
Even after successful delivery, a message may still fail during playback to the service. Such failures typically abort the playback transaction, which causes the message to return to the service queue. WCF will then detect the message in the queue and retry. If the next call fails too, the message will go back to the queue again, and so on. Continuously retrying this way is often unacceptable. If the initial motivation for the queued service was load leveling, WCF's auto-retry behavior will generate considerable stress on the service. You need a smart failure-handling schema that deals with the case when the call never succeeds (and, of course, defines "never" in practical terms). The failure handling will determine after how many attempts to give up, after how long to give up, and even the interval at which to try. Different systems need different retry strategies and have different sensitivity to the additional thrashing and probability of success. For example, retrying 10 times with a single retry once every hour is not the same strategy as retrying 10 times at 1-minute intervals, or the same as retrying 5 times, with each attempt consisting of a batch of 2 successive retries separated by a day. In general, it is better to hedge your bets on the causes for the failure and the probability of future success by retrying in a series of batches, to deal with sporadic and intermediate infrastructure issues as well as fluctuating application state. A series of batches, each batch comprised of a set number of retries in rapid succession, may just be able to catch the system in a state that will allow the call to succeed. If it doesn't, deferring some of the retries to a future batch allows the system some time to recuperate. Additionally, once you have given up on retries, what should you do with the failed message, and what should you acknowledge to its sender?
Transactional messaging systems are inherently susceptible to repeated failure,
because the retries thrashing can bring the system to its knees. Messages that
continuously fail playbacks are referred to as poison messages,
because they literally poison the system with futile retries. Transactional messaging
systems must actively detect and eliminate poison messages. Since there is no telling
whether just one more retry might actually succeed, you can use the following simple
heuristic: all things being equal, the more the message fails, the higher the likelihood
is of it failing again. For example, if the message has failed just once, retrying seems
reasonable. But if the message has already failed 1,000 times, it is very likely it will
fail again the 1,001st time, so it is pointless to try again. In this case, the message
should be deemed a poison message. What exactly constitutes "pointless" (or just wasteful)
is obviously application-specific, but it is a configurable decision. MsmqBindingBase offers a number of properties governing the
handling of playback failures:
public abstract class MsmqBindingBase : Binding,...
{
//Poison message handling
public int ReceiveRetryCount
{get;set;}
public int MaxRetryCycles
{get;set;}
public TimeSpan RetryCycleDelay
{get;set;}
public ReceiveErrorHandling ReceiveErrorHandling
{get;set;}
//More members
}With MSMQ 4.0 (available on Windows Vista and Windows Server 2008 or later), WCF retries playing back a failed message in series of batches, for the reasoning just presented. WCF provides each queued endpoint with a retry queue and an optional poison messages queue. After all the calls in the batch have failed, the message does not return to the endpoint queue. Instead, it goes to the retry queue (WCF will create that queue on the fly). Once the message is deemed poisonous, you may have WCF move that message to the poison queue.
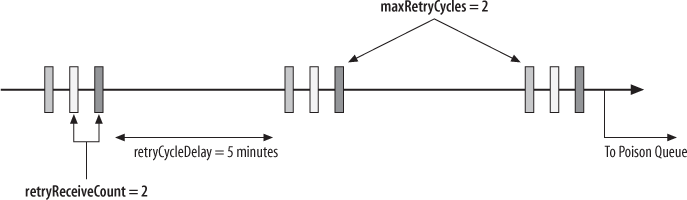
In each batch, WCF will immediately retry for ReceiveRetryCount times after the first call failure. ReceiveRetryCount defaults to five retries, or a total of
six attempts, including the first attempt. After a batch has failed, the message goes to
the retry queue. After a delay of RetryCycleDelay
minutes, the message is moved from the retry queue to the endpoint queue for another
retry batch. The retry delay defaults to 30 minutes. Once that batch fails, the message
goes back to the retry queue, where it will be tried again after the delay has expired.
Obviously, this cannot go on indefinitely. The MaxRetryCycles property controls how many batches at the most to try. The
default of MaxRetryCycles is two cycles only,
resulting in three batches in total. After MaxRetryCycles number of retry batches, the message is considered a poison
message.
When configuring nondefault values for MaxRetryCycles, I recommend setting its value in direct proportion to
RetryCycleDelay. The reason is that the longer the
delay is, the more tolerant your system will be of additional retry batches, because the
overall stress will be somewhat mitigated (having been spread over a longer period of
time). With a short RetryCycleDelay you should
minimize the number of allowed batches, because you are trying to avoid approximating
continuous thrashing.
Finally, the ReceiveErrorHandling property
governs what to do after the last retry fails and the message is deemed poisonous. The
property is of the enum type ReceiveErrorHandling,
defined as:
public enum ReceiveErrorHandling
{
Fault,
Drop,
Reject,
Move
}The Fault value considers the poison message as a
catastrophic failure and actively faults the MSMQ channel and the service host. Doing so
prevents the service from processing any other messages, be they from a queued client or
a regular connected client. The poison message will remain in the endpoint queue and
must be removed from it explicitly by the administrator or by some compensating logic,
since WCF will refuse to process it again if you merely restart the host. In order to
continue processing client calls of any sort, you must open a new host (after you have
removed the poison message from the queue). While you could install an error-handling
extension (as discussed in Chapter 6) to do some of that work, in
practice there is no avoiding involving the application administrator.
ReceiveErrorHandling.Fault is the default value
of the ReceiveErrorHandling property. With this
setting, no acknowledgment of any sort is sent to the sender of the poison message.
ReceiveErrorHandling.Fault is both the most
conservative poison message strategy and the least useful from the system perspective,
since it amounts to a stalemate.
The Drop value, as its name implies, silently
ignores the poison message by dropping it and having the service keep processing other
messages. You should configure for ReceiveErrorHandling.Drop if you have high tolerance for both errors and
retries. If the message is not crucial, i.e., it is used to invoke a nice-to-have
operation, dropping and continuing is acceptable. In addition, while ReceiveErrorHandling.Drop does allow for retries,
conceptually you should not have too many retries—if you care that much about the
message succeeding, you should not just drop it after the last failure.
Configuring for ReceiveErrorHandling.Drop also
sends an ACK to the sender, so from the sender's perspective, the message was delivered
and processed successfully. For many applications, ReceiveErrorHandling.Drop is an adequate choice.
The ReceiveErrorHandling.Reject value actively
rejects the poison message and refuses to have anything to do with it. Similar to
ReceiveErrorHandling.Drop, it drops the message,
but it also sends a NACK to the sender, thus signaling ultimate delivery and processing
failure. The sender responds by moving the message to the sender's dead-letter queue.
ReceiveErrorHandling.Reject is a consistent,
defensive, and adequate option for the vast majority of applications (yet it is not the
default, to accommodate MSMQ 3.0 systems as well).
The ReceiveErrorHandling.Move value is the
advanced option for services that wish to defer judgment on the failed message to a
dedicated third party. ReceiveErrorHandling.Move
moves the message to the dedicated poison messages queue, and it does not send back an
ACK or a NACK. Acknowledging processing of the message will be done after it is
processed from the poison messages queue. While ReceiveErrorHandling.Move is a great choice if indeed you have some
additional error recovery or compensation workflow to execute in case of a poison
message, a relatively smaller set of applications will find it useful, due to its
increased complexity and intimate integration with the system.
Example 9-19 shows a configuration section from a host config file, configuring poison message handling on MSMQ 4.0.
Example 9-19. Poison message handling on MSMQ 4.0
<bindings>
<netMsmqBinding>
<binding name = "PoisonMessageHandling"
receiveRetryCount = "2"
retryCycleDelay = "00:05:00"
maxRetryCycles = "2"
receiveErrorHandling = "Move"
/>
</netMsmqBinding>
</bindings>Figure 9-9 illustrates graphically the resulting behavior in the case of a poison message.
Your service can provide a dedicated poison-message-handling service to handle
messages posted to its poison messages queue when the binding is configured with
ReceiveErrorHandling.Move. The poison message
service must be polymorphic with the service's queued endpoint contract. WCF will
retrieve the poison message from the poison queue and play it to the poison service. It
is therefore important that the poison service does not throw unhandled exceptions or
abort the playback transaction (configuring it to ignore the playback transaction, as in
Example 9-9, or to use a new transaction, as
in Example 9-10, is a good idea). Such a poison message
service typically engages in some kind of compensating work associated with the failed
message, such as refunding a customer for a missing item in the inventory.
Alternatively, a poison service could do any number of things, including notifying the
administrator, logging the error, or just ignoring the message altogether by simply
returning.
The poison message service is developed and configured like any other queued
service. The only difference is that the endpoint address must be the same as the
original endpoint address, suffixed by ;poison. Example 9-20 demonstrates the required
configuration of a service and its poison message service. In Example 9-20 the service and its poison message
service share the same host process, but that is certainly optional.
Example 9-20. Configuring a poison message service
<system.serviceModel>
<services>
<service name = "MyService">
<endpoint
address = "net.msmq://localhost/private/MyServiceQueue"
binding = "netMsmqBinding"
bindingConfiguration = "PoisonMesssageSettings"
contract = "IMyContract"
/>
</service>
<service name = "MyPoisonServiceMessageHandler">
<endpoint
address = "net.msmq://localhost/private/MyServiceQueue;poison"
binding = "netMsmqBinding"
contract = "IMyContract"
/>
</service>
</services>
<bindings>
<netMsmqBinding>
<binding name = "PoisonMesssageSettings"
receiveRetryCount = "..."
retryCycleDelay = "..."
maxRetryCycles = "..."
receiveErrorHandling = "Move"
/>
</netMsmqBinding>
</bindings>
</system.serviceModel>With MSMQ 3.0 (available on Windows XP and Windows Server 2003), there is no retry
queue or optional poison queue. As a result, WCF supports at most a single retry batch out
of the original endpoint queue. After the last failure of the first batch, the message is
considered poisonous. WCF therefore behaves as if MaxRetryCycles is always set to 0, and the
value of RetryCycleDelay is ignored. The only values
available for the ReceiveErrorHandling property are
ReceiveErrorHandling.Fault and ReceiveErrorHandling.Drop. Configuring other values throws an
InvalidOperationException at the service load
time.
Tip
Neither ReceiveErrorHandling.Fault nor ReceiveErrorHandling.Drop is an attractive option. In MSMQ
3.0, the best way of dealing with a playback failure on the service side (that is, a
failure that stems directly from the service business logic, as opposed to some
communication issue) is to use a response service, as discussed later in this
chapter.