
Determining whether one can define what it is to be a good programmer demands that we consider two deeper questions:
What in a programmer gives good programming performance? Should you care about the amount of experience she has? Should you worry about her personality? Should you attempt to measure her IQ? And what about all this in the context of pair programming and team work?
What is good programming performance? For example, should you hire the person who can produce the most lines of code per unit time or the person who produces the code of highest quality (whatever that means), no matter the amount of time spent producing it?
These questions touch on fundamental and difficult issues. In the work life where one has to make strategic decisions, such issues are explicitly or implicitly dealt with on the fly by following intuitions or applying more or less ill-founded personal profile and aptitude tests. In academic research, the deeper and more general meaning of these questions has led to huge research efforts across several disciplines in attempts to gain some insight into these issues.
Characteristics that separate one individual from another—or individual differences, as researchers call them for short—can be classified along a continuum from fixed to malleable. Toward the fixed end, you find things such as personality and cognitive predispositions that are assumed to be relatively stable throughout a person’s life time. Malleable characteristics, on the other hand, include task-related skills, knowledge, and motivation, all of which are assumed to be affected by shorter-term circumstance, training, and learning, and hence may be subject to deliberate manipulation, e.g., improvement.
It is relatively quick, inexpensive, and easy to distinguish people by fixed characteristics, whereas it is a comparatively lengthy process to assess and develop someone’s skills. It is also perhaps human nature to discern people by stereotypes. No wonder, then, that the recruitment industry offers a range of tests to measure a person’s fixed characteristics.
We can discuss at length different opinions on how you should view your fellow human beings. Is hiring someone based on their fixed characteristics bordering on discrimination? Is it unethical to submit your staff to intelligence or personality tests? In some countries (especially in Europe), it is indeed considered non comme il faut to do so, and it is well known that IQ tests are biased across ethnic groups (resulting in lawsuits in the U.S.). But industries and governments continue to deploy their tests in various guises. So what predicts job performance better: fixed characteristics such as personality and intelligence or malleable characteristics such as skill and expertise?
Personality has been a subject of interest in the context of programming and software engineering for some time. For example, Weinberg predicted in The Psychology of Computer Programming that “attention to the subject of personality should make substantial contributions to increased programmer performance” [Weinberg 1971], a position he reaffirms in the 1998 edition of the book [Weinberg 1998]. Shneiderman states in Software Psychology that, “Personality variables play a critical role in determining interaction among programmers and in the work style of individual programmers” [Shneiderman 1980]. However, both authors admit to a lack of empirical evidence on the impact of personality on performance: “Personality tests have not been used successfully for selecting programmers who will become good programmers” [Weinberg 1971], [Weinberg 1998], “Unfortunately too little is known about the impact of personality factors” [Shneiderman 1980].
Since then, empirical studies have been conducted on personality and software development. For example, Dick and Zarnett conclude that “[b]uilding a development team with the necessary personality traits that are beneficial to pair programming will result in greater success with extreme programming than a team built based on technical skills alone” [Dick and Zarnett 2002]. Beyond the specific task of programming, Devito Da Cunha and Greathead conclude that “if a company organizes its employees according to personality types and their potential abilities, productivity and quality may be improved” [Devito Da Cunha and Greathead 2007], and there are arguments that one should map personality types onto specific roles in software development [Capretz and Ahmed 2010], [Acuña et al. 2006].
So what is personality? Informally, we speak of people’s personality all the time. “She has the perfect personality for being a lawyer,” or “He really has personality problems.” Indeed, important decisions are made every day based on such informal hunches. Maybe some of them turn out to be right, and maybe some turn out to be wrong. Adopting an evidence-based approach means to structure such decisions on knowledge that is obtained in a systematic (read, scientific) manner. I will say right now that this systematic approach has inherent limitations, but more on that later.
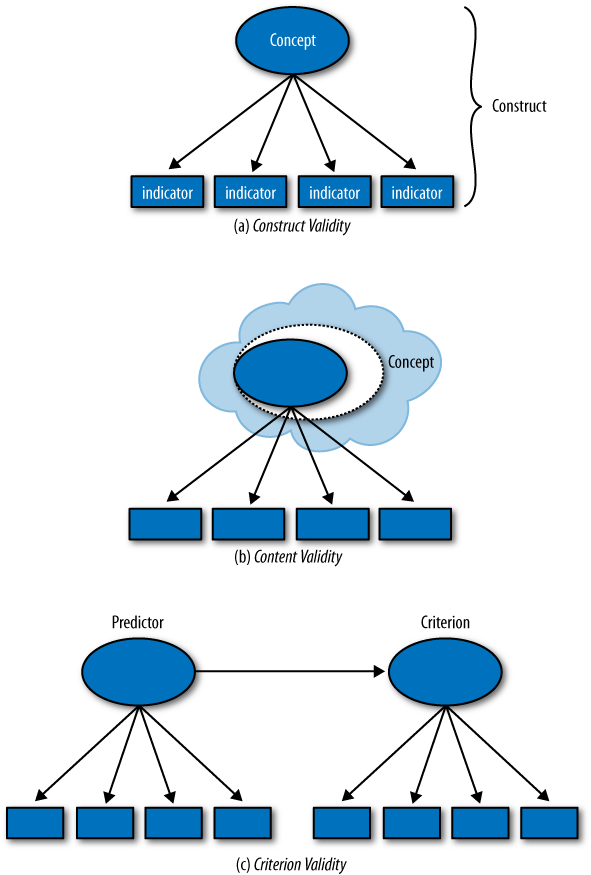
One must first ask whether it is possible to define and measure personality in the first place. That this should be possible is perhaps not obvious for technologists such as ourselves. We may soon be able to point to tangible (say, genetic or psychophysiological) mechanisms of a person’s personality [Read et al. 2010]. However, the main development of personality theory over the past century has followed a different path. Scientists have inferred that there might be differences in something we might call “personality” based on how people act or on what they say. These lines of research have been able to come up with convincing models of personality based on said behavioral and linguistic inferences. The most acclaimed models are perhaps the Big Five model and the related Five Factor Model (see next). So yes, personality is definable and measurable. It makes scientific sense to speak of a person’s personality, and there are tests that can reliably establish a person’s personality. Scientists would say that we have construct validity for the concept of personality.
Definitions of personality have been used to categorize people in a number of ways. For example, relating to the Big Five Model, we found that programmers deviated from a reference group in that they are lower on Extraversion, lower on Emotional Stability, and higher on Openness to Experience [Hannay et al. 2010]. See also [Moore 1991], [Smith 1989], [Woodruff 1979], [Capretz 2003], and [Turley and Bieman 1995] for related results. Programmers are also more homogeneous than the population as a whole; that is, programmers vary less in personality than do people in general. This confirms the stereotype of programmers being neurotic, introverted, and intellectual—and, by the way, male (which I know for a fact some people consider tantamount to a personality trait!).
As I said earlier, the systematic scientific approach has inherent limitations, in part as a result of its strengths. The one limitation to point out here, is what scientists call content validity: how reasonable is it to claim that your definition of personality captures all there is to what might be reasonably understood as personality? For example, most people would be reluctant to claim that a person can be characterized by only five factors. Other models of personality attempt to capture more complex types and subtle, complicated combinations of personality factors, but these lack construct validity. Being systematic inherently restricts what one can be systematic about! We’re running into a classic trade-off here. Simple models (such as the five factors) simplify reality and are amenable to validation and measurement. More complicated models pretend to capture reality better, but are hard to validate.
The ultimate question for us, though, is the utility of measuring personality. How much of a difference in performance does a certain difference in personality yield? How viable is it to use someone’s personality to predict other behavior, and programming performance in particular? There is a substantial body of research conducted on the link between personality and general job performance. This research has been summarized in large meta-analyses [Barrick et al. 2001], [Peeters et al. 2006], [Bell 2007]. According to Barrick et al., the general effects of personality on job performance are “somewhat disappointing” and “modest…even in the best of cases” [Barrick et al. 2001]. Thus, personality may have little direct effect on job performance in terms of efficiency.
Maybe, though, personality could have more substantial indirect effects on job performance via social factors that influence teamwork. In fact, the effects on teamwork are higher than on overall job performance for all of the Big Five factors [Barrick et al. 2001]. This suggests that it may be more relevant to study effects of personality in the context of collaborative performance rather than on individual performance. We investigated this prospect in the context of 198 professional programmers pair programming over one day [Hannay et al. 2010]. We found that personality was a weak predictor of pair programming performance. Even crude measures of expertise, task complexity, and even the country in which the programmers where employed had greater predictive power than personality. The study also included an analysis of personality on individual programming and whether the effect on performance of pairing up had anything to do with personality. Again, expertise and task complexity are stronger predictors than personality.
By the way, the extent to which a construct—here, personality—has predictive value on something else, is called criterion validity. For more on construct, content, and criterion validity, see next.
It may well be the case that effects of personality only manifest themselves after a while. In particular, pair programming over one day may not give sufficient time for the peers’ personalities to bring about any serious effect. There is also debate around short tests that may be conducted almost automatically (such as personality and intelligence tests) versus more holistic assessment methods that require a specialist interpretation. Take the case for a personality trait called Need for Achievement. Meta-analyses suggest that a controversial procedure for measuring Need for Achievement called the Thematic Apperception Test (TAT) has better predictive validity on real-world performance than standard questionnaire-based tests, which are better for predicting performance in controlled environments [Spangler 1992].[12] The TAT continues to receive skepticism from the scientific community. However, Spangler states that “[a]n unintended consequence of the scientific method may be to minimize the expression of individual differences and the interaction of individual differences and environmental characteristics” [Spangler 1992]. There you have your content validity challenge again! Note also that measuring long-term real-world performance is much harder than measuring performance in controlled conditions in the laboratory.
In summary, personality does not seem to be a very strong predictor of performance. Let’s briefly look at what effects there are. Conscientiousness is, in general, the most persistent of the personality factors when it comes to predicting both academic and job performance [Schmidt and Hunter 1998]. Guess what: this seems not to be the case for pair programming [Saleh et al. 2010]. In fact, in our data, we even found that conscientiousness had a negative effect (also for solo programmers). What seems to have a positive effect is openness to experience [Saleh et al. 2010] and difference in extraversion [Hannay et al. 2010]. Pairs whose peers have different levels of extraversion work quicker than those with more similar levels.
When given the prospect of trying out a scientifically validated test for measuring programming skill, an HR manager in a fairly large software development company stated that in her opinion, there is one, and one only, factor that predicts developer performance—namely, IQ. This view is interesting and illustrative: in a sense it is not wrong, but it is far enough off the mark to lead you down the wrong path.
General mental ability, or GMA for short, is a very general concept of intelligence or cognitive ability that one thinks resides in every human being. It is, roughly, what IQ tests purport to measure. See Factors of Intelligence for more on intelligence. GMA is a pretty good predictor of learning [Schmidt and Hunter 1998]. In other words, a person with a lot of GMA will likely learn new tasks quicker than a person with not as much GMA. GMA is also a pretty good predictor of future job performance for employees without previous experience [Schmidt and Hunter 1998]. So if our HR manager wants to hire inexperienced programmers who don’t yet know how to work with large, complex systems, then she’s not wrong; maybe she should indeed calculate their IQ.
The effect of GMA depends on the type of task at hand. A task is said to be consistent if, over time, the best performers develop similar strategies to solving the task. An inconsistent task, on the other hand, is a task for which substantially different strategies for solving the task emerge. When acquiring skills on consistent tasks, the effect of intelligence levels off or diminishes after a while, and job performance soon depends on other factors, such as experience and training ([Ackerman and Beier 2006], [Schmidt et al. 1988], [Schmidt et al. 1986]). This is especially the case for tasks that are highly dependent on domain knowledge, such as software development ([Bergersen and Gustafsson 2010], [Ackerman and Beier 2006]). Software development in general and programming in particular have both consistent and inconsistent task properties. This means that intelligence is important, but not all-important. For experienced job performers, GMA alone is not the ultimate predictor ([Ericsson 2006], [Schmidt and Hunter 1998], [Ackerman and Beier 2006]). So what is? The answer: intelligence and skill [Schmidt and Hunter 1998].
What these studies tell us is that relying solely on GMA isn’t “intelligent” in the long run. The problem with general mental ability is that it is too general. It is conceptualized as a universal human trait, and its means of measurement are purposefully designed to be independent of any task domain. (The weakness of depending on GMA is compounded by the observation that it isn’t really all that universal after all, but dependent on, for example, culture [Bond 1995].) This means that if you want to hire people who are good software developers, you need to assess them on something relevant to the job in addition to a general ability.
Skills are often measured by means of work-sample tests. These are tests that consist of small, representative tasks. The definition presents two challenges: “small” and “representative.” If you want to test potential or current employees’ programming skill, you need this to take as little time as possible. So test tasks need to be much smaller than what might be encountered in a normal job situation. But then, how can you be sure that you are testing something relevant? That is where representativeness comes in.
In fact, here you have construct and content validity again: how do you know that your measurement instrument is measuring what you want to measure, and do you really know what you want to measure in the first place? We had this for personality, we have this for intelligence (although we didn’t make a fuss about it), and here it shows up again in programming skill: define “programming skill” (this includes defining the task of programming), and then devise a rapid test that can assess it! In general, the construct validity of work-sample tests is problematic [Campbell et al. 1993].
At our research laboratory, we’re developing a measurement instrument for assessing programming skill [Bergersen 2010]. It is based on work-sample tests. The work-sample tests are small-sized to medium-sized programming tasks that have been carefully selected, replaced, and modified according to a growing understanding of the concept of programming skill.
The instrument is heavily based on measurement theory and satisfies stringent statistical standards. It is also based on theories of skill and expertise, all in the effort of obtaining construct validity. The instrument is therefore double-tuned: it keeps track of task difficulty, and it keeps track of the skill of the person solving the tasks. Like intelligence and personality, a person will be assessed relatively to the rest of the population who have taken the test. Unlike intelligence and personality, programming skill is directly relevant for hiring and keeping good programmers.
What, then, is good programming performance? Clearly, quality of code is one criterion. The meaning of “good quality” when it comes to code, of course, has been the subject of endless discussions. But for work-sample tests, there are some obvious as well as evidence-based quality measures, such as functional correctness, depth of inheritance, and so forth. Another criterion is the time spent producing it. You want good quality code in as little time as possible. You might expect that these two criteria are in conflict with each other, that you need more time to produce better quality code. This isn’t necessarily true [Arisholm and Sjøberg 2004], [Bergersen 2010b]. For some programming tasks, a given programmer either “gets it” or doesn’t, and if he does get it, he’ll get it quickly. For other programming tasks, however, the solution gets better the more time is spent on the task. It is important to know what kind of programming task in this respect one is dealing with.
Skill is something that can be improved. What’s actually a skill and how to improve it has been extensively researched in the field of expertise and learning. Expertise in general, and skill in particular, is related to a specific task or set of tasks. This is very different from both personality and intelligence.
There are other aspects of expertise beside skill. Expert knowledge (in our case, programming knowledge) is an important ingredient in expertise. So is experience (in our case, programming experience); see Factors of Expertise. There are dependencies between these factors. For example, experience contributes to knowledge, which contributes to skill.
Intelligence aids in this process of acquiring skill, but it does not determine skill. According to Cattell’s investment theory, the “investment” of Gf (so-called fluid reasoning, or the capacity to solve problems in a short-term perspective; see Factors of Intelligence) in learning situations that demand insights into complex relations, will benefit the acquisition of knowledge and skill. Recently, evidence was provided that suggests that this holds true for programming [Bergersen and Gustafsson 2010]; see Figure 6-3. Here, Working Memory Capacity (WMC) is used as a substitute for Gf. WMC has a substantial positive effect on programming knowledge, which in turn positively affects programming skill. However, the direct effect of WMC on programming skill seems to be negligible! In other words, WMC does not make someone skillful just like that, as a direct cause. It does so via facilitating the attainment of knowledge. Similarly, programming experience has an indirect (rather than a direct) effect on programming skill, but not as strongly as WMC.
![Investment Theory for Programming Skill [Bergersen and Gustafsson 2010]](http://imgdetail.ebookreading.net/software_development/33/9780596808310/9780596808310__making-software__9780596808310__httpatomoreillycomsourceoreillyimages2030920.png)
The upshot of all this is that intelligence is an asset when acquiring a skill. If you want good programmers, go ahead and test their intelligence, if you must, but be sure to test their programming skill first and foremost.
Success calls for both intelligence and skill. Combining intelligence and expertise in this manner draws attention to merit in a way that is more to the point of interest and perhaps less stigmatizing. In fact, efforts are being made to merge intelligence and expertise into a unified theory; see next. The common ground here is cognitive structures in the brain. Some are stable, some deteriorate with age, and some are improved by deliberate practice.
So what about other software engineering tasks? Can they be learned, and can the resulting skill on those tasks be measured? Let’s look at a notoriously hard task: software effort estimation, which is the task of estimating the effort of developing software.
The development of a software system is an inherently complex process. Estimating the effort needed to run a large software development project lifts this complexity to a higher order. Visible effects of the difficulty of this task are that effort estimates of software development are inaccurate and generally too low [Moløkken-Østvold and Jørgensen 2003], that software professionals tend to exhibit more confidence in their estimates than is warranted [Jørgensen et al. 2004], and that estimates are unreliable, in that the same person may judge the same project differently on separate occasions [Grimstad and Jørgensen (2007)]. There also seems to be no substantial improvement (learning from history) in estimation accuracy over the past decades, and learning from outcome feedback seems difficult [Gruschke and Jørgensen 2005].
As if complexity wasn’t enough, we know that the human judgment processes involved in forecasting an estimate are subject to a range of unconscious processes [Kahneman and Frederick 2004], [LeBoeuf and Shafir 2004], [Jørgensen and Sjøberg 2001], [Jørgensen and Carelius 2004], [Jørgensen and Sjøberg 2004]. For example, it is easy to manipulate the estimates that people produce by simply feeding them various base estimates beforehand (the anchor effect). The human judgment processes are also sensitive to the nature and format of the information (e.g., requirement documents) available when producing the estimate [Jørgensen and Grimstad 2008], [Jørgensen and Grimstad 2010], [Jørgensen and Halkjelsvik 2010], [Jørgensen 2010]. For example, it makes a significant difference whether you ask someone how much time he needs to complete a given amount of work, or whether you ask how much work he can complete in a given amount of time. The latter is the modus operandi for agile development’s time boxing. The result? Asking people to time box seems to increase underestimation. In addition, time boxing seems to reverse the tendency to overestimate the effort for completing small tasks while underestimating the effort for completing large tasks [Halkjelsvik et al. 2010].
Unlike for the task of programming, it seems that it is not enough simply to do more estimation of software development effort to become good at it. Evidence suggests that on-the-job feedback regarding the accuracy of estimation (either passive, in the form of historical data, or active, in the form of direct management assessment) doesn’t improve the tendency to be overly optimistic, overly confident, or unreliable in one’s estimations. According to classic learning theory, this in turn suggests that more refined feedback and active training of skills (so-called deliberate practice) is necessary. In other words, one needs to build estimation expertise in a conscious and deliberate manner.
The question is, however: is this possible? Targeted training, requires that one knows what the target is. In other words, one must know what expertise to induce. But when it comes to estimating the effort of software projects, the nature of expertise seems to elude us; it is not readily observable, because experienced project managers do not really stand out from inexperienced estimators, and further, the theoretical foundations of expertise do not give clear answers to what exactly the expertise of interest is. Moreover, software effort estimation is an instance of so-called ill-defined tasks. They transcend merely inconsistent tasks in that successful strategies seem to be difficult even to define. Neither the task of software effort estimation nor the expertise required to be good at this task are within our scientific grasp yet; in other words, we’re struggling with construct validity on these two concepts.
[11] B. T. Forer [Forer 1949] administered a personality test to his students. He then simply discarded their responses and gave all students the exact same personality analysis copied from an astrology book. The students were subsequently asked to rate the evaluation on a five-point low to high scale according to how accurately they felt that the evaluation described them. The mean was 4.26. Forer’s study has been replicated numerous times, and averages remain around 4 [Dickson and Kelly 1985], [Hanson and Claiborn 2006]. The Forer effect is also referred to as the “Barnum Effect” [Meehl 1956].
[12] There are additional factors here: the TAT criterion validity is conditional on motivational incentives related to task activities, whereas the criterion validity of the questionnaires is conditional on motivational incentives related to social achievement. This illustrates that research findings are hardly ever as clean cut as you might wish them to be, but they are still worth considering.