all hierarchies below the “context node” and still acquire the desired item (e.g., /employee//spouse).
Tolerant Readers should let sibling items in a data structure (e.g., XML elements in a complex type) occur in any sequence when the business rules permit. One common scenario in which this cannot be done occurs when the sequence of message items implicitly indicates the order in which data should be processed.
Tolerant Readers can ignore namespaces when processing XML. For example, the XPath expression //*[local-name()=‘order’] is able to acquire an order node regardless of the associated namespaces.
• Preservation of unknown content: While Tolerant Readers should extract and use only those parts of the message they are interested in, they should also attempt to preserve unknown content when the message must be passed on to other systems or back to the original sender. The reason is that these parties may be interested in the very same data which the reader doesn’t care about. There are many ways to accomplish this goal. The easiest way is to simply save the original message (in a memory-based variable), then pass it on to the next party. Some frameworks that use data binding provide special constructs that make it easy for recipients to get what they need out of a message while also preserving unknown content. An example of this is found in the ExtensionDataObject of Microsoft’s WCF.
• The second part of Postel’s Law: There is a second part to Postel’s Law. It states, “(be) conservative in what you send”. This means that all message senders should make every effort to conform to the agreed-upon protocols for message composition because a message sender that commits a gross violation of the “message contract” can cause significant problems, even for a Tolerant Reader. One such example occurs when the message sender fails to submit a required element or uses the wrong data type for some item. Message senders can therefore facilitate effective communications by using schema validation before sending a message. This stands in stark contrast to the Tolerant Reader, which typically avoids schema validation altogether.
• Use with Data Transfer Objects: Data Transfer Objects (94), a.k.a. DTOs, are frequently used to decouple Domain Models [POEAA] or internal APIs from message structures, and vice versa. One variation on this pattern allows these classes to be annotated with data-binding instructions that direct the recipient’s framework to map message content to or from one or several DTOs. Since the developer doesn’t have to write parsing logic, it becomes much easier to get or set message data. Unfortunately, binding annotations cause the Data Transfer Objects to become tightly coupled to the messages structures. The end result may be that a recipient which uses DTOs (with data binding) may have to regenerate and redeploy these classes whenever a message changes. This doesn’t mean that DTOs with data binding should never be used. However, developers should consider limiting their use to situations where the constituent parts of a message are relatively static and are modified through Dataset Amendments (237).
Alternatively, Data Transfer Objects can be created without data-binding instructions. These DTOs are Tolerant Readers in their own right. An example of this approach is provided in the code example that follows.
• Consumer-driven contracts: Client developers who create Tolerant Readers to receive service responses should demonstrate how the reader is supposed to behave through a suite of unit tests. These tests can be given to the service owner to help ensure that the client’s expectations will be met. For more information, see the Consumer-Driven Contracts pattern (250).
Example: A Tolerant Reader That Extracts Address Information
This example shows how a Tolerant Reader written with Java and JAX-RS can be designed to extract and validate only the message content that is required. The source XML message looks like this:
<CustomerInfo>
<CustomerAccount>
<BillingAddress street="123 Commonwealth Ave"
city="Boston" state="MA" zip="12345" />
</CustomerAccount>
<ShippingAddress street="234 State Street"
city="Boston" state="MA" zip="67890" />
<ExtraStuffThatIsIgnored>
<item id="678" count="1" />
<item id="876" time="2" />
</ExtraStuffThatIsIgnored>
</CustomerInfo>
The saveAddresses service shown below receives an InputStream from the client and passes it to the constructor of XPathParser, a class that encapsulates common XPath processing logic. The implementation details for this class have been omitted because they are tangential to the key concepts I wish to impart for this pattern. Anyway, once an XPathParser has been acquired, the service calls static methods on the BillingAddress and ShippingAddress classes in order to populate Data Transfer Objects (94) of the same name. Information from these DTOs is saved to a database; the logic for this has also been left out.
@Path("/addresses")
public class TolerantReader {
@POST
@Consumes("appication/xml")
public Response saveAddresses(InputStream stream) {
try{
XPathParser parser = new XPathParser(stream);
BillingAddress billAddress =
BillingAddress.Get(parser);
ShippingAddress shipAddress =
ShippingAddress.Get(parser);
// Save address information to a database here
}
catch(Exception x){
; // handle errors here
}
return
Response.status(Status.OK).type("text/plain").build();
}
}
The BillingAddress and ShippingAddress Data Transfer Objects (94) mentioned above extend a class named Address. This class is shown below.
public abstract class Address {
private String id;
private String street;
private String city;
private String state;
private String zip;
public String getId() {
return id;
}
public void setId(String value) {
this.id = value;
}
public String getStreet() {
return street;
}
public void setStreet(String value) {
this.street = value;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getState() {
return state;
}
public void setState(String state) {
this.state = state;
}
public String getZip() {
return zip;
}
public void setZip(String zip) {
this.zip = zip;
}
}
The DTOs shown below are the Tolerant Readers in this example. They have been designed to tolerate changes in data structures and accept, for whatever the business reason might be, the absence of individual address items (e.g., street, city, state, zip code). You should therefore assume that getNodeValueAsString does not throw an XPathExpressionException when an item can’t be found, but instead returns an empty string.
public class BillingAddress extends Address {
public static BillingAddress Get(XPathParser parser)
{
BillingAddress address = new BillingAddress();
try{
address.setId(
parser.getNodeValueAsString(
"//BillingAddress/@id"));
address.setStreet(
parser.getNodeValueAsString(
"//BillingAddress/@street"));
address.setCity(
parser.getNodeValueAsString(
"//BillingAddress/@city"));
address.setState(
parser.getNodeValueAsString(
"//BillingAddress/@state"));
address.setZip(
parser.getNodeValueAsString(
"//BillingAddress/@zip"));
}
catch(Exception ex){
// handle error here
}
return address;
}
}
public class ShippingAddress extends Address {
public static ShippingAddress Get(XPathParser parser)
{
ShippingAddress address = new ShippingAddress();
try{
address.setId(
parser.getNodeValueAsString(
"//ShippingAddress/@id"));
address.setStreet(
parser.getNodeValueAsString(
"//ShippingAddress/@street"));
address.setCity(
parser.getNodeValueAsString(
"//ShippingAddress/@city"));
address.setState(
parser.getNodeValueAsString(
"//ShippingAddress/@state"));
address.setZip(
parser.getNodeValueAsString(
"//ShippingAddress/@zip"));
}
catch(Exception ex){
// handle error here
}
return address;
}
}
Consumer-Driven Contracts
By Ian Robinson
A service has several clients, each with different needs and capabilities. Service owners know who their clients are, and client developers can establish a channel for communicating their expectations of the service’s API to service owners. Such interactions typically occur within an enterprise or corporate environment.
How can a web service API reflect its clients’ needs while enabling evolution and avoiding breaking clients?
Service APIs are often used by multiple clients in different contexts, but designing a web service interface to support these different usages can be difficult. If an API is too coarse-grained, its use will be limited to a very specific context. If it is too granular, clients will often have to supplement it with functionality or data sourced from elsewhere. Getting the balance right depends on understanding how clients expect to use the service. A client’s needs and capabilities around message types and representation formats, as well as the mechanisms used to invoke procedures and access resources, can vary from client to client; these needs and capabilities should drive the design and evolution of the service API.
A good service API decouples clients from the internal implementation of a service. But if the clients’ expectations of an API are not taken into account when designing the service, the resultant interface can inadvertently leak a service’s internal domain details. This is particularly true when wrapping a legacy system with a service API. In the struggle to make legacy functionality accessible through a web service interface, system and infrastructure details can make their way into the service API, thereby forcing the client to couple itself to the underlying system, and to what are often a lot of extraneous system-specific reference data, method signatures, and parameter values. Data Transfer Objects (94), Request Mappers (109), and Response Mappers (122) can help to prevent internal details from leaking to clients, but they do nothing to help service developers understand what clients really need or how they expect to use a service.
The use of Extension Points can help to make message and media type schemas backward- and forward-compatible. Extension points allow additional elements and attributes to be added to a message or resource representation at certain predefined places in the schema. But while extension points enable compatibility, they do so at the expense of increased complexity. By adding container elements to a message, they undermine the expressive power that comes from a simple schema. New clients often bring with them additional needs, many of which require the service API to evolve. If a service has to change to accommodate new requirements, it should do so in a way that doesn’t break existing clients. Maintaining backward and forward compatibility between different versions of a service API helps localize the cost and impact of change. When an API changes in a way that is neither backward- nor forward-compatible with previous versions of the API, there is a risk that it will introduce breaking changes (for more on breaking changes, refer to the section What Causes Breaking Changes? earlier in this chapter). Altering, testing, and rereleasing an updated client in lockstep with the modified service API results not only in the cost of change increasing, but also in it being shared between service and client owners.
Some service developers, in an attempt to prevent a service from having to change, try to design a comprehensive service API that encompasses all current as well as all future client needs and capabilities. These speculative APIs seek to protect against having to be modified at a later date by “getting things right the first time.” But no matter how much time and effort is invested in analysis and design up front, a service may still have to modify its published API if a missed requirement comes to light or an unanticipated change emerges sometime after the service is released. Such modifications reintroduce the risk of breaking existing clients.
On top of these design issues, service owners need to understand the relationships between services and clients so that they can diagnose problems, assess the impact of variations in service availability, and plan for evolving individual services in response to new or changed business requirements. In this context, service owners can benefit from understanding which clients currently use their service, and how they use it. Knowing which clients currently use a service API helps a service owner plan changes to the API and communicate those changes to client developers. Understanding how clients currently use an API helps service developers test changes to the API, identify breaking changes, and understand the impact of those breaking changes on each client.
Documentation can help communicate service and client requirements, and so smooth the evolutionary growth of a service. Documentation that describes each version of an API, its status, whether live, deprecated, or retired, and any compatibility issues can help client designers understand how to use an API and what to expect when the service changes. Client owners, in turn, can document how their client expects to use the service, and which versions of an API it uses. But unless the documentation is generated from code and schema artifacts, and regenerated every time those artifacts change, it can quickly become out of date and of little value. What the parties really need are a set of automated integration tests.
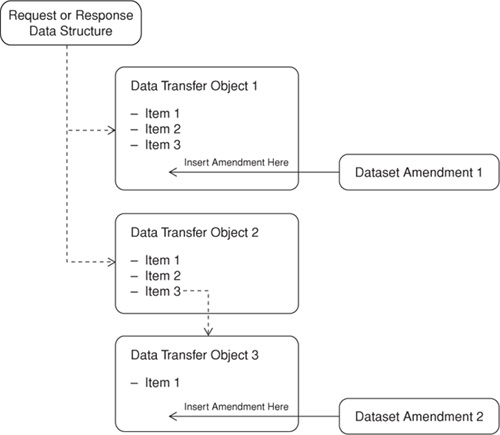
Client developers write integration tests that express the client’s expectations of a service API. These tests are given to the service owner, who incorporates them into the service’s test suite.
The Consumer-Driven Contract pattern helps service owners create service APIs that reflect client needs; it also helps service owners evolve services without breaking existing clients. Service owners receive integration tests from each client and incorporate these tests into the service’s test suite. The set of integration tests received from all existing clients represents the service’s aggregate obligations with respect to its client base. The service owner is then free to change and evolve the service just so long as the existing integration tests continue to pass. Breaking tests help service developers identify breaking changes, understand the impact of those changes on existing clients, and communicate the changes and their impact to the relevant client owners.
Consumer-Driven Contracts can be used at several different stages in the service development life cycle. During the design stage they can be used to shape an API by capturing in code examples how it might be used. During the development stage, they help decouple development activities in different work streams, while at the same time establishing a shared understanding of service and client responsibilities. At this stage, client developers work against stub implementations of a service API, and then share their integration tests with the service owner. Finally, Consumer-Driven Contracts can be used after a service has gone live, to record how specific clients actually use a service.
Client owners implement consumer contracts in the form of integration tests. These tests are usually written against a stub version of the service. When the contracts are given to the service owner, these stub implementations are replaced with a real service instance; the assertions, however, remain the same.
Tests can focus on several different aspects of the service contract.
• Content: These tests check for the presence of certain elements and attributes in messages and resource representations. They may also assert the data types of specific values, and even check that more complex invariants hold; that, for example, a <status> of rejected is always accompanied by a <reason>. Though the examples here focus on XML-formatted messages and resource representations, the Consumer-Driven Contract pattern is equally applicable to formats such as JSON and proprietary formats like Google’s Protocol Buffers.
• Processing context: Such tests assert the presence or absence of certain headers. A client may expect, for example, that an ETag header always accompany cacheable responses.
• Behavior: These tests communicate the client’s expectations regarding the service’s behavior, as evidenced by response codes, headers, and response data. Such tests may check that calculations are correct, that changes to state result in an event being published, or that the steps in a workflow proceed as expected.
• Quality of service: These tests communicate expectations around things such as response times, exceptions, security protocols, and compression and encryption algorithms.
The Consumer-Driven Contract pattern is a natural complement to the Tolerant Reader pattern (243). Clients acting as Tolerant Readers can use consumer contracts to communicate exactly which parts of a service API they use. When a contract test fails in the service test suite as a result of an essential breaking change to the API, the service owner can identify the relevant client from the test, and thereafter negotiate a plan for supporting or migrating the client.
Considerations
When using Consumer-Driven Contracts, developers and service owners should consider the following issues.
• Stub and real service implementations: Client developers typically write their consumer contract integration tests against a fake implementation of a service. At this stage, the tests are not real integration tests; they test neither the service nor the client’s behavior. Rather, they simply communicate the client’s expectations of the service. For them to be useful as consumer contracts, the tests should make it easy for service developers to substitute a real service instance for the client’s use of a fake. The tests realize their full value when they are handed over and run in a service (rather than client) test suite; that is, when they are run against a real service instance. This technique is different from clients using integration and certification environments to certify a product for use, though it can be used to complement such procedures.
• Exchanging and versioning contracts: Service and client owners should establish a means for exchanging tests and resolving contract disputes. Tests should be version-controlled so that owners can identify when a contract changed, and for what reason. Tests received from different clients should be clearly identified and versioned independently of one another. Many of today’s version control systems can import dependencies from external repositories, thereby allowing different consumer contracts to be pulled into a service test suite. Subversion, for example, provides support for external definitions. Git has the powerful concept of submodules.
• Enforce contracts with every change to a service: Contract tests should be run with every change to a service, regardless of whether the change occurs to the API or in the internal service logic. Automated, self-checking tests can be incorporated into a continuous integration pipeline, where they will be executed with every check-in of service code.
• Modifying contracts: Tests written in the early stages of a service’s design and development are different from those written once a service API has been published. The former helps to shape the API, but may be modified as service and client owners negotiate the scope and composition of the API. The latter makes assertions about a published API and should not, therefore, be changed while that API is being used.
• Platform dependencies: Contracts are often written as unit tests in a particular programming language. This can introduce unwelcome platform dependencies for service developers if the platform used to develop the contract is different from the platform used to develop the service. Schema languages such as Schematron can be used to write platform-independent tests for XML.
• Scope and complexity: The Consumer-Driven Contract pattern is applicable where service owners can identify their clients, and clients can establish a channel for sending contracts to service owners. This is usually the case in enterprise web service environments, but may also apply in situations where independent software vendors can solicit representative use cases and tests from clients. No matter how lightweight the mechanisms for communicating and representing expectations and obligations, service and client owners must know about, agree on, and adopt a set of channels and conventions, all of which add to the complexity of the delivery process.
• Test strategies: A comprehensive consumer contract suite of tests will cover exceptional as well as happy-path uses of the service API. Though focused primarily on unit testing, many of the patterns described in xUnit Test Patterns, Refactoring Test Code [Meszaros, Gerard] can be applied to these unusual cases. The book also describes several patterns, such as Test Double, which help decouple test routines and the service under test from other dependencies.
• Long-running, asynchronous services: Services that use the Request/Acknowledge/Poll pattern (62) or Request/Acknowledge/Callback (63) pattern can be difficult to test in a reliable and timely fashion end-to-end. Nonetheless, consumers can still express their expectations of an acknowledgment, a polled response, or a callback using XPath assertions, a Schematron rules document, or similar. The book Growing Object-Oriented Software, Guided By Tests [Freeman, Pryce] describes several strategies for testing asynchronous code. Nat Pryce, one of the authors of that book, also provides several interesting ideas at www.natpryce.com/articles/000755.html.
• Reasonable expectations: Consumer contracts express a client’s expectations of a service API, but these expectations must be reasonable and capable of being fulfilled. Allowing consumer contracts to drive the specification of a service API can sometimes undermine the conceptual integrity of that API. Service integrity should not be compromised by unreasonable demands falling outside the scope of the service’s responsibilities.
Example: A Consumer Contract for Service Behavior Implemented in C# and NUnit
This example shows a simple consumer contract for a news service Resource API (38). The contract has been written by developers of one of the service’s clients, and then given to the service owner who has incorporated it, together with other consumer contracts, in the service’s continuous integration pipeline to form a consumer-driven contract.
[TestFixture]
public class NewsServiceConsumerContract
{
private IIntegrationContext context;
private HttpResponseMessage response;
[SetUp]
public void Init()
{
context = CreateContext();
string xml =
@"<entry xmlns=""http://www.w3.org/2005/Atom"">
<title>Lilliput Siezes Blefuscudian Fleet</title>
<id>urn:uuid:897B5900-7805-4A61-BC63-03691EEE752D</id>
<updated>2011-06-01T06:30:00Z</updated>
<author><name>Jonathan Swift</name></author>
<content>Lilliput's Man-Mountain this morning...</content>
</entry>";
HttpContent content = new StringContent(xml);
content.Headers.ContentType =
new MediaTypeHeaderValue("application/atom+xml");
response = context.Client.Send(new HttpRequestMessage
{
Method = HttpMethod.Post,
RequestUri = context.TargetUri,
Content = content
});
}
[TearDown]
public void Dispose()
{
context.Dispose();
}
[Test]
public void ResponseIncludes201CreatedStatusCode()
{
Assert.AreEqual(HttpStatusCode.Created, response.StatusCode);
}
[Test]
public void ResponseIncludesLocationHeader()
{
Assert.IsNotNull(response.Headers.Location);
}
[Test]
public void ResponseBodyIncludesAnEditedElement()
{
XPathNavigator message = new XPathDocument(
response.Content.ContentReadStream).CreateNavigator();
Assert.AreEqual(1, message.Select("//*[local-name()='edited']").Count);
}
//Helper methods omitted
}
These contract tests have been written using the NUnit test framework. The setup for each test uses an HTTP client to POST a news article to the service. The tests then assert that the service has successfully created the article, assigned it a URI, and added an edited timestamp. The XPath expression used to select the edited element is quite forgiving of structure—it looks for the element at any depth in the response, ignoring any XML namespaces.
The tests use a pluggable IIntegrationContext to set up the HTTP client. Client developers create an implementation of IIntegrationContext whose HTTP client is configured with a fake Service Connector (168). Service developers replace this implementation with one that lets the client communicate with a service running in a local or remote host environment. When the tests run in the service test environment, the IIntegrationContext implementation used there connects the client to a real service instance. The IIntegrationContext interface is shown below.
public interface IIntegrationContext : IDisposable
{
HttpClient Client { get; }
Uri TargetUri { get; }
}
When developing the consumer contract, the client developers create a FakeNewsServiceIntegrationContext that returns an HTTP client configured with a fake response. This fake response exhibits the behavior expected of the service by the client, as shown below.
public class FakeNewsServiceIntegrationContext : IIntegrationContext
{
private readonly Uri targetUri;
private readonly HttpClient client;
public FakeNewsServiceIntegrationContext()
{
targetUri = new Uri("http://localhost/news/articles/");
string xml =
@"<entry xmlns=""http://www.w3.org/2005/Atom""
xmlns:app=""http://www.w3.org/2007/app"">
<app:edited>2011-06-01T06:30:00Z</app:edited>
</entry>";
HttpContent content = new StringContent(xml);
content.Headers.ContentType =
new MediaTypeHeaderValue("application/atom+xml");
HttpResponseMessage response = new HttpResponseMessage
{
StatusCode = HttpStatusCode.Created,
Content = content
};
response.Headers.Location =
new Uri("http://localhost/news/articles/123");
HttpClientChannel endpoint = new FakeEndpoint(response);
client = new HttpClient {Channel = endpoint};
}
public HttpClient Client
{
get { return client; }
}
public Uri TargetUri
{
get { return targetUri; }
}
public void Dispose()
{
//Do nothing
}
}
The NewsServiceConsumerContract fixture creates an appropriate IIntegrationContext by calling the CreateContext factory method before each test. CreateContext instantiates an IIntegrationContext instance based on a couple of settings in a configuration file. The code for CreateContext is shown below.
private IIntegrationContext CreateContext()
{
string contextAssembly =
ConfigurationManager.AppSettings["ContextAssembly"];
string contextImplName =
ConfigurationManager.AppSettings["ContextImplName"];
if (contextAssembly == null)
{
Type testHostType = Type.GetType(contextImplName);
return (IIntegrationContext) Activator.CreateInstance(testHostType);
}
return (IIntegrationContext) Activator.CreateInstance(
contextAssembly, contextImplName);
}
When the consumer contract is run in the client’s test environment, the CreateContext method returns a FakeNewsServiceIntegrationContext instance. When the tests are incorporated into the service test suite, the service developers can reconfigure the test fixture to return a NewsServiceIntegrationContext that connects the client to a real service instance. The code for NewsServiceIntegrationContext is shown below.
public class NewsServiceIntegrationContext : IIntegrationContext
{
private readonly ServiceHost service;
public NewsServiceIntegrationContext()
{
service = CreateNewsService();
service.Open();
}
public HttpClient Client
{
get { return new HttpClient(); }
}
public Uri TargetUri
{
get { return new Uri("http://localhost:8888/news/articles/"); }
}
public void Dispose()
{
service.Close();
}
private ServiceHost CreateNewsService()
{
//Implementation omitted
}
}
NewsServiceIntegrationContext controls the lifetime of a service instance. Here the service instance is running in a locally hosted environment. An alternative implementation of InvoiceServiceIntegrationContext might connect the client to a service instance running in a remote host environment. The Client property returns a simple HTTP client, which the consumer contract uses to POST a news article to the service.
Example: A Consumer Contract for Message Structure Implemented Using ISO Schematron
Code-based consumer contracts work well when both the client and the service are developed on the same platform. Many organizations, however, use multiple development platforms. In such circumstances, it is not always possible or feasible to exchange code-level contracts. This example shows a consumer contract written using ISO Schematron, a powerful validation language. Using an XSLT-based Schematron processor, a service owner can apply a Schematron document to the messages produced by a service to validate their conformance to the contract.
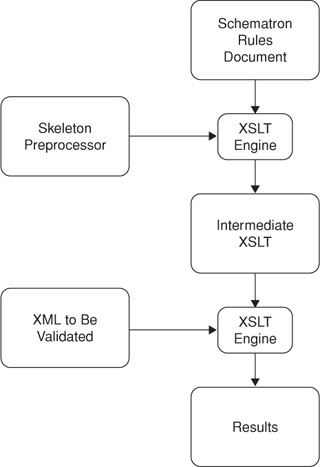
Schematron is a rule-based XML schema language for checking a document’s structure and its conformance to complex business rules. Schematron rules use XPath assertions to select XML elements and attributes and check that their values conform to the business rules specified by the schema author. As shown in Figure 7.1, a Schematron rules document, which in this instance has been written by the client developers, is transformed into an intermediate XSLT and applied to the XML to be validated. The skeleton implementation of Schematron, which is available from the Schematron site, includes an XSLT preprocessor that transforms the rules document into an XSLT transform. This transform is applied to the XML to be validated, creating another XML document that describes the validation results.
Figure 7.1. A Schematron preprocessor uses a Schematron rules document to create a validating transform. This intermediate XSLT is applied to the document to be validated.
The Schematron schema shown below validates that the necessary elements are present in an invoice. The schema is authored by a client owner and then given to a service owner to form a consumer contract.
<?xml version="1.0" encoding="UTF-8"?>
<schema xmlns="http://purl.oclc.org/dsdl/schematron">
<title>Invoice contract for client example.org</title>
<pattern>
<rule context="//*[local-name()='Invoice']">
<assert test="count(.//*[local-name()='InvoiceId']) = 1" >Expected
InvoiceId</assert>
<assert test="count(.//*[local-name()='WorkOrder']) = 1" >Expected
WorkOrder</assert>
<assert test="count(.//*[local-name()='Billed']) > 0" >Expected at
least one Billed element</assert>
</rule>
<rule context="//*[local-name()='Billed']">
<assert test="count(.//*[local-name()='BillCode']) = 1" >Expected
BillCode</assert>
<assert test="count(.//*[local-name()='Time']) = 1" >Expected
Time</assert>
</rule>
</pattern>
</schema>
This schema checks that an InvoiceId element, a WorkOrder element, and at least one Billed element are present in the context of an Invoice element. It also checks that each Billed element contains BillCode and Time elements. As with the code contract from the previous example, the XPath here is forgiving of depth and namespace.
On receiving the schema, the service owner incorporates it in a unit test.
[Test]
public void ApplySchematronConsumerContract()
{
XmlReader message = CreateInvoiceMessage();
ValidationResult result = Validate("Invoice.schematron.xml", message);
Assert.IsTrue(result.Success, result.ToString());
}
The ApplySchematronConsumerContract test calls a Validate helper method to execute the Schematron pipeline using the supplied consumer contract.
private ValidationResult Validate(string schematronUri, XmlReader message)
{
//Generate intermediate XSLT
Stream xsltStream = new MemoryStream();
XslCompiledTransform xsl = new XslCompiledTransform();
xsl.Load("iso_svrl_for_xslt1.xsl");
xsl.Transform(schematronUri, null, xsltStream);
xsltStream.Seek(0, SeekOrigin.Begin);
//Generate results XML
Stream resultStream = new MemoryStream();
XslCompiledTransform xslt = new XslCompiledTransform();
xslt.Load(XmlReader.Create(xsltStream));
xslt.Transform(message, null, resultStream);
resultStream.Seek(0, SeekOrigin.Begin);
XElement results = XElement.Load(resultStream);
IEnumerable<XElement> failedAsserts =
results.Descendants(XName.Get(
"failed-assert", "http://purl.oclc.org/dsdl/svrl"));
return new ValidationResult {Success = failedAsserts.Count().Equals(0),
Errors = failedAsserts};
}
The Validate method applies the skeleton preprocessor (iso_svrl_for_xslt1.xsl, which is supplied with the Schematron implementation available on the Schematron site) to the supplied rules document in order to generate an intermediate XSLT document. The method then validates the supplied message by transforming it with this intermediate XSLT. If there are any failed assertions in the output of this transformation, they are wrapped in a ValidationResult object. The code for ValidationResult is shown below.
public class ValidationResult
{
public bool Success { get; set; }
public IEnumerable<XElement> Errors { get; set; }
}
How the Patterns Promote or Hinder Service Evolution
This section briefly summarizes how many of the patterns in this book promote or hinder service evolution.
• RPC API (18):
– RPC APIs tend to create tight dependencies between clients and the procedures (i.e., handlers) used to process requests. Developers can make it easier to evolve the service if they use the Single-Message Argument pattern (234). These messages can be easily extended to support new customer requirements through the Dataset Amendment pattern (237).
– Service owners can support different versions of a given service, but this may confuse client developers. Older services can be deprecated in favor of newer ones, but the service owner must coordinate with client developers to determine the timing of such events.
• Message API (27):
– This pattern makes it very easy to add new message types, especially when the service doesn’t use a Service Descriptor (175). The logic used to process these messages can be easily rolled out without affecting clients that use older message versions.
– Messages can be easily extended to support new customer requirements through the Dataset Amendment pattern (237).
• Resource API (38):
– This pattern makes it very easy to support new media types and representation formats. Media Type Negotiation (70) can be used to meet new customer data requirements while simultaneously supporting older data requirements.
– New service logic can be introduced quite easily by providing clients new URIs. If a URI must be deprecated, the service can return HTTP codes in the 3xx range or use a URI Rewrite engine.
– Media types can often be extended to support new customer requirements through the Dataset Amendment pattern (237).
– Responses can contain Linked Services (77).
– This interaction style introduces strong temporal coupling between the client and service.
• Request/Acknowledge (59):
– Acknowledgments can contain Linked Services (77). Clients may use this information to poll for continuing updates or to acquire the final response. By including this information as Linked Services, the client avoids becoming coupled to specific service URIs.
– Clients can pass URIs for callback services and relay services in with the initial request. This helps to minimize the service’s coupling to specific services owned by the client (or its partners), and enables the client owner to easily add or change callback/relay service URIs and associated logic over time. However, the messages and media types must be known by all parties ahead of time.
• Linked Service (77):
– This pattern lets clients use new or altered services without becoming coupled to the service’s address. The client must, however, know how to parse each response to find information on the services it is interested in. It must also understand the requisite messages or media types, and must know what server methods (i.e., GET, PUT, POST, DELETE) should be used at various times.
• Data Transfer Object (94):
– This pattern effectively decouples the client from internal objects, database tables, and so on that are used to fulfill client requests. This makes it possible to evolve the client and internal resources at different rates.
– Data Transfer Objects that rely on data-binding technologies increase coupling between the DTO and message structures, making it harder to evolve both.
– The Abstract Data Transfer Object (105) variation on this pattern may be used to define a base type for a family of related structures.
– Request Mappers let service owners support new customer data requirements without forcing the change onto all clients. This pattern also helps to minimize the need to create separate services that process specific client messages.
– Service evolution can be promoted through this pattern when it is used with Message APIs (27) and Resource APIs (38).
• Response Mapper (122):
– Response Mappers provide a level of indirection between clients and the internal objects, database tables, and so on used to create responses. This lets the client and internal resources evolve at different rates.
– Specialized mappers can be created for specific clients.
– Response Mappers can be used to produce URIs for Linked Services (77).
– Service evolution can be promoted through this pattern when it is used with Message APIs (27) and Resource APIs (38).
• Datasource Adapter (137):
– Datasource Adapters generally result in a tight coupling among the client, service, and underlying resources (e.g., database table, domain object), thereby making it harder to evolve them at different rates.
– Developers can sometimes change service metadata to alter the service’s behavior without requiring clients to be updated as well. One might, for example, be able to alter the SQL used by an adapter to insulate the client from column name changes on a table.
• Operation Script (144), Command Invoker (149), Workflow Connector (156), and Orchestration (224):
– Services that implement or use these patterns provide a simplified interface or Façade [GoF] over a complex set of activities. Since the client is dependent on the service interface, the service owner can often change the algorithms used to manipulate the objects or tables referenced by the service without affecting the client.
– The logic within connectors can often be altered to accommodate service changes while leaving the client application unaffected.
– Connectors hide service URIs from clients, making it easier to change service addresses as the need arises.
– Connectors that are generated from Service Descriptors (175) often need to be re-created when the descriptor changes.
• Service Descriptor (175):
– Service owners can augment descriptors to support different service versions, but this may confuse client developers. Older services can be deprecated in favor of newer services, but the service owners should usually coordinate with client developers to determine the timing of such events.
– Breaking changes on descriptors usually require Service Proxies (168) to be regenerated. The rollout of these changes often has to be carefully coordinated with the client owners. (For more on breaking changes, see the section What Causes Breaking Changes? earlier in this chapter.)
– Descriptors used in RPC APIs (18) are automatically regenerated when the API is created through the Code-First practice. This often requires Service Proxies (168) to be regenerated.
– Messages defined in descriptors can be easily extended to support new customer requirements through the Dataset Amendment pattern (237).
• Service Interceptor (195):
– Service Interceptors make it easy to add new generic behaviors without having to update the client or service implementations. One can easily add new rules for logging, authentication, data validation, data encryption, message signing, caching, exception handling, and other similar functions.
• Service Registry (220):
– Registries can be used to support a formal governance process that guides service design from inception through retirement.
– Developer tools can frequently use registries to acquire up-to-date service metadata.
– Service Connectors (168) can contact registries at runtime in order to acquire recent service metadata.
• Enterprise Service Bus (221):
– By functioning as a Mediator [GoF], an ESB insulates clients from the actual services used to fulfill their requests. This can make it easier to add or change services as the need arises. However, the cost is often higher complexity, higher latency, and increased capital expenditures. While clients become less coupled to the real services that process requests, they often become tightly coupled to the bus. Additionally, developers may have to spend additional time creating Message Translators [EIP].
• Tolerant Reader (243):
– This pattern enables the message recipient to become more robust despite the fact that messages may contain unknown content and data structures.
• Consumer-Driven Contract (250):
– Consumer-Driven Contracts are the union of all client expectations. Service owners can use this pattern to understand how their clients are affected when a service changes. This pattern also enables service developers to gain insight into how services must be altered in order to meet the needs of all clients.