


Performance
In this chapter, we describe the ways in which the various components within IBM Content Manager OnDemand (Content Manager OnDemand) might be configured or tuned to enhance performance. In most cases, it is not possible to give specific parameter values; however, we provide broad concepts and recommendations in areas where tuning for performance is possible.
In this chapter, we cover the following topics:
13.1 Tuning Content Manager OnDemand to enhance performance
Two components make up performance: throughput and response time:
•Throughput: The number of transactions (Content Manager OnDemand requests) that can be satisfied for each unit of time. The more transactions that are run for each unit of time, the higher the throughput. Higher throughput implies that more users can be served concurrently and more load jobs can be run in parallel. If the throughput values are low, the system might not be able to support the required number of users.
•Response time: The amount of time it takes to service a single transaction (Content Manager OnDemand request). Faster response times imply that the users are able to retrieve their data faster from the archive, which in turn leads to more satisfied users. If the response time is slow, users are dissatisfied with the system.
A high performance system, such as Content Manager OnDemand, provides both high throughput and short response times.
The following sections describe the various components of a Content Manager OnDemand system and its architecture. They provide guidance about the parameters and configurations that you can change to improve performance.
The ability to separate the object server from the library server offers two main advantages:
•The ability to share workload by dedicating machines to individual tasks
•The ability to reduce the impact of retrieving a large piece of data over a network that is either slow or overloaded
13.1.1 Content Manager OnDemand configuration
How reports are defined, indexed, and stored within Content Manager OnDemand greatly influences the speed at which Content Manager OnDemand can retrieve them. Various hints and tips for the optimum way to define reports within Content Manager OnDemand are described in Chapter 3, “Administration” on page 45.
13.1.2 System logging
Use Content Manager OnDemand system logging for usage monitoring, charge-back, or troubleshooting. Because system logging involves writing all of the selected log messages to disk, you incur an increase in both resource usage and response time. Logging increases both the amount of the processor that is used and the amount of I/O to disk. For this reason, select only the types of logging that you want performed for a particular application group. Depending on your system usage requirements, you might decide to perform any of the following tasks:
•Turn off all system logging.
•Record a minimal amount of information (only the information that is needed for reporting functions).
•Record all transactions.
•Record the log information to one or more external files by using the system log exit.
•Turn on system logging only while you troubleshoot the system.
•Turn on system logging once every time period to sample the system usage patterns.
13.1.3 System management
For effective system management, set the appropriate value for ARS_NUM_DBSRVR and create the correct file systems for various Content Manager OnDemand components.
ARS_NUM_DBSRVR
The ARS_NUM_DBSRVR parameter is set in the ars.cfg file. This parameter is the maximum number of threads that are concurrently open between the Content Manager OnDemand library server and DB2. Typically, this value is set to a number between 4 - 30. This number must be large enough to support all of the concurrent database requests from all users and clients and Content Manager OnDemand commands and daemons, such as ARSLOAD, ARSDOC, ARSDB, ARSMAINT, and ARSADMIN. This number must not exceed the number of DB2 batch connections (MAXDBATS for z/OS and MAXAPPLS for Multiprocessing (MP)). The number of DB2 batch connections must be greater than the ARS_NUM_DBSRVR, plus all of the other connections that are required by all DB2 applications that you defined in your DB2 configuration.
For systems that are running several large load jobs in parallel, or for systems with large numbers of active users, increase this parameter from the default of 4.
File systems on UNIX
During the installation and setup of Content Manager OnDemand, one of the tasks is to create the file systems that are required to contain the various Content Manager OnDemand components.
For performance reasons, when the Content Manager OnDemand file systems are created, the following components must not be on the same physical media:
•Cache file system
•Database file system
•Primary logs file system
•Secondary logs file system
•Load/indexing file system
•Content Manager OnDemand temporary space file system
13.1.4 Storage management
Regardless of the platforms, storage management with Content Manager OnDemand can be divided into two areas: cache storage that is managed by Content Manager OnDemand and archive media that is managed by an external product, such as IBM Tivoli Storage Manager, object access method (OAM), Virtual Storage Access Method (VSAM), or Archive Storage Manager (ASM).
For effective storage management, one key performance feature of Content Manager OnDemand is its ability to load data to archive media, while simultaneously retaining a temporary cached copy of the most recent archived data on fast access media (such as the hard disk drive (HDD)). Content Manager OnDemand handles the expiration and management of this cached copy of the data. After a certain predefined period elapses, the data is removed from cache. The only remaining copy is held on the much slower archive media that is managed by either Tivoli Storage Manager, OAM, VSAM, or ASM, depending on the platform.
If performance problems are encountered at the storage manager level, the issue is almost always related to the inherent qualities of the slower media types (such as optical platters and tape volumes) or how the archive media manager is configured.
Several of the parameters that affect storage management are ARS_NUM_OAMSRVR, ARS_NUM_OAMSRVR_SLOW_RETRIEVE, and ARS_OAM_SLOW_RETRIEVE_THRESHOLD.
ARS_NUM_OAMSRVR
This parameter specifies the maximum number of concurrently attached threads between the Content Manager OnDemand object server and OAM for z/OS. Typically, this value is set to a number between 4 - 30, depending on client access patterns and object storage locations (disk versus tape). This parameter has a maximum value of 30. Any value larger than 30 result in a U0039 abend.
ARS_NUM_OAMSRVR_SLOW_RETRIEVE
This parameter determines the number of task control blocks (TCBs) that the Content Manager OnDemand server starts to handle connections to OAM for retrievals from objects with a slow retrieval time as defined by the ARS_OAM_SLOW_RETRIEVE_THRESHOLD parameter. The ARS_NUM_OAMSRVR_SLOW_RETRIEVE parameter applies to all object servers. If the value that is specified for this parameter is zero (0), no TCBs are dedicated for slow retrievals. All retrievals are processed by the TCBs that are associated with the ARS_NUM_OAMSRVR parameter. The default is zero (0). The ARS_NUM_OAMSRVR_SLOW_RETRIEVE TCBs are in addition to the ARS_NUM_OAMSRVR TCBs, and they use additional DB2 connections.
ARS_OAM_SLOW_RETRIEVE_THRESHOLD
This parameter specifies the threshold at which OAM retrievals are processed by the TCBs that are associated with the ARS_NUM_OAMSRVR_SLOW_RETRIEVE parameter. If the estimated retrieval time for an object (as indicated by QELQERRT) is greater than or equal to the value of the ARS_OAM_SLOW_RETRIEVE_THRESHOLD parameter, the OSREQ RETRIEVE is processed by an ARS_NUM_OAMSRVR_SLOW_RETRIEVE TCB. The default value is 12000. For other valid QELQERRT values, see the Object Access Method Application Programmer’s Reference, SC35-0425-08. An ARS_OAM_SLOW_RETRIEVE_THRESHOLD value of zero (0) with a nonzero ARS_NUM_OAMSRVR_SLOW_RETRIEVE value causes all OAM retrieve requests to be processed by the ARS_NUM_OAMSRVR_SLOW_RETRIEVE TCBs, while the ARS_NUM_OAMSRVR TCBs process store, query, and delete requests.
13.2 Data loading performance
The data loading process is illustrated in Figure 13-1 on page 301. The process begins with the Content Manager OnDemand Administrator Client defining the application group and application parameters for the reports to be loaded. These parameters are stored in the Content Manager OnDemand system tables on the library server.

Figure 13-1 Data loading
During the load process, in addition to any command-line parameters that are supplied, the application group and application parameters are retrieved from the library server. Then, based on the parameter definitions, the load process completes the following steps:
1. Selects the indexer to be used for indexing the report data and retrieves the indexing parameters.
2. Reads in the report data from the identified source location. The input report data can be of any data type.
3. Indexes the report data based on the defined indexing parameters.
4. Segments the report into “documents”.
5. Compresses the documents.
6. Stores the compressed documents in storage objects (10 MB by default).
7. Sends the storage objects to the object server where they are stored in the identified archive (storage node).
8. Sends the index data for the stored objects to the library server where the indexes are stored in the appropriate application group data table.
13.2.1 Factors that affect the load performance
Many factors affect load performance:
•Quantity, speed, and capacity of the available hardware (processors, memory, disks, I/O channels, network, and so on)
•Network bandwidth and throughput
•Operating system tuning components: DB2, TCP/IP, and Language Environment
•Content Manager OnDemand tunable components
•Storage management tunable components: UNIX System Services, z/OS file system (zFS), hierarchical file system (HFS), OAM, Tivoli Storage Manager, and ASM
•Data components:
– Report file size, document file size (or in the case of large objects, report segment size), and number of documents per report.
– Number and distribution of triggers, fields, and indexes per document.
– Data type and required data conversion (if any).
– Resource collection for AFP and Portable Document Format (PDF).
– Document compressibility, which is a function of document data complexity and data type. Text (such as Line Data or SCS) is typically more compressible than AFP, which is typically more compressible than PDF.
– Storage object size (10 MB default): Contains 100 KB compressed object, which contains a compressed document.
– Exit routines/programs.
13.2.2 Recommendations
For the most optimal performance in loading, we recommend the following practices:
•For Multiplatforms and z/OS, run parallel load jobs to take advantage of multiprocessors, large memory pools, multiple data paths, and multiple disk drives.
•Ensure that each parallel load is loading to a different application group.
•Ensure that you set up a different temp directory for each of the parallel loads. The -c indexDir indexer parameter (which specifies the directory in which the indexer stores temporary data) must always be specified for ARSLOAD and must be unique for each running ARSLOAD process.
•For IBM i, start multiple output queue monitors over a single output queue to improve throughput and take advantage of multiprocessors, large memory pools, and multiple disk drives.
•Each Content Manager OnDemand process is limited by the performance of a single processor. For example, the OS/400 indexer uses only one processor when it indexes a document. Using two or more processors in your system or LPAR does not improve the performance of the OS/400 indexer. However, by using two or more processors in your system or LPAR, you might be able to run multiple load jobs simultaneously. You can start multiple output queue monitors over a single output queue to improve document load performance.
•For IBM i, the use of the Merge Spooled Files (MRGSPLFOND) command can provide significant performance improvements when you load SCS spooled files.
•For IBM i, depending on your retrieval patterns and system hardware configuration, it might be advantageous to not store a duplicate set of documents in the Content Manager OnDemand cache when you use ASM because ASM might already be using disk space. If the application group uses ASM, caches the data, and specifies the migration of data at load time, two copies of the data are stored during the load. One copy is stored in cache, and one copy is stored in the ASMREQUEST directory.
To avoid storing a duplicate set of documents in cache for non-AFP data, change Cache Data to No on the Storage Management tab of your application group definition. To avoid storing a duplicate set of documents in cache for AFP data, you might change Document Data to No Cache but leave Resource Data in cache for faster retrieval.
•For IBM i, every user that loads data must have a home directory. If users do not have a home directory, the temporary files are stored in the root directory of the integrated file system (IFS).
•If the data source is on a remote system, you can load the data into Content Manager OnDemand on the remote system and directly store the export data to the specified Content Manager OnDemand library and object server.
Or, if the data source is on a remote system, you also can upload the data to the specified Content Manager OnDemand server through FTP and then load the data on the selected Content Manager OnDemand system.
•For Multiplatforms and z/OS, all file systems must be dedicated file systems that are mounted on their own mount points.
•For z/OS, when you load PDF reports (by using the PDF Indexer), placing the input report in the HFS or zFS causes the load to run nearly 50 times faster that compared to the input report that is placed in a VSAM file.
13.2.3 Load testing
The goal of load testing is to verify that, under stressful system conditions, the required amount of data can be loaded into the Content Manager OnDemand system within a time window.
A general approach to load testing a system is described:
•Parallel loads: Run a single load and measure the load throughput. If the throughput does not meet the requirements, run two loads in parallel and measure the throughput. While the loads are run, collect system statistics to determine the system resources that are being used and any potential bottlenecks. Tune or acquire additional system resources as needed. Progressively increase the number of parallel loads until the required throughput is met.
|
Note: For most users, a single load process meets the ingestion throughput requirements.
|
•Data types and exits: A different data type, and whether an exit is started during the load process, affects the load throughput. Test samples of the different types that represent the general loads.
13.3 Data retrieval performance
All Content Manager OnDemand clients (such as the Windows client, CICS client, IBM Content Navigator, ODWEK application programming interfaces (APIs), and structured APIs) retrieve data from the Content Manager OnDemand server by using a standard proprietary Content Manager OnDemand protocol. From a Content Manager OnDemand server perspective, no difference exists between one client and another client.
13.3.1 Data retrieval parameters
Various parameters affect data retrieval performance.
Folder parameters: General tab
In the Content Manager OnDemand Administrator Client, under the Folder parameter and on the General tab, the following option is available:
•Note Search: If the Annotation flags in a document database are set to No in the Advanced tab of the General window of the Application Group, this option determines when Content Manager OnDemand searches the database for annotations and notifies users that annotations exist for the documents that match a query. Content Manager OnDemand provides three search and notification methods:
– Hit List: Content Manager OnDemand searches for annotations when the user runs a query. When annotations exist for a document, the client programs display a note icon next to it in the document list. This method has a direct performance impact on the generation of the document list.
– Retrieve: Content Manager OnDemand searches for annotations when the user selects a document for viewing. This method is the default and recommended value.
– Note: Content Manager OnDemand searches for annotations when the user chooses the Note option while the user views a document.
Folder parameters: Permissions tab
In the Content Manager OnDemand Administrator Client, under Folder parameters and on the Permission tab, the following option is available:
•Max Hits: Determines the maximum number of hits that are retrieved and transmitted to the client. By reducing the maximum number of hits, users are forced to enter queries that better match the documents that they are searching for. By reducing the maximum number of hits, the system resources are used optimally both in performing the queries and in downloading the resulting document list.
TCP/IP considerations
A known Windows configuration setting might affect performance when you connect to a Content Manager OnDemand server. During repeated searches and retrievals on a Content Manager OnDemand server, many Windows sockets are opened and closed. Two default Windows settings might affect heavy traffic between the client and the Content Manager OnDemand server:
•When an application closes a Windows socket, Windows places the socket’s port into TIME_WAIT status for 240 seconds; during this time, the port cannot be reused.
•Windows limits the number of ports that an application can use to 5000.
To avoid the problems that might result, change the values for the timeout wait time and number of ports by editing the Windows registry:
•Change the value of the timeout wait time from 240 seconds to a lower number (valid values are 30 - 300 seconds). The key’s name is shown:
HKEY_Local_MachineSystemCurrentControlSetservicesTcpipParametersTcpTimedWaitDelay
•Increase the maximum port number from its default of 5000 to a higher number (valid values are 5000 - 65534). The key’s name is shown:
HKEY_Local_MachineSystemCurrentControlSetservicesTcpipParametersMaxUserPort
For more information about TcpTimedWaitDelay and MaxUserPort, see your Windows documentation.
Verify with your network personnel that you are setting the values that are appropriate for your environment correctly.
13.3.2 Factors that affect retrieval performance
Figure 13-2 shows the data retrieval performance testing, which is an illustration of the methodology that is used by the Content Manager OnDemand lab for its internal performance testing. On the client side (where the cTest program is), both throughput and response time are recorded. The definitions for throughput and response time are shown:
•Throughput: The amount of work that is performed over a period of time (How many transactions can the Content Manager OnDemand server (CMOD SERVER in the figure) run at the same time?)
•Response time: The time that is elapsed between when a request is submitted and when the response from that request is returned (How long does it take for a transaction to run?)
Maximizing performance is a balancing act between optimizing throughput (which is based on keeping the computing resources busy) and optimizing response times (which requires the computing resources to be available when they are needed). As the throughput increases, so does the response time.

Figure 13-2 Data retrieval performance testing
The concepts that are shown in Figure 13-2 are described for your reference.
The retrieval performance is mostly limited by the resources that are available to the Content Manager OnDemand server.
For example, for disk and I/O capacity, each retrieve requires that the data is obtained from the archive (Tivoli Storage Manager, OAM, ASM, and cache). This data is on a disk or another storage device. The storage device retrieval rate is part of the total response time that is observed at the client, and both of them are affected by the following resources and system demand:
•Real memory: The data that is retrieved from disk must be stored in memory for it to be processed. Virtual memory allows large amounts of data to be swapped in and out of real memory, but it does not remove the need for real memory.
•Processing: Any data transformations that are performed on the Content Manager OnDemand server require available processing capability. If the capability is not available, the server waits until it becomes available. This wait lengthens the total response time of the client request.
•Concurrent retrievals: Each retrieval requires resources on the server. The higher the number of concurrent retrievals, the greater the amount of resources that are needed to complete the work in an acceptable amount of time.
•Network bandwidth: The retrieved data is sent to the clients over the Internet Protocol network. If the network bandwidth is not wide enough to satisfy all of the concurrent requests, the response time to the clients is slower and data is queued up in the server buffers, further slowing down the system.
13.3.3 Retrieval testing
The goal of retrieval testing is to verify that, under stressful system conditions, the maximum number of concurrent users can be served while at the same time the system meets the business requirements. The following process is a good general approach to retrieval testing of the system:
•Transaction type: Different types of transactions present different types of workloads on the system. For example, logon, document query, and document retrieval all use different components of the Content Manager OnDemand system. For each transaction type, measure the throughput and response time for a number of concurrent users that exceed the maximum predicted number. Tune and add resources to the system as needed until the system exceeds the service level agreement (SLA) requirements.
•Data types: The stored documents might be different sizes and data types (and might invoke preview exits). Multiple document retrieval tests must be run to verify the performance for the various types of stored documents.
•User workloads: The users that access the system might all exhibit the same usage patterns or might exhibit two or more usage patterns. The following process shows an example usage pattern:
a. Log on.
b. Wait five seconds.
c. Issue a document query with a maximum hit list size of 12 documents.
d. Wait five seconds.
e. Retrieve a 10 KB document.
f. Wait 40 seconds.
g. Retrieve a 20 KB document.
h. Wait 60 seconds.
i. Log off.
For example, a total of 50 concurrent users might follow this pattern. Also, other patterns might run at the same time. So, the user workload test must model this behavior and it must also be able to meet the business requirements at peak loads.
•Test driver location: The code that generates the retrieval workload can be installed on either of the following machines:
– The same server on which the Content Manager OnDemand system is installed.
By using the same server, you can maximize the stress on the Content Manager OnDemand system by eliminating the network connection and by using system processing cycles to generate and measure the response time and throughput.
– A network-connected workstation.
This situation simulates either a web server that connects to the Content Manager OnDemand server or a user that connects to the Content Manager OnDemand server.
•Number of test drivers: The number of systems that issue the requests can be increased so that the number of concurrent requests that reach the Content Manager OnDemand server exceeds the maximum expected number of requests.
•Test measurement: Two sets of measurements are used. The first set is at the test driver, which represents the user or Content Manager OnDemand Client. At this location, both throughput and response time on a transaction basis need to be collected. Also, it is important to check that the system that issues the retrieve requests is not overloaded and therefore not the performance bottleneck. In addition, at the Content Manager OnDemand server, request service times can be observed in the Content Manager OnDemand system log. System performance measurements must be collected by using operating system-specific tools.
13.3.4 System testing
After the load and retrieval tests are performed individually, it is important to perform an overall system test. This test must include running everything in parallel up to the maximum expected system usage. Everything includes load, retrieval, expiration, migration, duplication, and backup operations. The goal is to ensure that under the most stressful conditions possible, the system meets business requirements.
|
Note:
•The performance tuning process demands great skill, knowledge, and experience, and it cannot be performed by only analyzing statistics, graphs, and figures.
•The goal is to tune the Content Manager OnDemand server. You can “see” the bottlenecks in the server only if both the client and the network are clear of bottlenecks.
|
13.4 Performance issues that are based on data type
This section describes issues that relate to individual data types that can significantly affect the overall performance of Content Manager OnDemand. Several issues can be addressed by selecting or clearing certain functions and features within Content Manager OnDemand. Several of the issues that we describe can be addressed only by changing the way in which the data is produced from the source.
13.4.1 PDF data
Portable Document Format (PDF) data is an increasingly common data type that can be archived within Content Manager OnDemand. The following key advantages are available by using this data type as a document format:
•It is a read-only format that does not require any external resources, such as images or fonts. It is self-contained.
•The viewer for PDF can be downloaded at no charge from the Adobe website and the browser plug-ins for PDF are also available at no charge.
During PDF document creation, resources, such as images and custom fonts, are placed in the data stream once and then referenced many times from within the PDF file. If a large report is produced from many small documents, that report requires only one copy of the resources.
However, when the PDF is indexed, the PDF Indexer creates many PDF documents from the input file. Each of these documents requires a certain number of PDF structures, which define a document. These documents are concatenated together in the .out file, and then loaded into Content Manager OnDemand as separate documents. Because the resources are extracted and placed into a separate resource file, they are not included in each document. For an illustration of the process, see Figure 13-3.

Figure 13-3 PDF indexing
If no resources are collected, the size of the .out file, which contains all of the individual documents, might be larger than the original file. For tips about how to reduce the size of the output file, see 7.3.5, “PDF indexing: Using internal indexes (Page Piece Dictionary)” on page 173.
The size of the input file and the output file can create problems during the load process:
•The temporary space that is used during indexing can be too small and the load fails.
•The maximum input file size that the PDF Indexer can process is 4 GB, but the recommended maximum size for a single document (after indexing) is 50 MB. If this size is exceeded, the system might run out of disk space or memory.
Create PDF data with the base 14 fonts, which do not need to be included in the PDF file. Because they are not included in the PDF file, they are not extracted during resource collection, which improves performance. For more information about the PDF data stream and fonts, see 7.3.1, “PDF fonts and output file size” on page 166.
13.4.2 Line data
Line data (ASCII or EBCDIC text-based reports) is the most common type of data that is stored in Content Manager OnDemand. The type of line data that we describe here is a special form of transaction-style report, where it is necessary to search on a value that appears on every line of the report. This transaction data has a transaction number that appears on every line and must be sorted either by column or row and either ascending or descending.
When you index transaction data, if each transaction number from each line of the report is treated as a database index, such as date or customer name, the database becomes large quickly. Content Manager OnDemand has a special type of field for transaction data, which is illustrated in Figure 13-4 by the boxed data on the left of the window.

Figure 13-4 Transaction data in graphical indexer
The transaction data field selects the first and last values from a group of pages and only these group level values are inserted into the database. Content Manager OnDemand queries the database by comparing the search value that is entered by the user to two database fields, the beginning value and the ending value. If the value that is entered by the user falls within the range of both database fields, Content Manager OnDemand adds the item to the document list.
From a performance perspective, the use of the transaction data field for transaction-style line data optimizes indexing performance by reducing the number of index values to be inserted into the database. Therefore, the process of loading and retrieving these large reports is faster and the Content Manager OnDemand database is many times smaller.
13.4.3 AFP data
AFP data is a multi-part data type. In addition to the variable data, external resources, such as images, fonts, and logos, are also referenced by the AFP data stream. When Content Manager OnDemand stores AFP data, the resources are also archived. When the data is viewed, the referenced resources are displayed.
It is a common misconception that if fonts are collected when the data is loaded, they are available for viewing in the Windows client. However, Windows does not recognize AFP fonts. It is not possible to use these fonts even if they are sent to the client as part of the resource. Windows clients require a mapping from AFP fonts to Adobe Type Manager (ATM) fonts or TrueType (TT) fonts. Content Manager OnDemand provides this mapping for most standard fonts. For more information about mapping custom fonts, see IBM Content Manager - Windows Client Customization Guide and Reference, SC27-0837.
One possibly useful implementation of storing fonts with the resource group is when server reprint is necessary. If the fonts are stored with the resource group, they can be retrieved from Content Manager OnDemand and used by AFP printers. However, if fonts are collected, they are also sent to the client as part of the resources group and then discarded. Storing the fonts with the resource group serves only to increase network traffic when transferring the resource to the workstation. A more practical option for server printing is to store the font in a fontlib and to keep only the reference (path) to the fontlib. Although the font is accessible on the server, Print Services Facility (PSF) or InfoPrint does not need the font to be inline (stored in the resource group). The use of this approach also allows all AFP data that references the font to use the single instance of the font without redundant inline storage.
Figure 13-5 on page 311 shows the indexer information in the application where you can select the resources to collect with the Restype= parameter. Unless reprints to AFP printers with 100% fidelity is a requirement, do not collect the fonts.

Figure 13-5 Collecting AFP fonts
The Content Manager OnDemand for i server does not collect the fonts and it does not give the administrator that option. The Resource Information window (under Indexer Properties) is not available to the Content Manager OnDemand for i administrator. If you are reprinting to an AFP printer, the fonts must be available on the IBM i server, or font substitution is performed.
13.4.4 Image data
To optimize performance with storing and retrieving image formats, such as Tagged Image File Format (TIFF), Graphics Interchange Format (GIF), and Joint Photographic Experts Group (JPEG), do not compress the data because the file sizes might increase. To turn off compression, select the Disable option from the Load Information tab within the application. See Figure 13-6.
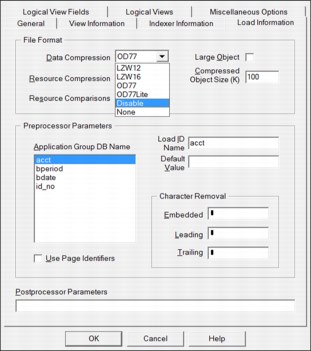
Figure 13-6 Disabling compression
Two methods are available to turn off data compression:
•Disable: Content Manager OnDemand does not compress the input data. Choose this option when the input data, such as PDF and compressed TIFFs, is already compressed. Documents are extracted by the appropriate viewer on the client (for example, Adobe Acrobat Reader).
•None: Content Manager OnDemand does not compress the input data when it loads the input data into the system. When the user selects a document for viewing, Content Manager OnDemand compresses the document before it transmits it over the network and extracts the document at the client.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.